組織内でのデータ共有基盤としてのデータ・カタログ
近年、多くの企業や組織がデータの蓄積や整備を始め、その量や種類は増加し続けています。そして増え続けるデータを活用するために多くの企業がデータベースにデータを保存しています。
そのため、データを使ってビジネスや業務を改善しようとする場合、データベースの利用は多くの組織や企業にとって避けられないトピックとなっています。
しかし、データベースからデータを取得するためにはSQLを使用する必要があり、これがデータ活用における様々な課題を生み出しています。
データベースのデータ(SQL)を扱うときの3つの問題
1. データの取得
SQLは自然言語ではないため、データを取得するにはSQLのコーディングスキルが必要です。そのため、SQLを書くスキルを持たない人にとっては、データベースにデータが存在していても、そのデータを取得することが困難になります。これが最初の大きな障壁となります。
2. データベースへの負荷
SQLに不慣れな人がデータベースに対して直接クエリを投げると、想定外のクエリが実行されることがあります。これによりデータベースに過度の負荷がかかり、データベースのパフォーマンスに悪影響を及ぼす可能性があります。
また、データベースがクラウド上にホストされている場合、コストの増加にもつながりかねません。
このようなリスクがあるため、誰にでもデータベースへのアクセス権限を与えることは難しくなっています。
3. データの整形
