線形回帰の使い方
線形回帰の使い方や結果の解釈の仕方、よくある質問をご紹介します。
線形回帰の歴史は長く、基本的な予測モデルを作るためのアルゴリズムですが、シンプルさと説明力の高さゆえに、現在でもデータサイエンスの世界では最もよく使われる統計学習(または機械学習)アルゴリズムの一つです。
線形回帰を使うことで下記の質問に答えていくことができます。
- このデータ(予測変数)を使うことで目的変数(例:売上)のばらつきの何%を説明できると言えるのか。
- どの変数が目的変数を予測する上で重要なのか。
- 変数の値が変わると、目的変数の値はどのように変わるのか。
- その予測変数は、目的変数の変化を説明するうえで有意と言えるのか。
- 他の変数が一定とした時に、変数の値が1上がると目的変数の値はどれだけ上がるのか、または下がるのか。
必要なデータ
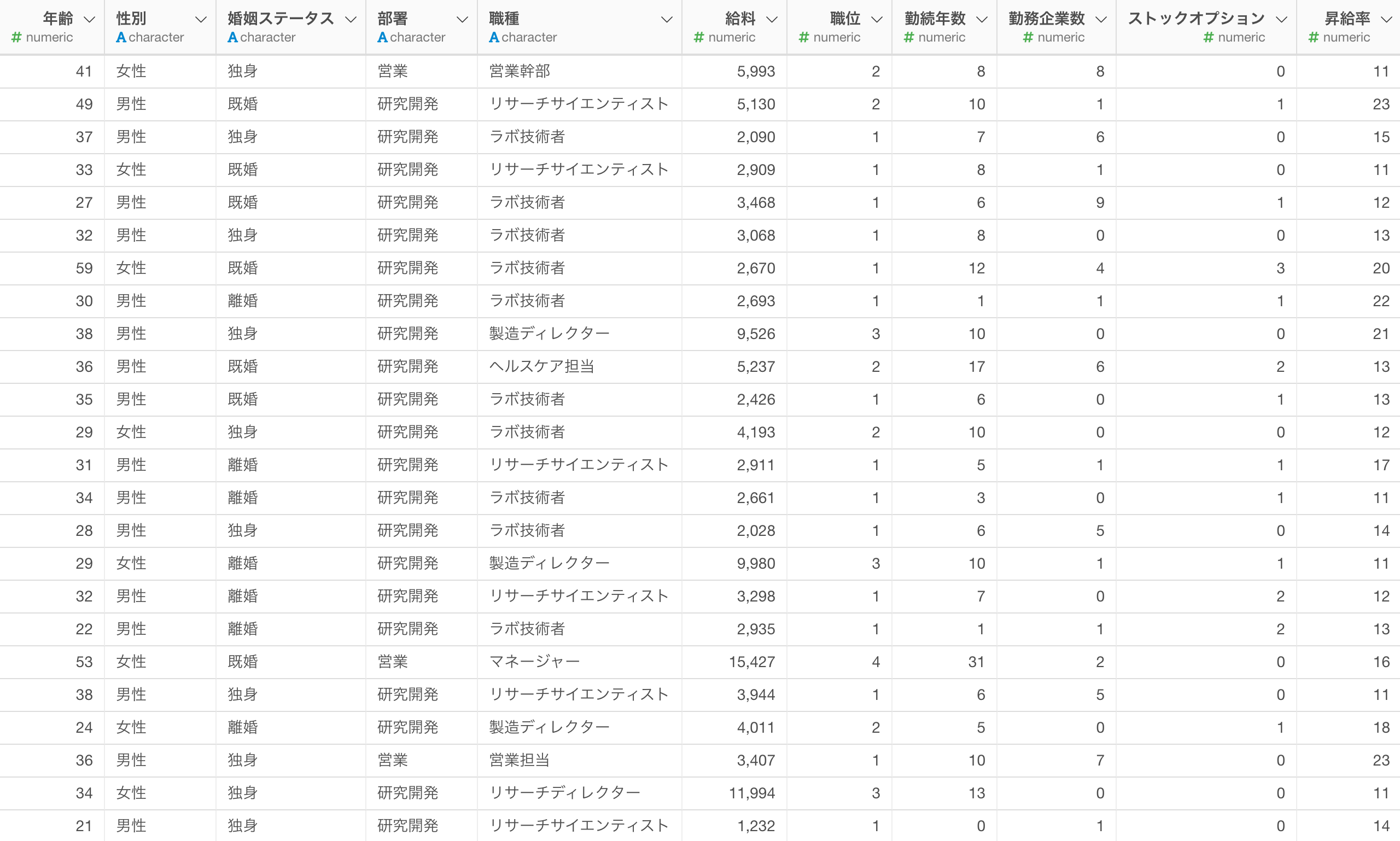
線形回帰を作成するためには、1行が1観察対象(例:1行が1従業員)となっているデータが必要です。
また、目的変数として使用できるデータタイプは「数値型」の列で、予測変数におけるデータタイプには特に縛りはありません。しかし、線形回帰などの統計系のモデル作成時には、予測変数どうしの相関があまりにも強い時に発生する「多重共線性」などの問題を考慮する必要があります。
線形回帰のモデルを作成する
今回は従業員の「給料」を予測する線形回帰のモデルを作成します。
アナリティクスビューを選び、タイプに「線形回帰」を選択します。
