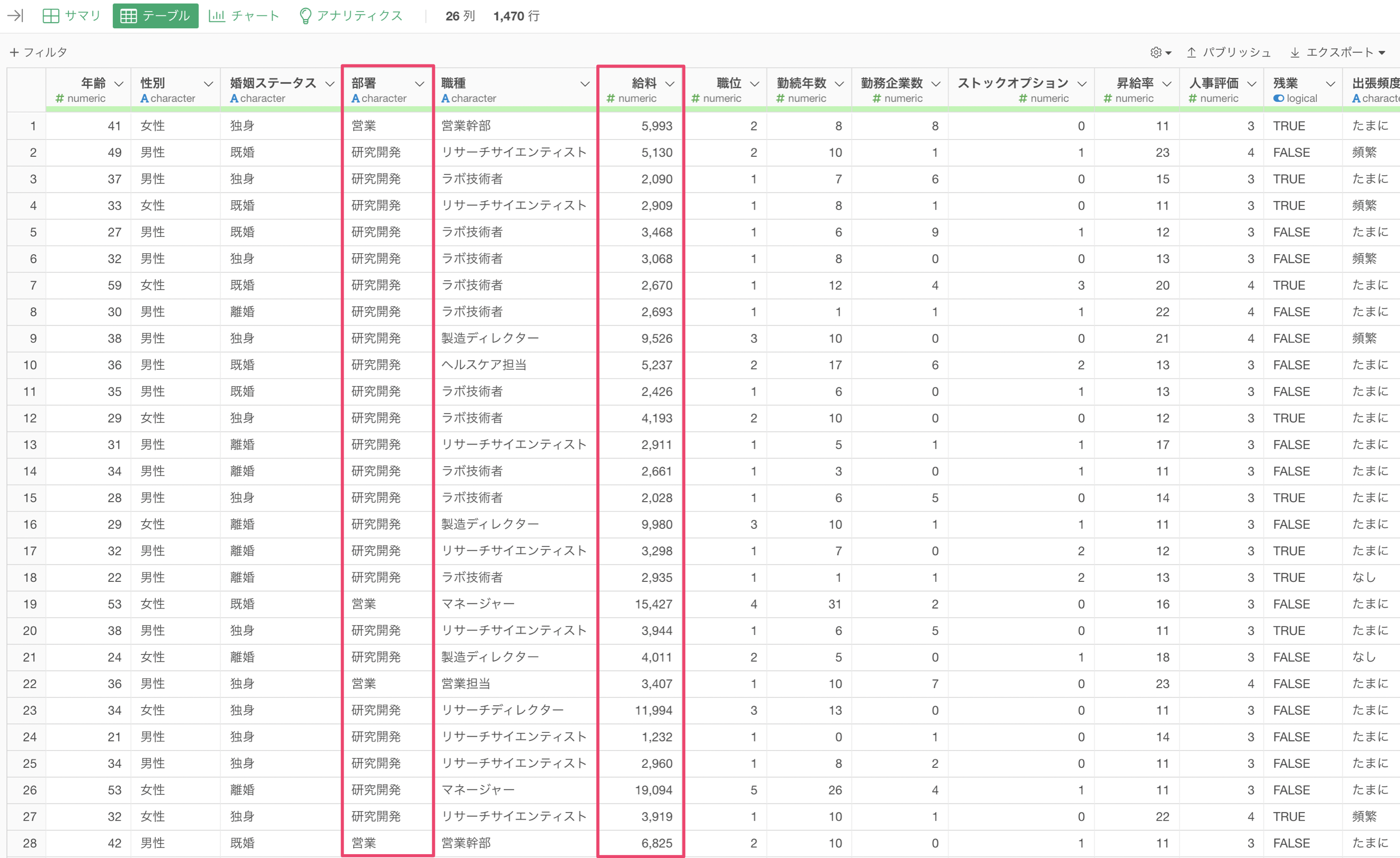
t検定の紹介
t検定とは統計的検定の手法の一つで、2つのグループ間の数値の平均値の差が有意かどうかを検定することができます。
例えば、営業の部署と研究開発の部署の給料の平均値を可視化したバーチャートがあったとします。この2つの部署の給料の平均値は、700ドルほどありますが、それが意味のある違いなのかどうかはこのバーチャートからでは判断できません。
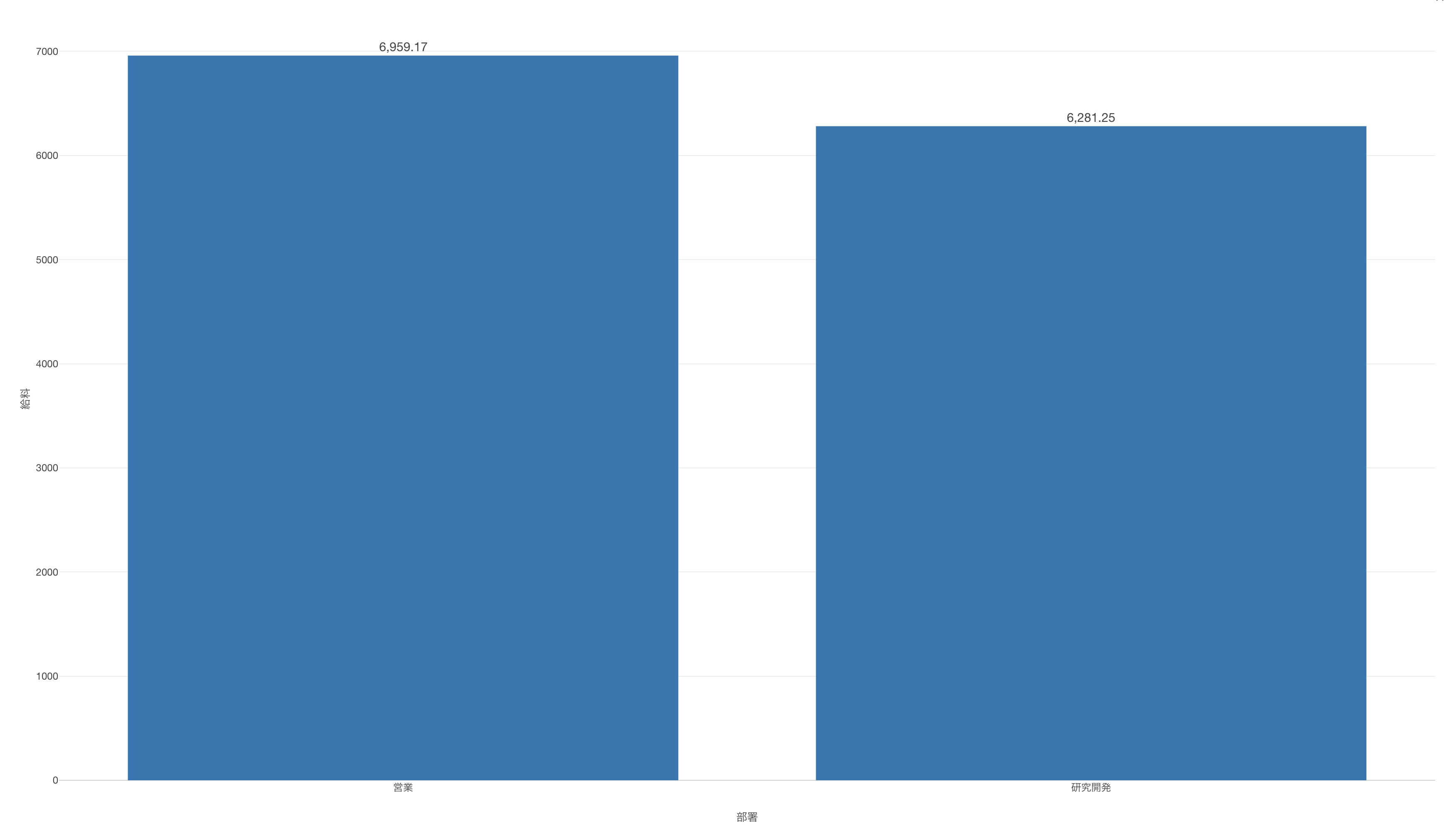
