上位/下位Nを残す方法
このノートでは、上位/下位N行を残す方法を紹介いたします。
例えば1行が1人の従業員を表し、列に給料や所属部署などの属性を持つ、従業員のアンケートデータがあったとします。
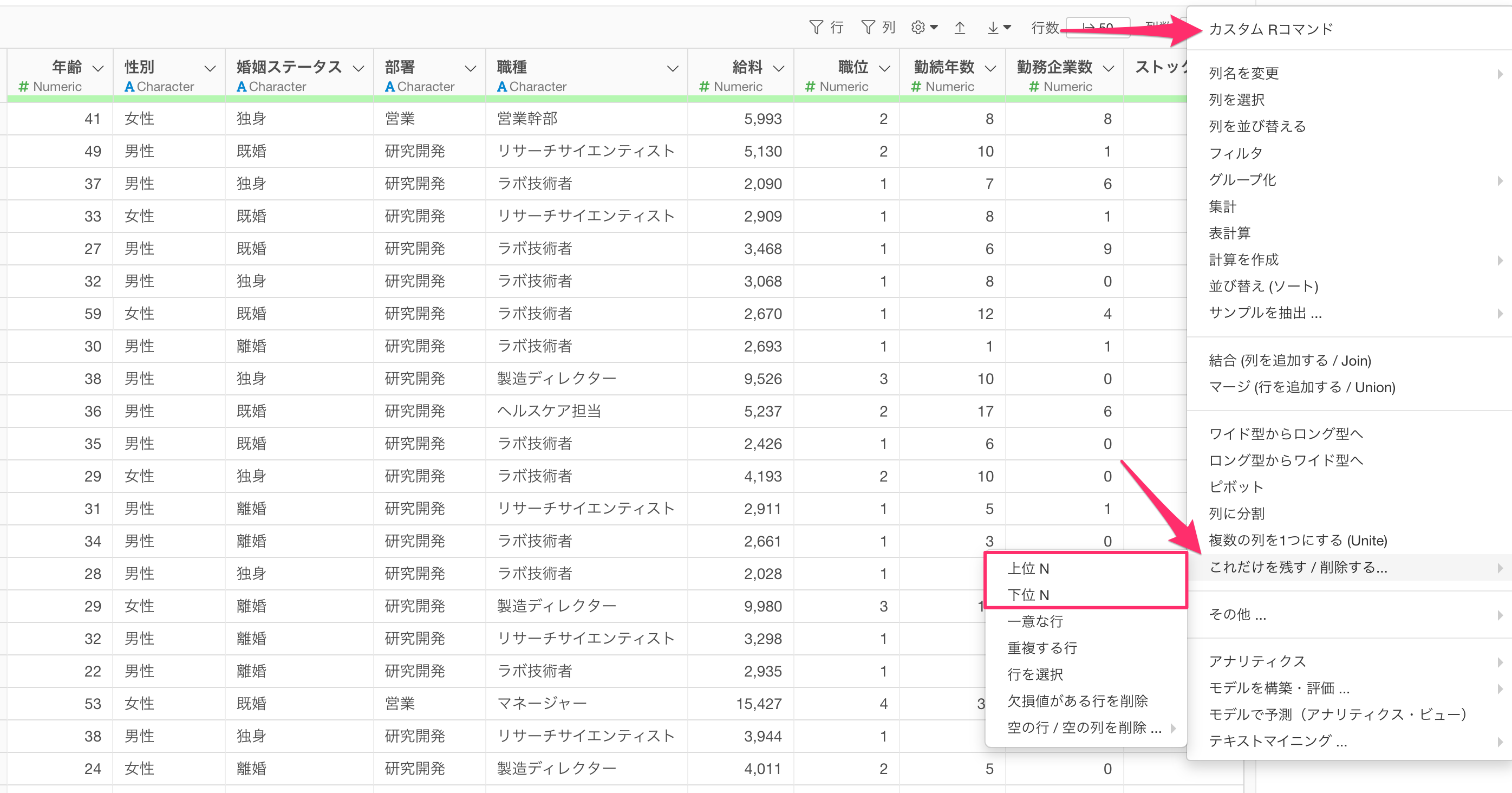
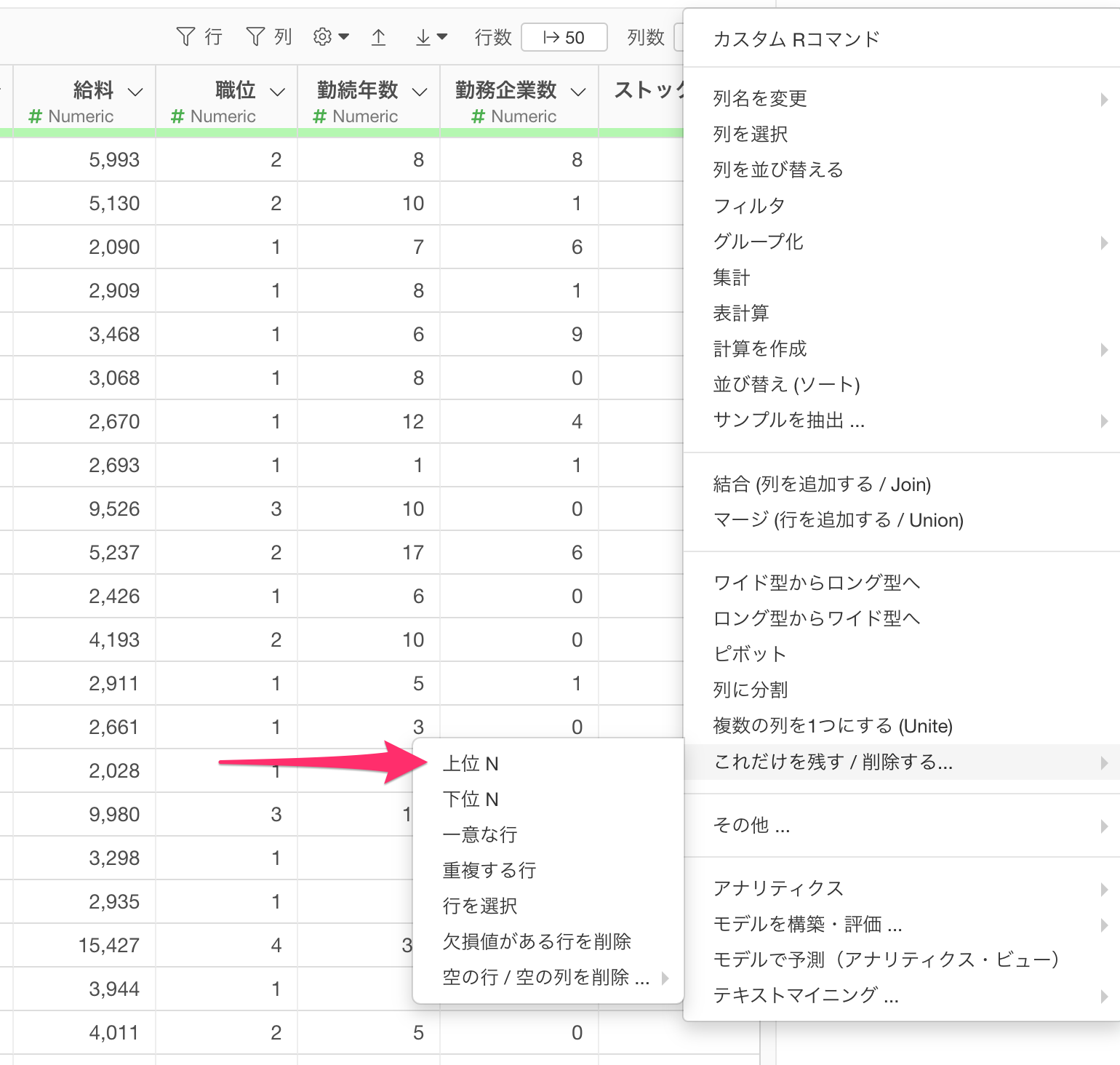
例えば、給料という数値列の上位10あるいは下位10のデータを残したいときにはステップメニューの「これだけを残す / 削除する...」から「上位 N」または「下位 N」を選択します。
