
こんにちは、Exploratoryの西田です。
さっそくですが、Exploratory DesktopのWindows32ビット版のサポートはじめました。詳細とダウンロードのリンクはこちらのページにありますので、仕事場で32ビット版しか使えないという人はぜひ試してみて下さい。
さらに、この6月に東京で開催するデータサイエンス・ブートキャンプ・トレーニングですが、今月末で早割のほうが終わるので、参加を検討されている方はこの機会にお早めにお申し込み下さい。詳細は下記よりご参照ください。
ところで今週は、データサイエンス、AI業界にとって、ターニングポイント(潮の変わり目)となるほど重要なエッセイがUC Berkeleyの教授で、統計、機械学習、AIの研究者でもあるMichael Jordan(あのバスケのMichael Jordanとは違います。)という人によって先週発表されたので、ここで紹介したいと思います。
ここ最近のビッグデータの世界では標準である、分散型高速データ処理のSparkを開発したのはもともとAMP LabというUC Berkeleyの研究所のチームなのですがそこを率いていた人がこのMichael Jordanです。
その彼が、AIとは何で、さらに何でないのかを解説し、これからは、AI(Artificial Intelligence)ではなく、IA(Intelligence Augmentation)、II(Intelligent Infrastructure)こそが、ビジネスと学問の両方にとっての現実的で急を要する大きな機会であると提唱しています。
これほど重要なエッセイはなかなかないので、長いですが、是非最初から最後まで読んでいただきたいと思います。
最近の興味深い英文の記事
AI- その革命はまだ起きていない
Artificial Intelligence — The Revolution Hasn’t Happened Yet - Link
AIはまるで今の時代の呪文のようで、テクノロジスト(技術者)、アカデミアの人間(学者)、ジャーナリスト、そしてベンチャーキャピタルリストによって日々合唱されています。今までも技術的で学問的な分野が一般の人達に知れ渡るときにみられたように、この単語の使い方にはとてつもない量の誤解が含まれています。しかし、これは一般の人たちが科学を理解しないという昔からの例ではありません。というのも実は、科学者でさえ一般の人達のように困惑しているのです。私達の時代にいよいよ私達と同じレベルの知能がシリコンのチップからでてきたというのは話としてはおもしろく、私達を興奮させ、または恐怖に押しやるものでもあります。しかし、残念なことに、そうした誤解は私達の注意を重要なものからそらしてしまうことになっています。
例として、1つ私の身の回りで起きた話をしましょう。それは人間、コンピューター、データ、生死を分ける意志決定に関する話で、コンピュータの知能というおとぎ話の話ではありません。
14年前に、私の妻が妊娠中のとき、超音波の診断をうけました。部屋にいた遺伝学の先生が言うには、胎児の心臓の近くに白いスポットが見えるというのです。
「それはダウン症のサインで、そのリスクは20分の1です。」
とその先生は言いました。
彼女はさらに、私達が羊水検査(amniocentesis)の処方を受けることで、子供のダウン症につながる遺伝子の異変がほんとに起きているのかをテストできると提案しました。しかし、羊水検査(amniocentesis)の処方にはリスクが伴います。およそ300人に1人の確率で、この処方を受けている間に、子供が死んでしまうかもしれないのです。
私は統計学者であることもあり、こうした診断の根拠がどこから出てきているのかを調べてみることにしました。長い話を短く簡単にすると、これに関する統計的な分析は10年以上も前にイギリスで行われ、カルシウムが溜まったものであるこうした白いスポットはダウン症の予測につながるというものでした。
しかし、それとは別の発見もありました。というのも、私達の病院でのテストに使われていた画像を処理する機械は、先ほどのイギリスでの研究で使われていたものに比べて、1インチ四方あたり数百ピクセル以上も処理能力が優れているものでした。そこで、私は病院に戻って先ほどの先生にその白いスポットはおそらく偽陽性(false positive)、つまりそれらはただの白いノイズである可能性があるということを説明しました。すると彼女は、
「なるほど、どうりで数年前からダウン症と診断するケースが急に増えていたわけだわ。というのも、ちょうどその時期にこの新しい機械が病院に届いたんだもの。」
私達は結局、羊水検査(amniocentesis)はしませんでした。そして、健康な女の子が数カ月後に産まれたのでした。
しかし、この話は私を困った気にさせます。というのも、単純に計算して何千もの人たちが同じ日に私が受けたような診断を受け、多くの人が羊水検査(amniocentesis)をすることを選択し、そこから数多くの死ぬ必要のなかった赤ちゃんたちが死んでしまったのです。そしてこれは、この問題が修正されるまで毎日起き続けていたのです。
この話の問題は、私の個人的な医療処方にあるのではありません。本当の問題は様々な場所と様々な時期にデータを収集しテストを計測し、そのテストの結果に対して統計分析を行い、そしてそこから得られた結論を違う場所、違う時代で使うという医療システムそのものにあるのです。
