Detecting a Language of Text with Google's Language Detection Algorithm
Recently, I encountered a situation where I wanted to label a language for each of the blog posts I have published in the past.
As you might have known, I sometimes publish my blog posts in English and sometimes in Japanese. Instead of manually labeling each post as either English or Japanese, I wanted to do it automatically. Yes, I'm lazy! ;)
Then, I found this open source algorithm called 'Compact Language Detection v3' built by Google. This consists of text inference codes and a trained neural network model for identifying the language for a given text.
Sounds good, right?
There is one problem.
This library is designed to run in Chrome browser and relies on code in Chromium. How can I use this in Exploratory?
Luckily, there is an R wrapper called 'cld3', which makes it possible to call the language detection algorithm mentioned above from R environment.
Yes, you guessed it right, this means that you can run it in Exploratory! Woo-hoo!
And this is what I wanted to share with you.
It's pretty straightforward, Install the package, then use it with the 'Create Calculation (Mutate)' step.
Install cld3 Package
First, you want to install the cld3 package from the 'Manage R Package' menu.
Type the package name 'cld3' under 'Install New Packages' tab and click the 'Install' button.
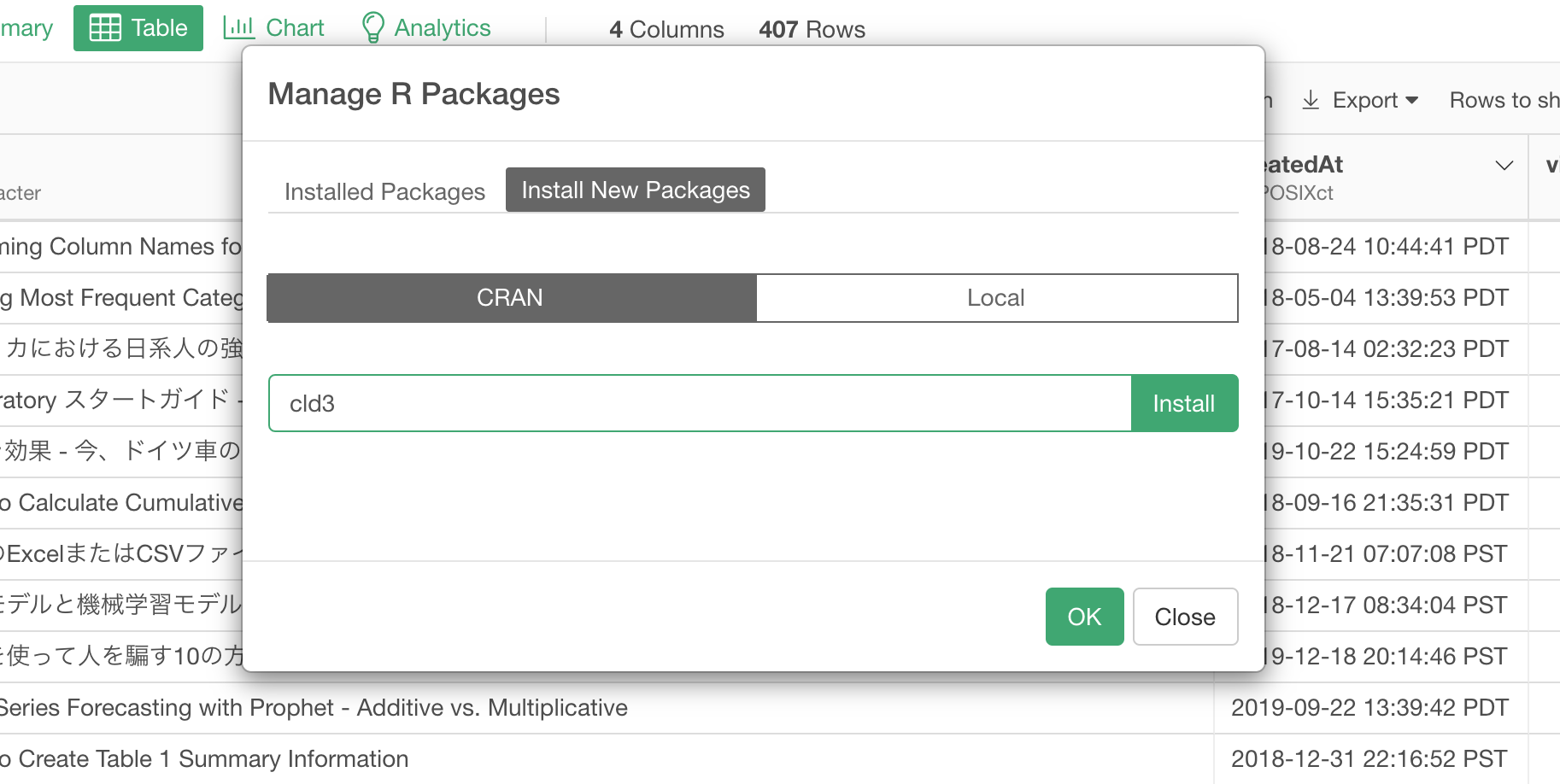
Now, it's ready to use it!
