
Faith: not wanting to know what is true (信仰:何が真実かを知りたくないということ)
Friedrich Nietzsche(フリードリヒ・ニーチェ)
こんにちは、Exploratoryの西田です。
今週中にExploratoryの次のバージョンであるv4.3をリリースする予定ですが、その準備のために慌ただしい毎日を過ごしています。
ところで先週もお伝えしましたが、今月の28日に東京でデータサイエンス力のある次世代ビジネスリーダーの育成についてのセミナーを開催します。AI/データサイエンス人材育成やプロジェクトの進め方などに興味のある方はぜひ参加していただければと思います。こちらのホームページに詳しい情報があります。
それでは、今週のWeekly Updateですが、今回は長いです。いつも長いですが、それより長いです。(笑)しかし、最初のアナリティカル・シンキングに関するものは、特に現在のようにデータが溢れている時代に、気づく、気づかないにかかわらず毎日意志決定を行っていかなければならない私たちにとっては非常に重要なものであるので、頑張って読んでいただければなと思います。
後の2本は、AIが現在の多くの単純な仕事を置き換えてしまうという現実を受け入れ、そういう時代に必要とされる人材の育成が必要だとする記事、企業のAI本気度を簡単に試すテストに関する記事になります。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
間違いの多い統計プロバガンダに騙されないためのアドバイス
Tim Harford’s guide to statistics in a misleading age - Link
最近ではフェイクニュースという言葉のおかげで、ニュースなどメディアでみかける主張や数値に対して疑問を持つというスタンスが以前に比べて少しづつではありますが見られるようになってきたように思います。それでもまだ多くの人がふだん毎日忙しい中で、センセーショナルなニュースのヘッドラインをついつい鵜呑みにしてしまって、さらにそれらをソーシャル・ネットワークなどで共有することで知らず知らずのうちにおかしな主張をどんどん拡散してしまっているというのが現状です。社会的に与える影響を考えるとこれは大変憂慮すべきことです。
今日は、Financial Timesのコラムニストで、経済学者のTim Harfordが、データや統計的な主張にまどわされることなく、正しく理解していくためのガイドを7つのアドバイスとしてまとめているので、ここで簡単に紹介したいと思います。
以下、要約
アドバイス1: 自分の感情に気づくこと
統計的な主張を目にしたり、聞いたりした時、まずは自分に湧き上がる感情に注意を払ってみてください。私たちには読んだりするものに対して直感的に抱く感情があるのです。それは格差の拡大と言ったニュースであったり、チョコレートが痴呆症を防ぐといったニュースであったりするかもしれません。
それでは、どういった感情でしょうか。防御的なもの、勝利に興奮するようなもの、正義感にともなう怒りなどがあるでしょう。または、チョコレートや痴呆症に関するものだと安堵のような感情があるのではないでしょうか。チャートやショッキングな数字を見せられて感情的に反応してしまうこと自体が問題なのではありません。そういった時に起こる感情を無視してしまったり、もしくはそうした感情に惑わされてしまったりすることが問題なのです。
なので、統計的な主張を理解し始める前にそうした感情を認めることが重要です。もし、私達がそうした感情的なハンディキャップを持っているということを認めなければ、何が本当に正しいのかを見極めるチャンスは限りなく小さくなってしまいます。
物理学者のRichard Feynmanによると、
“You must not fool yourself — and you are the easiest person to fool.(自分を騙してはいけません、自分というのは一番騙しやすいのですから。)”
ということです。
アドバイス2:主張を理解する
80年代のDouglas AdamsによるThe Hitchhiker’s Guide To The Galaxyというサイエンス・フィクションに出てくるDeep Thoughtというコンピューターの言葉を借りるならば、”答えの意味を理解するためには、まずは質問の意味を理解しなくてはならない。” ということです。
