XMLファイルのデータをインポートする方法
XMLは、タグで囲まれた階層構造でデータを表現するファイル形式です。アンケートシステムや業務システムからの書き出し、Web APIのレスポンスなどでよく使われますが、CSVのように「行と列」がそのまま並んでいるわけではないため、表(データフレーム)に変換するにはひと工夫が必要です。
ExploratoryではRスクリプト・データソースを使用することで、こうしたXMLファイルを取り込めます。XMLは構造によって取り方が変わるので、このノートでは「XMLの構造のパターンに合わせた」取得方法を整理します。まず基本となるExploratoryの操作を説明し、続いてパターン別の取り方を見ていきます。
Rスクリプトデータソースを使用する
ExploratoryでXMLを読み込むには、データフレームの作成方法として「Rスクリプト」を選びます。データ追加の「+」から「Rスクリプト」を選択します。
「Rスクリプト・データフレームのダイアログ」が開きます。
このダイアログのコードエディタにRコードを入力し、実行ボタンを押してデータが正しく取得できているか(プレビューに表が表示されるか)を確認します。
確認できたら保存すると、データソースとして取り込まれます。
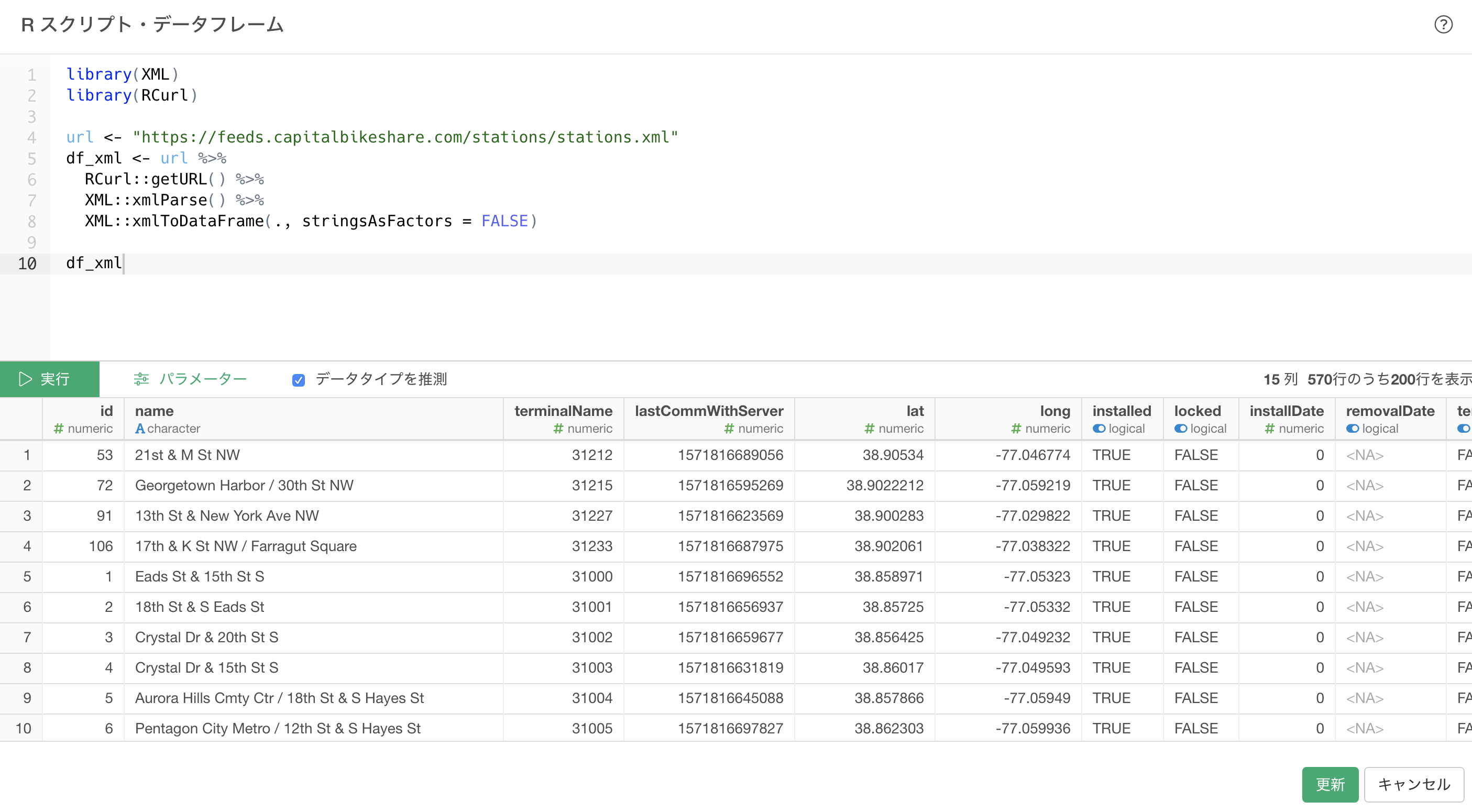
以降で紹介するパターンは全て、このRスクリプトデータソースを使用します。
取り方の全体像 - 構造を見てパターンを選ぶ
XMLを取り込むときは、まずファイルを開いて構造を確認します。見るべきポイントは以下の3点です。
- 1件のデータがフラットに並んでいるか、入れ子になっているか
- 値がタグに挟まれているか、属性に入っているか
- ルートタグに
xmlns=の宣言があるか
そのうえで、次の早見表からパターンを選びます。
| XMLの状態 | 取り方 | 主に使う関数 |
|---|---|---|
| フラット(1件分が並ぶだけ) | そのまま表にする | XML::xmlToDataFrame() |
| 入れ子(レコードが繰り返す) | レコードのノードを起点に抽出する | read_xml() + xml_find_all() +
xml_find_first() |
| 同じタグ名が複数の階層にある | レコードを起点に相対パス(直接の子)で取る | 同上(XPathの書き方を変える) |
| 値が属性に入っている | 属性を取り出す | xml_attr() |
ルートに xmlns= が付いている |
名前空間を取り除いてから取る | xml_ns_strip() |
| 読み込みでエラー・文字化けする | 末尾のゴミを除去・文字コードを指定 | readBin() /
read_xml(encoding=) |
以降、それぞれのパターンを具体的に見ていきます。
パターン1: フラットな構造のXML
タグが入れ子になっておらず、1件分のデータがフラットに並んでいるだけの単純なXMLなら、XMLパッケージのxmlToDataFrame()で、そのまま表にできます。employees_flat.xml
は次のような構造です。
<?xml version="1.0" encoding="utf-8"?>
<employees>
<employee>
<id>1001</id>
<name>佐藤太郎</name>
<department>営業部</department>
<age>34</age>
</employee>
...
