
こんにちは、Exploratoryの西田です。
こちらサンフランシスコは、先週から暖かく、先週末は25度くらいまで上がり絶好のビーチ日和となりました。こちらではだいたいこの時期から春が始まり、桜などの花が咲き始めます。逆に今のほうが、夏の6月、7月よりも暖かかったりするくらいです。
ところで、次回の3月に開催のブートキャンプですが、まだ席に余裕がありますので、この機会に興味のある方は是非参加を検討していただければと思います。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
アマゾンがどのようにしてAIカンパニーに変身したか
How deep learning came to power Alexa, Amazon Web Services, and nearly every other division of the company. - Link
今でこそ、大ヒットしているAmazon Echoなどのボイス・アシスタントであるAlexaのおかげですっかりAI先進企業としてGoogle、Facebook、Appleなど別のAIカンパニーと真っ向から勝負しているAmazonですが、実はほんの数年前まではこの業界の人間からはそこまで本気にされていませんでした。
”もし8年前にAmazonがAIの業界でどれだけ強い勢力なのかと聞かれたら、彼らはそもそもそこには存在しないと答えたでしょう。しかしこの間に彼らはとても積極的に成長した結果、今となっては強力な勢力であるのは確実です。” Pedro Domingos, コンピュータサイエンス教授、University of Washington
こちらの記事ではそんなAmazonがどのようにしてAIファースト・カンパニーとして生まれ変わっていったのかについて書いてあるので要約して紹介したいと思います。
Amazonのレコメンデーション・エンジンは、それこそレコメンデーションの代名詞としても有名で、創業以来この20年で地道な進化を遂げてきたようですが、数年前からそこにディープラーニングを使うというプロジェクトを初めたころから、AmazonのAIファースト・カンパニーとして生まれ変わる道のりが始まったそうです。
そうして次に、対話型のAIアシスタント、Alexaの開発が始まるのですが、最初からこれを作り上げることができる人材が社内にいたわけではなかったので、最初はそうした人材の採用に苦労したようです。何と言っても、お金に糸目をつけない、そしてAIの研究者に自由な空間を与えることで有名なGoogleやFacebookといった企業と人材獲得の競争をすることになるわけです。
Amazonの顧客第一主義は、研究にお金をかけるよりも、顧客にとっていかに役に立つものを早く安く提供するかに重きを置きます。そういった環境はAIの研究者には必ずしも魅力的とはいえません。さらに当時のAmazonはシリコンバレーの企業と違って研究の成果を公表する、もしくはオープン・ソースするという文化がありませんでした。
