
アンケートデータ分析 Part 2 - テキスト分析
このノートは、アンケートデータを有効活用して、ビジネスやサービスの改善につなげるための使い方を効率よく学ぶために作られた「アンケートデータ分析」のトライアルツアーの第2弾、「テキスト分析」版です。
Exploratoryでアンケートの自由記述のテキストデータから、どういった単語がよく使われるのか、一緒に使われているのかを素早く見つける時に使える「テキスト分析 - 単語のカウント」を体験していただければと思います。
所要時間は20分ほどとなっています。
それでは、さっそく始めていきましょう!
1. テキスト分析とは何か?
アンケートでは、5段階評価などではわからない回答者が持っている具体的な考えを引き出すために、「自由記述」の質問を設定することはよくやることの一つです。
しかし、自由記述のテキストのように定性データの解釈は人によって異なるため、全体的な特徴や傾向を客観的に捉えにくいために、うまく活用しきれないという声をよく耳にします。

そこで、文章を「単語」に分け、それぞれの単語の頻出回数を集計(定量化)することで、データの中にあるパターンや特徴を掴むことができるようになります。
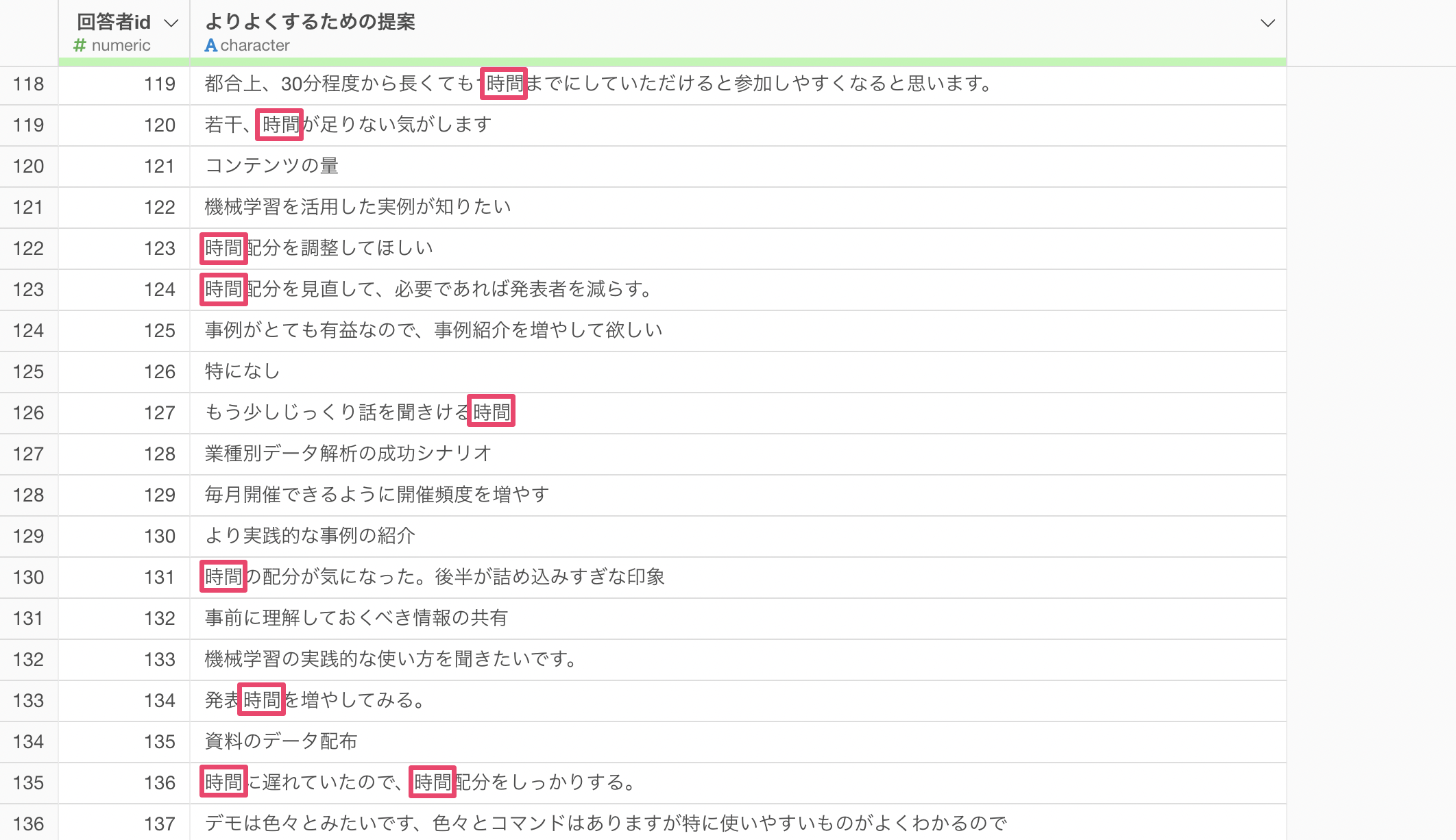
例えば、下記のように「時間」といった単語がどれだけ使われているのかを知ることで、アンケートの回答者が「時間」を気にしている人が多いのか少ないのかを比べていくことができます。
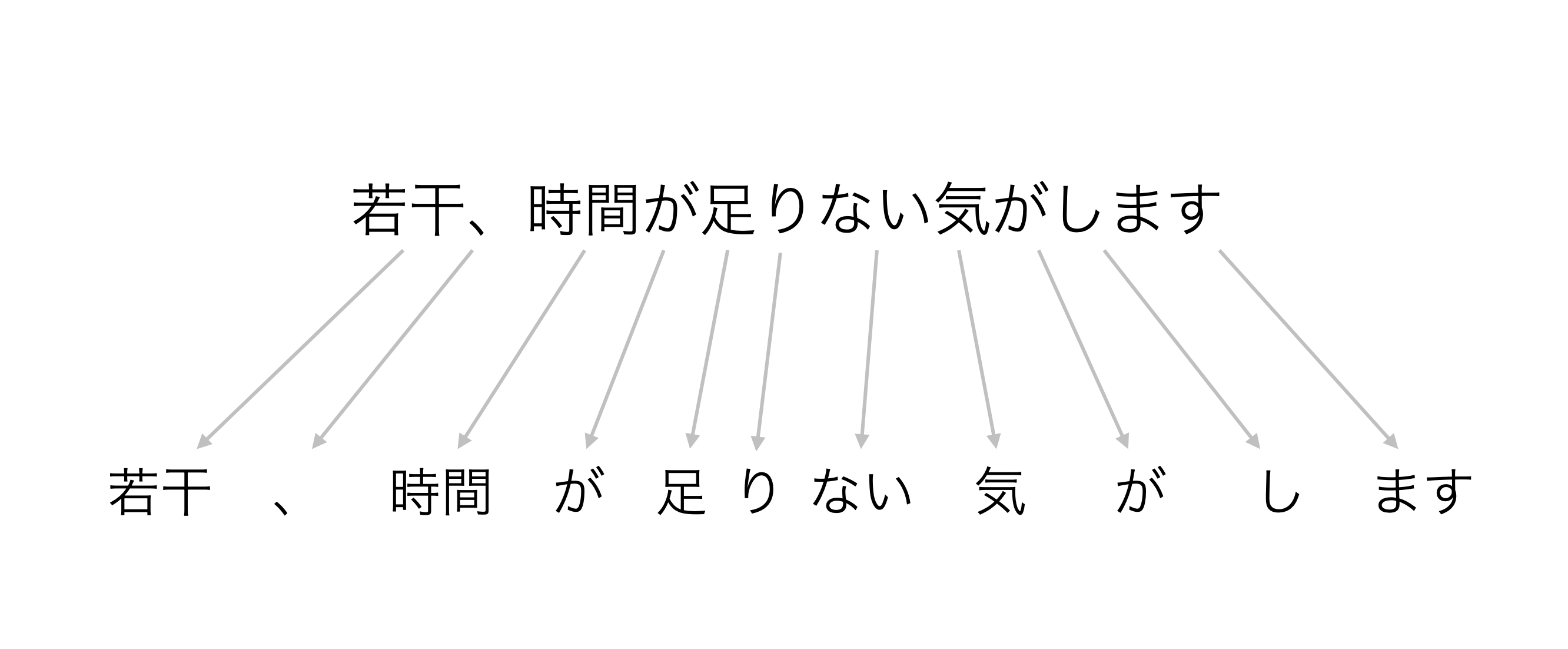
文章を単語化のイメージは下記のようなもので、それぞれの単語に分けていくことでその単語の頻出回数を集計していくことができ、このノートで紹介する「テキスト分析 -単語のカウント」にて簡単に実行できます。
さらには、「テキスト分析 - 単語のカウント」を使うことで下記の質問に答えていくことができます。
- どういった単語がよく使われているのか。
- 一緒に使われる単語にはどういった特徴があるのか。
2. データをインポートする
