本日、2018年10月31日、ついに、Exploratoryデスクトップv5.0をリリースしました!
このバージョンの一番の目玉は、新しいUIのデザインとエクスペリエンスです。これに関しては実は、まだv4.xシリーズを開発中から、同時進行で始めていたので、かれこれすでに過去6ヶ月ほど試行錯誤を繰り返しながらやっていたことになります。ですので、私達のとっては、ようやくリリースできた!という感じです。(笑)
ともあれ、Exploratoryデスクトップ v1.0を2016年の春にリリースしてからもうすでに2年以上になりますが、その間に多くのことをユーザーの方たちから学ばせていただきました。Exploratoryを長い間使っていただいている既存のユーザーの方たちから毎日のように届くたくさんのフィードバック、提案は私達にとっては学びの宝庫のようなものでした。
さらに、日本ではここ1年以上、通算8回ほど行ってきた、おなじみのデータサイエンス・ブートキャンプ・トレーニングを通して多くの勉強意欲旺盛な、これからデータ分析、およびデータサイエンスを本格的にはじめたいという素敵な方たちと出会う貴重な機会に恵まれました。そこでは、データ分析を始める時に何が問題になるのか、また、データを理解するにあたって、多くの人にとって何が重要なのかということを学ばせていただきました。
こうした学びをもとに、プロダクトの改善のために時間と努力を惜しまず、魂を込めて作り上げたのがこのv5.0です。
このリリースは私達のミッションでもあるデータサイエンスの民主化を実現するための重要な一歩だと思っています。私達がふだんから強く思っている、データ分析をより効率的に、さらにもっとおもしろくしたいという強い思いが反映されたものになったのではないかと思います。
