データを再インポートする方法
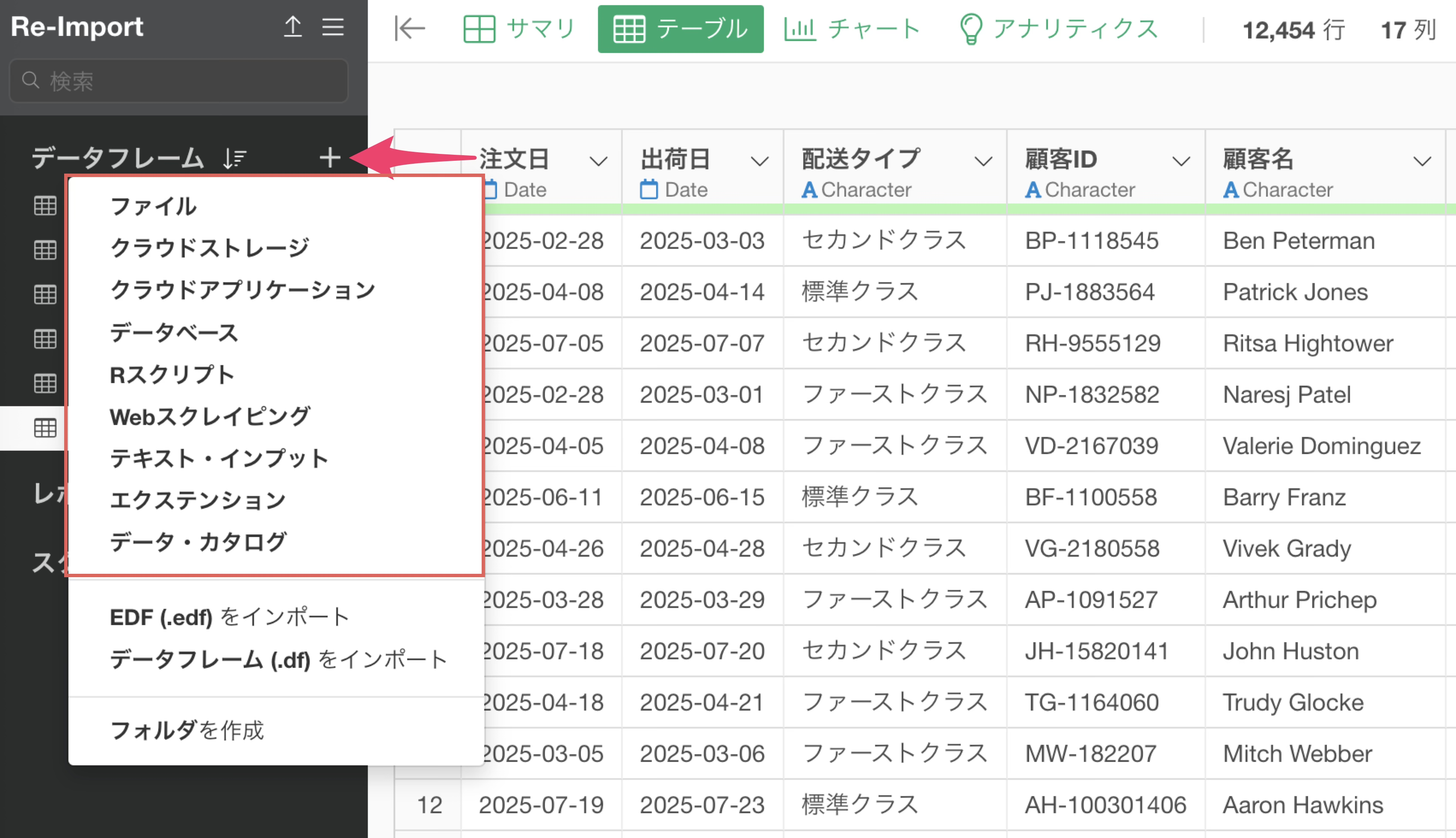
Exploratoryでは、PC上のローカルファイル、データベース、クラウドストレージやクラウドアプリケーションなど、様々なデータソースからデータをインポートできます。
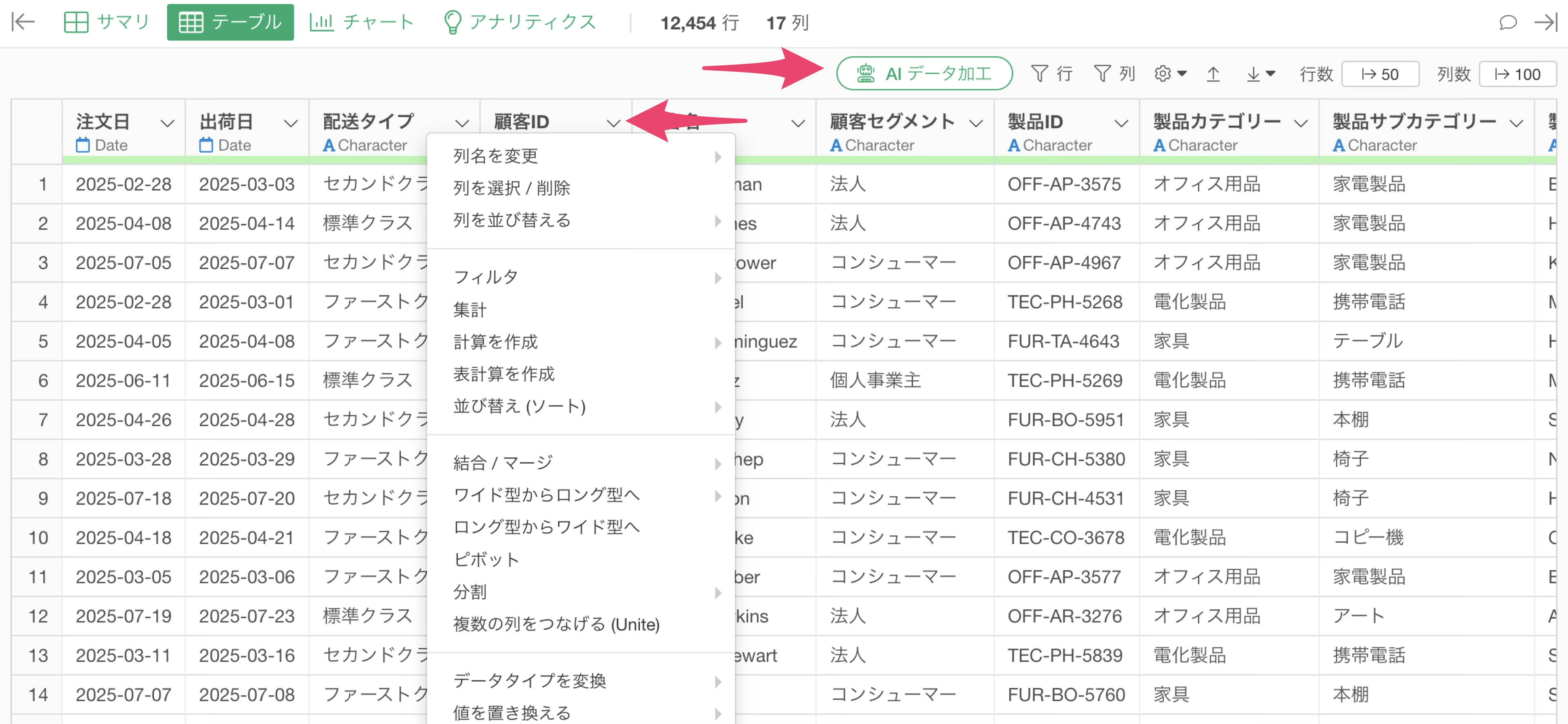
またデータをインポートしたら、AIまたはUIを通してデータを加工できます。