今回は給料の多いトップ10にデータをフィルタしたいので、「上位 N」を選択します。
「上位N」を選択すると、以下のように「上位/下位N行を残す」ダイアログが表示されます。
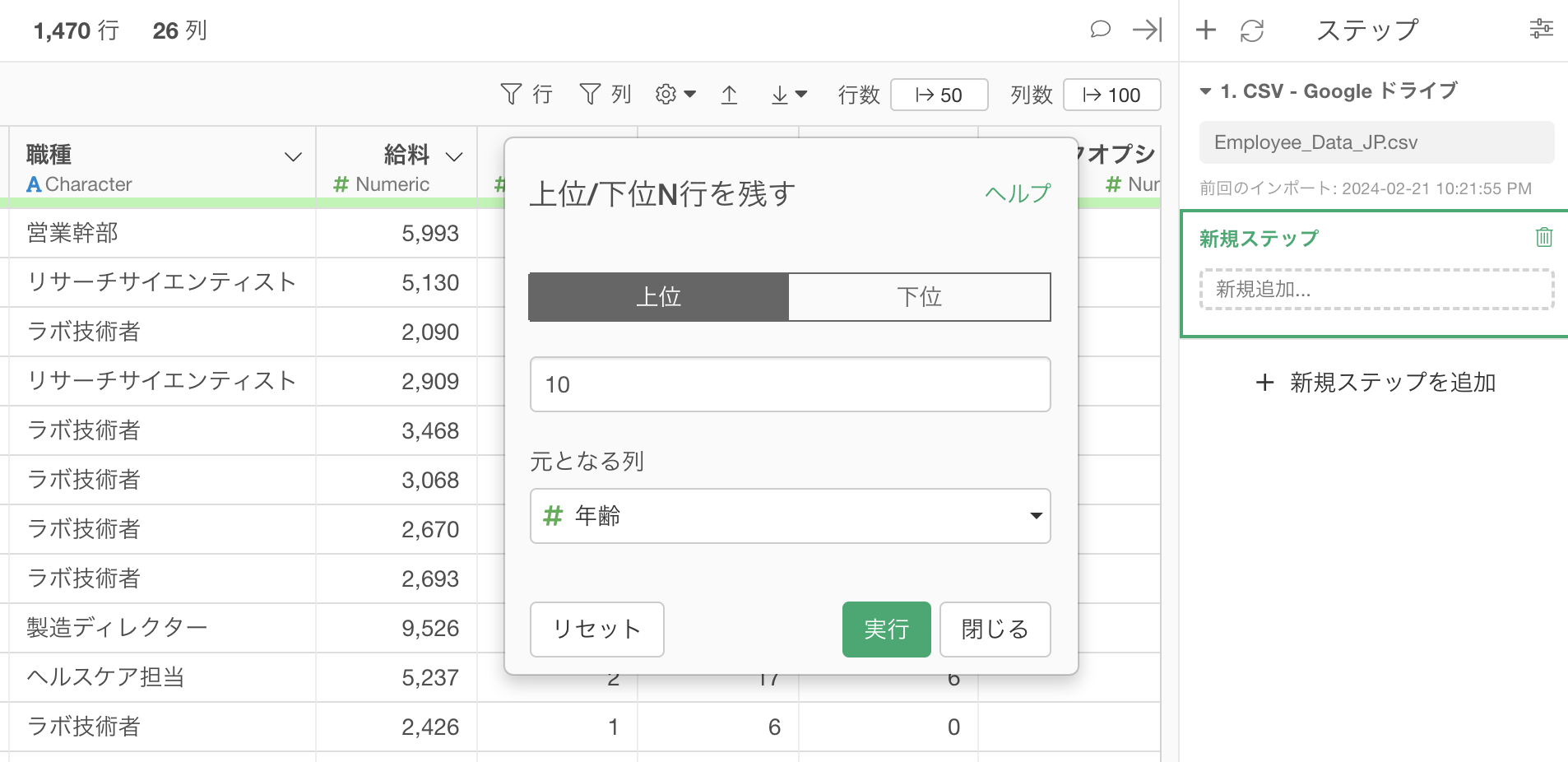
上部のタブでは、上位または下位のどちらを残すかを指定できます。
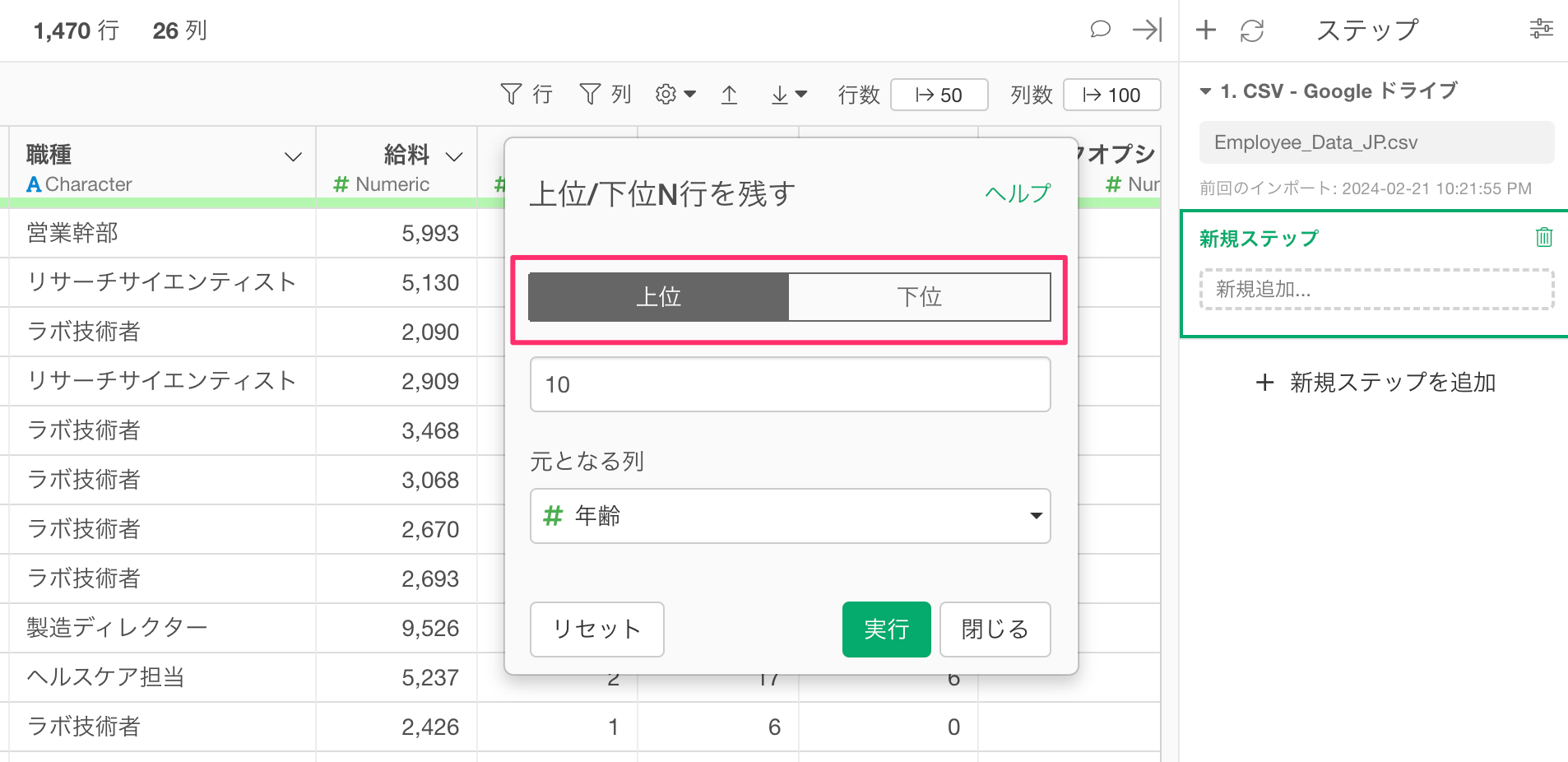