もちろん、その判断をするのはユーザーの皆さんですので、ぜひ手にとって触っていただき、率直な感想を聞かせていただければと思います。
v5.0では、もちろん新しいUIデザインとエクスペリエンス以外にも数多くの役立つ新機能を、データラングリング、チャート、アナリティクス、ダッシュボード、ノートなどのエリアに追加することができました。
それではさっそく、一つ一つ見ていってみましょう。
新しいUIデザインとエクスペリエンス
新しいUIのデザインとエクスペリエンスの大きなテーマはシンプリシティ(簡素)とフォーカスです。
ユーザーがデータを分析するときにはさまざまなタスクを行っていくことになりますが、その時々で最も重要なことによりフォーカスできるようなUIとエクスペリエンスを提供すべきだと、私達は思っています。
典型的なデータ分析では多くの時間をデータラングリング(データの加工)に費やすことになるので、このデータラングリングのエクスペリエンスは重要です。ただそれと同時に、ユーザーがほんとうに行いたいのはデータを可視化し、アルゴリズムを使って分析することで、データから意思決定に役立つインサイトを効率的に得ることです。
そこで、Exploratoryの強力なデータラングリングの機能を多くのユーザーにとってシンプルなエクスペリエンスとして提供し、それと同時にそのエクスペリエンスがデータの可視化や分析などの他のタスクのじゃまにならないようにするというのが私達に課された命題でした。
この点に関する変更点をひとつずつ見ていってみましょう。
データラングリングのステップの編集は右側から