Exploratoryでデータを加工すると、それぞれの処理はステップとして保存されます。
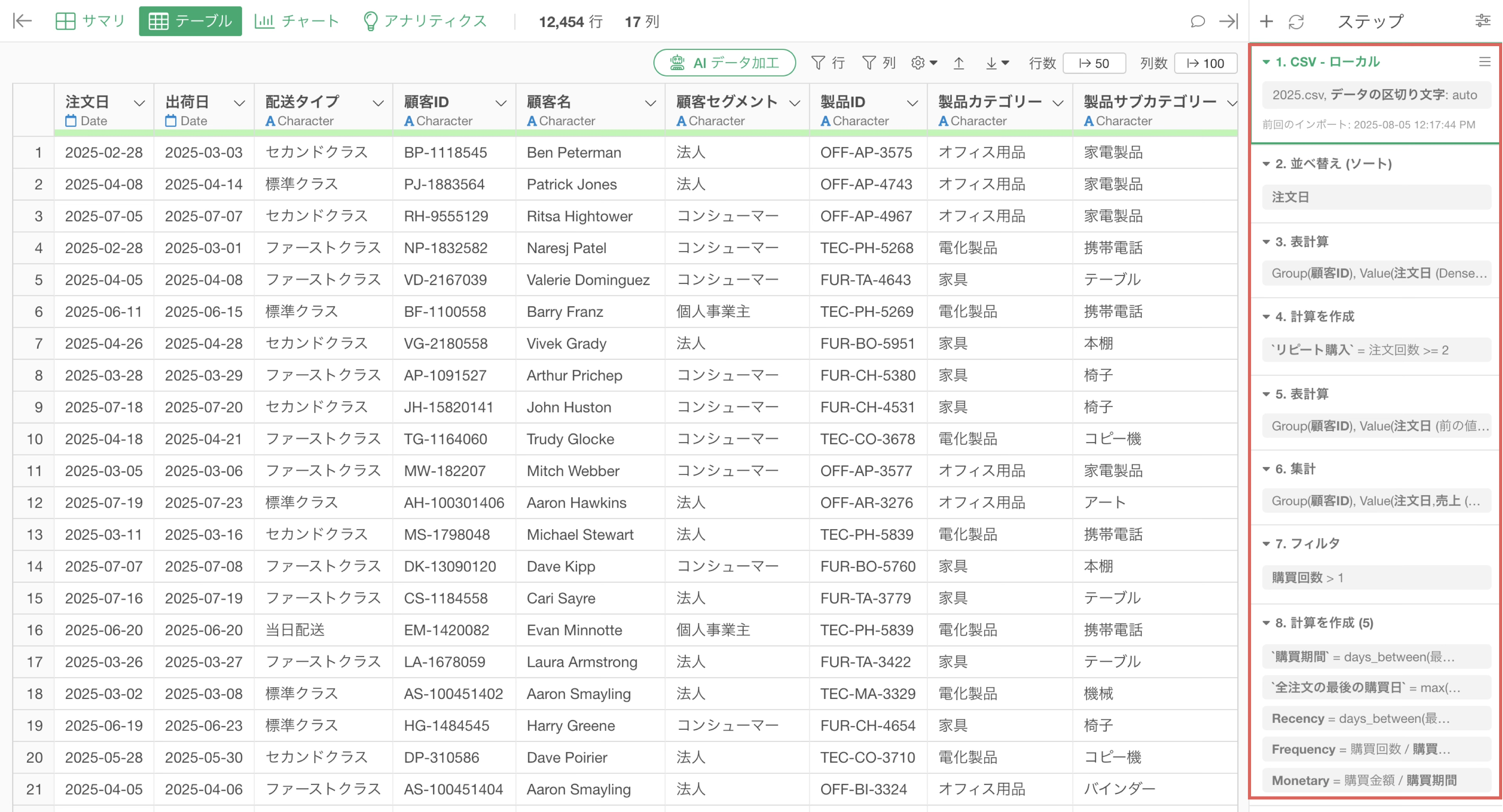
こういったデータ加工のステップは、更新したデータに対して再度適用したいことが少なくありません。
そういった時には、例えば同じ場所に保存されているファイルの中身が更新されたときには、ステップ上部のデータの再インポートボタンをクリックして、ファイルのデータを再インポートして、データを最新の内容に更新した上で、ステップを再実行できます。
