
こんにちは、Exploratoryの西田です。
一週間前に二人目の子供が無事に産まれ、それ以来嵐のような一週間を送っていました。新生児というのは4年ぶりになりますが、前回大変だった記憶というのはすっかり飛んでしまっているようで、戸惑いながらサバイバルしている毎日です。。。
とういわけで、一週間ほど産休を取っていたので先週のWeekly Updateは勝手にスキップしてしまいましたが、今週よりまた行ってみたいと思います。
ところで、これからますます盛り上がってくるであろうAI、データサイエンス業界ですが、知っている人と知らない人達の格差は開くばっかりです。今週は、こうしたギャップを埋めてくいくためにどういった人材がこれから必要になるのか、企業の重役、マネージャーが理解しておくべきAIのチャレンジ、中国やシリコンバレーの企業がどのようにこの分野の人材を確保していっているのか、についてのおもしろい記事が3本あったのでそちらを紹介したいと思います。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
AIのプロジェクトを始める時にぶち当たる5つのハードル
What AI can and can’t do (yet) for your business - Link
私達が普段から言っていることですが、現在AIに対して多くの人が抱く想像に関して、Over Estimate(過剰な期待) とUnder Estimate(過小な期待)という問題があります。Over Estimate(過剰な期待)はAIを使うと全ての問題が自動的に解決されるというもので、Under Estimate(過小な期待)はAIを使えば実は簡単に解決される問題なのにそのことに気づいてもいないということです。今日のように、AIに関連するツールが周りにあふれている状況では、どんどん使って試しながら自分なりの正しい期待値を設定していくことが重要だと思います。
最近マッキンゼーから実際にAIのプロジェクトを始める時につまずくよくある5つの問題とそれを解決するための最新のトレンドをまとめたものが出ていましたので、ここに紹介しておきます。
以下、要約
1. データのラベル付け
AIのシステムは一般的には正解付きのデータによってトレーニングされる必要があります。(日本語ではこれを教師付き学習と呼ぶ)このトレーニングのためには大量のデータを必要とし、さらにこのデータに正解となる答えをラベル付けする作業はものすごい手間と時間がかかります。
例えば、自動運転のテクノロジーを開発している会社は、試験走行から得られる膨大な時間のデータに何百人という人が手作業で注釈を入れて(ラベル付け)から、そのデータを使ってシステムをトレーニングしています。
この手作業の部分を自動化または効率化させる試みとして、教師なし学習や半教師付き学習などを組み合わせたり、強化学習のように報酬と罰を決めることによって、後はアルゴリズムがシミュレートしながらある意味データを勝手に作っていったりというものがあります。さらにはここ最近のトレンドとしてはGAN(Generative Adversarial Networks / 敵対的生成ネットワーク)という手法で二つの反するディープニューラルネットワークのモデル(一つは相手を騙すためのデータを作るためのモデル、もう一つはそれが正しいか間違っているかを判断するためのモデル)を使ってトレーニングすることで少ないデータから多くのデータを仮想的に作り出すやり方などが研究されています。
2. ブラックボックスな予測モデル
予測、レコメンデーション、意志決定の精度を上げるのに使われたりする機械学習のモデルはディープラーニングのモデルを筆頭にその中で何が起きているのかが人間にはわかりにくいという問題があります。人間が実際に意志決定を行うためには、なぜそういう予測の結果が出たのかの理解が必要になります。例えば、お金を貸すための審査をAIにやらせる場合、なぜある人は安く借りれて他の人は高いのかという説明は、もちろん法律で求められているということもありますが、貸すための意志決定をおこなっている人間にとっても欠かせないものであります。
