データラングリング Part 3 - テキストデータの加工
このノートは、データラングリング(データの加工・整形)に関するExploratoryの機能を効率的に手を動かしながら体験していただくために用意された「データラングリング」のトライアルツアーの第3弾、「テキストデータの加工」編です。
テキストデータを扱っていく際によくある問題として、表記揺れがあったり、不要な文字や記号などが含まれていて文字列が綺麗に整えられていない、またはある文字列を置換、抽出したいといったことがよくあります。
Exploratoryでは、テキストデータの加工のUIを使って柔軟にテキストデータを加工していくことができます。
そこで、このパートでは、テキストデータを加工して文字列を綺麗に整えたり、文字列に対して置換や抽出する際の便利な機能を体験していただければと思います。
所要時間は20分ほどとなっています。
それでは、さっそく始めていきましょう!
テキストデータの加工の文法
これらの文字が主体となったデータのことを「テキストデータ」と言い、ExploratoryではデータタイプがCharacter型(文字列型)として表されます。
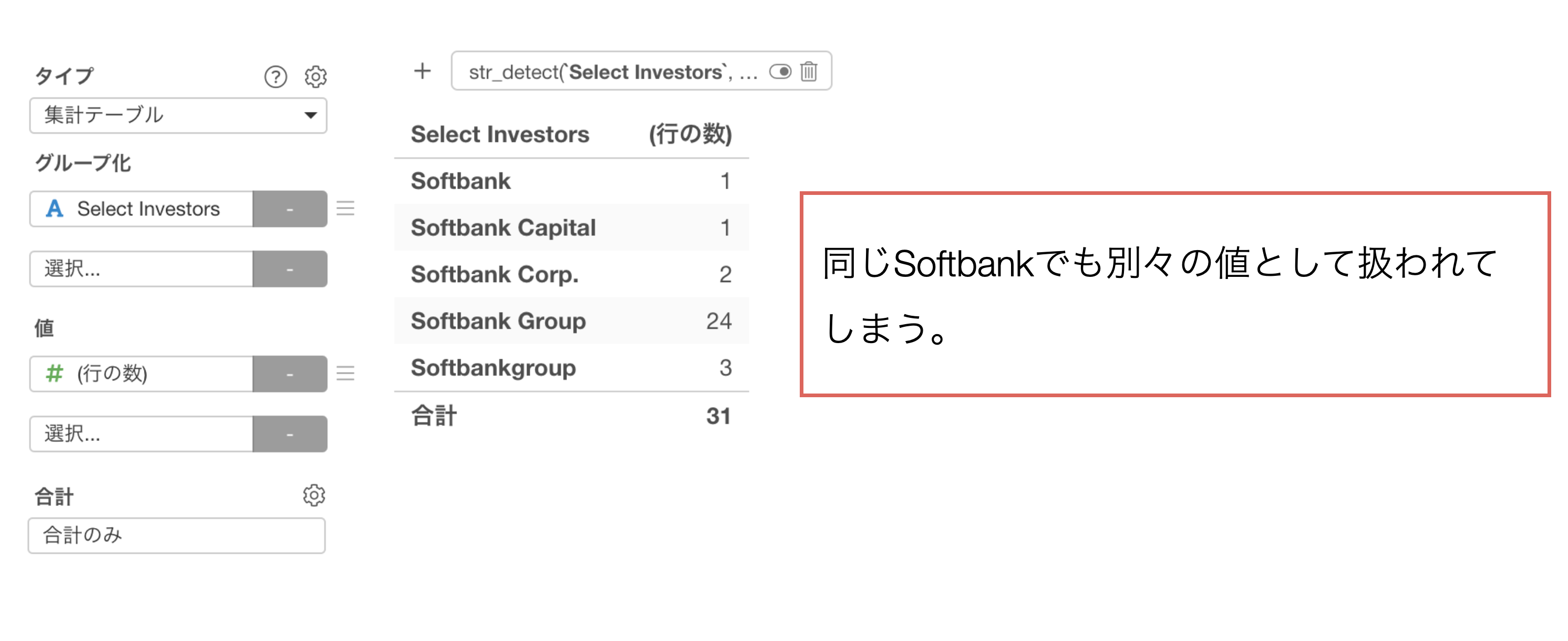
人間の目で見れば同じものだと認識できますが、システムとしては文字列の表記が異なるだけで別々の値として扱われてしまい、集計やチャートで可視化した際に間違った結果につながってしまうことがあります。
そこで、同じ意味を表す値は、同じ文字列として整える必要があります。これを行うのが「テキストデータの加工」です。
 テキストデータの加工には、大きく分けて以下の4つのタイプがあります。
テキストデータの加工には、大きく分けて以下の4つのタイプがあります。
- 削除
- 置換
- 抽出
- 変換
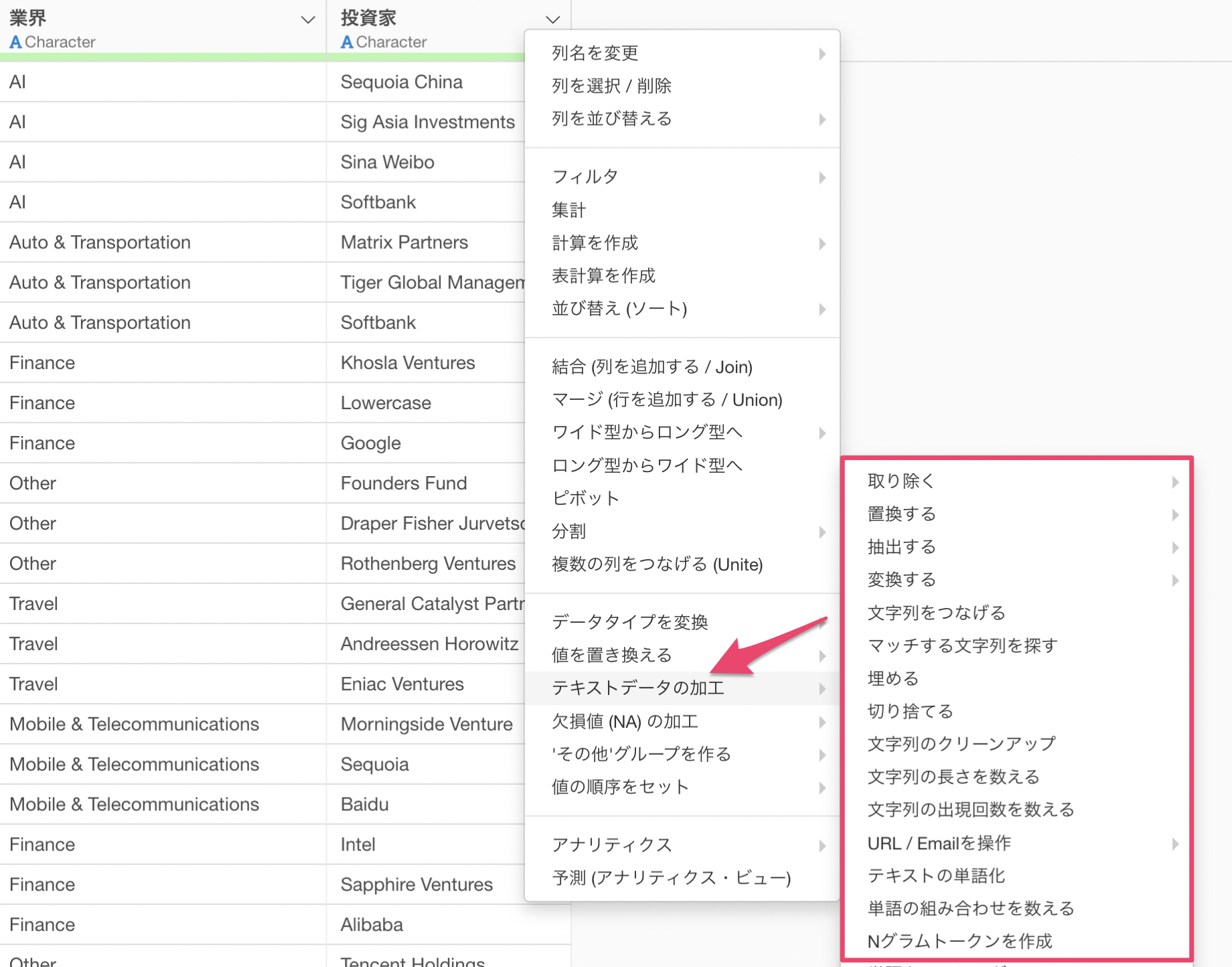
Exploratoryでは、列ヘッダメニューから「テキストデータの加工」を選択することで、豊富な操作タイプを呼び起こして、さまざまなテキストデータの問題を簡単に解決していくことが可能です。
データをインポートする
今回はサンプルデータとして、以下の2つのデータを使用します。それぞれのデータはリンク先のページからダウンロードできます。
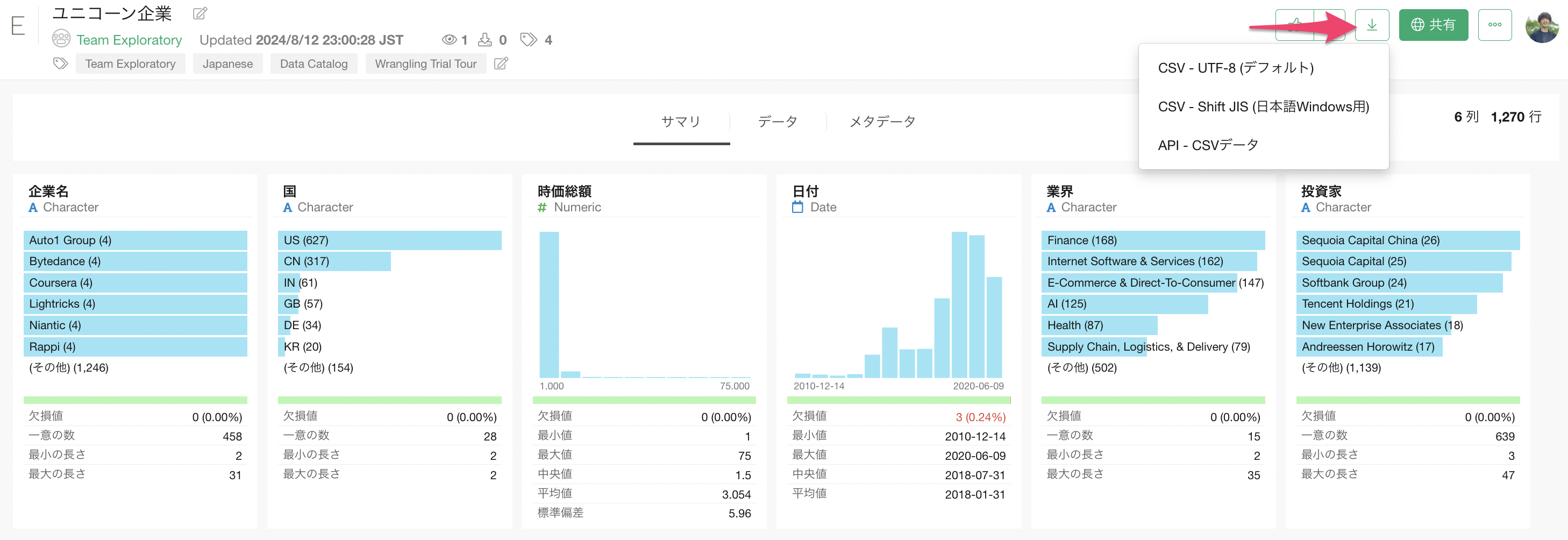
