
こんにちは!
Exploratoryの西田です。
今週はデータサイエンス業界では有名な、データサイエンスのベンダイアグラムの考案者であり、Machine Learning (機械学習)for Hackersの著者でもあるDrew Conwayによるニューヨークのデータサイエンス・シーンに関する話、日本では民泊サービスプラットフォームとして知られているシリコンバレーのスタートアップのAirbnbがRを使ってどのようにデータサイエンスを行っているかという話、そしてRの世界では神のような存在であるHadley Wickhamのインタビュー記事を紹介したいと思います。
さらに、先週、私が”データサイエンスのすゝめ”というブログポストを投稿しましたのでそちらの方も読んでいただき、フィードバック等いただければと思います。
それでは、行ってみましょう。
最近の興味深い英文の記事
データサイエンスのさらなる成長と機会にとってなぜニューヨーク市が最高の場所なのか - URL (訳)
New York City: Data Science’s Best Bet for Growth and Opportunity - 9/29 - URL
ニューヨークには活発なデータサイエンスシーンがあって多くのデータ先進スタートアップ (MongoDB, Stackoverflow, Etsy等)が出て来ていますが、実はそれは2008年の金融危機(リーマンショック)がきっかけでそれまでは既存の金融、メディア、マーケティング、リテールなどの大企業にいたデータに関わる人達が外に出てきたことがきっかけだったんですね。そして、そこにニューヨークの地理的、経済的利点、さらにコロンビア大学やニューヨーク市立大学といったデータサイエンスへの取り組みが先進的なアカデミアの協力が重なって、ニューヨークのデータサイエンスシーンがここまで盛り上がりを見せるようになったようです。こちらに、本人の許可をとって一部翻訳したものがあるので、興味のある方は参照してみてください。
話を日本に移すと、特に東京のような大都市はニューヨークのように様々な業界の企業の本社がありますし、データ・AIに優れた大学もたくさんありますし、今はデータサイエンティストという肩書を持っていなくとも実は思った以上にそのポテンシャルを持った方がたくさんいます。今こそこうした力を結集させ、日本ならではのデータサイエンス、データ分析のメソドロジー、新しい手法、ベストプラクティスなどを共有できる場をもっと作っていく必要があるなのだなと強く思いました。現在何名かの有志の方たちとデータサイエンス・クラブというのを始めようと計画しております。もし、興味のある方いらっしゃいましたらぜひご連絡ください!
AirbnbがRを使ってどうデータを活用しているか - URL (訳)
How R Helps Airbnb Make the Most of Its Data: Great overview of how R is used at Airbnb - 8/23 - URL(オリジナル)
私が日本に行く時はホテルでなく、いつもAirbnbで普通のアパートを一週間ほど渋谷のあたりに借りるのですが、このAirbnbはシリコンバレーのスタートアップで、今や3兆円近い企業価値がついている超ユニコーン企業です。彼らはシリコンバレーのスタートアップの中でも特にデータの使い方がうまい会社として有名で、いろいろとデータに関するツールをオープンソースとして公開もしています。そんなAirbnbのデータサイエンス・コミュニティーではRが一番人気があるというのは以前から広く知られていることですが、彼らがどうRを使っているのか、どのようにプロダクトに関するインサイトを抽出し、A/Bテストなどの実験結果を評価し、予測モデルを作り、さらにどう社内でトレーニング、情報共有行っているかなどに関してかなり詳しい情報を共有していたので、こちらに著者の許可を得た上で簡単に訳してみました。シリコンバレーのスタートアップがどうデータサイエンス、データ分析行われているかというのも興味深いですが、それ以上に彼らがどうやって社内教育を行っているかというのはそれ以上に参考になるのではないでしょうか。
統計への愛: ハドリー・ウィッカムとの会話
For the Love of Statistics: A Conversation with Hadley Wickham - 9/29 - URL
現在、Rの世界だけでなく、データサイエンスの世界でHadley Wickhamを知らない人はいないと思います。モダンRの父と言ってもいいすぎではないと思います。もしからしたら知らなくても、彼の作ったツールもしくは彼のデータ分析に関する哲学に、知らないうちに何らかの形で触れていると思います。かくいうExploratoryも彼の作ったdplyrというData Wranglingのグラマーがコアになっています。そんな彼の短いインタビューです。最後にある、これからデータサイエンスもしくはデータ分析を始める人へのメッセージがものすごくいいです。
“Try and find some data that you are interested in. Whether you’re really into sports or knitting, try to find some data that’s of interest to you because that will help you get through the initial frustrations. If you get frustrated with it don’t give up, because everyone gets frustrated. You just have to take a break and remind yourself that you’re human.”
