テューキーのHSD(範囲)検定をExploratoryで行う方法
テューキーのHSD(範囲)検定は、3つ以上のサンプル間の、どの組み合わせに有意差があるかを見つけるために使用されます。
Exploratoryのバージョン6.0のアナリティクス・ビューでのテューキーのHSD検定はサポートされていませんが、カスタムRステップから、RのTukeyHSD関数を利用することで実行が可能です。
このノートではそちらのやり方を紹介します。
データ
今回は織り糸の切断データを利用していきます。このデータは1が1台の織機のデータとなっており、 利用した糸の種類(A、B)とその張力の強さ(High, Middle, Low)と、糸の切断数を表しています。
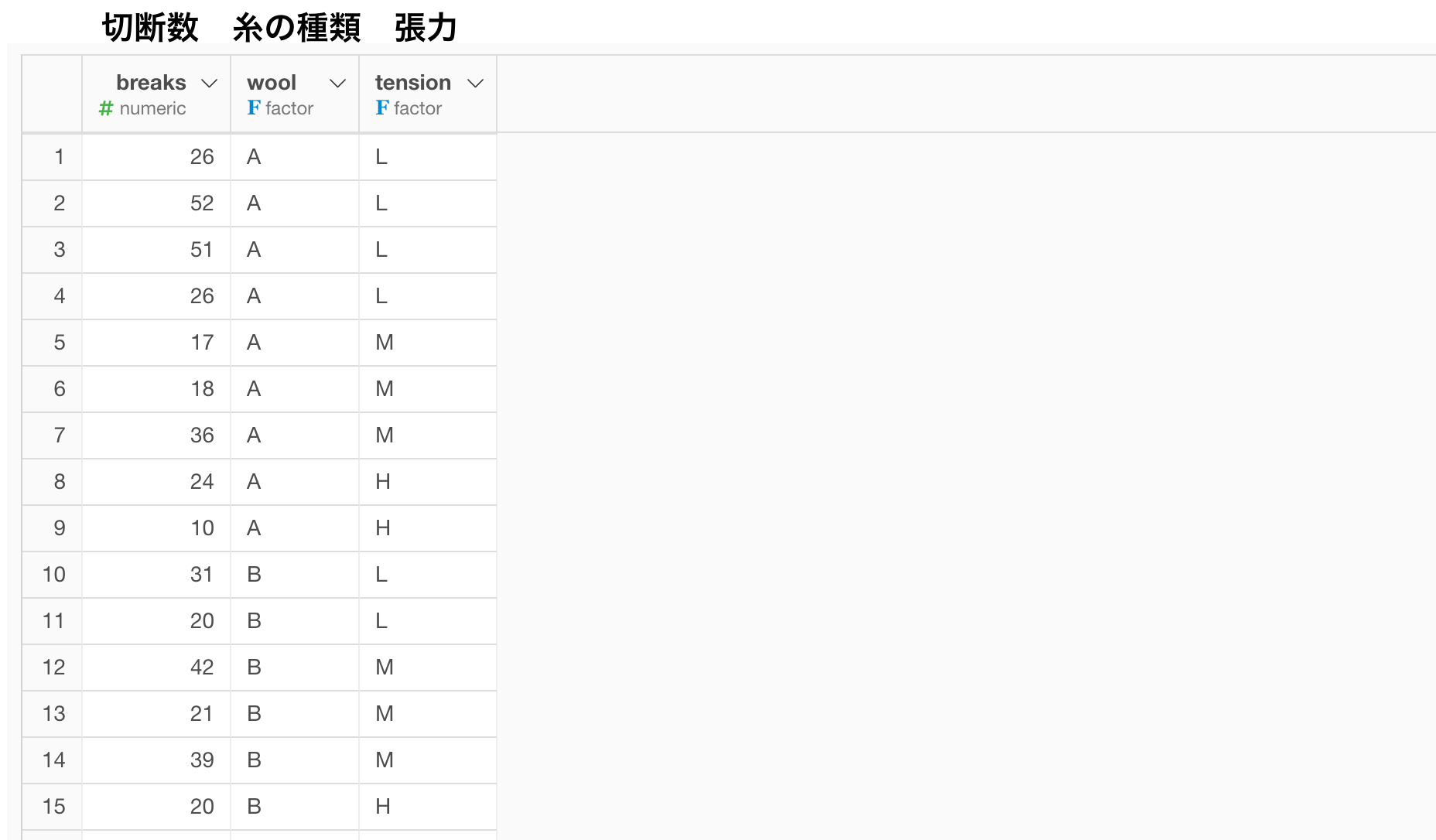