データをダウンロードできたら、ダウンロードしたフォルダを開き、「ユニコーン企業」と「コピー機の注文データ」のファイルをまとめて選択し、Exploratoryの画面にドラッグ&ドロップします。
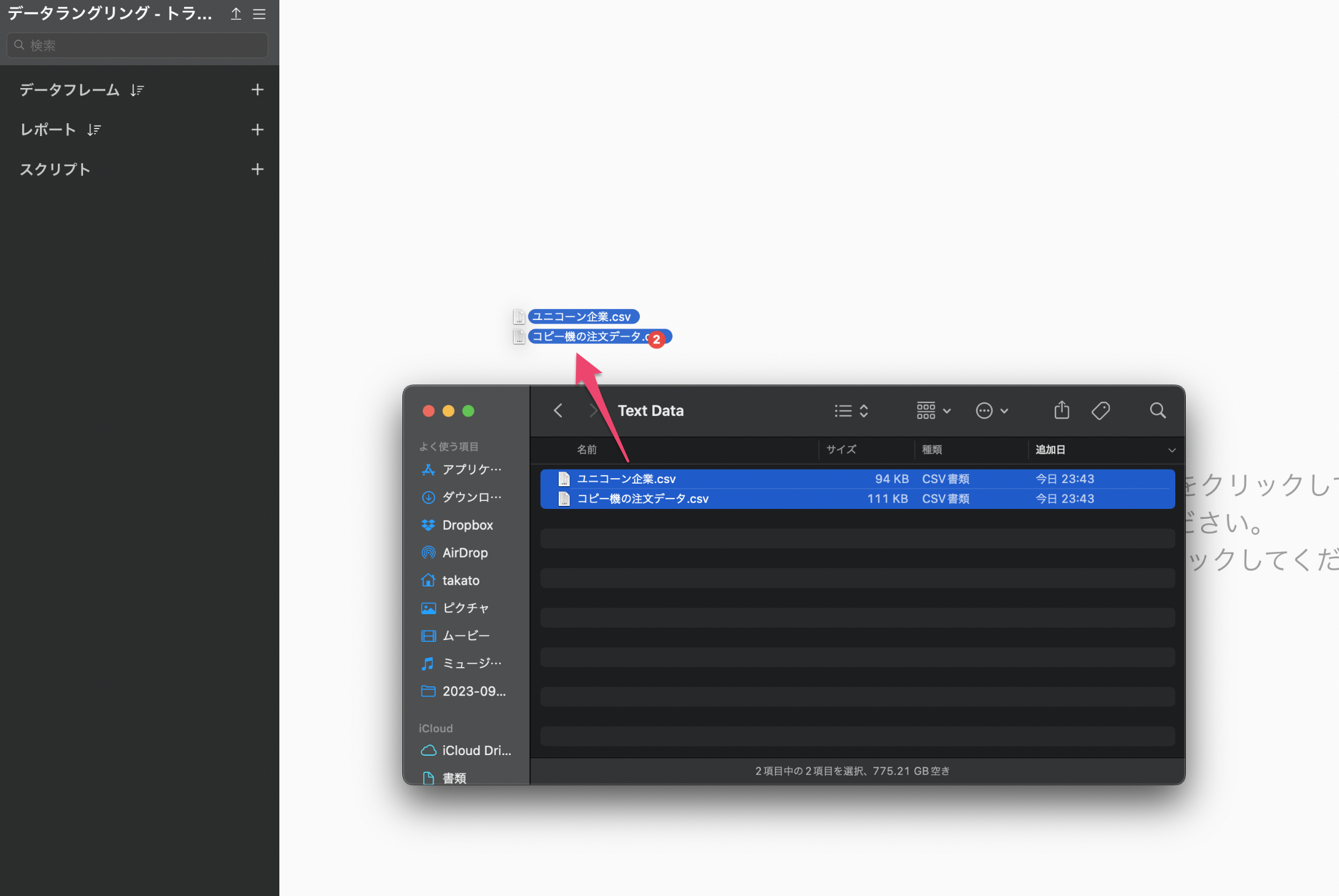
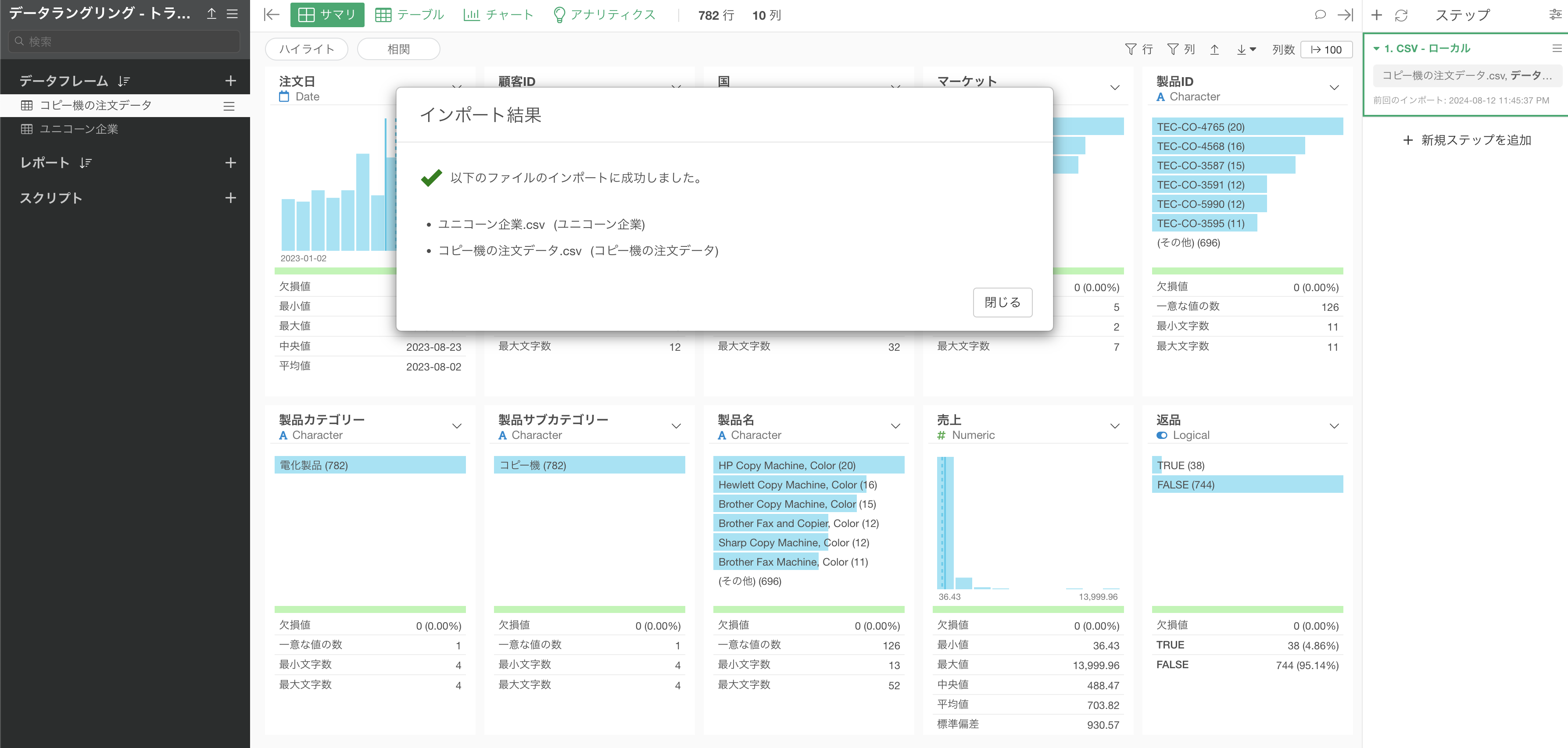
インポートのファイル選択のダイアログが表示されるため、「インポート」のボタンをクリックします。
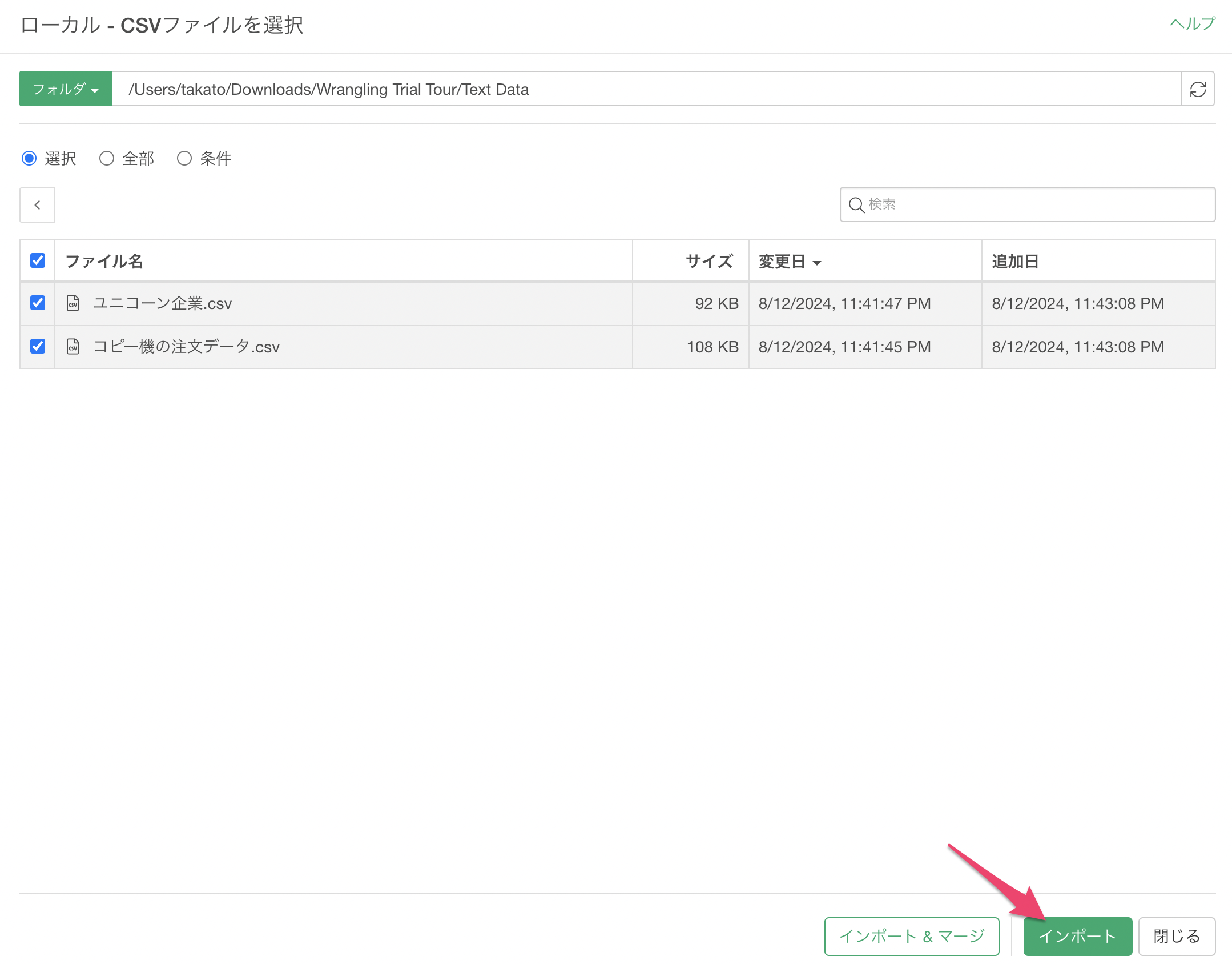
インポートダイアログの左側にある項目から、インポート時の設定を行うことが可能ですが、今回は設定は不要なため「全てをOK」のボタンをクリックします。
「ユニコーン企業」と「コピー機の注文」のデータを一気にインポートすることができました。
ここからはインポートしたデータを使って3つのタイプのテキストデータの加工を体験いただきます。
データを加工する2つの方法:「AI プロンプト」と「UI メニュー」
Exploratoryでデータを加工するときには、2つのやり方があります。
1つは自然言語でデータを加工できる「AI プロンプト」を利用した方法で、もう1つは列などからアクセス可能なデータの加工の「UI メニュー」を利用した方法です。
こちらのトライアルツアーでは、その両方を使ったデータの加工方法を紹介します。
なお、「AI プロンプト」はBusiessプランやPersonalプランなどの有償ライセンスをお持ちのユーザー様とそれらのプランをトライアル中のユーザー様のみ利用可能なメニューです。
また、AI プロンプトはご利用の端末がインターネットに接続できるときにのみご利用可能な機能です。そのため、上記のプランをご利用でない場合や、インターネットに接続していない端末をご利用の場合、「UIでデータを加工する」セクションにお進みください。
AI プロンプトでデータを加工する
AI プロンプトの紹介
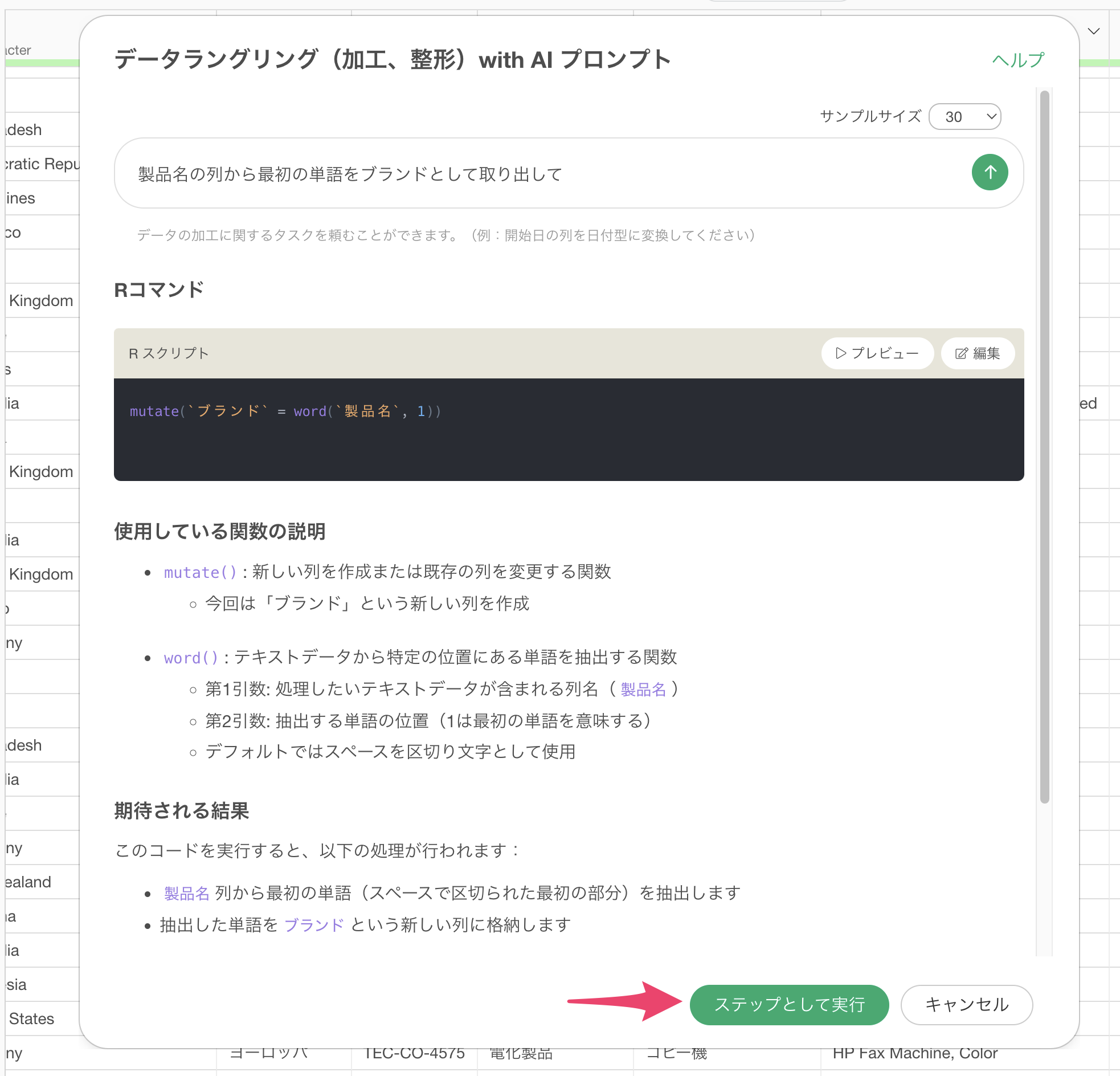
AI プロンプトでは、データ加工に関して実行したい処理を指示することで、やりたいことを実現するためのRコードを生成します。
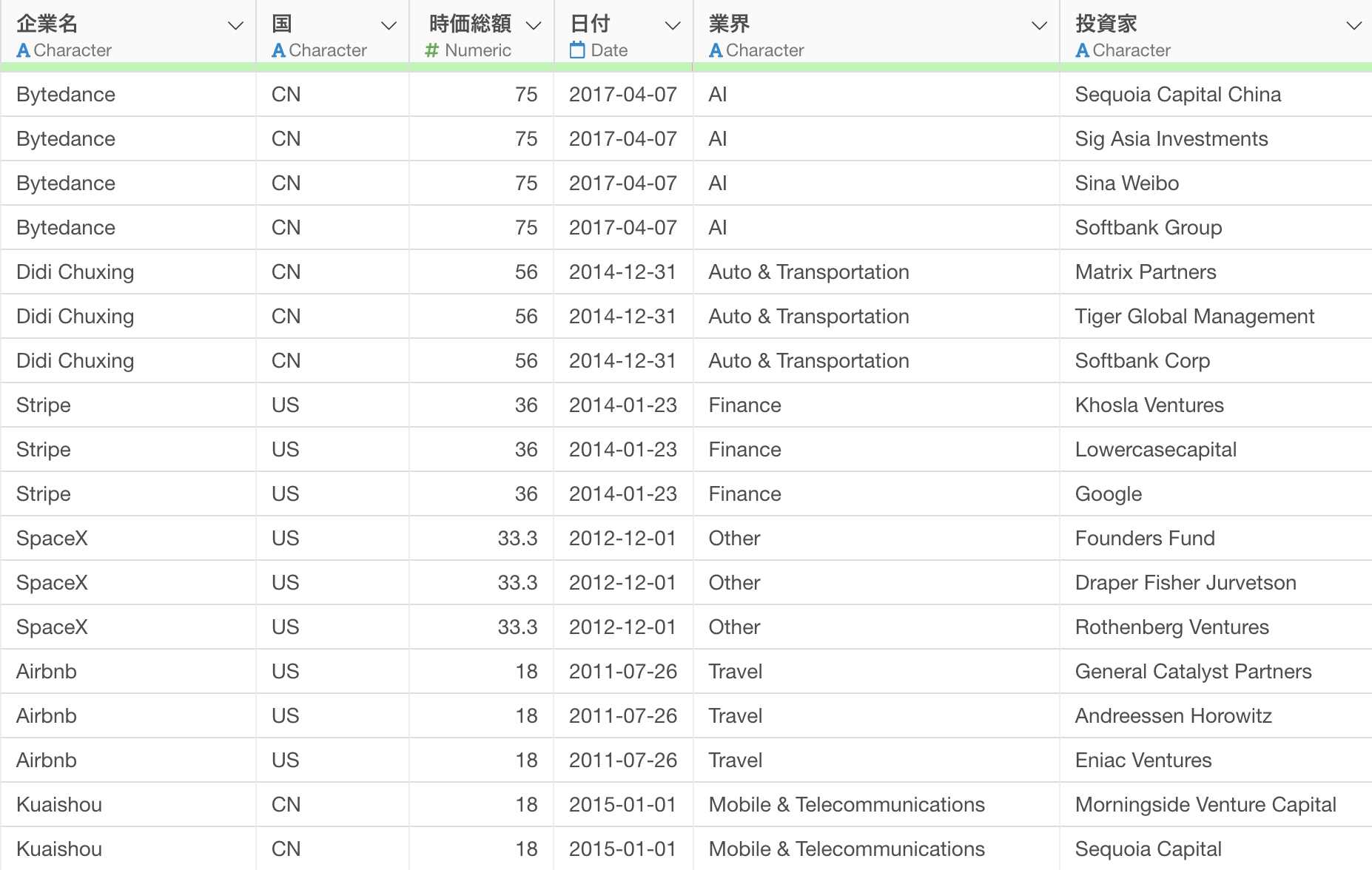
プロンプトを実行すると、「Rコマンド」と「使用している関数の説明」、「期待される結果」の3つが出力されます。