そしてこれこそがAIが本来ならもっと浸透しても良いエリアに浸透していない一つの理由です。つまり、多くの分野ではコンピュータによって行われる処理に対して、どのようにしてその結果にたどり着いたのかという説明を求められるからです。
こうしたブラックボックスなモデルがどのようにして予測結果を導いているのかを解き明かすための手法として、最近はLIME(Local Interpretable Model Agnostic Explanations)という手法が注目されています。これは一部のデータをモデルに渡し、その中の属性がどのようにして予測結果に影響を与えているのかを明らかにするというもので、ディープラーニングだけでなく、機械学習のなかでも予測精度を上げるためによく使われるアンセンブル・ラーニング(集団学習)モデルにも使えるなど、様々なモデルで使うことができます。
3. トレーニングのために必要になる大量のデータ
AIのモデルの予測精度を上げるためには一般的には大量のデータを必要とします。例えばディープラーニングのモデルでそれなりの結果を出すには少なくとも何百万といったレベルのデータが必要になります。(西田:これはスタートアップのように持ってるデータ量がまだ少ない場合や、必要なデータをまだ集め始めてばっかりの時にチャレンジとなります。)
最近はワン・ショット・ラーニングという、AIが少ないデータから予測対象を学習することを可能にするという手法が注目されています。
4. AIモデルの一般化
現在はAIモデルと言っても、結局は狭い分野で一つのことをこなすといった用途に限られ、一般に期待されているような人間のような知能をもって様々なタスクを行っていくには至っていません。つまり、一つのプロジェクトで作ったAIのモデルは使い回しができないので、企業はプロジェクトごとに、さらには用途ごとにAIのモデルを一から作り直す必要があります。
最近では一つの用途で作られたモデルが別の似たような用途でも使えるようにするというトランスファー・ラーニングという手法が研究されています。アルファ碁で有名なDeepMindの研究者はシミュレーションの中で学習したモデルをロボットの腕を動かすために使うということをやっています。他にも、石油やガスの生産者であれば油井のメンテナンス時期を予測するために作ったモデルを使ってパイプライン、採掘プラットフォームのメンテナンス時期も予測することができます。
さらに、機械学習のモデルのデザインそのものを自動化するというメタ学習(meta-learning)という手法にも注目が集まっています。Google Brainでは自動機械学習(AutoML)を使ってイメージの識別のためのニューラル・ネットワークのデザインを自動化しています。これらの手法は最近では人間によってデザインされたものと同等の結果を出すまでになっています。
5. データとアルゴリズムの中のバイアス
AIのモデルがデータをもとに作られるということは、どういったデータを使うのか、データをどこからとってくるか、どのようにしてとってくるかといったところに人間のバイアスが入ってしまう余地があります。アメリカの場合であれば、白人の多い地域で取得されたデータで作ったモデルには白人以外の予測にはまったく役立たないかもしれません。
そして、このバイアスというのが実は一番やっかいで、一度モデルの中に入ってしまうとなかなかそれがバイアスだと気づくことができません。高度なデータサイエンス、独自のデータとアルゴリズム、客観的な分析などといった旗印のもとに、しばらく長い間隠されてしまっているというケースが多々あります。
あなたが重役、もしくはマネージャーであれば何をすべきか
1. まずは自分でできる勉強、調査はしっかりしておくこと
AI、データサイエンスに関する一般的な理解は少なくとも持っておくべきです。現段階でできることは何なのか、どういったツールが使えるのか、さらに長期的にこの分野のテクノロジーはどう発展していくのかということに関する理解です。身近にいるデータサイエンス、機械学習、AIの専門家からたえず知識を習得し、最新の動静に詳しくなっているべきです。
