
Google BigQueryからデータを取得する方法
Exploratory デスクトップからGoogle BigQueryのデータをインポートするには、Google Cloud Platform上で「プロジェクト」と「データセット」が作成されている必要があります。
もし、Google BigQuery上で「プロジェクト」と「データセット」を作成していない場合は、先にそちらを進めてください。
OAuth認証で接続する
データフレームの横にある+(プラス)ボタンをクリックして、「データベースデータ」を選択します。
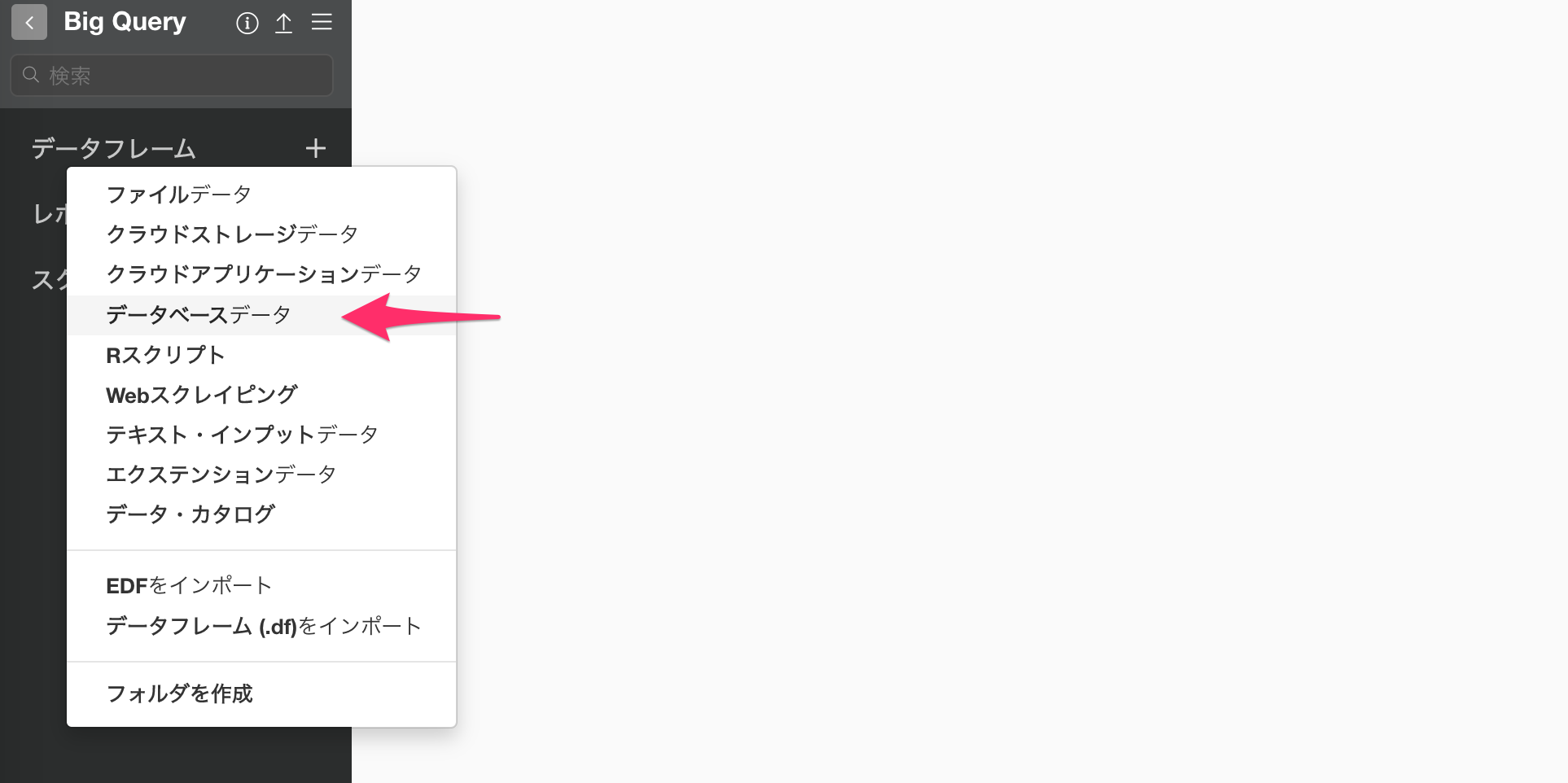
OAuth認証で接続でしたい場合は、「Google BigQuery (OAuth)」を選択します。

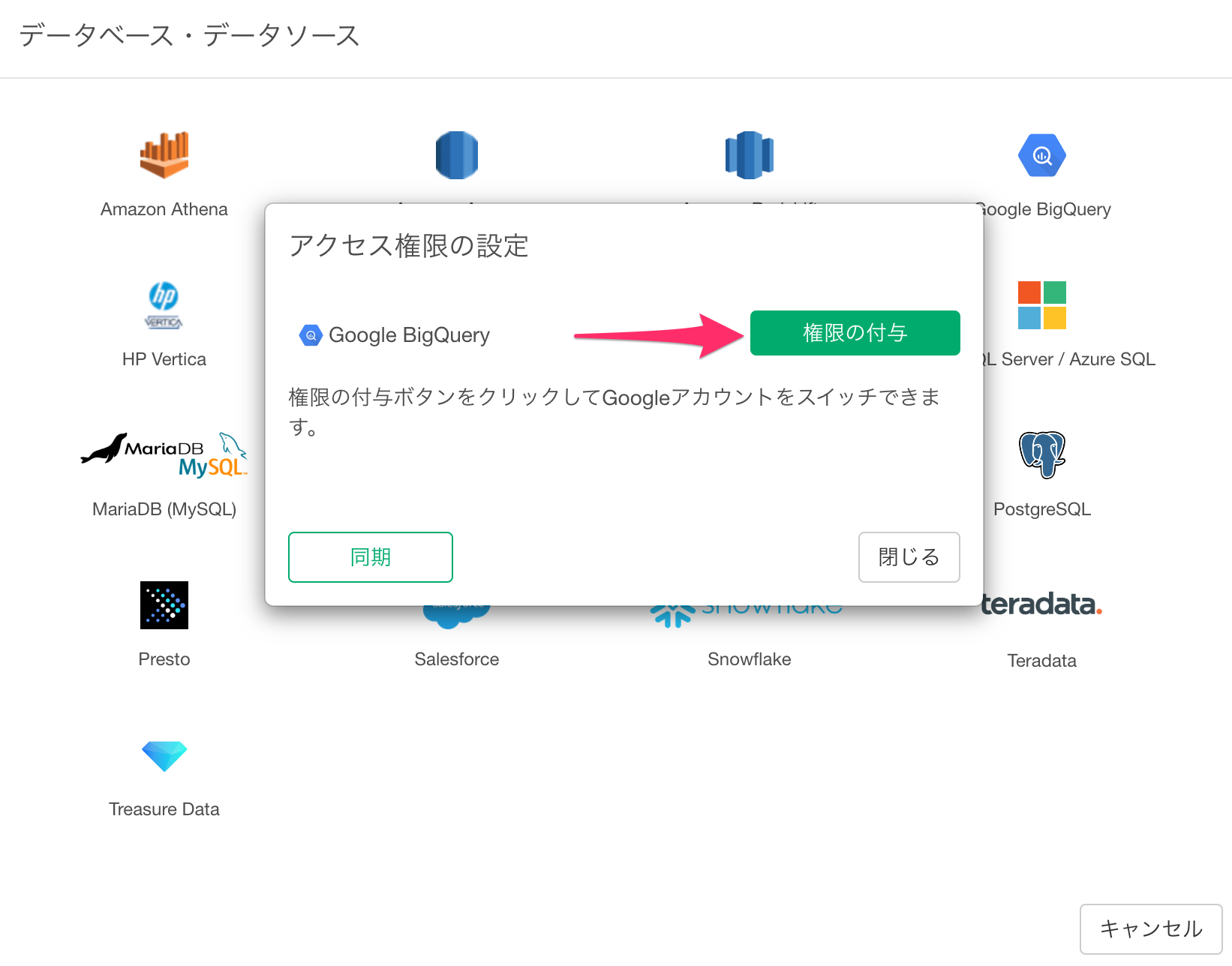
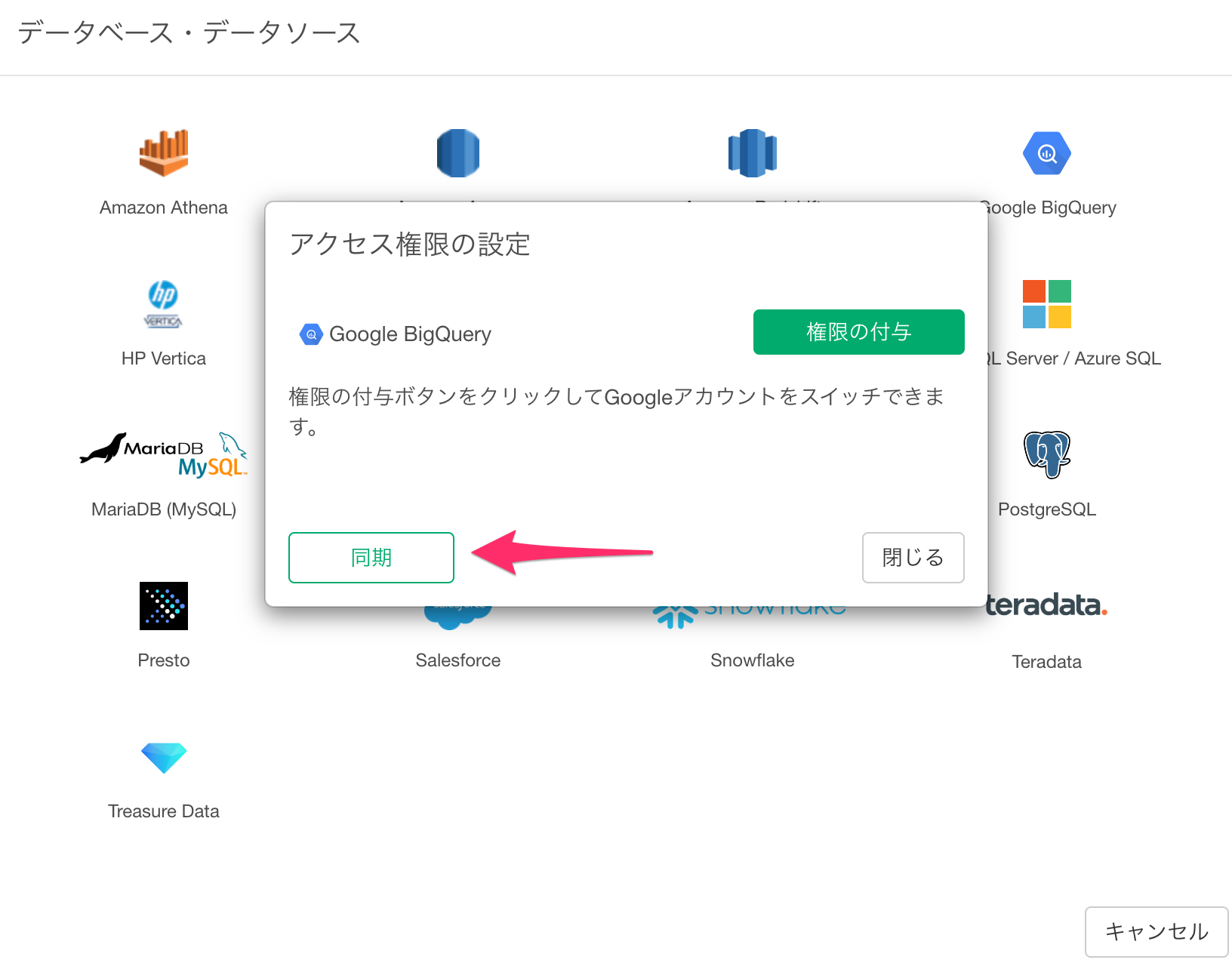
アクセス権限の設定ダイアログが表示されるので、「権限の付与」を選択します。