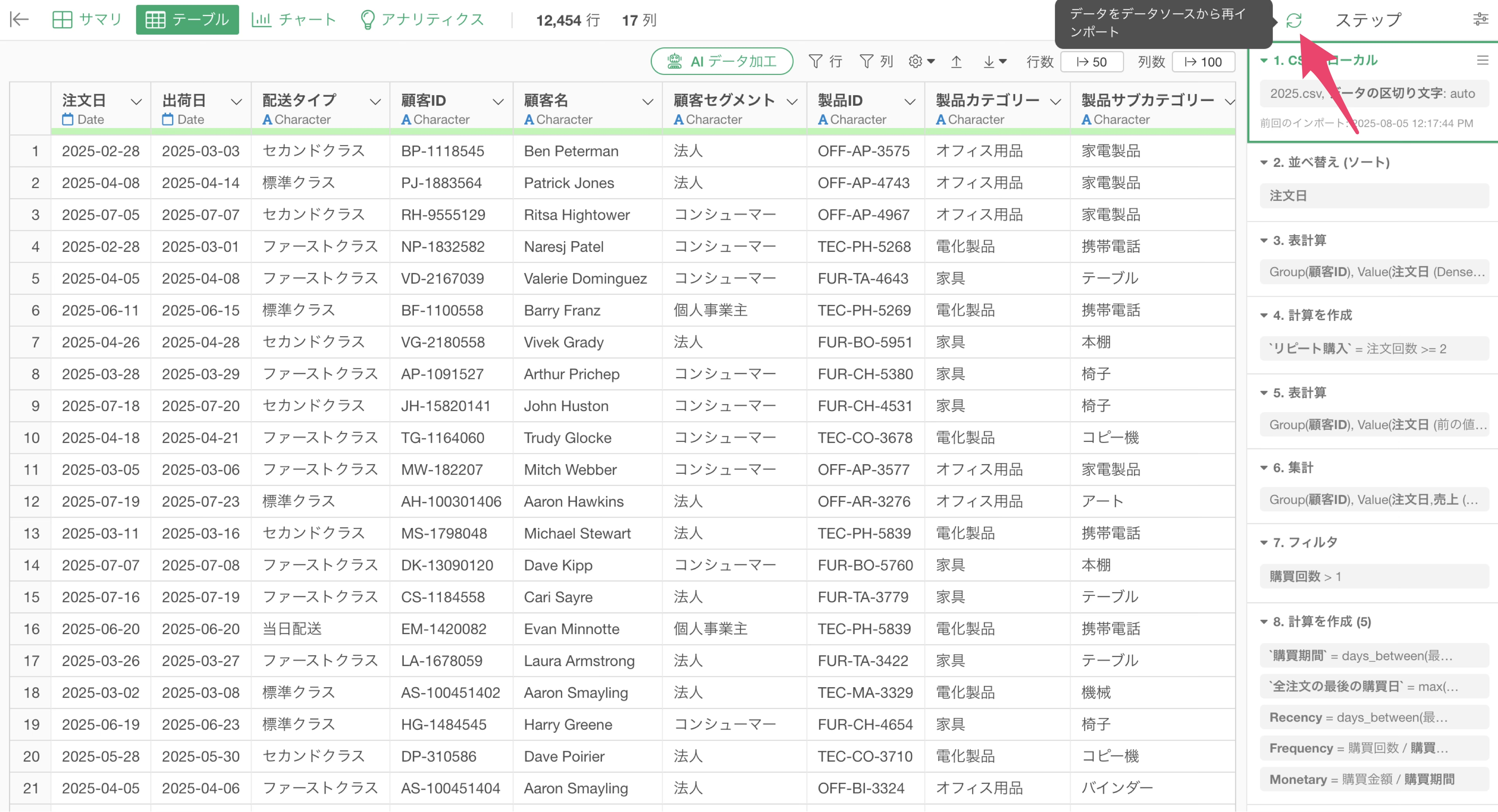
なお、データの再インポートはファイルに対してだけではなく、全てのタイプのデータソースに対して実行できます。
さらにExploratoryでデータを加工するときには、単一のデータだけを使ってデータを加工するだけでなく、複数のデータを列結合したり行結合したりして、複数のデータフレームをを組み合わせた処理も可能です。
例えば、以下の例では、二番目のステップに「マージ」と呼ばれる行結合のステップがあります。