実際、現在はFacebookでAI研究所の所長を務めるYann LeCunという人を、それ以前にまだNYU(ニューヨーク市立大学)でデータサイエンス研究所の所長であった時に雇おうとしていたらしいのですが、彼は結局Facebookを選ぶことになります。彼は当時、Amazonで600人ほどを相手に講演をしたらしいのですが、講演のあとに小さなグループに別れてそれぞれのチームとのディスカッションの時に感じた秘密主義、つまり質問しても何も答えてくれないということが、行きたくなかった原因らしいです。さらにFacebookは彼のチームが行うほとんどの研究結果を公表することを保証してくれたというのも彼がFacebookという民間の企業で研究を続けることを決断する原因だったようです。
たださすがに、最近ではAmazonでもAI研究者は研究の成果を公表できるらしいです。これはAppleでも聞いた話です。Appleほど秘密主義で有名な会社はないですが、彼らもそれが故にAI分野の人材の獲得に苦労していたらしいですが、最近は特にこの分野ではAppleもオープンになってきています。Appleの機械学習のチームがどんなことをリサーチしているかというのは、現在こちらのブログのページで積極的に公開しています。
何はともあれ、タレントのあるAIの人材を惹き付けることに苦労していた当時のAmazonですが、キャッシュは大量に持っていたので、いくつものAIに関する会社の買収をし、それによって人材の確保を始めるという戦略に打って出ます。これがその後のAlexaの開発に役立ったようです。
2011年にYapというスピーチをテキストに変える技術を開発していた会社を買収。2012年にイギリスのケンブリッジにある対話型のソフトウェアを開発していたEviを買収。2013年にはポーランドのテキストをスピーチに変える技術を開発していたIvonaを買収しています。
ところで、当時のAmazonに加わることになったAIのエンジニア、研究者にとってはAmazonのAIに関するドメイン知識のなさというのは問題というよりもいいチャンスであったようです。例えば、GoogleやMicrosoftであればスピーチ認識に関してはもう既に何年もの間様々な研究がなされ、すでに製品やサービスとしてリリースされてるものもあったわけですが、Amazonではゼロからスタートすることになるわけです。新しいものを作りたいといったクリエイティブな人たちにとってはやりやすい環境であるといえるでしょう。
こうして初代のAmazon Echoを開発し市場に投入し、実際にユーザーがAlexaとインタラクトしはじめると、Alexaの脳に当たる部分、つまり計算処理が行われる部分はクラウドにあるので、そのデータがどんどんとAmazonのクラウドの方に大量に集められていきます。そしてこれがAmazonにとっては良い相乗効果を産んでいったようです。つまり、より多くの人がAlexaを使うと、より多くのデータをもとにAlexaをさらにトレーニングできるのでAlexaの品質がさらに良くなる、さらにAmazonの機械学習に関するインフラも改善される、そして何よりそこで集めれたデータをもとに様々な研究ができるということでAI、機械学習分野の研究者がどんどん集まってくるということです。AIの研究にはデータ量がものをいうので、持っているデータが非常に多いとそれ自体が研究者を惹き付ける材料になります。もともと、AIの研究者がGoogleやFacebookに行きたいという理由も実はここにあります。
