列名の全角/半角を統一して正規化(標準化)する方法
Exploratoryには列名の文字列を一括で変換できる機能があります。カタカナなどの全角/半角が混在する列名は全角に、数字や記号の全角は半角に統一することで列名を標準化(正規化)することが可能です。
役立つ人
データの列名に全角/半角が混在していて統一したい方に役立ちます。
問題
データの列名にカタカナなどの全角/半角が混在していると、データの可読性が低下し、後続の分析にも支障をきたす可能性があります。手動で1つずつ修正するのは非効率的で、データ更新の度に同じ作業が必要になってしまいます。
解決方法
Exploratoryの列名変更機能を使用することで、全角/半角が混在する列名を一括で統一することができます。列名に対して「変換する」機能を使用し、全角または半角に一括変換することで、文字種を統一できます。
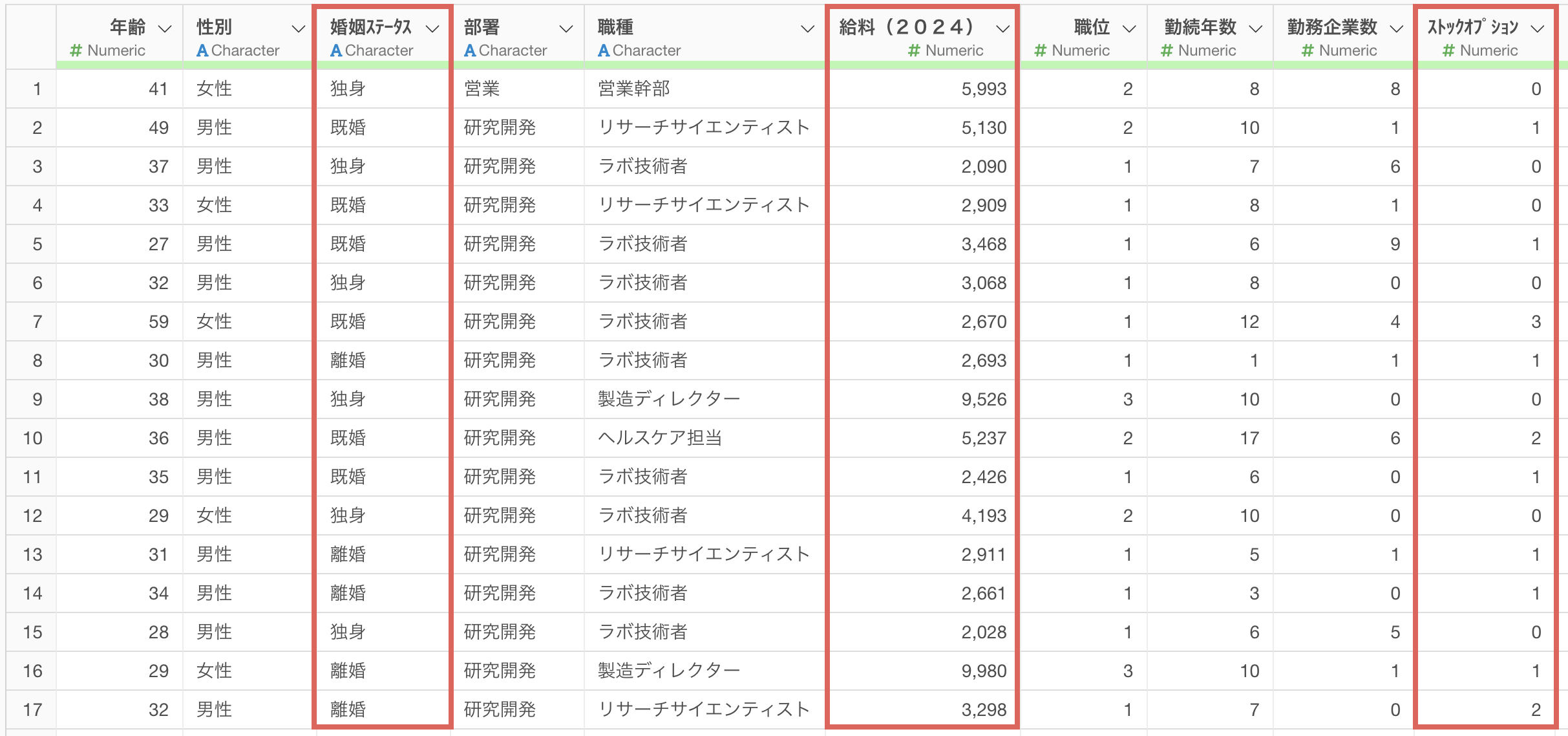
