
こんにちは、Exploratoryの西田です。
この数週間ほど日本でのデータサイエンス・ブートキャンプ・トレーニング、ならびにオンラインでのグローバル・データサイエンス・トレーニングに追われ、すっかりこのWeekly Updateの方が滞ってしまいましたが、今週よりまたデータサイエンス関連で皆様のお役に立つであろう情報をどんどんと共有していきたいと思いますので引き続きよろしくお願いします!
ところで、さっそくですがExploratory v4.3の方が先週リリースされました。多くの新機能の追加、既存機能の強化、さらにバグの修正が入っていますのでExploratoryユーザーの方はぜひ最新版にアップグレードして試してみて下さい。新機能の紹介はこちら (英語)にありますので、ぜひご参照下さい。
さらに、私どもが東京で数ヶ月に一度行っているデータサイエンス・ブートキャンプ・トレーニングですが、次回は6月の下旬に開催することが決定しました。ここ数回は平日版のみの提供となっていたのですが、ここ最近は毎回定員に達してしまい、キャンセル待ちが出てしまっていたので、今回からまた週末版も再開することになりました。興味のある方は是非参加の方ご検討下さい!詳細は下記よりご参照ください。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
AI、強化学習を使って人間の心理と行動を操作するための4つのテクニック
What worries me about AI - Link
現在AIに対して多くの人達が不安や恐怖感を持って、これからやってくるであろう暗い世界を心配しています。しかし実は、1980年代、90年代に私達は同じような不安や恐怖感をコンピューターに対して持っていました。その後コンピューターによってもたらされる新しい機会や可能性に人々の意識が移っていくとともに、それに対する不安や恐怖感はなくなっていきます。しかし、現在私達が実際に直面しているコンピュータによる脅威、例えば、ハッカーによる設備基盤やプライベートデータへのアクセス、ソーシャルメディアによる心理的な孤独感、簡単に影響されやすいマスによる政治的、宗教的な極端化、敵対的な国によるソーシャル・ネットワークの操作による西側民主主義国に対する妨害などは、当時の私達の誰に想像できたでしょうか。
それと一緒で、現在私達が心配している、AIによってすべての仕事が奪われるだとか、AIによって支配されるシンギュラリティの世界などというのは実際には現実に起こるような問題ではなく、それよりも今多くの人達が心配していないことの中にこそ、現実に起こり得る我々が真に憂慮すべき問題があるのではないでしょうか。
それを踏まえた上で、私が現在、AIについて本当に憂慮すべきだと思っているのは、多くの人の心理、行動を効果的に操作することのできるAIが作れるということ、そして悪意を持った企業や政府がそれを使えるという事実です。
私達の生活がどんどんデジタル化されるにつれ、ソーシャル・メディア企業は私達の生活そして気持ちに対する理解をどんどんと高めています。彼らは私達の行動に影響をおよぼすための多くの変数へのアクセスを持ち、私達が普段消費する情報をコントロールするためのアルゴリズムを持っています。これは人間の行動を最適化の問題として捉えることができるということです。つまりそれはAIの問題ということです。つまり、ソーシャル・メディア企業は繰り返し変数に変更を加えながら最終的に私達の行動を彼らの思うようなものにすることができるのです。それはゲームをするAIがゲームをプレイする戦略をスコアというフィードバックをもとに何度も繰り返し修正していくことで、どんどんと次のステージに駒を進めていくという強化学習と一緒の原理です。このプロセスに関するボトルネックはその学習のループのなかにあるアルゴリズムの能力ですが、世界最大のソーシャル・ネットワーク企業 (Facebook)はちょうどそうしたAIのリサーチに現在何千億円ものお金をつぎこんでいます。
