トピックモデルの仕組み
1. トピックモデルとは?
トピックモデルとは、大量のテキストデータから、どのような話題(トピック)について書かれているかを自動的に発見する手法です。例えば、ニュース記事を分析して「政治」「スポーツ」「経済」などのトピックを見つけ出し、それぞれの記事がどの話題をどのくらい含んでいるかを数値で表すことができます。
代表的な手法として、LDA(Latent Dirichlet Allocation)と呼ばれる方法があります。この手法は、文章を単語の集まりとして捉え、よく一緒に現れる単語の組み合わせから潜在的なトピックを見つけ出します。
2. トピックモデルの基本的な考え方
トピックモデルは「似たような単語が一緒に現れる文章は、同じトピックについて書かれている」という考え方に基づいています。
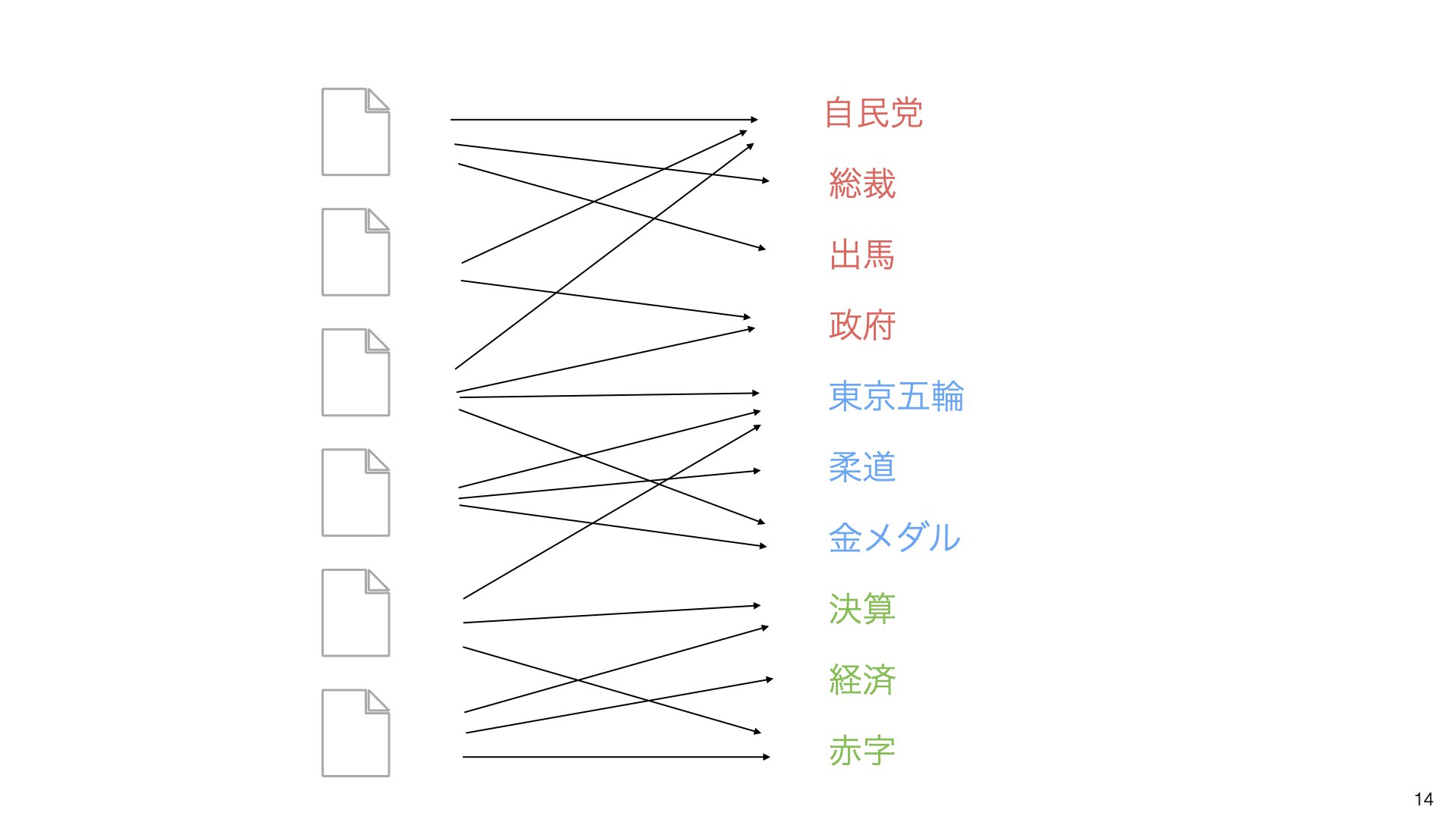
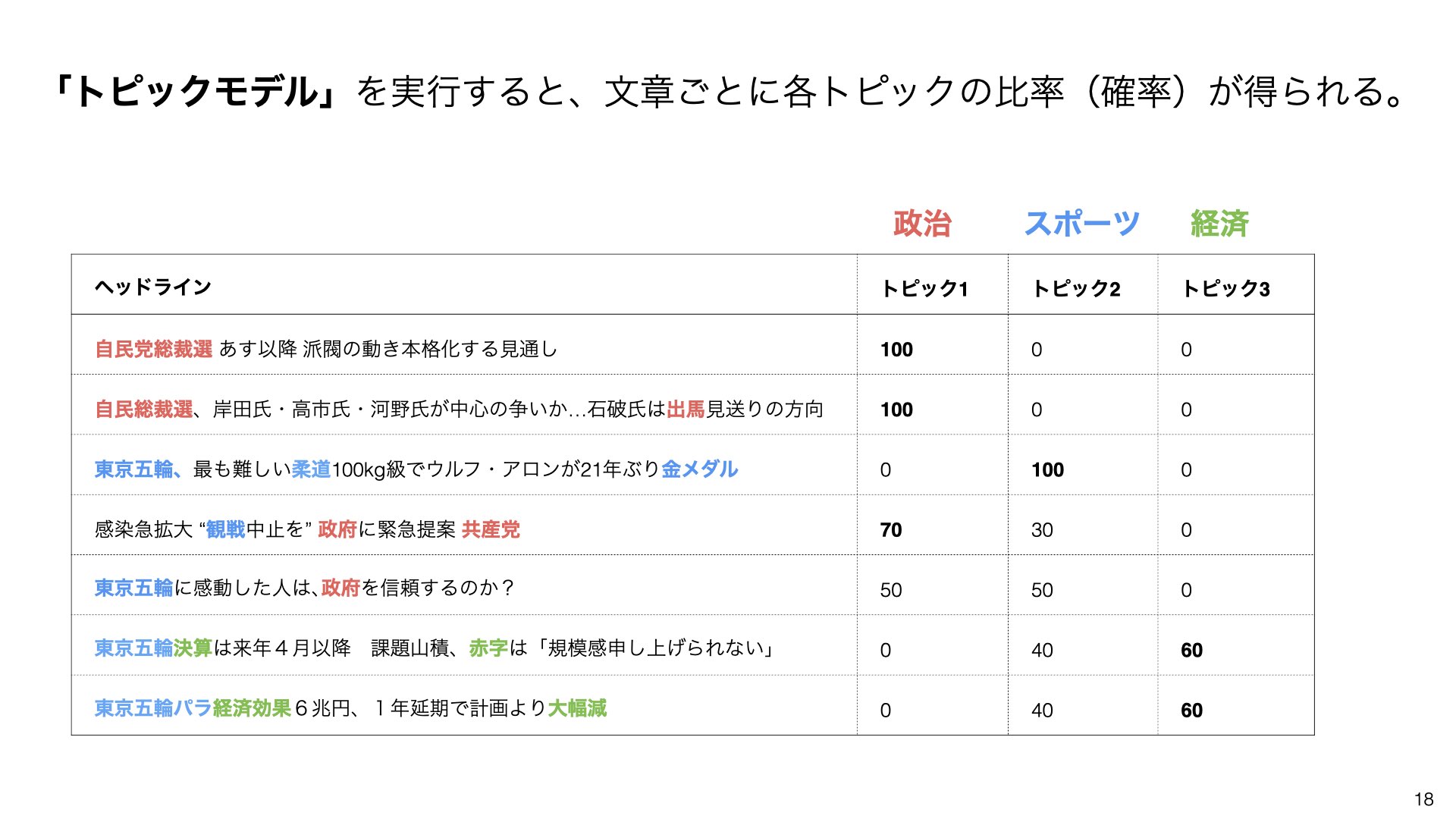