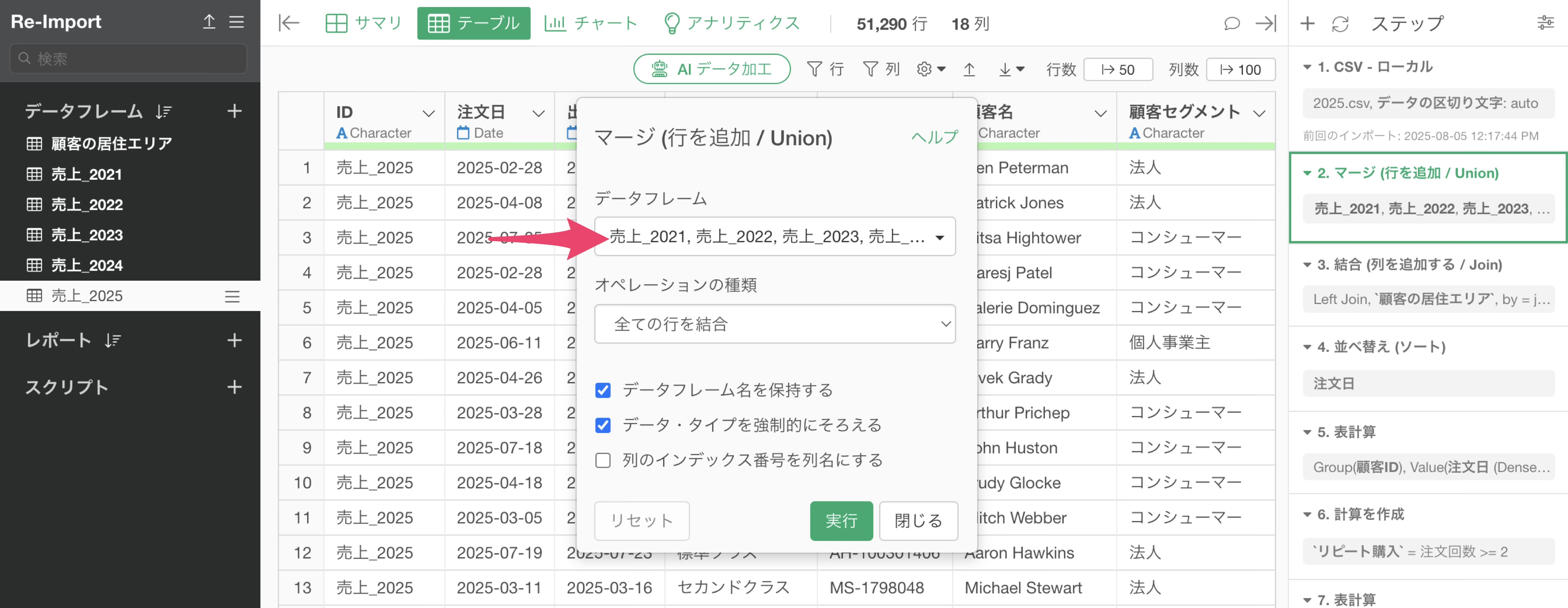
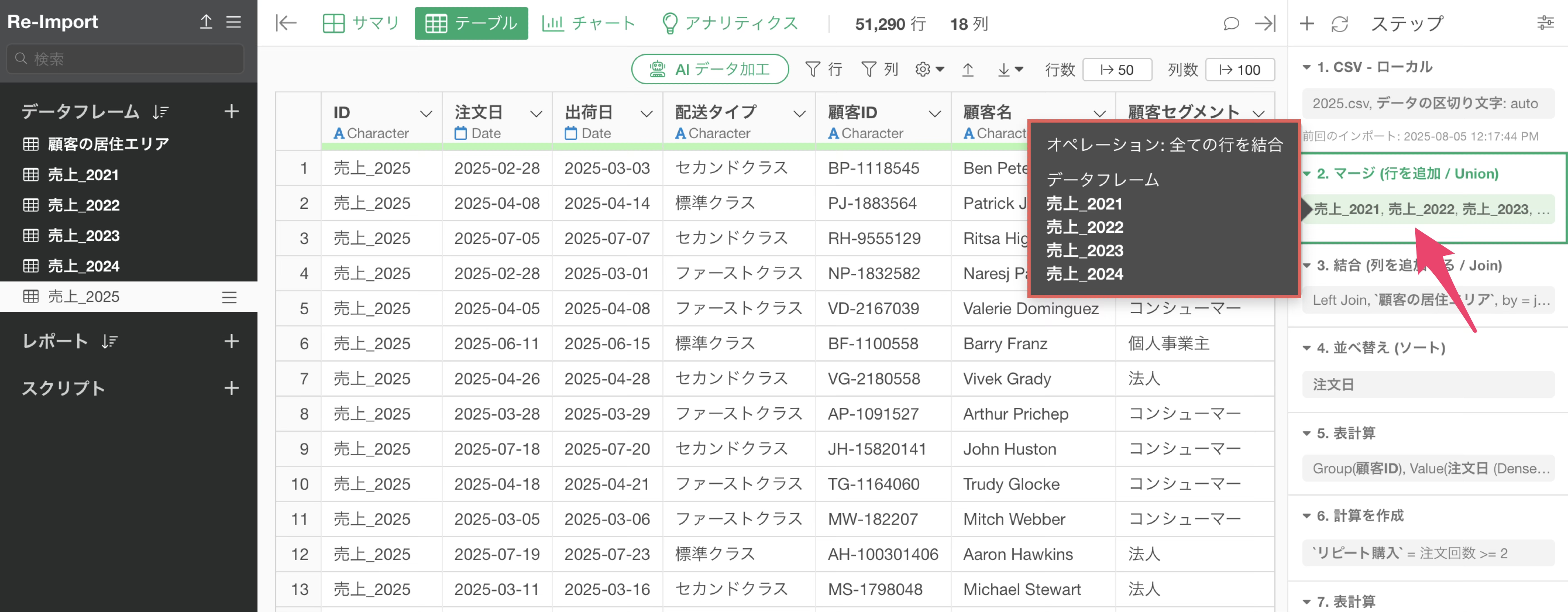 このステップでは、現在、開いている2025年の売上のデータフレームに、2021年から2024年のデータフレームを行結合しています。
このステップでは、現在、開いている2025年の売上のデータフレームに、2021年から2024年のデータフレームを行結合しています。
