複数のExcelまたはCSVファイルをいっぺんに読み込む方法
複数のExcelまたはCSVのファイルを読み込んで1つのデータフレームとしたいということがたまにあります。
そんなときは、1つづづ読み込んで、その後にbind_rowsというコマンドでくっつけることができます。
ところが、ファイルの数が多いと一つ一つ読み込むことがめんどくさくなってきます。そんなときは、Rスクリプトを書いて、それをデータソースとして登録することで解決できます。
複数ファイル読み込みのためのRスクリプト
例えば、以下のような複数のExcelのファイルがこのフォルダーの下にあったとしましょう。
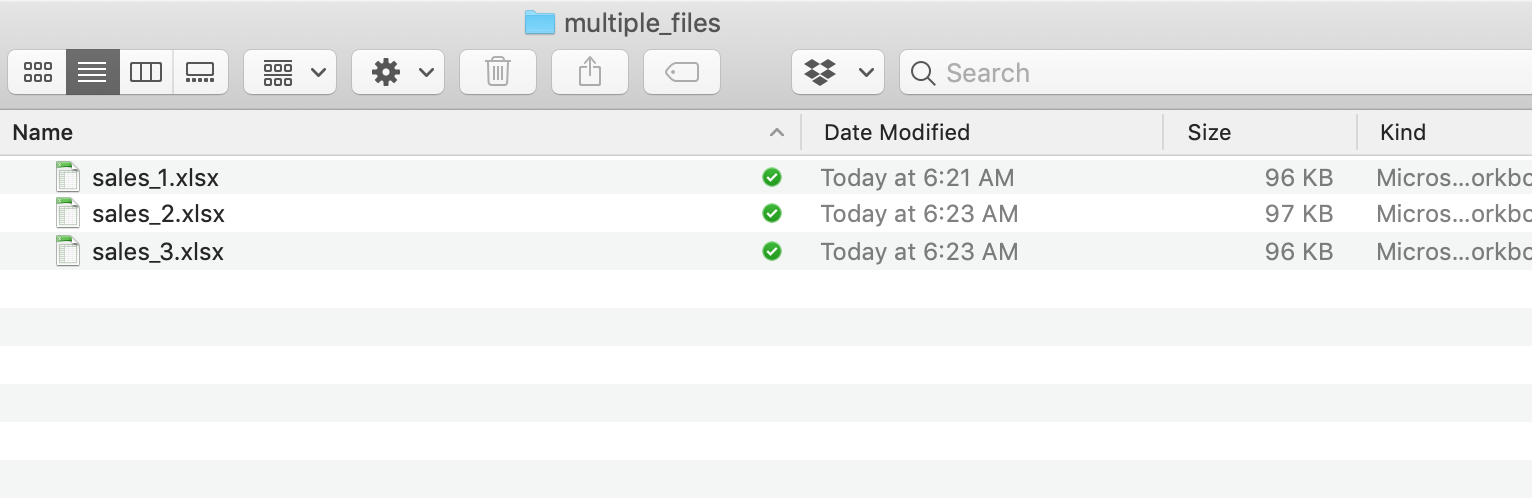
こちらが、これらのファイルをいっぺんに読み込むためのRスクリプトになります。
library(readxl)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.xlsx", full.names = T)
tbl <- sapply(files, read_excel, simplify=FALSE) %>%