Use it
Select 'Create Calculation (Mutate)' from the column header menu of the column you want to detect the language for.
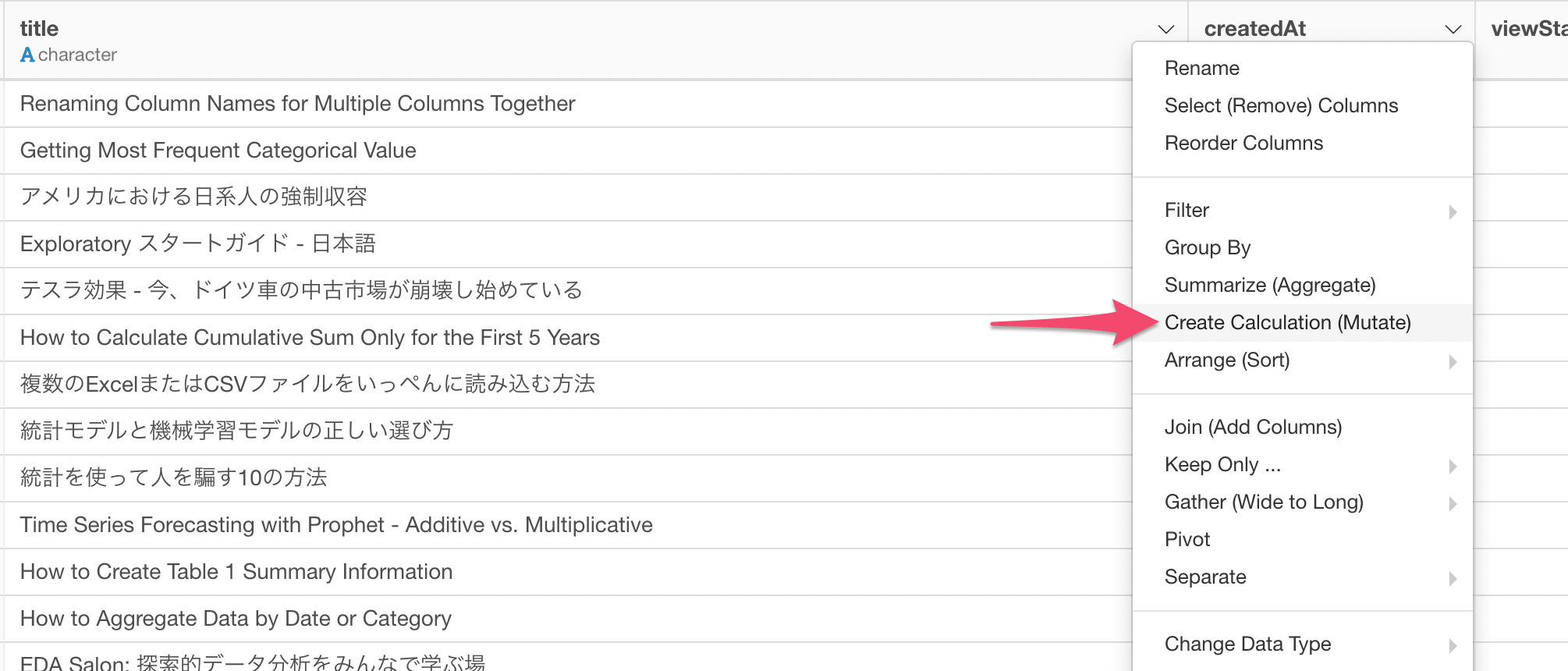
And type the following.
detect_language(column_name)In my case, the column name is 'title', so it can be something like below.