あなたの意見や行動は他の何千もの同じような人たちと相関関係を持っているので、そうした情報から何があなたを特定の行動へと導くのかをAIは理解することができます。それはあなたがあなた自身に対する理解以上であり、それを持ってAIはあなたがいつ新しい恋愛関係を始めるか、さらにそうした関係がいつ終わるかも予測することができるのです。
私達が消費する情報のアルゴリズムによるキュレーションは、私達がどういう人間であるか、私達がどういう人間になるかに関してのとてつもなく大きな影響力をアルゴリズムに持たせるということになります。もしFacebookが、何年にも渡ってあなたがどのニュースを見るか(リアルであれフェイクであれ)、誰の政治的なアップデートを見るか、誰があなたのアップデートを見るかを操作するとしたら、それはFacebookがあなたの世の中に対する理解、あなたの政治に対する信条を操作することが出来るということになります。
最適化の問題としての人間の行動
ソーシャル・ネットワークを提供する企業は私たちの行動を計測することができます。そして同時に私達が消費する情報をコントロールすることができます。消費と行動の両方にアクセスすることが出来るのであれば、それはAIで解決できる問題ということになります。あなたがそうしたいと思う対象の人の行動を観察し、その人があなたの要求通りの意見や行動をとるまで与えるデータを変えたりチューニングしていくことで、人間の行動に対する最適化ループを作ればいいわけです。
AIの中の一つの分野である強化学習というのは実はこうした最適化の問題を効率的に解決しターゲットに対する完全なコントロールを得ることで完了とするアルゴリズムです。
私達人間がこの強化学習の対象になる場合は以下の4つのタイプがあります。
アイデンティティの強化学習
これは広告業界では古く昔からよく使われるトリックで現在でも相変わらず効果の高い手段です。それはマニピュレーター(操作する者)がプロモート(宣伝)したい対象を、あなたが自分と関連付けたいと思うものといっしょに表示することで、あなたが自動的にその対象となるものに賛同しやすくするというものです。AIによって最適化されたソーシャル・メディアの消費という文脈においては、マニピュレーターがあなたに持ってほしいと思う視点とあなたが自己を表現すると思うものとを同時に表示されるよう、アルゴリズムを使ってコントロールします。逆の場合もそうで、マニピュレーターがあなたに持って欲しくないという視点があればそれをあなたが見たくないと思うものと一緒に表示されるようにアルゴリズムを使ってコントロールすることで、そうした視点を載せたニュースなり記事から遠ざけるようにできます。
否定的な社会的強化学習
マニピュレーターがあなたに持って欲しくないという視点をもったコメントをあなたがした場合、そのコメントに対して逆の立場を持っていてきびしく批判するであろうという人たち(知人であったり、知らない人であったり、もしくはボットであったりするかもしれません。)だけに見せるようにアルゴリズムを使ってコントロールすることができます。そうしたソーシャルなバックラッシュ(過激な反動、反発)を何回か繰り返し経験すると、あなたは最初に持っていた視点から離れたいと思いはじめるでしょう。
肯定的な社会的強化学習
もしあなたが、マニピュレーターが広めたいと思うような視点を表現するようなコメントをした場合、それに対して”いいね”ボタンを押すであろう人やボット等にだけ見せるようにアルゴリズムをコントロールすることができます。これはあなたに自分が信じていることが正しいと再確認させることとなり、さらにあなたはそうした視点に賛同する多くの人達があなたの仲間だと思い込むようになるでしょう。
サンプリングのバイアス
マニピュレーターがあなたに持ってほしいと思う視点をもつ友達やメディアからのポストだけをあなたのニュースフィードに流すようにアルゴリズムをコントロールすることができます。こうした偏った情報バブルの中で生活することで、そうした視点は広く多くの人たちにも受け入れられているのだという認識を植えつけることができます。
