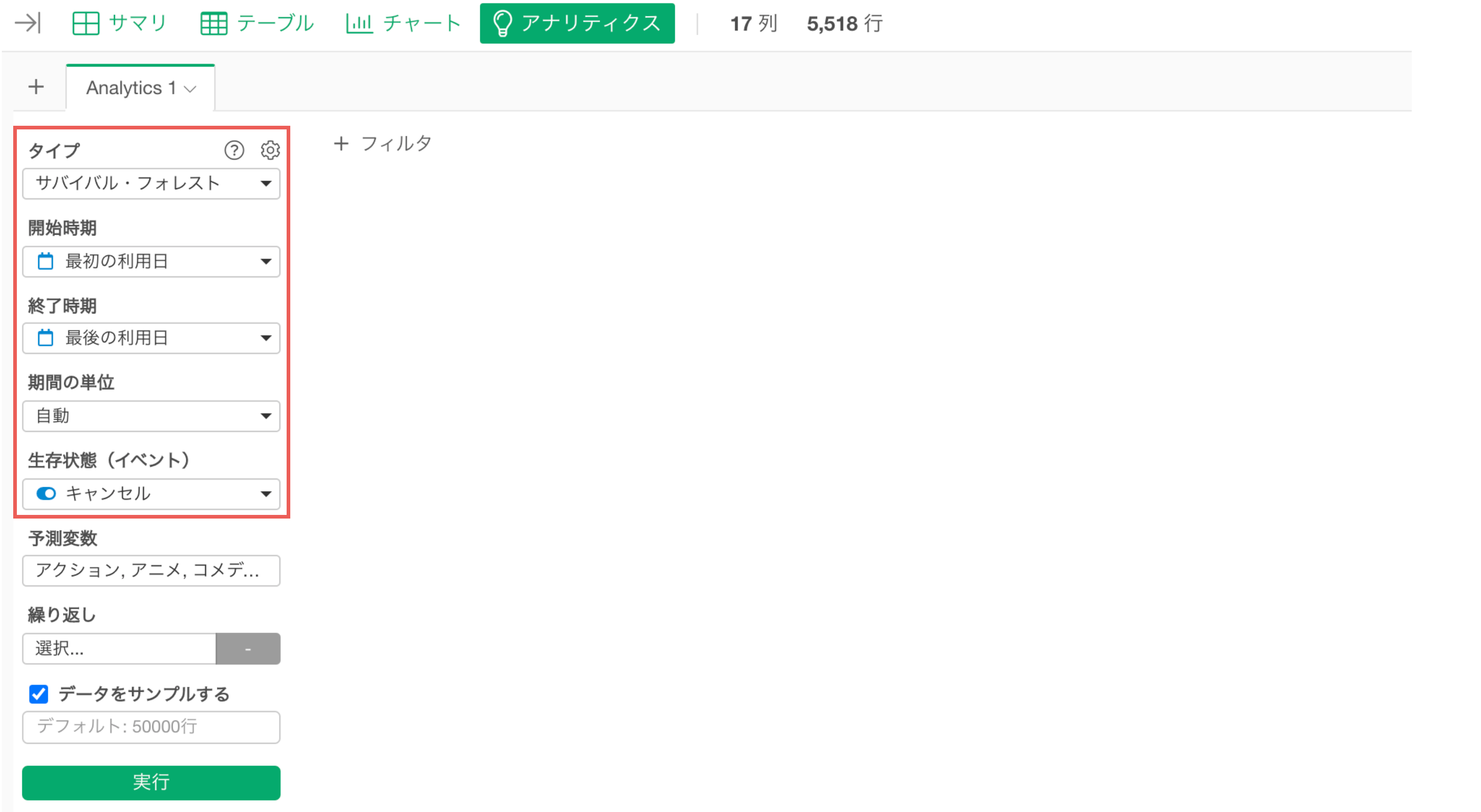
サバイバル・フォレストの紹介
アナリティクスの「サバイバル・フォレスト」を紹介します。
例えばサブクリプション型のビジネスにおける顧客のキャンセルについて考えるときは、「サービスをキャンセルするかどうか」ではなく、「どれくらいの期間でキャンセルが発生したのか」が重要です。
そこで、生存分析のアルゴリズムの1つのサバイバルフォレストを使うと、下記の質問に答えられます。
- このデータ(予測変数)を使うことで、あるタイミング(例:サービスの利用開始から1年後)における生存状態(例:サービスのキャンセル)のTRUE/FALSEをどれだけ上手く分けられているのか。