</employees>このときは、ファイルパスを渡すだけで表になります。
library(XML)
df <- XML::xmlToDataFrame(
doc = "/Users/takatoshiroto/Downloads/XML/employees_flat.xml",
stringsAsFactors = FALSE
)
df
docにローカルファイルのパスを指定します。Windowsの場合はパスの区切りのバックスラッシュを2つ重ねて書きます(例:"C:\\Users\\Tanaka\\Desktop\\employees_flat.xml")。stringsAsFactors = FALSEは、文字列を因子(factor)に変換せずそのまま文字列として読み込む設定です。
xmlToDataFrame()は手軽ですが、対応できるのはこのフラットな構造までです。次に示す入れ子の構造では、レコードがうまく1つの表に展開できないため、xml2パッケージを使います。
パターン2: 入れ子の構造(レコードが繰り返す)
1件の中に複数のレコードがぶら下がっている入れ子構造のときは、xml2パッケージで「取り出したい繰り返しレコードのノード」を指定し、各ノードから必要なタグの値を1列ずつ抜き出して表を組み立てます。以下は、1件のアンケート(<Survey>)の中に回答者(<Respondents>)と設問(<Questions>)が複数ぶら下がった構造です。
<?xml version="1.0" encoding="utf-8"?>
<SurveyFile>
<Survey>
<Id>65</Id>
<Title>2024年度 従業員満足度アンケート</Title>
<Year>2024</Year>
<Respondents>
<Respondent>
<Id>1001</Id>
<Gender>男性</Gender>
<Age>34</Age>
<Department>営業部</Department>
</Respondent>
<Respondent>
<Id>1002</Id>
<Gender>女性</Gender>
<Age>41</Age>
<Department>開発部</Department>
</Respondent>
<Respondent>
<Id>1003</Id>
<Gender>男性</Gender>
<Age>29</Age>
<Department>人事部</Department>
</Respondent>
</Respondents>
<Questions>
<Question><Id>1</Id><Text>仕事のやりがい</Text></Question>
<Question><Id>2</Id><Text>職場の人間関係</Text></Question>