データを取得できたとしても、多くの場合、そのままでは使えないことが多く、分析や可視化しやすい形に整形する必要があります。そのためには、単純にデータを取得するだけでなく、欲しい形にデータを加工するためのSQLを書くためのスキルも求められます。
一方、このような作業をExcelで行おうとしても、大量のデータを扱うことが難しく、セルごとに処理をすることになるため、SQLほど効率的には作業ができません。
このようなハードルがあることで、データを作れる人(SQLを扱える人)が限られてしまっているのが多くの企業と現状といえます。
組織の内でのデータ活用基盤としてのデータ・カタログ
上記に挙げたような理由から、多くの企業ではなかなかデータの活用が広がりません。しかし、今日のようなデータを元により精度の高い根拠ある意思決定を高速で行っていくことが求められるビジネス環境では、これは死活的な問題です。
そこで企業にとって多くの人がSQLを書くことなしに、自分たちが欲しいデータにすぐにアクセスし、データから意思決定に役立つ知識を素早く得ることができる環境の構築が早急に求められます。
そこで役立つのがExploratoryのデータ・カタログです。
データ・カタログを使えば、一部の人によってSQLを使って抽出されたマスターデータを、目的に応じて使いやすいように加工したサブセットとなるデータをいくつも、組織の誰もがアクセスすることができる場所に安全に共有することができます。
データ・カタログのユーザーは、共有されたデータにExploratoryデスクトップから直接アクセスすることもできますし、Exploratoryデスクトップをお持ちでない方はウェブ・ブラウザより直接アクセスし、データのダウンロード、またはブラウザ内で直接チャートやレポートの作成を行うこともできます。