また、三番目のステップには列結合のステップがあり、顧客の居住地域の情報を「顧客の居住エリア」のデータフレームから結合しています。
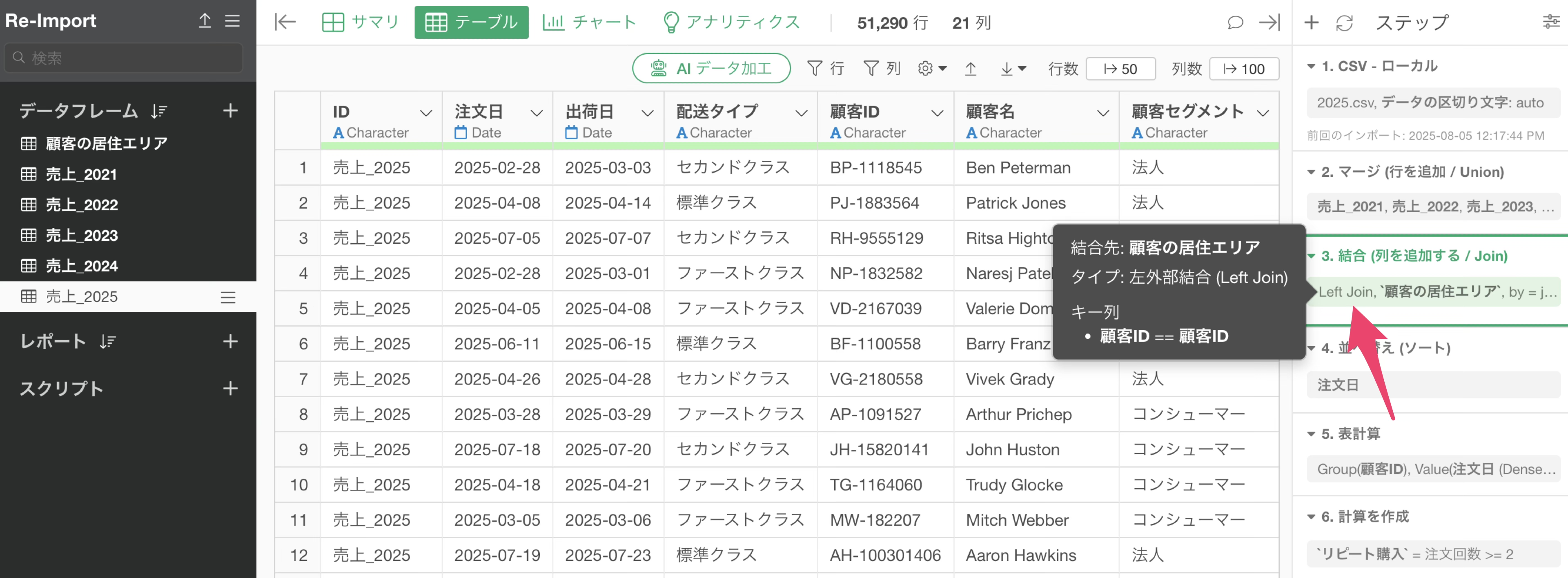
このように、Exploratoryでは複数のデータフレームを組み合わせてデータを加工していくステップを追加できます。
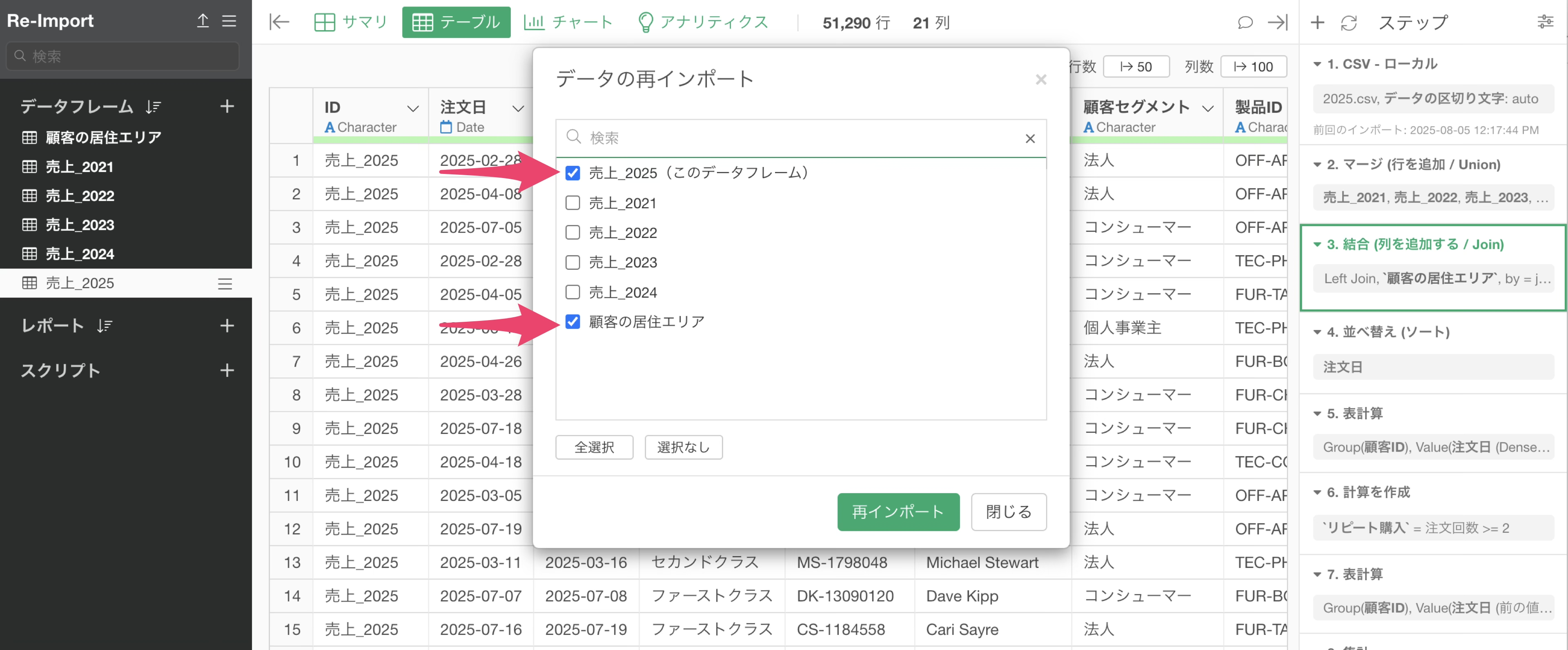
データの再インポートは、このように複数のデータを組み合わせて加工している時にも、同じように実行できます。