今回はサンプルデータとして「セミナーアンケート」のデータを使用します。このデータは1行が1回答者のデータで、列にはセミナーを「よりよくするための提案」という自由記述の回答の列があります。

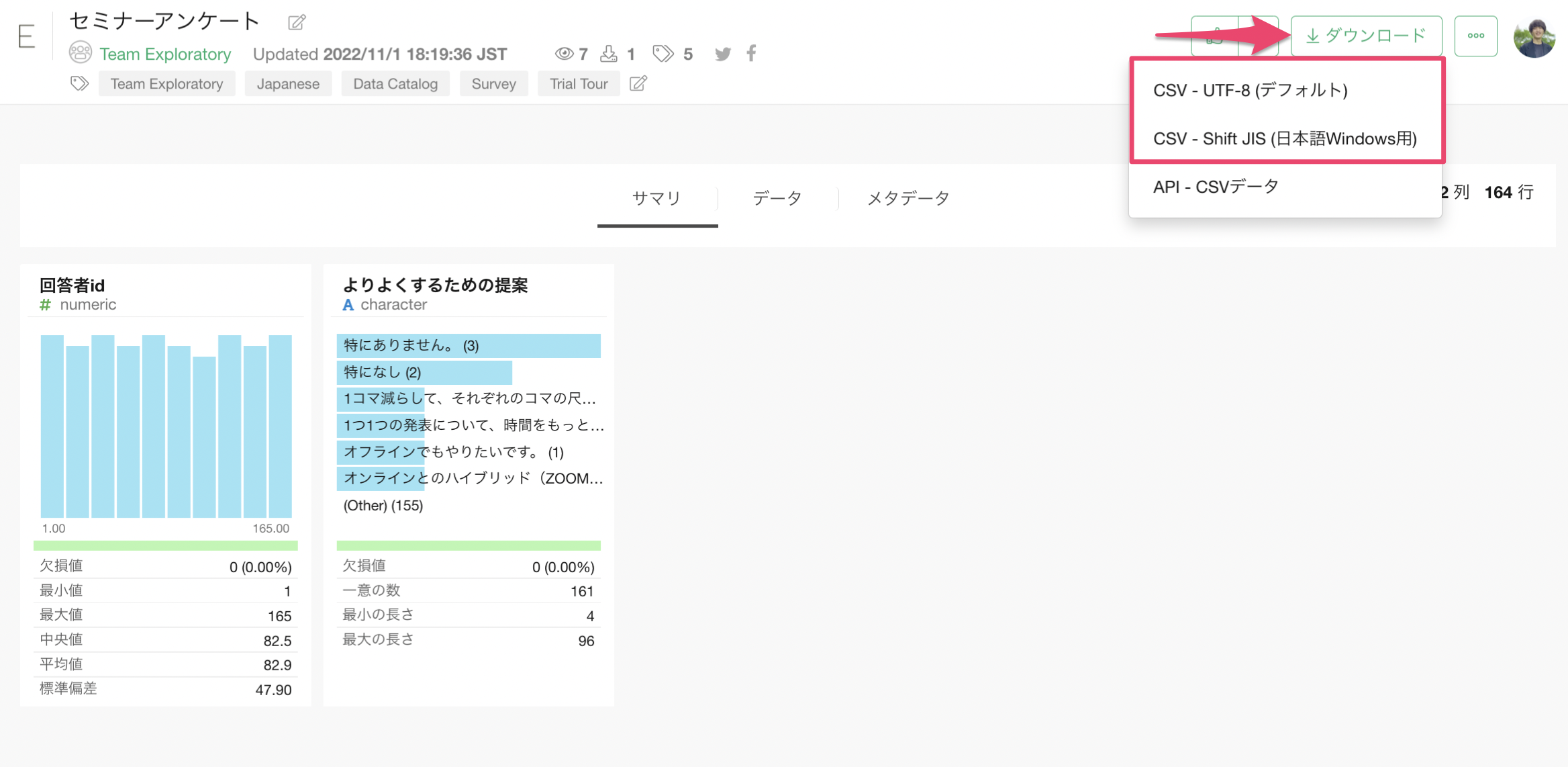
データはこちらのページからダウンロードできます。Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。
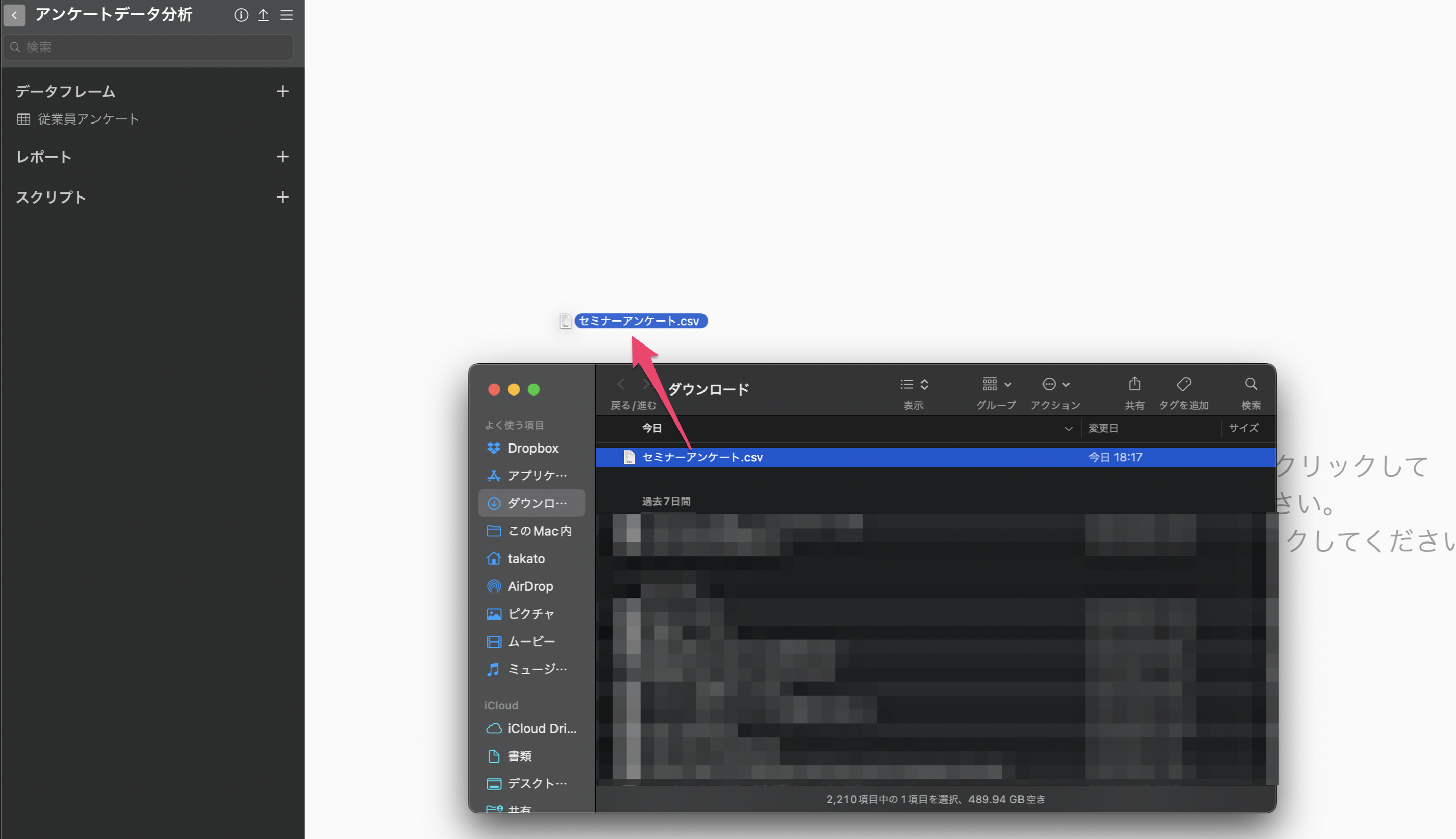
セミナーアンケートのデータをダウンロードできたら、ダウンロードしたフォルダを開き、「セミナーアンケート.csv」をExploratoryの画面にドラッグ&ドロップします。
インポートダイアログが表示されました。インポートダイアログの左側にある項目から、インポート時の設定を行うことが可能ですが、今回は設定は不要なため「保存」ボタンをクリックします。
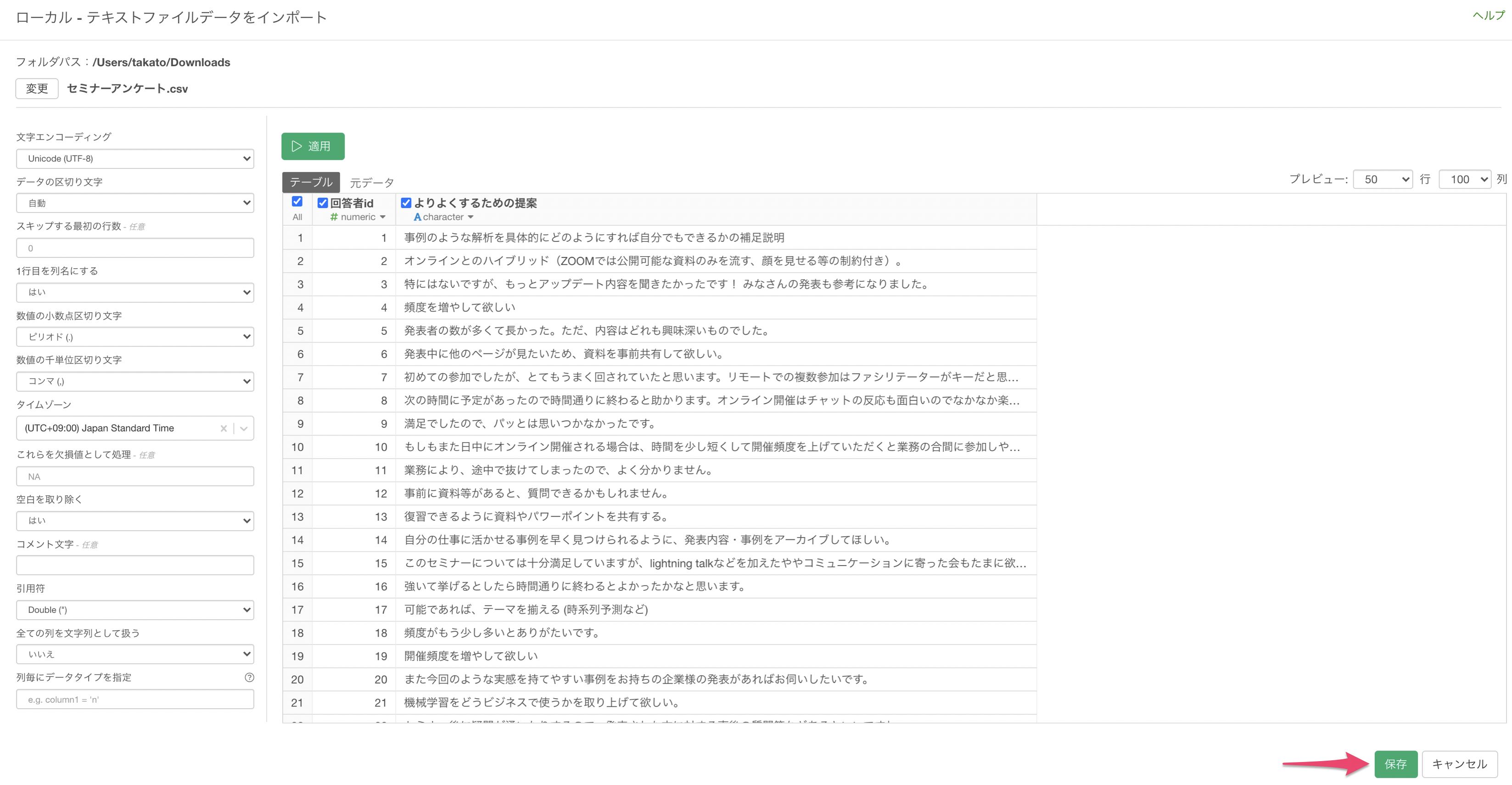