また、パラメーターを使って自分の興味の対象のデータを絞り込んだり、スケジュール機能を使ってデータベースより定期的に最新データを取得し、いつもデータ・カタログのデータを自動更新したりすることもできます。
それではここから、データ・カタログの機能や使い方を紹介してみたいと思います。
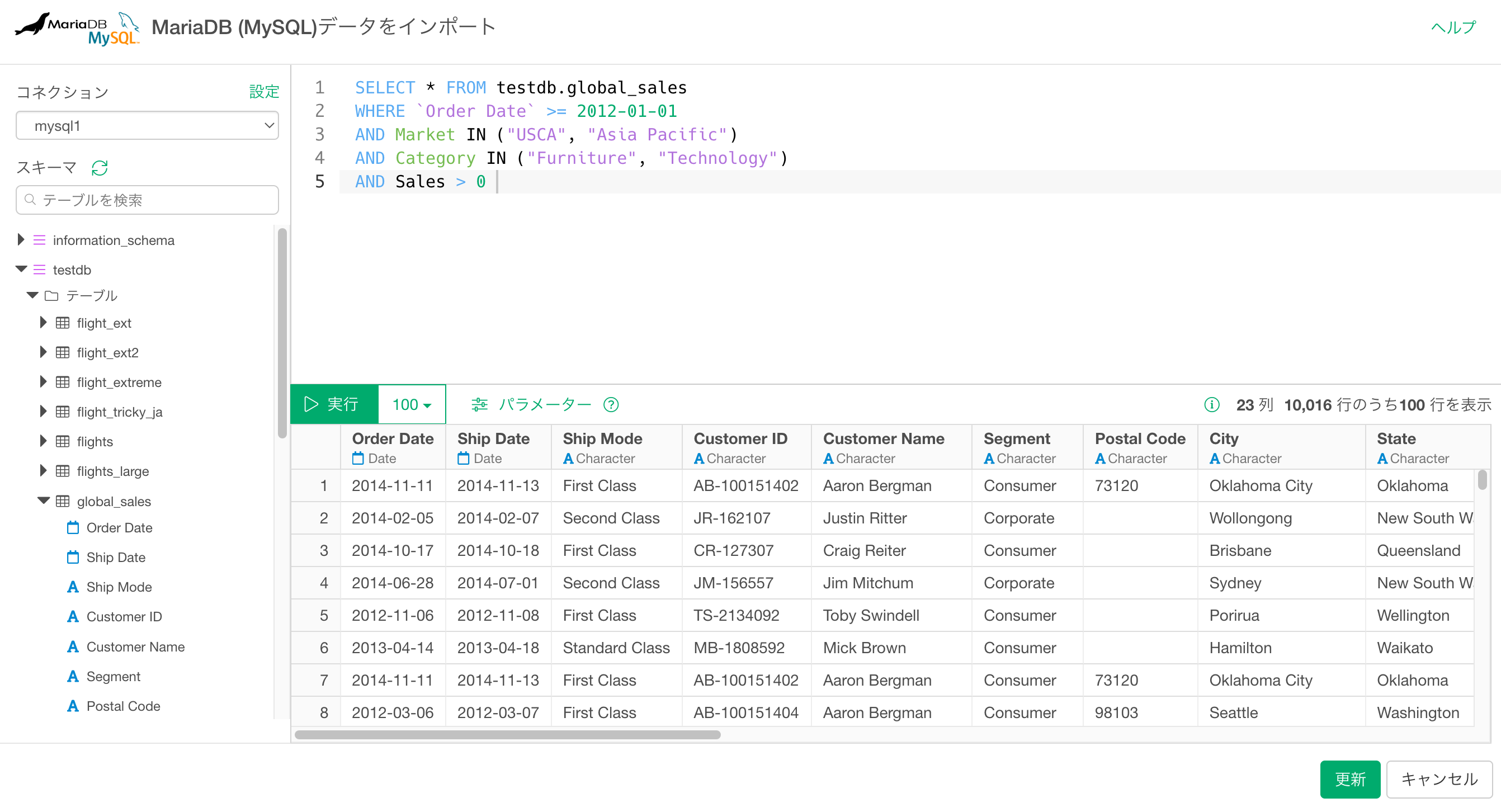
データの取得
データベースのデータをSQLを書いて取得することもできますし、さらにクラウド環境のデータやPCに保存されたデータも取り込み、データ・カタログで共有することができます。
データの加工
データを取得したら、列ヘッダーメニューから適用したい処理を選択して、UIを通して柔軟にデータを加工できます。
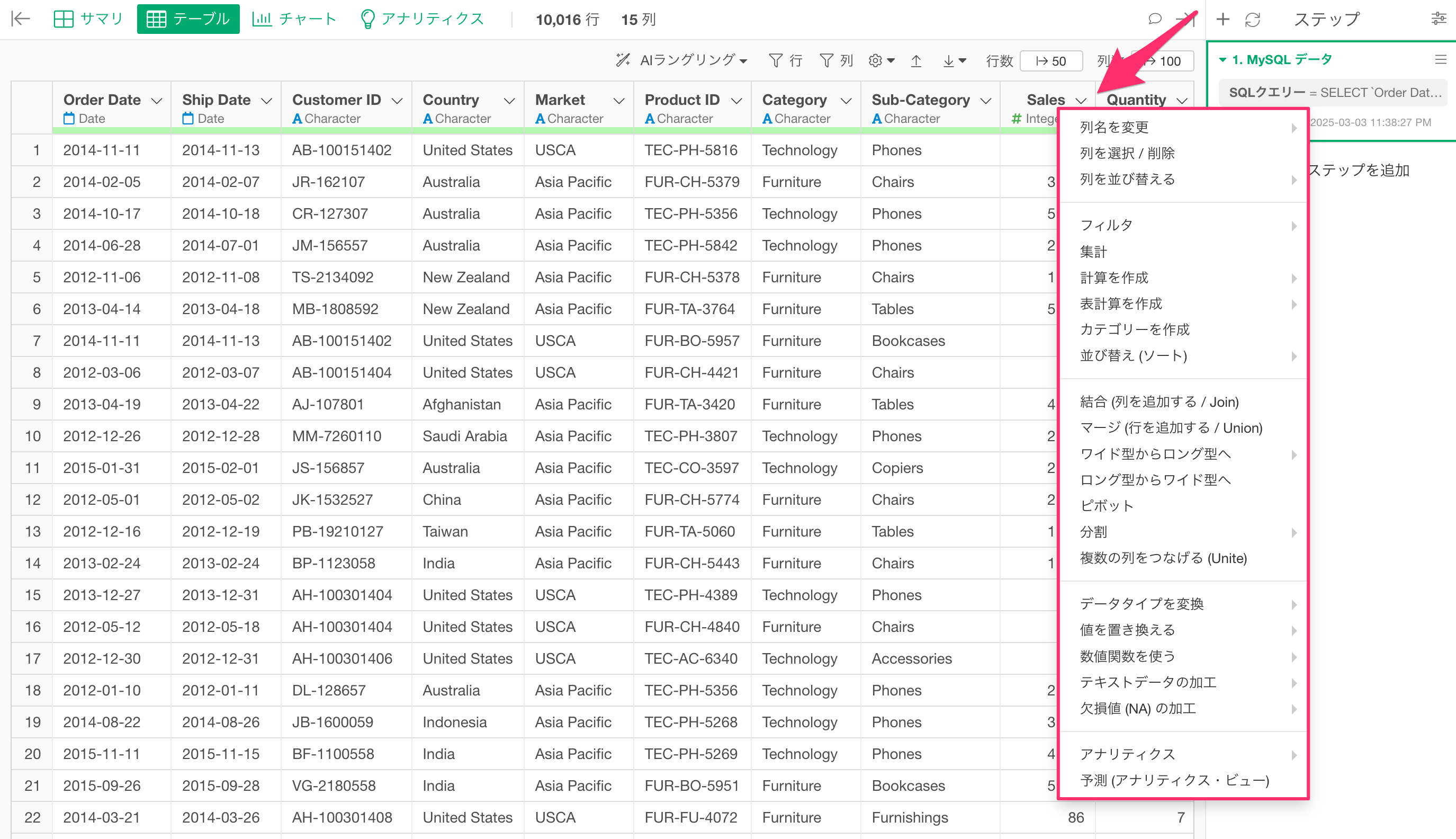
データの加工の処理を追加すると、Exploratory デスクトップの右側にあるデータラングリングのステップに、データの加工の処理が、その処理ごとに保存されます。
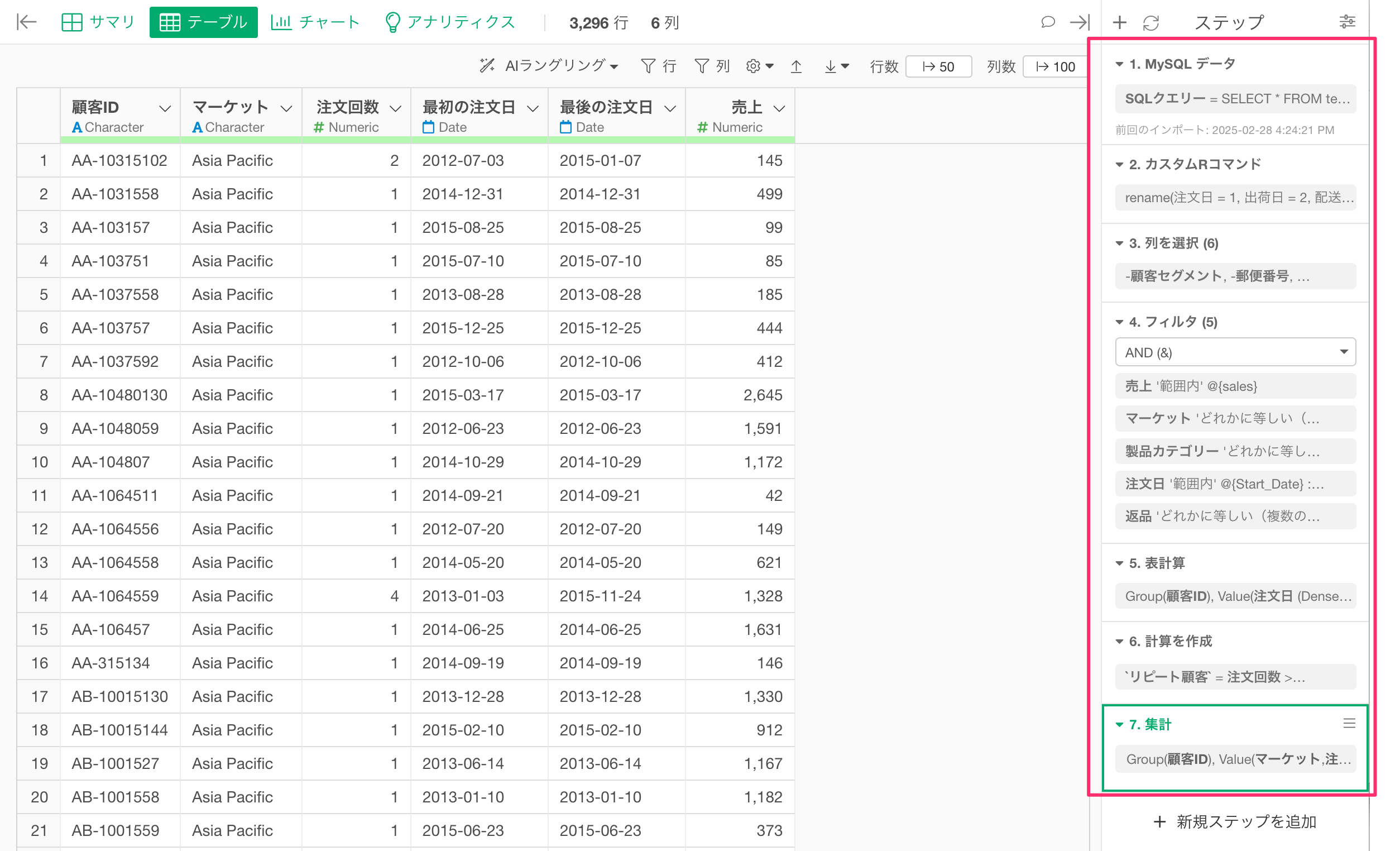
データのパブリッシュ
どの時点のステップのデータも、Exploratoryサーバーにパブリッシュして他のメンバーと共有することができます。
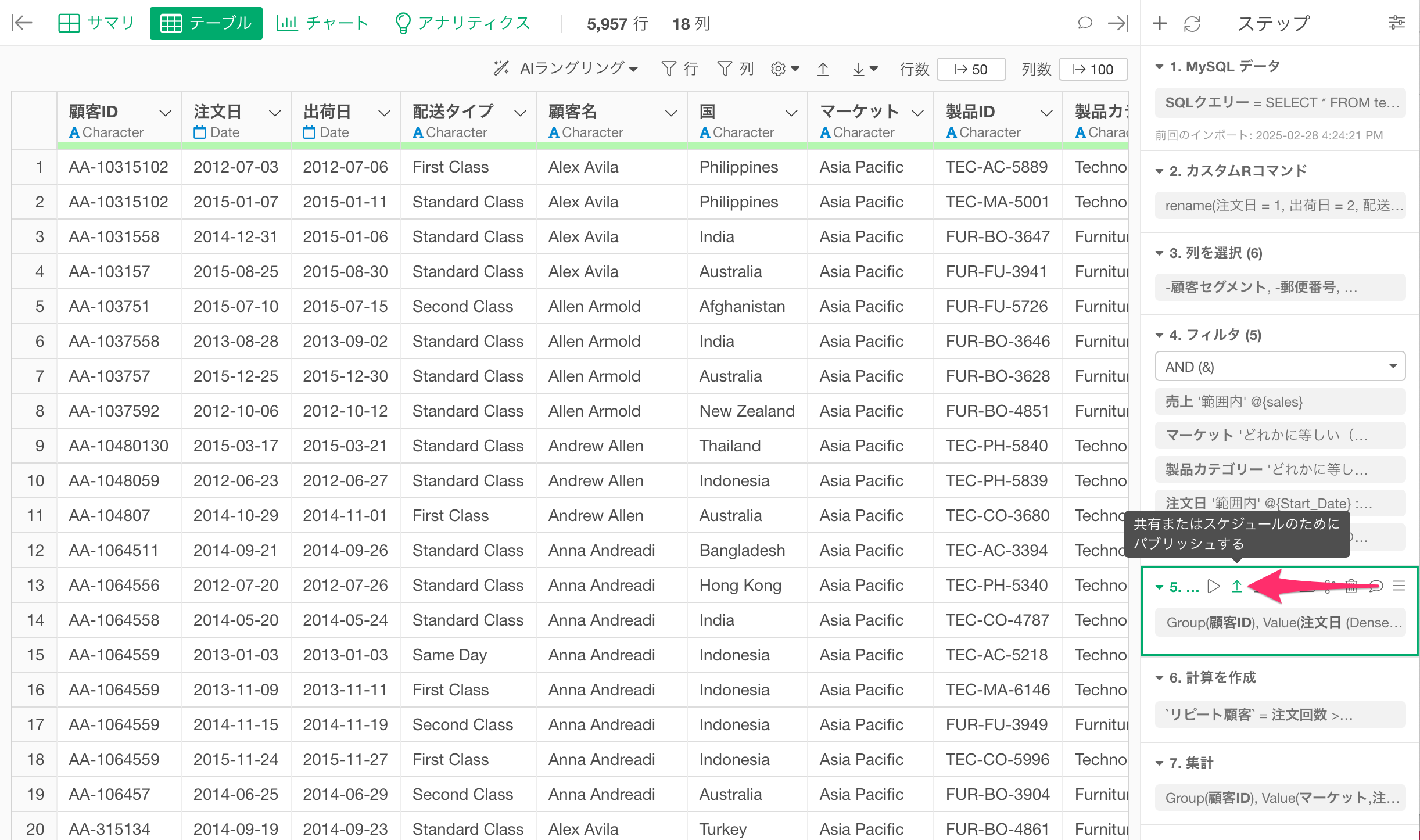
