
クリプト(仮想通貨)は分権、AIは中央集権。イデオロギー的に言うなら、クリプトはリバタリアン(自由主義者)、AIは共産主義者。(リンク)
Peter Thiel, Paypal founder, Venture capitalist, etc.
こんにちは、Exploratoryの西田です。
アメリカでは2月の中旬にスキーウィークというのがあるのですが、そのせいで先週は学校が休みでした。これがバケーションに行かない子供のいる家庭にとってはけっこう大変だったりします。先週お伝えしたように、2週間前に二人目の息子が産まれたのですが、それだけでもたいへんなのに、さらに4歳の子が一週間朝からハイパーなエネルギーもてあましているのには、すっかりやられてしまいました。(笑)
ところで、3月の後半に東京でのデータサイエンス・ブートキャンプのために日本に行きますが、そのタイミングでデータサイエンス力のある次世代ビジネスリーダーの育成についてのセミナーを開催します。AI/データサイエンス人材育成やプロジェクトの進め方などに興味のある方はぜひ参加していただければと思います。こちらのホームページに詳しい情報があります。
今週は、Facebookのデータサイエンティストが考える価値を生み出すデータ分析とは、なぜAI、機械学習がもっと広く浸透しないのか、Airbnbがどのようにすべての従業員のデータ力を育成しているのか、についてのおもしろい記事が3本あったのでそちらを紹介したいと思います。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
データとの対話こそがデータ分析の価値を生み出す
FacebookのデータサイエンティストでSean Tylerという、もともとFRBなどで経済データの計量分析や予測を行っていた人で、最近ではProphetという時系列データの予測をするアルゴリズムを開発したりと、この業界では有名な人がいます。その彼が先週Twitterで、真の価値を生み出すデータ分析はなぜAIで予測の精度を上げることや自動化ではなしとげることができないのかについての本質にせまった議論をこちらのスレッドでしていたので、以下に簡単に訳してみます。
I'm as enthusiastic about the future of AI as (almost) anyone, but I would estimate I've created 1000X more value from careful manual analysis of a few high quality data sets than I have from all the fancy ML models I've trained combined.
— Sean J. Taylor (@seanjtaylor) February 20, 2018
以下、訳
I’m as enthusiastic about the future of AI as (almost) anyone, but I would estimate I’ve created 1000X more value from careful manual analysis of a few high quality data sets than I have from all the fancy ML models I’ve trained combined
他の誰もと同じほどAIの未来には情熱を持っているけど、今までトレーニングしてきたかっこいい流行りの機械学習のモデルを作るのと比べて、いくつかの高い品質のデータセットを使った、注意深い手作業(自動でない)の分析からの方が1000倍以上のバリューを得ているよ。
It’s worth reflecting on why this might be the case. I think often when we generate value from data, it’s a result of a dialog we have with it. As opposed to knowing the exact question in advance and setting some precise process in motion to answer it.
なぜこういうことになるのか、ちょっと考えてみるのはいいかもしれない。データから価値を生み出すというのは、データとの対話の結果である。これは、最初にすべき質問がはっきりと分かっいて、それに答えるための正しいプロセスがあるというものの逆である。
I think that’s the key: we don’t often know the right question to ask when we start a line of empirical inquiry. We refine some initial vague set of question as we interact with data, answer some of them, and generate new ones.
これがこの謎を解き明かすための鍵となるのではないか。分析の過程ではデータに対していくつもの質問を投げかけていくことになるが、最初から正しい質問など分かっている場合なんてほとんどない。データとやり取りしていく中で最初の曖昧な幾つかの質問を磨き上げていき、その中の幾つかの質問に答えるうちに、さらに新たな質問が湧いてくるものである。
I’m sure AI systems will eventually be capable of working interactively with humans to mimic and streamline this process. For now, mucking about with simple tools in a curiosity-driven dialog with our data is the best we’ve got.
