ランダムフォレストの使い方
ランダムフォレストの使い方や結果の解釈の仕方、よくある質問をご紹介します。
ランダムフォレストは複数のモデルに学習させ、それぞれの予測結果を一つの予測にまとめるアンサンブル学習の代表的なアルゴリズムの一つです。ランダムにサンプリングした複数の決定木を作成し、その結果の平均値(または多数決)をとることで、一つの決定木よりも予測精度が高いのが特徴です。
統計学習のモデルの線形回帰では目的変数が数値型、ロジスティック回帰ではロジカル型しか扱えませんが、機械学習のモデルであるランダムフォレスト(決定木、XGBoost)では目的変数には数値型、ロジカル型のどちらも扱うことができます。
ランダムフォレストを使うことで下記の質問に答えていくことができます。
- 目的変数が数値型の場合:このデータ(予測変数)を使うことで目的変数(例:売上)のばらつきの何%を説明できるか。
- 目的変数がロジカル型の場合:このデータ(予測変数)を使うことで目的変数(例:コンバージョン)のTRUE, FALSEをどれだけ上手く分けられているか。
- どの変数が目的変数を予測する上で重要なのか。
- 変数の値が変わると、目的変数の値はどのように変わるか。
必要なデータ
ランダムフォレストを作成するためには、1行が1観察対象(例:1行が1従業員)となっているデータが必要です。
また、目的変数として使用できるデータタイプは、「数値型」と「ロジカル型」の両方を扱うことができます。予測変数におけるデータタイプには特に縛りはありません。しかし、予測変数同士の相関が強い場合は影響度を取り合ってしまい、変数重要度の順番が低く見積もられることがあります。
数値型を目的としたランダムフォレストのモデルを作成する
従業員の「給料」を予測するランダムフォレストのモデルを作成します。
目的変数に「給料」を選択します。
予測変数をクリックします。
予測変数を選択します。Shiftキーを押しながら列を選ぶことで、一気に列を選択できます。
目的変数と予測変数を割り当てることができたら、「実行」ボタンをクリックします。
ランダムフォレストのモデルが作成されました。
結果の解釈
変数重要度
変数重要度タブでは、どの変数が目的変数との関係がより強いのか、予測する時により重要なのかを調べることができます。
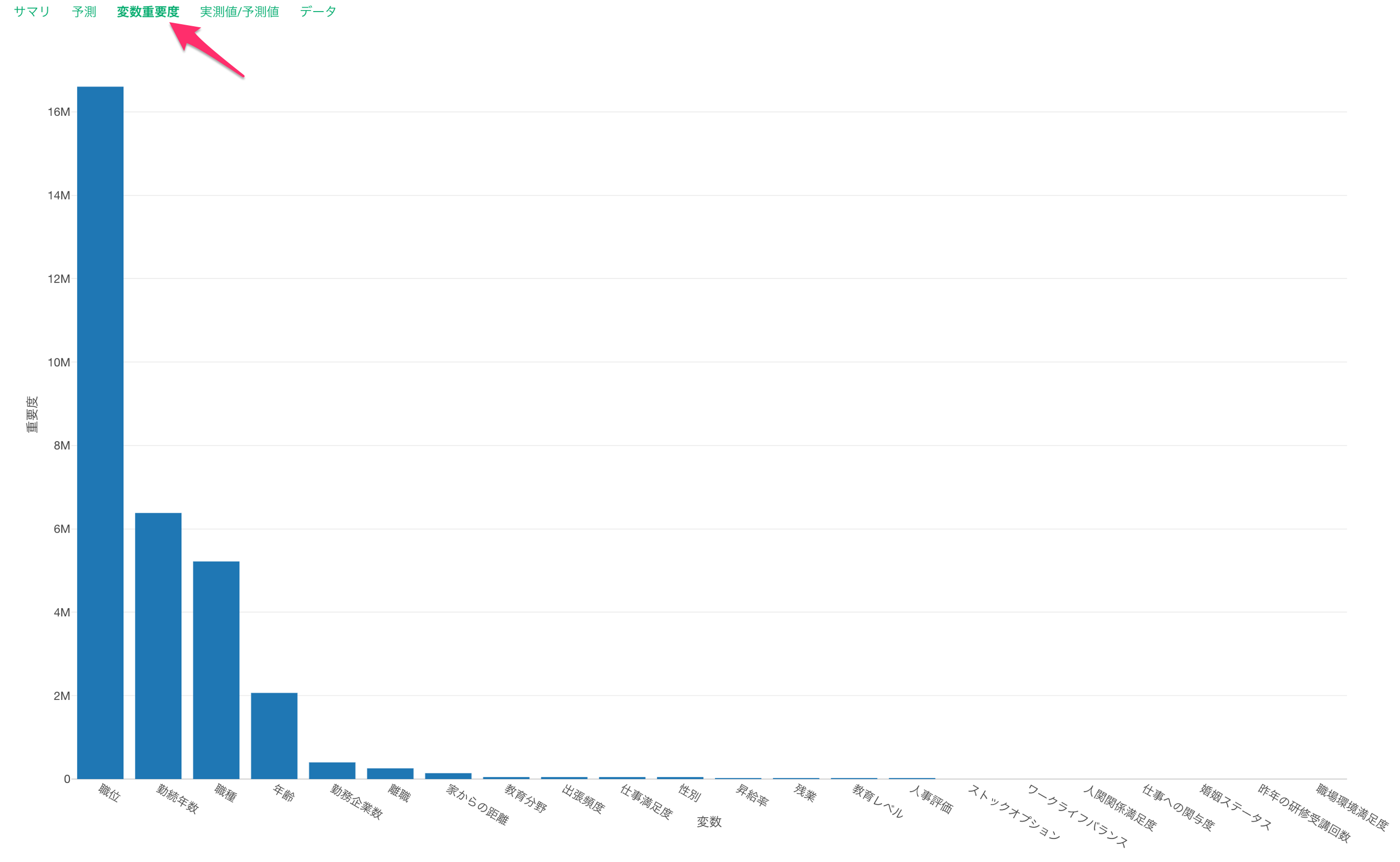
職位と職種、勤続年数、年齢が給料の予測に重要な変数なことがわかります。
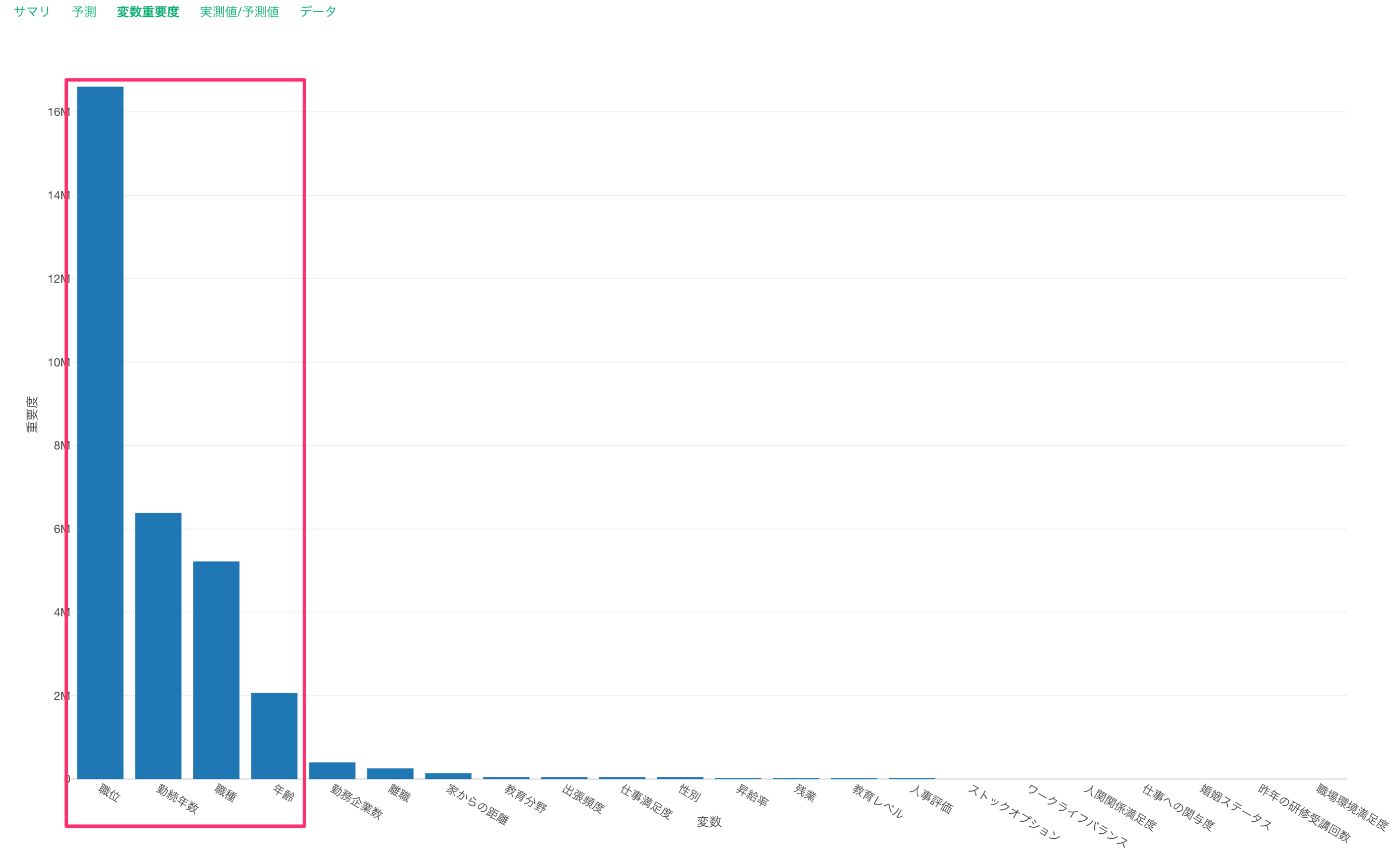