というのも、それぞれの部署における人数(行の数)や給料のばらつきには大きな違いがあるかもしれません。そこで、意味のある違いがあるのかどうかを知るために、t検定を使って検証することができます。
必要なデータの形式
Exploratoryのt検定では、1行が1つの観察を表し、列には比較対象の2つのグループの情報を表すデータが必要です。
例えば、上記の例では、1行が1人のタイピング速度の計測値を表し、ステータスの列が講習の「受講前」と「受講後」のいずれかを表しています。
一方で手元にあるデータが以下のように列に1行1人を表し、列には複数の計測に関する値を持つワイド型のデータの場合があります。
このようなデータしか手元にない状態でt検定を実行するためにはデータの形式を変換する必要があります。
具体的には、計測値の列を選択し、列ヘッダーメニューから、ワイド型からロング型に変換して、t検定を実行するための形式にデータの形を変換することが可能です。(ロング型への変換の詳細はこちらをご参考ください。)
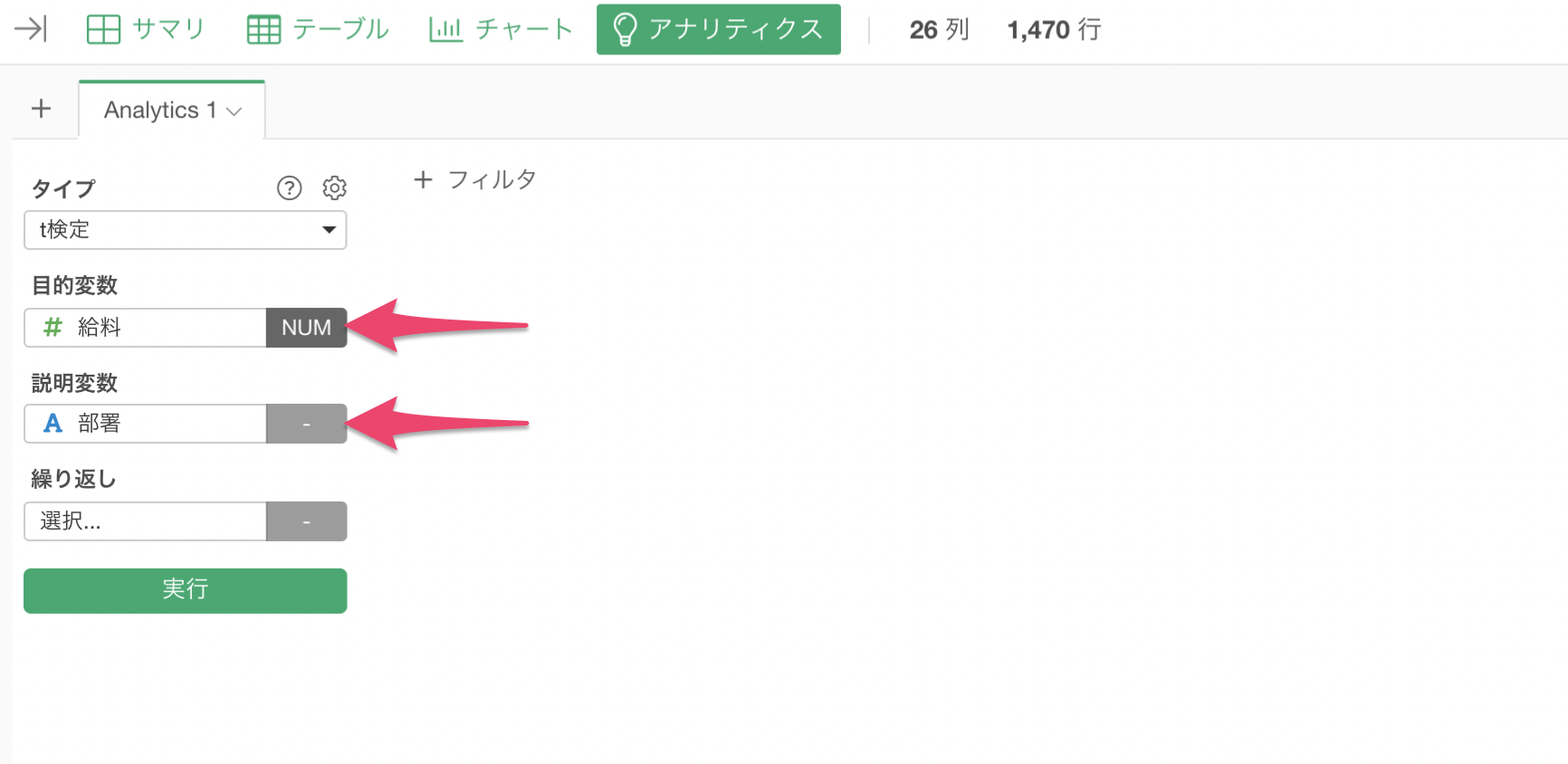
データをロング型に変化できたら、目的変数に計測値、説明変数にグループの情報を選択することで、t検定を実行することが可能です。