現在、AIのタレントはAmazonの社内の様々な部署に散らばっているようです。AI本部といった中央集権的なオフィスはさすがに無いようですが、そのかわりに、機械学習の技術の普及とサポートを社内で促進するための部署があるようです。さらに、GoogleやFacebookに習って社内でのAIのタレントの育成にも力を入れているようです。AIのイニシアティブが始まった頃は社内の機械学習の会議には数百人が参加する程度だったものが、今では数千人もの人たちが参加しているようです。
現在でもAmazonが社外、社内で行うすべての活動にAIを使うために様々な取り組みが行われているようです。例えば、最近では配送に使う箱のサイズをどうやって最適化させるかや、在庫の需要予測のクオリティをにどうやって向上させるかなどです。
”家電に関わって30年が経つが、そのうちの25年の間のフォーキャストは人間の勘、エクセル、ダーツの矢を投げて行っていた。フォーキャスティングに機械学習を使い始めてからエラーの率がはるかに下がりました。”
現在、AIにおける業界再編の波が吹き荒れていますが、シリコンバレーのGoogle、Facebookに代表される技術力とさらにはデータを集める力のある企業群が勝ち組としてすでに勝負が決まっている感があります。しかし、このAmazonのAI素人カンパニーから、AIファースト・カンパニーへの自己変革の例は、現在AI、データサイエンスに関しては出遅れている会社への参考になるのではないでしょうか。もちろん、資金力は必要となりますが、そのへんは日本の企業にとっては問題ではないでしょう。あとは決断力とリーダーシップではないでしょうか。
データサイエンティストが3年連続でベストな仕事に選ばれる
Data Scientist – best job in America, 3 years in a row - Link
仕事先を探すプラットフォームとしてこちらで有名なGlass Doorが、アメリカで最も”いい”職種というのを”50 Best Jobs in America”として毎年発表していますが、先週2018年版の発表がこちらのページでありました。今年もやはりトップは相変わらずデータサイエンティストとなっています。2016年に初めて1位になってからこれで3年連続です。仕事の募集案件の数、給料、仕事の満足度という3つの指標をもとにスコアを出しているようです。
以前こちらのWeekly Updateで、データサイエンティストは給料が一番良いと言うだけではなく、ワーク・ライフ・バランスも一番良いといわれているということを紹介しましたが(リンク)、今回はさらに仕事の満足度の方も高いということでした。
ちなみに、アナリティクス、 ビッグデータ、データサイエンスに関する仕事でトップ50に入っているのは以下のとおりです。
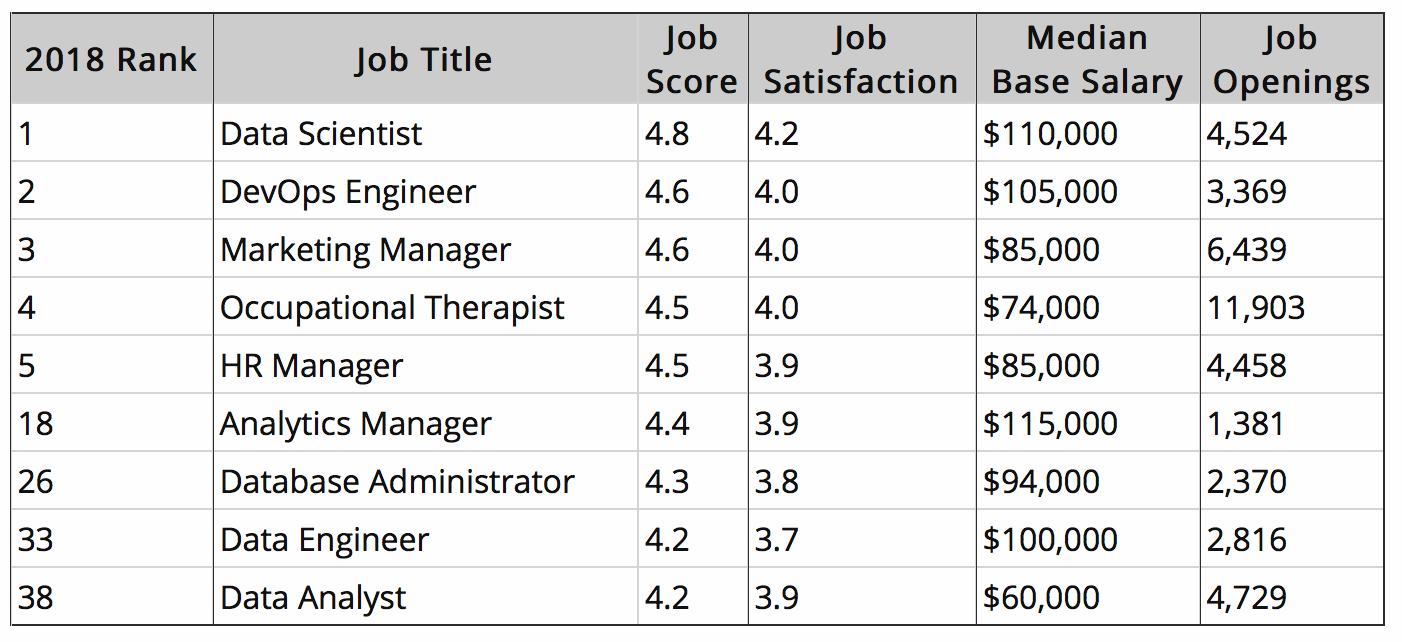
2017年は3位だったData Engineerが今年は33位まで落ちてしまっているのには驚きました。供給がニーズに追いつきつつあるということでしょうか。Big Dataの波が一段落したと考えることもできるのかもしれません。Data Engineerというのは技術の問題なのに対して、データサイエンスとういうのはビジネスにおける分析力の問題であり、クリエイティビティが要求されます。さらに分析のための手法、機械学習のアルゴリズムの方も物凄い速さでどんどん進化していっているので、この先もなかなか供給が需要に追いつかないのではないでしょうか。
なぜ、データサイエンティストは失敗、もしくは辞めていくのか?