</Questions>
</Survey>
</SurveyFile>回答者(<Respondent>)の一覧を表にするには、<Respondent>のノードをまとめて取得し、各ノードから直接の子タグの値を取り出します。
library(xml2)
doc <- xml2::read_xml("/Users/takatoshiroto/Downloads/XML/employee_survey.xml")
# 取り出したい繰り返しレコード(回答者)のノードをすべて取得
nodes <- xml2::xml_find_all(doc, "//Respondent")
# 各ノードから直接の子タグの値を取り出して1列ずつ組み立てる
df <- data.frame(
Id = xml2::xml_text(xml2::xml_find_first(nodes, "Id")),
Gender = xml2::xml_text(xml2::xml_find_first(nodes, "Gender")),
Age = xml2::xml_text(xml2::xml_find_first(nodes, "Age")),
Department = xml2::xml_text(xml2::xml_find_first(nodes, "Department")),
stringsAsFactors = FALSE
)
df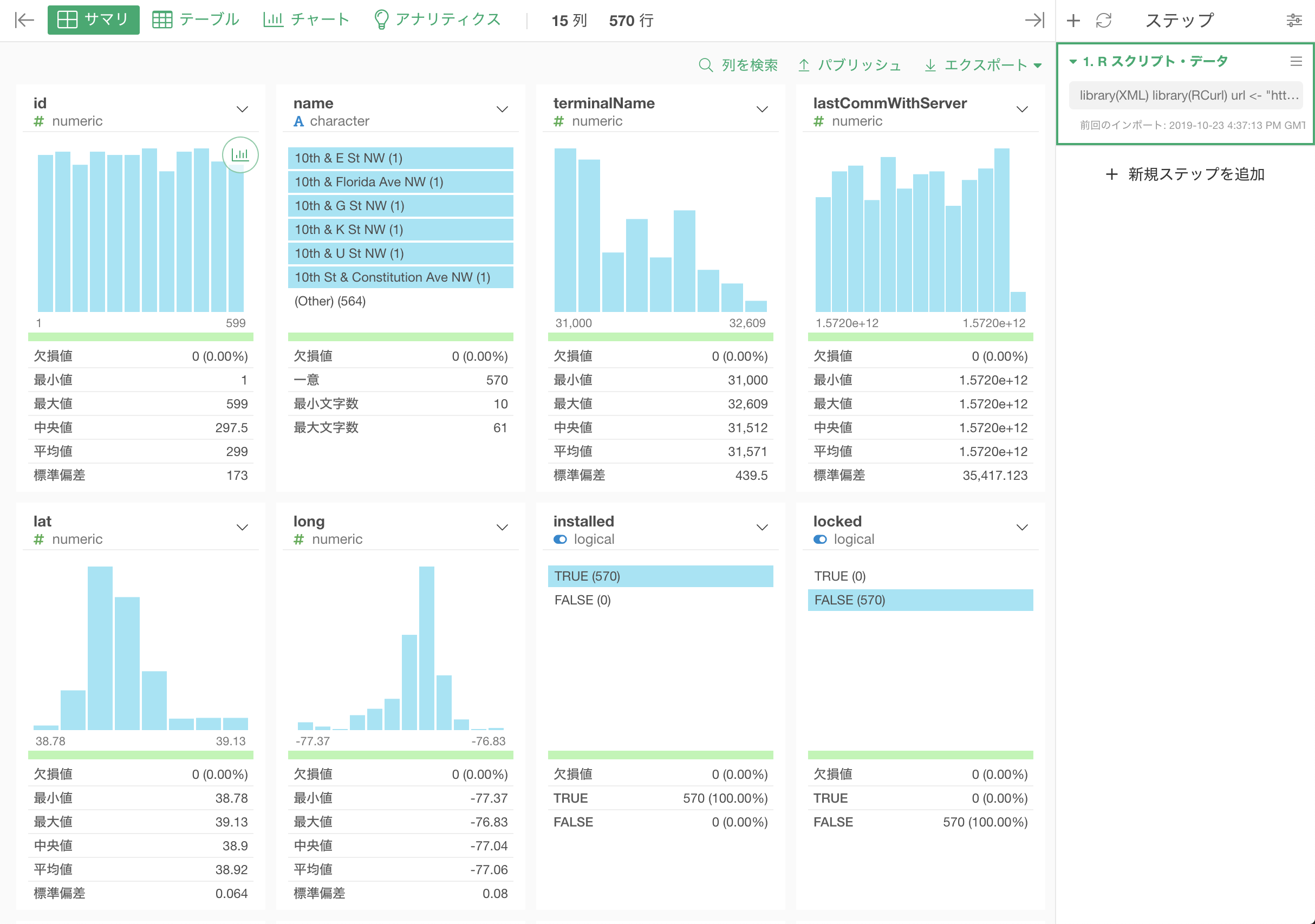
これが入れ子XMLの基本の型です。関数の役割は次のとおりです。
read_xml(): XMLファイル全体を読み込みます。xml_find_all(): 条件に一致するすべてのノードをまとめて取得します。繰り返しレコード(行)の取得に使います。xml_find_first(): 各ノードの中から条件に一致する最初の1つを取得します。1件ぶんのフィールド(列の値)の取得に使います。該当タグが無いレコードでは自動的に欠損(NA)になるため、行数がズレません。xml_text(): ノードからテキスト(タグに挟まれた値)を取り出します。
設問(<Question>)の一覧がほしいときは、//Respondentを//Questionに変えて同じやり方で取れます。
パターン3: 同じタグ名が複数の階層にある
入れ子のXMLでは、同じタグ名が違う階層に何度も登場することがよくあります。例えば以下のXMLでは、Idというタグが3つの階層に出てきます。アンケート自体のId、各回答者のId、各設問のIdです。
<?xml version="1.0" encoding="utf-8"?>
<SurveyFile>
<Survey>
<Id>65</Id>
<Respondents>
<Respondent>