detect_language(title)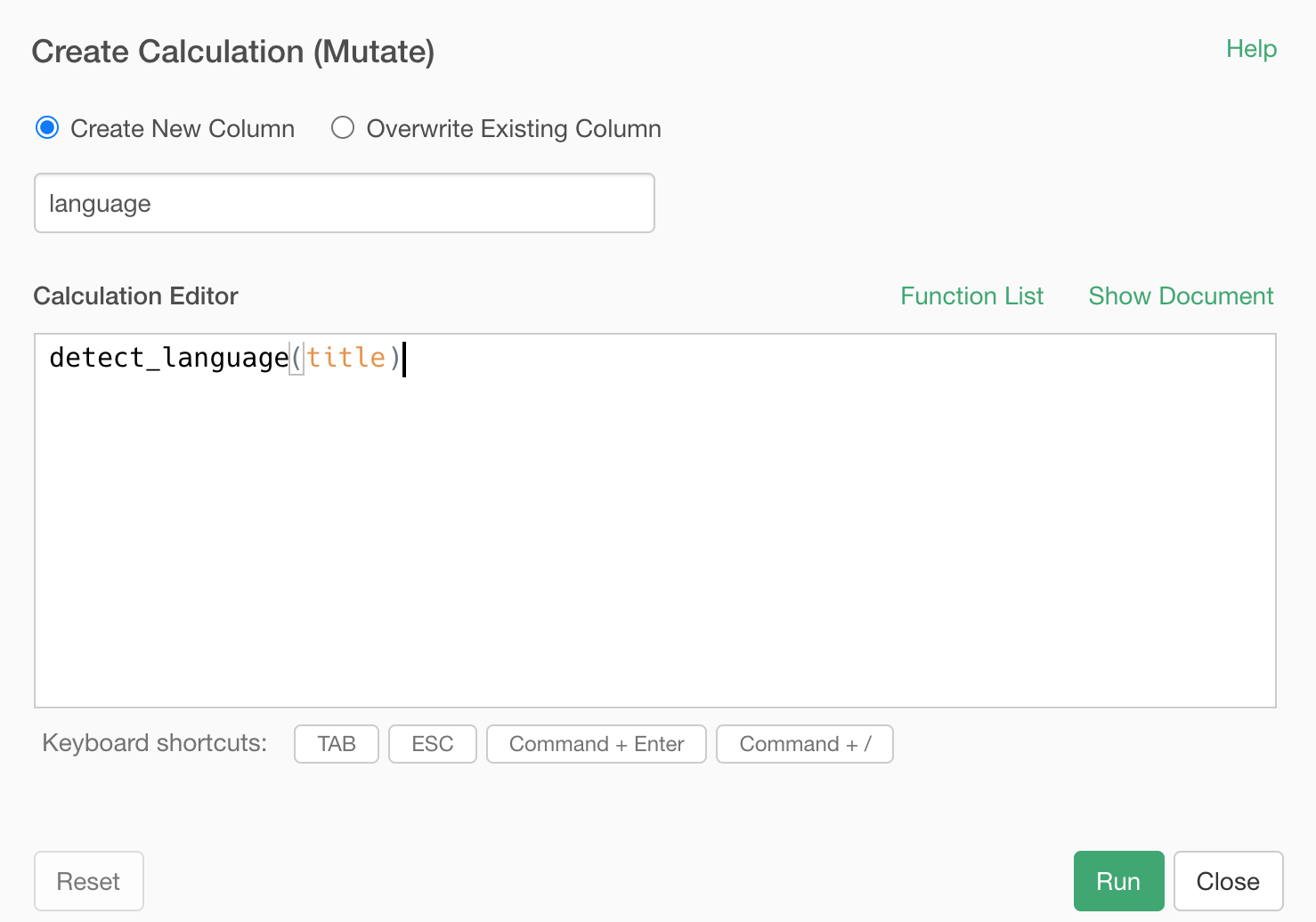
By the way, I'd recommend you use something called 'namespace', which is the package name (e.g. cld3) as part of the function name like below.
cld3::detect_language(title)Right after you install the R package in Exploratory it is setup so that it will load the package every time you open the project.
So technically, you don't need to set the 'namespace' thing when you use it. But, having the namespace as part of the function name like above guarantees that the package will be loaded whenever it's used regardless you have configured the projects to load the package or not.
Anyway, once you run it you'll get a new column that has the language code.
