
こんにちは、Exploratoryの西田です。お元気ですか?
まず最初に1月の日本でのデータサイエンス・ブートキャンプのほうですが、おかげさまで、大変反響がよく、もう既に残りわずかの席となっております。定員に達し次第受付の方が終了しますので、興味はあるがまだ申し込まれていない方は、この機会にぜひご検討下さい。
今週は、USのWarby Parkerというファッショナブルなメガネを作って売っているスタートアップから、ビジネスにとって価値のあるデータサイエンスのプロジェクトを行うための提案、データとアナリティクスがどうビジネスに影響を与えているのかに関するマッキンゼーからのレポート、映画・ビデオのストリーミングの大手NetflixがレコメンデーションのアルゴリズムのA/Bテストをどう行っているのかという記事を紹介したいと思います。
最近の興味深い英文の記事
ステークホルダーを中心にしたデータサイエンス
Stakeholder-Driven Data Science at Warby Parker - Link
データサイエンスのプロジェクトを始めるのは比較的簡単ですが、そうしたプロジェクトを顧客、もしくは社内のビジネスにとっていかに価値のあるものとして成功させるかというのは大変難しいです。というのも、そうしたプロジェクトの多くが“興味深い”インサイトを提供するにとどまってしまい、実際のビジネスの現場での意志決定に影響を及ぼすレベルのインサイトを提供するに至らないからです。これでは、結局こうしたデータサイエンスのプロジェクトは単なる流行りで終わってしまい、会社の文化を変える前にそうした予算は次の流行りへと移っていってしまいます。これはこのデータサイエンス業界のリスクというよりも、本来データを使うことで競争的優位を確立しようとしていたコアビジネス、そして企業そのものにとっては大きな損失だと思います。
そこで、Warby Parkerというファッショナブルなメガネを手頃な値段で提供するスタートアップがこちらUSにあるのですが、そこのデータサイエンティストのMax Shronが”Stakeholder-Driven Data Science”と言うタイトルでプレゼンを行っていたのですが、そこで提示されているプロジェクトの進め方が参考になるのではないかと思います。