<Id>1001</Id>
<Gender>男性</Gender>
</Respondent>
<Respondent>
<Id>1002</Id>
<Gender>女性</Gender>
</Respondent>
</Respondents>
<Questions>
<Question><Id>1</Id><Text>仕事のやりがい</Text></Question>
<Question><Id>2</Id><Text>職場の人間関係</Text></Question>
</Questions>
</Survey>
</SurveyFile>回答者の一覧表を作ろうとして、Id列を//Idで取ると、エラーにはならないのに中身がめちゃくちゃな表ができてしまいます。
library(xml2)
doc <- xml2::read_xml("/Users/takatoshiroto/Downloads/XML/employee_survey.xml")
# 回答者は3人のはず
nodes <- xml2::xml_find_all(doc, "//Respondent")
df <- data.frame(
Id = xml2::xml_text(xml2::xml_find_all(doc, "//Id")), # Idだけ6個返ってくる
Gender = xml2::xml_text(xml2::xml_find_first(nodes, "Gender")), # Genderは3個
stringsAsFactors = FALSE
)
df
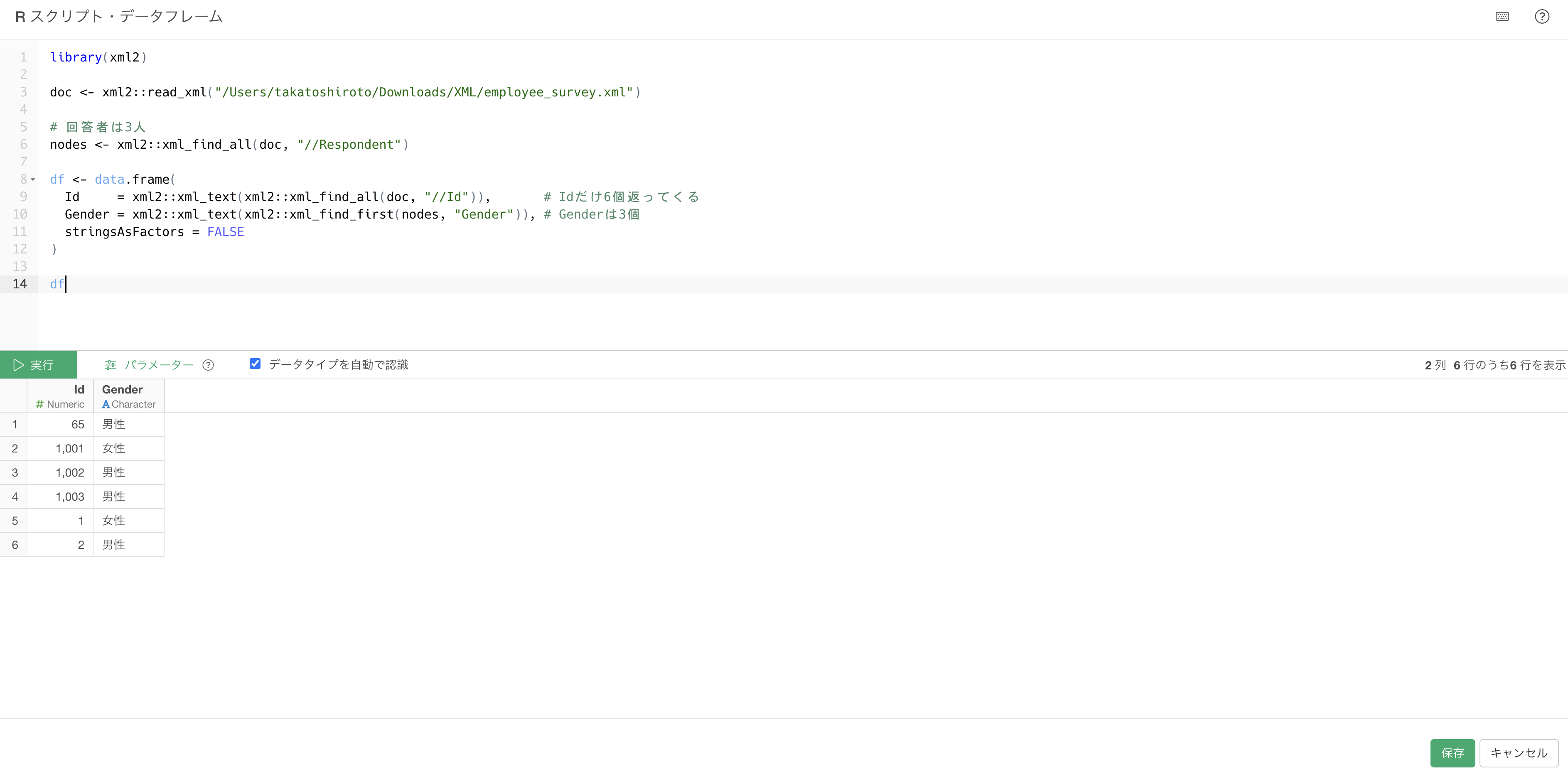
//Idはドキュメント全体からIdという名前のタグを探すため、アンケートのId(65)も回答者のId(1001〜1003)も設問のId(1,
2)も混ざった6個が返ってきます。回答者は3人なのでGenderは3個ですが、data.frame()は列の長さが倍数関係(6と3)だと短い方を繰り返して長さをそろえてしまう(リサイクル)ため、エラーも警告も出さずに6行の表ができあがります。結果、Id=65(アンケートのId)にGender=男性が割り当たるなど、IdとGenderの対応が完全に崩れています。エラーで止まればすぐ気づけますが、こうして黙って通ってしまうのが//Idの怖いところです。
このパターンの取り方は、繰り返しレコードのノードを起点にして、その直接の子だけを取ることです。パターン2と同じくxml_find_all(doc, "//Respondent")で回答者ノードに範囲を絞り、各ノードに対してxml_find_first(nodes, "Id")と相対パス(直接の子)で指定すれば、回答者のIdだけが取れて、列の長さもそろいます。
library(xml2)
