
こんにちは、Exploratoryの西田です。
日本では連日相撲関連の話題で盛り上がっているようですが、それにつられて私どもExploratoryのチームの方でも先週、データハッカソンとして相撲データを分析してみました。思った以上にネットから相撲関連のデータは簡単に取れるのですが、日本でのブートキャンプに来られた方にはおなじみのサバイバル分析のアルゴリズムを使って突っ張りを得意技とする横綱は引退が早くなるということが分かって面白かったりと、なかなか面白かったです。
さて、1月の日本でのブートキャンプのほうですが、今週末で早割のほうが終わりますので、興味はあるがまだ申し込んでない方はこの機会にぜひご検討下さい。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
先々週になりますが、こちらでは特に仕事をしている女性の方に人気のあるStitchFixという服のパーソナル・スタイリング・サービスを提供しているシリコンバレーのスタートアップがIPO(株式公開)をしました。スタートアップの世界ではIPOは大きな成功のマイルストーンという意味があるので、たいへん盛り上がっていましたが、この会社はこの業界では初であるChief Algorithm Officerという職を設けて、AIを使ってパーソナル・スタイリングを効率化させていくということを最初の段階からやってきたデータサイエンス先進企業です。
普通の会社ですと、データサイエンティストはサイドからサービスを提供するという立場が多いのですが、ここでは会社の中の主要なポジションを占め、さらにこの会社が提供する価値のあるモノを作っている主体がデータサイエンティストです。こうしたStichFixのようにデータサイエンティストが異色人種だとみなされるのではなく、会社の主要なポジションを占める会社がシリコンバレーに増えてきているというのは、これからの5年、10年を考えたときには無視できないトレンドだと思います。
ところで、StitchFixがどのようにAIを使ってパーソナル・スタイリングを行っているのかというのをこちらのページでアニメーションを使ってわかりやすく説明しています。先週もお伝えしましたが、ここでもAIで全てを自動化するのではなく、プロのスタイリストがAIを’パートナー’として使うことでより効率的にスタイリングを行い、よりクオリティの高いサービスをより多くのお客様に提供できるといういい例だと思います。
彼らはAIを使ってどの服を顧客に送るかというレコメンデーションを行っているのですが、こうしたレコメンデーション・エンジンを作るときは一般的に協調フィルタリングというテクニックが使われます。つまり、今までに顧客のフィードバックをもとに(例えばどの映画を見たか、好きかなど)、顧客名と製品名(映画の名前)のマトリックス(碁盤のようなもの)を作ります。そうするとそれぞれの顧客がまだ見ていない映画というのがたくさんあるので隙間の多いマトリックスになるわけですが、そこをクラスタリングのテクニックなどを用いて埋めていくわけです。こうして、あなたが気に入った映画を過去に気に入った人は他のこういった映画を気に入っていますよというレコメンデーションをすることができるわけです。
ただ、この手法にはコールド・スタートという問題があります。つまり、まだサービスを使い始めてばっかりの人はそもそもレコメンデーションするための過去のデータが全く無いわけです。しかしStichFixのようなAIを使ったパーソナル・スタイリングを売りにしているサービスの場合はこの問題は死活的になります。なぜなら、サービスを使い始めてから、最初の2、3回の間で自分のスタイルに合った気にいるようなものが送られてこなければ結局はそのサービスを使うのを止めてしまうからです。
そこでStitchFixは最初にユーザーがサインアップした段階で、自分のスタイルに関しての細かい質問をします。さらに服に関してもたくさんの属性をスタイリストが登録していきます。
ただ、人に自分の服の嗜好を説明しようとしても難しかったりします。自分の好きなものを見た時は”これだ!”となりますが、なぜそれが好きなのかを説明するのは難しいからです。そこで、顧客が好きな服のイメージ(ここでは、Pinterestなども活用しているようです。)そのものをデータとして扱い、それに似たようなものを在庫から探し来るようです。ここではやはりディープラーニングを使っています。
さらに顧客のリクエストの記述やフィードバックを自然言語処理の手法を使って数値データに落とし、それをもとにそれぞれの服にスコア(得点)をつけているようです。