ここでもやはり、社内にデータサイエンスのチームがあるのですが、社内の様々な部署にデータサイエンスのコンサルティング・サービスを提供するチームという位置づけのようです。
データサイエンスのプロジェクトというと多くの人は、アルゴリズムを使って分析そのものを行っていると想像しがちですが、現実は、その分析のためのデータを用意する、つまりデータラングリングに費やされる時間がほとんどです。しかし、ここでShronはさらに一歩進んで、最終的にデータ分析の結果をもとに意志決定を行うことになるステークホルダーの話を聞き、彼らの要件を理解するための時間を、プロジェクトの最初のステージでしっかり確保すべきだと言います。以下のチャートを見るとわかりますが、これはかなりの時間ですね。

このステークホルダーとのディスカッションの段階で、ビジネス上の問題をどうやってデータで解決できる質問に落とし込んでいくかということが重要になります。そして、一度その質問が決まったならば、モックアップ(UI、ダッシュボードなどを手書きしたもの)を使って、”こういう分析ができて、その結果がこういった形で見えることになるが、これはあなたの意志決定に直接役立ちますか”という提案をするようです。ここで実際のビジネスにおいての価値があるということが確認できてから、初めてデータ分析に関わる作業を始めるということです。
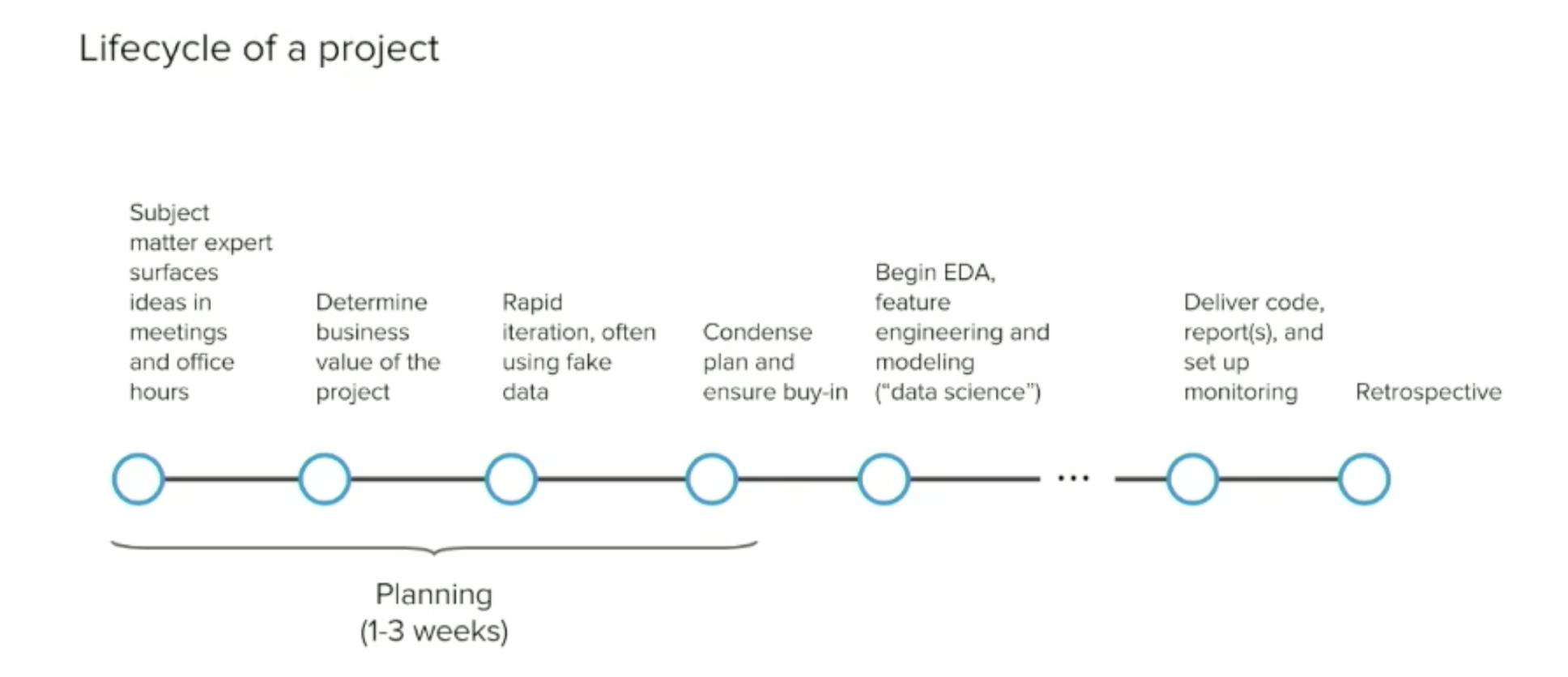
あと上記のチャートにもあるのが最後のモニタリングに費やす時間です。分析が終わって報告を出して終わりというデータサイエンスのプロジェクトをよく見かけますが、そのときの分析に使った予測モデルというのはその時点で持っていたデータ、認識できていた理解に基づくわけなので、たいていの場合は時間とともに、つまり新しいデータが入ってきたり、ビジネスの環境が日々変わっていく中で、そうした予測モデルの結果が現実とは合わなくなってくることがよくあります。そこで、こうした分析が新しいデータが入ってきても再現可能な状況を作っておき、さらにその予測モデルの品質をモニタリングする仕組みが必要になります。