任意のデータフレーム名を指定して、「作成」ボタンをクリックします。
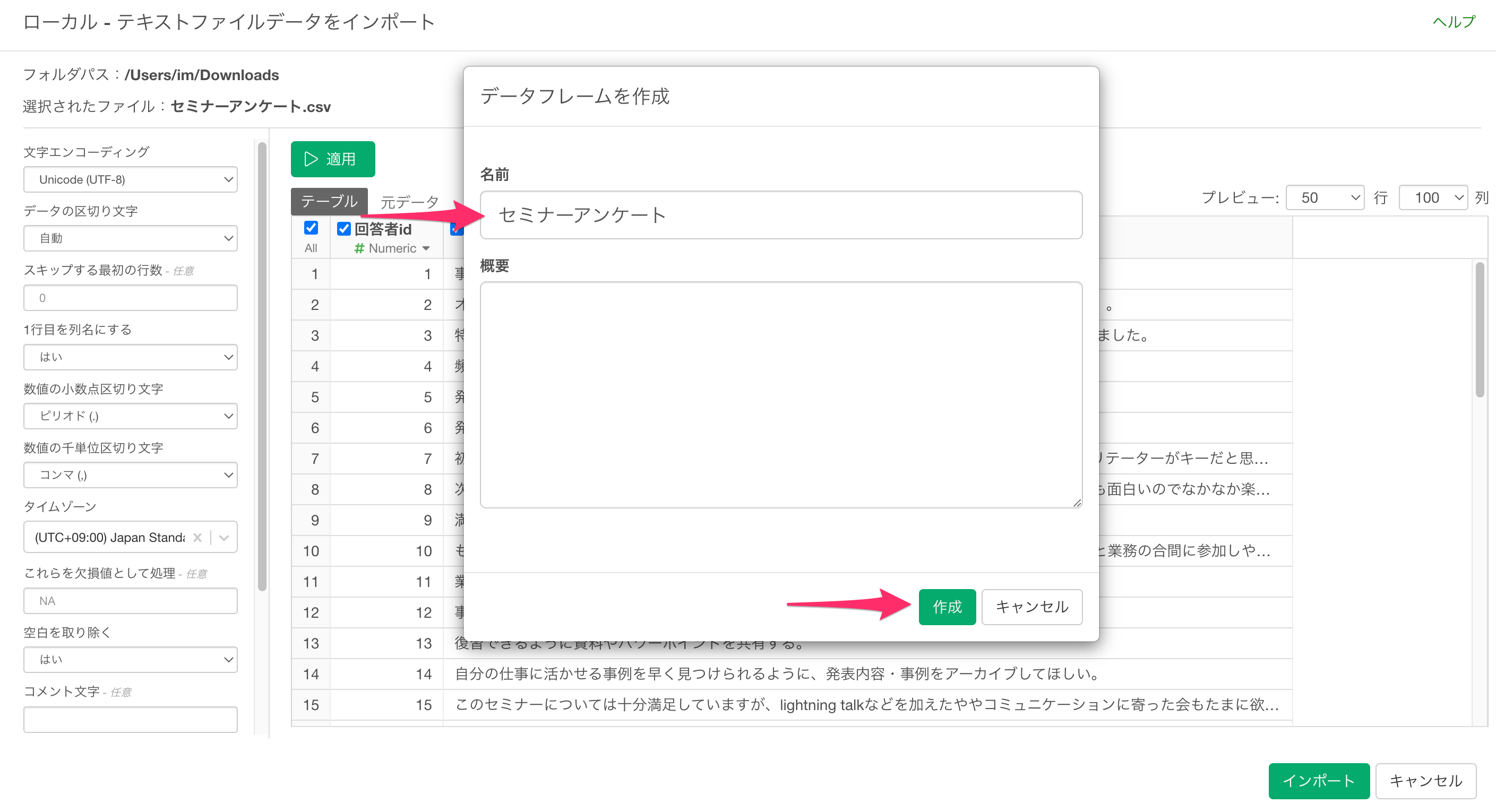
セミナーアンケートのデータをインポートすることができました。
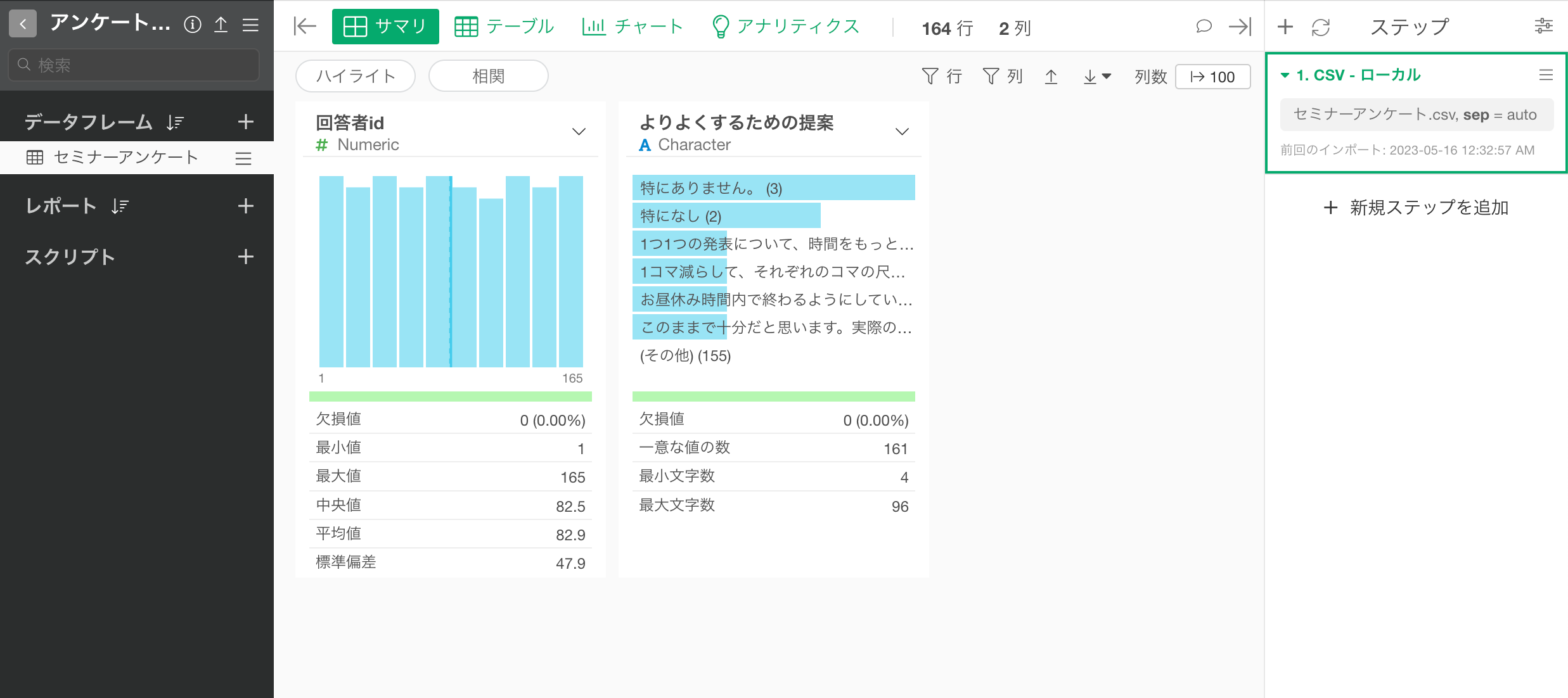
3. テキスト分析 - 単語のカウントを実行する
今回は「よりよくするための提案」といった自由記述の回答で、どういった単語がよく使われているのかを調べてみましょう。
アナリティクスビューを選び、タイプに「テキスト分析」の「単語のカウント」を選択します。
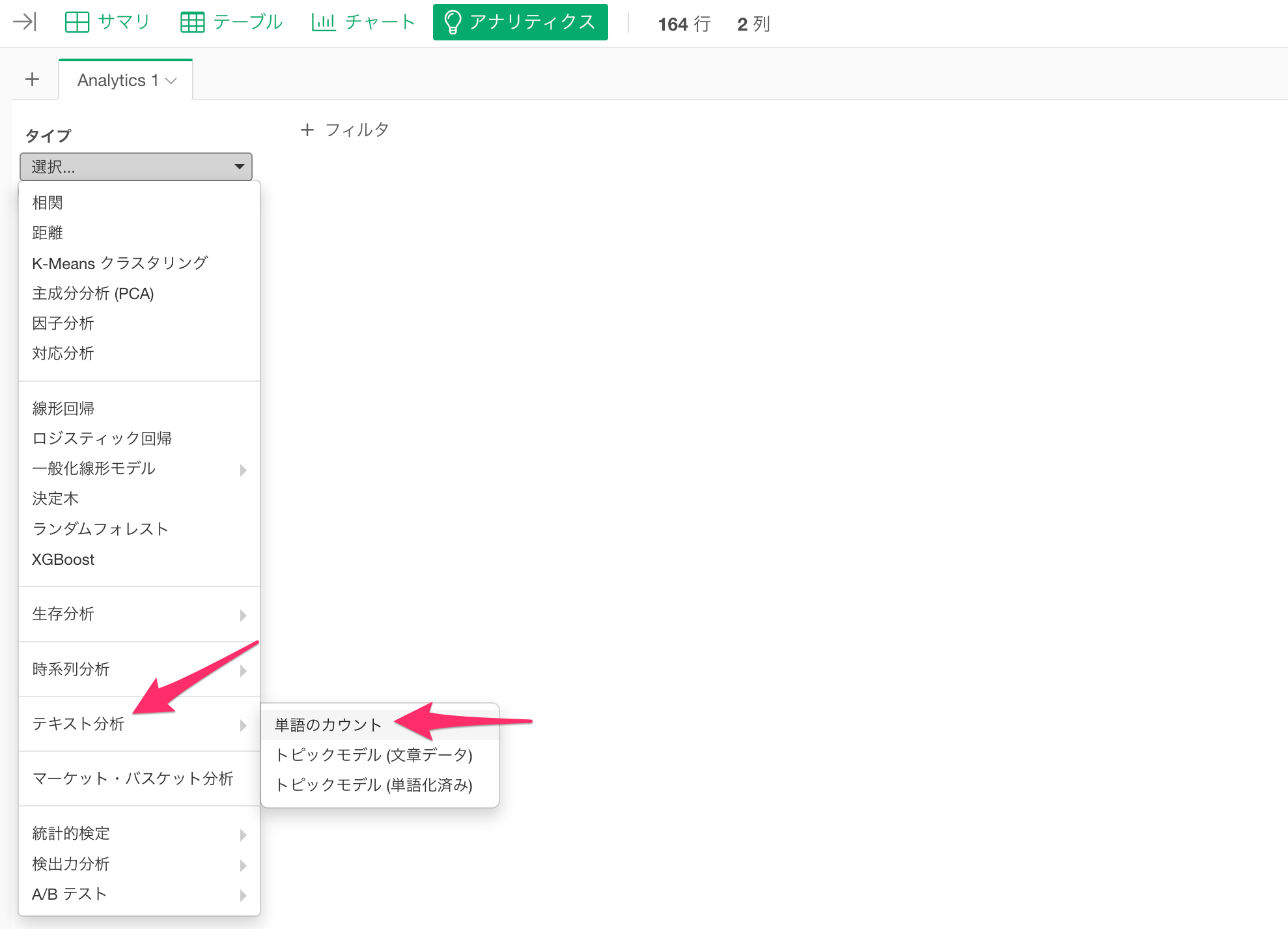
テキストの列に「よりよくするための提案」を選択します。
もしデータが「5000行」以上の場合、全てのデータを使いたい場合は「データをサンプルする」のチェックを外してください。しかし、データの行数によっては実行までに時間がかかってしまうために、デフォルトでは「5000行」でサンプルされていることになります。