以前のリリースでは計算の作成、フィルター、集計などのデータラングリングのコマンドの編集は上部にあるトークンをクリックして行い、ステップの移動やコピーなどのタスクは右側にリストアップされているステップのエリアで行うというものでした。v5.0では、上部にあるコマンドの編集エリアはなくなり、データラングリングに関するすべてのタスクは右側に統合されることになりました。
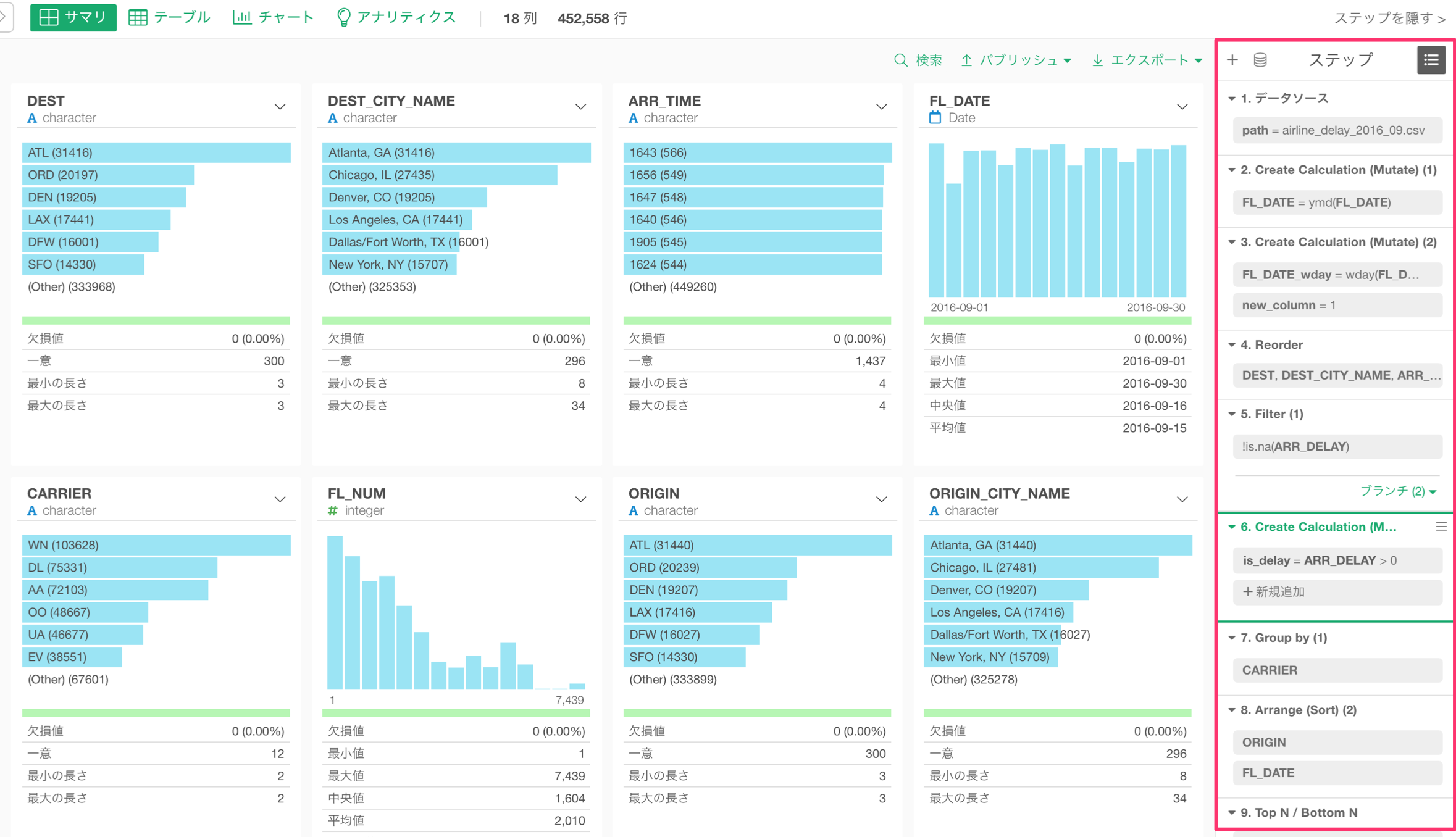
この右側のステップでは以前のようにRのコマンドをそのまま表示するかわりに、トークン(グレーの背景色のボックス)が表示されます。このトークンを直接クリックして編集のためのダイアログを開くことができます。
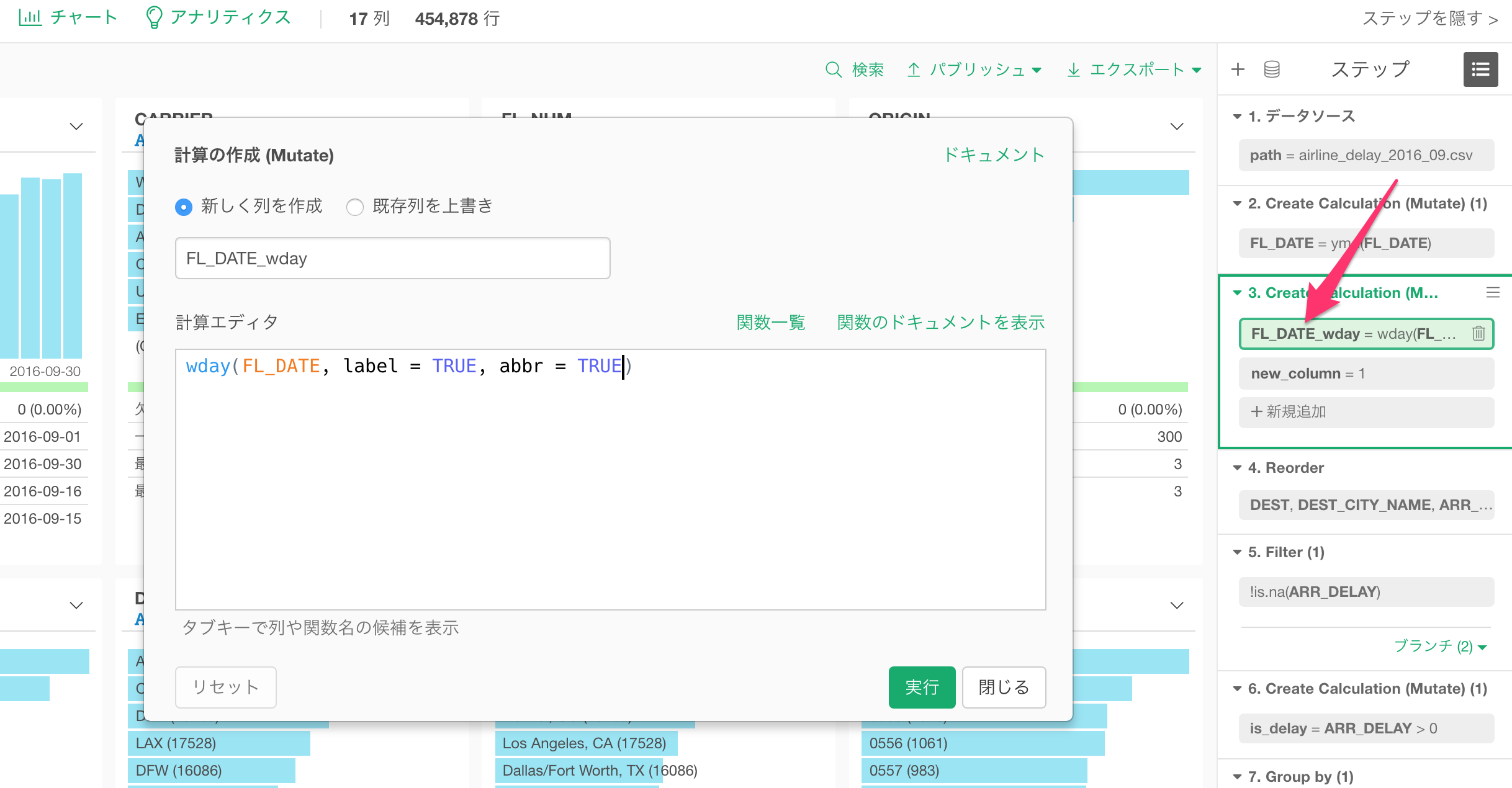
ステップで何が起きているのかを調べたいとき
データラングリングを行っているときに重要なことのひとつに、そのステップのどこで何が行われているかを理解することです。これはデータラングリングのプロセスのどこかでエラーが起きているときには特に重要です。この問題を解決するためにいくつかの改善があります。
トークンの中身を表示するインスタント・ポップアップ
それぞれのトークンの上にマウスを持っていくことで、トークンの中で具体的に何が起きているのか見ることができます。
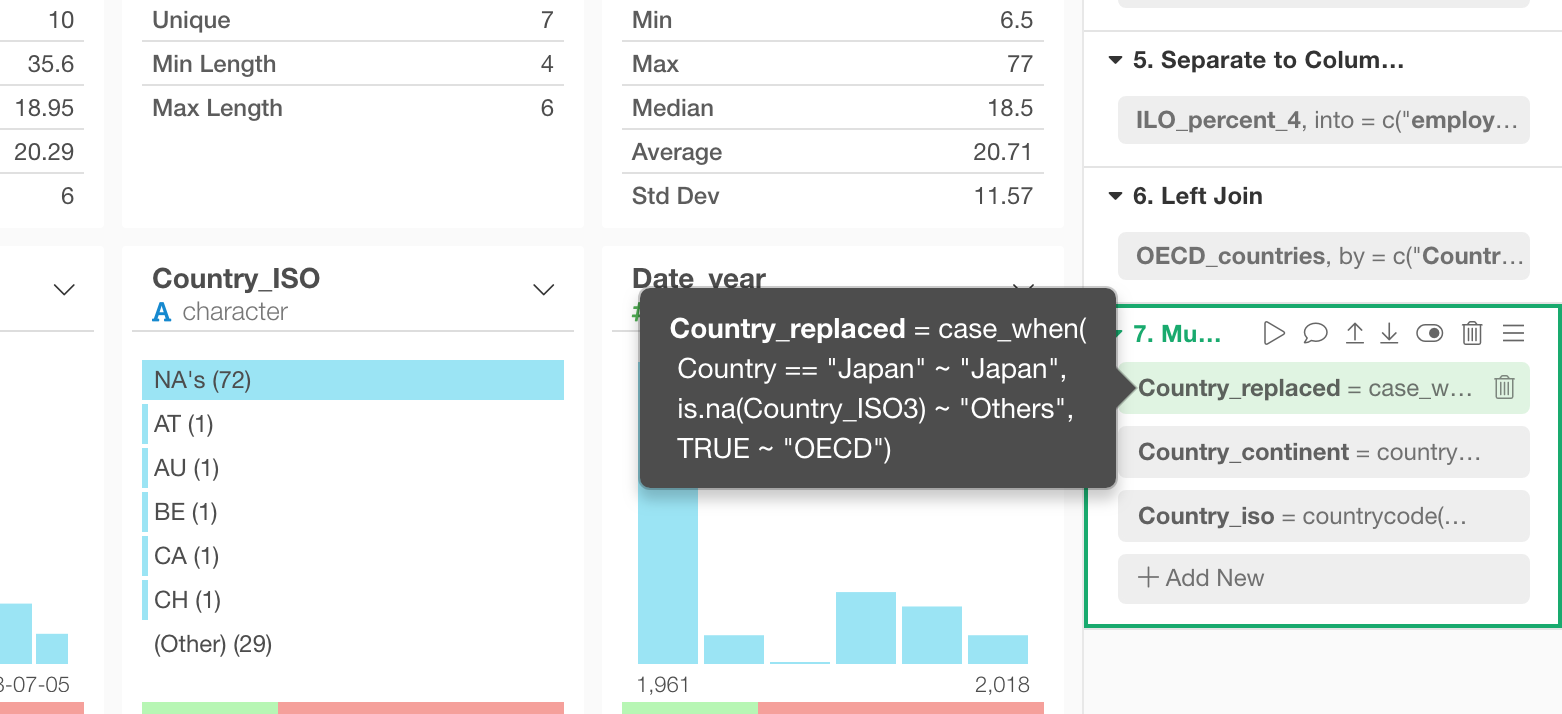
また、マウスをステップのタイトルの上に持っていくことで、そのステップ全体のRのコマンドを見ることができます。この情報は、以前のリリースではステップに表示されていた情報とまったく同じです。