目的変数に「給料」を選択します。
予測変数をクリックします。
予測変数を選択します。Shiftキーを押しながら列を選ぶことで、一気に列を選択できます。
目的変数と予測変数を割り当てることができたら、「実行」ボタンをクリックします。
線形回帰のモデルが作成されました。

結果の解釈
変数重要度
変数重要度タブでは、どの変数が目的変数とより相関が強いのか、予測する時により重要なのかを調べることができます。
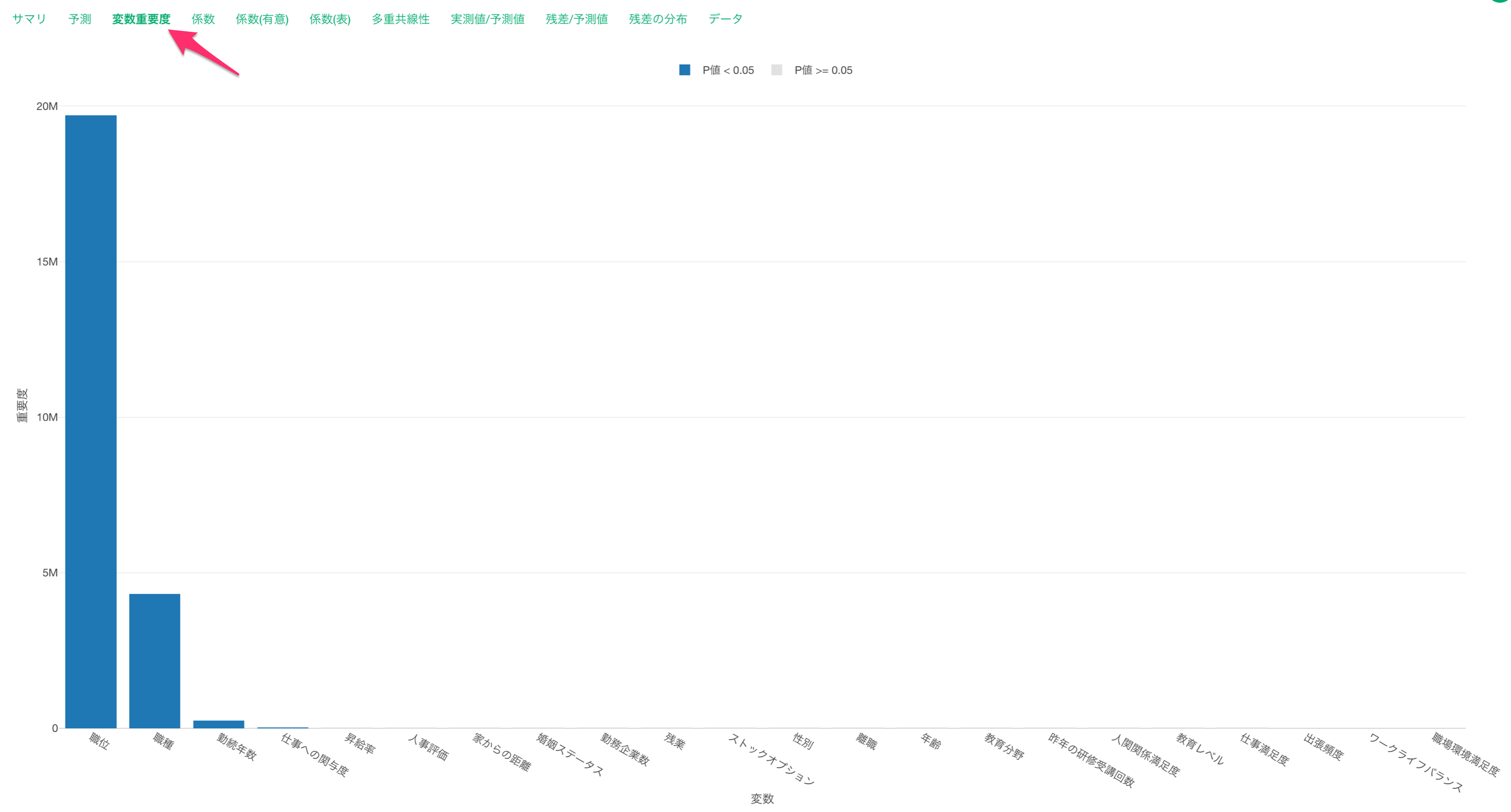
職位と職種、勤続年数が給料の予測に重要な変数なことがわかります。
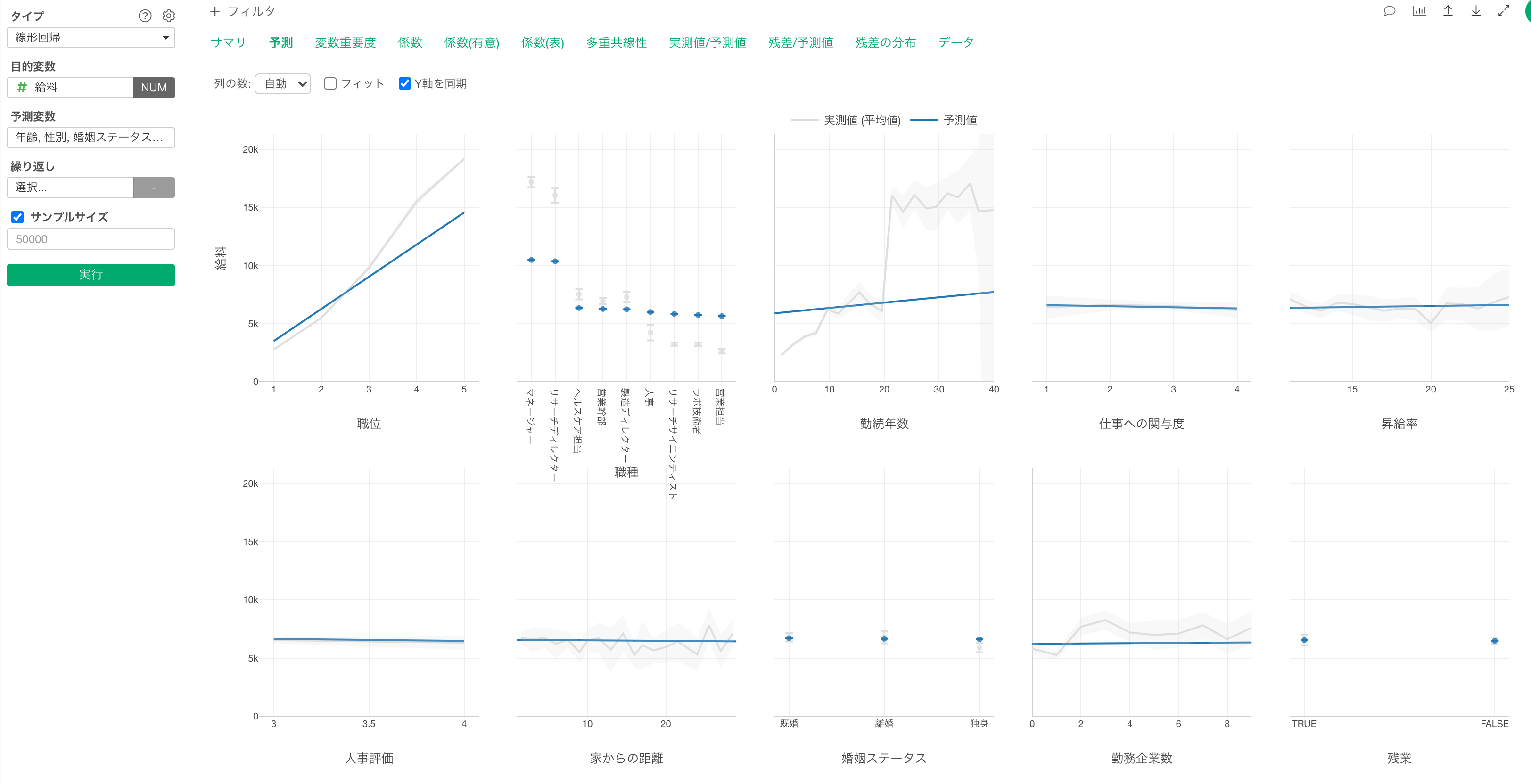
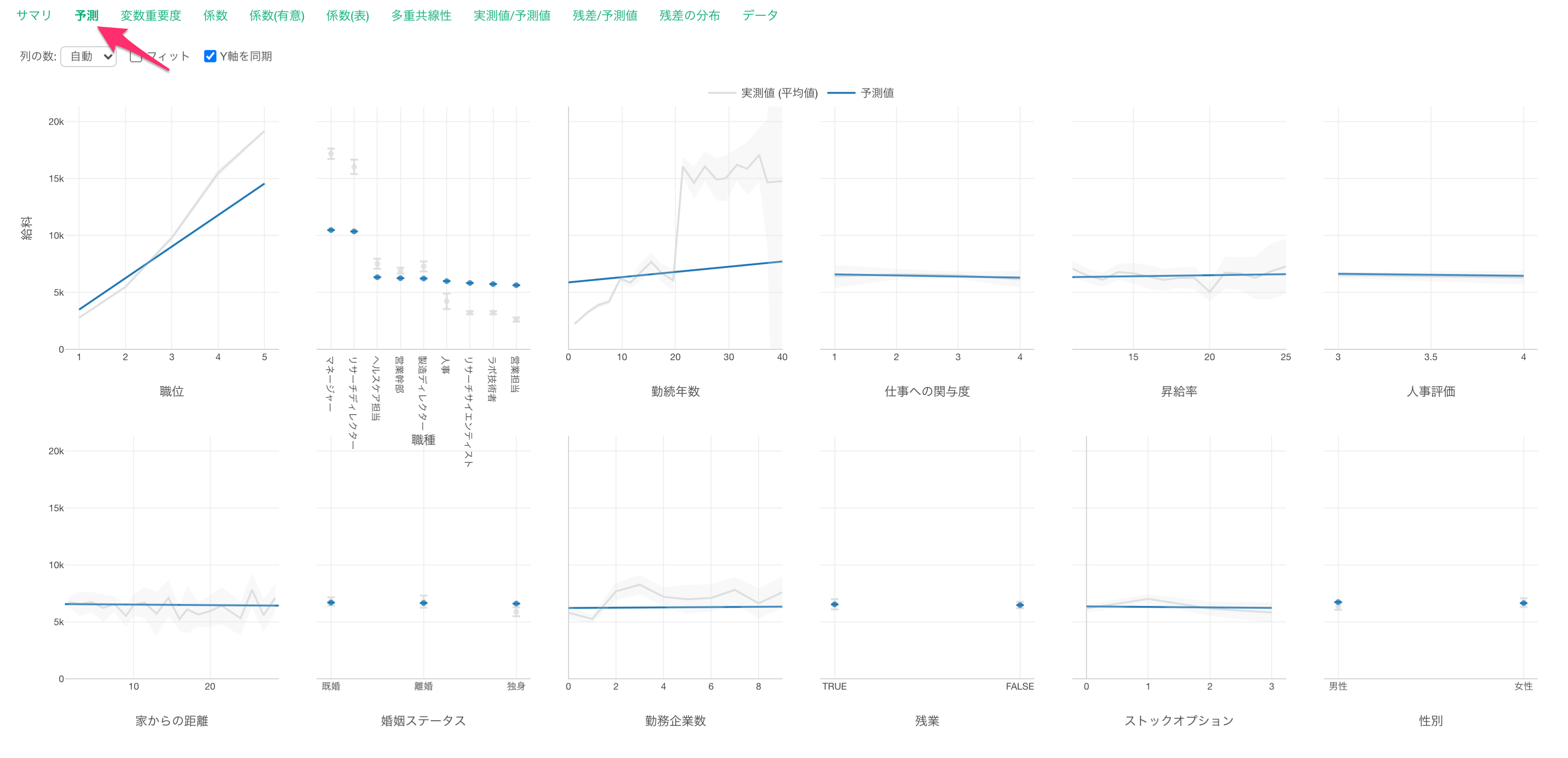
予測
予測タブでは、それぞれの変数の値が変わると、目的変数の値はどのように変わるのかがわかります。
グレーの線は実測値を表しています。
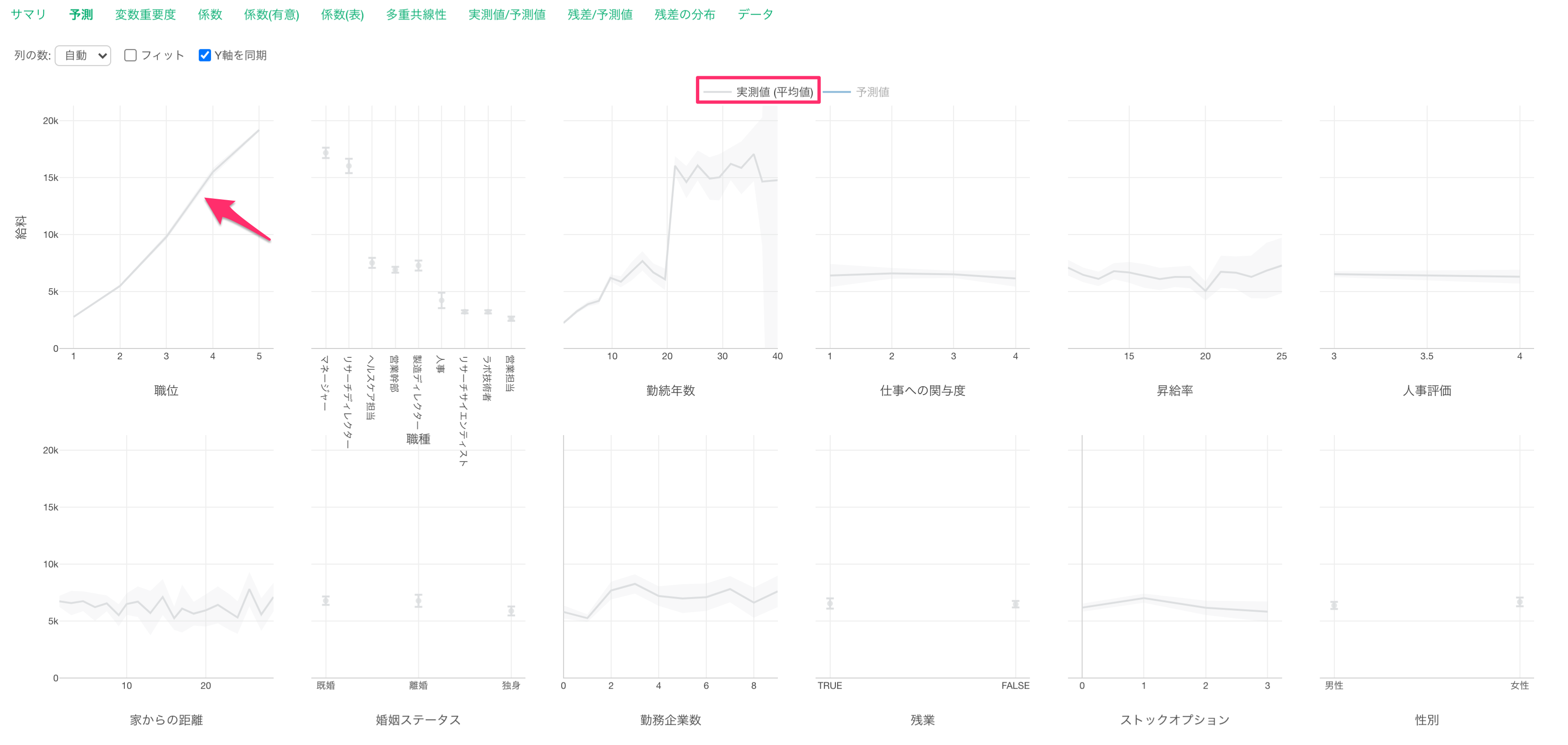
青い線は予測値を表します。
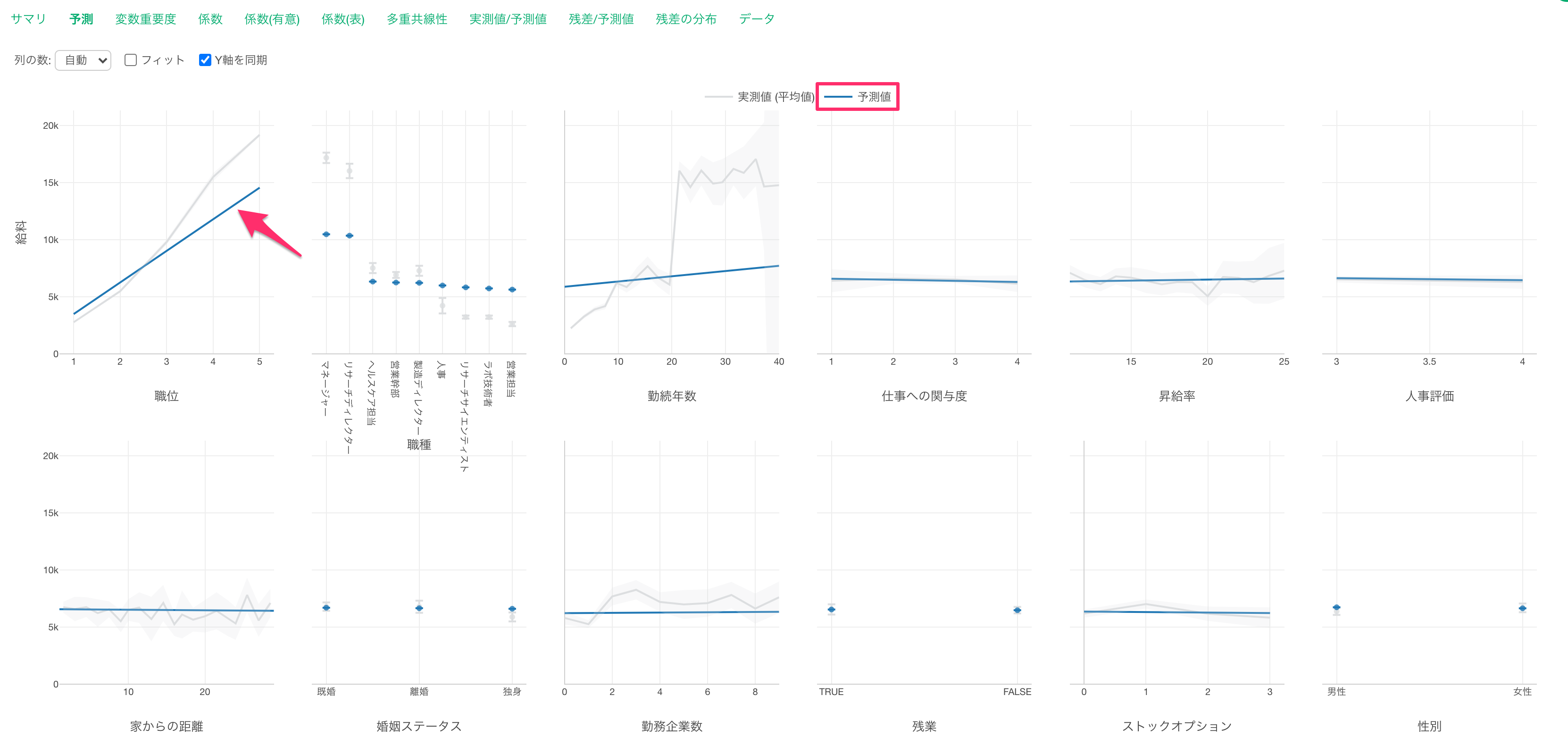
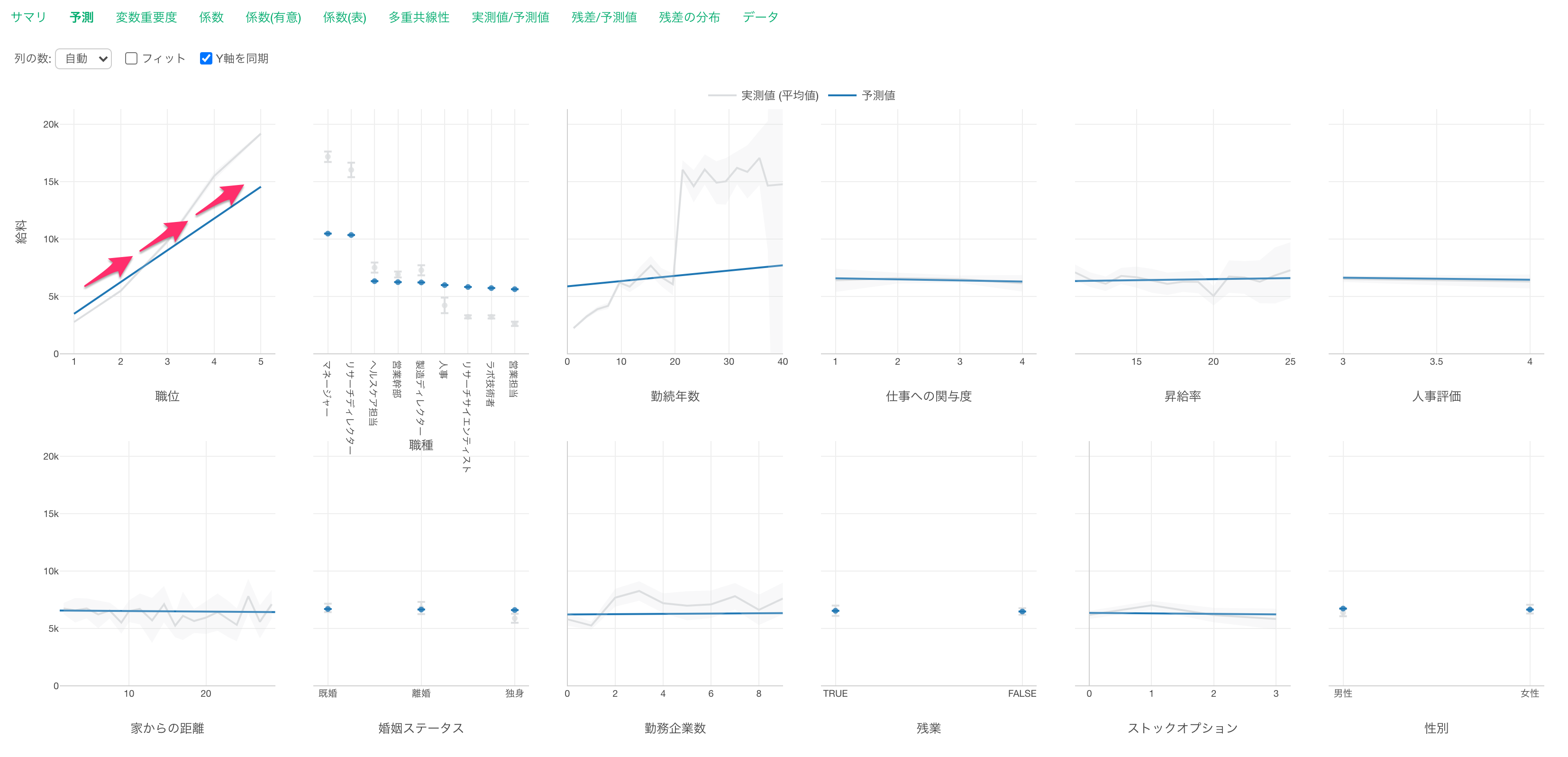
職位が上がると給料が高くなる関係があることがわかります。
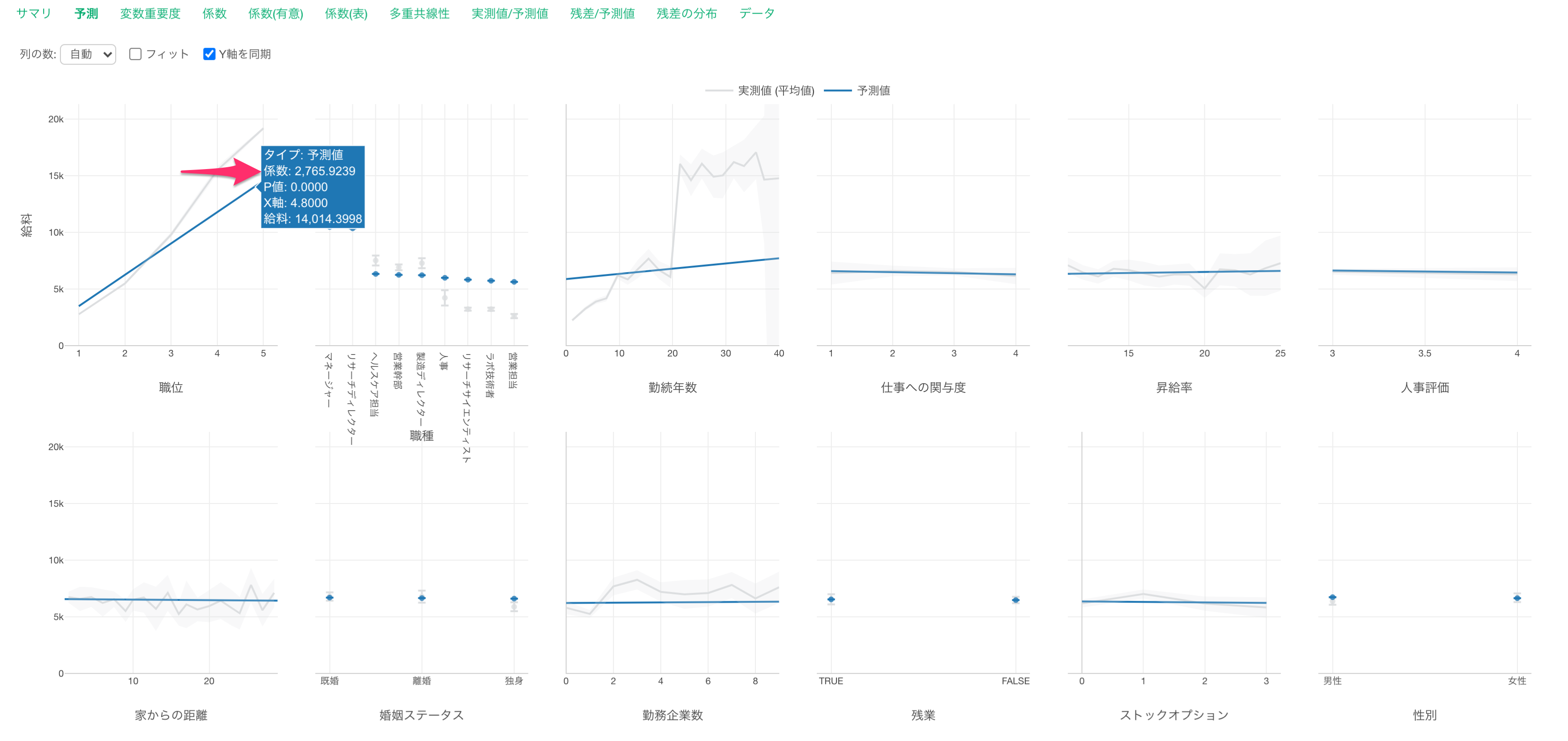
