全プロジェクトのID・名前・説明を取得する方法
Exploratoryでは、プロジェクトを新規作成すると、自身で設定したリポジトリの配下にある
projects
フォルダ(例:~/.exploratory/projects/)にプロジェクト専用のフォルダが自動的に生成されます。
ただし、生成されるフォルダの名称は、プロジェクト作成時に設定したプロジェクト名とは一致しません。フォルダ名にはプロジェクトの内部IDが使用されており、Mzz5LKS8
のようなランダムな英数字の文字列になっています。
そのため、ファイルシステムを直接確認しても、どのフォルダがどのプロジェクトに対応しているのかを判断することができません。これは、複数のプロジェクトを一気にバックアップしたいときや、新しい端末に引っ越したいときに不便になることがあります。
そこで、こちらのノートで紹介する
get_exploratory_projects()
関数を使うと、全プロジェクトのIDと名前を一覧のデータフレームとして取得できるため、目的のプロジェクトIDを素早く特定することができます。
Rスクリプトの登録
まず、Rスクリプトファイルのコードをプロジェクトのスクリプトとして登録します。
プロジェクト画面の上部にある「スクリプト」メニューから「スクリプト」を選択してください。

スクリプトの編集画面が開いたら、任意のスクリプト名(例:get_projects)を設定します。
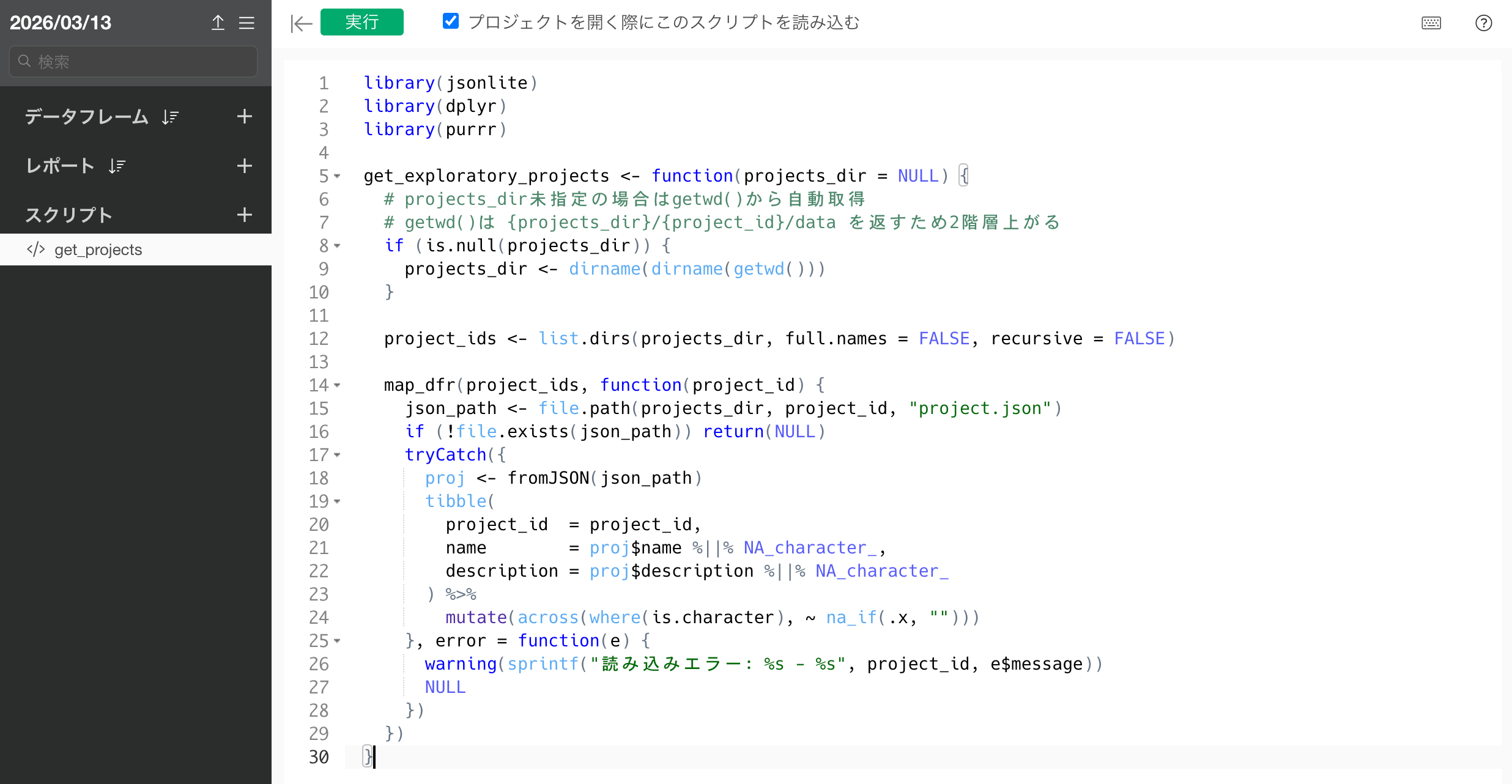
次に、エディタに以下の内容を貼り付けてください。
library(jsonlite)
library(dplyr)
library(purrr)
get_exploratory_projects <- function(projects_dir = NULL) {
# projects_dir未指定の場合はgetwd()から自動取得
# getwd()は {projects_dir}/{project_id}/data を返すため2階層上がる
if (is.null(projects_dir)) {
