アナリティクスで作成したモデルの予測結果を元データに追加する方法
アナリティクス・ビューで作成した予測モデルのトレーニングデータに対する予測セクションでは観察対象ごとの予測結果が表示されます。
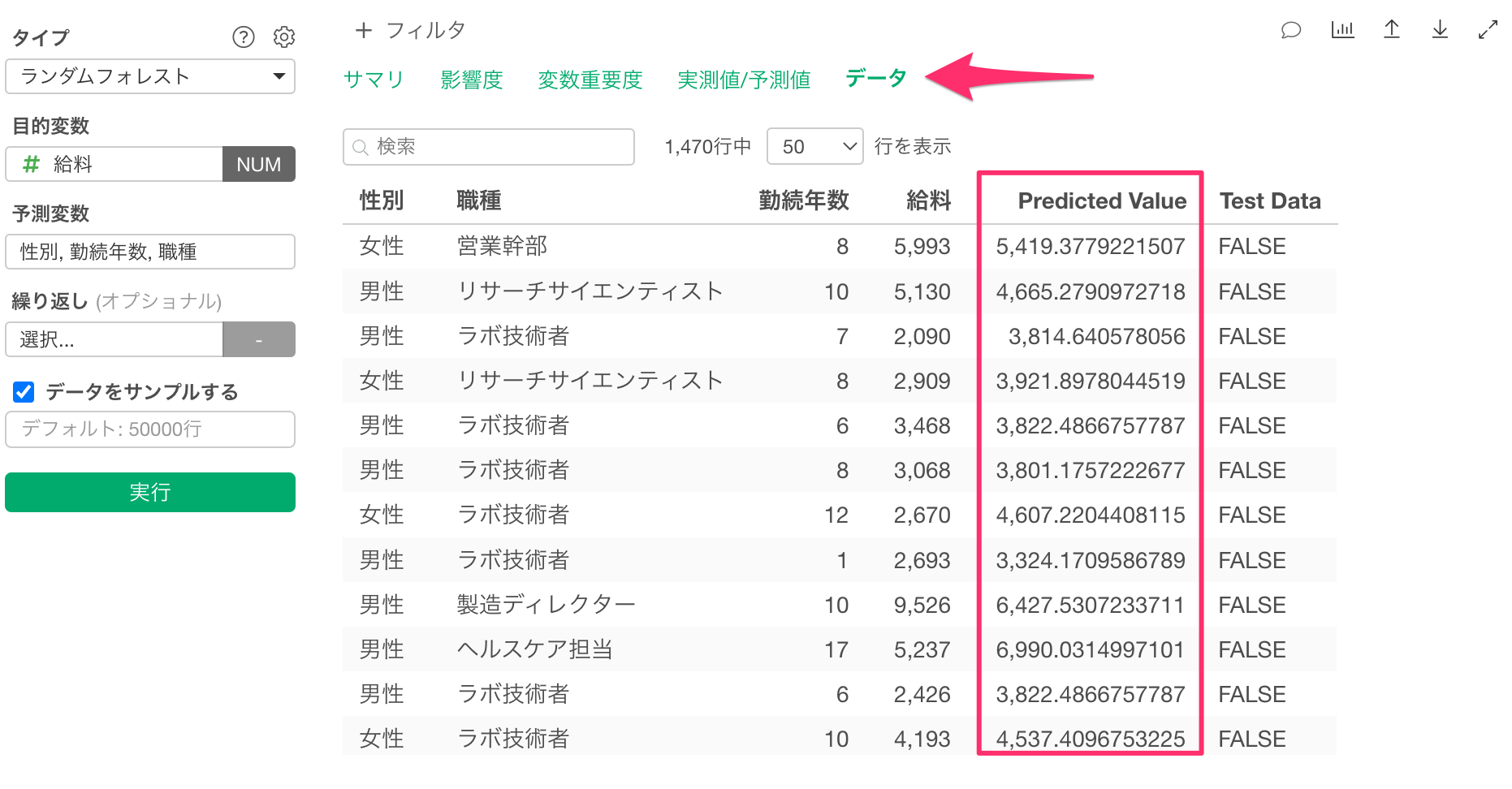