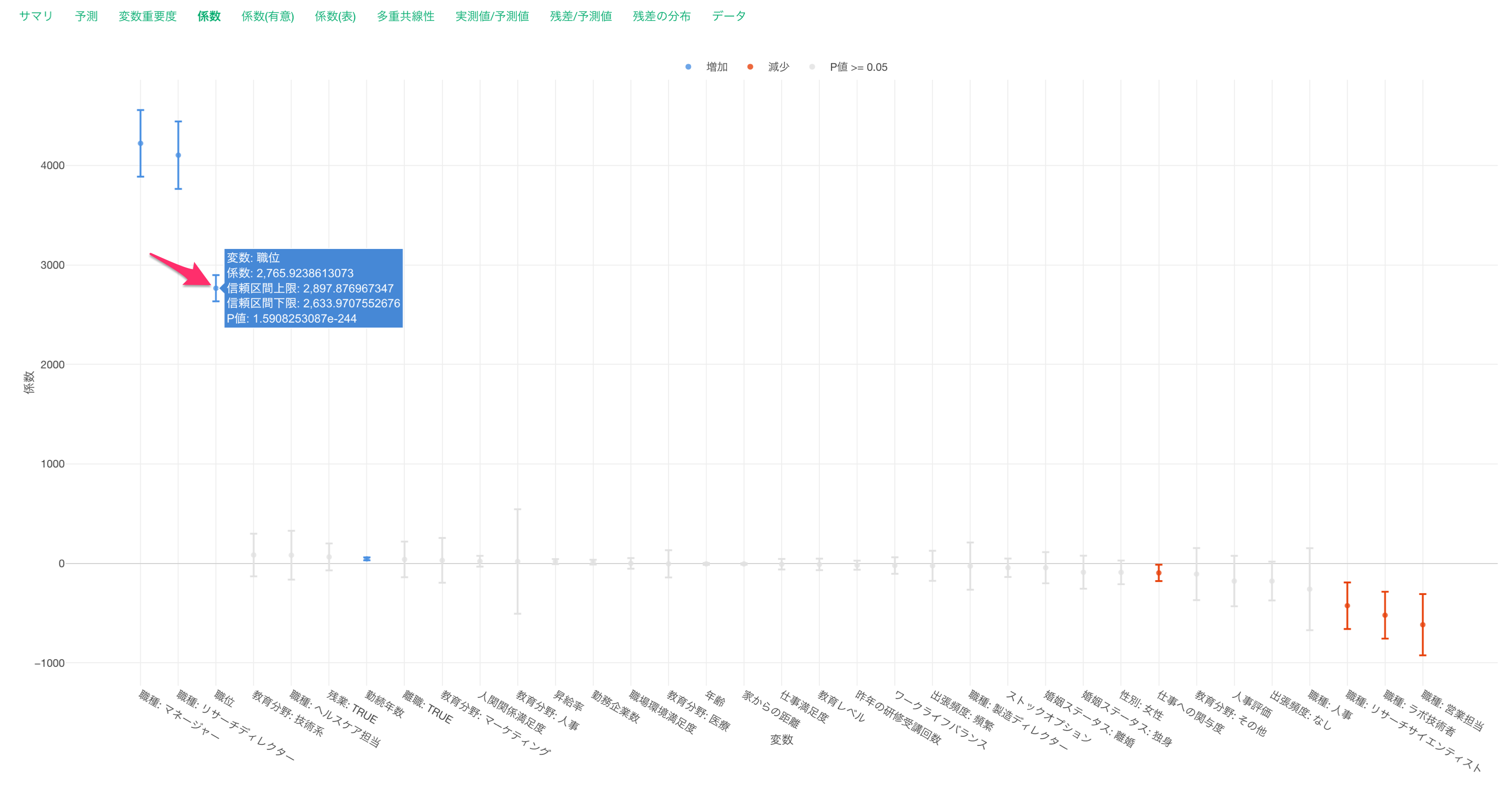
他の変数が一定だった時に、職位の値が1上がると給料が2,765ドル(係数)上がる関係があるようです。
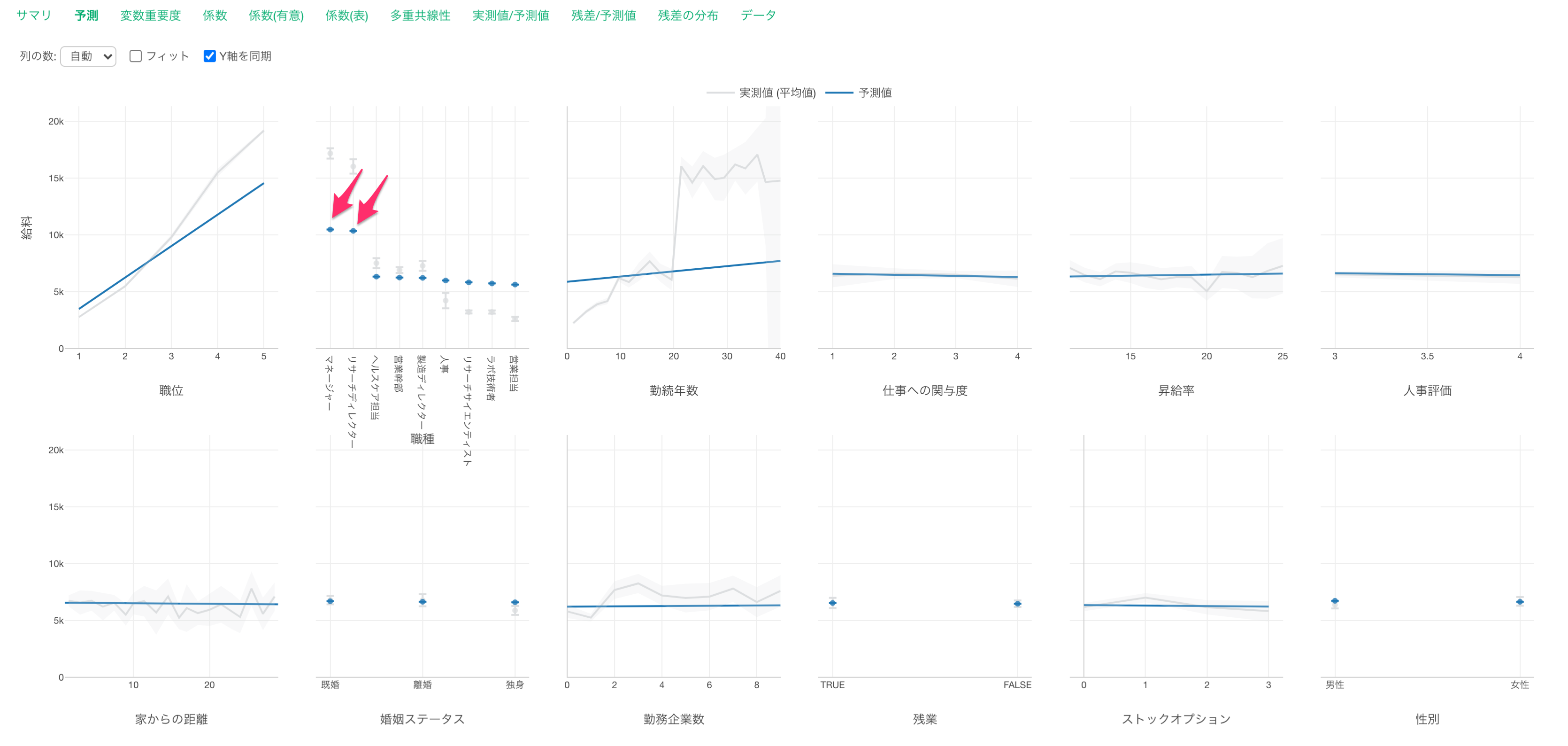
職種で見ると、マネージャーとリサーチディレクターの給料が高いようです。
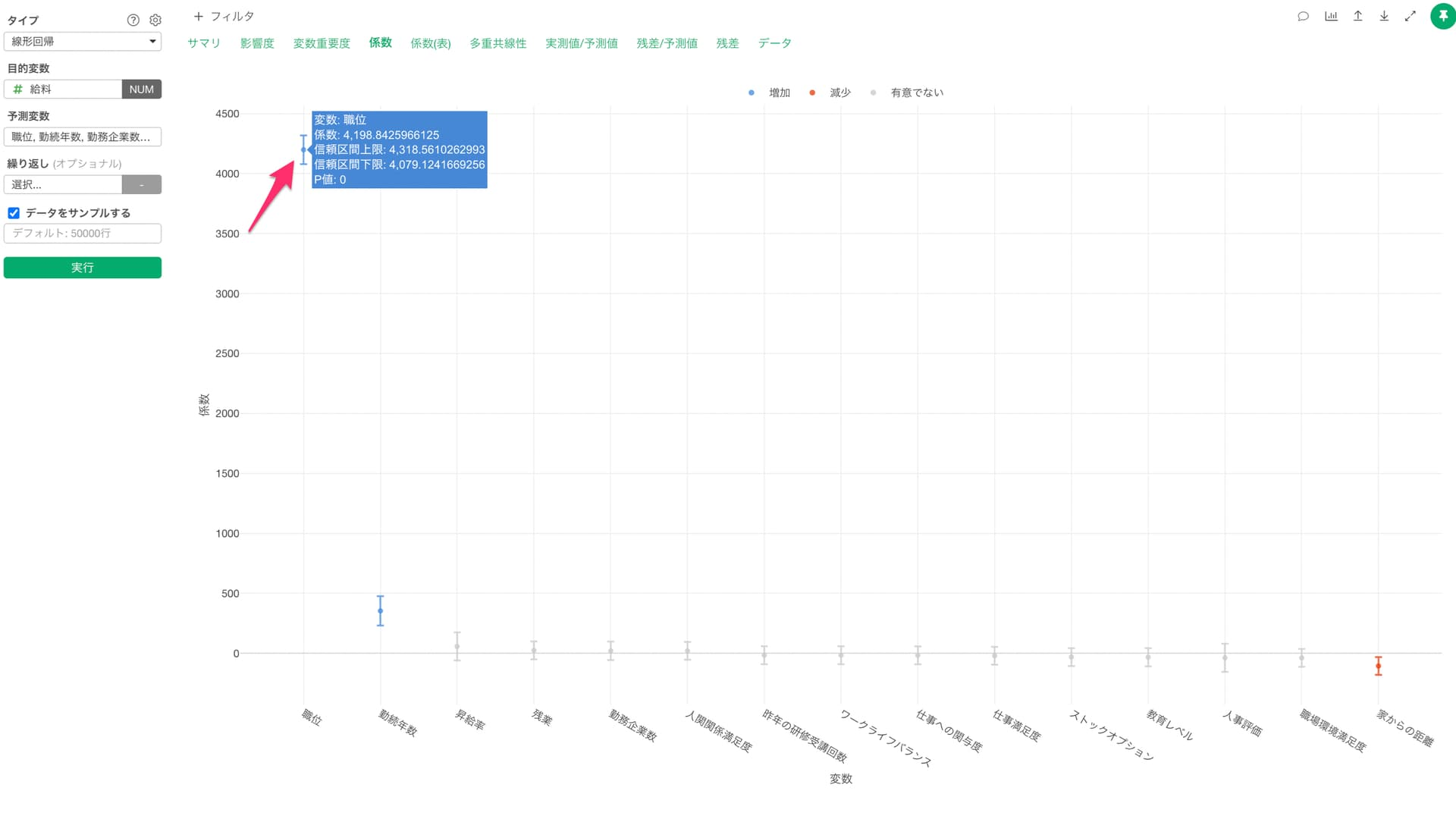
係数
係数タブでは、それぞれの変数の傾きとその信頼区間、有意性がわかります。
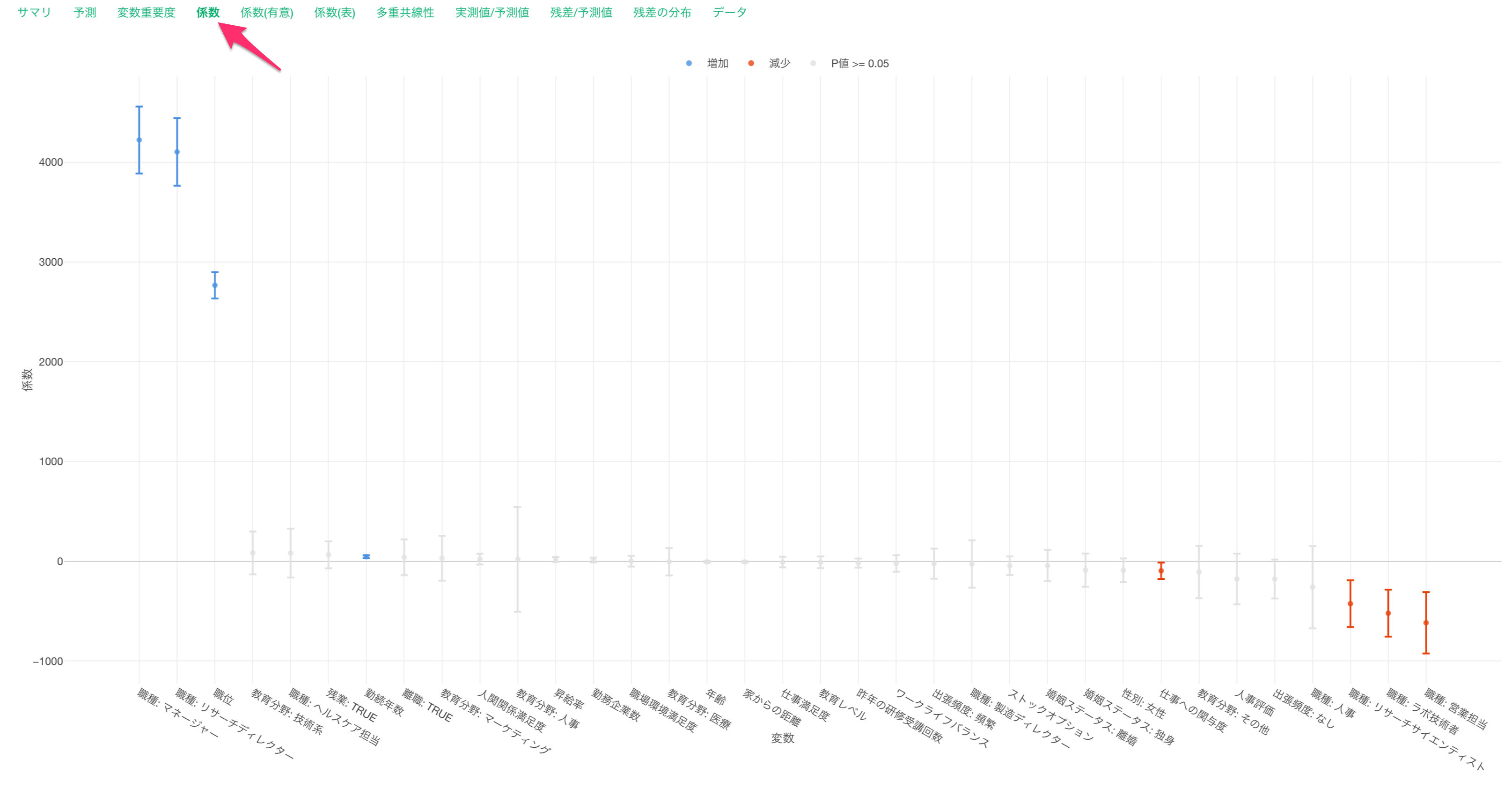
係数が増加(青)または減少(赤)の場合は、目的変数である給料との関係が有意な変数で、P値は5%以下です。これらの有意な変数は係数の信頼区間が0に重なっていない、つまり傾きが0であることはないと言えます。
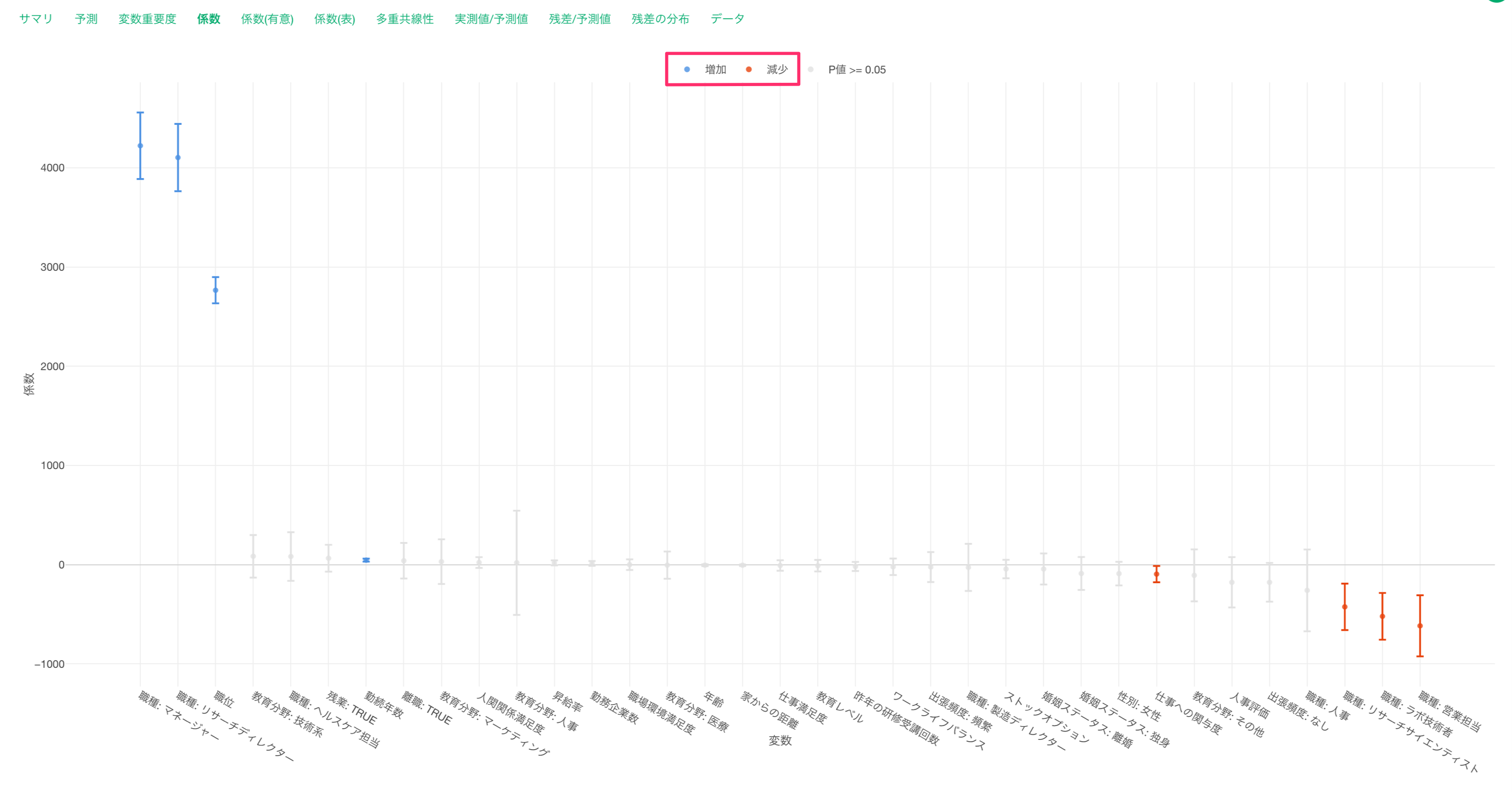
係数がグレーの変数はP値が基準値の5%以上で、統計的に有意であるとは言えない変数です。これらの変数は係数の信頼区間が0に重なっているため、傾きが0の可能性があります。
他の変数が一定だった時に、職位の値が1上がると給料が2,765ドル上がると期待されます。
他の変数が一定だった時に、仕事への関与度が1上がると給料が94ドル下がると期待されます。
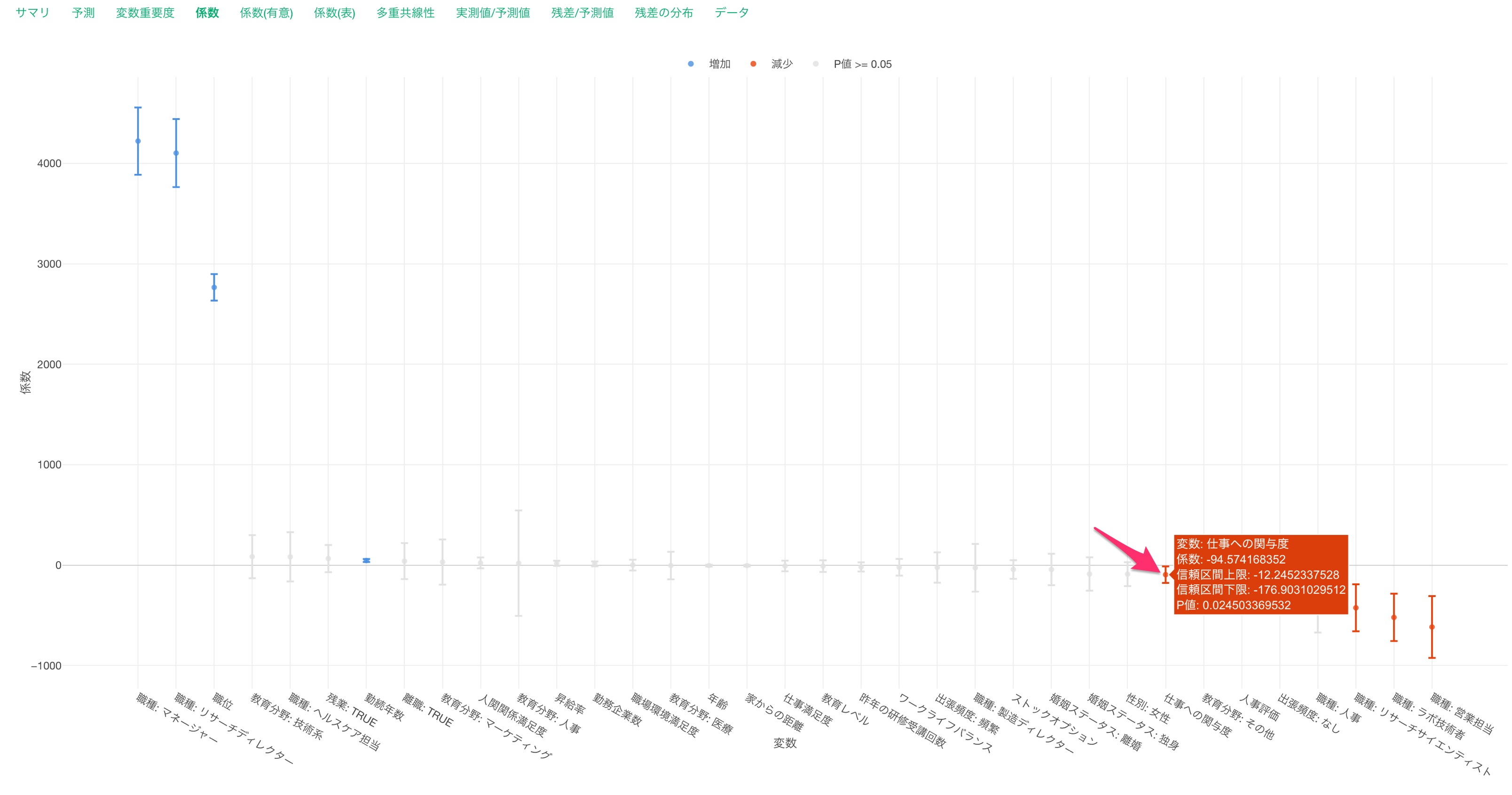
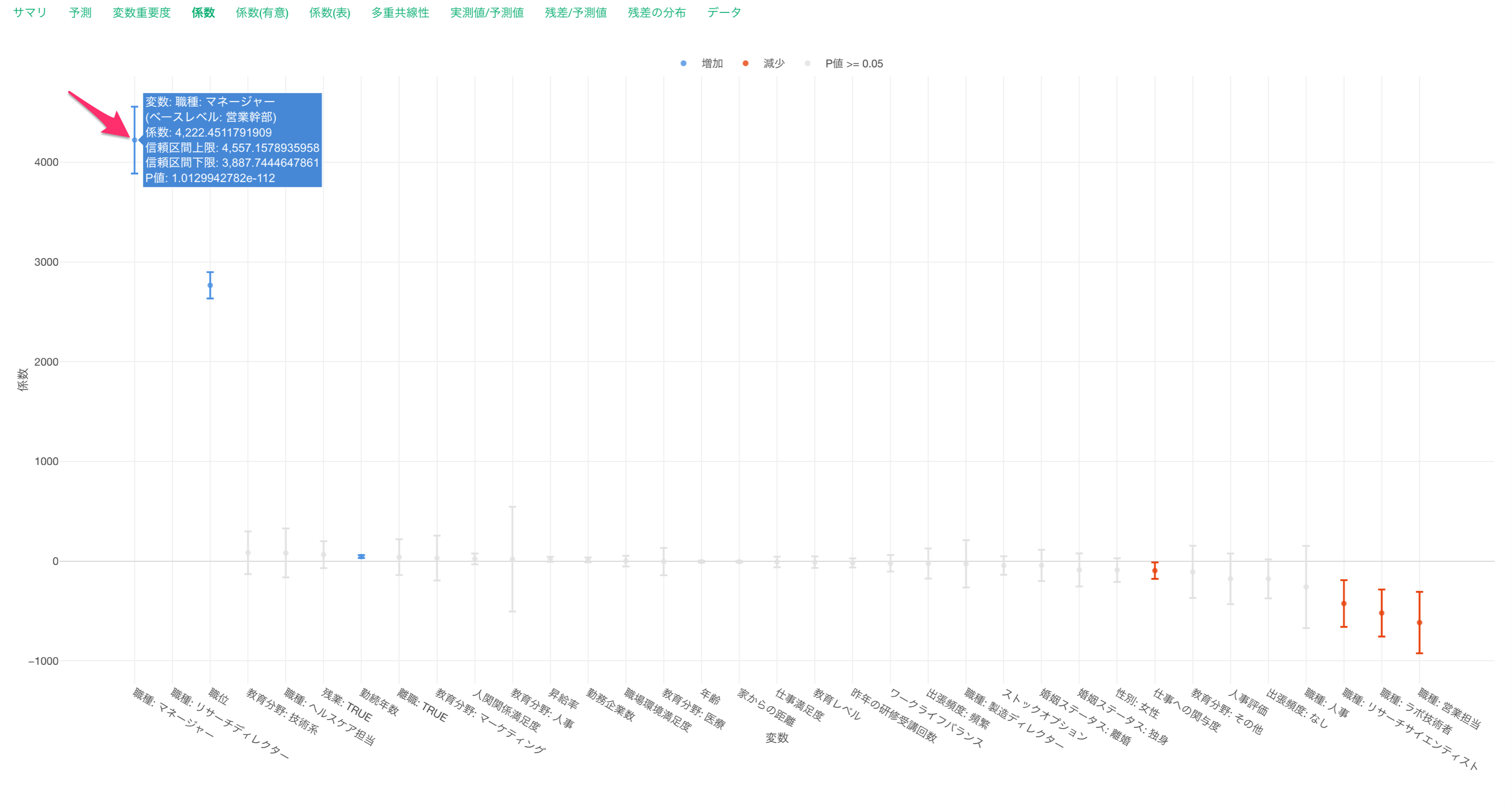