こうしたプロジェクトを行っていく時にはいろいろな思惑があって、プライオリティをつけていくのが大変ですが、彼らは以下のように考えているようです。
- ステークホルダーの現在のワークフローにフィットするか、意志決定の仕方に役立つか
- 分析、予測モデルの正確さ
- コードの品質と再現性
- 現在はまだ起きていない将来に起こるであろうエラーなどの事態に対処できる仕組み
- 興味深い技術
いちばん重要なプライオリティとして、現在のワークフローにフィットするかどうかを上げていますが、これはまったくそのとおりだと思います。データサイエンス、またはデータ分析のプロジェクトを行う最終的な目的は、人間の意志決定の部分の効率化でありその精度を上げることであって、既存のビジネスの仕組みを変えることにあるのではないと思います。ですので、既存のビジネスにおける意志決定のワークフローにあったかたちで、分析に基づくインサイトを提供することができると、実際のビジネスに影響を与える確率が高まり、それがこうしたプロジェクトを成功に導くわけです。
最後にShronからのコメントでこちらの紹介の方を閉めたいと思います。
データサイエンスの成果物を価値あるかたちでステークホルダーに提供することに夢中になるのは信頼区間を出すための正しい計算をするのに夢中になるのと同じくらい満足のできるものです。これは他の多くのデータ分析に携わる人も共感できることだと思います。そして、データサイエンスを行う全ての人がこういう態度で望んでいくことによって、このできてまだ間もないデータサイエンスという分野がもっと洗練され、正しく周りからも尊敬され、必要な予算と注意が払われるようになっていくのだと思います。
データの収益化によるビジネスの成長
Fueling growth through data monetization - McKinsey & Company - Link
マッキンゼーから、データとアナリティクスの使用がビジネスにどう影響を与えているかについての聞き取り調査の結果をまとめたレポートが最近出ていました。
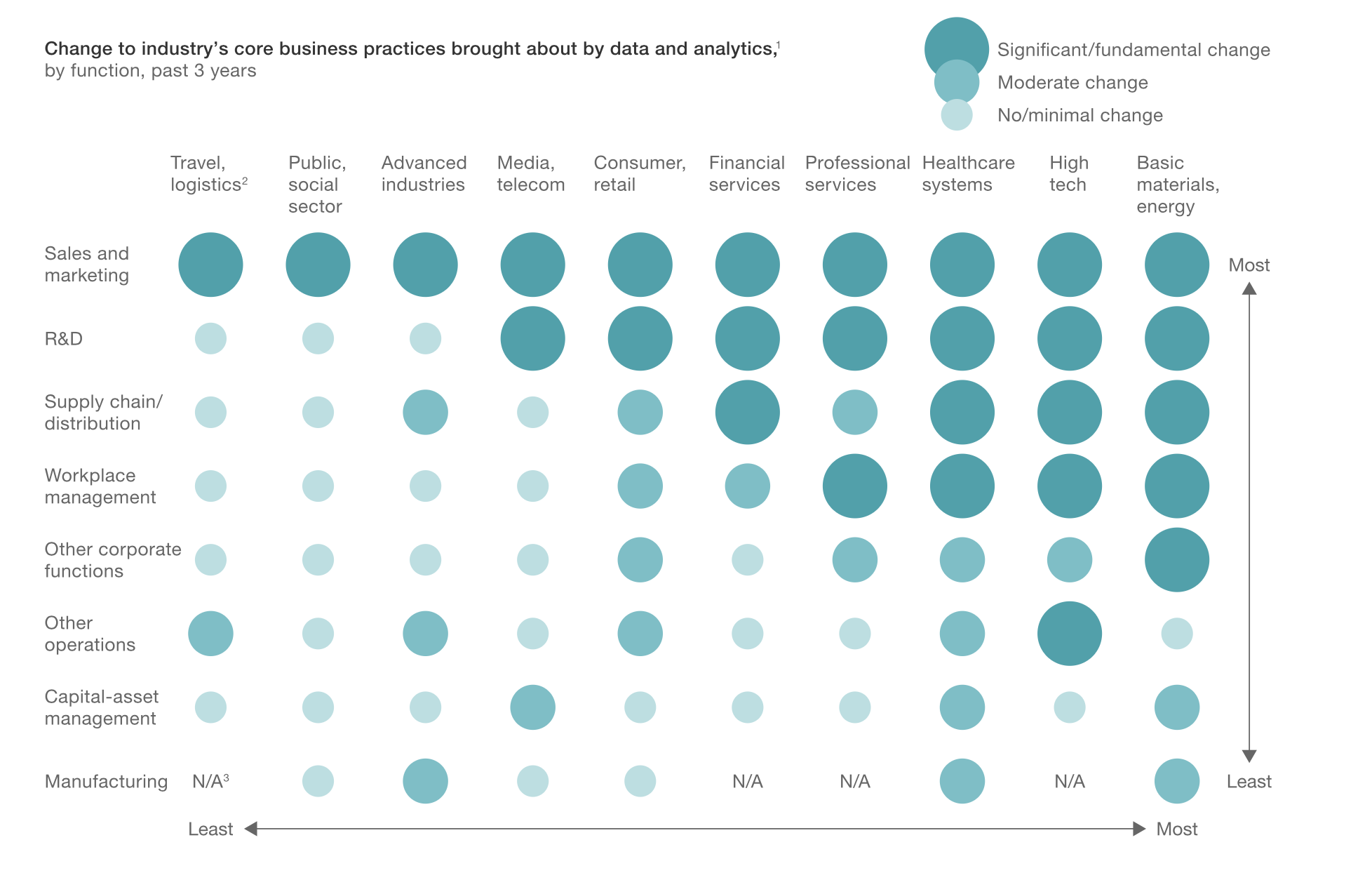
