NBDディリクレモデルによるブランド分析の実行方法
NBDディリクレモデルは、消費者の購買行動を分析するための確率モデルで、特にマーケティング分野で広く利用されています。このモデルは、消費者の購入頻度やブランド選択のパターンを理解し、需要予測やマーケティング戦略の策定に役立ちます。
NBDモデル(Negative Binomial Distribution: 負の二項分布)は、消費者が特定の期間内に特定のブランドを何回購入するかをモデル化します。このモデルは、購入頻度のばらつきを捉えるのに適しています。
一方、ディリクレ分布は、消費者が複数のブランドの中からどのブランドを選ぶかという選択行動をモデル化します。これにより、各ブランドの選択確率を推定することが可能です。
NBDディリクレモデルは、これら二つのモデルを組み合わせたもので、消費者の購入頻度とブランド選択の両方を同時に分析することができます。これにより、各ブランドの市場シェアや顧客ロイヤルティをより正確に評価することが可能となります。
このモデルは、消費財やサービスの市場分析において、消費者行動の理解やマーケティング戦略の最適化に活用されています。
1. Rパッケージのインストール方法
NBD/ディリクレモデルの実行には、NBDdirichletパッケージを利用します。
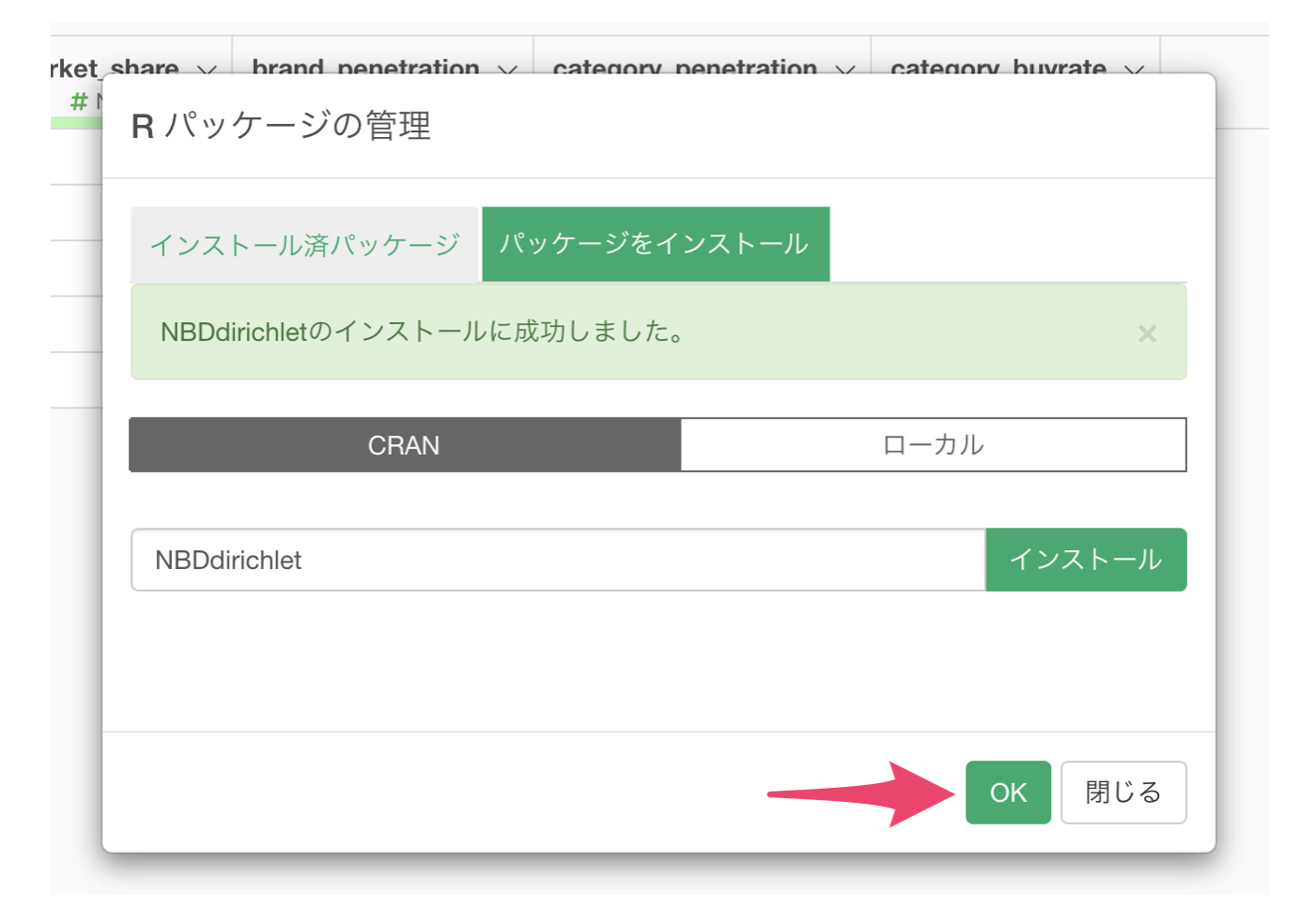
プロジェクトメニューから、「Rパッケージの管理」を選択します。
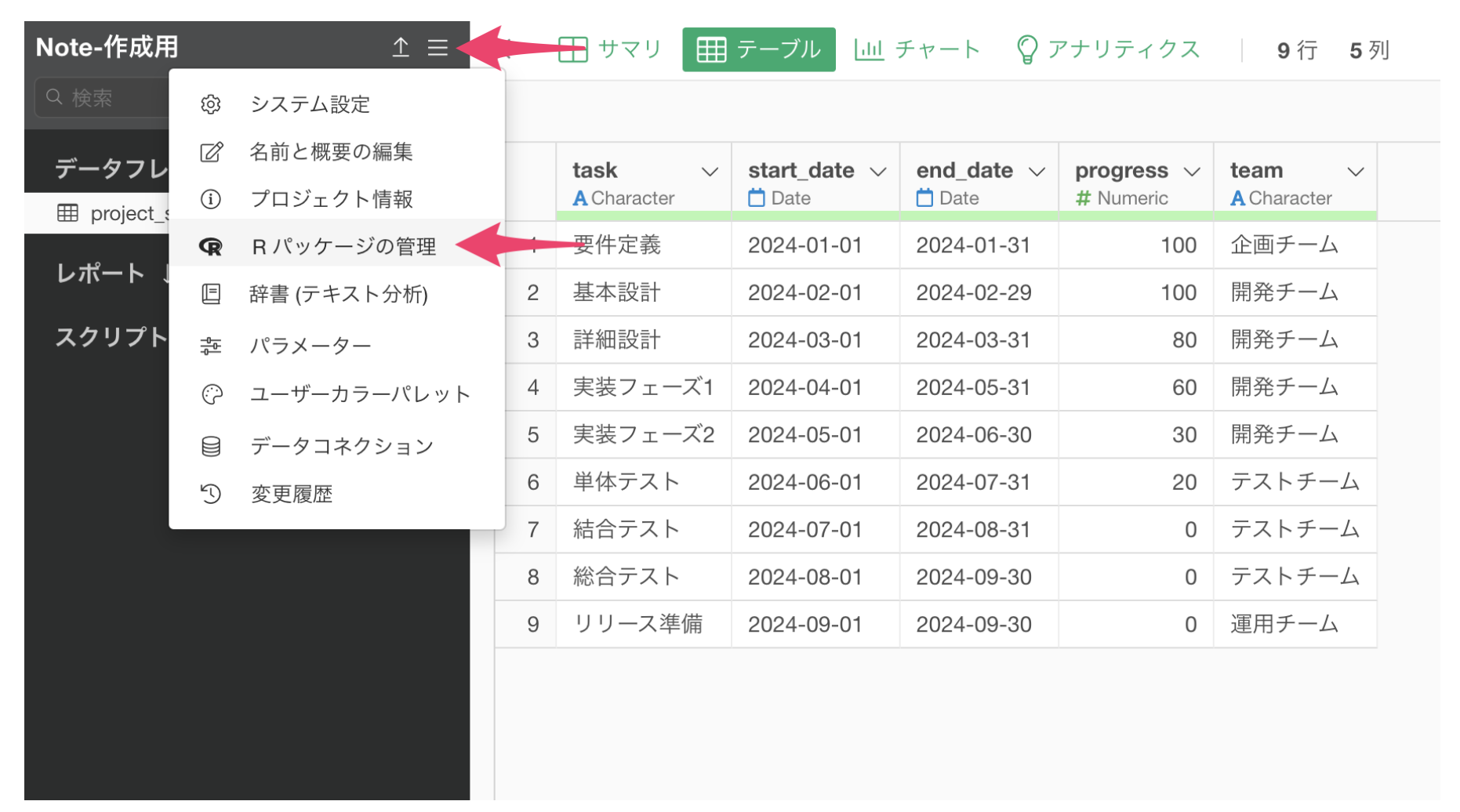
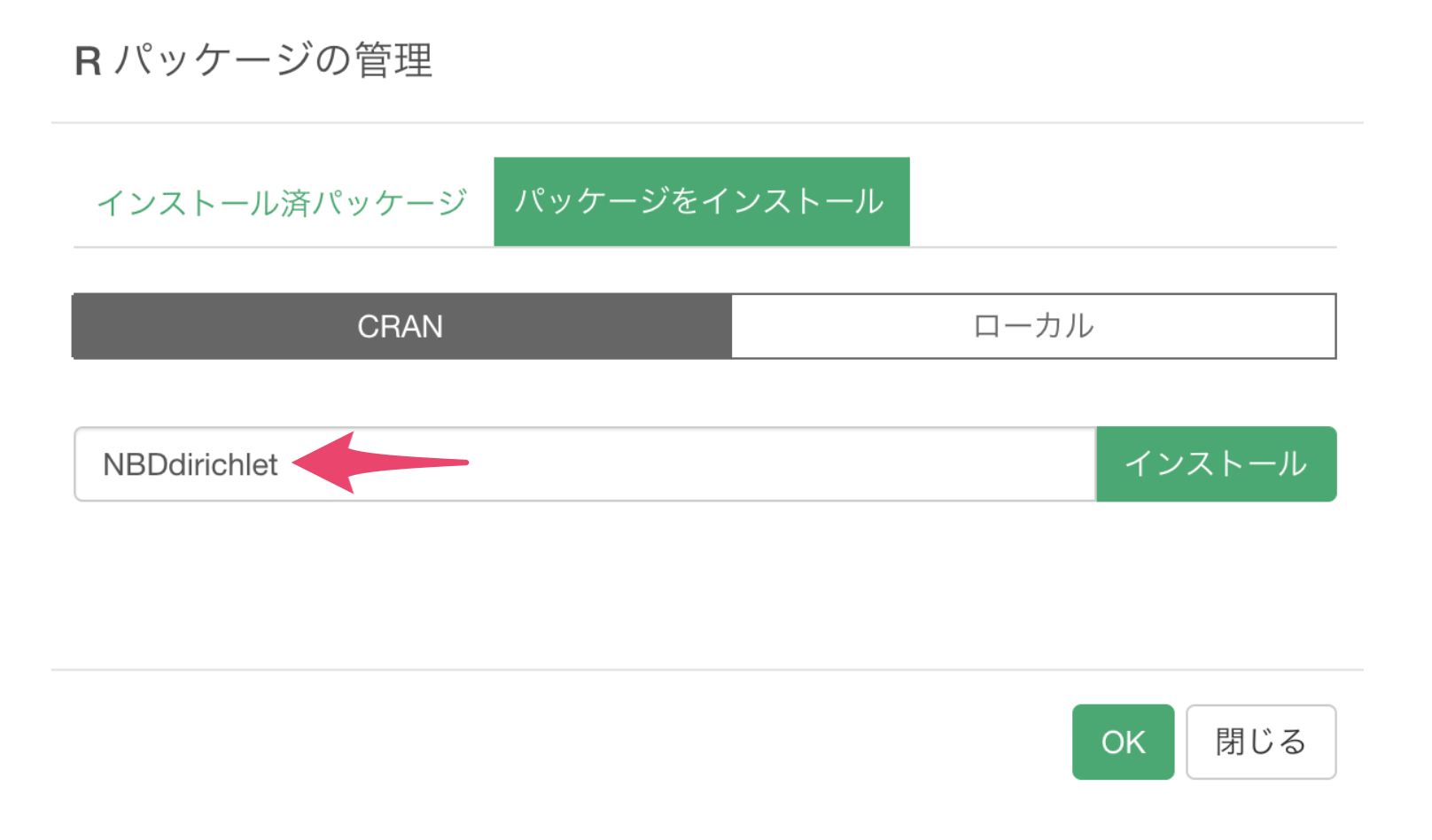
Rパッケージの管理のダイアログが開くので、「パッケージをインストール」を選択し、「NBDdirichlet」を入力してインストールボタンをクリックします。