bind_rows(.id = "id")もし、Excelでなく、CSVファイルだった場合は以下のようになります。
library(readr)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.csv", full.names = T)
tbl <- sapply(files, read_csv, simplify=FALSE) %>%
bind_rows(.id = "id") 違いは、 CSVを読み込むときは'readr' というRパッケージの 'read_csv' という関数を使い、Excelを読み込むときは'readxl' というRパッケージの'read_excel' という関数を使っています。
どちらにしても、上のスクリプトは以下のことを行っています。
- 指定されたフォルダーの下にある、 'xlsx'か'csv'で終わる全てのファイルのロケーション情報を'files'という変数の中に読み込みます。
- 'files'の中にあるファイルのロケーション情報をもとにファイルを一つ一つ読み込んで、その後それらをマージ(くっつける)します。
タブ区切り形式のファイルを読みたい
以下のパラメーターを使って指定することができます。
sep="\t"以下はスクリプトの全文です。
library(readr)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.csv", full.names = T)
tbl <- sapply(files, read_csv, sep="\t", simplify=FALSE) %>%
bind_rows(.id = "id") ファイルの文字エンコードを指定したい
以下のパラメーターを使って指定することができます。
encoding="文字コード"文字コードは日本語の場合は、CP932、Shift_JISといったものがあります。
以下は文字コードをShift_JISにしたスクリプトの例です。
library(readr)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.csv", full.names = T)
tbl <- sapply(files, read_csv, sep="\t", encoding="shift-jis", simplify=FALSE) %>%