なお、ステップメニューから「上位」を選んだ場合、「上位」のタブが選択された状態でダイアログが開き、「下位」を選んだ場合、「下位」のタブが選択された状態でダイアログが開きます。
上位/下部の切り替えタブの下のウィンドウには、どれだけの数の行を残すのかを指定します。
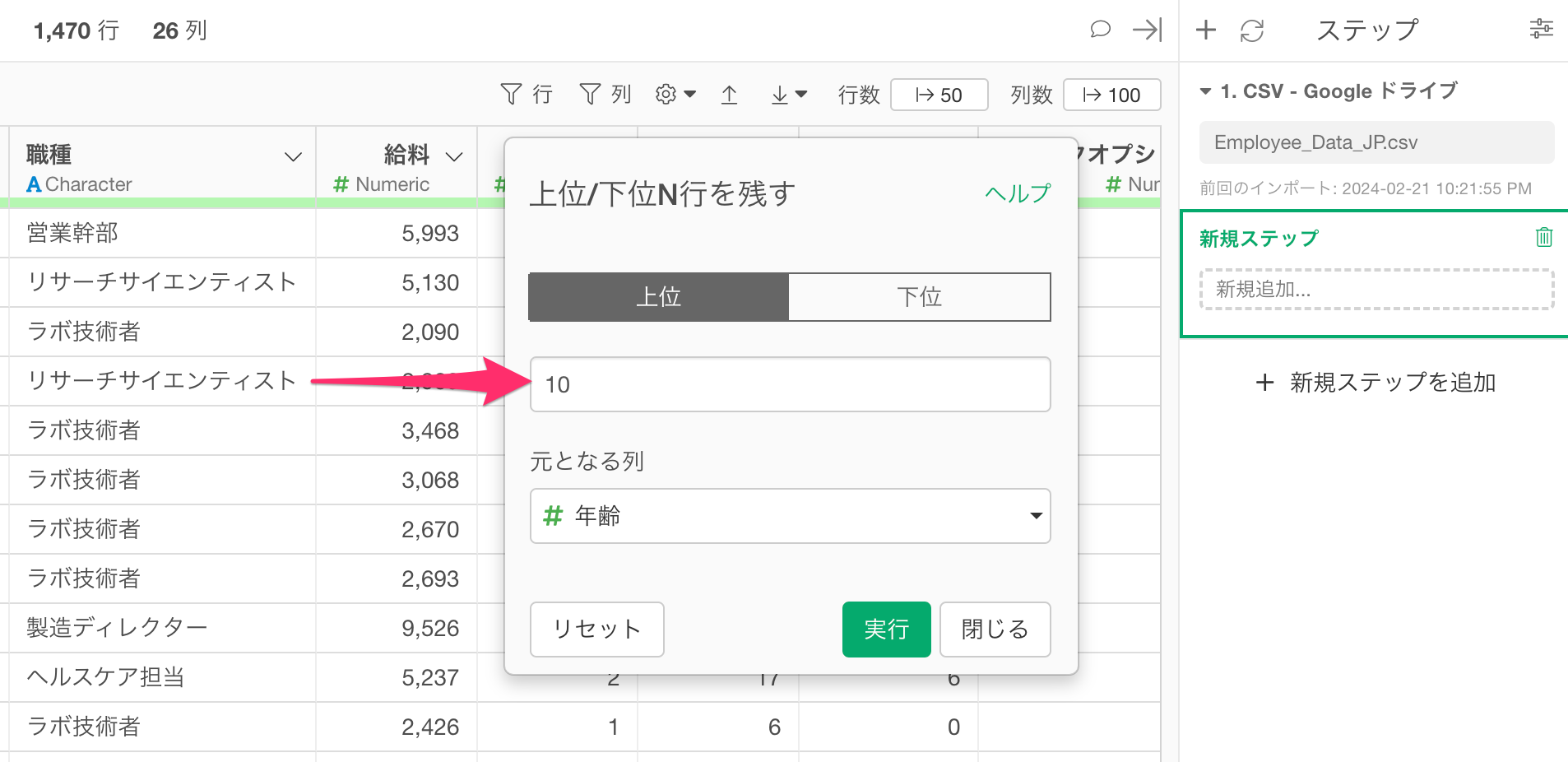
例えば、上位「10」行を残したければ、ウィンドウに「10」と入力するわけです。
続いて「元となる列」では、どの列の数値をもとに、上位または下位N行を残すのかを指定します。