「NBDdirichletのインストールに成功しました。」というメッセージが表示されたら、OKボタンをクリックします。
2. 使用するデータ
今回は「brand_data」を使用します。データはこちらからダウンロードが可能となっています。
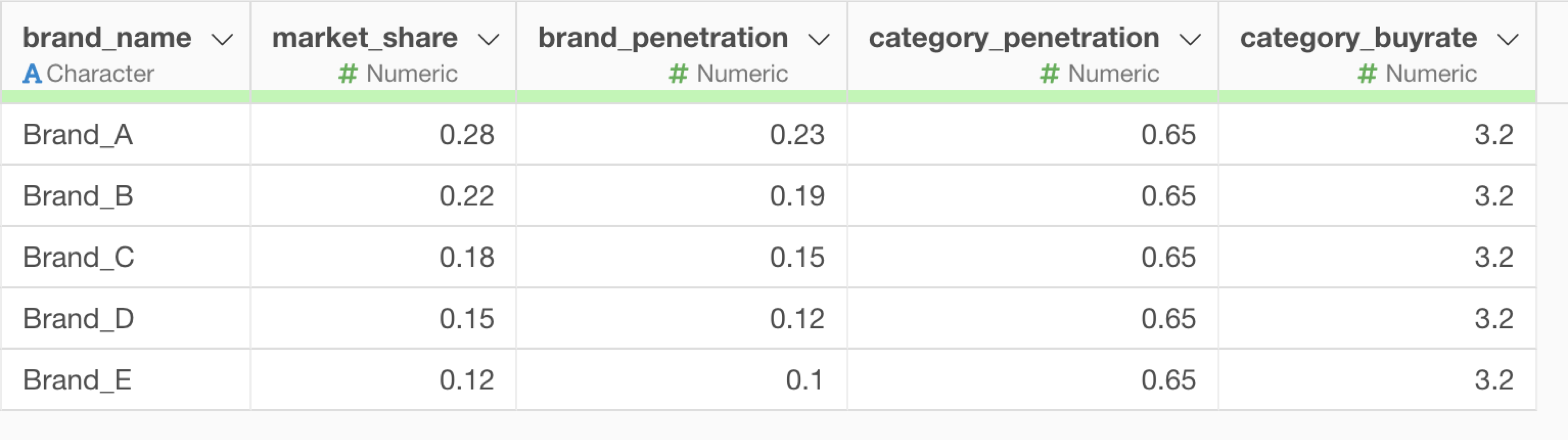
このデータは1行が1ブランドで、列には以下のデータが含まれています:
- brand_name: ブランド名
- market_share: 市場シェア
- brand_penetration: ブランド浸透率
- category_penetration: カテゴリー浸透率
- category_buyrate: カテゴリー購買頻度
NBDディリクレモデルを実行するためには、以下のようなデータ構造が必要となります:
- ブランド名(文字列)
- 各ブランドの市場シェア(合計が1になる)