以下のチャートにあるように、業界、部門によってデータの使用が及ぼす影響度に差があるようです。影響が高い業界は、資源、エネルギー、ハイテク、ヘルスケア、コンサルティングで、影響が高い部門は、営業とマーケティング、R&D、サプライチェーン・流通といったところのようです。
データとアナリティクスが市場での競争にどう影響しているかとの質問では、とアナリティクスを使いこなす新しいタイプのビジネスを脅威として一番に上げているところが、現実を表していると思います。やはりスタートアップのように積極的にデータサイエンスを使いこなしてくる新しいビジネスが既存のビジネスを飲み込んでいっているいう構図があるということでしょう。
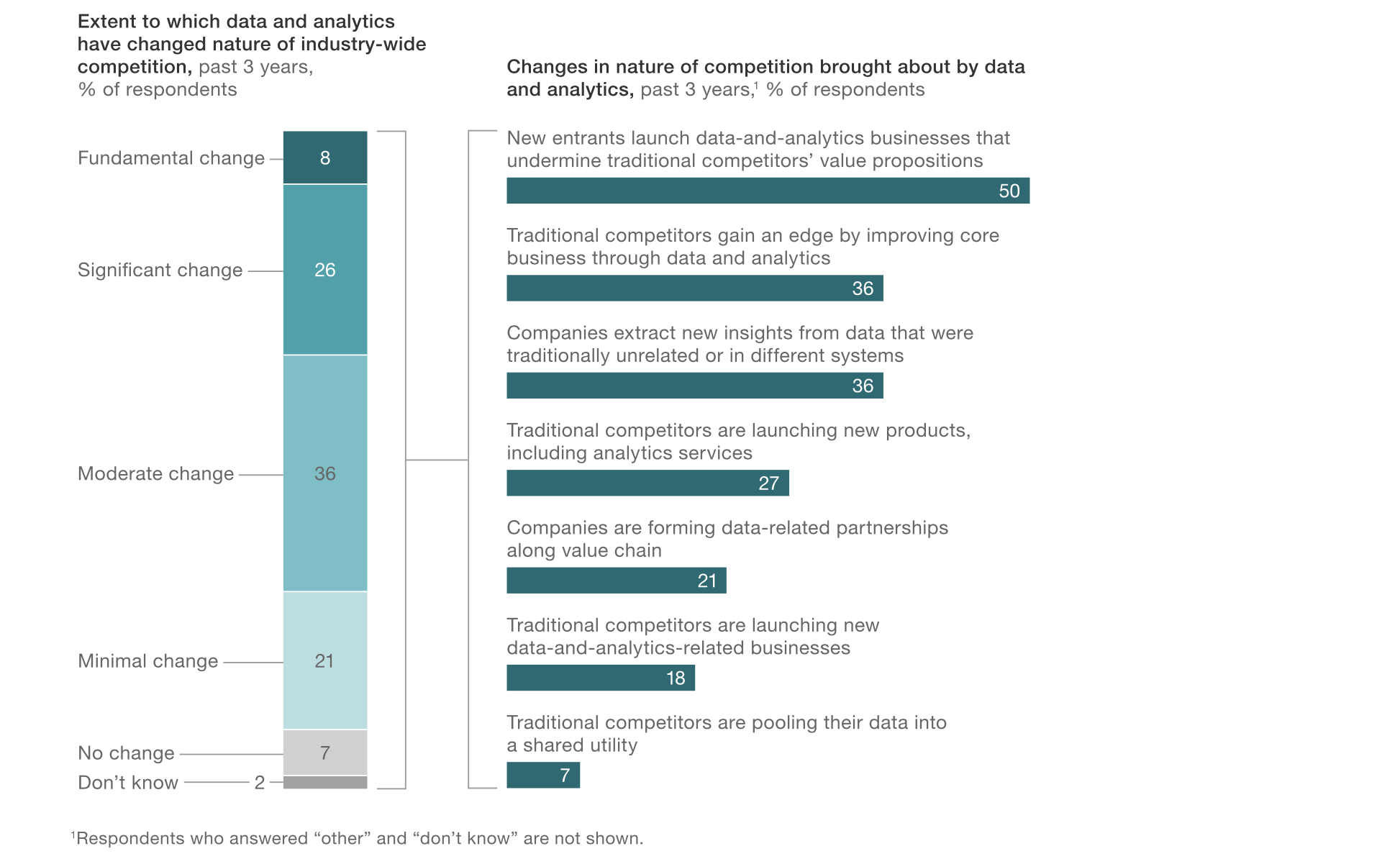
こちらに関しては、以前データサイエンスのすゝめ-シリコンバレーに全てを飲み込まれる前にという記事の中に詳しく書きましたので、興味のある方はぜひご参照下さい。
タレント
USでは相変わらずデータサイエンティストを獲得するための競争が激しいですが、さらにデータサイエンスだけでなく、広い意味でのデータ分析ができる人材でさえ、採用が年々大変になってきているようです。去年は大変だと答えていた人が全体の48%だったのに対し、今年はその割合が60%になっています。さらにデータサイエンスの技術を理解し、ビジネスのドメイン知識も高いような、ビジネスとアナリティクスの架け橋になれるような人材がデータ分析のチームのリーダーシップに必要なのですが、そうした人材はさらに見つけるのが大変なようです。
ここは私も共通の認識です。残念ながら現状はデータサイエンティストはデータサイエンスの技術的、数学的な部分は得意なのですがビジネスの知識、経験を学ぶ機会が与えられてなく、ビジネスのドメイン知識、経験のある人間はデータ分析に関してはデータサイエンティストに丸投げの状態です
これからは、もっとデータサイエンティストを会社の隅の方に隠すのではなく、ビジネスの現場にどんどん送り出すという努力と、ビジネスサイドの人間にある程度のデータサイエンスの知識を教えていくという努力の両方を行っていくべきだと思います。この辺は、こちらのWeekly Updateの方で、HotelTonightというスタートアップでデータ分析部門を率いているAmandaからのアドバイスとして以前紹介しましたので、見ていただければと思います。