2. データ戦略を持つこと
最終的にAIのクオリティを決めるのはデータであるわけですから、どういったデータをどのように取得し、ラベル付けを含めてどう加工するプロセスを設計するのか、その品質をどう保つのかという事に関するデータ戦略を組織横断したものとして持っておくべきです。
3. 情報と成果が共有されやすい環境を作る
社内でAI、データサイエンスのプロジェクトにおける成果の共有を広く行うべきです。一つの部門での成功事例が別の部門が抱えている問題を解決するきっかけになるかもしれません。(西田:これは以前AmazonがどのようにAIに関する知識、経験を社内横断で共有していったかという記事の中でも触れたので参考にしていただければと思います。)AI、データサイエンスの世界では、絶えず新しいアルゴリズムやツールがオープンソースとして出てきて、さらに新しい手法や研究成果がオープンに議論されています。こういう世界ではそういった最新の情報をいかに効率的に取得し、さらに自分たちの組織で使うことによって学び、その学びを組織の中で共有していくことが重要です。
最後に
もしあなたがAIのテクノロジーの進化に対して無視を決め込み、他のみんながやり始めてからの成功事例を参考にあとで急速に挽回できると思っているのなら、もう一度考え直したほうがいいでしょう。現在のように日々ものすごいスピードで進化している世界、さらにすでに先を走っているGoogle、Facebook、AmazonのようなAI先進企業でさえ毎日ものすごいスピードで進化している世界では、立ち止まっている場所から一気に飛躍するというのは夢の様な話です。なんといっても、ちょっと前までできないと思っていたことがすでに今日にはできるようになり、それをもとにさらに新たな手法が生まれていくという世界なわけですから。
以上、要約
AIをコアにしたスタートアップを始める人達が私達の周りにも多いですが、ここであげられているチャレンジはまさによく聞く話です。データ量、そのラベル付けは特にスタートアップのような始めて間もない人たちにとっては乗り越えるのが難しいハードルです。
そしてこのデータにラベルをどうつけていくかというのは、データの加工の問題であり、それはデータの品質の問題となります。そしてそれはAI、機械学習のモデルの品質に直接影響します。英語では、Garbage In, Garbage Outといいますが、ゴミのようなデータが入ってきたらどうあがいてもそこから出てくるものはゴミでしかないということです。これが、データサイエンスのプロジェクトの80%の時間が実はデータ・ラングリング(データの加工)に費やされるという所以です。
最後に、Exploratoryではランダムフォレストの機械学習モデルを使った変数重要度分析というのがアナリティクス・ビューにあります。このランダムフォレストもアンセンブル機械学習モデルの代表ですが、予測精度を高めることができるのはいいのですが、その予測の結果がどのように導き出されているのかが理解しづらいというこの記事でも挙げられていたブラックボックスの問題があります。この問題を解決するために私達もこの記事で紹介されていたLIMEを使った手法を試してみたのですが、結局それよりももっと直感的にわかりやすいということでEDARF(Exploratory Data Analysis using Random Forest)という手法を採用してPartial Effectというかたちで提供することになった経緯があります。ただこのEDARFという手法は残念ながら名前が示す通りランダムフォレスト(Random Forest)にしか使えません。
データサイエンティストとビジネスを結ぶ仕事こそ今必要とされている
You Don’t Have to Be a Data Scientist to Fill This Must-Have Analytics Role - Link