t検定を実行する
今回は、部署が「営業」と「研究開発」で「給料」の平均値に統計的に有意な差があるのかをt検定で確認したいです。ちなみに、部署には一意な値の数が3つあり「営業」と「研究開発」の他に、「人事」という部署も存在します。
アナリティクスビューを開き、タイプに「t検定」を選択します。
目的変数に「給料」を選び、説明変数に「部署」を選択します。

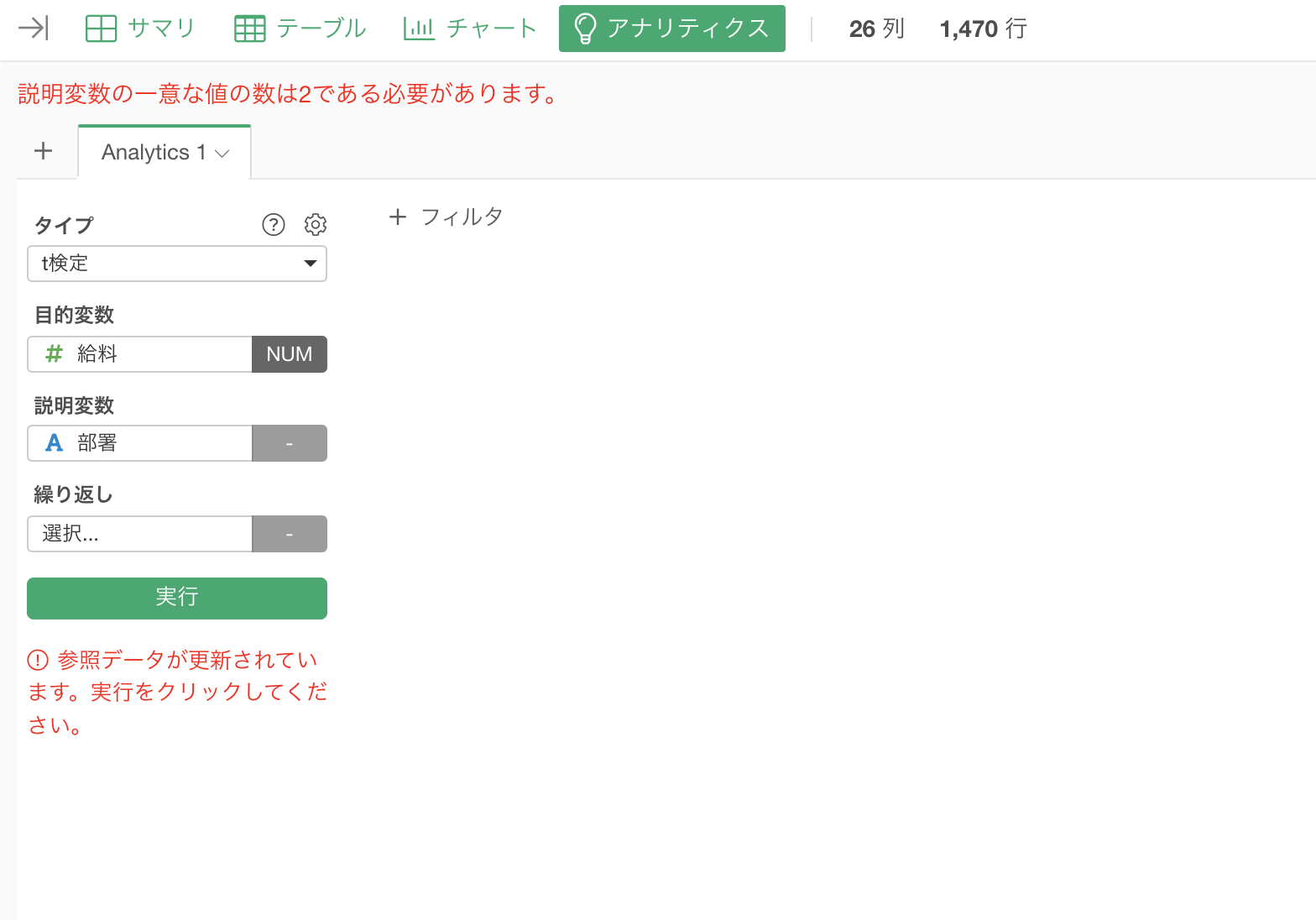