訳:“まずはなんでもいいから興味のあるデータを探してみる。それはスポーツでも編み物でも何でもいいです。自分が興味のあるデータだと最初に経験することになる挫折、いらいらを乗り越えるための助けになります。もし挫折しそうになっても、とにかく諦めないでください、なぜならそれはみんな同じように経験することですから。そんな時はちょっと休んで、自分は人間なんだなと気づいけばいいんです。”
興味深いデータ
tidyquantパッケージで取ってくる株価データ
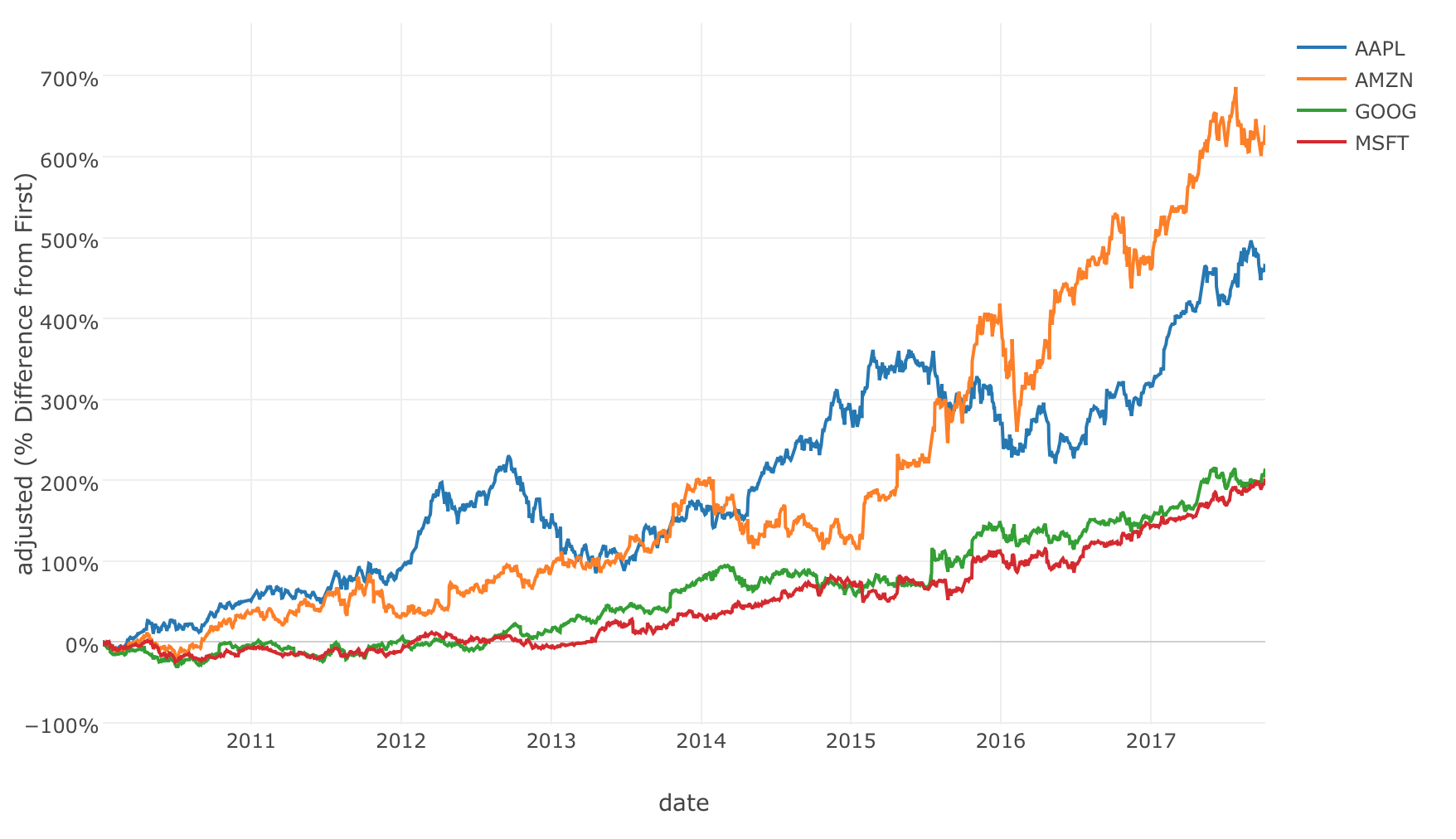
多くの方がすでに知っているかもしれませんが、株価のデータを簡単に取ってくるためのtidyquantというRのパッケージがあります。そちらを使ったサンプルEDFをこちらに共有していますのでよかったら、ダウンロードしてインポートしてみてください。(EDFについてはこちらにドキュメントがあります)tidyquantパッケージの方を先にインストールする必要がありますが、Rパッケージのインストールの仕方のドキュメントはこちらです。
ブログポスト from Team Exploratory
この夏に何度か来日してたくさんの方たちとディスカッションを重ねたうえで、これからの日本にとってなぜデータサイエンスが必要か、どのように広めて行くことができるかという点に関して、私が思ったことをまとめてみました。よろしければぜひ読んで感想を聞かせていただければ幸いです。
データサイエンスのすゝめ — シリコンバレーに全てを飲み込まれる前に by Kan - URL
What Are We Working On?