日本でもデータサイエンティストを雇ってデータサイエンスのプロジェクトを始める企業が増えてきているようですが、そうしたプロジェクトが失敗するときによくあるパターンの一つに、データサイエンティストを雇ってその人達にデータ分析を丸投げしてしまうというものです。ここで問題になるのは、分析をするデータサイエンティストとその分析から得られるインサイトを持って意志決定を行うはずのビジネス側の人間との間のコミュニケーションが上手く取れないことです。これは以前にも”多くの企業がデータサイエンティストを活かしきれない4つの理由”という記事で取り上げました。
もちろんこうした問題は日本だけでなくアメリカでも起きているのですが、この二つのグループの人たちの間を取り持つことを期待されているトランスレーターという職種がこれから必要になってくるという内容の記事がHBR(Harvard Business Review)から出ていたので、ここで簡単に紹介したいと思います。
以下、抜粋
多くの企業ではAIならびにデータサイエンスのプロジェクトにはデータサイエンティストだけではなく、様々な専門のスキルを持った人たちが必要ということが分かってきました。データ・エンジニア、データ・アーキテクト、データの可視化の専門家、そして、おそらく一番重要であろうトランスレーター(翻訳する人)といった人たちです。ここでトランスレーターと言っているのは何も言語の翻訳をする人のことではありません。データサイエンスの言葉とビジネスの言葉を仲介することができる人のことです。つまり、データサイエンティストやデータエンジニアといった人たちの技術的な専門性とビジネスの前線に出ているマネージャー達のマーケティング、サプライチェーン、製造、金融などといった業務に関する専門性を結びつける役を担う人たちです。
彼らはデータサイエンスの分析から得られた深いインサイトが組織にとって大きなインパクトを与えるものであるように調整する人たちなわけですが、マッキンゼーによると、2026年までにアメリカだけで400万人ものこうしたトランスレーターが必要になるということです。
データサイエンス、データ分析のプロジェクトを始めるにあたって、トランスレーターはビジネス・リーダーが彼らのビジネスの問題をデータによって解決しやすい問題として定義するのを手伝います。そして、自分の持つAIやデータサイエンスの知識をもとにデータサイエンティストたちにビジネスの問題、プロジェクトのゴールを伝えます。そして、データサイエンティストがデータより導き出したインサイトを、今度はビジネスサイドの人間が理解できるかたちでコミュニケートします。ここでは、ただの予測の結果だけではなく、なぜそういう結果になっているのかを説明することも求められます。
トランスレーターに求められるスキルとしては以下のものが挙げられます。
- 業務知識
- 一般的なAI、データサイエンスの技術に関する理解
- 量的分析と構造的に問題を解決できる力
- プロジェクト管理のスキル
- 起業家精神
一般的なAI、データサイエンスの技術に関する理解とは、自分で機械学習のモデルを作る必要はないにせよ、どういった機械学習のアルゴリズムがあって、それらがどういうビジネスの問題を解決するために使われるのかを知っておく必要があります。さらに機械学習のモデルから得られる予測結果やインサイトを理解することができ、ビジネス担当者にわかりやすいかたちで伝えることができるべきです。さらにドメイン知識を使って、モデルの結果がおかしい時にはそのことに素早く気づくことができるというのも、この仕事に求められています。
それではそういった人材はどこにいるのでしょうか。こうした人材が必要とされる緊急度を考慮すると外からの採用が手っ取り早いと思ってしまいがちです。しかし外から取ってくる人材にはトランスレーターの成功のために最も重要なスキルである、あなたの会社特有の業務知識が欠けています。結果として既存の社員に対してこうしたデータサイエンスの手法、AIの新しい技術、アルゴリズムに関する知識を提供するようなトレーニングを行っていくほうが効果があるというのがこれまでの経験より証明されています。