一方で、このデータタブには予測モデルで使用した変数しか表示されません。
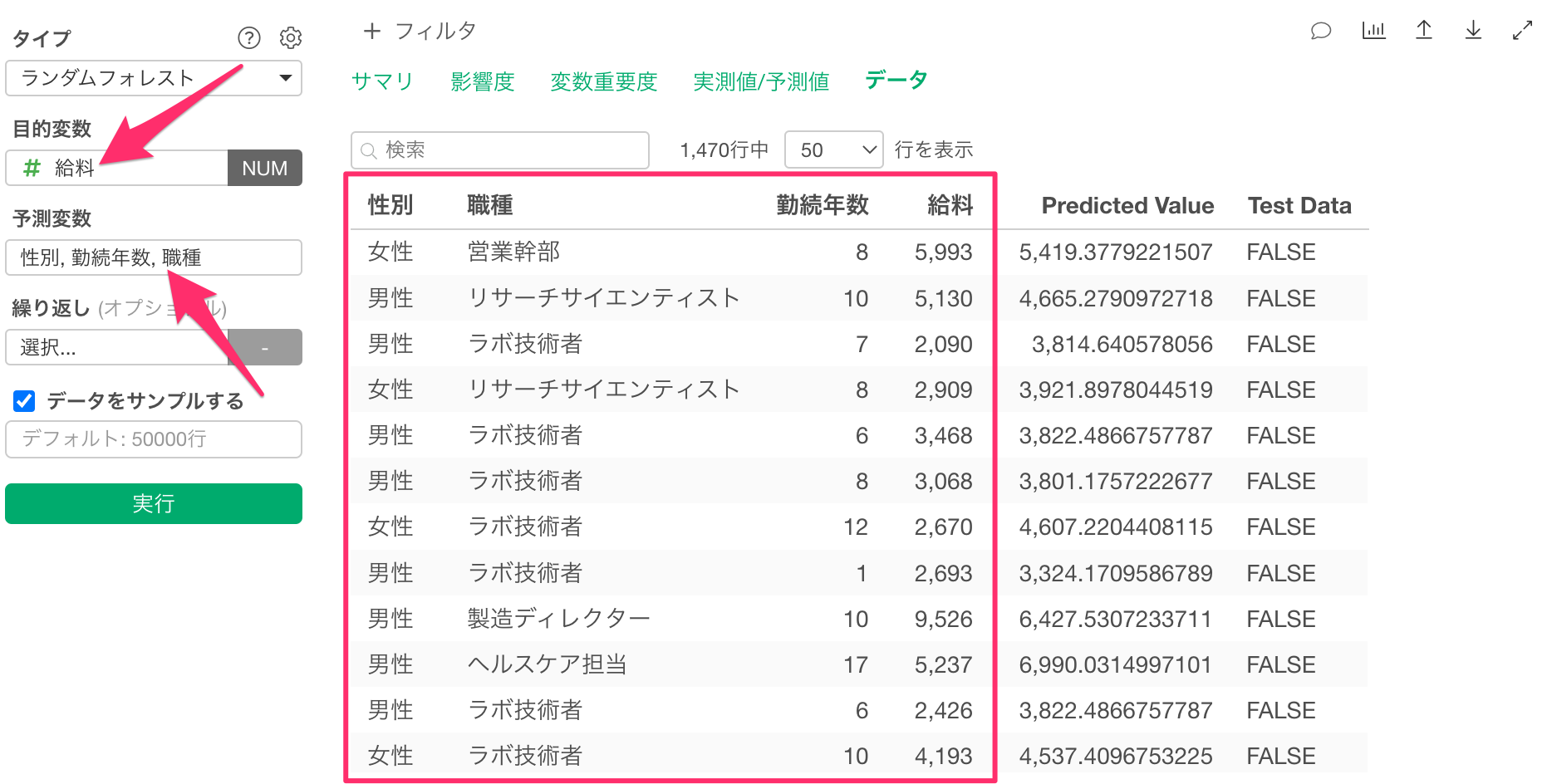
そのため、元のデータに含まれているものの説明変数に使っていない列を含むデータに予測結果を追加するためには、データを加工する必要があります。
そこで、このノートではそちらのやり方を紹介します。