Rコマンドでは、質問された内容を処理するために必要なデータラングリングのタスクがRのコードとして出力されるため、ステップとして実行を押すことでその処理が適用されます。
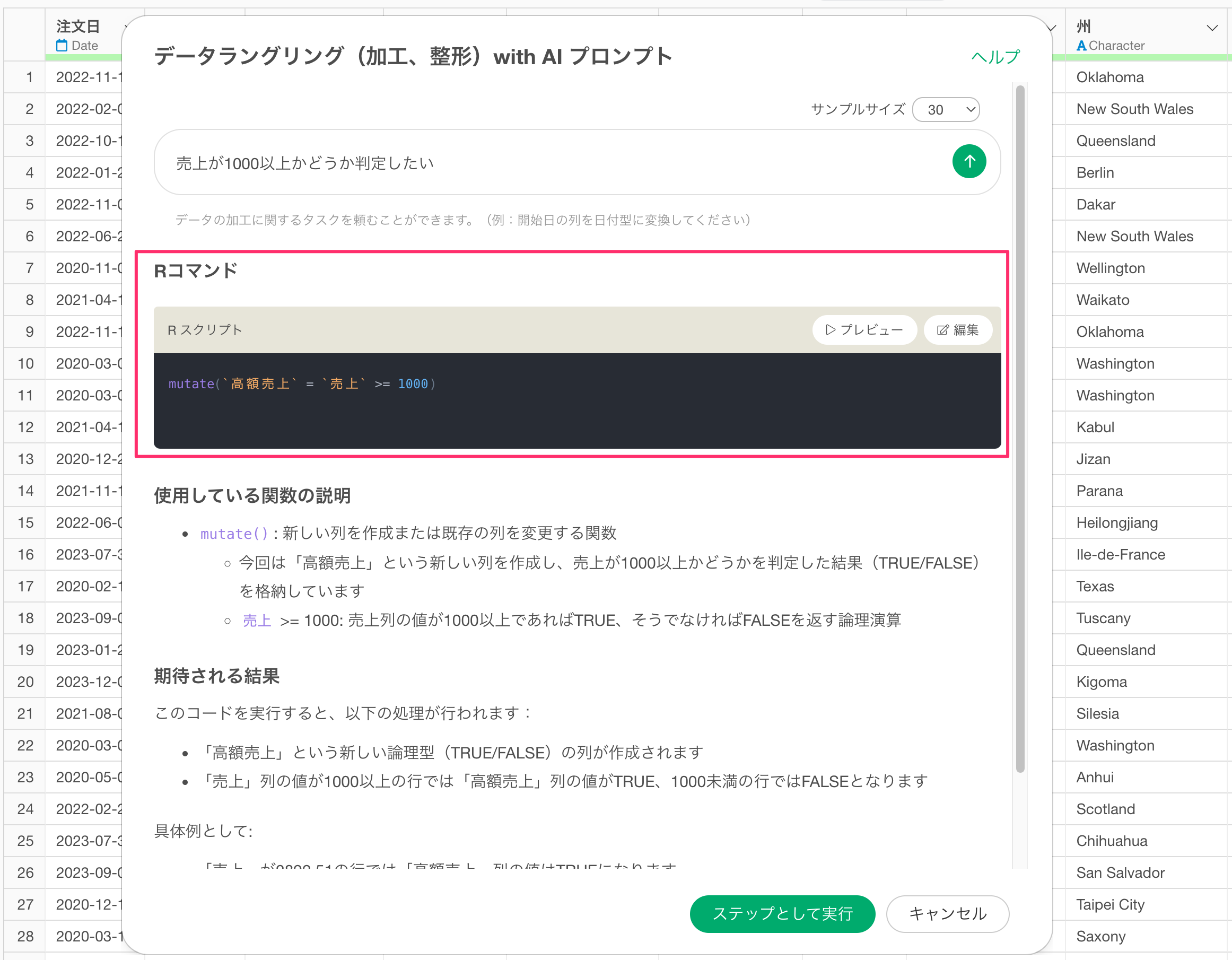
Rコマンドで使用している関数は、「使用している関数の説明」の方でどういった関数や引数が使われているのかを説明しています。
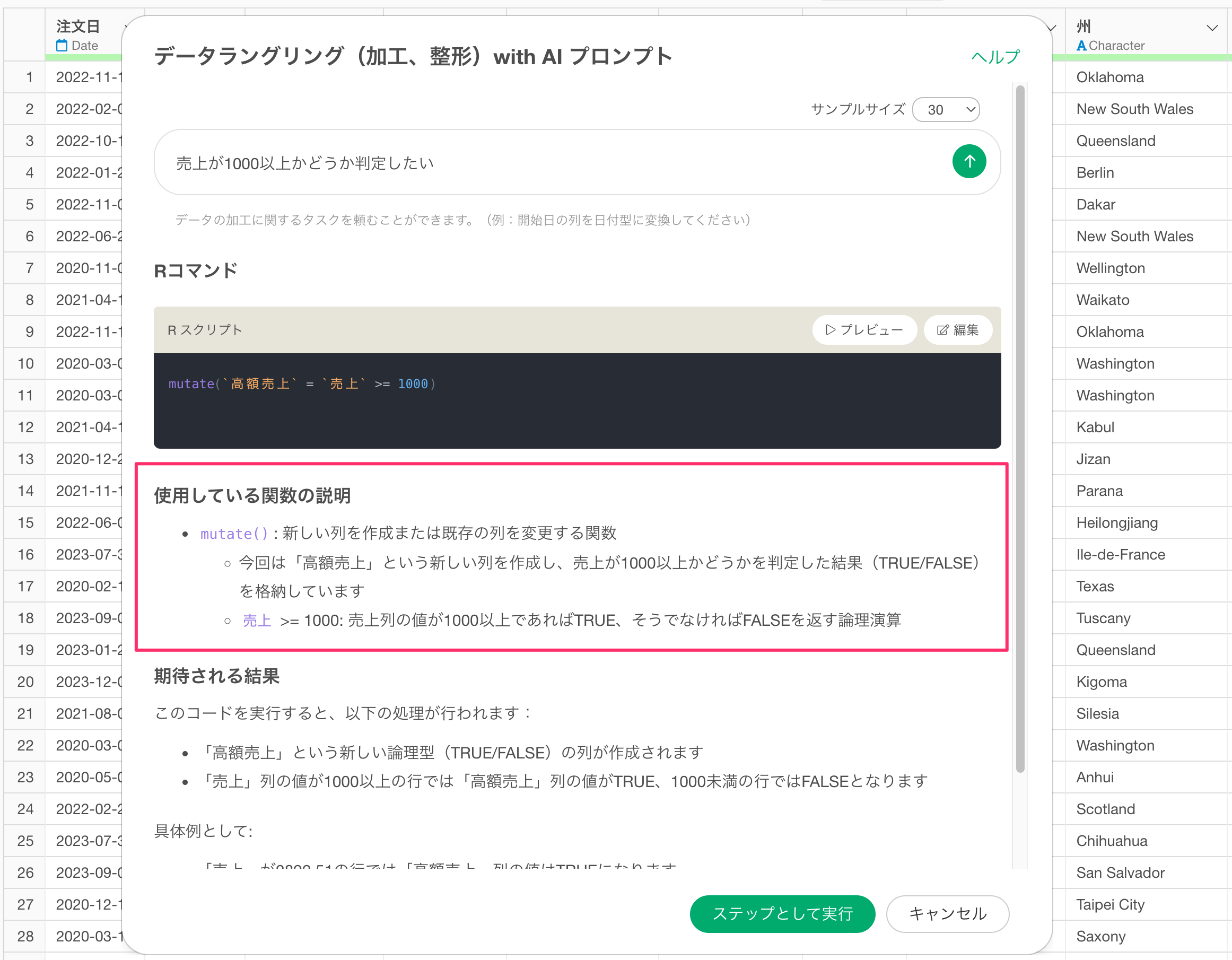
最後に、「期待される結果」のセクションでは、このコードを実行することでどういった結果が得られるのかを説明するようになっています。
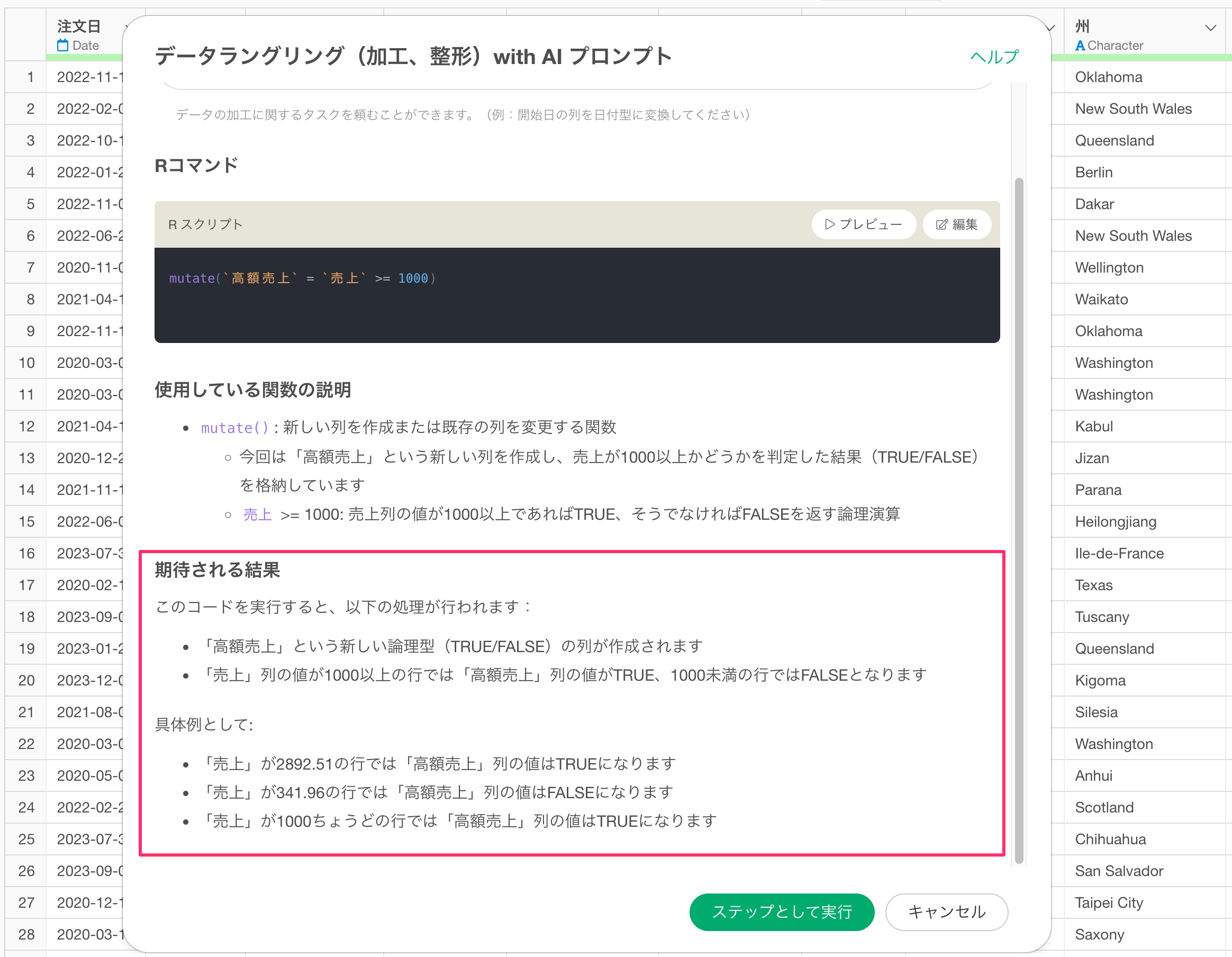
ではAI プロンプトを使ってデータを加工していきましょう。
1. 取り除く
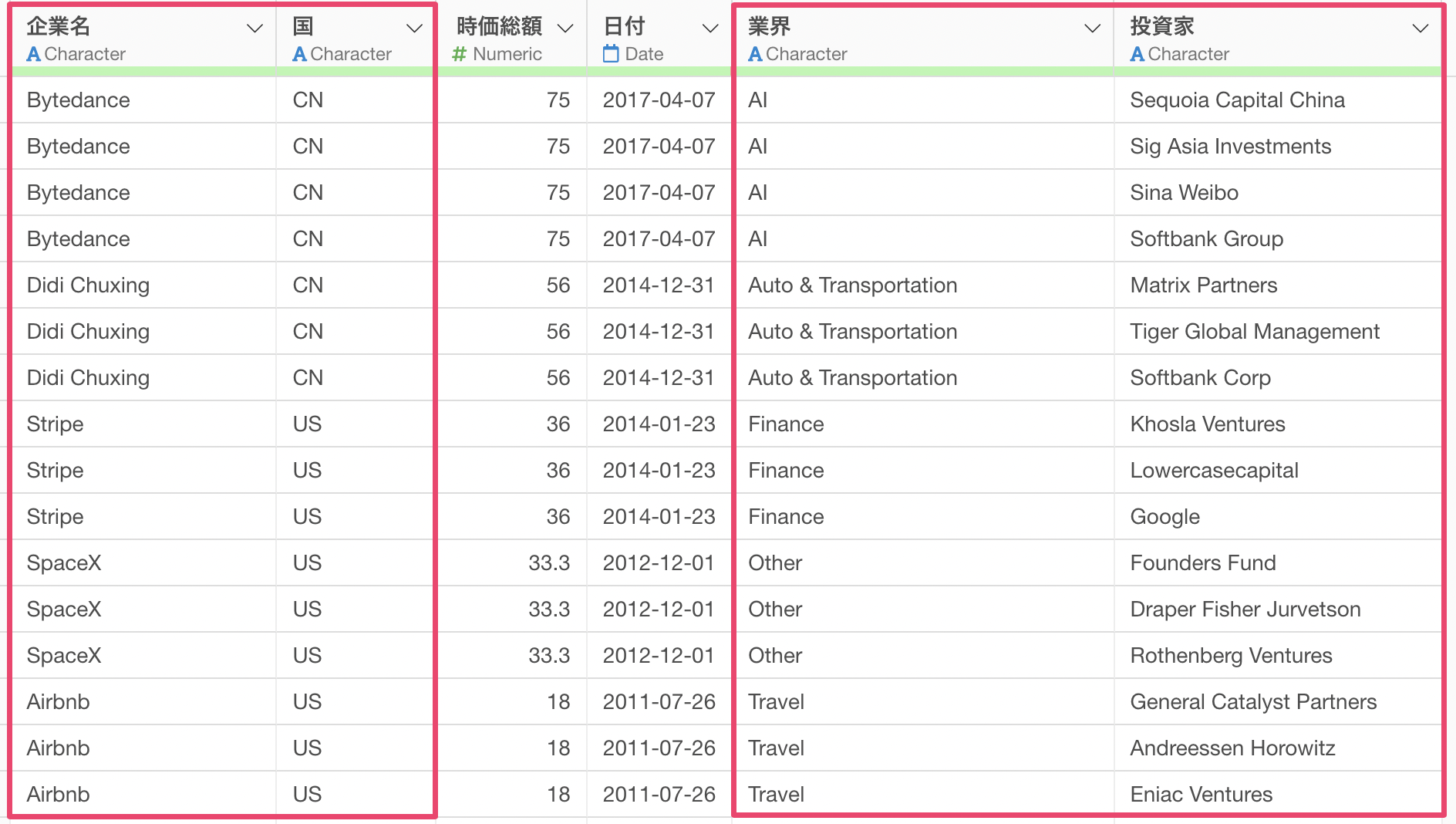
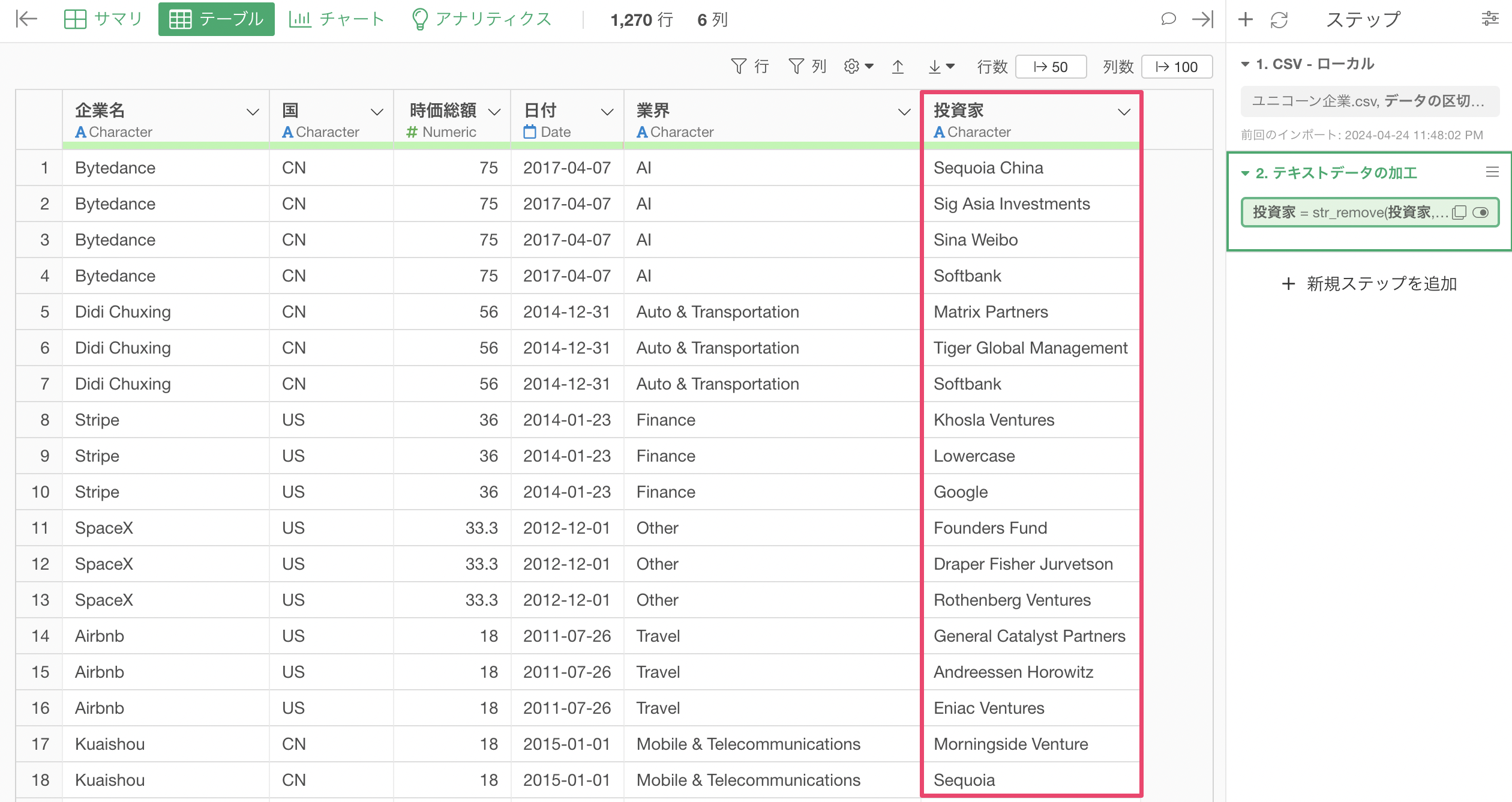
このパートではユニコーン企業のデータを使用していきます。1行が1企業かつ、投資家ごとに行が分かれているデータとなっています。
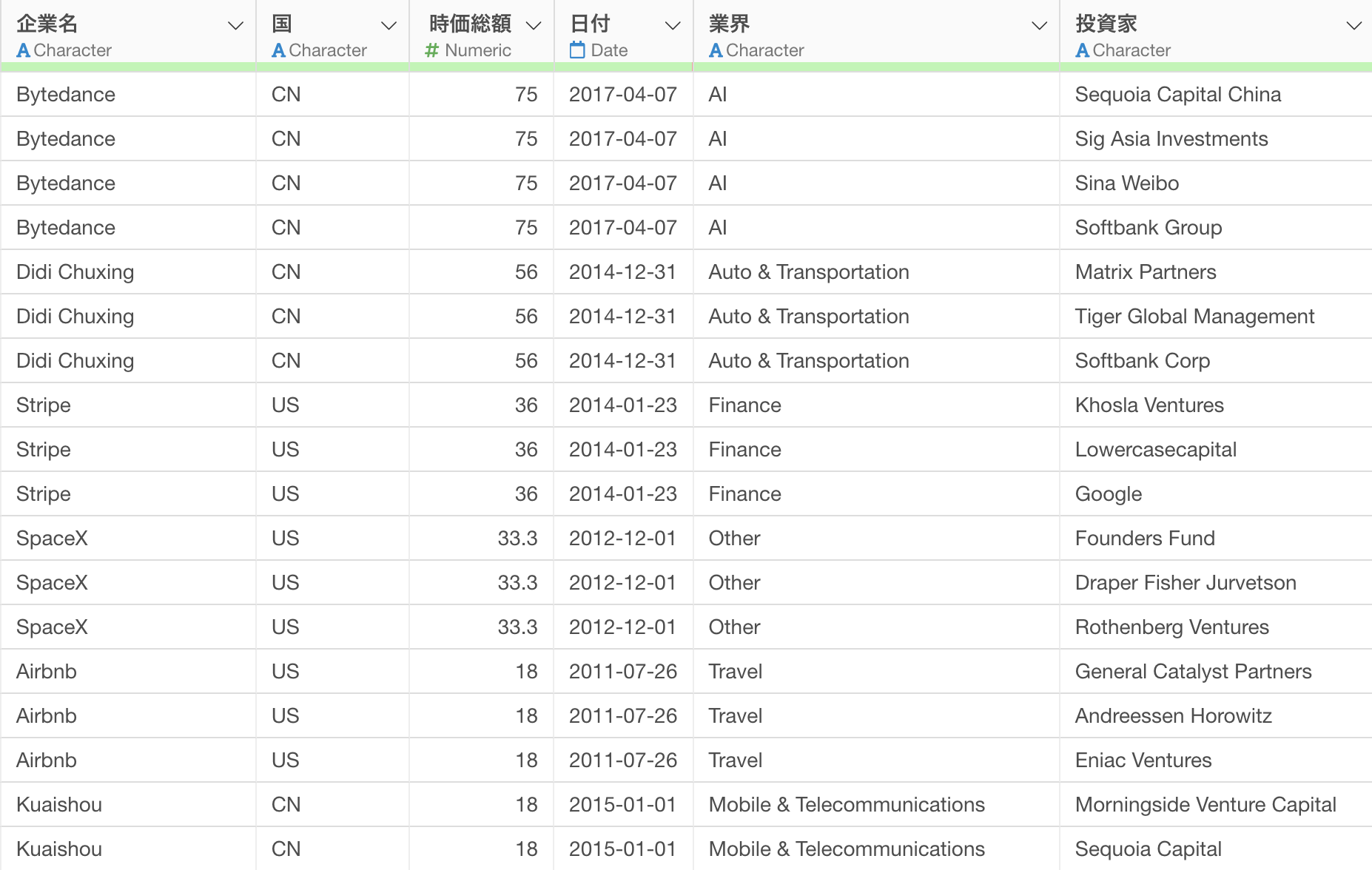
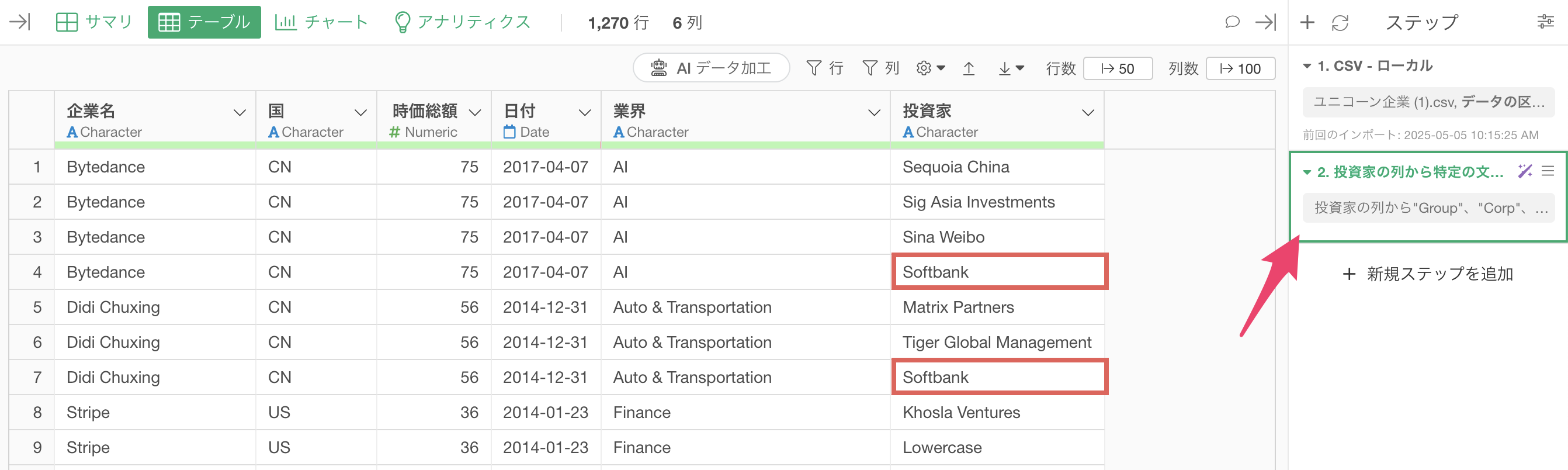
投資家の列にある「Softbank」に注目をしてみると、「Softbank Group」や「Softbank Corp」といった文字列になっていることがわかります。
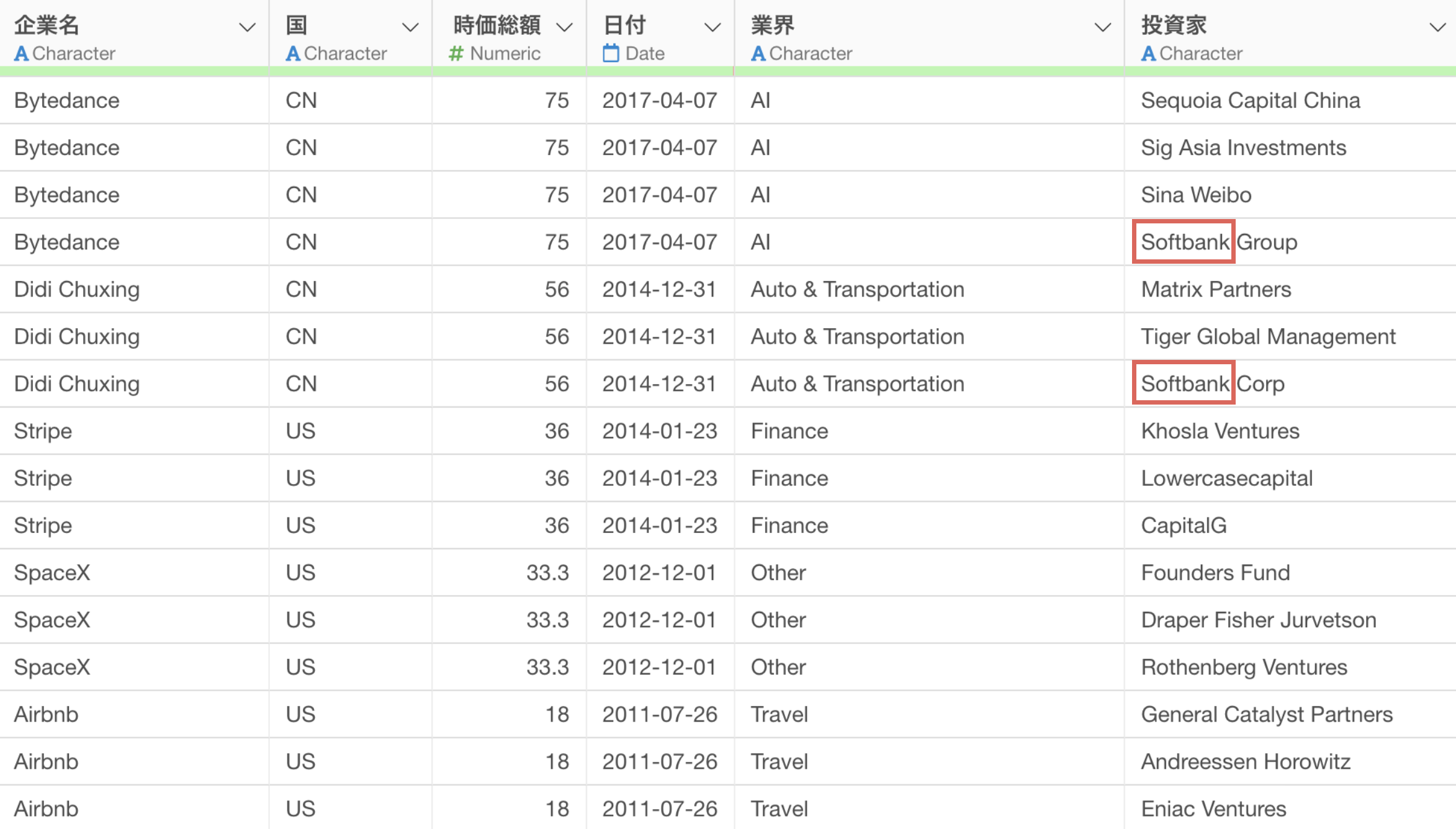
また、「Softbank Capital」といった文字列になっていることも確認できます。
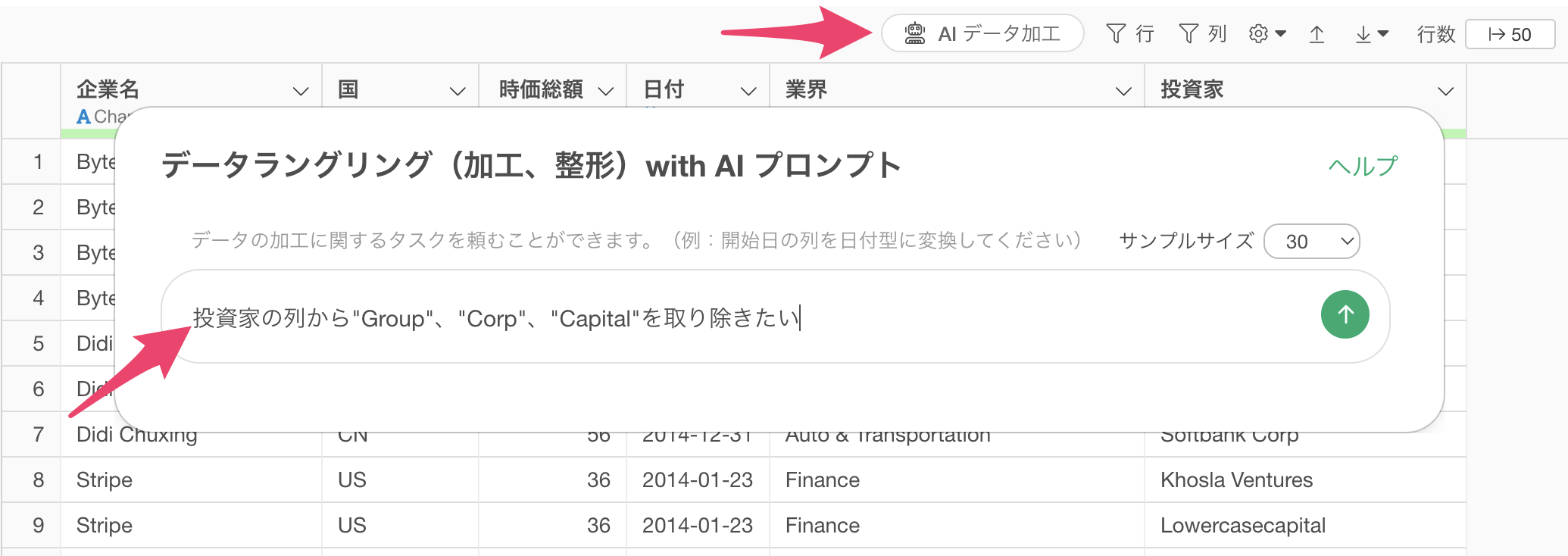
そこで、Group、Corp、Capitalといった文字を取り除いて、Softbankにしていくために、「AI データ加工」ボタンをクリックします。
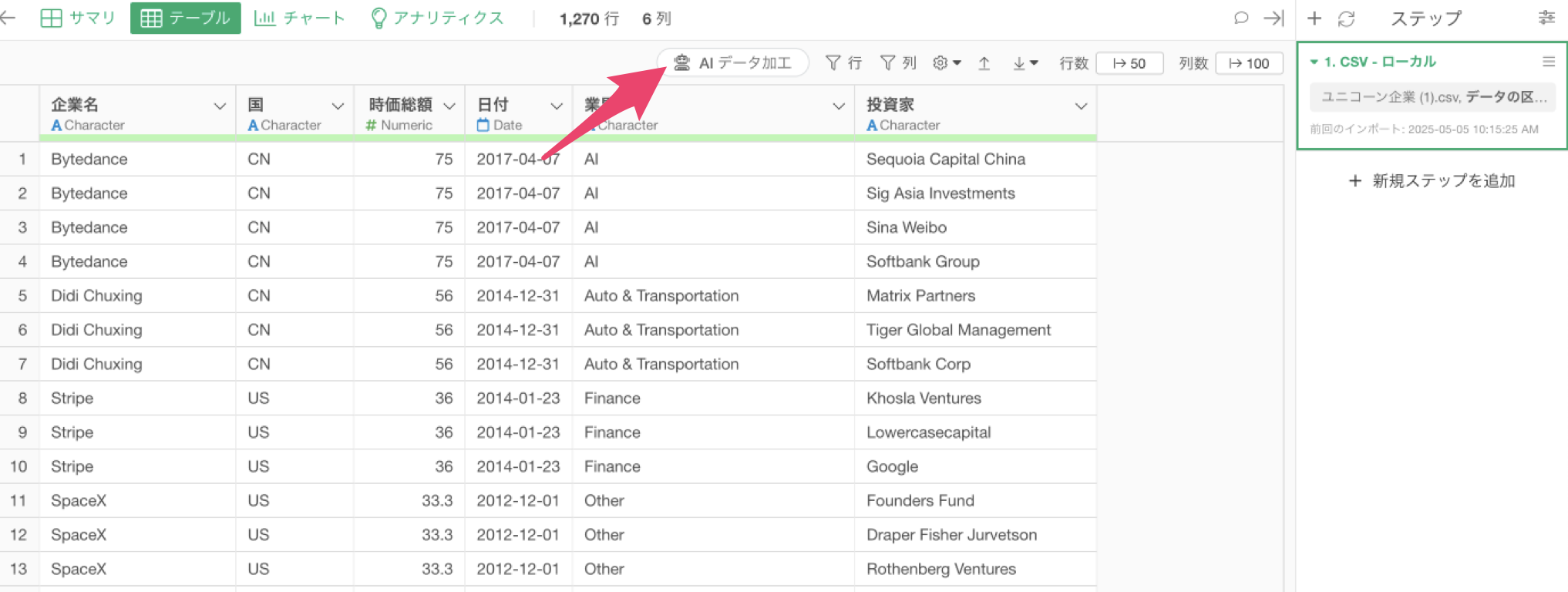
AI プロンプトのダイアログが表示されたら、以下のようなテキストを入力し、実行します。
投資家の列から”Group”、“Corp”、“Capital”を取り除きたい
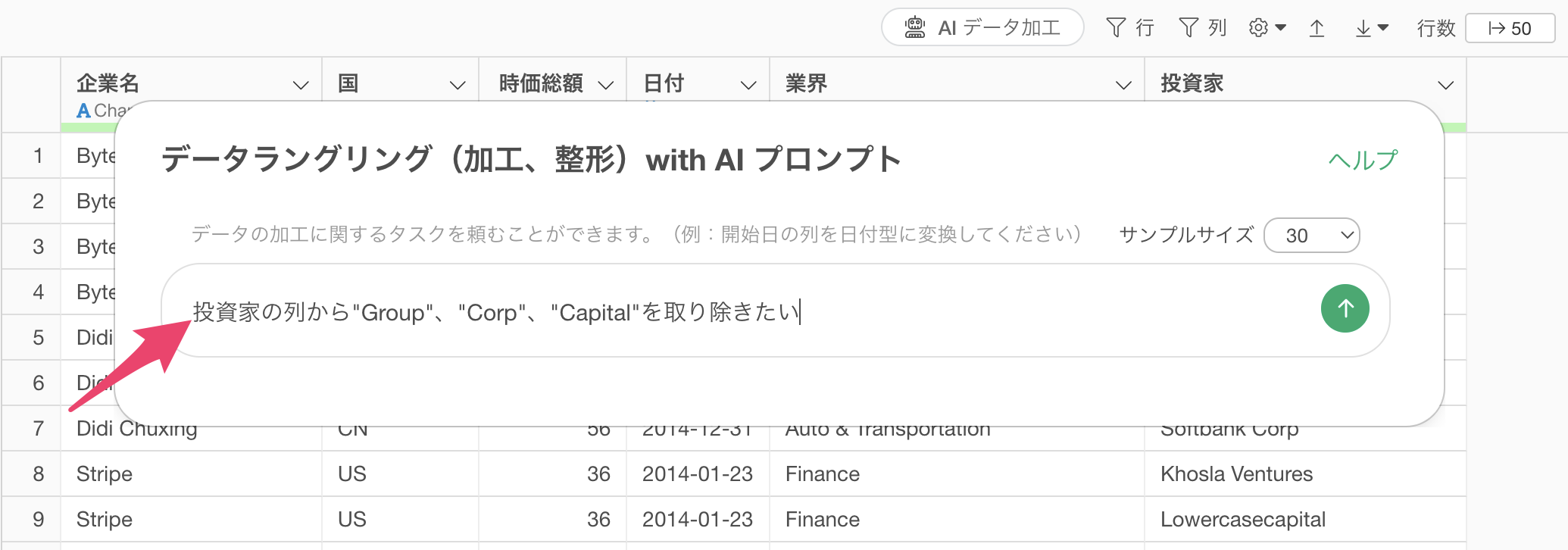