ここに4つほど挙げたような人の心理や行動を操る手法を情報セキュリティの世界では脆弱性と呼びます。ハッカーはこうした脆弱性をもとにシステムの乗っ取りを試みるわけです。やっかいなのはこうした脆弱性は人間の場合はパッチが出てきて修正されるということはありません。なぜならそうした脆弱性は私達が人間たる所以で、私達のDNAの中に深く刻まれているからです。
こうした大衆の操作、特に彼らの持つ政治的意見をコントロールするための情報の最適化に使うAIアルゴリズムは、別に最先端なものが必要になるわけではなく、現在使えるもので十分に実行可能です。実際多くの企業は今日でもロジスティック回帰のアルゴリズム等を使っていたりするものです。
ソーシャル・ネットワークを提供する企業はすでにこの数年の間、こうしたニュースの最適化を現実の世界で実験しており、大きな成果をあげています。もちろん、そうした企業はユーザーのエンゲージメントを最大化し、あなたの購買に関する意志決定に対して影響を及ぼすことを目的としているのかもしれません。
しかし、2016年のイギリスがEUから離脱することになる住民投票や2016年のアメリカの大統領選挙などで見られたように、彼らの作り出したツールはすでに政治的な目的を持った敵意のある国々によってハイジャックされているのです。これは何もこれからやってくるかもしれない世界を予想しようとしているのではなく、すでに今日現実に起きていることなのです。
さらに、おそらく最も心配すべき脅威はFacebookではないかもしれません。例えば中国のソーシャル・クレジット・システムのような情報をコントロールするための仕組みを使って全体主義をこれまでにはありえない規模で広めることができるということこそ、憂慮すべきことでしょう。多くの人達は、いくつかの大企業こそが今日、非常に大きな力を持った支配者だと思っています。しかし、彼らの力は彼らの政府にはかないません。もしアルゴリズムが私達の心をコントロールできるのであれば、企業ではなく、政府こそがそうしたアルゴリズムの最悪の使い手となるでしょう。
ただ、AIが私達が情報にアクセスするためのインターフェースとなる事自体が問題なのではありません。そうしたAIのインターフェースは、しっかりとデザインされていれば、非常に役立ち、私達の可能性を広げることができます。重要なのはユーザーがアルゴリズムの目的をしっかりとコントロール出来るかどうかです。私達がAIを私達のゴールを追求するためのツールとして使えるべきです。
AIによって収入の多い仕事のタイプや場所が変わる
AI is rapidly changing the types and location of the best-paying jobs - Link
UCバークレーのHaasビジネススクールの経済学者であるLaura Tysonによると、AIと自動化によって無くなる仕事よりも、新たに生み出される仕事の質とそうした仕事が生み出される場所こそが心配すべきとのことです。
特に製造業で働くミドルクラスに位置する人たちに対する影響です。今までの経験から言って、低いレベルのスキルを必要とする仕事は恐らく自動化されるでしょう。そうして、収入の格差がさらに問題になります。
自動化とAIは新しい仕事を作り出します。しかし必ずしもそうした新しい仕事は自動化によって失われた仕事がもともとあった場所に作られるということではありません。それは多くの仕事がなくなったアメリカの中西部を見れば分かります。
産業革命以来、技術の進化は仕事そのものを変えてきました。しかし、そうした進化のスピードは今日ではどんどん早まるばかりです。私達は労働者を再トレーニングすることができるのでしょうか?もしそうだとすれば、誰がそのお金を出すのでしょうか?こうした質問にまだ誰も答えることができていないのです。