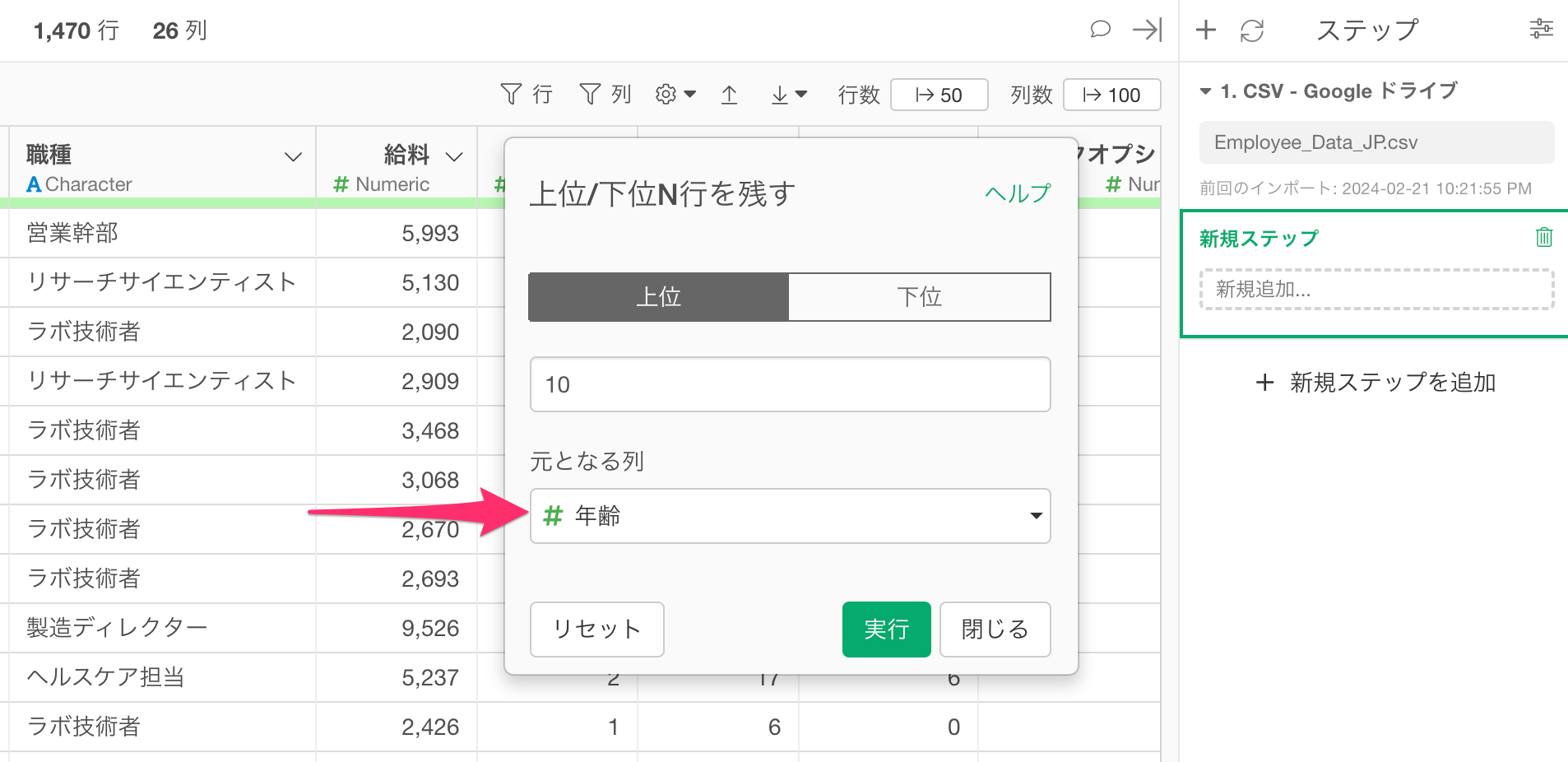
今回は、給料が多いトップ10の行を残したいので、元となる列に「給料」を選択して実行します。
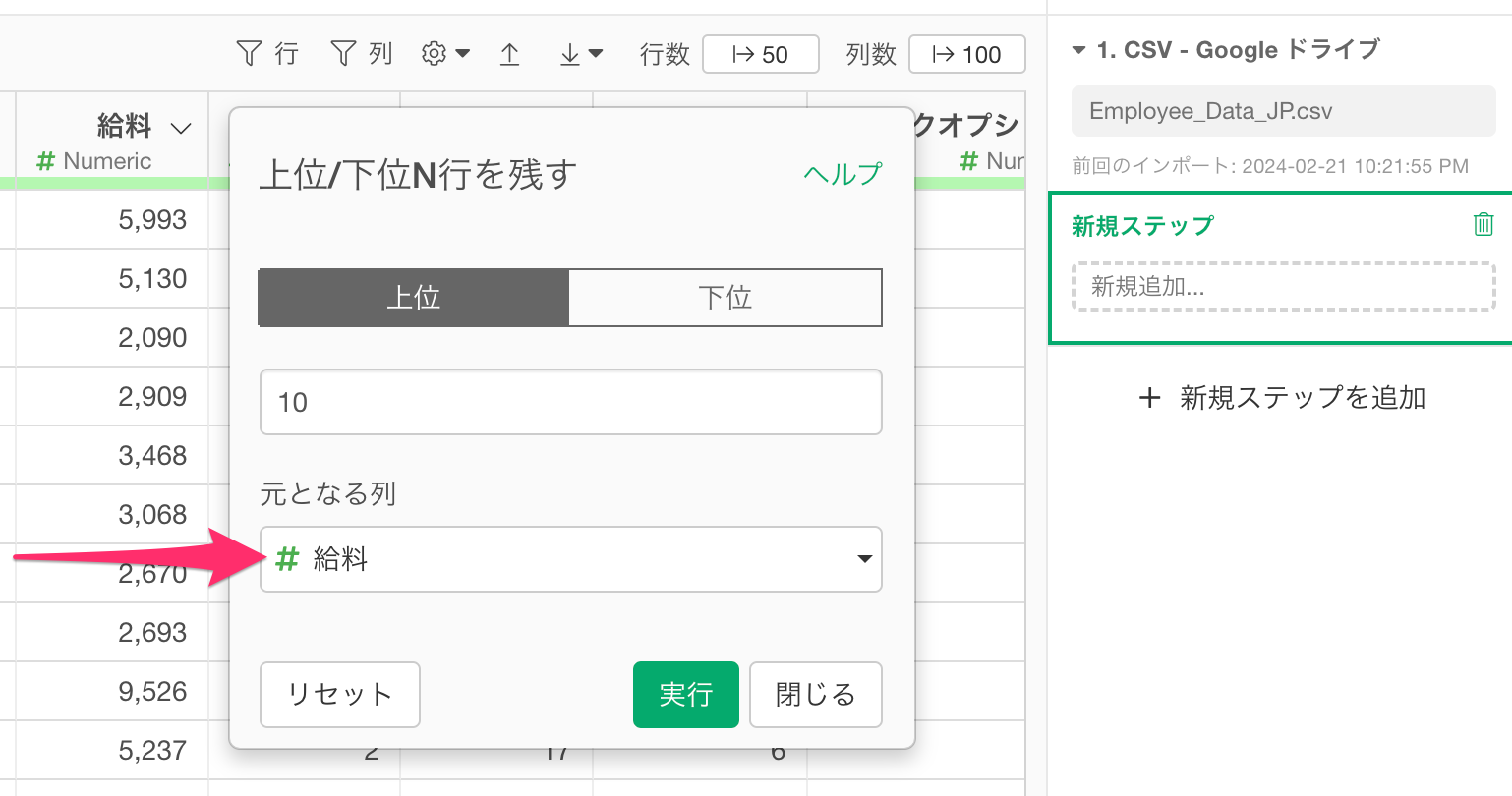
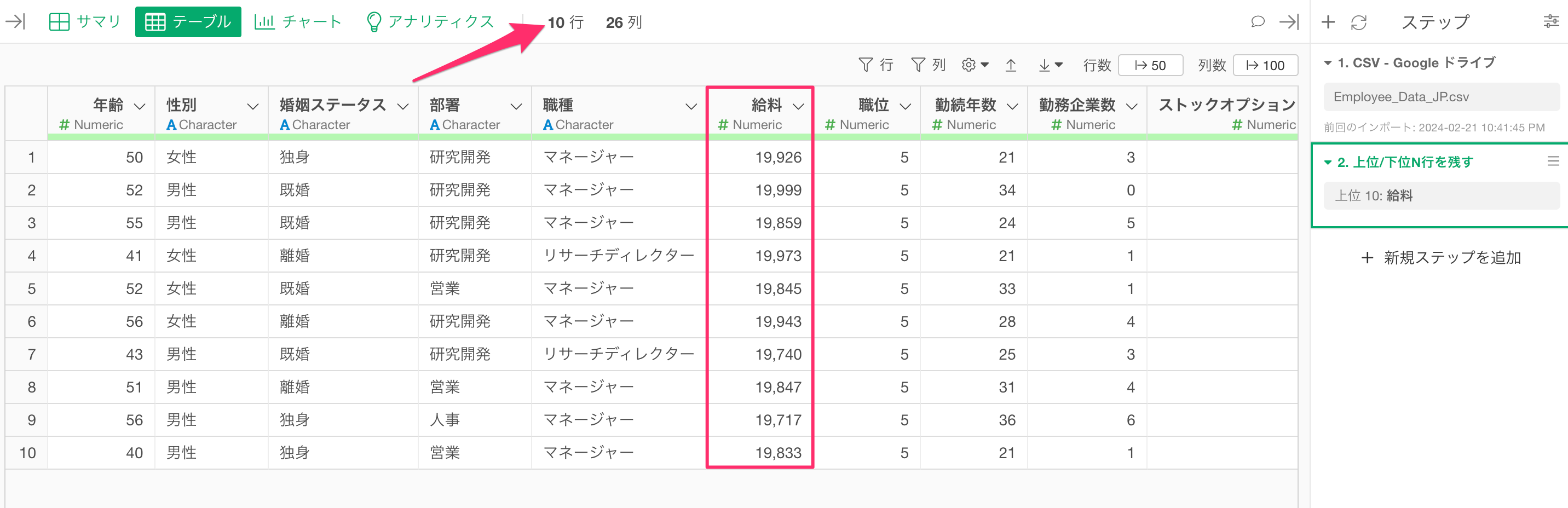
すると、給料の多いトップ10の従業員にフィルタができるわけです。
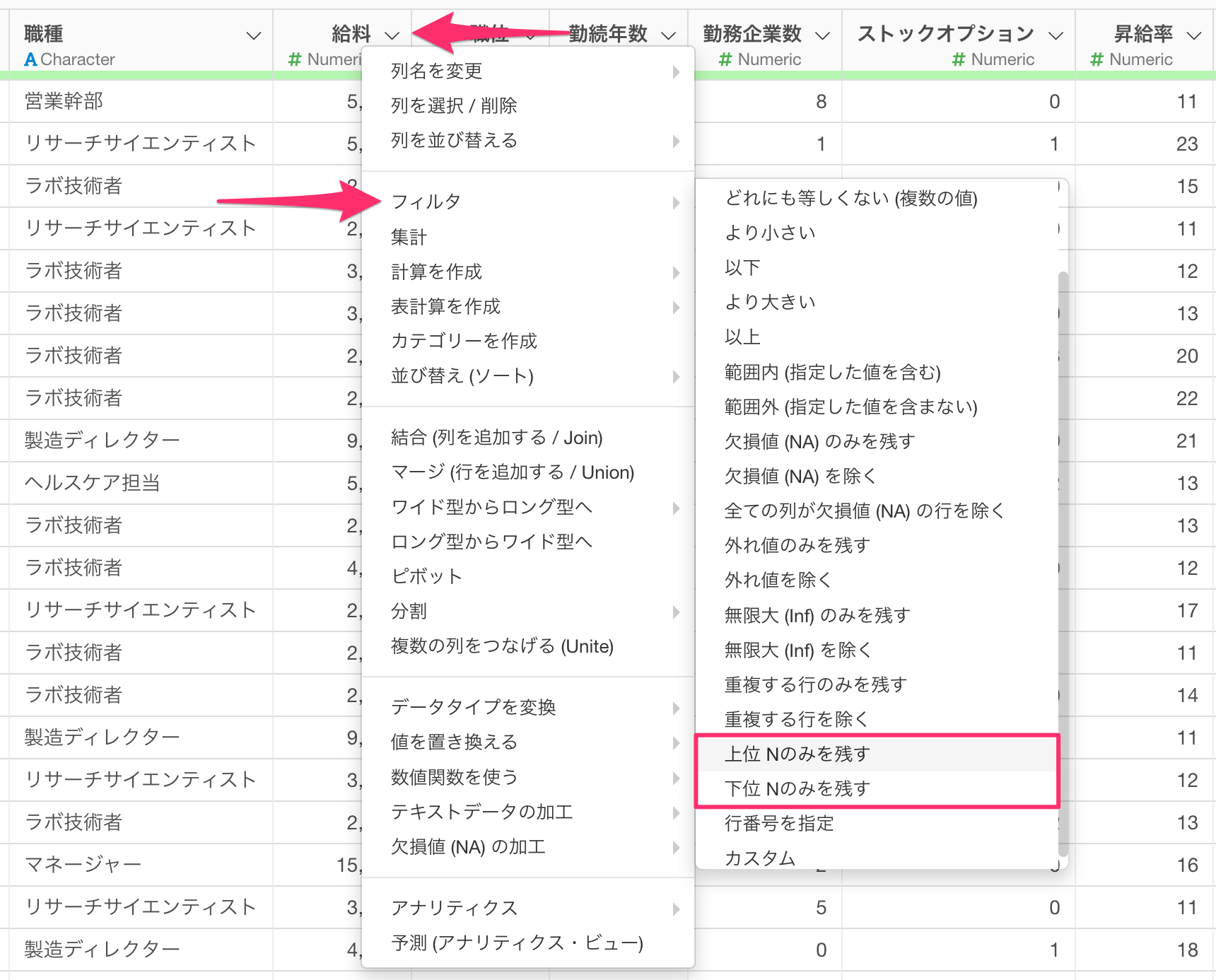