doc <- xml2::read_xml("/Users/takatoshiroto/Downloads/XML/employee_survey.xml")
# 回答者ノードを起点にする
nodes <- xml2::xml_find_all(doc, "//Respondent")
# 各列を「直接の子」を指す相対パスで取る
df <- data.frame(
Id = xml2::xml_text(xml2::xml_find_first(nodes, "Id")),
Gender = xml2::xml_text(xml2::xml_find_first(nodes, "Gender")),
stringsAsFactors = FALSE
)
df
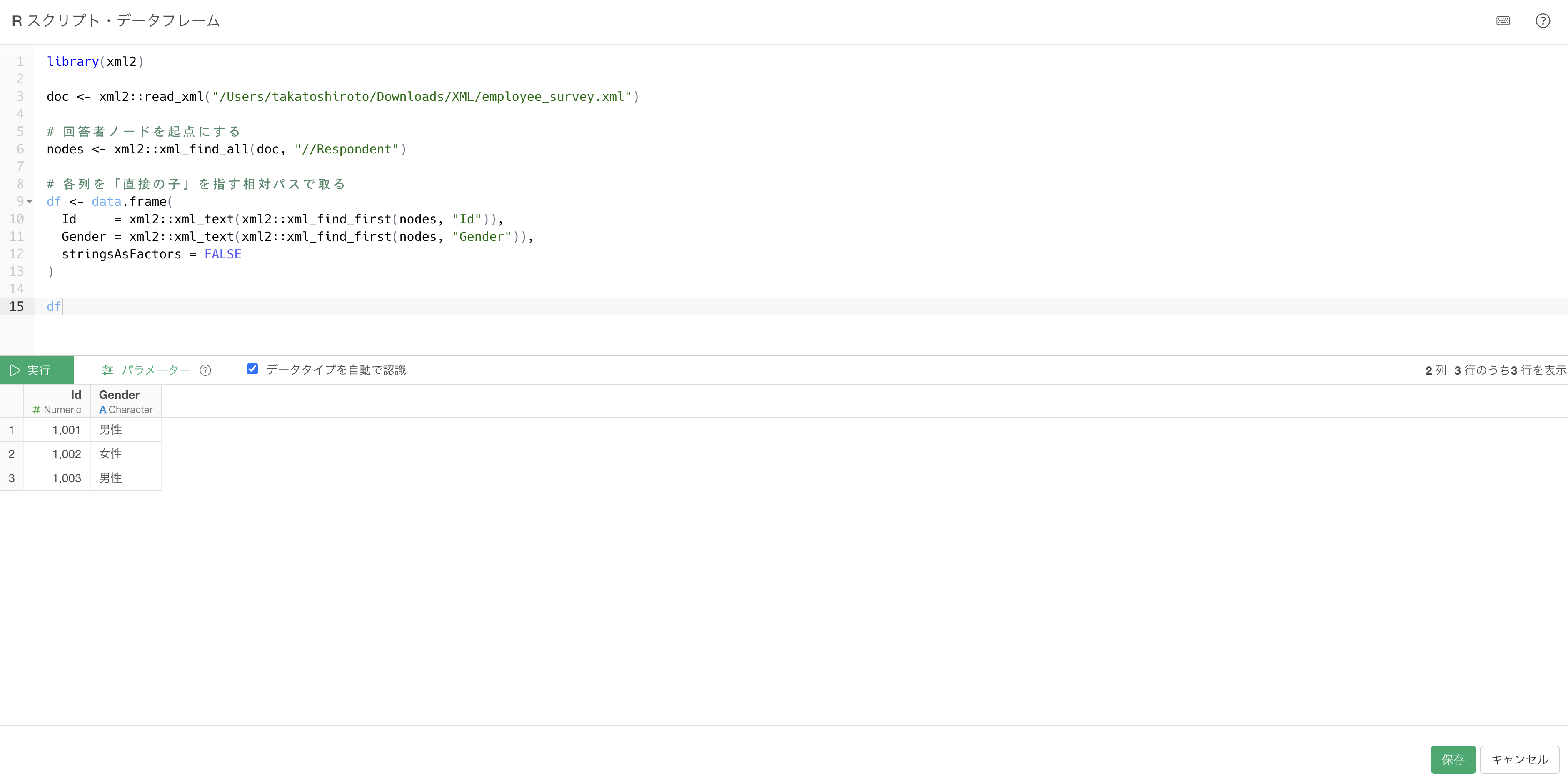
//Idで混ざっていた6個ではなく、回答者のIdだけが3個取れて、Genderと長さもそろった表になりました。違いを生んでいるのはXPathの書き方です。整理すると次のようになります。
| 書き方 | 検索の起点 | 取得される範囲 |
|---|---|---|
//Id |
ドキュメント全体(ルート) | どの階層のIdも全部拾う |
.//Id |
現在のノード | そのノード配下のすべての子孫のId(入れ子だと内側も拾う) |
Id(または./Id) |
現在のノード | そのノードの直接の子のIdだけ |
先頭に//が付くと、たとえノードを起点に呼び出したつもりでも、検索はドキュメントの先頭(ルート)から行われます。レコードのノードをxml_find_all()で取得し、フィールドはIdのような直接の子を指す相対パスで取る
——これが、同じタグ名が複数階層にあるXMLを正確に取るコツです。パターン2で複数の列を組み立てたときにxml_find_first(nodes, "Id")と書いていたのも、この相対パスの考え方に沿っています。
パターン4: 値が属性に入っている・名前空間が付いている
業務システムやWeb
APIのXMLには、値をタグで挟むのではなく<temperature celsius="22.3" />のように属性として持たせ、さらにルートタグにxmlns="..."という名前空間の宣言が付いているものがよくあります。weather.xmlがその例です。
<?xml version="1.0" encoding="utf-8"?>
<stations xmlns="http://example.com/weather">
<station id="47662" name="東京">
<temperature celsius="22.3" trend="rising"/>
<humidity percent="68"/>
</station>
...