今回は1行が1人の従業員を表し、列には「給料(2024)」「婚姻ステータス」「ストックオプション」など、カタカナの全角/半角が混在する列名を持つデータを利用します。
Exploratoryの操作方法
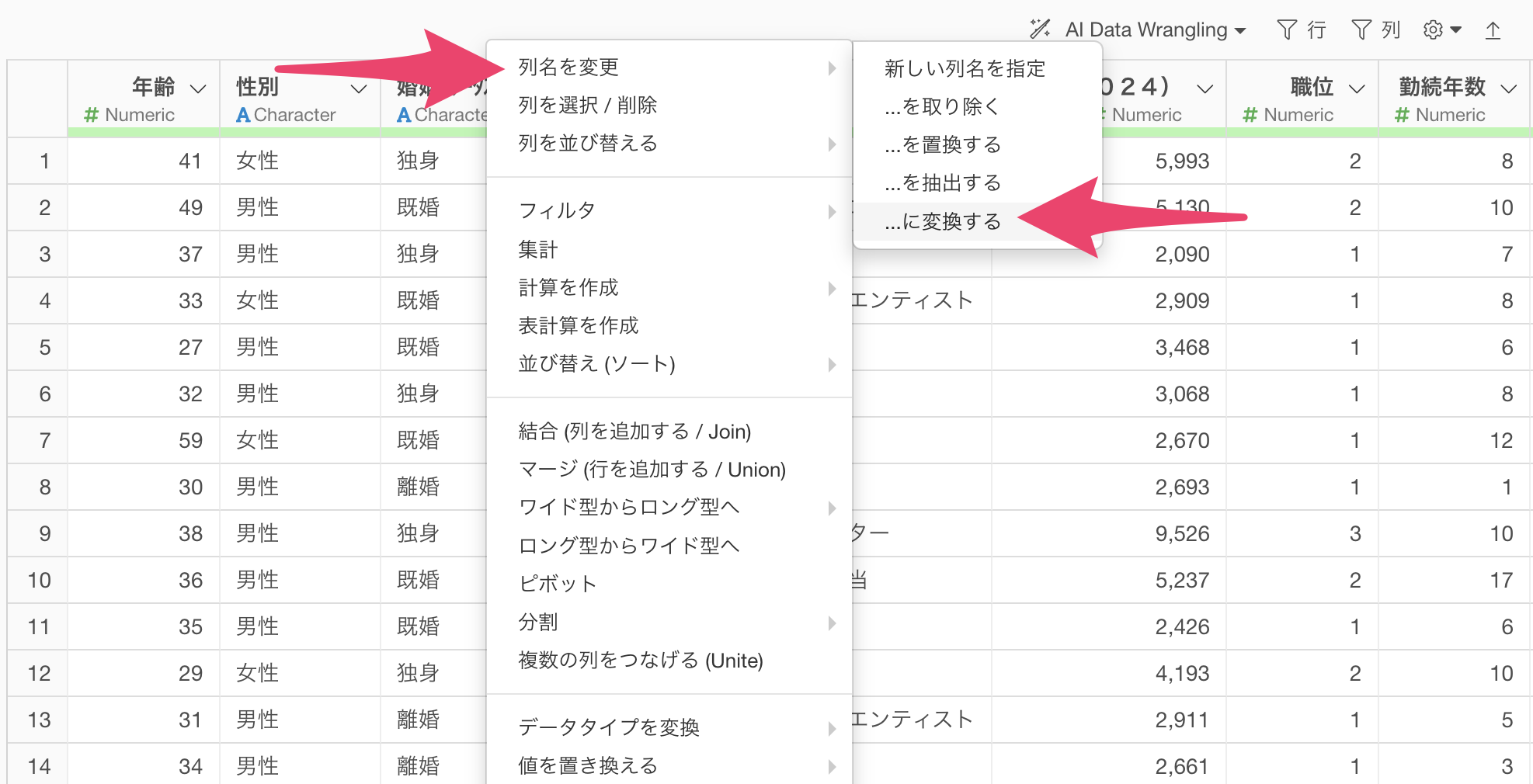
列名の全角・半角を統一 して、標準化(正規化)するために任意の列のヘッダーメニューから「列名を変更」、「…に変換する」を選択します。
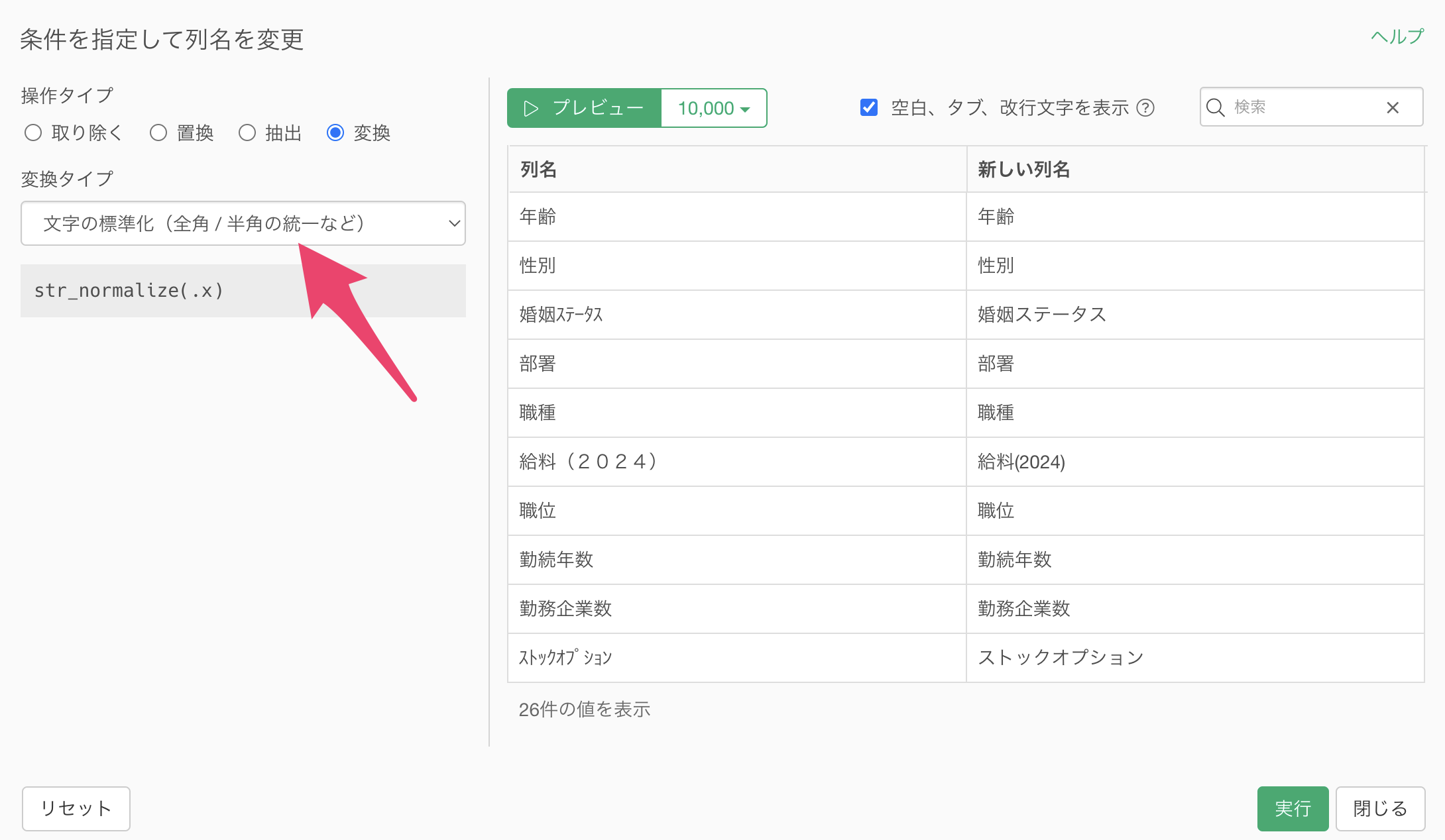