他の変数が一定だった時に、職種が営業幹部からマネージャーになると給料が4,222ドル上がることが期待されます。
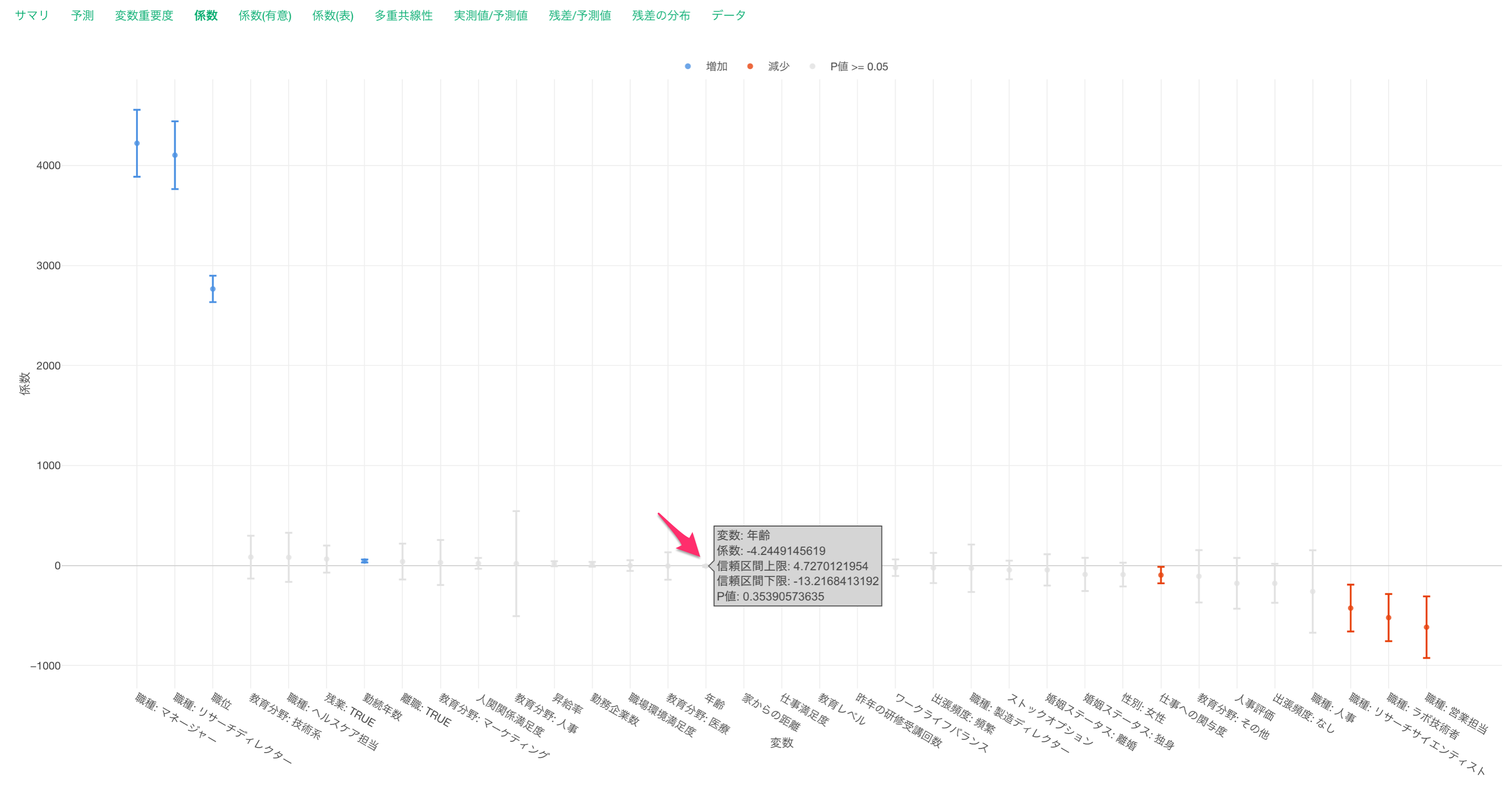
他の変数が一定だった時に、年齢が1歳増えると給料が4ドル下がることが期待されます。また、年齢は信頼区間が0をまたいでおり、P値も35%(0.35)と高いため給料に関係があるとは言いきれません。
サマリ
サマリタブでは、この予測モデルの評価を確認できます。

R2乗はデータの平均からのばらつきをモデルが説明できている割合の指標で、0から1の間の値を取ります。1に近ければ近いほど、モデルがデータのばらつきをよく説明できていることを示します。

今回は、R2乗が0.944とこのモデルを使うと給料のばらつきの94.4%説明できていると言えます。
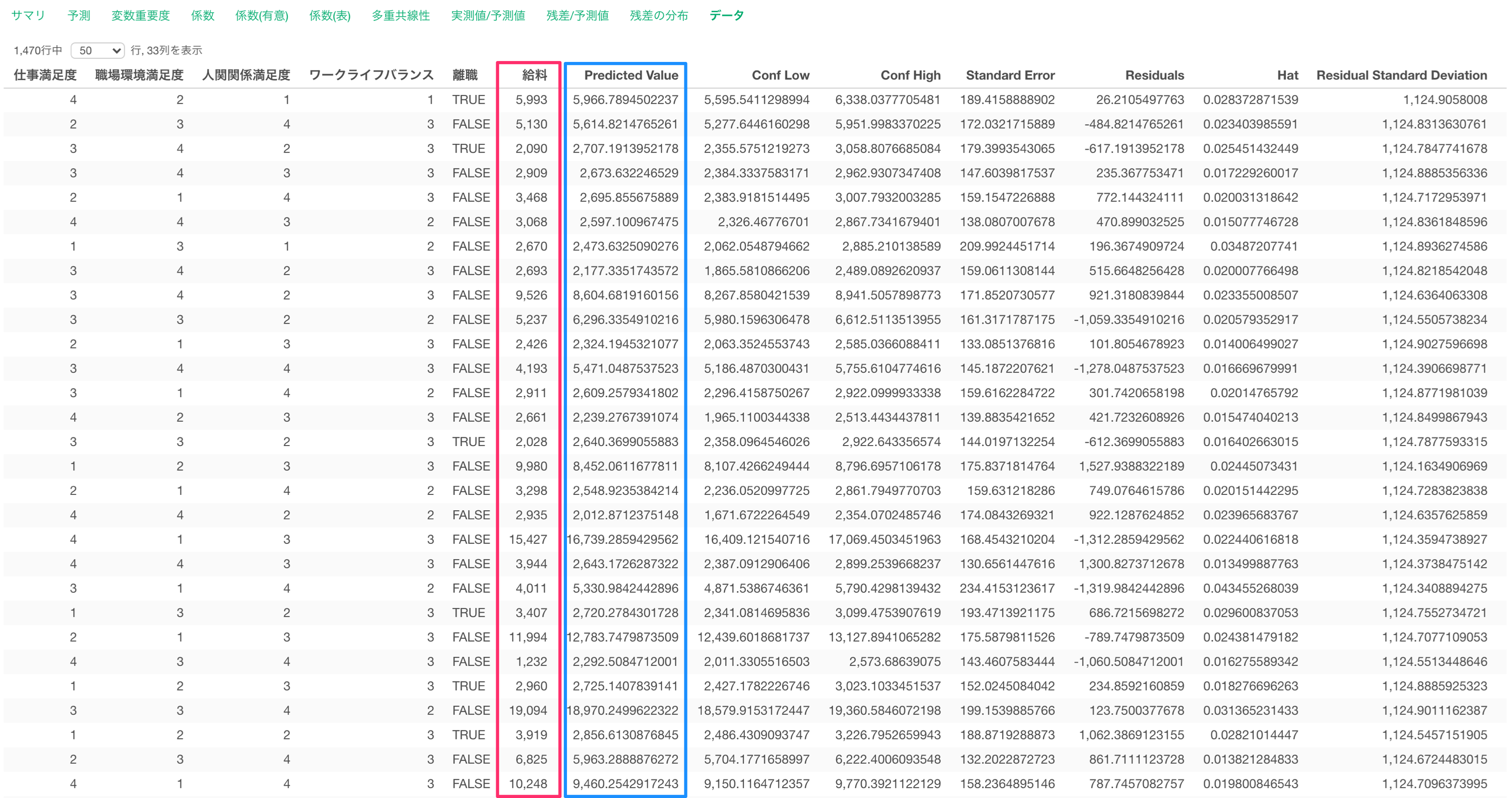
データ
データタブでは、モデルに使用したデータと予測値をテーブル形式で表示されます。
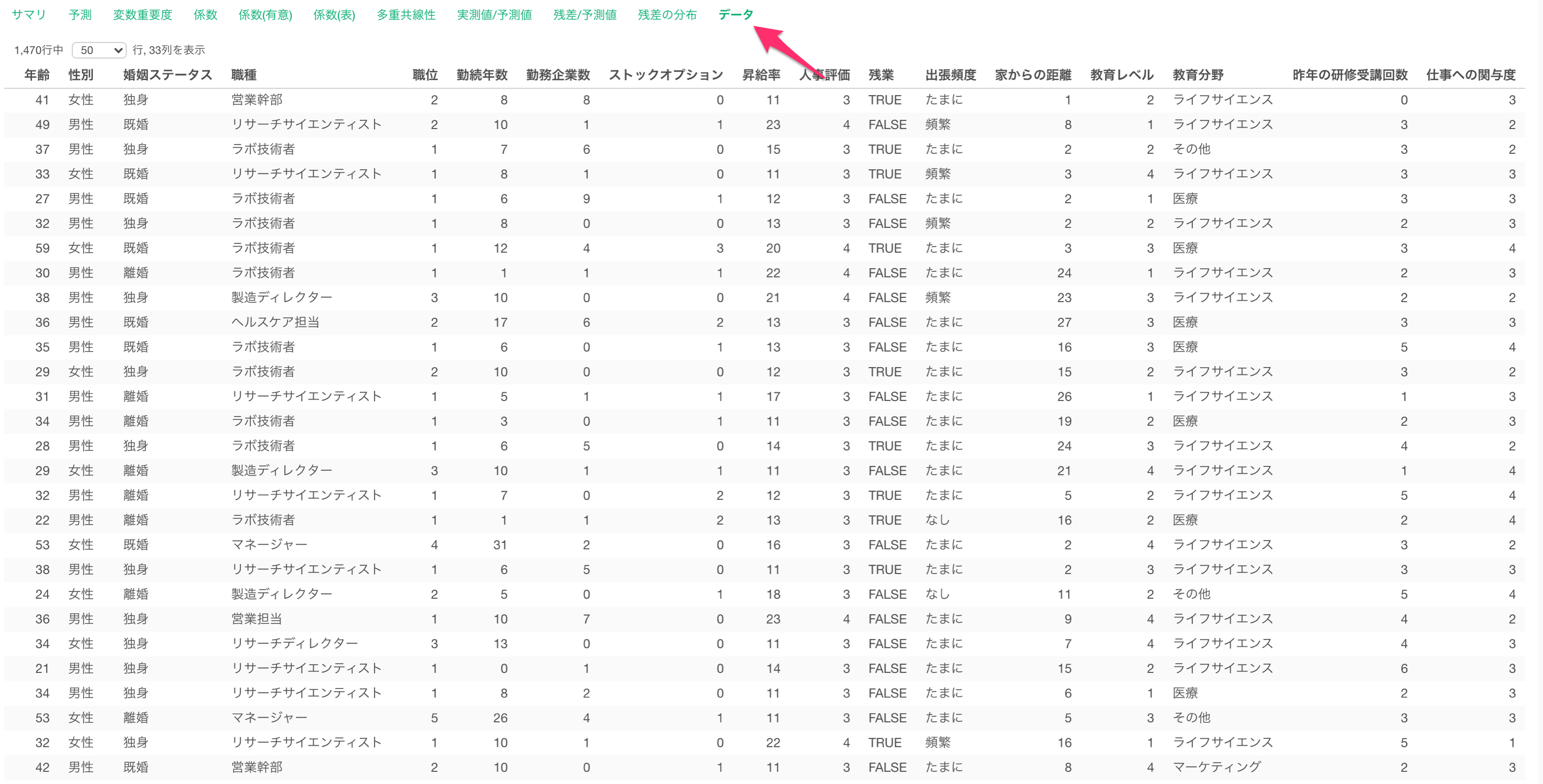
目的変数である給料と、このモデルで算出された予測値(Predicted Value)を確認できます。
参考資料
線形回帰に関する参考資料は下記をご覧ください。
線形回帰に関するよくある質問
Q: 予測タブで表示されている実測値はどのように求められているのですか?
予測タブの実測値はそれぞれの予測変数のデータタイプによって表示が異なります。 詳しくはこちらのノートをご覧ください。