こうしたAIによる服のスコアや、顧客のスコアは最終的に顧客に割り当てられたスタイリストに渡され、これを参考にしてスタイリストは最終的に何を顧客に送るかを調整するわけです。
AIであれば、どのコンピュータでもいっしょですが、人間はもっと多様です。人間のスタイリストの場合は顧客によって合う合わないがあるので、このスタイリストと顧客のマッチングにもAIを使っています。これをするのに、まずは現在空いているスタイリストと発送をリクエストしてきた顧客のマッチングをスコアリングします。これは、もちろん今までの履歴も参考にしますが、そういった履歴そのものがない場合が多いので、顧客のスタイルの好みとスタイリストの好みのマッチングによりスコアリングします。
先程も申しましたが、人間とAIのパートナーはお互いを補完するところから始まりますが、StitchFixはその辺をしっかりと認識してうまくやっています。
”AIはパターンをもとにした計算や学習は得意ですが、即興、社会的な常識(空気を読む)、顧客の気持ちを理解するといったタスクは得意でありません。そしてこうしたタスクこそは人間が得意とするものなので、ここでは私達のスタイリストが人間にしかできないようなコンピュテーション(計算処理)を行うわけです。”
そして、AI、機械学習はフィードバック・ループというのが死活的に重要になりますが、そこもしっかりとデザインできているようです。
“彼女(顧客)が送られてきたパッケージを開けると、気に入ったもの以外は送り返すことになります。このタイミングで彼女がそれぞれのアイテムに関してどう思ったかをフィードバックとして私たちに言ってきてくれるのですが、この時に顧客と私達を結ぶ重要な関係が生まれます。ここでの洞察に満ちたフィードバックが次回の彼女に対するサービスの向上だけでなく他の顧客に対するサービスの向上にもつながるのです。”
ファッションをアナリティクスと機械学習を使って解明する
Interview: Brad Klingenberg, StitchFix on Decoding Fashion through Analytics and ML - Link
もう一つ、少し前の記事になりますが、StitchFixでスタイリング・アルゴリズムのディレクターをやってるBrad Klingenbergのインタビューです。こちらは前述のようなシステムを実際に作っている人なのでもう少し足を踏み入れたインサイトが得られます。
例えば、私達がマーチャンダイジングのチームは新しい在庫を買う時にそれぞれのアイテムをかなり詳しく記述し、構造的なデータを作りだします。これは簡単なことではなく、ファッションの専門家の時間を必要とします。このデータをしっかり作るのはものすごく重要で、何が顧客が最終的に送られてきたものを気に入るかどうかに影響するのかを理解していなくてはいけません。服のサイズが会うだけではなく、それが顧客の要求するスタイルと値段に合うか、また彼女の持っている別の服に合うかということが重要になります。
もう一つ重要なことは私達の顧客は私達とゴールを共有しているということです。これが実はものすごく重要です。顧客は私たちにいい仕事をしてもらいたいとおもっていて、さらにフィードバックをもとに私たちにさらに良くなって欲しいと願っているわけです。こうした動機が、彼女たちが具体的でよく考えられたフィードバックを私達に提供することを促します。そしてこれこそが私達のビジネスにとってもっとも重要な情報なのです。
最後にデータサイエンティストに求められるスキルがこちらに
この仕事をするにあたって二つの重要な素質は、問題を定義してモデルを作ることに対してどれだけ熟練であるか、あいまいということに平気でいられるかということだと思います。最初のものはデータとモデルに関する仕事の経験から来ます。ビジネスの問題を理解できてそれをデータを使って解決するためのアプローチを提案できる人材をというのを私たちは求めます。最高の人材は、シンプルなソリューションが正しいものであるということが分かっていて、こういう時に取るアプローチを必要以上に複雑にしない人たちです。
データサイエンス・機械学習の2017年の状況
2017 The State of Data Science & Machine Learning - Link
Kaggleという機械学習のコンテストを行うプラットフォームがありますが、そこで16,000のデータサイエンティスト・分析者を対象にデータサイエンス・機械学習に関する聞き取り調査を行った結果をこちらのページにまとめてあります。
What is the title of your job?