- どの変数が、あるタイミングにおける生存状態を予測するうえで重要なのか。
- 予測変数の値が変わると、生存曲線はどのように変わるのか。
- とある観察対象(例: 顧客、従業員)の生存確率が50%を下回るのはいつか。
- とある観察対象に注目したときに、1ヶ月後の生存確率はどの程度か。
必要なデータ
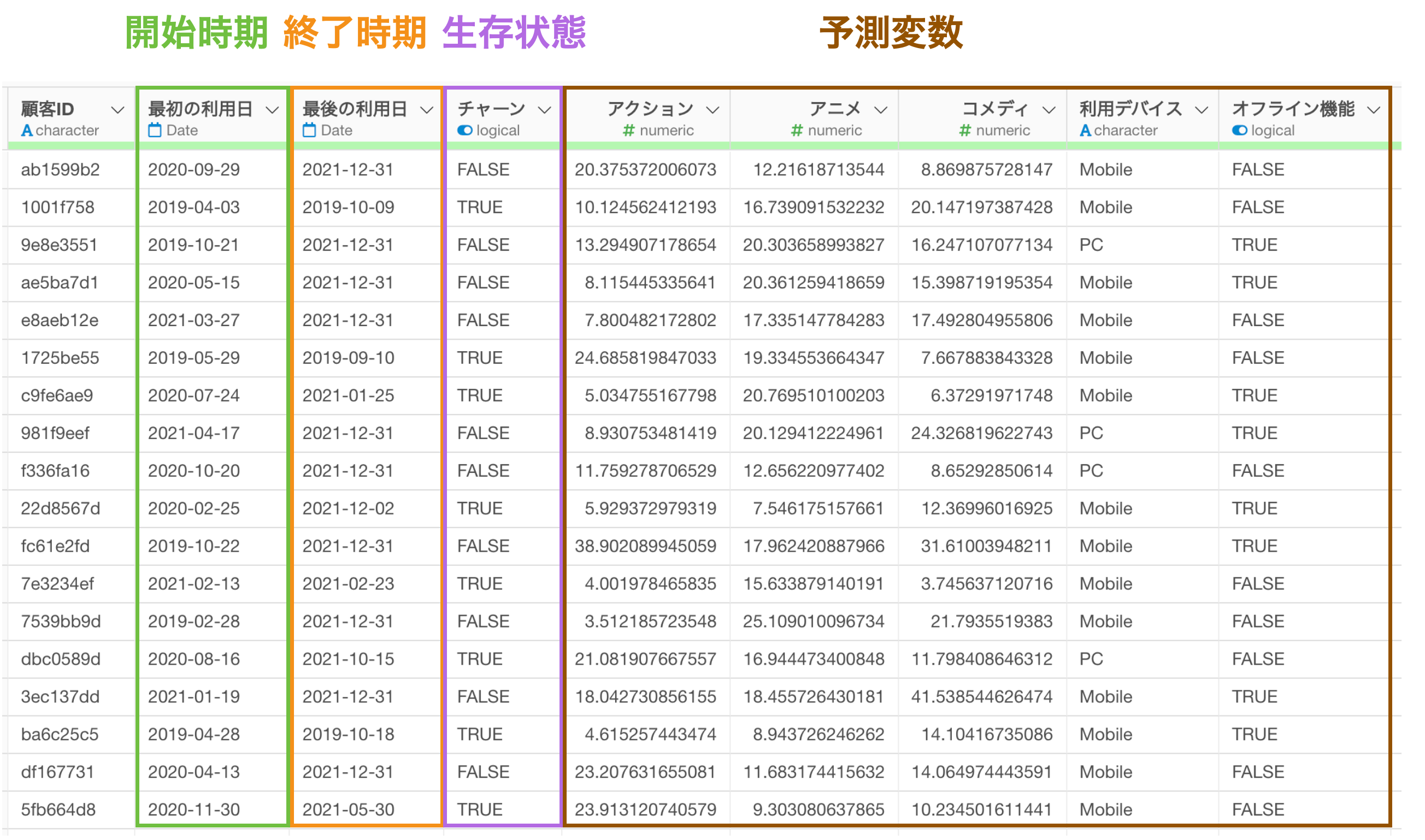
サバイバル・フォレストのモデルを作成するためには、**1行が1観察対象(例:1行が1顧客)**となっているデータが必要です。
また、以下の情報も列に必要です。
- 開始時期:観察対象の観察の開始時期を表す、Data(日付)型、またはPOSIXct(日付時間)型の列
