
こんにちは、Exploratoryの西田です。
私はサンフランシスコからゴールデンブリッジを渡ってちょっと北へ行ったところに住んでいるのですが、先週はナパ、ソノマでの山火事の影響で町は煙に包まれておりました。多くの人が犠牲になり、現在も避難命令が出ていて、まだ鎮火のめどが立ってない場所が多くあります。私の奥さんの実家もナパの山の中にあるのですが現在避難中で、家は無事なのか、いつ帰れることになるのか、などと心配の日々です。犠牲になられた方にはこの場を借りてご冥福をお祈りしたいと思います。カリフォルニアはこの時期になると毎年何処かで山火事が起きるのですが、ここまで身近で大きなものを個人的に経験するのは、こちらに17年住んでる中でも初めてです。あらためて、こうした自然災害に対する人間の非力さを感じます。
これを読んでいる方のご家族、お知り合いの方などにナパ、ソノマ近郊に住んでる方がいらっしゃるかもしれませんが、みなさんの無事を祈ってます。もし何かこちらでサポートできることがあれば連絡してきてください。
それでは、気を取り直して、今週も行ってみましょう。
最近の興味深い英文の記事
R言語のものすごい成長
The Impressive Growth of R - URL
Stackoverflowというテック系の人なら誰もがお世話になったことのあるQ&Aウェブサイトがありますが、そこのデータサイエンティスト、David Robinsonが彼のチームのお気に入りのデータ分析の言語であるRが、どのようにここ数年の間に急速に成長してきたかということを、Stackoverflowで飛び交う質問と答えのデータから分析しています。
数週間ほど前に別のプログラミング言語であるPythonもものすごく成長しているという分析をしていたのですが(リンク)、Rもそれと同じスピードで成長しています。他の様々な用途に使える一般的なプログラミング言語に比べて、Rはデータ分析のためだけに使われる言語ですので、これは特別にすごいことだと思います。
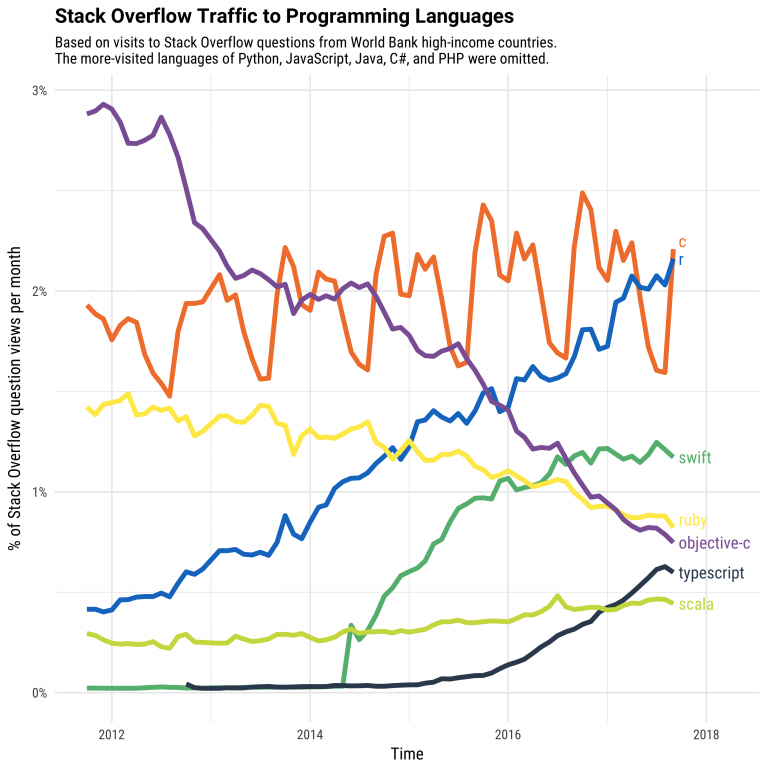
質問の多いトップ5の業界は大学、ヘルスケア、政府、コンサルティング、保険となっています。Rの成長はテック系の企業ではPythonほどではないようです。Rを使うということは様々なパッケージを使うということになるわけですが、そんな中でトップ3のパッケージは、dplyr、ggplot2、data.tableの順です。知ってる方も多いと思いますが、Exploratoryの中で、データ・ラングリング(加工)する時に使うのが、実はこのdplyrのコマンドなのです。ggplot2はRを使ってデータを可視化する時によく使われますが、ExploratoryでもMarkdownでノートを作る時に使えます。こちらにサンプルがあります。
SpotifyのDiscover Weekly: 機械学習がどうやってあなたが好きになる新しい曲を見つけるのか - 音楽レコメンデーション・エンジンの仕組み
Spotify’s Discover Weekly: How machine learning finds your new music The science behind personalized music recommendations - URL