そこで気づいたのですが、人間という要素を考慮した上で、コンピューターサイエンスと統計の力を使い、地球規模でこの手の推論と意志決定を行えるためのシステムを構築するために必要な学問の分野というのは私の知っている教育の世界では、どこにも見当たらないのです。
医療だけでなく、商業、輸送、教育といったドメインでも必要になるこうした研究分野の開発は、少なくとも、ゲームをプレイしたり、見たり、聞いたりといったスキルのあるAIシステムを構築するのと同様に重要なのです。私達が近い将来に知能を理解できるかどうかに関わらず、人間の生活を向上させるという意味で私達はコンピューターと人間を結びつける必要があるのです。
こうした努力は人工知能の誕生の一部であると思われがちですが、むしろ新しいエンジニアリングの学問の分野の誕生と考えられるべきです。土木工学や化学工学が過去何十年もの間にそうであったように、この新しい学問の分野はいくつかのキーとなるアイデアを結びつけ、新しいリソース(資源、資産)と能力を、安全性を考慮した上で、人間にもたらすことになります。
土木工学、化学工学がそれぞれ物理、化学を土台に構築されたように、この新しいエンジニアリングの学問の分野は、それ以前に生まれた、情報、アルゴリズム、データ、不確定要素、コンピューター処理、推論、最適化などのアイデアを土台に構築されることになります。
土木工学が確立される前に、人間はビルや橋をすでに建てていたように、私達はすでに社会的規模で、機械、人間、そして環境を含んだ、推測と意志決定のシステムを構築しています。初期に作られたビルや橋はときどき倒壊し、予見することのできなかったような悲劇的な結果を招いたのと同様に、私達が現在構築している社会的規模での推測と意志決定のシステムには、すでに深刻な概念上の欠陥があるというのがわかり始めてきました。
現在のこうした問題に関する議論ではAIという単語が、知能のワイルドカードとして非常に頻繁に使われています。このことが、このエリアの新しいテクノロジーの影響範囲とそれによってもたらされる結果に関する議論を難しくしています。そこで、AIという言葉が一体何をそもそも意味するものとして使われてきたのかを歴史的に、そして最近の文脈に照らして整理してみましょう。
今日、特に一般の人たちが使うときのAIという言葉は何十年も前からよばれていた、いわゆる機械学習のことを指しています。機械学習とは1つのアルゴリズムの分野で、統計学、コンピューターサイエンス、と他のたくさんの学問の分野からのアイデアを混ぜあわせることで、データを処理し、予測し、意志決定を助けるためのアルゴリズムをデザインするメカニズムです。
現実世界への影響という意味では、機械学習はすでに現実の世界のもので、それは何も最近のことではありません。実際、機械学習が広く産業の世界で使われることになるのは1990年代初めで、2000年になる頃にはAmazonのような先見的な企業は不正の検出や物流の予測と言ったバックオフィスの問題の解決や、消費者が実際に手に触れることになるレコメンデーションシステムの構築に使ったりしていました。この20年の間にデータとコンピューターの能力が飛躍的に向上するに連れ、機械学習はAmazonのような企業だけでなく、どんな企業でも大規模なデータに基づいた意志決定を可能にするために使えることが明らかになってきました。新しいビジネスモデルの誕生です。
こうした現象を表すのにデータサイエンスという言葉が使われ始めました。それは、大規模で頑丈な機械学習のシステムを作るには、データベースや分散処理の専門家といっしょに、機械学習の専門家が必要であるということの反映であり、そうして作られるシステムが与える大きな社会的、環境的な影響の反映でもあります。
歴史を振り返ると、1950年代にソフトウェアとハードウェアを使って人工的に人間レベルの知能を作り出したいという願望のもとにAIという言葉が誕生しました。この願望を表現するものを「人間のようなAI」とここでは呼ぶことにします。身体的なもの、もしくは少なくとも心理的なものとして、(そもそもそれがどういうものかはさておき)AIというものは私達の一員であるということを強調するためです。
こうしたAIは多くはアカデミックなものでした。関連している学問の分野としてはオペレーショナルリサーチ、統計、パターン認識、情報理論、そして制御理論などがすでに存在しますが、それらも人間の知能(もしくは動物の知能)からインスパイアされたものです。これらの分野は低レベルのシグナルと意思決定にフォーカスしています。リスが自分の住む森を3次元のものとして捉えることができ、枝の間をジャンプすることが出来るというのはこうした分野の研究にとってはインスピレーション(発想の源)なわけです。
ところが、AIはもともと違ったものにフォーカスしようとしていました。それは、理論を構築したり、考えたりするといった人間の高レベルな認知能力です。しかしながら60年たった現在、AIによる高いレベルでの理論や思考といったものはただの幻想に過ぎません。結局、現在AIとよばれるものは、工学関連の分野での低レベルのパターン認識やモーション・コントロールに関するものか、統計学の分野でのデータの中からパターンを検出し、根拠のある予測をし、仮説の検証をし、意志決定に役立てることにフォーカスしたものというのが現実です。