さらに、どの変数が重要でどの変数は意味がないのかを判断をするために変数重要度に統計的手法をかけ合わせた「ボルータ」という手法を使うこともできます。
変数重要度やボルータの詳細については、以下のセミナーをご覧ください。
<div style=“position: relative; overflow: hidden; width: 100%; padding-top: 56.25%; margin-bottom: 1.4em”><iframe style=“position: absolute; top: 0; left: 0; bottom: 0; right: 0; width: 100%; height: 100%;” src=“https://www.youtube.com/embed/bkxmV7DRwWY” title=“YouTube video player” frameborder=“0” allow=“accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share” allowfullscreen></iframe></div>
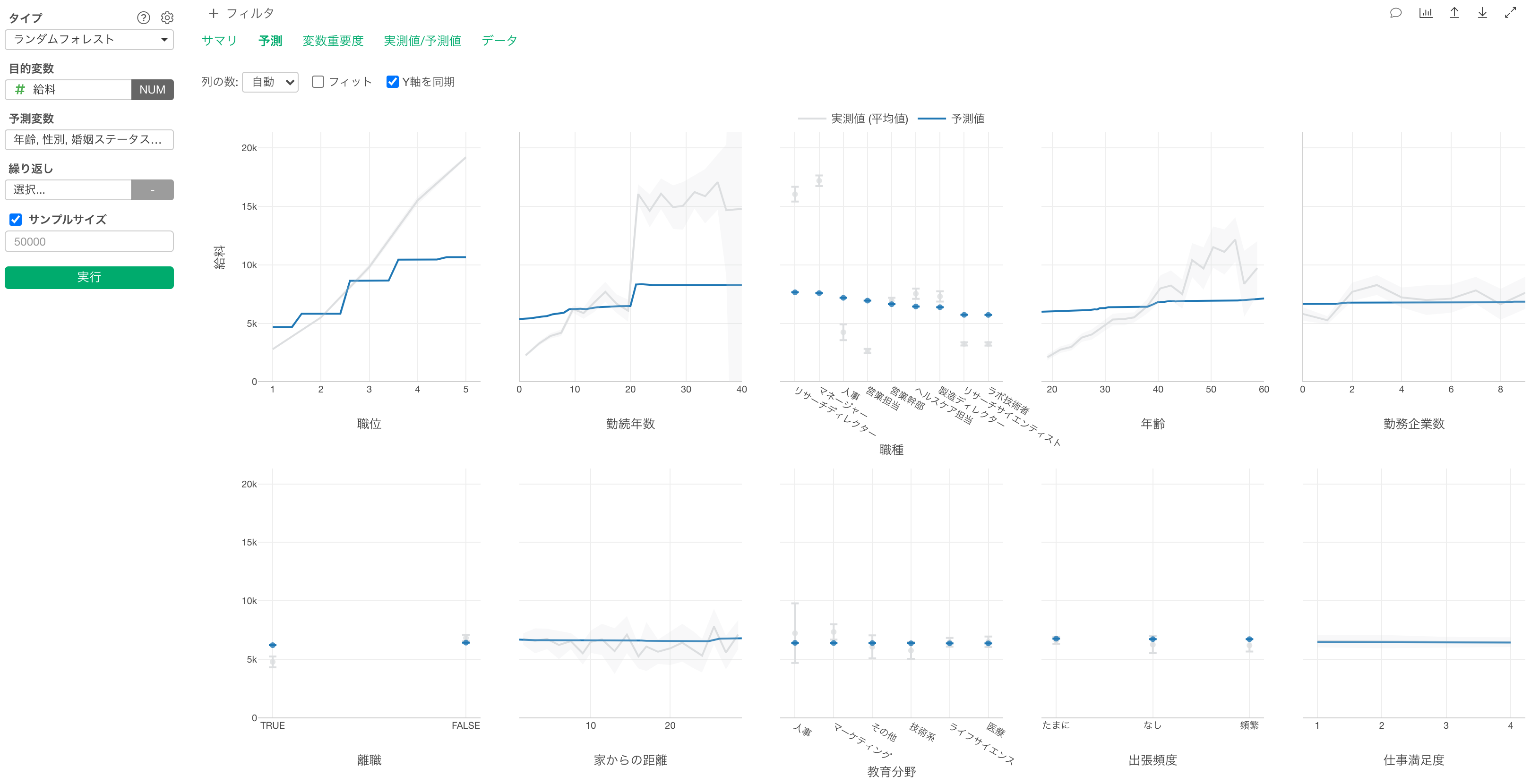