今回は1行が1人の従業員を表し、列には年齢、性別、給料、職位、勤続年数、勤務企業数、残業状況、出張頻度などの従業員の属性情報を持つデータを利用します。
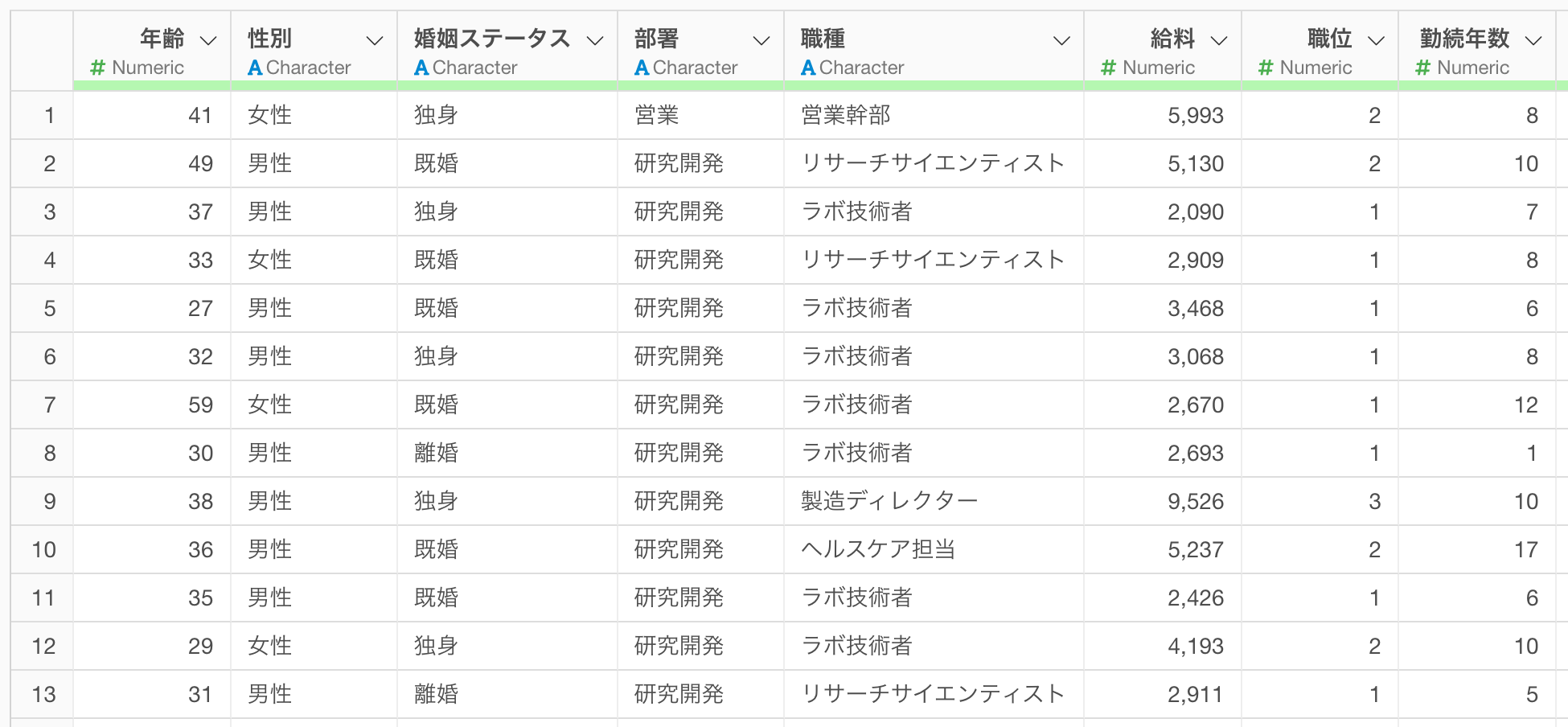
例えば、このデータを使って「給料」を目的変数とし、