例えば、ニュースサイトのヘッドラインを見てみましょう:
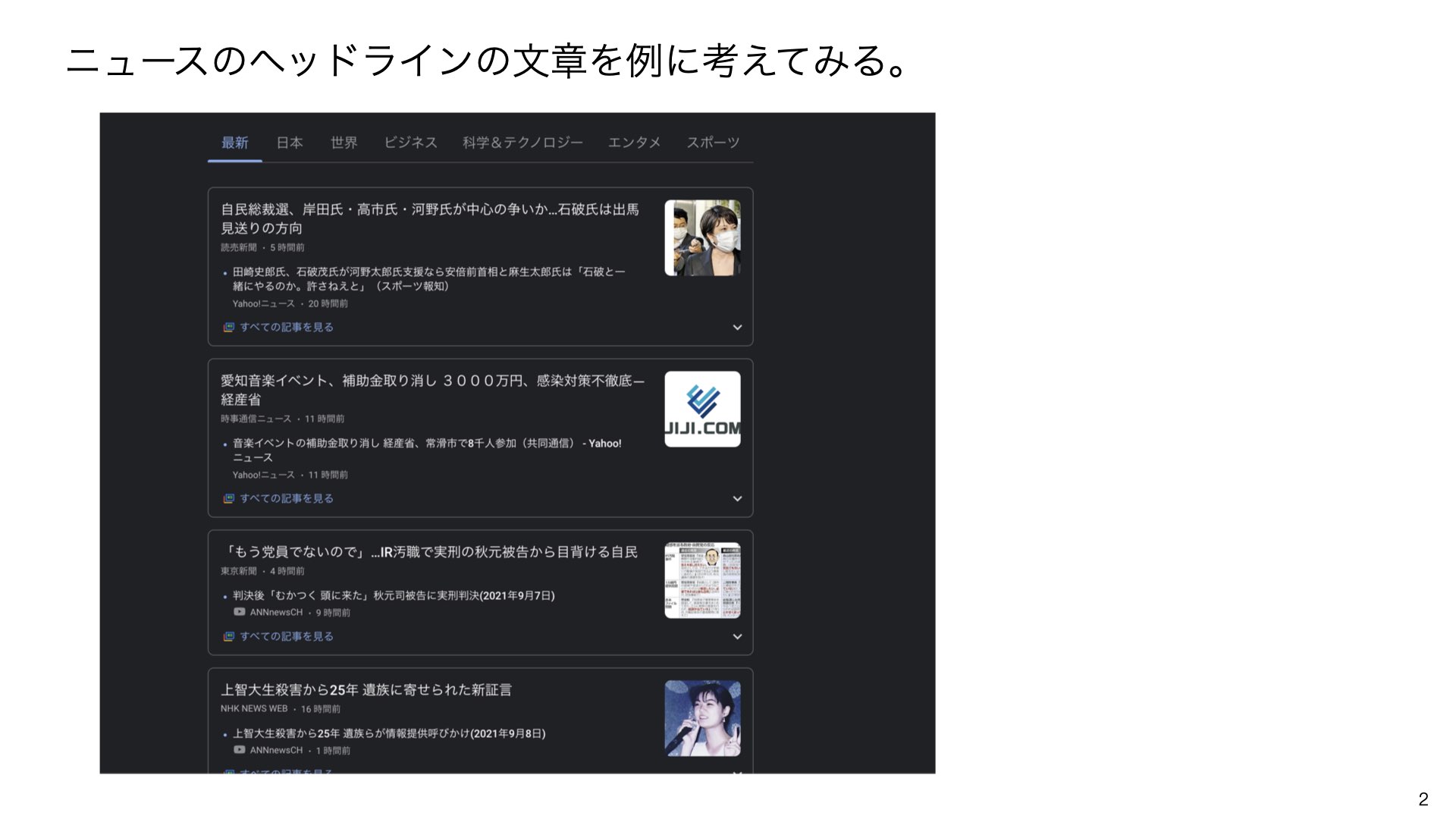
これらの文章を分析すると、以下のようなパターンが見えてきます:


「自民党」「総裁選」「岸田氏」などの単語が一緒に現れる文章は、**「政治」**というトピックに分類されます。

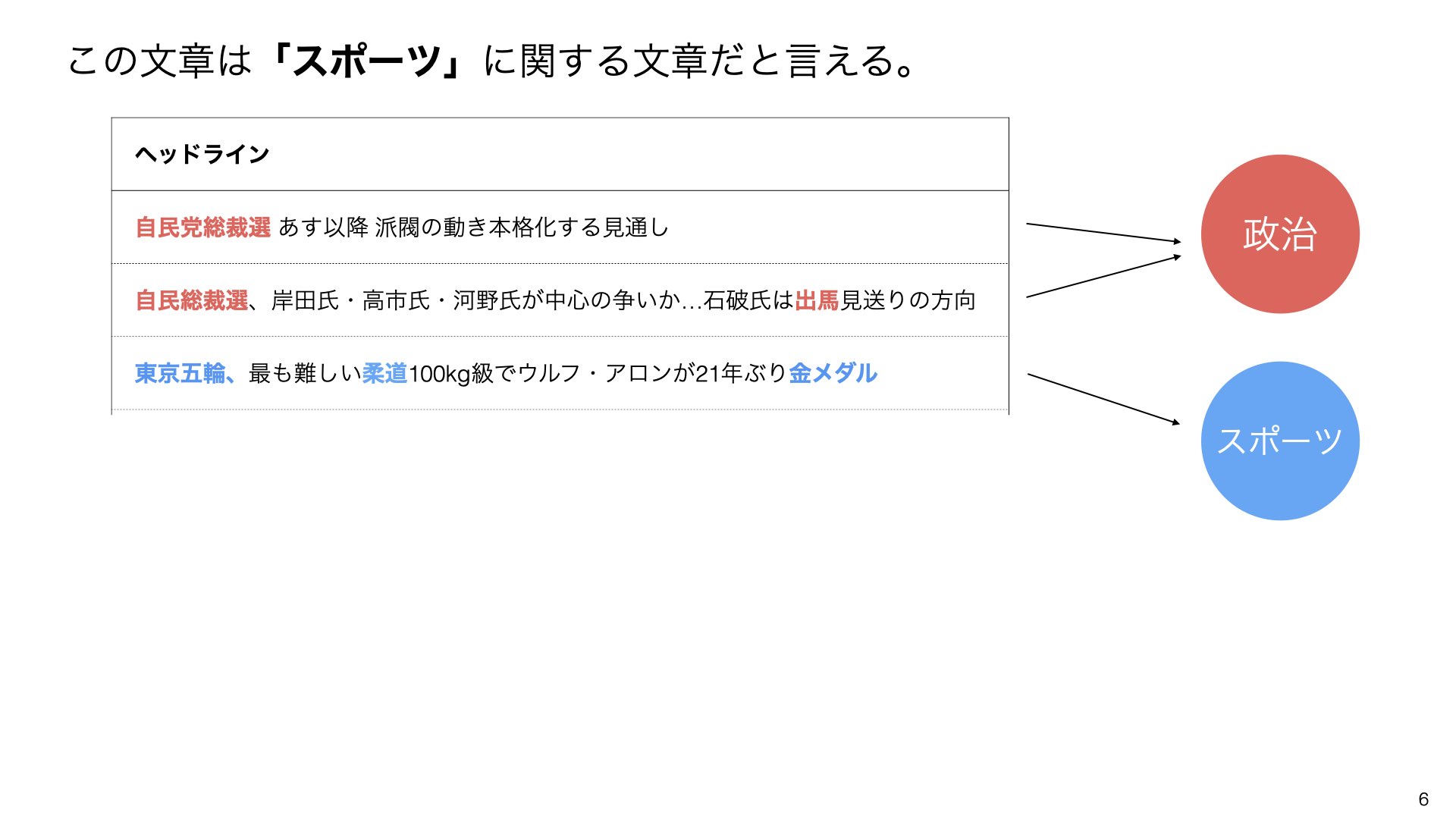