実際、例の有名なバックプロパゲーションのアルゴリズムは、David Rumelhartによって1980年台の初期に再発見されました。今でこそAI革命とよばれるもののコアなものとして位置づけられているこのアルゴリズムは、もともと1950年代、60年代に制御理論の分野で生まれたものです。初期の頃のアプリケーションとしてはアポロ宇宙船が月に向かっていた頃のロケットの推力を最適化するといったものでした。
1960年代以降にこの分野では多くの進展がありました、しかしそれは「人間のようなAI」を追求した結果ではありません。それはアポロ宇宙船の時がそうであったように、これらのアイデアの多くは縁の下的なものであり、ある特定のエンジニアリングの問題を解決することにフォーカスした研究者の手による仕事の結果であったのです。
しかし一般の人たちからは見えないところで、文書検索、テキスト分類、不正検出、レコメンデーション・システム、パーソナライズ・サーチ、ソーシャルネットワーク分析、計画、処方、A/Bテストなどの分野での研究やシステムの構築は大きな成果を生み出しました。こうした進展が後のGoogle、Netflix、Facebook、Amazonなどの企業の原動力となっていったのです。
こうしたもの全てはAIであると単純に主張する人もいるでしょう。そして、実際のところそうした主張は世の中に受け入れられてしまったようです。こうしたラベル付けはもともと最適化や統計の研究を行っていた人たちにとっては驚きであったかもしれません。というのも、ある朝起きたら突然自分たちがAI研究者と呼ばれることになってしまったのですから。しかし研究者のラベル付けはさておき、もっと大きな問題は、間違った定義をもとにした、何にでも使われるこのAIという文字は、知能とビジネスをまたぐ問題を正確に理解するのを難しくします。
この20年の間に、産業界と学問の世界の両方で、「人間のようなAI」に対する願望を補完するものとして、よく“Intelligence Augmentation(拡張知能)” (IA)とよばれるものには大きな進展がありました。この分野ではコンピュータ処理とデータが、人間の知能と創造性を拡張するためのサービスを作るために使われます。
人間の記憶と正確な知識を拡張するサーチエンジンがIAのいい例でしょう。自然言語翻訳も、人間の意思疎通能力を拡張するものとして捉えることができます。コンピュータを使った音とイメージを生成するようなサービスもアーティストにとっての素材と創造性を強化するものとして使われます。この手のサービスは将来どこかの時点で、高度な理論構築と思考を含むことになるかもしれませんが、現在はそうではありません。というのも、多くの場合、様々なタイプのテキストの組み合わせや数字の計算を行うことで人間にとって役に立つパターンを発見するということにとどまっているのが現実です。
ここでまた新しい頭文字となってしまうのですが、知能インフラ(II - Intelligent Infrastructure)という分野を私はここで定義したいと思います。それは人間の世界をサポートし、おもしろいものとし、さらに安全なものとするためのコンピュータ処理とデータと物理的なものが絡み合ったものです。
そうしたインフラは輸送システム、医療、商業、そして金融の分野ですでに出現してきました。それは、個人や社会に大きな影響を及ぼすことになるものです。この概念はIoT(Internet of Things/モノのインターネット)に関しての会話の中にときどき出てきます。しかしIoTに関する話しの多くは「もの」をインターネットに持っていくときの課題に関するものがほとんどで、これによって集められることになるデータを分析することで世界の事実を発見することができる「もの」に関する課題や、そして人間と他の「もの」が双方向に対話することによって起きうる、もっと抽象的で高いレベルの課題に関してのものではありません。
例えば、冒頭で話した私の個人的な話のように、私達の生活は社会的なスケールの医療システムの中に取り込まれているわけですが、そうしたシステムでは、デバイスが人間の体の中や周りに置かれるているので、絶えず流れているデータを絶えず分析することで、処方しケアを与える人間、つまり医者の知能をサポートすることになります。そのシステムは体の細胞、DNA、血液テスト、環境、遺伝といったデータや、薬や治療に関する多くの科学文献といったもの全てからの情報を取り組むことができます。
今の医療テストが一部の人や動物に対して行われた実験の結果を他の人達にも適用するのと同じで、一人の患者と一人の医者だけにフォーカスするのではなく、全ての人間の関係にフォーカスすることになります。それは妥当性、起源、信頼性といったものを保証するのに役立つでしょう。それは金融と支払いに関する問題にフォーカスしている今の銀行システムと同じようなものです。
この分野ではこれから、プライバシー、責任、安全などの多くの問題が生じてくると思いますが、そこであきらめるのではなく、解決すべき問題として捉えることでさらに進展していくことが出来るでしょう。
ここで重要な問題を提起することになります。
古典的な意味での「人間のようなAI」の研究を続けることがほんとうにこうした大きな問題を解決するための最良の方法なのでしょうか?