設定ができたら、「実行」ボタンをクリックします。
テキスト分析の「単語のカウント」が実行されました。

4. 結果の解釈
テキスト分析の「単語のカウント」では、大きく分けて「単語の出現頻度」と「一緒に使われる単語の関係性」の2つに関するタブがあります。

ワードクラウド
「ワードクラウド」のタブでは、それぞれの単語の出現頻度に応じて単語の「サイズ」や「色」が決まります。

今回の場合は「時間」や「発表」、「事例」などの単語が多く使われていることが確認できます。

単語 - バー
ワードクラウドはビジュアル的には面白いチャートですが、それぞれの単語が何回出現したのか、どの順番で多いのかは知ることができません。
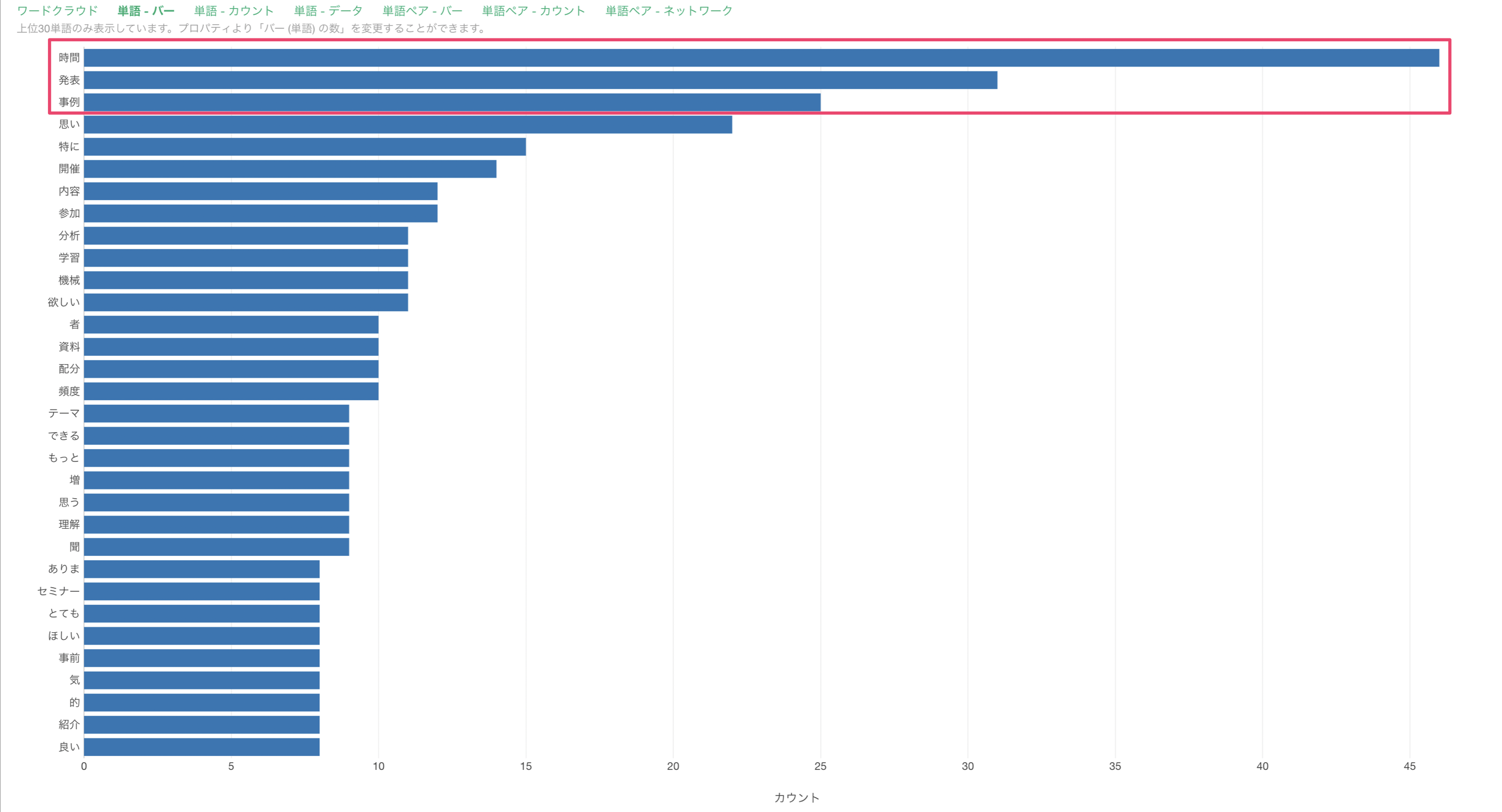
「単語 - バー」のタブでは、それぞれの単語の出現回数がバーチャートとして可視化されるため、単語の出現回数が多いのか、少ないのかが比べやすくなっています。
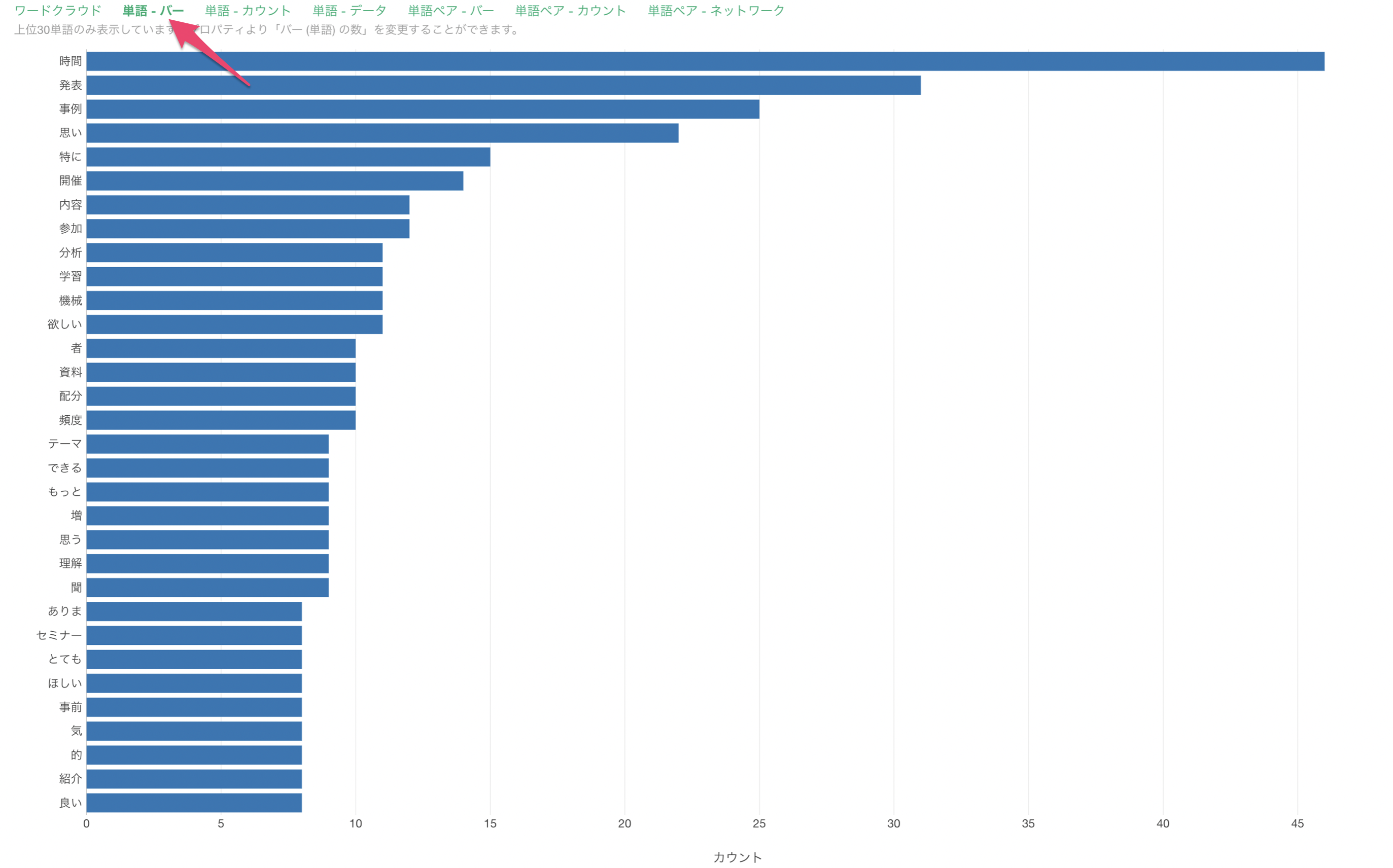