- 各ブランドの浸透度(0-1の範囲)
- カテゴリー浸透度(0-1の範囲)
- カテゴリー購買頻度(正の実数)
自分のデータで使用する際には、以下の点に注意してください。
- データには上記で説明した必要な列がすべて含まれていること
- 数値データが適切な範囲内にあることを確認
- 各ブランドの浸透度、カテゴリー浸透度は0から1の範囲
- 市場シェアの合計が1になることを確認
3. NBD/ディリクレモデルの実行
レポートの右横にある+ボタンを押して、「ノートを作成」をクリックします。
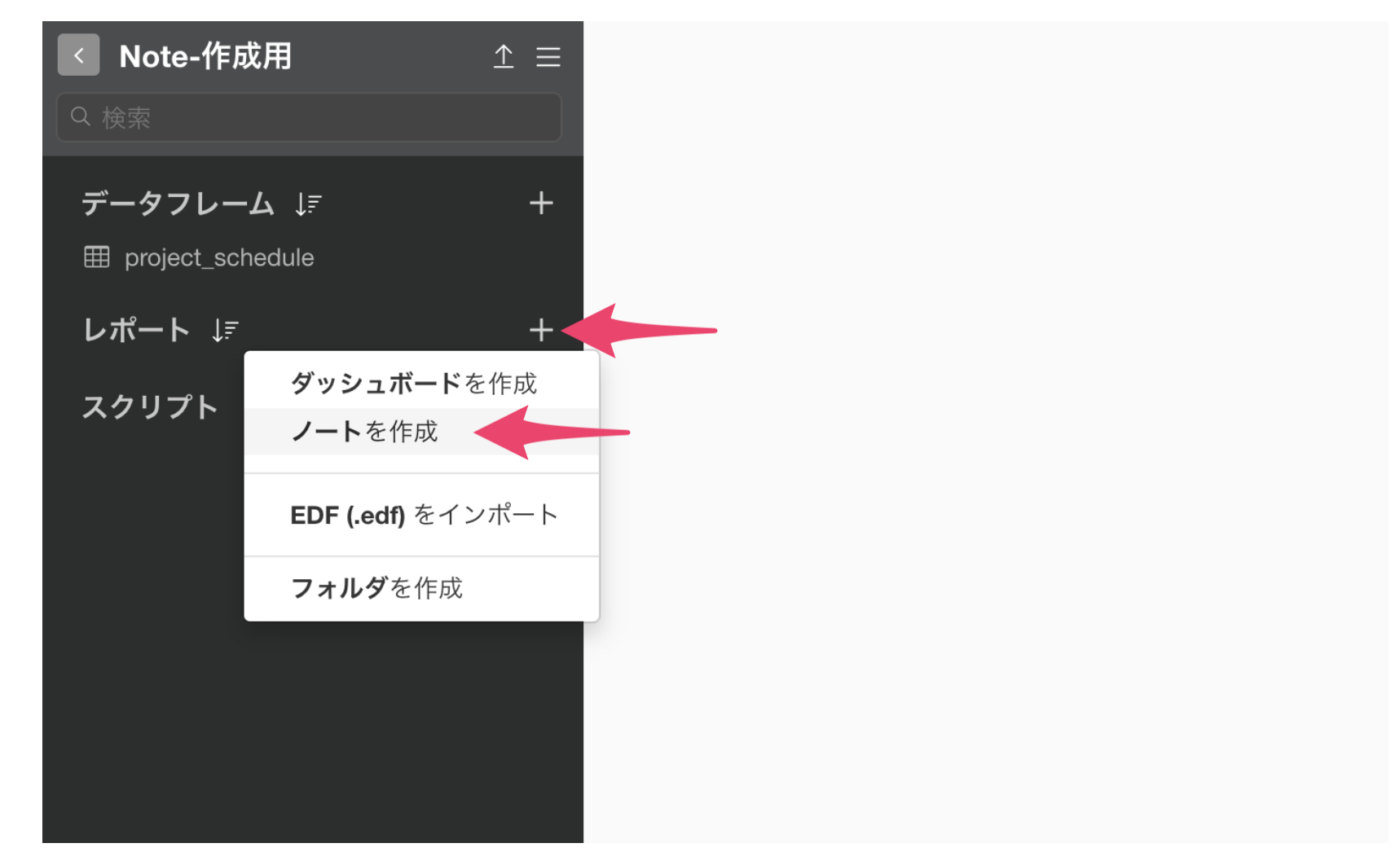
するとノートのウィンドウが開きます。
NBD/ディリクレモデルを実行するためにはRスクリプトを書く必要があるため、ノートのプラスボタンから「Rスクリプト」を選択します。
これにより、ノートにRスクリプトのコードブロックが追加されました。