こちらがアンケートの質問に答えたKaggleのユーザーの人たちの職種です。
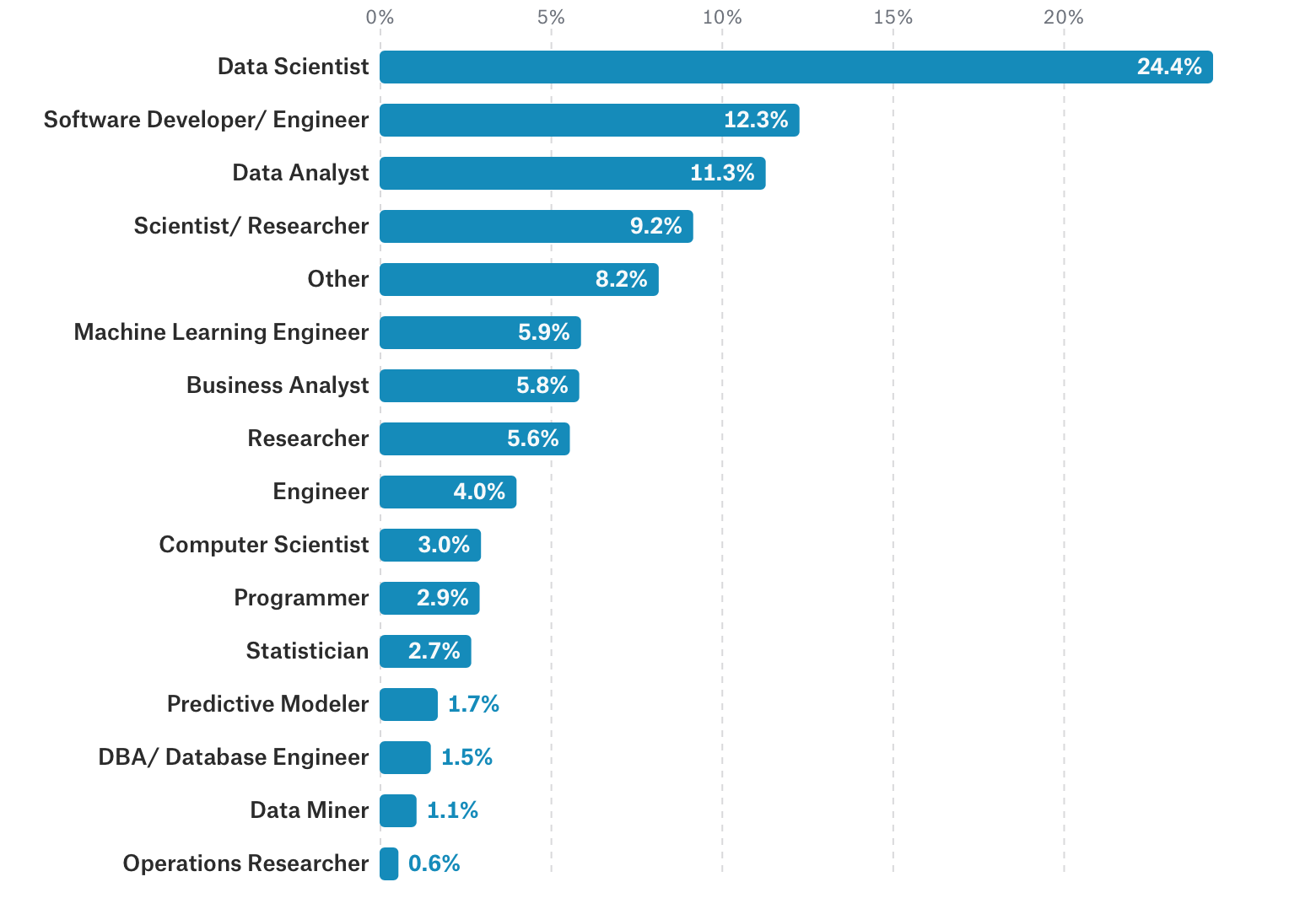
この世界は日々変化が激しいので職種の方も結構あいまいです。特にデータサイエンティスト、データアナリスト、スタティスティシャン(統計者)などは会社によって使われ方、定義が違います。私達のお客様のFacebookの人たちはリサーチャー、リサーチ・アナリストという肩書の人たちが多いですがやってることは別の会社だとデータサイエンティストの仕事だったりします。
