Exploratoryでの正規表現の使い方
Exploratoryでテキストデータを行う際に、「正規表現」を組み合わせることで、どんなテキストデータでも自由自在に加工していくことができるようになります。「正規表現」とはある特定の文字列のパターンを記号などを使って表す手法のことで、このノートでは一般的に使われる正規表現の書き方や使い方について紹介しています。
正規表現のチートシート
ExploratoryではR標準(base)の正規表現に対応していますが、よく使われる正規表現をチートシートとしてまとめています。
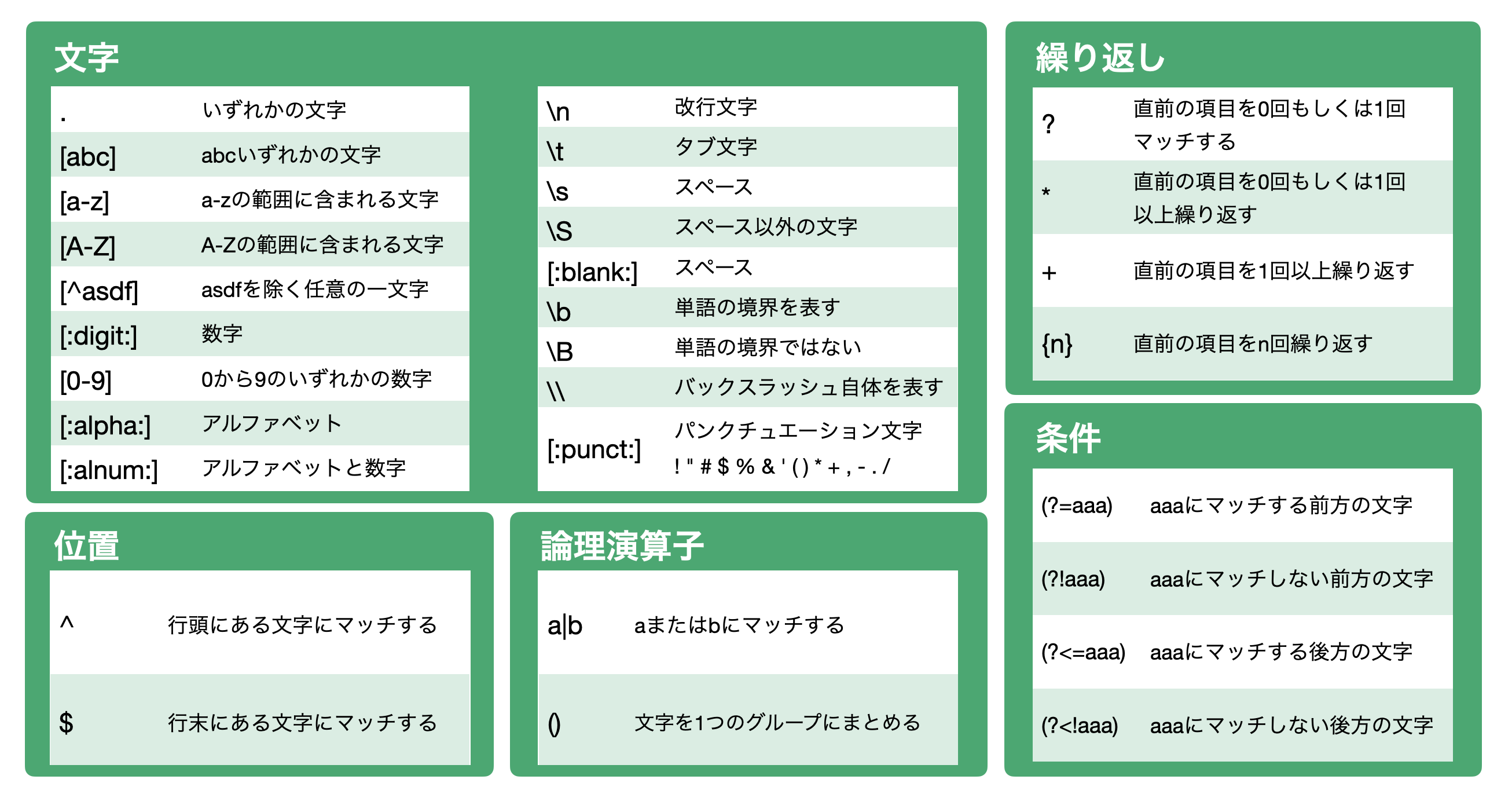
PDFで確認されたい場合は、こちらをご覧ください。
その他の正規表現について知りたい方は、こちらを参考にしてみてください。
正規表現を書くときの便利なTips
後方参照
後方参照は、テキストデータの中で特定のパターンを検出し、その一部を再利用して新しい形式に変換する必要がある場合に特に有効です。
例えば、「Hello World」というテキストを「World Hello」に変換する場合を考えてみましょう。