- 終了時期:観察対象の観察の終了時期を表す、Data(日付)型、またはPOSIXct(日付時間)型の列
- 生存状態:観察対象のイベントのステータスを表す、ロジカル型の列(例:キャンセル、解約、離職、死亡など)
- 予測変数:生存状態を予測するための列(データタイプには特に縛りはありません)
サンプルデータ
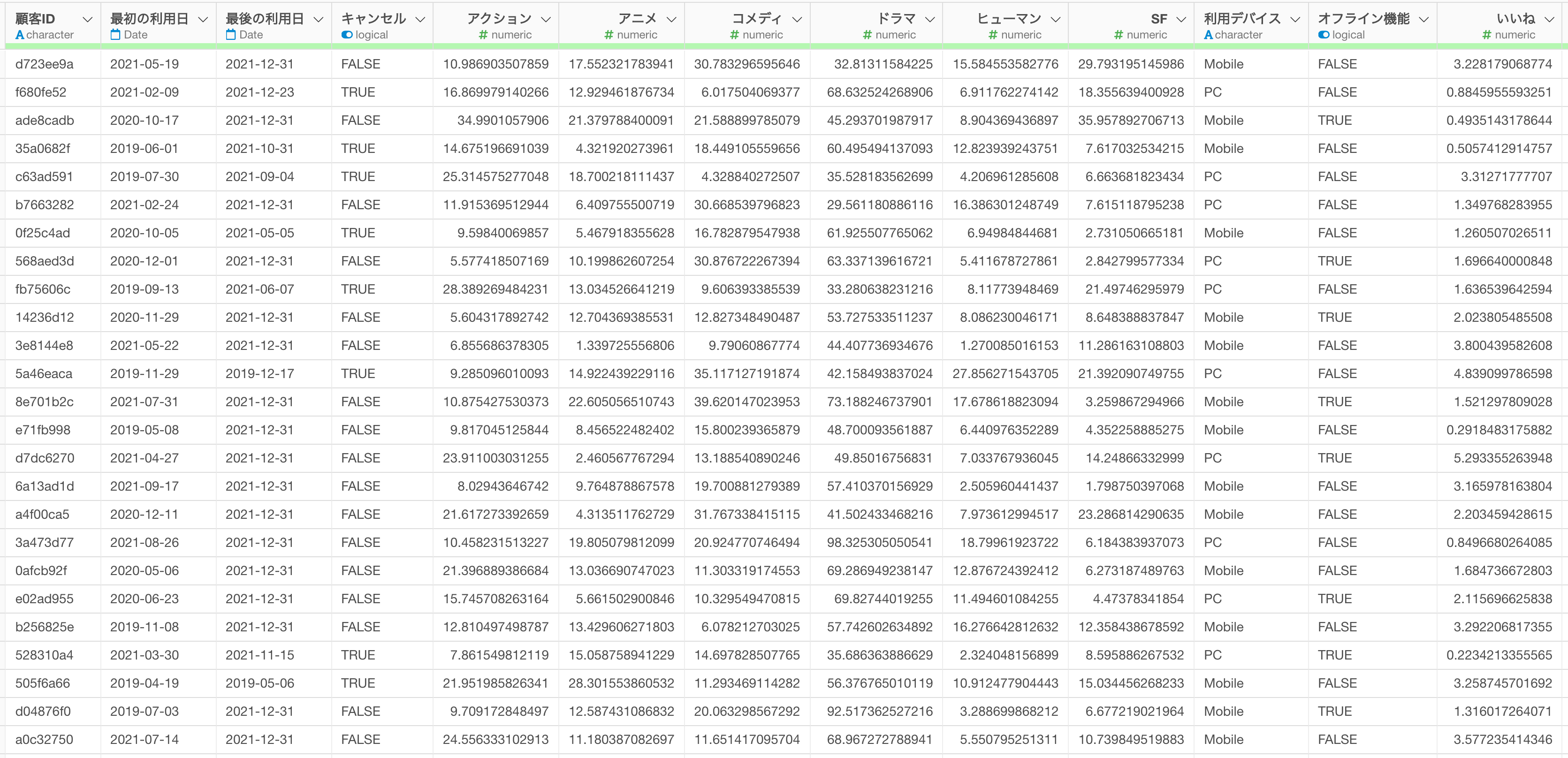
今回はサンプルデータとして、Netflixのような動画視聴のサブスクリプション・サービスのデータを使用していきます。
このデータは1行が1顧客のデータで、列には顧客のコンテンツの視聴時間や、主な利用デバイス、サービスが提供する機能の利用状況、年齢や性別などの属性を表す列があります。
サバイバル・フォレストのモデルを作成する