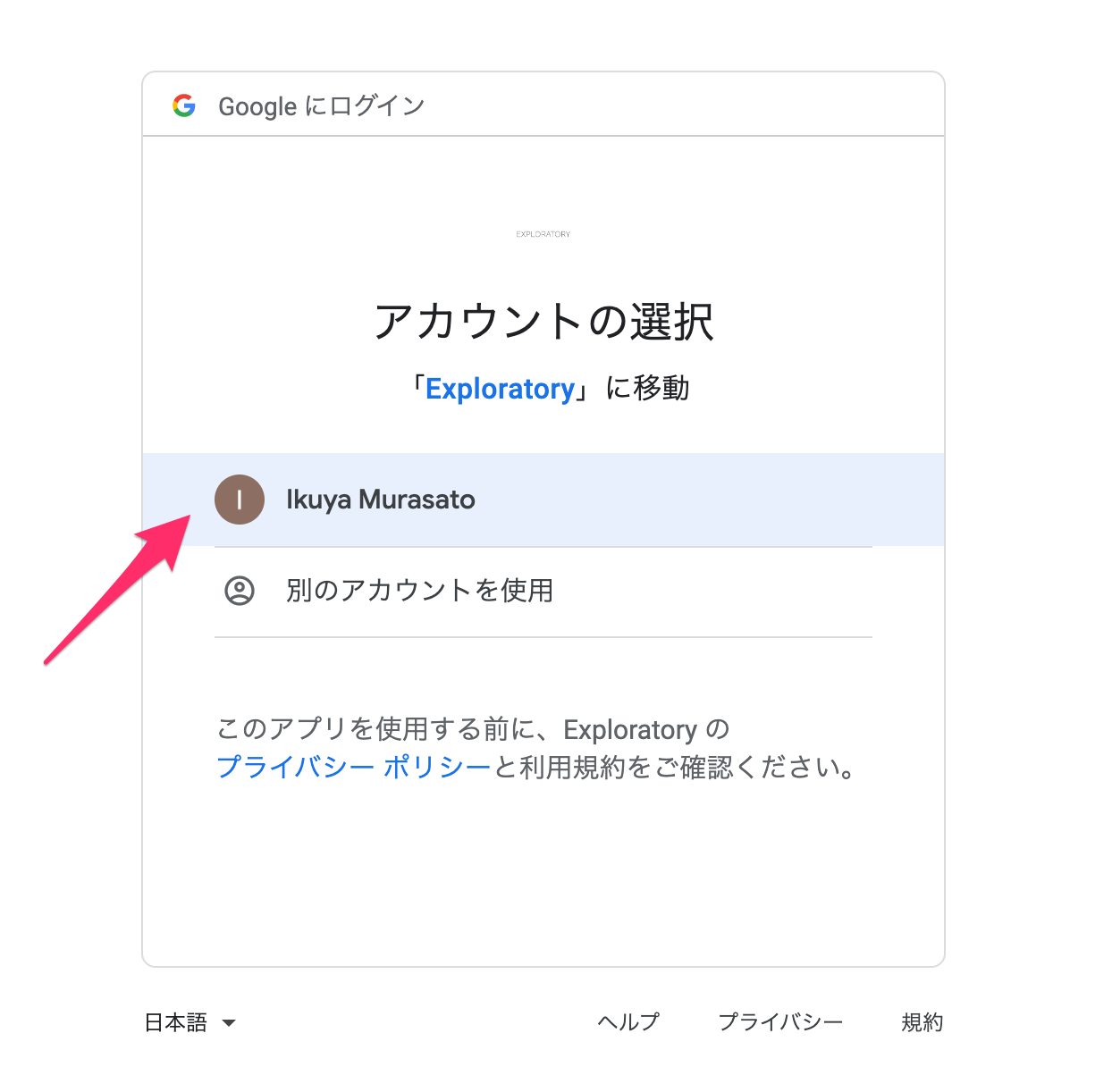
ブラウザが起動し、アカウントの選択画面が表示されるので、Google BigQueryで使用するアカウントを選択します。
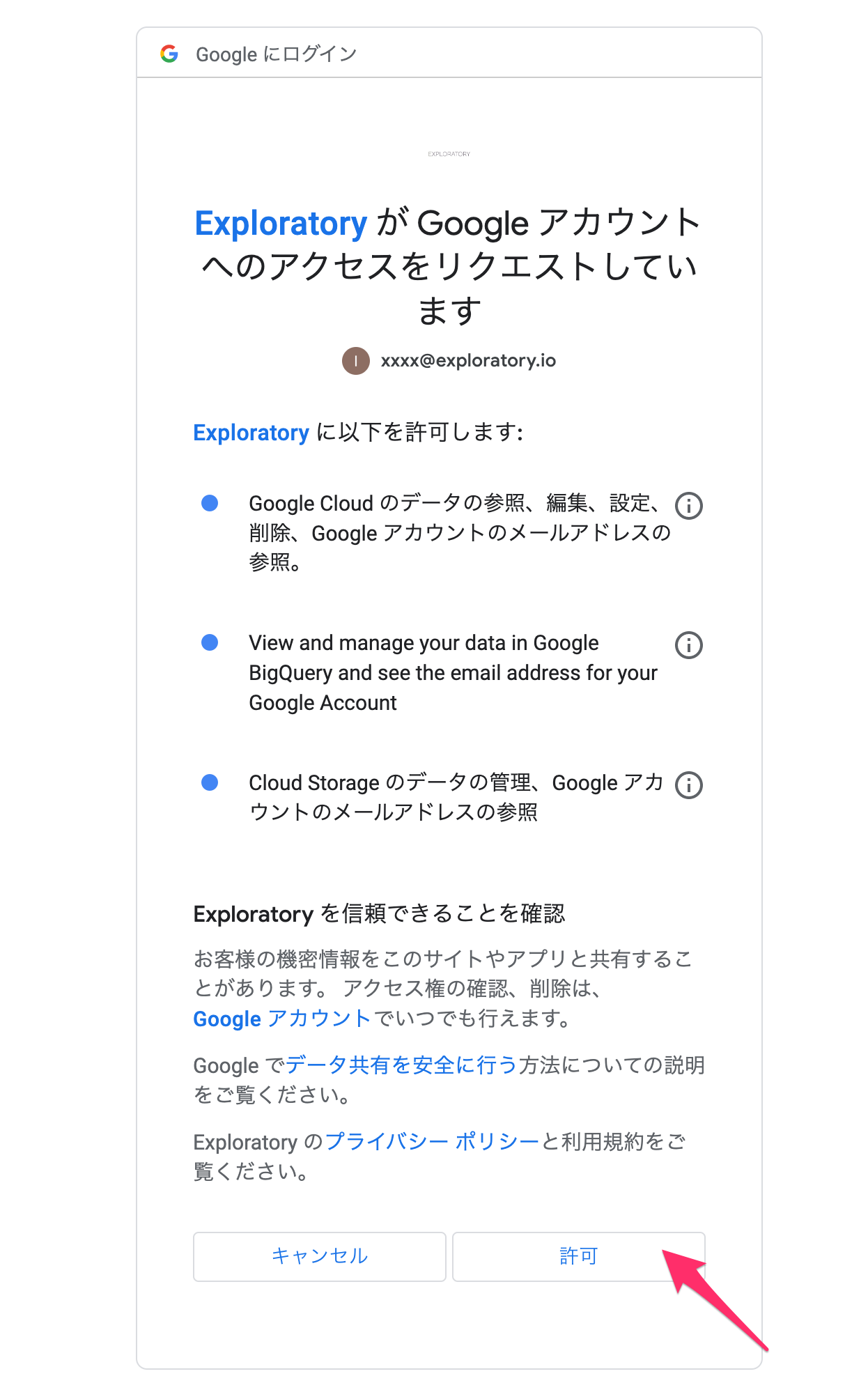
「Exploratory が Google アカウントへのアクセスをリクエストしています」というダイアログが表示されるので、「許可」をクリックします。
「権限の付与に成功しました!」画面が表示されたらアクセス権限の設定は完了です。
Exploratoryデスクトップに戻り「同期」ボタンをクリックします。
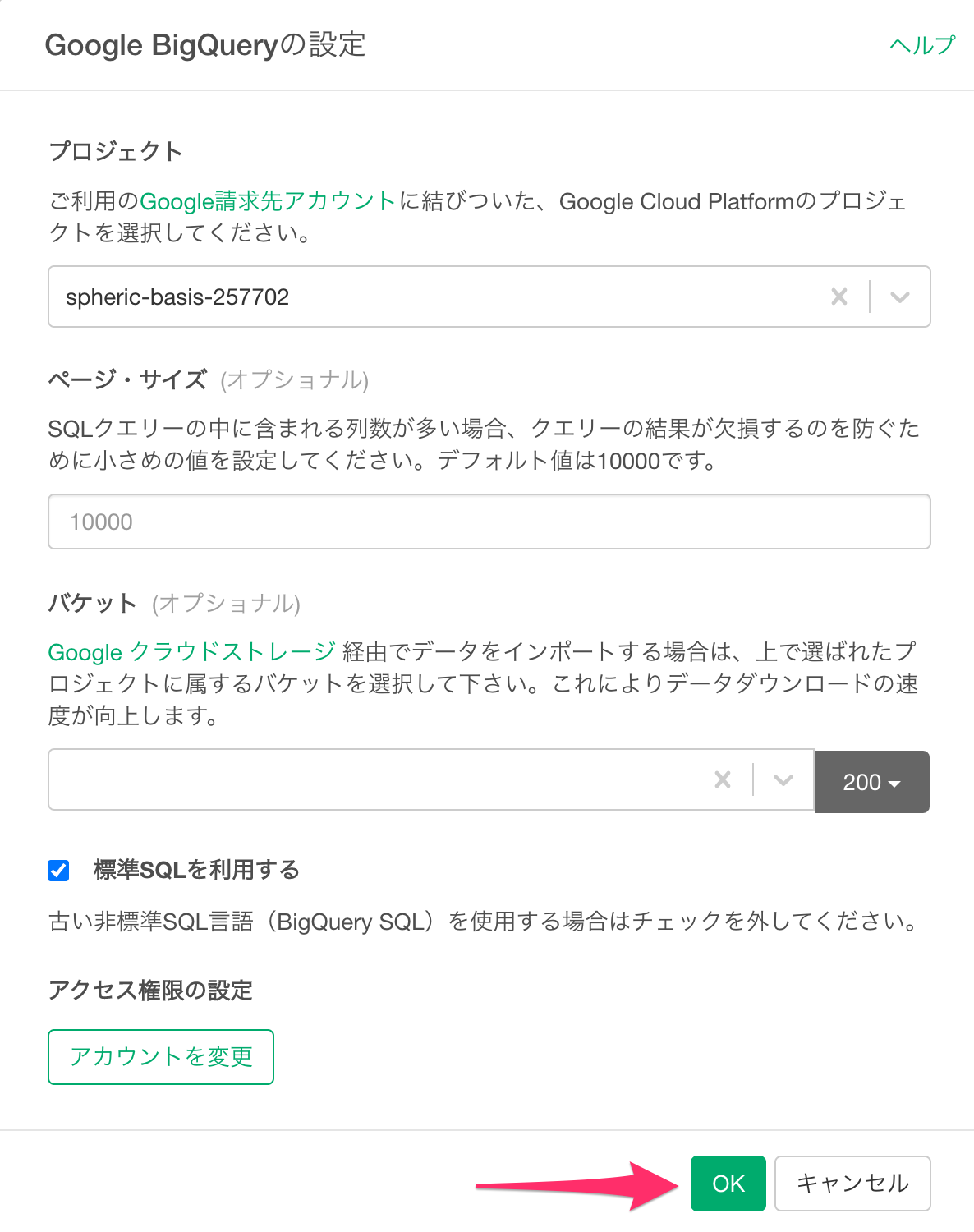
コネクションの作成を進めると、Google BigQueryの設定ダイアログが表示されるので、「プロジェクト」を選択し、「ok」ボタンをクリックします。
サービスアカウントで接続する