What is your full-time annual salary?
給料に関する質問もあったようですが、全体ではUSでは以下のようになっています。中央値は$110,000のようです。
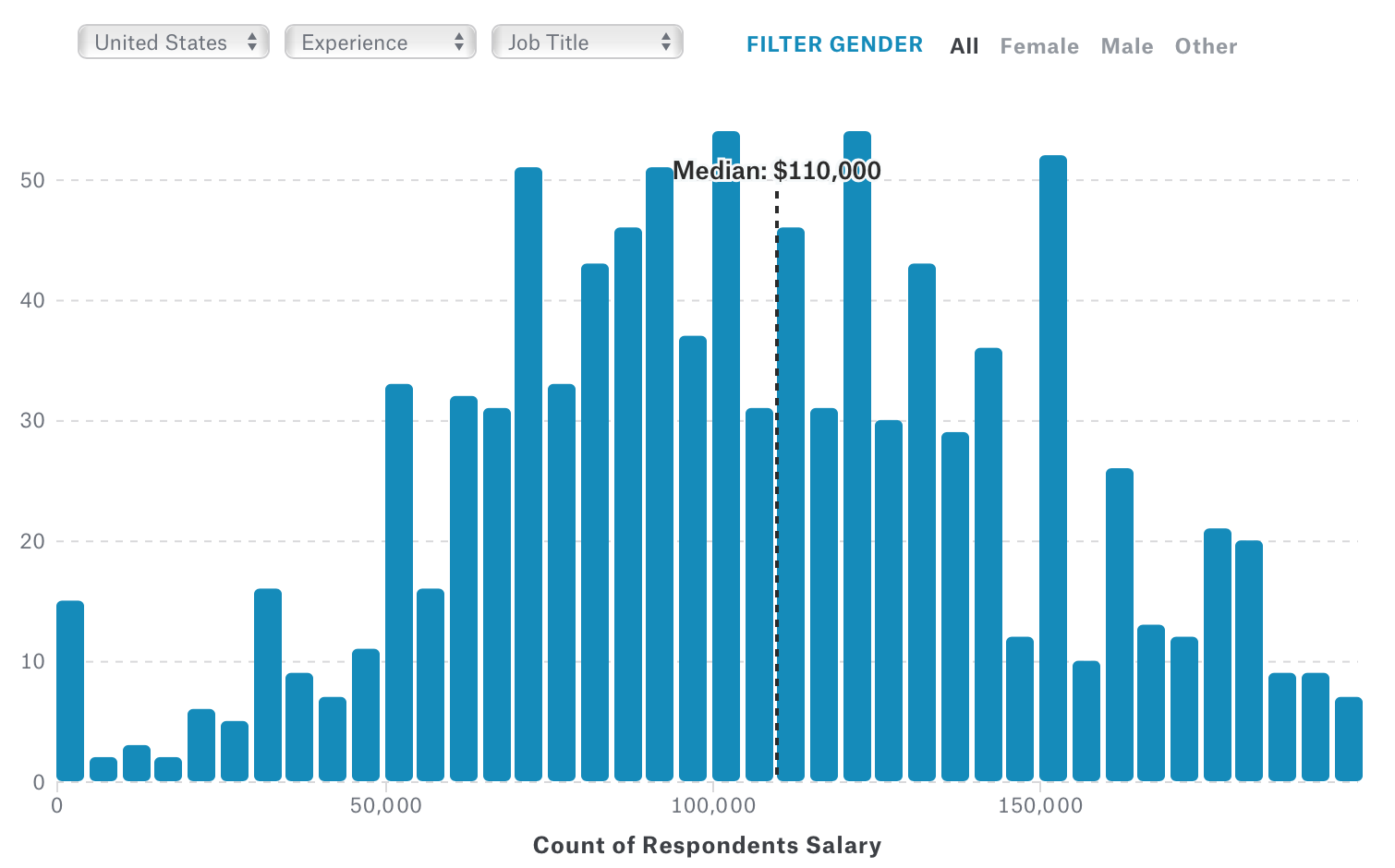
ただ、これをデータサイエンティストという職種に絞るとその中央値は$122,500に上がり、分布は以下のようになります。
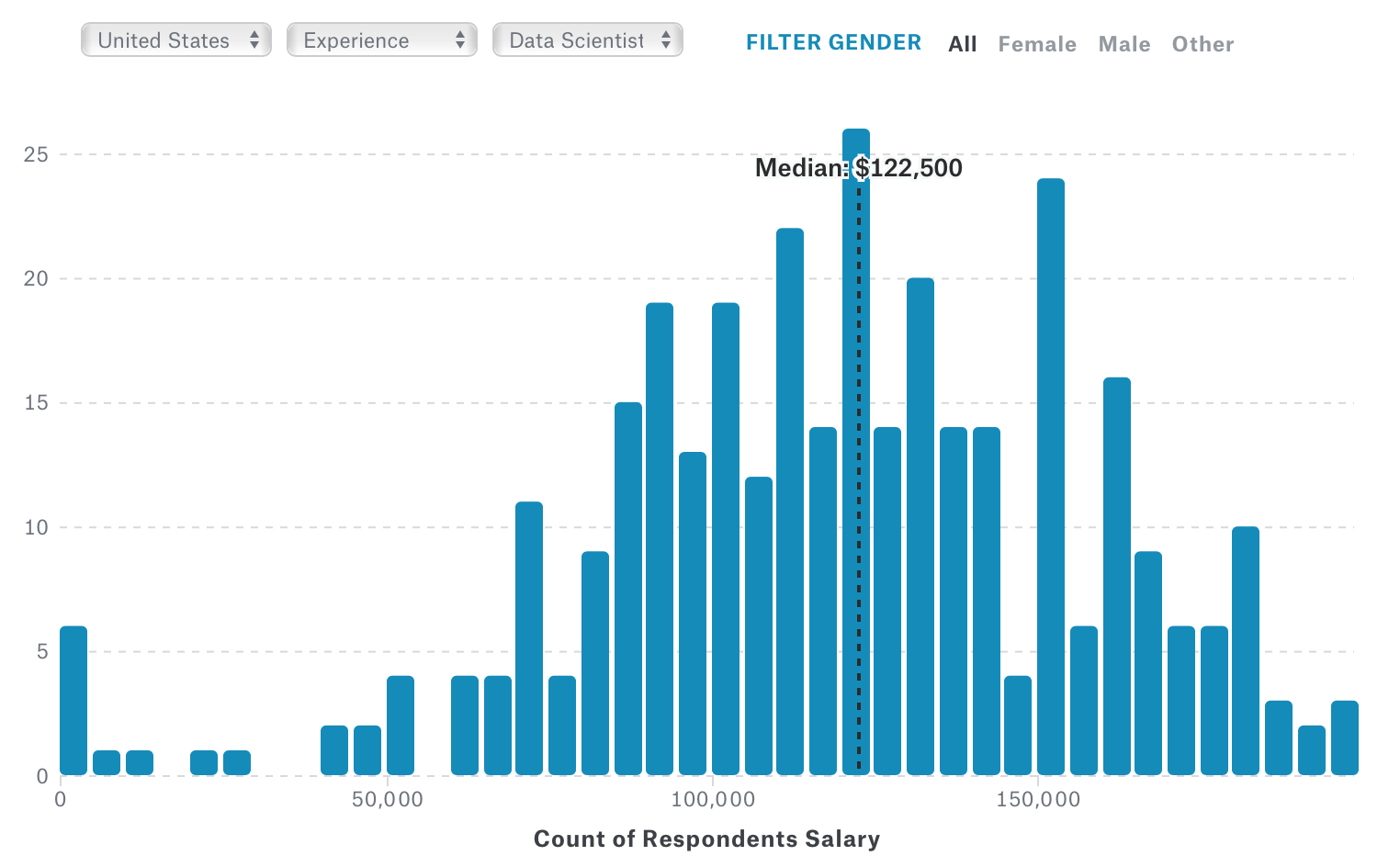