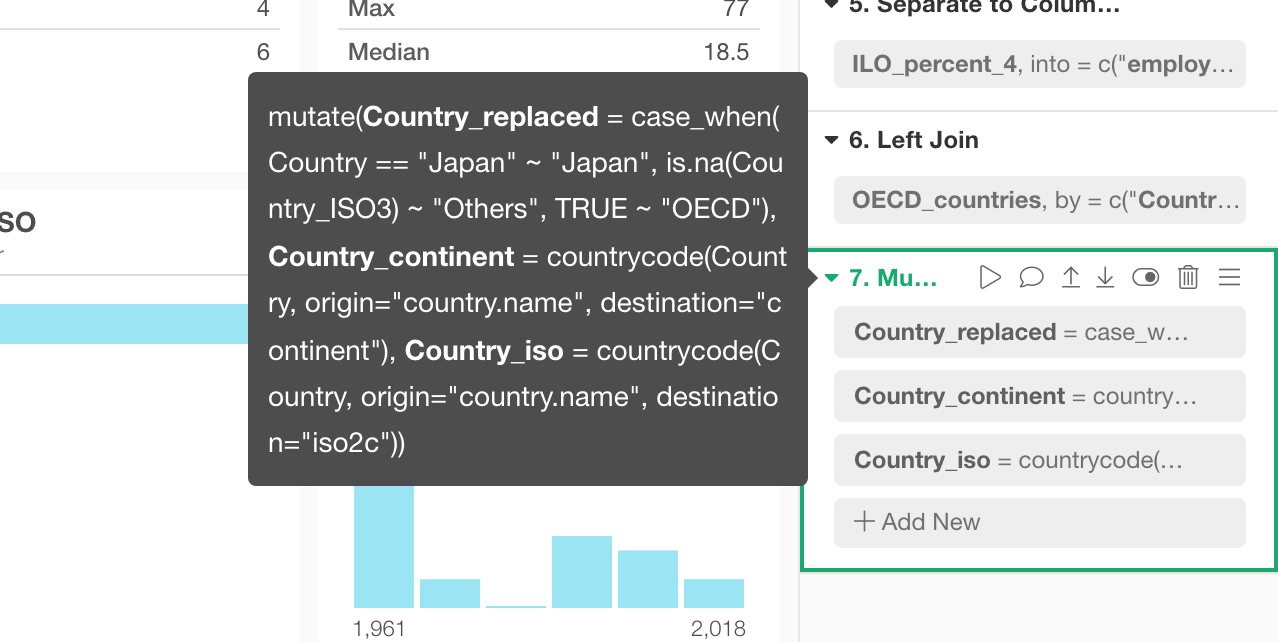
サマリ、テーブル・ビューで列をクリックしたときのトークンのハイライト
サマリやテーブル・ビューで列をクリックすると、右側のデータラングリングのステップの中にある、それに関連するトークンが緑色でハイライトされます。これはその列がどのように作られたのか、またどこで使われているのかを理解したいときに便利です。
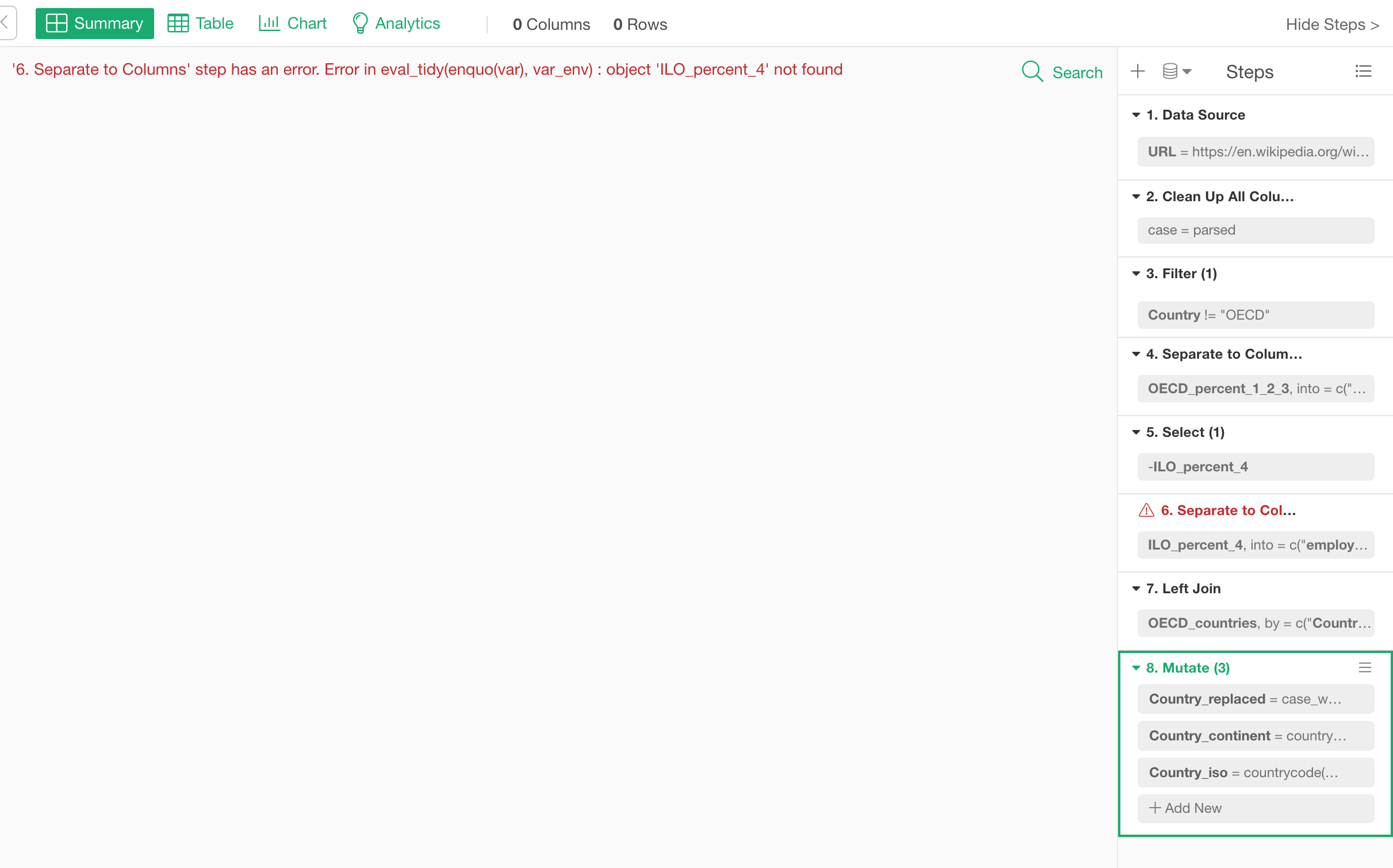
エラーが出たとき
データラングリングのプロセスのどこかでエラーが起きたとき、具体的にどのステップでエラーが発生しているのかが表示されるようになりました。
グループを解除してステップを分割する
計算の作成(Mutate)やフィルタのように1つのステップの中に複数のトークンがあり、そのどこかでエラーが発生している場合には、デバッグが難しいときがあります。
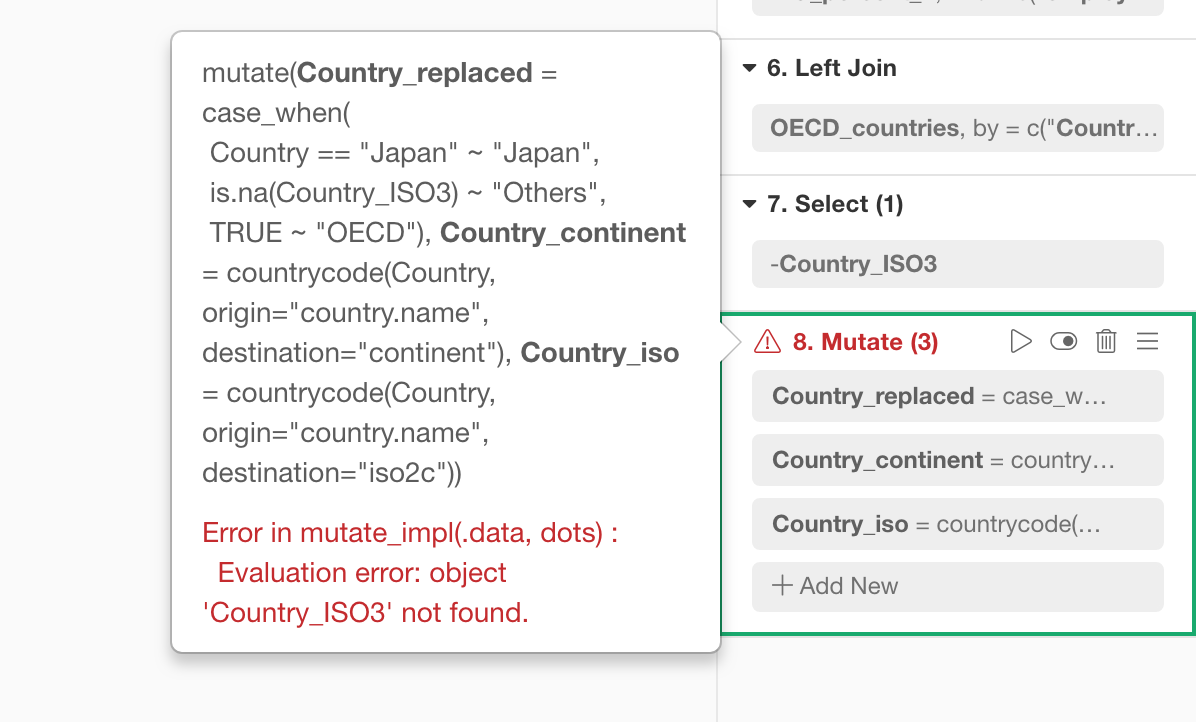
こんなときは、「ステップを分割」することをおすすめします。
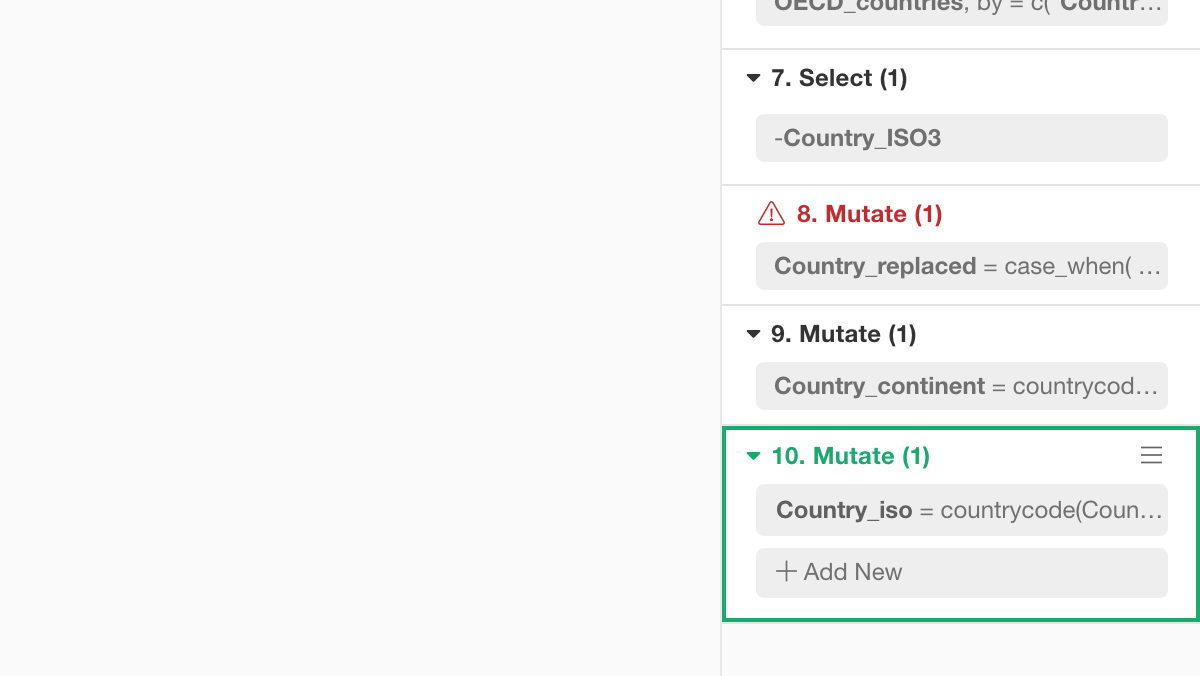
これにより、それぞれのトークンがそれぞれ独立したステップとなります。このスクリーンショットの例では、分割後にできた一つ目のステップ(ステップ8)に問題があるということがわかります。
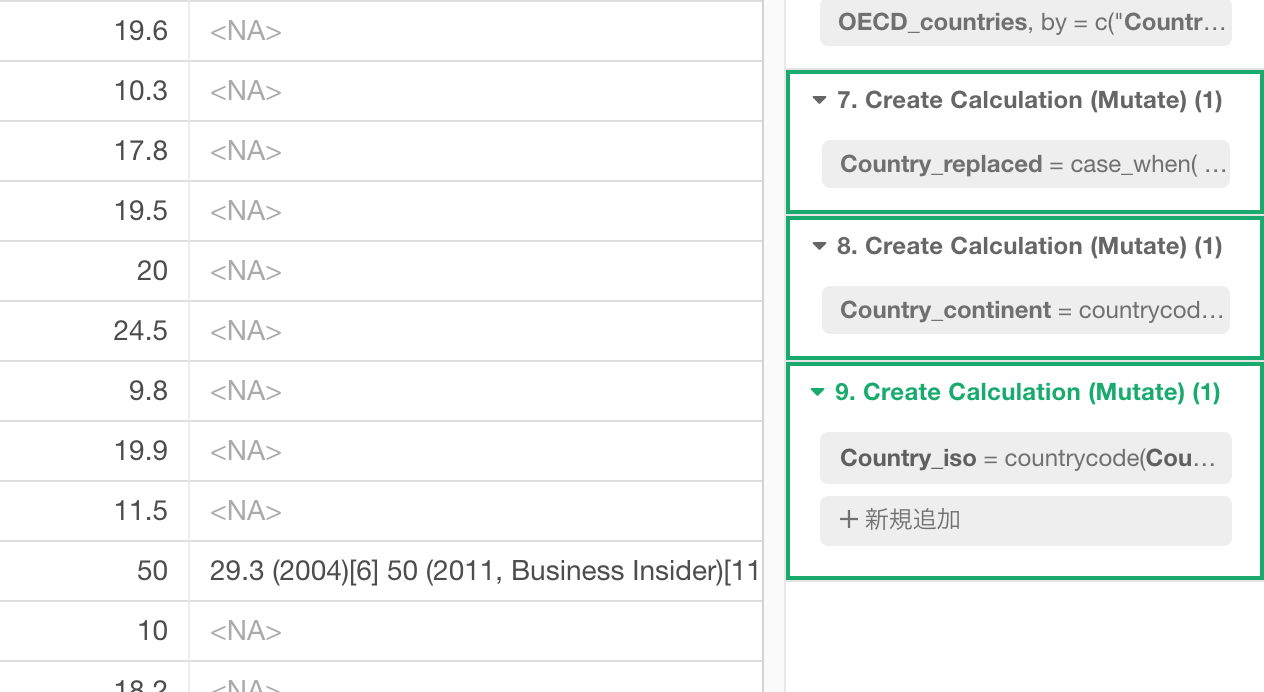
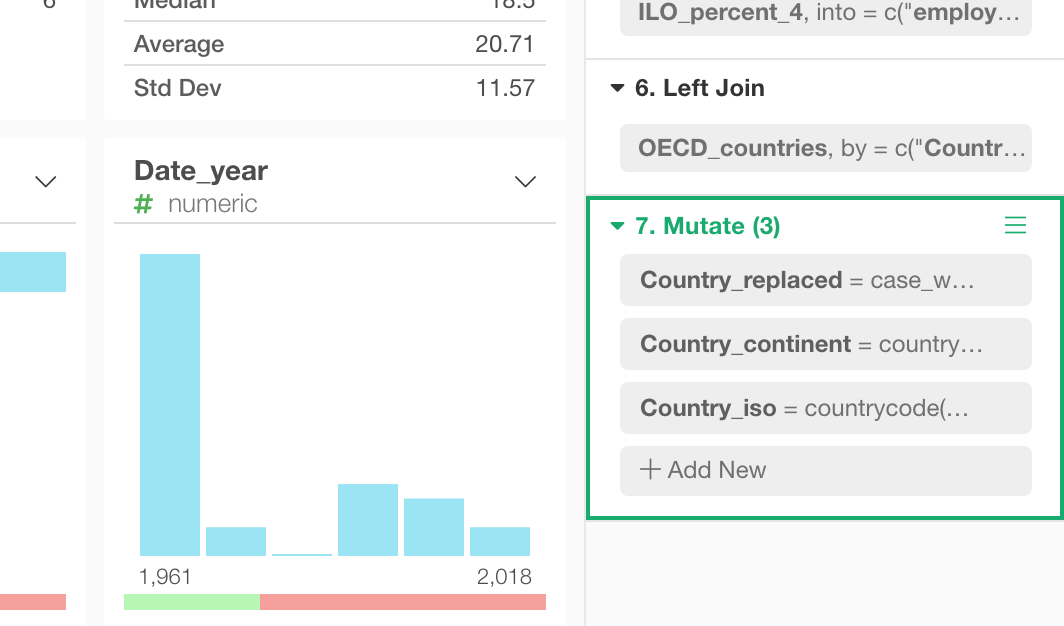
グループ化で複数のステップを結合する