データフレームの横にある+(プラス)ボタンをクリックして、「データベースデータ」を選択します。(修正済みの問題があるため、もしv14.5より前のバージョンのExploratoryデスクトップをご利用の場合は、初めにExploratoryを最新のバージョンにアップデートしてください)
サービスアカウントで接続でしたい場合は、「Google BigQuery (Service Account)」を選択します。

コネクションを追加のダイアログが表示されるため、コネクション名に任意の名前をつけた後に、サービスアカウントファイルをクリックします。
サービスアカウントファイルには、Google BigQueryでのサービスアカウントのJSONキーファイルを指定します。このファイルには認証情報が含まれており、Exploratory DesktopがGoogle Cloud APIにアクセスするために必要です。
サービスアカウントJSONファイルの取得手順
ステップ1:Google Cloudコンソールでサービスアカウントを作成
Google Cloud Consoleにアクセス
左上のハンバーガーメニュー(☰)から「IAMと管理」→「サービスアカウント」を選択
「+ サービスアカウントを作成」ボタンをクリック
以下の情報を入力:
- サービスアカウント名:分かりやすい名前(例:bigquery-service-account)
- サービスアカウントID:自動生成される
- 説明:用途を記載(例:BigQueryデータアクセス用)
ステップ2:必要な権限を付与
作成時またはサービスアカウント作成後に、以下の権限(ロール)を付与します:
必須ロール:
BigQuery データ編集者- データの読み書き権限BigQuery ジョブユーザー- クエリ実行権限
クラウドストレージ経由でのインポートをする場合は、追加で以下のロールが必要となります。:
Cloud Storage ストレージ管理者- BigQueryとCloud Storage間のデータ転送時
ステップ3:JSONキーファイルを作成・ダウンロード
- サービスアカウント一覧から作成したサービスアカウントをクリック
- 「キー」タブを選択
- 「鍵を追加」→「新しい鍵を作成」をクリック
- キーのタイプで「JSON」を選択
- 「作成」ボタンをクリック