現在はこうしたトランスレーターの職種における資格などはないので、多くの企業ではそうした人材を育てるための社内アカデミーを作っています。例えばある世界的な鉄鋼会社では300人のマネージャーを対象とした1年間の教育プログラムを実施しています。マッキンゼー自身も社内でアカデミーを作り、去年だけで1000人のトランスレーターをトレーニングしています。アカデミーのカリキュラムはAIを使うと何ができるようになるのかというものから特定の技術や手法の勉強など様々です。フォーマットはコースとして比較的長い期間で行うものから、短期集中で行うものもあります。
以上、抜粋
私は個人的には、こうやってまた別の新しい職種を作ってそこに放り投げてしまうよりも、これから次世代を担っていくことになるビジネスリーダーたちが自分たちの手で、旧世代がすでにワードやエクセルを使ってビジネスを普通に行っているように、最新のデータサイエンスの手法を使いこなしながらデータ分析をしていくことができるべきだと思っています。というのも、データ分析を通したアナリティカル思考こそが私達人間に残されているクリエイティブで自動化できなり仕事であるからです。それもあって、私たちはデータサイエンスをプログラミングなしで行うことができるツールを作り、ビジネスユーザーを対象にしたデータサイエンスのトレーニングを行っています。
しかし、そこへいきなり行くのは企業としては難しいというのも現実かもしれません。その場合は、このようなかたちでトランスレーター的な役割の人たちを社内でトレーニングしていくというのも、移行期には必要なのかもしれません。そして、将来のリーダーはこうしたAI,データサイエンス、ビジネスを理解することができるトランスレーター的な人の中から出てくることにもなるのかもしれません。
アメリカ政府が無策の間に、世界のAIのリーダーへの道を突き進む中国
As China Marches Forward on A.I., the White House Is Silent - Link
以前こちらのWeekly Updateでもお伝えしましたが、中国政府はAIの分野で世界のリーダーとなるための計画を去年の夏に発表し、現在その計画を着実に実行しています。しかし、その反面、現在、世界のAIのリーダであるアメリカでは、現トランプ政権が国としての取り組みの方針すら出せていない状態です。ただ、こうした状態でもシリコンバレーの企業を筆頭に、民間企業はおかまいなしにどんどん猪突邁進しているのがアメリカらしいですが。
以下、要約
去年の7月、中国は2030年までに世界のAIのリーダーになり、15兆円にも上る産業をつくり上げるための計画を発表しました。ただ、そのマニフェストは基本的にはアメリカの前オバマ政権の作った“未来のAI”に関するレポートの焼き直しのようですが。
その計画の実行として、AIの研究のための長期的な投資を大量に増やし、この分野の技術をより多くの生徒に教育し、そして他の国から専門家をたくさん連れてきて、AIの研究者の大きなコミュニティーを作るということです。
さらに、企業に対してより多くの技術とデータを提供することを求めています。AIをトレーニングするには大量のデータが必要となりますが、例えばアメリカであるとその殆どのデータはGoogleやFacebookといった企業の中にあります。中国の場合は,ここに優位性があります。というのも、10億を超える大量の人口は他の国と比べて、より多くのデータを作ることになりますし、中国の企業は政府へデータを提供することに関して躊躇しません。
さて、AIに投資というのはどういう規模なのでしょうか。
中国全体でAIにどれくらいのお金が投入されているのかははっきりしませんが、一つの省は5000億円近くの投資をAI分野に行うことを約束しています。北京は2000億円かけてAIの開発センターを作ることになっています。