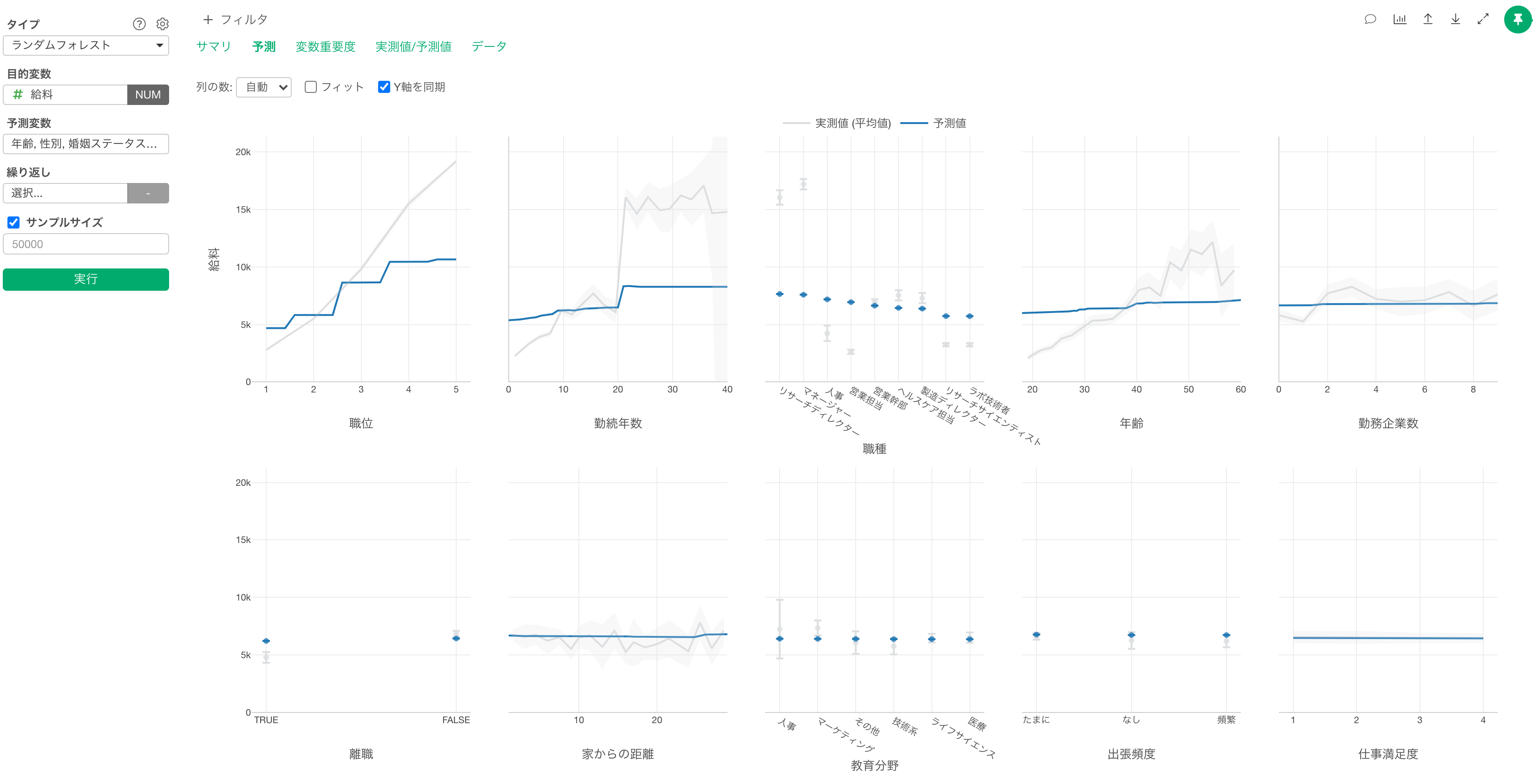
予測
予測タブでは、それぞれの変数の値が変わると、目的変数の値はどのように変わるのかがわかります。
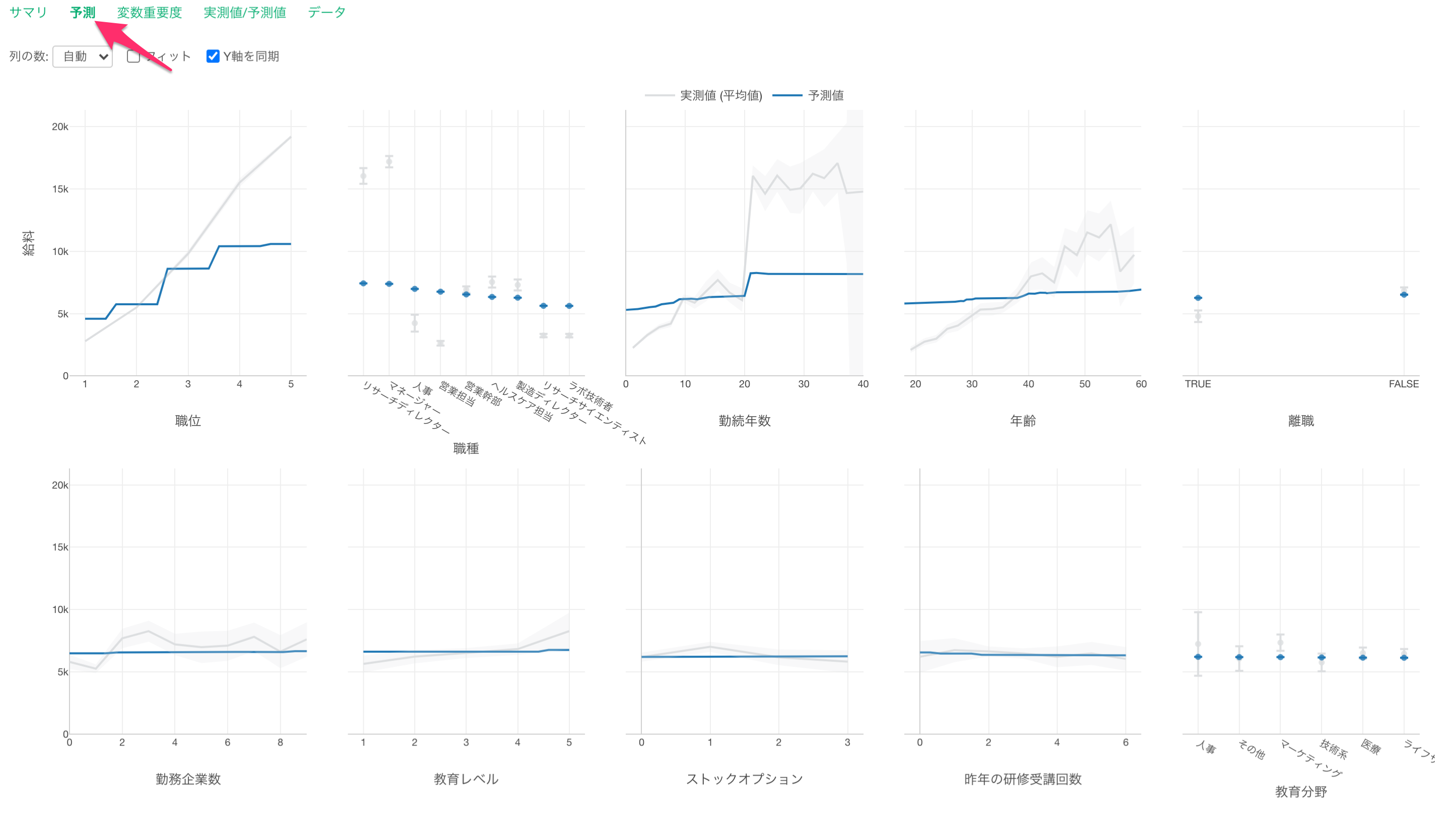
グレーの線は実測値を表しています。
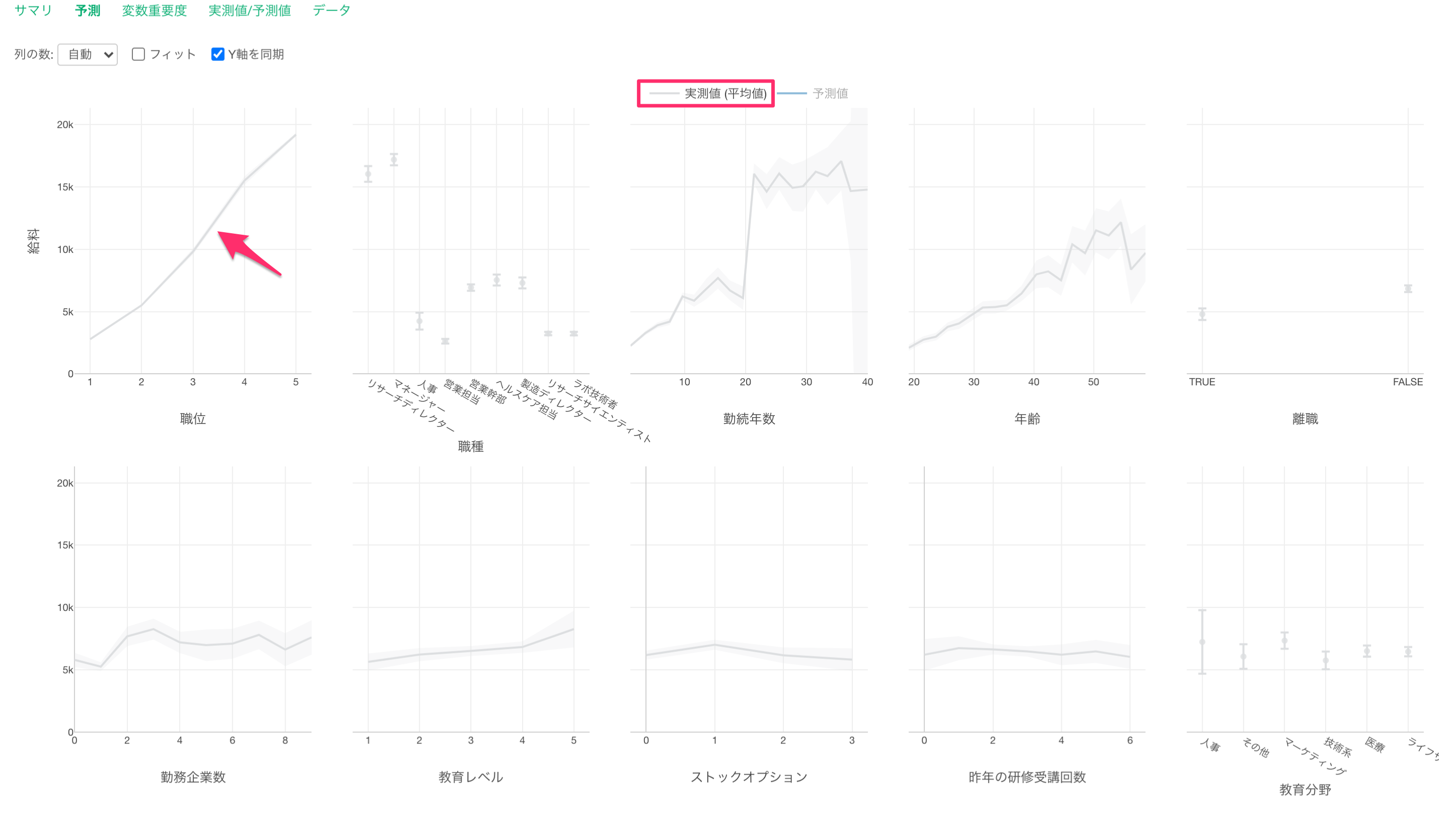
青い線は予測値を表します。
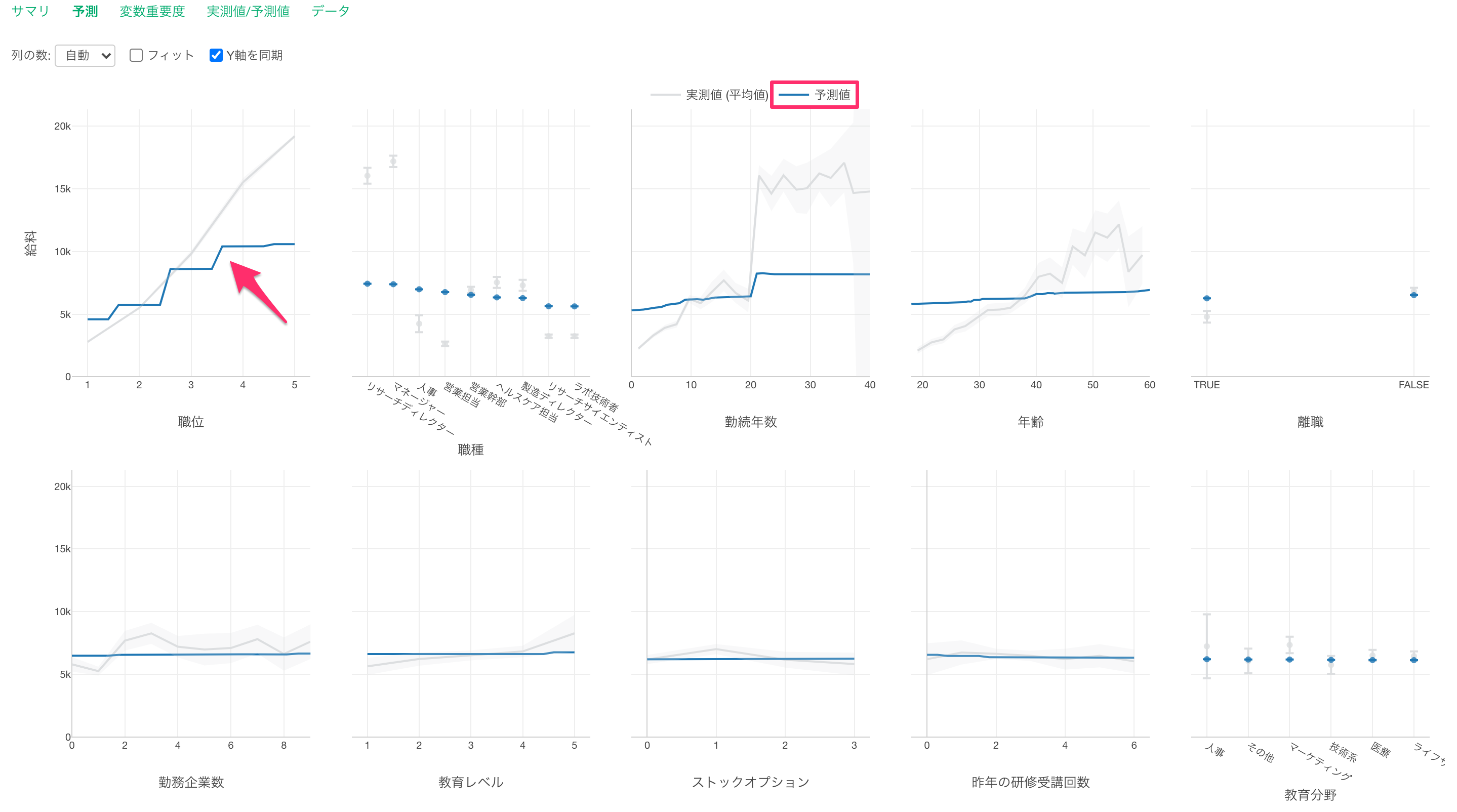
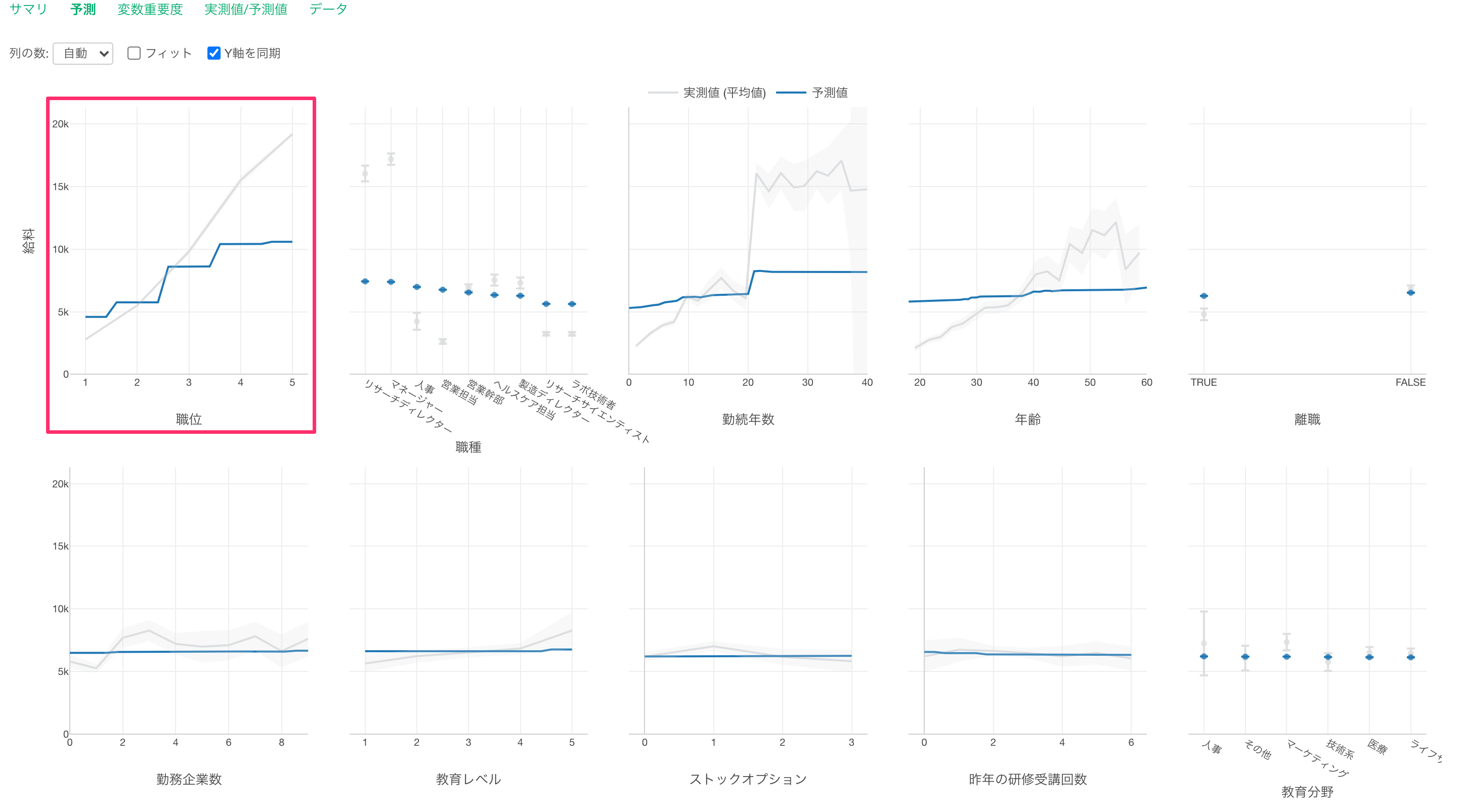
職位が上がると給料が高くなる関係があることがわかります。
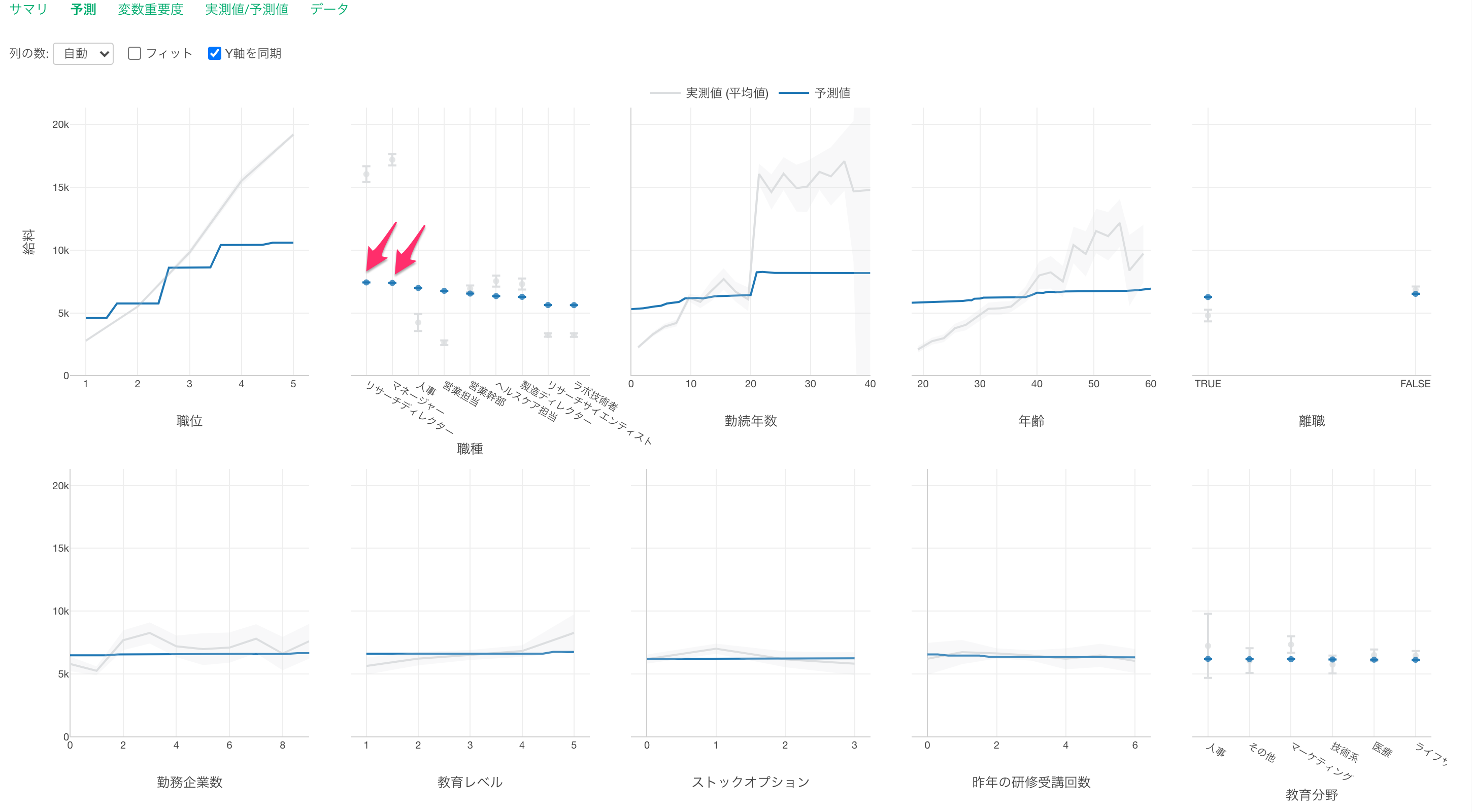
職種で見ると、他の職種に比べてリサーチディレクターとマネージャーの給料が高いようです。
サマリ
サマリタブでは、この予測モデルの評価を確認できます。
R2乗はデータの平均からのばらつきをモデルが説明できている割合の指標で、0から1の間の値を取ります。1に近ければ近いほど、モデルがデータのばらつきをよく説明できていることを示します。