正規表現「([^ ]+) ([^ ]+)」を使うと、ハイフンの前後の文字列をそれぞれグループとして捉えることができます。そして、後方参照「\2 \1」を使用することで、捉えたグループを逆順に組み替えて、「World Hello」にすることができます。
ちなみに、([^ ]+)について解説をすると、以下のような構成要素となっており、これを使うことでスペース以外の任意の文字列が連続するグループとなっています。
- ( ) - グループを作成
- [^ ] - スペース以外の任意の1文字にマッチ
- + - 直前のパターンの1回以上の繰り返しにマッチ
では、これを使って顧客のデータで試してみましょう。
例えば、以下のような顧客名のデータがあったときに、「Last Name, First Name」の形式になっているため「First Name, Last Name」の形式に変換をしたいとします。

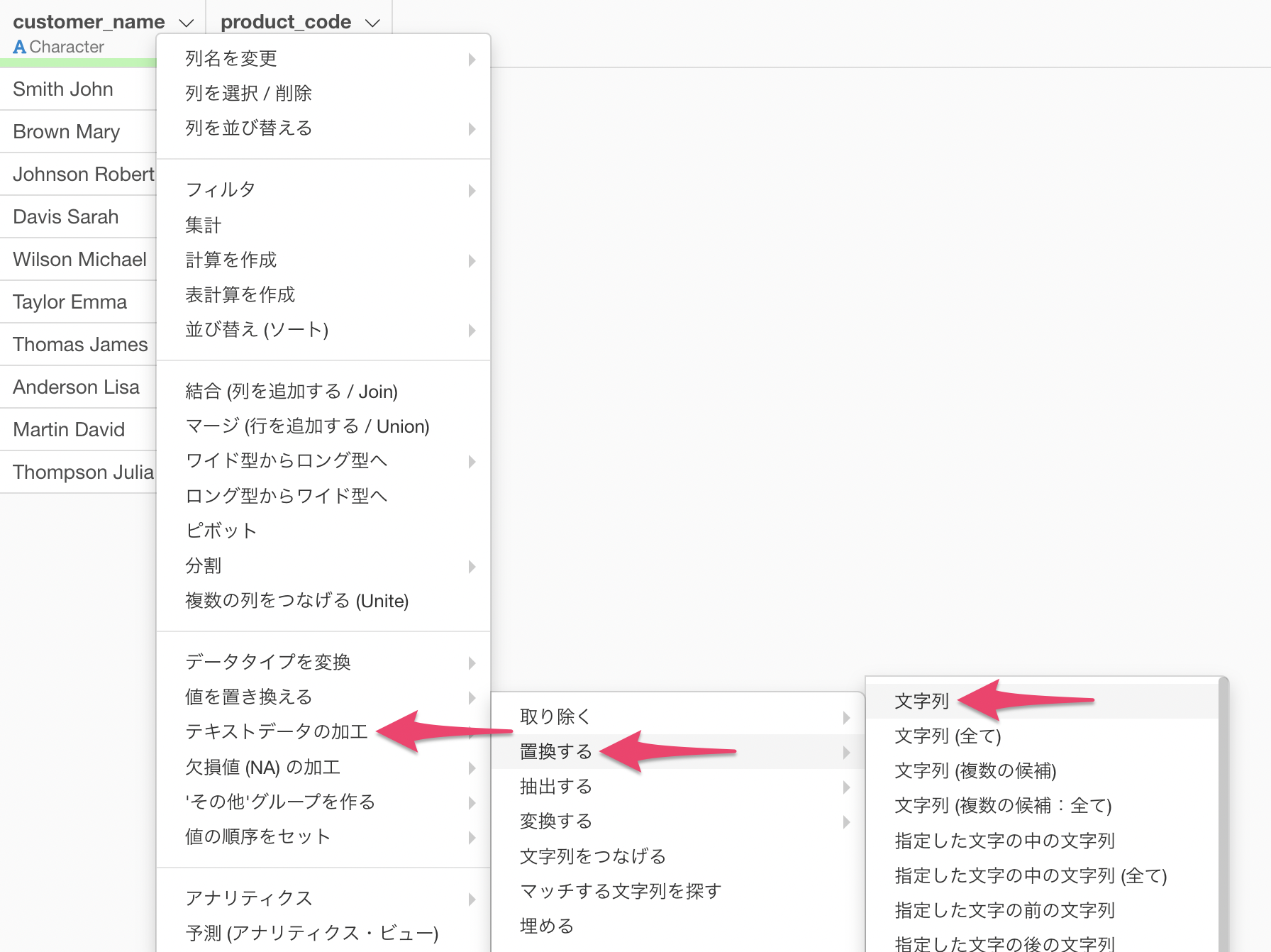
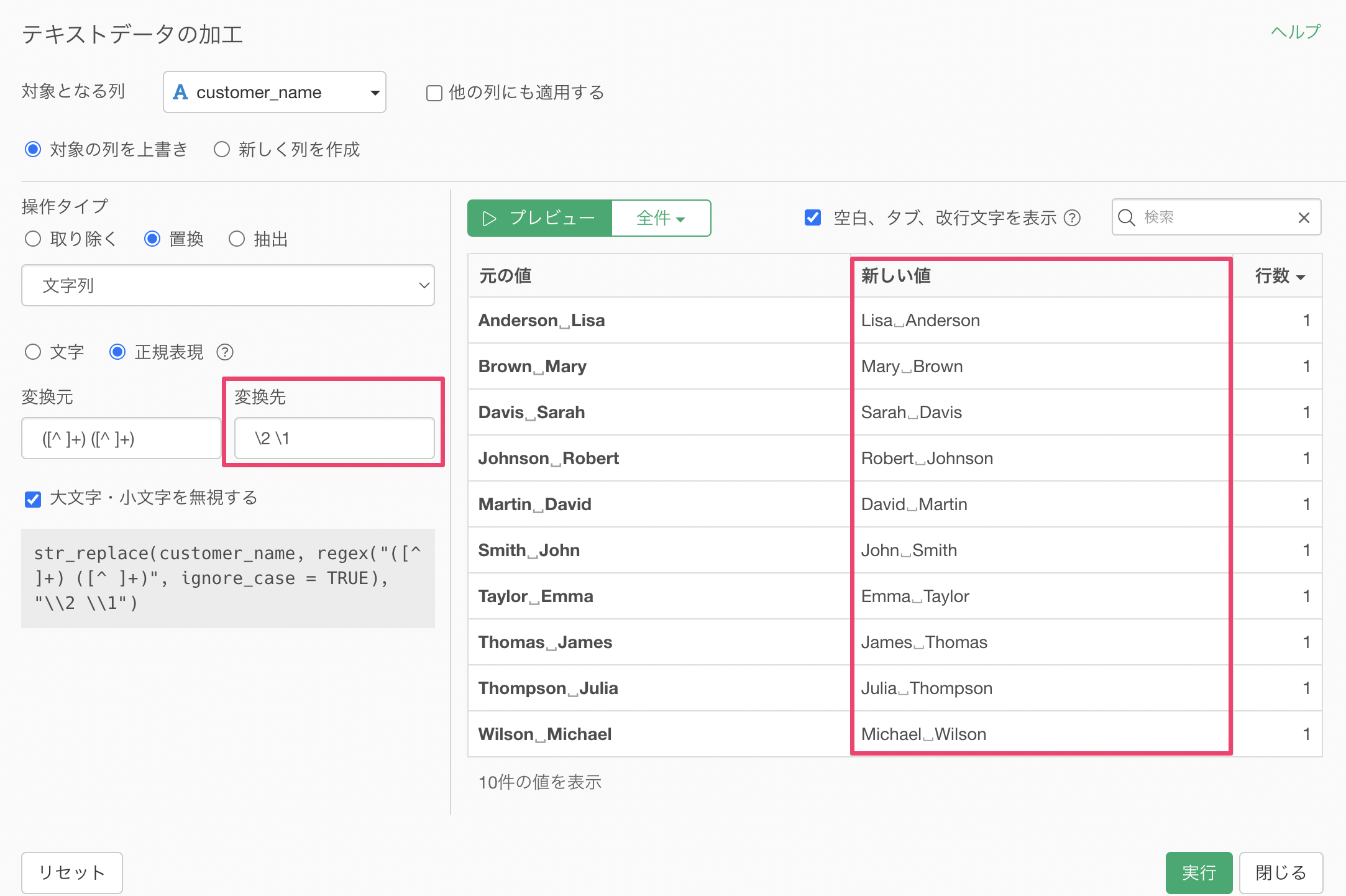
customer_nameの列ヘッダメニューから「テキストデータの加工」の「置換する」の「文字列」を選択します。
テキストデータの加工のダイアログが表示されるため、「正規表現」にチェックをつけます。
