
こんにちは、Exploratoryの西田です。
みなさんゴールデンウィークを楽しく過ごすことが出来ましたか?
ところで、この6月に東京で開催するデータサイエンス・ブートキャンプ・トレーニングですが、まだ平日版、週末版ともに空きがありますので参加を検討されている方はこの機会にお早めにお申し込み下さい。詳細は下記よりご参照ください。
それでは、今週のWeekl Updateですが、2つの記事を紹介したいと思います。
1本目は、“結局、機械学習と統計学は何が違うのか?”についてです。これは私達が行っているトレーニングでもよく聞かれる質問です。こちらに、私達も普段親しくさせてもらっているシリコンバレー・データサイエンスという、データサイエンス領域のコンサルティングを提供していた会社(最近Appleに買収されました。)があるのですが、そこの人たちが2年ほど前に“Machine Learning vs. Statistics”という記事の中で、この質問に正面から答えていたので、そちらの方を紹介したいと思います。
2本目は、未来の仕事にどう備えるかについての記事です。これからAIの技術で多くのことが自動化されていく時代に、仕事はどう再定義されるのか、我々はそういった時代に生き残っていくために、今何をするべきなのかという議論がこちらでは今、盛んに行われています。そんな中、もとオバマ政権の時の大統領経済諮問委員会のメンバーで、現在はHamilton Projectというシンクタンクの理事長をやっているJay ShambaughがMITのTechnology Reviewとのインタビューでちょうど、このトピックに関して話しいておもしろいなと思ったので、こちらで紹介したいと思います。
どちらも興味深いので是非読んでみて下さい!
最近の興味深い英文の記事
結局、統計学と機械学習は何が違うのか?
Machine Learning vs. Statistics - link
歴史を振り返ると、機械学習はいつも統計学とぎこちない形で共存してきました。それはまるで、結婚式で、新婦の昔のボーイフレンドが新郎の家族とたまたま席が一緒になってしまったかのようです。両者とも会話がどこに向かうのか予想できず、気まずい思いをしながら時間を過ごしてしまうものです。
なぜこんなことになるかというと、実は機械学習が、多くの統計学の手法を取り入れてきたにもかかわらず、統計学を置き換える気はそもそもなく、さらにもっといえば、統計学の基本を踏襲する気も端からないからです。にもかかわらず、統計学者と機械学習を使う人はよく一緒に働くことになり、同じようなタスクをこなし、そしてお互いが何をやっているのか疑問に思ったりするものです。
機械学習とはおおまかにいうとハイブリッドな分野です。そのインスピレーションと手法は様々なところから拝借してきました。その歴史において、目指す方向はその時その時で変わり、外の世界にいる人達にとっては何か捉えどころのない不思議なものとして映ってきました。統計学は1つの分野として確立されているのですが、機械学習も統計学と重なる領域が多くあるため、「結局、統計学と機械学習は何が違うのか」という質問がよくでてくるわけです。そしてたくさんの答えが与えられてきました。
例えば、こちらは中立的、もしくは否定的なものです。
- 「機械学習とは結局のところ、応用統計学である。」
- 「機械学習とは統計学をかっこよくしたものだ。」
- 「機械学習とは統計学のビッグデータ版だ。」
- 「短い答えとしては、特に違いはない。」
まともに受け止めることは出来ないもの、ちょっと人を小馬鹿にしたようなものもあります。
- 「統計学では損失関数は事前に定義されていて、どういった手法を使うかに結びついている。機械学習では、あなたの問題解決のためにユニークな損失関数をプログラムして作ることになるでしょう。」
- 「機械学習とはコンピューターサイエンスは修了したが、統計学のコースは修了することができなかった人たちのものである。」
- 「機械学習は、統計学からモデルや仮説の検証を引いたものである。」
- 「機械学習が次の10年でどうなるかわからないが、どうなるにせよ、統計学者は自分たちの方がとっくにやっていたと泣き言を言っていることだろう。」
こうした質問は、Quora、StackExchange、LinkedIn、KDNuggetsや別のソーシャルメディアなどでもよく出てきます。
私達の一人(Tom)は機械学習のプロで、もう片方(Drew)は統計学のプロですが、何年もの間一緒に仕事をしてきて、お互いの分析と問題解決に対するアプローチを観察し、思考プロセスの違いを理解しようとして多くの議論を重ねてきました。そこで、データサイエンスの世界でのそれぞれの分野の役割に関しての私達の理解をもとに、その違いを正確にここで説明してみたいと思います。
(続きはこちらのリンクよりどうぞ。)
アメリカは未来の仕事にどう備えているのか?