例えば、格差が拡大しているという一般的に受け入れられている主張を例に取ってみましょう。特に議論の余地もなく、そして緊急の問題のようです。しかし、それは一体どういう意味なのでしょうか?人種間の格差なのでしょうか。それとも性別間の格差でしょうか。機会の格差、消費の格差、教育の格差、富の格差いろいろありますがどの格差の話でしょうか。さらに、その格差はそれぞれの国の中での問題なのかそれとも世界の国々の間での問題なのでしょうか。
ここで一度、焦点を絞って、税金前の収入の格差という問題を話していることにしましょう。この場合も、いつから比べて格差が広がっているといえるのか、どのようにその格差を計測しているのかという疑問がわきます。よくあるのは、下から90%の人たちの収入と上から10%の人たちの収入を比べるやり方です。しかしこの計測の仕方ではスーパーリッチな人たちや中間にいる普通の人達の姿はまったく見えてきません。別の方法として、上位1%の人たちを調べることができますが、これは最下層の人たちがマジョリティの人たちと比べてどうなのかがわかりません。
実際、格差に関してたくさんの正しいと言われる主張ができます。穿った見方をすれば、都合の良い計測値を持ってきて自分の主張を統計的に正しいと主張することができるのです。しかし、もしその主張が一体何を意味しているのかを理解していなければ、それを検証することにはほとんど意味がないでしょう。
たとえば、ビデオゲームで遊ぶ子どもたちは実社会で暴力的になると示す研究報告があったとしましょう。統計のリテラシーを上げるためのプロジェクトであるSTATSの理事長で、数学者でもあるRebecca Goldinは、「遊び」、「暴力的なビデオゲーム」、「実社会での暴力」といったコンセプトが何を意味しているのかに対して質問すべきであると言います。「撃つ」というコンセプトが含まれているインベーダーゲームは暴力的でしょうか。「暴力的」というのは、実験室で20分ほどゲームをプレイした後にした質問に対する答えをもとに計測しているのでしょうか。それとも一週間に30時間ほどゲームをプレイした人たちの殺人願望を計測しているのでしょうか。ほとんどの研究では暴力そのものを計測することはありません。その代わりにアグレッシブな態度などといった抽象的なものを計測するのです。
アドバイス3:因果関係なのか、相関関係なのか
私たちは相関関係と因果関係をよく勘違いします。例えば、「背の高い子供は読解力が高い」というニュースがあったとしましょう。これは栄養や認知力をもとにした注意深い研究の成果をまとめたものなのかもしれません。もしくは、単純に8歳の子が4歳の子よりも読解力があって、さらに背が高いという、当たり前のことを言っているのかもしれません。
因果関係というのは哲学的にも技術的にもややっこしいものです。しかし、カジュアルに統計データを消費しているわれわれが、聞くべき質問というのはそんなに複雑ではありません。その統計的な主張が因果関係にもとづくものなのか、そうであれば、それはどのように正当化されるのか、聞いてみればいいのです。
先ほどの暴力とビデオゲームの関係であればこんなふうに聞くことができるでしょう。これは因果関係なのか、それとももっと一般的な相関関係なのか。それは実験的な環境で検証されたのか、といった具合です。実は、子どもたちを暴力的にさせる別の要因があり、それがそうした子どもたちを暴力的なビデオゲームへも導いていただけなのかもしれません。この点をはっきりさせることができない統計的な主張には、空虚な見出しという以外には、何の価値もないのです。
アドバイス4:要約データは真実を必ずしも反映しない
忘れてはいけないのは、私達の目にする統計データ、もしくは数値というものはもっと複雑な真実を要約したものでしかないということです。例えば、人々がもらっている給料を理解しようとしたとします。膨大な量の人達の給料が毎月支払われていますが私達が目にするのはその要約された数値だけです。しかしそれは何を要約したものなのでしょうか。例えば給料の平均を算出したとしても、ほんの一握りの物凄い高い給料をもらっている人たちによってその平均値は歪んでしまいます。それでは中央値はどうかというと、たしかにデータの分布の真ん中の値ではあるものの、それ以外がどうなっていようがまったく影響されることのない数値なので、全体像を推測することには向いていません。
イギリスの統計局で以前局長をやっていたAndrew Dilnotが言うには、「平均は複雑である世界の全体像を伝えることができません。それはまるで、部屋の中に何があるのかを鍵穴から見るようなものなのです。」