そのうちAIも人間と双方向の会話ができるようになることでこうした我々が行っているような分析をもっと効率よく出来るようになるでしょう。しかし、現在のところシンプルなツールを使ってデータと好奇心をもとにした会話を行っていくような分析こそが、データから価値を生み出すということに関しては一番よい方法なのでしょう。
以上、訳
AI、機械学習のアルゴリズムは今日のデータ分析には必須といえますし、もちろん役立つのですが、それはあくまでもデータからインサイトを得るということに関してであって、逆に言えばどんなに予測の精度が高くても、ビジネスの意志決定に役立つインサイトが得られないのであれば意味が無いわけです。
そして、ただ単に興味深いではなく、意志決定に役立つという意味でのインサイトを得るプロセスというのは、英語でIterativeといったりしますが、行ったり来たりを繰り返しながら少しづつ確信に迫っていくという、ある意味探偵小説にあるようなプロセスになります。
余談ですが、こういう考察というのは書くとついつい長くなってしまいますが、Tweetにすると簡潔にまとめざるを得ないのでフレームワークとしていいですね。
人が理解できないAI/機械学習はその真価を発揮できない
Machine Learning won’t reach its potential without the human element - Link
ちょっと前にMatterMarkというスタートアップでデータのトップをやっていたのですが、現在はAmplify PartnersってVCで投資家をやってるSarah Catanzaroのインタビューがこちらにあるのですが、AI/機械学習によって作られる予測モデルの説明・解釈のしにくさがなぜ問題なのかという点について話しています。英語ではExplainability(説明可能性)、Interpretability(解釈可能性)と言ったりしますが、これがAI/データサイエンスのプロジェクトを行う時に問題になっていると言うのは先週話したとおりですが、こちらの記事ではそこにもう一歩踏み込んで書いてあるので、参考になると思います。
以下、抜粋
よくVC(Venture Capital/ベンチャーキャピタル) の世界では全てのスタートアップが最終的には機械学習のスタートアップになると言われています。実際全てのスタートアップが何らかのかたちで機械学習の恩恵をうけると思います。しかし、全ての問題が機械学習で解決されるというわけではありません。
機械学習は全ての人のツールボックスに入っているべきですが、大量のデータが手に入り、その中にたくさんの属性があり、さらに、解決するべき問題が明確に定義されている場合に威力を発揮します。しかし、現実にはそうでないタイプの問題が多く存在し、手に入るデータ量も限られていることが多いので、その場合はデータサイエンスの別の手法を使うことが求められます。
さらに、AI/機械学習の予測結果を理解するためのもっと効果的な仕組みができるまでは、AI/機械学習が広く使われることはないと思います。多くの人はアカデミアによる医療分野でのAIの研究の成果やメディアの報道に興奮し、すぐにそれがほんものの医者によって採用されると思いがちです。しかし、AI/機械学習の予測結果を採用することによってもし何か問題が起きた時に責任を負うことになる人間、そして組織がいるということを忘れているようです。
医療過誤というリスクを負うことになる医者は、ただ以前のモデルに比べて予測の精度がよくなったというだけで、AI/機械学習の予測モデルをそのまま採用することはありません。彼らはそのモデルがどのようにしてそうした結果にたどり着いたのか、どこで間違っている可能性があるのか、もし間違っていた場合に最も影響を受けることになる人達はだれなのかということを知りたいわけです。
私たちは今日まだAIを信用していませんし、AIが何を知らないのかを認めることができるまでは、この先も信用することはないでしょう。
別の例では、これまでの医療データをもとに作った薬の処方をレコメンドするシステムがあったとします。この予測モデルはトレーニングのために集められたデータを基盤としています。もしこのデータの中に入っていないようなタイプの患者が来た場合、このシステムはおかしな処方箋を出してしまうかもしれません。この場合は、私たちはこのシステムがその結果に対して自信がないということを知りたいわけです。(西田:これは先週お伝えしたバイアスの問題ですね。)