日本ではどれだけSpotifyという音楽のストリーミング・サービスが人気があるのか知りませんが、こちらUSでは大変人気です。その中で、Discover Weeklyというパーソナライズされた音楽のレコメンデーション機能があるのですが、そこでどのようにデータサイエンスの手法が使われているのかをまとめてくれています。
大きく以下の3つの手法を組み合わせているようです。
- Collaborative Filtering models (協調フィルタリング)
- Natural Language Processing (自然言語処理) models
- Audio (音響)models, 生の音を分析しています。
Colaborative Filtering (協調フィルタリング)はNetflixがレコメンデーションエンジンに使ってたことで、(今ではさらにもっと高度にいろいろ組み合わせたものを使っているらしいですが。)有名になりましたが、実は比較的昔から存在するテクニックです。要は、全てのユーザーと全てのプロダクト(好きな曲や映画など)のかけ合わせた表みたいなものを作って、どのユーザーがどのプロダクトを好きかという情報から、似たようなユーザーを見つけ出し、それをもとに、あなたがまだ見ていない曲や映画の中から、あなたと似たような人が好きと言っている曲や映画をレコメンドするという手法です。よくあるのは、ユーザーが’いいね’や星(スター)のボタンをクリックするかどうかでその曲や映画が好きかどうかを判断しますが、音楽の場合にはさらに、その曲をプレイリストに入れたか、ダウンロードしたか、最後まで聞いたかといったことを考慮します。
2番めの自然言語処理ですが、Spotifyは常にウェブをクローリング(crawling)して様々な曲やアーティストに関して話しているブログやウェブサイトの記事などを集めているようです。こうして集めたテキストのデータから、似たような曲やアーティストを探し出します。(Exploratoryのユーザーは、CosineSimilarityに関する記事などでこの辺のやり方を見たことがあるかもしれません)
そして、最後のそれぞれの曲の音響データの解析ですが、ここでDeep Learningの一つのアルゴリズムであるConvolutional Neural Networks: CNN(畳み込みニューラルネットワーク)を使っているようです。こうして、まだリリースされたばかりで、ユーザーの評価もブログ等の記事もまだほとんどないような曲でも、うまくユーザーの好みに合わせてレコメンドすることを可能にするのに役立っているようです。
ちなみに、これがSpotifyのデータ分析とレコメンデーションシステムの構築のためのデータ・パイプラインです。
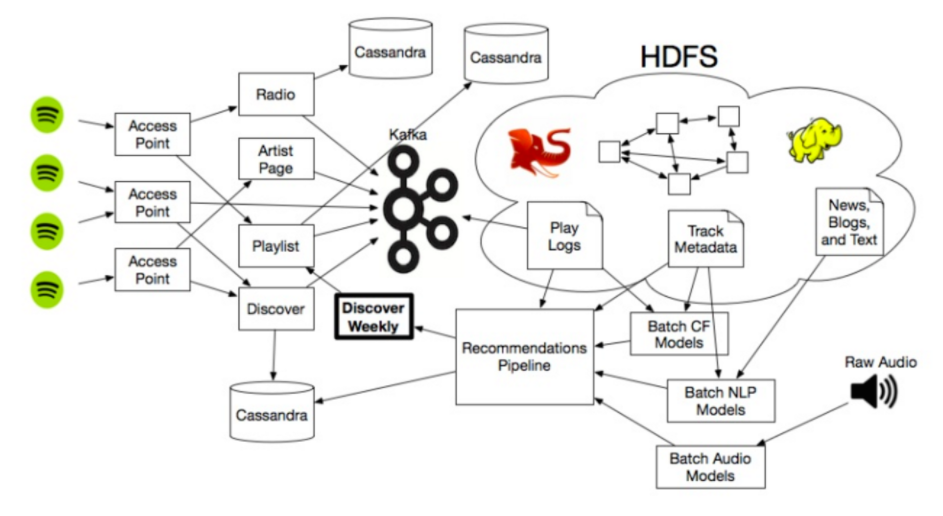
右半分の部分がこのレコメンデーションの構築に当たる部分です。
AIを医療に応用する - ここまでの私達の成果
Applying Artificial Intelligence in Medicine: Our Early Results - URL