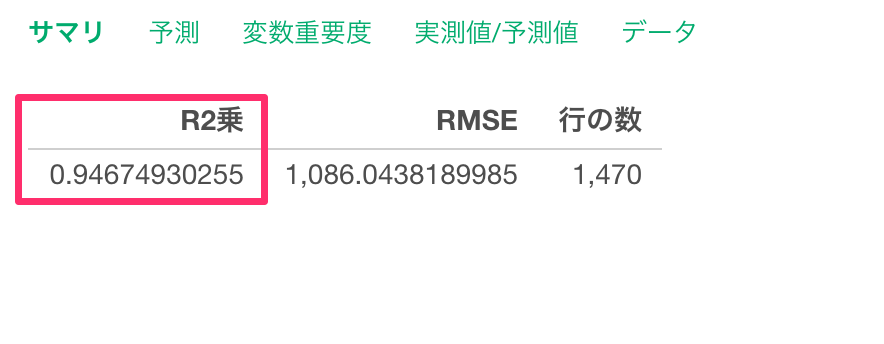
今回は、R2乗が0.947とこのモデルを使うと給料のばらつきの94.7%説明できていると言えます。
データ
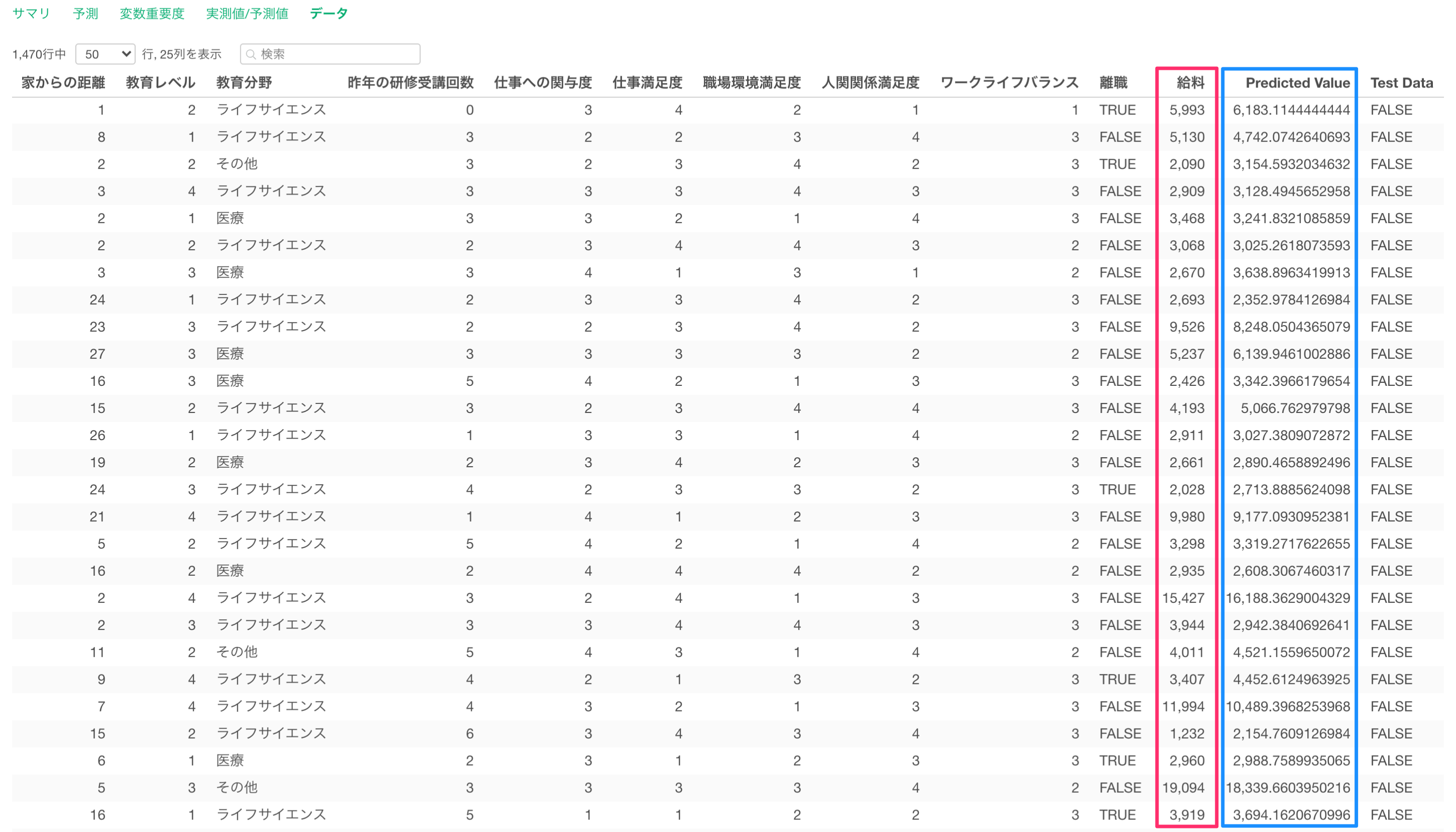
データタブでは、モデルに使用したデータと予測値をテーブル形式で表示されます。
目的変数である給料と、このモデルで算出された予測値(Predicted Value)を確認できます。
ロジカル型を目的としたランダムフォレストのモデルを作成する
従業員が「離職」しているかどうかを予測するランダムフォレストのモデルを作成します。
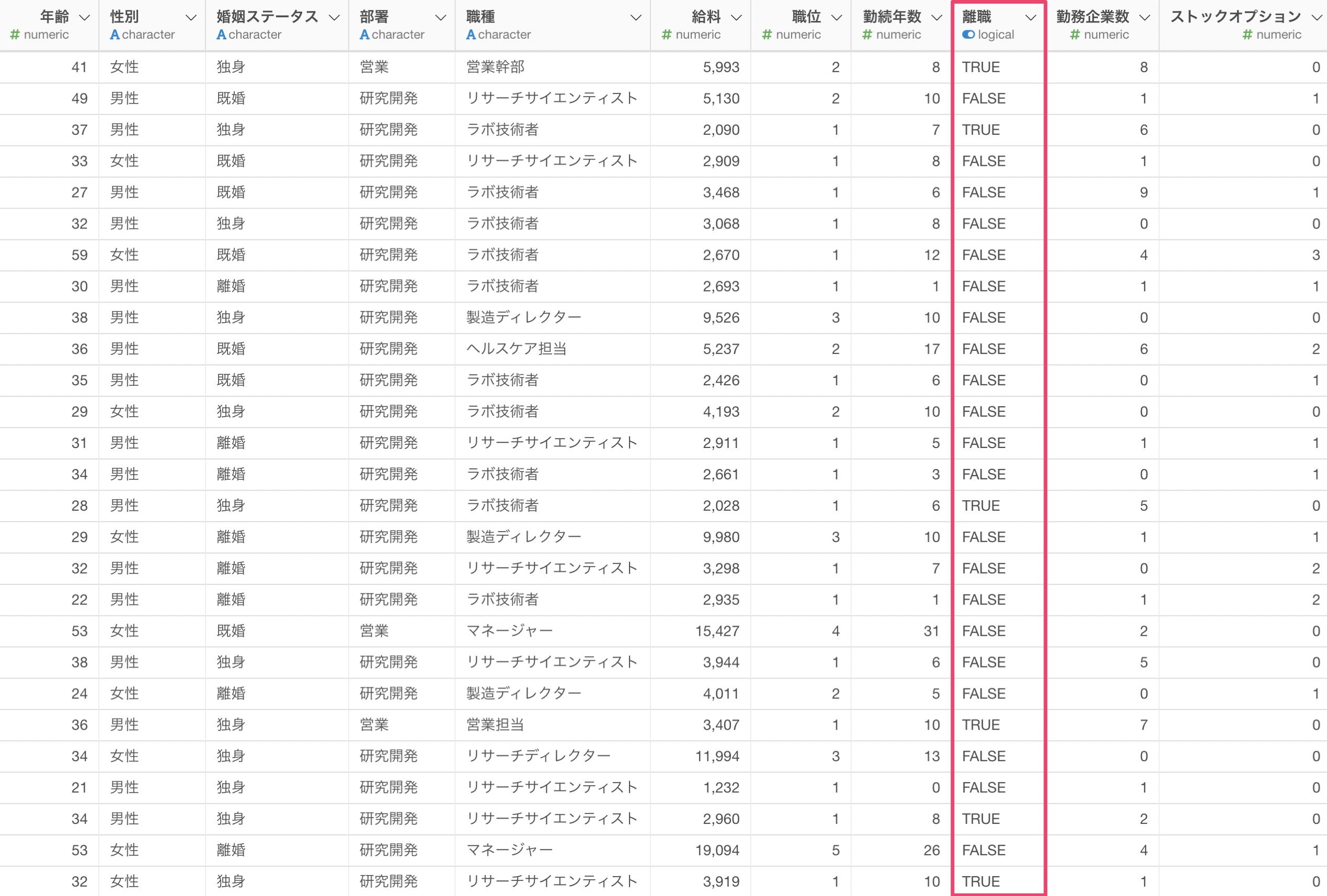
目的変数に「離職」を選択し、予測変数に任意の列を選択します。
目的変数と予測変数を割り当てることができたら、「実行」ボタンをクリックします。
ランダムフォレストのモデルが作成されました。
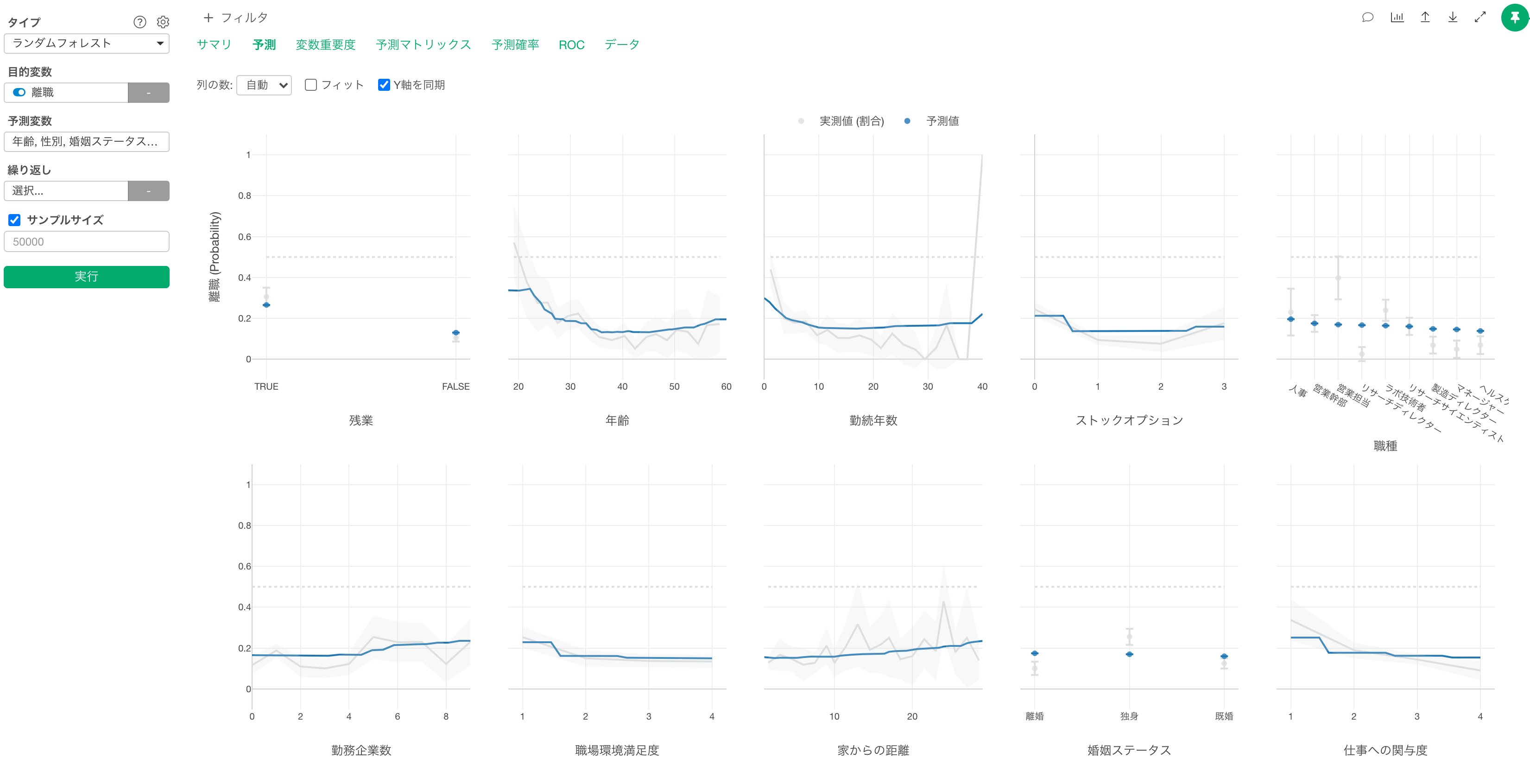
結果の解釈
先程の数値型で紹介しているものは一部省いて説明しています。
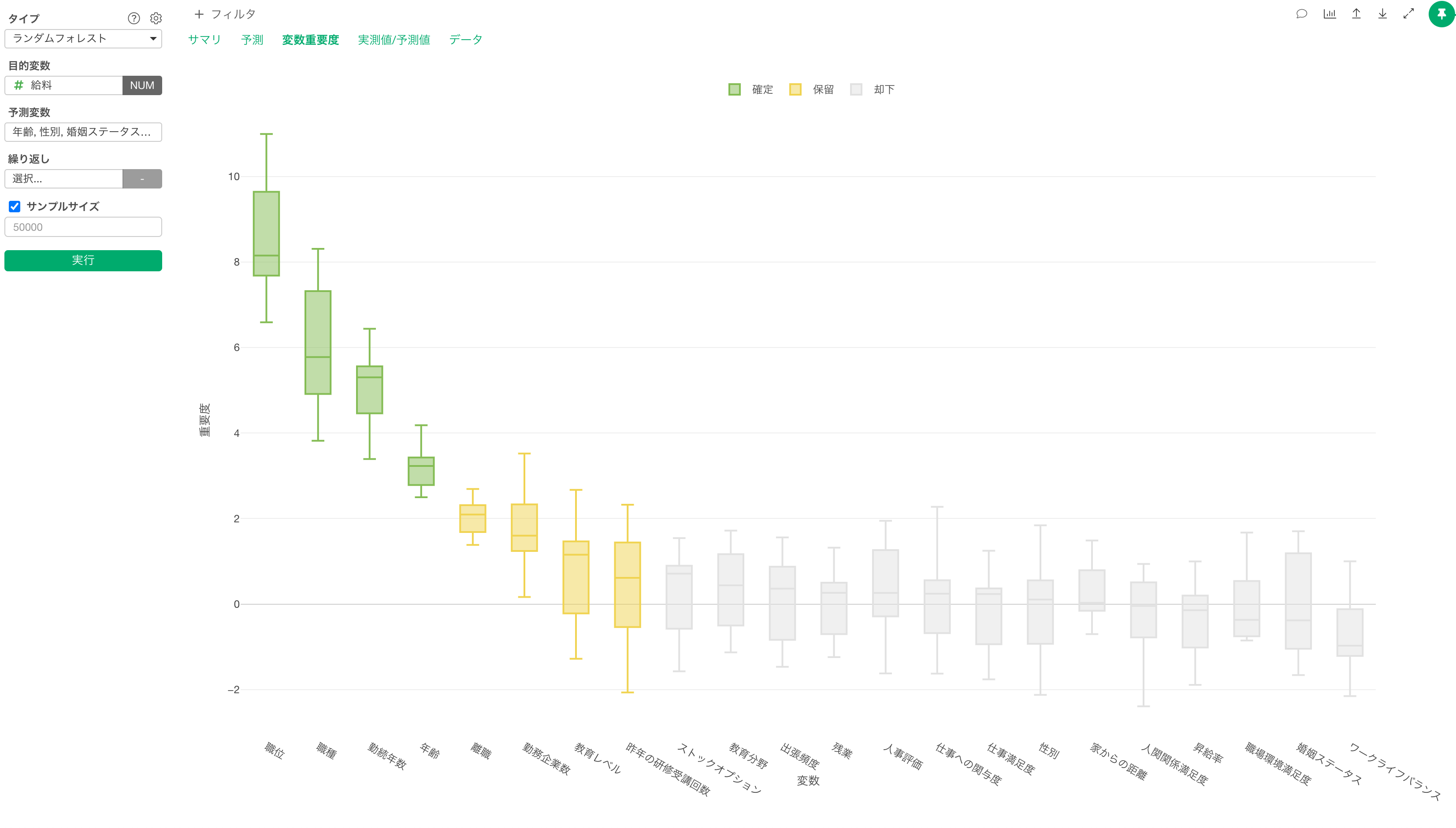