- JSONファイルが自動的にダウンロードされます。
Google BigQueryの設定
Google BigQueryの設定として、以下の項目がサポートされています。
ページ・サイズ
SQLのクエリの中に含まれる列数が多い場合、クエリの結果が欠損値になることがあります。SQLのクエリの中に含まれる列数が多いときに、「ページ・サイズ」小さめの値を設定することで、この問題を回避できます。
また、クエリの結果に多くのリスト型の列が含まれている場合も、ページサイズを小さくしてクエリ結果を取り込むようにしてくだしさい。なお、ページサイズを小さくすると、データの取り込み処理が遅くなりますので、ご注意ください。ページサイズはインポートダイアログからも変更が可能です。
バケット
Google クラウドストレージ 経由でデータをインポートする場合は、選択したプロジェクトに属するバケットを選択して下さい。これによりデータダウンロードの速度が向上します。
標準SQLを利用する
古い非標準のSQL言語であるBigQuery SQLを使いたいときは「標準SQLを利用する」のチェックボックスを外してください。
なお、Google 標準SQLはSQL 2011標準に準拠し、ネストされ繰り返されたデータのクエリをサポートする拡張機能を備えています。標準 SQLには、レガシー SQLに勝る次のような利点があります。
- WITH 句と SQL 関数を使用したコンポーザビリティ
- SELECTリストと WHERE句内のサブクエリ
- 相関サブクエリ
- ARRAYデータ型とSTRUCTデータ型
- 挿入、更新、削除
- COUNT(DISTINCT ) は正確でスケーラブルであり、EXACT_COUNT_DISTINCTの精度をその制限なしで提供
- JOINによる自動述語プッシュダウン
- 任意の表現を含む複雑なJOIN述語
これらの機能の一部を示す例については、Google 標準 SQL の要点をご覧ください。また、標準SQLへの移行についてはこちら参照してください。
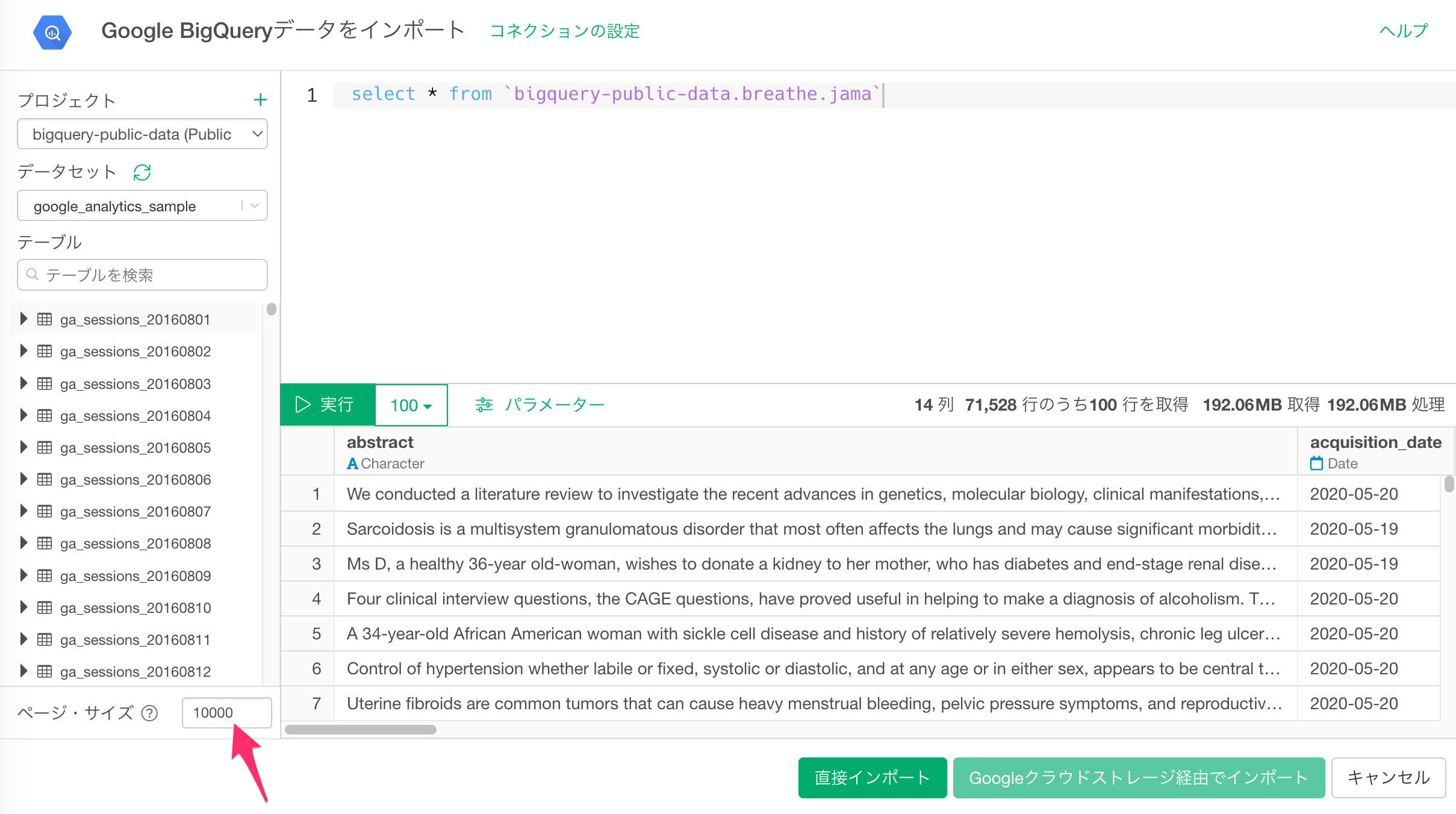
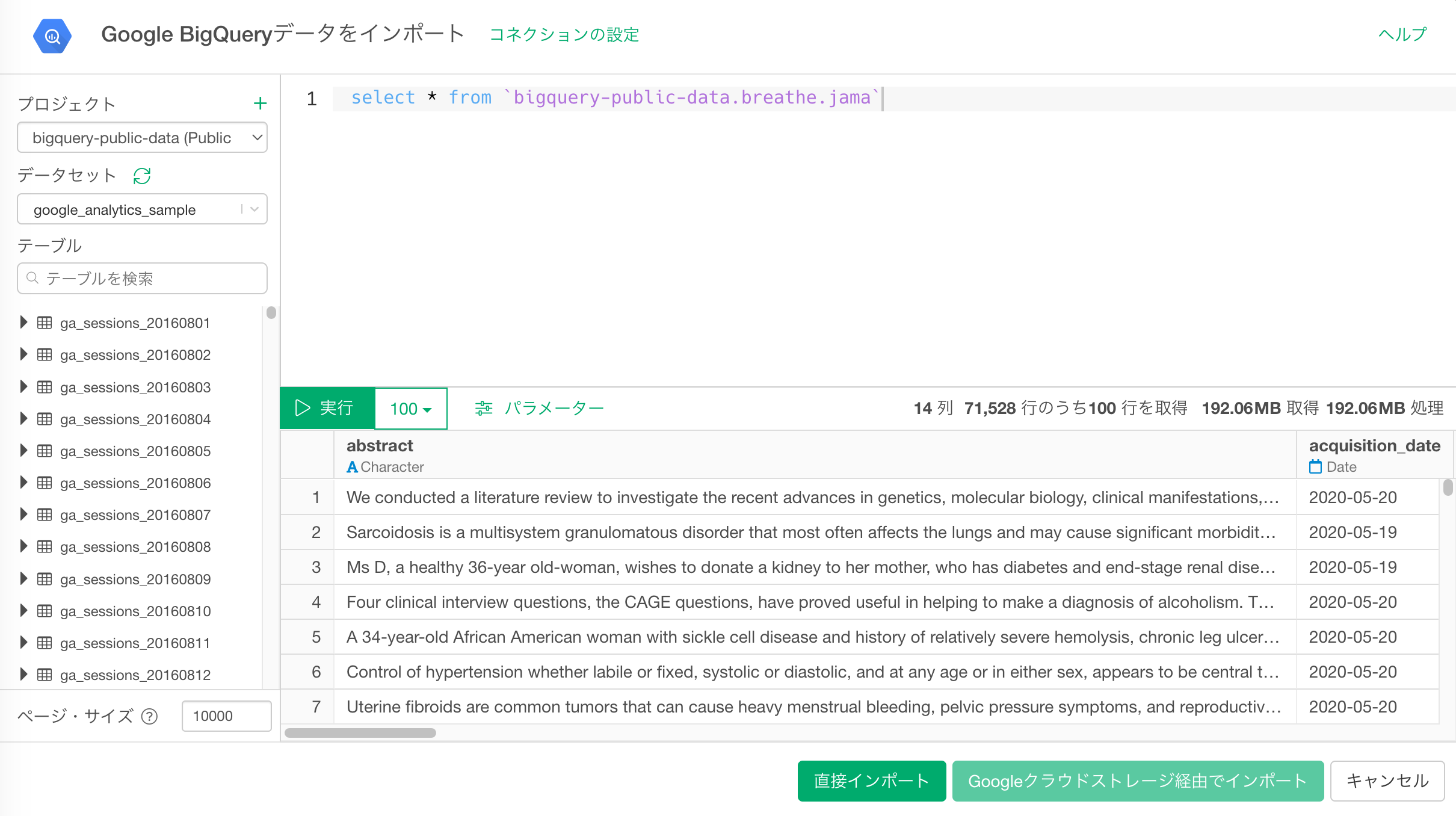