</stations>このXMLにいつものXPathを使うと、結果が0件になります。
doc <- xml2::read_xml("/Users/takatoshiroto/Downloads/XML/weather.xml")
xml2::xml_find_all(doc, "//station")
#> {xml_nodeset (0)} ← 名前空間のせいで一致しないxmlnsが宣言されていると、すべてのタグが「その名前空間に属するstation」として扱われ、名前空間を考慮しない//stationという書き方とは一致しなくなるためです。このパターンでは、xml_ns_strip()で名前空間をいったん取り除いてから取ります。取り除いた後は、これまでどおりのXPathが使えます。さらに値が属性に入っているので、各列はxml_text()ではなくxml_attr()で取り出します。
library(xml2)
doc <- xml2::read_xml("/Users/takatoshiroto/Downloads/XML/weather.xml")
xml2::xml_ns_strip(doc) # 名前空間を取り除く
# レコード(観測地点)のノードをすべて取得
nodes <- xml2::xml_find_all(doc, "//station")
# 属性の値を xml_attr() で1列ずつ取り出して組み立てる
df <- data.frame(
id = xml2::xml_attr(nodes, "id"),
name = xml2::xml_attr(nodes, "name"),
celsius = xml2::xml_attr(xml2::xml_find_first(nodes, "temperature"), "celsius"),
humidity = xml2::xml_attr(xml2::xml_find_first(nodes, "humidity"), "percent"),
stringsAsFactors = FALSE
)
df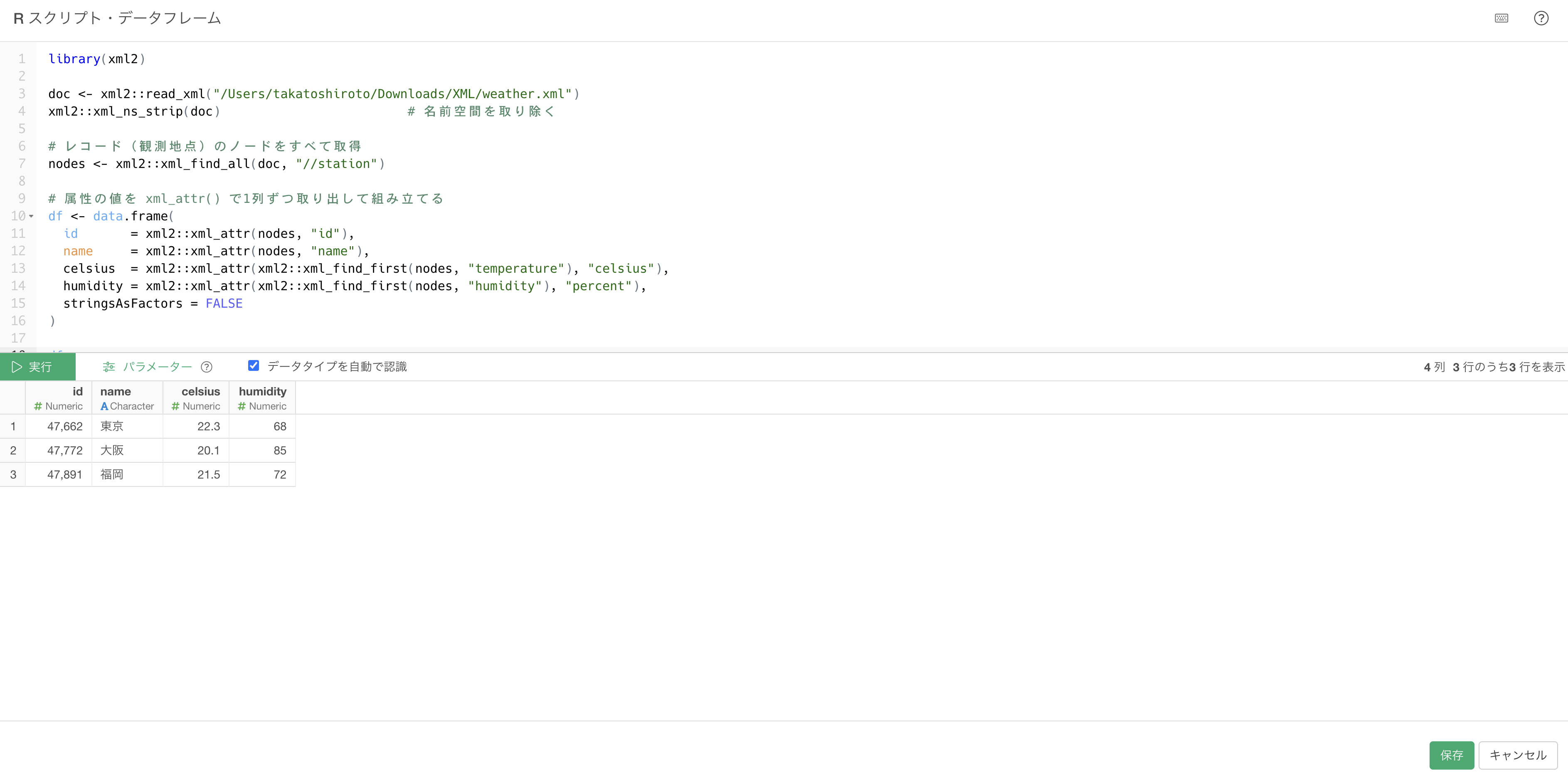
xml_text()がタグに挟まれた値を取るのに対し、xml_attr()はタグの属性の値を取ります。どちらも「ノードをxml_find_all()で取得し、そこから列を組み立てる」流れは同じです。
パターン5: ファイルがそのまま読み込めないとき
read_xml()で読もうとして、次のエラーが出て止まることがあります。
Error: Extra content at the end of the document [5]これは「ルート要素(一番外側のタグ)の閉じタグより後ろに、余分なデータがある」ときに起きます。XMLは仕様上ルート要素が1つだけと決まっているため、その後ろに何かが続いているとパーサーがエラーにします。