今回は顧客のある時点での生存確率を予測するサバイバル・フォレストのモデルを作成します。
サバイバル・フォレストのモデルを作成するときは、アナリティクス・ビューからタイプに「ランダム・フォレスト」を選択し、以下の項目に先程、紹介した列を選択し実行します。
- 開始時期
- 終了時期
- 生存状態(イベント)
- 予測変数
結果の解釈
サバイバル・フォレストを実行すると、予測モデルを解釈するための複数のタブが表示されます。
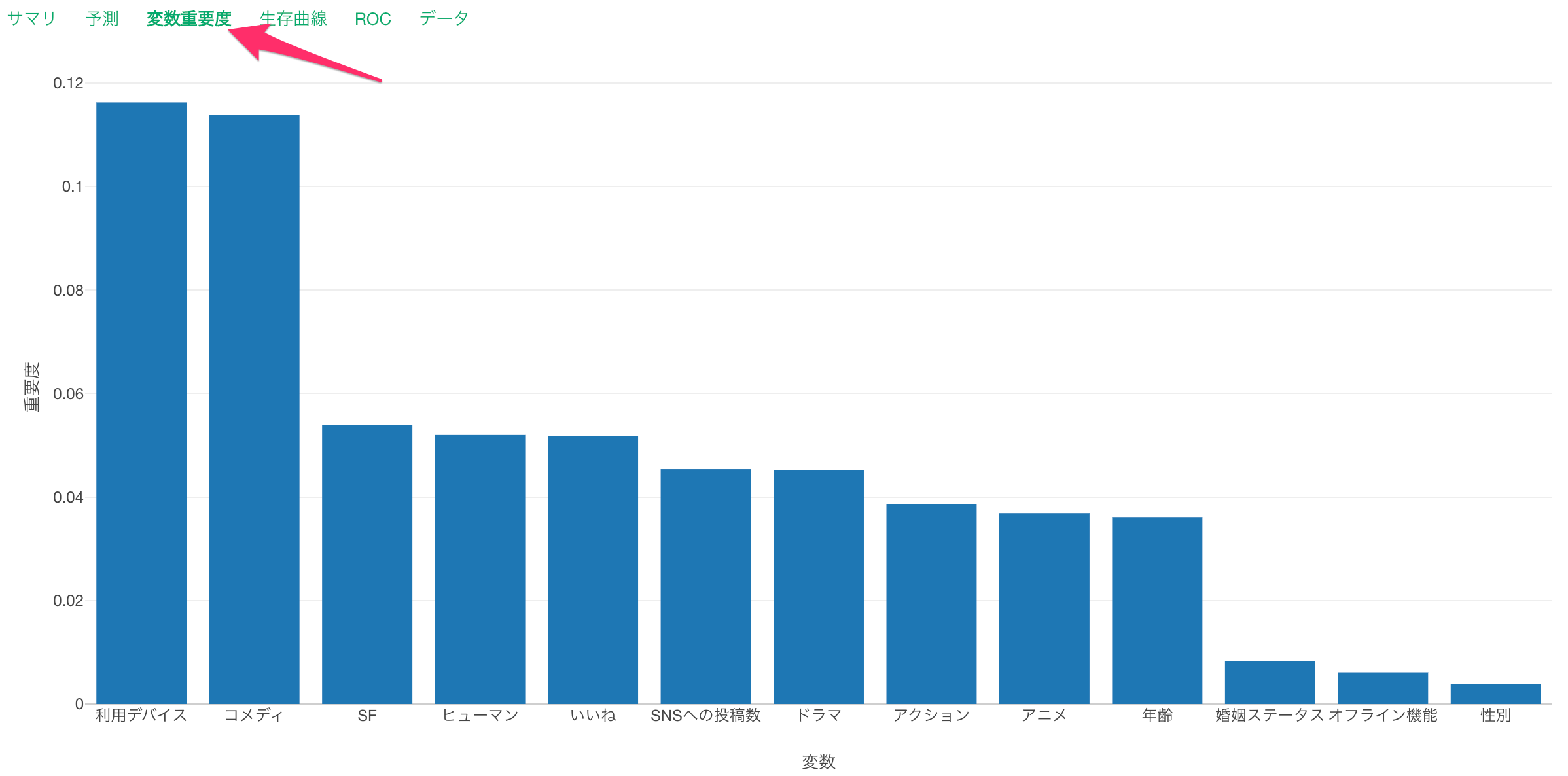
変数重要度
変数重要度タブでは、どの変数が生存曲線の傾きと、より相関が強いのか、予測する時により重要なのかを調べられます。