Apple Watchのセンサーが認識することのできるシグナルをもとに、不整脈の一種の心房細動を早期発見することのできるアルゴリズムを開発したチームが、これまでの成果を共有してくれています。ここでもディープラーニングを使っていますが、このモデルはAUCが0.97、Sensitivityが98.04%、Specificityが90.2%といった結果を出せるようです。(私どものブートキャンプに来られた方たちは、覚えていますか?例のAUCです。)
ディープラーニングを使っているので大量のデータが必要ですが、やはりこのデータを集めるということが一番のチャレンジのようです。グーグルやフェイスブックのような、リンクをクリックしたか、してないか、というデータと違って、こうした医療のデータは一人一人がほんとに心筋梗塞だったのかどうかといったようなまさに人の命がかかったデータになります。ですので、こうしたデータを上手く既存の医療機関とパートナーシップを結んでとってくるか、自分たちでテストのためのデバイスを被験者に無料で配るかということになります。この人たちは後者のようですが。
Machine Learning Vocabulary - URL
英語になりますが、Googleが最近、機械学習に関する単語の辞書のようなものを作っています。参考までに。
興味深いデータ
USの山火事のデータ - URL
Monitoring Trends in Burn Severity (MTBS)
アメリカ国内の1984年から2015年までの間の2万ヶ所以上にのぼる場所で確認された山火事のデータです。もっと最近のデータは基本的にはイメージデータになりますがGeoMACなどにあります。上記のページからだとShapefileという地理データを扱うためのフォーマットでのダウンロードになりますが、こちらに私どもがRを使ってCSVのフォーマットに変換したものを共有してあります。
サンフランシスコ湾の水質に関するデータ - URL
こちらはサンフランシスコ湾の水質を湾の中の30ほどの観測地点毎に測ったデータですが、1969年から2015年までとかなり長い観測期間となっています。station, depth, temperature, and salinity、chlorophyll, oxygen, nitrate, ammoniumなどの指標があります。やはり、サンフランシスコに近いあたりの水が一番冷たいようです。この辺でトライアスロンのトレーニングで泳いでたことがありますが、むちゃくちゃ冷たかったです。(笑)
USでの抗議、プロテスト、意思表明等の集会のデータ - URL
こちらUSでは大統領がトランプになって以来、特に最近色んな所で頻繁に集会が行われていますが、ボランティアの人達がどういった集会なのか、何人くらい来ていたのかという情報を、日付、場所とともに月単位で集計し、公開しています。
ブログポスト from Team Exploratory
- 過去70年間、アメリカが国連でどう孤立していったのか - URL
- 国連に参加している国々を、DistanceとMDSアルゴリズムでクラスターしてみる - URL
- 決定木(Decision Tree)をRパッケージを使って可視化する - URL
あと、こちらに日本語のExploratoryを始める際のチュートリアルがありますので、もしまだの場合は、ぜひ試してみてください。
- Exploratory クイック・スタートガイド - URL
What Are We Working On?