気になる日本ですが、サンプル数が少ないのでどうかなと思いますがそれでも、アメリカに比べて異様に安いですね。(データサイエンティストだけだとデータが無いので全ての職種が選ばれています。)
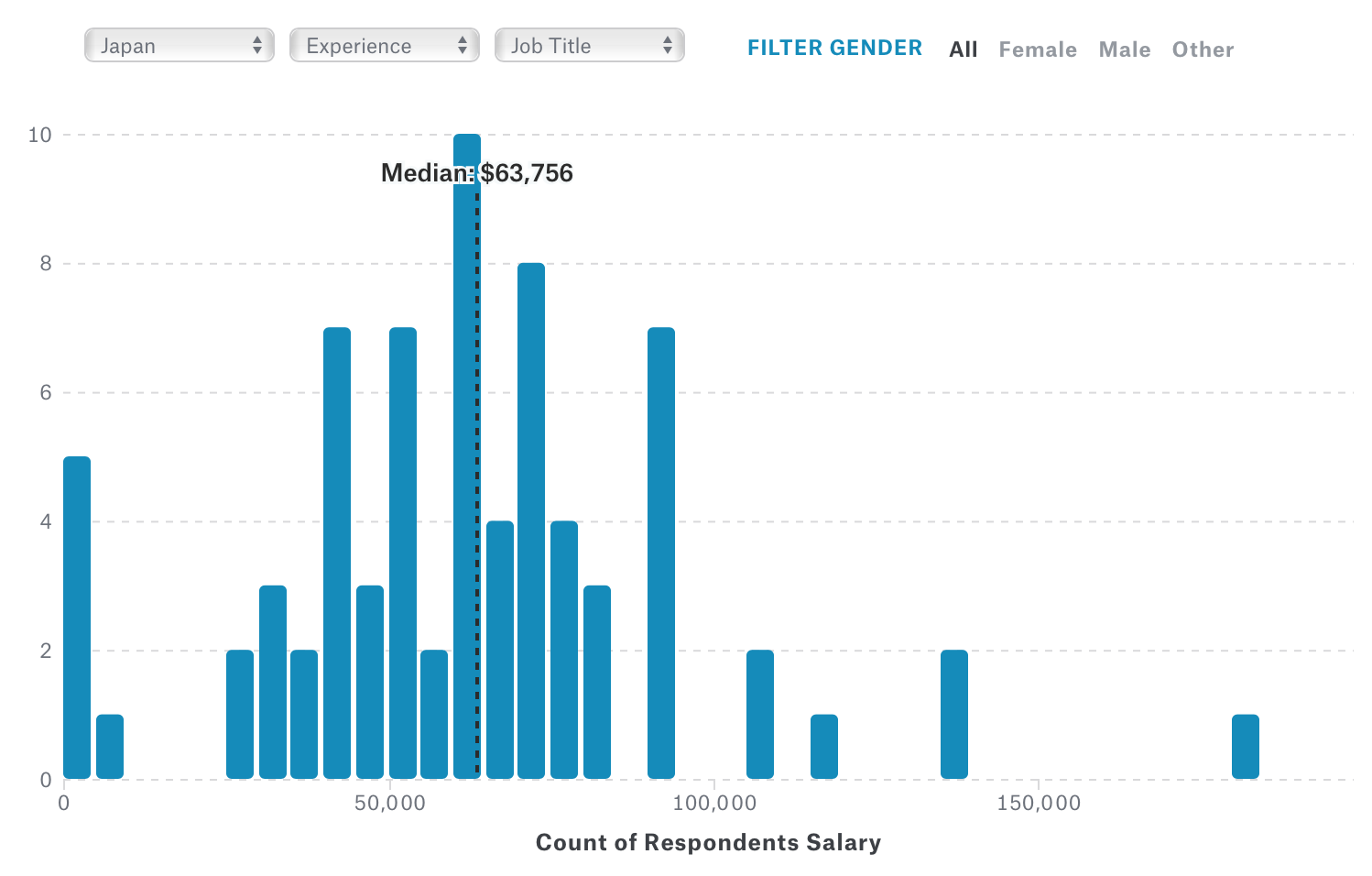
先々週にお伝えしたように日本ではこれからAI・データサイエンスがいよいよ本格的に盛り上がっていくようですので、それとともに給料の方も上がっていくと思います。そうでなければ、頭脳流出が深刻なことになると思います。
What data science methods are used at work?