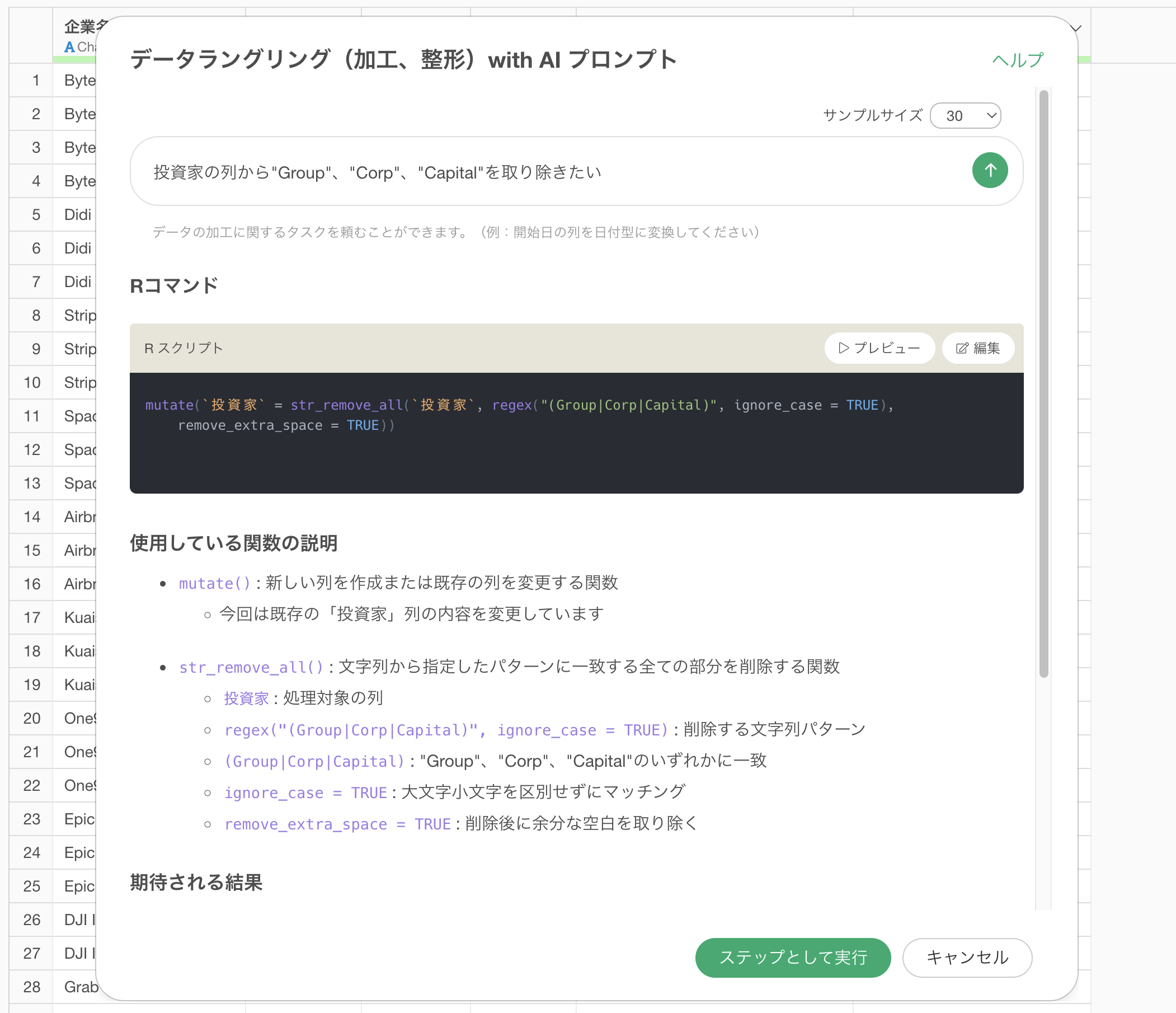
すると、投資家の列から指定した文字列を取り除くためのコードが生成されます。
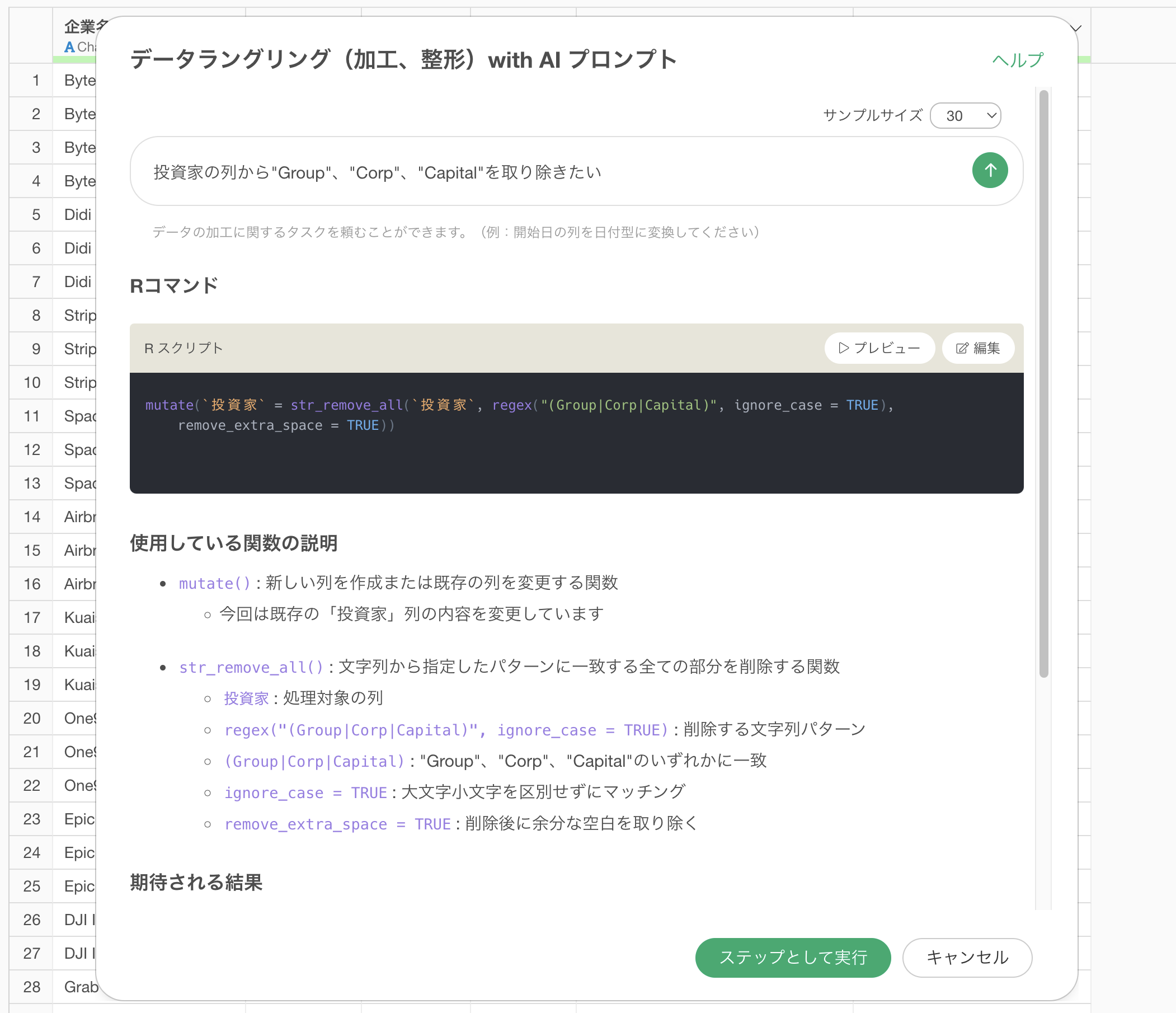
使用している関数の説明や期待される結果を確認し、「ステップとして実行」ボタンをクリックします。
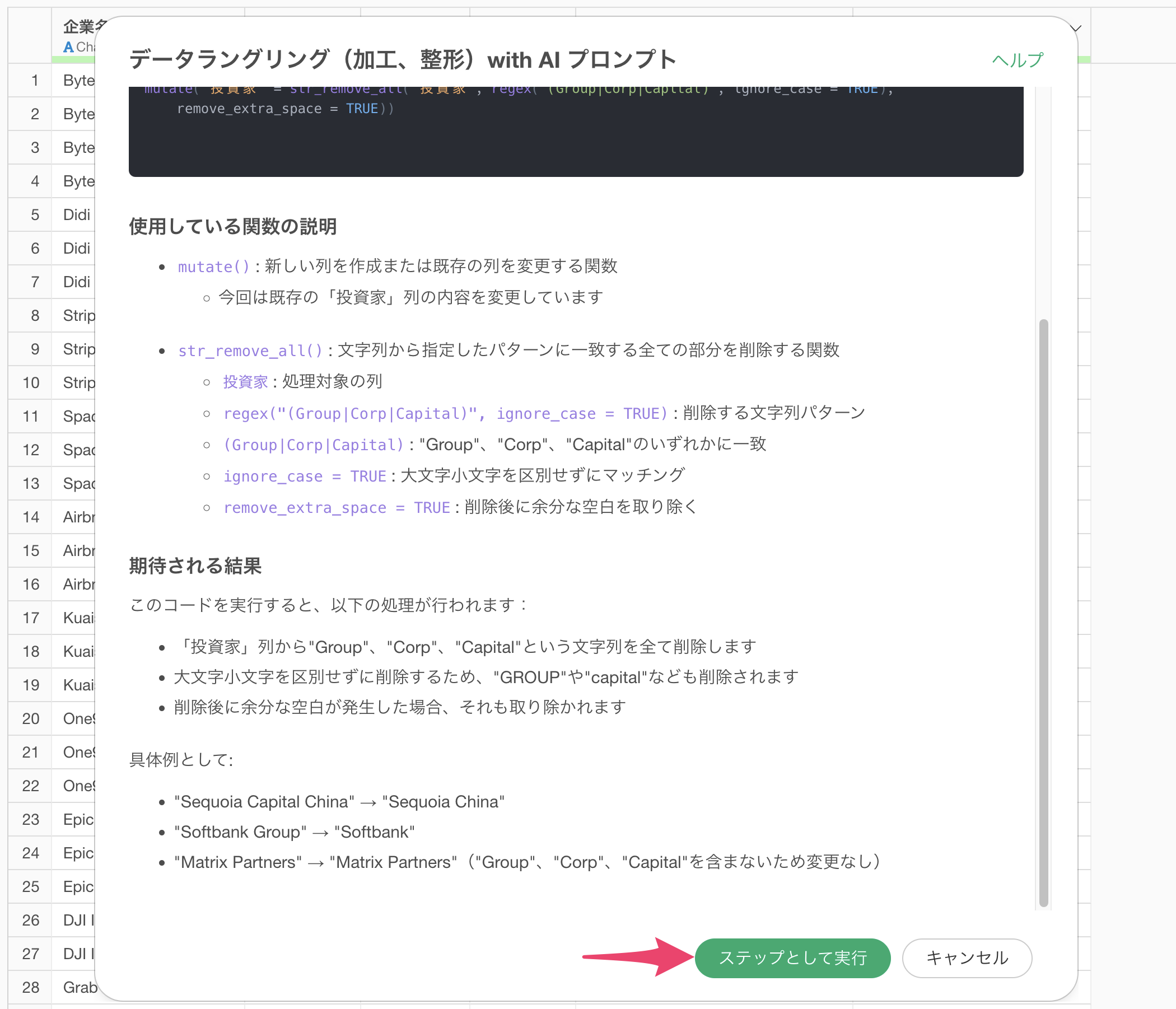
ステップが追加され、「Softbank Group」や「Softbank Corp」などの文字列から「Group」や「Corp」などの部分が取り除かれ、「Softbank」のように整理されました。
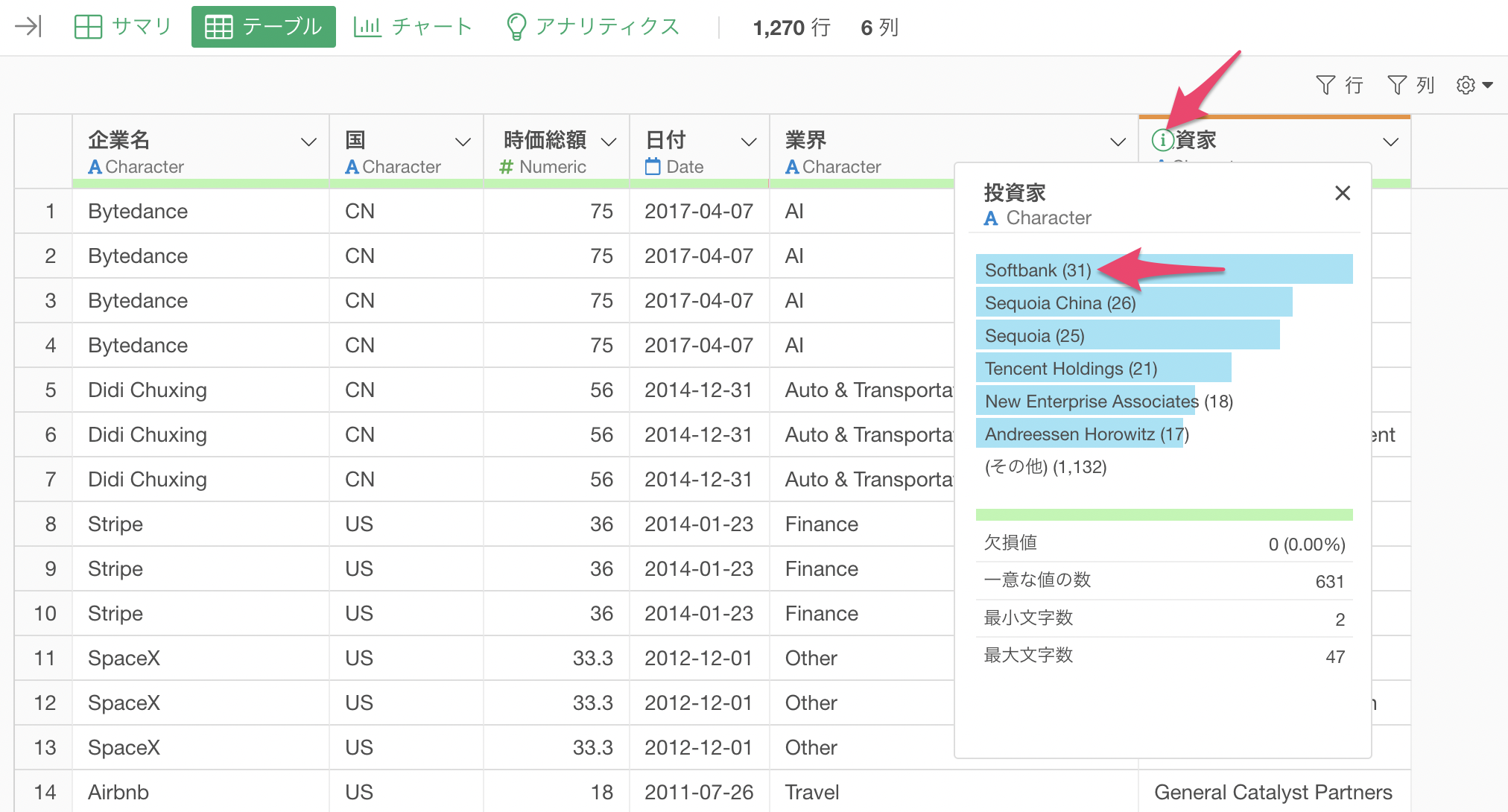
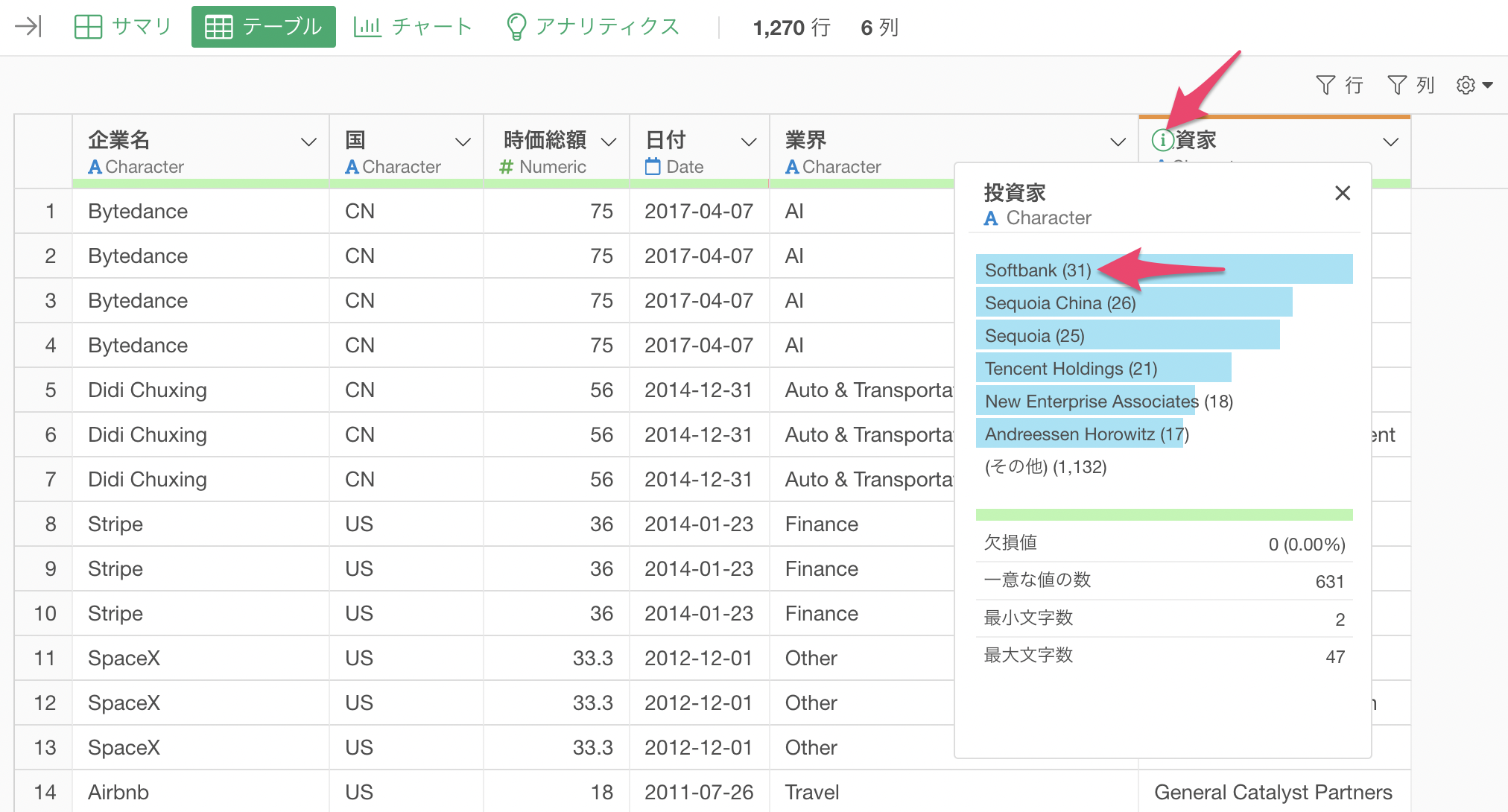
投資家の列の「i」をクリックすることで、「Softbank」が投資した企業数は31件あることがわかります。
2. 置換する
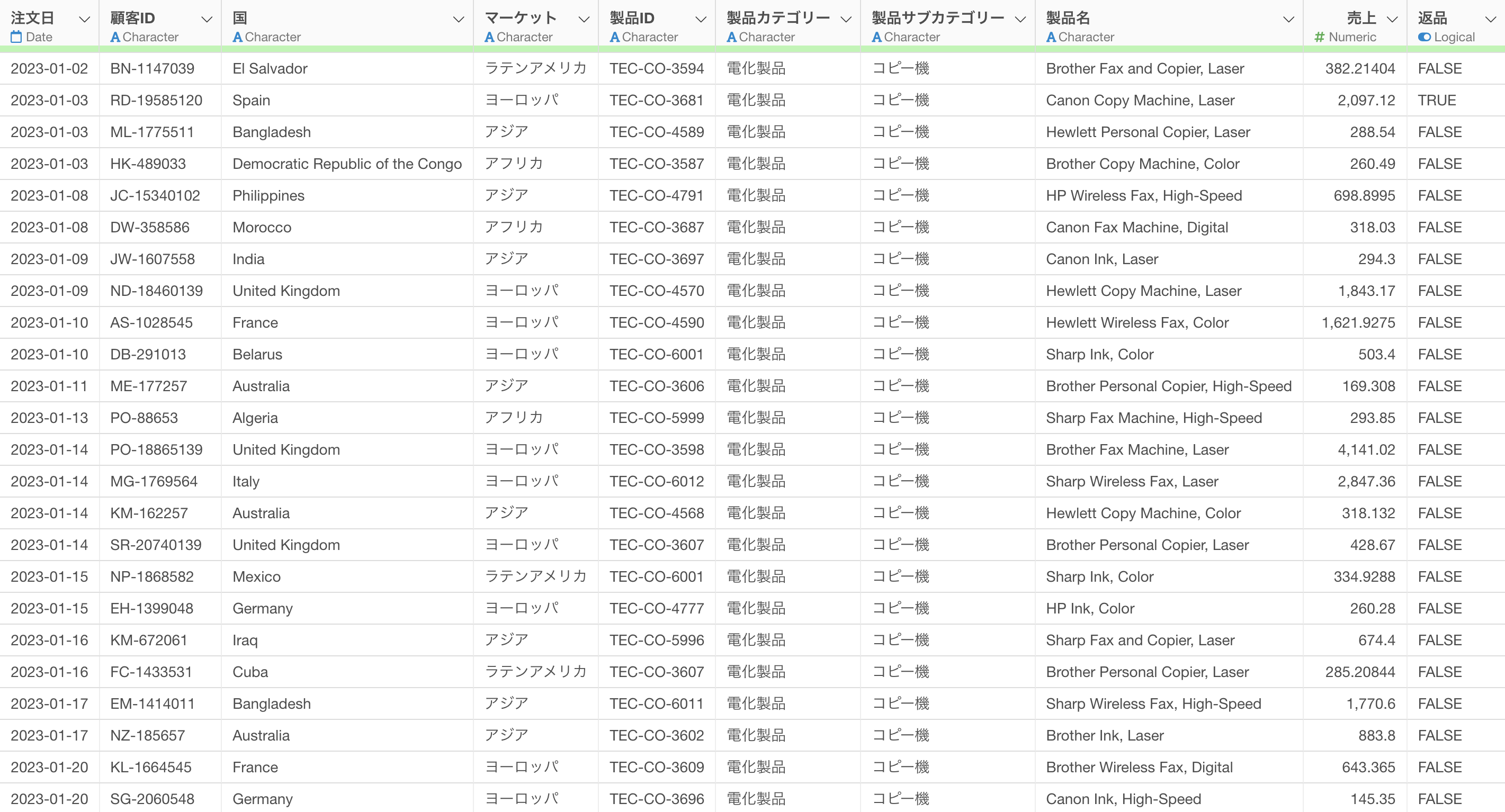
このパートでは、コピー機の注文データを使用していきます。1行が1つの注文、かつ商品ごとに行が分かれているデータです。
自分がコピー機の販売担当をしているケースとして、製品サブカテゴリーを「コピー機」に絞り込まれています。
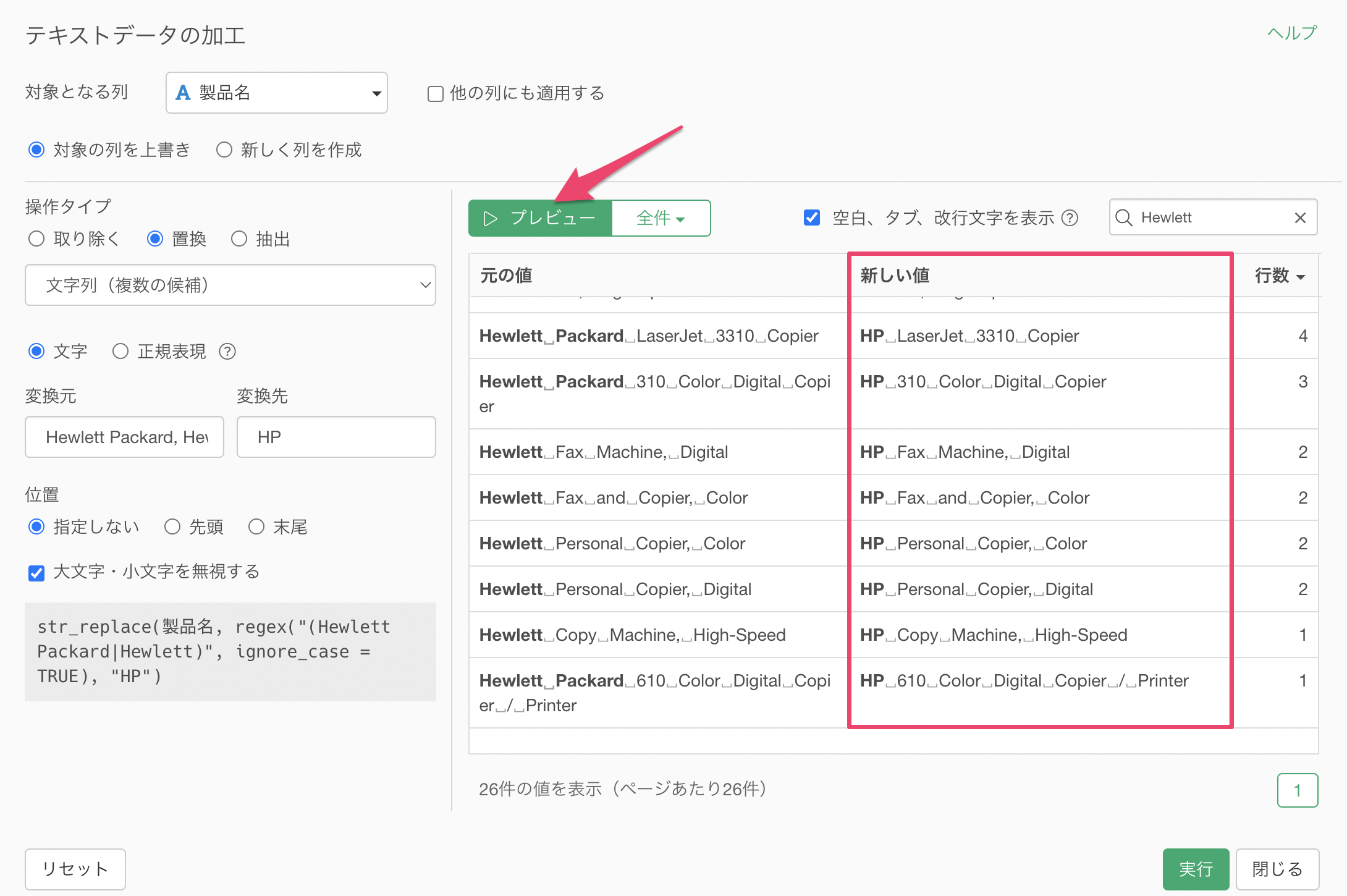
製品名の列に注目すると「Hewlett Packard」の製品は「HP」や「Hewlett」といった文字列になっており、表記が統一されていないことがわかります。
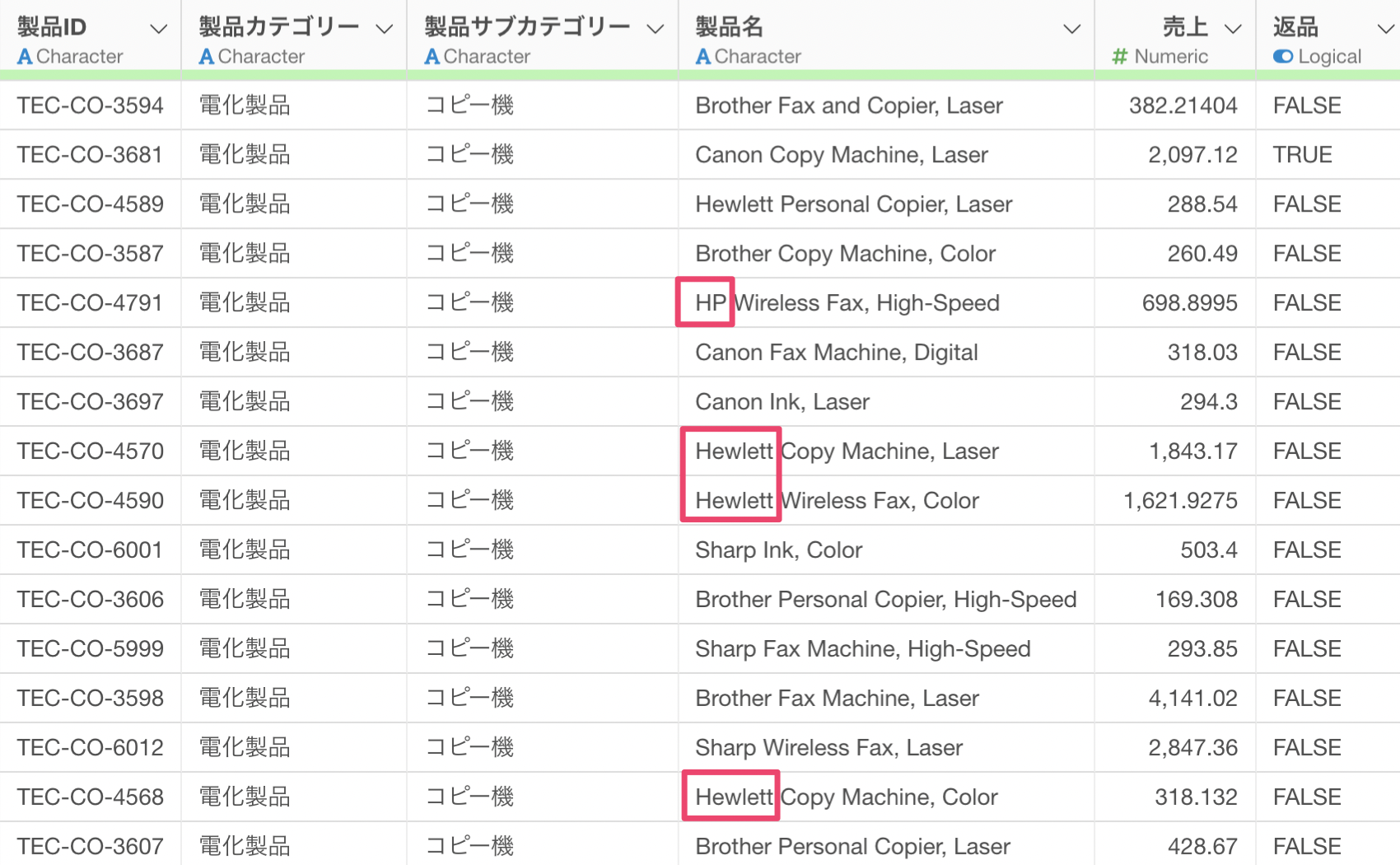
そのため製品名の中にある「Hewlett」といった文字列を「HP」に置き換えるために、「AI データ加工」ボタンをクリックします。
AI プロンプトのダイアログが表示されたら、以下のようなテキストを入力し、実行します。
製品名の列の”Hewlett Packard”と”Hewlett”をHPに置換して
すると、製品名の列から「Hewlett Packard」と「Hewlett」を「HP」に置換するためのコードが生成されます。
使用している関数の説明や期待される結果を確認し、「ステップとして実行」ボタンをクリックします。