以上、要約
現在私も個人的に感じていることなのですが、同じカリフォルニアの中でもシリコンバレーの中とその外の世界には経済的にものすごいギャップがあるのを感じます。そしてそれは主にシリコンバレーでは当たり前とされている技術力、データ力がシリコンバレーの外では当たり前でないということによってもたらされているのではないでしょうか。
昔であれば大学くらい行っていればビジネスを行うのに必要な最低限の知識やスキルを入社時にみんな共有していたわけですが、現在はあまりにも技術の進化のスピードが早く、ビジネスで必要となるスキルの変化もかなり速いです。ですので、新しいカリキュラムの準備に2年も3年も要するような既存の教育システムがこうした需要に対応できていないというのが現状です。
結果の格差というのはいつの時代もあるわけですが、現在、そしてこれから将来どんどんひどくなっていくであろう機会の格差こそ深刻な問題としてとらえるべきではないでしょうか。現在のような絶えず変わっていく世界では一般的な学習方法、スキルの取得方法というものが確立されません。生涯学習を前提とした新しいタイプの教育、トレーニングが必要とされています。
4年間のデータサイエンス・マネージャーとしての仕事を振り返って
4 Years of Data Science at Schibsted Media Group - Link
Schibsted Media Groupでデータサイエンスマネージャーとして仕事しているAlex Svanevikがこの4年ほどの間に学んだことをこちらに書いてあります。これから実際にビジネスの世界でデータサイエンスもしくはデータ分析の仕事をしていく方にとっては参考になる点がいくつかあると思います。
以下、要約
複雑性はコストがかかるので、まずはシンプルに始めるべき
最初はいつもシンプルなアプローチから始めるべきです。複雑なアルゴリズム、モデルは説明するのも大変だし、間違いも起こしやすいし、実装にも時間がかかります。
ベースラインを持つこと
モデルを作る場合はいつもベースラインを気にするべきです。
ある時、ユーザーのリテンションに関する予測モデルをユーザーの行動に関する15の変数(属性)をもとに作りました。そこでできた予測モデルのクオリティの方はAUCが0.8ほどで、ランダムに予測するものと比べれば全然良いということで当初は満足していたのですが、後にRecency(最後に訪問してからの期間)とFrequency(過去にどれだけ訪問したか)の2つの変数だけでシンプルなロジスティック回帰のモデルを作るとAUCにして0.78という結果が出ました。言い方を変えるともともとのモデルの97%のパフォーマンスをもともと使っていた85%の変数を捨てたにもかかわらず出せたわけです。
シンプルなモデルによるベースラインを持たずにいきなり複雑なモデルでの結果に満足しているデータサイエンティストを多く見かけますが、どんなときでも、「同じ結果をもっと簡単なモデルで出すことはできないのか」という質問を投げかけるべきです。
データに対するオーナーシップを持つ
データの品質や十分さというのはいつも問題になるものです。そんなときに、だれかがきれいなデータを用意してくれるのを待っているのではなく、自分で出ていって解決策を示すべきです。それは自分でデータ加工のためのパイプラインを作ることになるかもしれません。データエンジニアに頼っていては前に進めません。
データを一度忘れる
解決すべき新しいビジネスの問題がある時は、一度データのことは忘れ、その問題の解決のためのディスカッションにまずはフォーカスするべきです。なぜなら、既存のデータで出来ることは限られているので、最適なアプローチを見つけようとする努力から遠ざかってしまうことになりかねないからです。さらにその結果、新しいデータが必要であるということにも気づかずに終わってしまうことにもなります。
因果関係に関するニュアンスを持った感覚を身につける