最後にどういったAI・機械学習のアルゴリズムがデータサイエンティストの間ではよく使われているのかというのがこちらのチャートです。
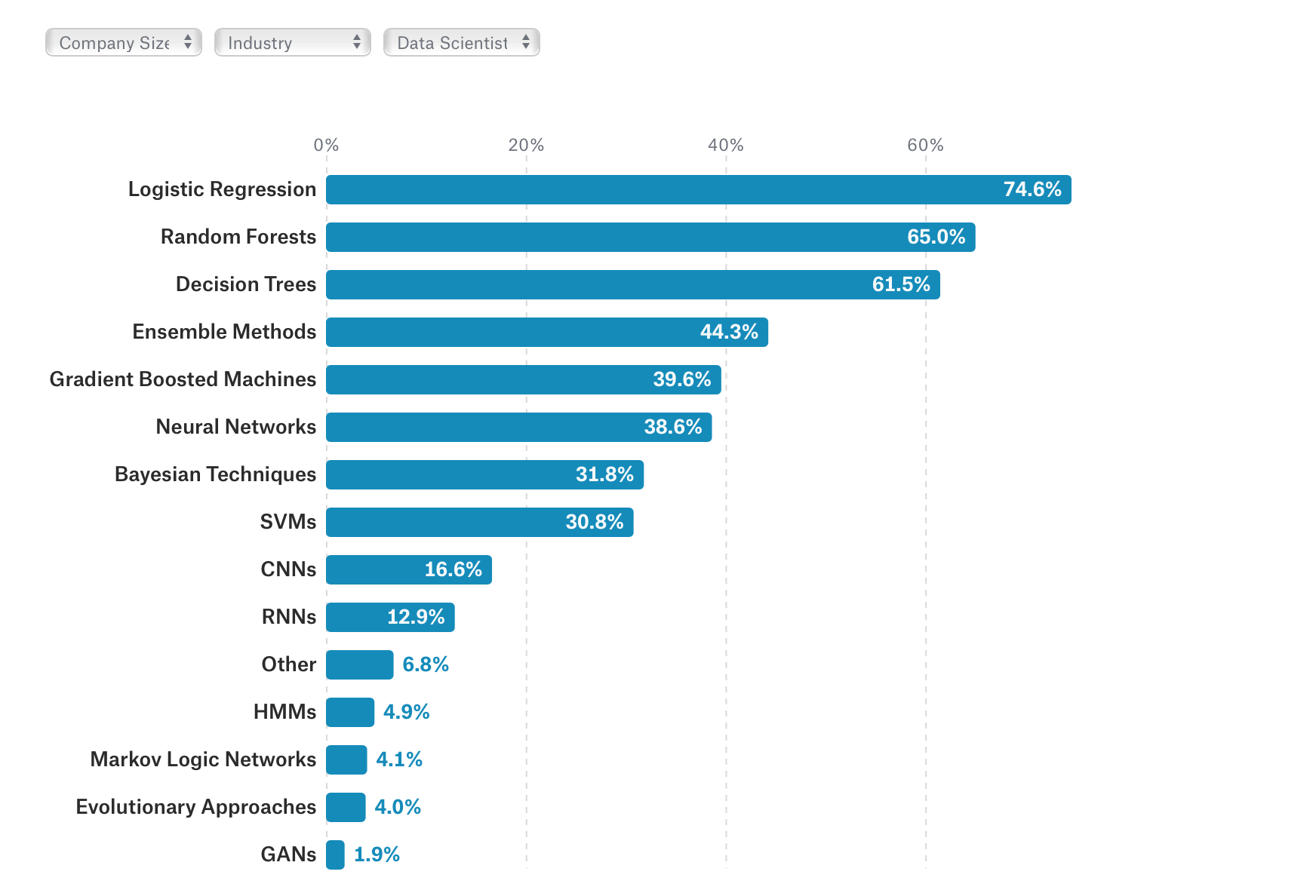
ロジスティック・リグレッション(ロジスティック回帰)、ランダム・フォレスト、ディシジョン・ツリー(決定木)が上位3位に来ています。
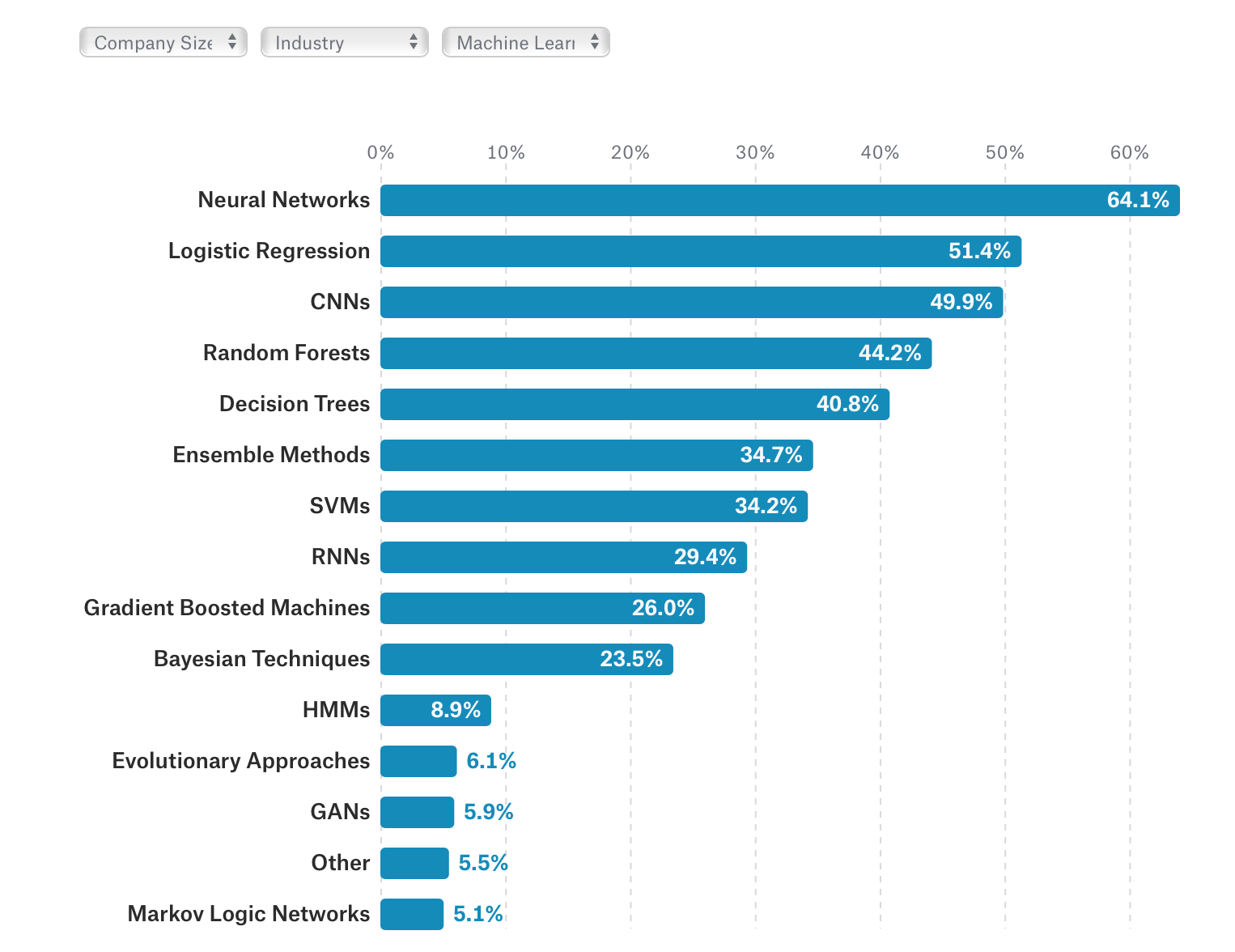
職種をMachine Learning Engineerにするとさすがにディープラーニング系のアルゴリズムが上位に来ます。
興味深いデータ
過去16年の相撲の取り組み結果データ
過去16年の取り組み結果を相撲協会公式サイトからスクレイプしてきたものをこちらに共有してあります。
ブログ記事 from Team Exploratory
先週は最近何かと話題の相撲に関するデータを分析するデータハッカソンを私達のチーム内で開催しました。その中でおもしろいものが二つほど出てきましたので、ぜひご覧いただければと思います。もし気に入ってただければぜひそちらのページでLikeボタンを押していただければと思います。
What Are We Working On?