端的にいうと、ガーディアンのデータ・エディターのMona Chalabiが言うように、何がそこでは見えていないのかと自分で問いただす必要があるということです。それは、棒グラフの縦軸が都合のいいように切り出されていて、小さな変化を大きく見せるような、よく使われるトリックに遭遇したときにも当てはまります。
アドバイス5:出版バイアスを理解する
次に出版のバイアスです。例えば、喫煙がガンの原因であると言うのはいまさらニュースにはなりません。しかし、驚くような研究の結果、このケースで言うと、喫煙がガンの原因ではなかった、などというのはニュースになります。しかし、例えそういった新しい研究というのはしっかりとしたプロセスでなされていたとしても、おそらく間違っているものでしょう。なぜなら、過去何十年もに渡るそれとは反対の研究結果という重みに耐えるものでなくてはいけないわけです。
出版バイアスというのはアカデミア(学問)の世界では大きな問題です。驚きを呼ぶような研究結果は出版されやすく、後でみると間違っていたというのは隅の方で取り上げられるか、そもそも取り上げられさえしないものです。そして、このバイアスはメディアとなるとさらに大きく、ソーシャルメディアではもっと大きくなります。
王立統計学会の会長であるDavid Spiegelhalterはグラウチョの法則を提案しています。コメディアンのグラウチョ・マークスの有名な文句で、「もし私を受け入れるようなクラブであれば入りたくない。」というのがあります。そんなクラブであれば大したことはないであろうからということです。Spiegelhalterはヘッドラインやソーシャルメディアを賑わすような統計的な主張にも同じような考えが当てはまるのではないかというのです。つまり、「もし私の注意をひくような驚くべき事実や直感に反したものである場合、おそらく間違っているでしょう。」と。
アドバイス5:数値をどう理解するか
たくさんの提示される数値は、私達が知っている数値と比べるまではほとんど意味を成しません。ある数値が自分が直感的に理解できる別の数値と比べてどれだけ大きいのでしょうか。先ほどの給料の平均という数値があったとして、それは1年前、5年前、30年前と比べてどれだけ大きいのでしょうか。そういう時は歴史的なトレンドをみることが重要になります。もちろんデータがあればですが。
別の例では、赤ちゃんがお母さんのお腹の中にいる間に熱波にさらされていた場合は大人になってから稼ぐ収入が低いという研究結果があります。その発見は統計学的に有意とされていました。しかし、その影響というのは取るに足らないもので、一年あたり3000円ほどの違いがでるというものです。つまり、ある発見が統計的に有意だとしても、私達にとっては実際どうでもよかったりするかもしれません。
アドバイス6:正確でないことをよしとする
Carveth Read がLogic (1898)の中で、「だいたい正しいということのほうが、まったく間違っているよりもいい。」と言っていますが、正確さにこだわることで人々を混乱させてしまうことがよくあります。
2016年のアメリカの大統領選挙のとき、政治関連の予測をするウェブサイトである FiveThirtyEightはトランプの勝率を28.6%と予測していました。この予測はある意味では素晴らしいことです。というのも当時の他のほとんどの人たちはトランプが勝つ可能性はほとんどないと予測していたわけですから。しかしこの28.6%という数字の小数点の部分の0.6もしくは一桁目の8という数値がどれだけ重要だったのでしょうか。そしてこうした数字のせいで多くの人は基本的なメッセージの理解に失敗してしまったのです。実はその予測の数値から導き出される重要なメッセージというのは、トランプには勝つためのチャンスが十分に有ったということだったのです。つまり、「およそ4回に1回のチャンスで勝つ可能性がある」という情報のほうがもっと直感的だったわけです。
アドバイス7:データに対して好奇心をもつ
”好奇心は猫には問題だがデータにはいい”
好奇心をもつというのは非常に重要です。なぜなら、好奇心が旺盛だと、言われたことをさらに理解しようと一生懸命になりますし、そうした理解の過程での驚くような発見を楽しむこともできます。
そもそも、ほとんどの統計的な主張というのは多くの質問を呼び起こすものです。これは誰が主張しているのか、この数値は何を意味するのか、何がここには足りていないのか、などと様々な質問が湧いてきます。
イギリスの統計局のEd Humpherson のことばを借りるなら、「もう一個クリックしよう」という気持ちが重要なのです。もし、その見ている数値や統計的な主張が他の人と共有するほど重要なのであれば、まずは自分でその意味することころを理解できていることが重要だと思いませんか?