Q: 予測タブで表示されている予測値はどのように求められているのですか?
予測値のチャートはPartial Dependence Plot(PDP)と呼ばれるもので、注目している変数の値を変化させたときに、予測結果がどう変わるかを可視化したチャートとなります。詳しくはこちらのノートをご覧ください。
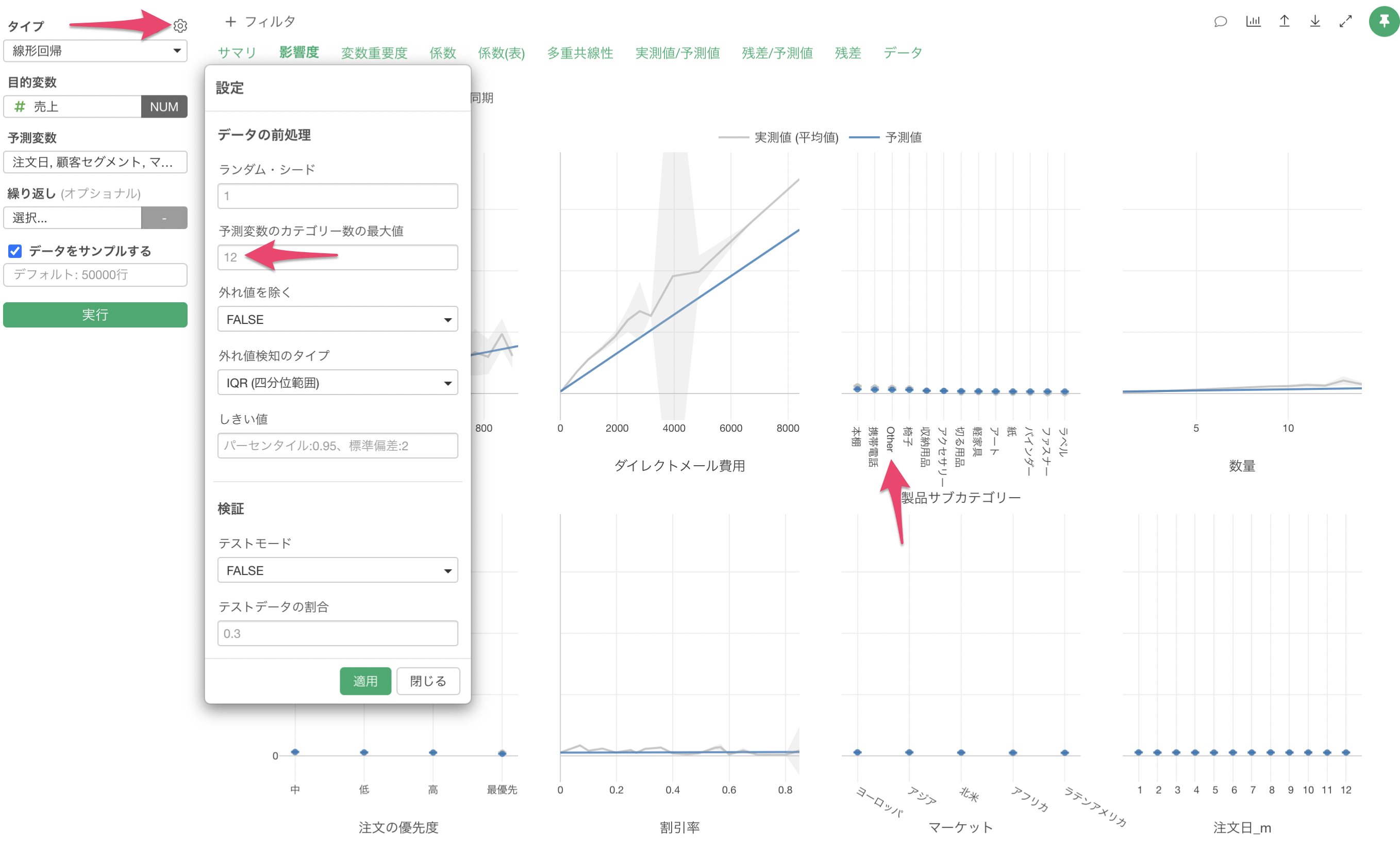
Q: 予測変数に割り当てているカテゴリー列の全ての値が表示されない。
線形回帰で予測変数にカテゴリー列を割り当てた際は、一意な値の数が12個以上の時は行の数の多い上位12のカテゴリーとそれ以外をまとめたOtherグループが作られます。 プロパティから「予測変数のカテゴリー数の最大値」を変更していただくことで、使用するカテゴリー数を調整いただけます。
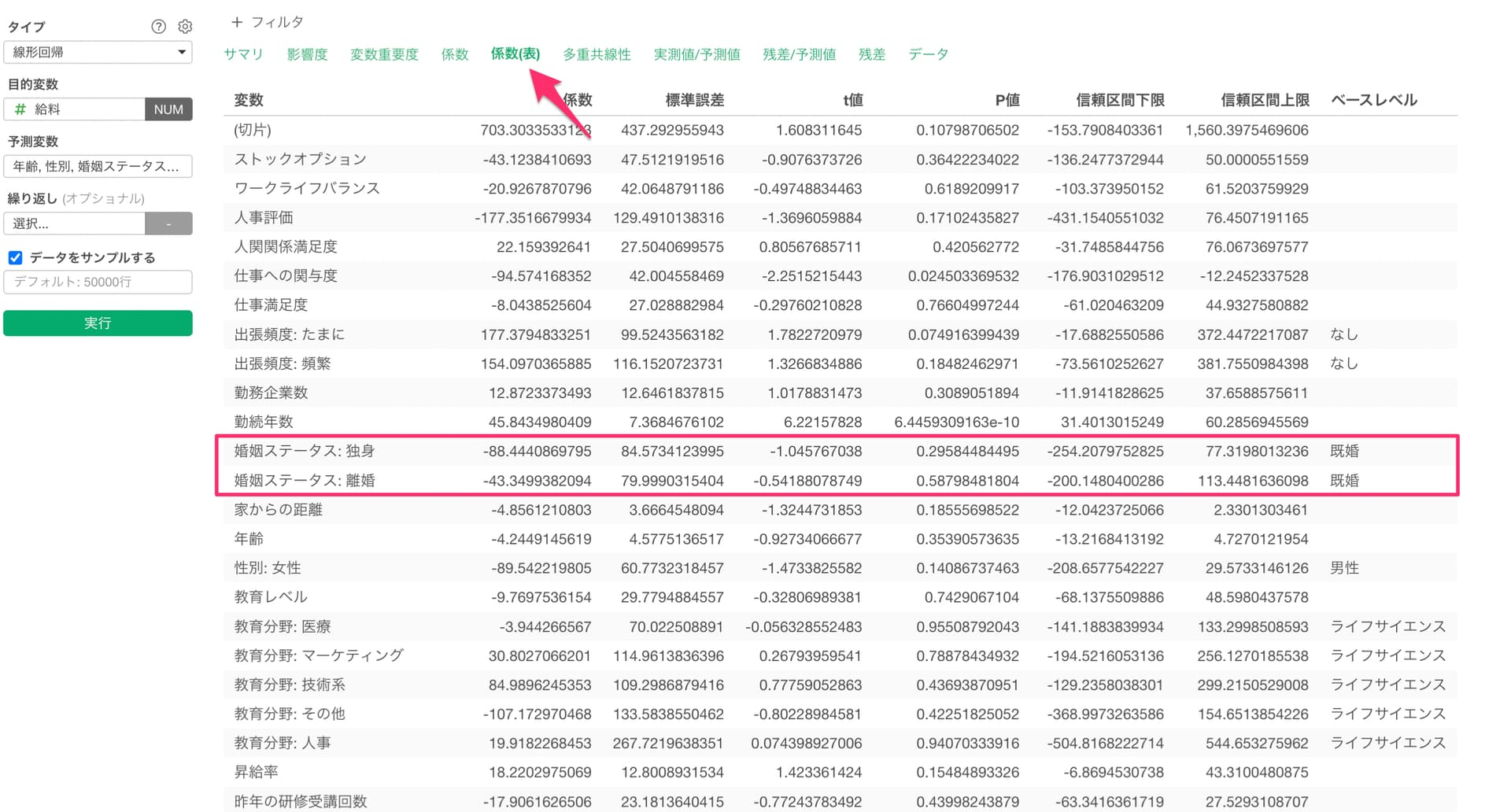
Q: 予測変数にあるカテゴリー型の列のベースレベルを変更したい
線形回帰などの統計のモデルでのカテゴリー型の列を予測変数に選択して実行した際には、ベースレベルと比べて特定の値だった時に有意なのかどうかが分かるようになっており、ベースレベルはその列の値で最頻値(行の数が最も多い)が自動的に選ばれます。
ベースレベルを変更したい場合は、こちらの投稿をご覧ください。
Q: 係数タブや係数表タブで表示される係数は標準化回帰係数ですか、それとも、偏回帰係数ですか?