実務でよくあるのが、ファイルの末尾に大量のNUL(空文字・0x00)が詰まっているケースです。システムが固定長のバッファでファイルを書き出すと、実データの後ろが0x00で埋められたまま保存されることがあります。
見た目には閉じタグできれいに終わっているのに、バイト単位で見ると後ろに不要なゴミが続いている状態です。
このパターンでは、パースする前に末尾の不要なゴミを取り除きます。バイトとして読み込んでNULを除去してからread_xml()に渡します。
library(xml2)
path <- "/Users/takatoshiroto/Downloads/XML/employee_survey_broken.xml"
# バイト列として読み込み、NUL(0x00)を取り除いてからパースする
raw <- readBin(path, what = "raw", n = file.info(path)$size)
raw <- raw[raw != as.raw(0)]
doc <- xml2::read_xml(rawToChar(raw))
# ゴミを取り除いた後は、パターン2と同じように抽出できる
nodes <- xml2::xml_find_all(doc, "//Respondent")
df <- data.frame(
Id = xml2::xml_text(xml2::xml_find_first(nodes, "Id")),
Gender = xml2::xml_text(xml2::xml_find_first(nodes, "Gender")),
Age = as.integer(xml2::xml_text(xml2::xml_find_first(nodes, "Age"))),
Department = xml2::xml_text(xml2::xml_find_first(nodes, "Department")),
stringsAsFactors = FALSE
)
df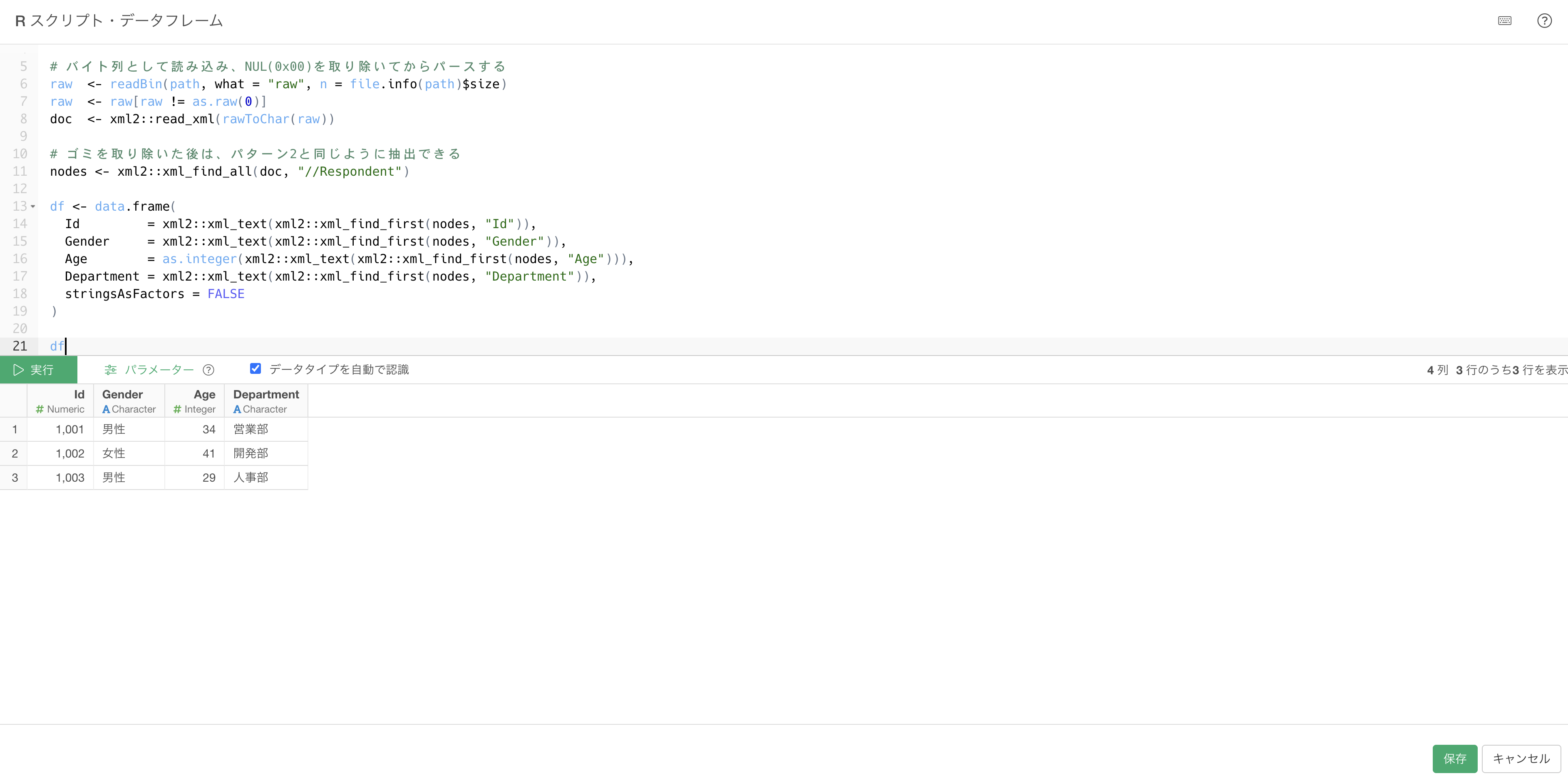
readLines()で一度テキストとして読み込む方法でも、埋め込まれたNULが落ちるため同じ効果が得られます。読み込みの部分だけを次のように差し替えれば、あとは上と同じくnodesを取得してdfを組み立てます。
library(xml2)
# readLines() でテキストとして読み込むと、埋め込まれたNULが落ちる
lines <- readLines("/Users/takatoshiroto/Downloads/XML/employee_survey_broken.xml", encoding = "UTF-8", warn = FALSE)
doc <- xml2::read_xml(paste(lines, collapse = "\n"))