Why Are Data Science Leaders Running for the Exit? - Link
Are You Setting Your Data Scientists Up to Fail? - Link
先ほども述べたように、データサイエンティストは人気があって、給料も一番いいと言われていますが、最近、そうしたデータサイエンティストを雇う時に多くの企業が犯す失敗について書いてある記事がち2つほどあったので、ここで紹介します。
アカデミアの罠
多くの大企業が間違えるのはデータサイエンスをやるのにはPhD(博士号)が必要だと思ってしまうことです。ある特定の狭い領域に限っての深い知識を持っているPhDの人たちは、データサイエンスのように様々な領域に渡る知識、経験を必要とする仕事に対しての適応力が高いと言えません。ですので、こういった人たちを連れてきて、データサイエンス部門のトップに置くよりも、ビジネスのわかる人間をトップにおいてその下で支える立場にこういった専門家を持ってくるほうが成果を出しやすいとのことです。
アジャイルの罠
ソフトウェア開発で効果を発揮するアジャイル開発ですが、これをデータサイエンスのプロジェクトに応用しようとするとおかしなことになります。ソフトウェア開発が作り上げていくものであるのに対して、データサイエンスは発見することに意義があります。必要なデータが集まらなければ意味のある発見はまったくなく、段階的にリリースしていく意味のある成果物と言うものがないわけです。
マネジメントの罠
多くの会社で、せっかく雇ったデータサイエンティストが失敗してしまうのは大抵の場合、データサイエンティストをうまく管理(マネージメント)できていないからです。最悪の間違いは、スマートなデータサイエンティストをたくさん雇って、データへのアクセスを可能にして、大したガイドも与えずにほったらかしにしてしまい、その後何か素晴らしい発見を自ら持ち込んでくることを期待してしまうことです。
データを使って解決できる問題、作り出すことのできる機会を明確に定義した上で、データサイエンティストをそうした問題を解決できる最適な場所に配置すべきです。マーケティングの最適化に関することであれば、マーケティング部署に配置すべきであり、石油の採掘の最適化であればそうした作業が行われている場所に近いところに配置すべきであり、何か新しい製薬の発見に関することであれば研究所に配置といった具合です。まずはデータに関するパイロットプロジェクトを始めるといった場合でも、明確に定義されたゴールを設定してからデータサイエンティストを配置すべきです。
多くの人がデータサイエンスのプロジェクトをビジネスでなく、技術(IT) 的なイニシアティブとしてとらえてしまっているというのはよくある間違いのパターンです。
コミュニケーションの罠
別の問題として、コミュニケーションがあります。データサイエンティストが話す内容がそのカウンターパートであるビジネスサイドの人間に理解しにくいことが問題です。このコミュニケーションに関しては、何もデータから得られたインサイトの説明に関するものだけではありません。データサイエンスのプロジェクトでは最初に問題のフレーミングを行うことになりますが、データサイエンティストがデータを使って答えようとしている問題をどう定義しているのか、なぜそのように定義しているのかといったことも普通の人間にはわかりにくかったりするわけです。
以上が要約です。
現在、AI、データサイエンスに関して、過剰な期待と低すぎる期待の問題があります。過剰な期待とは、何かミラクル、マジックがおきて難しい問題が一気に解決してしまうと思ってしまうことで、低すぎる期待とは、実は今の時代であれば簡単にできることでも、難しいからできないと思いこんでしまっていることです。
こうした認識のギャップも、実際にデータサイエンティストを雇っても活用しきれないで終わってしまうことになる理由ではないでしょうか。
これからどんどんとAI、データサイエンス、データ分析に関するプロジェクトは増える一方だと思いますが、安易にデータサイエンティストを雇っても、実際のビジネスで抱えている問題が解決することはありません。まずは何が問題になっているのか、それがどうデータで解決できるのか、ほんとうにデータサイエンティストを雇う必要があるのかということをしっかり議論すべきです。そして、雇う必要がある場合はどういったタイプのデータサイエンティストが必要なのか、どの問題を解決するのに必要なのか、どこに配置すべきなのかということをまずは議論するべきでしょう。
さらにそうした人材を雇うか雇わないかにかかわらず、社内の人間が、AI、データサイエンスを使うと何ができて何ができないのかくらいはしっかり理解できているべきですので、そのへんの社内教育は早いうちからしっかりとやっていくべきだと思います。
興味深いデータ
インスタントラーメン・データベース
The Ramen Rater - Link
やっぱりいるもんですね。世界中のインスタントラーメンを食べて評価しているHans Lieneschという人がアメリカのワシントン州にいます。彼の作っているRamen Raterというウェブサイトがありますが、彼がこれまでに試食してきた2600にも上る世界中のインスタントラーメンのレビューの結果がこちらにあります。エクセルとしてこちらのリンクから直接ダウンロードすることもできます。
もちろん、日清、明星、マルちゃんなどのラーメンも入っています。;)
世界の貿易データ
The Atlas of Economic Complexity というハーバード大学にある国際開発に関する研究機関が50年以上にも渡る世界中の貿易データを国連の貿易に関するデータベースから引っ張ってきて、それを分析しやすいように加工したものをこちらで公開しています。データのフォーマットはこの手の政治経済学系の人たちにありがちなのですが、STATAというものです。Exploratoryを使ってる方はそのままインポートできます。
What Are We Working On?
Exploratoryの次期バージョンv4.3では、チャートやアナリティクスで列を選ぶ時にフィルターができるようになります!
