決定木の紹介
このノートでは、機械学習を代表するアルゴリズムの一つである「決定木」についてご紹介します。
決定木は、一連の質問とその答えによる分岐で結果を予測する手法です。ランダムフォレストやXGBoostなどのアンサンブル学習に比べて、決定木では一つのツリーしか作らないためにそこに至るまでの条件を確認することができ、解釈や説明がしやすいといった特徴があります。一方で、一般的にアンサンブル学習に比べて予測精度は低いと言われています。
決定木を使うことで、下記の質問に答えていくことができます。
- 目的変数を予測する上で、どういった条件があるか。
- 目的変数と関係の強い変数はどれか。
- 変数の値が変わると、目的変数の値はどのように変わるか。
- このモデルでは目的変数の動きのどれくらいを説明できるのか。
それでは、Exploratoryで決定木をどのように使っていけるのか見ていきましょう。
必要なデータの形式
決定木を実行する際には、1行が1観測対象となっているデータを使う必要があります。
目的変数には数値型、ロジカル型のどちらも扱うことができます。予測変数におけるデータタイプには特に縛りはありません。しかし、予測変数同士の相関が強い場合は影響度を取り合ってしまい、変数重要度の順番が低く見積もられることがあります。
決定木を実行する
今回は、従業員の「給料」を予測する決定木のモデルを作成します。
アナリティクスビューを開き、タイプに「XGBoost」を選択します。
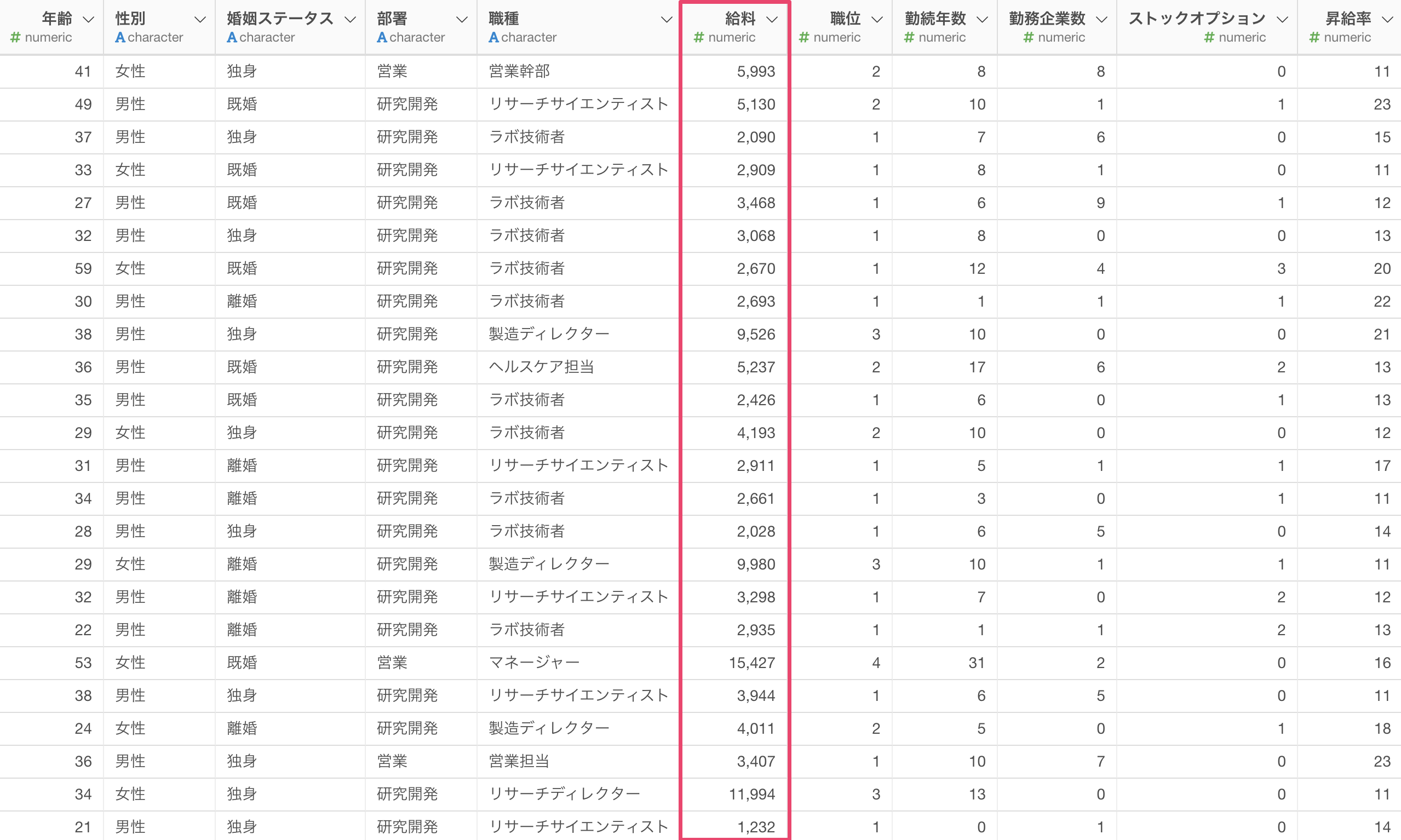
目的変数に「給料」を選択します。
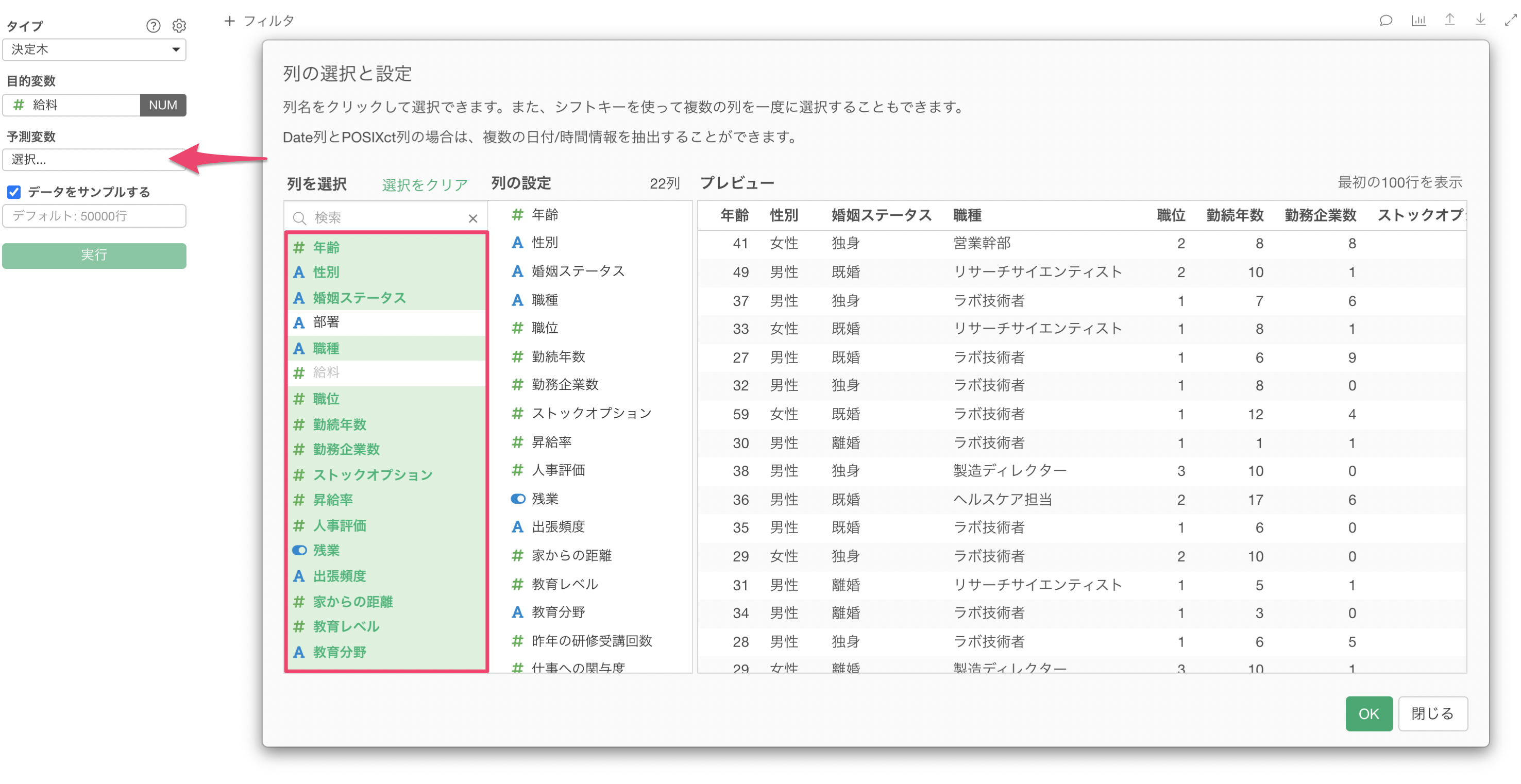