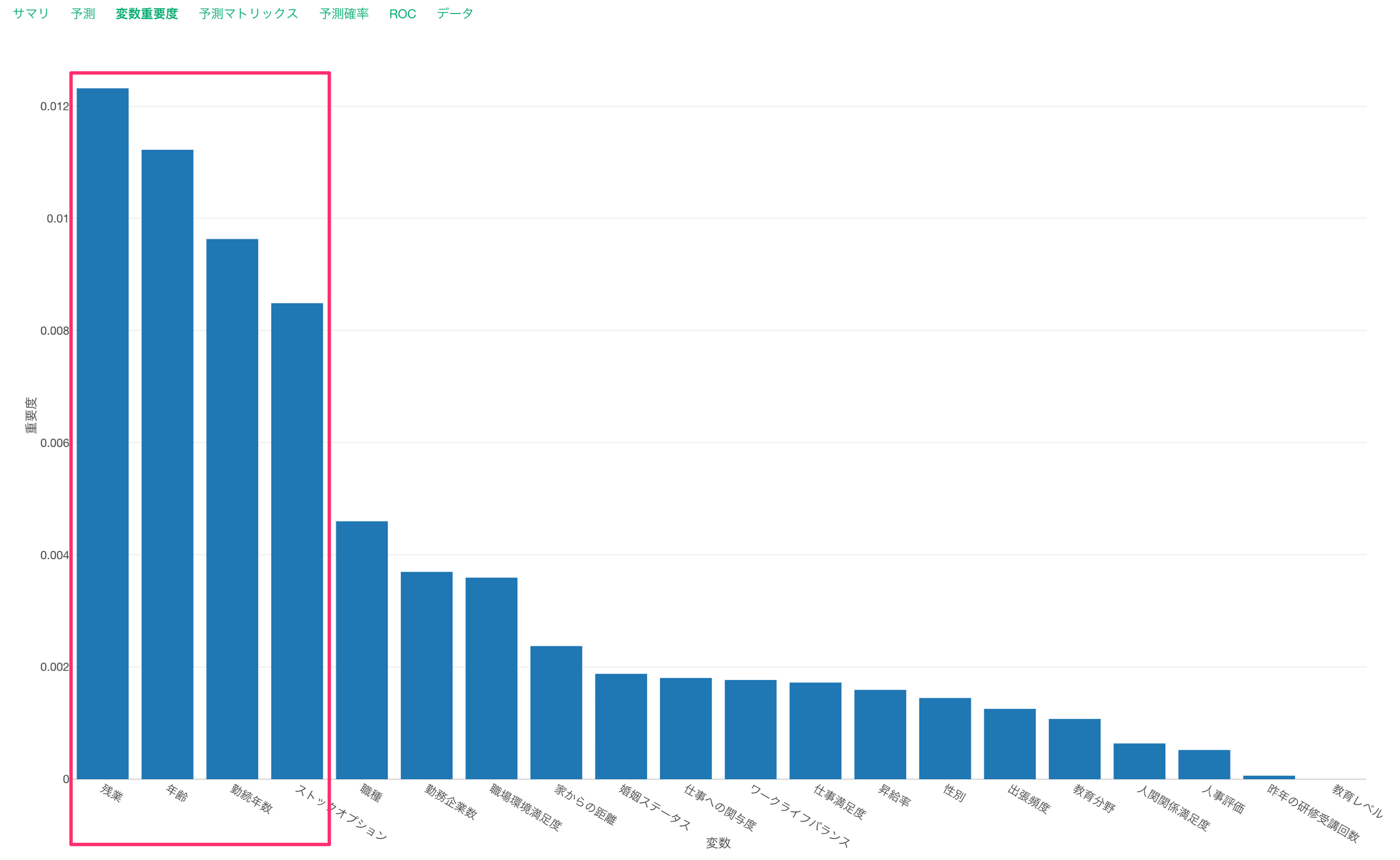
変数重要度
変数重要度タブを見ると、残業、年齢、勤続年数、ストックオプションが離職を予測する上で重要な変数のようです。
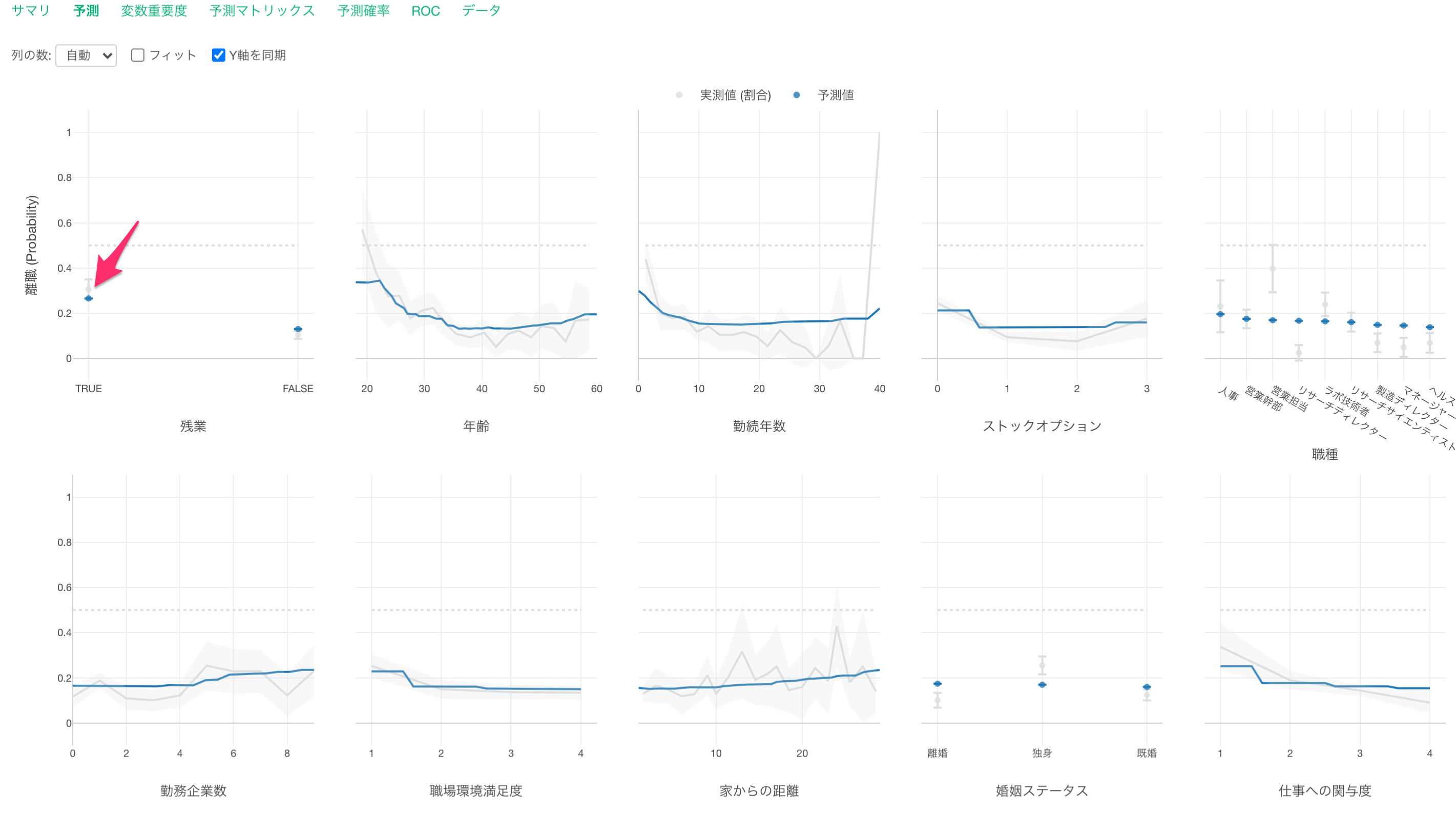
予測
それぞれの変数の値が変わると、離職率の値がどのように変わるかを予測タブで確認します。
残業している場合は、していない場合に比べて離職率が高いようです。
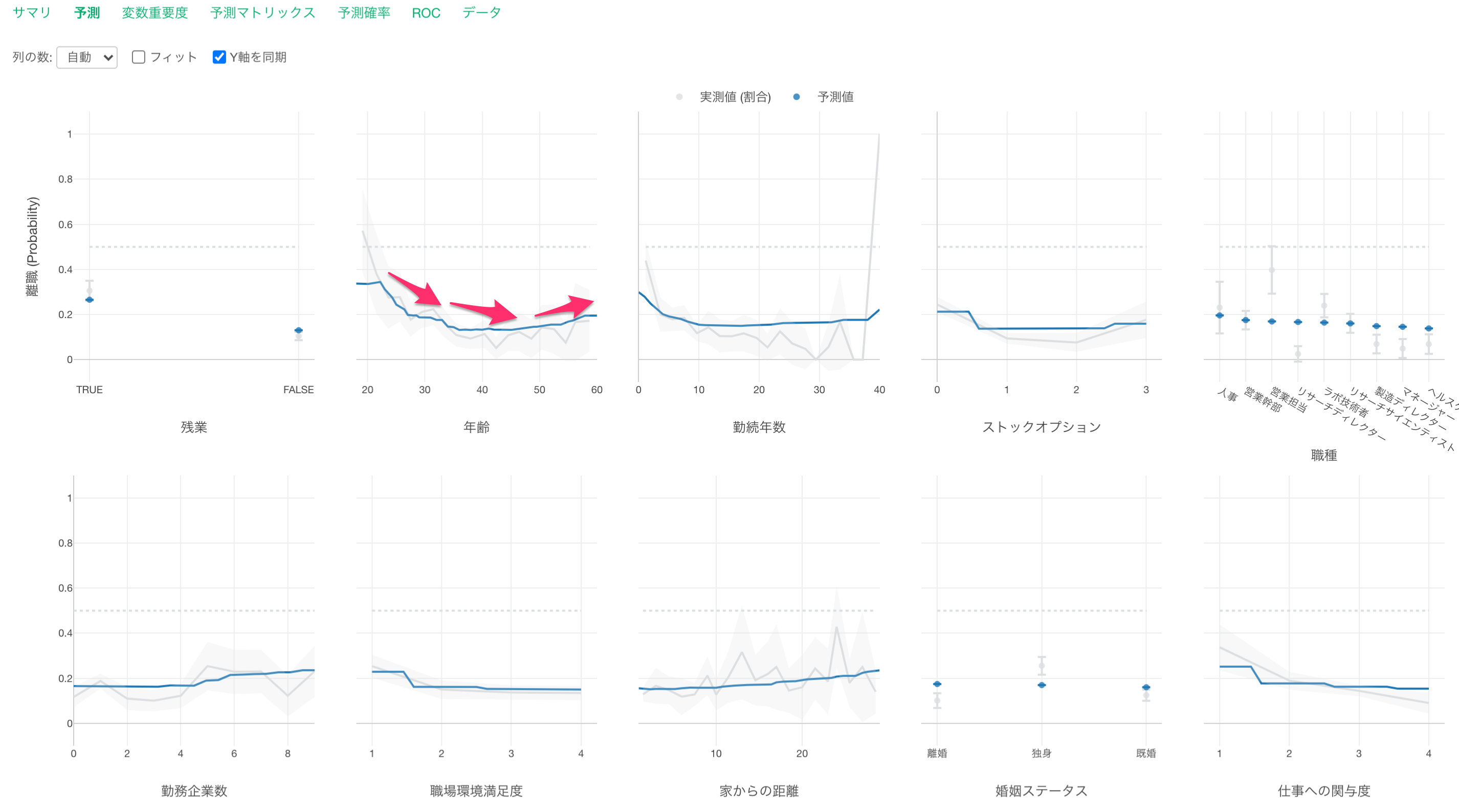
年齢が高くなるにつれ離職率が低くなり、年齢が50歳以上になると離職率が少し高くなる関係があることがわかります。
サマリ
サマリタブでは、この予測モデルの評価を確認できます。

AUCは離職のTRUE/FALSEをこのモデルでどれだけ上手く分けられているかの指標で、0.5から1の間の値を取ります。1に近ければ近いほど、モデルがデータのTRUE/FALSEを上手く分けられていることを示します。

今回は、AUCが0.96と1に近いため、このモデルを使うとTRUEとFALSEを上手く分けられていそうです。
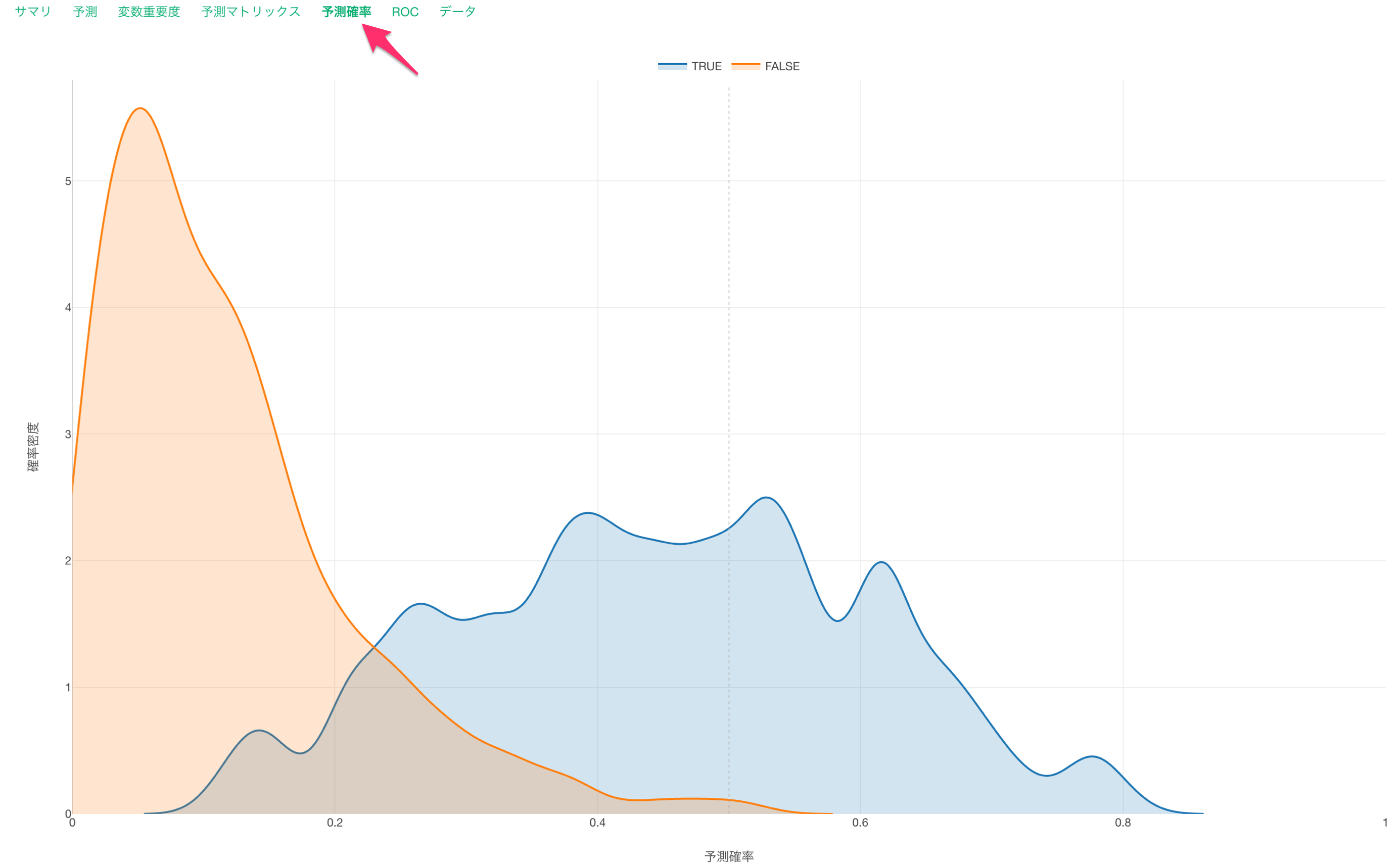