同様に、「東京五輪」「柔道」「金メダル」などの単語が含まれる文章は、**「スポーツ」**というトピックに分類されます。
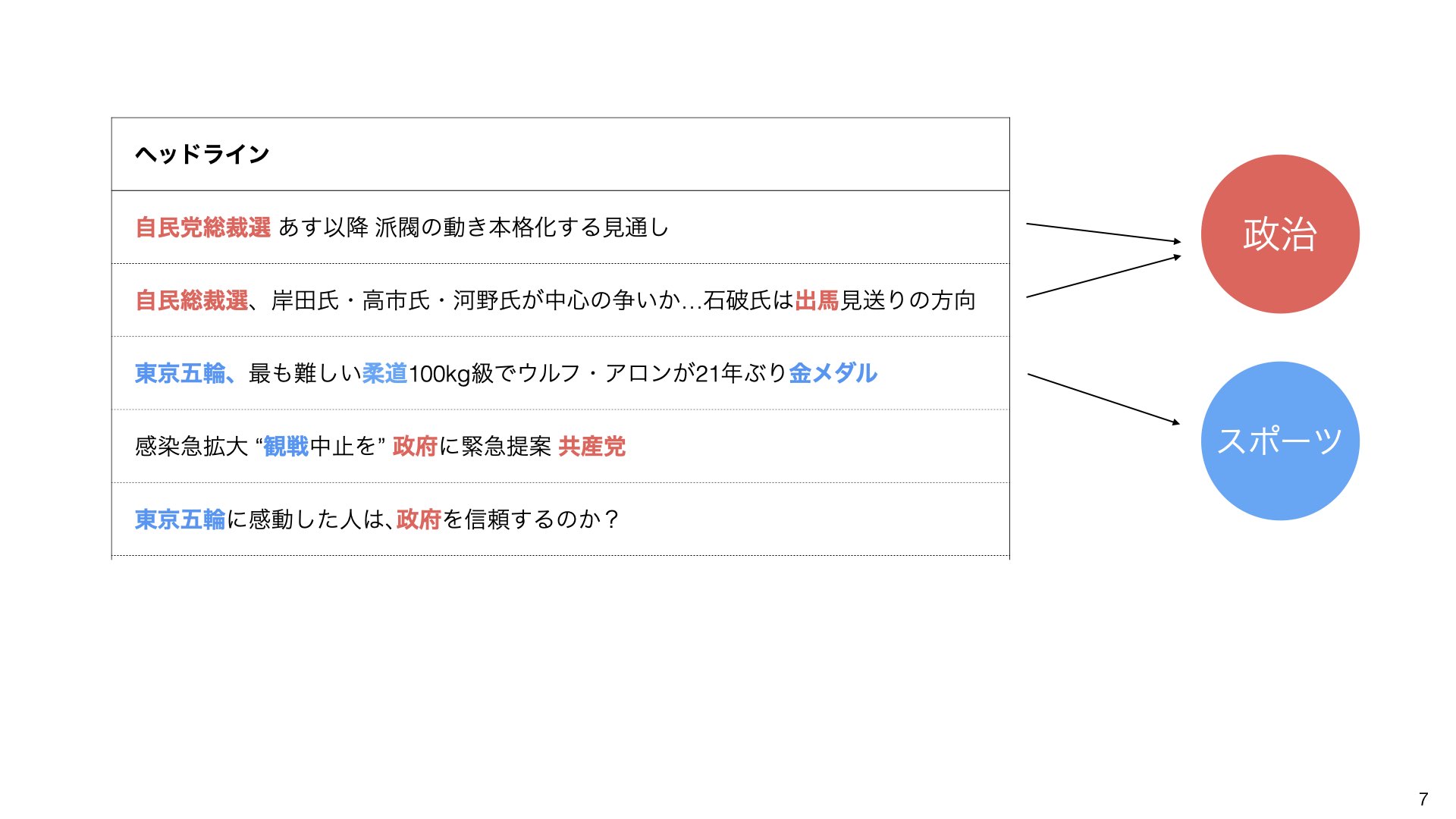

重要なのは、文章によっては複数のトピックが混在することです。例えば、東京五輪と政府の関係について書かれた文章は、「スポーツ」と「政治」の両方のトピックを含みます。
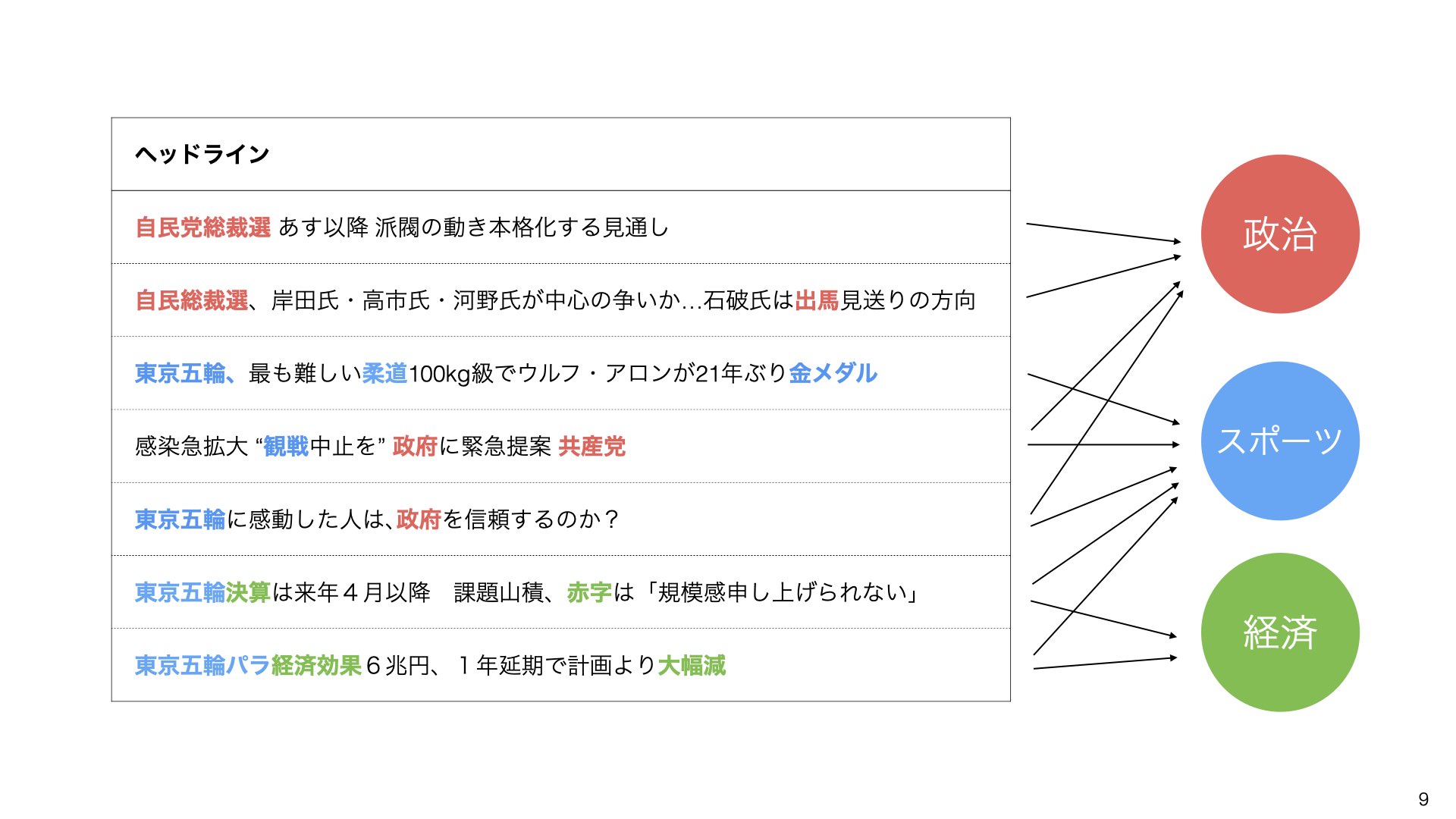