そのため、集計前の整形データだけでなく、集計後の整形データも別のデータとして、同じデータフレームの中でパブリッシュできます。
- 参考: Exploratoryサーバーにプロジェクト、データ / ステップ、チャート、アナリティクス、ノート、ダッシュボードをパブリッシュする方法 - リンク
データの共有
サーバーにパブリッシュしたデータは、サーバーを通して他のメンバーにプライベートな形で共有したり、URLを通して特定の人だけに共有したりすることができます。
 URL共有の場合は、パスワードを設定してセキュリティを確保した状態でデータを共有できます。
URL共有の場合は、パスワードを設定してセキュリティを確保した状態でデータを共有できます。
- 参考: パブリッシュしたコンテンツの共有方法について - リンク
データの閲覧
共有されたデータはウェブブラウザから閲覧できますが、単にデータを見るだけでは内容を理解するのが難しいこともあります。
そこでExploratoryサーバーでは、データを深く、早く、効率的に理解するための4つのビューを提供しています。
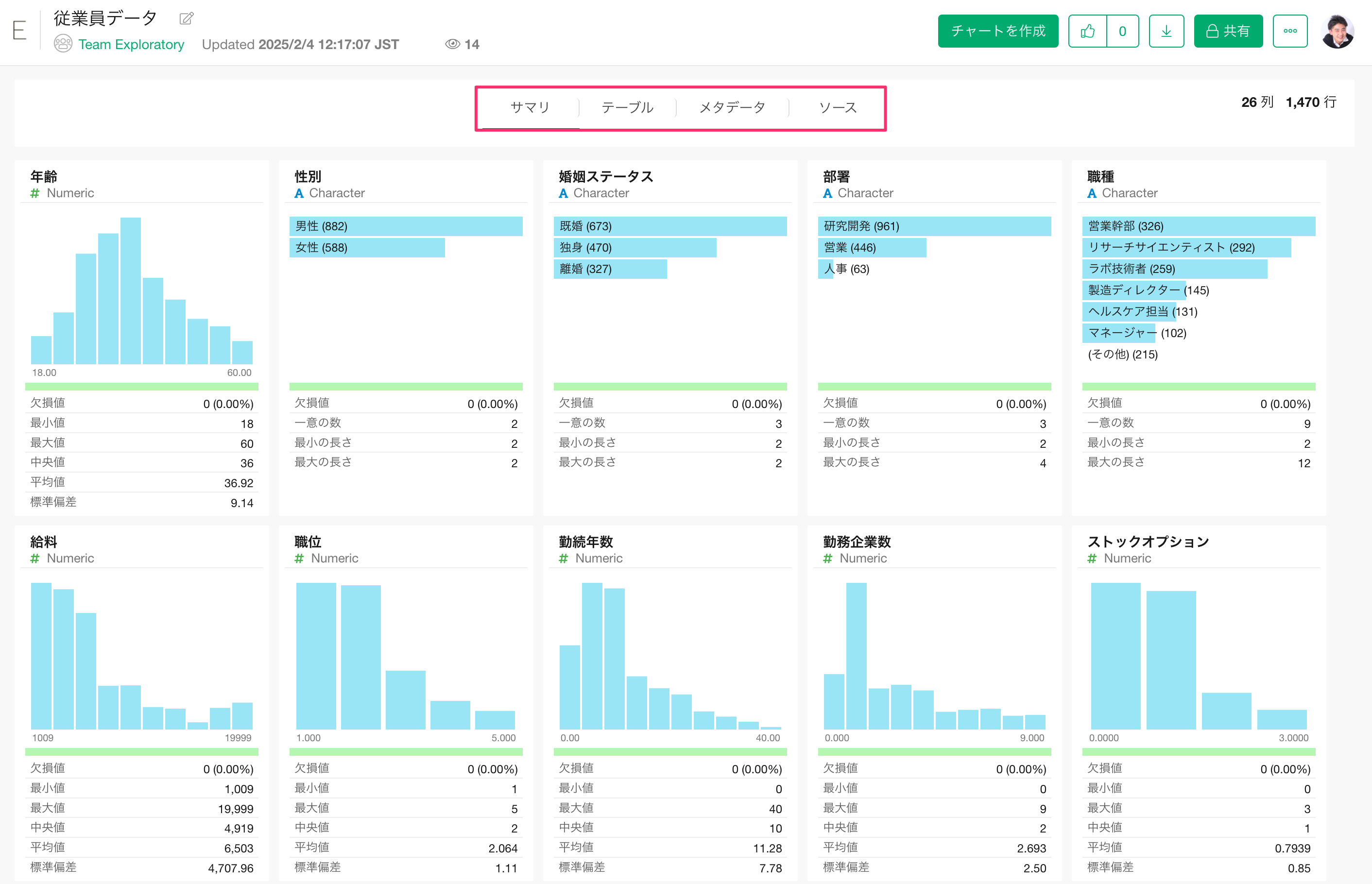
サマリー
サマリービューでは、Exploratory デスクトップと同様にデータのサマリー情報が表示され、データの概要を瞬時かつ直感的に把握できます。
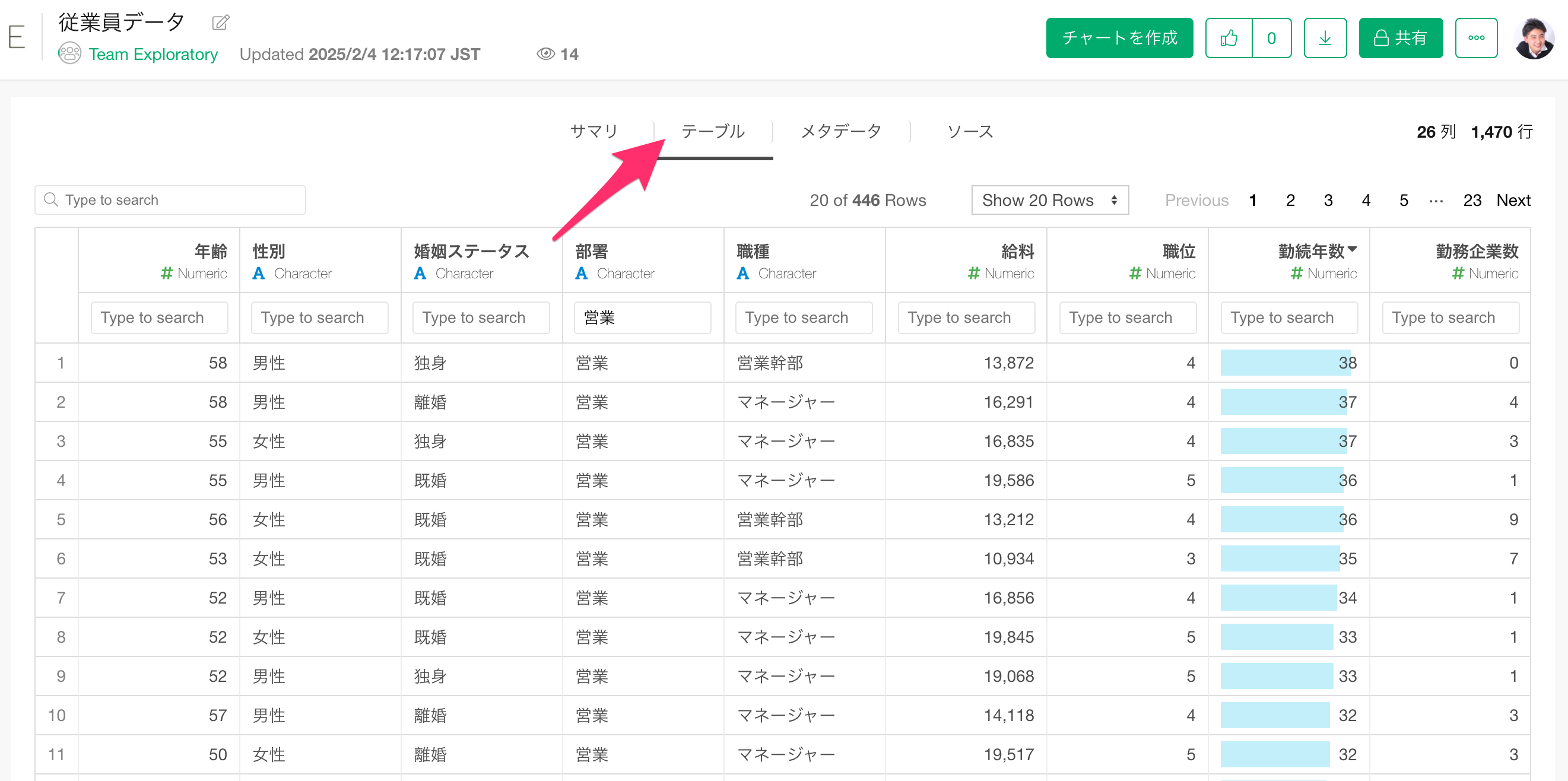
テーブル