係数タブや係数表タブで表示される係数は予測変数の値を標準化した後の係数(標準化回帰係数)ではなく、「元の単位」における係数(偏回帰係数)となります。
Q: 予測変数が一つのときと、複数の時で予測値や傾き(係数)が異なるのはなぜでしょうか?
線形回帰などの統計の予測モデルで、予測変数が一つの時は「単回帰」と呼びます。
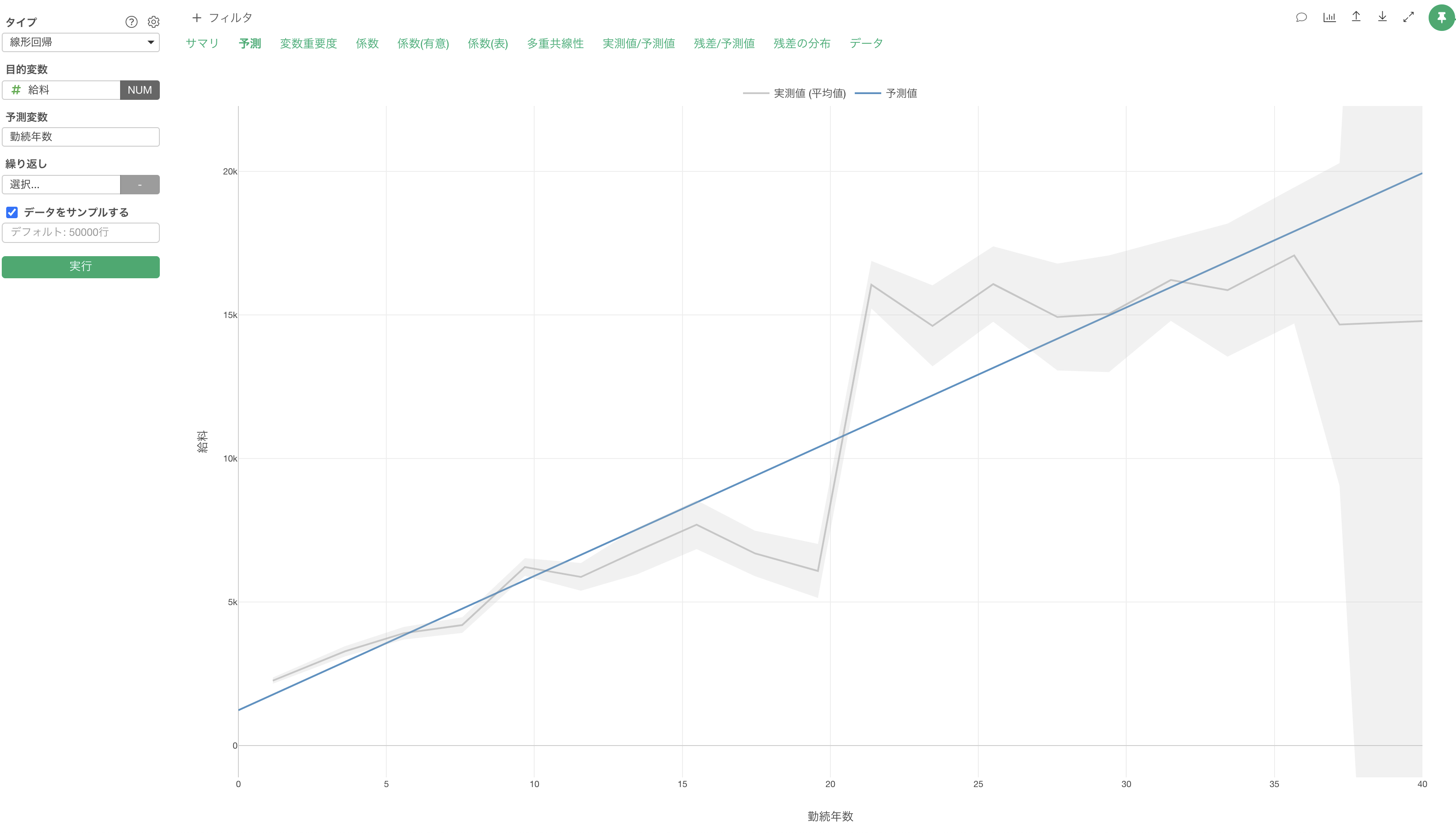
予測変数が複数の時は「重回帰」と呼ばれます。
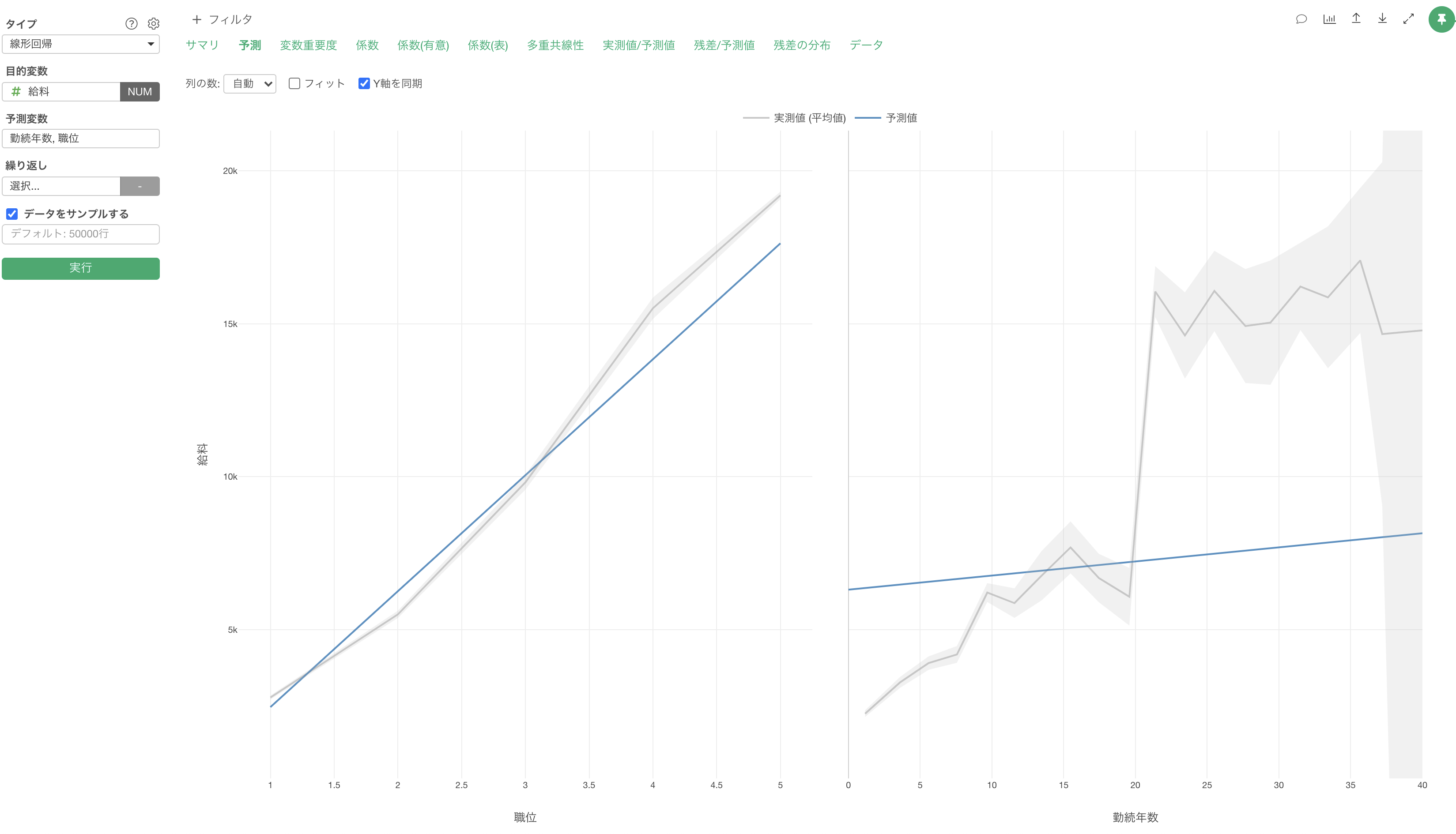
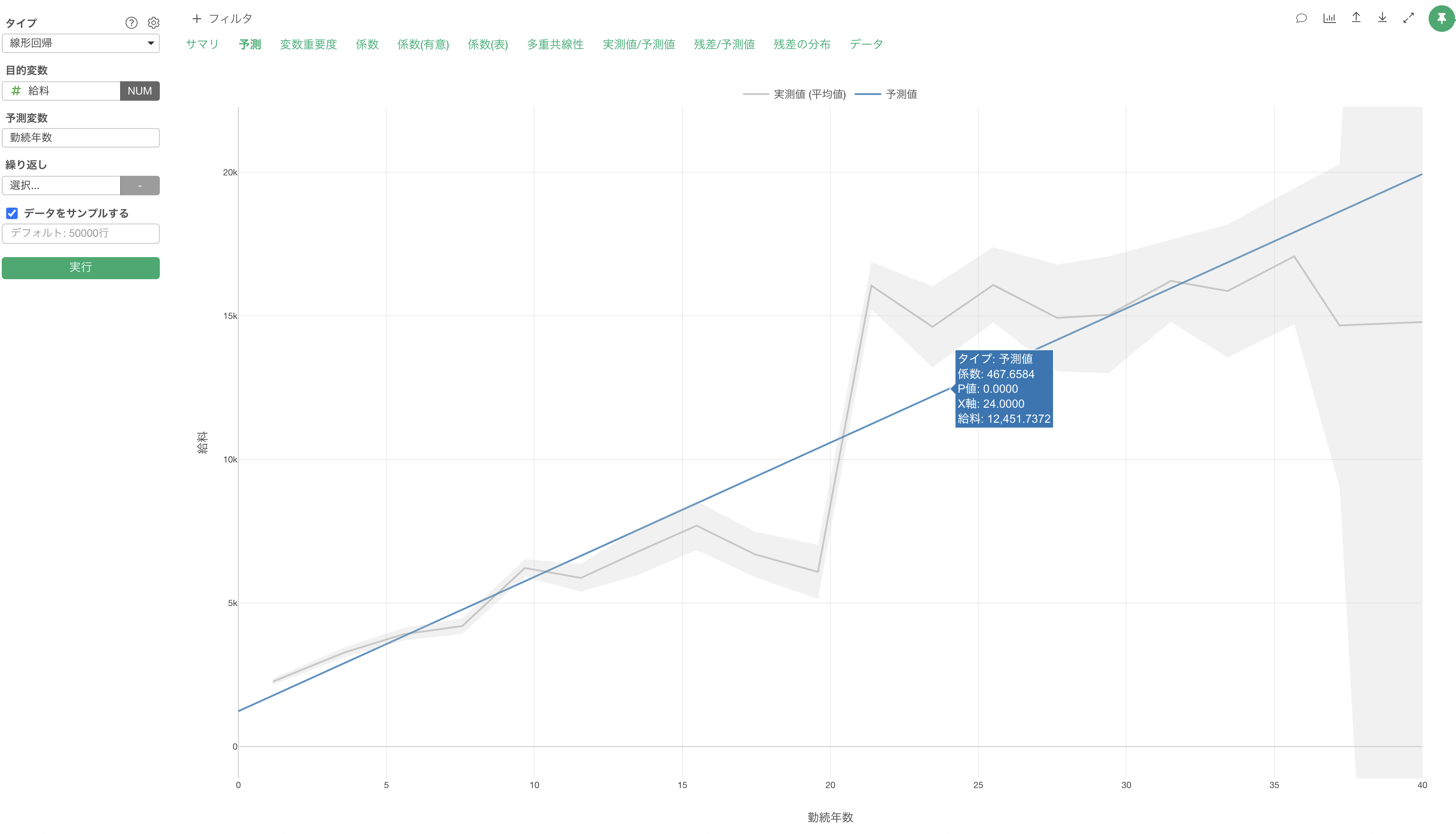
例えば、「給料」を予測する線形回帰のモデルを作成した際に、予測変数に「勤続年数」だけを割り当てた「単回帰」の時は、勤続年数の傾き(係数)は468ドル程となります。
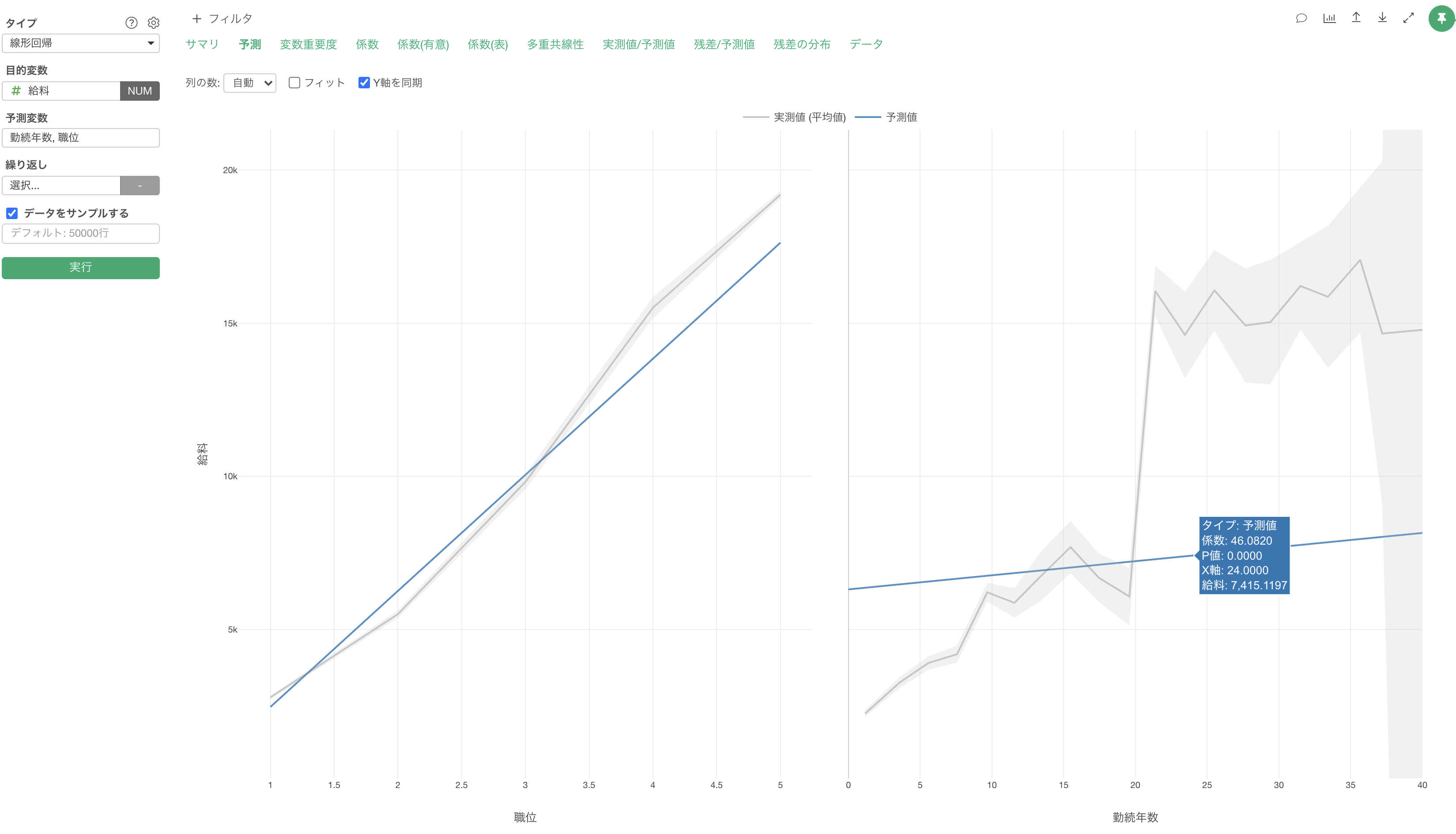
しかし、予測変数に「勤続年数」と「職位」を割り当てた「重回帰」の時は、勤続年数の傾き(係数)は46ドル程となり、傾きに違いがあることがわかります。
線形回帰で予測変数に複数の列を割り当てた「重回帰」の時には、他の変数を固定した上で、その変数での効果が出るようになります。つまりは、他の変数の効果を除いて、その変数だけの効果が見れるようになっています。
もし、予測変数が一つしかない「単回帰」の場合は、その変数が他の変数の効果を内包している可能性があります。上記の例では、「勤続年数」は「職位」と相関関係があったために、「勤続年数」単体だと職位の効果も内包していたということになります。
何が本当に関係しているのかを知りたい場合には、予測変数に複数の列を割り当てた方が、どの変数が重要なのか、それはどういった予測(効果)があるのかを調べていくことができます。
Q: 予測変数の値が上がると目的変数の値を増加させる関係があると思っていたんですが、結果は係数がマイナスになっています。どう解釈したら良いでしょうか?