重要度の値が大きいほど、生存曲線の傾きと相関が強いということになります。
変数重要度の詳しい説明については、こちらの「機械学習モデル - 変数重要度の仕組みと解釈」のセミナーをご覧下さい。
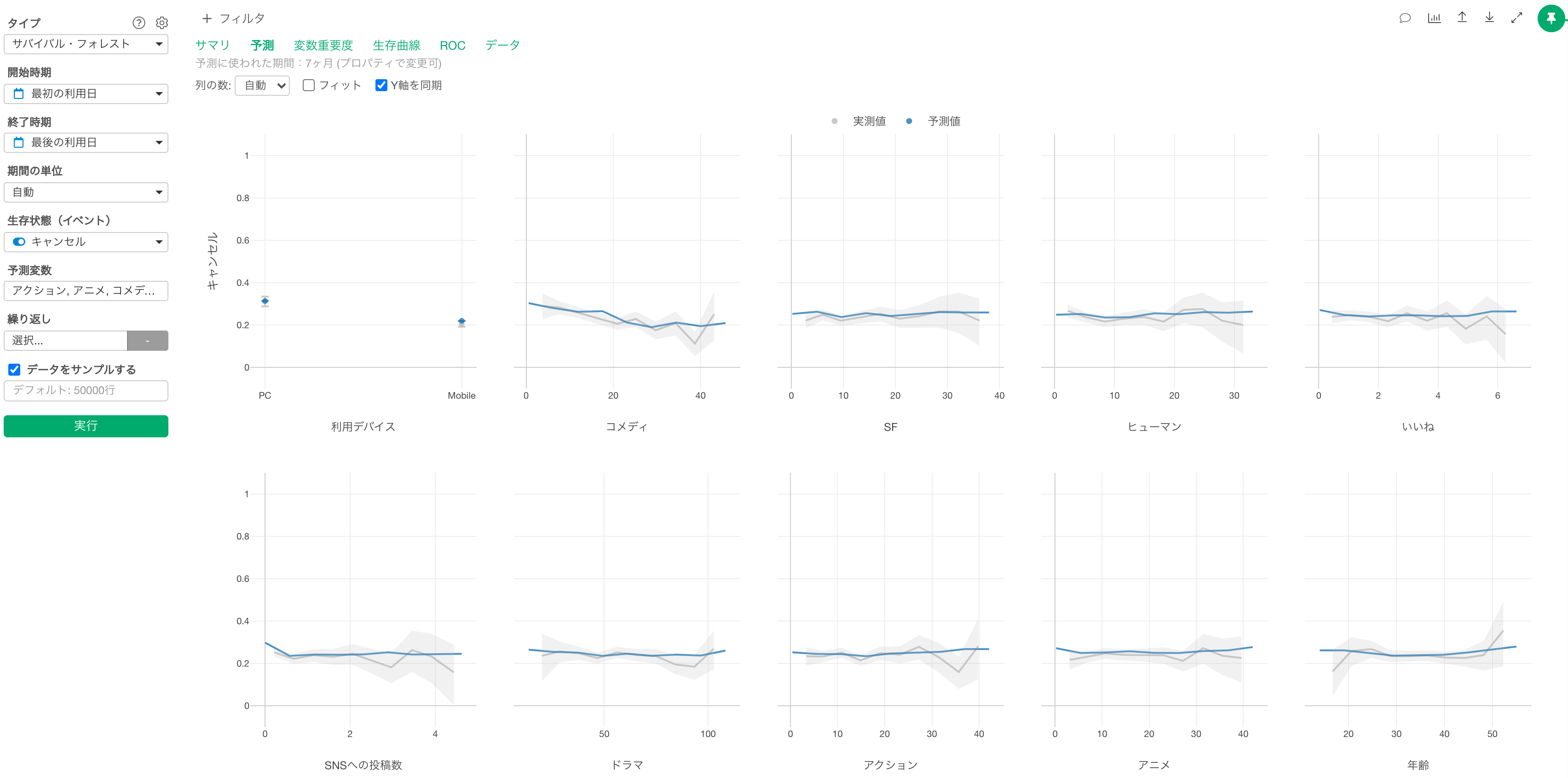
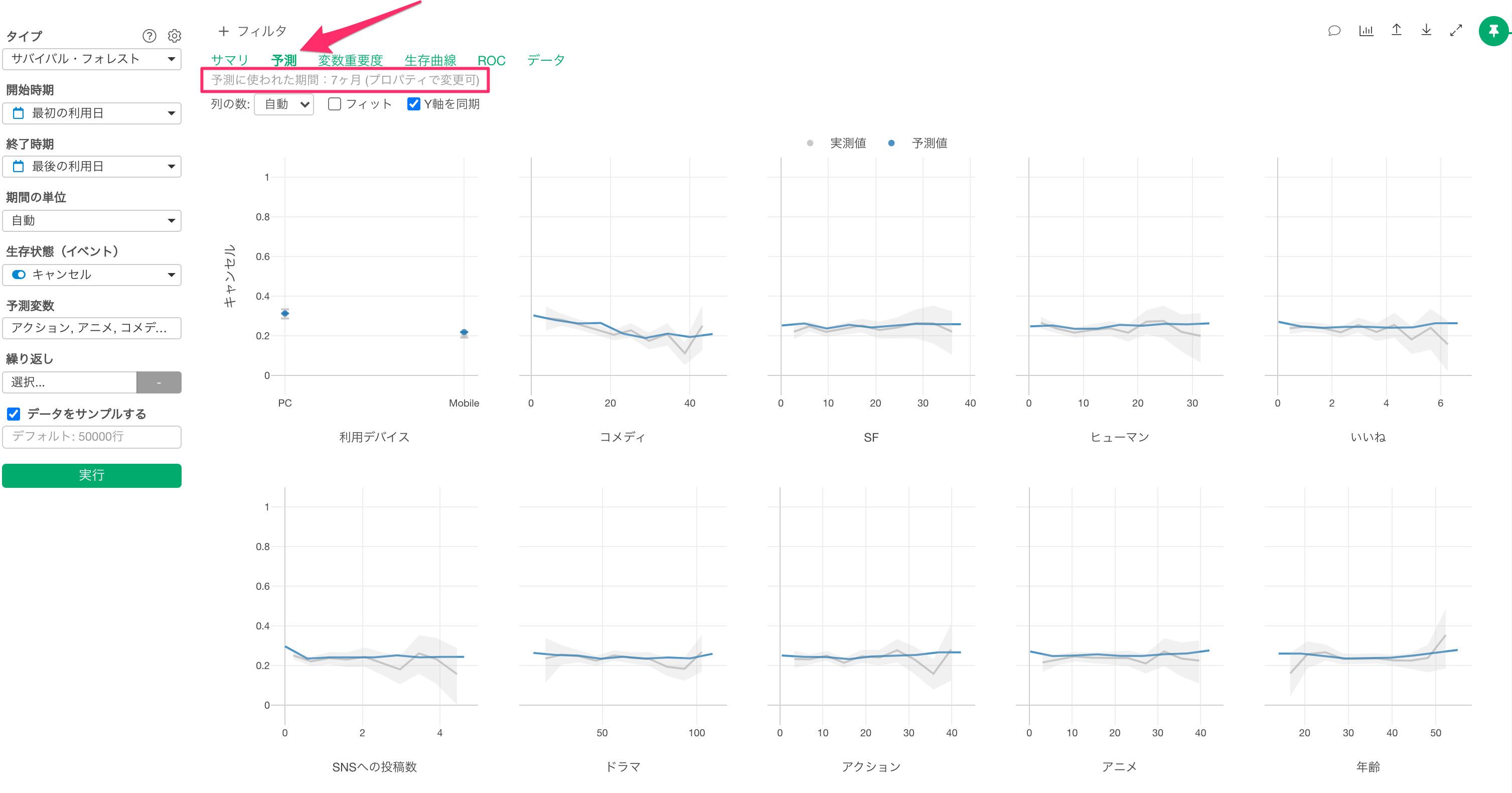
予測
予測タブでは、それぞれの変数の値が変わると、「生存状態(イベント)の割合がどのように変わるのかがわかります。
このとき利用される生存期間は、「生存状態」が「TRUE」の観察対象の生存期間の平均値です。従って、今回のデータでは、「サービスの利用を開始してから7ヶ月後のキャンセル率」が可視化されます。
また、実際のデータから計算された実測値はグレー色で、予測結果が青色で表示されます。