SQLクエリの作成
- 左側のメニューの「プロジェクト」から利用するプロジェクトを選択します。
- SQLのクエリエディタにクエリを入力します。
- 「実行」ボタンをクリックすると、プレビューが表示されます。
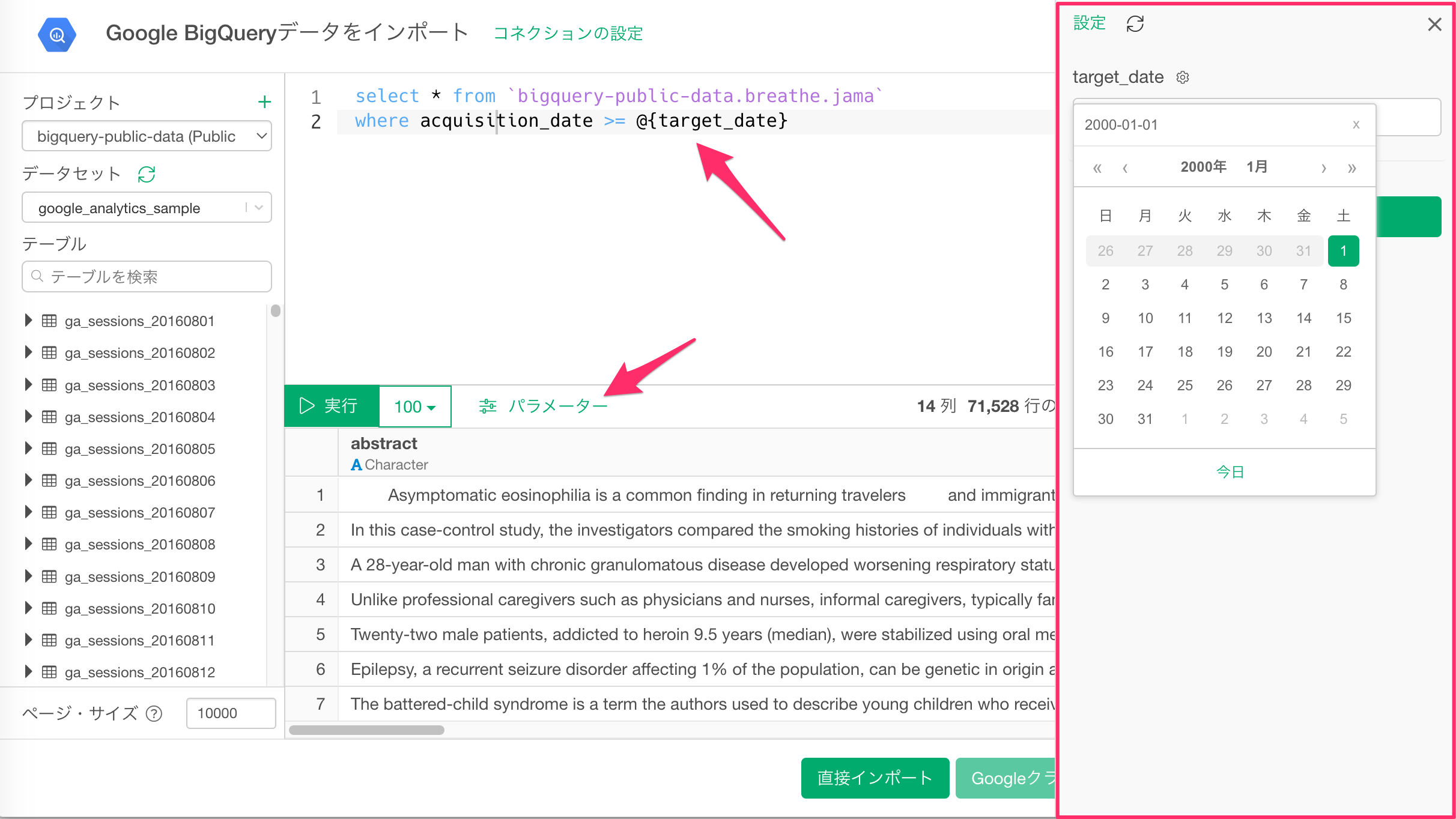
SQLでパラメータを使う
SQLのクエリエディタでは、SQLをパラメーター化してクエリの内容をダイナミックにアップデートして、インポートするデータをダイナミックに変更することが可能です。
SQLでパラメータを使う方法の詳細はこちらをご覧ください
インポート
SQLのクエリを実行して、プレビュー画面から必要なデータを取得できていることを確認できたら、「直接インポート」を選択し、データをインポートすることができます。
このとき、Google BigQueryの設定から「バケット」を設定している場合、「Google クラウドストレージ経由でインポート」することも選択できます。
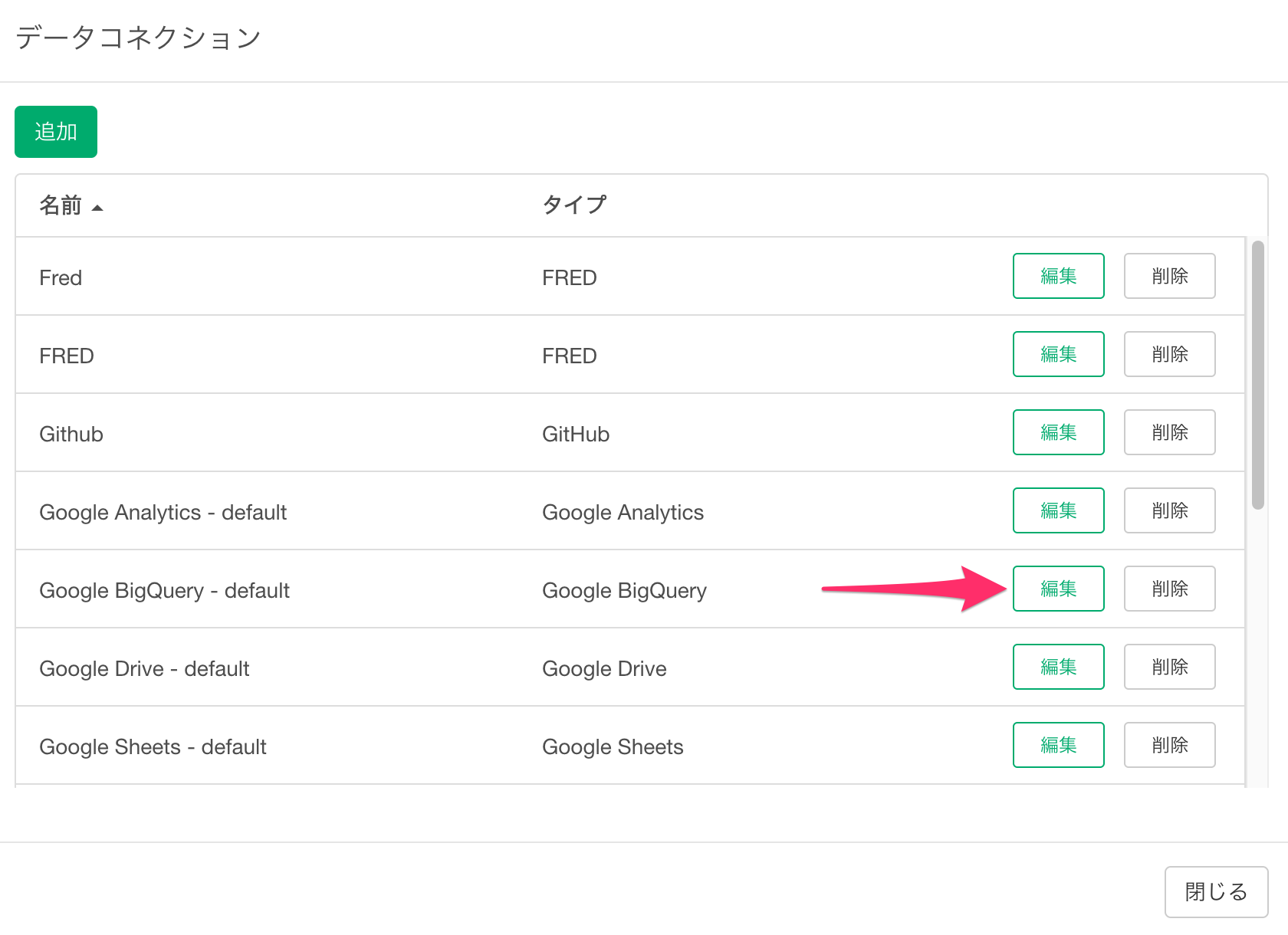