なお、上位/下位N行を残すときには、「元となる列」に指定したい列の列ヘッダーメニューのフィルタの「上位/下位Nのみを残す」から同じダイアログを呼び出すことが可能です。
グループごとに上位/下位Nを残す
ところで今回のデータには、「部署」という列があり、部署ごとに上位/下位Nを残したいこともあります。
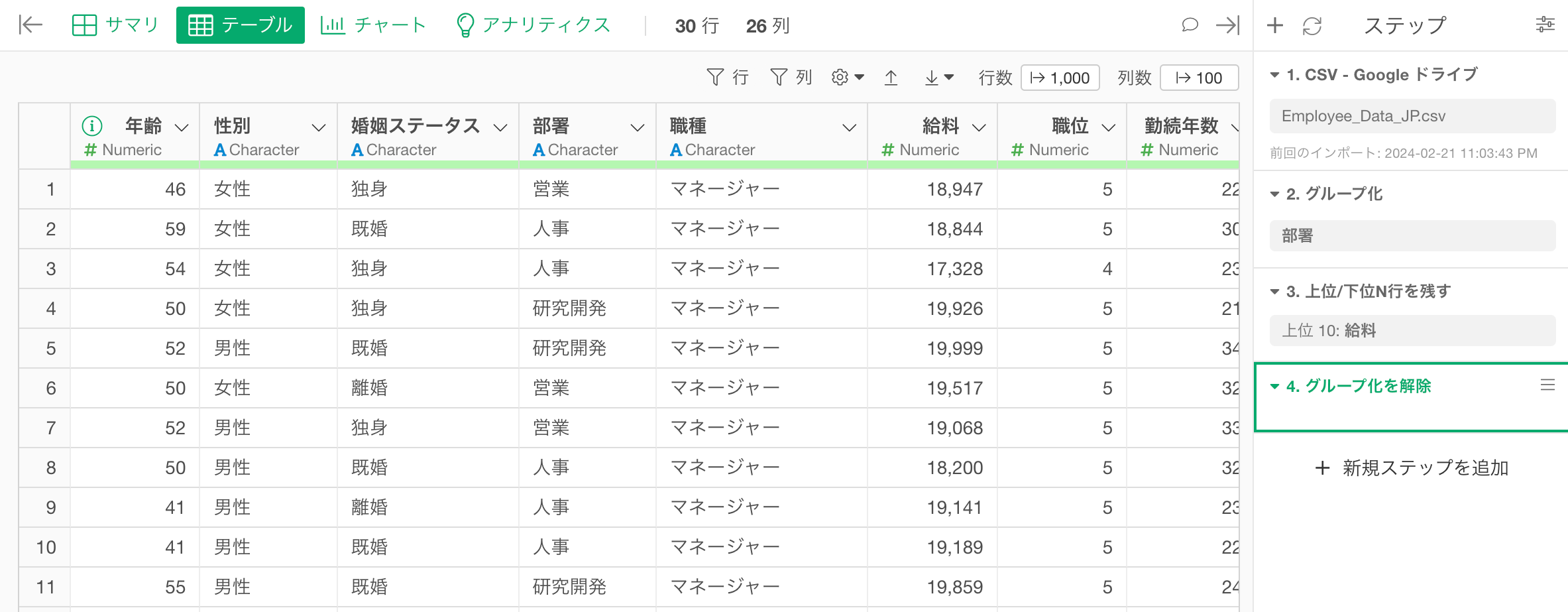
そういったときには、上位または下位N行を残すステップを追加する前に、部署で「グループ化」をしておくことで、グループごとに上位または下位N行を残すことが可能です。