引き続き、v4.2のリリースに向けての開発で忙しい毎日を送っています。
前述の”データサイエンス・機械学習の2017年の状況”にもありましたように、どんなに新しいAIのアルゴリズムが出てきても根強くデータサイエンティストの間で人気のある老舗アルゴリズムにロジスティック回帰というのがありますが、そちらがアナリティクス・ビューの回帰分析の方に追加されます。
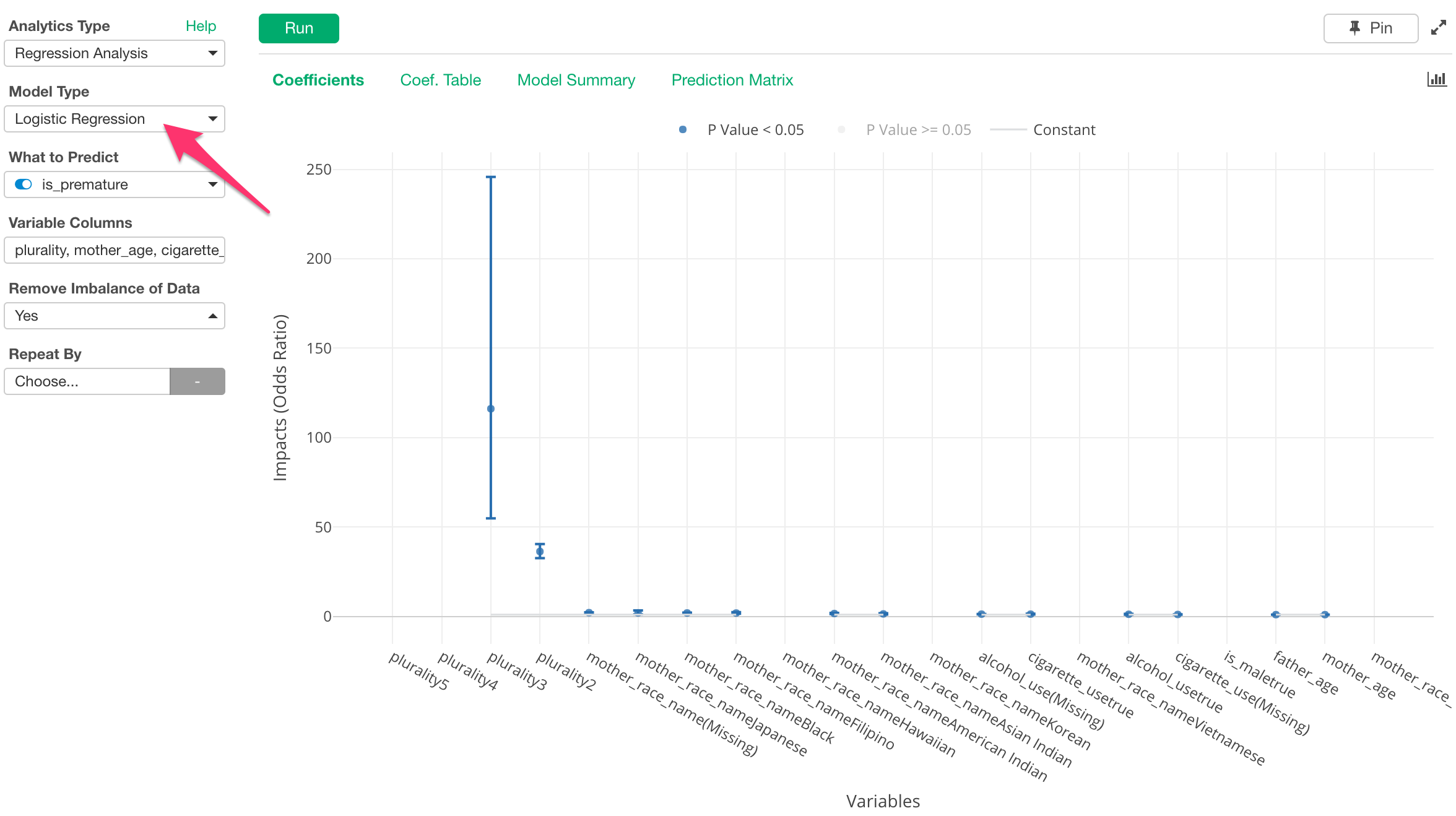
顧客が辞めるか辞めないか、コンバートするかしないかなど、Yes/Noとなる二つのアウトプットを予測する時に、それぞれの変数がどれくらい結果に影響するのかを分析したい時に便利です。
データサイエンス・ブートキャンプ・トレーニング
先週もお伝えしましたが、1月の中旬にデータサイエンス・ブートキャンプを行います。今週で早割の期間が終わりますので、参加の方をご検討されている方はこの機会にぜひお申し込みいただければと思います。また、お知り合いに興味のある方がいらっしゃれば、ぜひお声おかけください。詳しくはこちらのブートキャンプ・ホームページにありますのでご覧ください。
それでは、今週は以上です。
素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)