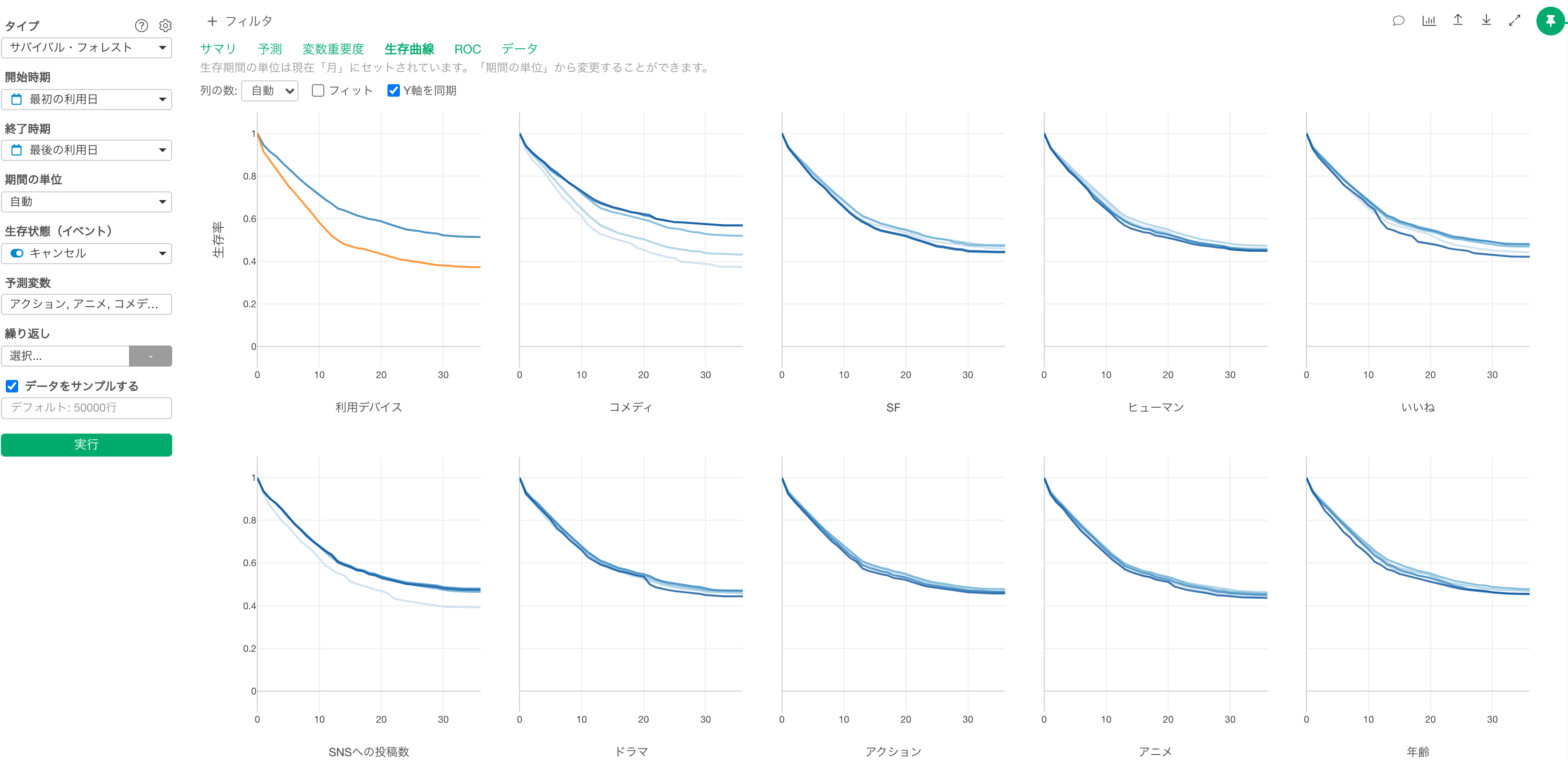
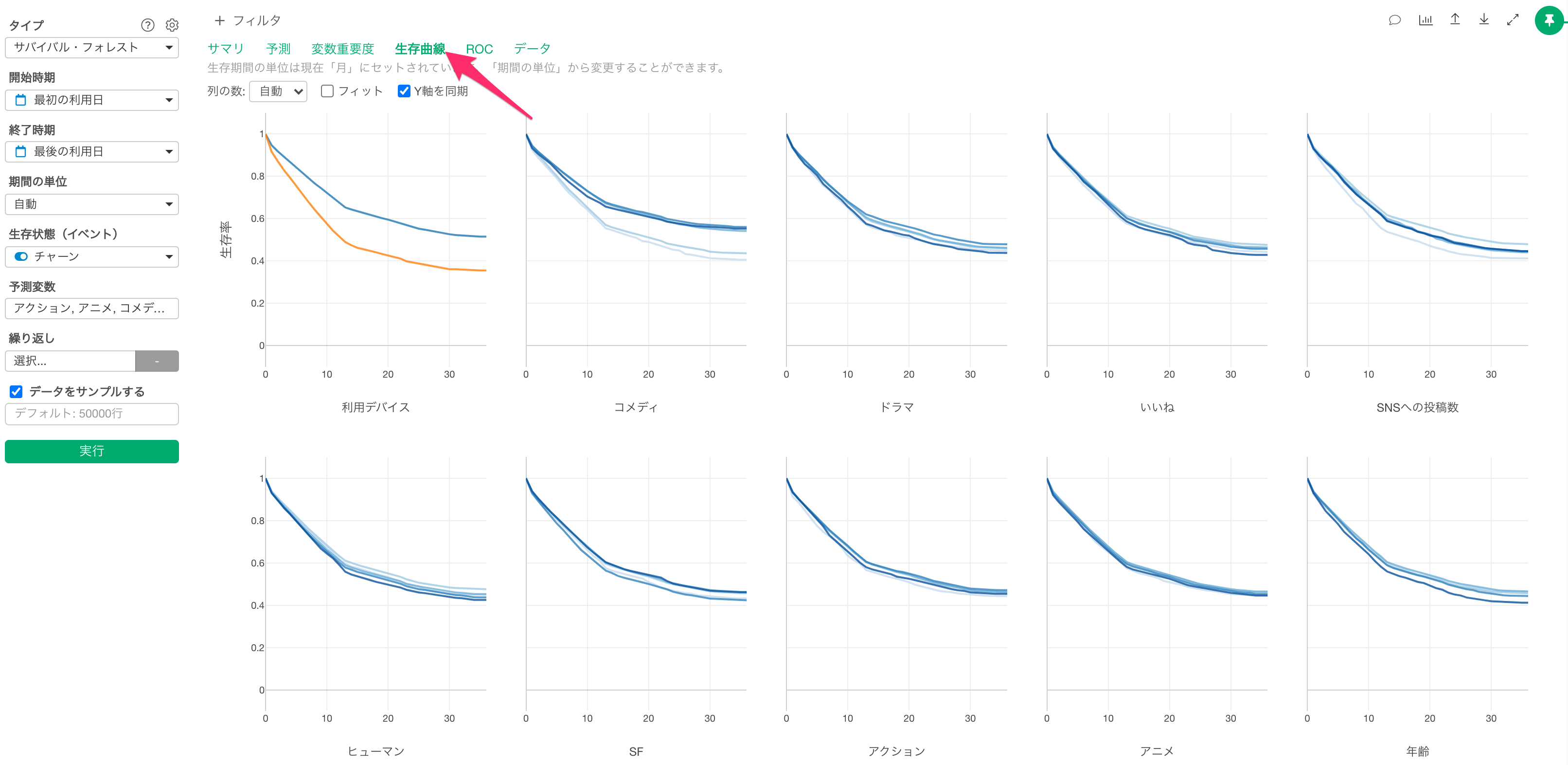
生存曲線
生存曲線タブでは、予測される生存曲線が予測変数によってどう変化するのかがわかります。
サマリ
サマリタブでは、この予測モデルの評価を確認できます。

時点AUCは、ある時点におけるチャーンのTRUE/FALSEをこのモデルでどれだけ上手く分けられているかの指標で、0.5から1の間の値を取ります。1に近ければ近いほど、モデルがデータのTRUE/FALSEを上手く分けられていることを示します。

今回は、AUCが0.82と1に近いため、このモデルを使うとTRUEとFALSEをある程度は分けられていそうです。