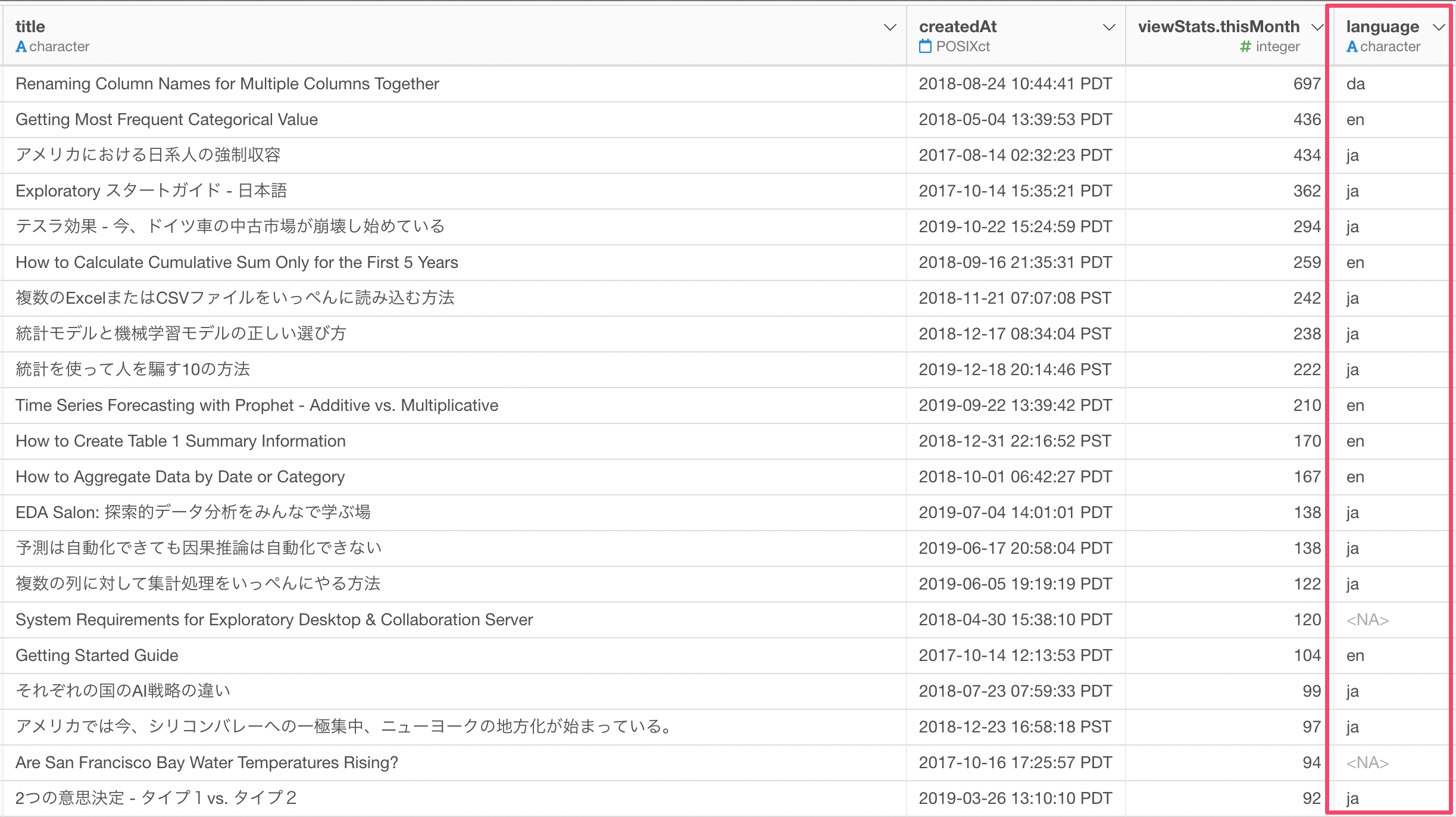
Quality Check
I would say the result is pretty good to me, though it is not perfect.
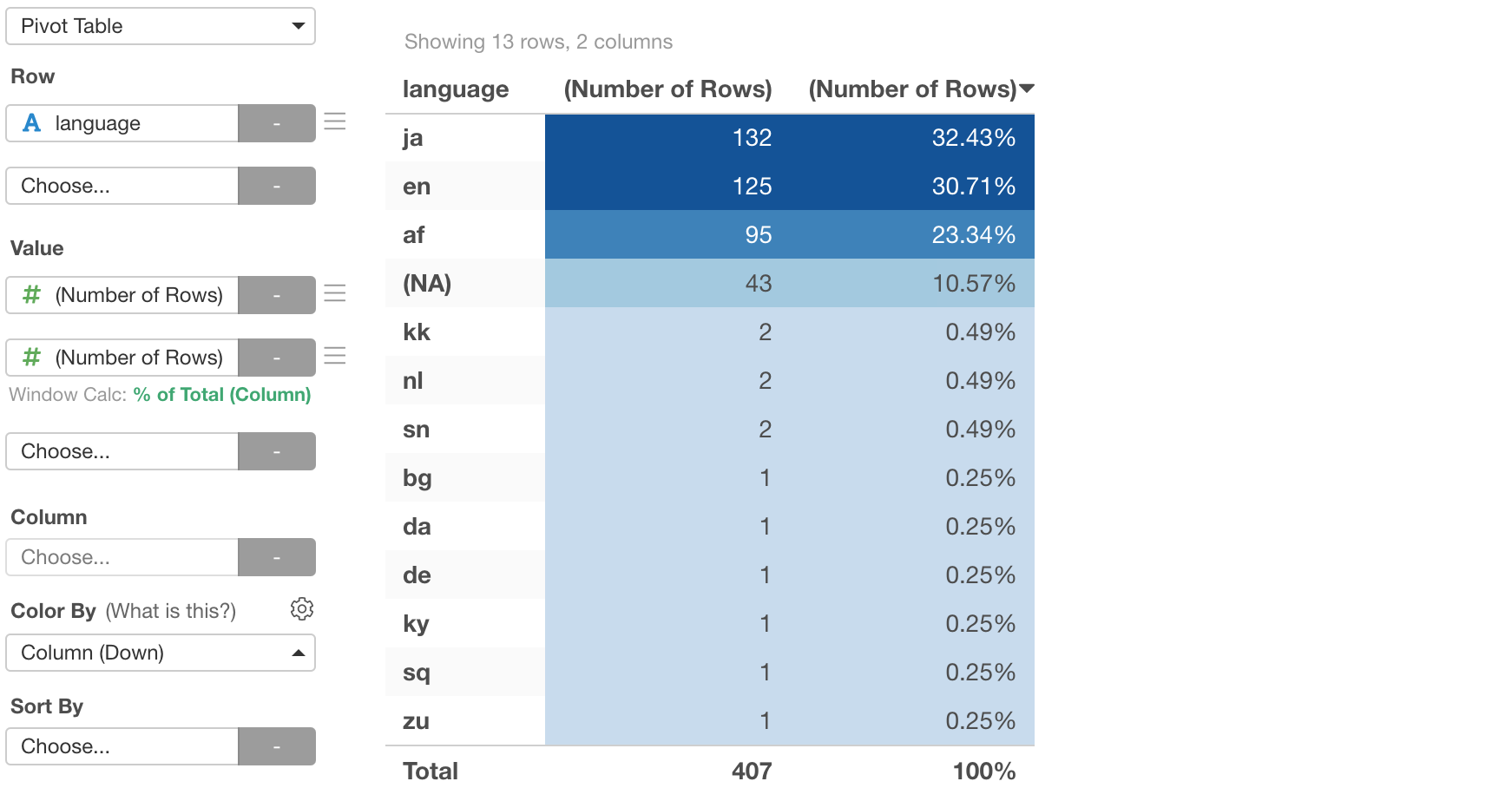
All the titles are supposed to be either