 このRスクリプトの中に、下記のスクリプトをコピー&ペーストしてください。
このRスクリプトの中に、下記のスクリプトをコピー&ペーストしてください。
# パッケージの読み込み
library(NBDdirichlet)
# brand_dataから必要なパラメータを抽出
cat.pen <- brand_data$category_penetration[1] # 全ての行の値が同じためどの行でも同じ値が取れる。ここでは1行目を指定。
cat.buyrate <- brand_data$category_buyrate[1] # 全ての行の値が同じためどの行でも同じ値が取れる。ここでは1行目を指定。
brand.share <- brand_data$market_share
brand.pen.obs <- brand_data$brand_penetration
brand.name <- brand_data$brand_name
# ディリクレモデルの実行
dobj <- dirichlet(
cat.pen,
cat.buyrate,
brand.share,
brand.pen.obs,
brand.name
)
summary(dobj)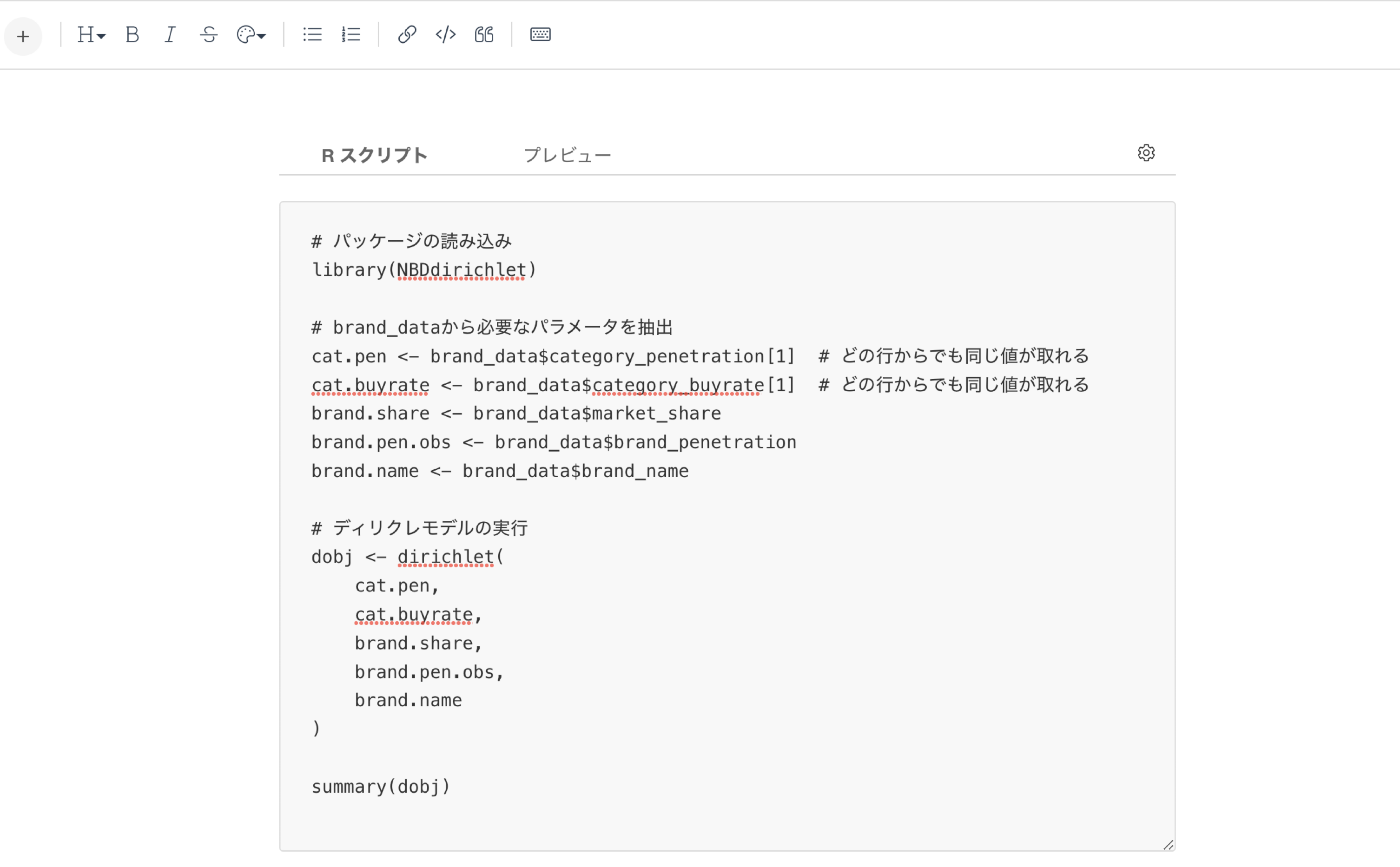
Rスクリプトを貼り付けることができたら、「プレビュー」ボタンをクリックします。
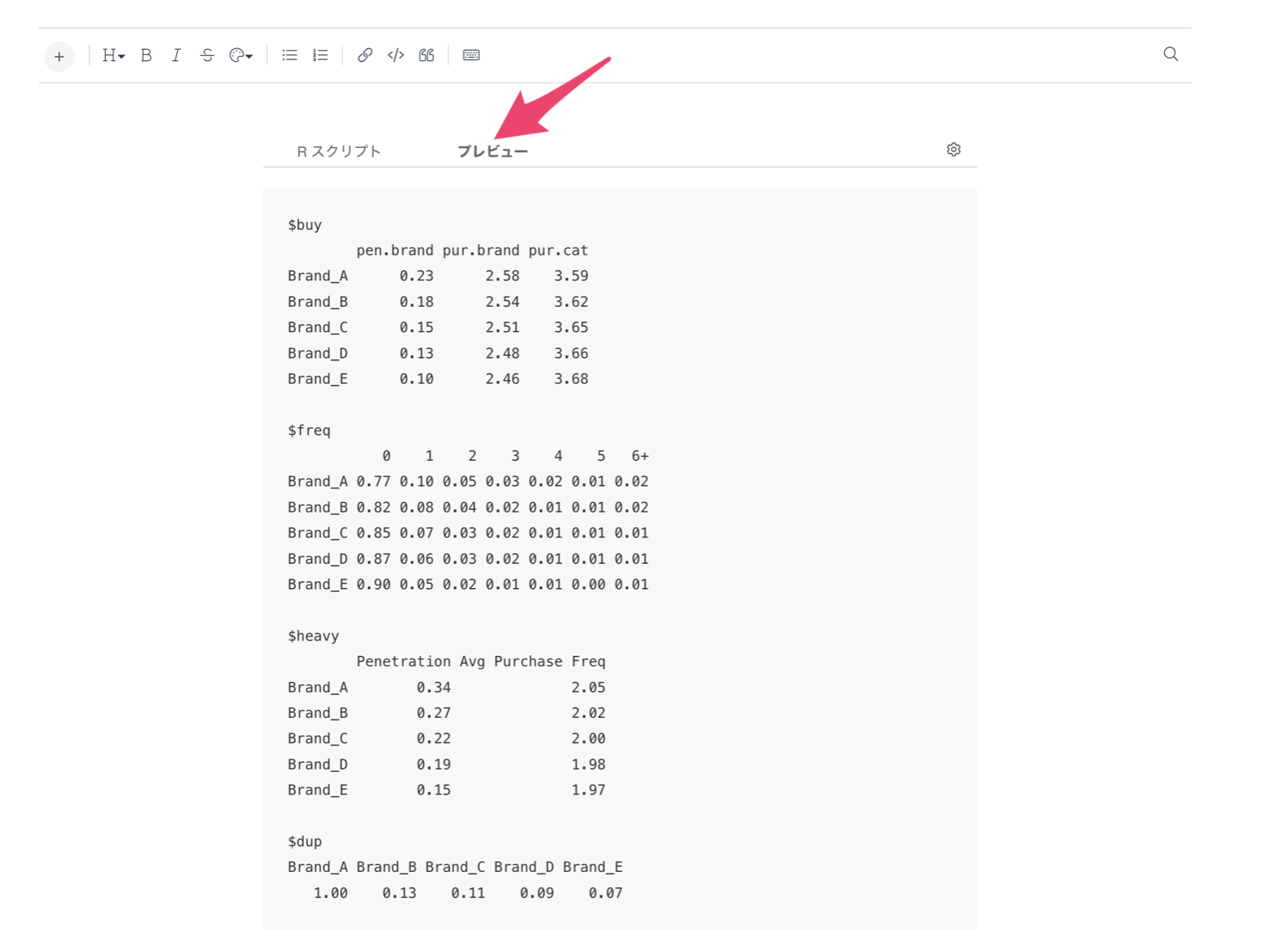
プレビューすると、以下のような結果が表示されます。結果の解釈については、こちらの公式ドキュメントの11pにも記載しております。
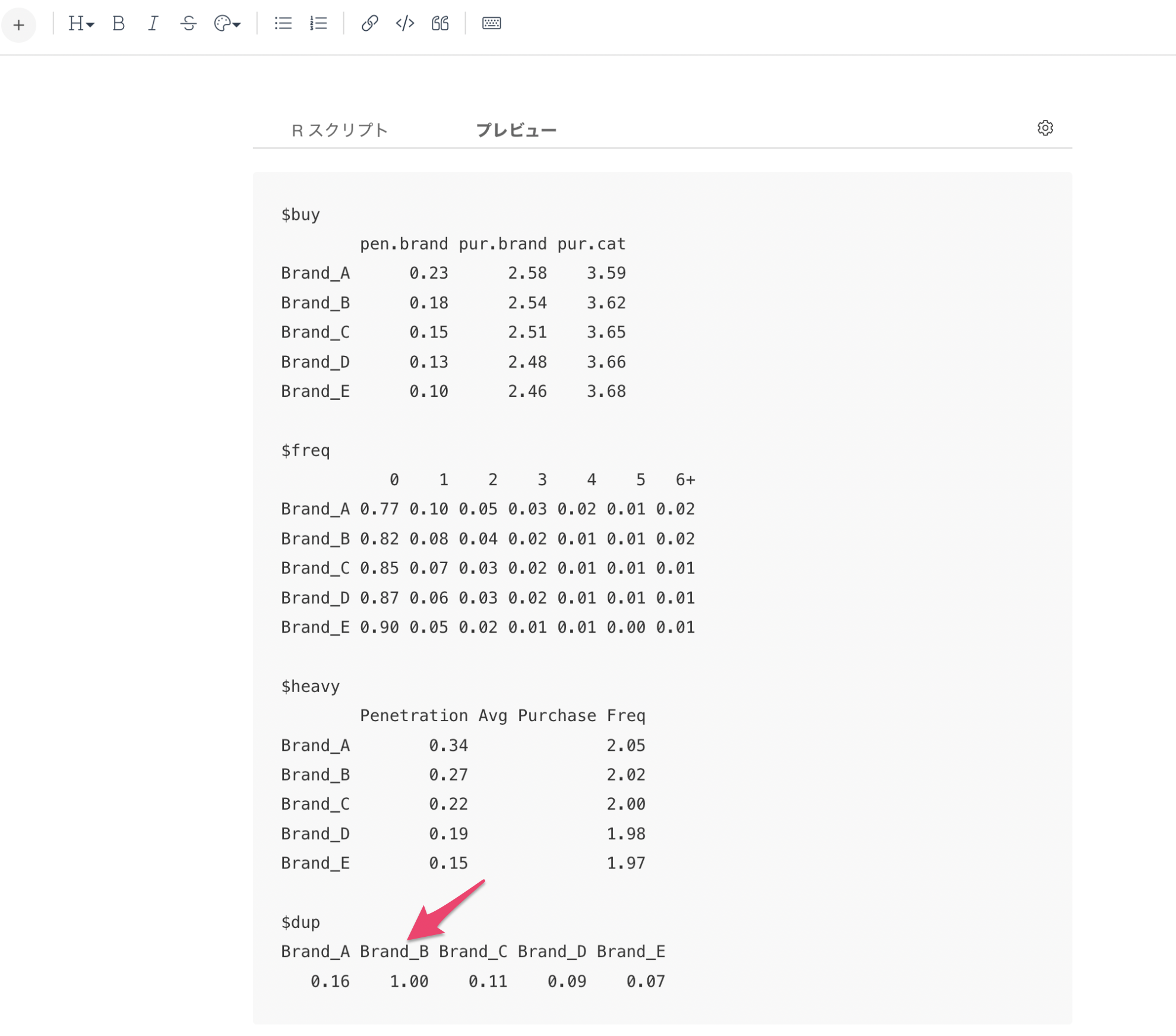
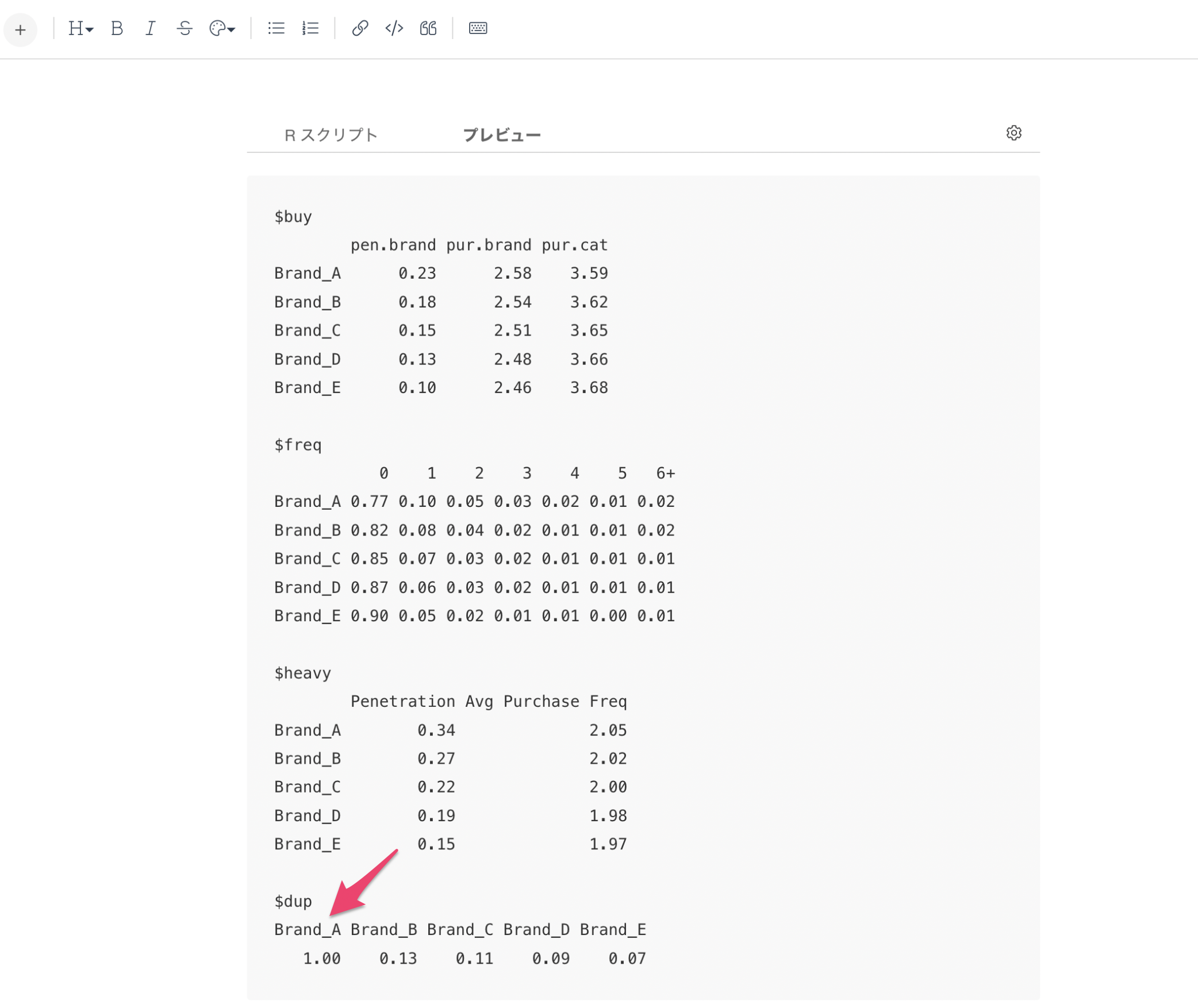
1. buy(基本購買指標)