この状態で実行してしまうと「説明変数の一意な値の数は2である必要があります。」と表示エラーが出てしまいます。というのもt検定では冒頭でも紹介したように、2つのグループ間での平均値の差を検定するものです。

そのため、アナリティクスのフィルタを使用して部署が「営業」と「研究開発」のみのデータに絞り込んでいきます。
※ もし説明変数に割り当てている列の一意な値の数が2の場合は、こちらのステップは必要ありません。
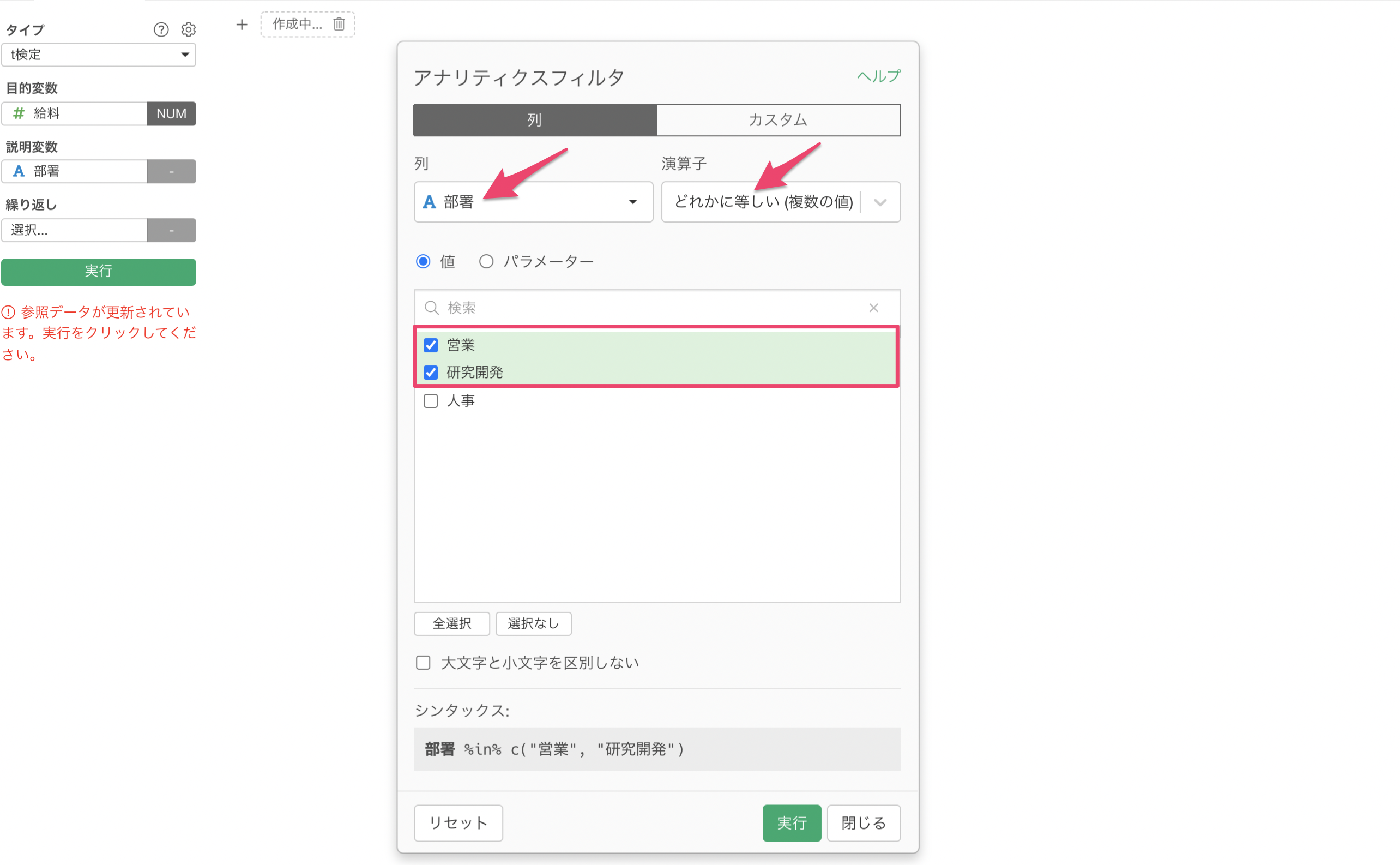
アナリティクスの上部にある「フィルタ」を選択します。