異なる張力のペア(たとえば、HighとMiddle、またはMiddleとLow)間で、切断された織り糸の数に大きな違いがあるかどうかを調べてみましょう。
なおこのデータを含むデータフレームは、RスクリプトデータフレームとしてRからロードすることで作成できます。

検定用にモデルオブジェクトを構築する
それでは、テューキーのHSD(範囲)検定を実施していきます。

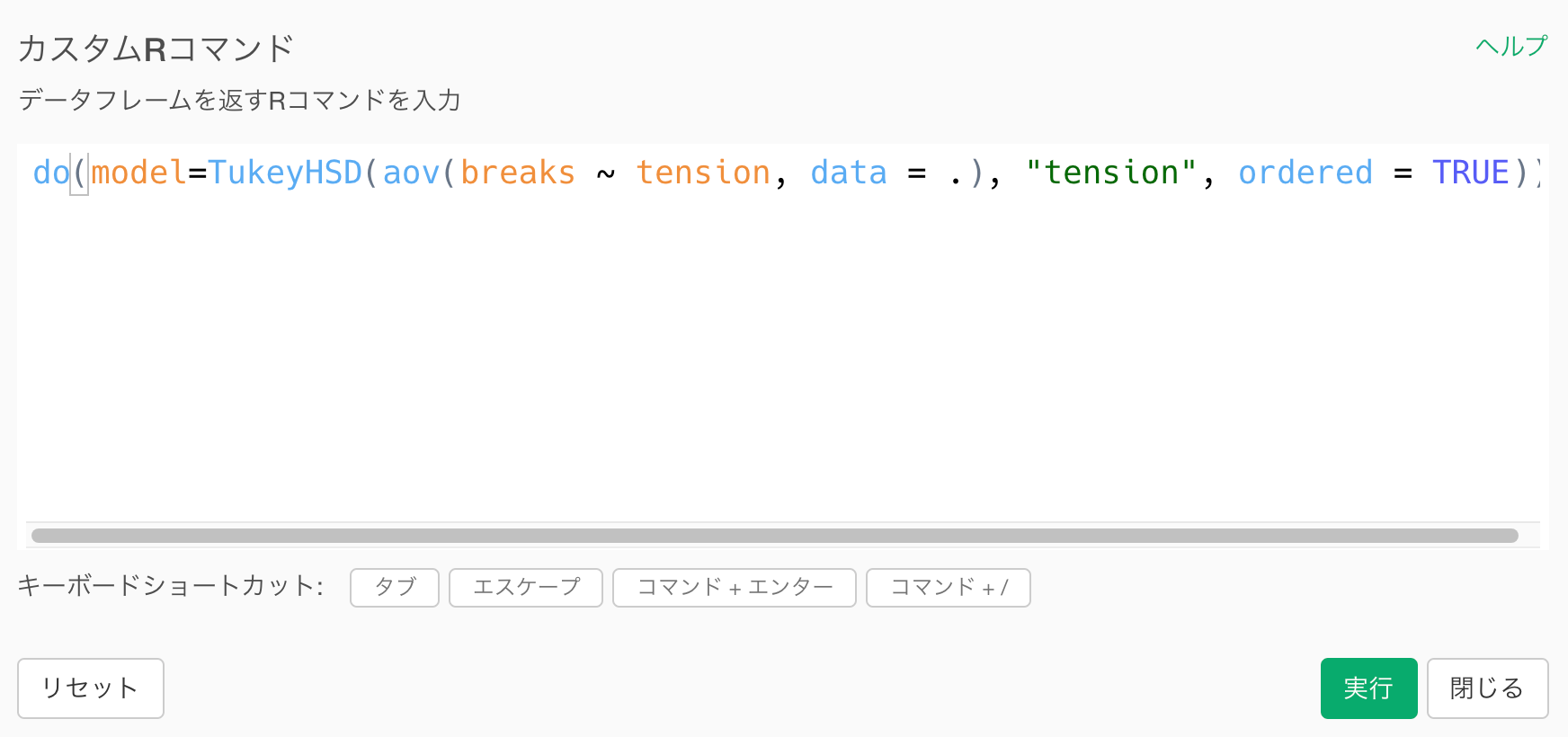
以下のスクリプトでカスタムRコマンドのステップを追加し、modelという名前でデータフレームを作成します。
do(model=TukeyHSD(aov(breaks ~ tension, data = .), "tension", ordered = TRUE))上のスクリプトの.は元のデータフレームを意味していて、元のデータフレーム上にTukeyのHSD(範囲)検定用のモデルオブジェクトを作成し、結果のデータフレームをmodelという列に格納しています。