予測変数の列をクリックして、給料を予測する上で使用する列を選択します。シフトキーを押すことで、複数の列を一気に選択できます。
目的変数と予測変数を割り当てることができたら、「実行」ボタンをクリックします。
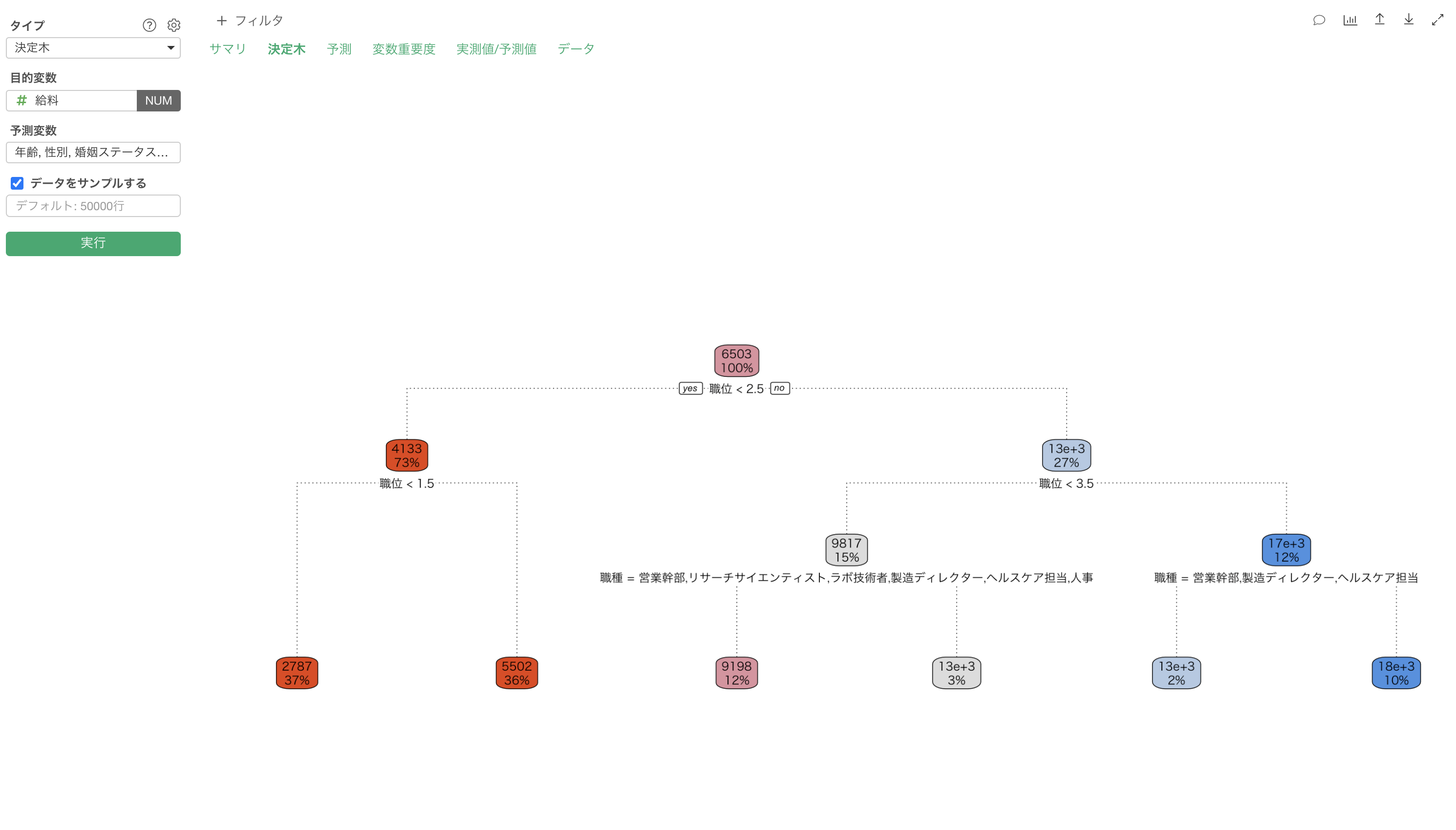
給料(数値)を予測する決定木のモデルが作成されました。
結果の解釈
決定木
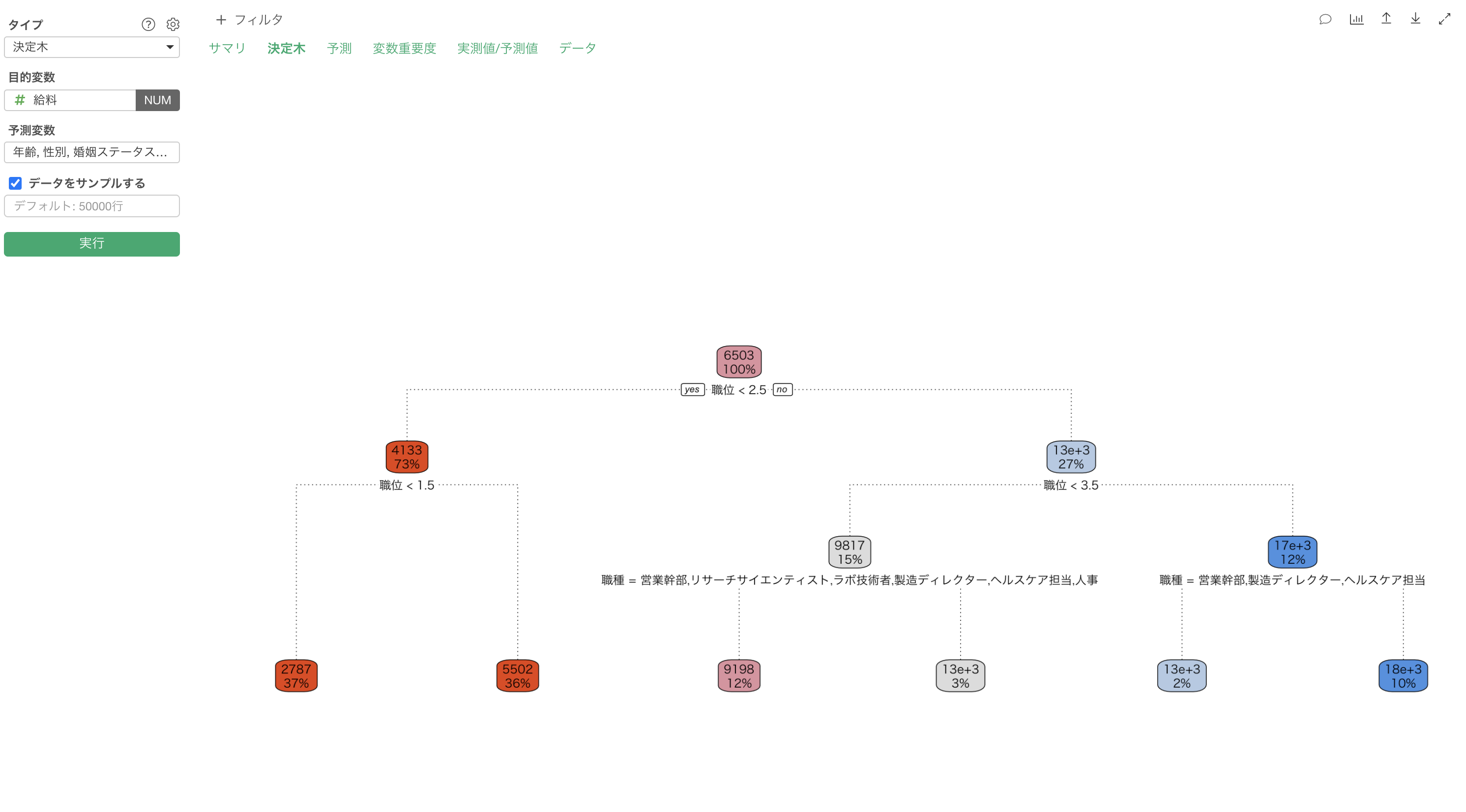
「決定木」タブでは、目的変数を予測する際に作られた条件分岐を確認することができます。

各ボックスの下には条件が表示されており、左が「yes」、右が「no」となっています。例えば、一つ目の条件では「職位 < 2.5」という条件がありますが、左(yes)の場合は、「職位が2.5より小さい」、右(no)の場合は「職位が2.5以上」と解釈できます。