好奇心はもう一つクリックしようという動機を与えてくれますが、さらにもう一つ重要な役割があります。それは自分たちの考えを変えることにオープンであるということです。
好奇心は驚くような統計的な発見に対しての心構えでもあります。そうした驚きをミステリーとして解決しようとすると統計的な間違いを発見することにもつながりますし、それ以上に新しい確証に対して心を開きやすくなります。
Asheley Landrum、Katie Carpenter、Laura Helft、Kathleen Hall Jamieson、Dan Kahanによって行われた研究によると、本質的にサイエンスに対して好奇心旺盛な人たちは、政治的な質問をされた時に二極化した反応を示すことが少ないということが分かっています。私たちは驚くべき発見を脅威としてではなく、ミステリーとして捉えるべきです。
科学での世界でもっとも興奮する時に使われるフレーズは‘Eureka!’ではなく、「That’s funyy….(これはおもしろい)」である。これは重要な真実だと思います。もし私達が質問を、単に答えるためのものとしてではなく、興味深い議論を呼び起こすものとして捉えることができると、それはより賢くなるための道になるわけです。
最後に、みなさんには以下のようなことをするために毎日少しだけ頑張ってみてはいかがでしょうか。
- 防御的になるのではなくオープン・マインド(心を開く)になってみる。
- 主張、数値が何を意味しているのかを理解するために簡単な質問をしてみる。その主張、数値はどこから来たのか、それが本当だったとして私達にとって意味があるのか、など。
- こうした質問に対しての答えを見つけ出すためにも世界に対して好奇心を持つ。
これは何も、議論に勝つのが目的ではなく、それは私達の住む世界とは好奇心を持つに値する素晴らしい場所だからです。
以上、要約
このエッセイではニュースで目にする数値や統計的な主張に関する問題、そしてどう対処していくべきかということに対して書かれていますが、実は同じことが普段のビジネスを行う上でも知らず知らずのうちに起きていたりします。つまり、データに裏打ちされた意志決定と言っているものの、そのデータ自体が間違っていたり、その解釈の仕方が間違っていたり、もしくは解決するべき問題とはあまり関係のないデータからのインサイトにもとづいて、意志決定をしていたりということがよくあります。さらにデータから得られたはずのインサイトやその手法が理解できないがばっかりに、意見を変えることができず、意志決定に反映させることもできないといったこともよくあります。
ビジネス上の問題を解決するための質問を定義し、それに答えるためにデータを様々な角度から理解した上で、仮説を設定し、さらにそれに対して疑問を持ちながら検証して解き明かしていくという思考プロセスを繰り返すことによって、意志決定に役に立つインサイトを導き出すということを、私たちはアナリティカル・シンキングとよんでいます。こうしたスキルこそ今日のように様々なデータが溢れている時代により高度な意志決定を求められる人にとって、緊急に習得すべきことが求められるのではないでしょうか。
テック企業、AIが人間から仕事を奪うことはないというふりはもうやめよう
Tech companies should stop pretending AI won’t destroy jobs - Link