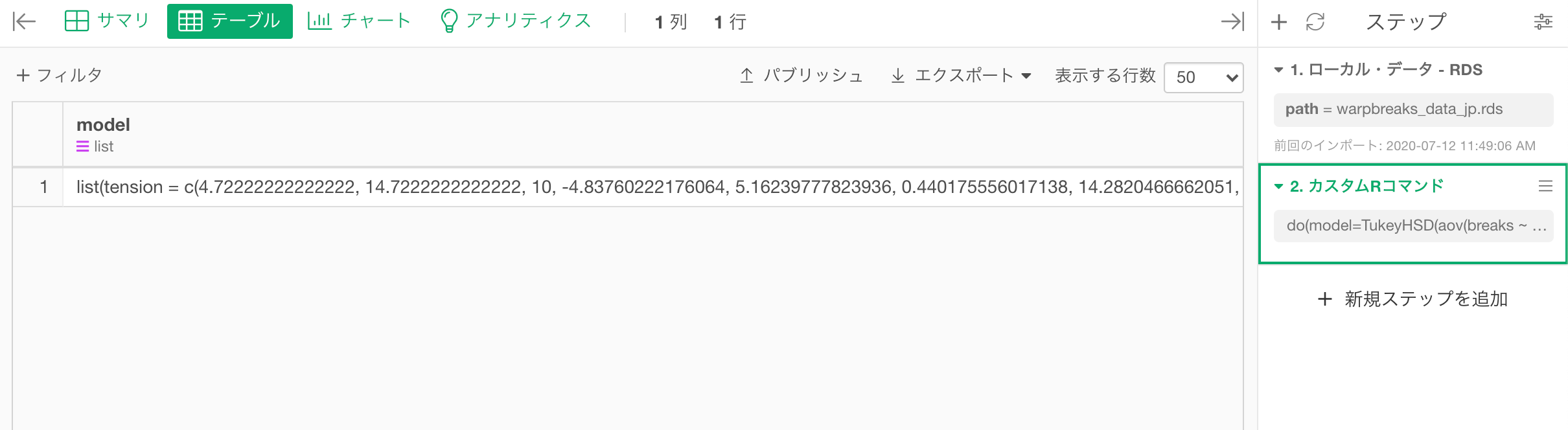
つまり、modelという列は、その値として、検定の結果を保持するモデルオブジェクトとなっているわけです。
検定の結果をデータフレームとして取り出す
検定の結果を取得するために、再びカスタムRコマンドのステップを追加します。
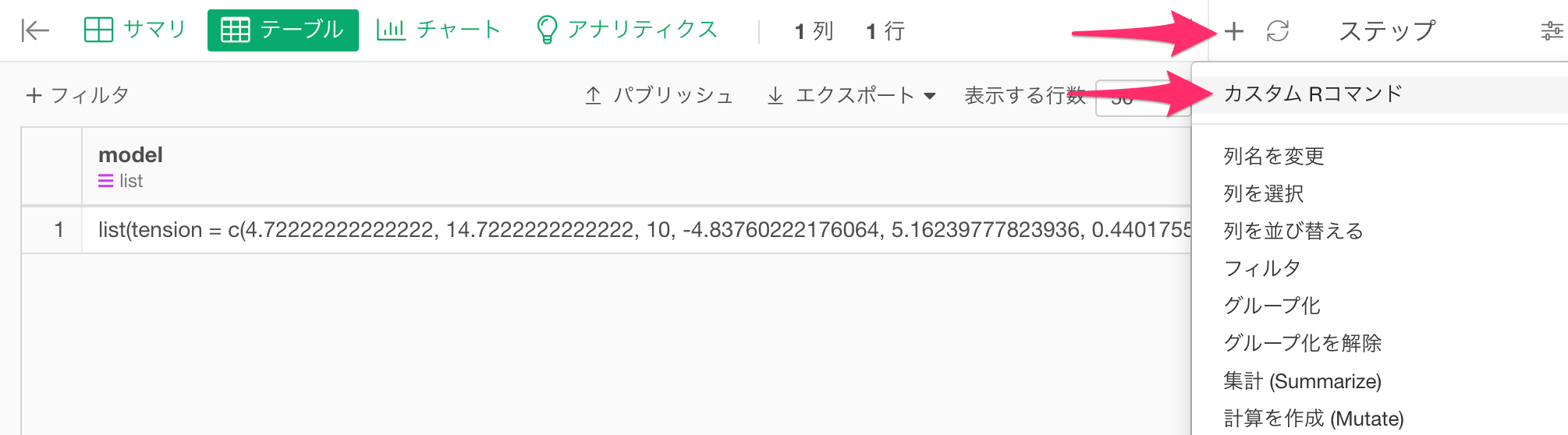
カスタムRコマンドの入力ウィンドウが表示されたら以下のスクリプトを入力し実行します。
model_info(model, output="variables")
結果がデータフレームとして出力されました。