リーダーシップ
データとアナリティクスを使った意志決定を社内で浸透させるというのは、やはりトップのリーダーシップとコミットメントが求められます。しかし、ただ単に社長や重役が4半期に一回そういった号令を出すというのでは結局は何も変わらないわけです。ここでの調査によると、データとアナリティクスをうまく使いこなしている企業の重役は彼らのミーティングの時間の20%は社内のデータとアナリティクスに関する活動に関する議論に費やしているようです。
Netflixがレコメンデーション・アルゴリズムのクオリティと開発のスピードを上げる仕組み
Innovating Faster on Personalization Algorithms at Netflix Using Interleaving by Netflix Tech Team - Link
日本にもすでに入ってきて人気があるようですが、Netflixという映画やテレビ番組のストリーミングを行う会社がシリコンバレーにあります。ここはその昔、Netflix Prizeという、一億円ほどの賞金をかけたレコメンデーション・エンジンの精度を上げるコンテストをやったり、ユーザーの映画の嗜好データを使うことで、人気が出るかどうかをわかった上でオリジナルの映画・テレビ番組の作成を行っていることでも有名です。
そんな彼らが最近映画のレコメンデーションの品質を上げるためにどうやってアルゴリズムを作っているのかを発表してました。
ちなみに、レコメンデーションのアルゴリズムと言ってもNetflixではいろいろあります。以下のようなNetlifxの一般的な画面ですと、最初の行に出てくるレコメンデーションはユーザー一人ひとりの履歴をもとにしたランキングにもとづくレコメンデーションになりますし、2行目のトレンディングでは、最近Netflixのユーザーの間で何が流行っているのかというランキングをもとにしたレコメンデーションになります。
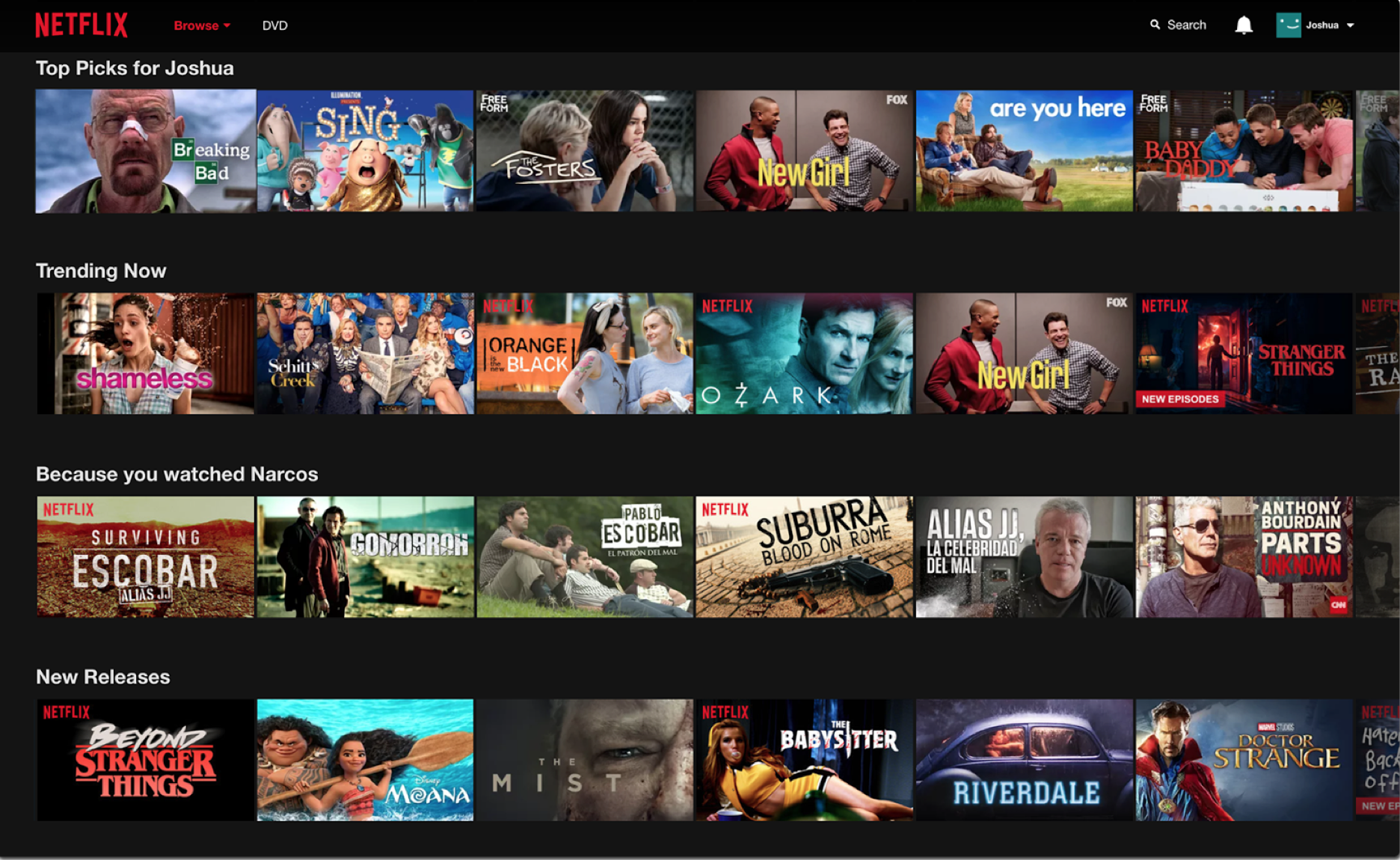
普通こういったものは、いくつものアルゴリズムを作ってその中からどれが一番いいのかをA/Bテストなどをして決めていくのですが、Netflixではこのテストを二つのフェーズに分けているようです。