いくつかの熱狂的に歓迎された最近の機械学習の成功話は、コンピューター・ビジョン、スピーチ認識、ゲーム、ロボットなどの分野での「人間のようなAI」に関するものです。もしかしたら、私達はこれらのドメインのさらなる発展を待つべきなのかもしれません。
しかし、それには二つの注意点があります。
一つ目は、ニュースメディアを読んでいるだけでは知ることはないかもしれませんが、「人間のようなAI」を作るという視点からすると、それらの成功は実はまだたいへん限られていて、「人間のようなAI」を作るというビジョンからはまだはるかに遠いところにいるのです。しかし残念ながら、「人間のようなAI」を作るということに関しては、その進展がわずかでも、そのスリルと恐怖は他のエンジニアリングの分野では現在見られないような、ものすごい興奮とメディアによる注目をよびおこします。
二つ目は、実はこれこそが重要な点なのですが、こうした「人間のようなAI」を作るという分野での成功は、IAやIIの問題を解決するのに十分でない、もしくは必要ですらないという点です。充分でないかどうかということに関して自動運転を考えてみましょう。自動運転のテクノロジーが実際に実用可能になるには、多くのエンジニアリングの問題が解決される必要があり、それらは人間の持つ能力とはほとんど関係がありません。自動運転を支える全体的な輸送システム(つまりIIの問題)は、いつも前を向いて運転する、連携の取れていない不注意なドライバー達の集まりから学ぶよりも、現在の航空管制システムから学んだほうがいいでしょう。ただここで必要になるシステムは現在の航空管制システムよりももっと複雑で、特に細かい意志決定のための情報の生成に欠かせない大量のデータと適応能力のある統計モデリングが必要とされます。ですので、こうした問題やハードルこそが注目されるべきで、こうしたときに「人間のようなAI」というのは私達の注意を問題の本質からそらすことになるだけなのです。
これに関連した議論としては、人間の知能こそが、そもそも私達の知っている知能というべきものなのだから、まずは最初のステップとしてそれを復元することを目指すべきというのがあります。しかし、私達はあるタイプの理論構築はあまり得意でありません。私達は間違えることがよくありますし、バイアスをもっていますし、限界もあります。さらに、そしてこれが致命的に重要なのですが、これからのIIシステムが行う必要のある大規模なスケールでの意志決定ができるように、もしくはそういったシステムの中で起きてくる不確定要素に対応できるように、私達人間は進化してきたわけではないのです。