bind_rows(.id = "id") 複数のログファイルを読み込みたい場合
ログファイルを読み込む場合は、read_excelやread_csvの代わりにread_log_file関数を使うことができます。
以下がスクリプトとなります。
library(readr)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.csv", full.names = T)
tbl <- sapply(files, read_log_file, simplify=FALSE) %>%
bind_rows(.id = "id") ファイル名に日本語が使われている場合
ファイルのパスに日本語が使われている場合、上記のスクリプトを流してファイルデータをインポートした際にできるデータフレームの「id」列の値が文字化けしていることがあります。
この「id」列にはそれぞれのファイル名が入っているはずなのですが、そちらが文字化けしてしまうケースがあります。
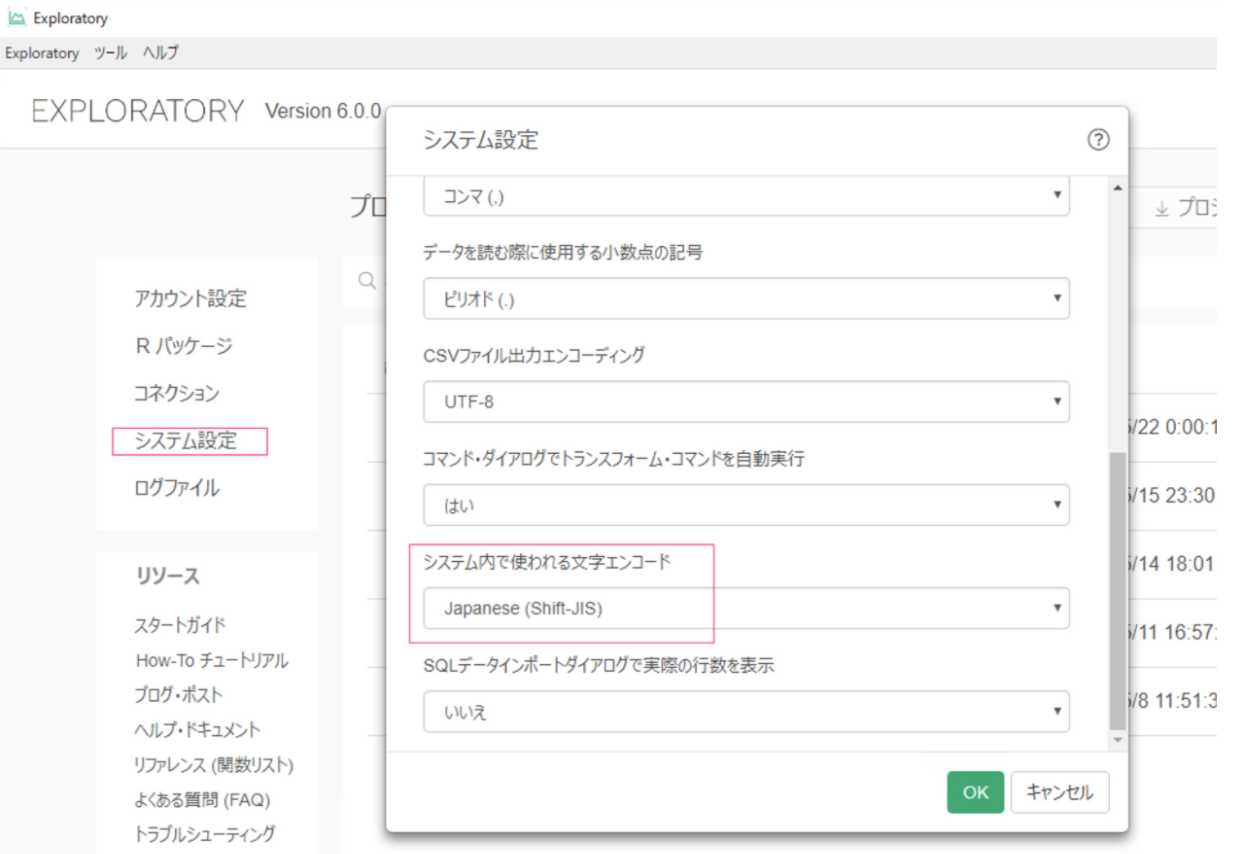