「性別」、「勤続年数」、「職種」を説明変数としたランダムフォレストモデルを事前に構築していたとします。
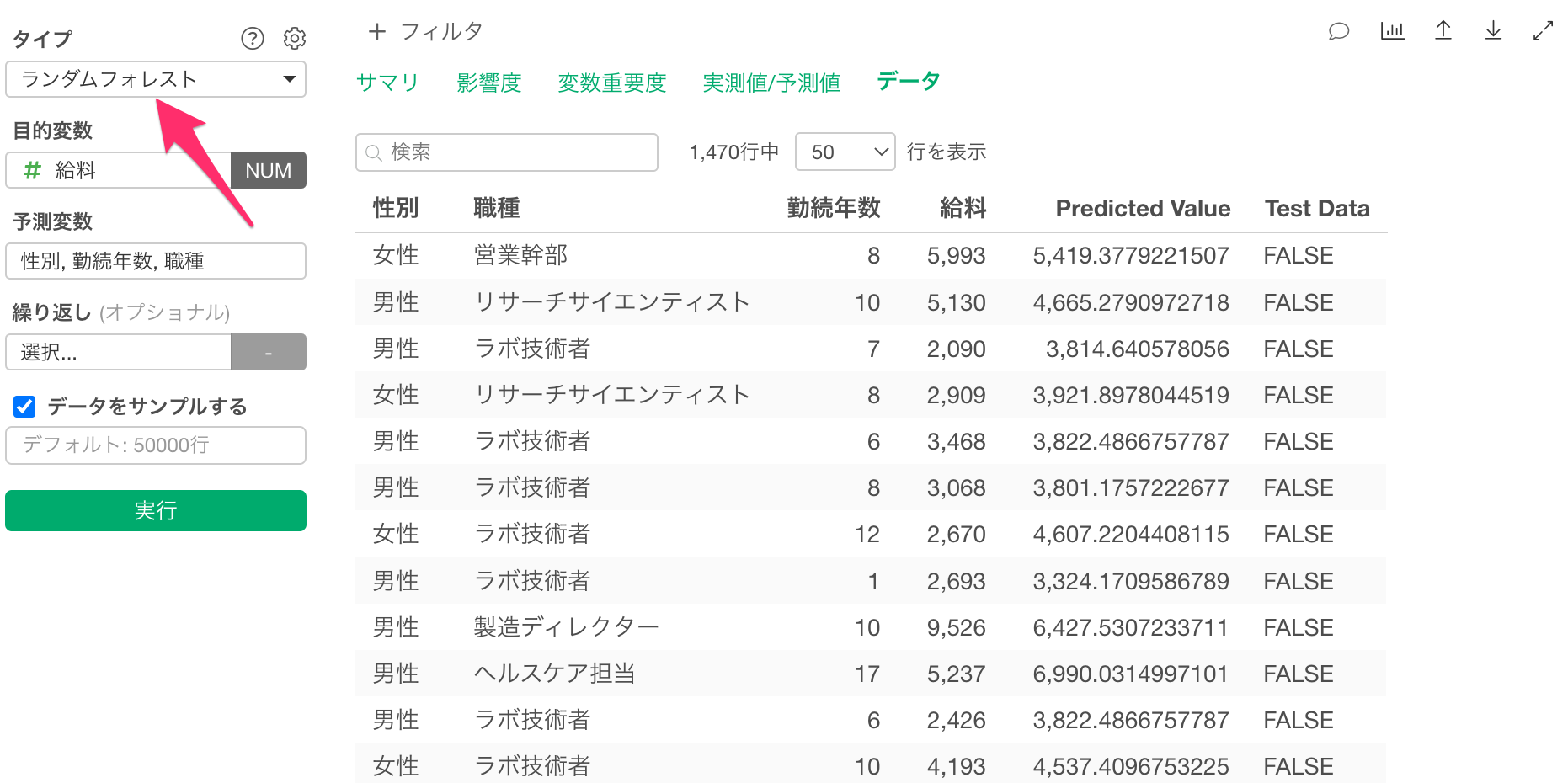
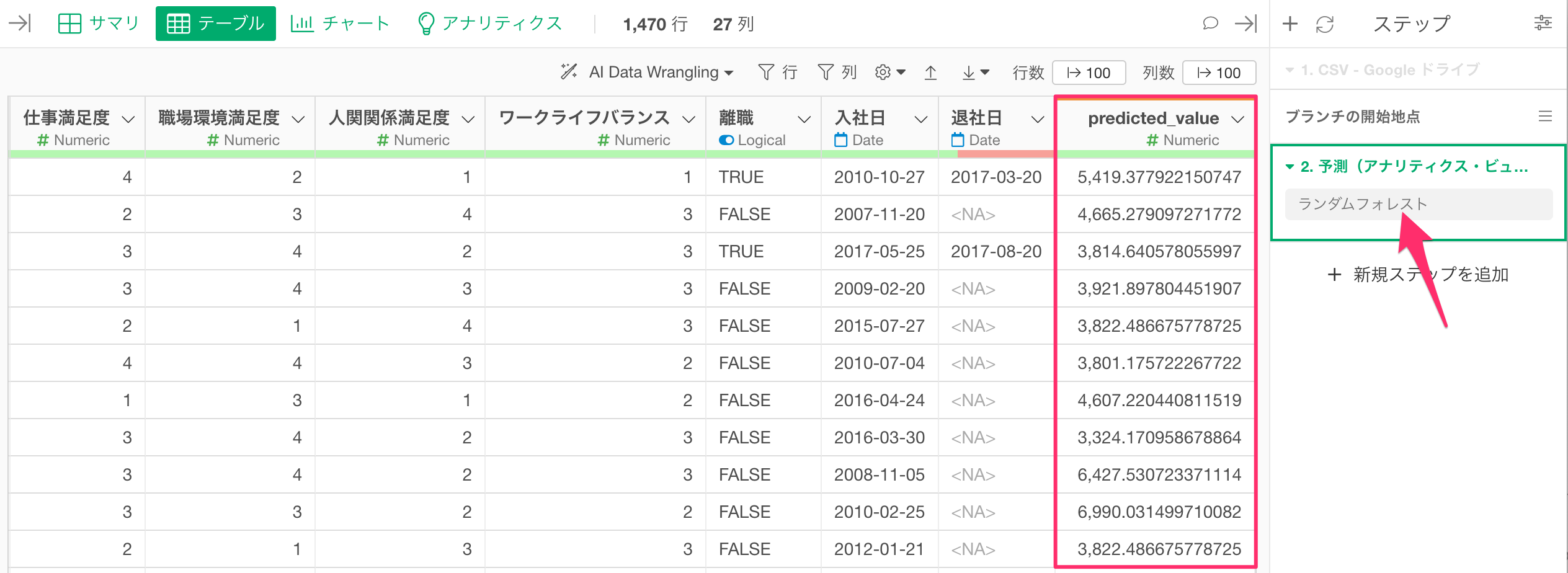