テーブルビューでは、データを表形式で見ることができ、さらにデータをフィルターしたりソートしたりすることができます。データの内容確認自体がデータ活用につながる場合は、これだけで作業が完結することもあります。
メタデータ
データの概要や列ごとの詳細情報をメタデータとして記録しておくことで、データを作った人がデータを使う人に効率的にデータの意味を伝えることができます。
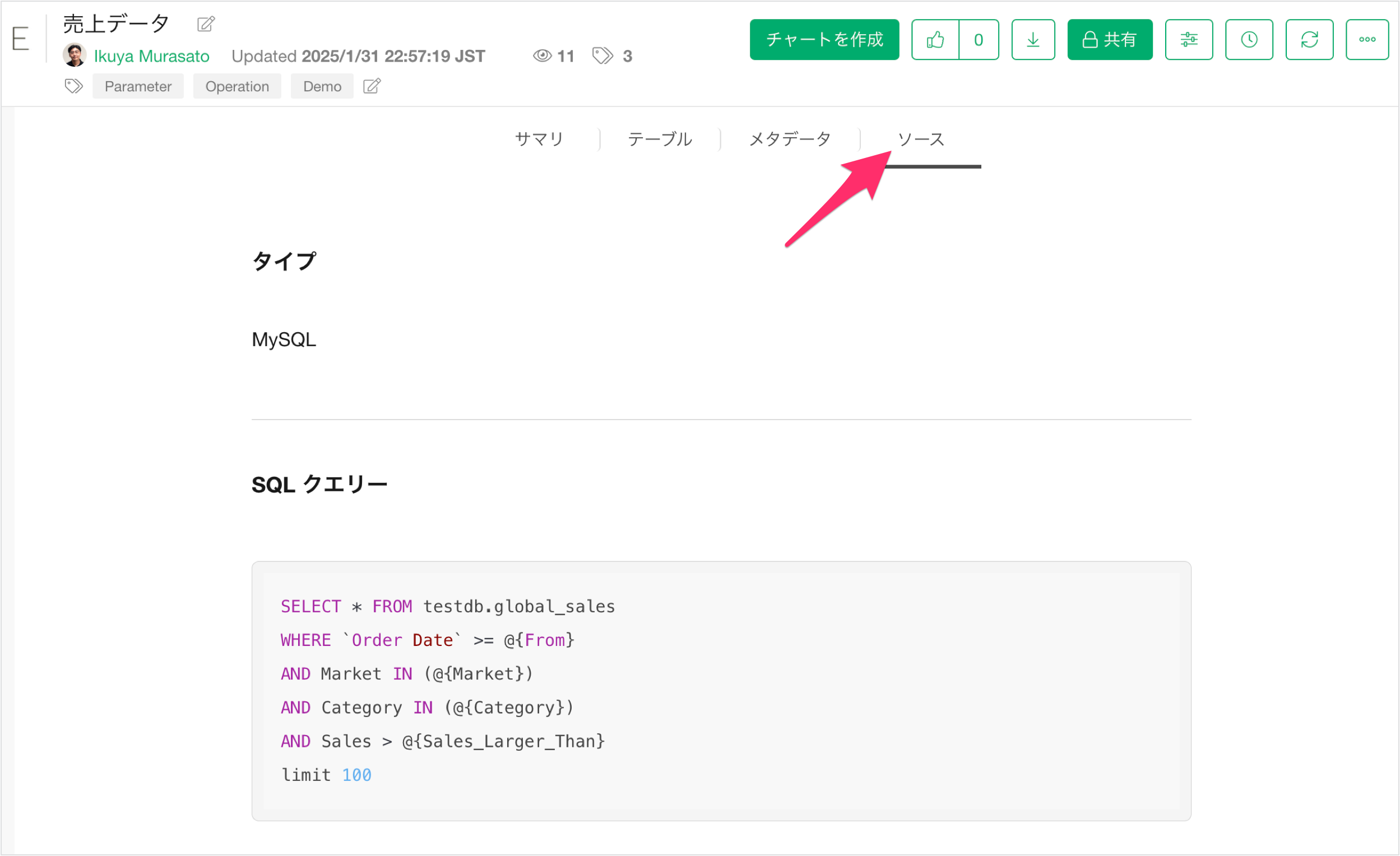
ソース
ソースビューでは、このデータがどのようなデータソースから来ているのか、どのようなクエリを使用しているのかを確認できるため、ユーザーは安心してデータを使うことができます。
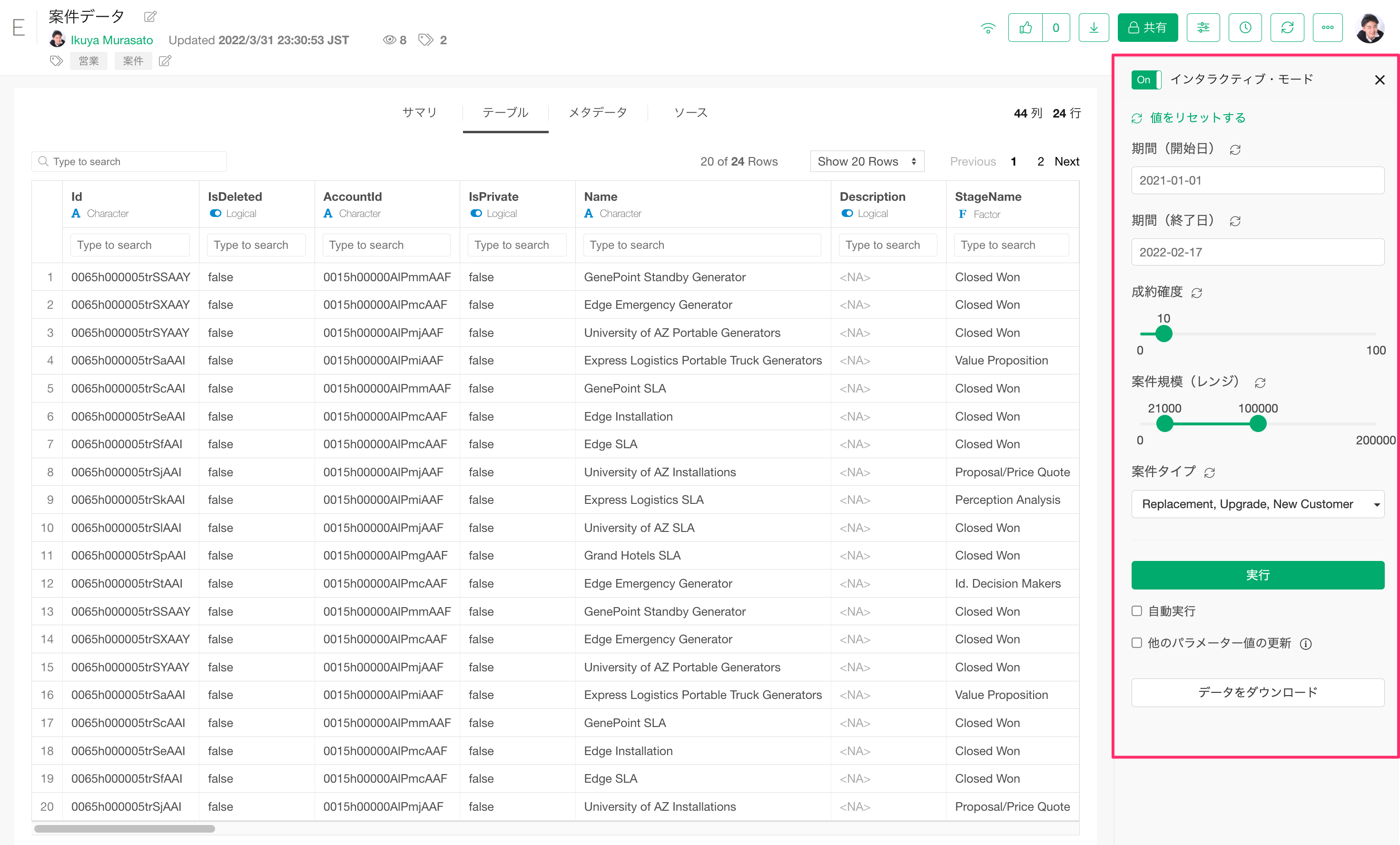
パラメーターを使ったデータの絞り込み
SQLクエリーやデータラングリングのステップにパラメーターを利用することで、データの閲覧者は自分が見たい内容にデータを絞り込めます。
- 参考: Exploratoryのパラメーターの紹介 - リンク
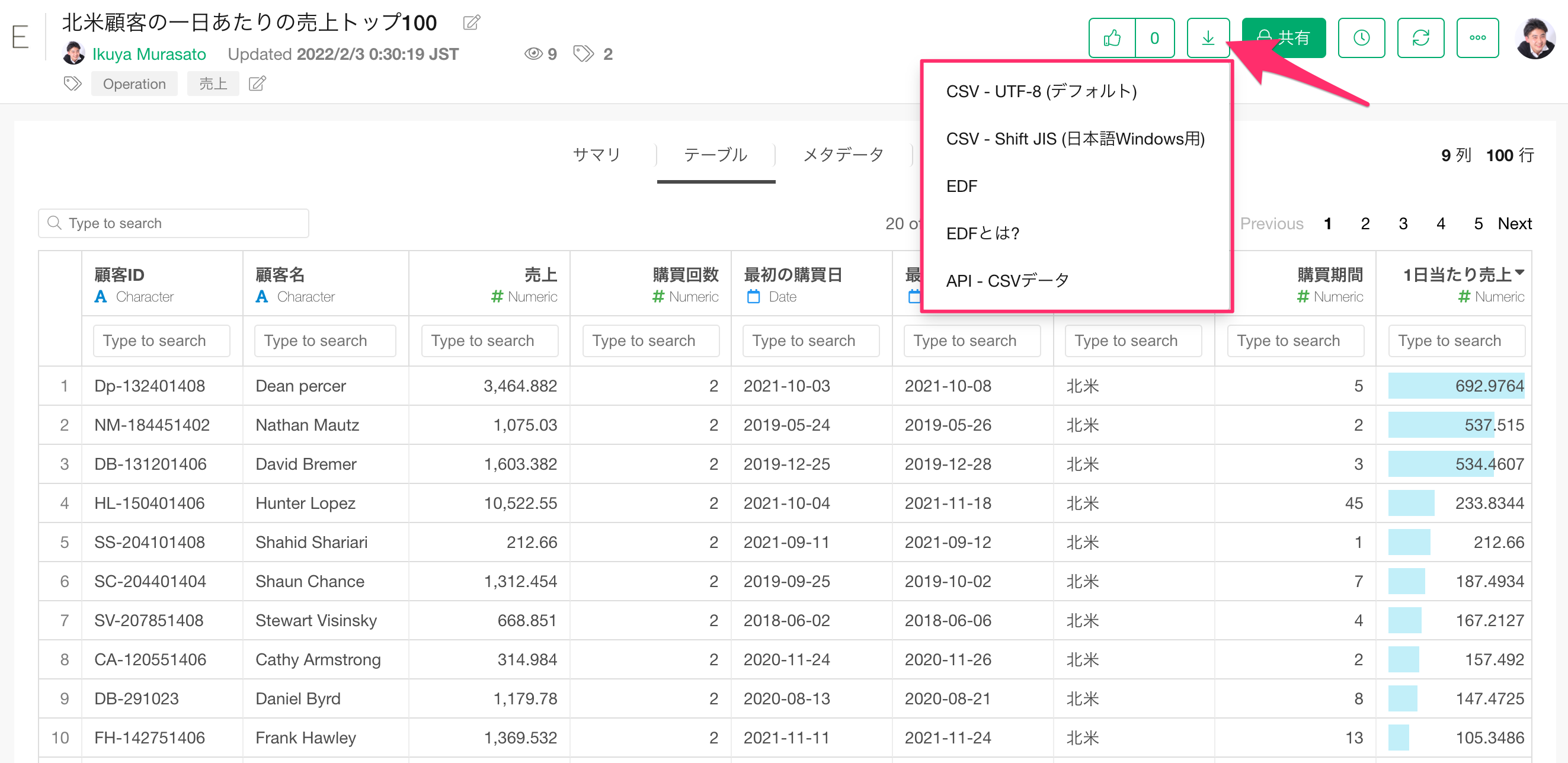
データのダウンロード
サーバーにパブリッシュされたデータの閲覧権限を持っている人は、CSV、REST API、またはEDFフォーマットでデータをダウンロードして、ツールに縛られずにデータを様々な用途で活用できます。
また、Exploratoryデスクトップの利用者であれば、サーバーで共有されたデータを直接取り込むことができます。これにより、サーバー側でデータが更新された際には、「再インポート」ボタンをクリックして簡単にデータの変更を取り込むことができます。
