
AI時代の著作権 - ニューヨーク・タイムズ vs. OpenAI
去年の年末、ニューヨーク・タイムズがChatGPTの開発元であるOpenAIとそのパートナーであるMicrosoftに対する訴訟を起こしました。(リンク)
OpenAIがChatGPTのAIモデルをトレーニングするために、ニューヨーク・タイムズの記事を勝手に使ってサービスを提供しているというのがこの訴訟のポイントです。
ただ、これは難しい訴訟になるかもしれません。というのも、アメリカのコピーライト(著作権)に関する法律は私達一般人が思っているほど単純ではないからです。この点に関してテック企業やテックのトレンドに関していつも鋭い視点から解説してくれるベン・トンプソン氏が最近こちらの「The New York Times’ AI Opportunity」の中で詳しく説明していました。
現在のような生成AIブームの中では、そうしたテクノロジーを使って新しいサービスを提供するチャンスがたくさんあります。ただ気をつけなくてはいけないこともあるので、アメリカの最新動向を皆さんと共有できればと思い、ここで前述の記事を元に簡単に解説したいと思います。
インプットとアウトプット
まず、ここで訴訟の根拠となるのがコピーライト、つまり著作権というものですが、アメリカのコピーライト法を考えるときにインプットとアウトプットという2つのことを考える必要があります。
例えばあなたがニューヨーク・タイムズの記事を無断でどこかのサーバーに保管し、誰もが勝手にアクセスできるようにしていたとしましょう。
すると、インプットはこの記事で、アウトプットもこの記事となります。
その結果、もし元の記事が有料であったり、元の記事のページにアクセスすることがニューヨーク・タイムズにとって利益になる場合(例えば広告など)、あなたのサーバー上にあるアウトプットに誰もが勝手にアクセスできるようになってしまうと、その人達は元記事のあるニューヨーク・タイムズのページに行かなくなります。それは元の記事を作成したニューヨーク・タイムズに対して不公平な競争関係を作ってしまうことになり、彼らのビジネスにダメージを与えたとみなされます。
これがコピーライトの侵害ということになります。
それでは、このChatGPTのケースはどうでしょうか?
インプットはニューヨーク・タイムズによると彼らがパブリッシュしてきた何百万もの記事になります。
アウトプットは、そうしたトレーニングデータを元にChatGPTが作り出すテキスト情報です。
ここでコピーライト法の観点から重要なのは、最初の例で見たように、アウトプットはインプットとどれだけ同じなのかという点です。つまり、ユーザーのプロンプトに対してChatGPTが返すアウトプットはどれだけ元の記事と同じなのかということです。
ChatGPTは世界中のニュース記事や論説記事などをデータにしているので、吐き出すアウトプットには元の記事から何らかの影響はあるでしょう。しかし、だからといってそれがそのままコピーライトの法律に触れるというわけではないのです。
というのも、もしあなたがニューヨーク・タイムズの記事を普段から読んでいたとします。すると、あなたの考えには自ずとそれらの記事が何らかの形で影響を及ぼすでしょう。そしてあなたが作り出す記事やエッセイなどにはそうした影響が姿を表すでしょう。これはあなたがそうした記事を読む限り避けがたいことです。
そこでChatGPTの方としても、吐き出すアウトプットには何らかの元記事からの影響があるのは間違いないが、それは私達人間といっしょで避けられないではないかということです。
もちろん、違法にニューヨーク・タイムズの記事にアクセスしたのであればそのこと自体は悪いと言えますが、少なくともアメリカではニュース記事などにアクセスして使うこと自体は「フェアーユース」として認められています。そして、今回ニューヨーク・タイムズがおこした訴訟の根拠に上がっているのはコピーライトについてであり、アクセスしたり使用した事自体を問題としているわけではないのです。
そして、コピーライトの侵害として訴えるのであれば、アウトプットがどれだけインプットと「同じ」なのかを証明しなくてはいけないのです。
これが去年コメディアンであるサラ・シルバーマンがMeta(Facebook)に対して起こした訴訟で勝てなかった理由です。