English or Japanese, and about 60% of them are correctly identified. but we can see other language codes.
English
Let's take a look at the ones that are identified as English.
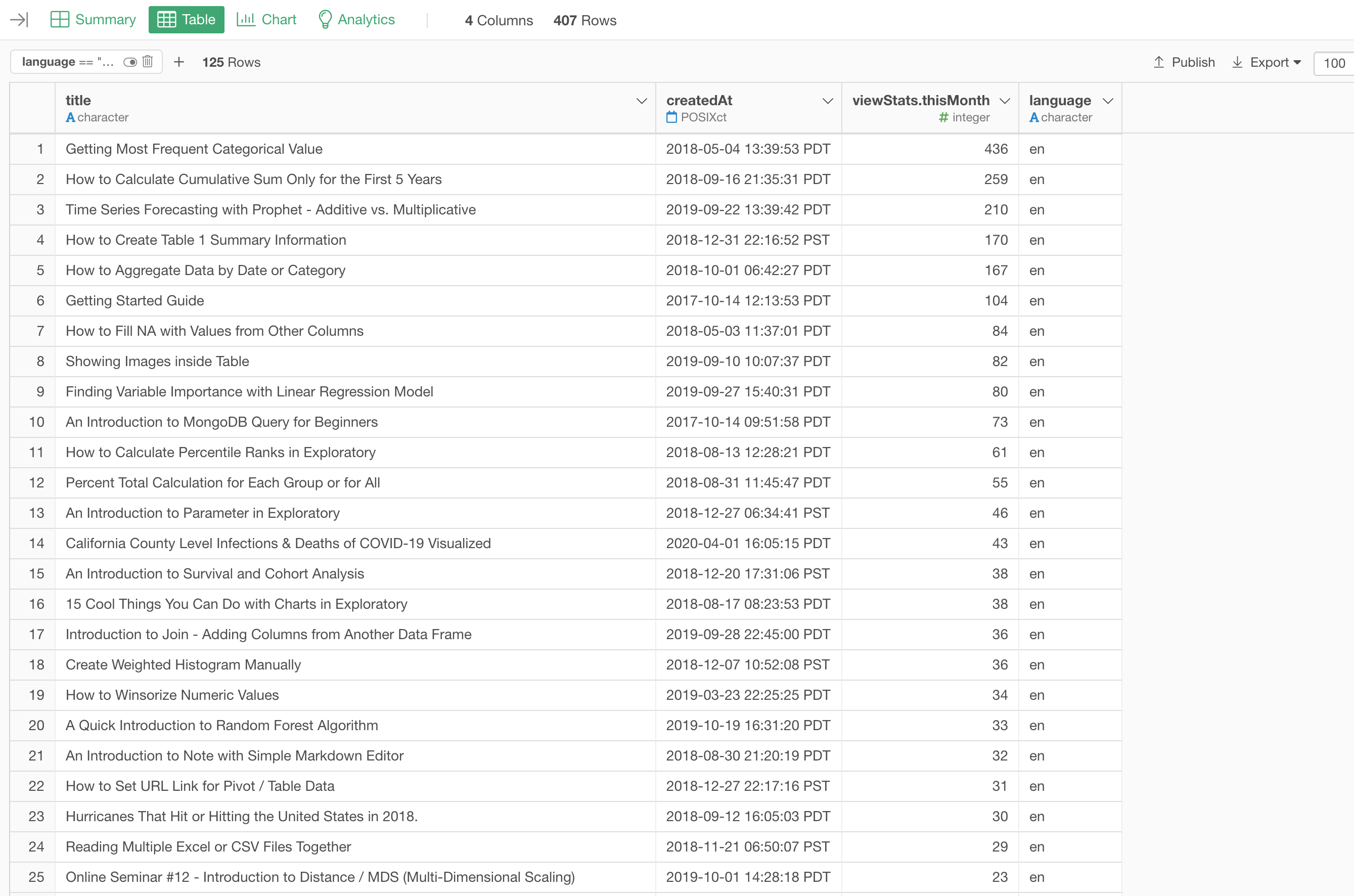