ステップが追加され、製品名の列にあった「Hewlett Packard」と「Hewlett」を「HP」として置き換えることができ、異なる表記になっていた文字列を統一することができました。
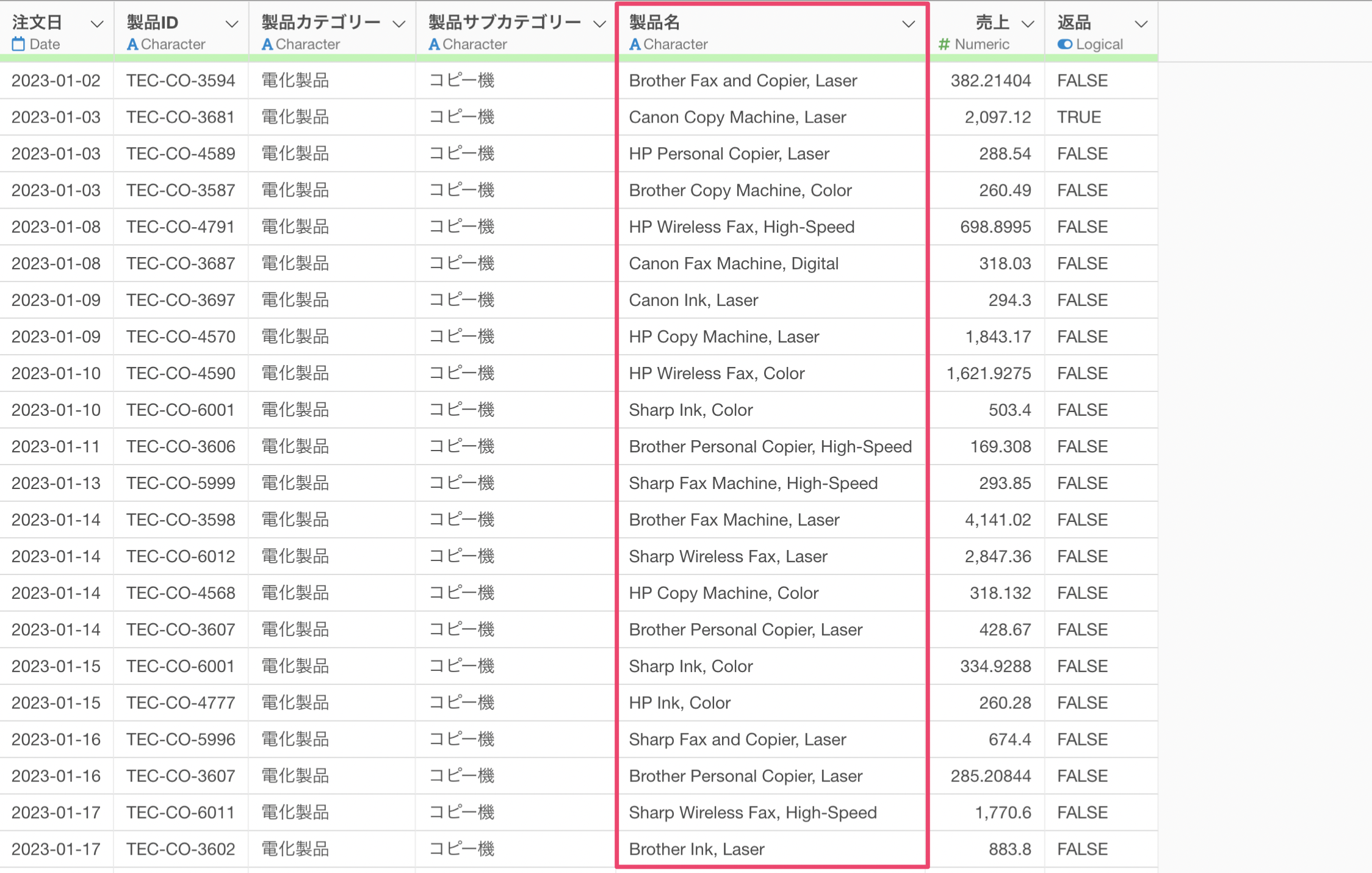
3. 抽出する
1つ前のパートで使用したものと同じ、「コピー機の注文データ」を使用します。
先程は、製品名の「Hewlett Packard」と「Hewlett」を「HP」として置き換えましたが、今回は「製品名」の列から「最初の単語」をブランド名を抽出して新しく列として作成したいです。
そこで「AI データ加工」ボタンをクリックして、AI プロンプトのダイアログに以下のようなテキストを入力し、実行します。
製品名の列から最初の単語を取り出して
すると、製品名の列からブランド名を抽出するためのコードが生成されます。
使用している関数の説明や期待される結果を確認し、「ステップとして実行」ボタンをクリックします。
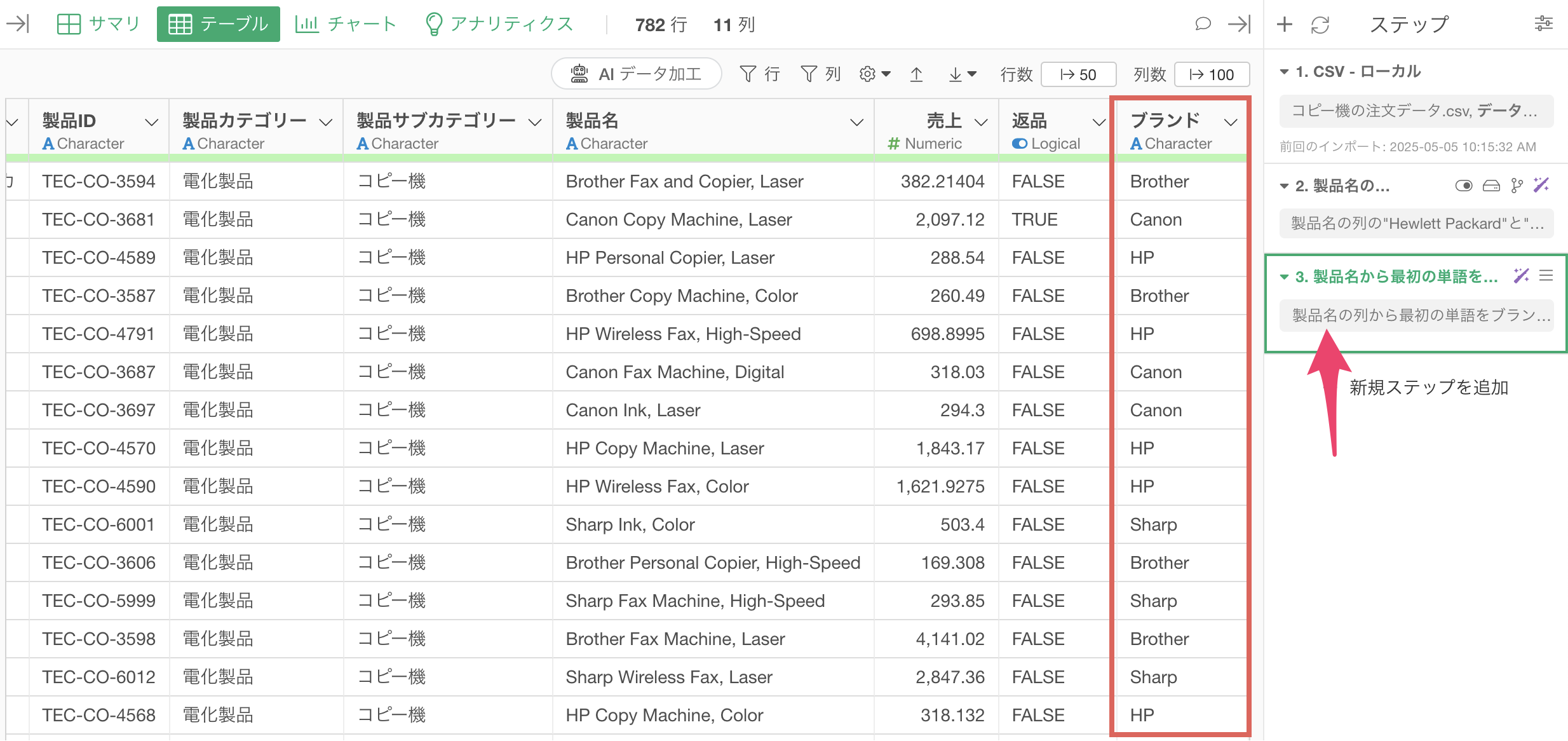
製品名からブランド名を抽出した「ブランド」の列を作成することができました。
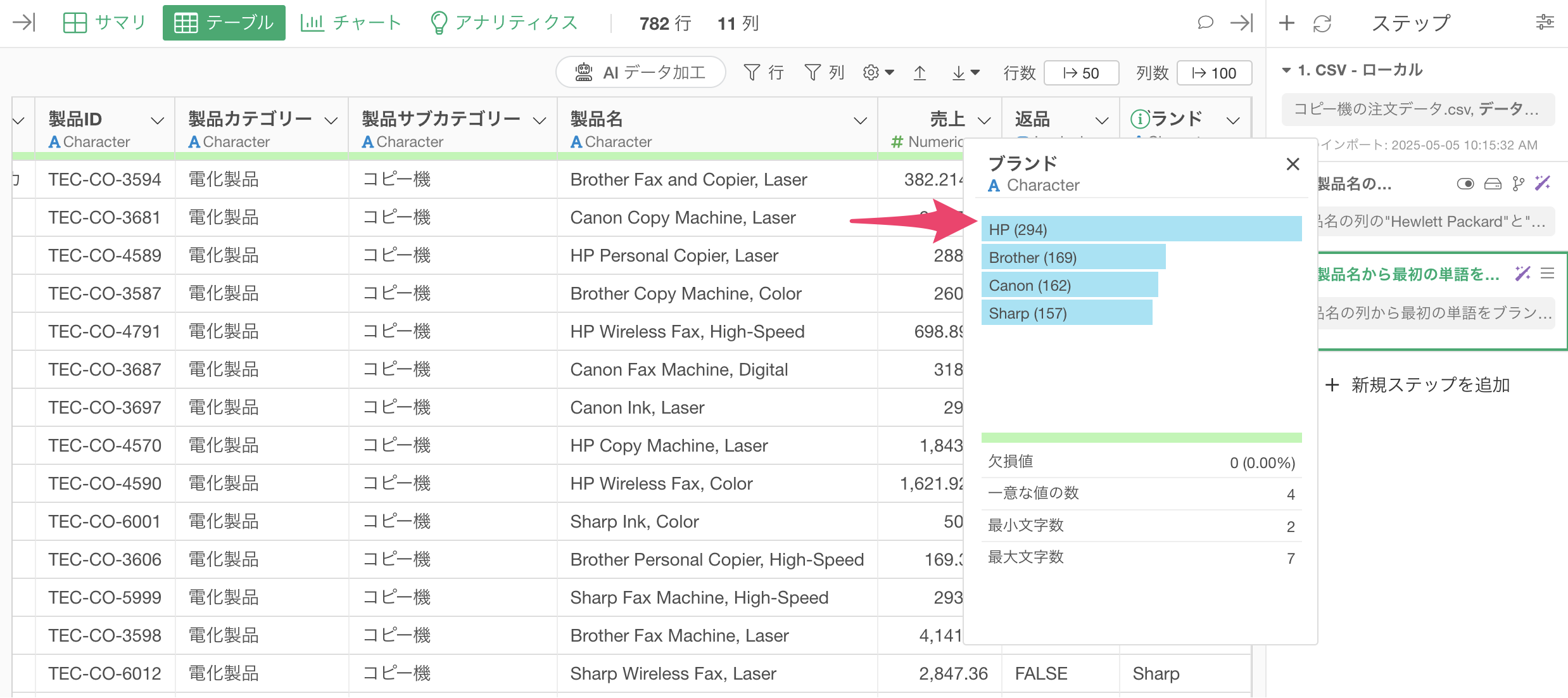
ブランドの列の「i」をクリックすることでどのブランドの販売数量が多いのかを確認することができます。今回のデータでは、「HP」は294件と最も多いことがわかります。
UIでデータを加工する
1. 取り除く
このパートではユニコーン企業のデータを使用していきます。1行が1企業かつ、投資家ごとに行が分かれているデータとなっています。
投資家の列にある「Softbank」に注目をしてみると、「Softbank Group」や「Softbank Corp」といった文字列になっていることがわかります。
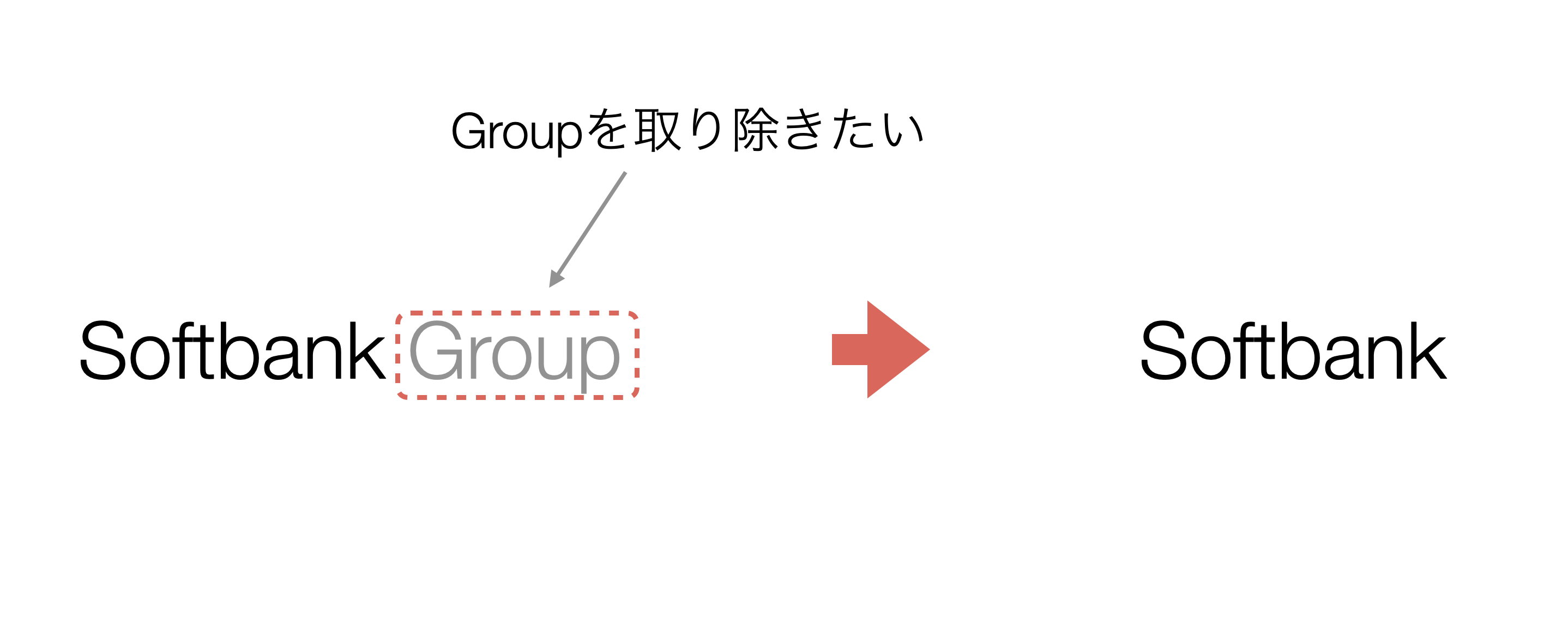
Softbank GroupのGroupの文字を取り除いて、Softbankにしていきたいです。
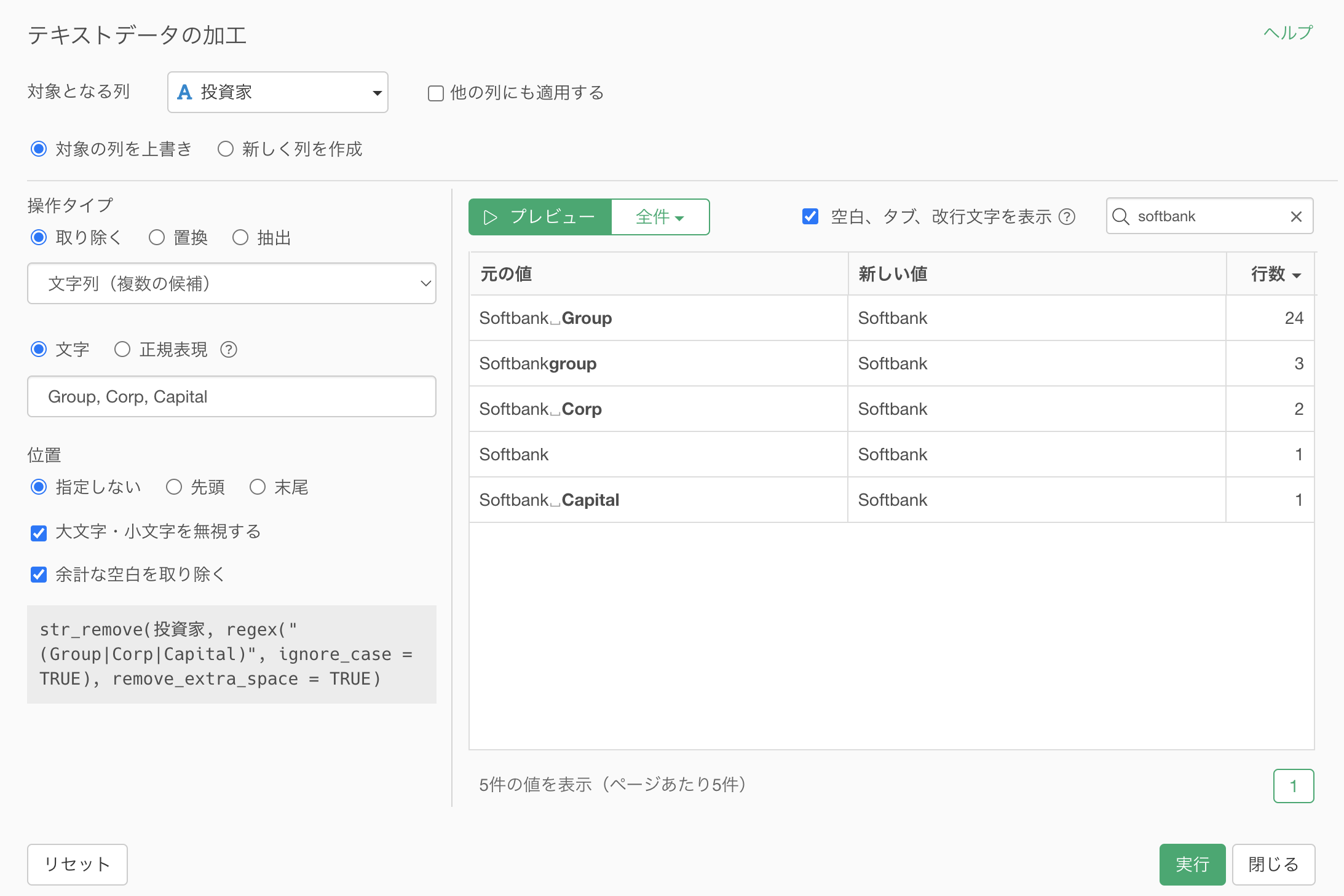
列ヘッダメニューから「テキストデータの加工」の「取り除く」の「文字列」を選択します。
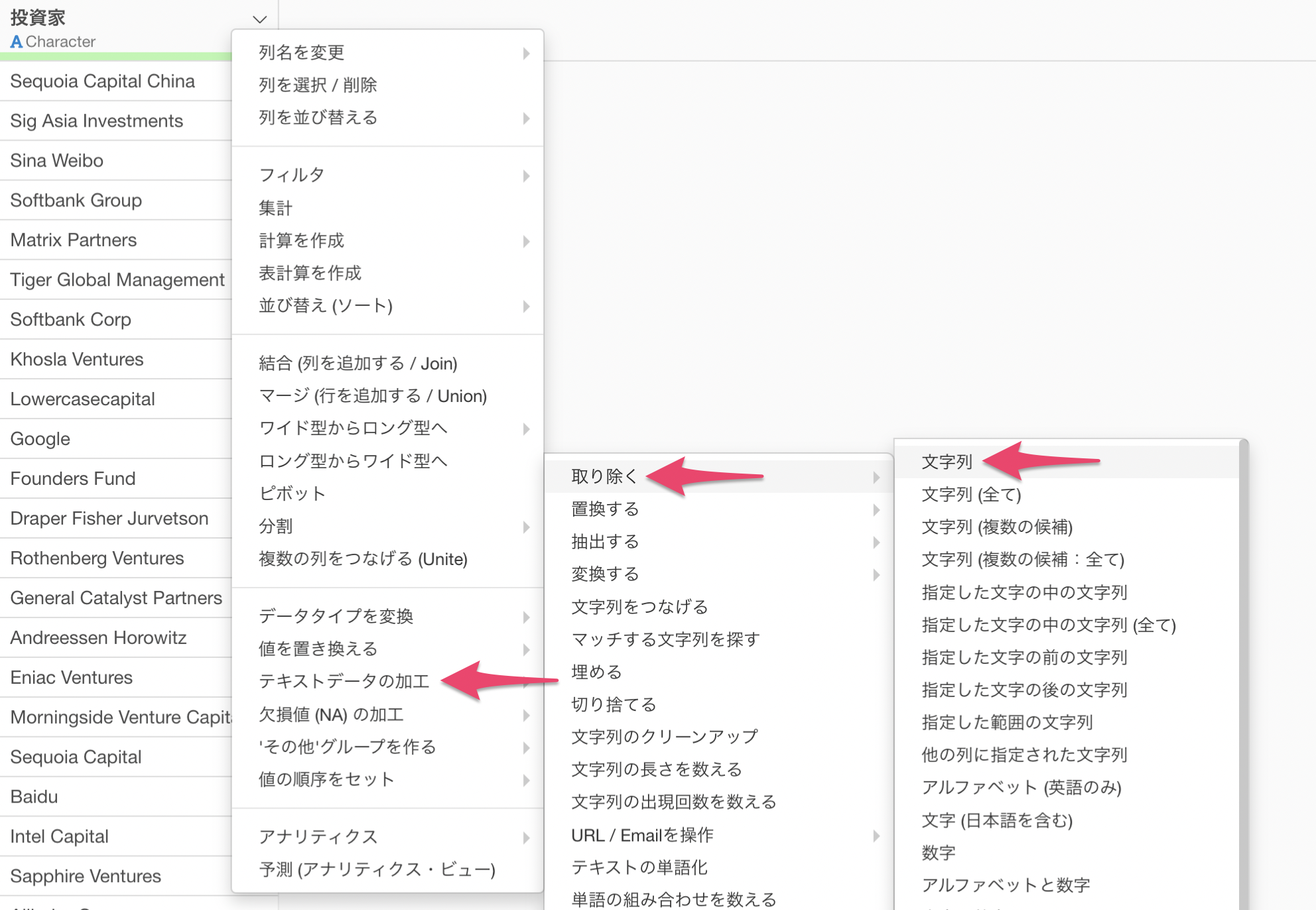
テキストデータの加工のダイアログが表示されました。
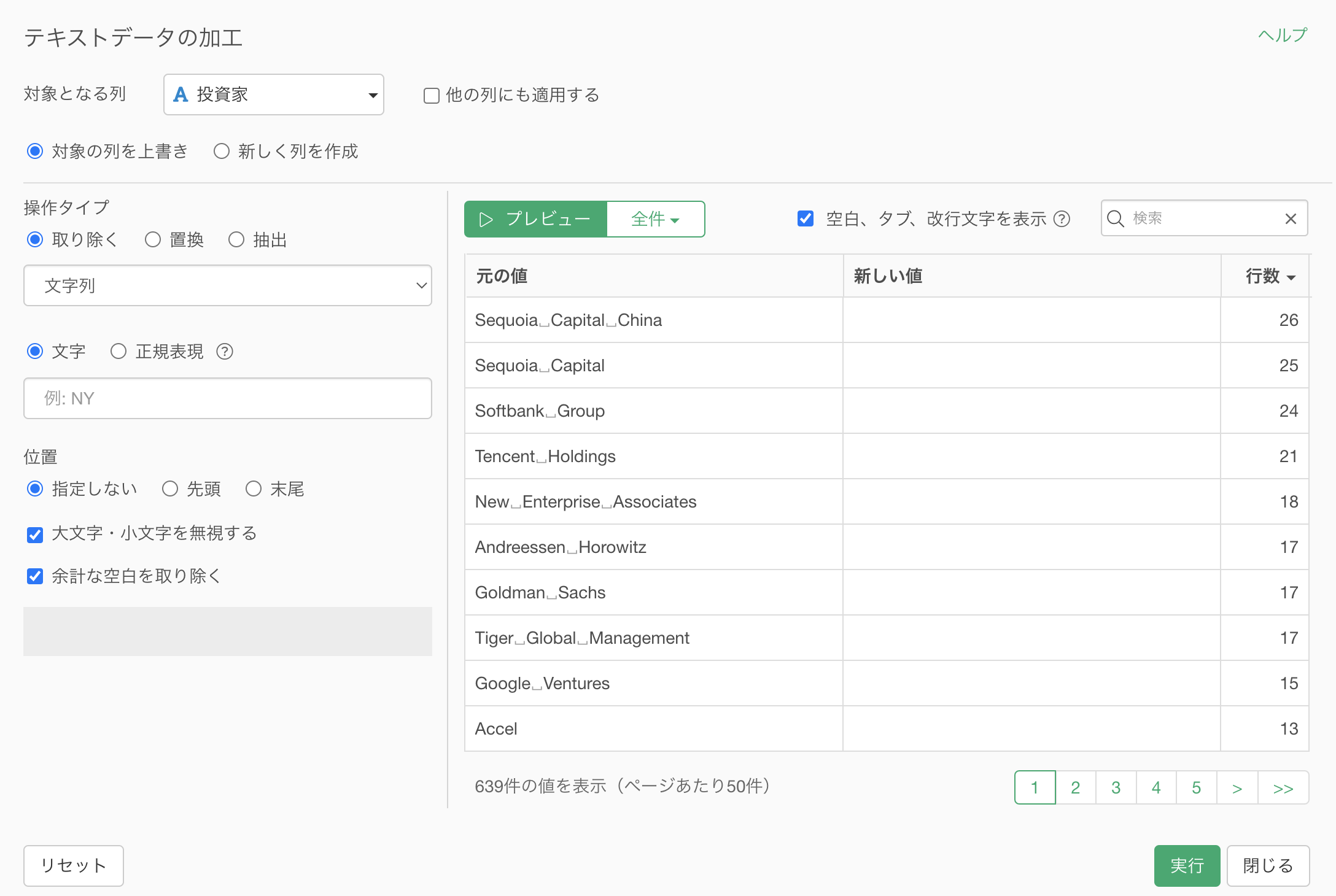