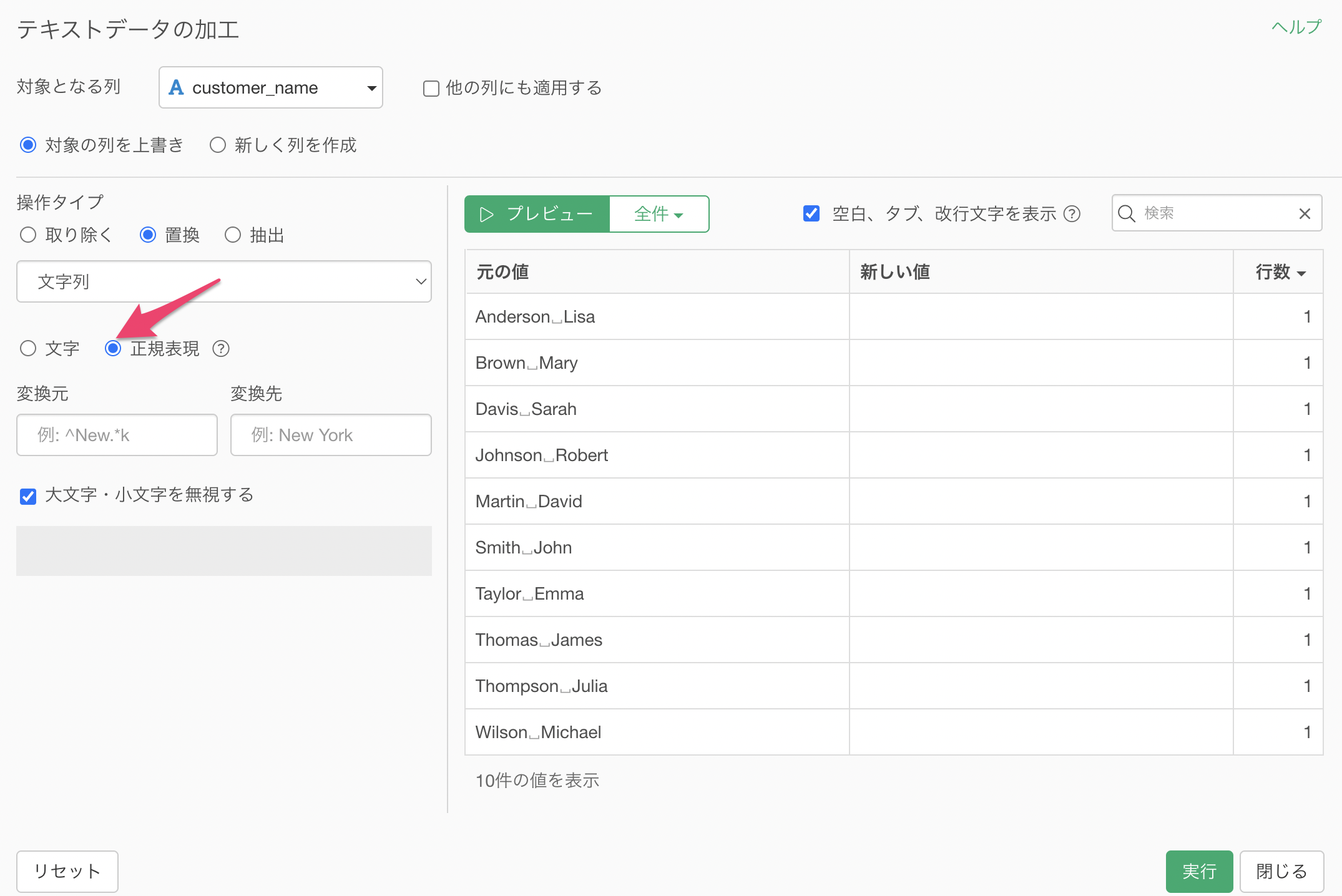
変換元に「([^ ]+) ([^ ]+)」を指定し、変換先に「\2」を指定してみます。これによって「Last Name, First Name」といったグループの順番のうち2番目の「First Name」を取り出すことができています。
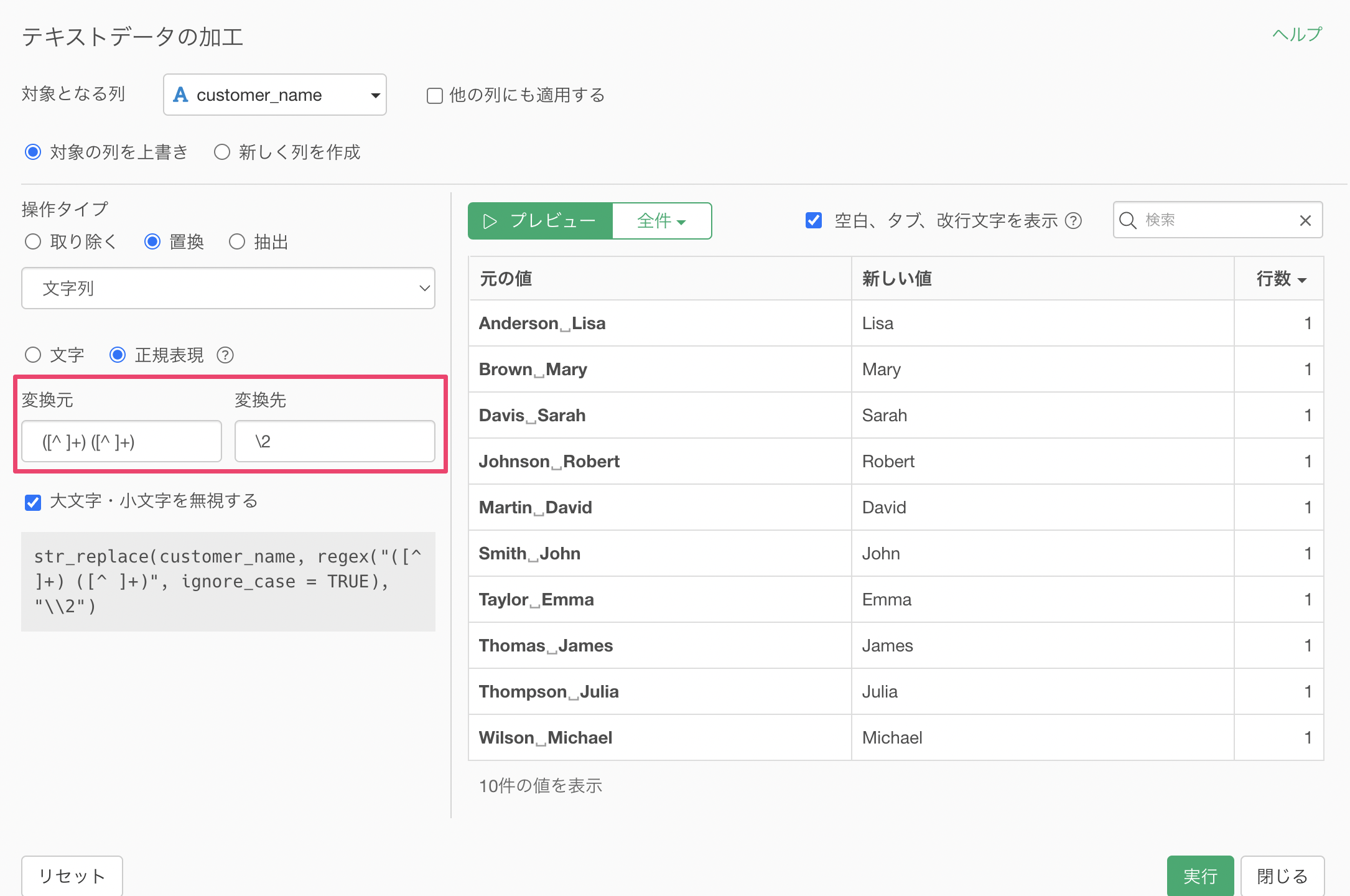
変換先に「\2 \1」を指定することで、「First Name, Last Name」の順番に入れ替えることができていることがわかります。