予測確率
予測確率タブでは、このランダムフォレストのモデルで離職を予測した確率を、実際のデータでTRUEだったとき、FALSEだったときに分けて、それぞれ分布(密度曲線)にして可視化しています。
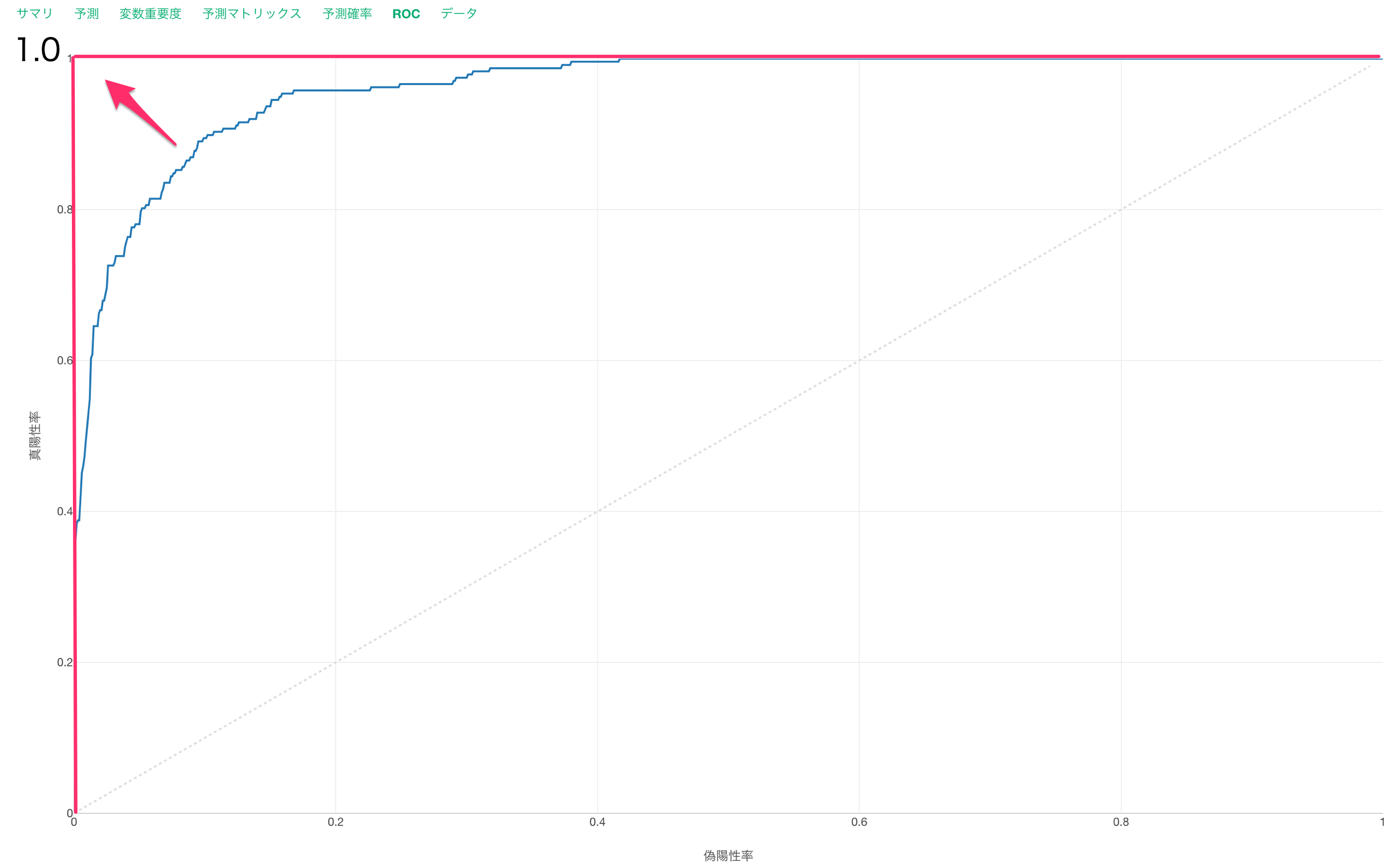
ROC
ROCタブでは、AUCの元となる面積をROC曲線から確認できます。
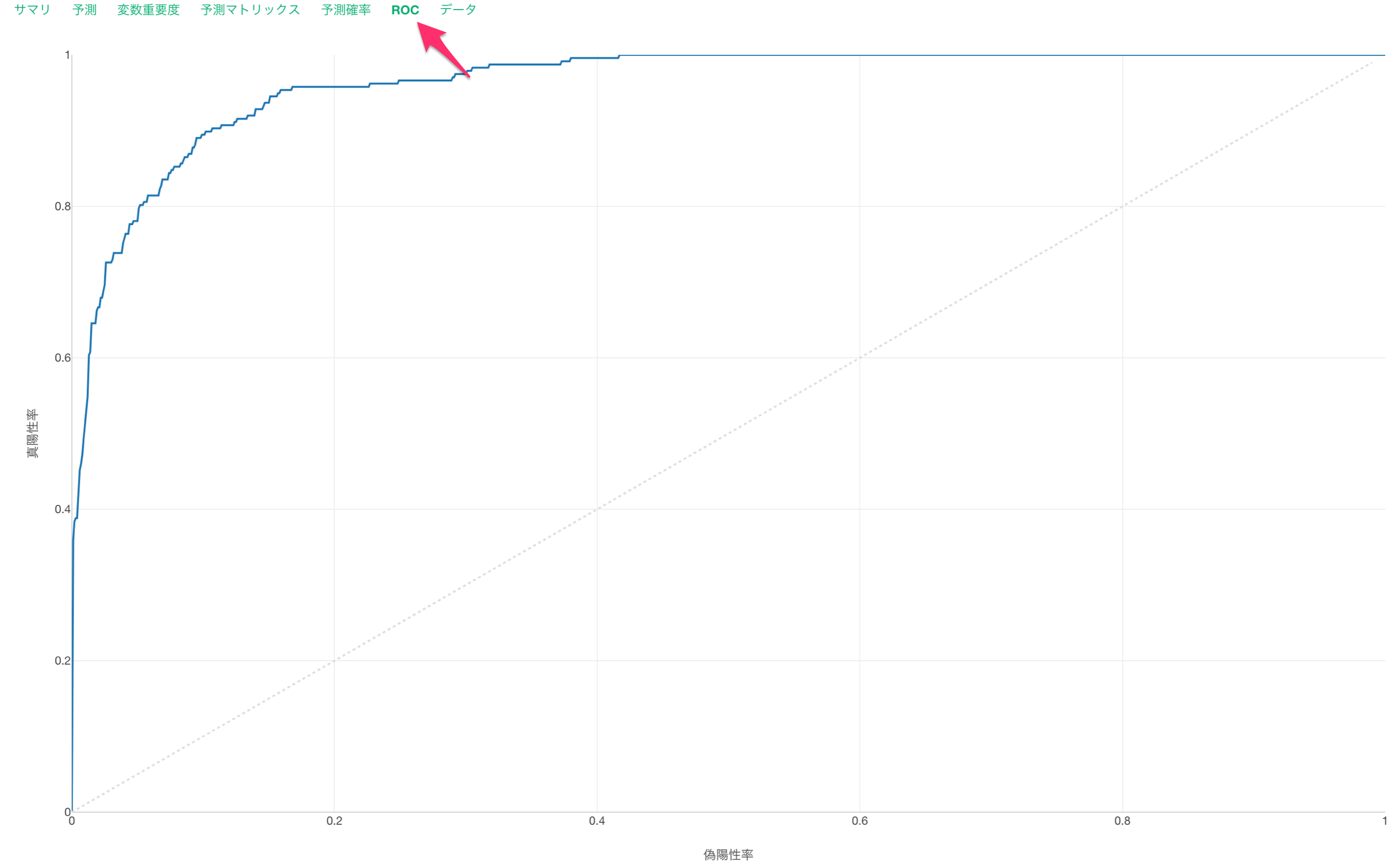
AUCが低い時はROC曲線が対角線上に近づいていきます。
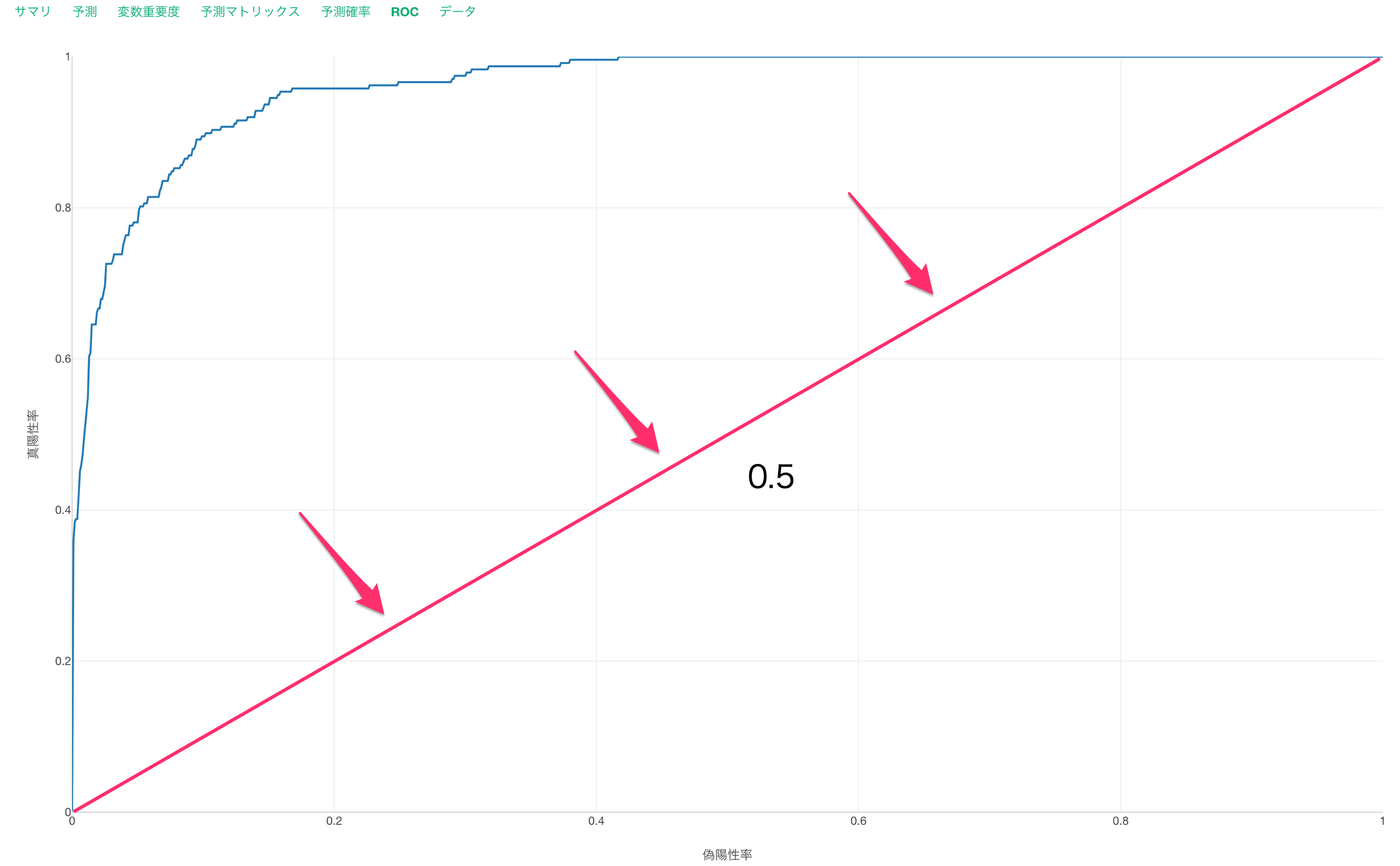
AUCが高い時はROC曲線が直角に近づいていきます。
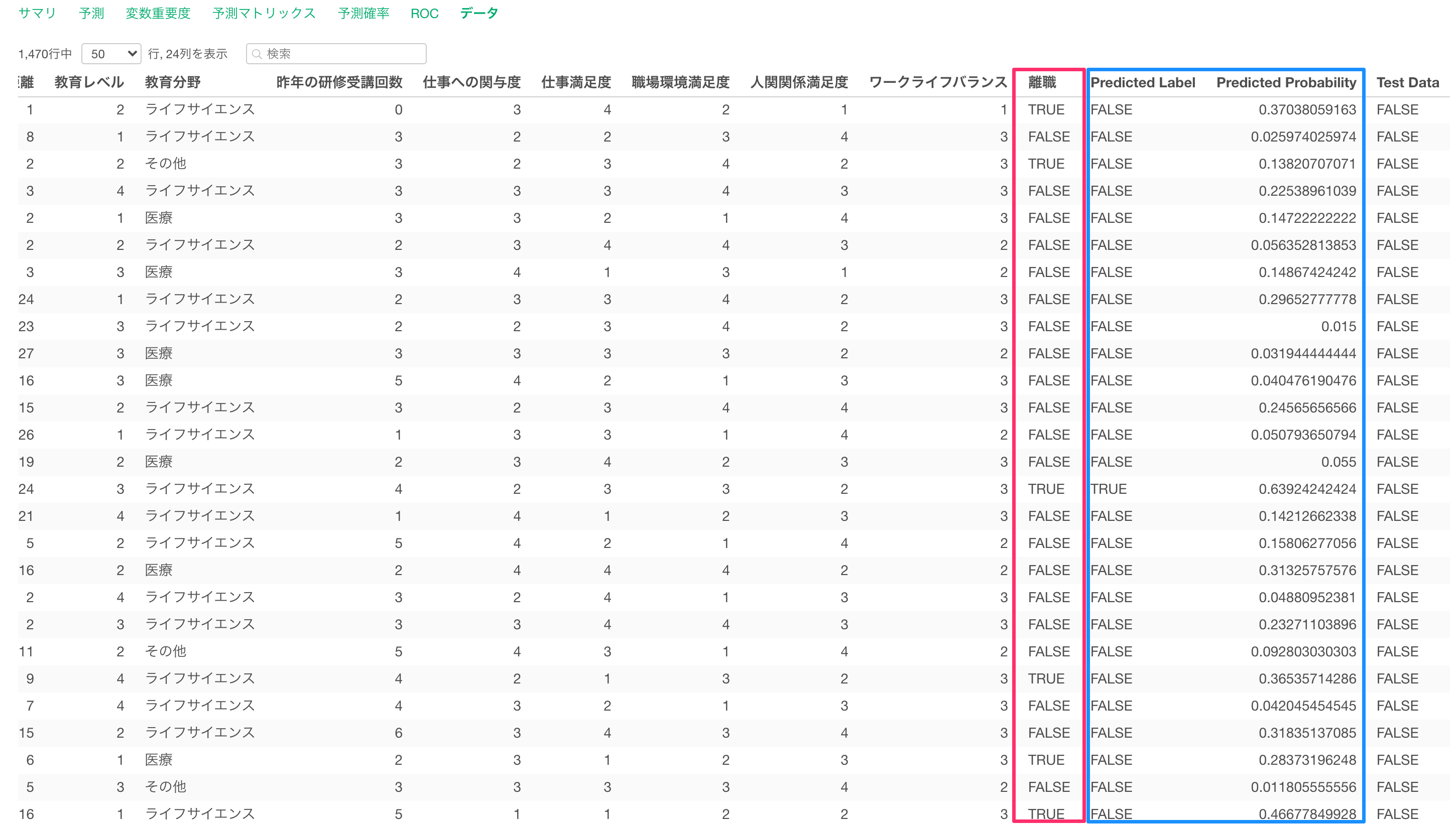
データ
データタブでは、目的変数である離職と、このモデルで算出された予測値(Predicted Value)と閾値を元にしたTRUE/FALSEのラベル(Predicted Label)を確認できます。
参考資料
ランダムフォレストに関する参考資料は下記をご覧ください。
ランダムフォレストに関するよくある質問
Q: 予測タブで表示されている実測値はどのように求められているのですか?