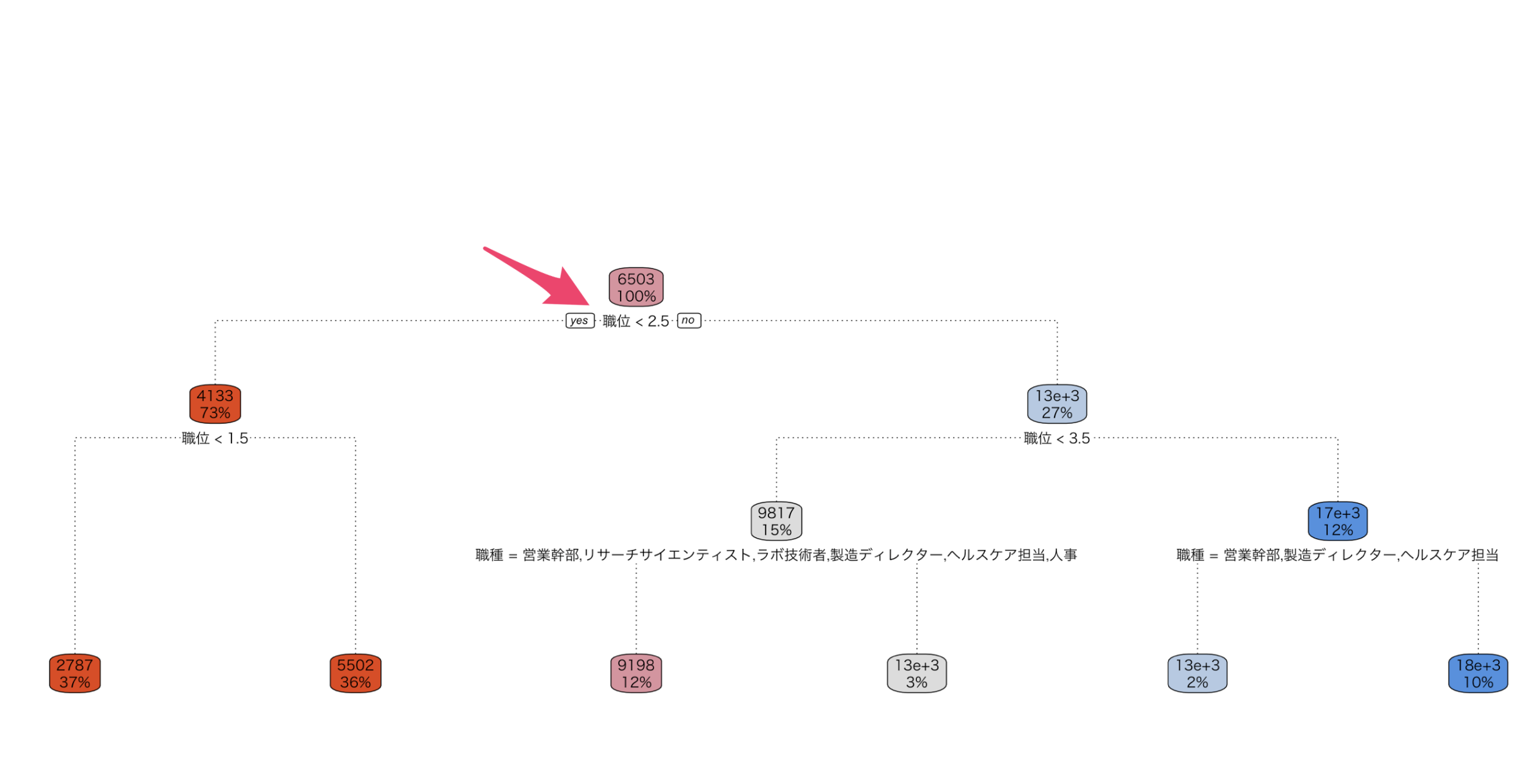
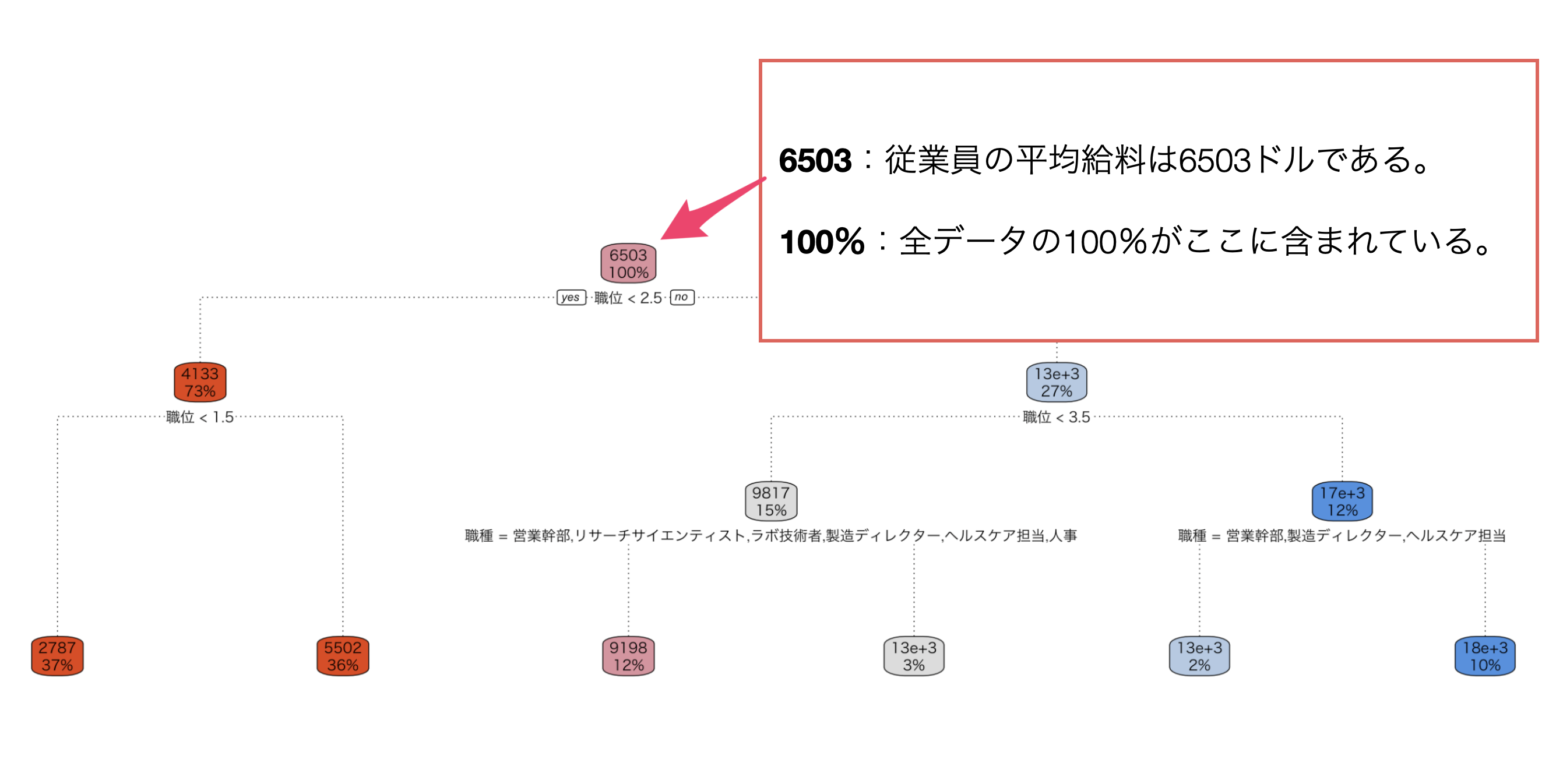
数値の場合
各ボックスには、数値を目的とした場合は、その条件に含まれるデータの目的変数の平均値、そして全データに対する割合が表示されています。
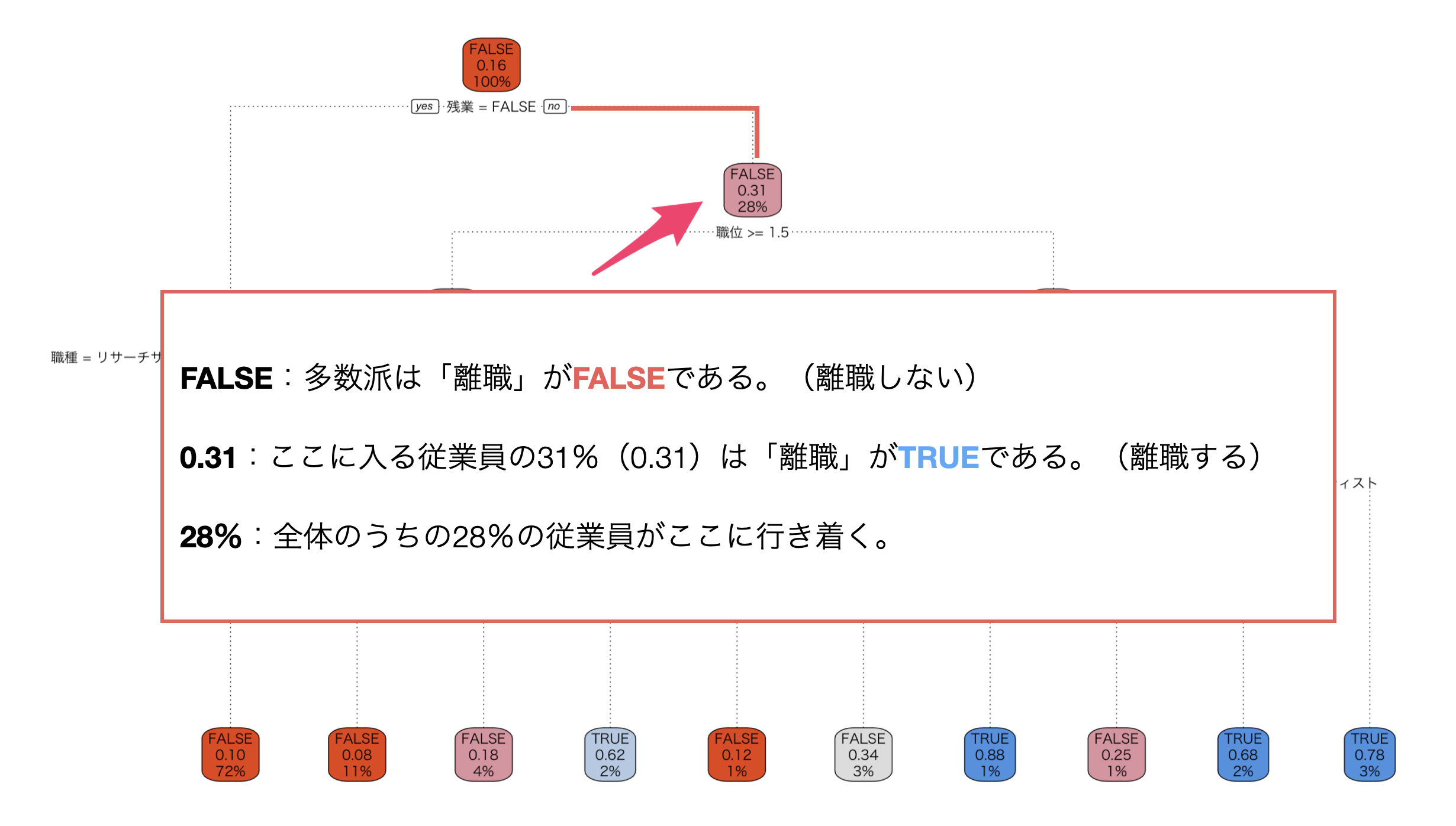
ロジカルの場合
ロジカルを目的とした場合は、その条件に含まれるデータの多数派(TRUEまたはFALSE)、TRUEの割合、全体に対するデータの割合が表示されています。
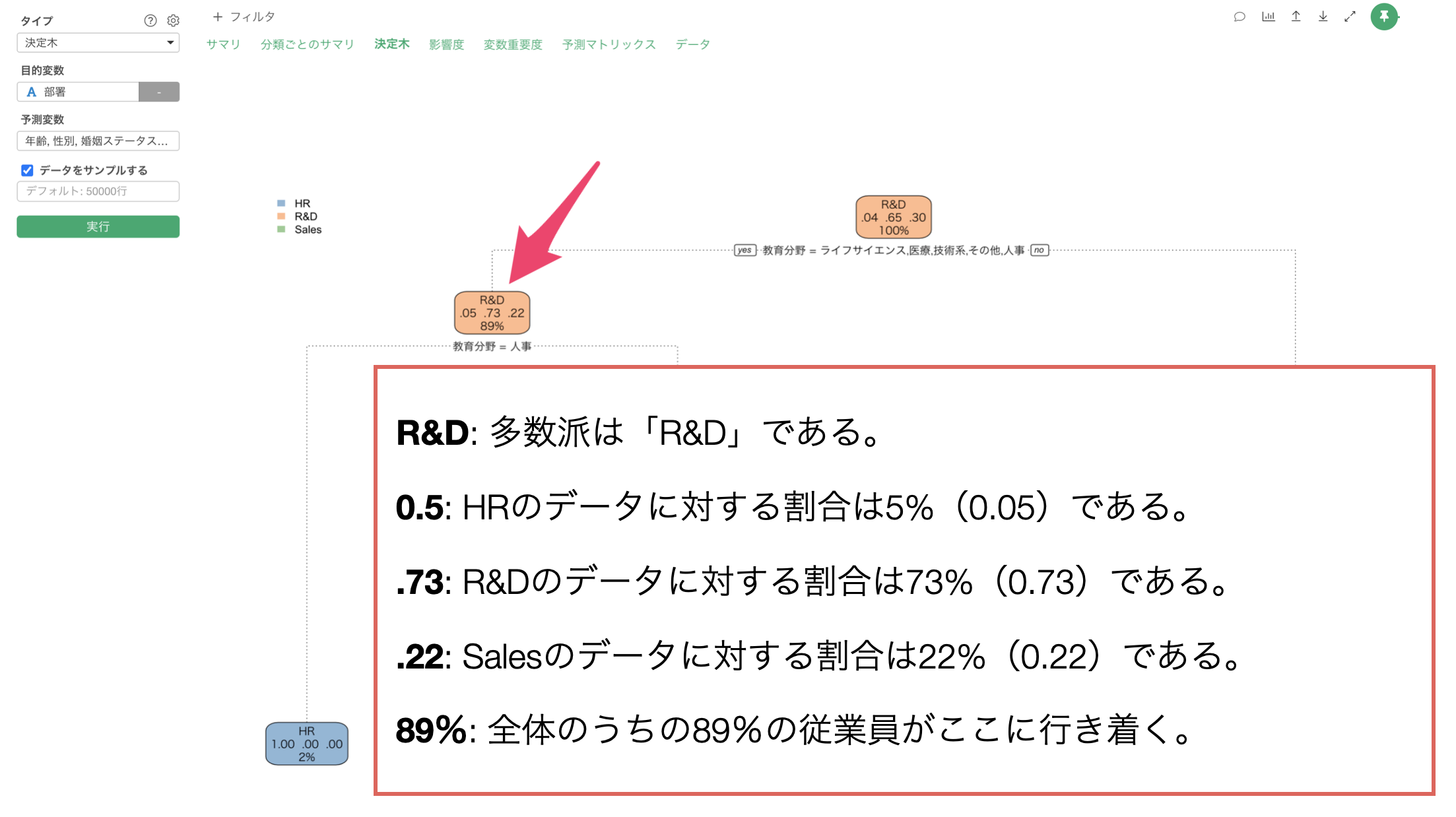
カテゴリーの場合
カテゴリーを目的とした場合は、その条件に含まれるデータの多数派(行数が最も多いカテゴリーの値)、それぞれのカテゴリーの値の割合、全体に対するデータの割合が表示されています。