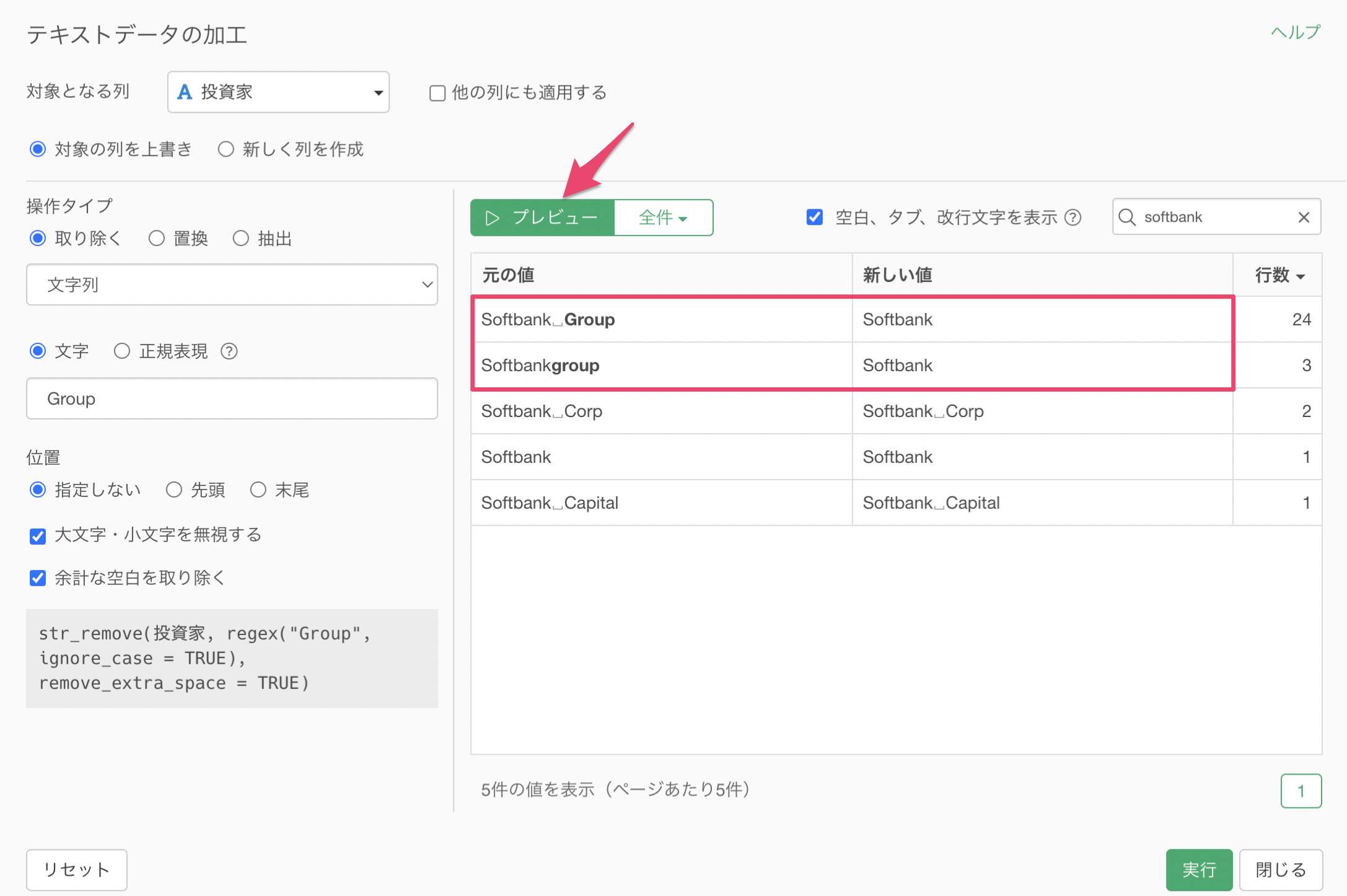
検索ボックスに「softbank」と指定することで、「softbank」の文字列が含まれる値のみが表示されます。
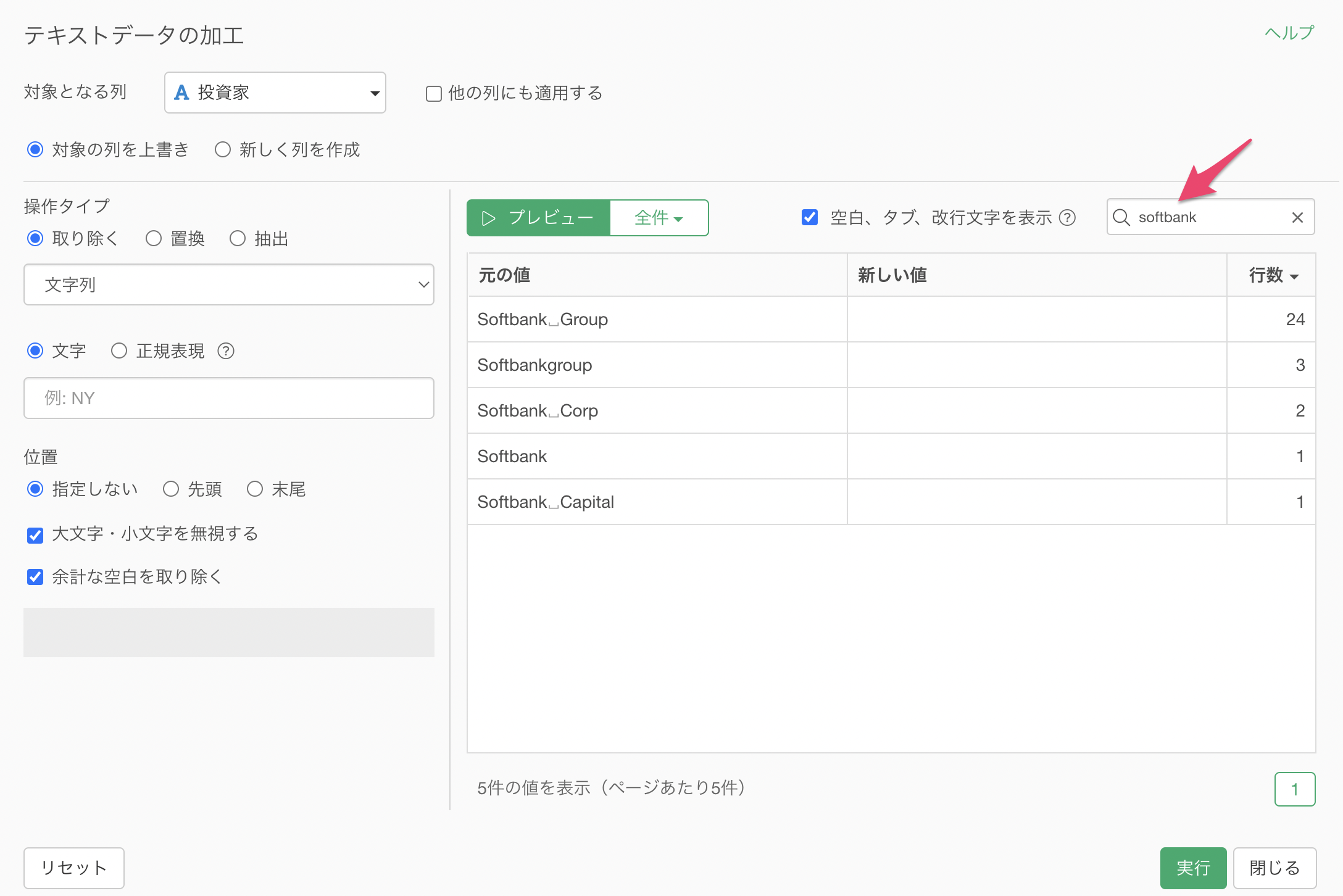
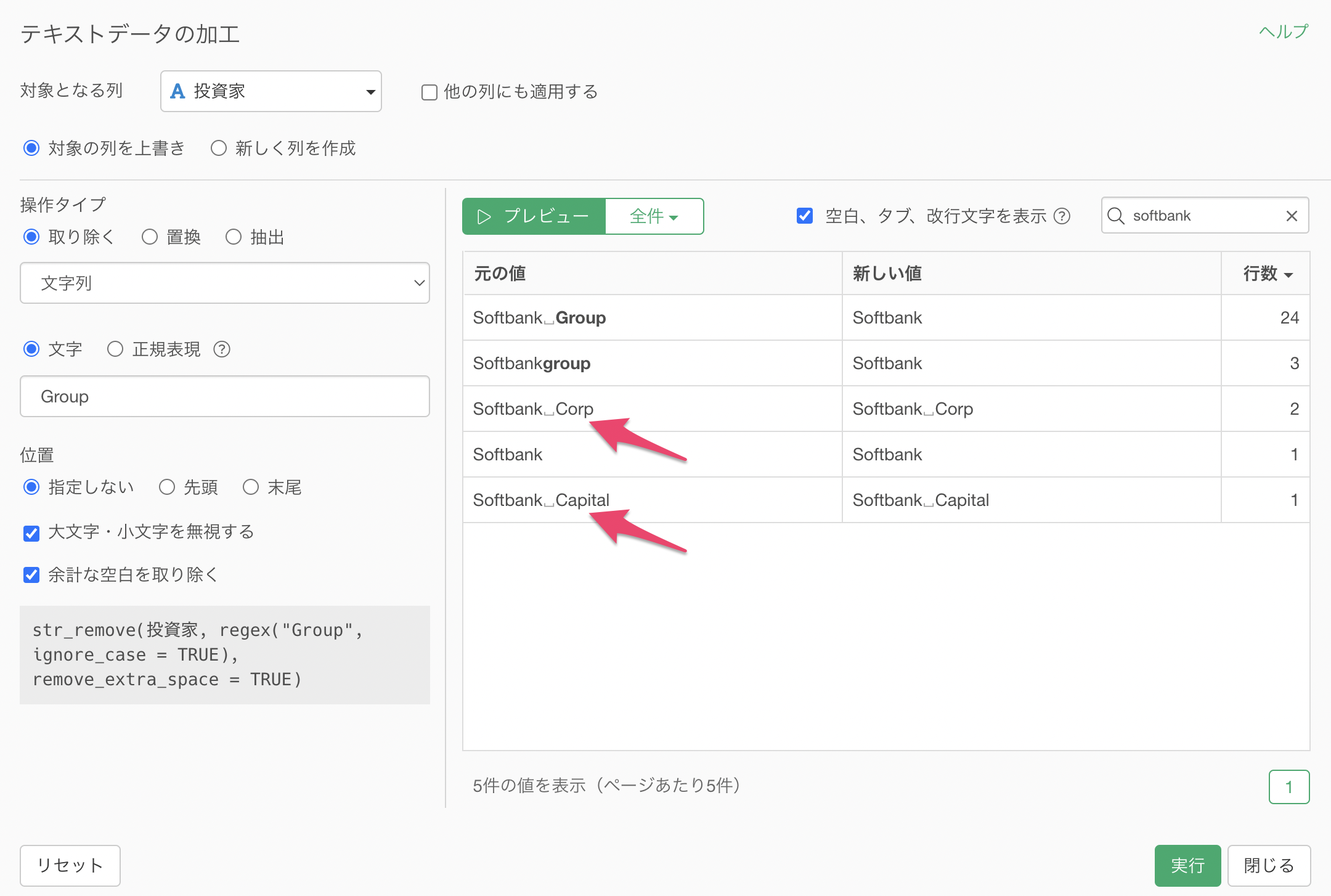
「Softbank Group」の「Group」の文字を取り除いて、Softbankにしたいです。
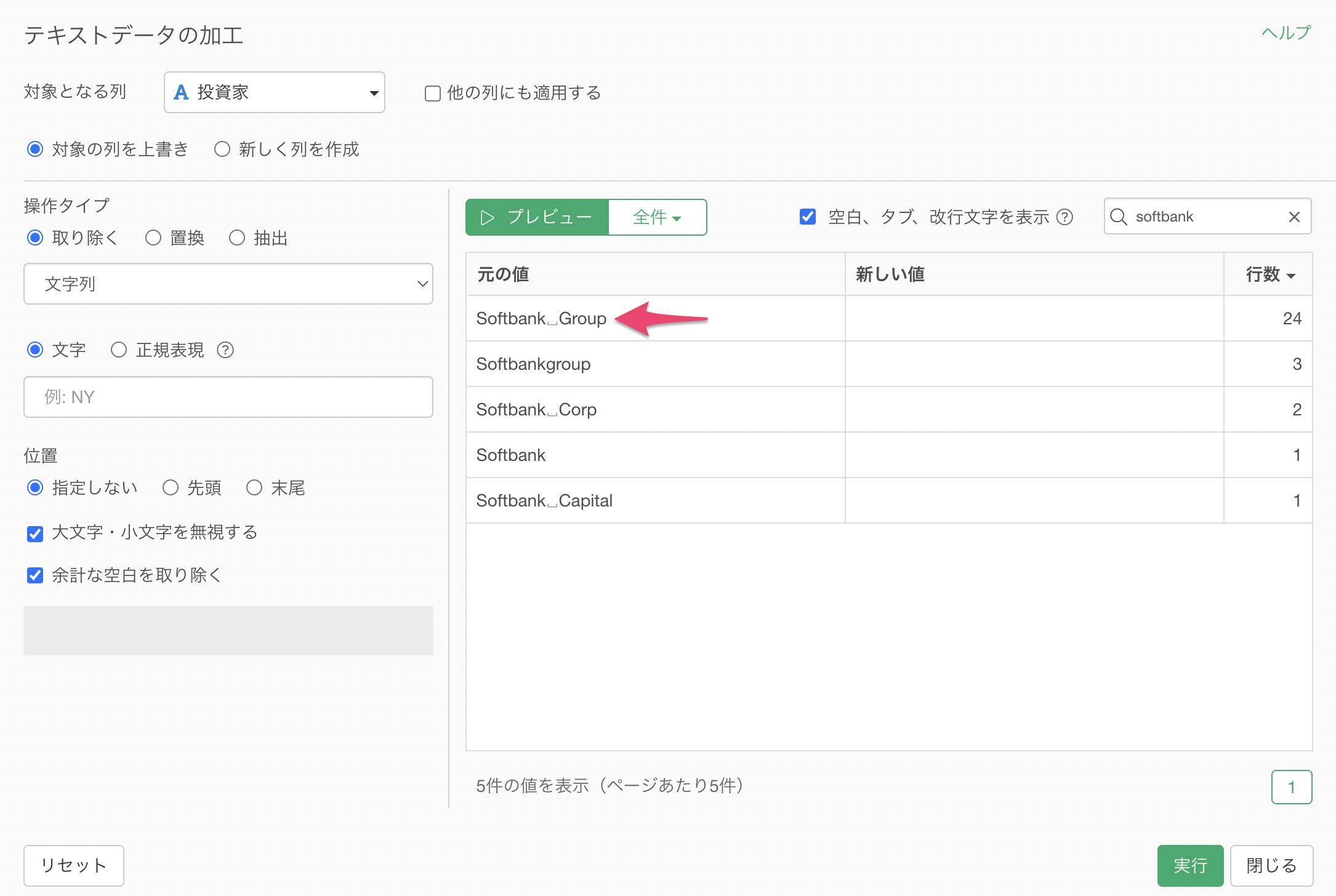
文字に「Group」を指定します。そうすることで、元の値のGroupという文字が太文字でハイライトされています。
プレビューボタンをクリックすると、Groupを取り除いてSoftbankになっていることがわかります。
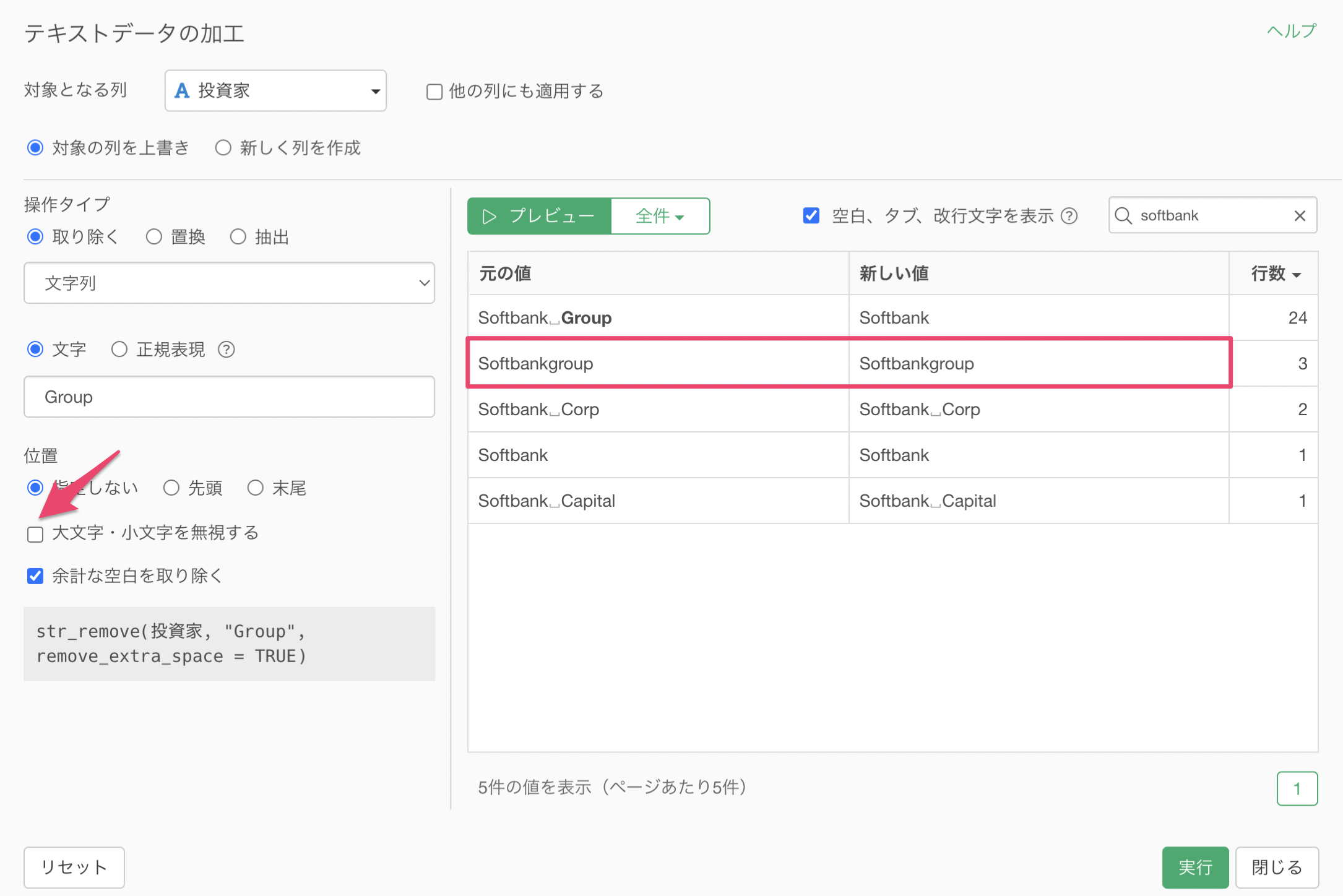
ちなみに、「大文字・小文字を無視する」のオプションが適用されていたために、「group」といった先頭が全て小文字のものでも文字列が一緒なので取り除かれていました。
「大文字・小文字を無視する」のチェックを外すと、「文字」に指定したものと完璧にマッチしない限り、取り除かれないようになっています。
今回は文字列さえ一致していれば大文字・小文字は関係なしに取り除きたいため、「大文字・小文字を無視する」にチェックをつけます。
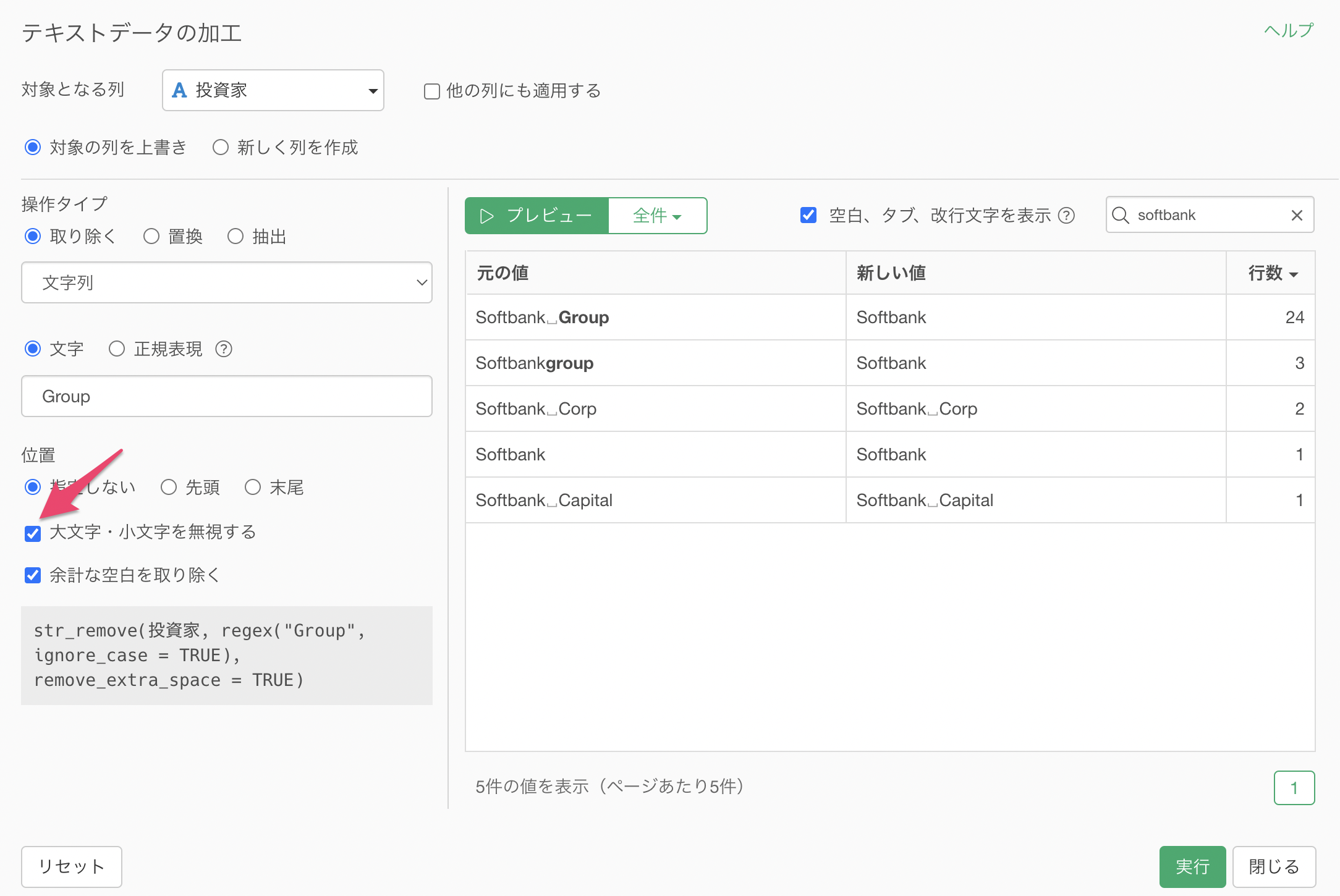
Groupの文字列は取り除くことができましたが、「Corp」や「Capital」といった文字列も一緒に取り除きたいです。
タイプに「文字列(複数の候補)」を選択します。
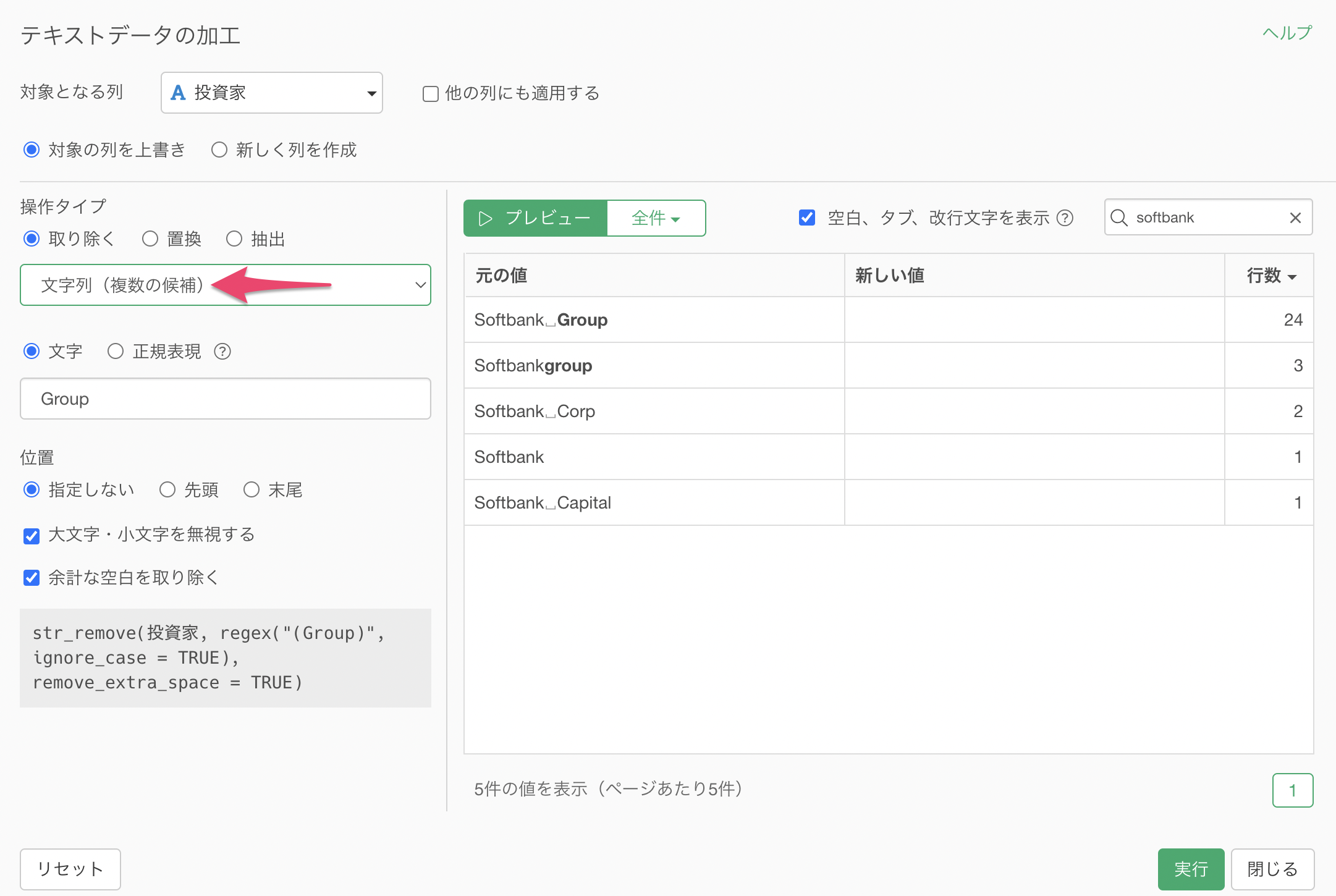
文字に「Croup, Corp, Capital」のように、カンマ(,)区切りで取り除きたい文字列を複数指定します。
プレビューボタンをクリックすることで、新しい値を「Softbank」としてきれいに整えることができました。
実行をすることで、「Group」や「Corp」などの文字列を取り除き、「Softbank」のようにきれいに整えることができました。
投資家の列の「i」をクリックすることで、「Softbank」が投資した企業数は31件あることがわかります。
2. 置換する