最終的に、「決算」「経済効果」「赤字」などの単語から「経済」というトピックも発見されます。
3. 実際のトピックモデルの計算例
トピックモデルの処理は以下の手順で行われます:
手順1:文章を単語に分解する
各文章(ドキュメント)を単語の集合に変換します。
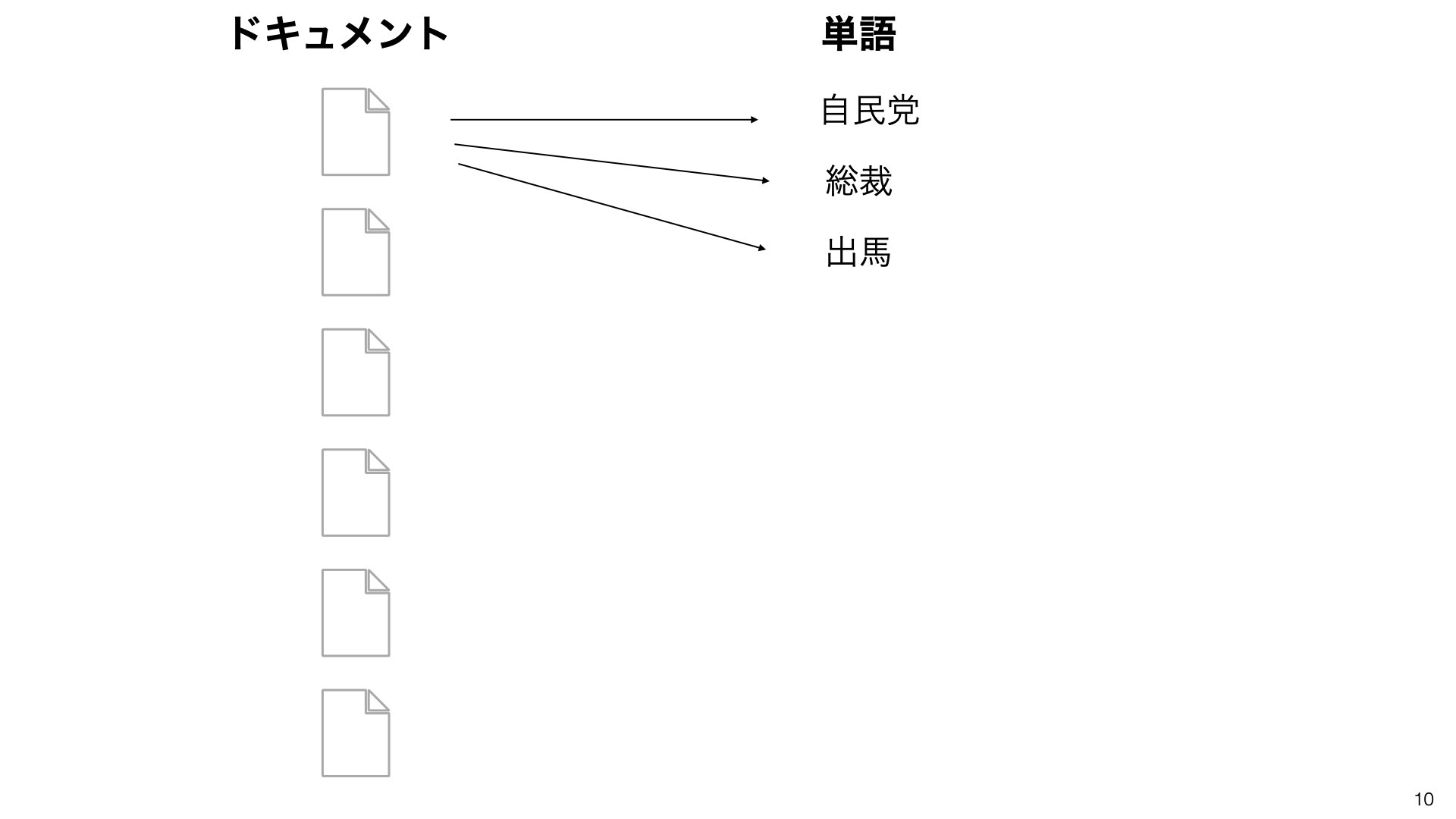
手順2:単語の共起関係を分析する
どの単語が一緒に現れやすいかを調べます。