今回の場合、張力が低いグループとその他の2つの張力(L-MおよびL-H)の間でP値(adj.p.value列)は0.05以下です。
つまり張力が低い場合は、織り糸の切断に違いが生じますが、張力が中ぐらいのときと高いとき(M-H)の間に大きな差があるとは言えません。
なおエラーバーを利用して、各張力ごとの織り糸の切断回数95%の信頼区間を可視化して、各エラーバーの重複具合を確認すると、検定の結果に対応するような結果が得られることが分かります。
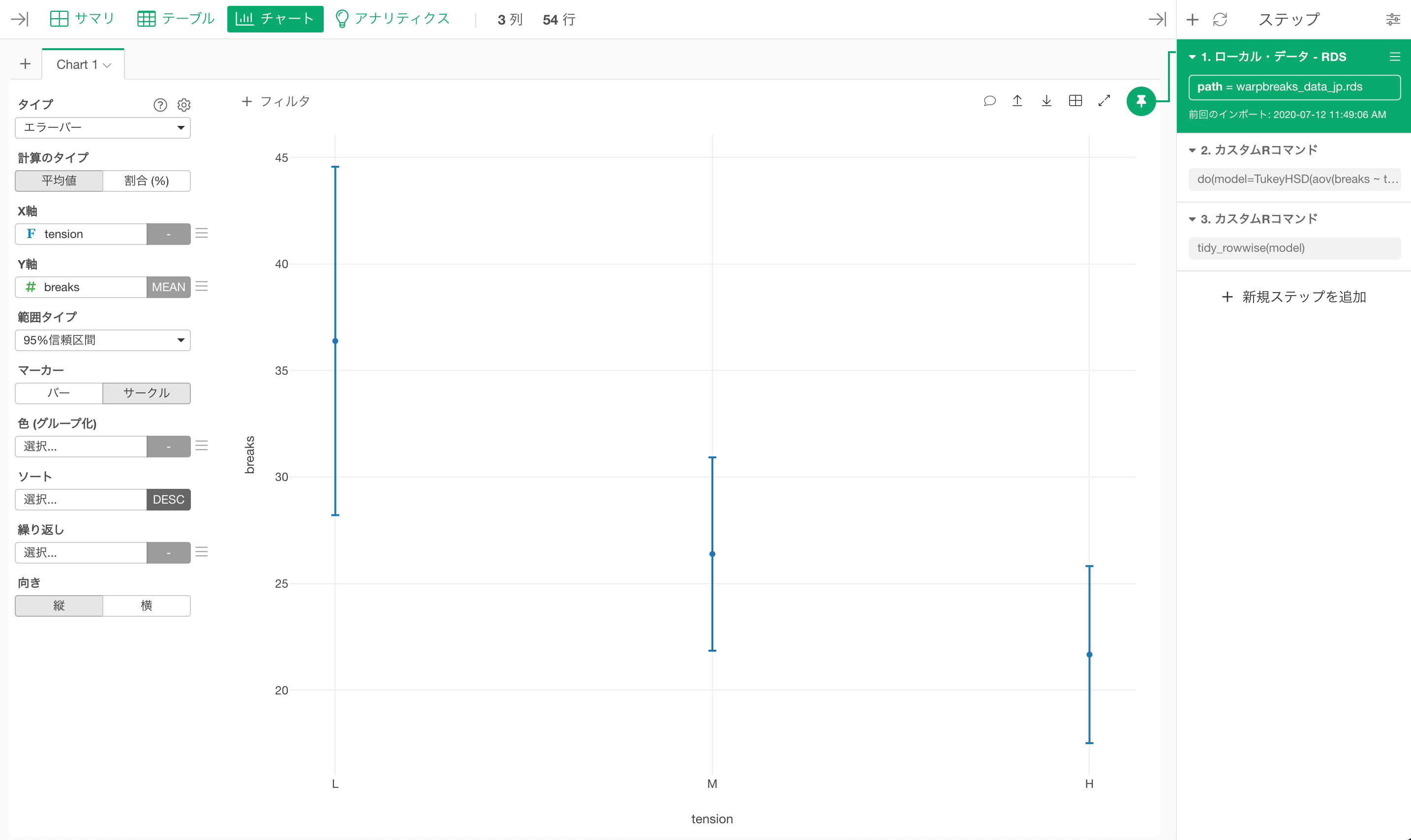
なお今回利用したRのTukeyHSD関数は、TukeyのHSD検定の改良版であるTukey-Kramerメソッドを利用しています。
今回のケースでは、張力ごとのデータ数は同じでしたが、Tukey-Kramerメソッドにより、異なるサイズのサンプルも同じ方法で扱うことが可能となります。