巨大なテック企業によって集められた私達の嗜好、ソーシャル・ネットワーク、購買履歴といったデータをもとにアルゴリズムはトレーニングされます。しかし、そうしてできたアルゴリズムがいつどのように我々に対して使われているかはまったく知ることができません。例えば、もし私が見ているニュースの記事のランキングがアルゴリズムによって生成されていたら、私はどう反応するでしょうか。もし記事の書いた人の人種がそのアルゴリズムにとって影響を及ぼしている属性であることを知ったら、私は違った反応をするのではないでしょうか。どの属性を使ってそうしたニュースのランキングがなされるかを消費者である我々がコントロールできてもいいのではないでしょうか。アルゴリズムにたいする透明性がもっと確保されれば消費者がもっと主導権を握る事ができるようになるでしょう。
機械学習の商用化がもっと進むと、AIの安全性というのは単純に機械学習のエンジニアと数学者の責任というわけには行かなくなります。ユーザーエクスペリエンスのデザイナーからプロダクト・マネージャー、営業やマーケティングにいたる製品を作ることに関わるすべての人達の責任になります。
すべての人が機械学習のモデルを作れるようになるべきだとは思いませんが、会社の中のすべての人が少なくとも機械学習の理解はできているべきで、機械学習を使うことによって生じる結果に対する説明ができるくらいにはなっているべきです。
率直に言って、AI/機械学習は多くの組織で機能していません。機械学習の研究者は組織の中で孤立しています。私ももともとデータ製品のプロダクトマネージャーをやっていましたが、プロダクトマネージャーと機械学習のエンジニアの協業の仕方は大抵の場合壊れています。一般的にプロダクトマネージャーは機械学習を使えば全ての問題が簡単に解決されると思っています。しかしほんとうに必要なのは、隠されたコストを理解し、機械学習から得られる結果がどうユーザーに消費されるのかを理解した上で、しっかりとした方向性を与えることができるプロダクトマネージャーです。
機械学習のエンジニアは最適化の指標(プレシジョン、リコールなど)を提供することに対して責任をもつべきで、プロダクトマネージャーはこうした指標をもとに製品のデザインを決定していくべきです。なぜならこれらはユーザーがプロダクトにどのように反応することになるかに直接影響するからです。
現在AIと自動化によって仕事が置き換わるということに対して多くの人が不安と恐怖を持っています。しかしそのうち人々はAIをAugmented Intelligence(拡張知能)として理解することでそうした不安や恐怖をなくすることになるでしょう。つまり、生産性を上げるためにAIやロボットに仕事を取られるということではなく、どのようにAIのインテリジェンスを使って私達自身の生産性を上げることができるかということです。
このWeekly Updateの読者の方は以前にも聞いたことがあるかもしれませんが、AIと人間がパートナーとなることによってはじめて、我々人間社会の中でのAIの価値が実現されるのだと思います。
この記事にあるように、現在AIによる自動化によって仕事が奪われるという不安、恐怖を持つ人も多いと思いますが、本当に不安を持つべき相手はAIではなく、AIを使いこなすことのできる競争相手としての個人や組織だと思います。そしてそういったAI・データ先進企業は確実にAI・データを使いこなせない既存のビジネスを飲み込んでいくことになるでしょう。
Airbnbがデータ・ユニバーシティによってデータサイエンスを民主化する仕組み
How Airbnb Democratizes Data Science With Data University - Link
先週のWeekly Updateでもお伝えしたように、これからより多くのAI、データサイエンスのプロジェクトが行われていくにあたって、社内でデータサイエンスの手法を理解し普段のビジネスのデータ分析に使うことのできる人材の育成がますます必要になって来ると思います。これは何も日本だけでなく、アメリカ、さらにはシリコンバレーでも大きな課題となっています。
そこで、Airbnbが社内の全従業員を対象にデータのリテラシーを向上し、さらにもっとデータサイエンスの手法を広めていくために作ったデータ・ユニバーシティというのを去年立ち上げたのですが、Weekly Updateの方ではまだ取り上げていなかったので、今回こちらに簡潔に要約したものを紹介します。
以下、要約
Airbnbでは、すべての従業員がデータに裏打ちされた意志決定を行うことを期待されています。それは、新しい製品の機能を決めている人たち、どのように従業員が仕事をしやすくするかを考えている人たちなどを含めた全ての従業員です。
しかし、現実にはデータサイエンスの手法を使いこなすことのできる人材というのは、結局は100人くらいの規模のデータサイエンスのチームに限られていました。ちなみに現在は全従業員の数は3100人ほどです。さらにサンフランシスコ以外にも世界中に22のオフィスがありますが、そのほとんどではデータサイエンスを使える人たちがいませんでした。