AIシステムは人間の知能を真似するだけでなく、それを修正することも出来、さらに大きな問題に対応できるように自律的に成長していくことができると主張する人もいるかもしれません。しかし、これは私達がサイエンス・フィクションの世界の話をしはじめてしまったということになります。そうした推測的な議論は、物語としては楽しいものですが、今、現実となってきている深刻なIA、IIの問題と向き合っていくための主要な戦略となるべきではありません。私達はIAやIIの問題にふさわしい解決策を考えるべきであって、「人間のようなAI」というアジェンダありきで考えるべきではありません。
そのようなシステムは高速で分散された意志決定を可能にするためにクラウドをベースとしたものであるべきで、いくつかの個人的なものに関しての大量のデータとほとんどの人に関する少量のデータといったロングテールの現象にも対応できるものでなくてはなりません。国境や競争的な枠を超えてデータを共有する時に直面することになる難しさを解決する必要もあります。
最後に、これが特に重要なのですが、IIシステムは、統計、コンピュータ・インフラストラクチャーを使った人間同士、価値のあるもの同士をつなぐための、インセンティブと価格といった経済的なアイデアも必要とします。そうしたIIシステムはただ単純にサービスを提供するというだけではなく、市場を作り出すものになります。音楽、文学、ジャーナリズムのようにそうした市場ができるのを待ちわびているドメインがあります。そこではデータ分析が、作る人たちと消費する人たちを結びつけるのです。これは進化していく社会的、道徳的、法的な枠組みの中で行われる必要があります。
もちろん、いわゆる「人間のようなAI」の問題はこれからも大きな関心を持ち続けられるでしょう。しかし、現在のような、データを集め、深層学習の基盤を用意し、ある特定の狭く定義された人間の持つスキルを真似することができるということを単に証明するためのシステムを構築することへのフォーカスは、いわゆるAIのなかでも、最も大きく未解決の問題から私達の注意をそらすことになるだけです。そうした問題は、意味づけと理論づけができ、自然言語を操ることができ、因果関係を推測し表現することができ、不確定要素をコンピュータで扱うことの出来るかたちに表現することができ、そして長期的なゴールを定義し追求することができるシステムの開発を必要とします。これらは「人間のようなAI」に昔から求められているゴールです。しかし、現在のAI革命といった大騒ぎの中では、こうした問題は未だ解決されていないということを簡単に忘れてしまいます。
IAもこれから必要不可欠なものとして残り続けるでしょう。近い将来、コンピューターが現実の世界の出来事を抽象的に理論付けすることが出来ることはないからです。私達が直面する問題を解決するためには、よく熟考することのできる人間とコンピュータのインタラクションが必要です。そして私達はコンピュータに私達にとっての新しいレベルの創造性を刺激してほしいのであって、私達の創造性をコンピュータに置き換えて欲しいと思っているわけではないのです。