Dremioって知ってますか?HDFS、S3、MongoDB、Redshift、PosgtresなどにあるデータやJSON/CSV等のファイルデータに対してSQLで高速にアクセスすることができ、最近こっちで話題になっているオープンソースのフレームワークです。そちらのデータソースのサポートが次のリリースに加わります。大規模データを効率よく取ってきて、Exploratoryに取り込みたい時に便利です。
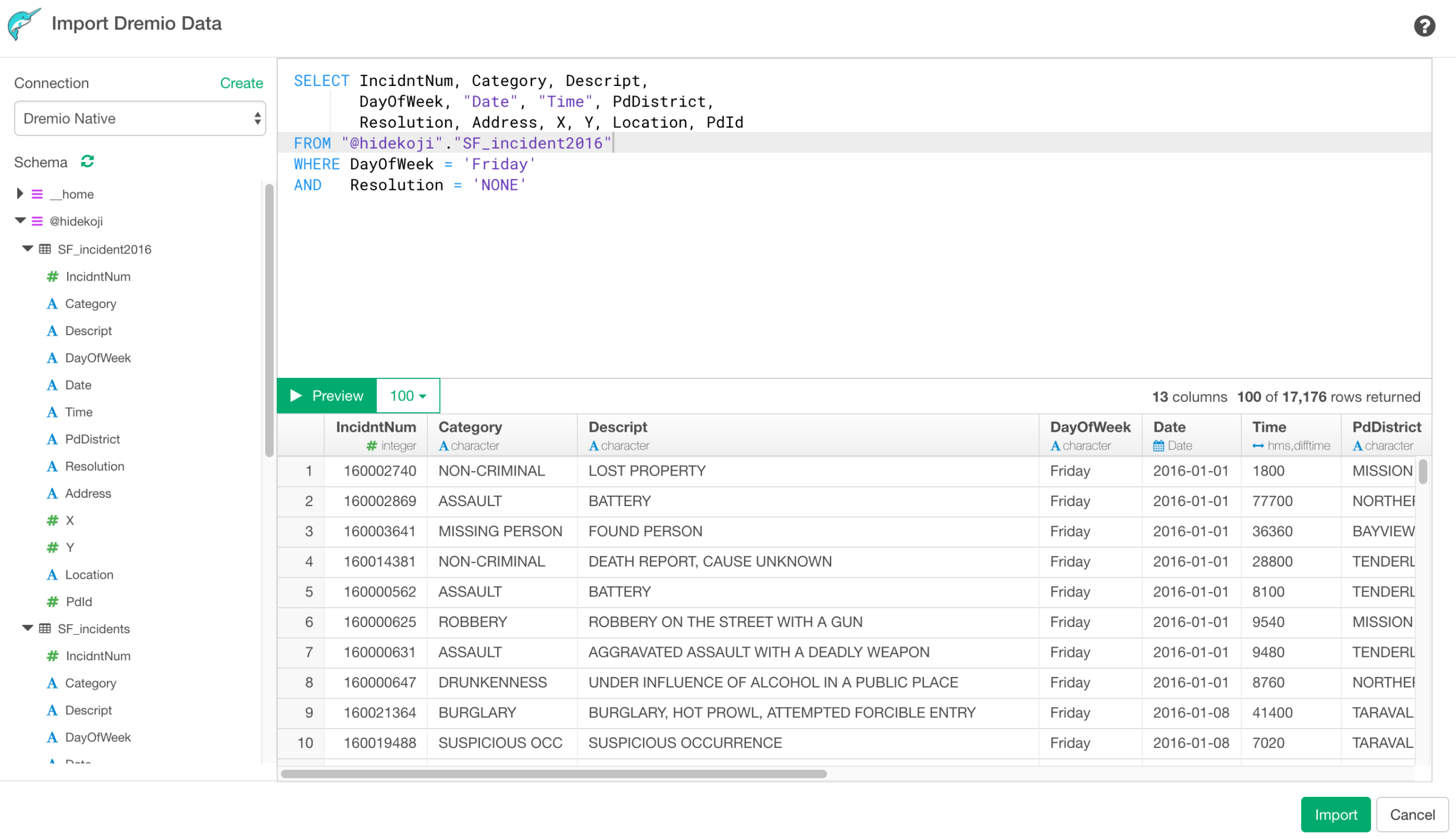
v4.1の機能の開発自体はようやく終わりました!今週から最後のテスト、クオリティチェックの方に入ります。Stay tuned!
ブートキャンプ・トレーニング
最後になりますが、今月の終わりにこのシリーズ最後の日本でのデータサイエンス・ブートキャンプ・トレーニングを開催します。もし周りに興味のある方などいらっしゃいましたら、ぜひお声をかけていただければと思います。よろしくお願いします!
それでは、素晴らしい一週間を!
西田, Exploratory/CEO