一度分割した複数の’計算の作成(Mutate)’のステップをもう一度1つのステップにまとめることも簡単にできます。
まずは、まとめたい複数のステップをコマンド・キー / コントロール・キー、またはシフト・キーを押しながら選択します。
次に、「複数のステップにまとめる」のアイコンをクリックします。
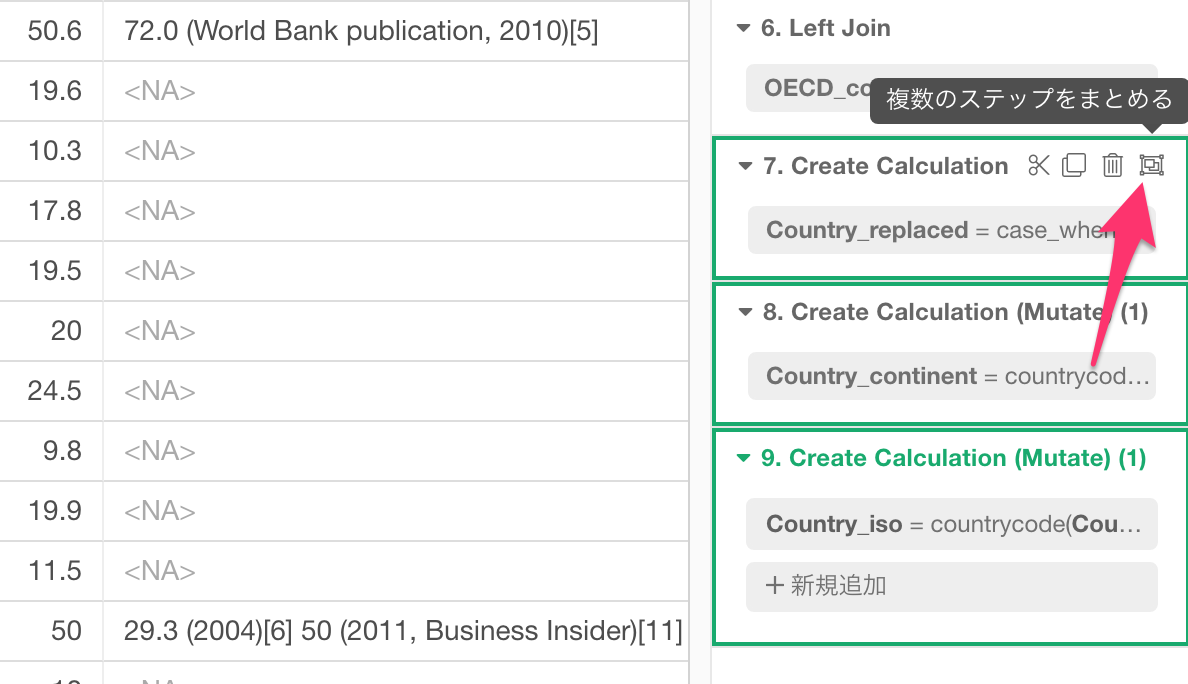
すると、さきほどの3つのステップが1つのステップのなかの3つのトークンになっているのが確認できます。
ステップの位置を動かす
これは以前のリリースでもできていたことですが、このバージョンでも引き続き、ステップの位置をドラッグ・アンド・ドロップで動かすことができます。ステップのタイトルのあたりをマウスでつかんで、あとは移動したいところに落とすだけです。
ほかにも、ステップのコピー、カット、削除などのオペレーションは以前とかわらずそのままサポートされています。
ステップを開く、または閉じる
分析を進めていくとデータラングリングのステップはどんどんと長くなっていくものですが、そうするとデータがどのように作られたのかを追っていくのが難しくなります。そこで、ステップの「開く」モードと「閉じる」モードをさぽーとすることになりました。
ステップの上にあるボタンを押してモードを切り替えることができます。
データラングリング・ステップのエリアを隠す
データラングリング・ステップがあるとデータがどのように作られたのかを理解するのに便利ですが、特にデータを可視化したり、アナリティクスを使って分析しているときは必要でないかもしれません。そんなときは、そのエリアを隠して、チャートやアナリティクスにもっと広い領域を与えてあげましょう!