最初のステージではもっとも結果の出そうなランキングのアルゴリズムを、インターリービングという手法を用いてピックアップします。そして2番めのステージで長期的に重要な指標をもとにしたいわゆるA/Bテストを行います。
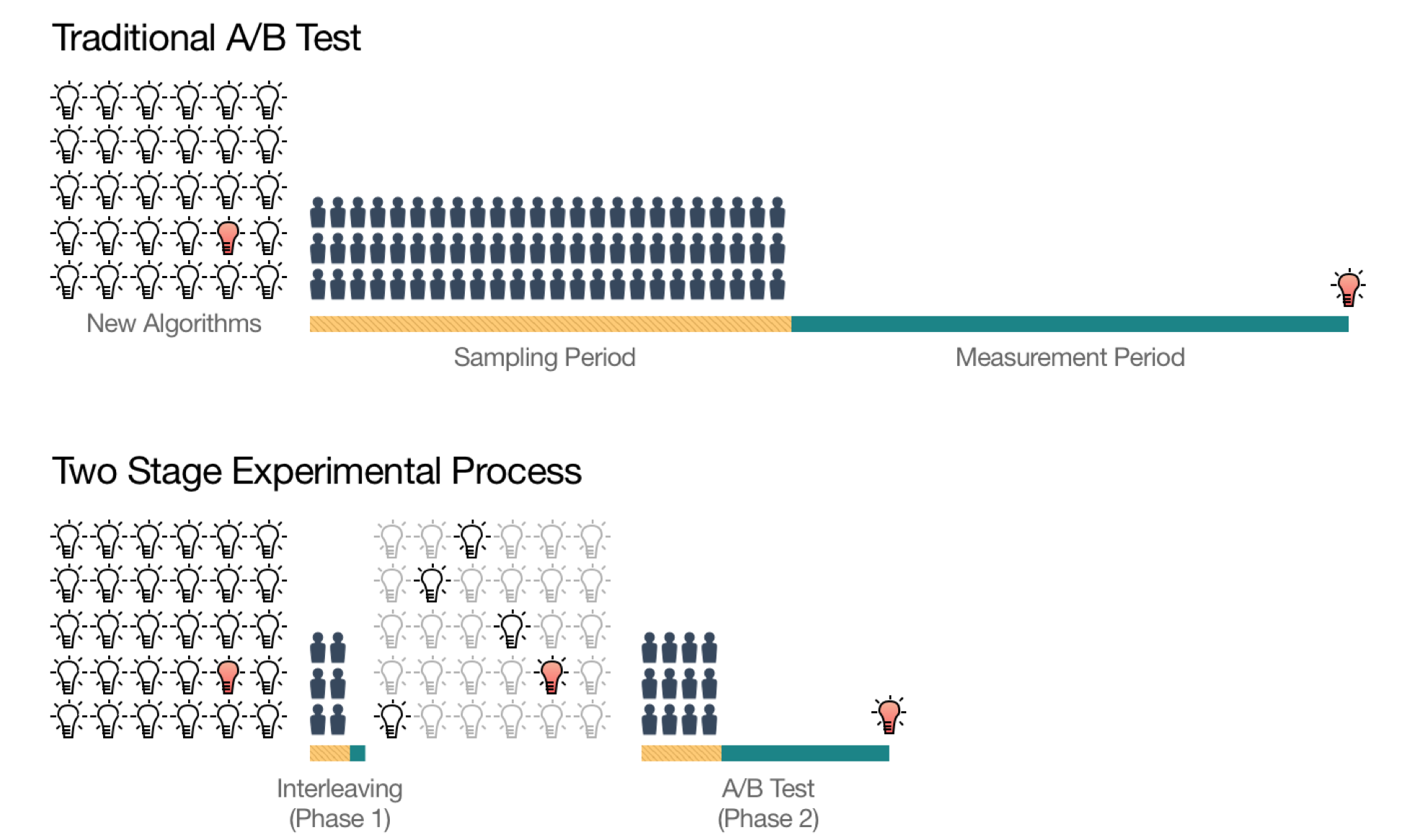
このやり方がいいのは上のチャートにもあるようにインターリービングのフェーズですでに可能性のあるアルゴリズムの数を絞ってしまうので、その後のA/Bテストのフェーズではテストするユーザーの数と期間が、最初から全てのアルゴリズムをA/Bテストにかけてしまう場合に比べて、大幅に短縮されるということです。
それでは、インターリービングとはそもそも何なのでしょうか。
普通のA/Bテストでは、二つのアルゴリズムAとBがあったとすると、一部のユーザーをアルゴリズムAにアサインして、別のグループのユーザーをアルゴリズムBにアサインした上で、二つのアルゴリズムのパフォーマンスをそれぞれのグループのユーザーのアクティビティをもとに評価します。ただ、このユーザーのグループ分けの際に、グループAとグループBのユーザーの特徴を同じにするというのがかなり難しいということが問題になります。
それは、あるユーザーはものすごく視聴時間が長いかもれしないし、あるユーザーは視聴時間は短いかもしれないがたくさんの番組を見るかもしれません。さらに、このものすごく視聴時間が長いユーザーというのは全体から見ると少しの人数しかいないかもしれませんが、全視聴時間の合計からすると大きな割合を占めているかもしれません。つまり、こうしたユーザーが、分析の結果に必要以上に影響を及ぼしてしまうということが起きます。
インターリービングでは、それぞれのユーザーを二つの別々のアルゴリズムのグループに分けるのではなく、どのユーザーも両方のアルゴリズムに触れるようにします。
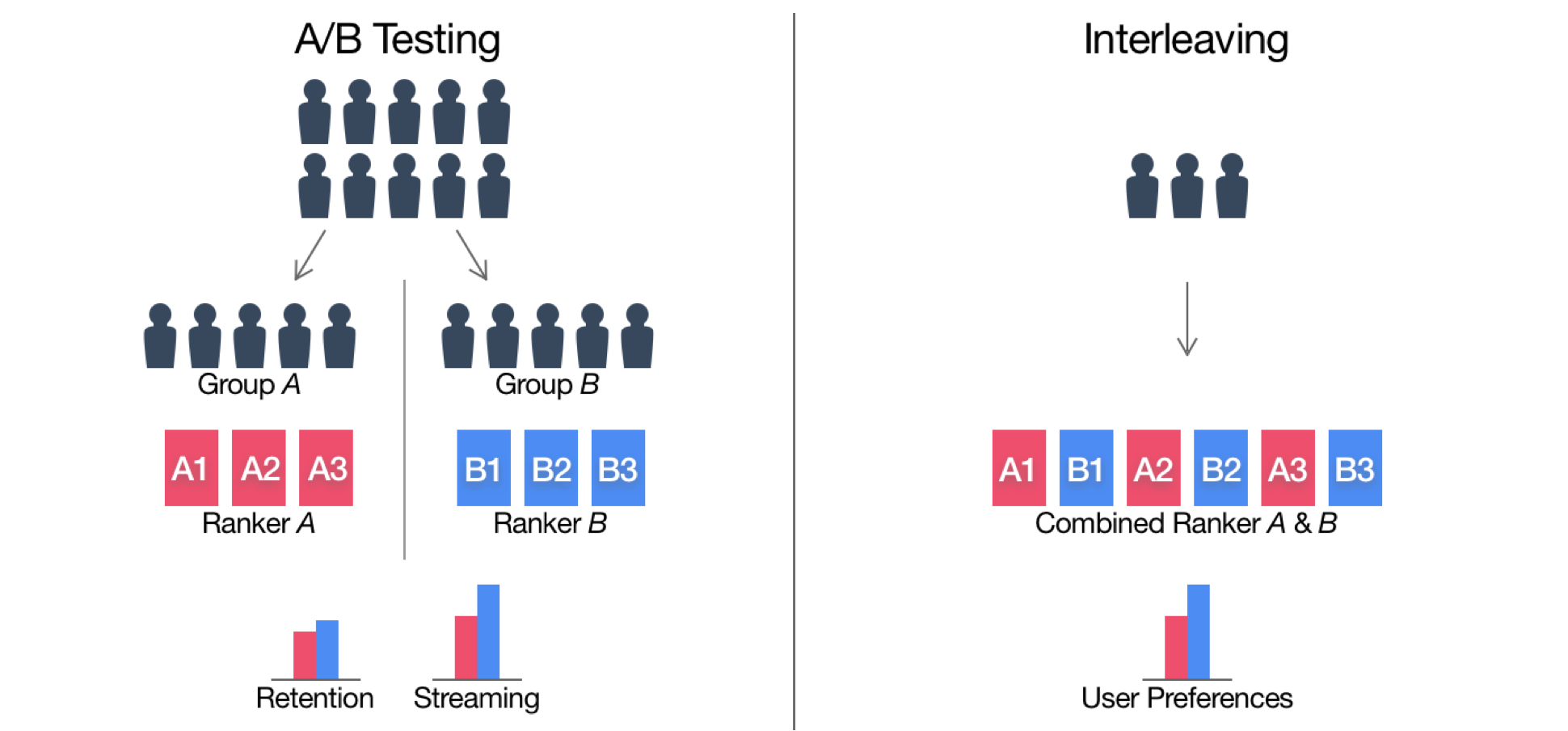
例えば以下のようにA(ピンク)とB(青)の2つのレコメンデーションのアルゴリズムがあったとします。それぞれがレコメンドする映画とそのランキングは少し違います。

そしてそれぞれのアルゴリズムによってレコメンドされる映画を以下のように交互に提示します。