変数重要度
変数重要度タブでは、どの変数が目的変数とより相関が強いのか、予測する時により重要なのかを調べることができます。
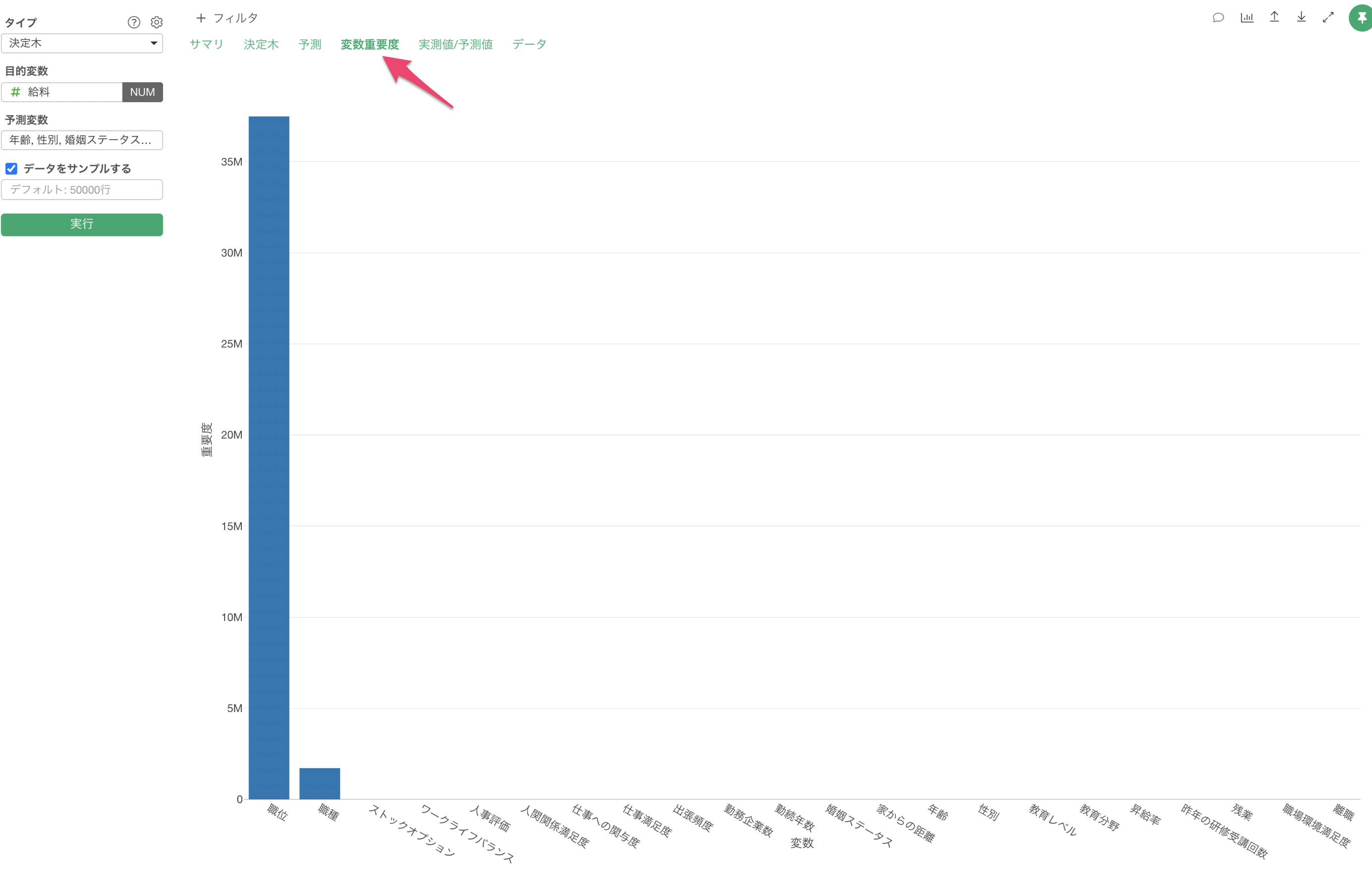
変数重要度の詳細については、機械学習モデル - 変数重要度の仕組みと解釈のセミナーをご覧ください。
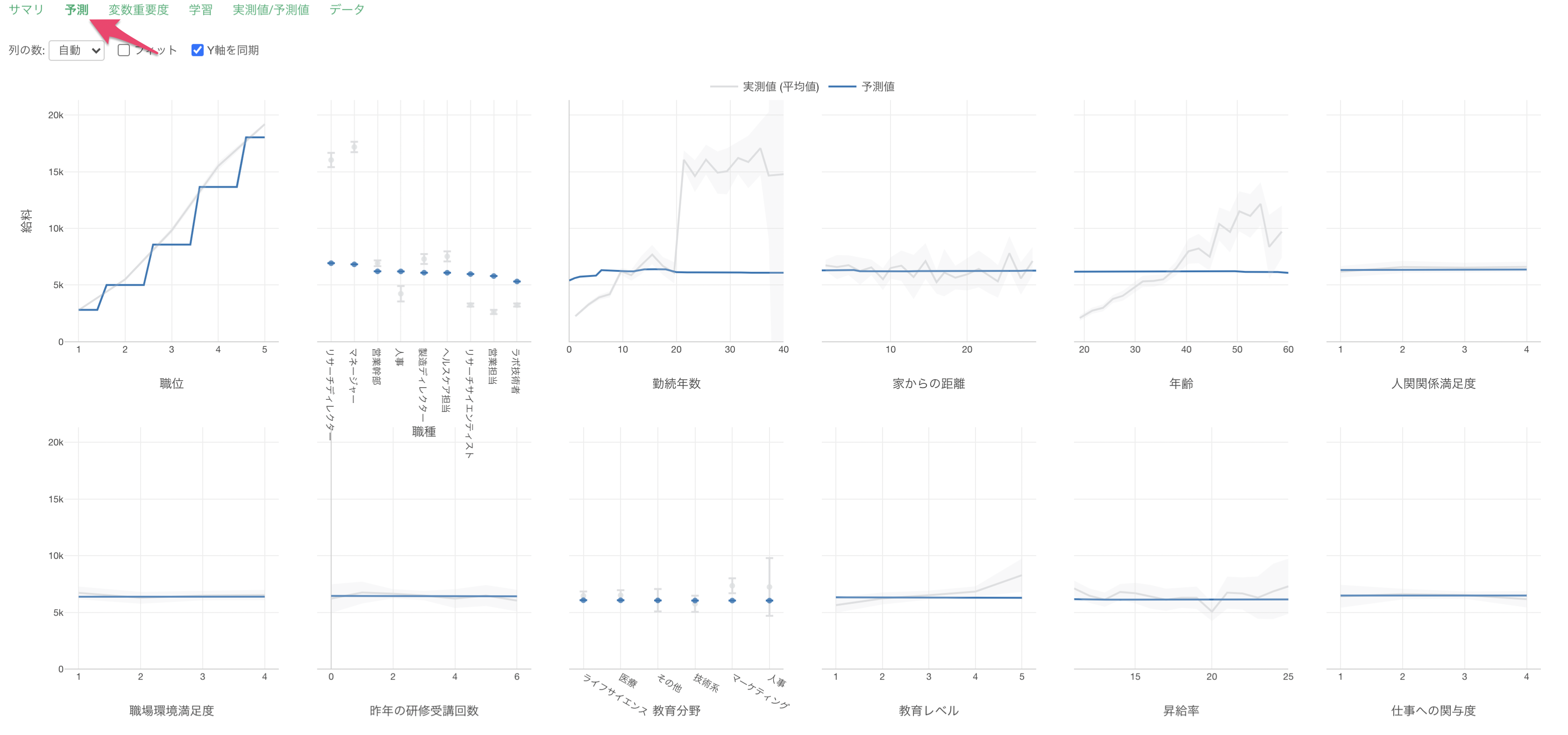
予測
予測タブでは、それぞれの変数の値が変わると、目的変数の値はどのように変わるのかがわかります。
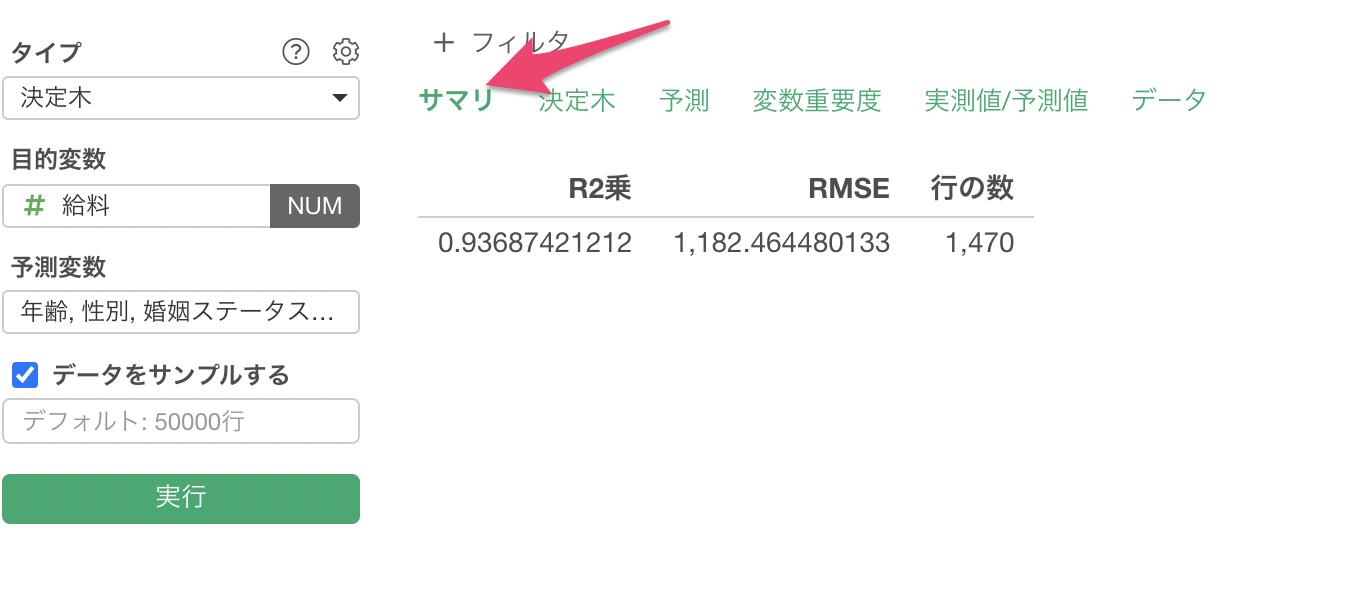
サマリ
サマリタブでは、この予測モデルの評価を確認できます。R2乗はデータの平均からのばらつきをモデルが説明できている割合の指標で、0から1の間の値を取ります。1に近ければ近いほど、モデルがデータのばらつきをよく説明できていることを示します。
参考資料
XGBoostに関する参考資料は下記をご覧ください。
決定木に関するよくある質問
Q: 予測タブで表示されている実測値はどのように求められているのですか?
予測タブの実測値はそれぞれの予測変数のデータタイプによって表示が異なります。 詳しくはこちらのノートをご覧ください。
Q: 予測タブで表示されている予測値はどのように求められているのですか?
予測値のチャートはPartial Dependence Plot(PDP)と呼ばれるもので、注目している変数の値を変化させたときに、予測結果がどう変わるかを可視化したチャートとなります。詳しくはこちらのノートをご覧ください。
Q: 決定木の設定にある分岐による改善率の最小値は何を意味していますか?