They are all looked correctly identified.
Japanese
And here is a list of the titles that are identified as Japanese.
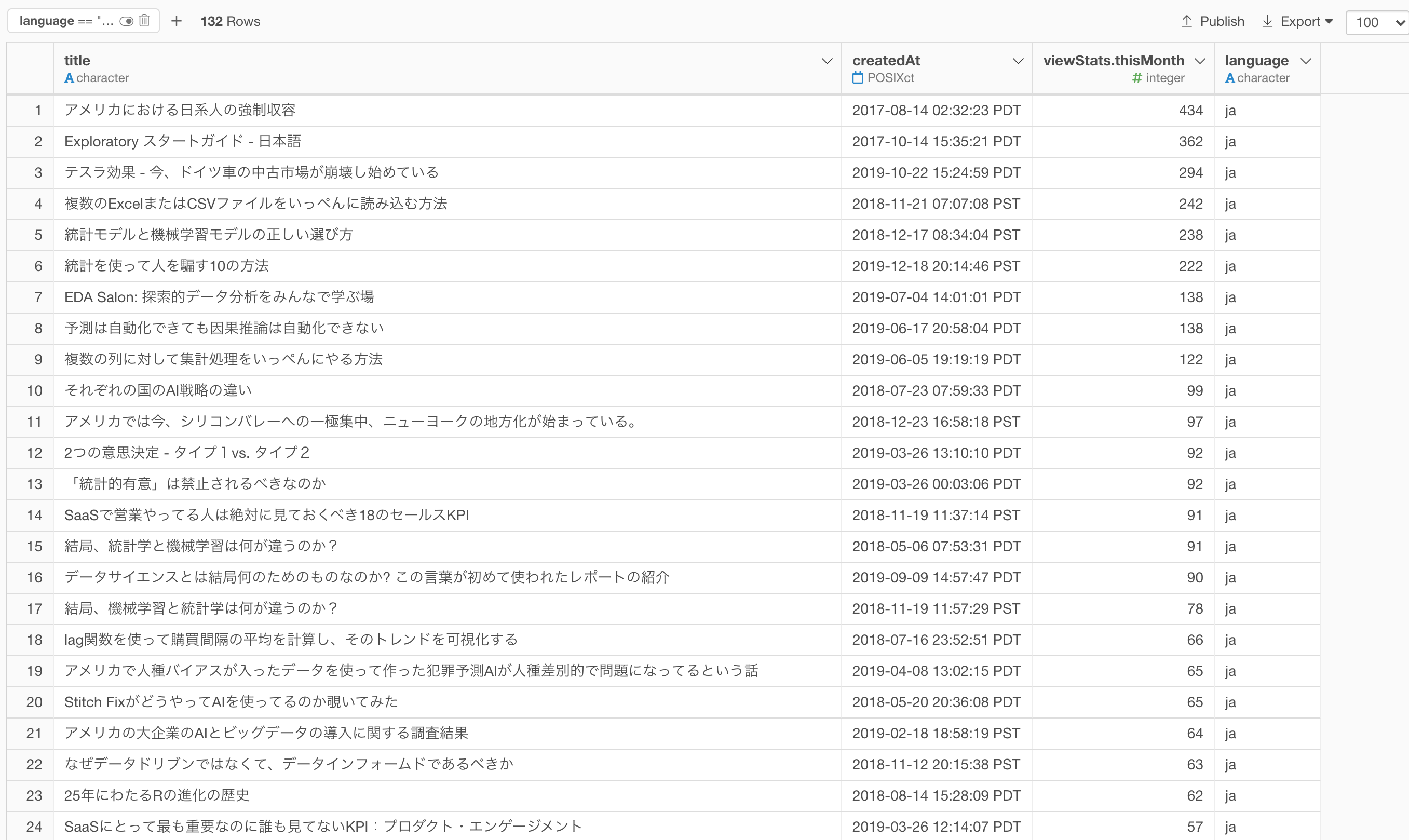
These, too, are correctly identified.