後からGoogle BigQueryの設定を変更する
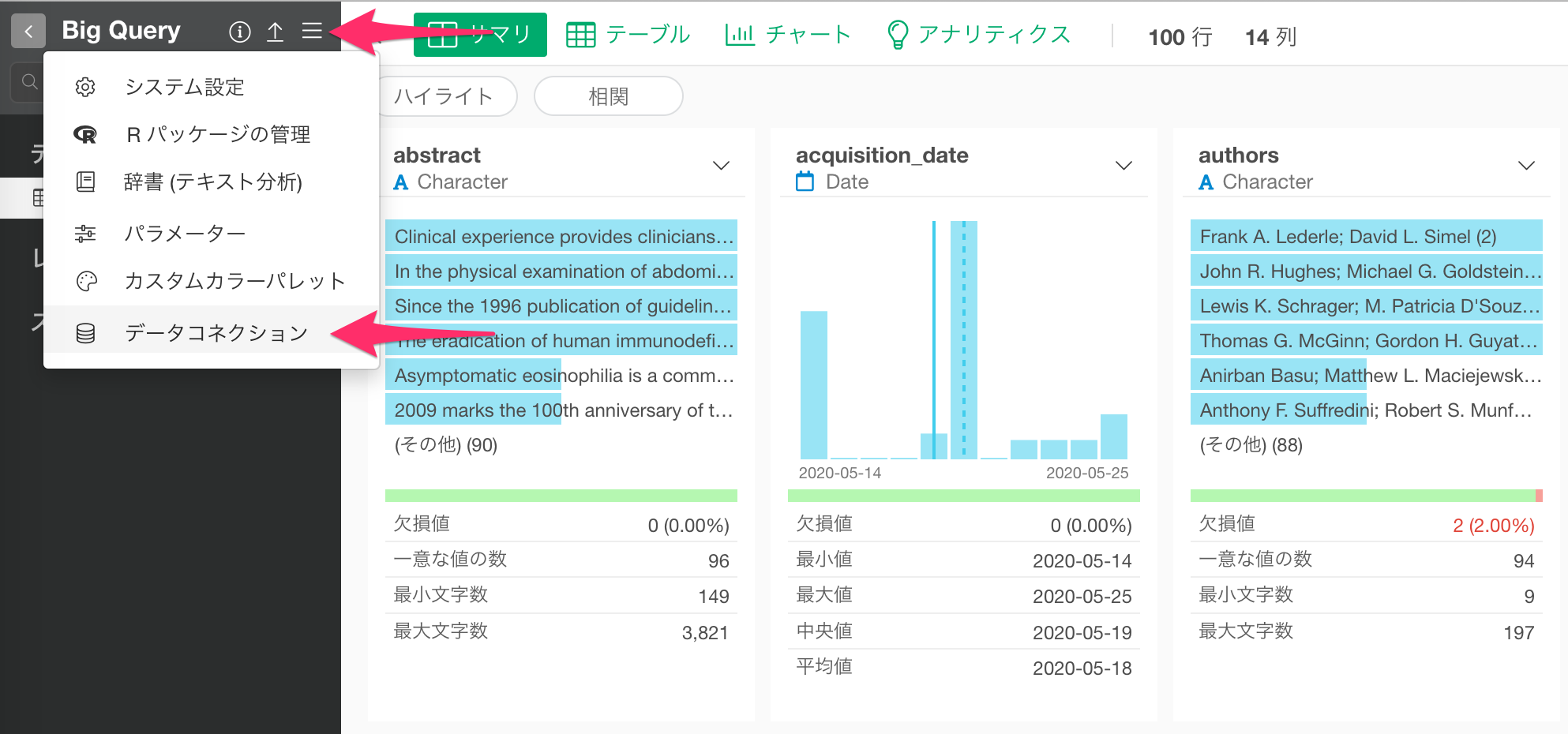
設定したBig Queryの設定は、プロジェクトメニューの「データコネクション」から変更が可能です。
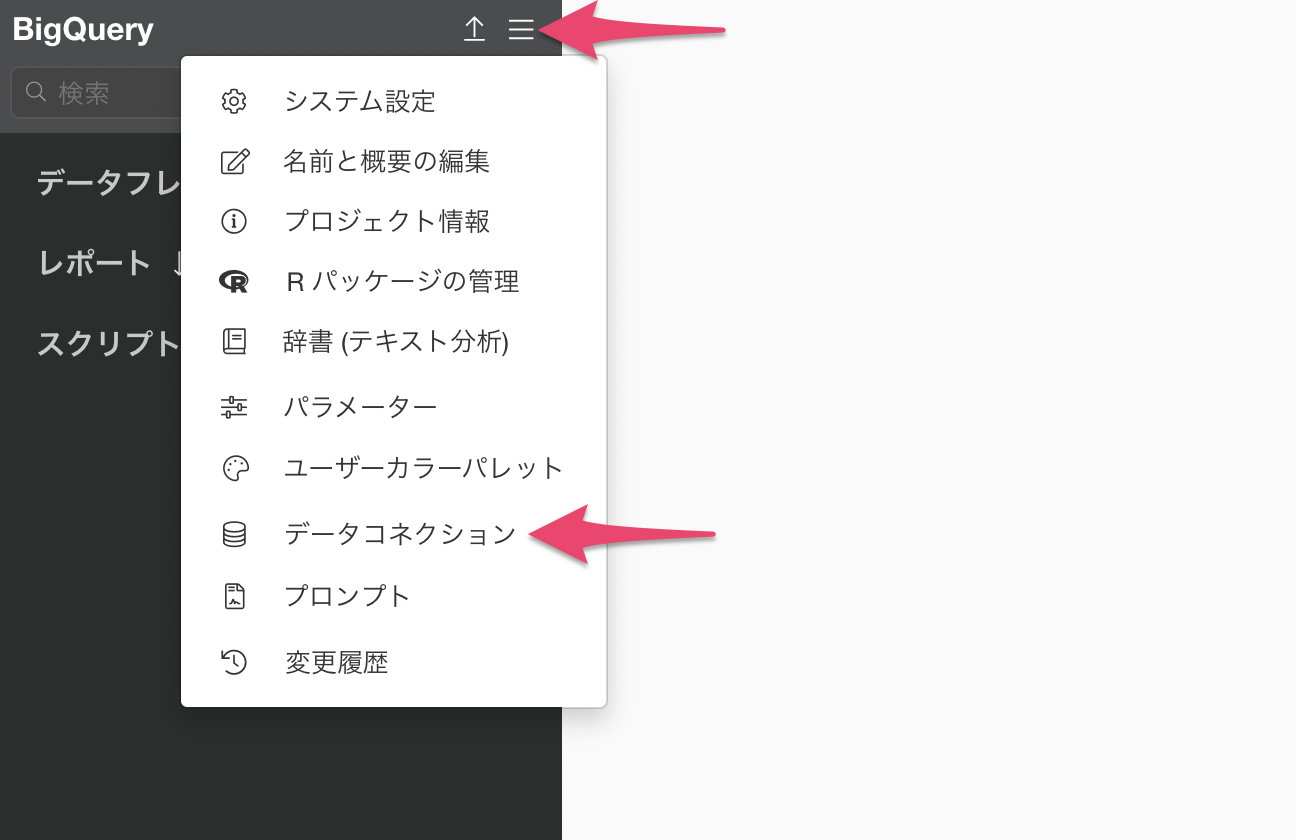
データコネクションの一覧からGoogle BigQueryのコネクションの「編集」ボタンをクリックします。
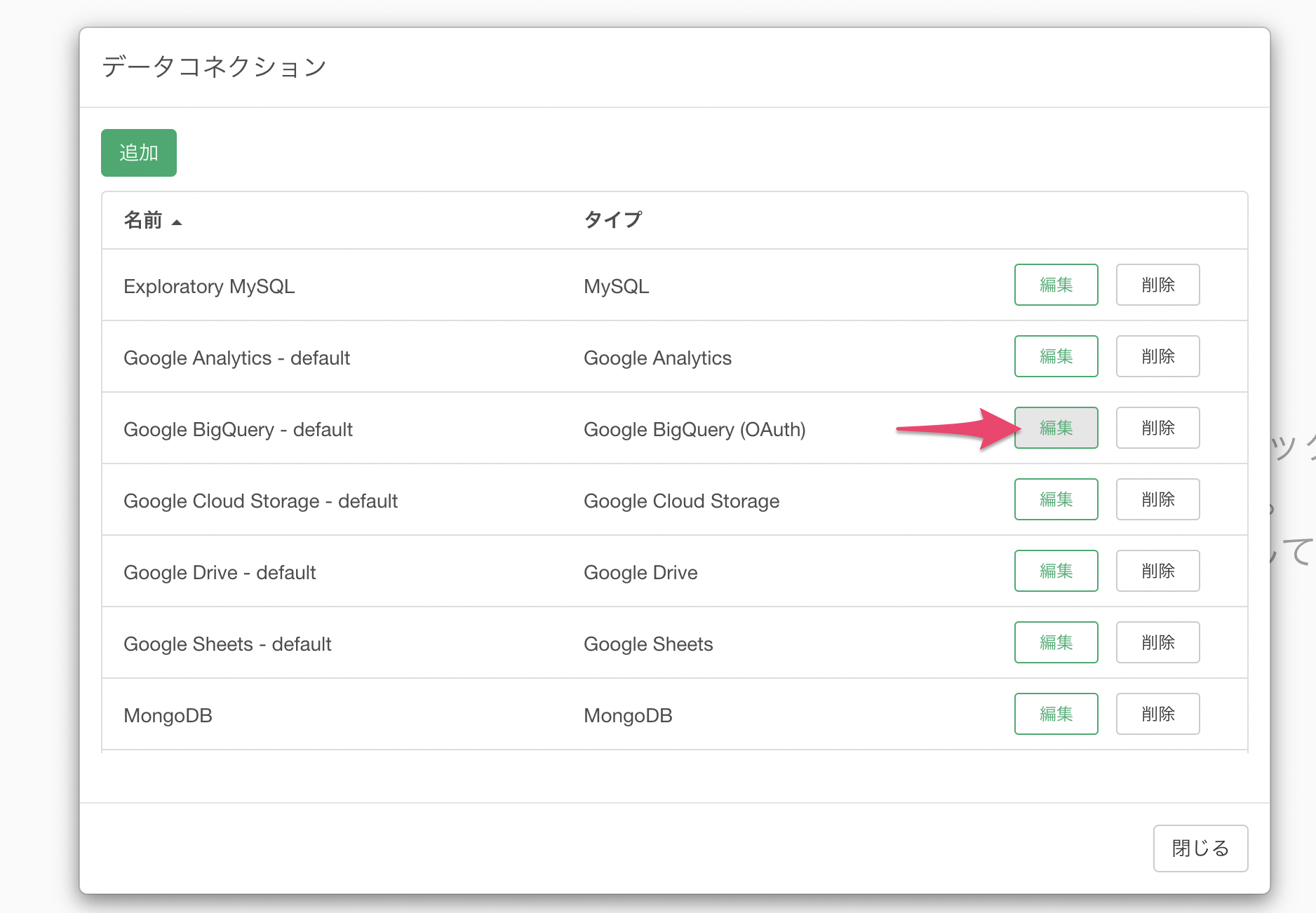
すると、Google BigQueryの編集ダイアログが表示されるので、設定を変更することが可能です。
よくあるGoogle BigQueryの問題と解決法
以下のリンクからよくあるGoogle Big Queryの問題と解決法の確認が可能です。Google BigQueryからのデータをインポートするときに問題があった方はこちらをご覧ください。
- よくあるGoogle Big Queryの問題と解決法 - リンク