「トレーニングデータに対する予測」のセクションに移動し、予測結果を表示させると、目的変数や説明変数に利用した列に加えて、予測結果が表示されていることが確認できます。
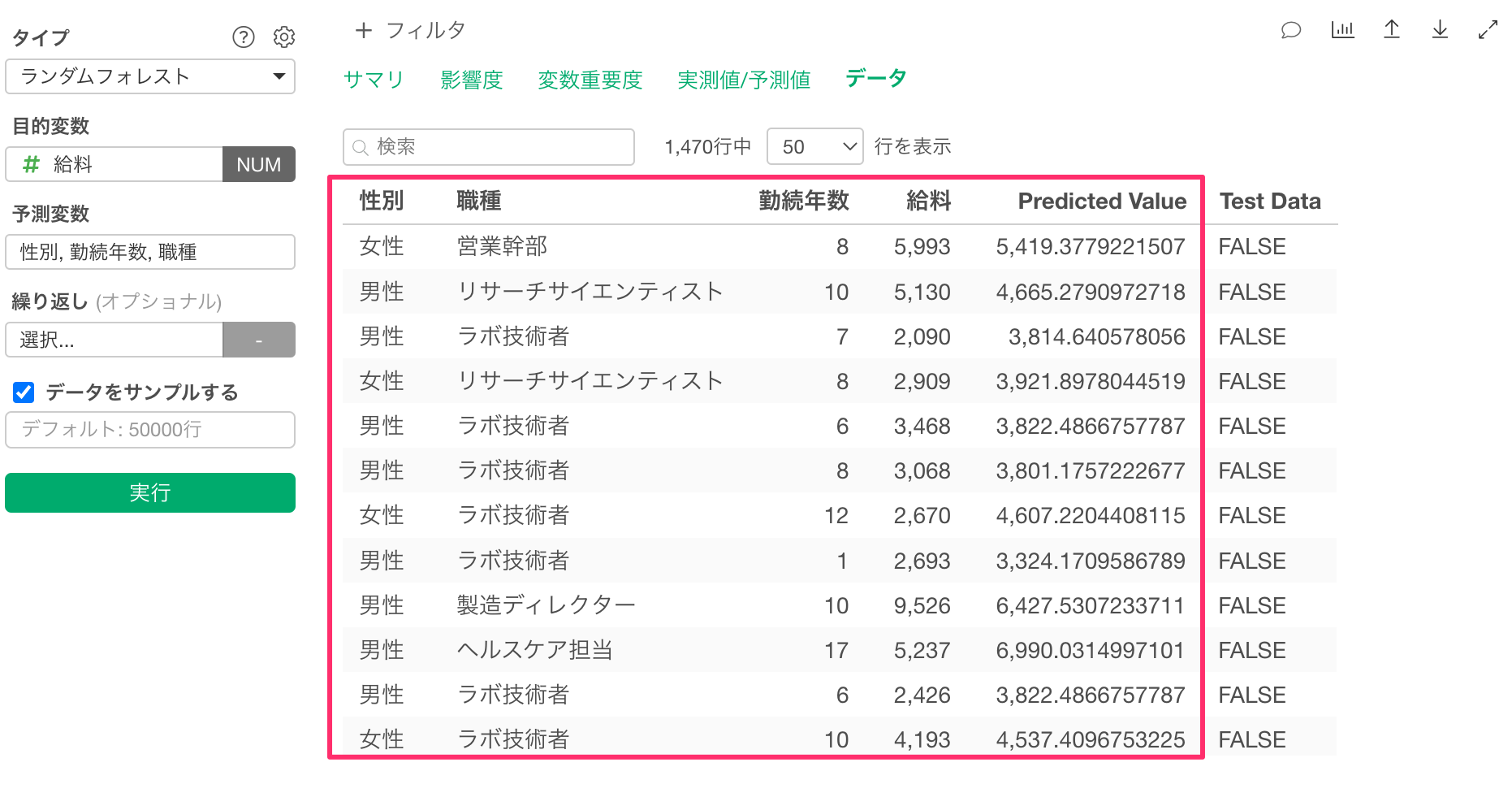
一方で、今回のデータには、「年齢」や「勤務企業数」などの説明変数には利用されていな列の情報は含まれていません。