以前からこのWeekly Updateでも度々取り上げていますが、中国のAI分野における発展は凄まじいものがあります。今回はそうした発展に詳しい、以前Google Chinaの初代社長をやっていて現在はSinovation Ventures でCEOをやっているKai-Fu Leeが、私たちは今後AIによって、多くの仕事が置き換えられることになるという現実を受け入れ、そうした世界に備えるために新しい教育の仕方を考えるべきだという内容の記事を書いていたので簡単に紹介したいと思います。
以下、抜粋
どんどん過熱していく中国とアメリカのAI分野での競争はさらなるAIの進化を生み、多くの人が想像していたよりも遥かに早く、多くのことがAIによって実現することになるでしょう。その変化の波は大きく、そしてそれはいいことづくめではありません。「格差」はさらに拡大するでしょう。
AIは多くの仕事を置き換えます。それは社会的な不満の原因になるでしょう。例えば2016年に碁の世界チャンピオンを破ったGoogleのDeepMindの作ったAlphaGoというのがありましたが、その次の年には、自分自身とゲームをし続けることによって勝手に進化することができるAlphaGo Zeroによって打ち負かされてしまいました。こういった進歩が他のエリア、例えば、カスタマーサービス、テレマーケティング、組み立て工場、受付デスク、トラックの運転、そして他のブルーカラー、ホワイトカラーを問わず繰り返しの多い仕事にも適用されることを想像してみて下さい。現在の半分ほどの仕事は、AIやロボットのほうが私達よりもはるかこなすことができ、人件費という点でのコストもほとんどかからないということに、多くの人がそのうち気づくことになるでしょう。
もちろん、楽観的な人たちは、AIだけ、もしくは人間だけで行うよりも、AIと人間が協力することでより良い結果を出せると主張します。(西田:ちなみに、これは私の取るポジションです。)これは、例えば医者、弁護士などの、ある特定の職にとってはそうかもしれません。しかし殆どの仕事はそういったカテゴリーにあてはまらないでしょう。多くの仕事は繰り返しで、AIが人間を遥かに上回ることができるような単純な作業であるのです。
そして、AIには何も恐れることはないと主張する人たちがいます。これはAIに強い多くの巨大テック企業が取るポジションでもありますが、AIの専門家たちがこうした問題を解決しようとしていないことは残念です。しかし、さらに残念で、信じられないほどに自己中心主義だと私が思うのは、彼らはそもそもこうした問題の存在すら認めようとしないということです。
こうした変化は確実に押し寄せ、現実になってきています。私達は本当のこと、真実を話す必要があります。AIができない仕事とは何なのかを見つけだし、人々がそうした仕事ができるようにトレーニングする必要があります。現在の教育システムを作り直す必要があります。今私達が生きている現在は最高の時であると同時に、最悪の時でもあるわけです。今、合理的に素早く行動を起こすことで、最悪の事態になってから苦しむ前に、多くの人にとって最高の機会を作り出すことができるではないでしょうか。
これとは別に、ちょうど先週、なぜ今こそ生涯学習が必要なのかに関して話している”5-Hour Rule: Why you Should Spend Time Learning”という記事があったのですが、その中にあったイラストレーションが、この本文のメッセージとマッチしていると思ったのでこちらにのせておきます。