# 以降はパターン2と同じ
nodes <- xml2::xml_find_all(doc, "//Respondent")
df <- data.frame(
Id = xml2::xml_text(xml2::xml_find_first(nodes, "Id")),
Gender = xml2::xml_text(xml2::xml_find_first(nodes, "Gender")),
Age = as.integer(xml2::xml_text(xml2::xml_find_first(nodes, "Age"))),
Department = xml2::xml_text(xml2::xml_find_first(nodes, "Department")),
stringsAsFactors = FALSE
)
df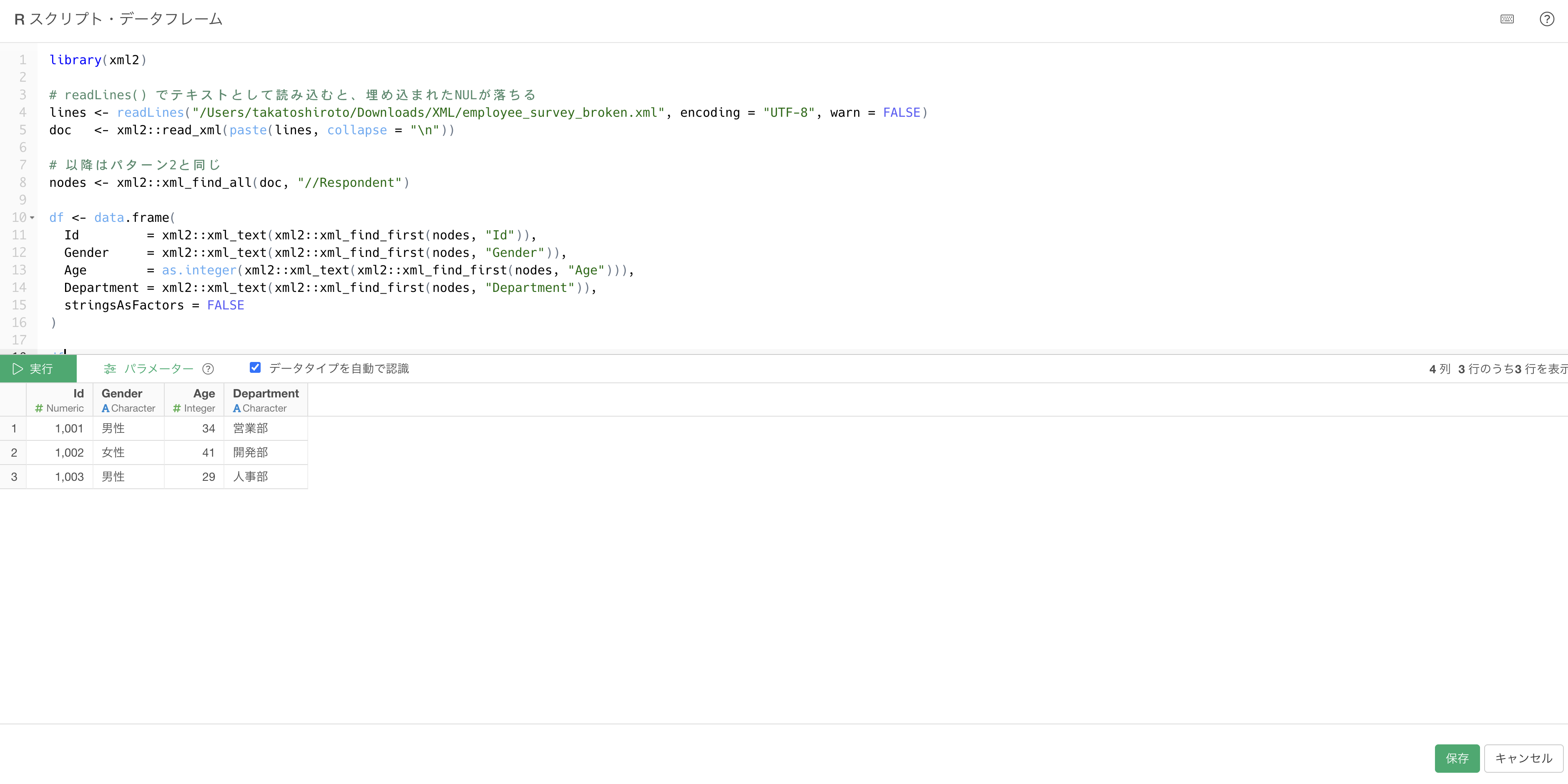
なお、read_xml()には壊れたXMLの回復を試みるoptions = c("RECOVER", "NOERROR", "NOWARNING")がありますが、末尾の余分なデータについてはこのオプションだけでは解決しないことがあります。まず末尾の不要なゴミを取り除いてから読むのが確実です。
また、日本語のXMLで文字化けする場合は、ファイルの文字コードが宣言(encoding="utf-8"など)と食い違っていることがあります。Shift_JISのファイルならread_xml(..., encoding = "cp932")のように明示的に指定すると読めることがあります。
まとめ
ExploratoryでXMLファイルを取り込むには、「Rスクリプト・データソース」を使うことで可能です。フラットな構造ならXMLパッケージのxmlToDataFrame()でそのまま表にでき、レコードが入れ子になっているならxml2パッケージで繰り返しレコードのノードをxml_find_all()で取得し、各ノードから直接の子タグの値を抜き出して組み立てます。
同じタグ名が複数の階層にあるときはレコードを起点にした相対パスで取り、値が属性に入っているときはxml_attr()、名前空間が付いているときはxml_ns_strip()で末尾のゴミで読み込めないときは読み込み前にゴミを除去するというように、構造に応じて対応を選んでください。
XMLは一見とっつきにくく見えますが、「まず構造を確認し、パターンに合った取り方を選ぶ」という手順に落とし込めばテーブル形式のデータへ変換できます。
レコードのノードを起点に直接の子で取り出すという基本を軸に、属性・名前空間・末尾のゴミといった状況別の対応を一度押さえておけば、業務システムから書き出された実データのXMLでも、必要なデータを安定して取り出せるようになります。