ステップの無効化
たまに、ステップを作ってみたものの、そのステップなしでデータはどうなるのかを見てみたいときがあります。そんなときには、「ステップを無効化」してしまいましょう。
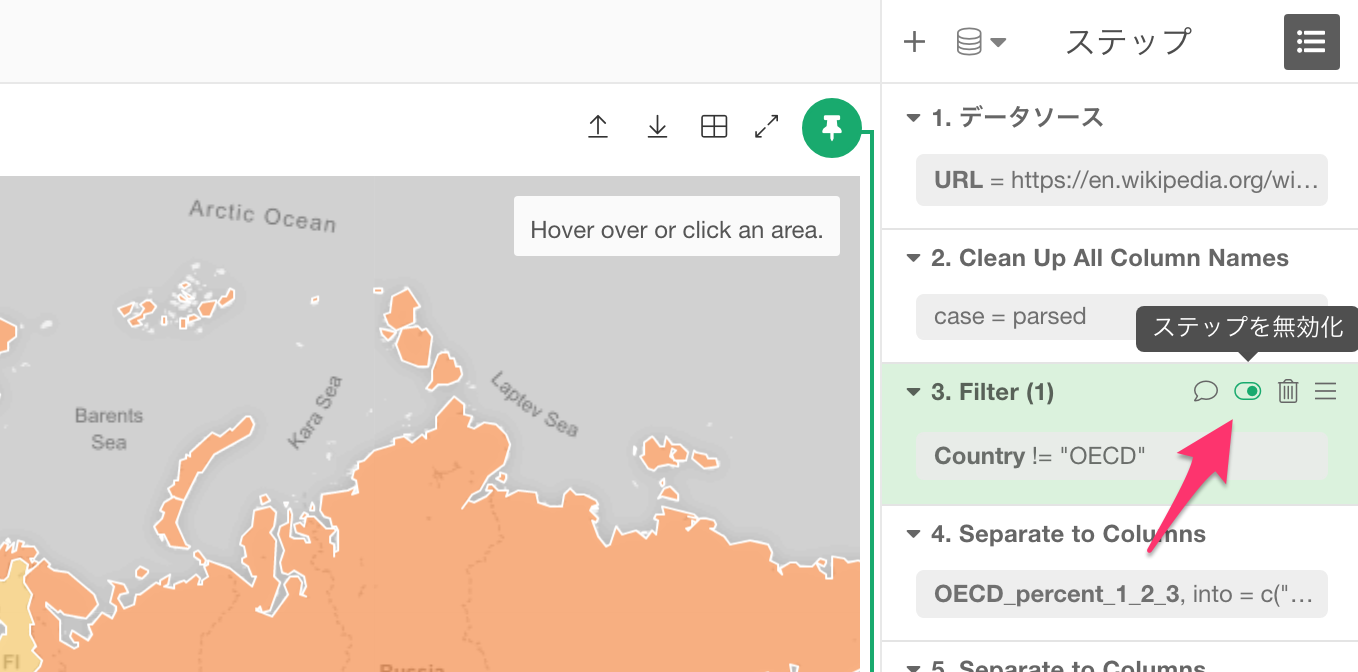
無効化されたステップは半透明な状態になります。
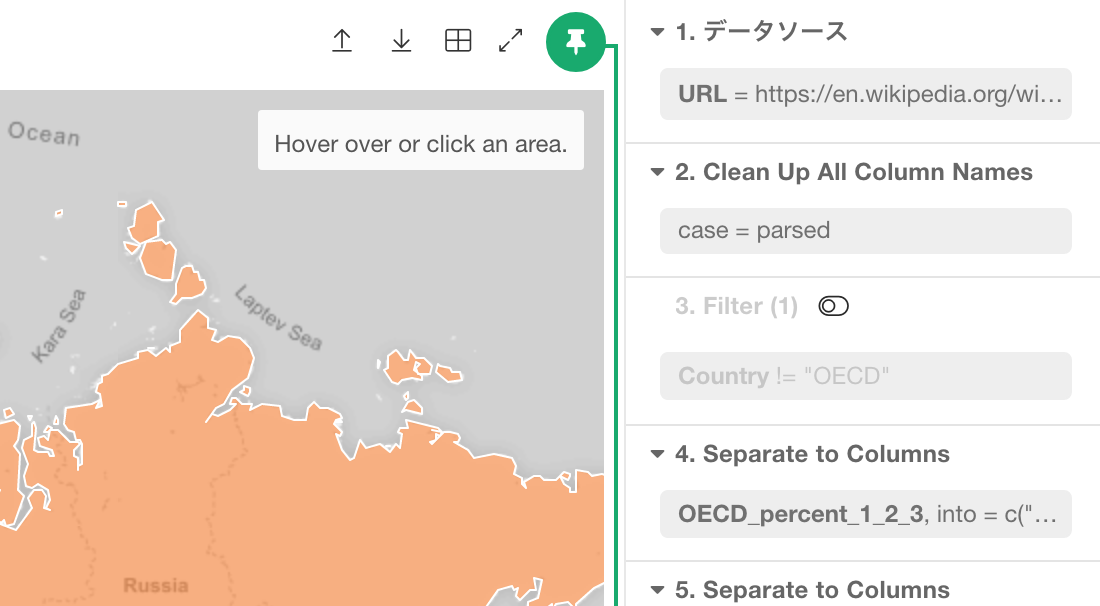
そこででてくる「ステップの有効化」のボタンをクリックすることで、ステップを再び有効にすることができます。
ステップの追加
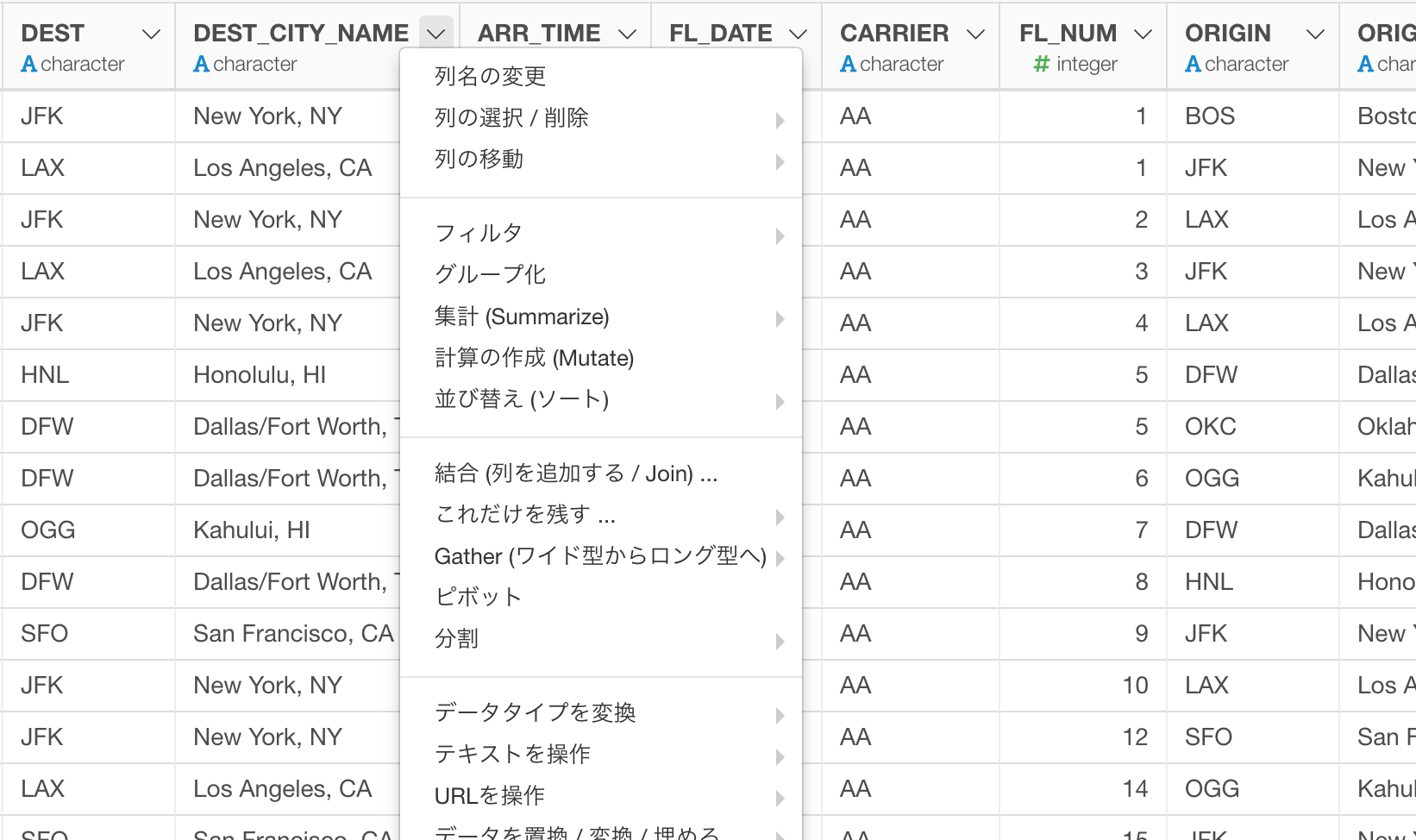