「分岐による改善率の最小値」は、不純度の改善(減少)率のしきい値を設定するもので、デフォルトの0.01の場合は改善率が1%までの決定木を作るようになっています。
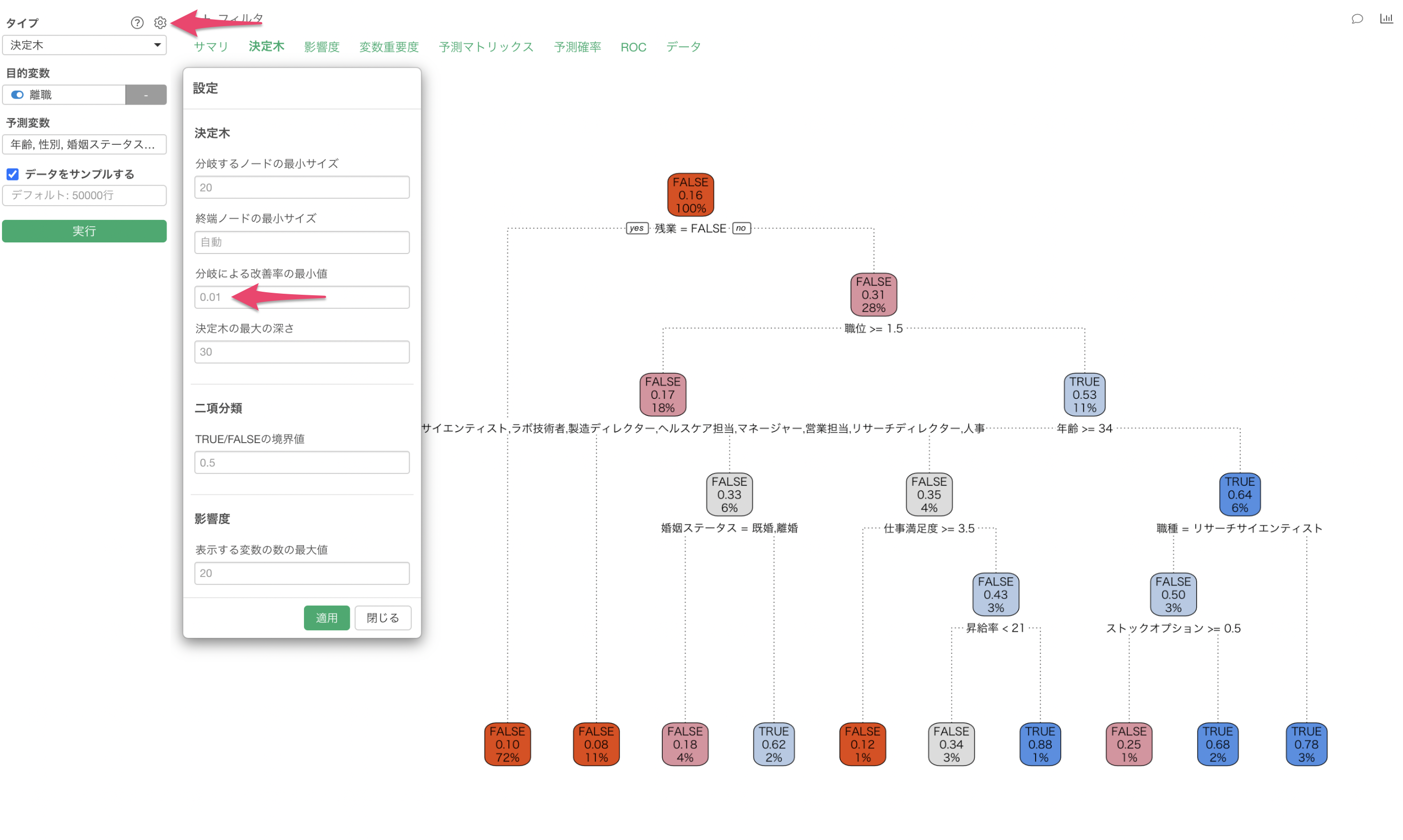
もし、この値を小さくすると、改善率(減少率)が小さいものでも組み込むため、作成される条件の数が増えるようになっています。
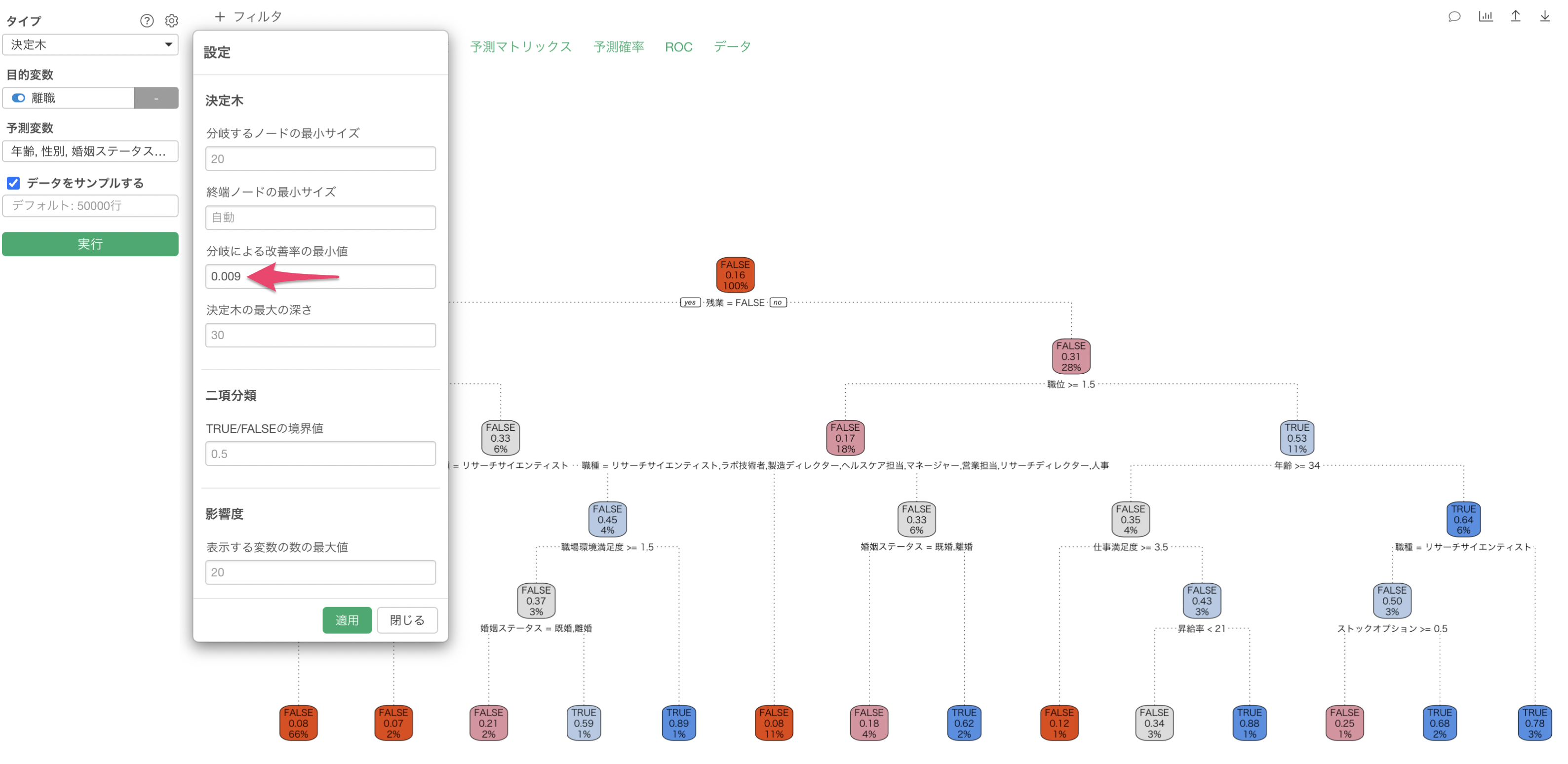
不純度については、こちらのセミナーにて紹介しております。
Q: 決定木の条件で13e+3といった表記がされますがどういった値になりますか?