Airbnbでは比較的早い時期からデータ・インフラを整備し、様々な内製のツールも開発し、データサイエンスがしやすい環境を作ってきていたのですが、そういった環境を活かすことのできる人たちというのは、他のGoogle、Facebook、Uberなどに比べて少なかったのです。
そこで技術系の社員だけではなく、全社員を対象とした、データサイエンスの知識を身につけ、そういったツールを使いこなすことのできる人材を育てるための研修プログラムとしてデータ・ユニバーシティの設立という運びになりました。
こうしたトレーニングを提供してシチズン(市民)・データサイエンティストを作り出すというのは強力なことです。なぜなら意志決定をデータに裏付けさせるだけではなく、人々が自分たちの意志決定を自信を持って行うことができるようになるからです。このことは重要です。なぜなら、ビジネスの問題を持っている人こそがその問題の背景を一番良く理解しているので、その人がデータを使いこなすことができるようになることで複数の人間、もしくは部門を行ったり来たりする必要がなくなるからです。
もちろんデータサイエンティストを他のデータを使えない人たちをサポートする作業から解放し、本業に集中させることができるというメリットもあります。
データ・ユニバーシティの設立にあたり 既存のCoursera、Udacityといったオンラインのクラスなどを提供することも考えましたが、Airbnb独自のデータ、独自のユース・ケースをもとにしたコンテンツを作って教えていったほうがより効率的で高い価値を提供できるということになりました。
クラスは大きく分けて3つのレベルがあります。
初級レベルとして、データに裏打ちされた意志決定を行うための基礎を教えるクラスがあります。これはすべての社員が対象です。中級レベルとして、SQLを使ってデータにアクセスしたりBIツールを使ってデータを可視化したりします。これは主にデータの集計による初歩的な分析にあたります。最後に上級レベルとして、R、Python、Hive等を使って、機械学習を使ったデータの分析並びにデータの加工について教えます。これは主にエンジニアとデータサイエンティストを対象としています。

最初のころの殆どの講義のクラスはErin Coffmanによって作られ、教えられていました。その後30人にも及ぶボランティアが集まりどんどんと新しいトレーニングのためのコンテンツづくりが行われ、教える人達も増えていっています。
以上、要約
こういったなにか新しいものを社内で始めようというときには、やはり最初のうちは誰かが物凄い馬力をもって引っ張っていかなくてはいけないということですね。最初からみんなで協力してやろうなんてやってると、いつまでも始まりません。もちろん、これはシリコンバレーなやり方なのかもしれませんが。
ちなみにこのデータ・ユニバーシティ、最初の6ヶ月でAirbnb全従業員の12.5%に当たる500人がすでに参加したようです。このコミットメントはすごいですね。そしてこれによって、一週間あたりでAirbnbのデータインフラにアクセスする人の割合が全従業員の45%まで上がったということです。ここでいうデータへのアクセスが一体何を意味するのかがはっきりしませんが、それでも社員半分近い人が何らかのかたちで自分たちのビジネスに関連するデータに自分でアクセスしているという現実はすばらしいと思います。
こういった活動が Airbnbのデータカルチャーを形作っていっているのでしょう。
ところで、こうした取り組みの隠されたメリットとしては、実は優れた人材の採用にあると思います。特に現在のような、AI、データサイエンスのスキルを持っていることが、個人のキャリアアップにつながる環境では、こういう仕組みのある会社というのはかなり魅力があるのではないでしょうか。シリコンバレーでは会社の中にかっこいいオフィスがあったり、食事が無料だったり、健康食品が溢れていたりとみんな自社のイメージの向上のため頑張っていますが、こういう中身のあるユニークな取組みこそ、優秀な人材の確保につながるのではないでしょうか。
興味深いデータ
アメリカによる経済制裁データ
財務省のOffice of Foreign Assets Controlによって現在アメリカが経済制裁を行っている国と人のリストのデータが公開されています。
世界中で亡くなったジャーナリスト・データ - Link
暗いデータとなってしまうのですが、1992年以来の世界中のジャーナリストの死亡に関する詳細のデータが Committee to Protect Journalistsという組織によって集められていて公開されています。日本人のジャーナリストも7人ほど含まれています。この場を借りてお悔やみ申し上げたいと思います。
What Are We Writing?