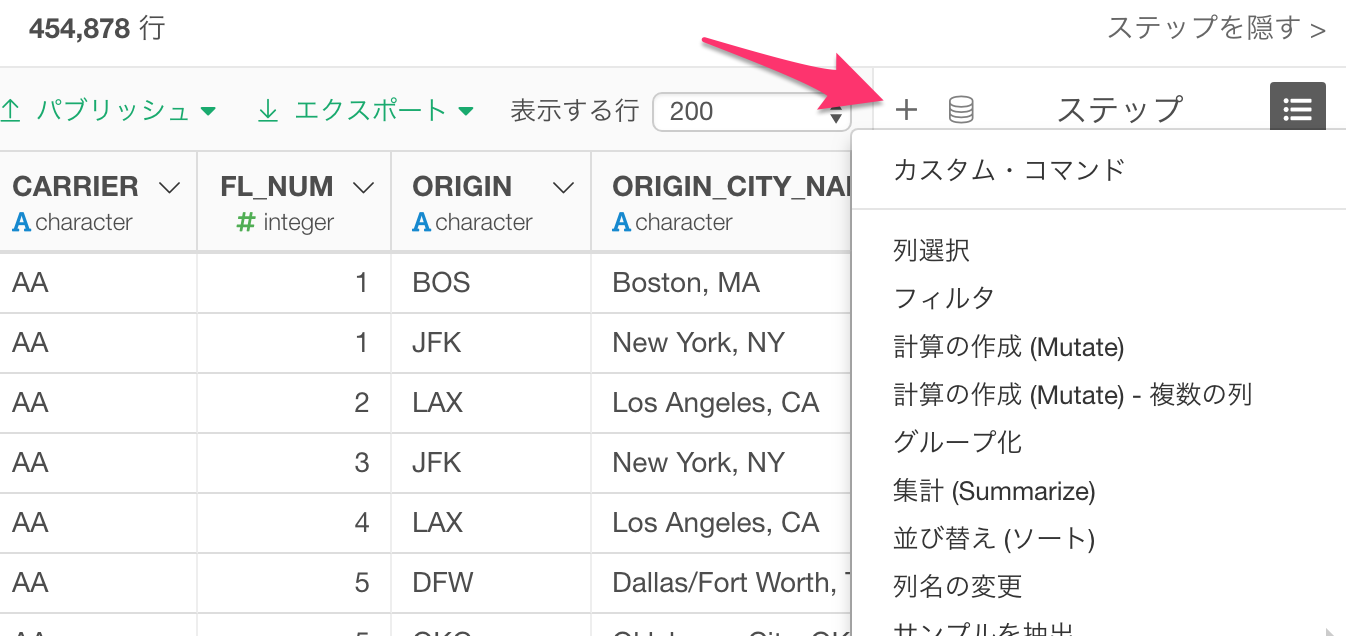
ステップを追加するのは、以前のリリースとほぼ同じです。列ヘッダー・メニューから選ぶか、ステップの上部にあるプラスボタンからコマンドを選ぶかのどちらかです。
列ヘッダー・メニューから
ステップ上部のプラスボタンから
データのエクスポート
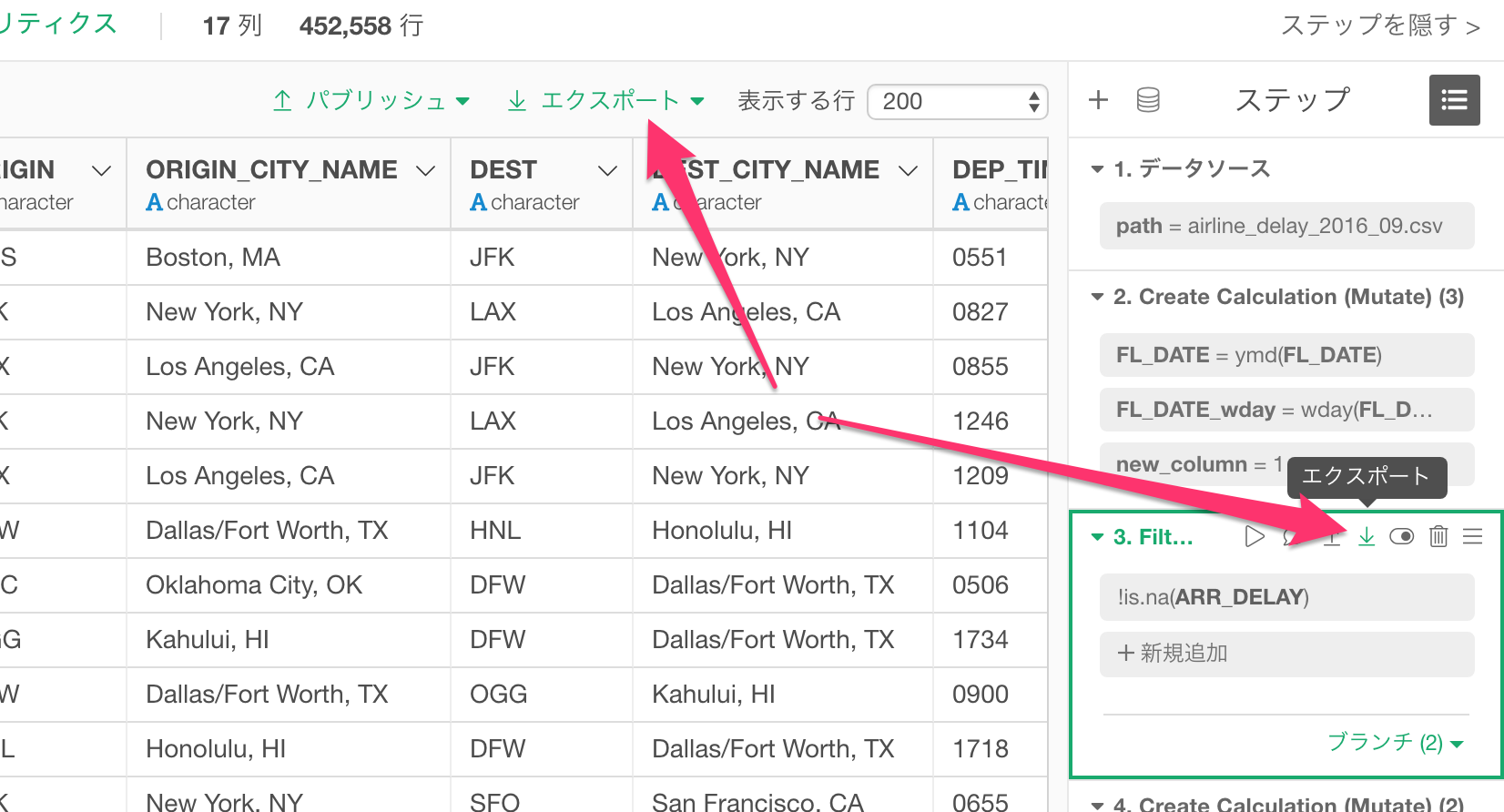
データをエクスポートするにはいくつかのパターンがあります。
ステップごとのデータ
選ばれたデータラングリングのステップの時点でのデータをエクスポートできます。