決定木の条件では、以下のように「13e+3」といった形で表記されることがあります。
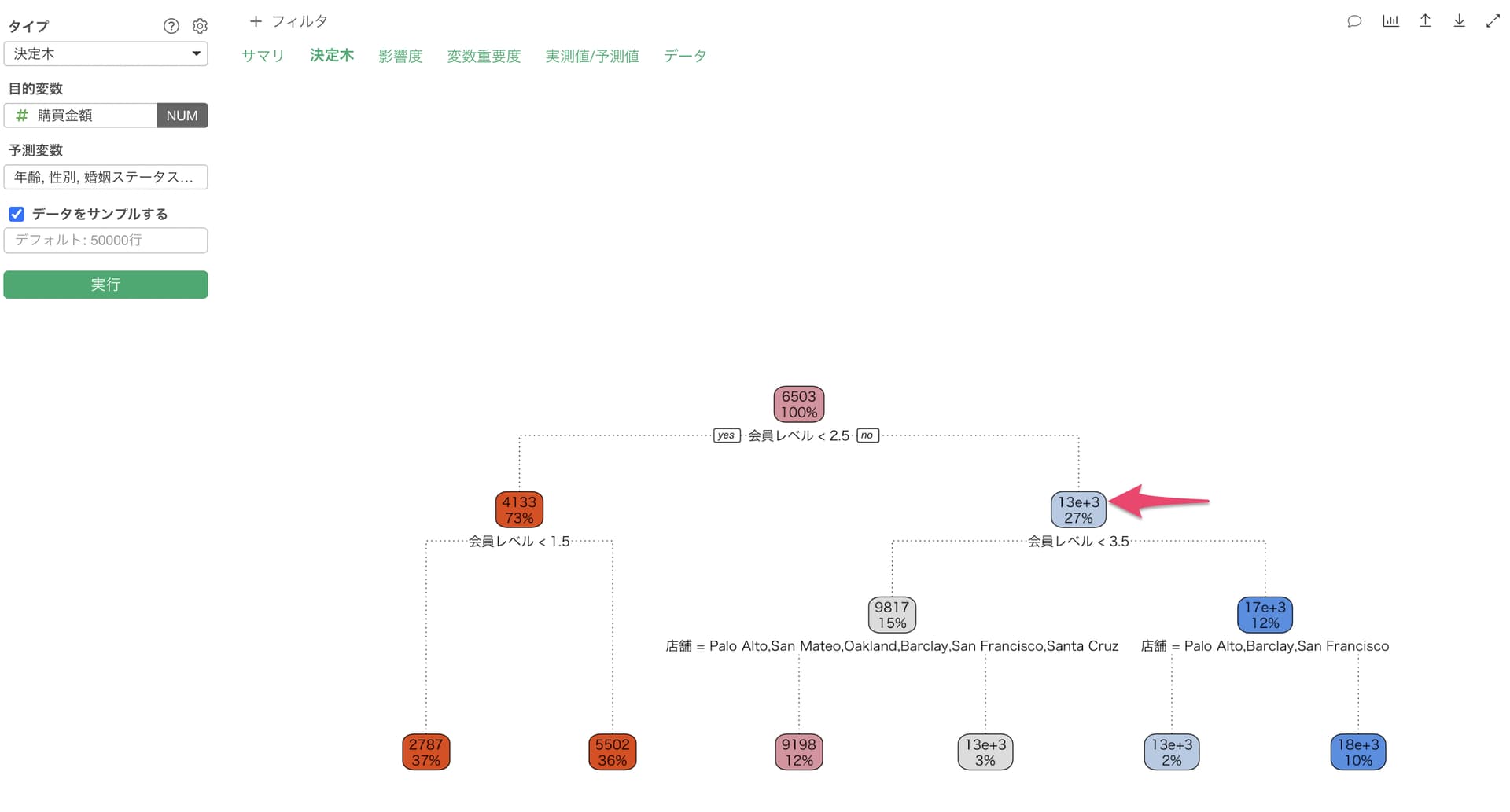
これは「e表記 / 指数表記」と呼ばれるもので、桁が大きい時に省略して表示する時に使われる方法で、下記のように表現されます。
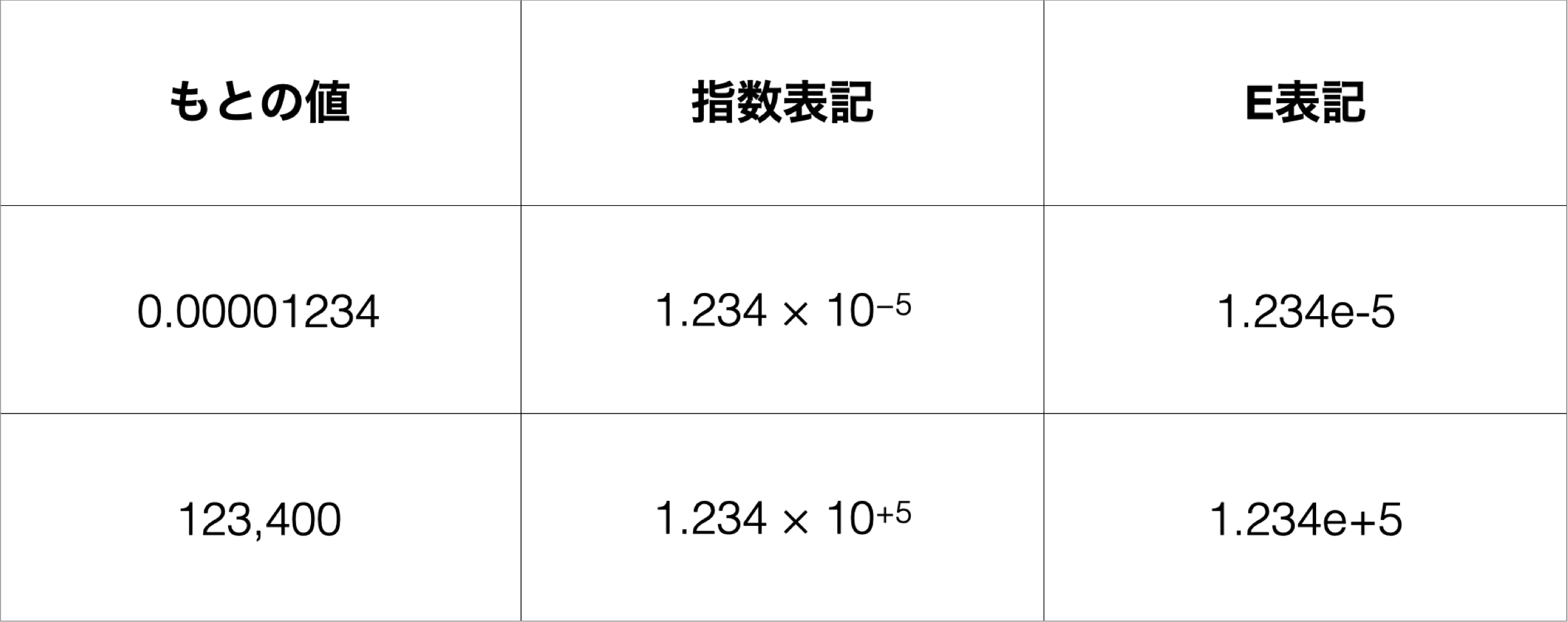
13のe+3の値は13 × 10³で、値としては「13,000」となります。
Q: カテゴリーを予測したモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまう
決定木などを使ってカテゴリー列の値を予測するモデルを作っていたとします。
そのモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまうことがあります。
主な原因としては、以下の2つが考えられます。
- 予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在している。
- 予測対象の新しいデータ側で予測変数に使われていた列で欠損値がある。
予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在しているといったケースに該当する場合は、今後もモデルで予測をする際に、そのカテゴリーが含まれる可能性がある時には、モデル側にもそのカテゴリの値があるように組み込んでいただくと良いかもしれません。