そこで、この予測モデルを使って、改めて予測をすることで、説明変数に利用していない元の列の情報を含むデータを用意することが可能です。
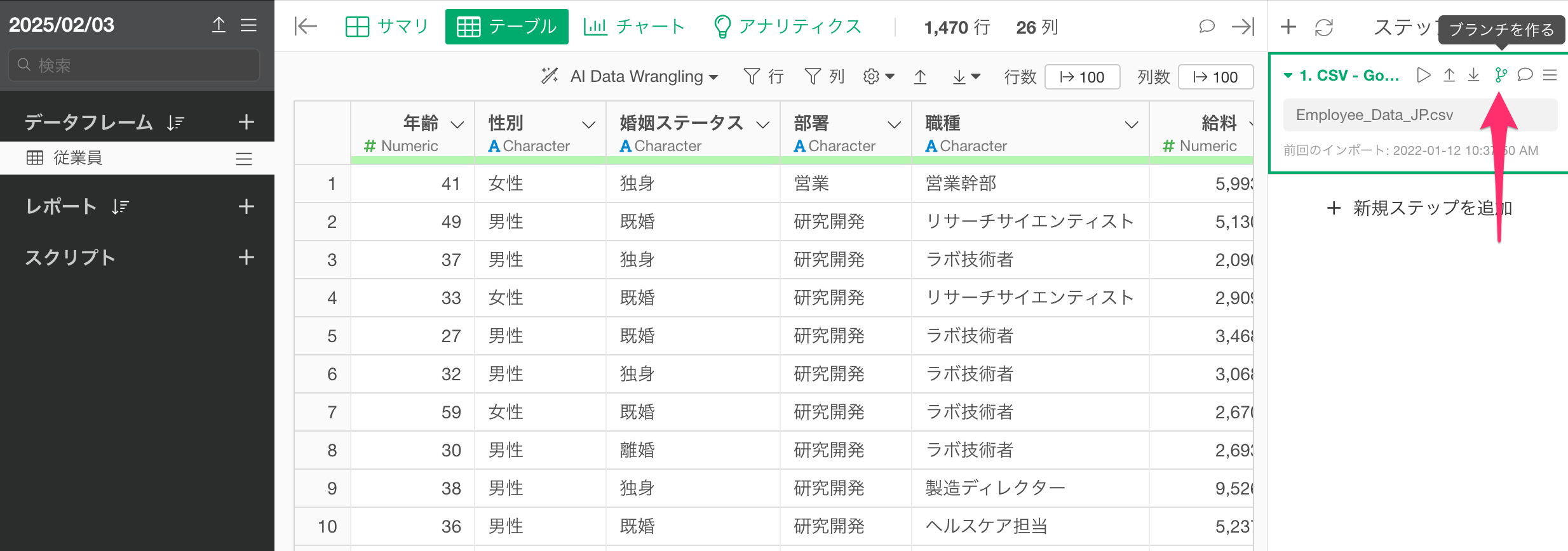
ただし、現状は予測モデルを作成したデータフレームに対して予測をすることができませんので、一番簡単な方法は予測モデルを構築したステップのブランチを作成し、そのブランチに対して予測を行うことです。
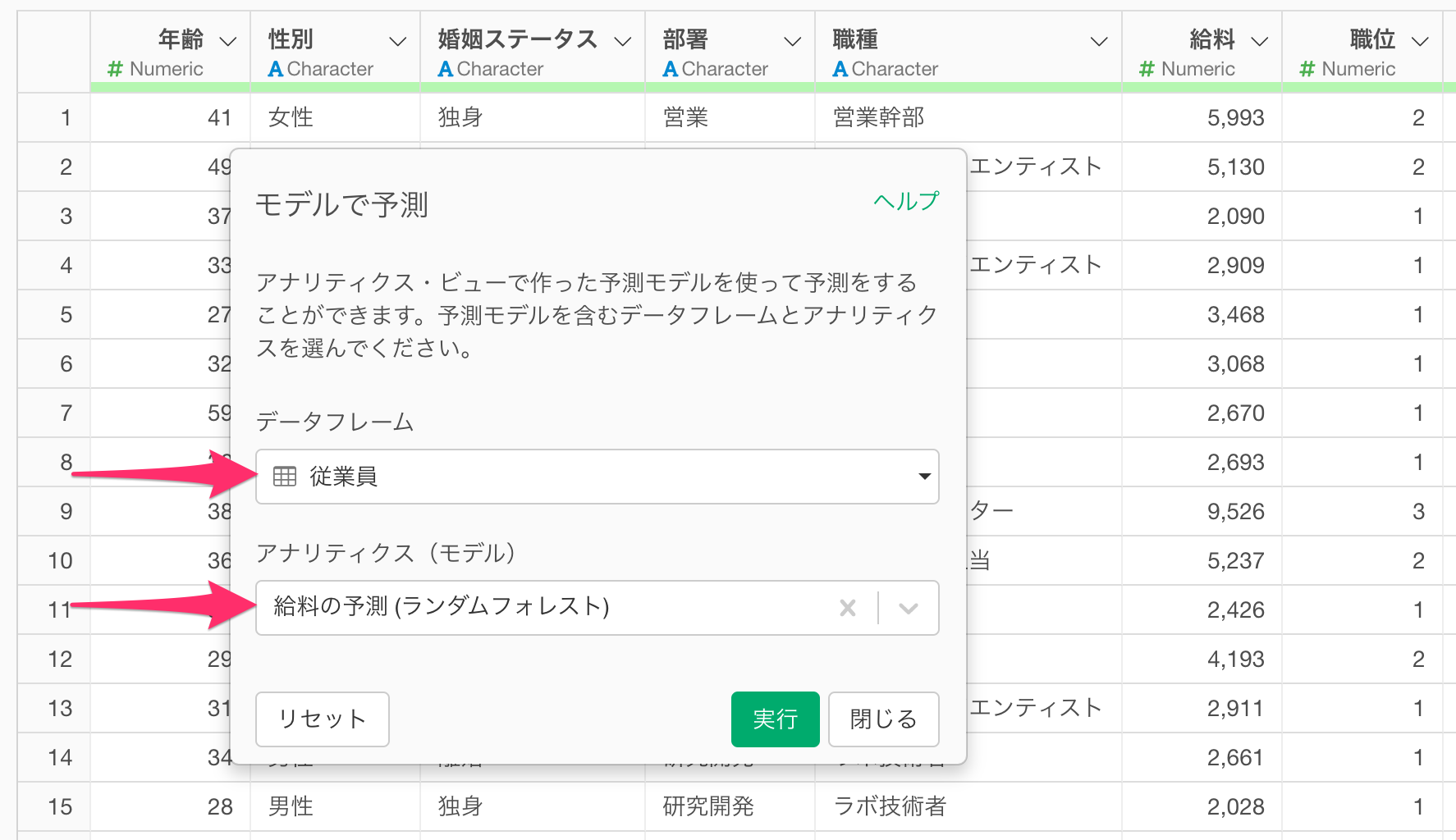
作成したブランチのステップメニューから、「モデルで予測-アナリティクス・ビュー」を選択します。