今回のように複数のデータフレームを組み合わせてステップを組んでいる場合、再インポートボタンをクリックすると、該当のデータフレームに関係する全てのデータフレームがリストとして表示されます。
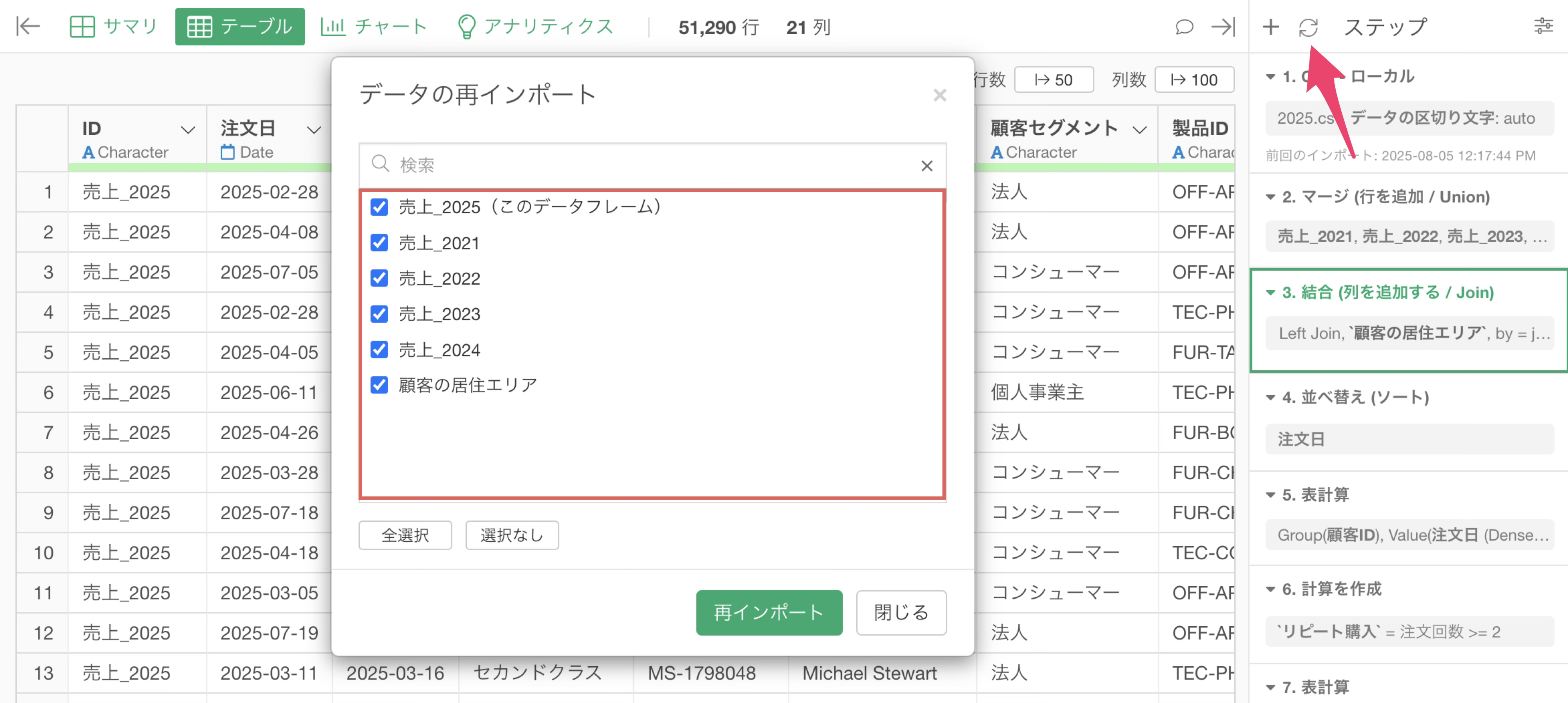
この時、すべてのデータを再インポートしたければ、全てのデータフレームにチェックがついている状態で再インポートボタンをクリックしてください。