その場合はまず、Windowsの場合はシステムのロケールが日本語になっているのを確認して下さい。
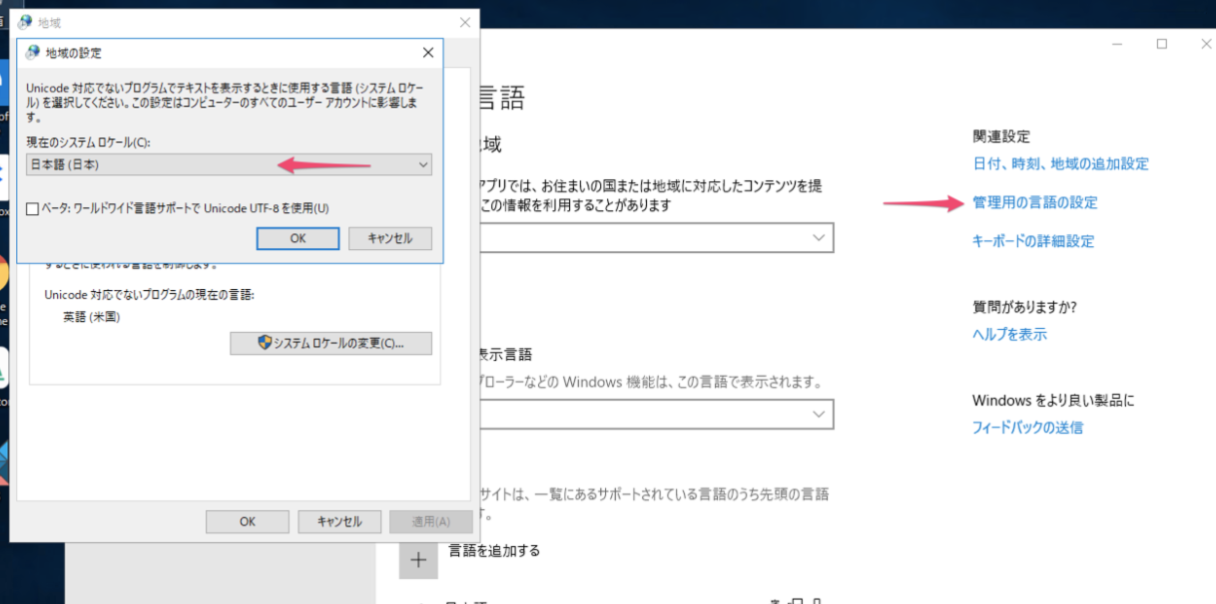
その次に、Exploratoryのシステム・エンコーディングが「Japanese (Shift-JIS)」になっているのを確認して下さい。
最後に上記のスクリプトに以下の行を追加して下さい。
files <- enc2utf8(files)上の一行を加えた後は以下のようになっているはずです。
library(readr)
files <- list.files(path = "~/Dropbox/Data/multiple_files", pattern = "*.csv", full.names = T)
files <- enc2utf8(files)
tbl <- sapply(files, read_csv, sep="\t", encoding="shift-jis", simplify=FALSE) %>%
bind_rows(.id = "id") 上記のスクリプトを以下のステップに沿ってExploratoryの中で登録して使用すれば、うまくいくはずです。