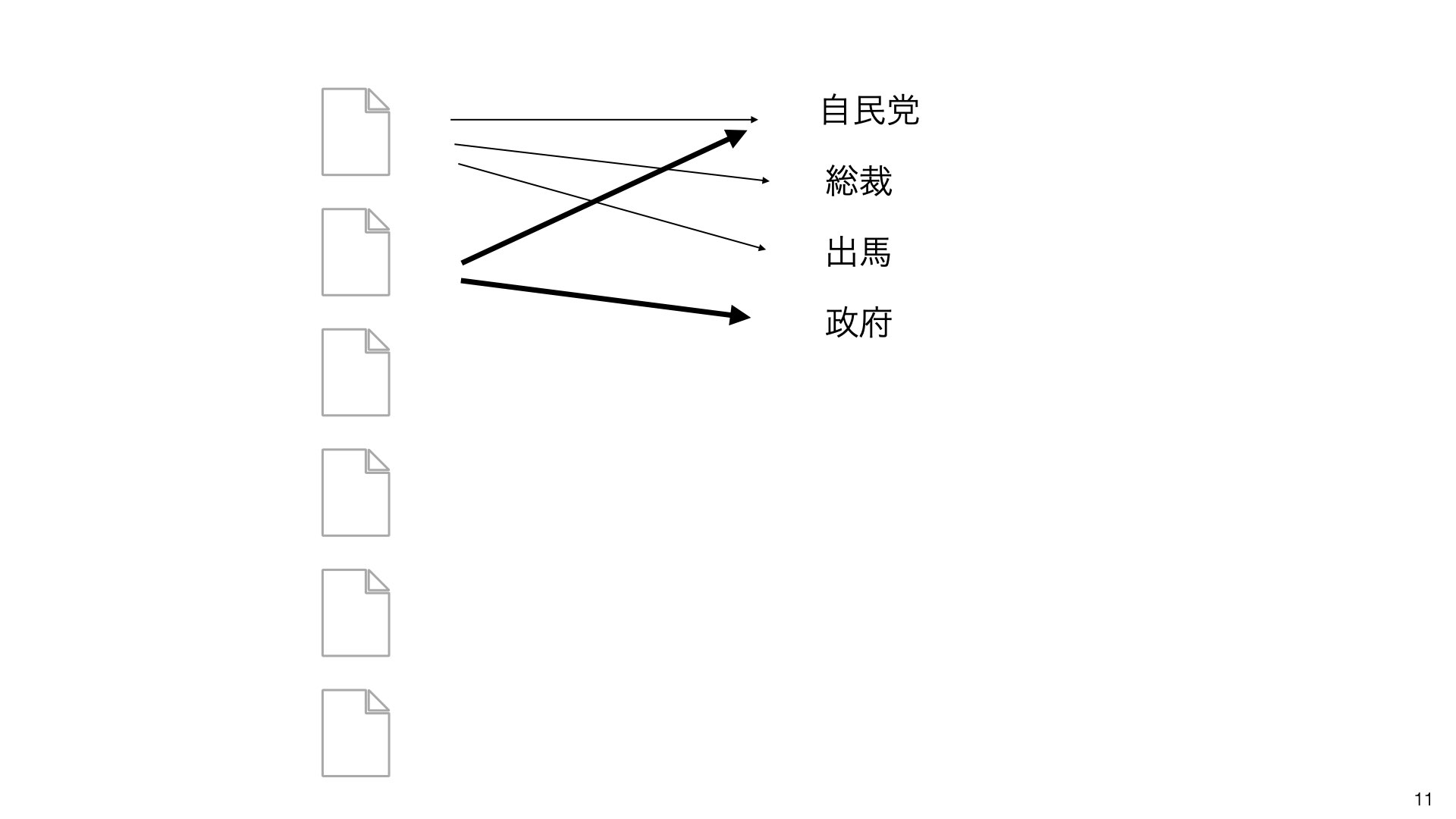
「自民党」と「総裁」、「政府」などが一緒に現れることが多いことがわかります。
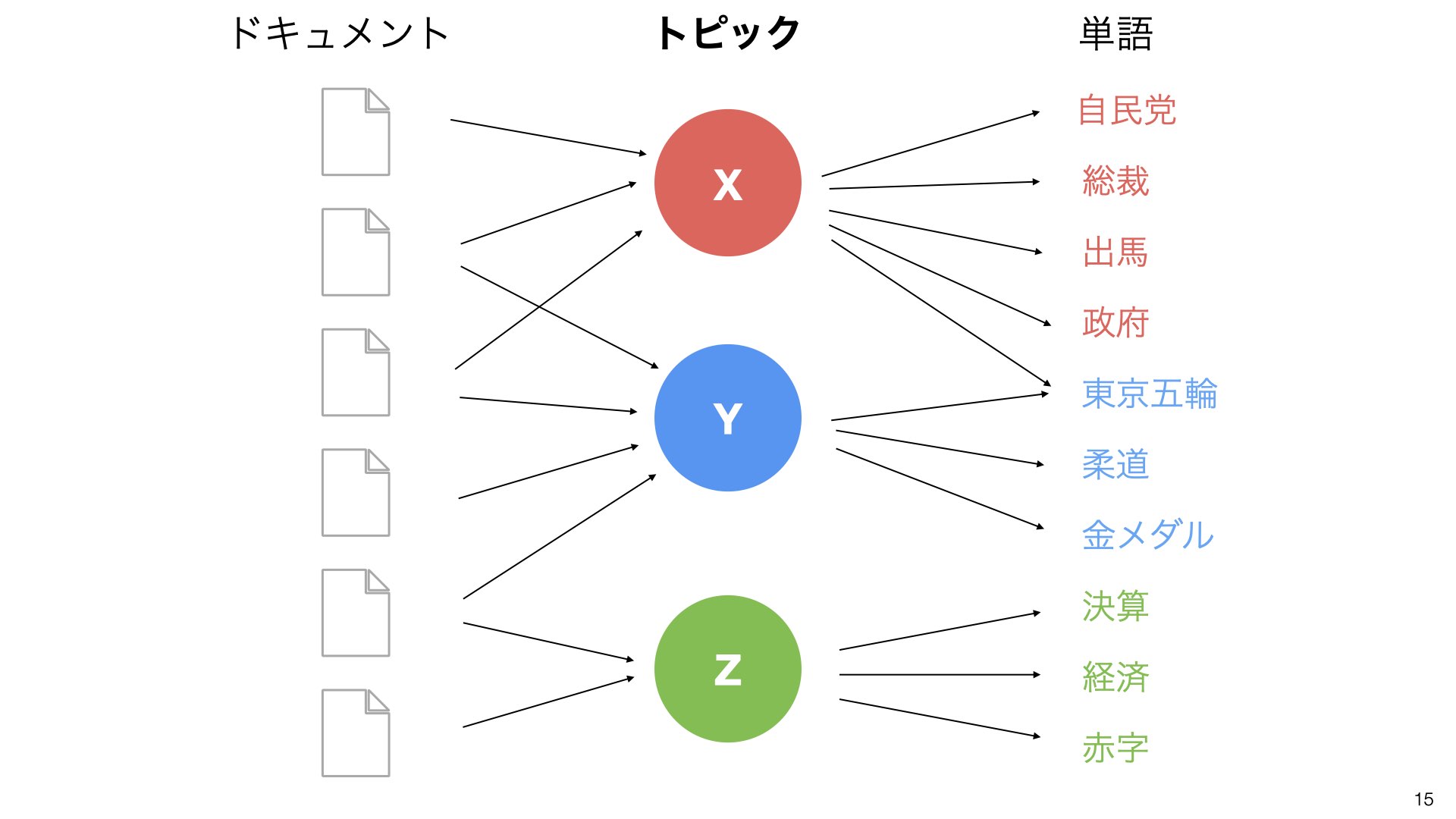
手順3:単語のグループ化を進める
関連の強い単語をさらにグループ化していきます。
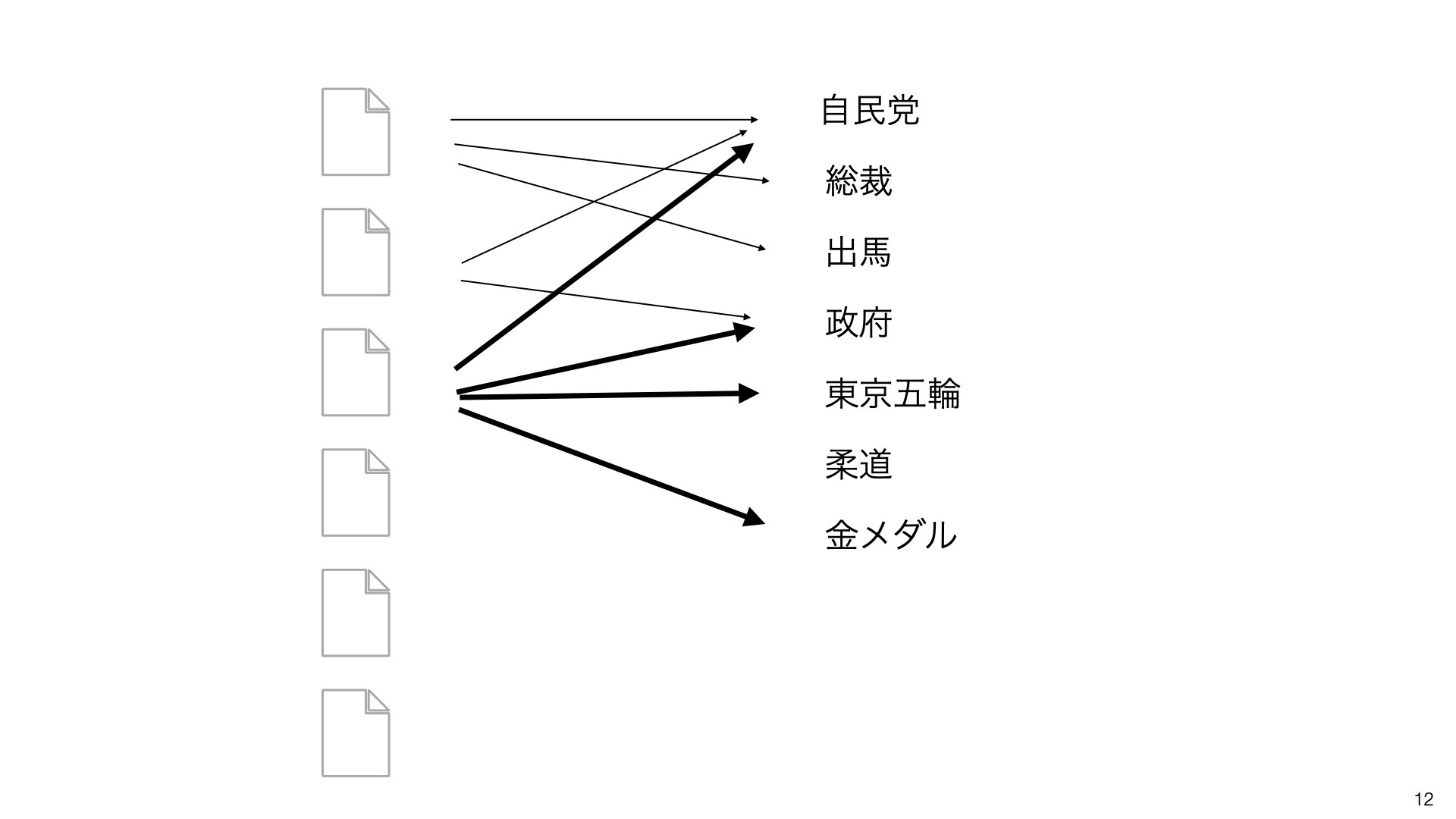