一方で、仮に2021年から2024年のデータが過去のデータであれば、それらのデータが更新されることはありませんので、わざわざデータを再インポートする必要はありません。
データ量が多い場合であれば、不要なデータフレームを再インポートすることで、処理に不必要な時間がかかってしまいます。
また、該当のデータソースがデータベースに由来する場合、データベースではデータが既になくなってしまっている、つまりはデータを再インポートすることによって、本来は残っていてほしいデータがなくなってしまうといったことも起こりえます。
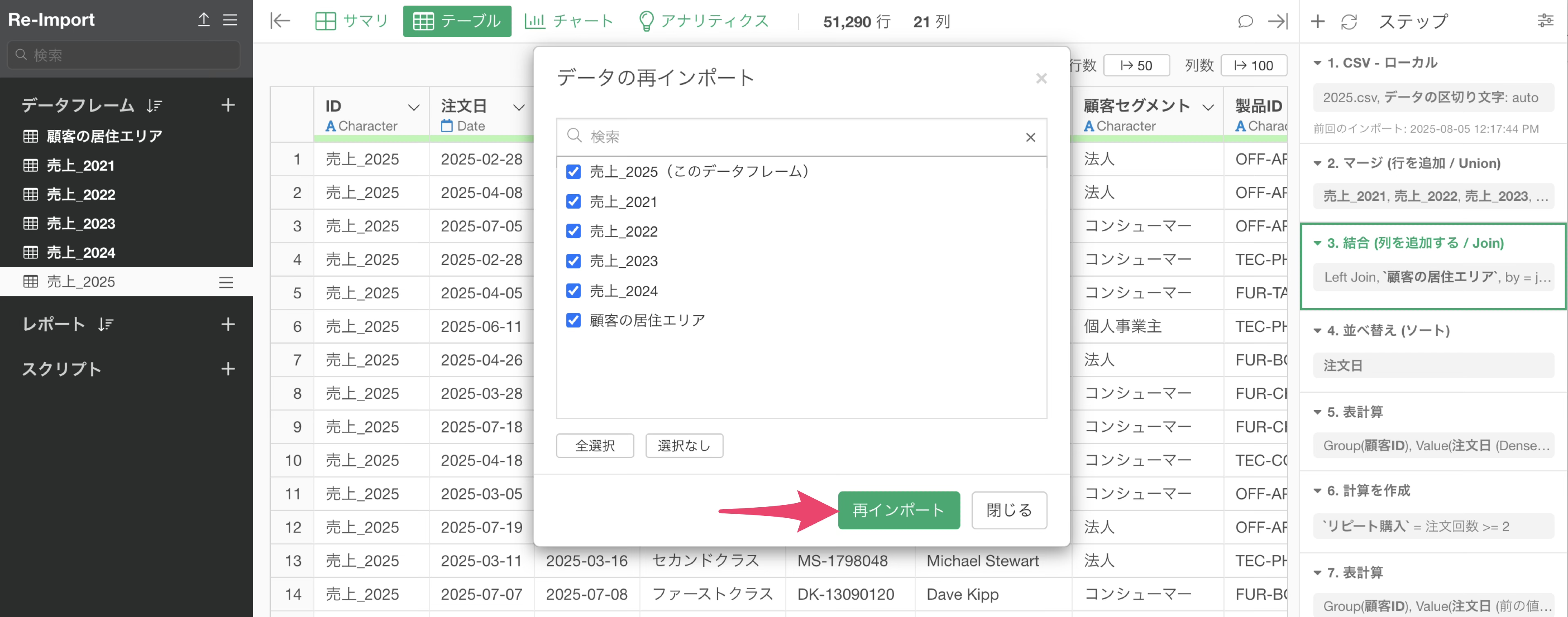
そういった時には、再インポートするデータを選択をして、再インポートする対象を指定できます。
例えば、今現在自分がいる2025年のデータフレーム、それから顧客の居住エリア、この二つのデータフレームからデータを再インポートしたいときには、この二つだけにチェックを付けてデータを再インポートします。
こうように再インポートするデータを指定することで、パフォーマンスに負荷をかけるだけでなく、意図しないデータフレームの更新を防げます。