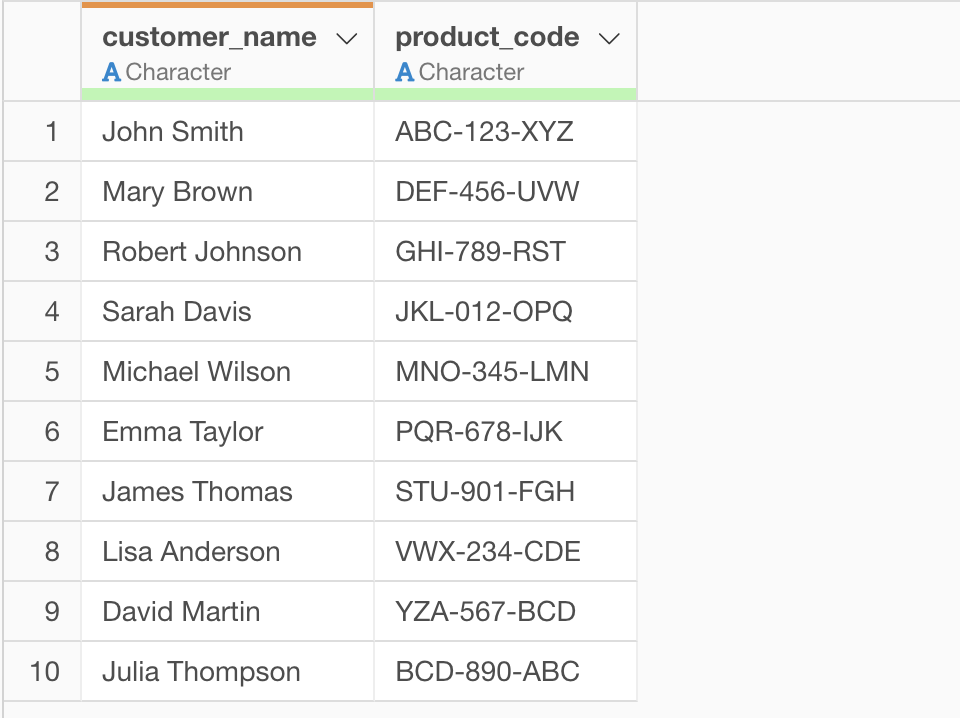
実行することで「Last Name, First Name」の形式になっているデータを「First Name, Last Name」の形式に変換することができました。
正規表現を使ったテキストデータの加工
このセミナーでは正規表現の基本とよく使用される正規表現を使ったテキストデータの加工の例をExploratoryを使ったデモとともに紹介しています。
- 正規表現とは何か
- よく使用される正規表現のパターン
- 正規表現を使ったテキストデータの加工