projects_dir <- dirname(dirname(getwd()))
}
project_ids <- list.dirs(projects_dir, full.names = FALSE, recursive = FALSE)
map_dfr(project_ids, function(project_id) {
json_path <- file.path(projects_dir, project_id, "project.json")
if (!file.exists(json_path)) return(NULL)
tryCatch({
proj <- fromJSON(json_path)
tibble(
project_id = project_id,
name = proj$name %||% NA_character_,
description = proj$description %||% NA_character_
) %>%
mutate(across(where(is.character), ~ na_if(.x, "")))
}, error = function(e) {
warning(sprintf("読み込みエラー: %s - %s", project_id, e$message))
NULL
})
})
}
コードを貼り付けたら、「実行」ボタンをクリックします。エラーが表示されずに完了すれば、スクリプトの登録は完了です。
関数の使い方
データフレームの追加ボタンをクリックして、データソースとして「Rスクリプト」を選択してください。
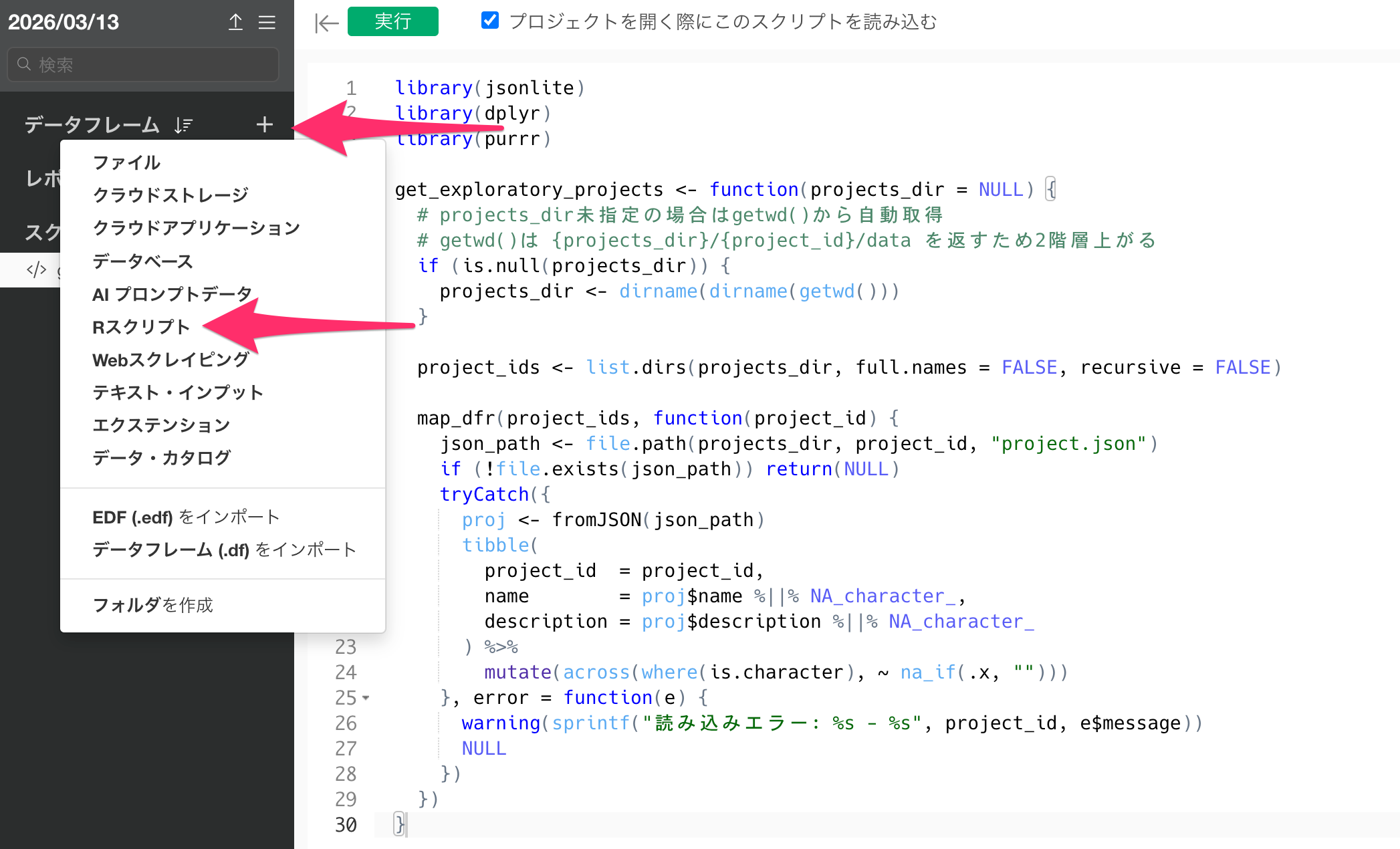
Rスクリプトのエディタが開いたら、以下のように記述して先ほど登録したスクリプトを実行します。
get_exploratory_projects()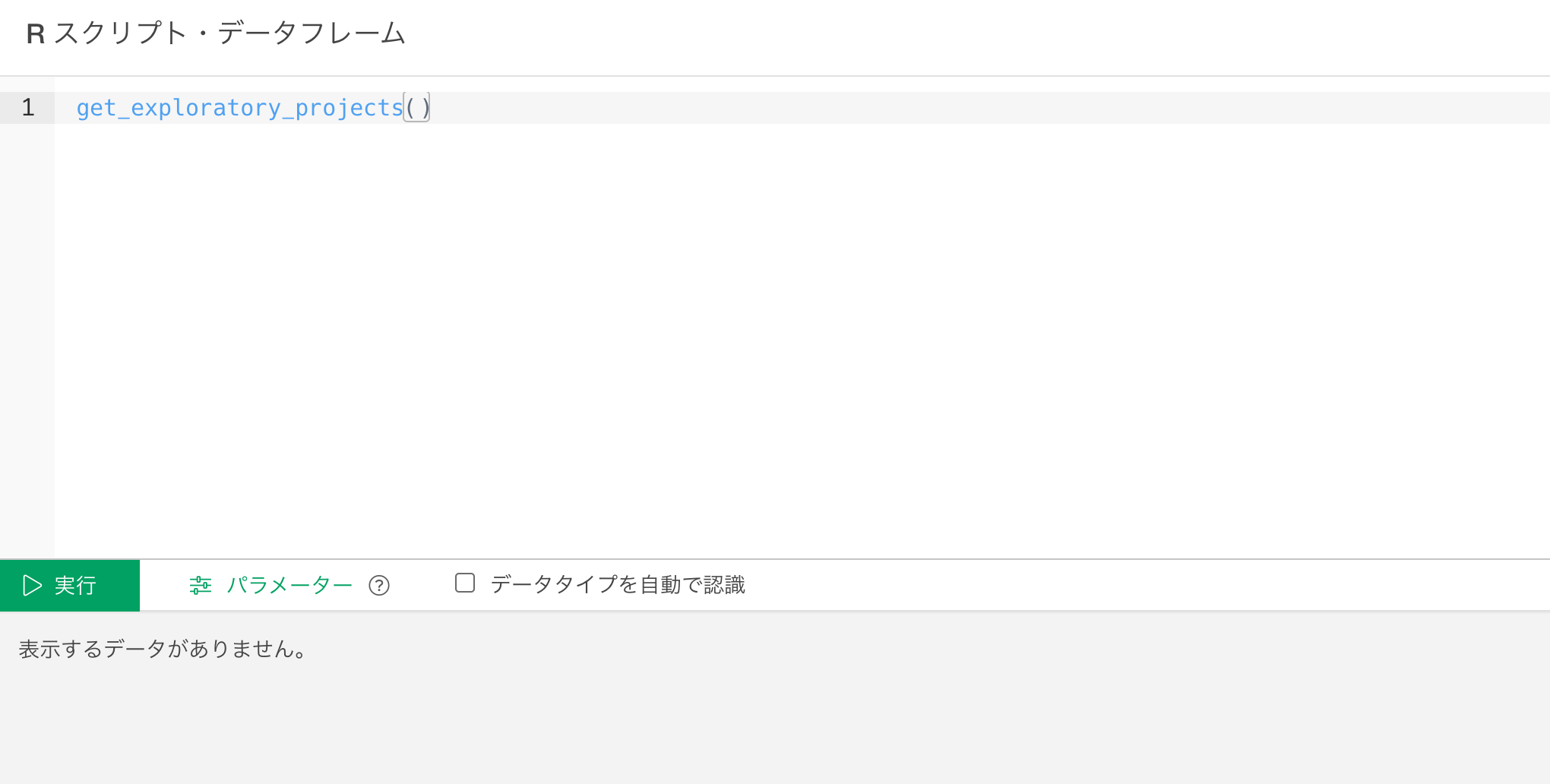
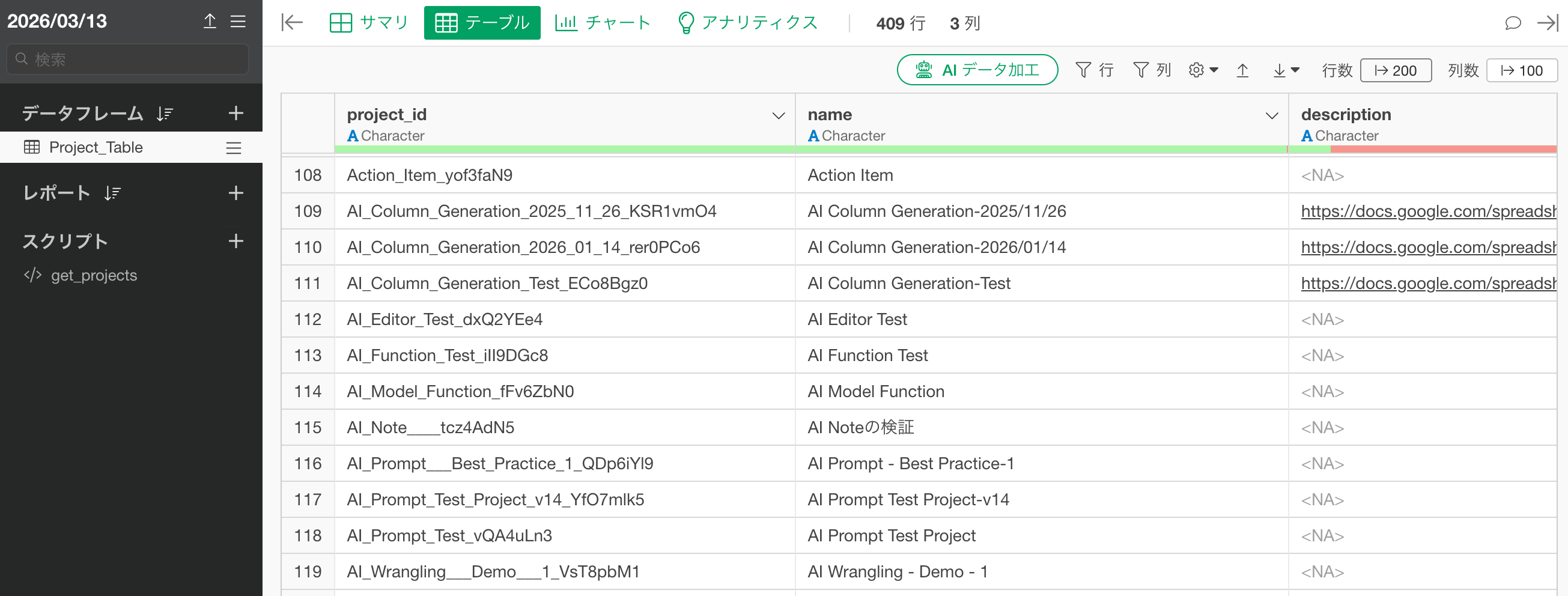