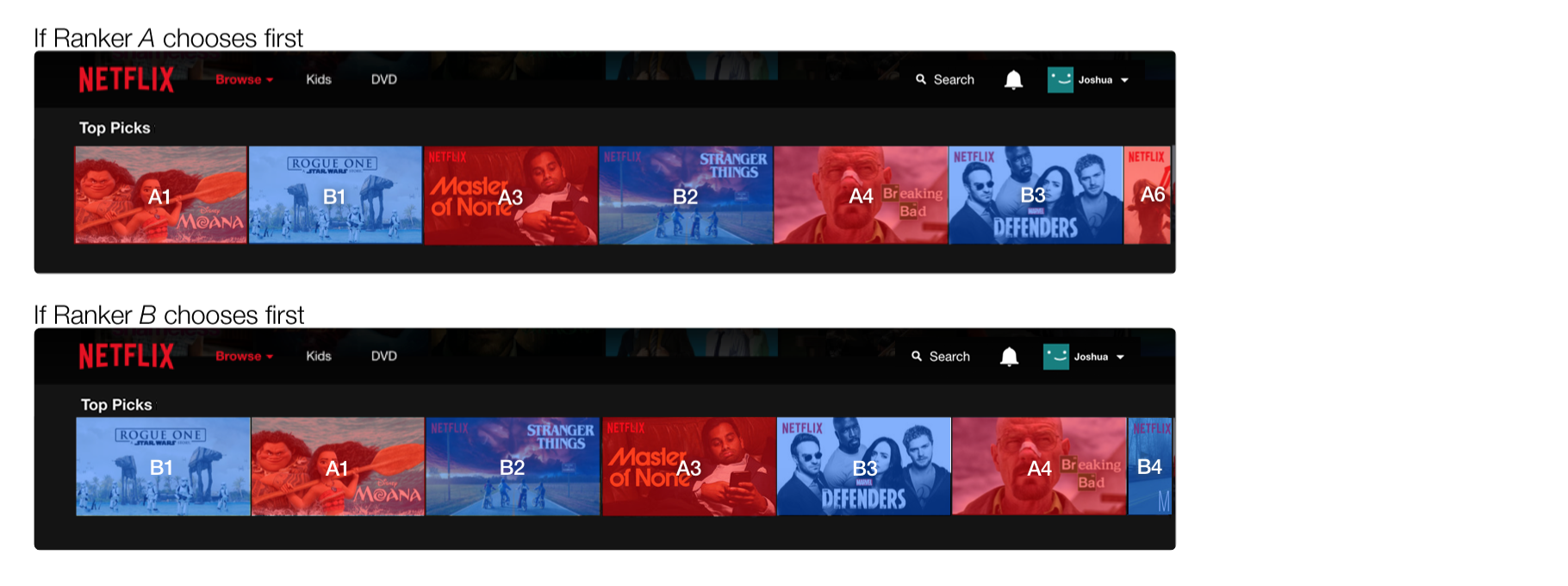
こうしてそれぞれのユーザーがどちらのアルゴリズムでレコメンデーションされたものをどれだけの時間視聴したかという情報をモニターすることで、どちらのアルゴリズムがよいかを判断します。
こうして、ユーザーを別々のアルゴリズムのグループに分けた際に生じる不均衡という問題を解決しているわけですが、このインターリービングの手法にも限界があります。というのもそれぞれのユーザー毎の好みのアルゴリズムという情報が分かるのはいいですが、ユーザーのリテンション、エンゲージメントなどという長期的なビジネスにとって重要な指標にどう影響するのかを判断するには、アルゴリズムAに割り当てられたユーザーとアルゴリズムBに割り当てられたユーザーのアクティビティを比べる必要があるからです。
Netflixはこの評価を、2つ目のフェーズで行う一般的なA/Bテストで行っています。
私も映画、テレビ番組を見るときはよくNetflixを使いますが、NetflixのレコメンデーションはApple、Amazon、Googleなどに比べてもほんとにクオリティが高いですが、こうして現状に満足せず絶えず改善をしているところがすばらしいと思います。なんといってもこのレコメンデーションこそが、今日におけるプロダクト、サービスのユーザー・エクスペリエンスそのものになり得るわけですから、もちろんここにしっかりと投資をするというのは、ビジネス的にも理にかなっていると思います。
興味深いデータ
過去20年に及ぶセクハラの苦情データ
USには仕事場で起きたセクハラを報告する仕組みがあって、それをthe U.S. Equal Employment Opportunity Commissionがまとめているのですが、そこからBuzzFeedというメディアの人たちが 1995年から2016年におよぶ20年ほどのデータを取ってきて、公開しています。被害にあった人たちの、性別、年齢、人種、出身国、働いていた企業のカテゴリーなどと言った属性のデータがあります。このデータに基づくBuzzFeedによる記事はこちらにありますが、分析の方はあまり大したことないので、誰かチャレンジしてみませんか?