列には「部署」を選び、演算子には「どれかに等しい(複数の値)」を選択します。 次に、値には「営業」と「研究開発」を選択して、実行ボタンをクリックします。
これにより、部署が「営業」と「研究開発」の給料の平均値の差が有意かどうか調べるためのt検定が実行されました。
結果の解釈
サマリ
「サマリ」タブでは、検定の結果が有意かどうかを確認できます。2つのグループ間に差がないことを前提とした時に、この結果が得られる確率を表すP値から有意かどうか判断ができ、一般的には0.05(5%)を下回ると有意であると言われています。

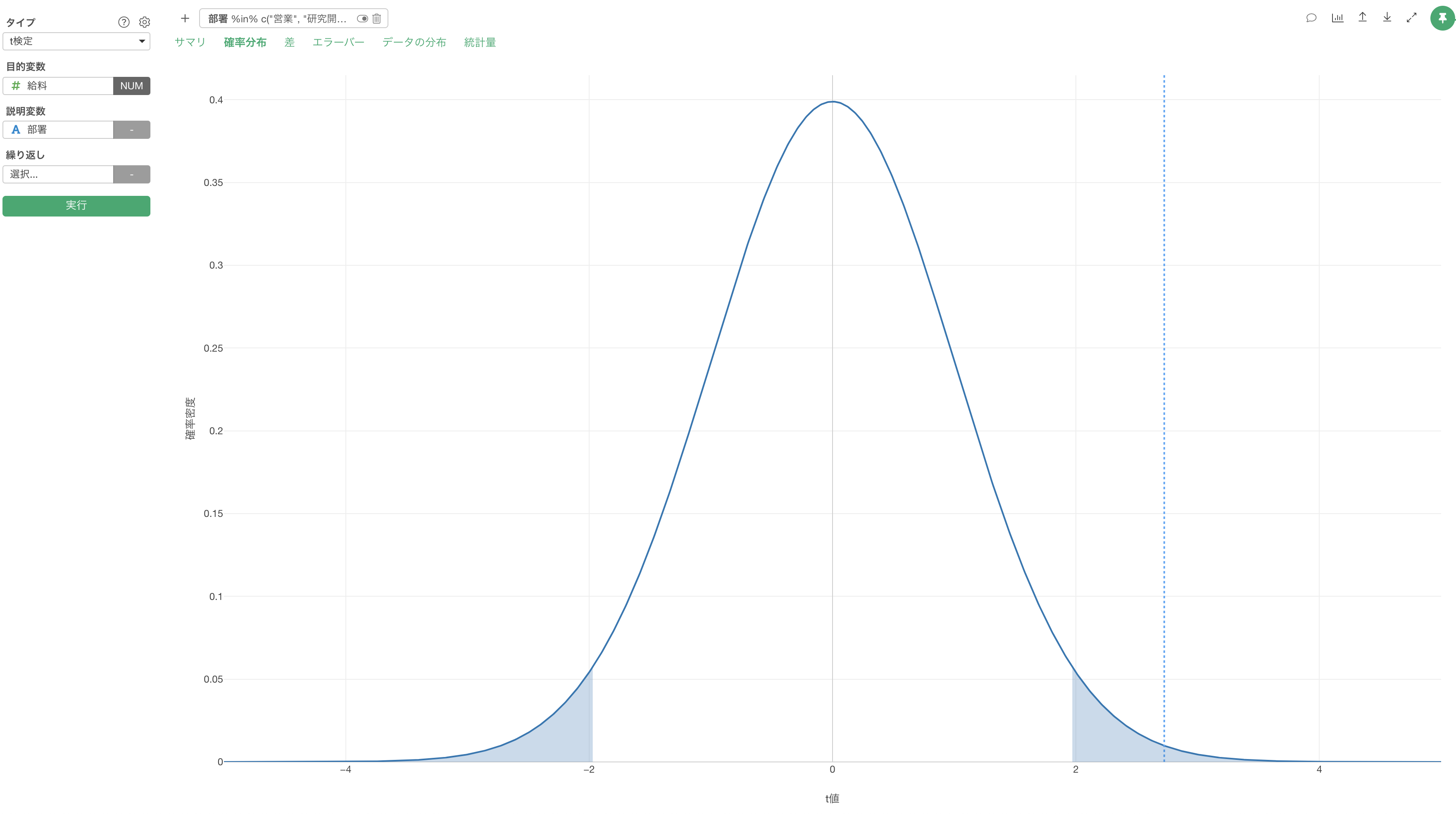