How is America preparing for the future of work? - Link
未来の仕事場で仕事をしていくための準備として、それぞれの個人にはいったい何が出来るのでしょうか?
おかしく聞こえるかもしれませんが、正直な解答としては、学校にとどまり続けることです。経済全体を考えたとき、教育というのは、賃金の伸びという問題の答えとしては十分ではありません。しかし、個人という場合には十分です。個人にとっては、より多くの教育を受けていたほうが失業する可能性は低くなり、より賃金は高くなるのです。他にできることがあるとすると、あなたがこれからの労働生活に必要だと思うことを支持している政治家の支援をすることです。
誰が労働者の再教育(再トレーニング)に責任を持つべきで、誰がそれをより効果的に行えるのでしょうか?
公的機関にこうしたトレーニングの全てを任せることは出来ません。なぜなら、労働者の全ての人生をみこして彼らに必要になるトレーニングを提供することは不可能だからです。ですので、そうしたトレーニングの一部は企業の中で提供されるべきです。他の国ではもっと大きな見習い制度が行われていると指摘する人がいます。たしかにそれは魅力的な制度なのですが、それぞれの国のシステムには、それぞれ適した進化の仕方があります。アメリカでは、他の国で言ういわゆる見習い制度は、コミュニティーカレッジのレベルで行われています。。
アメリカの未来の仕事はどうなると思いますか?
アメリカを含めたほとんどの国では1980年までは、経済がより豊かになると、人々は今までよりも働く時間が少なくなってきていたものです。ドイツ、フランス、その他多くの国では、一年の間に働く時間というのは減少傾向にあります。もっと多くのバケーションをとっているか一週間に35時間の労働時間制に移行したかのどちらかです。しかし、1980年以来のアメリカでは、労働時間に変化が見られません。これは不思議なことです。ロボットが私達の仕事を奪うという恐怖の世界は抜きにしても、私達がもっとレジャーを楽しむ時間が増えて、仕事をする時間は減るという世界が来てもよさそうなものです。しかし、アメリカの経済はそういった方向に向かってはいないようです。
What Are We Writing?
先週出した日本語での記事は前回のWeekly Updateで紹介した“Netflixがカスタマーを誰よりも理解するためのデータ分析プロセス、コンシューマー・サイエンスの紹介”のみですが、実は、“Japanese” というタグのついたブログ記事のページをこちらのリンクから開けます。こちらにTeam Exploratoryが過去に書いた記事がリストされていますので、Exploratoryを使っていらっしゃる方はぜひ参照してみて下さい。
以下に役に立ちそうな過去の記事をいくつかピックアップしてみました。
What Are We Working On?