その訴訟ではシルバーマンの弁護士はシルバーマンが出版した複数の本がそのままコピーされてトレーニングデータとして使われたので、アウトプットがどうなのかは関係ないと主張しましたが、それは判事に却下されました。
アウトプットが元となる本の一部をそのまま不適切な形で使っていると、訴訟した側は証明しなくてはならないというのが判事の指摘です。
もちろん、こうした背景はニューヨーク・タイムズの弁護士もすでに知っているようで、今回の訴訟ではアウトプットがいかに元の記事と「同じ」であるかを強調しています。
以下は訴訟で出された資料(Exhibit J)の中には100ほどの「ChatGPTがニューヨーク・タイムズの記事をそのまま出している」という例を示しています。
例えば、以下はChatGPTに対して「どうしてアメリカはiPhoneの仕事を失ったのか」という記事のURLとその記事の出だしの文章をプロンプトとして提示しました。
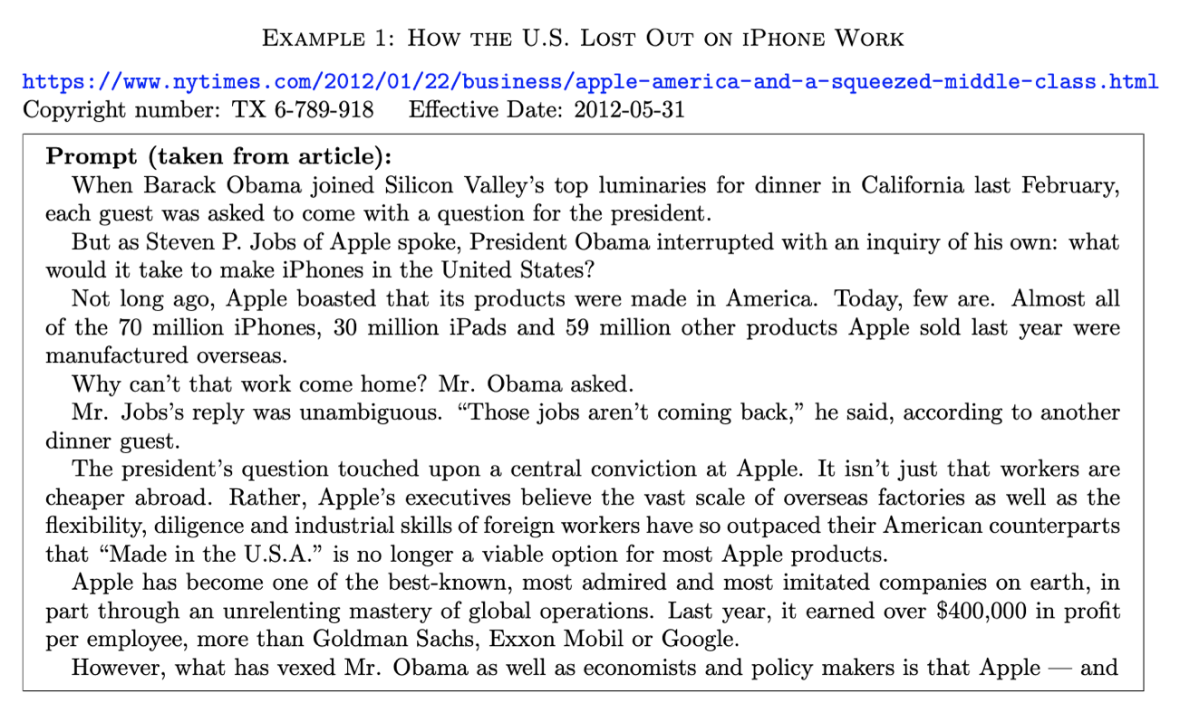
そしてChatGPTに対して、残りの文章を書くようにリクエストした結果、返ってきたのが左側、元の記事が右側です。赤くなっているテキストの部分がChatGPTの結果が元の記事のテキストと全くいっしょである部分です。
これだけ見るとChatGPTは人間のように記事を読んでそれに影響を受けながらも自分で「考えて」自分の「言葉」で返しているわけではなく、ただ同じものをそのままアウトプットとして返しているように見えます。
ただ、そもそも上記のようなプロンプトをChatGPTに投げかける人がいるのか、という疑問は残り、元の記事と同じアウトプットが出るように無理やり不自然なプロンプトを入力したようにも見えます。
さらに、元のエッセイの著者であるトンプソン氏が最近同じようなプロンプトをChatGPTに投げかけたところ、以下のような答えが返ってきており、元の記事の文章そのままとはなりませんでした。OpenAIの方ですでにこの件に関しては修正を加えたということなのでしょう。
実際に今週の月曜日にOpenAIから出された声明によると、こうしたものは「バグ」であるとのことで、見つかり次第早急に修正しているとのことです。私は個人的にこの「バグ」というのも言い訳な気がしますが、まあ、それは置いておきましょう。
ここまで、コピーライトが侵害されているかどうかは、インプットとアウトプットがどれだけ「同じ」かということを見てきました。
ところが、例えばインプットとアウトプットが「同じ」であっても、コピーライトが侵害されているかどうか判断する際には他にも重要な点があります。
iPhoneで記事をコピーしたら、Appleを訴えれるのか
例えば、私が元のニューヨーク・タイムズの記事を読み、それをiPhoneのプリント機能を使ってPDFに保存し、それを他の誰かと共有したとしましょう。その場合、このプリント機能を提供しているAppleはニューヨーク・タイムズのコピーライトを侵害したとして訴えられるべきなのでしょうか?もちろん、そんなことはないというのが現状です。
Google Booksという前例
さらにもう一つニューヨーク・タイムズに不利な前例があります。それはGoogle Booksの件です。
Googleは著者の承認を得ることなしに世界中のありとあらゆる本や出版物をスキャンしまくり、それを検索エンジンは使い、さらに結果として表示しています。この件に関しては一部の著者や出版社がGoogleを相手に訴訟を起こしましたが、Googleは著者のコピーライトを侵害していないという判決がすでに出ています。
というのも、Googleは本の一部を検索結果として出しているだけで、それはその本の著者や出版社の利益を奪うことにならないからとのことです。ここでのポイントは本のコピーライト(著作権)はその価値が、他の人(例えばGoogle)によって奪われる、または競合されることから守るためにあるのであって、その本の中にある情報を他の人が提供できないとするものではない、ということです。
より多くの人がより簡単に元の本を検索できるようになったことで、Googleは元の本にアクセスすることを助けているということのようです。
ハルシネーション
そして最後にもう一つ、ニューヨーク・タイムズにとって決定的に不利な問題があります。
それはChatGPTが間違った結果をあたかも正しいかのように返してくる「ハルシネーション」と呼ばれる現象です。これはChatGPTに限らずこの手の生成AIには一般的によく見られる現象でもあります。