いよいよ今週にv4.1をリリースの予定です。今までにもお見せしてきたように、いろいろと新しい機能が入ってますが、そのうちの一つに回帰分析がアナリティクスUIからもできるようになります。
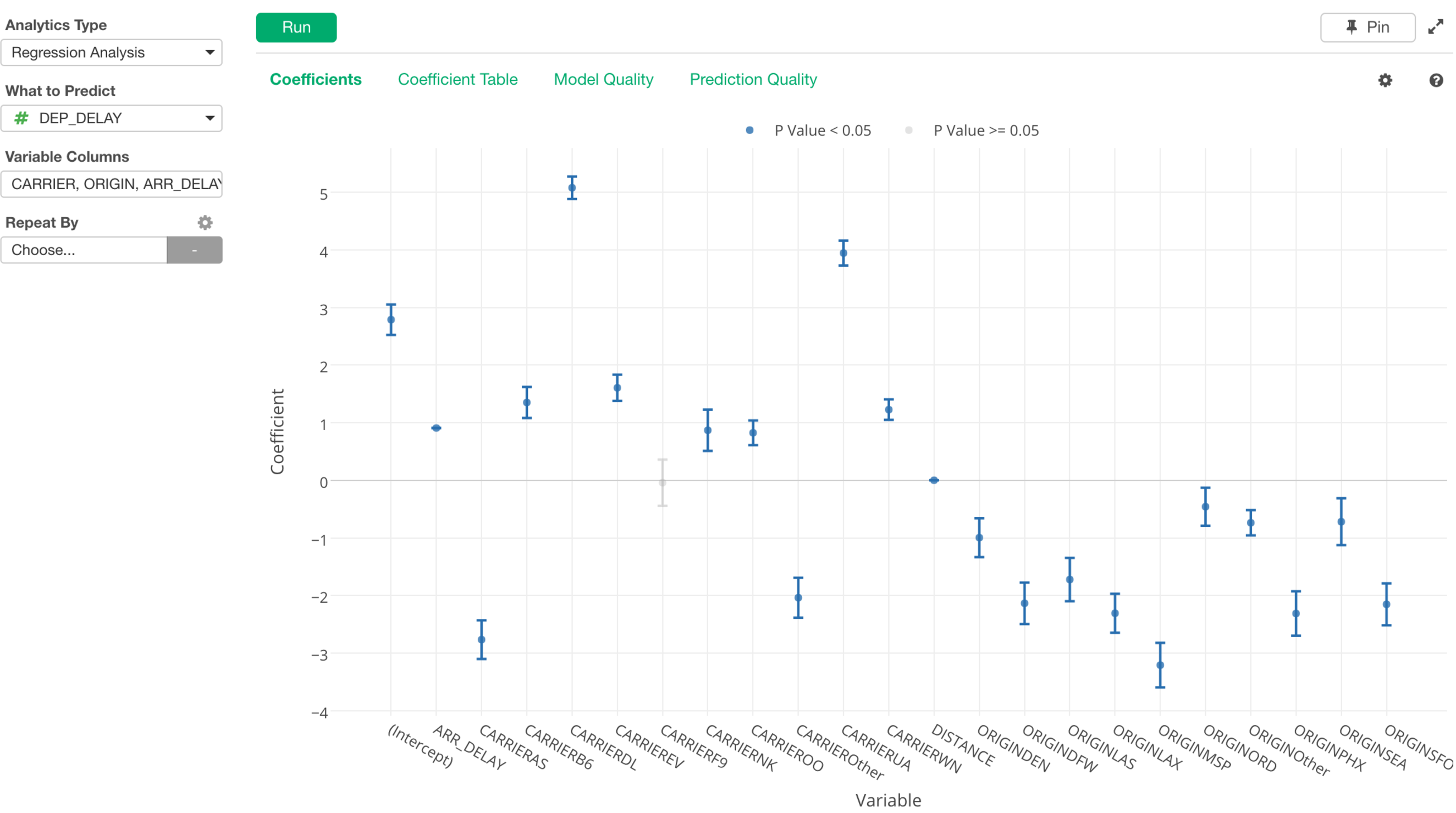
どの変数(列)が予測したい数値の結果に対してどれくらいの影響力があるのかを簡単に見たいときなどに便利です。
過去のアーカイブ
今までに送ってきたWeekly Updateのほうがこちらにアーカイブとしてありますので、もし周りにも興味のある人がいらっしゃったらぜひ共有してみてください。
それでは、素晴らしい一週間を!
西田, Exploratory/CEO