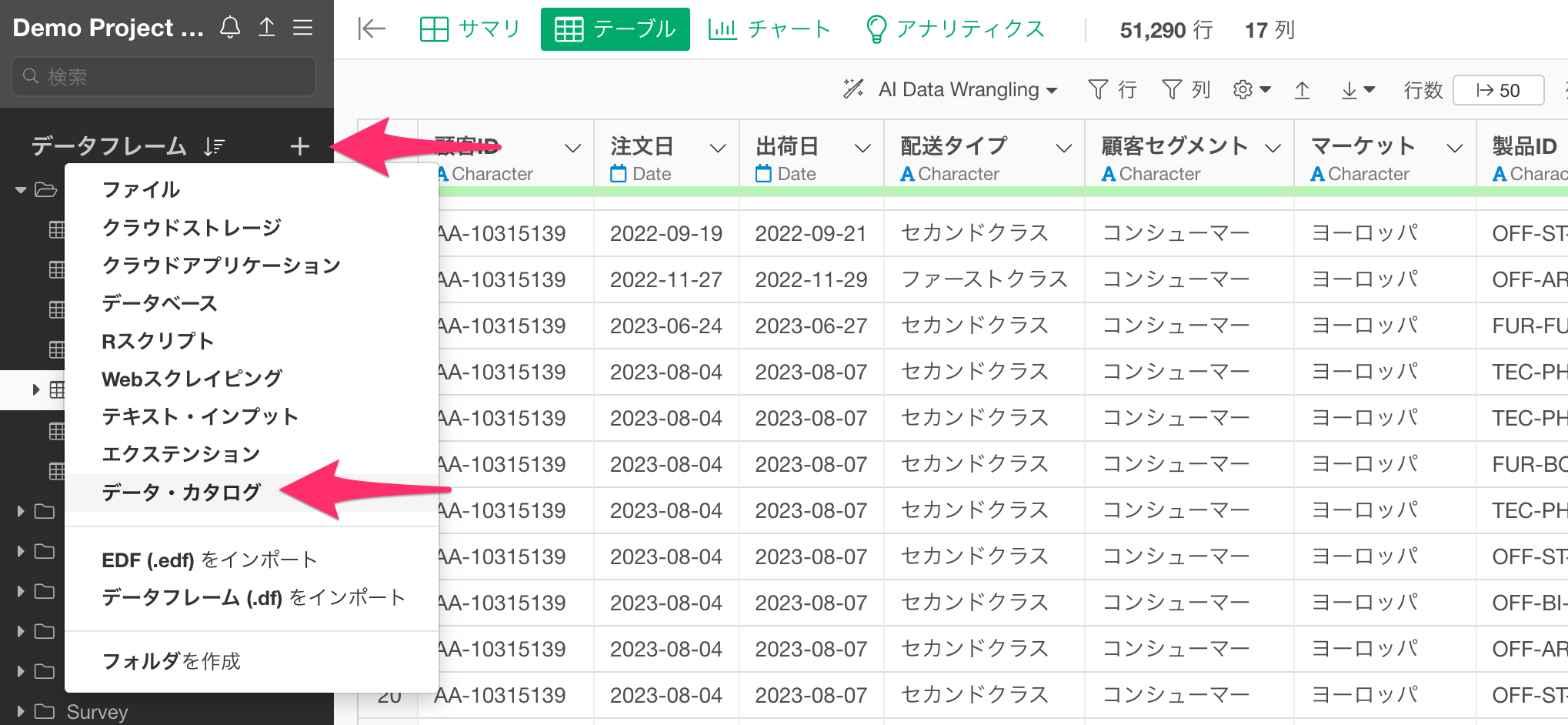
- 参考: データ・カタログを使ってデータをインポートする方法 - リンク
チャートの作成
Exploratoryデスクトップを使ってデータ・カタログのデータに直接アクセスして、データの加工、可視化、分析を行うこともできますが、直接ウェブブラウザー内でチャートを作成することもできます。
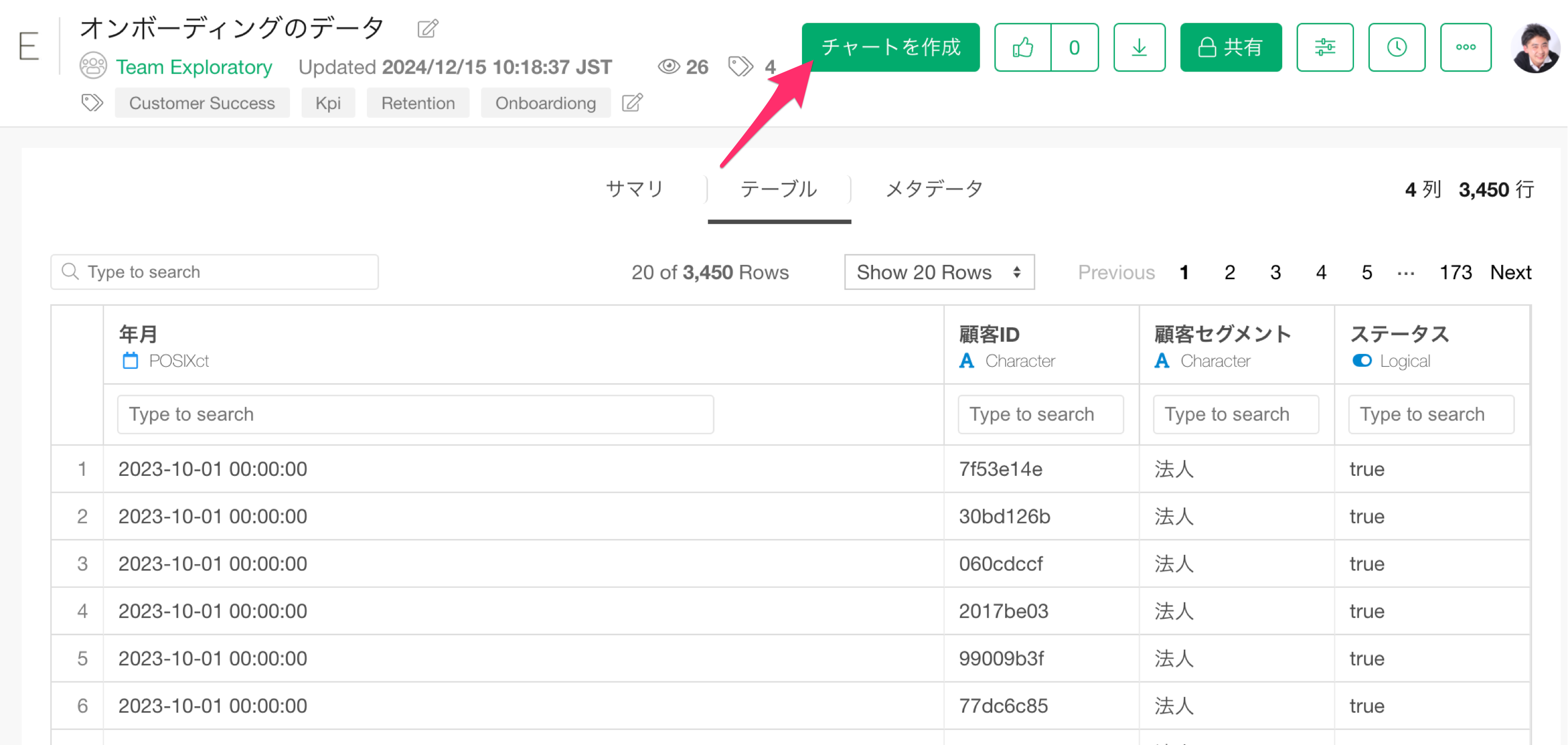
共有されたデータのページ上に表示されるチャートの作成ボタンをクリックすると、チャートを作成・保存するためのダイアログが表示されます。

多種多様なチャートタイプから利用したいチャートのタイプを選択できるだけでなく、フィルターも利用できるため、自分が見たい切り口でデータをフィルタして、ブラウザを通して分析ができます。
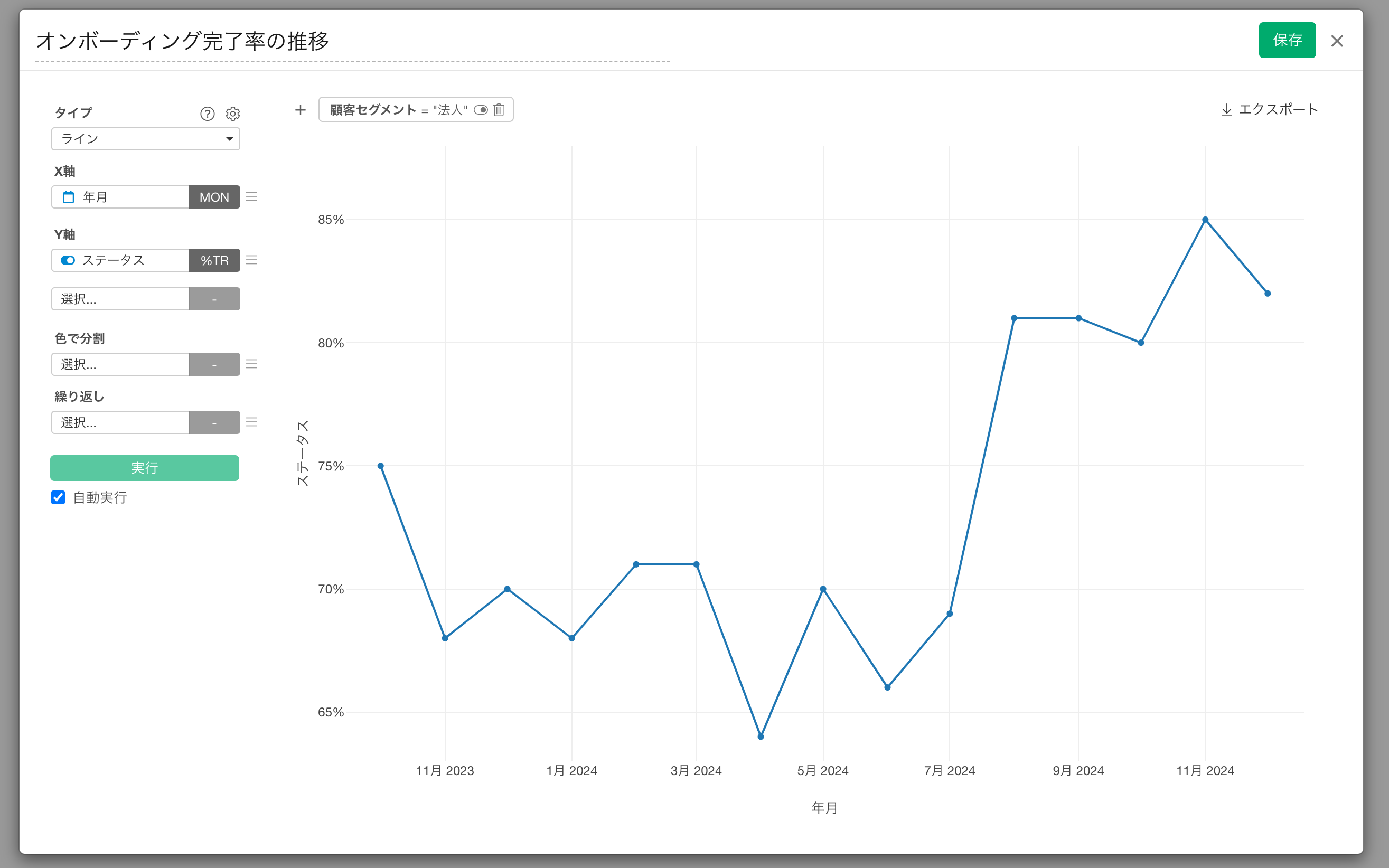
なお、作成したチャートはサーバーに保存され、いつでもブラウザを通して確認することができます。
また、チャートの再編集ボタンをクリックすれば、後からチャートのタイプ、フィルタ、可視化に利用する列を変更できます。
- 参考: Webブラウザ上でチャートを新規作成する機能の紹介 - リンク
レポート(ノート)の作成
Amazonをはじめとするデータを活用している先進企業では、単一のチャートだけでなく、複数のチャートを組み合わせたレポートを作成し、データから得られる示唆や、それをもとにどのようにビジネスを改善できるかといったストーリーを構築します。