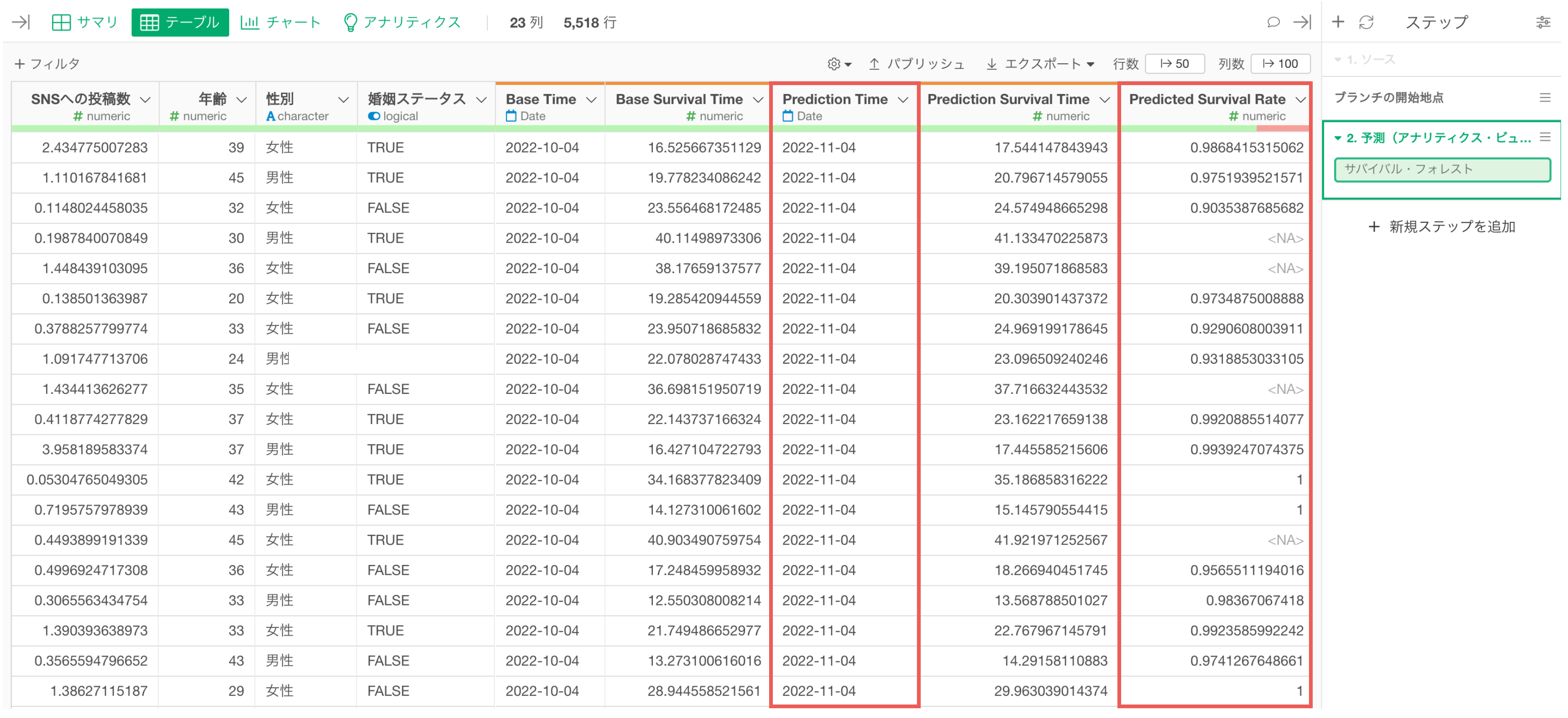
Nヶ月後の生存率の予測
作成したサバイバル・フォレストのモデルを使うと、今日を起点にしたときに1カ月後の各観察対象(例: 顧客)の生存確率を予測できます。
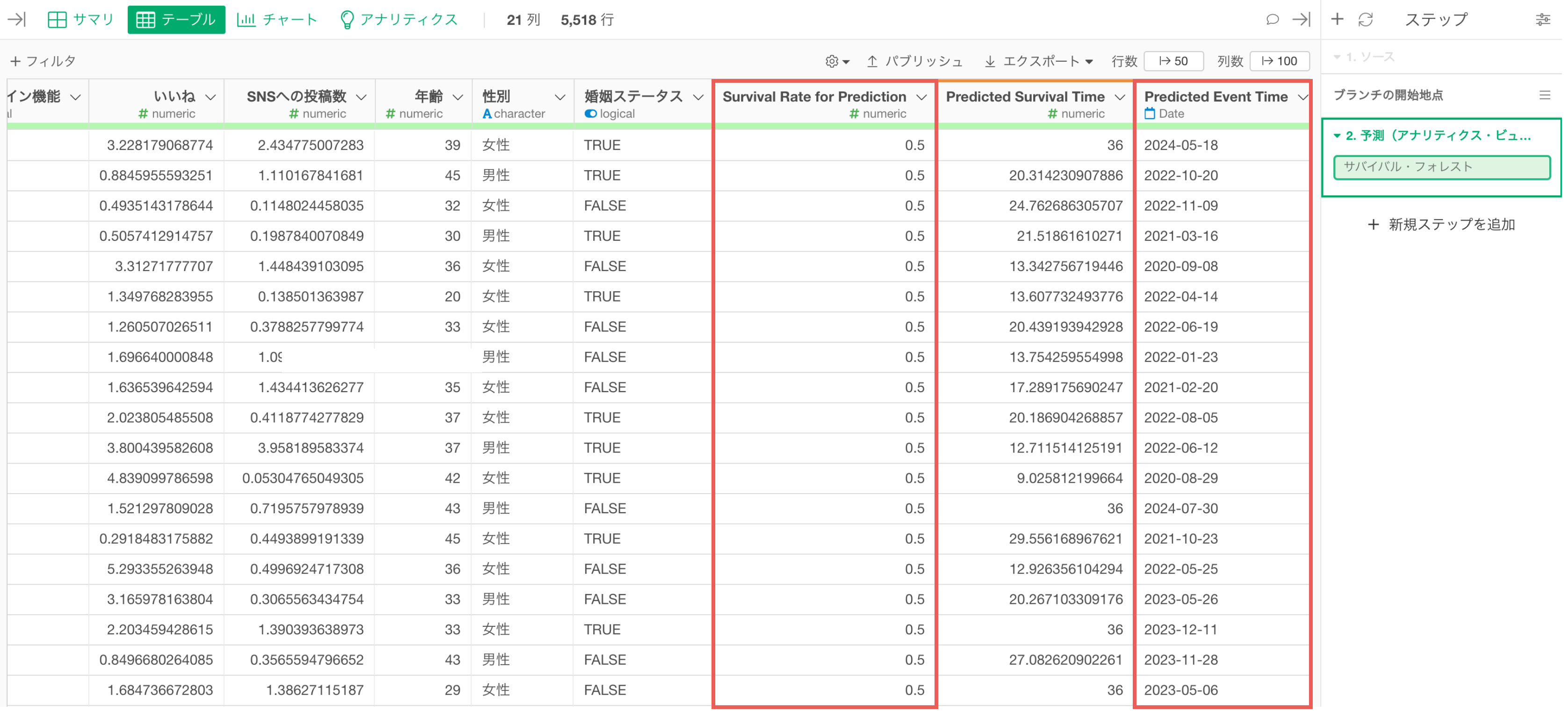
特定の生存率になる日付の予測
また、各観察対象(例: 顧客)の生存確率が50%になる「日付」も予測できます。
参考資料
サバイバル・フォレストに関する参考資料は下記をご覧ください。
サバイバル・フォレストに関するよくある質問
Q: 予測タブで表示されている実測値はどのように求められているのですか?