先週はサマリーのビューから、ワンクリックで簡単にチャートが作れ、さらにチャートの画面から直接ダッシュボードが作れるというユーザー・エクスペリエンスをデザイン、開発してました。
サマリーからチャートへ
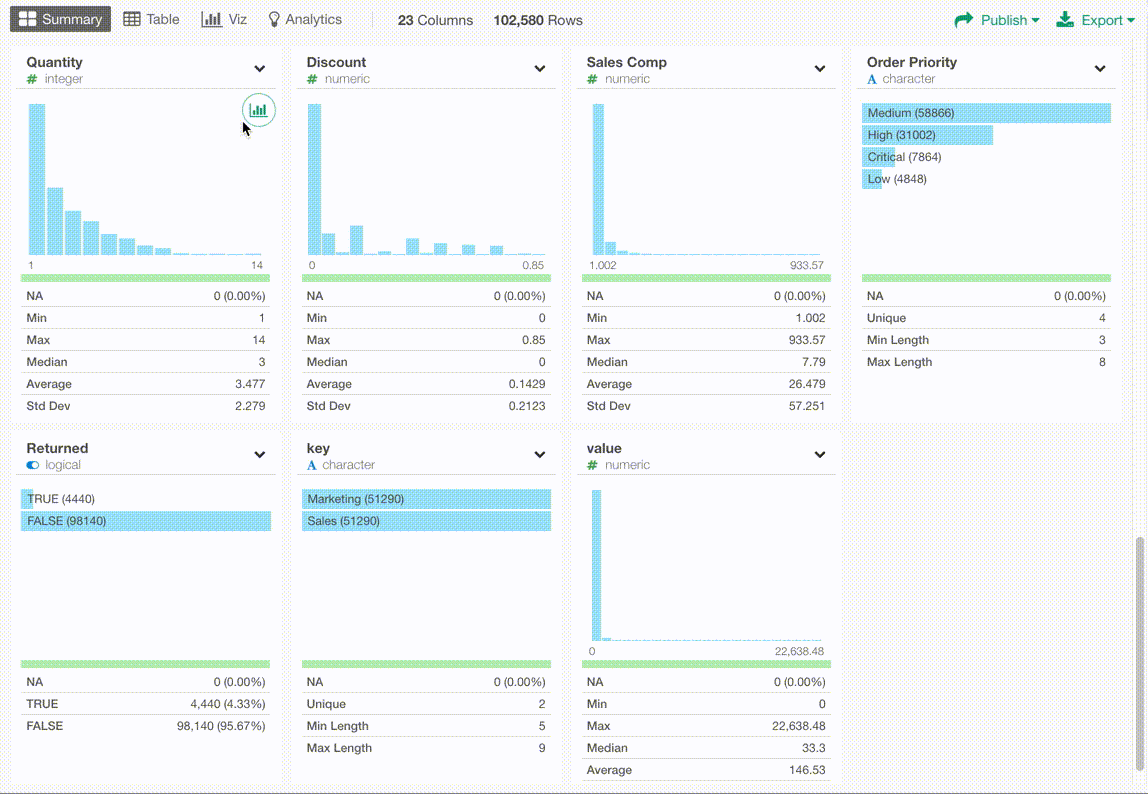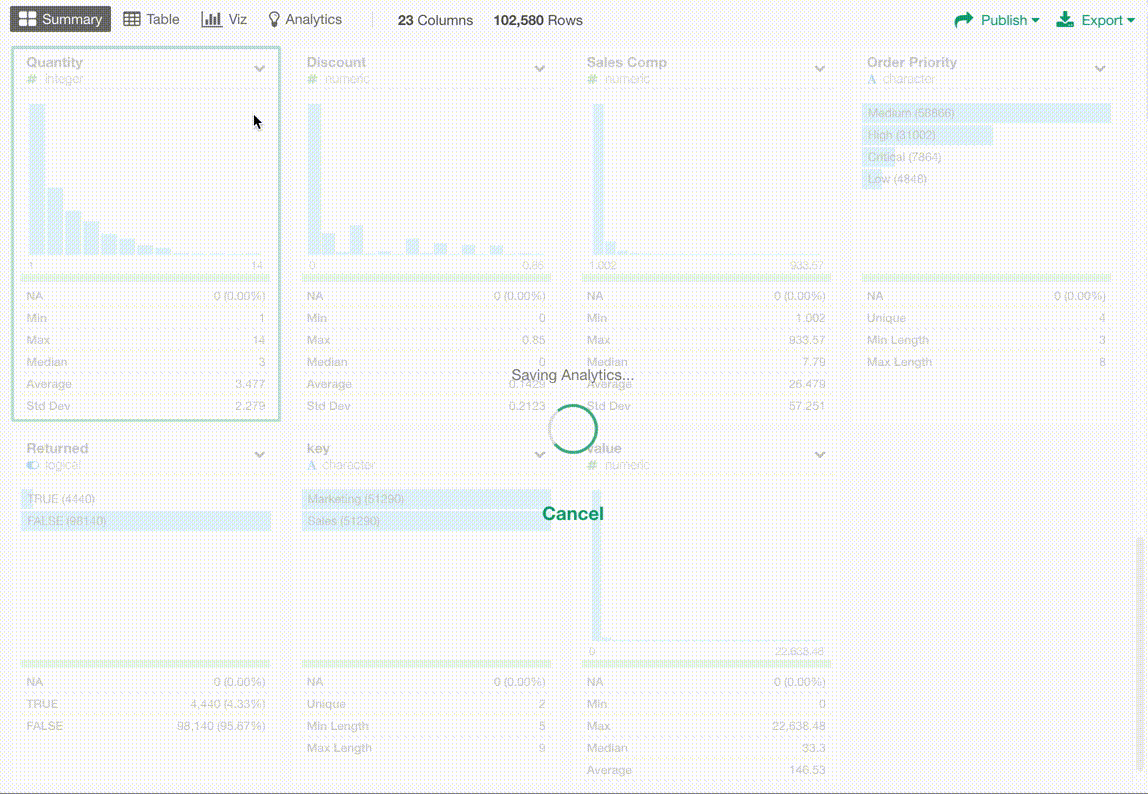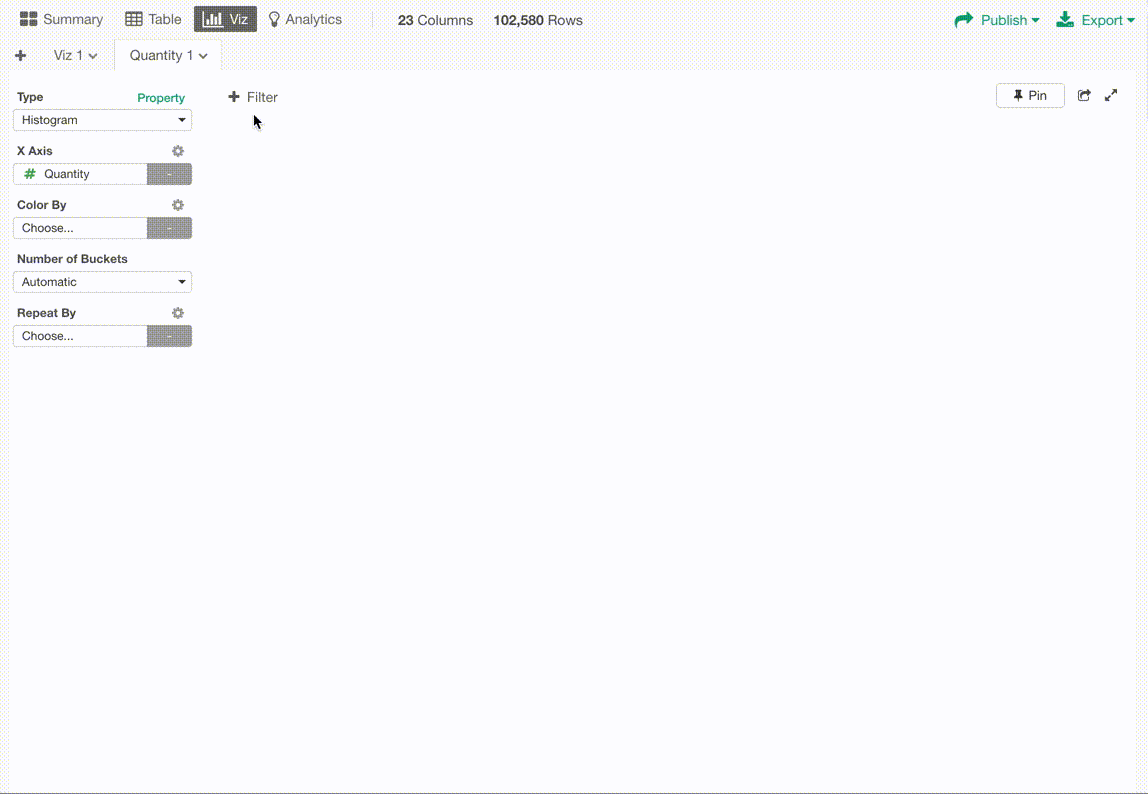