ニューヨーク・タイムズは訴訟の資料の中で、ChatGPTがある元の記事からの情報として出した情報が間違っていた例を出し、こうした間違いによって元の記事の信用性が失われると訴えています。
しかし、最初の方にも述べましたが、コピーライトが侵害されているかどうかにおいて重要な点はアウトプットがコピーライトで守られている元の記事であるインプットと「同じ」であるかどうか、そしてそのことによってコピーライトによって守られている価値(金銭的な価値や、元の本が読まれたり記事がアクセスされることで生まれる価値)が失われてしまう、または不利な競争にさらされてしまうかどうかということです。
ところが、元の記事を含む大量の記事をトレーニングデータとして使ったChatGPTが返した結果の一部は正しいが、一部は間違っているかもしれないという場合、ユーザーはその答えが正しいかどうか判断するために元の記事を確認しなくてはいけなくなります。これは、ニューヨーク・タイムズの「ユーザーは元の記事を読むことなくChatGPTで記事の情報を得ることが出来てしまうため、自分たちのビジネスがダメージを受ける」という主張と矛盾してしまいます。
つまり、ChatGPTがハルシネーションを持つ限り、ニューヨーク・タイムズのコピーライトに守られた価値は侵害されないということになってしまいます。
生成AI時代のコピーライトとは?
今回のニューヨーク・タイムズ vs. OpenAIの訴訟に関して、感情的にはニューヨーク・タイムズの主張の方が正しく、OpenAIは他の人たちの作り上げてきた情報によって不公平な利益を得ていると思いがちです。
しかしそれは感情的な判断であって、法的、論理的な判断とは言えません。
ここで解説したように、コピーライト(著作権)の解釈はそう単純ではなく、さらにコピーライトに関する法律が最初に作られたときと今日では、利用可能な技術、私達の生活スタイルや期待、そして政治や世論に影響力を持ったプレイヤーたちも違います。
生成AIの時代におけるコピーライトとはどうあるべきなのか、この判断は最終的には最高裁に持ち込まれることになるのかもしれません。
そういった意味でも、この訴訟は現在の生成AIブームの時代にとって最も注目すべきものの1つではないかと思います。感情的な観点からだけではなく、できるだけ論理的な観点からもその動向を見守っていきたいものです。
最後に
最後に付け加えたいのは、こうした法律の曖昧さや解釈の難しさが、アメリカでの訴訟に強いシリコンバレーなどのスタートアップ、テック企業にとって有利な点で、逆に日本などのアメリカ国外のスタートアップには対抗するのが難しい点であるということです。
今でこそYoutubeは当たり前になりましたが、最初は様々な訴訟に巻き込まれていました。それがGoogleに買収された大きな理由でもあります。ワシントンDCにいる強力なロビー団体と強力な弁護士チーム、そして巨大な資金を持つGoogleだから乗り切れましたが、普通のスタートアップのままであれば簡単にもみ消されてしまっていたでしょう。
よく日本では、シリコンバレーに比べ日本のスタートアップの数が圧倒的に少ないのは、日本人のイノベーション能力が足りないからといった話を聞きます。もちろん、イノベーションがなければ何も始まらないというのは確かなのですが、それと同時に、今回の話のようにスタートアップが成功するかどうかは単純にイノベーションの問題ではなく、こうした「周辺」の問題にしっかりと対抗していけるかどうかでもあります。
そのためにはアメリカの政治や世論を動かすための強いロビー力が必要になり、そしてそのスタートアップの存在がアメリカの国益になるかどうか、といったことも重要だったりする現実を頭に入れておいてもいいのではないでしょうか。
以上。
データサイエンス・ブートキャンプ・トレーニング

いつも好評のデータサイエンス・ブートキャンプへの参加申し込みを現在受付中です!
データサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使える実践的なスキルを身につけていただくためのトレーニングです。
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。
興味のある方は、ぜひこの機会にご参加検討ください!