当時はDartmouthの教授で、その後MITに移ることになるJohn McCarthyがAIという名前をつけました。それは彼の行っている研究のアジェンダを、当時MITの教授であったNorbert Wienerが行っている研究と対比させるためでした。Wienerの知能システムに対するビジョンはサイバネティクスと名付けられ、オペレーショナル・リサーチ、統計学、パターン認識、情報理論、制御理論と深く結びついていたものであったのに対し、McCarthyのものはロジックとの結びつきを強調したものでした。皮肉なことに、その後、AIというのはMcCarthyの言葉として残るのですが、そこでの知能に関する主要なアジェンダというのはWienerの描いたものとなるのです。
業界の一部とアカデミアの一部のみに対象を絞った、今のAIに関しての一般的な議論は、AI、IA、IIが関連するもっと広大な影響範囲にある問題と機会から目をそらさせてしまうことになります。
ここで話しているのは、サイエンス・フィクションの夢や、超人的な機械の出現といった悪夢が現実になるということではありません。テクノロジーがもっと私達の周りに溢れ、私達の日々の生活に大きな影響を及ぼす事になっている今日、私達人間がそうしたテクノロジーをもっと理解しその進化に責任を持っていく必要があるということなのです。
産業界は引き続き多くのこの分野の開発を行っていくことになるでしょう。そしてアカデミアの世界も欠かせない役割を担うことになります。それは最も先進的で技術的なアイデアを提供できるというだけでなく、コンピュータと統計学の世界からの研究者と、その貢献と視点がこれからもっと必要となる社会科学、認知科学、人文学のような分野からの研究者を一緒に集めて、こうした問題に取り組むことができるからなのです。
一方で、人間性と科学は重要で無くてはならないものであるのは間違いないのですが、これは今まで見たこともないような規模と範囲のエンジニアリング(工学)以外のことを話しているわけではありません。私達の社会は新しいタイプのシステムを作ることを目指しているのです。そのシステムはそれが出来ると主張したものを実現するべきです。だれも、医療、輸送、商業のシステムを作ったあとで、実はそのシステムはうまく機能しないということに気付きたくはありません。そうしたシステムが人の命や幸福を犠牲にするようなエラーを起こすようなものであって欲しくはないのです。
この点で、すでにここで強調したように、データにフォーカスした分野、学習にフォーカスした分野のための新たなエンジニアリング(工学)の学問の分野が生まれることになるでしょう。こうした分野はエキサイティングであるのと同様に、それらはただのエンジニアリングの学問の一部を構成するものとして片付けてしまうべきではありません。