予測タブの実測値はそれぞれの予測変数のデータタイプによって表示が異なります。 詳しくはこちらのノートをご覧ください。
Q: 予測タブで表示されている予測値はどのように求められているのですか?
予測値のチャートはPartial Dependence Plot(PDP)と呼ばれるもので、注目している変数の値を変化させたときに、予測結果がどう変わるかを可視化したチャートとなります。詳しくはこちらのノートをご覧ください。
Q: 機械学習と統計学習の違いで、統計学だと少ないサンプルで予測する、機械学習だと大きなデータで予測する。なにかデータ数の基準はありますか?
特にありません。
Q: ランダムフォレストには多重共線性の問題は関係ないのでしょうか?
多重共線性という名前で呼ばれることはないのですが同様の問題はあって、同じような情報が複数の列から得られると、変数重要度などの分析結果が不安定になることがあります。
Q: ランダムフォレストで決定木を作る回数などは分析者がチューニングするのでしょうか?
予測する際にはチューニングしすぎると、オーバーフィッティング(過学習)が起きる可能性があるのでテストが必要になります。
Q: 変数重要度がマイナスになってしまう時はどう解釈すれば良いでしょうか?
変数重要度ではPermutationという手法を使用しており、下記のような仕組みになっています。
- 1つの予測変数を除いてモデルを作り、除かなかった場合に比べて予測精度がどれだけ悪くなるのかを計算する。
- これを全ての変数で繰り返す。
- どれだけ予測精度が悪くなるのかというスコアをもとに、それぞれの変数の相対的な重要度を評価する。
変数重要度の詳細はこちらのセミナーをご覧ください。
まずは変数重要度がプラスになる時とマイナスになる時の2つの例を簡単な計算で紹介をします。
変数重要度がプラスの時
- 変数が含まれる時の予測精度: 90
- 変数が含まれない時の予測精度: 50
- 変数重要度 = 90 - 50 = 40
変数重要度がマイナスの時
- 変数が含まれる時の予測精度: 20
- 変数が含まれない時の予測精度: 30
- 変数重要度 = 20 - 30 = -10
上記の計算にあるように、特定の変数があった時の予測精度に比べて、その変数を除いた時の方が予測精度が良いという時に変数重要度がマイナスになってしまいます。そのため、変数重要度がマイナスになるケースの多くは、あまり関係のない変数のことが多いかと思います。
Q: ランダムフォレストでボルータを使用した時に変数重要度がマイナスになるのはなぜでしょうか?
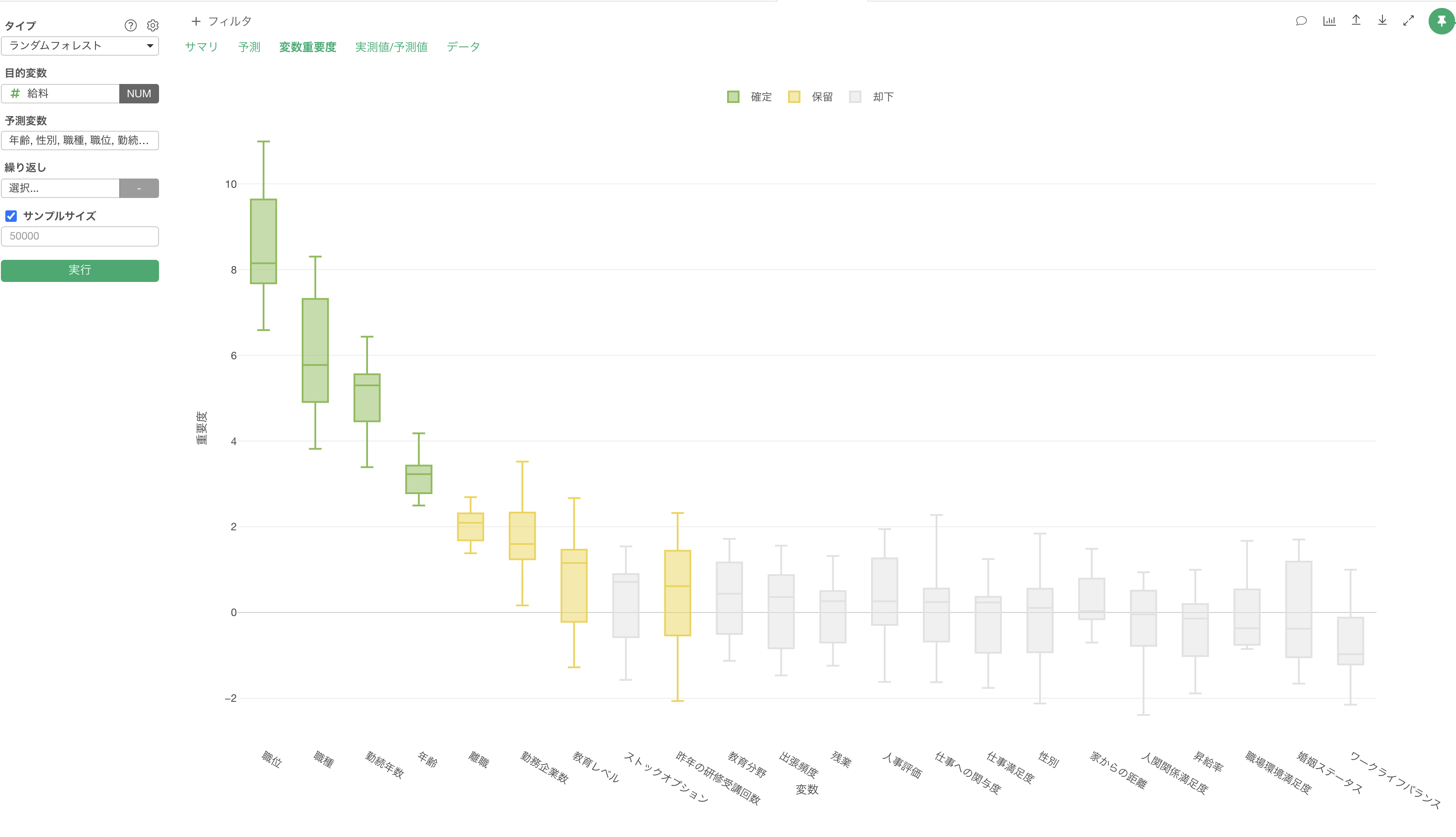
ボルータで下位の変数の重要度の中央値が負になるのは、その変数が予測にほとんど役に立っていないためゼロ近辺で重要度が分布していて、それがばらつきによってたまたま負になったと考えるのが自然と思います。
複数ある変数の最下位近辺になると、たまたま重要度の中央値が負になった変数が最下位として表示されることになりますので、そういった結果は珍しくありません。
Q: カテゴリーを予測したモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまう
カテゴリー列の値を予測するモデルを作っていて、そのモデルを使って新しいデータに対して予測をした際に、予測ラベルに欠損値が出てしまうことがあります。
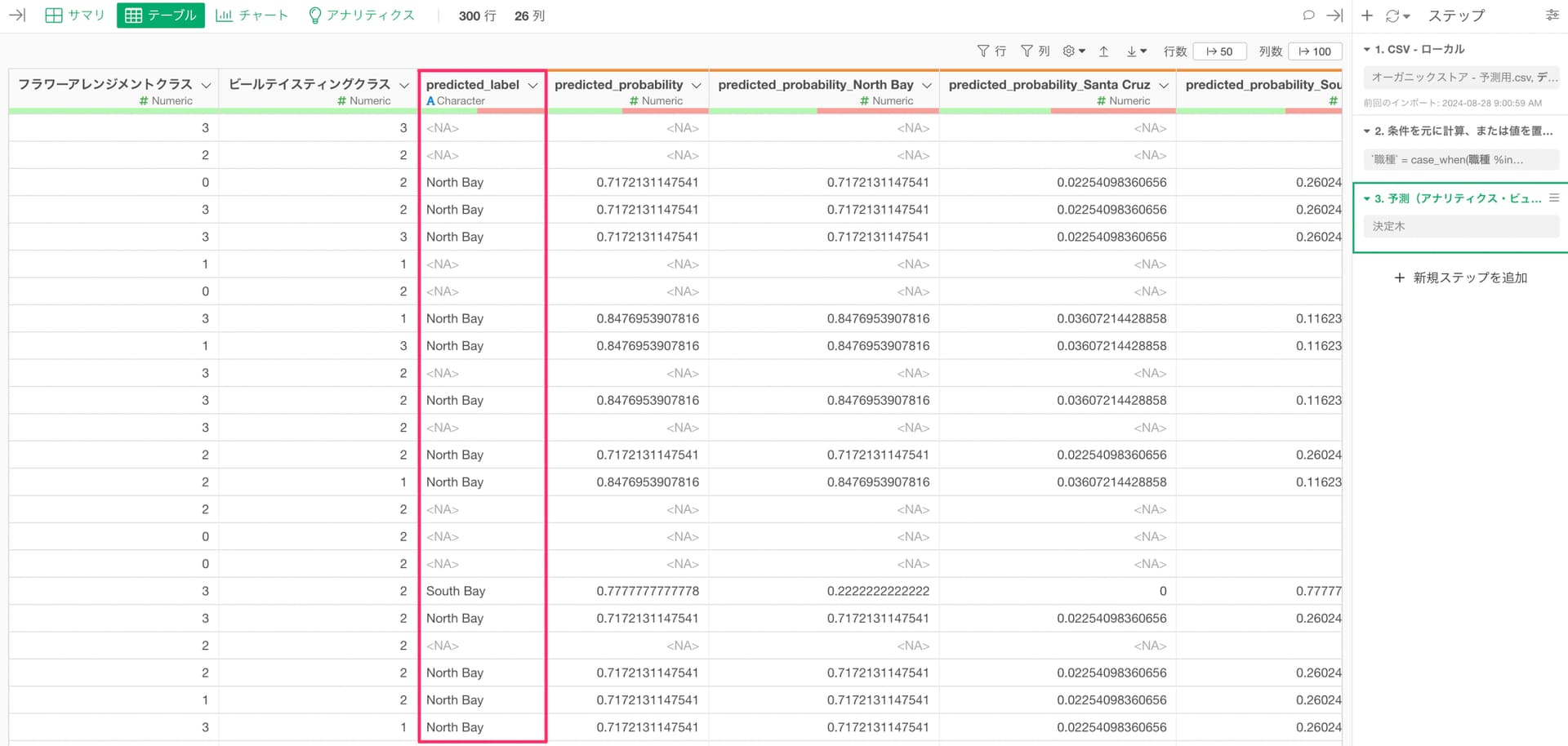
主な原因としては、以下の2つが考えられます。
- 予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在している。
- 予測対象の新しいデータ側で予測変数に使われていた列で欠損値がある。
予測モデルの作成時には予測変数側に無かったカテゴリー値が予測対象の新しいデータ側で存在しているといったケースに該当する場合は、今後もモデルで予測をする際に、そのカテゴリーが含まれる可能性がある時には、モデル側にもそのカテゴリの値があるように組み込んでいただくと良いかもしれません。