- pen.brand:理論的なブランド浸透率
- pur.brand:そのブランドの購入率
- pur.cat:そのブランドの買い手によるマーケット内での購入率
2. freq(購買回数の分布)
- 0での値は、未購入者の顧客の割合を示す
- 例:Brand_Aは未購入の割合が77%
- 1から6+までの値は、その回数購入した顧客の割合を示す
- 例:Brand_Aの1回購入している割合が10%、6回以上購入が2%
3. heavy(ヘビーユーザー分析)
- Penetration:購買頻度が高い層での理論的なブランド浸透率
- Avg Purchase Freq:購買頻度が高い層での平均購買回数
4. dup(ブランド間の重複購買)
- そのブランドの購入者が他のブランドも購入する割合
- 例:Brand_Aの購入者の13%がBrand_Bも購入している
これらの指標を組み合わせることで、ブランドの市場での位置づけや消費者の購買行動パターンを把握することができます。
dup(ブランド間の重複購買)のベースとなる値を指定する
そのブランドの購入者が他のブランドも購入する割合を表すdupですが、デフォルトでは最初の値(今回の場合はBrand_A)をベースとして、Brand_Aを買っている人がBrand_Bを買っている人の割合を算出しています。
このベースとなる値を変更して結果を見たい場合は、summaryで結果を出力する際に、dup.brand=2のように指定をします。dup.brand=2の場合は2番目の値(今回はBrand_B)をベースとして結果を返すこととなります。
summary(dobj, dup.brand=2)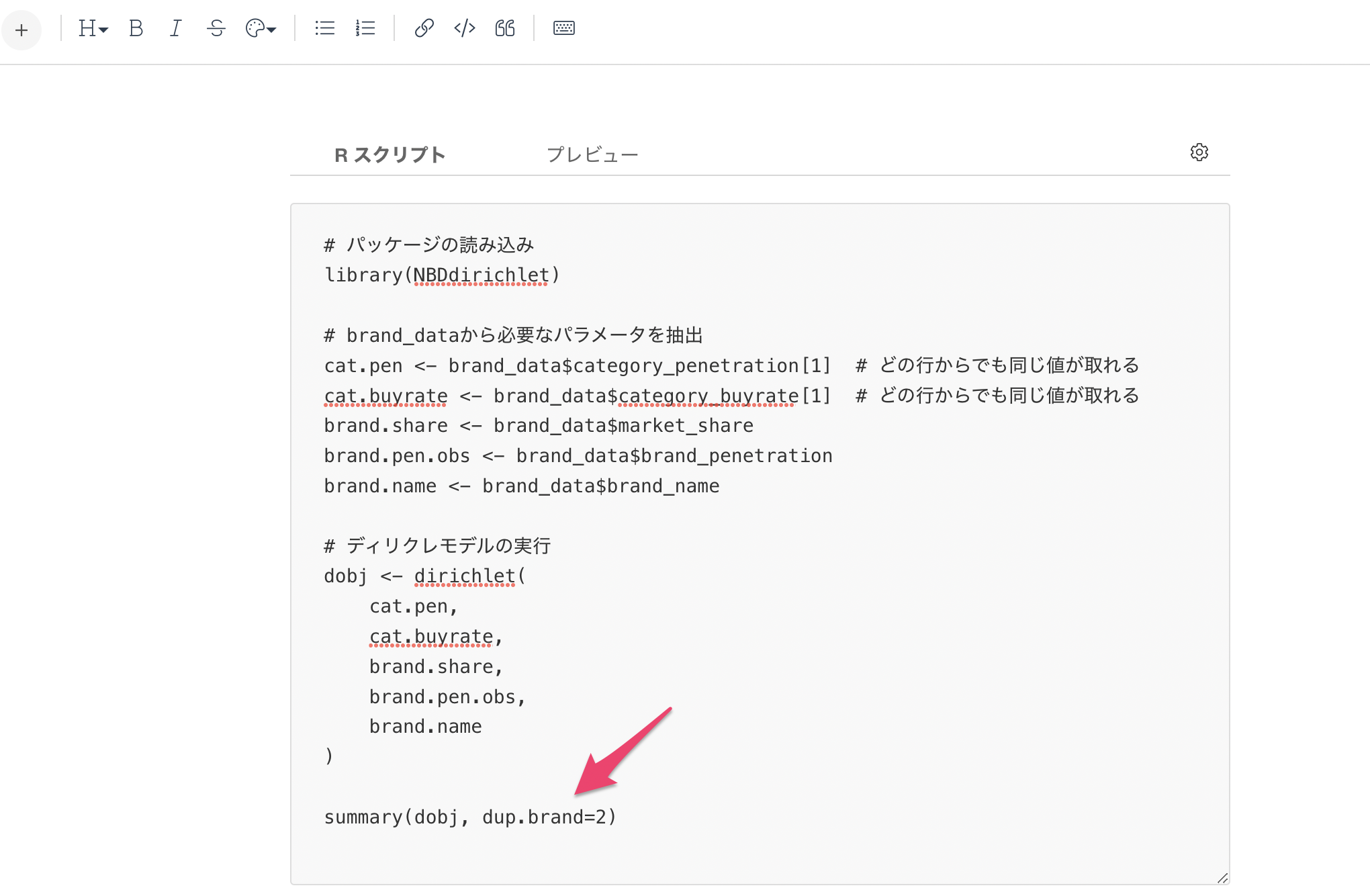
これによって、Brand_Bをベースとして、そのブランドの購入者が他のブランドも購入する割合を表すことができます。