プロジェクト内のデータフレームとレポートのサイズを確認する方法
1つのプロジェクトの中に多くのデータフレームやレポートを作成していると、「どのデータフレームが容量を多く占めているのか」「あのダッシュボードはどのデータフレームを参照していて、そのサイズはどのぐらいなのか」といった疑問が生まれることがあります。
そこで、こちらのノートでは、Rスクリプトを使ってこれらの情報をデータフレームとして取得する方法を解説いたします。
2つのスクリプト
こちらのノートで使用するRスクリプトは以下の2つです。
- get_dataframe_sizes
- get_report_dataframe
get_dataframe_sizes()
は、プロジェクト内の全データフレームのディスク使用量を計算し、合計サイズの大きい順に並べたデータフレームを返す関数です。
get_report_dataframe()
は、プロジェクト内のダッシュボードおよびノートが、どのデータフレームを参照しているかを一覧で返す関数です。レポートの種類と紐付いたデータフレームのサイズ情報をあわせて確認することができます。
どちらの関数も引数なしで呼び出すことができます。
Rスクリプトの登録
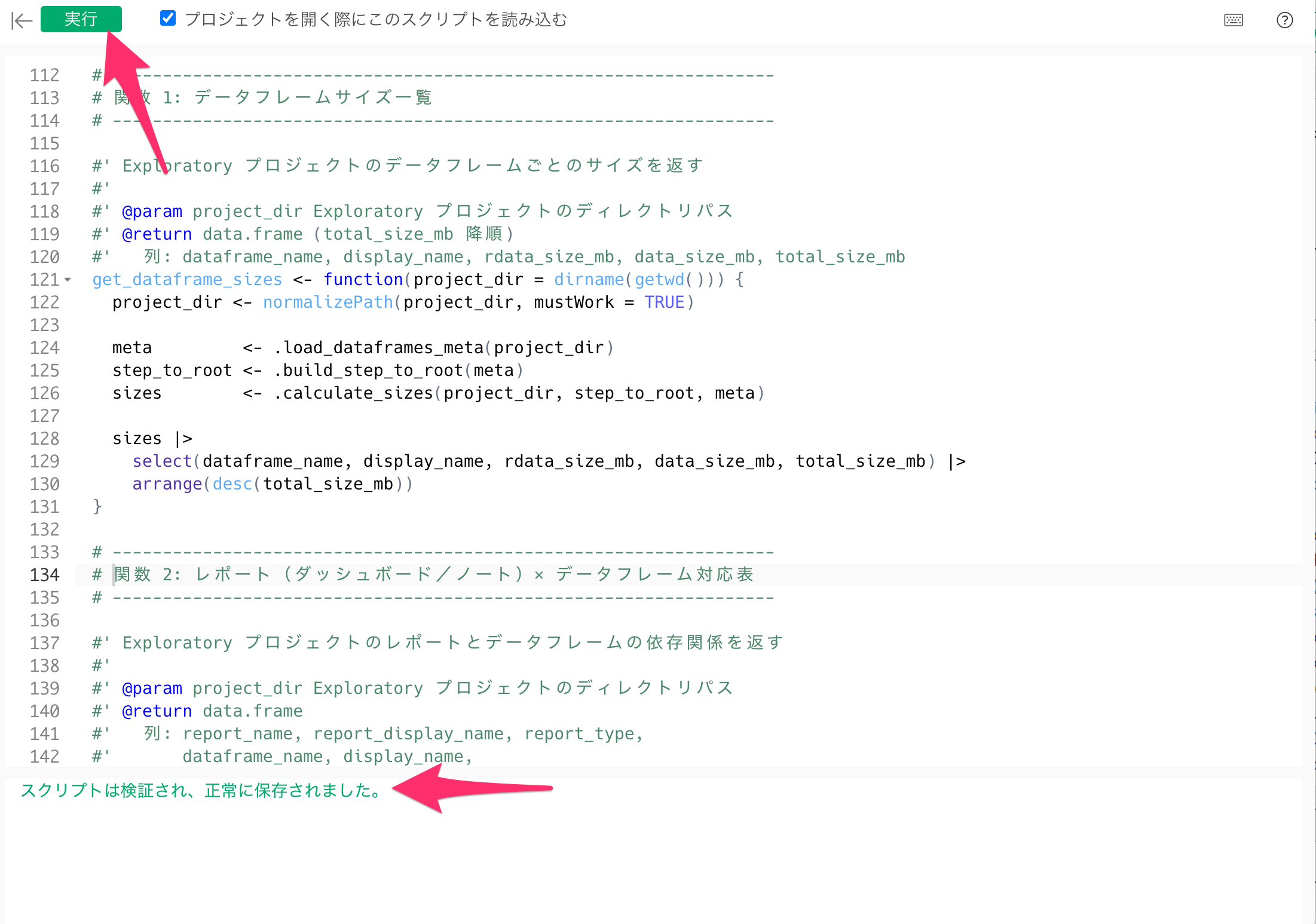
まず、Rスクリプトファイルのコードをプロジェクトのスクリプトとして登録します。
プロジェクト画面の上部にある「スクリプト」メニューから「スクリプト」を選択してください。

スクリプトの編集画面が開いたら、任意のスクリプト名(例:size_check)を設定します。
次に、エディタに以下の内容を貼り付けてください。
library(jsonlite)
library(dplyr)
# JSON ファイルを安全に読み込む。失敗時は NULL を返す。
.load_json <- function(path) {
tryCatch(
jsonlite::fromJSON(path, simplifyVector = FALSE),
error = function(e) NULL
)
}
# dataframes/ 以下の全 JSON を読み込む。
# 戻り値: list(name = list(display_name, belongs_to))
.load_dataframes_meta <- function(project_dir) {
df_dir <- file.path(project_dir, "dataframes")