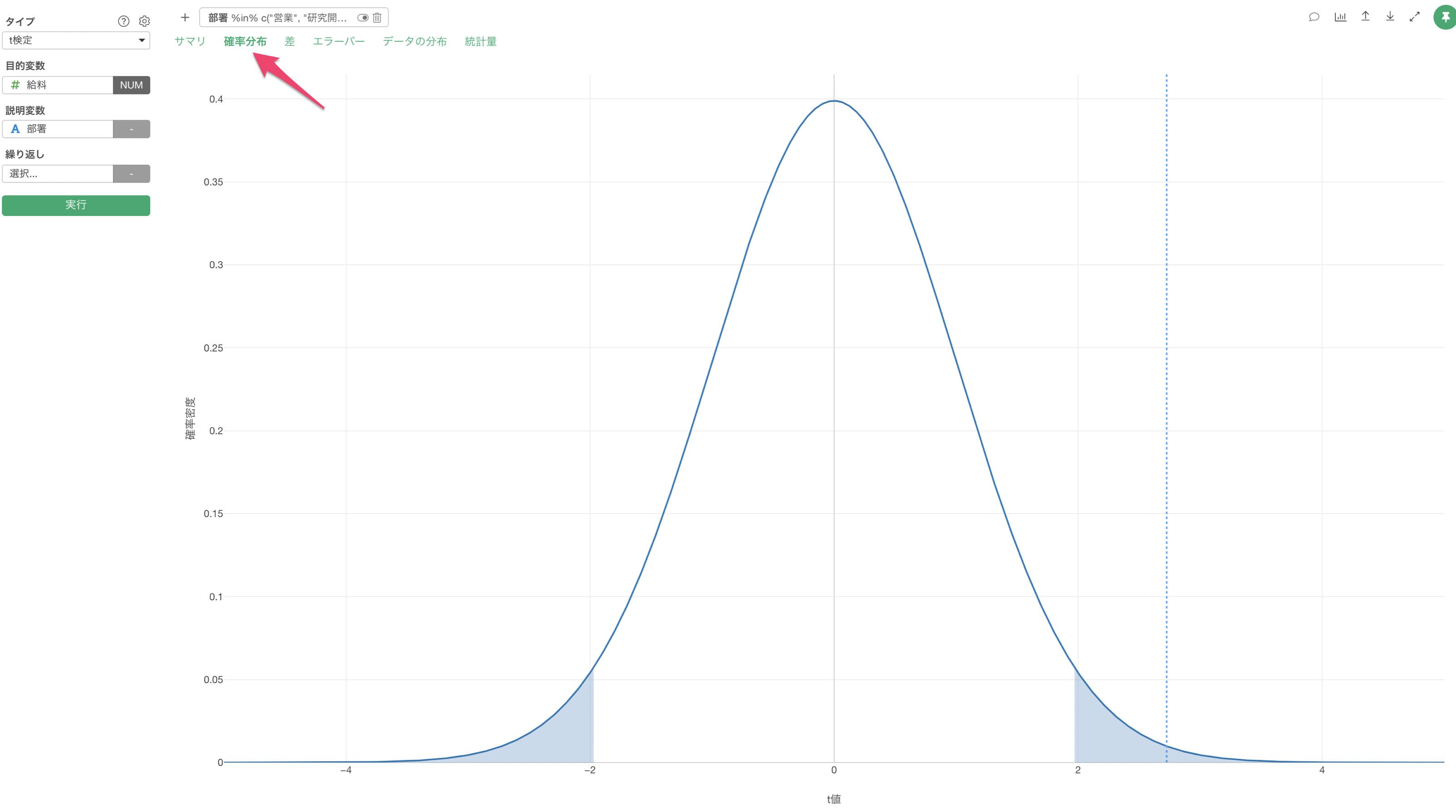
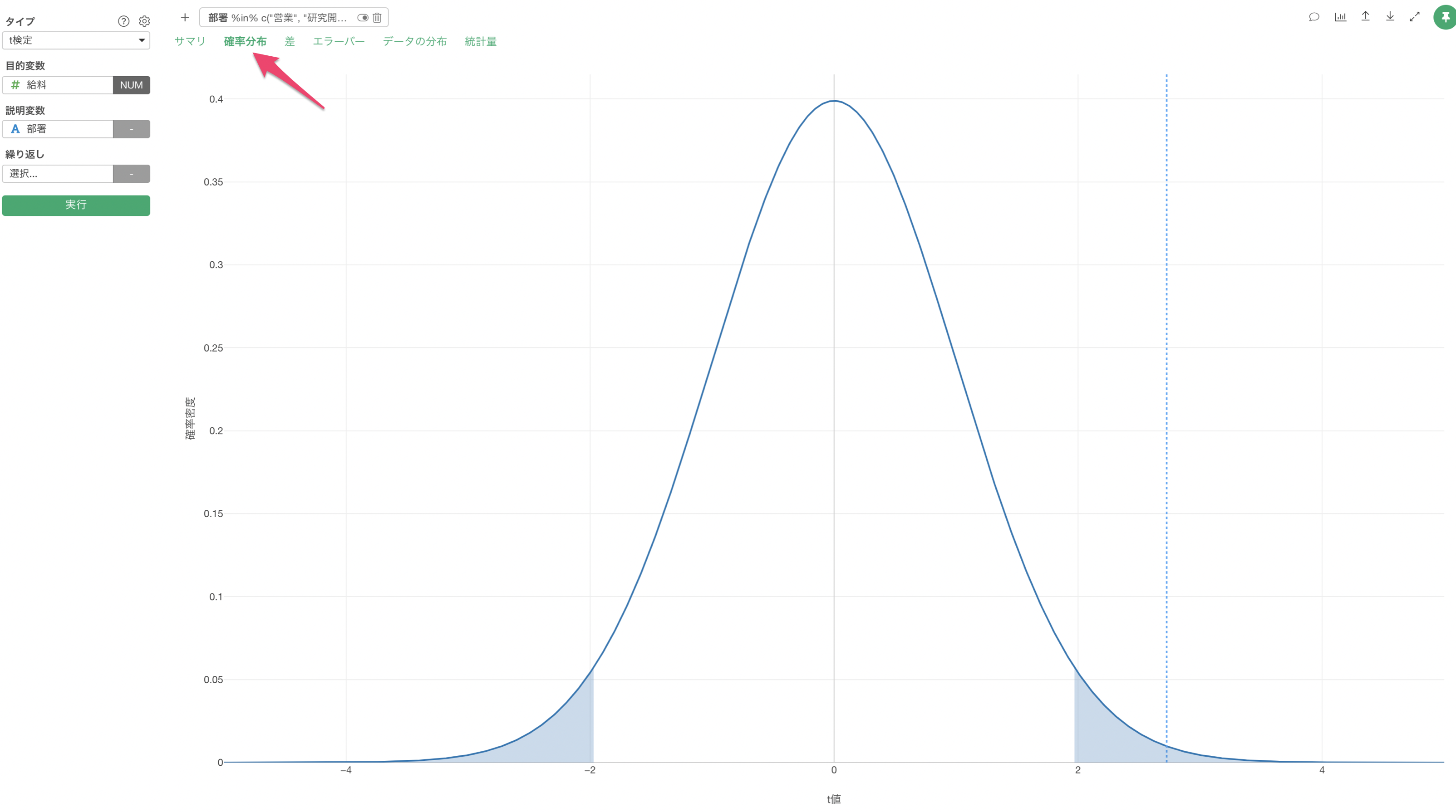
確率分布
「確率分布」タブでは、使用したデータの自由度を元に、t検定で使用する確率分布である「t分布」を描き、今回の結果である「t値」がt分布の中でどの位置にあるのかを点線として表示されます。
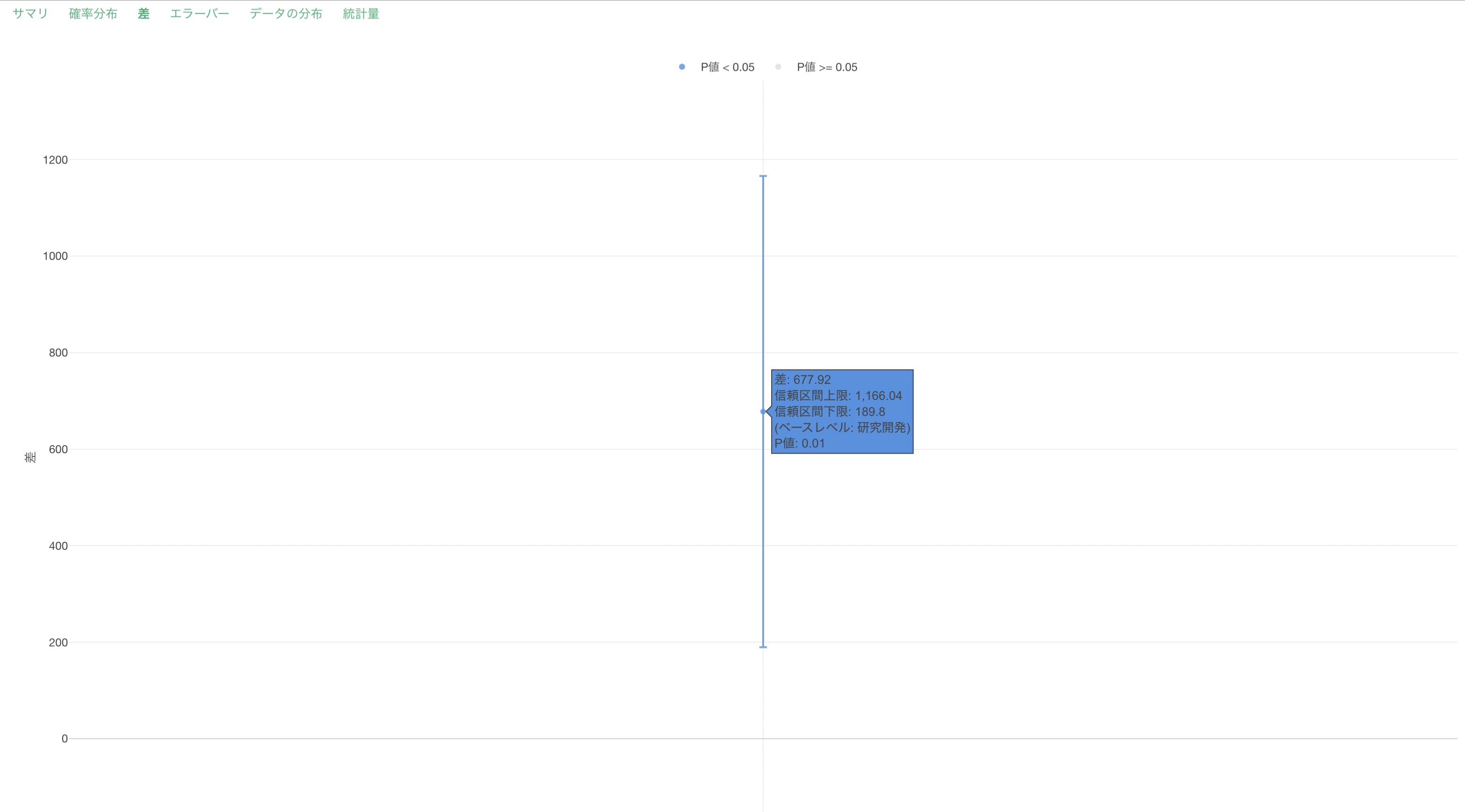
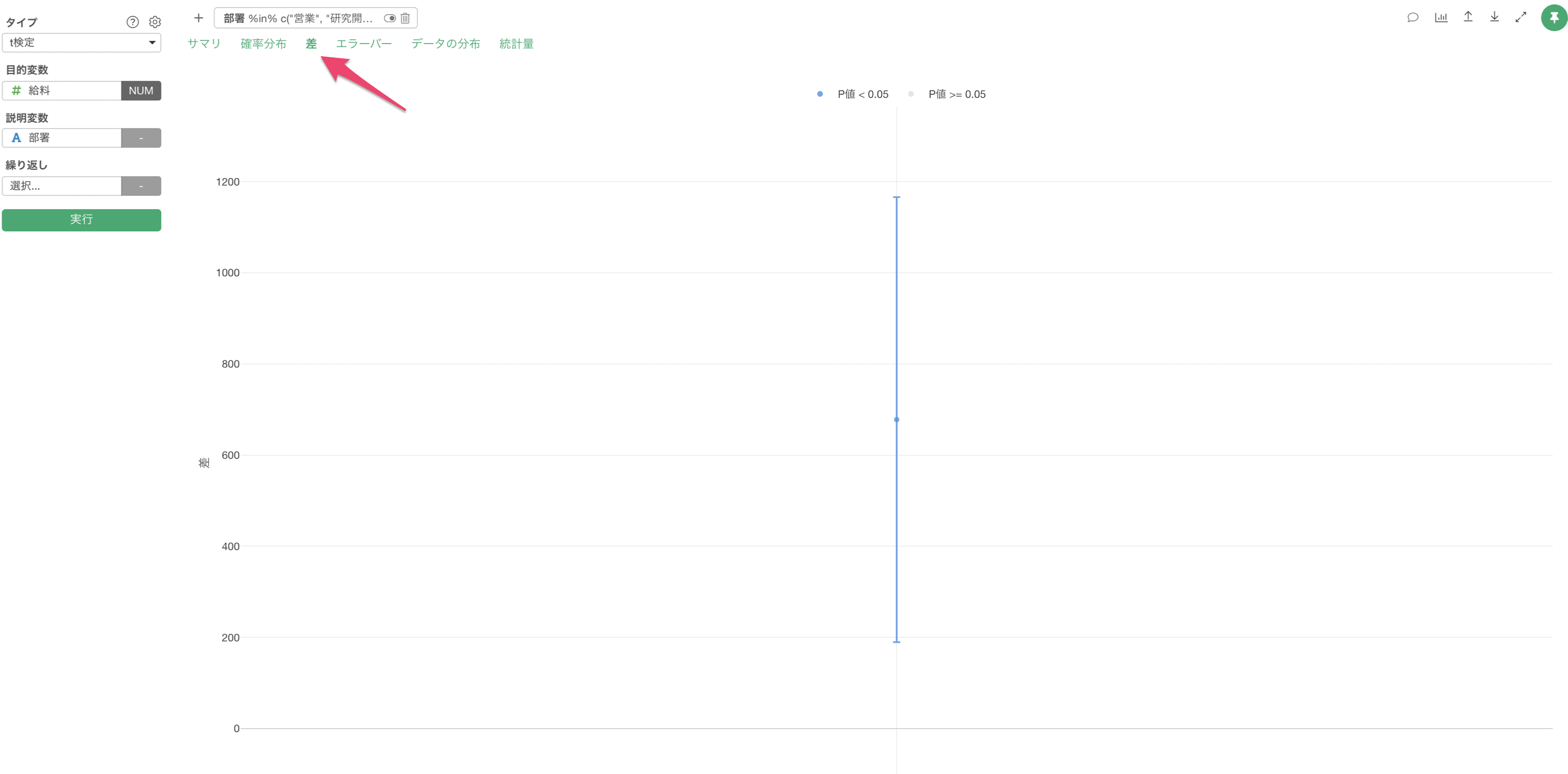