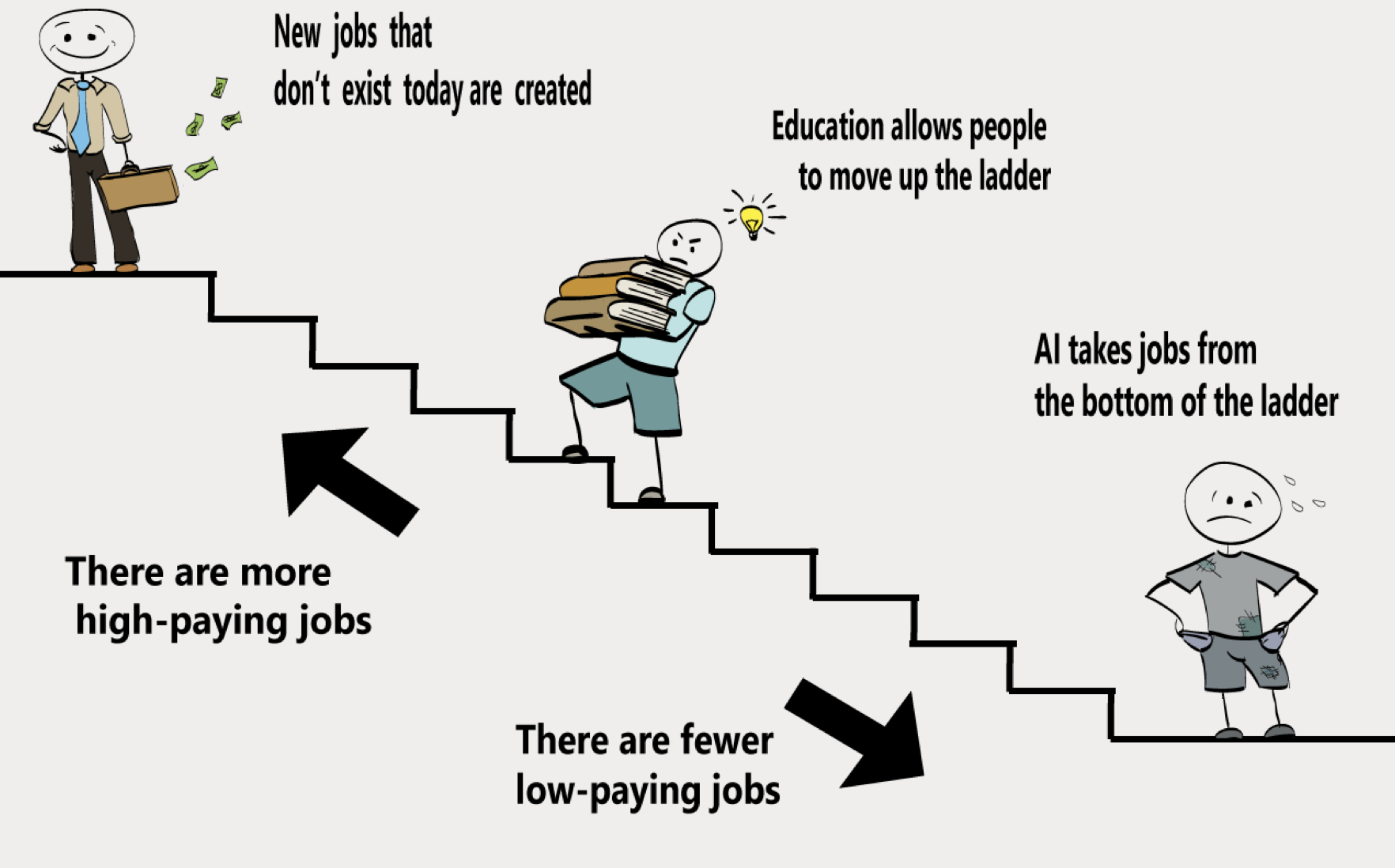
AIファースト・カンパニーであるかどうかは机の配置を見ればわかる
What does it mean by being AI first company? - Link
今は、どこの会社のトップもマーケティング部門も何かの機会を見つけてはAIという名前を使いたくてしょうがないというトレンドがありますが、そんな時にその会社がどれだけ本気なのかを試す簡単なリトマス試験の仕方がこちらの記事で紹介されています。
以下、抜粋
大きなテック企業の優先順位を知りたければ机の配置を見ればいいのです。
Googleのシリコンバレー本社はCEOのSundar PichaiはAIに特化したリサーチ・ラボであるGoogle Brainの人たちと同じフロアにいます。
Facebookでも状況は同じです。AIチームの座っている場所はCEOのマーク・ザッカーバーグのデスクの隣ということです。この場所には以前はヴァーチャル・リアリティに関する製品を作っているチームがいたらしいですが今は別の場所に移ったようです。つまりヴァーチャル・リアリティはFacebookにとって今一番重要なものではないということでしょう。
多くのテック企業がAIのリサーチ・ラボをCEOに近い場所に設けています。つまり、彼らの行っていることはCEOにとって直接関係があるということです。そもそも、それが会社の将来であるかもしれないのですから。
世界の動きはテクノロジーとイノベーションによってどんどん速くなっています。そして多くの企業はテクノロジーとイノベーションは彼らの全てのビジネスの中心にあるべきだと結論づけています。
以上、抜粋
Weekly Updateの読者にはAIファースト・カンパニーというのはおなじみの言葉だと思いますが、この手のテック企業は一昔前はモバイル・ファーストであり、その前はソーシャル・ファーストという旗印を挙げていました。こうした、特にシリコンバレーのテック企業がXXXファーストという旗印をあげるのは、IBMやオラクルだったりという古いタイプのテック企業が今の流行りに乗ろうとするマーケティングやブランディングの戦略とは一線を画しています。Google、Amazon、Apple、Facebookといった企業がしめる現在の独占的な地位というものが実はいかに危ういものであるかということを、過去に一時は独占的な地位を築いていたがその後消えていった他のテック企業から学習しています。つまり、次の波に乗り遅れるということがどれだけ彼らのビジネスにとって致命的なのかということを理解し、肌で感じているわけです。このへんはイノベーターのジレンマという本に詳しく出ています。
さて、今後もさらに多くのCEO、社長といった地位の人やマーケティング担当者がAIの話をすることになりますが、そんな時にそれが本気なのかを試すための質問はみんな分かってますね。(笑)
興味深いデータ
戦争に関するデータ - Link
US Armyにあるデータベースには1600から第2次世界大戦ころまでの戦争に関する詳細なデータが入っています。こういうデータはいろいろなところに散らばっていてフォーマーともばらばらだったりするものですが、政治学者のJeffrey Arnoldが、他の人が分析しやすいようにと一連のCSVファイルにしてまとめてくれています。
What Are We Writing?