今回の場合は、「時間」や「発表」、「事例」などの単語がよく使われていることが確認でき、「時間」といった単語は45回ほど出現していたことがわかります。
単語ペア - バー
「単語ペア - バー」のタブでは、一緒に使われている単語の組み合わせの出現回数をバーチャートとして可視化しています。
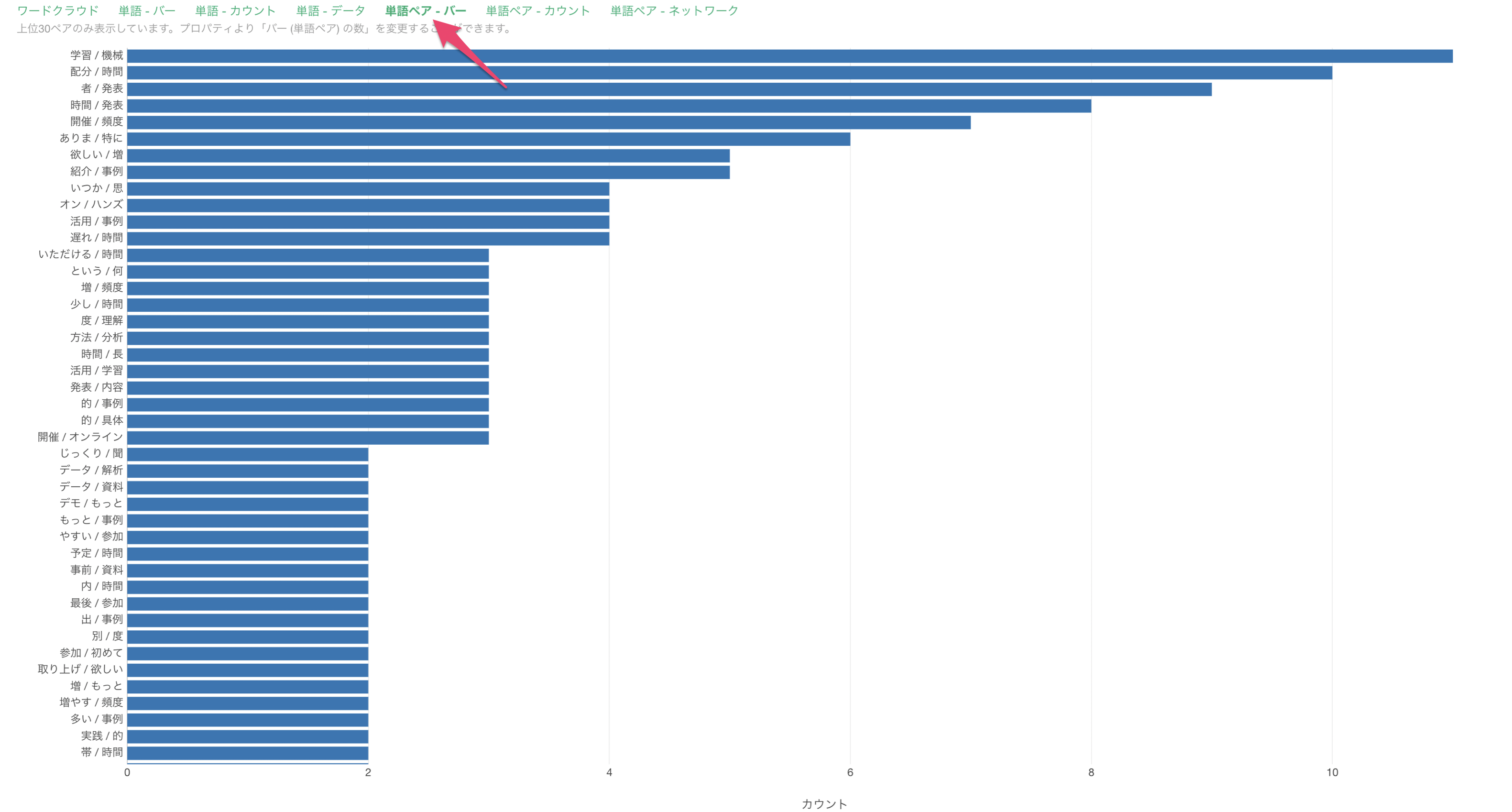
今回の場合は、「学習/機械」や「配分/時間」、「者/発表」といった単語がよく一緒に使われていることがわかります。
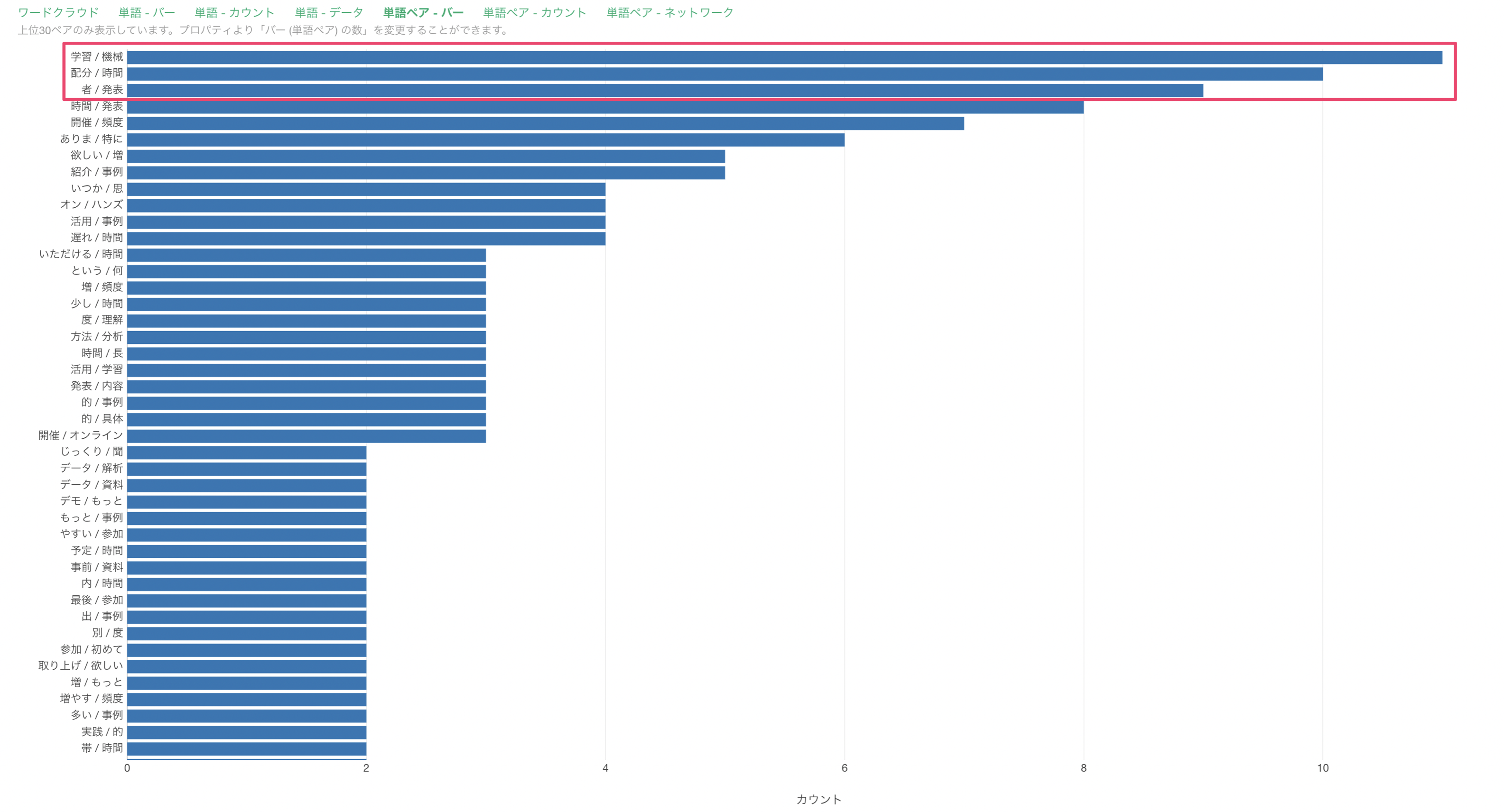
ただ、これらの単語は「機械学習」や「時間配分」として使われていることが想定されます。そういった分けてほしくない単語については、この後紹介する「つなぐ単語」の辞書機能にて一つの単語として登録することができます。
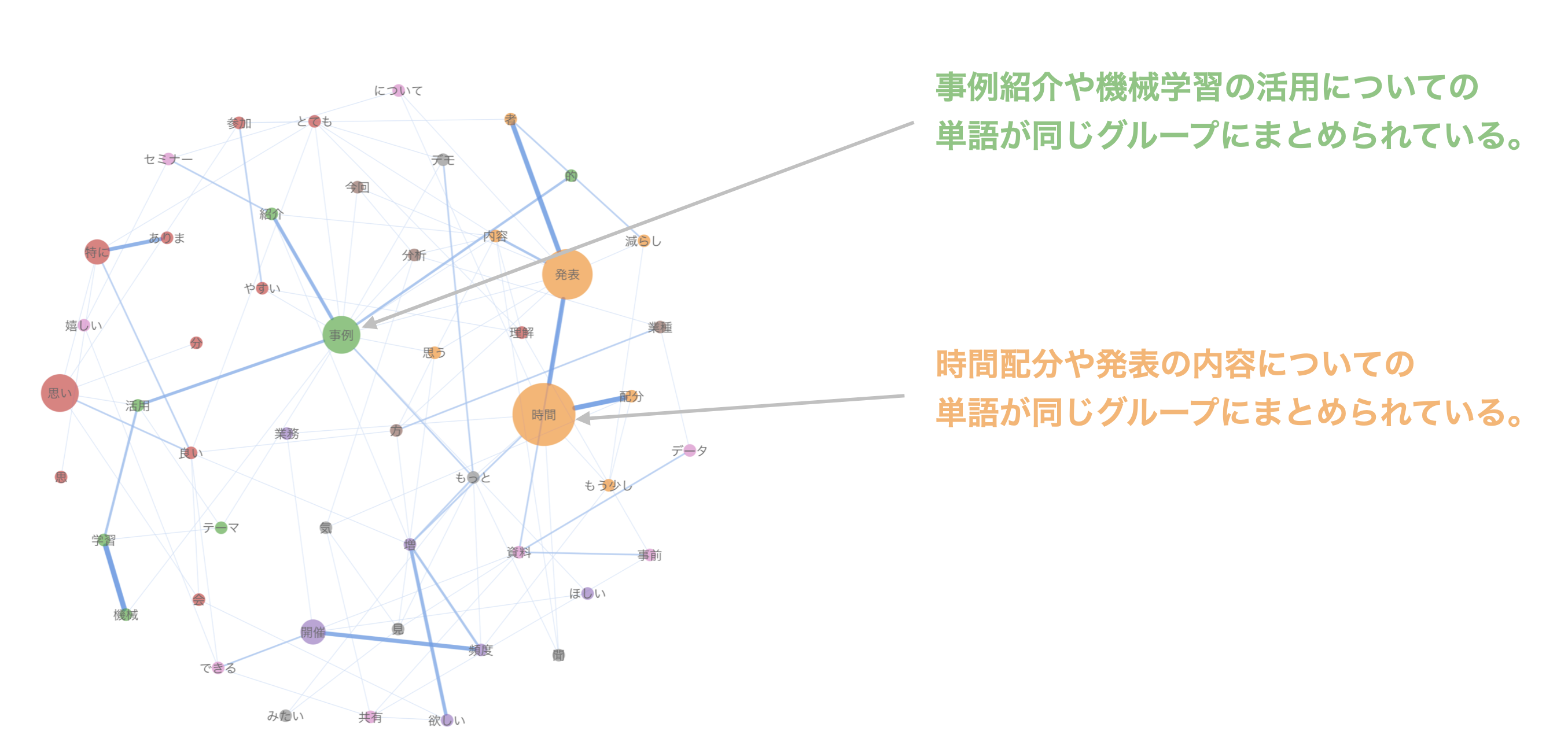
単語ペア - ネットワーク