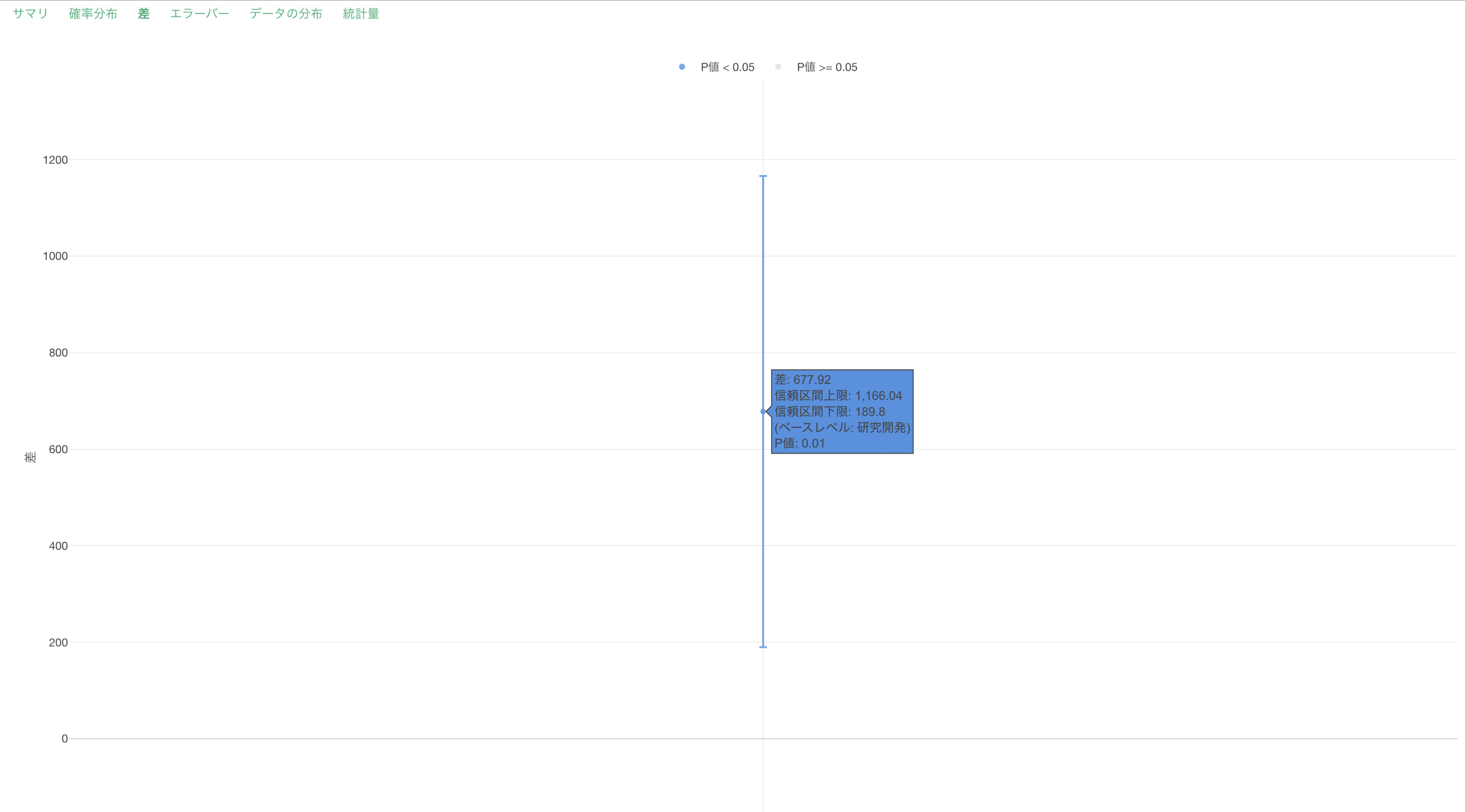
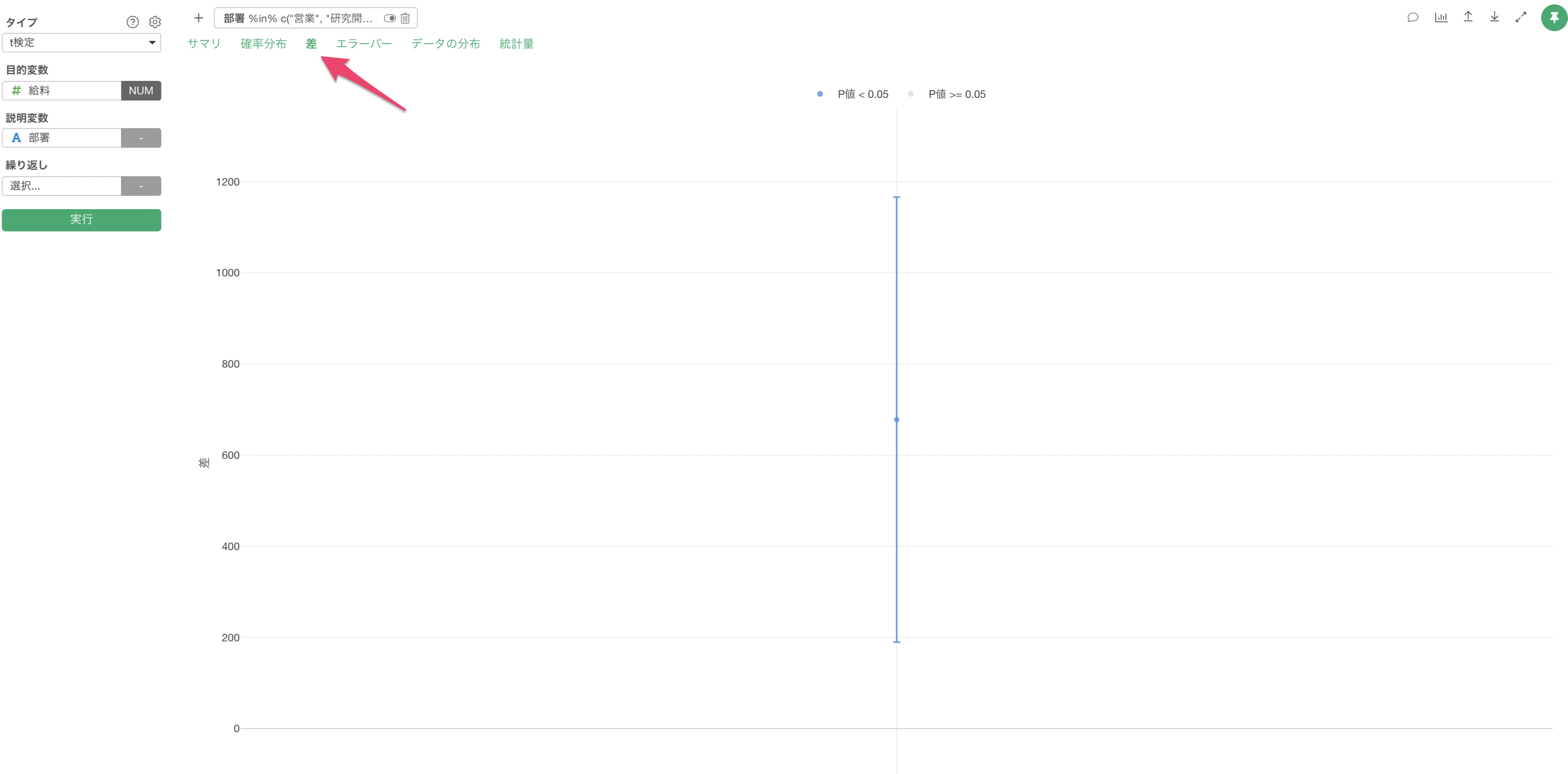
差
「差」のタブでは、グループ間の平均値の差とその信頼区間がエラーバーとして可視化されます。
差はベースレベル(行数が最も多いカテゴリー値)と比べての差となります。さらに、差の信頼区間が0を跨いでいるときは、「差が0であるかもしれない」と解釈でき、逆にさの信頼区間が0を跨いでいないときは、「差がであることはない」と解釈できます。