そんな中、アメリカのトランプ政権の2018年の予算はサイエンスとテクノロジーに関する予算を15%減らすということです。そもそもこの政権は前オバマ政権が提示したAIのロードマップに関してのフォローアップすら殆どできていない状態です。
この5年ほどのAIテクノロジーの発展はGoogle、Facebook、Amazon、Microsoftなどのアメリカの企業によって導かれてきましたが、こうした企業ではAIの技術者がアメリカで働く必要はありません。現在のAIの盛り上がりの中心的人物であるジェフリー・ヒントンはGoogleで働いていますが、現在は、もともと教授として働いていた大学のあるカナダのトロントでGoogle研究所を運営しています。
そのGoogleですが、他にも世界中に研究所を作っています。例えば同じカナダのモントリオールや、パリと北京にも重要な研究所がありますし、ロンドンにあるDeepMindというAlphaGo(アルファ碁)で有名な研究所は最高レベルのAI研究者を世界中から集めています。Facebookはカナダのトロントやパリに研究所を作っていますし、Amazonはドイツに研究所を近くオープンする予定です。
こうした研究所では、もちろん研究者はアメリカの会社のために新しい技術を開発します。しかし研究所が大きくなり、製品もよくなっていくに連れ、何人かの従業員は辞めて自分たちの会社を作り、新たな社員を現地で雇っていくことになるでしょう。実際、GoogleやMicrosoftの中国にある子会社を辞めて行った人たちがすでにいくつかの重要なAI関連の会社やファンドを中国に作っています。
以上、要約
この記事にもあるように、シリコンバレーの企業を筆頭にアメリカのAI企業はどんどんと世界中にAIの才能を求めて進出していっています。シリコンバレーほど世界中から優れた技術者が大量に集まってくる場所はないですが、そのシリコンバレーをしてもGoogle、FacebookなどのAI企業の食欲を満たすことはできないということでしょう。現在はとにかくAI、データサイエンス業界はスキルを持った人間の供給がまったく需要に対応できていない状況なので、こうした企業も世界中に積極的に手を伸ばして行かざるをえない状況です。
日本はこうした、まさに今必要な人材を提供できていないというのが残念です。日本の一部の企業がアメリカのほうへ人材を求めて進出するという話は聞いたことがありますが、逆にシリコンバレーの企業が日本にこうした技術者を求めてやってくるという話はあまり聞いたことがありません。以前にもこちらのWeeklyUpdateでお知らせしましたが、世界には6つほどAIハブと言う都市または地域がありますが、その中に日本の都市は入っていません。
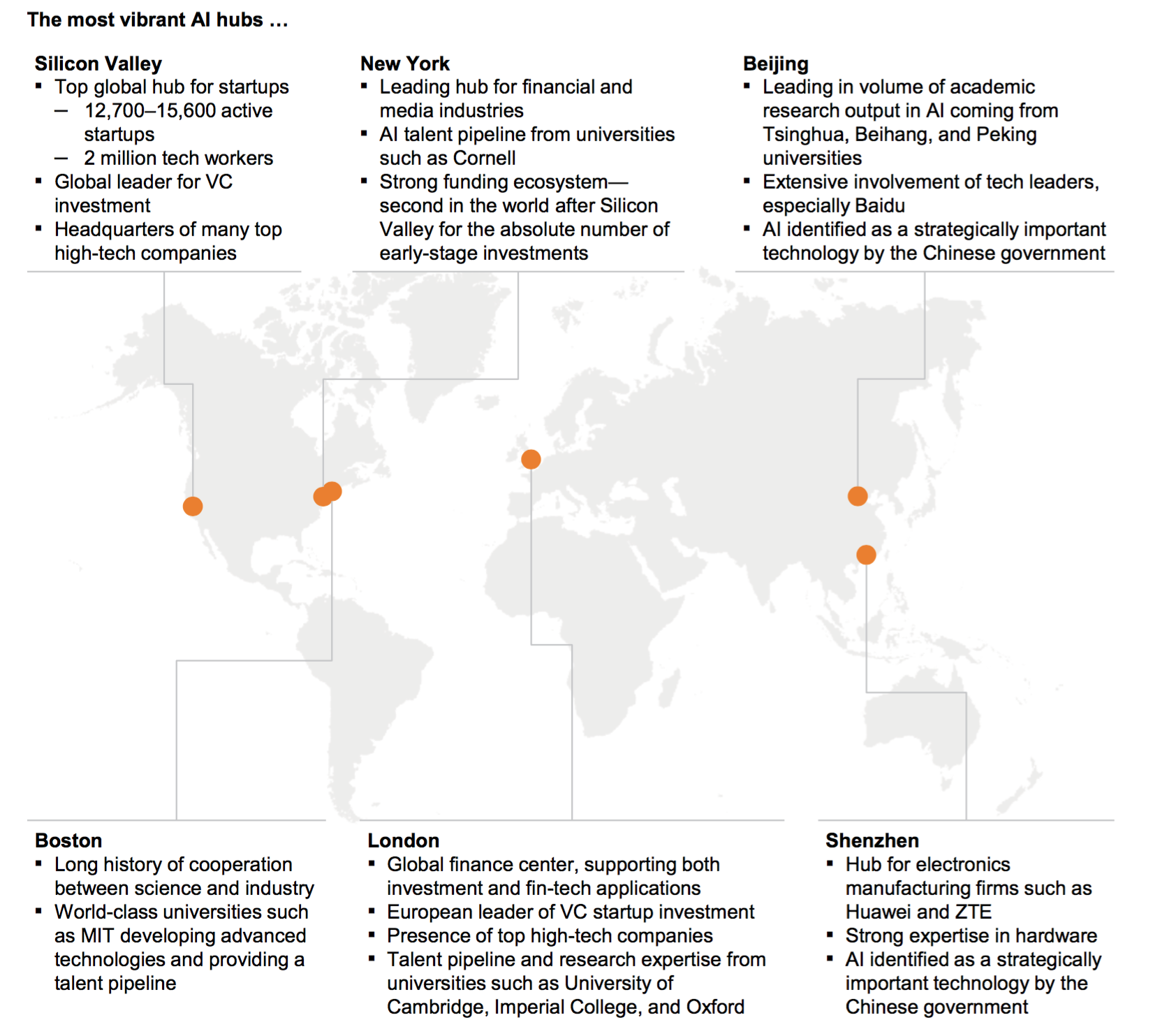
日本は資金もあるし、大きなマーケットもある、人口もたくさんいる、さらに世界で活躍する大企業の本社もたくさんあります。しかし今日、そして明日の世界で必要とされる人材を排出できていないというのは致命的な問題です。これこそは日本の抱える教育の危機、さらには政治における現状認識能力の欠如だと思います。既存の教育機関はこれから必要となる人材を育成することに失敗しているというのが現状なのですから、日本もアメリカのように比較的フットワークが軽い民間企業が自分たちでそういった人材を育てながら危機感をもって今起きている変革の波に対応していくべきではないでしょうか。
興味深いデータ
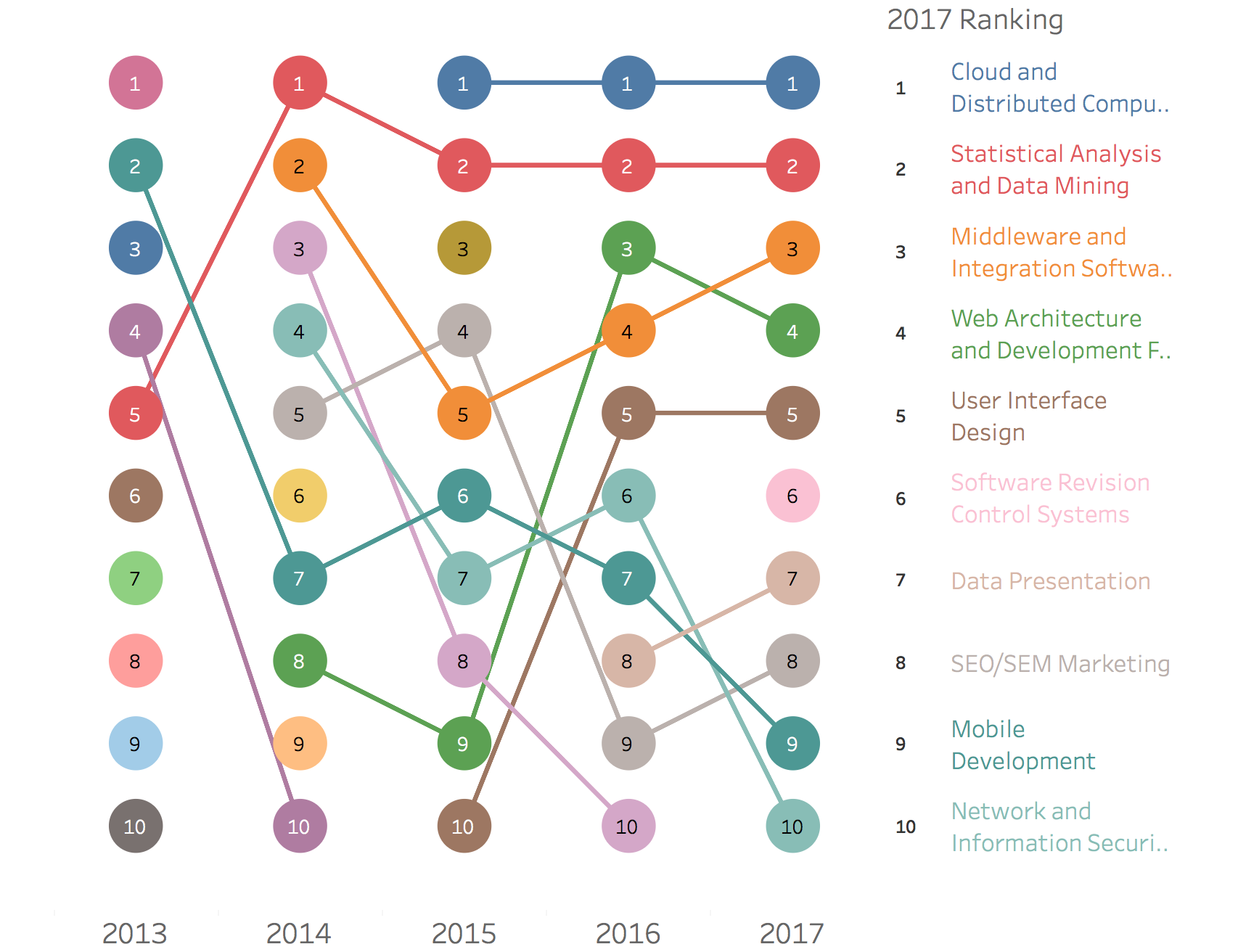
最も必要とされているスキルトップ10
LinkedIn Top 10 Skills by Year - Link
LinkedInが毎年発表している最も必要とされているスキルトップ10のデータを2013年から2017年分までのものをまとめてあります。ちなみにStatistical Analysis & Data Miningというスキルが第2位です。昨今のデータサイエンスの盛り上がりを考えればもちろんという感じではありますが。
What Are We Writing?