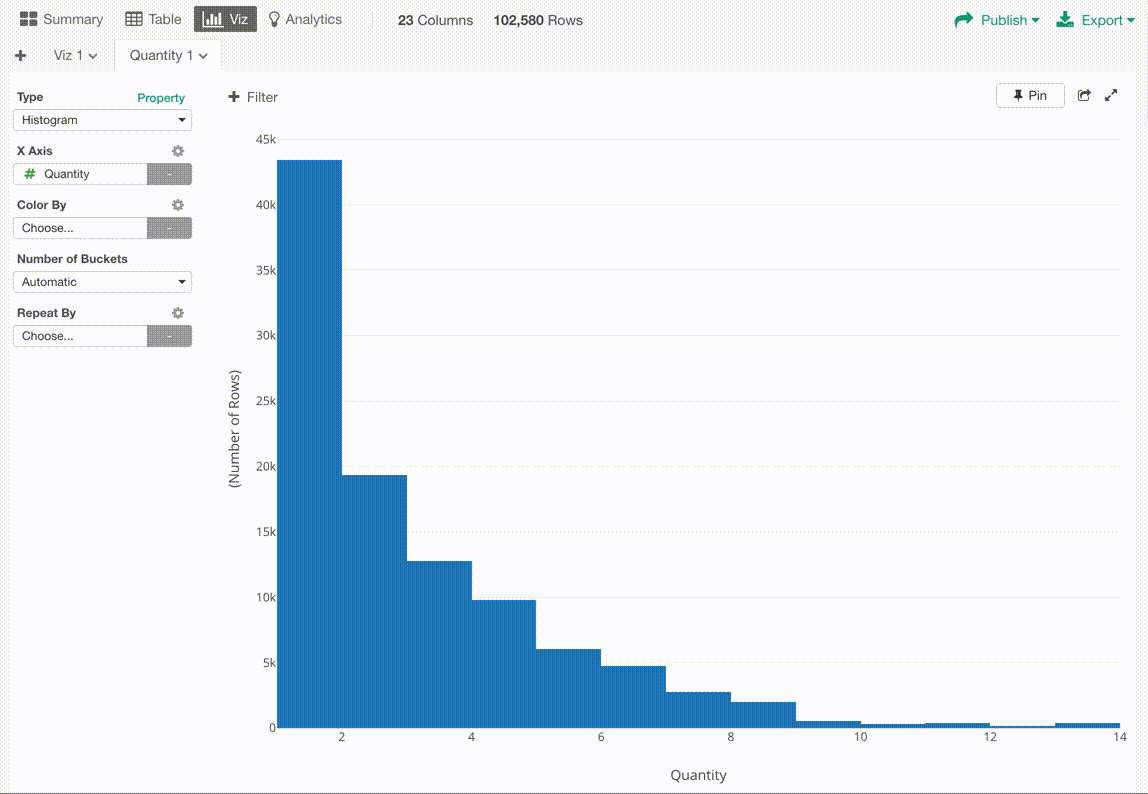
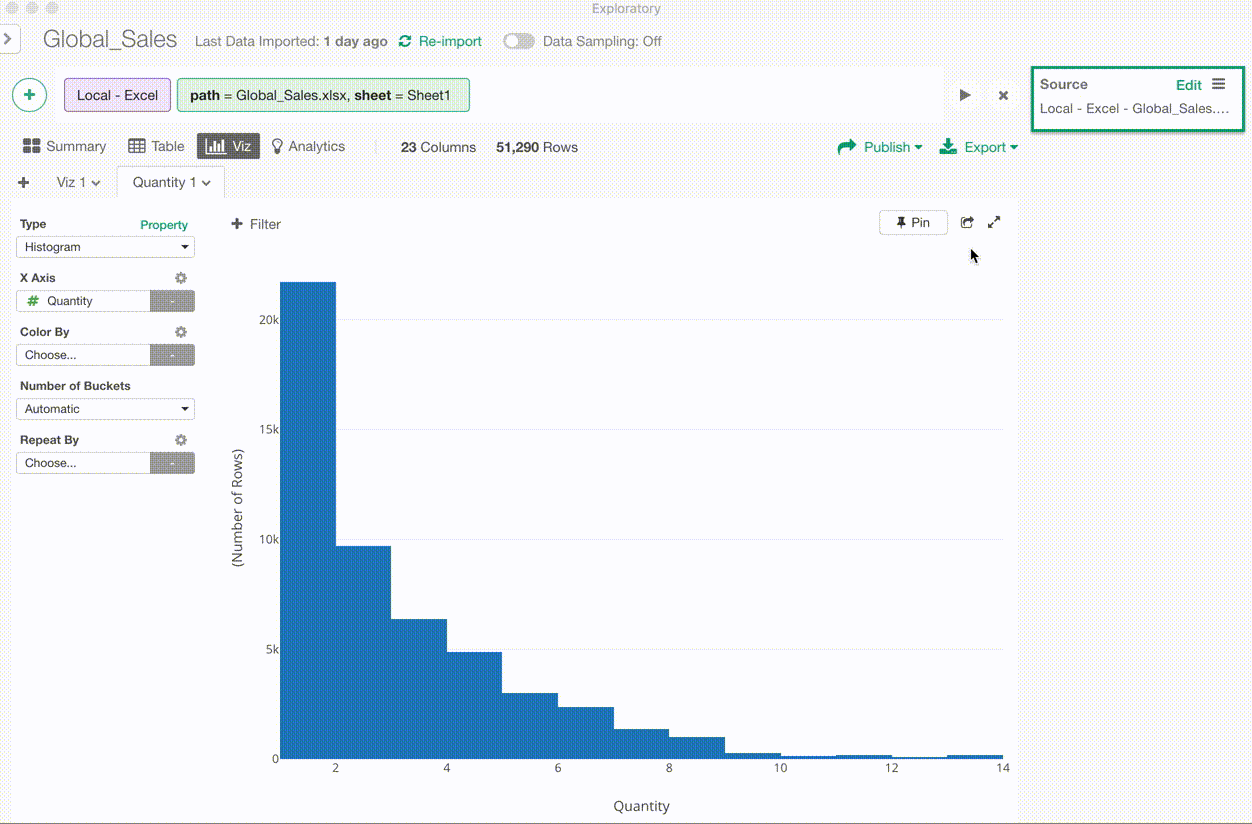