「単語ペア - バー」ではどの単語が最もよく一緒に使われているかがわかりますが、 2つの単語の組み合わせ以上の関係性はわかりません。
そこで、「単語ペア - ネットワーク」では、一緒に使われる単語を「単語間の関係」として 見ていくことができます。
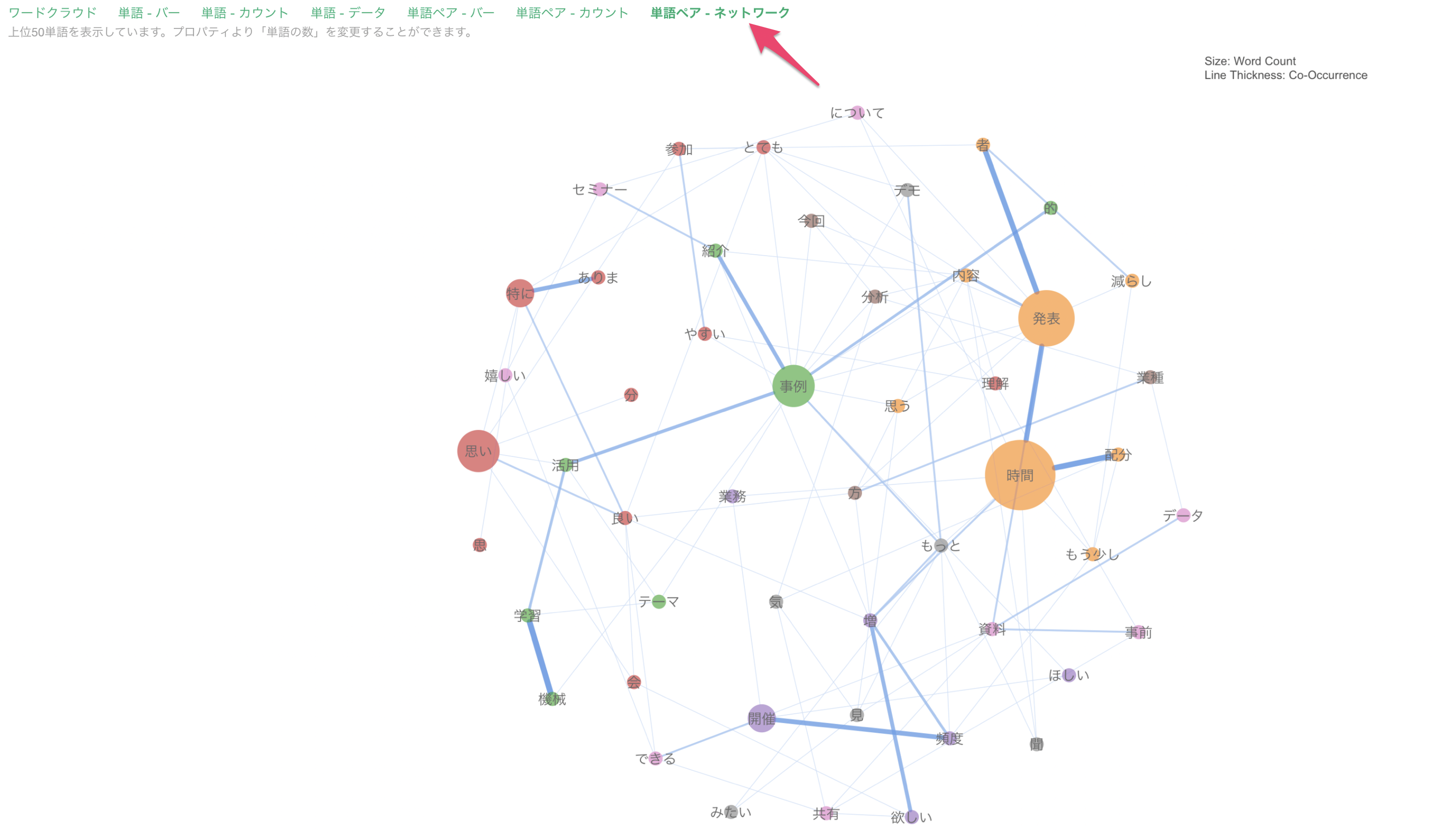
それぞれの単語を一緒に使われる頻度を元にグループ分けし、グループ毎に「色」が割り当てられています。
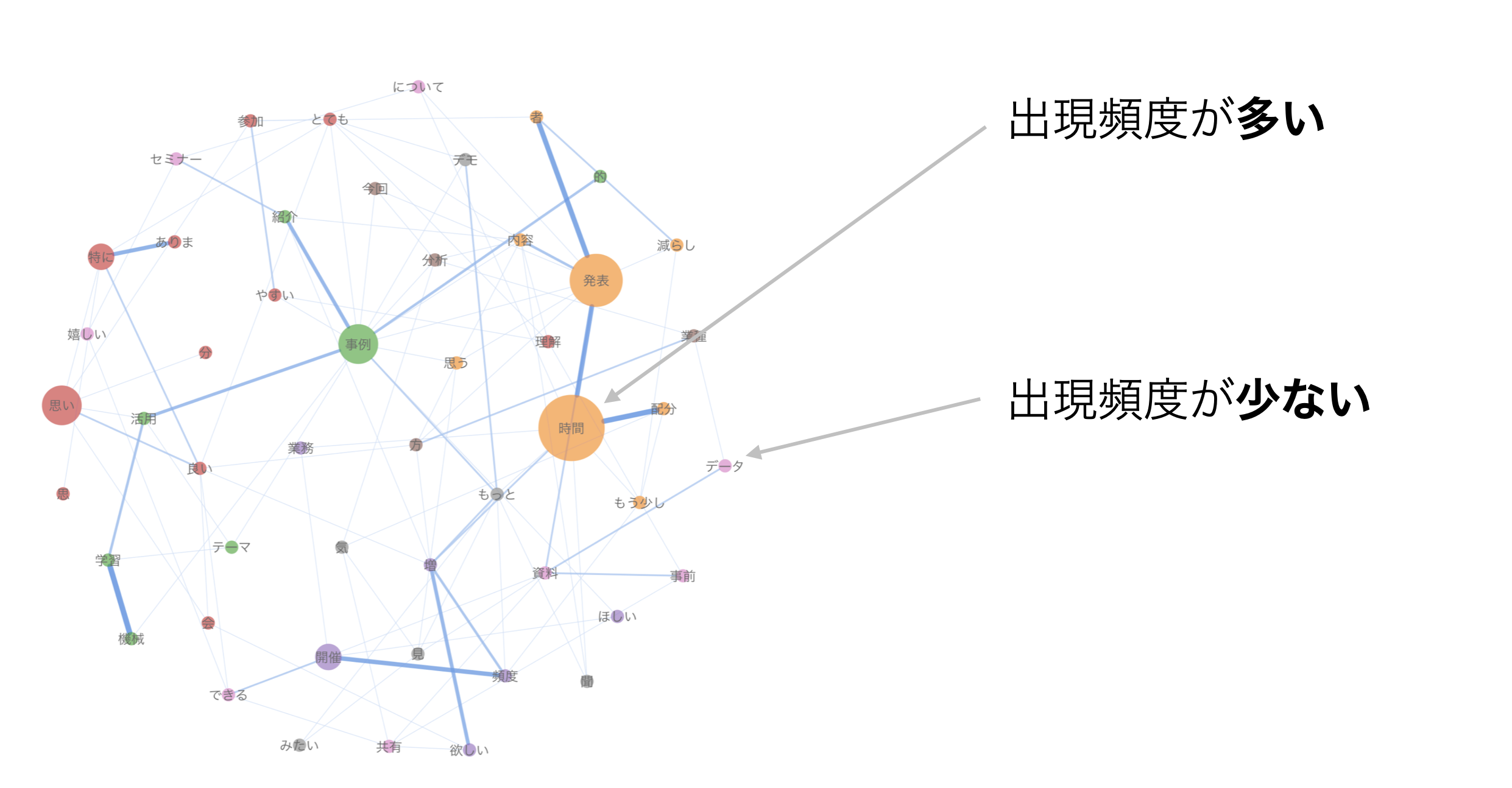
円の大きさは「出現頻度」によって決まり、出現頻度が多いと円は大きくなり、出現頻度が少ないと円は小さくなります。
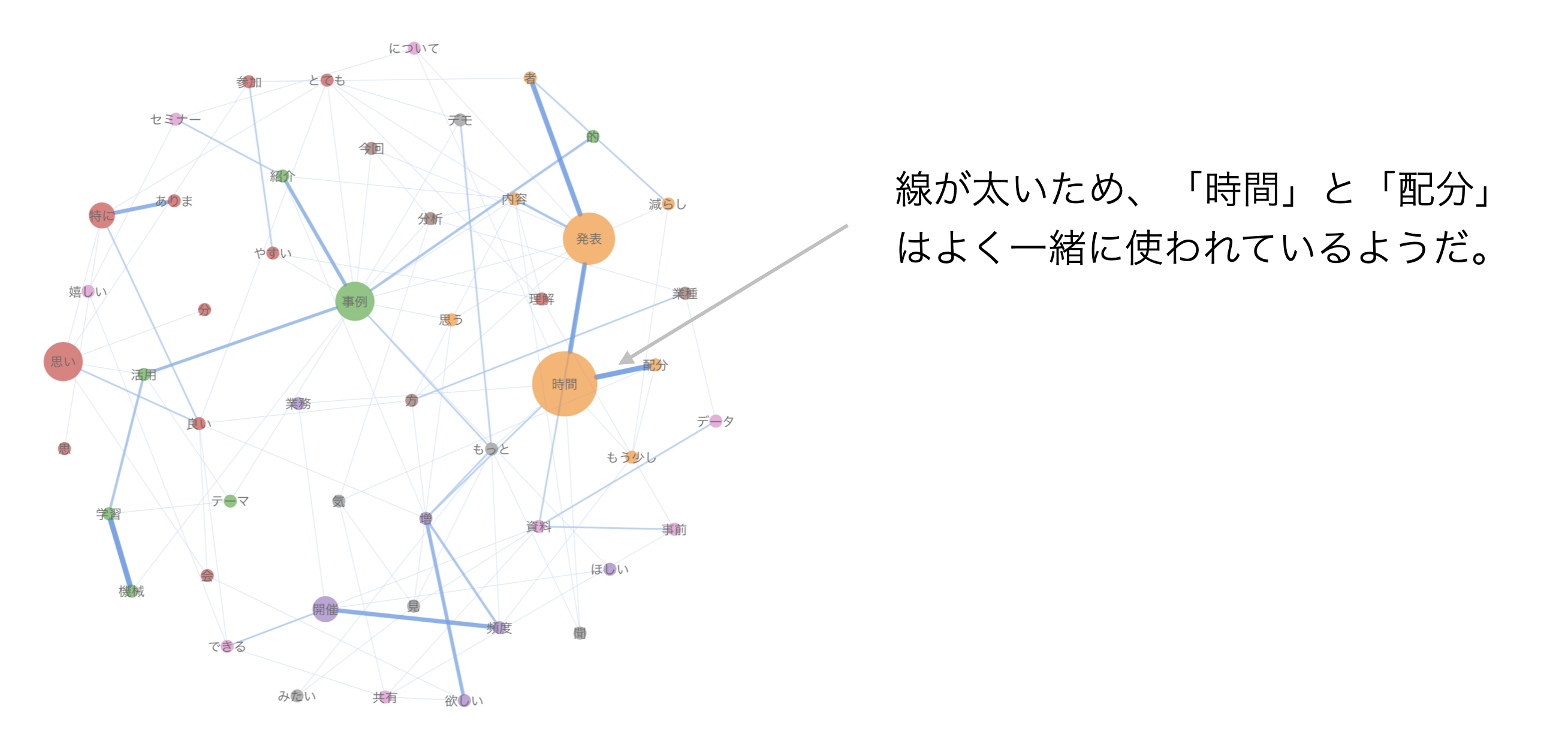
さらに、よく一緒に使われる単語の組み合わせは、より太い線で表わされます。
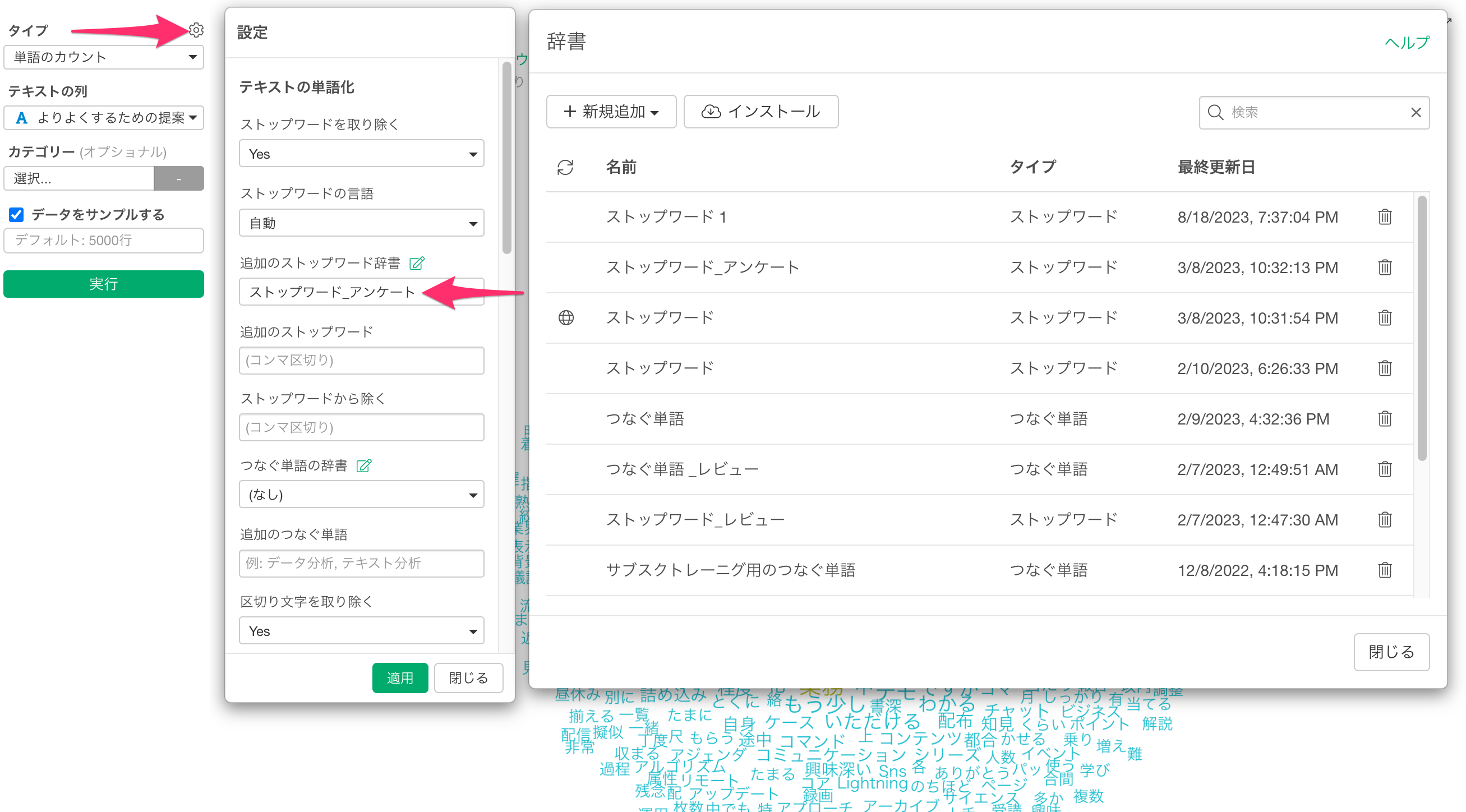
5. ストップワード、つなぐ単語の辞書の設定