さらに、私達はエンジニアリングという学問の新しい分野が作られることになるという事実を喜びを持って受け入れるべきです。エンジニアリングという言葉はアカデミアの世界では、冷たい、感動のない、機械的な、さらには人間のコントロールの及ばないと言った否定的な意味を持つ狭い感覚で捉えられることがよくあります。しかし、エンジニアリングは私達がそうあってほしいと思ったような学問の分野にすることが出来るのです。この時代に、歴史的に何か新しい、人間中心のエンジニアリングの学問の分野を創り出すチャンスを私達は手にしているのですから。
こうした新しい学問の分野の名前がAIとよばれることに私は抵抗します。しかしそれでも、他にいい代替え物がないので、AIという頭文字が使われ続けるのだとしたら、このAIという言葉がもつ限界は知っておきましょう。私達は影響範囲を広げるべきです。ハイプ(誇大宣伝)を落ち着かせて、代わりにほんとうに深刻な問題を認識するべきなのです。
以上、要訳
現在このエッセイはデータサイエンス業界でもテック業界でも話題となっていますが、特にシリコンバレーのスタートアップ、ベンチャーキャピタル、エンジニア、データサイエンティストなど、業界に与える影響は大きいと思います。これでAIに関する潮目が変わるのではないでしょうか。
こちらでたまに使われる表現で、
「潮が引いたときに、誰がそれまで裸で海の中にいたのかがわかる。」
というのがありますが、結局今AIと言っているものがみんなの期待していたものでないと分かってしまったときに、何が残るのでしょうか。筆者によるとIA(Intelligence Augumentation)であり、II(Intetelligence Infrastructure)とのことですが、私もこれには賛成です。特にIAに関しては、私達はAugumented IntelligenceとしてAIと呼んでいますが、この視点での現在のデータサイエンスの進化はこれからも加速度的に続くと思います。ただそこの中心にいるのは、人間であって、人工知能ではありません。
これはエキサイティングなことです。なぜならいわゆるAIといわれるようなアルゴリズムとデータを使って今まで解決できないような問題を、私達人間が解決していくことが出来るわけです。しかしその反面、チャレンジでもあります。というのも、人工知能でなく人間が中心であるということは、理論付けや意志決定を含めた全てのプロセスが自動化されるのではなく、結局のところ、私達人間がAIのアルゴリズムとデータを使って行っていくということを意味するのですから。