files <- list.files(df_dir, pattern = "\\.json$", full.names = TRUE)
meta <- list()
for (f in files) {
data <- .load_json(f)
if (is.null(data) || is.null(data[["name"]])) next
belongs_to <- data[["belongsTo"]][["id"]] # NULL なら root
display_name <- data[["displayName"]]
if (is.null(display_name) || !nzchar(display_name)) display_name <- data[["name"]]
meta[[data[["name"]]]] <- list(
display_name = display_name,
belongs_to = belongs_to
)
}
meta
}
# belongsTo チェーンをたどって各ステップのルートを解決する。
# 戻り値: list(step_name = root_name)
.build_step_to_root <- function(meta) {
cache <- new.env(hash = TRUE, parent = emptyenv())
resolve_root <- function(name, visited = character(0)) {
if (exists(name, envir = cache, inherits = FALSE)) {
return(get(name, envir = cache, inherits = FALSE))
}
if (name %in% visited) return(name) # 循環参照ガード
df <- meta[[name]]
if (is.null(df) || is.null(df[["belongs_to"]])) {
assign(name, name, envir = cache)
return(name)
}
visited <- c(visited, name)
root <- resolve_root(df[["belongs_to"]], visited)
assign(name, root, envir = cache)
root
}
for (name in names(meta)) resolve_root(name)
as.list(cache)
}
# rdata/ と data/ をスキャンしてルートごとにサイズを集計する。
# 戻り値: data.frame(dataframe_name, display_name,
# rdata_bytes, data_bytes,
# rdata_size_mb, data_size_mb, total_size_mb)
.calculate_sizes <- function(project_dir, step_to_root, meta) {
roots <- names(meta)[sapply(names(meta), function(n) is.null(meta[[n]][["belongs_to"]]))]
sizes <- data.frame(
dataframe_name = roots,
display_name = sapply(roots, function(n) meta[[n]][["display_name"]]),
rdata_bytes = 0L,
data_bytes = 0L,
stringsAsFactors = FALSE
)
# rdata/ の Parquet を集計
rdata_dir <- file.path(project_dir, "rdata")
for (f in list.files(rdata_dir, pattern = "\\.parquet$", full.names = TRUE)) {
stem <- tools::file_path_sans_ext(basename(f))
root <- step_to_root[[stem]]
if (!is.null(root) && root %in% roots) {
idx <- which(sizes$dataframe_name == root)
sizes$rdata_bytes[idx] <- sizes$rdata_bytes[idx] + file.info(f)$size
}
}
# data/ の全ファイルを集計(形式問わず)
data_dir <- file.path(project_dir, "data")
if (dir.exists(data_dir)) {
all_files <- list.files(data_dir, full.names = TRUE)