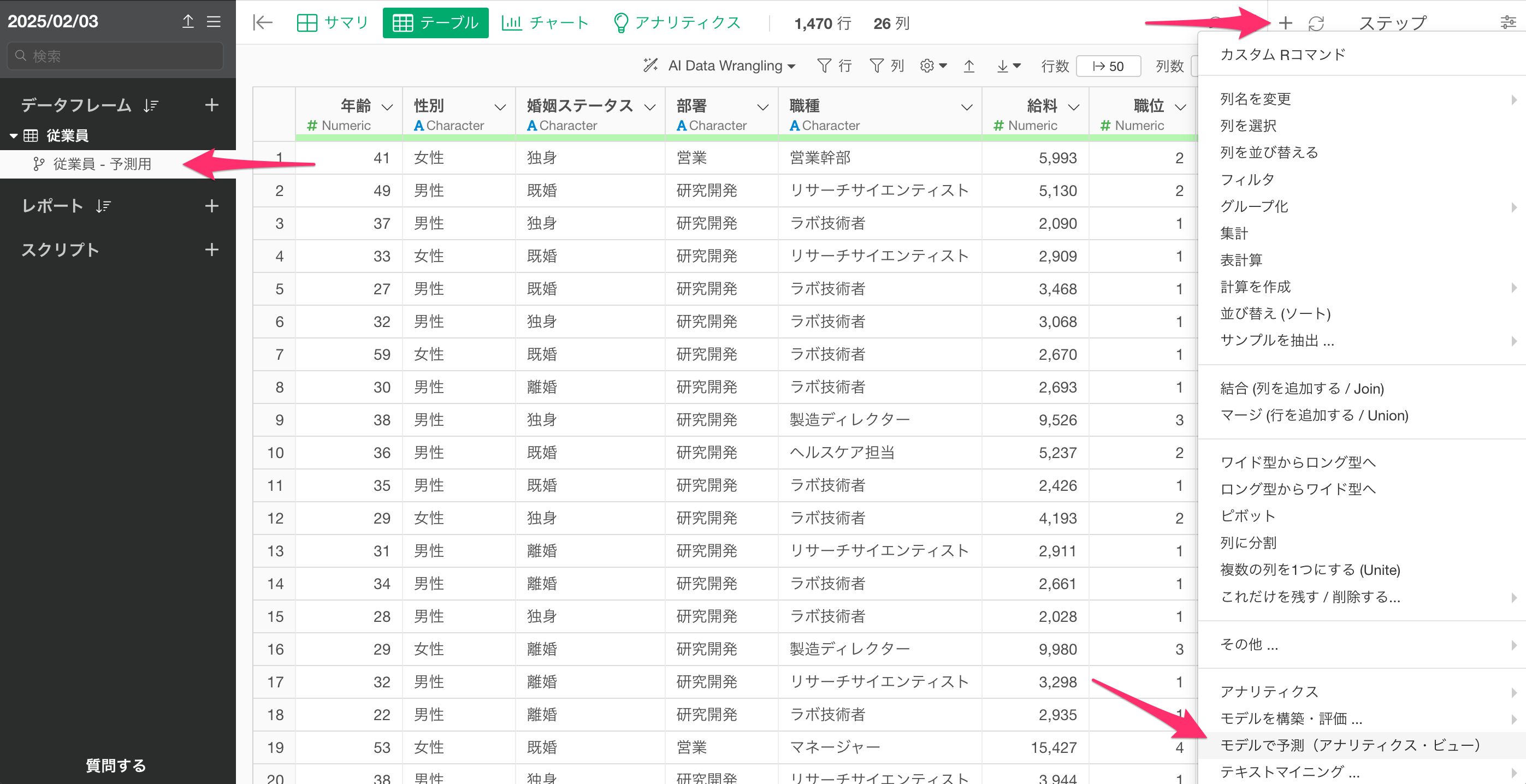
予測のダイアログが開いたら、予測モデルを構築した「データフレーム」と「アナリティクス(モデル)」を選択して実行ボタンをクリックします。
これで元のデータに予測値が追加され、全ての列と予測結果を1つにまとめられます。