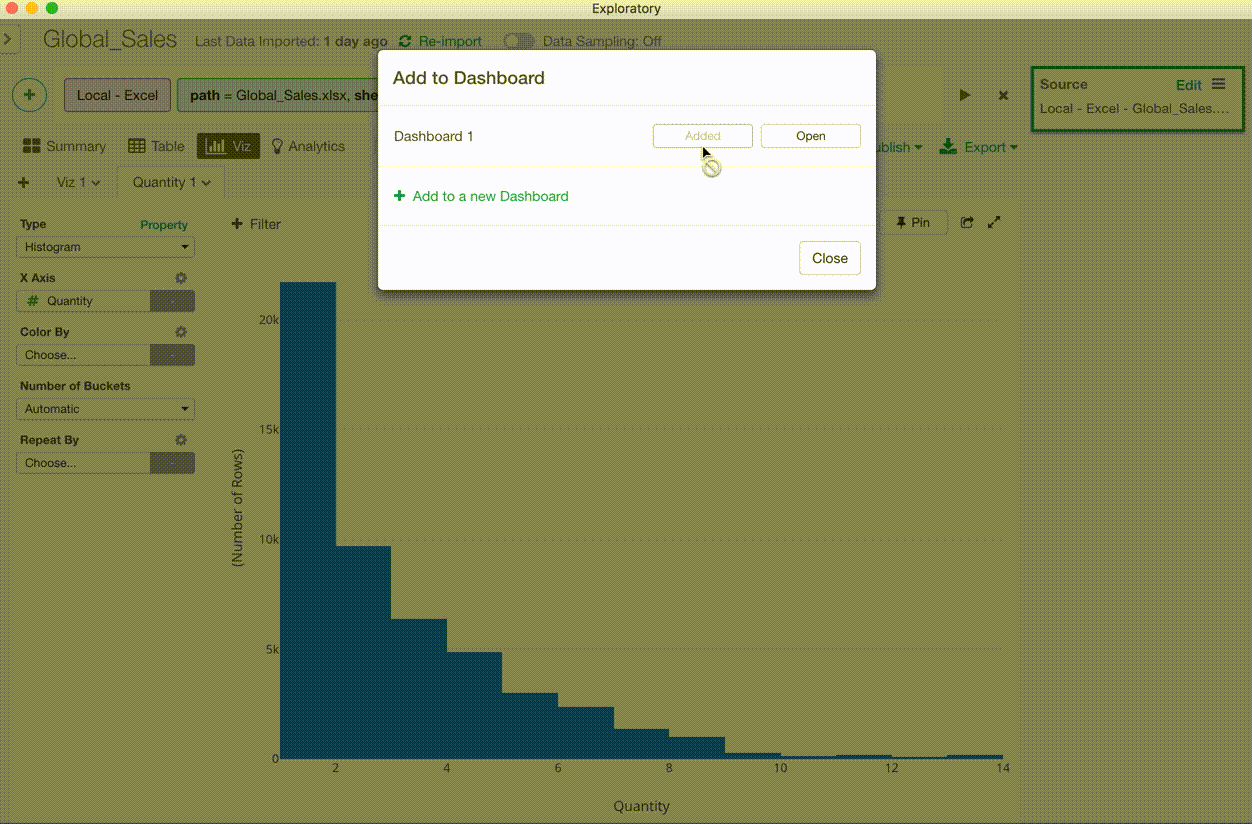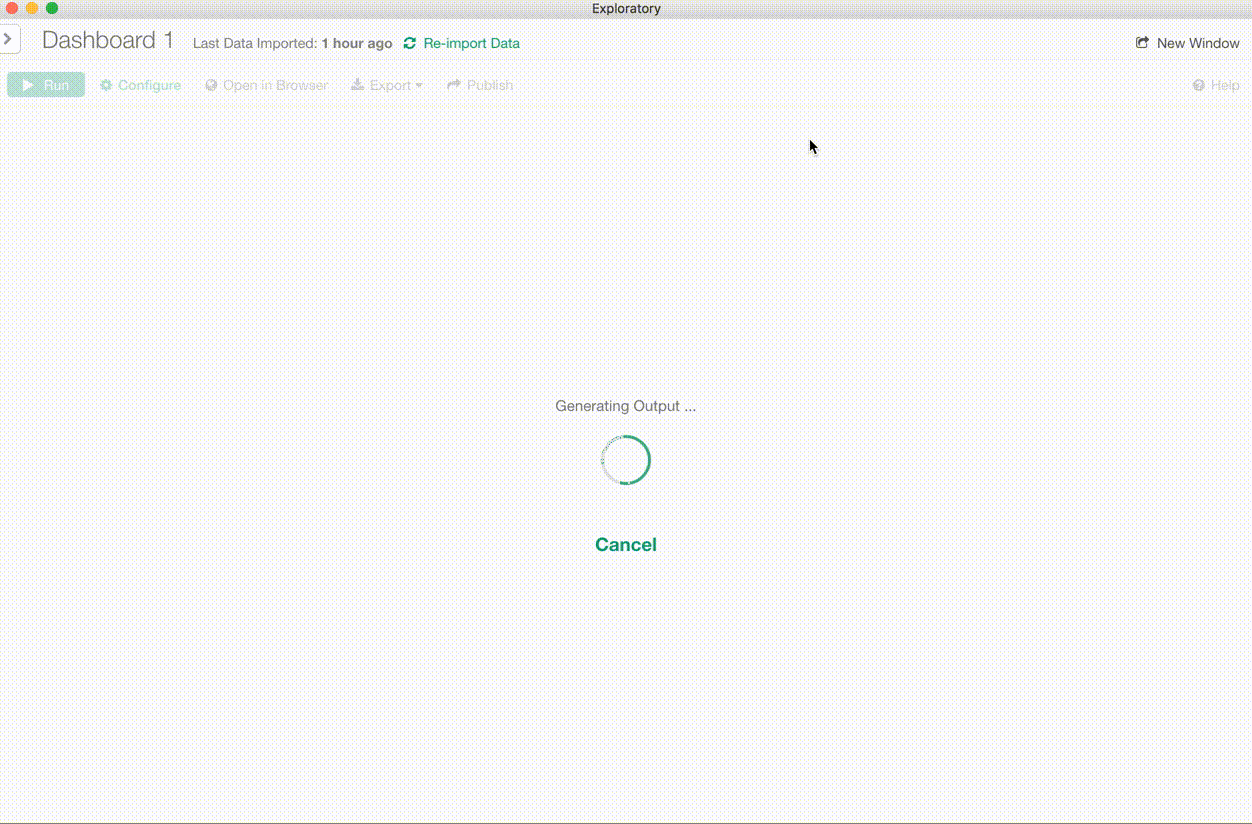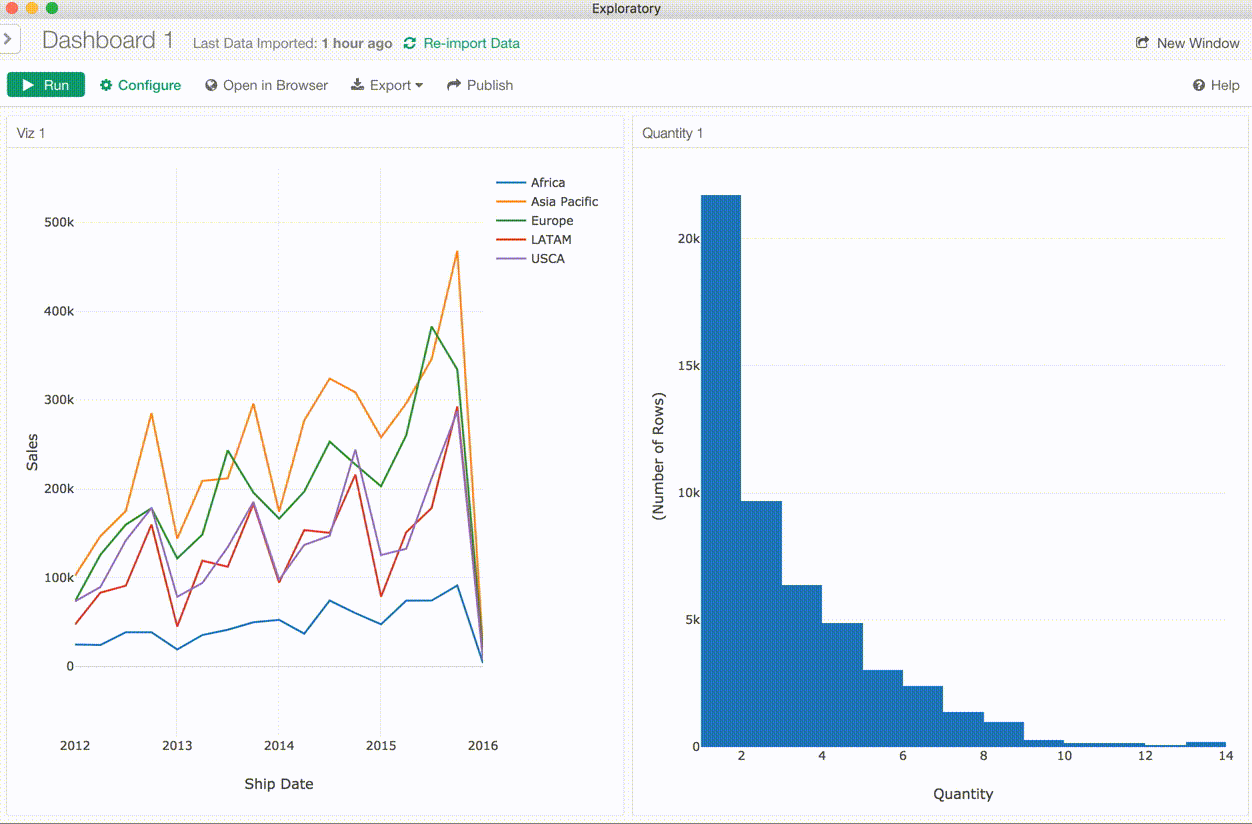
チャートからダッシュボードへ
データサイエンス・ブートキャンプ・トレーニング
次回のブートキャンプを東京にこの6月に開催します。まだお席の方に空きがありますので、データサイエンスを始めたい、データ分析を本格的に学んでみたいという方はこの機会にぜひ参加をご検討下さい。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。