係数の値だけではなく、係数の信頼区間の上限と下限を見て、0を跨いでいないか確認してみてください。もし、0を跨いでいる場合は係数がマイナスになるかもしれないしプラスになるかもしれないので、有意とは言えない変数になります。もし、信頼区間が0を跨いでいない状態で係数がマイナスになっている場合は、他の変数の効果を一定とした時にその変数の独立した効果として目的変数の値を下げる方に影響していると判断できます。
Q: 不要な変数を減らした方がよりいいモデルになるんですか?
モデルの予測精度をよくしたいならば、ノイズになるような変数は削った方がよい場合が多いです。ただ、モデルによっては1,000行のうち10行のみを予測するのにそのデータが役立つといった場合もあるので、できるだけ入れるという考え方もあります。 もし、因果関係を明確にしたいという目的なら、予測力の向上には不要な変数でも加えておくと「〜が一定だったとしたら」という因果関係の話ができることがあります。因果関係を調べるときには、まずドメイン知識をもとにバックドア基準などの変数選択基準をもとに、因果効果を見積もるのに最適な変数セットを選ぶべきという考えもあります。
Q: 多重共線性タブでVIFが10を超える変数が複数あった時にはどのように予測変数を除いたらいいですか?
VIFが10を超える変数が複数あった時の予測変数の選び方については、こちらの投稿をご参照ください。
Q: 変数重要度は、係数の大きさと関係しているのでしょうか?
変数重要度と係数の大きさには基本的には関係がありません。一般的に、重回帰において係数はそれぞれ単位が違うため、変数重要度のようにお互いを比較することができません。変数重要度は特定の変数の値をシャッフルしたときに元の予測よりどれだけ精度が落ちているかをもとに計算され、こちらはお互いに比較することができる値です。
Q: 変数重要度で単位が違う変数どうしを比較してもいいのでしょうか?
係数どうしでは、変数の単位が違う場合は比較することはできないのですが、変数重要度(Permutation Importance)の場合は単位の違いは気にしなくて大丈夫です。
Q: 変数重要度は具体的にどのような計算をしていますか?
変数重要度については、下記のセミナーにて詳しく紹介しておりますので、そちらをご参考ください。
https://exploratory.io/note/kanaugust/56-Svv7VWV8tA
また、変数重要度の仕組みについては、以下のようになります。
1つの予測変数を除いて(厳密にはシャッフルして)モデルを作り、除かなかった場合に比べて予測精度がどれだけ悪くなるのかを計算する。
これを全ての変数で繰り返す。
どれだけ予測精度が悪くなるのかというスコアをもとに、それぞれの変数の相対的な重要度を評価する。
計算の概念の例:
変数Aが含まれる時の予測精度: 90
変数Aが含まれない時の予測精度: 50
変数Aの重要度 = 90 - 50 = 40
詳細はこちらのノートにて説明をしています。
また、変数重要度の計算の際にはmmpfパッケージのpermutationImportanceを使用しています。
この変数重要度の計算の際には、線形回帰のように数値を目的とした予測モデルであれば、「平均二乗誤差」を利用しています。
変数重要度の具体的な計算式に興味がある場合は、下記のページが参考になるかと思います。
https://hacarus.github.io/interpretable-ml-book-ja/feature-importance.html
Q: 単回帰では有意にならない変数が、重回帰にすると有意になりました。どう解釈すればいいのでしょうか。
単回帰では有意な関係がないと見えていたものが、重回帰にすると有意になることを負の交絡(Negative Confounding)と言います。詳しくはこちらをご覧ください。
Q: 線形回帰でのt値やP値は何を表しているのでしょうか。
線形回帰でのt値は、係数を標準偏差で割った値になります。 P値は、「傾きが0または確率分布(t分布)の範囲内に収まる」が帰無仮説で、今回得られた傾きやt値がどれだけおき得るものか表しています。
Q: 係数(表)タブに表示されているInterceptは何を表しているのでしょうか。
Interceptは線形回帰のモデルでの切片を表します。