線形回帰のアルゴリズムはデータ分析を行う中で頻繁に使われます。これはそのアルゴリズムとデータをもとに作られる予測モデルから得られる情報が比較的シンプルで解釈しやすいからです。最近のディープラーニングに代表されるAIのトレンドの中ではついつい存在が薄くなってしまいがちですが、ビジネスのデータ分析をする現場のデータサイエンティストたちの間では今も一番良く使われるアルゴリズムの一つです。
そこで、英語になりますが、こちらにその便利なアルゴリズムをもっと多くの人たちに知ってもらおうということでブログのシリーズをはじめました。もし、興味のある方はチュートリアルとして参照していただければと思います。まずは一回目のエピソードとなります。
- A Practical Guide of Exploratory Data Analysis with Linear Regression - Link
What Are We Working On?
先週もお伝えしたようにExploratoryの次期バージョンv4.3では、統計のテスト(検定)に関する機能が強化されますが、その一つとして、データが正規分布なのかどうかを検証するShapiro-Wilkテストがアナリティクス・ビューの方から簡単にできるようになります。
例えば以下のようなデータの分布をもつ8つの変数があったとします。
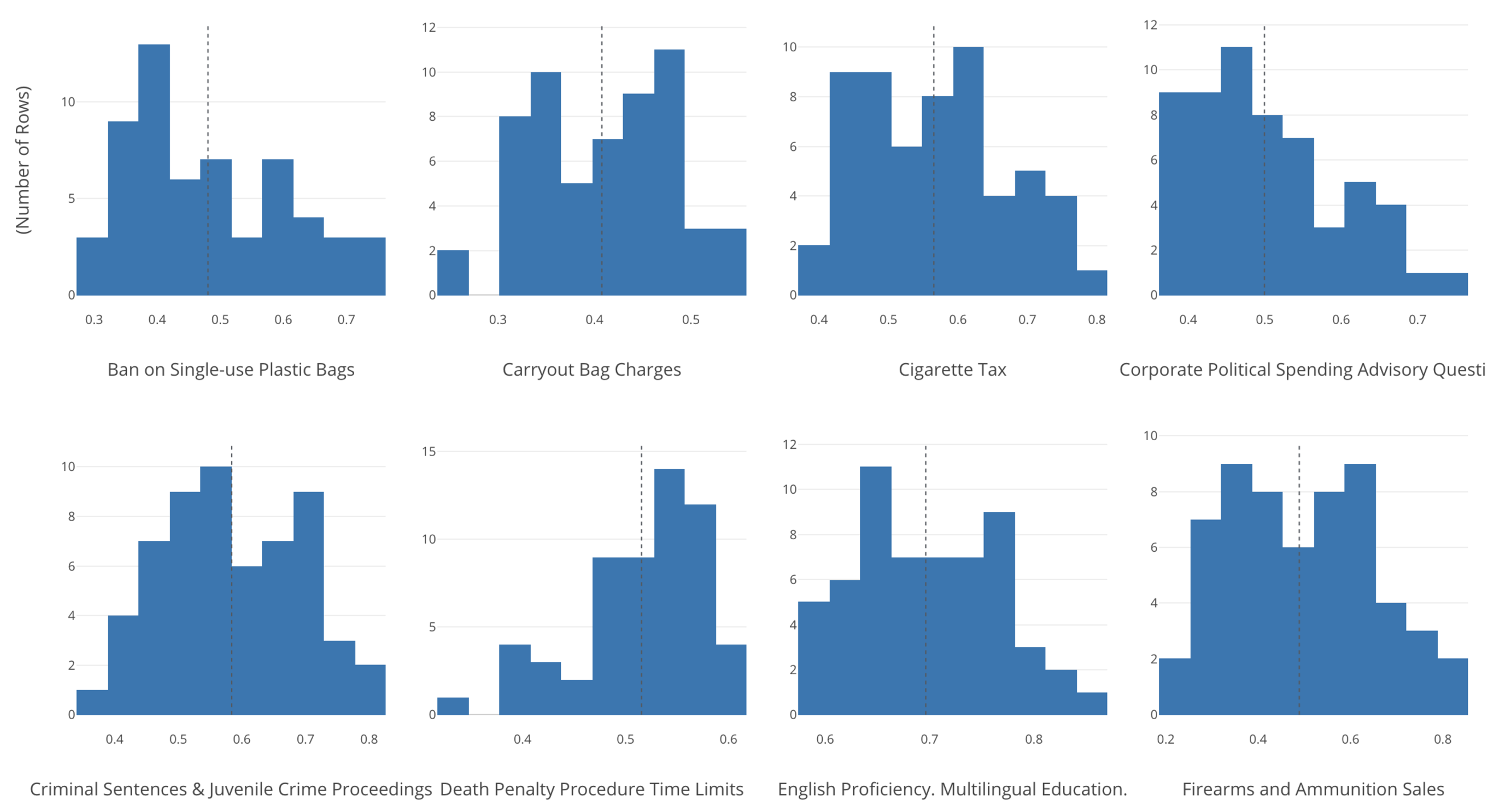
これをShapiro-Wilkテストにかけるといくつかは正規分布しているといえますが、その他はそうとはいえないことがわかります。
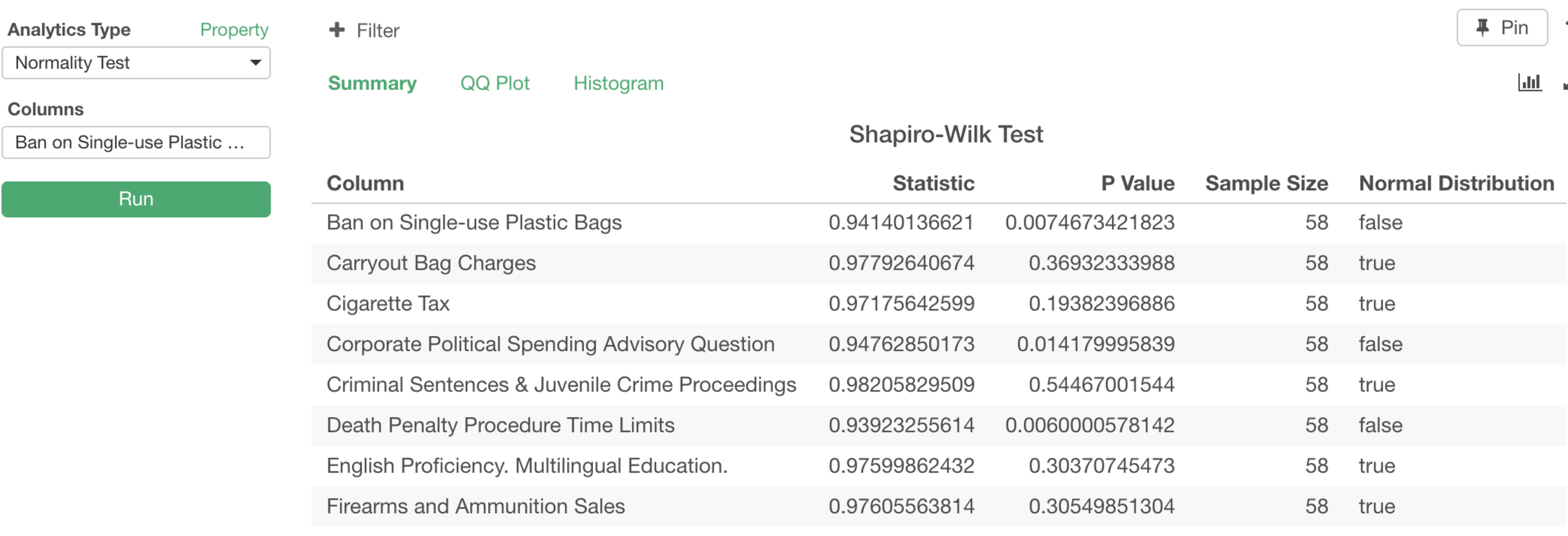
ここではP値を判断基準に使っていますが、QQプロットというタイプのチャートを使って視覚的な検証も簡単にできるようになります。
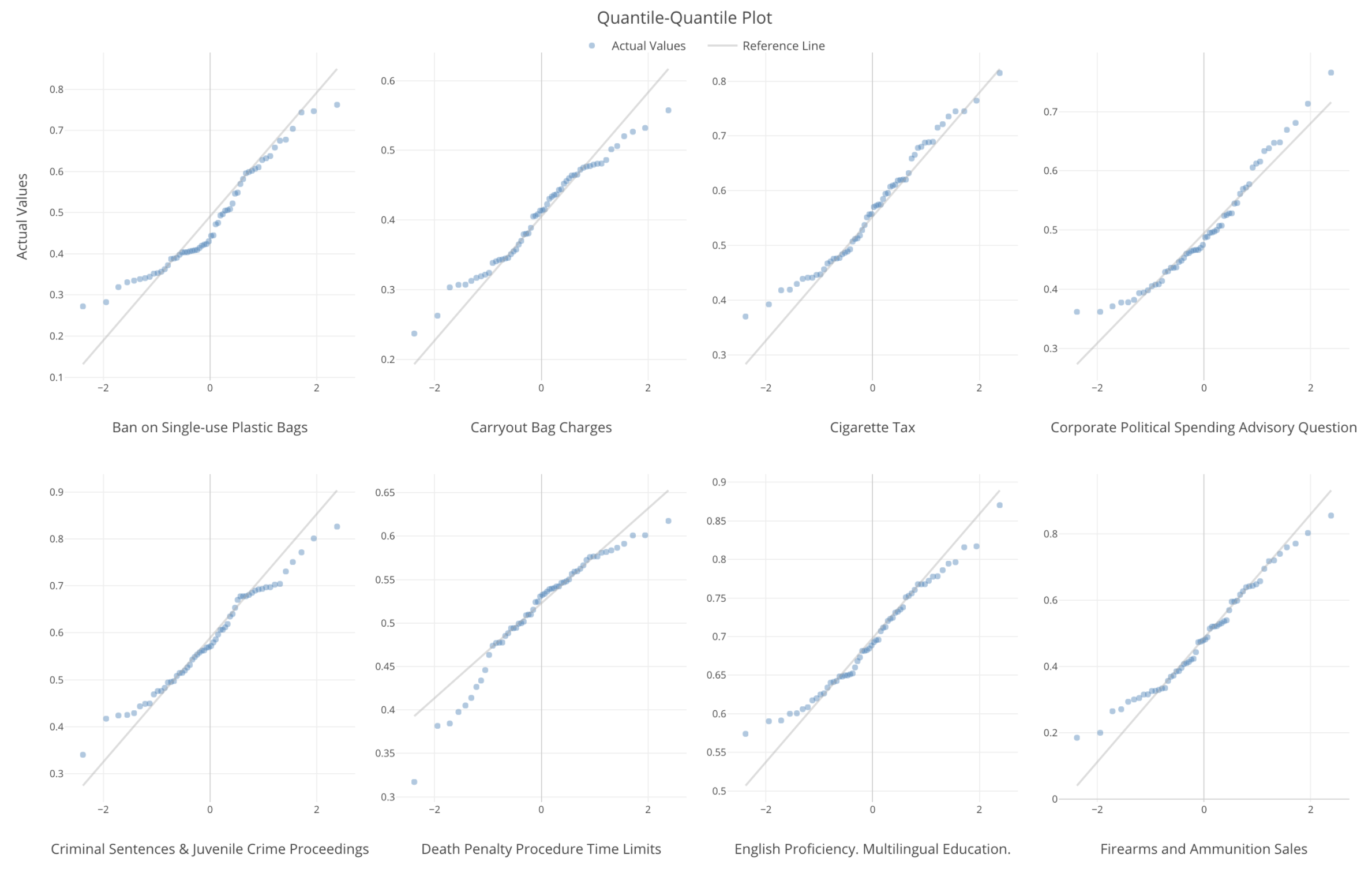
グレーの対角線に青い点が乗っかっていると正規分布していることになります。これによって、データのどの辺が正規分布から外れてるのかがわかりやすくなります。
変数が正規分布していると仮定している統計のアルゴリズムを使う時に、簡単にここで検証することができます。
Exploratory社主催セミナー in 東京
来月のブートキャンプでの来日のタイミングで、データサイエンス力のある次世代ビジネスリーダーの育成についてのセミナーを開催します。私どもがデータサイエンス・トレーニングを実施している、シリコンバレーと東京のデータ先進企業での事例も織り交ぜながら、AI/データサイエンス人材育成に課題をお持ちの皆様に役立つ情報を共有させていただきます。社内人材育成やプロジェクトの進め方などに興味のある方がまわりにいらっしゃいましたらぜひお声をかけていただければと思います。こちらのセミナーのページに詳細があります。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。