相関関係と因果関係は違うということはみんな知っていると思います。ただ問題は多くのデータサイエンティストはここで止まってしまうということです。
これがなぜ問題かと言うと、プロダクト・マネージャー、マーケティング・チーム、CEOなど、あなたが一緒に働く事になる人たちは誰も相関関係なんて気にしていません。彼らが知りたいのは因果関係なのです。
因果関係を明らかにするためによく使われる手法はいわゆるA/Bテストです。
あまり知られていない別の手法としては因果モデリングというものがあります。簡単に説明すると、まずは因果の構造を仮定し、その仮定が実際のデータと整合が取れているか検証する、または違う要因による影響の強さを推測することになります。
私の経験上、ほとんどのデータサイエンティストはオフラインで機械学習のモデルを作って検証することに関してはたくさんの経験があります。しかしオンラインで実験して評価することに関しての経験はほとんどありません。
モデルをオンラインで評価するのには実世界へのアクセスを必要とします。例え何百万ものユーザーがいるインターネットの会社であったとしても、機械学習のモデルをユーザーの前に出すにはたくさんの努力を必要とします。
もしオンラインでモデルの実験をすることができるようなデータサイエンティストがあまりいないのであれば、因果モデリングができるようなデータサイエンティストはさらにいません。多くの理由があると思いますが、その中でも大きいのは因果関係に関する書籍がどれも理論的すぎて、実世界でどのように因果モデリングをやり始めたらいいのかについての実用的なガイドが殆どないからです。ただ、次の2、3年でこのタイプの実用的なガイドがもっと出てくるとは思います。
ということで、データ・サイエンティストしての威厳を損なうことなしに、完全でなくとも因果関係に迫ることの出来るようなインサイトをステークホルダーに説明できれば、実際に行動を起こすことにつながる提案となるのです。
社内政治とうまく渡り合う
データサイエンス・マネージャーとして気をつけなくてはいけないのが、社内政治です。特に大企業や複雑な組織の場合です。
いくつかの例を紹介します。
- あるVP(部長)が新しい戦略イニシアチブを提案しようとしています。彼女はすでに98%のスライドを作り上げ、あとはあなたのチームに彼女の主張をデータでサポートしてほしいというものです。
- あるビジネスユニットはあなたのチームとデータを共有するのを拒否しました。なぜならあなたのチームが彼らの気づいていない問題を発見してしまうかもしれないことを恐れているからです。
- ある部署はデータサイエンティストが必要だと主張しています。しかしよく調べてみると単に人員を増やしたいというだけで、データサイエンティストの必要はありませんでした。
- 社内にあなたのチームと少し仕事の内容が似通っている別のチームがあるのですが、彼らがあなたのチームと一緒に仕事をしたがりません。なぜなら、あなたのチームが彼らの仕事を取ってしまうのではないかと恐れているからです。
こういう問題に対する対処方法として一番効くのは、ナイーブかもしれませんがトランスペアレンシー(透明、情報の公開)ではないでしょうか。これは単に口だけではなく行動を伴わなくてはなりません。全てのミーティングのノートは社内の誰もが見えるようにしておく。チームとそれぞれ個人のゴールも誰でも見えるようにしておく。こうして他のチームからの不安、恐怖を無くす努力をするべきです。
もちろん、トランスペアレンシーだけでは十分でありません。積極的にあなたとステークホルダーとの間に信頼関係を作る努力をするべきです。信頼関係を気づくのは時間がかかりますが、それを壊してしまうのには時間がかからないので、これには気をつけて取り組むべきです。
What Are We Writing?
先週はTeam Exploratoryのヒデから以下の3つのブログ記事が投稿されましたので興味のある方はぜひ。(英語です。)
What Are We Working On?