今回は部署ごとに給料の多い10行を残すために、最初のステップに移動します。
続いてステップメニューから「グループ化」を選択します。
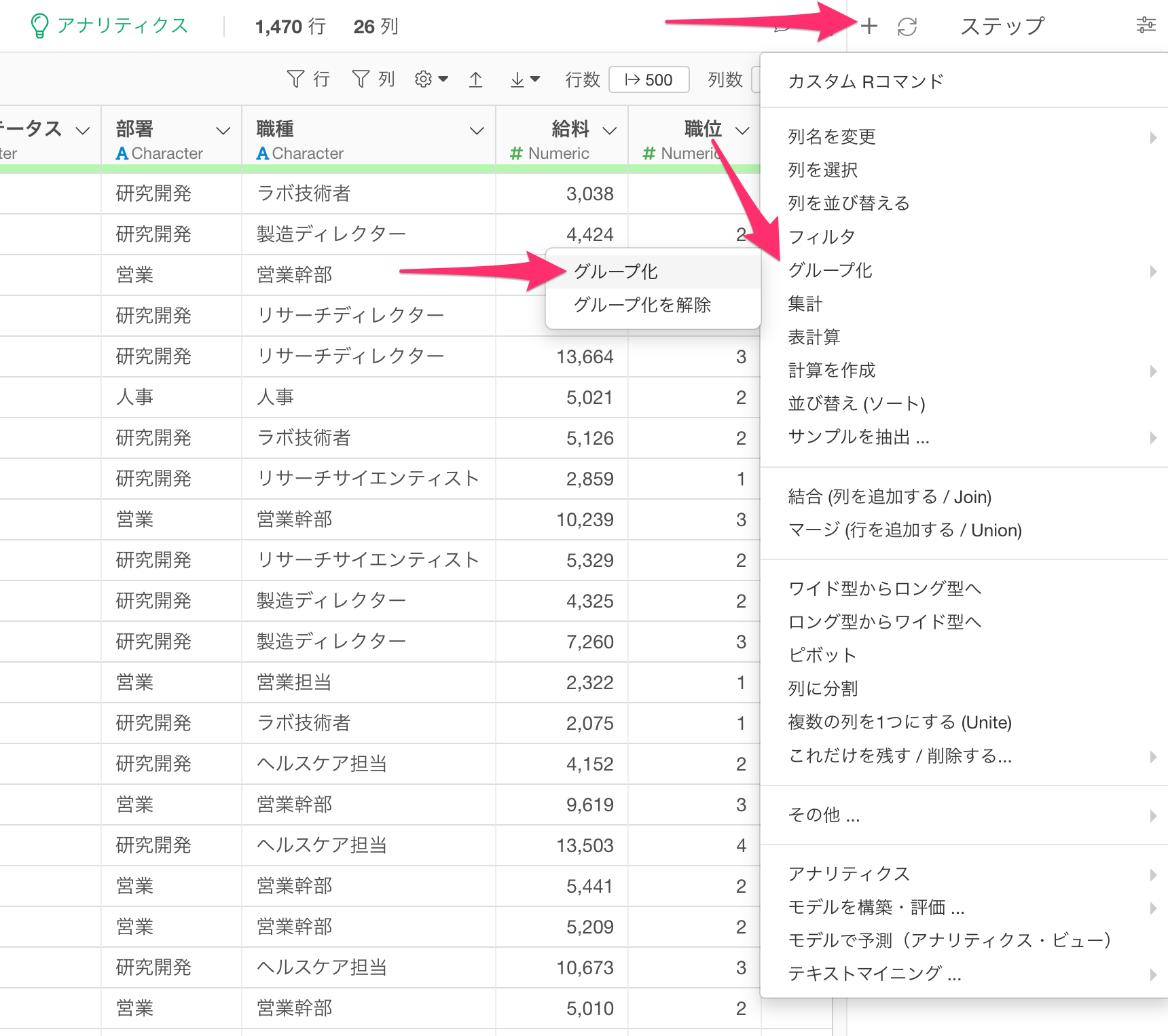
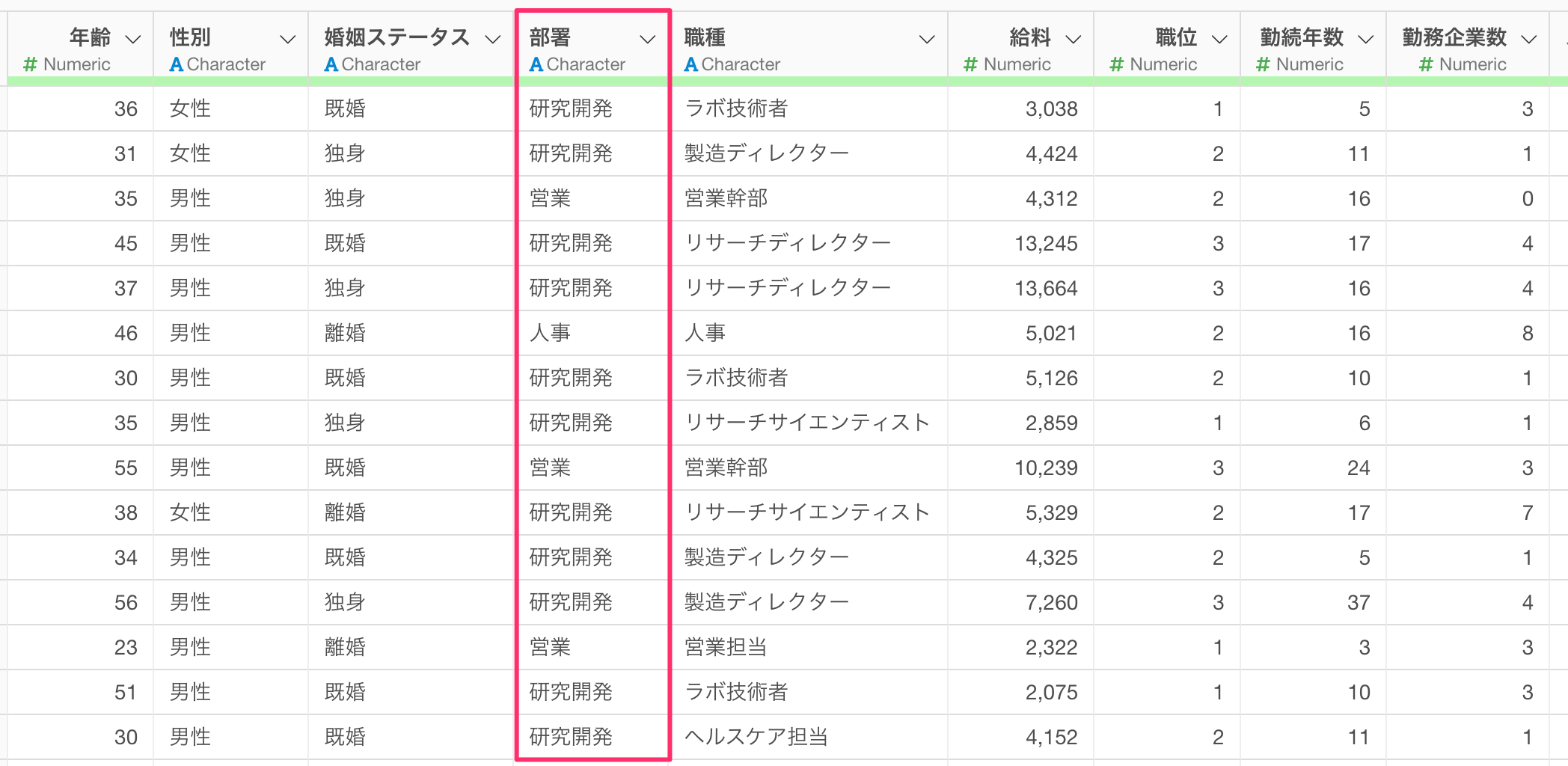
すると、どの列でデータをグループ化するかを指定するダイアログが表示されます。今回は部署ごとにデータをグループ化して、給料の多いトップ10の行を残したいので、列に「部署」を選択し実行します。