先週もお伝えしましたが、普段のデータ分析をする時に非常に便利なツールとしての線形回帰のアルゴリズムをもっと多くの人たちに知ってもらおうということでブログのシリーズを先週より始めています。
以下は第2回目のエピソードとなります。(英語ですが。。。)
- A Beginner’s Guide to Exploratory Data Analysis with Linear Regression Part 2- Link
What Are We Working On?
いよいよv4.3のリリースが近づいてきました。今回はバグの修正と既存の機能に対するエンハンスメントがたくさん入っています。その中の一つでダッシュボードに関するエンハンスメントとして、今まではチャートを4つまでしか入れることができなかったのですが、このバージョンからは最大で12個まで入れれるようになります。シングル・バリュー(指標)タイプを含めると最大で16個までになります。さらに、ダッシュボードのレイアウトの設定のダイアログも見やすく使いやすくなっています。
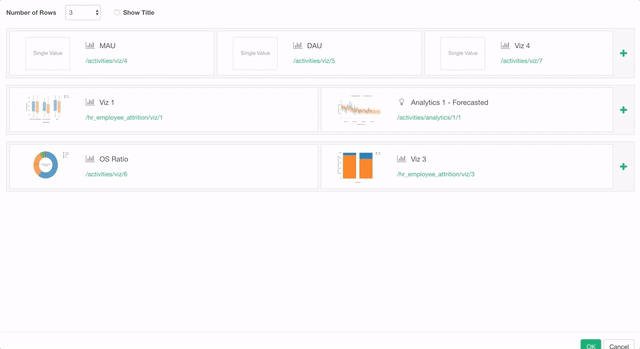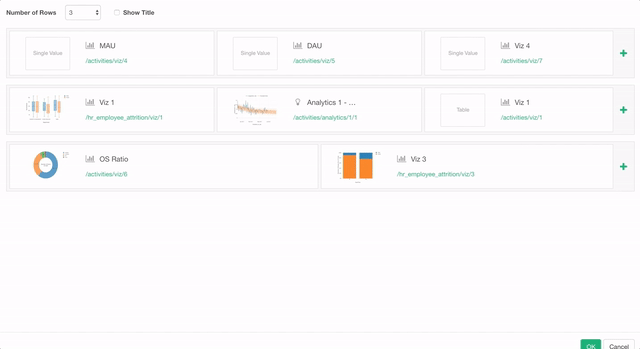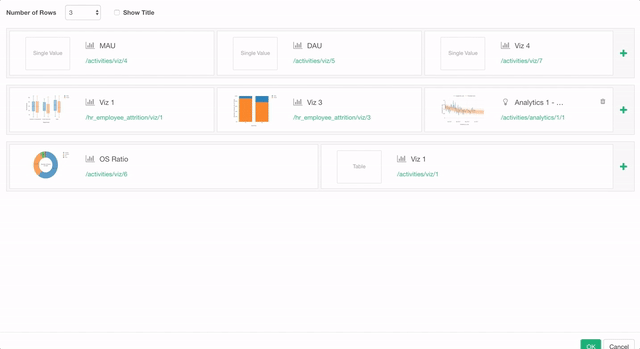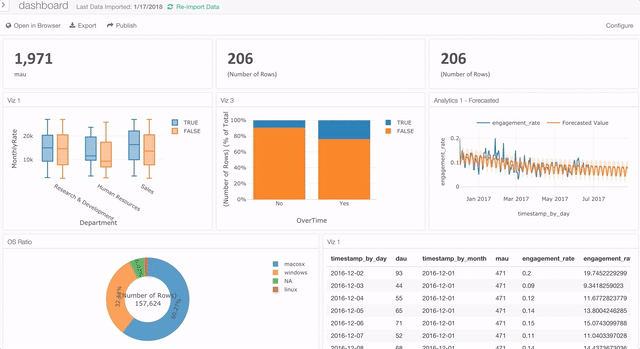
Exploratory社主催セミナー in 東京
今月のブートキャンプでの来日のタイミングで、データサイエンス力のある次世代ビジネスリーダーの育成についてのセミナーを開催します。私どもがデータサイエンス・トレーニングを実施している、シリコンバレーと東京のデータ先進企業での事例も織り交ぜながら、AI/データサイエンス人材育成に課題をお持ちの皆様に役立つ情報を共有させていただきます。社内人材育成やプロジェクトの進め方などに興味のある方がまわりにいらっしゃいましたらぜひお声をかけていただければと思います。こちらのセミナーのページに詳細があります。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。