変換のダイアログが開いたら、変換タイプから「文字の標準化(全角/半角の統一など)」を選択します。
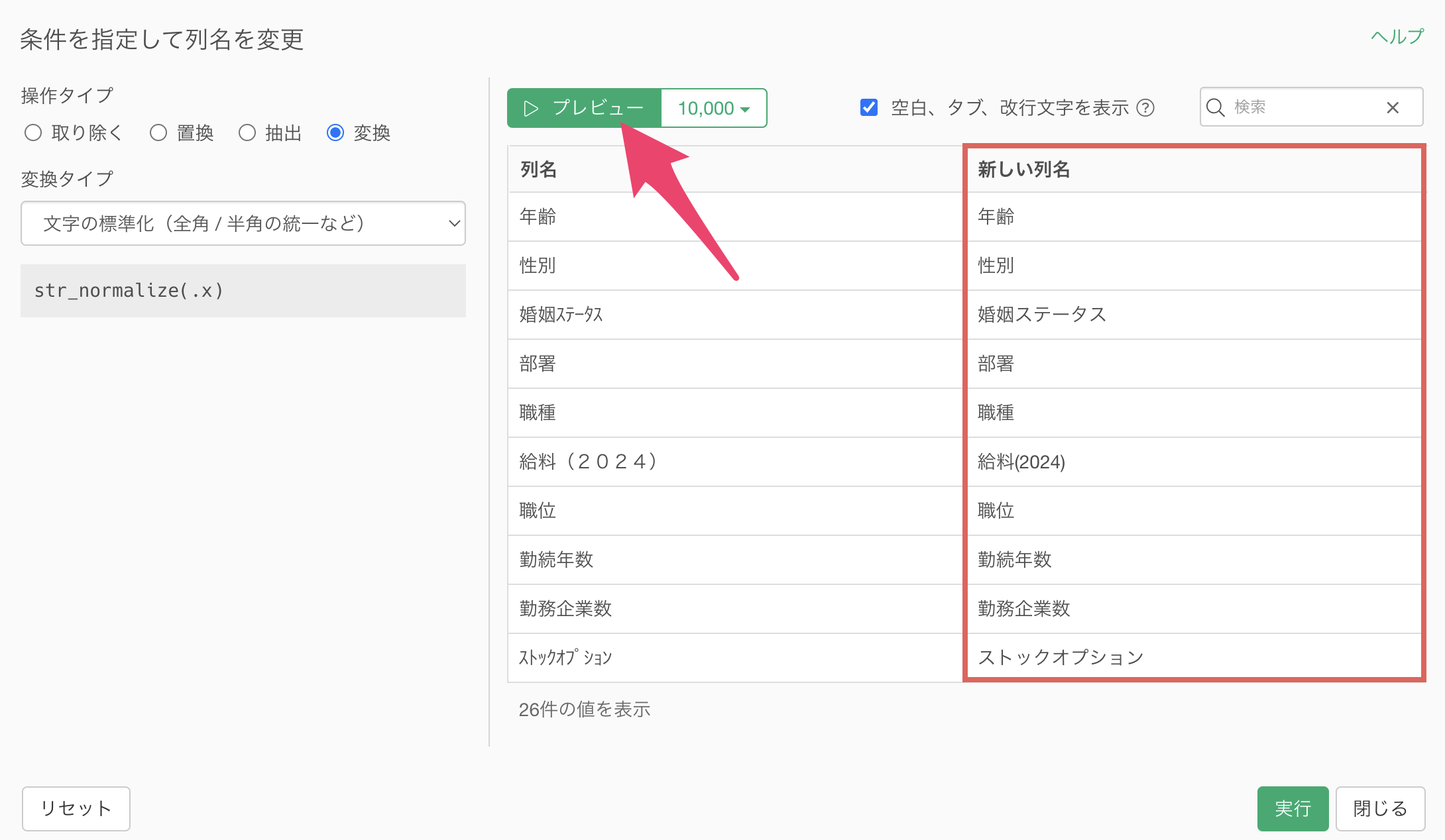
「プレビュー」ボタンをクリックすると、変換後の列名を確認できます。
 「実行」ボタンをクリックすると、文字種を統一した列名に変更されます。
「実行」ボタンをクリックすると、文字種を統一した列名に変更されます。
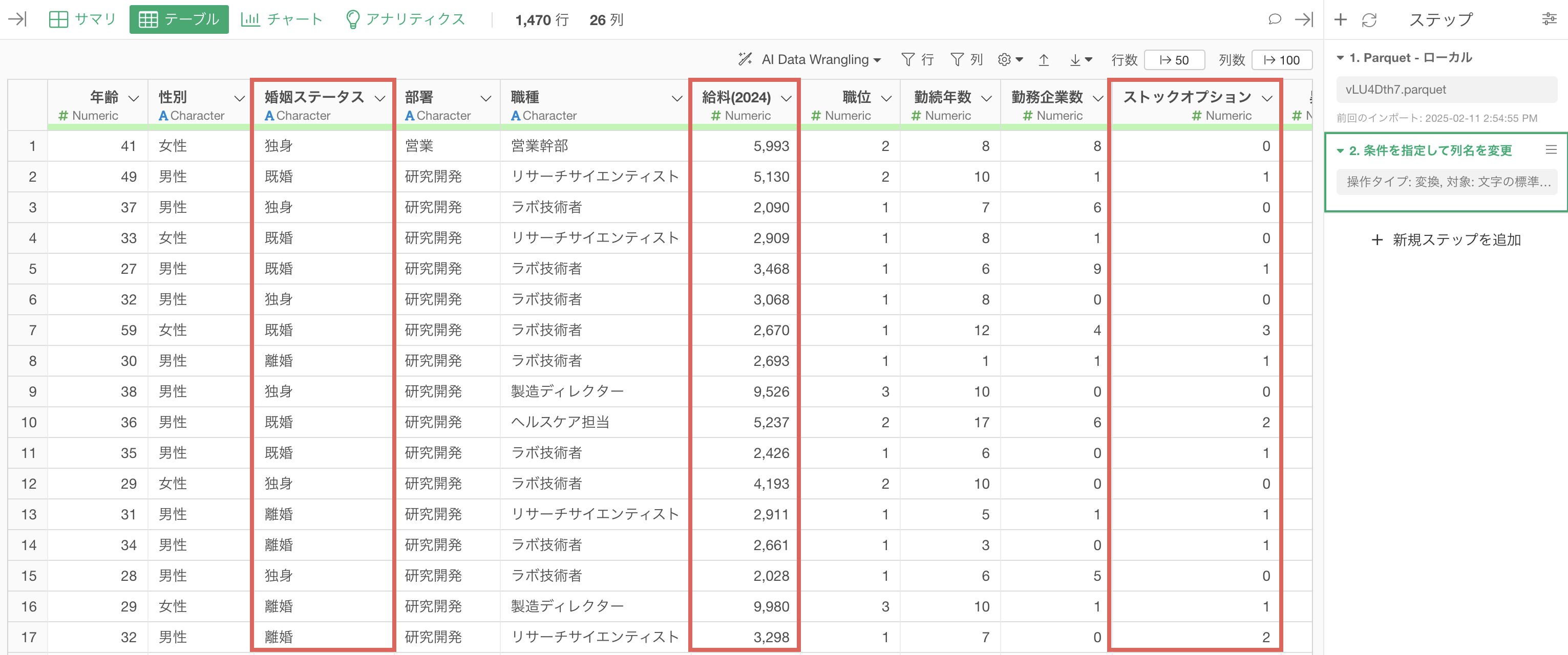
これで列名の全角/半角を統一し、列名を標準化(正規化)できました。
列名の全角/半角を統一して正規化(標準化)する方法(Rコード)
従業員データの場合
今回の従業員データを使って、カスタムRコマンドで「列名の全角/半角を統一して正規化(標準化)」したい方は、以下のRコードをご参考ください。
列名の全角/半角を統一して正規化(標準化)するためのRコマンド
rename_with(.fn = ~ str_normalize(.x))