このパートでは、コピー機の注文データを使用していきます。1行が1つの注文、かつ商品ごとに行が分かれているデータです。
自分がコピー機の販売担当をしているケースとして、製品サブカテゴリーを「コピー機」に絞り込まれています。
製品名の列に注目すると「Hewlett Packard」の製品は「HP」や「Hewlett」といった文字列になっており、表記が統一されていないことがわかります。
そのため製品名の中にある「Hewlett」といった文字列を「HP」に置き換えたいです。
列ヘッダメニューから「テキストデータの加工」の「置換する」の「文字列」を選択します。
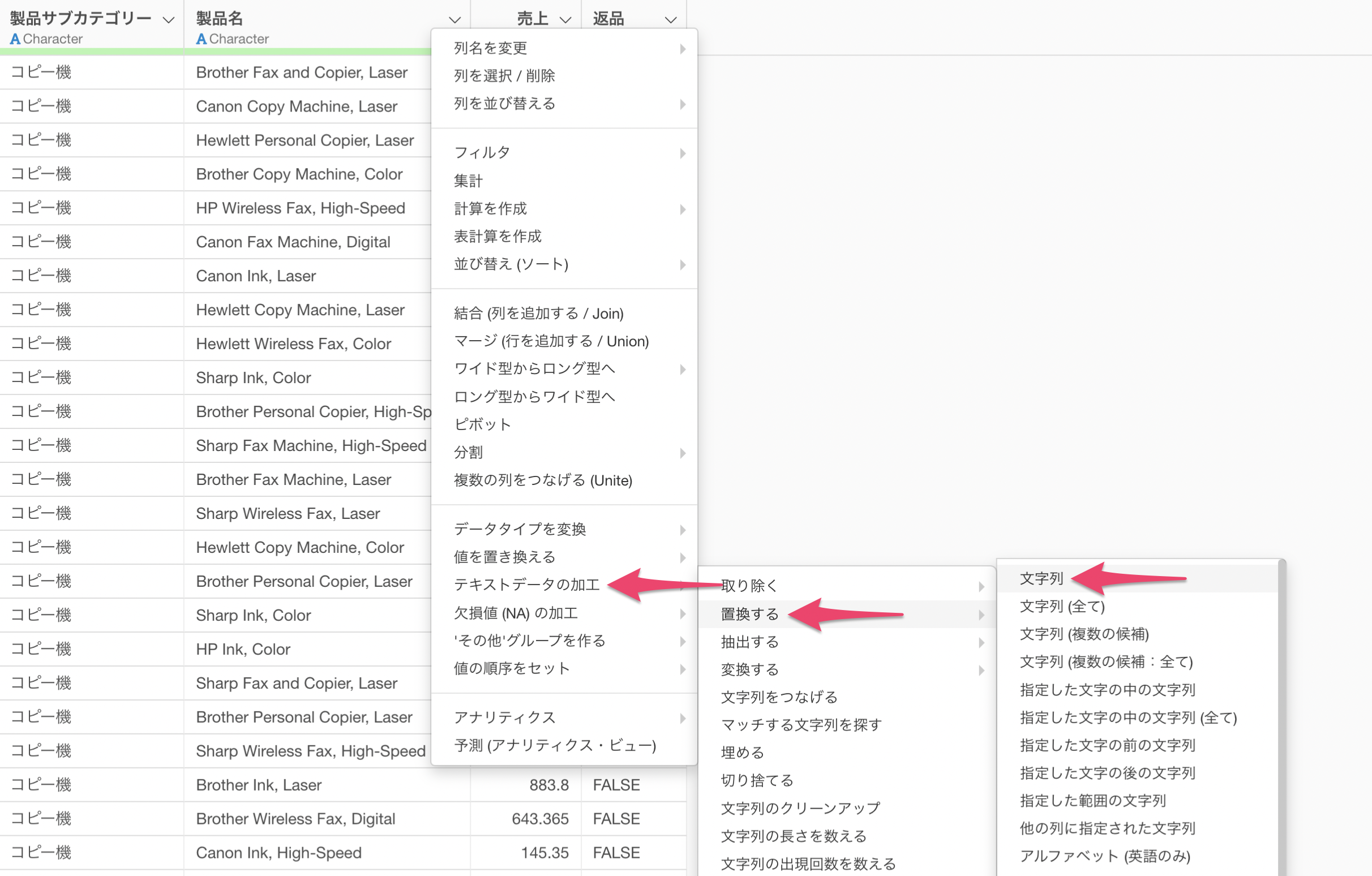
テキストデータの加工のダイアログが表示されました。
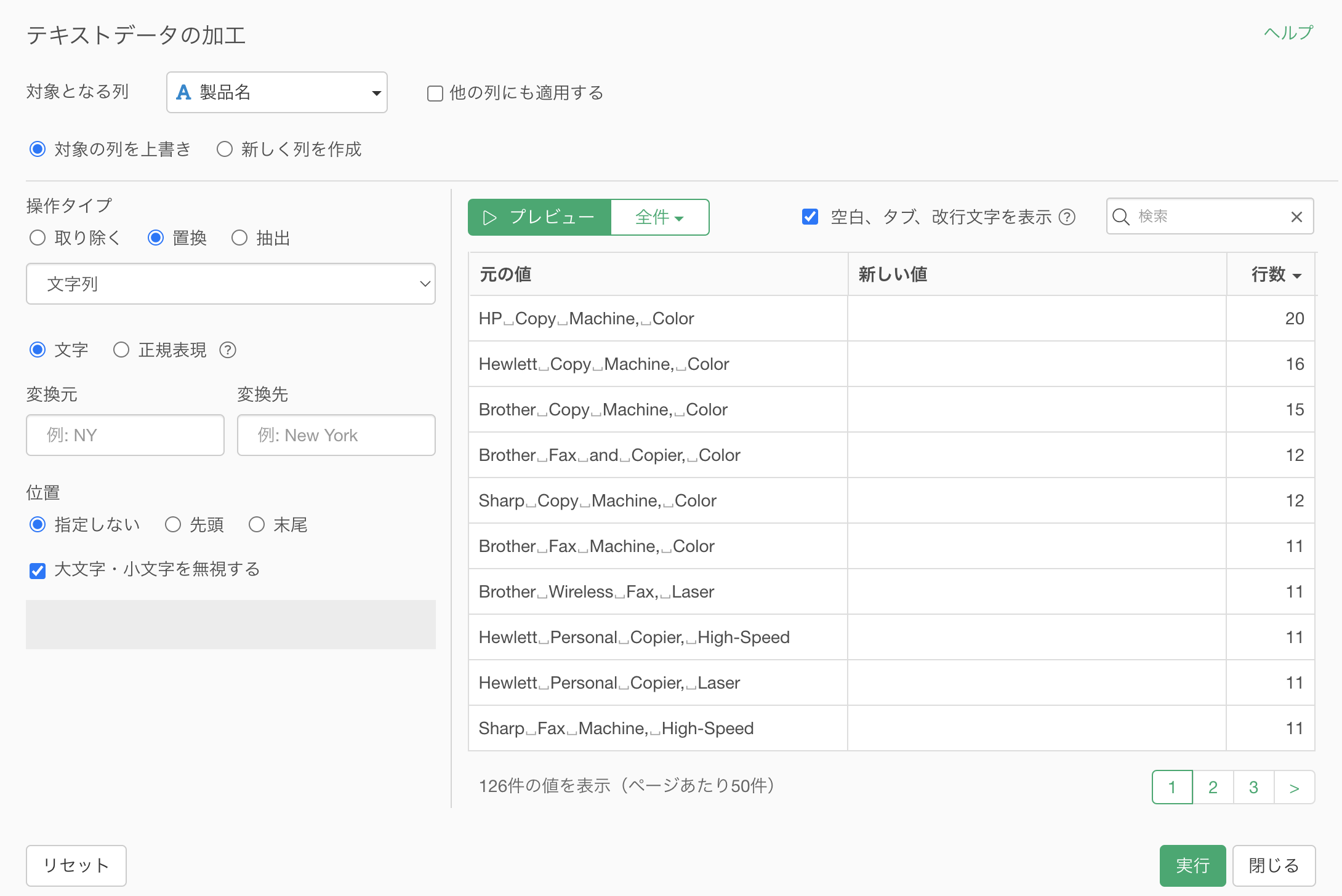
検索ボックスに「Hewlett」と指定することで、「Hewlett」の文字列が含まれる値のみが表示されます。
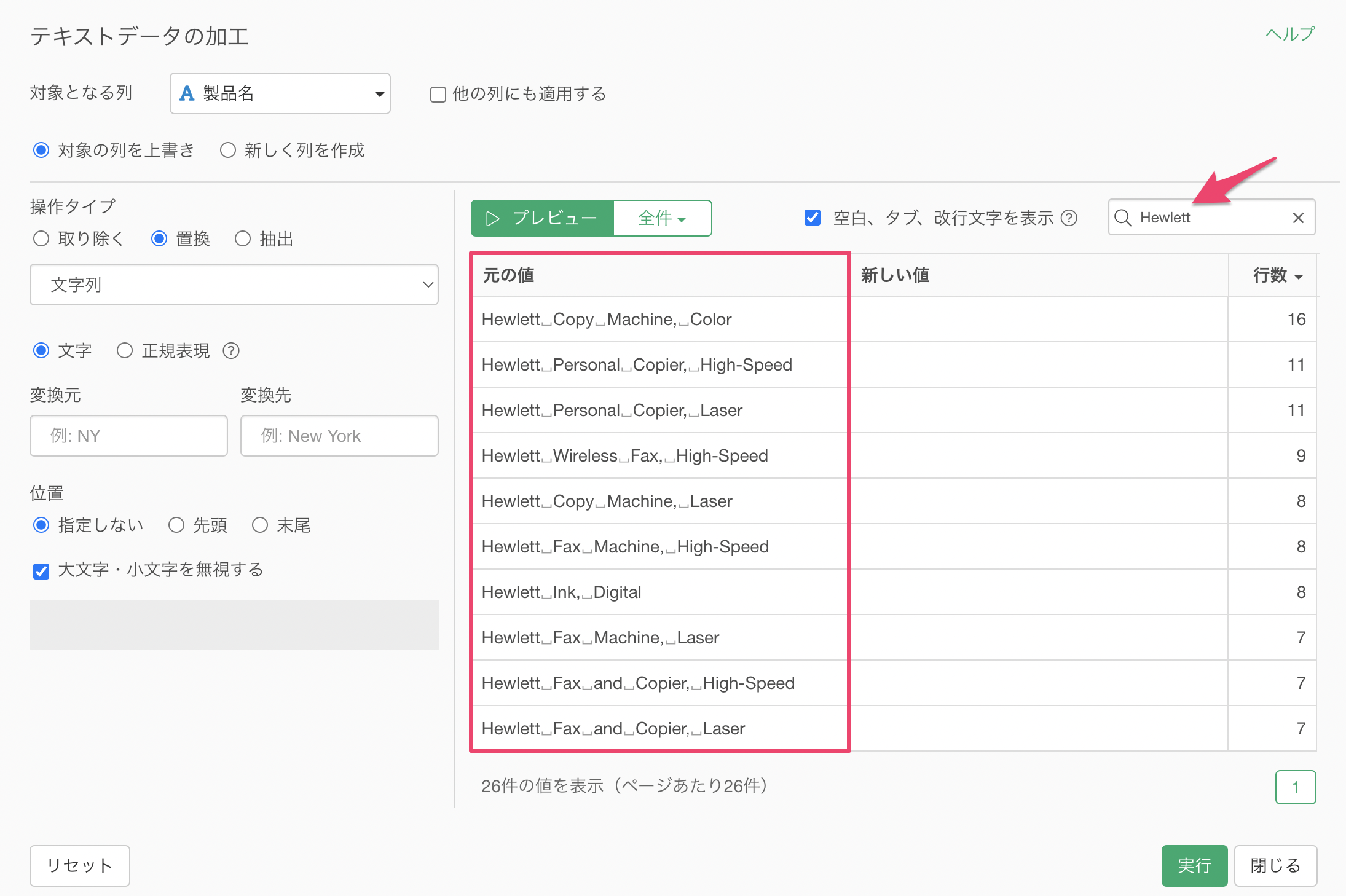
変換元の文字に「Hewlett」を、変換先の文字に「HP」を指定します。そうすることで、元の値の「Hewlett」という文字が太文字でハイライトされています。
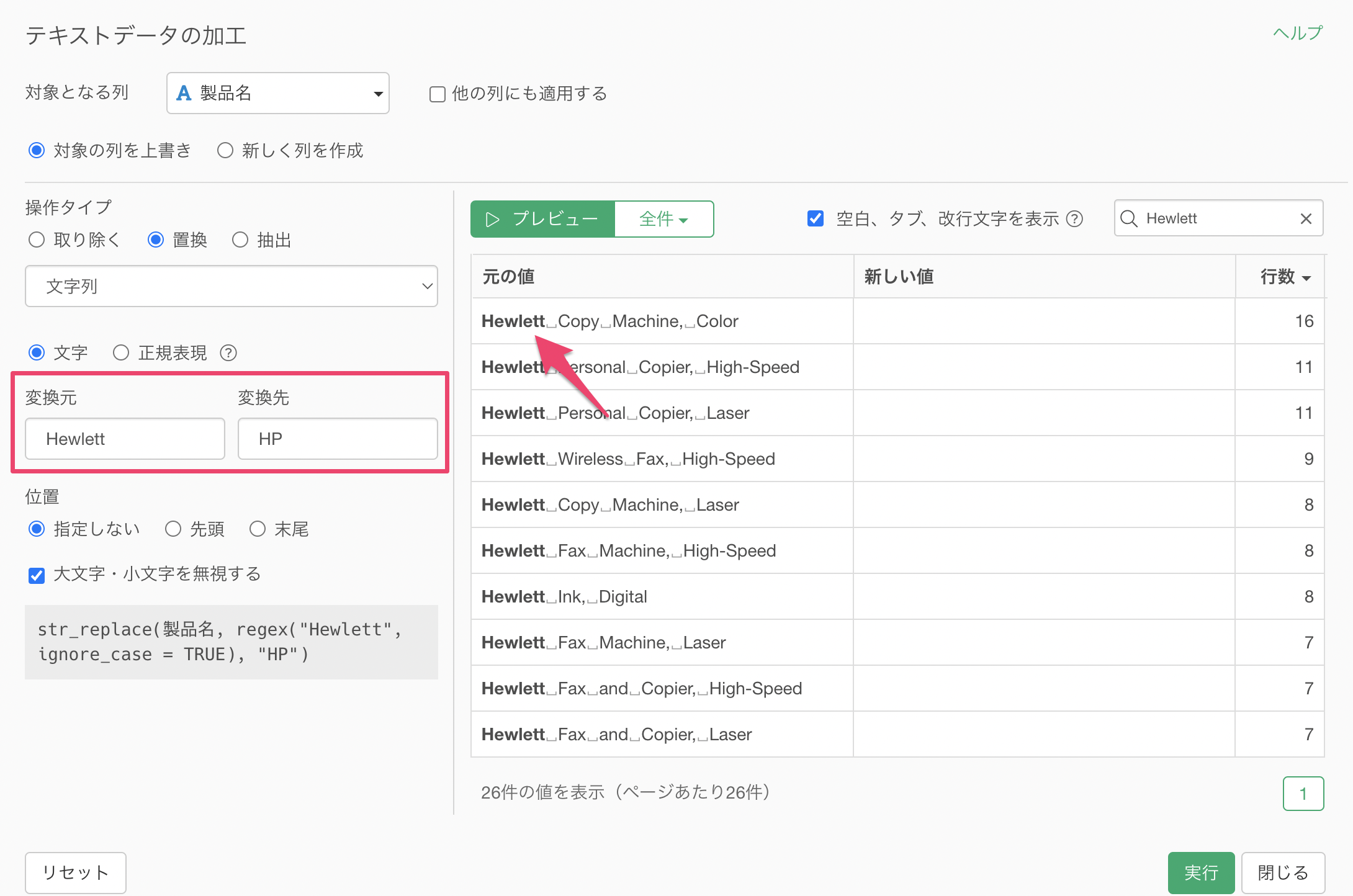
プレビューボタンをクリックすると、「Hewlett」が「HP」といった文字で置き換わっていることがわかります。
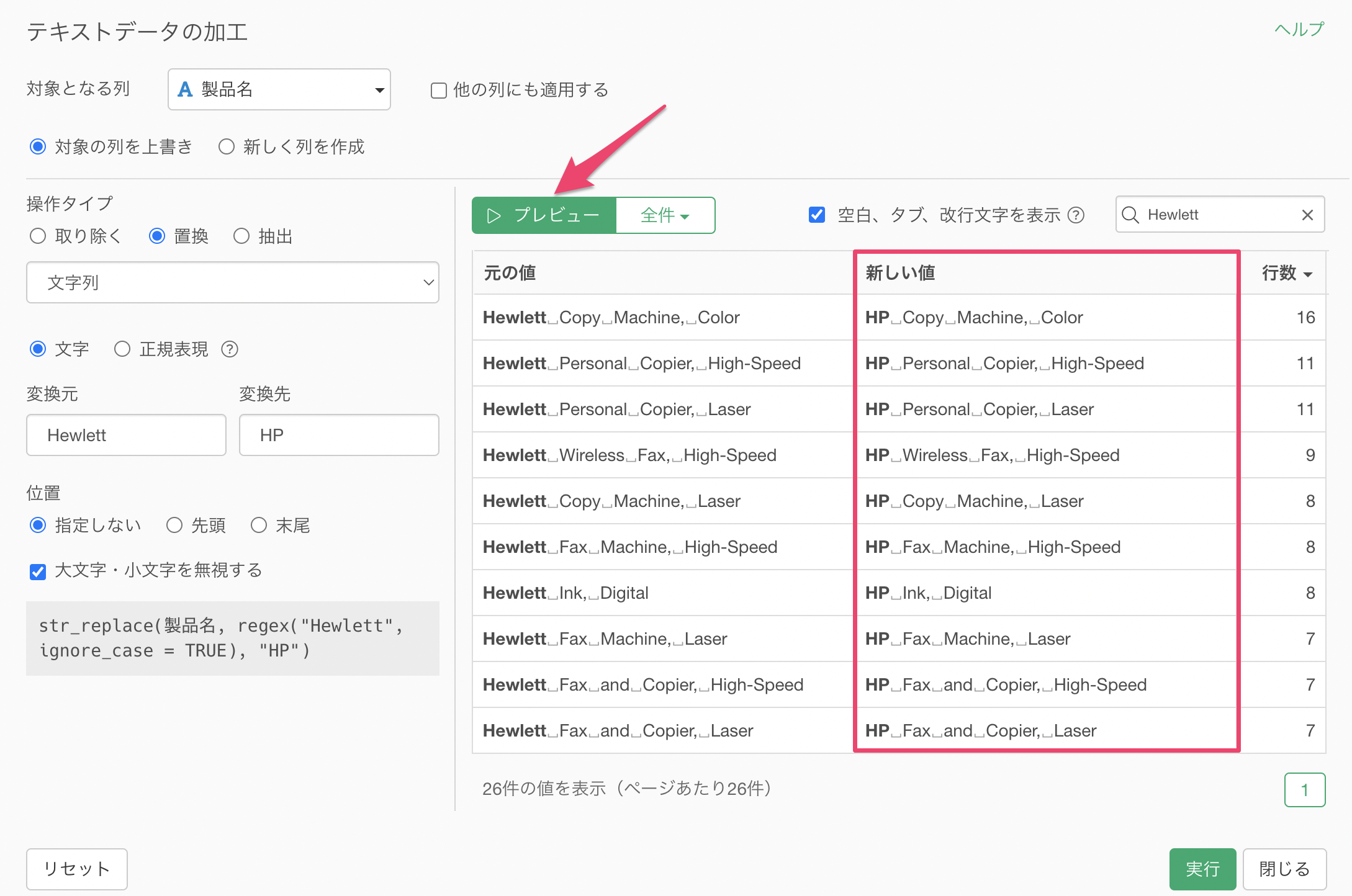
「Hewlett」を「HP」に置き換えることはできましたが、他にも「Hewlett Packard」といった文字列が含まれていることがわかります。そのため、「Hewlett Packard」と「Hewlett」を同時に「HP」に置き換えたいです。
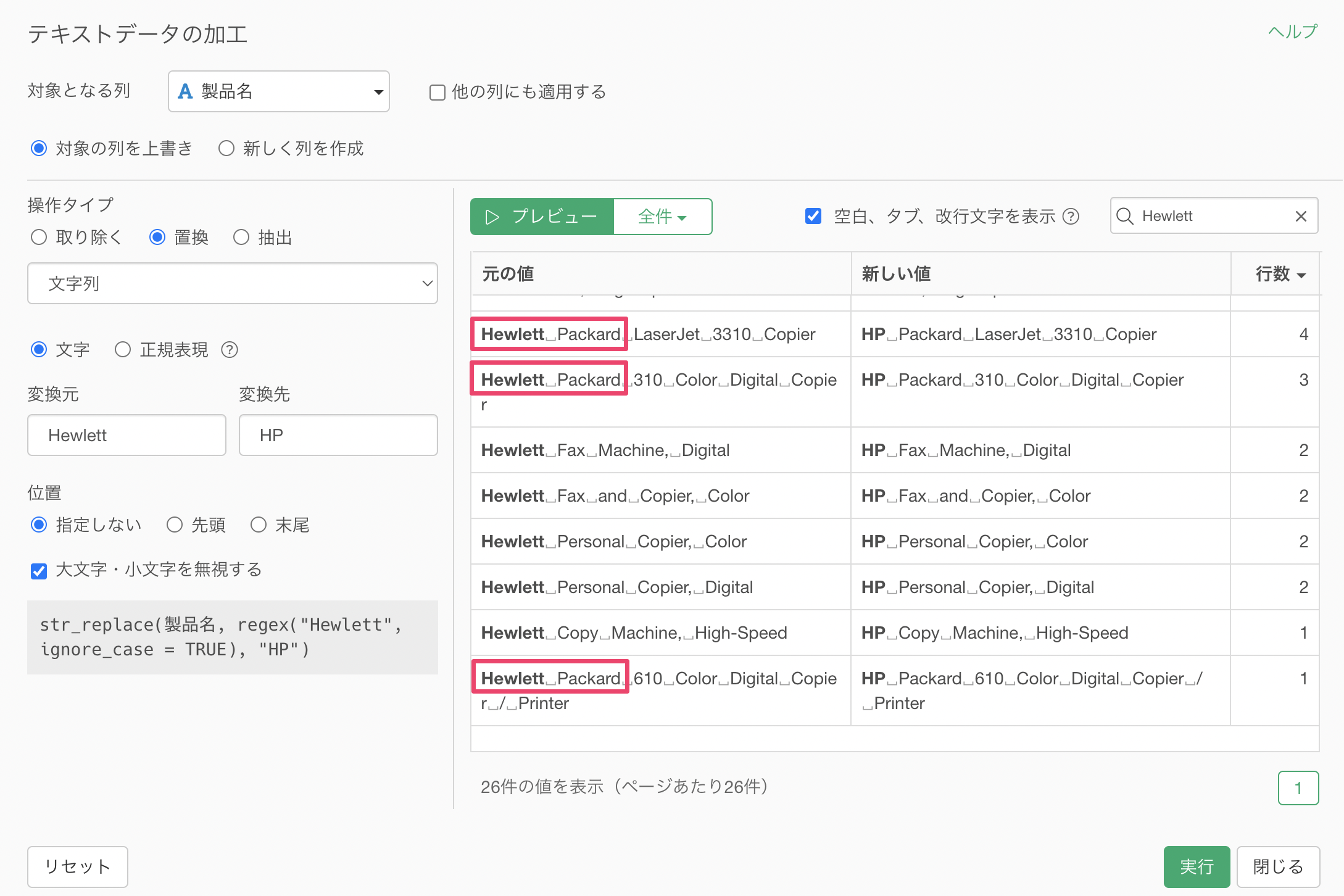
タイプに「文字列(複数の候補)」を選択します。
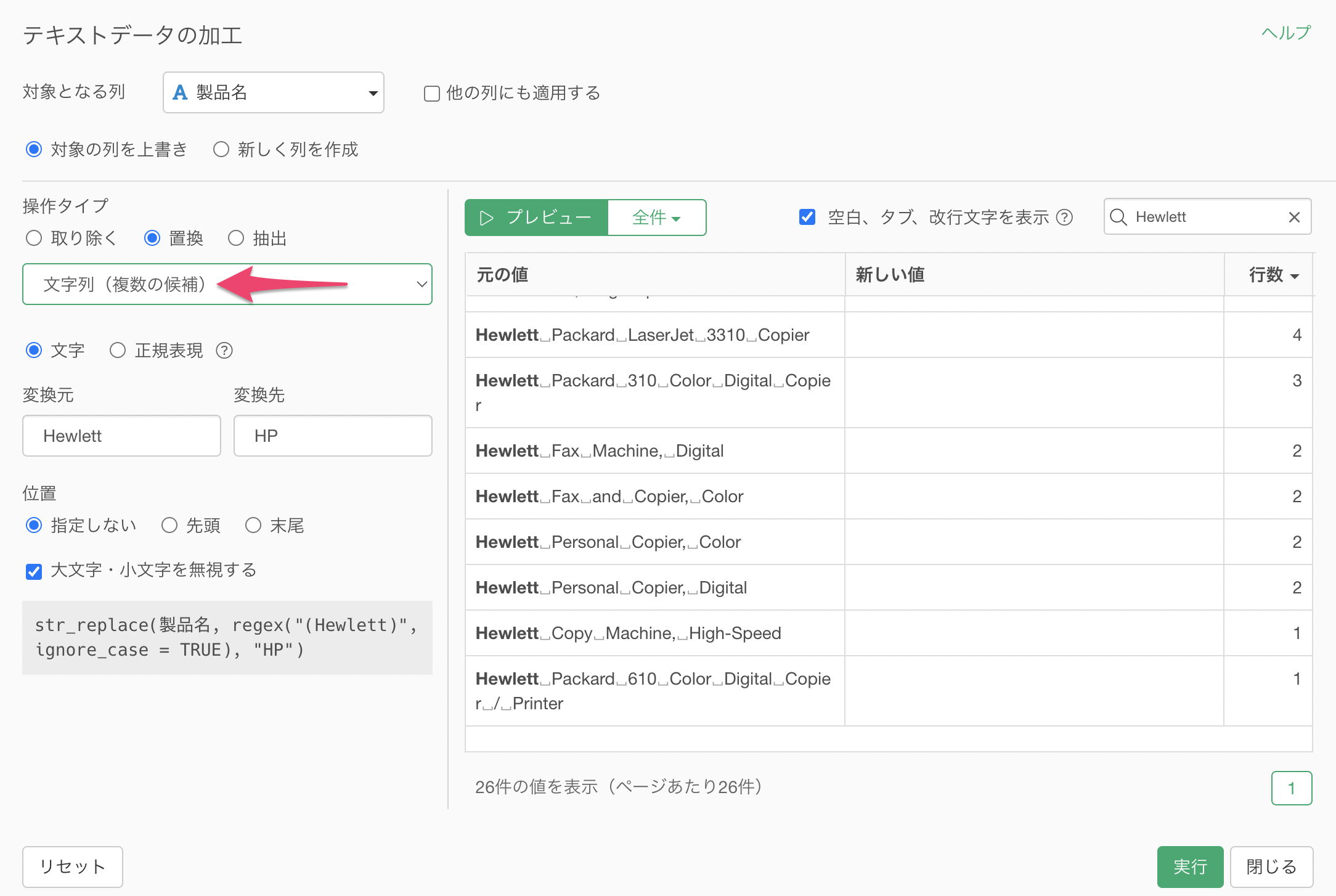
文字に「Hewlett Packard, Hewlett」のように、カンマ(,)区切りで置換したい文字列を複数指定します。
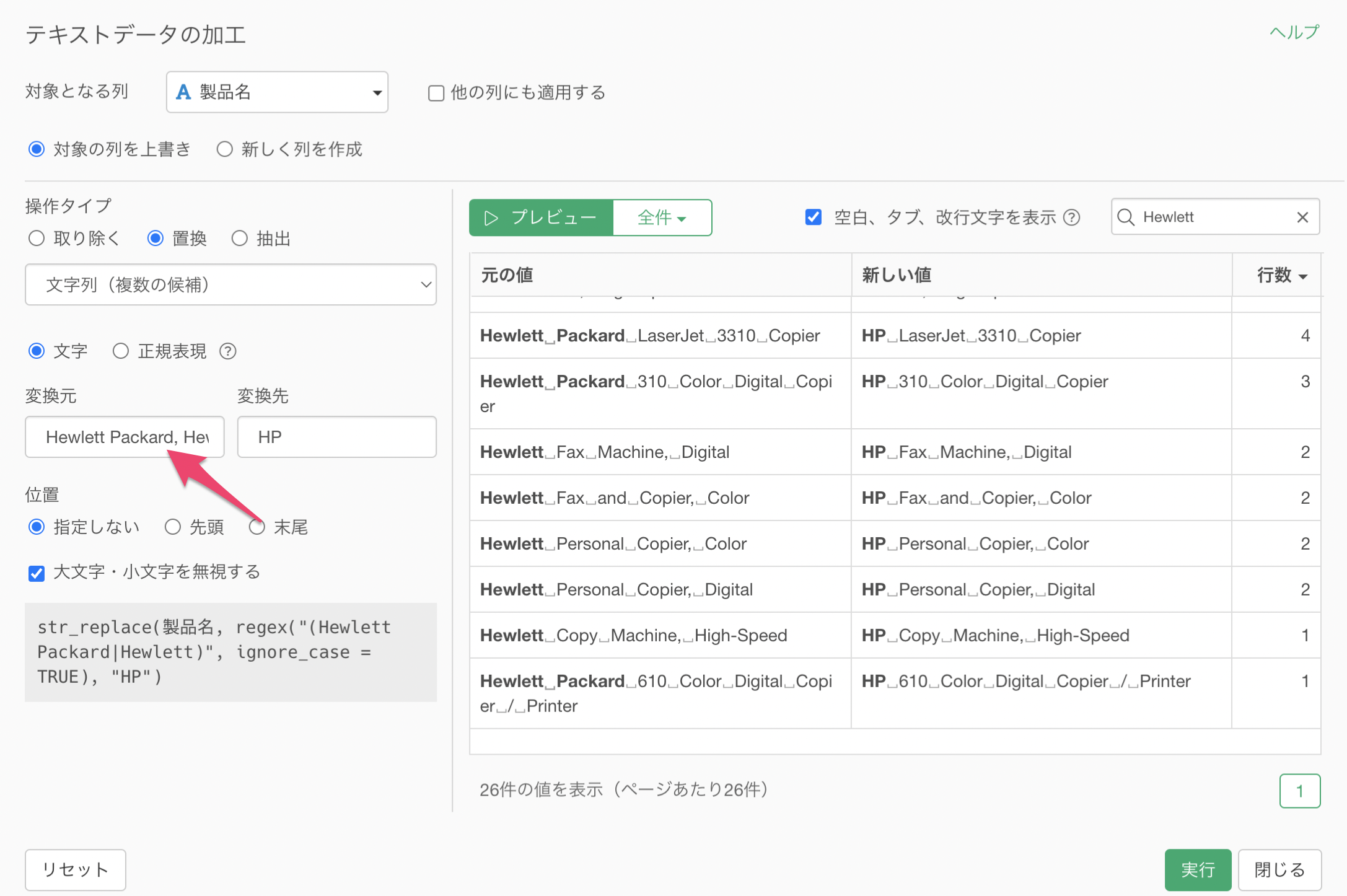
プレビューボタンをクリックすることで、「Hewlett Packard」と「Hewlett」を「HP」として置き換えられていることがわかります。