そしてそのことは、テクノロジーだけでなく私達人間の能力の方にも進化が求められるということを意味します。データ、AIに関するリテラシーの向上とともに、それらを使って、質問を構築し、仮説を構築、検証し、因果関係と影響の範囲を理解していくといった、アナリティカル・シンキングを身につけることが重要となってくるのではないでしょうか。
AIのハイプが終わるからと言って、ここ10年の進化が意味なかったと言うのでは決してありません。自動運転に見られるようなデータとアルゴリズムを使った自動化はいろいろな業界、職場でこれからもどんどんと起きていくでしょう。そして現在の勝ち組であるGoogle、Apple、Facebook、Amazon、Netflix、AirBnBなどのようなデータとアルゴリズムを使って顧客とビジネスをより深く理解することで、より精度の高い意志決定をしていくという流れはこれからもどんどん加速していくことでしょう。
そうした世界で生き残るだけでなく、活躍していくためにも、テクノロジーの技術的な側面だけにフォーカスするのではなく、人間の思考的な側面にもフォーカスして、絶えず進化していくことが次世代のビジネスリーダーには求められます。
What Are We Writing?
先週はTeam Exploratoryから以下の3つのブログ記事が投稿されましたので興味のある方はぜひ。
What Are We Working On?
次のリリースのv4.4はアナリティクスの時系列予測の方をもっと充実させていこうという計画です。手始めとして先週は既存のProphetによる時系列予測の機能強化の方の開発をしてました。
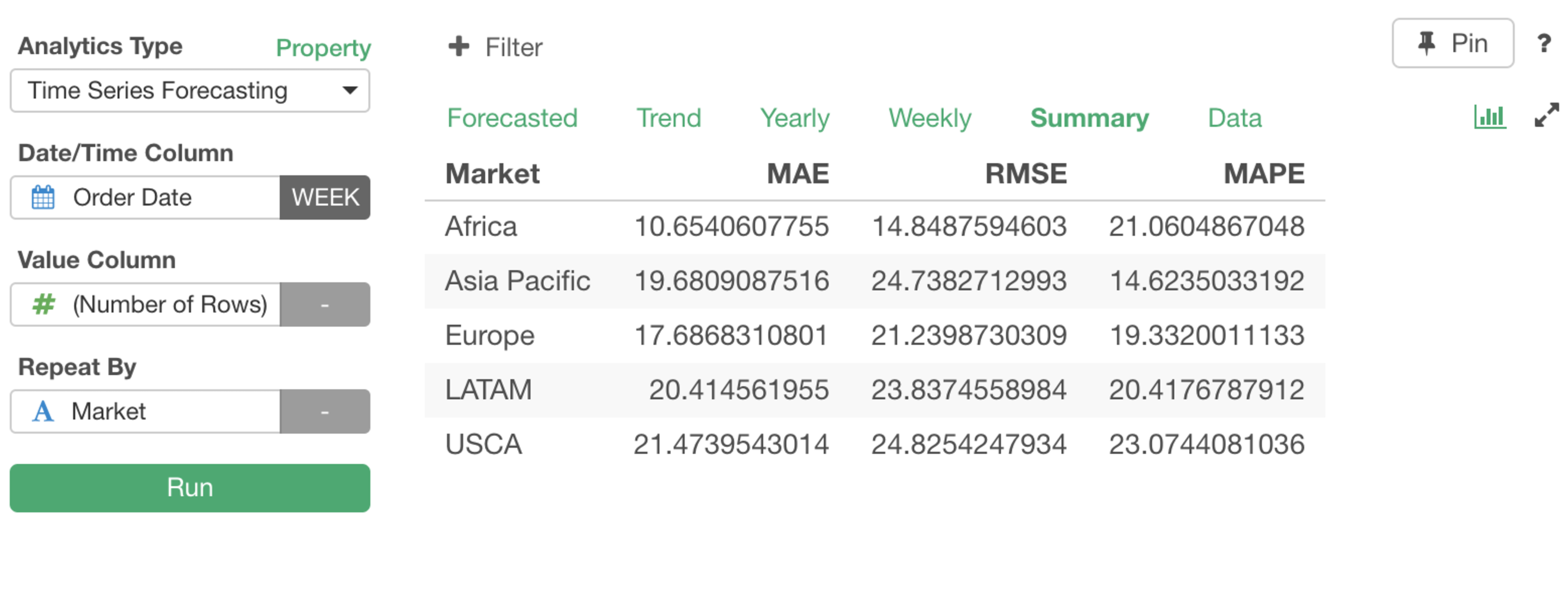
まずは、サマリーのタブが追加され、そこではバックテストという手法を使ってトレーニングデータとテストデータを自動的に生成しそこから予測の精度をMAE(Mean Absolute Error)、RMSE、MAPE(Mean Absolute Percentage Error)などの指標を使って測ることができるようになります。
サマリー
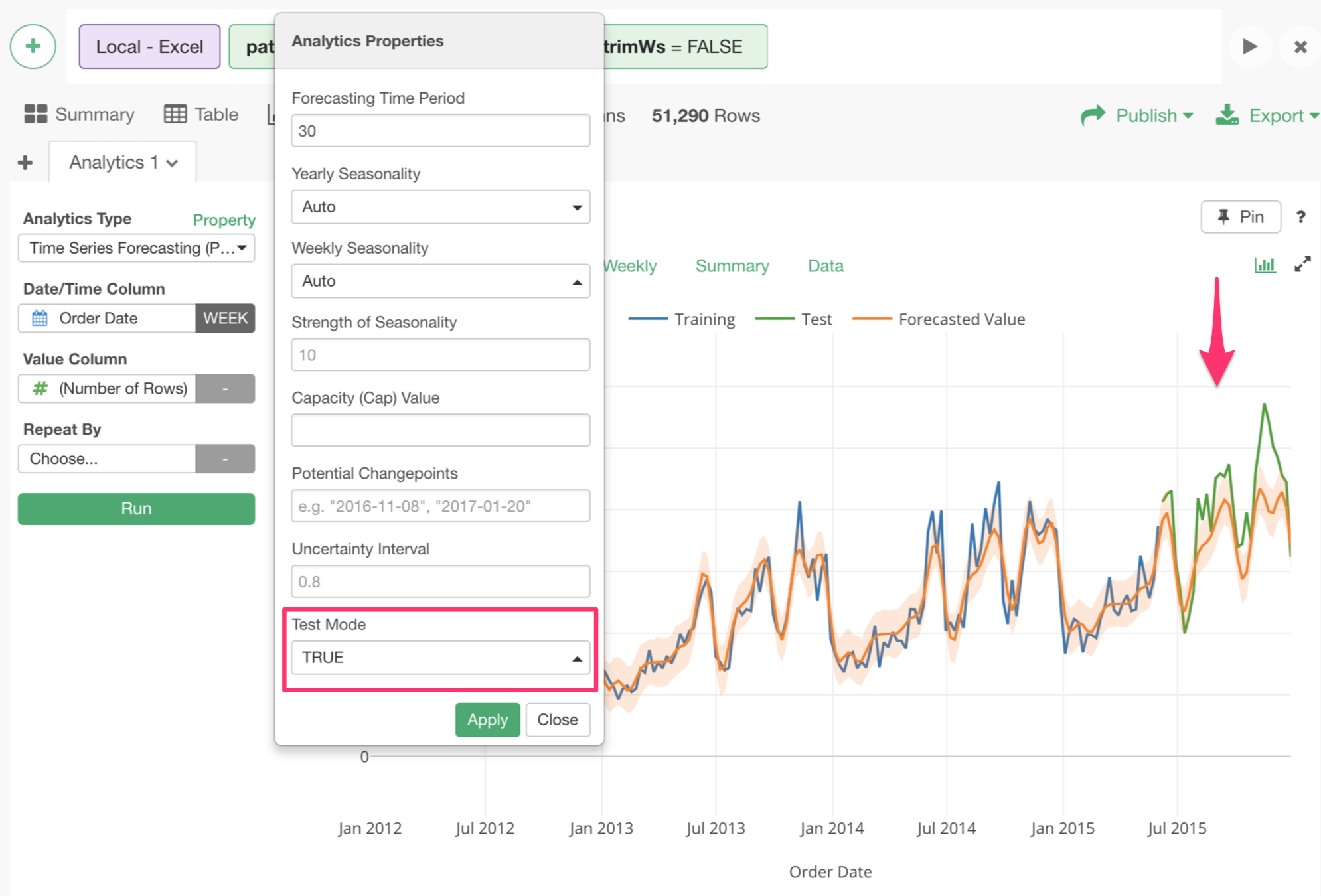
トレーニングデータとテストデータ
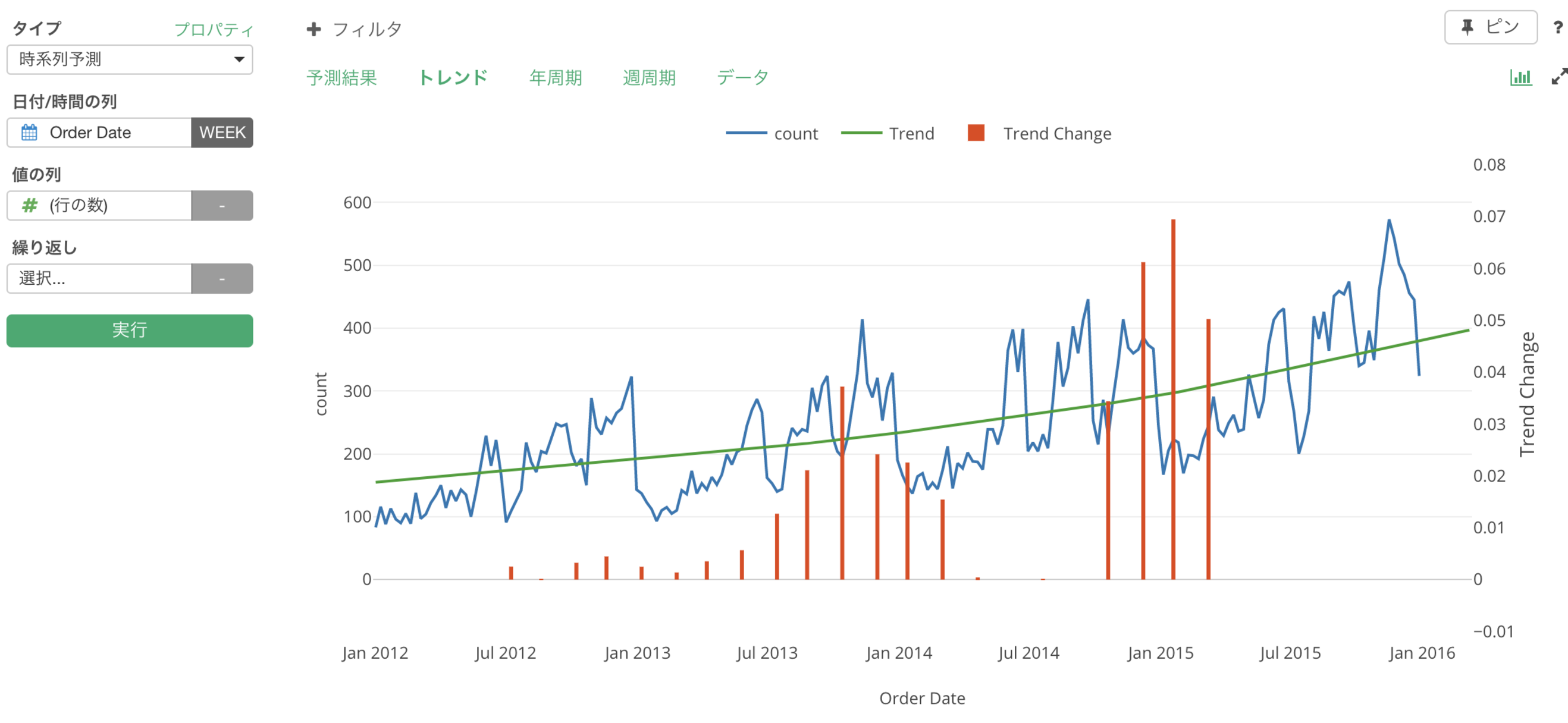
トレンドの変更時点
さらに、トレンドがどこで変わっていったのかという情報を抽出しさらにそれが可視化されます。
データサイエンス・ブートキャンプ・トレーニング
冒頭にも書いたように、次回のブートキャンプを東京にこの6月に開催しますが、その早割が今月末で終わります。データサイエンスを始めたい、データ分析を本格的に学んで自分のキャリア、または自分のビジネス、組織の向上に役立てたいという方はこの機会にぜひ参加をご検討下さい。
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。