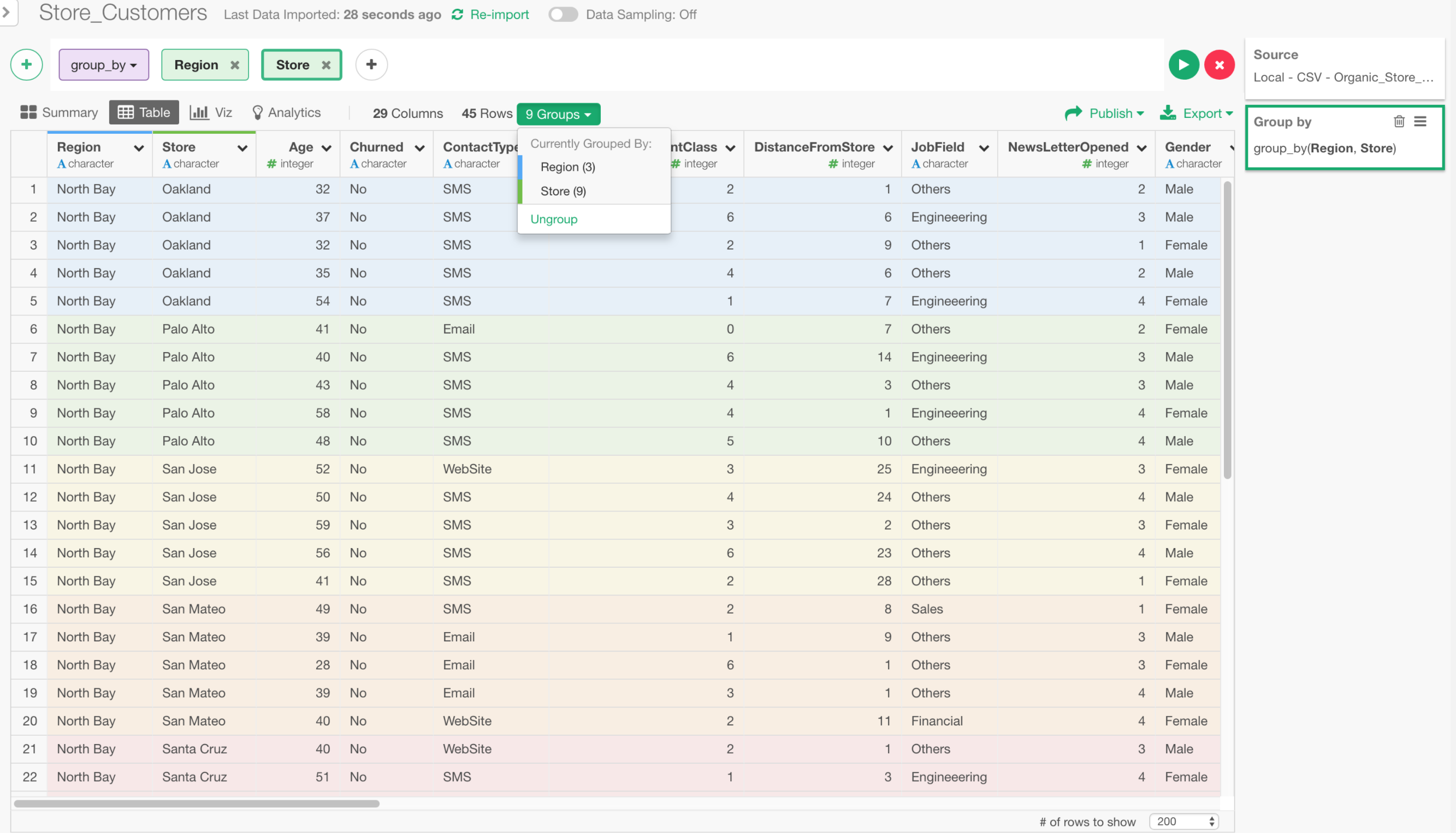
データ・ラングリングのコマンドの一つにグループ化(Group By)という、一度理解するとむちゃくちゃ便利なものがありますが、問題はこのコマンドを実行した後に出てくるテーブル・ビューが特に何も変わって見えないので、Group Byに慣れていない場合は混乱してしまうということです。
そこで、次期バージョンではデータフレームがグループ化されている時は、どのようにデータがグループ分けされているか色によってわかるようになります。
データサイエンス・ブートキャンプ・トレーニング
冒頭にも書いたように、次回のブートキャンプを東京でこの6月に実施することが決まりました。今回のブートキャンプは私達が日本でやり始めてからちょうど一周年となりますが、これまでのトレーニングに参加していただいた方達に頂いたフィードバックをもとにトレーニングの内容、さらにそこで使うExploratoryもこの1年の間にかなりの進化を遂げることができました。
データサイエンスを始めたい、データ分析を本格的に学んで自分のキャリア、または自分のビジネス、組織の向上に役立てたいという方はこの機会にぜひ参加をご検討下さい。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。