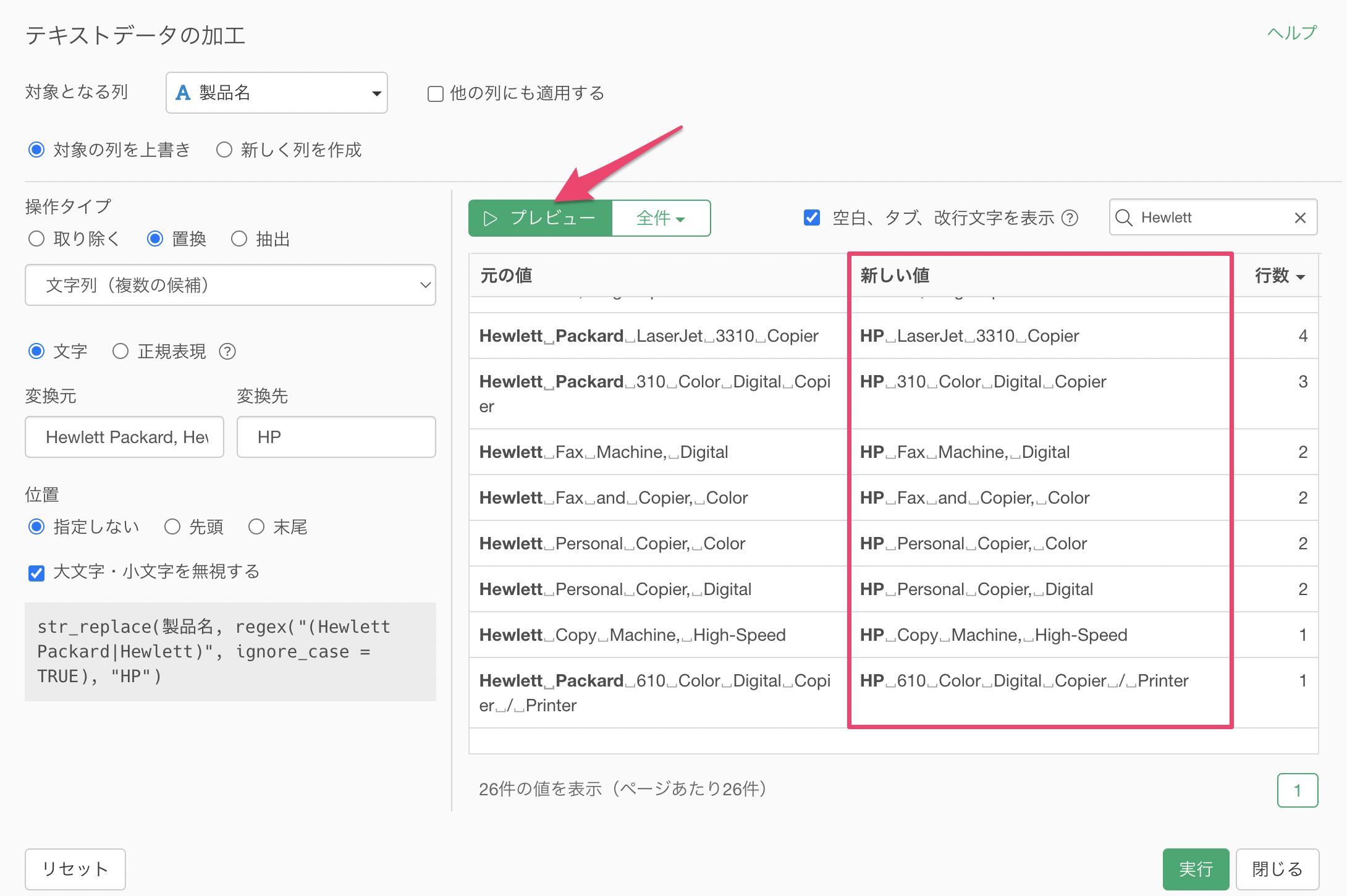
実行をすることで、「Hewlett Packard」と「Hewlett」を「HP」として置き換えることができ、異なる表記になっていた文字列を統一することができました。
3. 抽出する
1つ前のパートで使用したものと同じ、「コピー機の注文データ」を使用します。
先程は、製品名の「Hewlett Packard」と「Hewlett」を「HP」として置き換えましたが、今回は「製品名」の列からブランド名を抽出して新しく列として作成したいです。
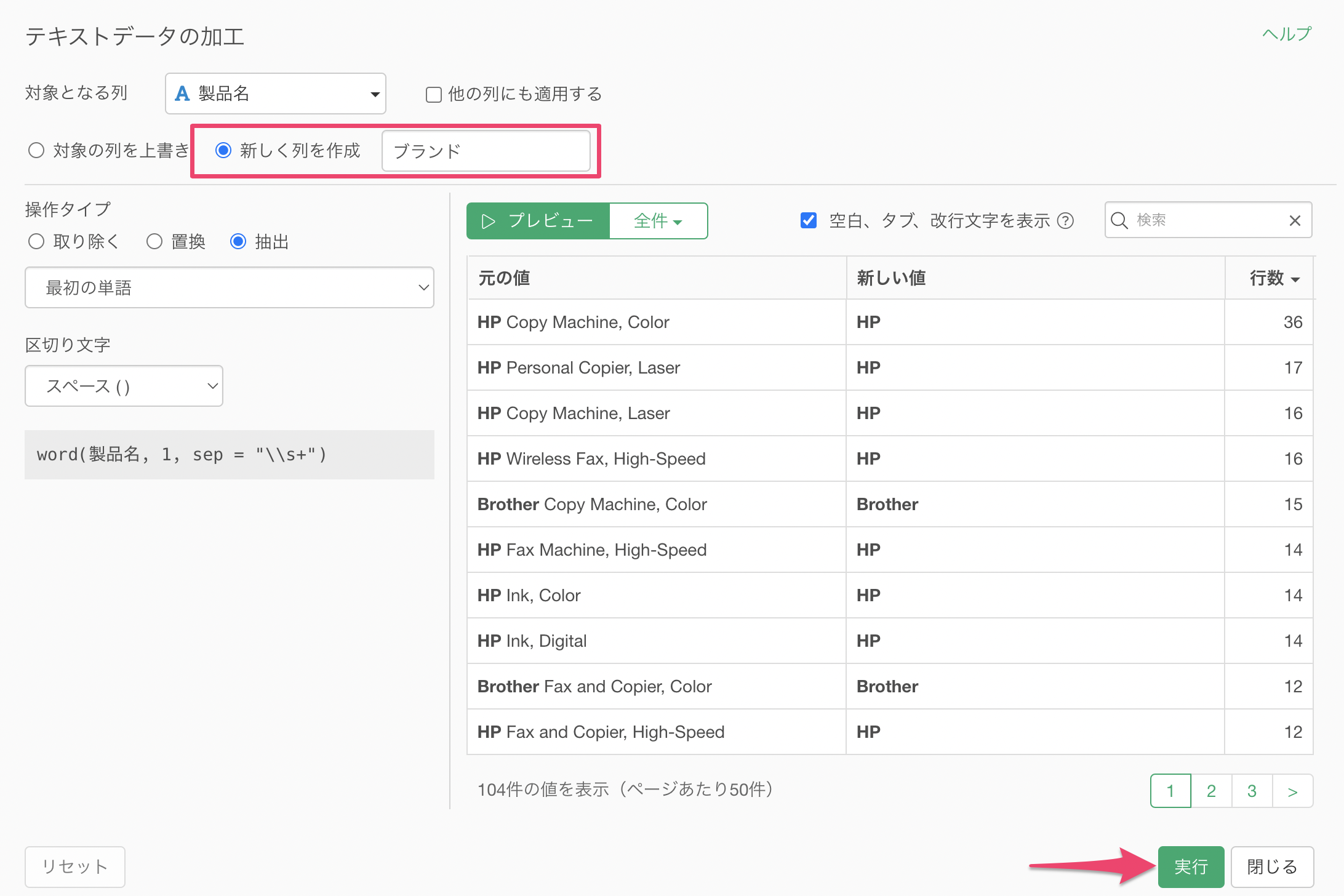
製品名の列から「テキストデータの加工」の「抽出する」の「最初の単語」を選択します。
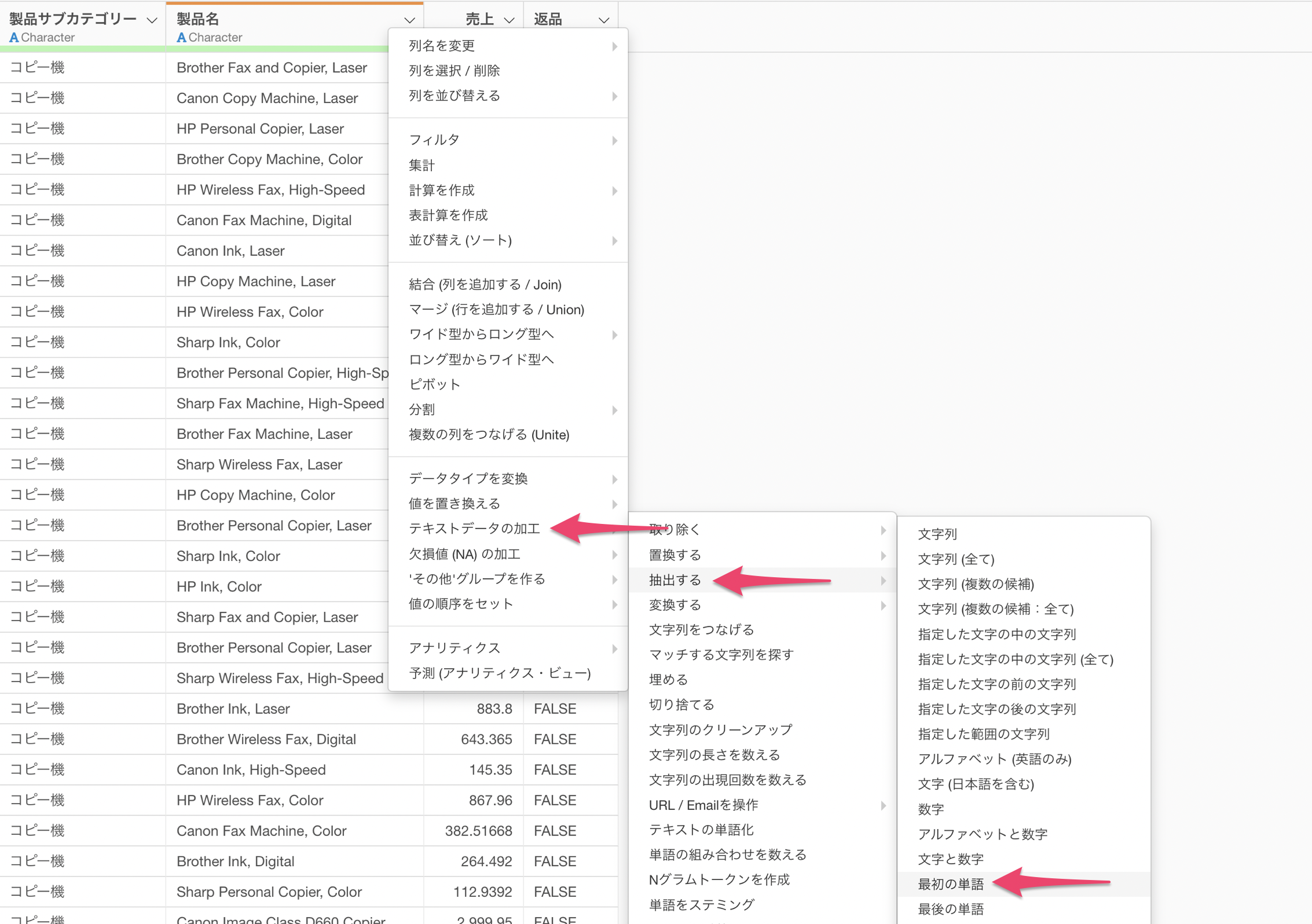
抽出する単語のタイプには「最初の単語」を、区切り文字には「スペース( )」を選択します。
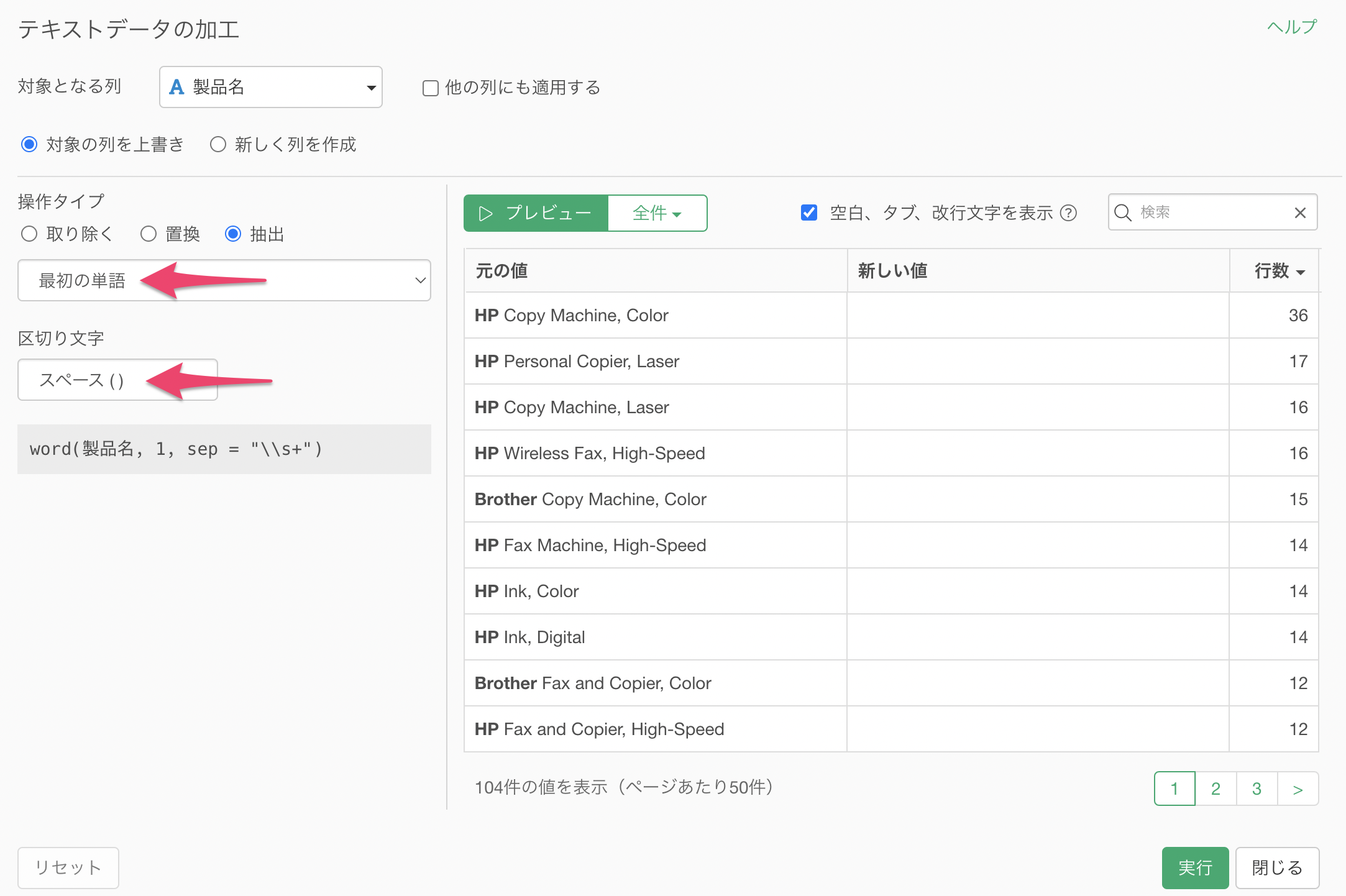
プレビューを実行することで、最初の単語にあるブランド名を抽出できていることが確認できます。
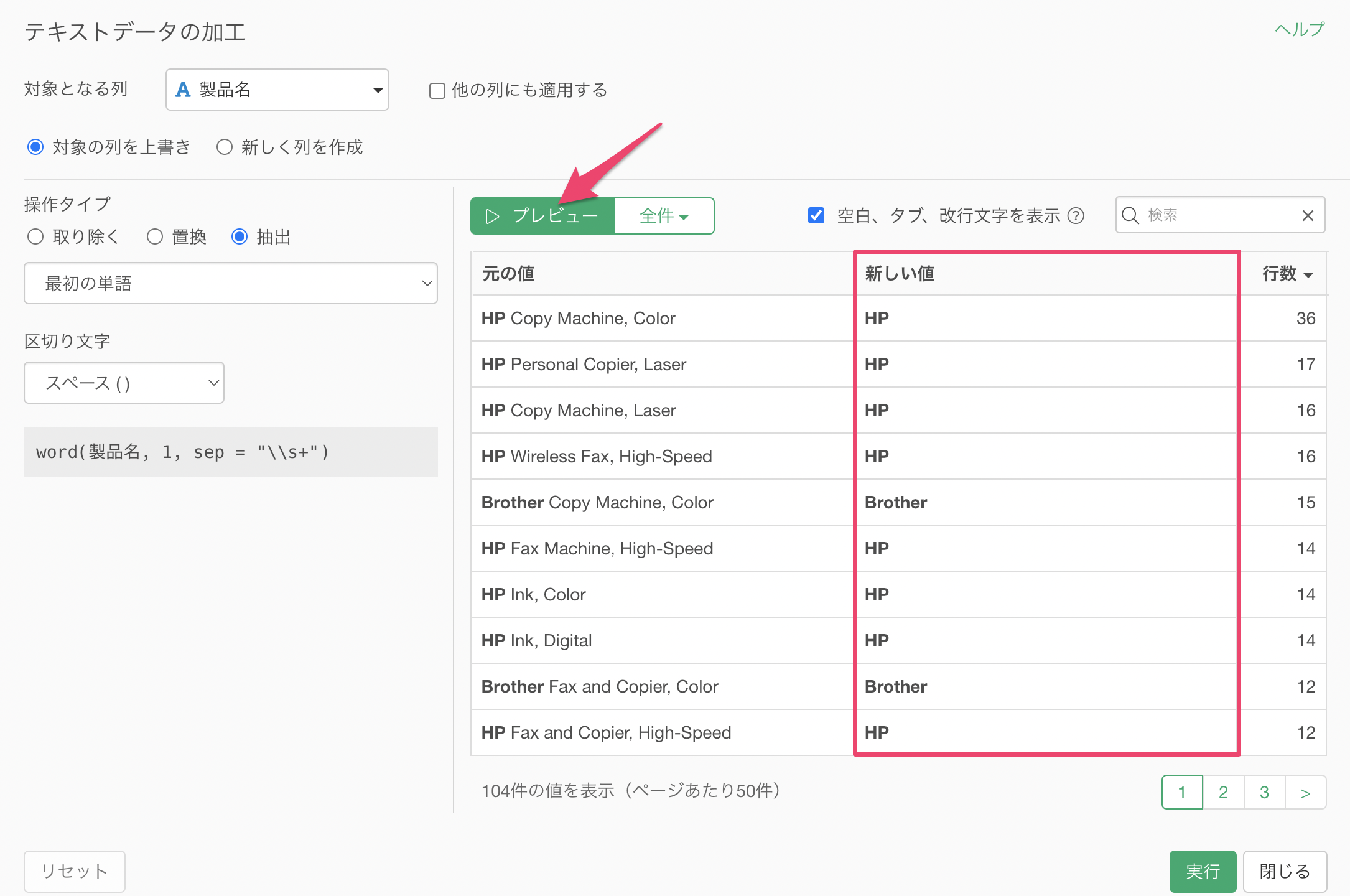
新しく列を作成にチェックをつけて列名を指定し、「実行」ボタンをクリックします。
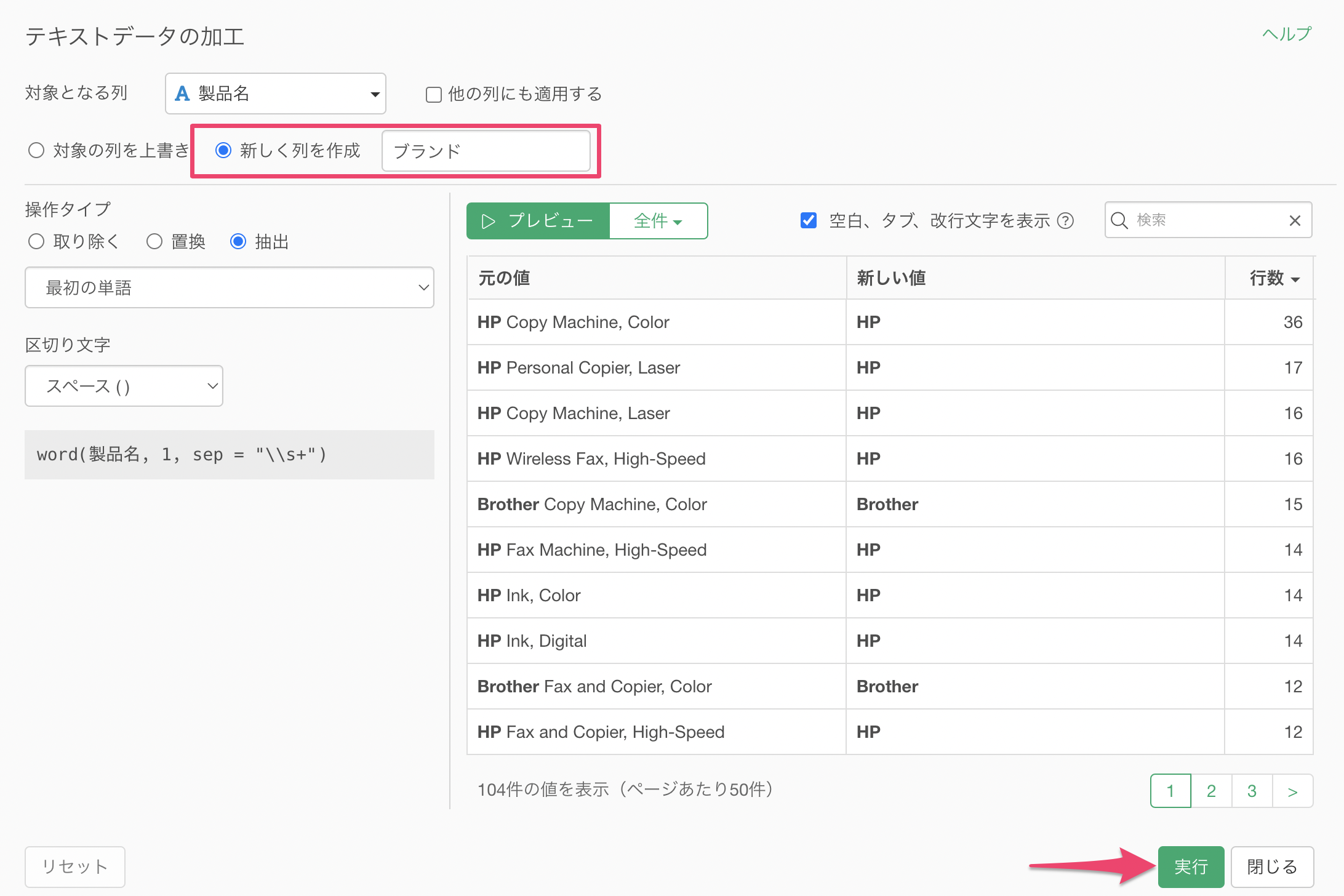
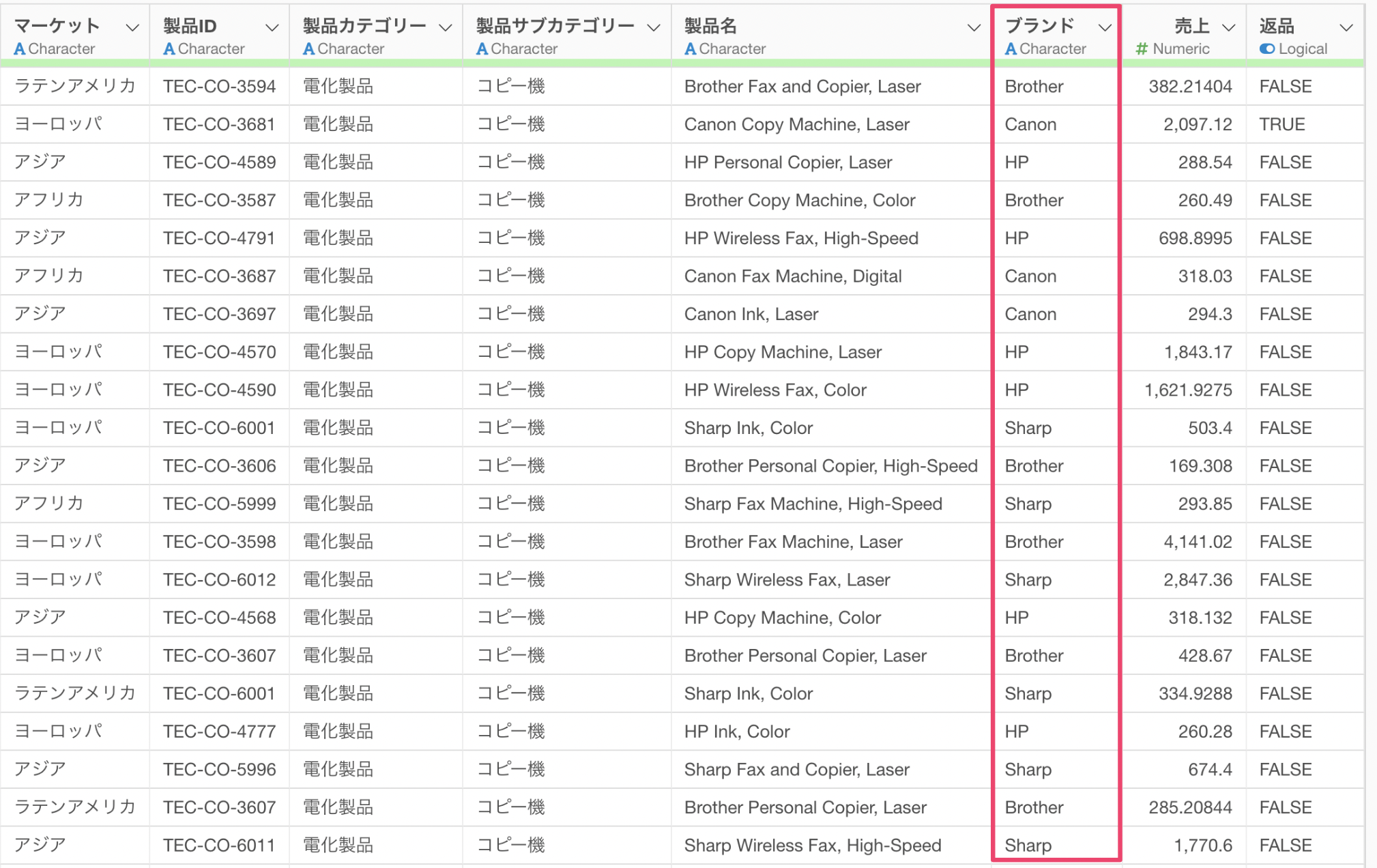
製品名からブランド名を抽出した「ブランド」の列を作成することができました。
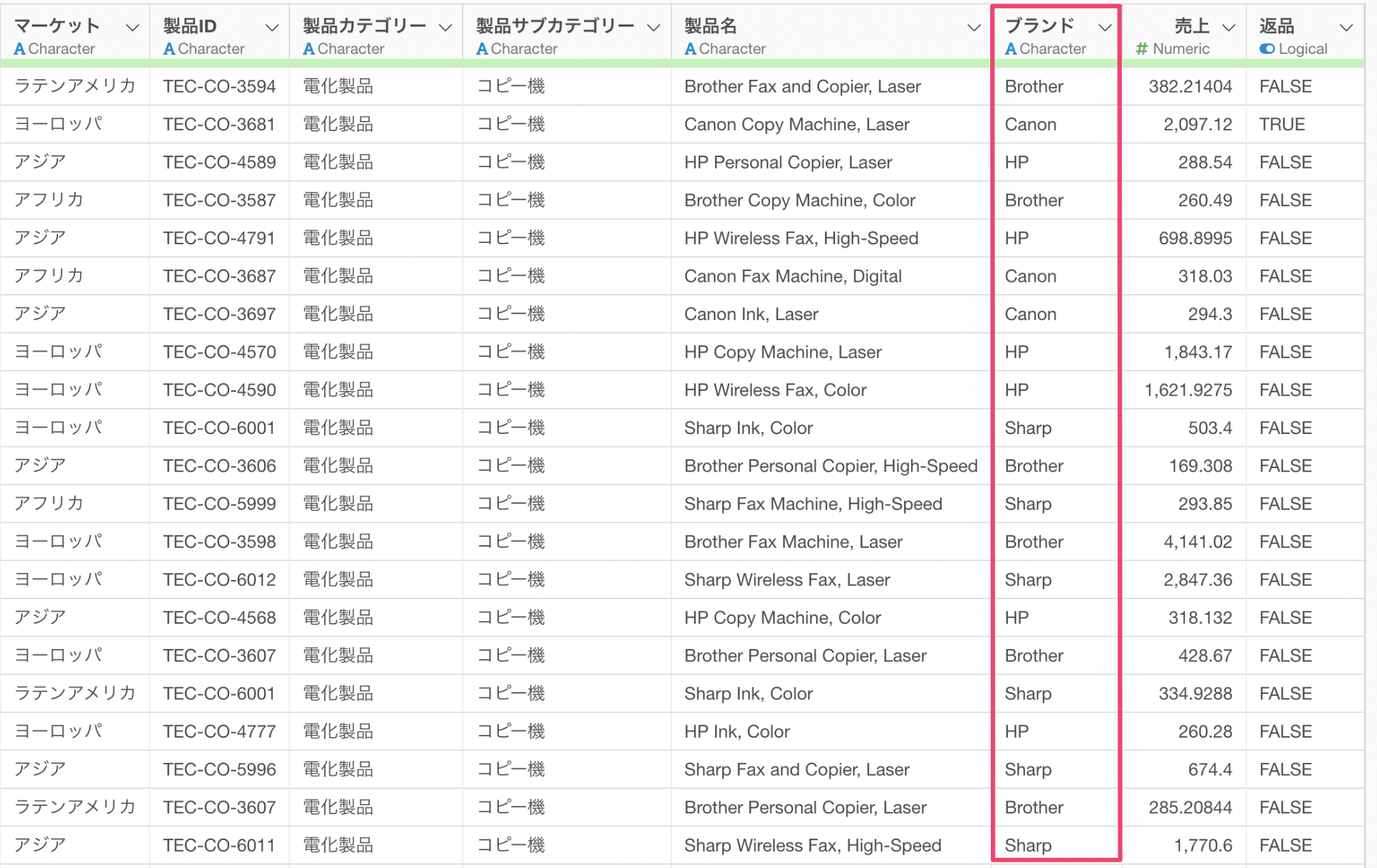
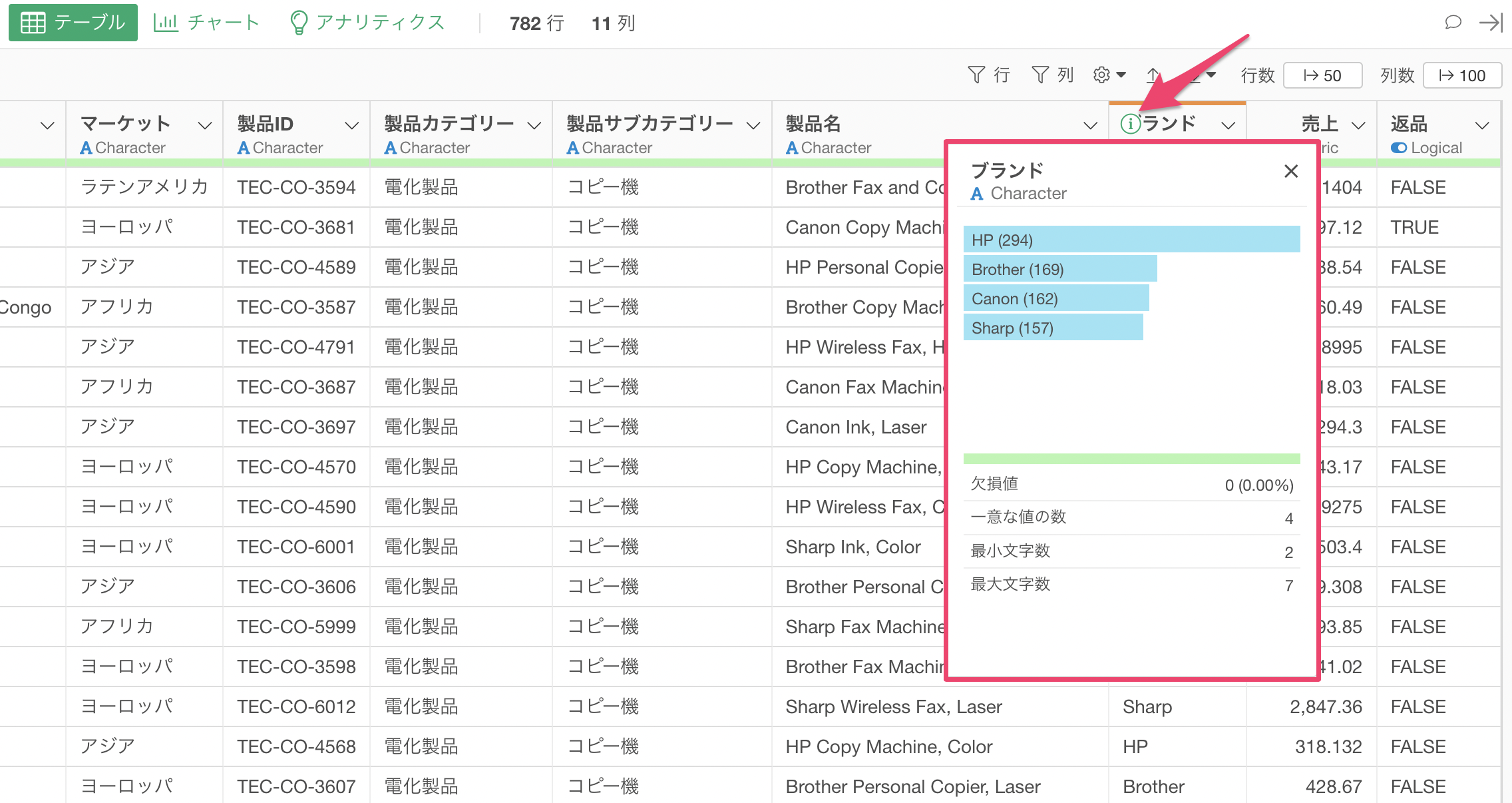
ブランドの列の「i」をクリックすることでどのブランドの販売数量が多いのかを確認することができます。今回のデータでは、「HP」は294件と最も多いことがわかります。
データラングリングのトライアルツアーのテキストデータの加工編は以上となります!
データラングリング - トライアルツアー
データラングリングのトライアルツアーの他のパートは下記のリンクからご確認いただけます。ぜひ次の「ラングリングの便利な機能」のパートも実施してみてください。