all_files <- all_files[!file.info(all_files)$isdir]
for (f in all_files) {
stem <- tools::file_path_sans_ext(basename(f))
root <- step_to_root[[stem]]
if (!is.null(root) && root %in% roots) {
idx <- which(sizes$dataframe_name == root)
sizes$data_bytes[idx] <- sizes$data_bytes[idx] + file.info(f)$size
}
}
}
sizes$rdata_size_mb <- round(sizes$rdata_bytes / 1024^2, 2)
sizes$data_size_mb <- round(sizes$data_bytes / 1024^2, 2)
sizes$total_size_mb <- round(sizes$rdata_size_mb + sizes$data_size_mb, 2)
sizes
}
# ------------------------------------------------------------------
# 関数 1: データフレームサイズ一覧
# ------------------------------------------------------------------
#' Exploratory プロジェクトのデータフレームごとのサイズを返す
#'
#' @param project_dir Exploratory プロジェクトのディレクトリパス
#' @return data.frame (total_size_mb 降順)
#' 列: dataframe_name, display_name, rdata_size_mb, data_size_mb, total_size_mb
get_dataframe_sizes <- function(project_dir = dirname(getwd())) {
project_dir <- normalizePath(project_dir, mustWork = TRUE)
meta <- .load_dataframes_meta(project_dir)
step_to_root <- .build_step_to_root(meta)
sizes <- .calculate_sizes(project_dir, step_to_root, meta)
sizes |>
select(dataframe_name, display_name, rdata_size_mb, data_size_mb, total_size_mb) |>
arrange(desc(total_size_mb))
}
# ------------------------------------------------------------------
#関数 2: レポート(ダッシュボード/ノート)× データフレーム対応表
# ------------------------------------------------------------------
#' Exploratory プロジェクトのレポートとデータフレームの依存関係を返す
#'
#' @param project_dir Exploratory プロジェクトのディレクトリパス
#' @return data.frame
#' 列: report_name, report_display_name, report_type,
#' dataframe_name, display_name,
#' rdata_size_mb, data_size_mb, total_size_mb
get_report_dataframe <- function(project_dir = dirname(getwd())) {
project_dir <- normalizePath(project_dir, mustWork = TRUE)
meta <- .load_dataframes_meta(project_dir)
step_to_root <- .build_step_to_root(meta)
sizes <- .calculate_sizes(project_dir, step_to_root, meta)
markdowns_dir <- file.path(project_dir, "markdowns")
layout_dir <- file.path(project_dir, "layout")
rows <- list()
for (md_file in sort(list.files(markdowns_dir, pattern = "\\.json$", full.names = TRUE))) {
md <- .load_json(md_file)
if (is.null(md)) next
report_name <- if (!is.null(md[["name"]])) md[["name"]] else tools::file_path_sans_ext(basename(md_file))
report_display <- md[["displayName"]]
if (is.null(report_display) || !nzchar(report_display)) report_display <- report_name
report_type <- if (isTRUE(md[["_isDashboard"]])) "dashboard" else "note"
# viz ID を収集
viz_ids <- character(0)
if (!is.null(md[["dependencies"]])) {
for (dep in md[["dependencies"]]) {
if (!is.null(dep[["type"]]) && dep[["type"]] == "viz" && !is.null(dep[["id"]])) {
viz_ids <- c(viz_ids, dep[["id"]])
}
}
}
# viz → dataframe 名を収集(重複排除)
df_names <- character(0)
for (viz_id in viz_ids) {
viz_file <- file.path(layout_dir, paste0(viz_id, ".json"))
if (!file.exists(viz_file)) next
viz <- .load_json(viz_file)
if (is.null(viz) || is.null(viz[["dependencies"]])) next
for (dep in viz[["dependencies"]]) {
if (is.character(dep)) df_names <- c(df_names, dep)
}
}
df_names <- sort(unique(df_names))
# サイズ情報をジョインして行を生成
for (df_name in df_names) {
size_row <- sizes[sizes$dataframe_name == df_name, ]