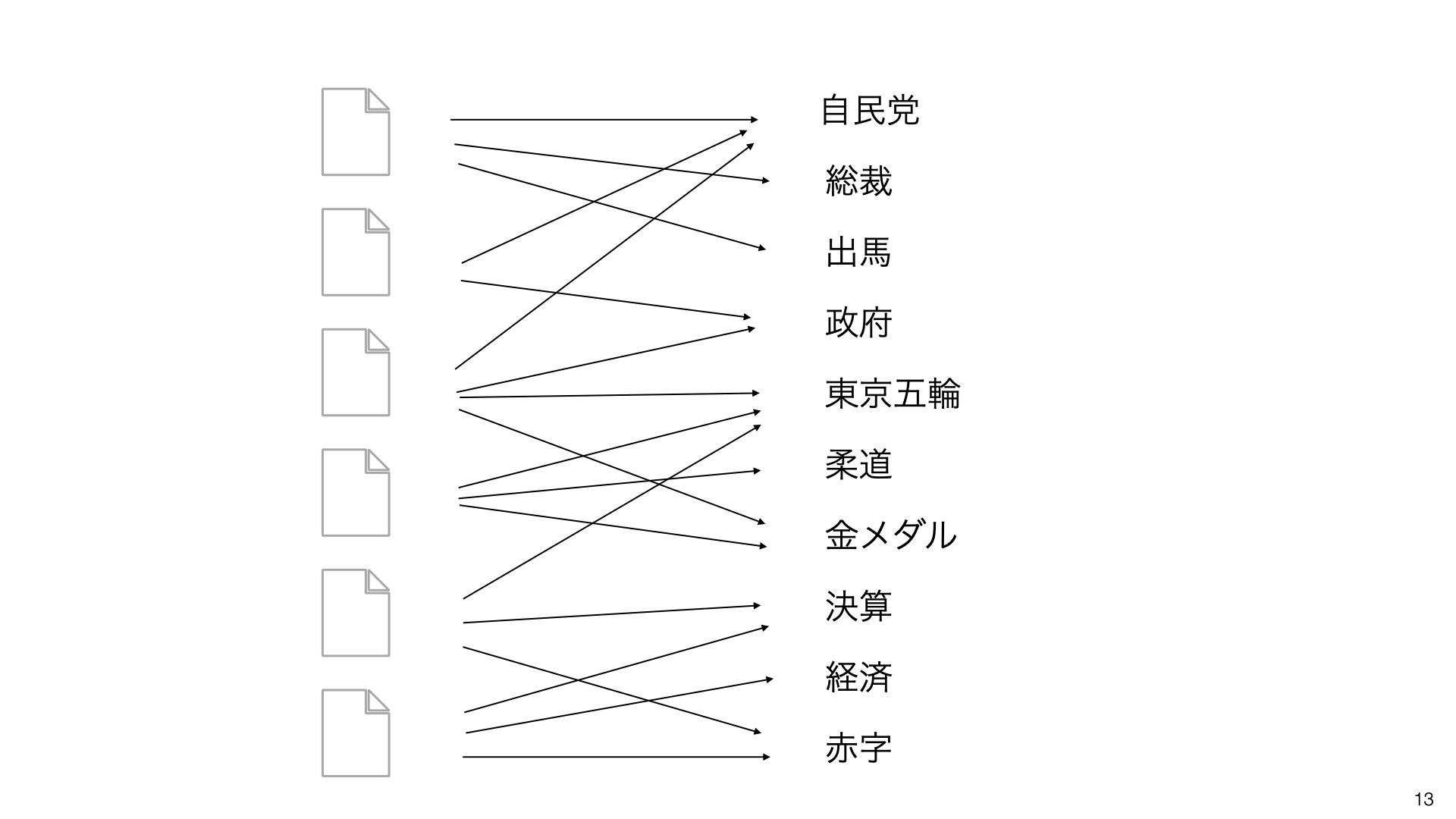
手順4:トピックを特定する
最終的に、単語のグループをトピックとして色分けします。
赤色:政治関連の単語
青色:スポーツ関連の単語
緑色:経済関連の単語
手順5:文章とトピックの関係を定量化する
各文章がどのトピックをどの程度含んでいるかを確率で表します。
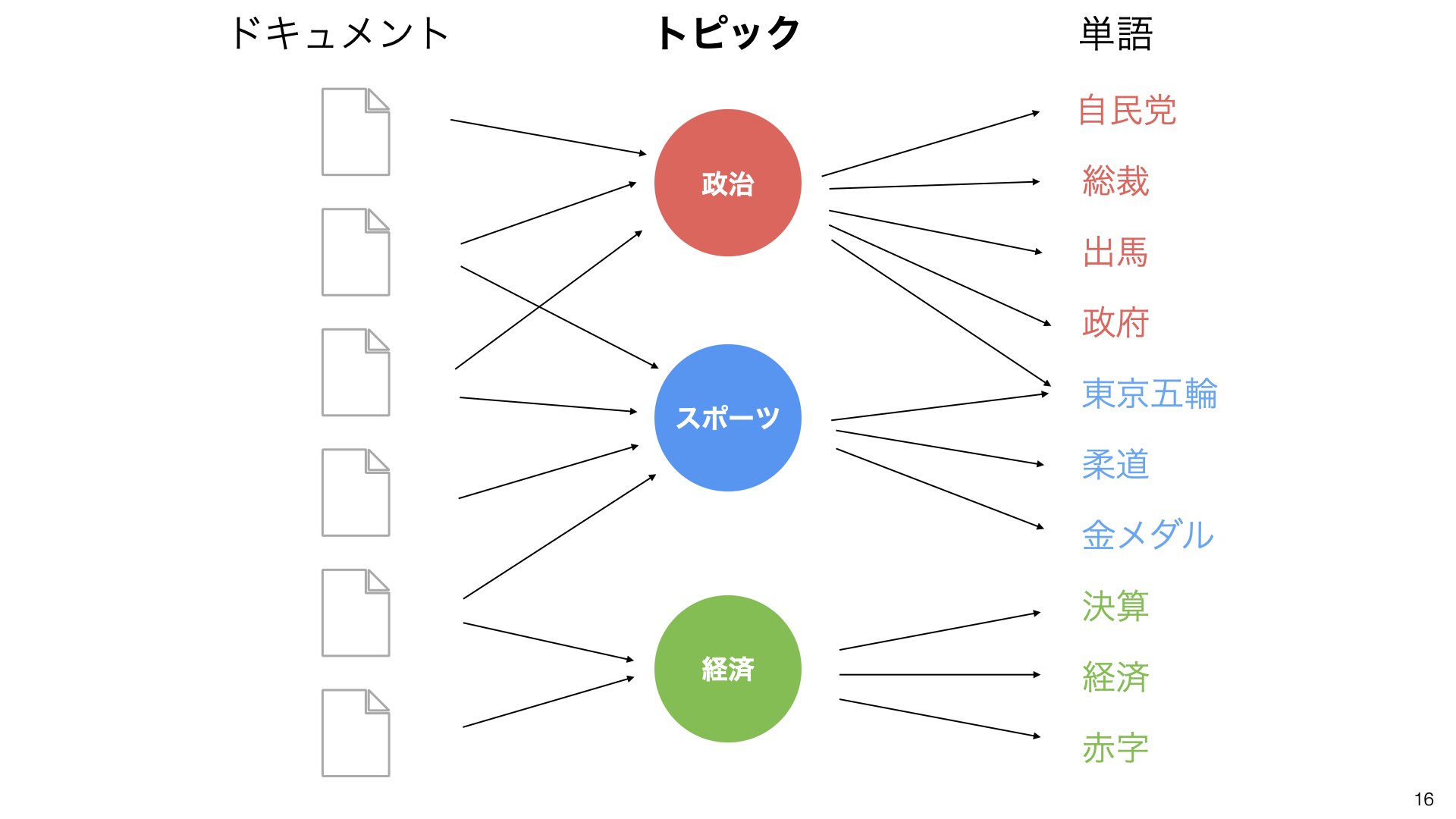
計算結果の例