Now, how about the other ones?
For example, there are 95 titles (23%) that are identified as 'af (afrikaans)' and 43 titles (10%) couldn't be identified.
af - Afrikaans
It turned out that those that were identified as the Afrikaans language are all 'Weekly Update' related titles.
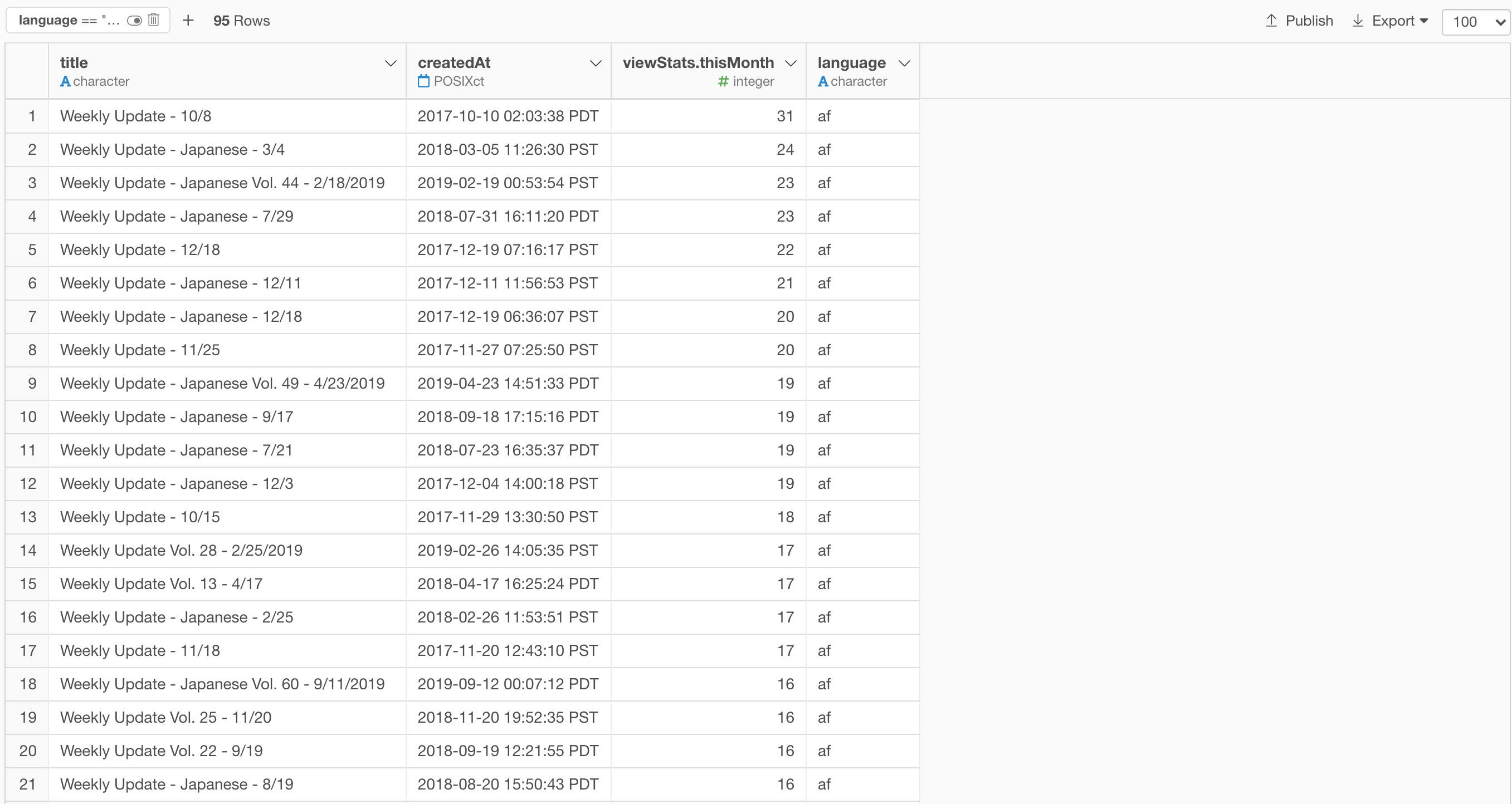
I have no idea why they are identified as 'Afrikaans', but at least there is at least a consistency there. ;)
NA
And here are the titles that could't be identified as any language.