- 参考: パワポのスライドと箇条書きが人間を駄目にする - リンク
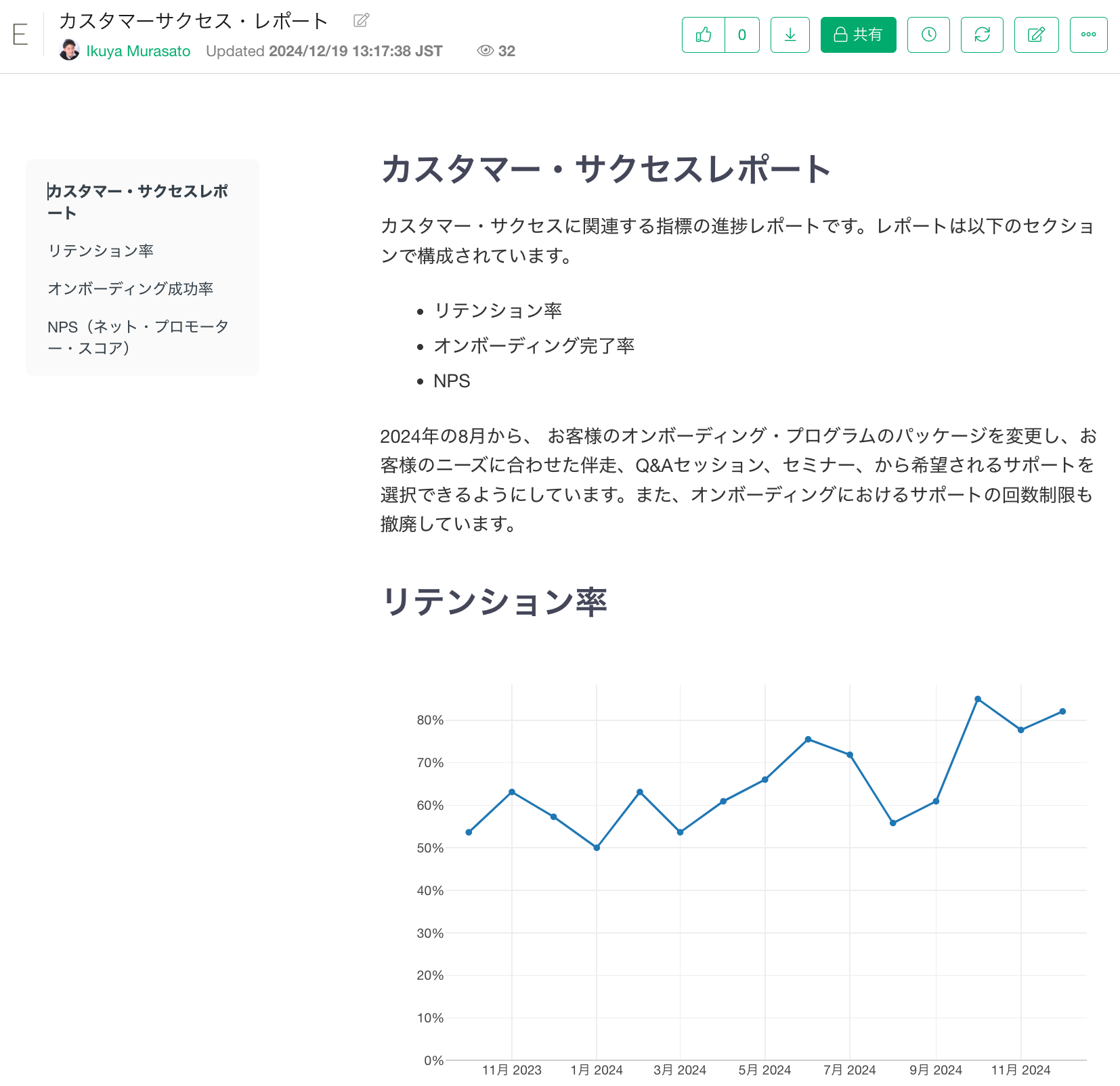
Exploratoryでは、ブラウザからノートの作成ボタンをクリックしてレポートを作成することができます。
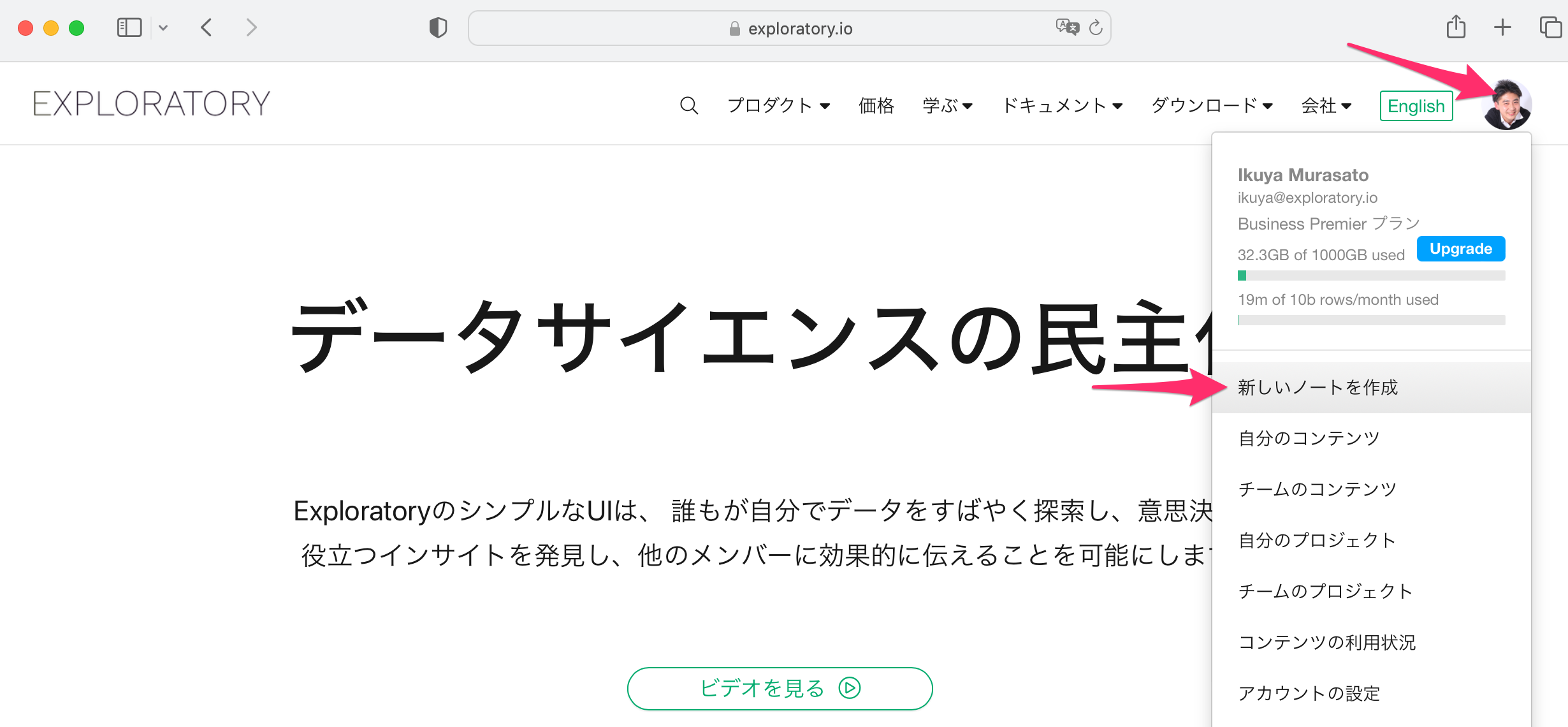
ノートエディターが立ち上がったら、文章を記述し、自分にアクセス権があるチャートを挿入できます。
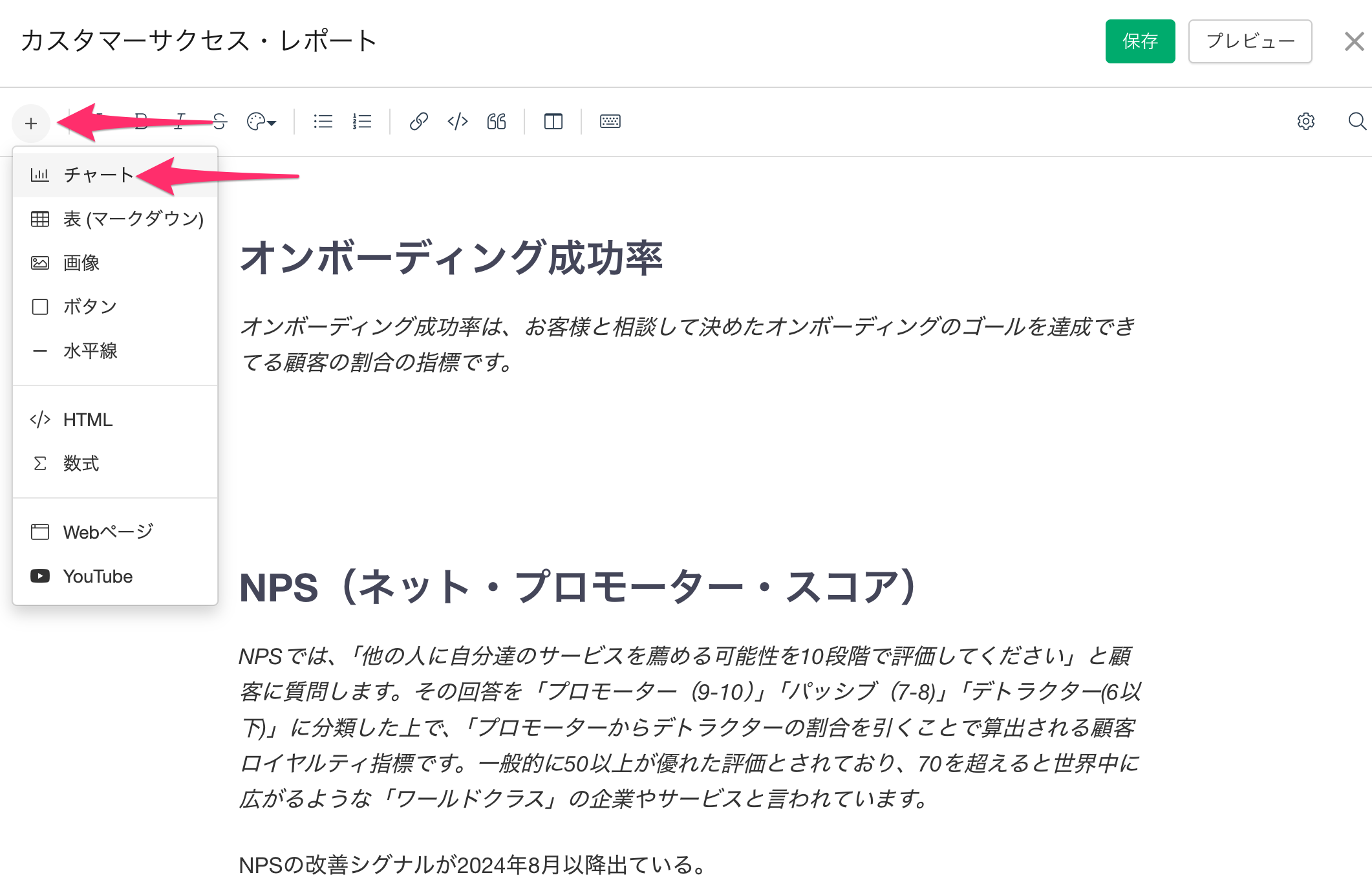
このとき、サーバー上に保存されていて、アクセス権のある全てのチャートをノートに挿入できます。
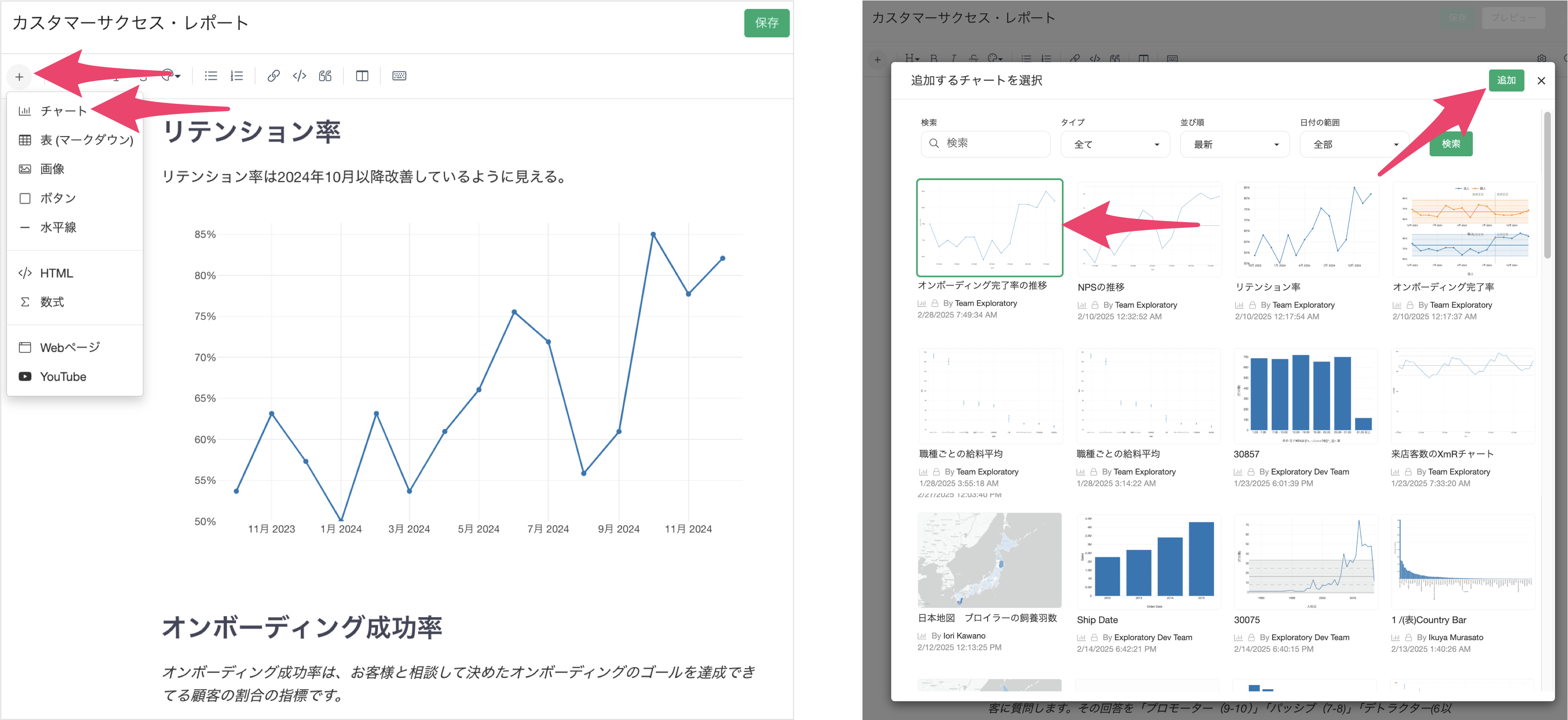
ノートでは、見出しや目次、コンテンツへのリンクやアンカーリンクをサポートしているだけでなく、テキストのフォーマット、箇条書きなどを利用した表現も可能で、表・画像・ボタン・YouTube・TwitterといったコンテンツもUIを通して挿入でき、幅広い表現が柔軟に行えます。
これらの機能を駆使することで、データから得られる示唆や、それをもとにどのようにビジネスを改善できるかのストーリーを簡単に構築できます。
- 参考: Web Authoring: Webブラウザ上のノートの編集・新規作成機能の紹介 - リンク
データ・チャート・レポートの自動更新と編集