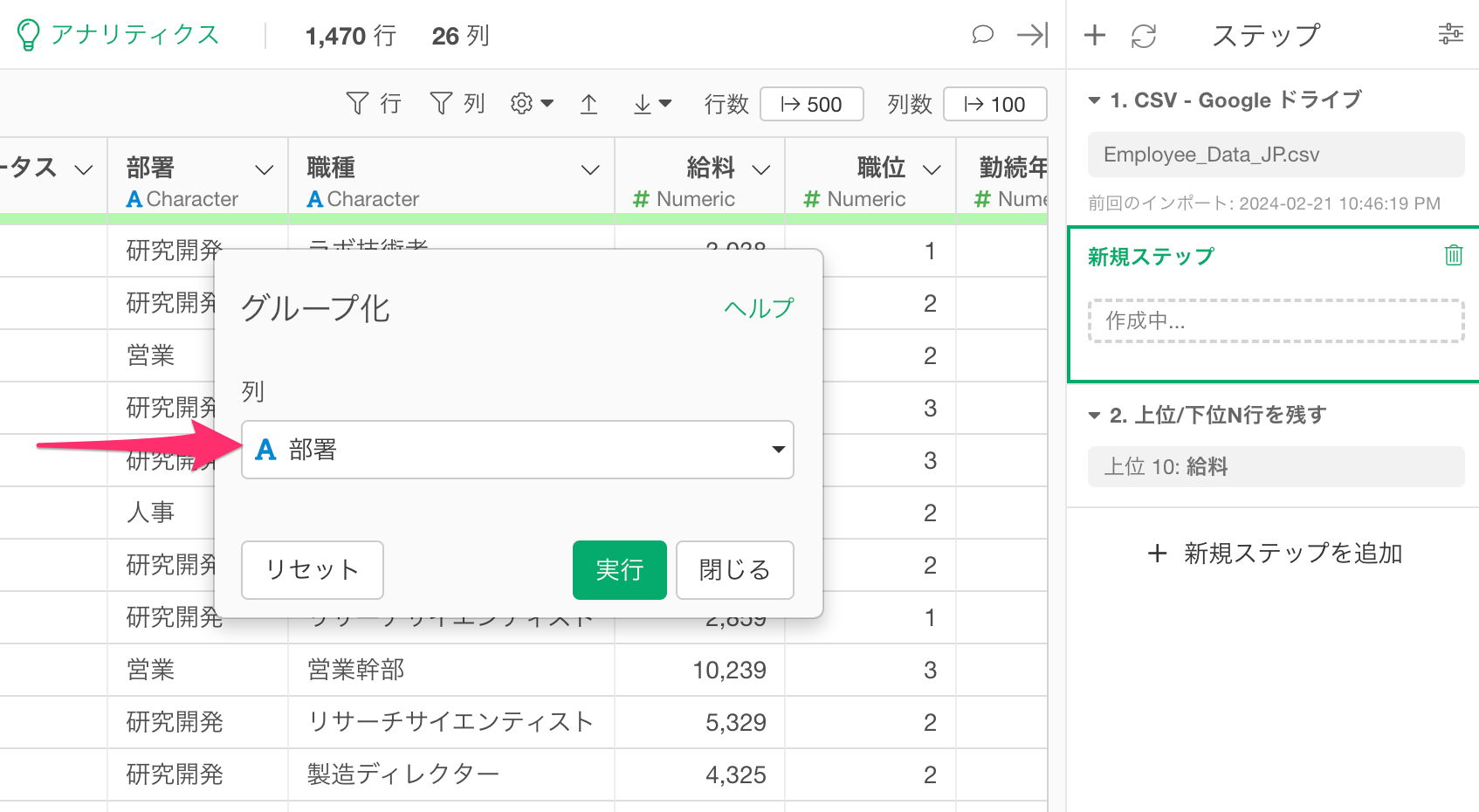
グループ化のステップが追加され、部署ごとにデータがグループ化され、グループごとにデータ(行)に色が塗り分けられます。
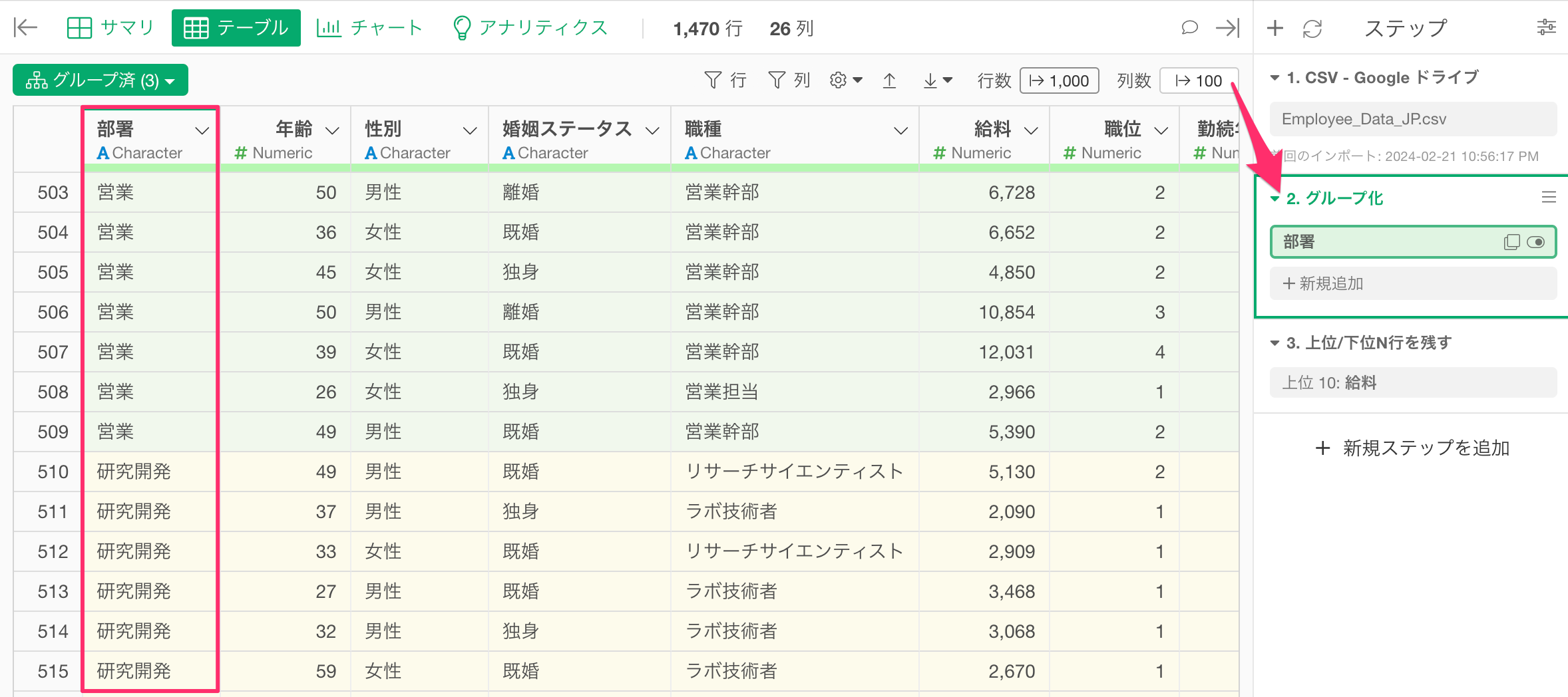
今回は既に給料の多いの上位10行を残すステップを追加しているので、後はそのステップに移動するだけです。
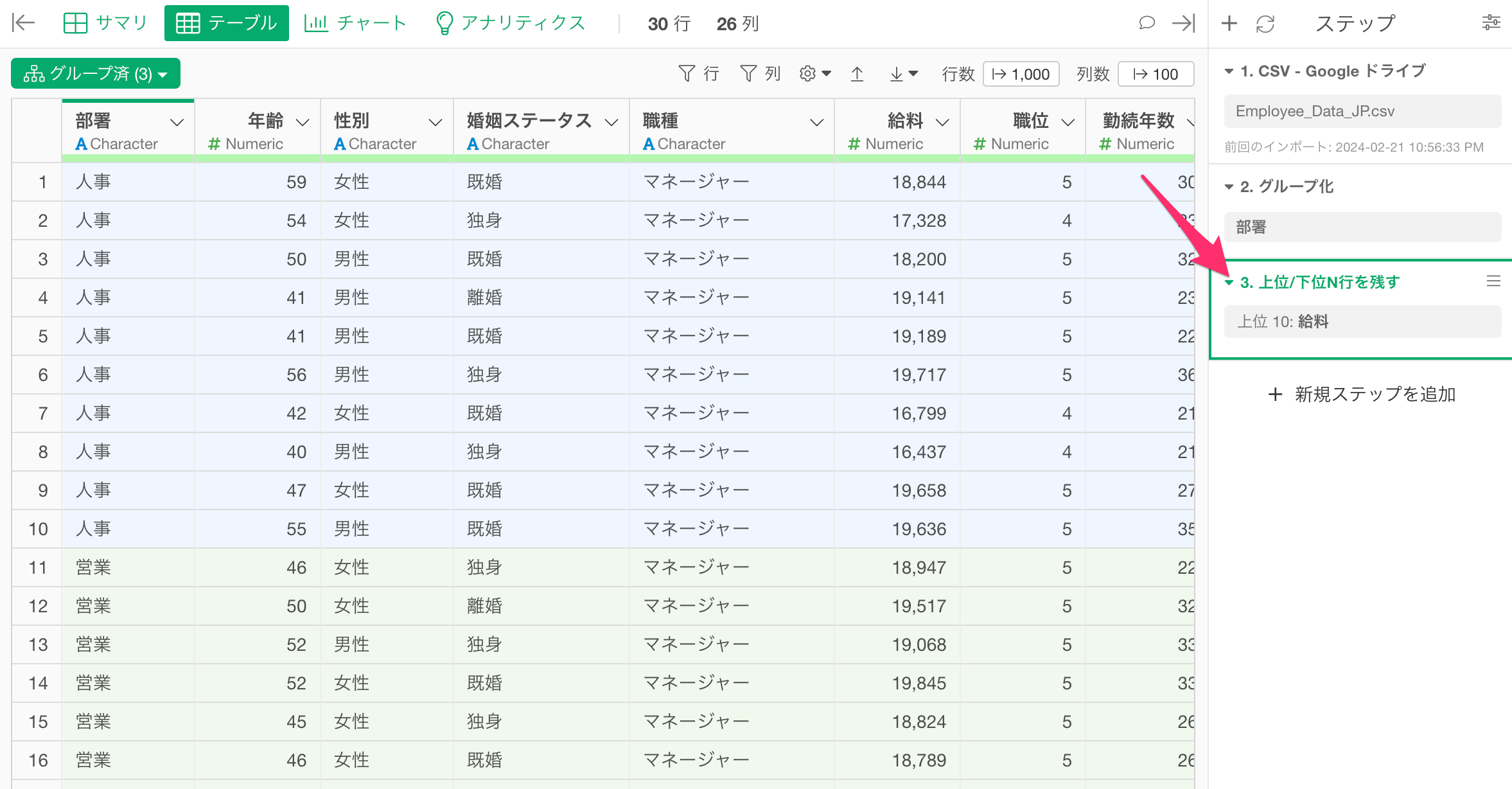