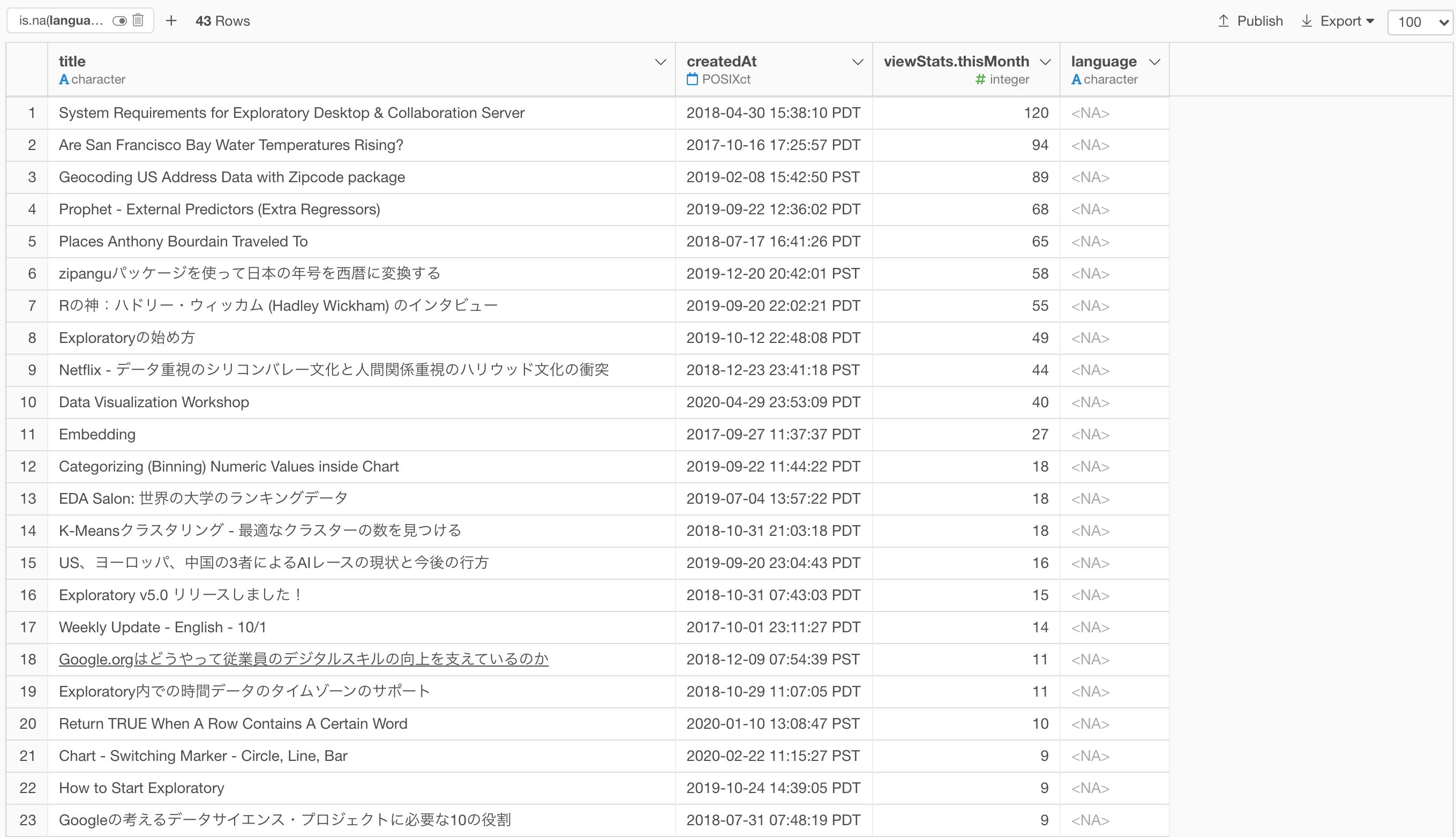
As far as I can see, they tend to have mixed languages of English and Japanese in the title text or they are probably grammatically wrong. ;)
Conclusion
So the quality is not bad. But it still requires some manual labeling to correct some of them. And it might increase the quality by including the first paragraph of the blog contents rather than giving just the title text to the algorithm.
Reference
Here are the open source packages used in this post.