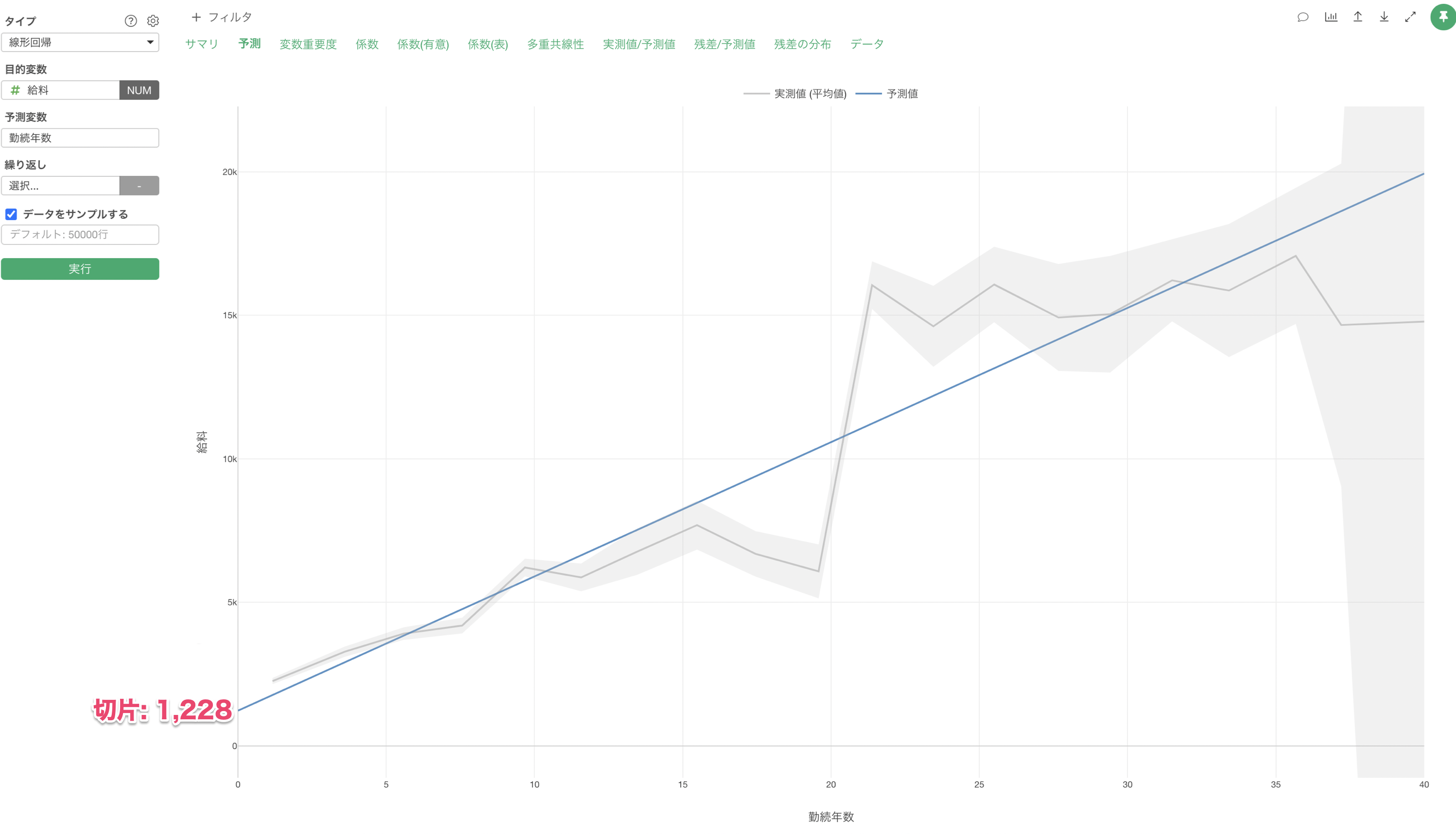
この線形回帰のモデルは勤続年数をもとに給料をを予測するモデルですが、下記の式で表せます。
給料 = 468 * 勤続年数 + 1228(切片)予測タブで見ると、係数(表)から確認したように切片は「1,228」であることがわかります。
Q: 予測変数でP値は有意になっているが、R2乗が低い時の解釈について
予測変数と目的変数で有意な関係性があっても、R2乗を見ると使用している予測変数では目的変数の3%ほどしか説明できていないことがあります。
どの変数が関係しているのかを知るためには、予測変数と目的変数の関係性は貴重な情報になります。しかし、これらの変数で将来の値を予測していきたいとなると、目的変数のばらつきを説明する能力が低いので、うまく予測できるモデルにはなりません。 そのため、他の変数を探してモデルに追加してみて、予測精度が向上しているかを確認していく方法が良いかと思います。
Q: データの行数より予測変数(列)の数の方が多い時に、一部の予測変数しかモデルで使用されない。
線形回帰などのアルゴリズムでは、データの行数が予測変数よりも多いことを前提としています。
例えば、データの行数が30行で、予測変数に100列指定して線形回帰を実行したとします。 その場合は、目的変数である1つの列と予測変数の29列しか使用されずにモデルが作られます。
そのため、データの行数が指定している予測変数よりも多いか確認してから、線形回帰を実行してください。
Q: 予測に利用したデータ量に対して、予測されたデータ量が少ない。
予測に利用したデータ量に対して、予測されたデータ量が少ないときには、数値型の予測変数に欠損値が含まれていることが想定されます。
Exploratoryでは数値列のデータの中に欠損値があると、欠損値を含む行を除いて線形回帰を実行します。
Q: 予測変数に欠損値があった場合はどのように扱われますか。
予測変数が数値型の場合
Exploratoryでは数値列のデータの中に欠損値があると、欠損値を含む行を除いて線形回帰のアルゴリズムを実行しています。
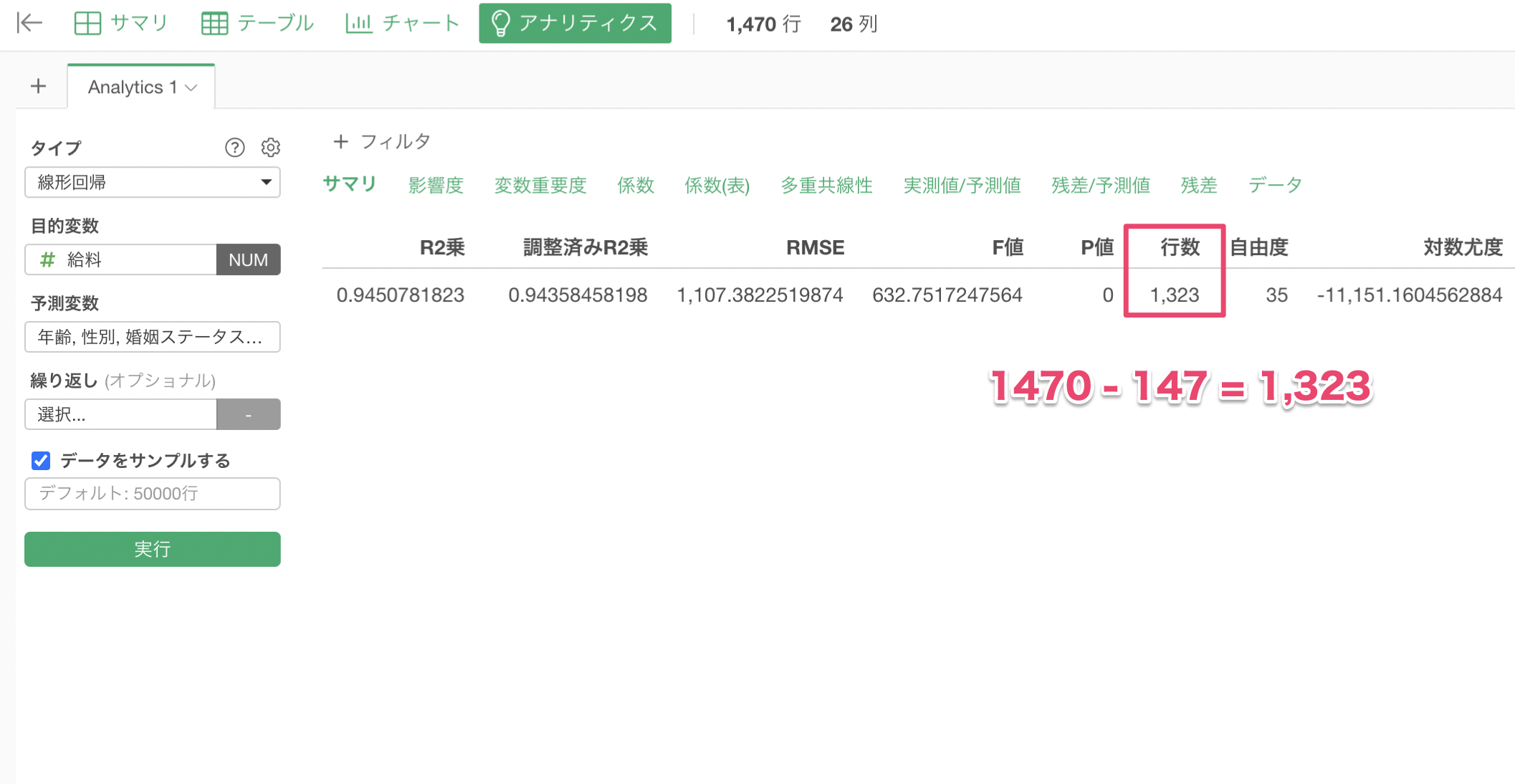
例えば、年齢の列に147行の欠損値があったとします。
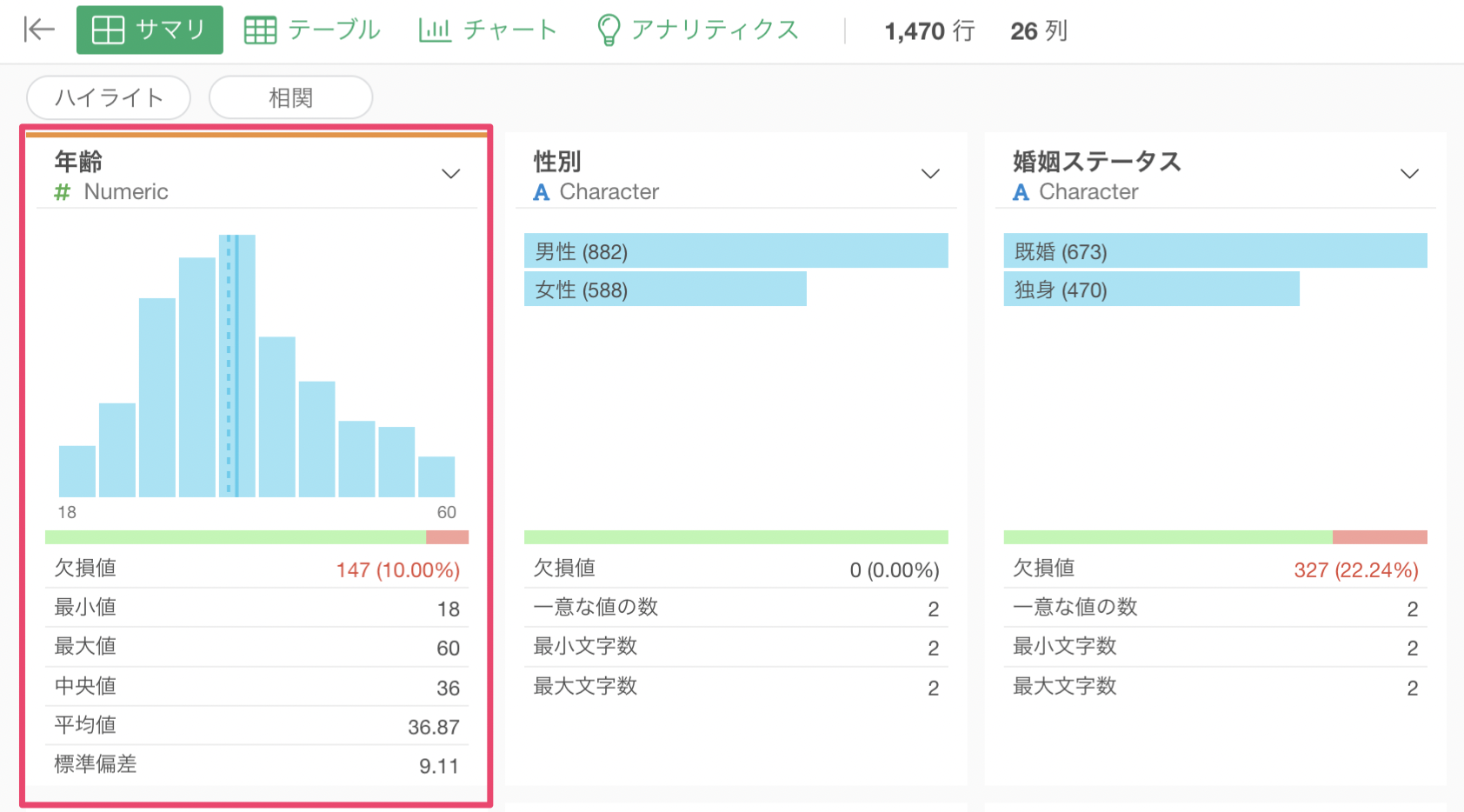
予測変数に年齢を割り当てて線形回帰を実行したところ、モデルで使用している行の数はデータ全体の行の数である1,470行ではなく、147行を引いた「1,323行」になります。
予測変数がカテゴリー型の場合
カテゴリー型の列に欠損値がある場合は、欠損値自身を1つのカテゴリー値として扱うことになります。
例えば、カテゴリー型の列である婚姻ステータスの列に欠損値があったとします。
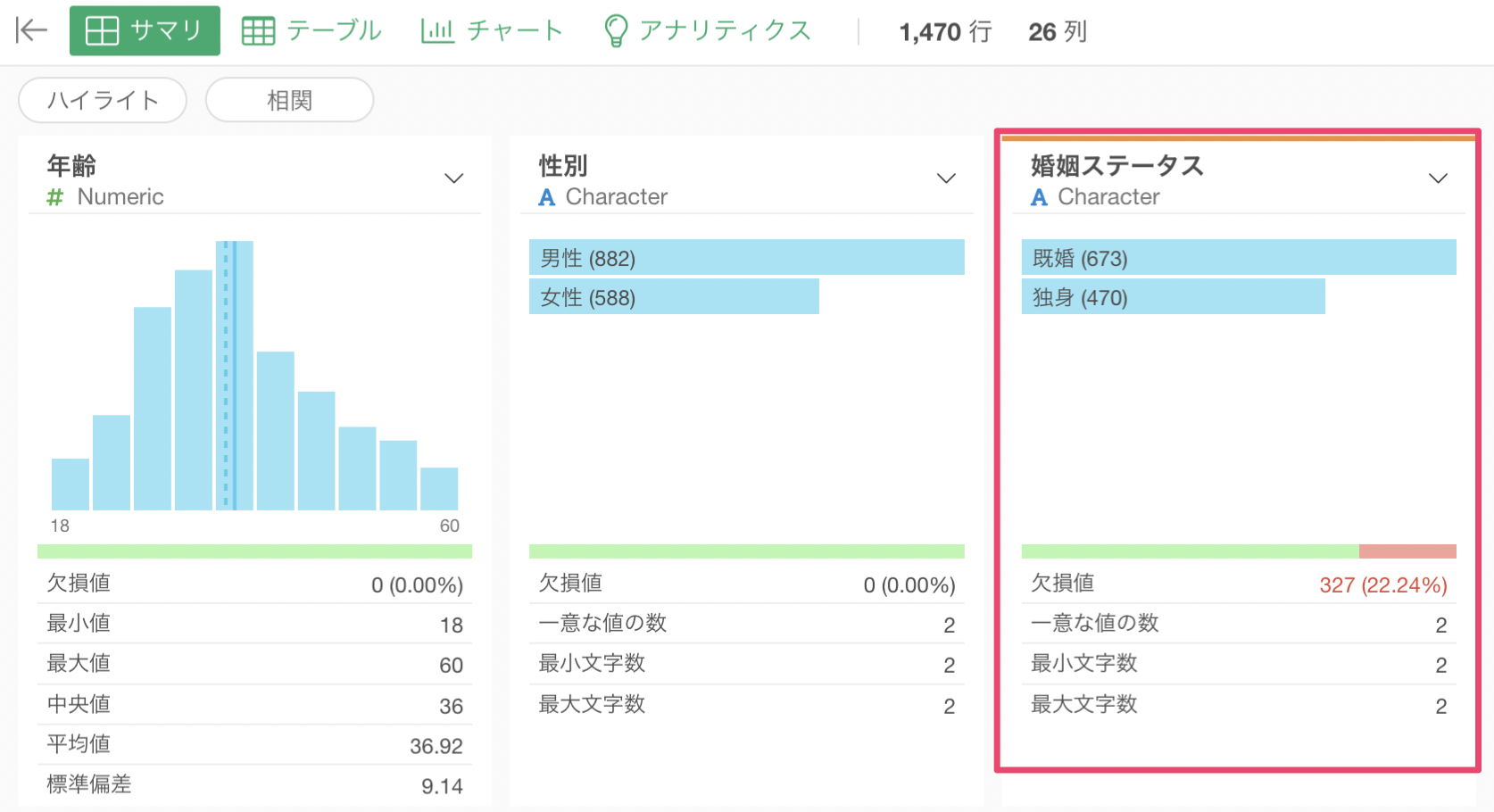
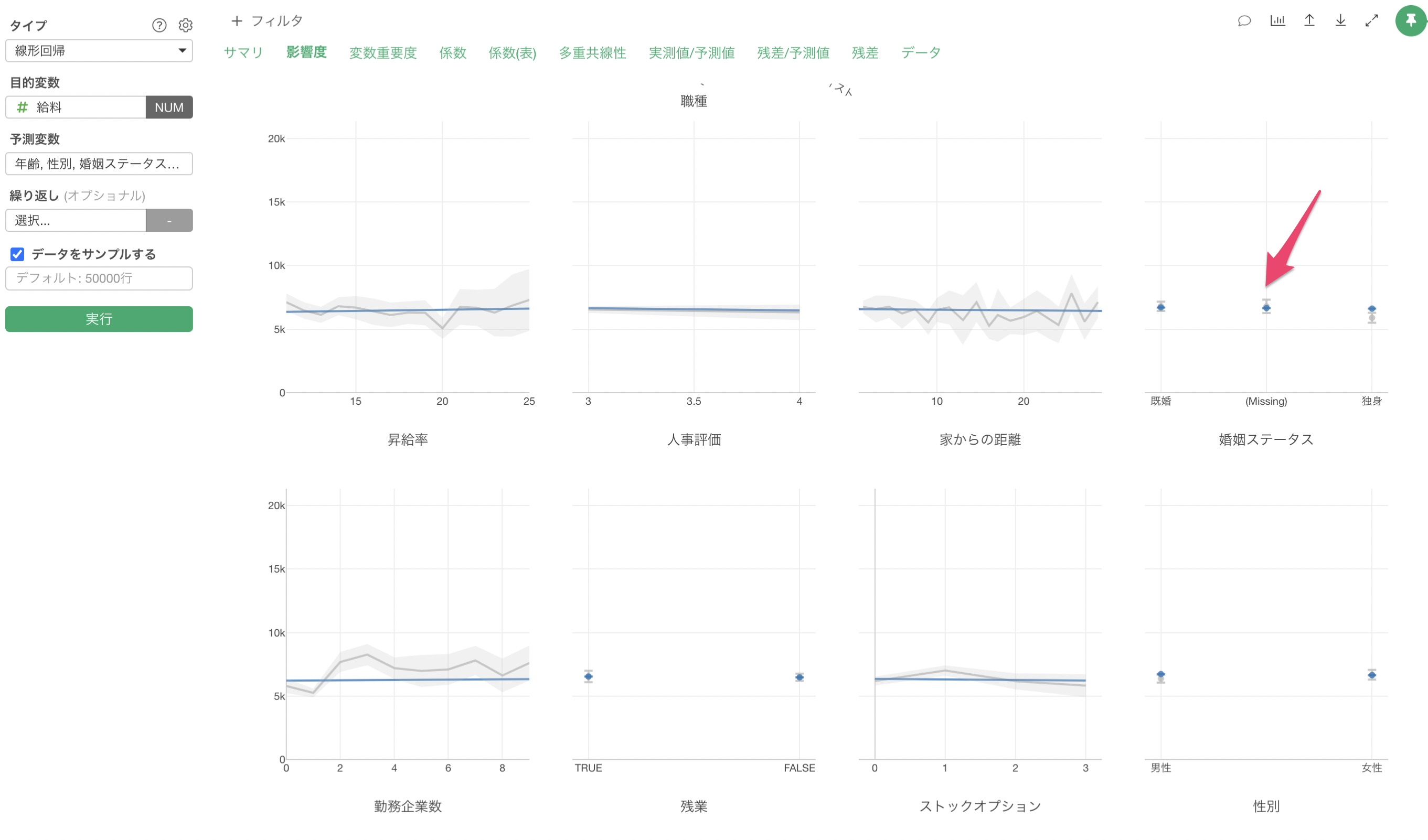
カテゴリー列の欠損値の場合は、下記のように欠損値(Missing)というカテゴリー値として扱われます。
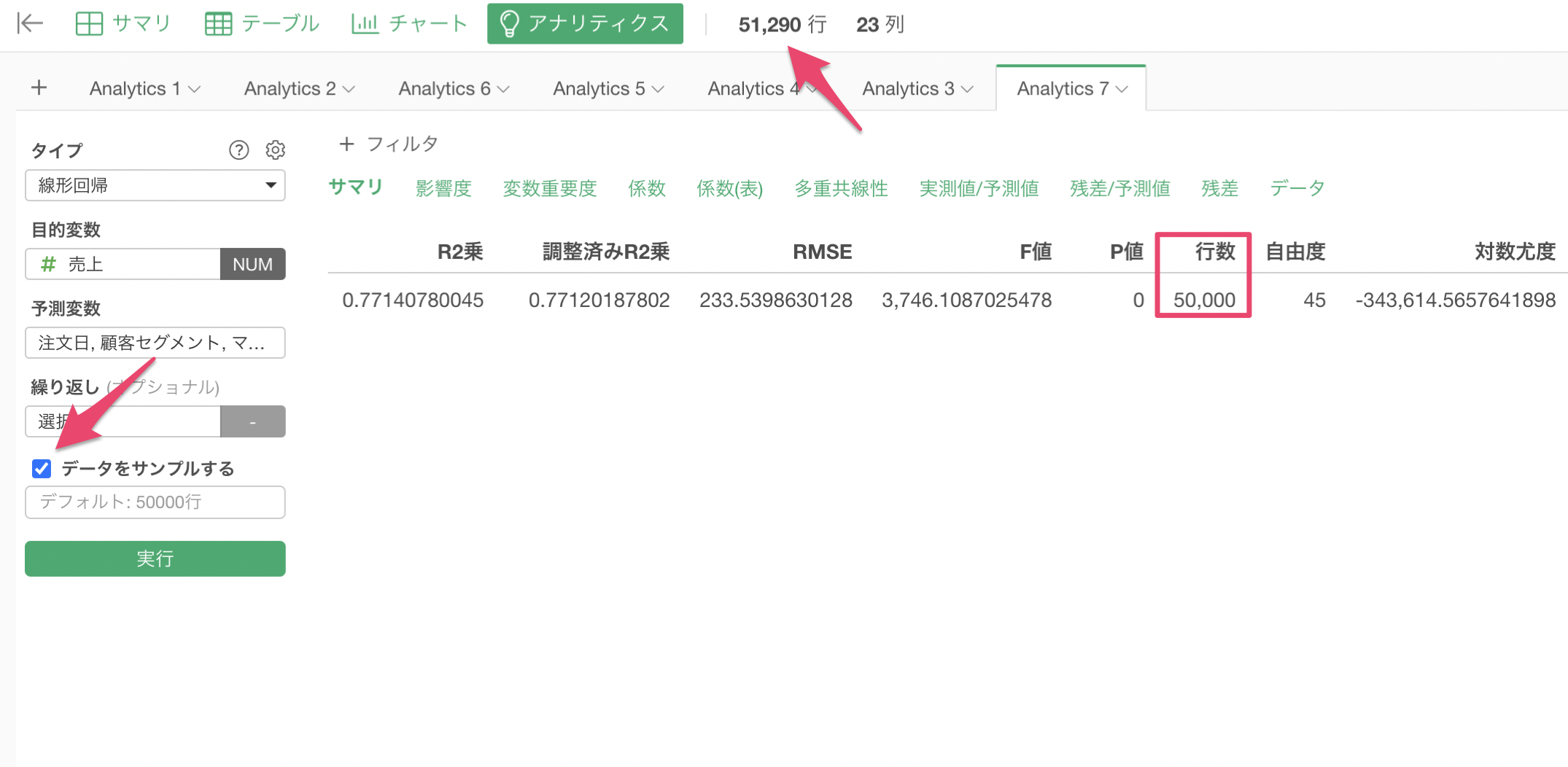
Q: データのサンプルは何を表しますか?
Exploratoryで線形回帰などのアルゴリズムの実行した時には、「サンプルサイズ」にチェックが付いている場合はデータを50,000行のみ使うようにサンプルして実行しています。
サンプルするデータの行数を変更したい場合は、サンプルサイズに行数を指定する、またはチェックを外していただくことで使用するデータの行数を指定することができます。
Q: 線形回帰で標準偏回帰係数を求めることはできますか。
標準偏回帰係数を求めるためには、線形回帰を実行する前に数値列を「標準化」しておき、そのデータを使うことで可能です。
具体的には、標準化後に線形回帰の「係数」タブを見た時の係数が、標準偏回帰係数に該当します。
数値列の標準化の方法についてはこちらの資料をご覧ください。
Q: 線形回帰での予測変数は標準化しておく必要がありますか?
どの予測変数が目的変数により関係しているのかを調べたい場合であれば、標準化をしておく必要はなく、変数重要度タブから確認いただけます。
詳しくはこちらの投稿をご覧ください。