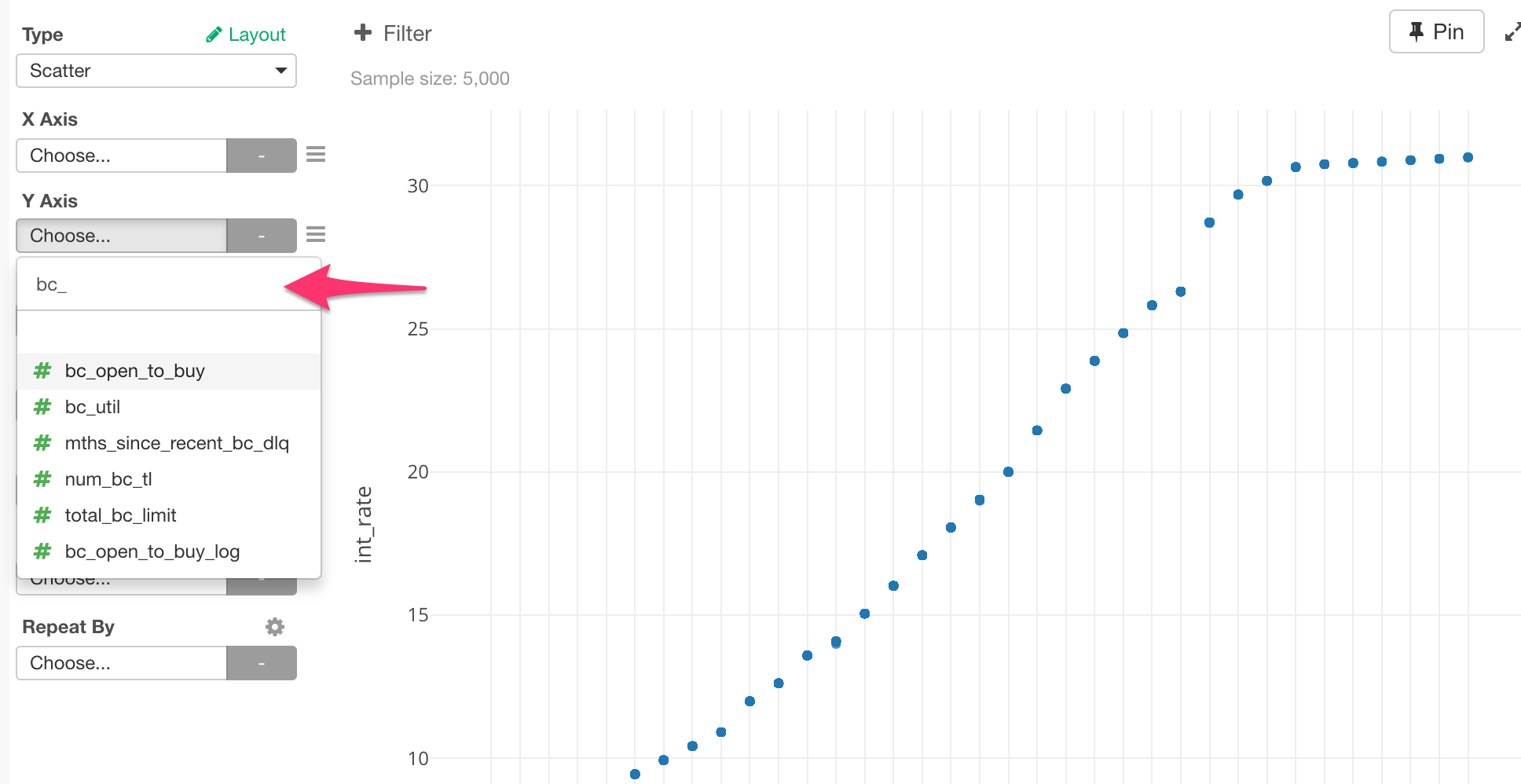
特にデータフレームに列がたくさんある時に便利です。
データサイエンス・ブートキャンプ・トレーニング
冒頭にも申し上げた通り、この3月の終わりに次回のデータサイエンス・ブートキャンプを行います。ぜひ周りにデータサイエンスに興味のある方がいらっしゃればお声をかけていただければと思います。詳しくはこちらのブートキャンプ・ホームページをご覧ください。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら(https://exploratory.io/tag/weekly%20update%20-%20japanese) よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。