rows <- c(rows, list(data.frame(
report_name = report_name,
report_display_name = report_display,
report_type = report_type,
dataframe_name = df_name,
display_name = if (nrow(size_row) > 0) size_row$display_name else df_name,
rdata_size_mb = if (nrow(size_row) > 0) size_row$rdata_size_mb else 0.0,
data_size_mb = if (nrow(size_row) > 0) size_row$data_size_mb else 0.0,
total_size_mb = if (nrow(size_row) > 0) size_row$total_size_mb else 0.0,
stringsAsFactors = FALSE
)))
}
}
if (length(rows) == 0) {
return(data.frame(
report_name = character(0), report_display_name = character(0),
report_type = character(0),
dataframe_name = character(0), display_name = character(0),
rdata_size_mb = numeric(0), data_size_mb = numeric(0), total_size_mb = numeric(0)
))
}
bind_rows(rows)
}コードを貼り付けたら、「実行」ボタンをクリックします。エラーが表示されずに完了すれば、スクリプトの登録は完了です。
関数の使い方
データフレームのサイズ一覧を確認する
データフレームを追加ボタンをクリックして、データソースとして「Rスクリプト」を選択してください。
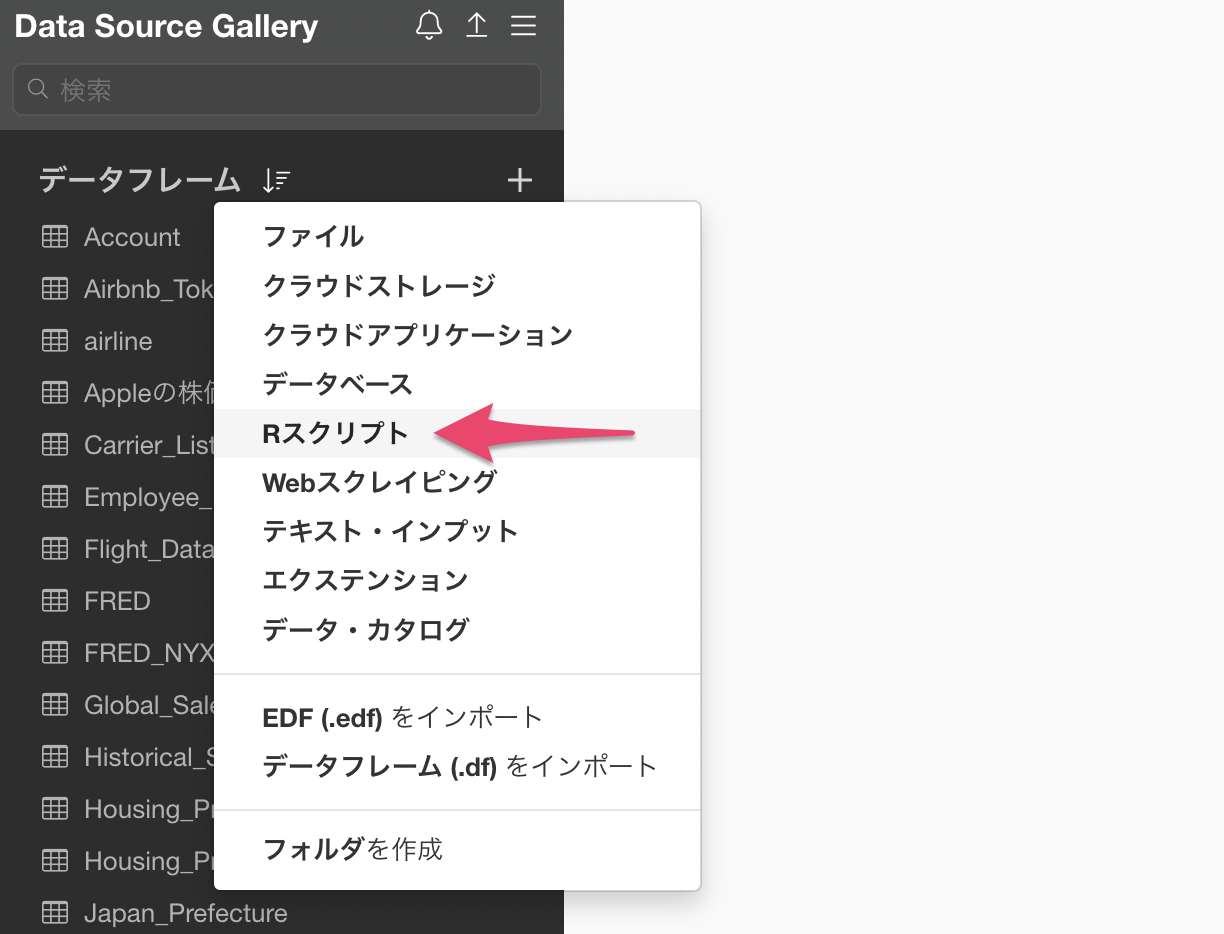
Rスクリプトのエディタが開いたら、以下のように記述して先ほど登録したスクリプトを実行します。
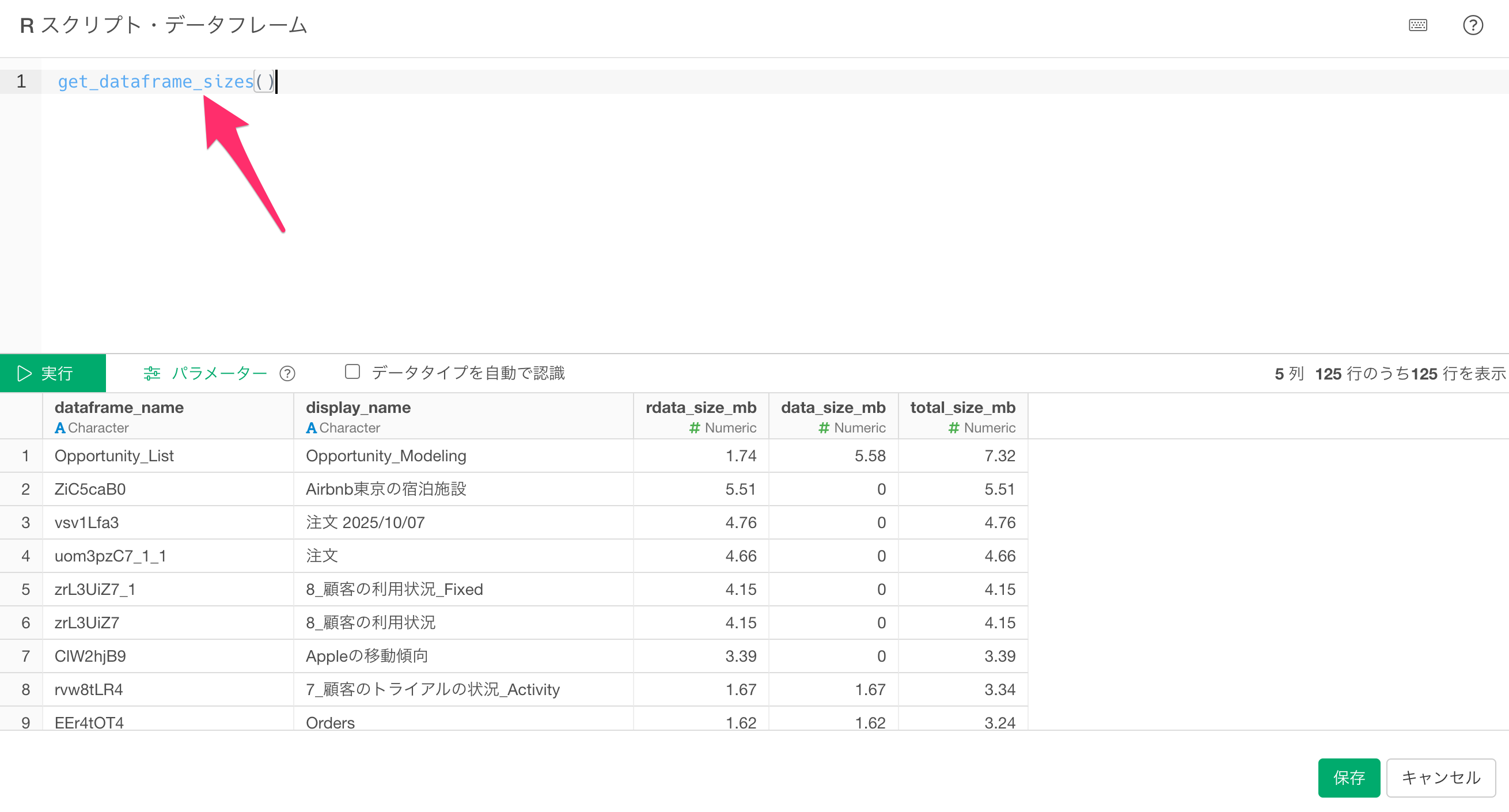
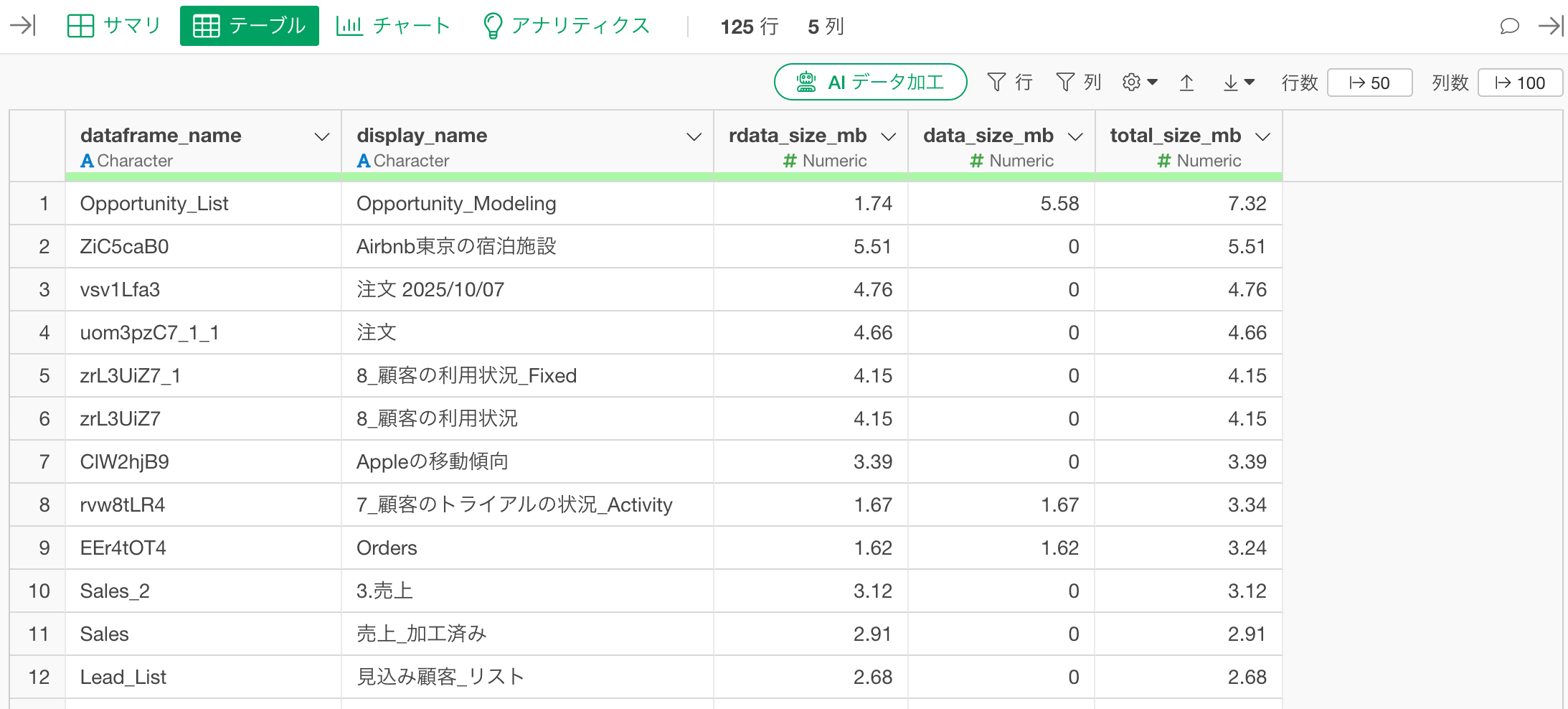
get_dataframe_sizes()