レストランの顧客来店データ by リクルート
データサイエンスのコンテストを行うKaggleのほうで日本のリクルートからレストランの将来の来店顧客数を予測するコンテストが現在行われています。1月30日が締め切りで、賞金総額としては総額$25,000(約280万円)となっています。コンテストに参加するしないに関わらず、こちらで提供されているレストランの過去の顧客による予約、来店に関するデータは分析、データラングリングの練習にちょうどいいと思います。さらに他の人達が共有しているEDA(Exploratory Data Analysis/探索的データ分析)の結果は参考になると思います。例えばこのあたりがおもしろいです。
- Be my guest - Recruit Restaurant EDA - Link
ブログ記事 from Team Exploratory
先週は最近異様な盛り上がりを見せているビットコインの値段のデータの分析に関する記事を書きました。現在は英語版しかないのですが、興味のある方はぜひご覧ください。
What Are We Working On?
相変わらず次期バージョン、v4.2の開発を猛ピッチで進めています。
PCA (主要因分析)というデータサイエンスの世界では有名なアルゴリズムがありますが、こちらがアナリティクス・ビューに次期バージョンより追加されます。たくさんの変数(列)があるときなどに、変数どうしの相関関係を見たり、それをもとにデータをクラスタリングしたりすることもできる便利なアルゴリズムです。
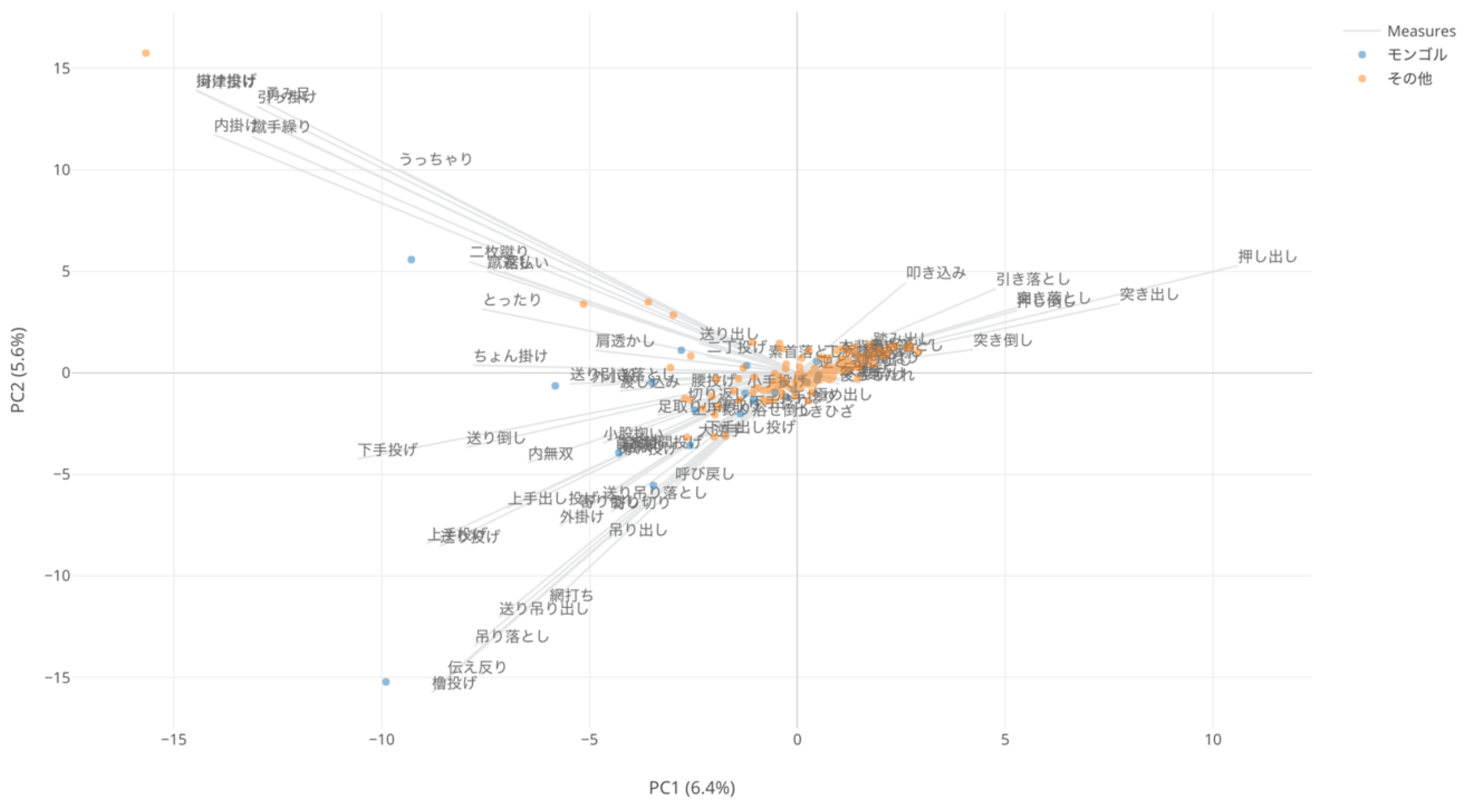
上記のチャートはPCAを使って先週のWeekly Updateでお伝えした相撲の対戦結果データから得意技の類似を見ようとするものです。
データサイエンス・ブートキャンプ・トレーニング
冒頭にもお伝えしましたが、来年1月中旬に開催のデータサイエンス・ブートキャンプの残りの席があと僅かとなっておりますので、参加をご検討されている方はお早めにお申し込みくださいませ。詳しくはこちらのブートキャンプ・ホームページをご覧ください。
それでは、今週は以上です。
素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)