最終的に、各文章のトピック分布が数値で得られます:
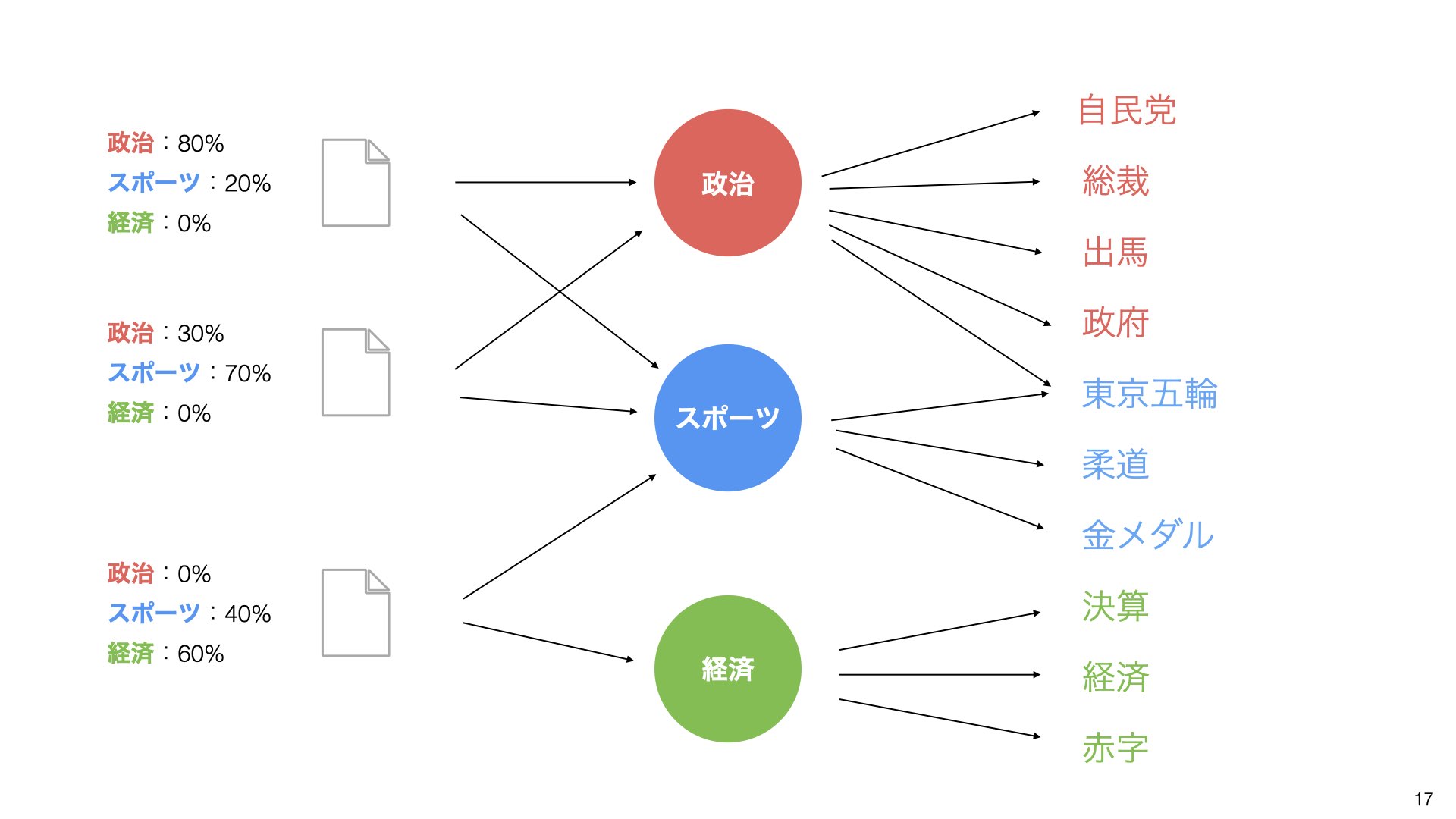
1つ目の文章:政治80%、スポーツ20%、経済0%
2つ目の文章:政治30%、スポーツ70%、経済0%
3つ目の文章:政治0%、スポーツ40%、経済60%
4. まとめ
トピックモデルは、大量のテキストデータから隠れた話題を自動的に発見し、各文章がどの話題をどの程度含んでいるかを確率で表現する手法です。