すると、グループごとに給料が多い上位10の従業員が残っていることを確認できます。
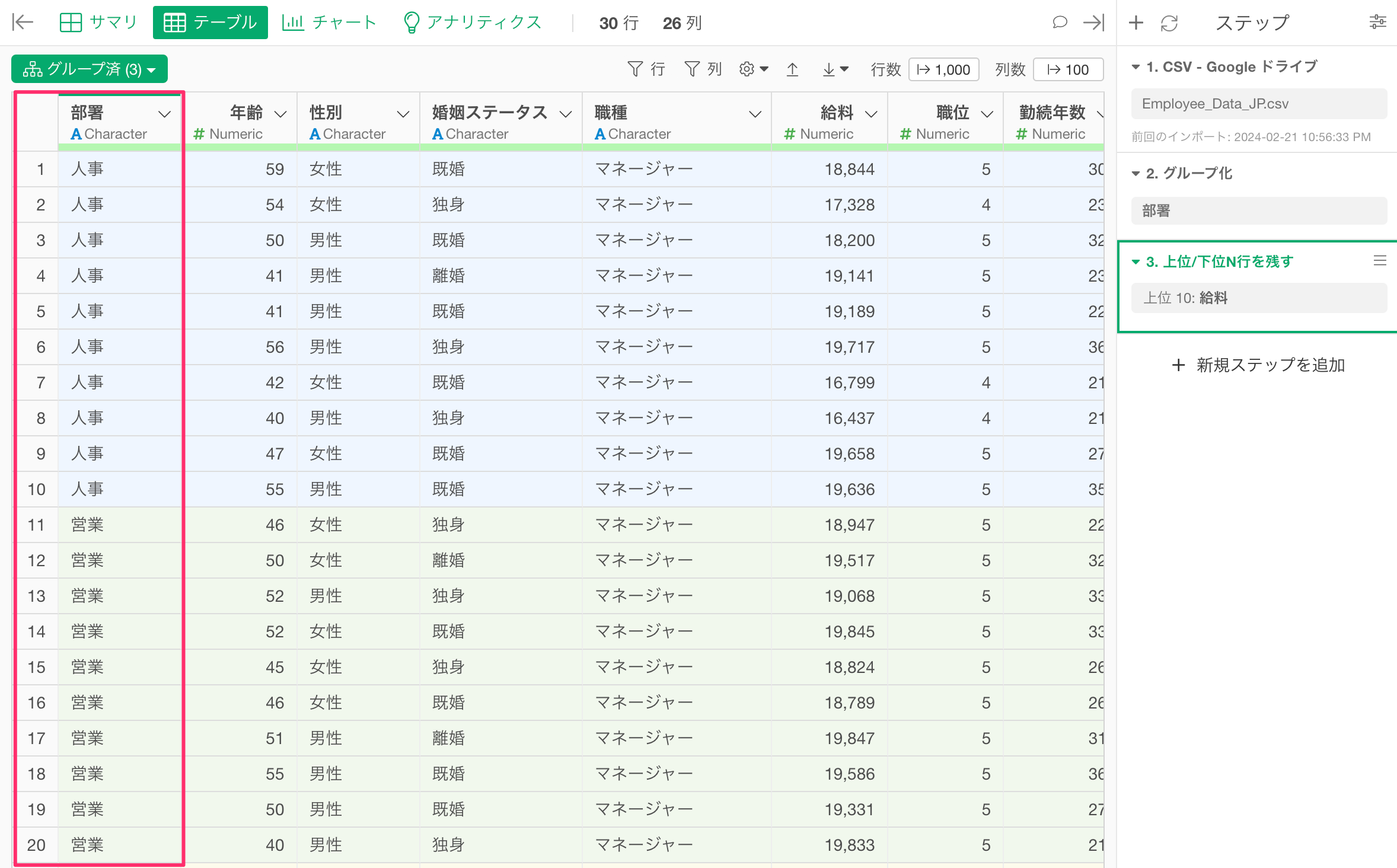
最後に、ステップを追加したときに、その処理がグループごとに適用されないように、グループを解除することを忘れないでください。
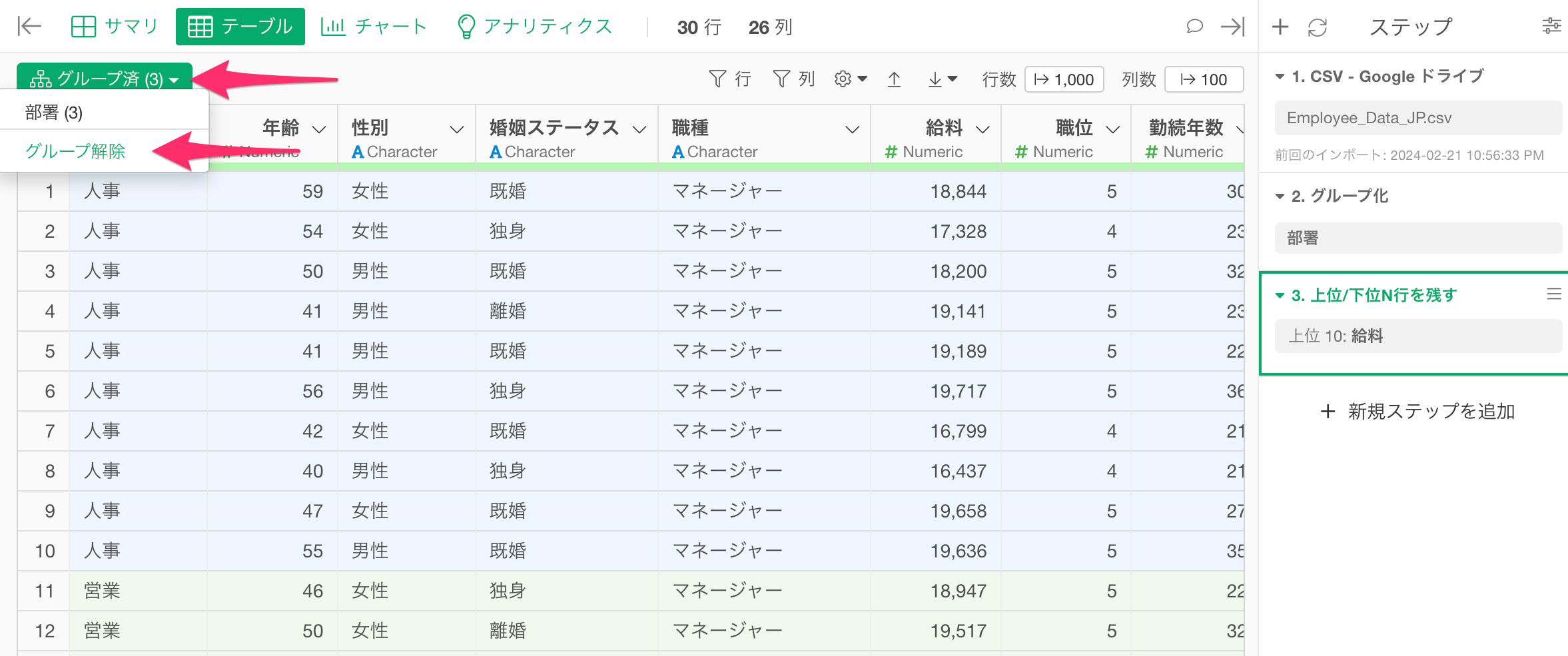
グループ化を解除すると、グループごとに付いていた色がなくなり、グループが解除れていることを確認できます。