サーバー上にパブリッシュされたデータ、およびそこから作成されたチャートやレポートは、データソースがExploratoryサーバーからのアクセスが可能であれば、データの更新を自動化できます。
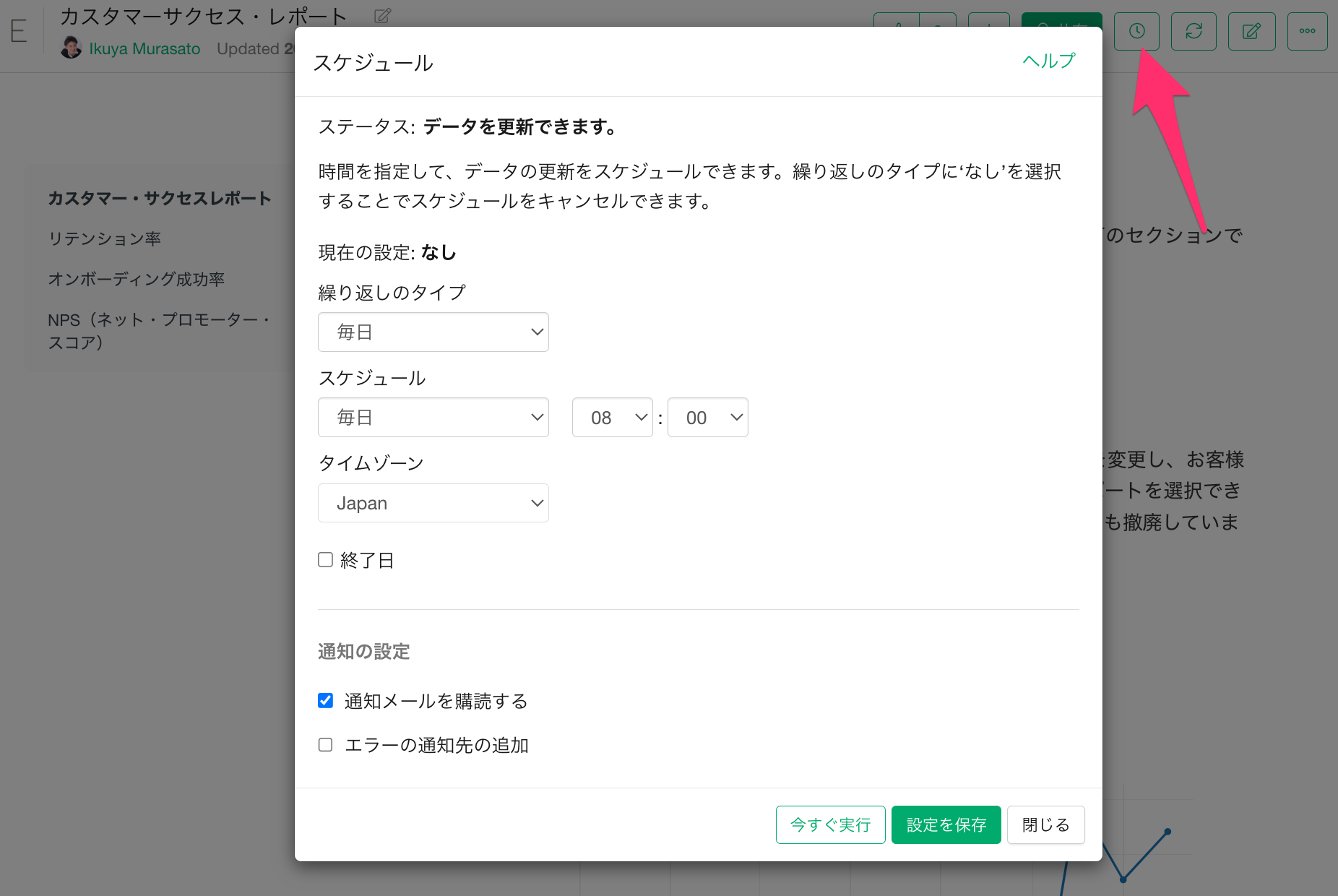
- 参考: サーバーにパブリッシュしたコンテンツのスケジュールを設定する方法 - リンク
これにより、作成したレポートを一度きりのレポートとして終わらせるのではなく、定期的なレポートとして運用できます。
また、データが更新されると、チャートから得られる解釈が変わるだけでなく、時間の経過とともに見たいチャートが徐々に変わるといったことも良くあることの1つです。
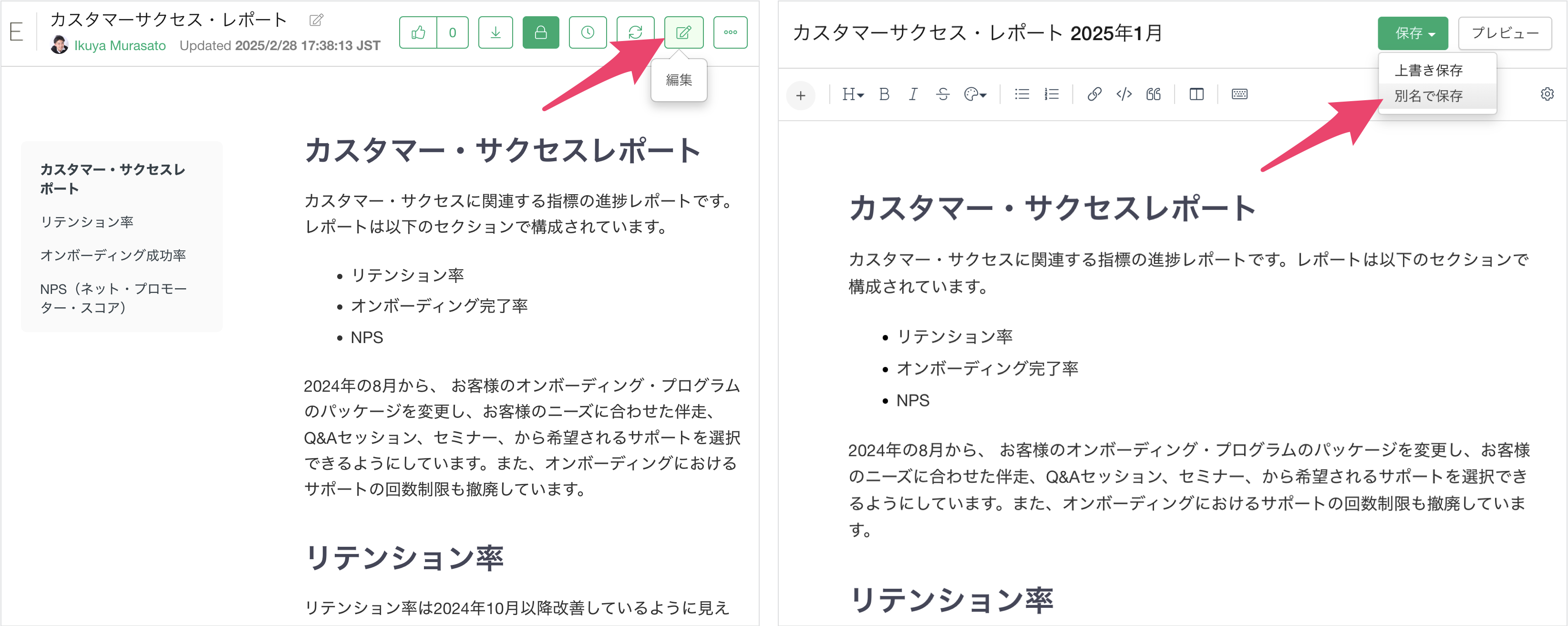
そこで、サーバー上で作成したレポートはブラウザを通して再編集できるだけでなく、別のレポートとして保存できるようになっています。
共有されたデータやコンテンツの探し方
共有されたデータやコンテンツを探すときは、Exploratoryの「学ぶ」のメニューから、「コンテンツを探す」を選択します。

コンテンツの検索ページが表示されたら、検索ウィンドウの下にあるフィルタメニューから、詳細を指定して、共有されたデータやコンテンツに効率的にアクセスできます。

なお、コンテンツの検索では、「意味合い」と「キーワード」検索をサポートしています。
「意味合い」検索を利用すると、検索語に関連する情報を含むコンテンツが表示されるため、効率的にコンテンツを探せます。