「実行」ボタンをクリックすると、以下の列を持つデータフレームが返されます。
- project_id: プロジェクトのID(プロジェクトフォルダ名)
- name: プロジェクトの名前
- description: プロジェクトの説明(未設定の場合はNA)
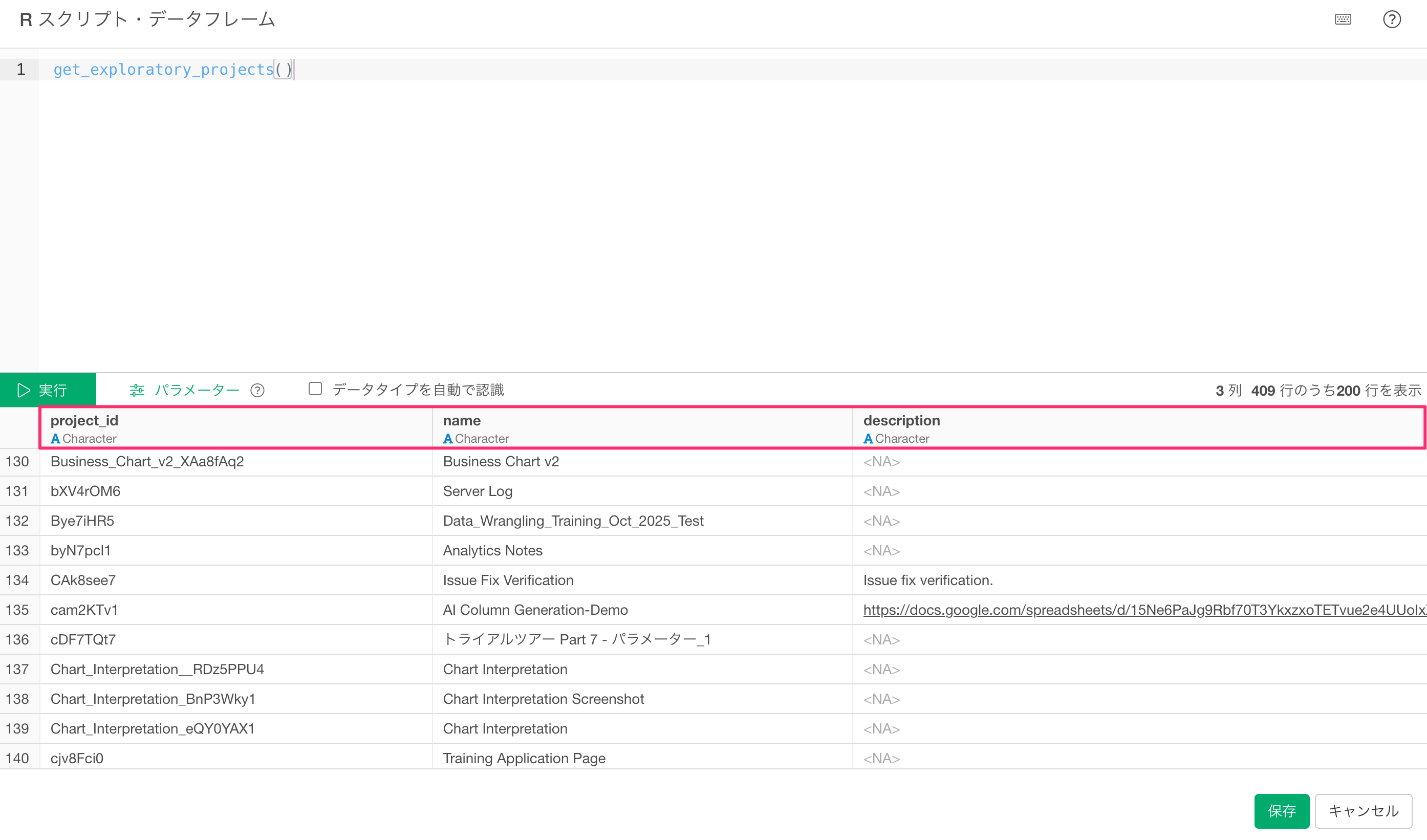
保存ボタンをクリックすることで、データフレームとし、プロジェクト情報の一覧を取得できます。
なお、通常は引数なしで、今回の関数は動作しますが、プロジェクトディレクトリのパスを明示的に指定することもできます。
Macの場合は以下のように指定します。
get_exploratory_projects("/Users/im/.exploratory/projects")Windowsの場合は以下のように指定してください。
get_exploratory_projects("C:/Users/ユーザー名/.exploratory/projects")