少し遅れましたが、こちらにExploratory v4.2のリリース・アナウンスメントの日本語版を投稿しました。
What Are We Working On?
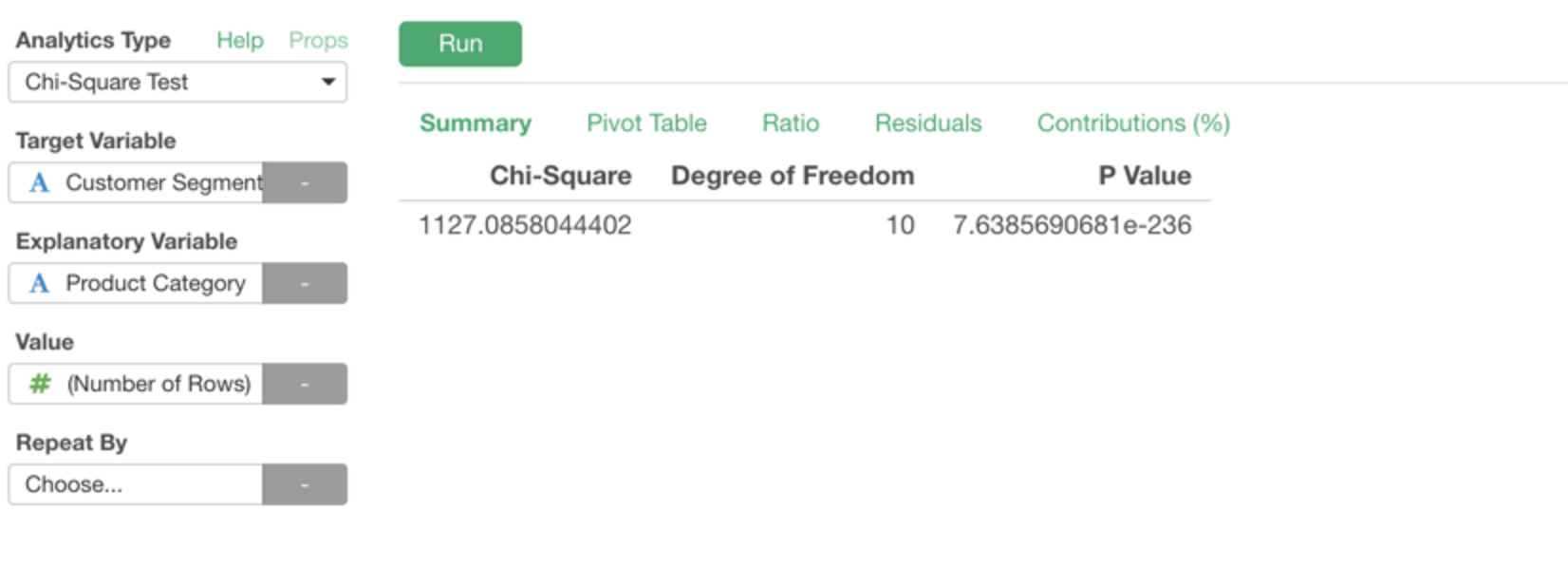
Exploratoryの次期バージョンv4.3では、統計のテスト(検定)に関する機能が強化されます。その一つとしてカイ二乗検定(Chi-Square Test)がアナリティクス・ビューから簡単にアクセスできるようになります。
さらにテストをするだけでなく、データの可視化をうまく使うことでカイ二乗検定からインサイトを得やすくするために試行錯誤しています。以下はカイ二乗に貢献している、つまり普通じゃないトレンドを示しているある列の値と別の列の値の組み合わせを見やすくするためのチャートです。
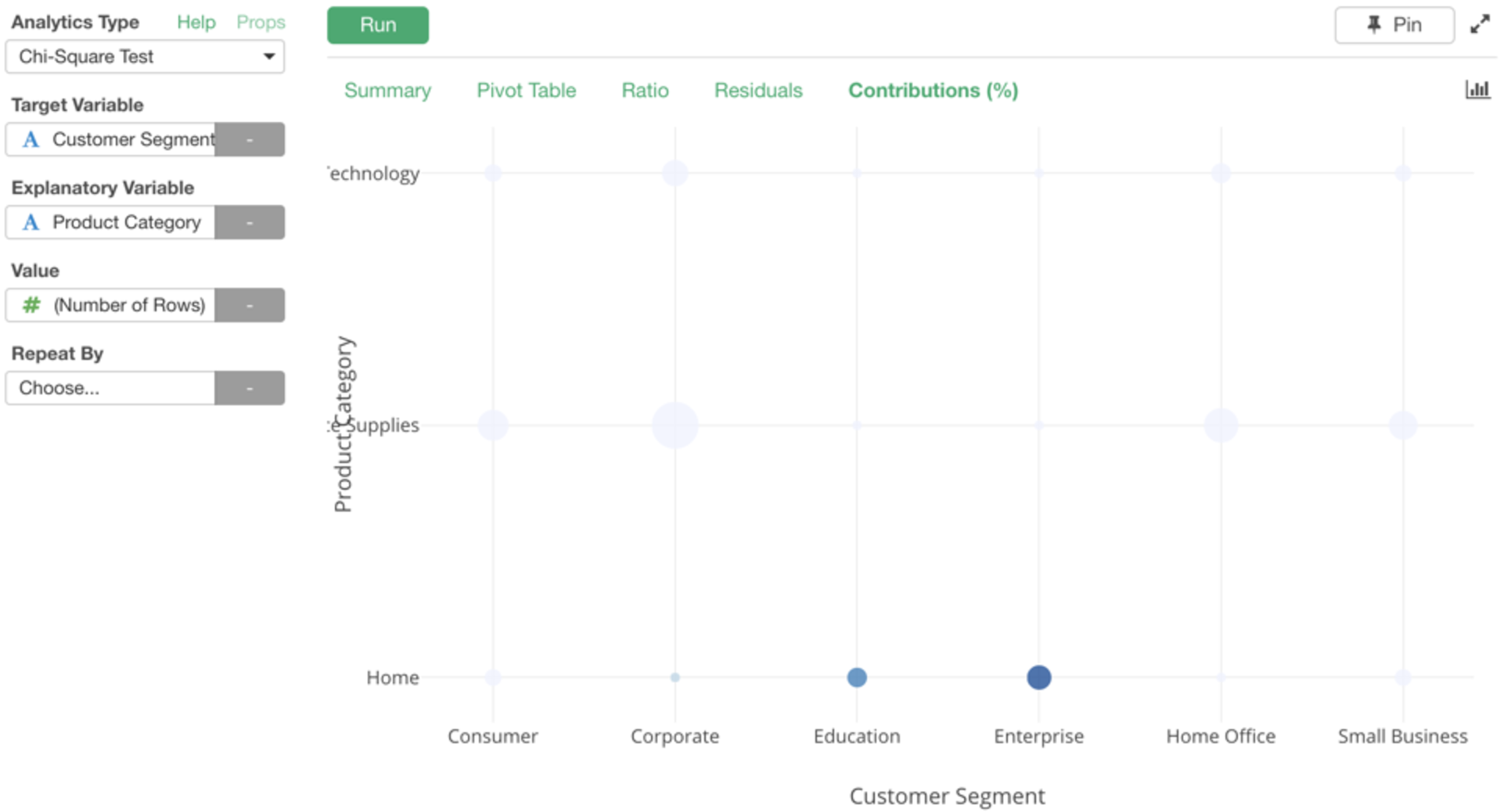
もし、ふだんカイ二乗検定をよく使っている方で試してみたい方はぜひ連絡してきて下さい。ベータ版をお渡しします。
データサイエンス・ブートキャンプ・トレーニング
次回の3月に開催のブートキャンプですが、おかげさまで席の方がすでにいっぱいとなってしまいました。もし、キャンセル待ちリスト、もしくは次回6月開催の通知リストに登録したいという方がいらっしゃいましたら、こちらのメールに直接返信していただければと思います。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら(https://exploratory.io/tag/weekly%20update%20-%20japanese) よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。