Exploratoryでは、あまりにも一般的な単語でそれぞれの文章を特徴づけることがない「ストップワード」や、分かれてしまう単語を一つの単語として扱える「つなぐ単語」を辞書として登録して使うことができます。
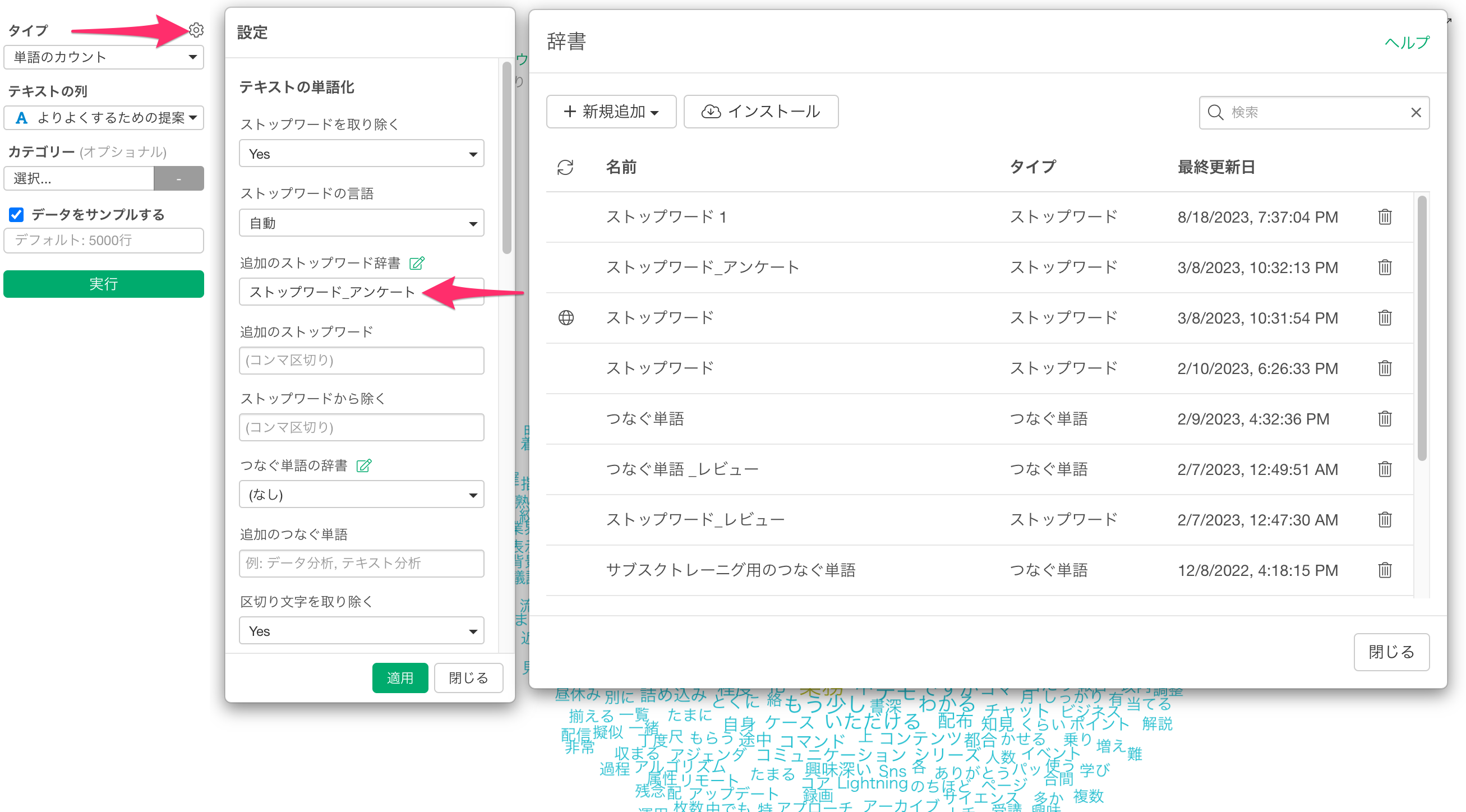
辞書では下記のように、1行ごとに単語を入力して登録することができます。
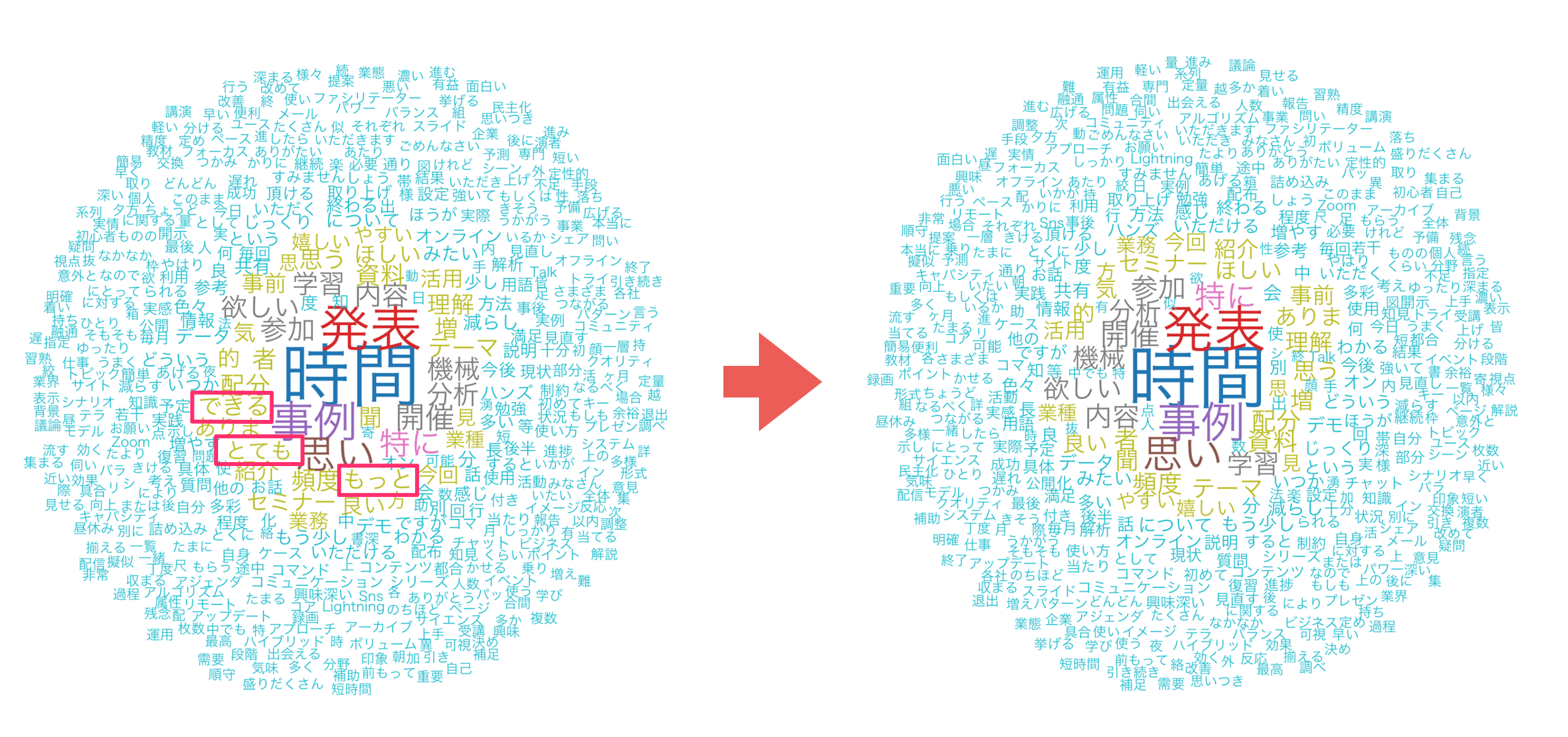
例えば、「もっと」、「できる」、「とても」といったストップワードを辞書として登録をして使用すると、これらの単語が削除されていることが確認できます。
さらに、辞書はExploratoryサーバーにパブリッシュして、チームメンバーや他の人たちにも共有することができます。
辞書の詳しい使い方については、こちらの資料をご参照ください。
アンケートデータ分析のテキスト分析編は以上となります!
アンケートデータ分析 - トライアルツアー
アンケートデータ分析の他のパートには下記のリンクからご確認いただけます。ぜひ次の「因子分析」のパートも実施してみてください。