それでもまだ問題がある場合は、こちらサポート (support@exploratory.io)までお問い合わせ下さい。
Exploratoryの中でRスクリプトをデータソースとして登録
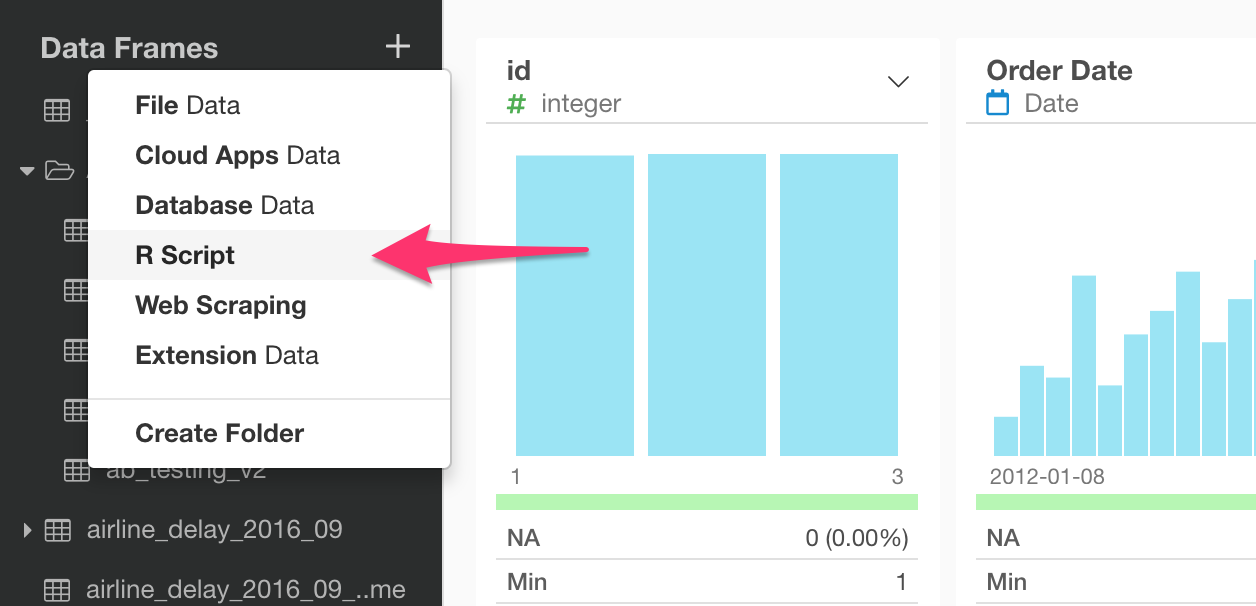
Rスクリプトを書けるということは、Exploratoryの中でそれをデータソースとして登録することができます。
'R Script'をデータフレームのメニューから選びます。
Rスクリプト・エディターの中に上のスクリプトをコピーし貼り付けます。以下は、Excelファイルを読み込む例です。
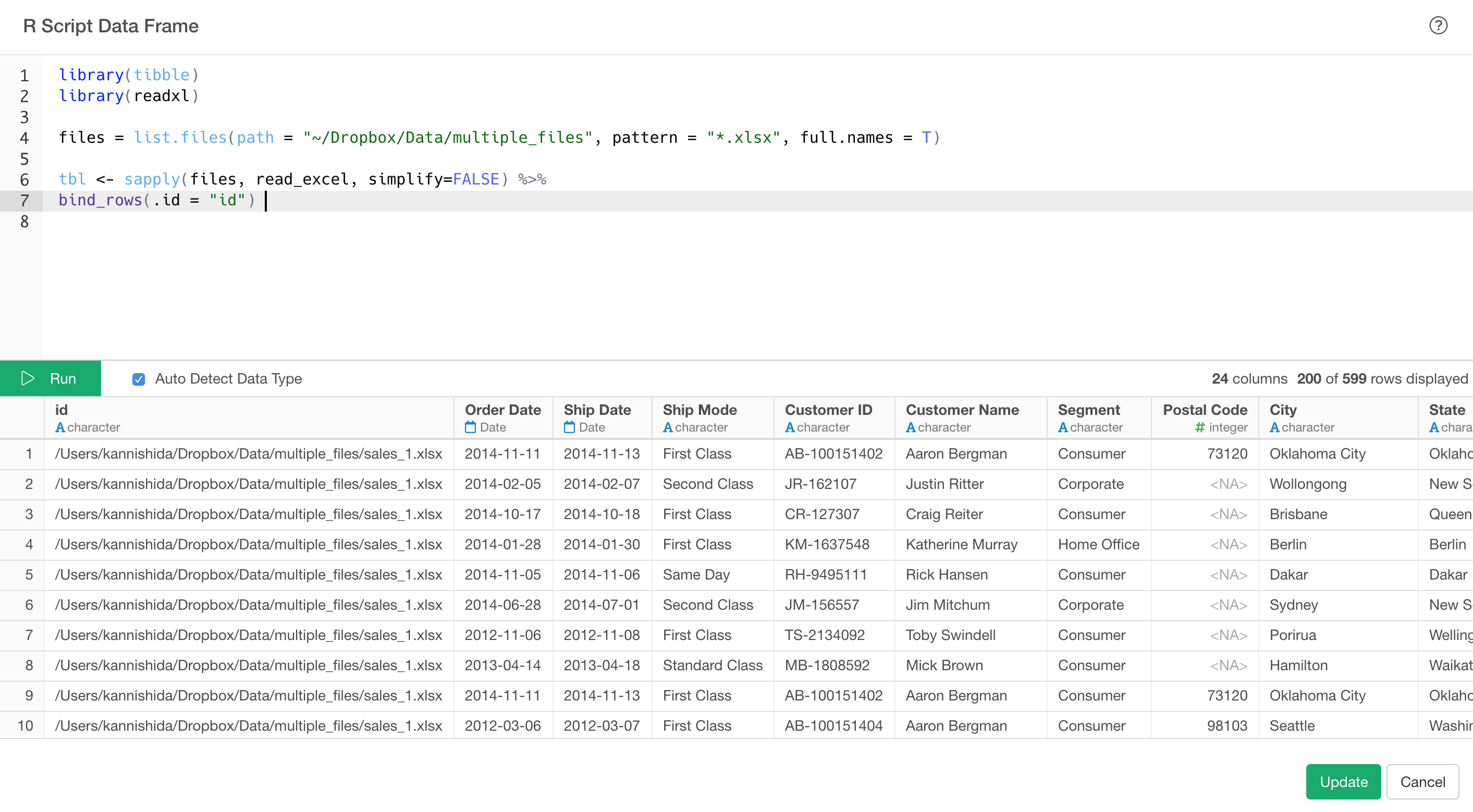
あとは、「保存」ボタンを押すと、ひとつのデータフレームとしてインポートされます。
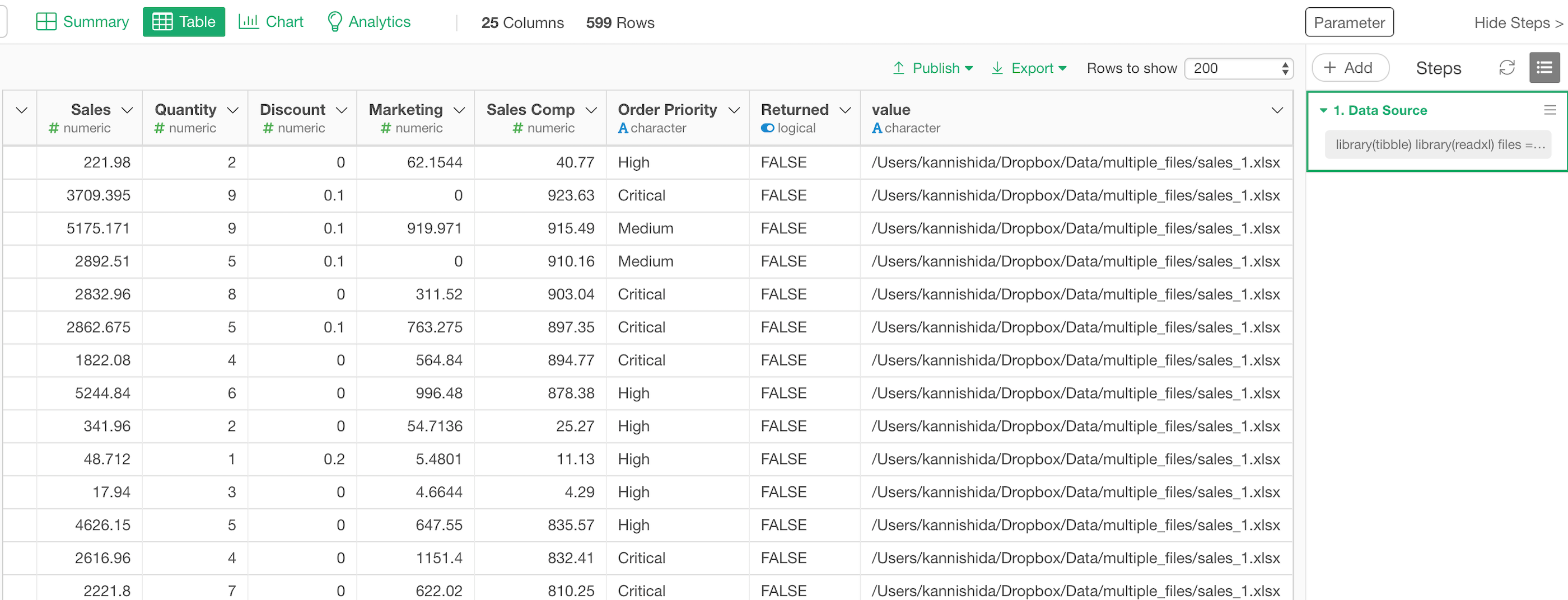
最後の列にもとのファイル名とロケーション情報(パス)を参照することができます。
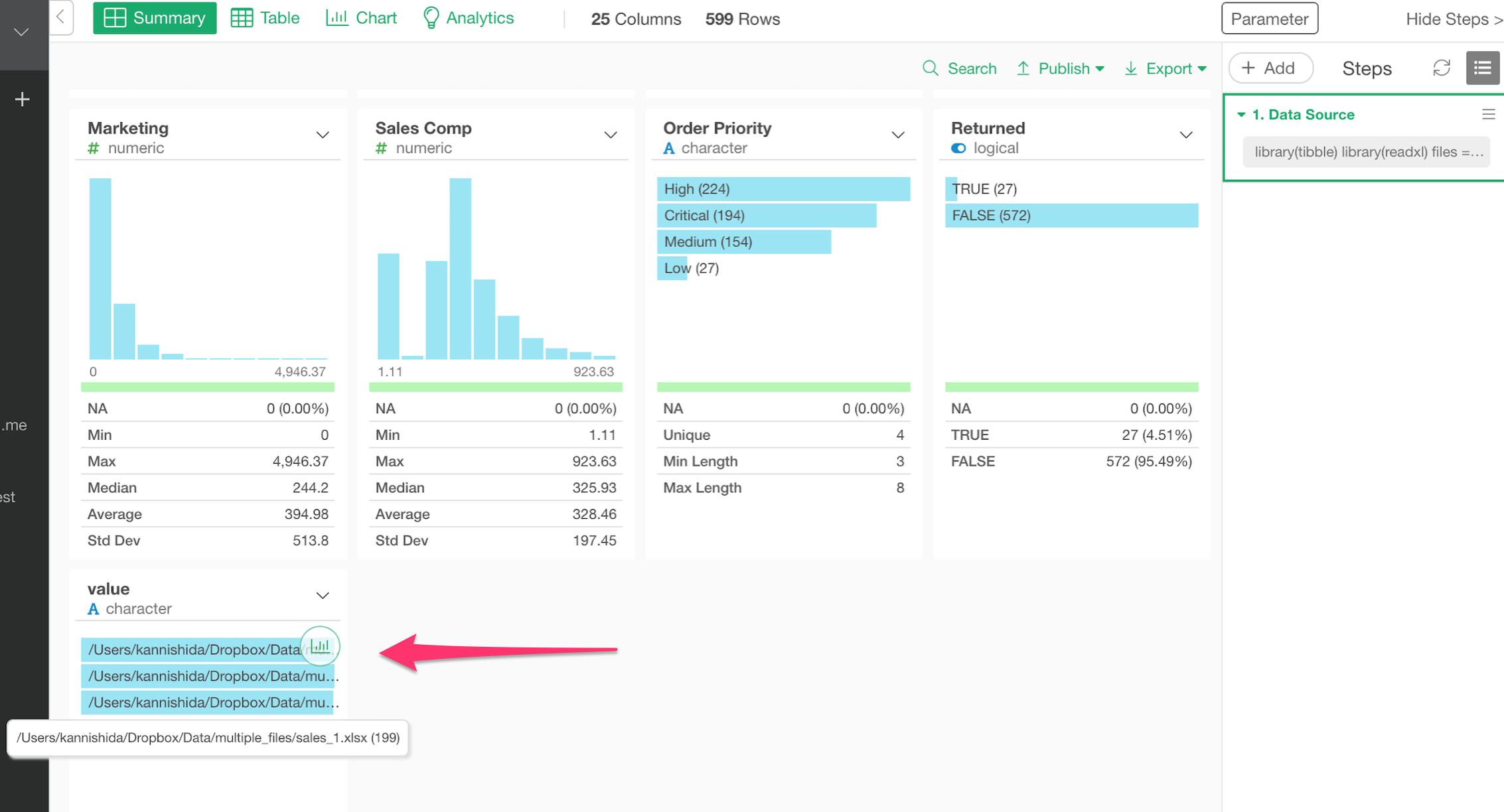
テーブル・ビューだと以下のように見えます。