「実行」ボタンをクリックすると、以下の列を持つデータフレームが返されます。
- dataframe_name: データフレームの内部名称
- display_name: Explorer上のデータフレーム名
- rdata_size_mb: 該当のプロジェクトのrdataフォルダに保存されているParquetファイルのサイズ(MB)
- data_size_mb: dataフォルダに保存されている元データのサイズ(MB)
- total_size_mb: 両者の合計サイズです。
なお、結果はtotal_size_mbが大きい順でソートされています。
実行ボタンをクリックすることで、プロジェクト内の全てのデータフレーム情報をデータフレームで確認できます。
レポートとデータフレームの依存関係とサイズを確認する
get_dataframe_sizes関数と同じように、get_report_dataframe関数を利用することで、各ダッシュボードやノートがどのデータフレームを参照しているのかと、そのサイズを一覧で確認できます。
同じく「Rスクリプト」データソースのエディタに、以下のように記述してください。
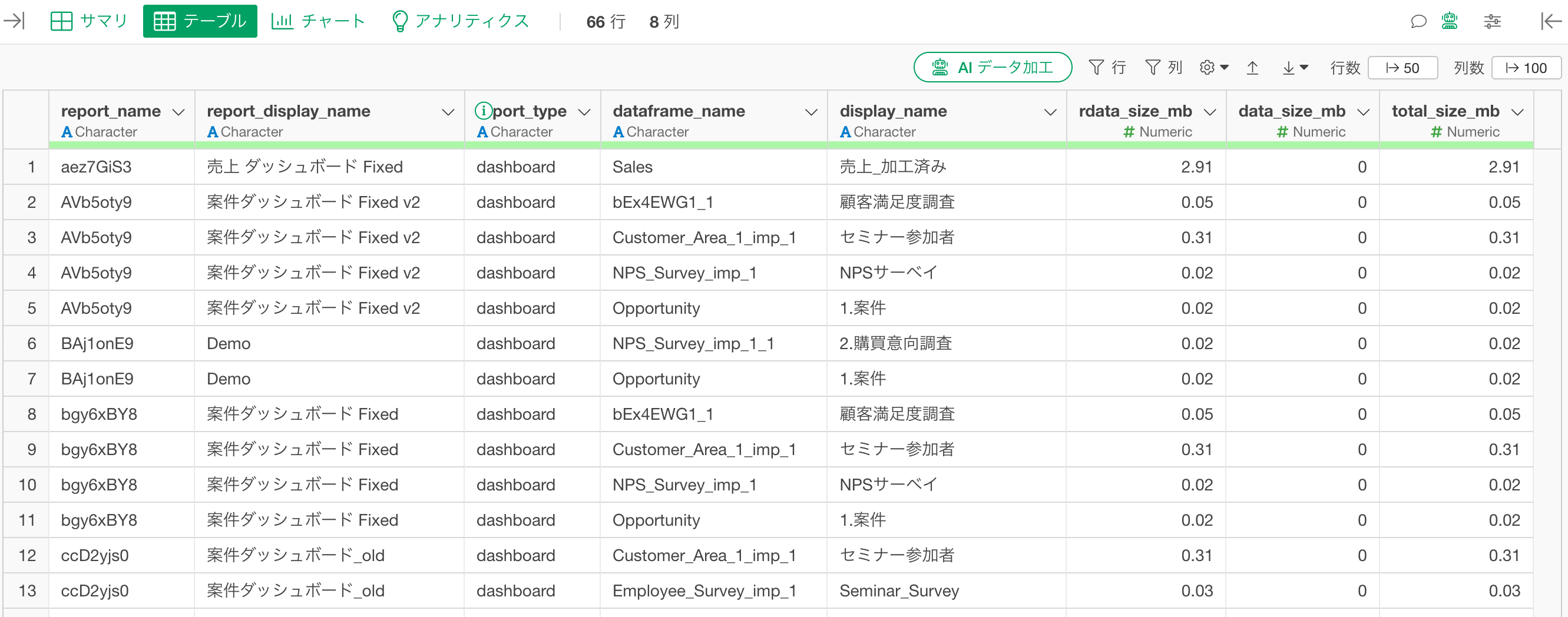
get_report_dataframe()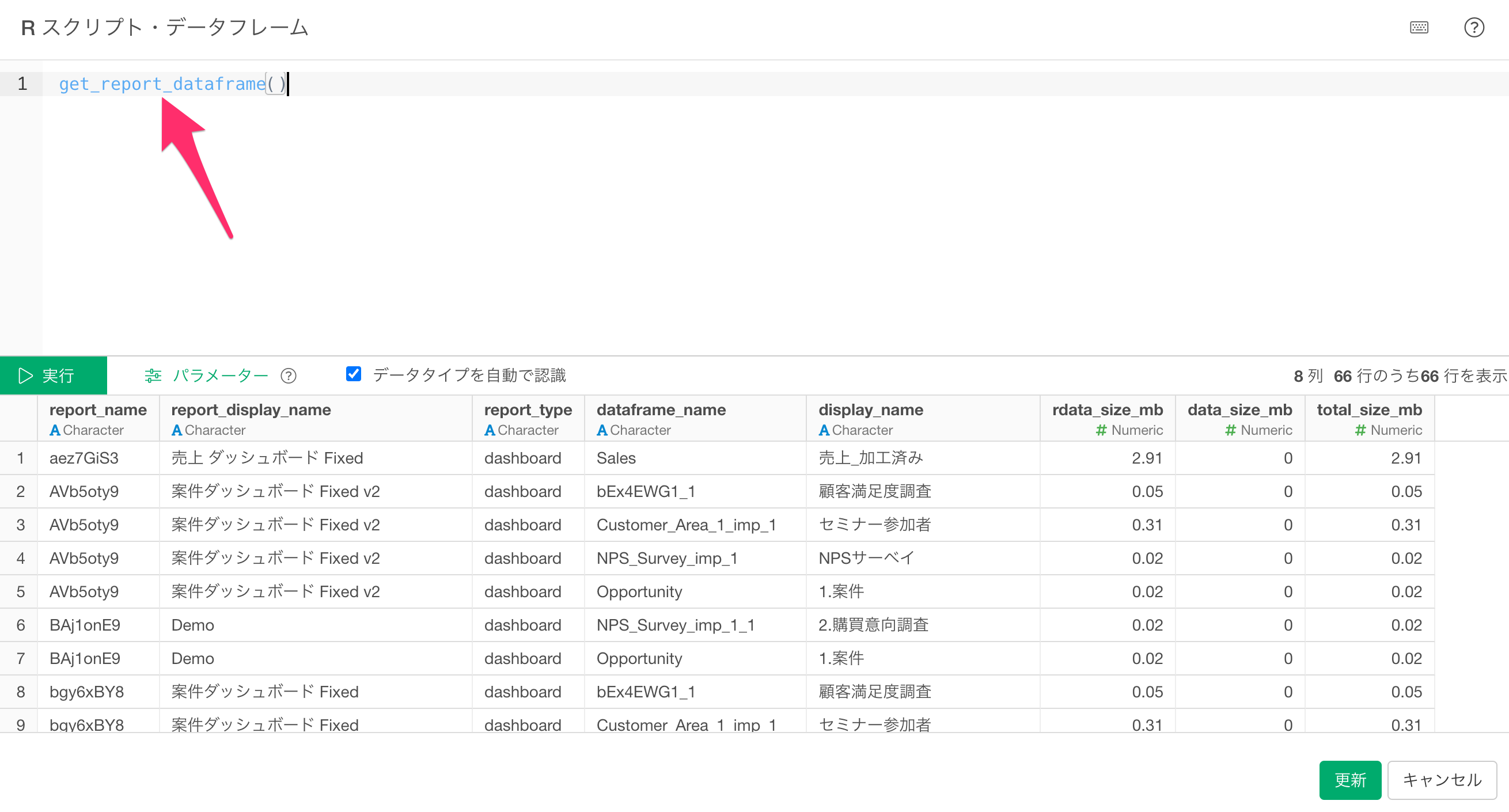 「実行」ボタンをクリックすると、以下の列を持つデータフレームが返されます。
「実行」ボタンをクリックすると、以下の列を持つデータフレームが返されます。
report_name: レポートの内部名称
report_display_name: Explorer上で表示されているレポート名
report_type: レポートの種類(“dashboard” または “note”)
dataframe_name: そのレポートが依存しているデータフレームの内部名称
display_name: そのデータフレームの表示名
rdata_size_mb: 該当のプロジェクトのrdataフォルダに保存されているParquetファイルのサイズ(MB)
data_size_mb: dataフォルダに保存されている元データのサイズ(MB)
total_size_mb: 両者の合計サイズです。
なお、結果はtotal_size_mbが大きい順でソートされています。
参考情報
- パフォーマンスを向上させるためのベストプラクティス - リンク