予測タブの実測値はそれぞれの予測変数のデータタイプによって表示が異なります。 詳しくはこちらのノートをご覧ください。
Q: 予測タブで表示されている予測値はどのように求められているのですか?
予測値のチャートはPartial Dependence Plot(PDP)と呼ばれるもので、注目している変数の値を変化させたときに、予測結果がどう変わるかを可視化したチャートとなります。詳しくはこちらのノートをご覧ください。
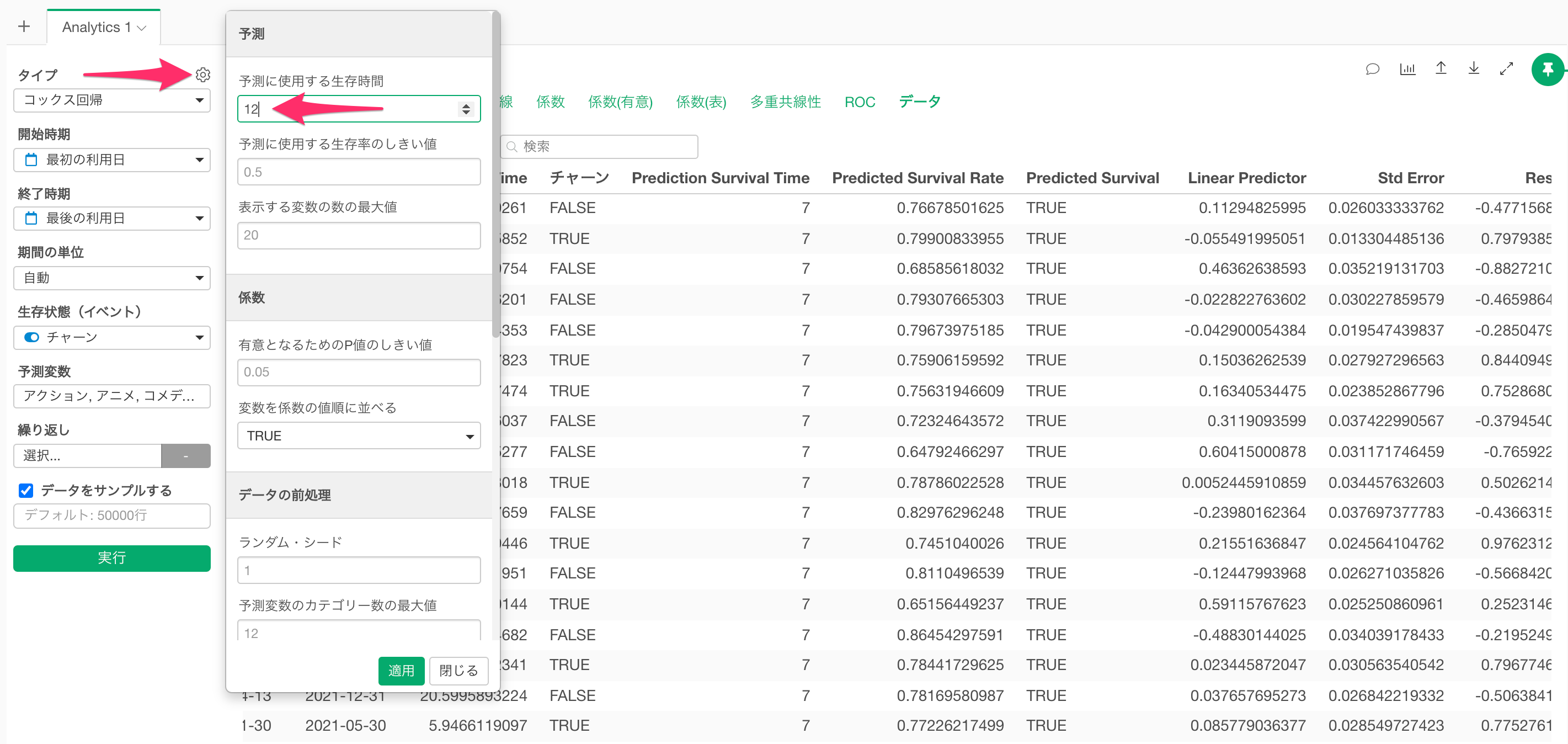
Q: 予測に使用する生存期間はどのように変更できますか?
「予測に使用する生存期間」のデフォルト値は観察対象の生存期間の平均値ですが、プロパティの「予測に使用する生存期間」から変更できます。
Q: 予測使用する生存率のしきい値はどのように変更できますか?
プロパティの「予測に使用する生存率のしきい値」から変更できます。しきい値のデフォルトは0.5になっており、0.5以上の場合はTRUEと予測し、0.5よりも小さい場合はFALSEと予測します。
Q: 時点AUCと一致係数はどちらを優先してみればいいでしょうか?
決まりのようなものはないのですが、予測において、何を重視したいかによってどの指標を重視するかを決めていただければよいかと思います。
例えば、一年後のように、特定の時点までにイベントが発生するのかどうかを予測することが重要であれば、1年後の「時点AUC」を見ていただくのがよいと思います。
どの時点ということに関係なく、イベントが発生しやすそうなほうから観察対象(例:顧客、従業員、など)にランク付けすることが重要なのであれば、「一致係数」をみていただくのがよいと思います。