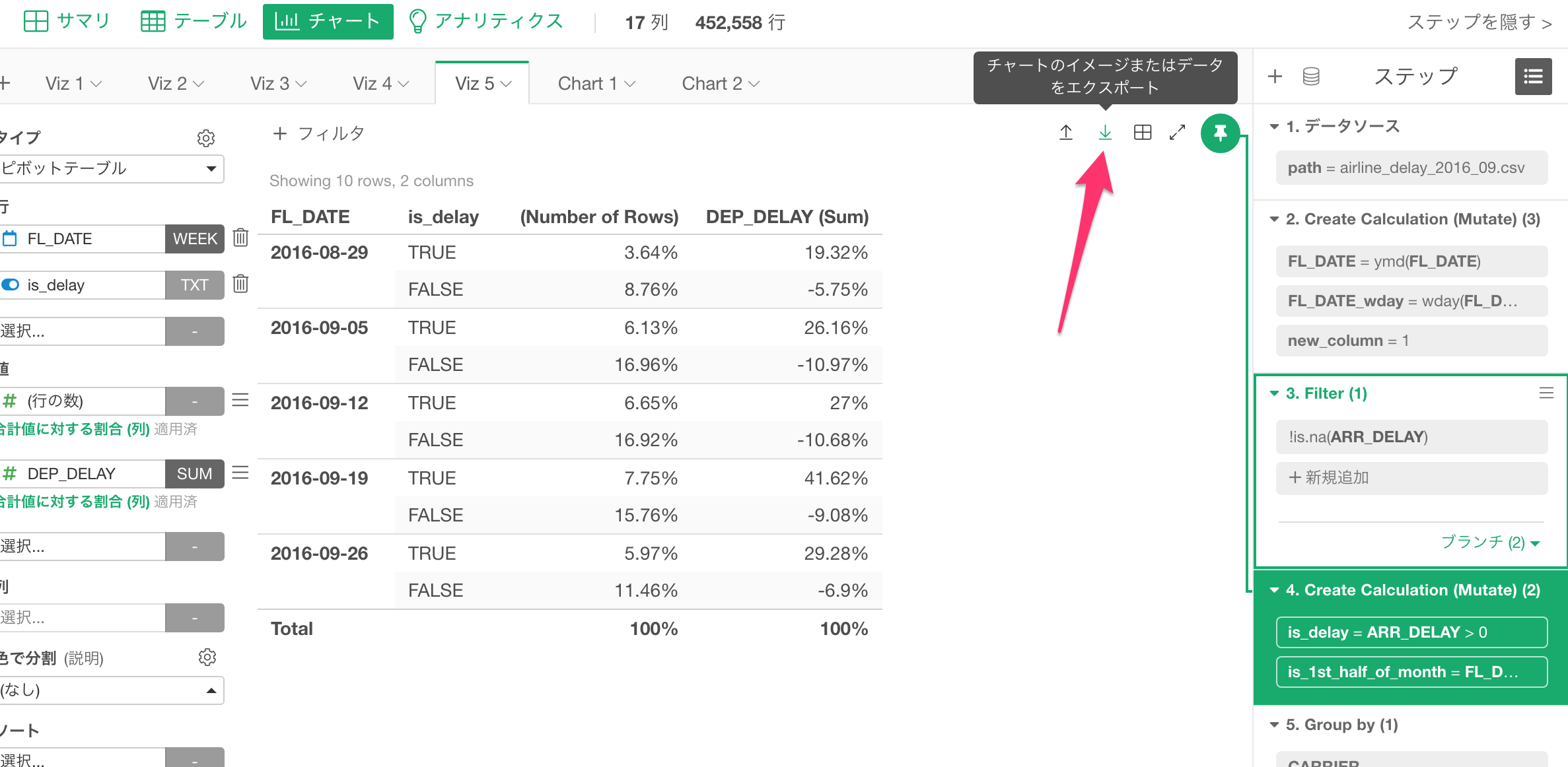
チャート、アナリティクスのデータ
チャートやアナリティクスに表示されているデータをエクスポートすることができます。
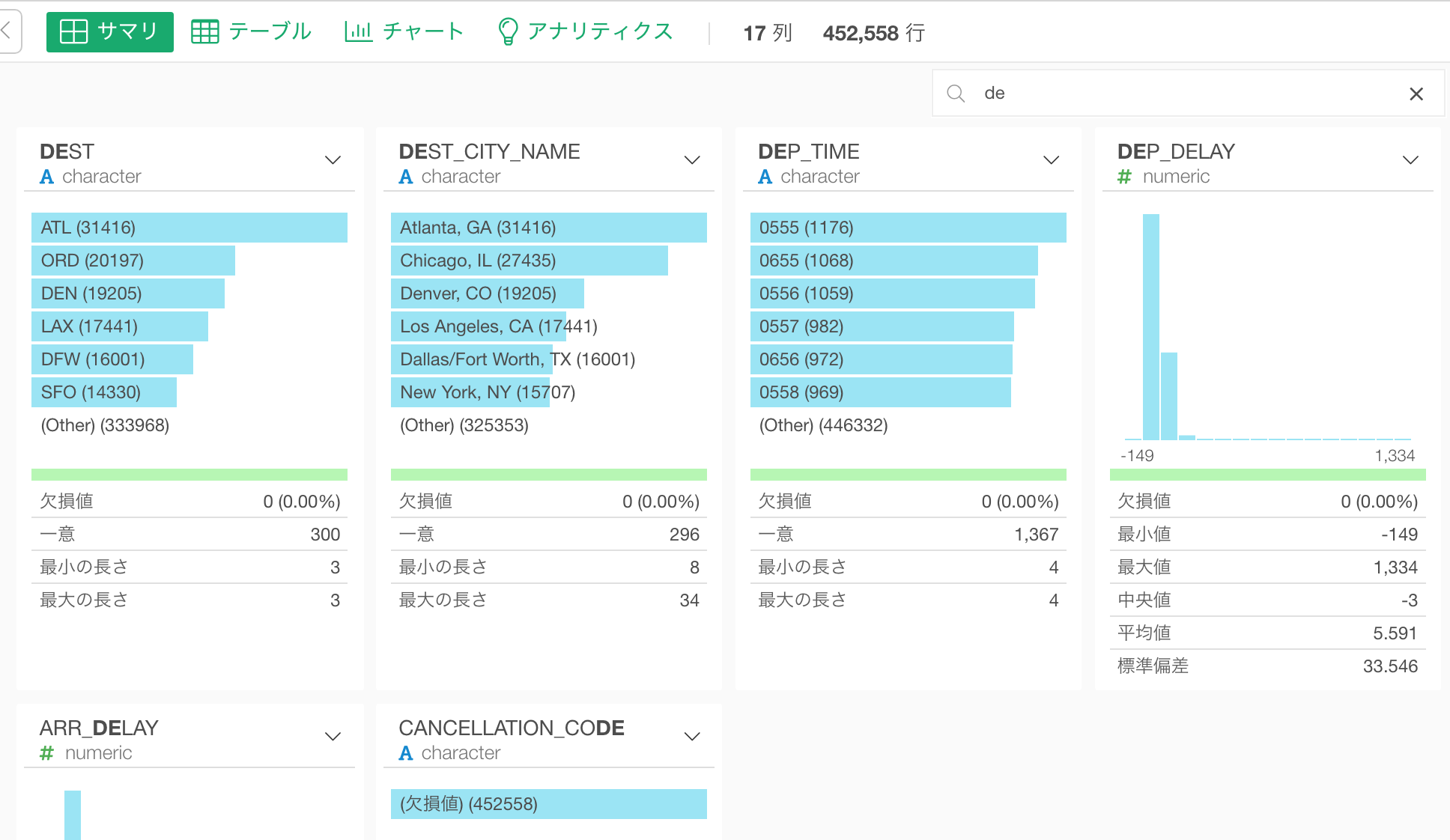
サマリ・ビュー
列名列名の一部をタイプすることで列を探すことができるようになりました。
データラングリングのコマンドUI
データラングリングをもっと簡単におもしろいものにするために、これまでも、どんどんと用途に応じたUIを足してきていましたが、今回もいくつかの改善点があります。まずは、2つの新しいUIから。
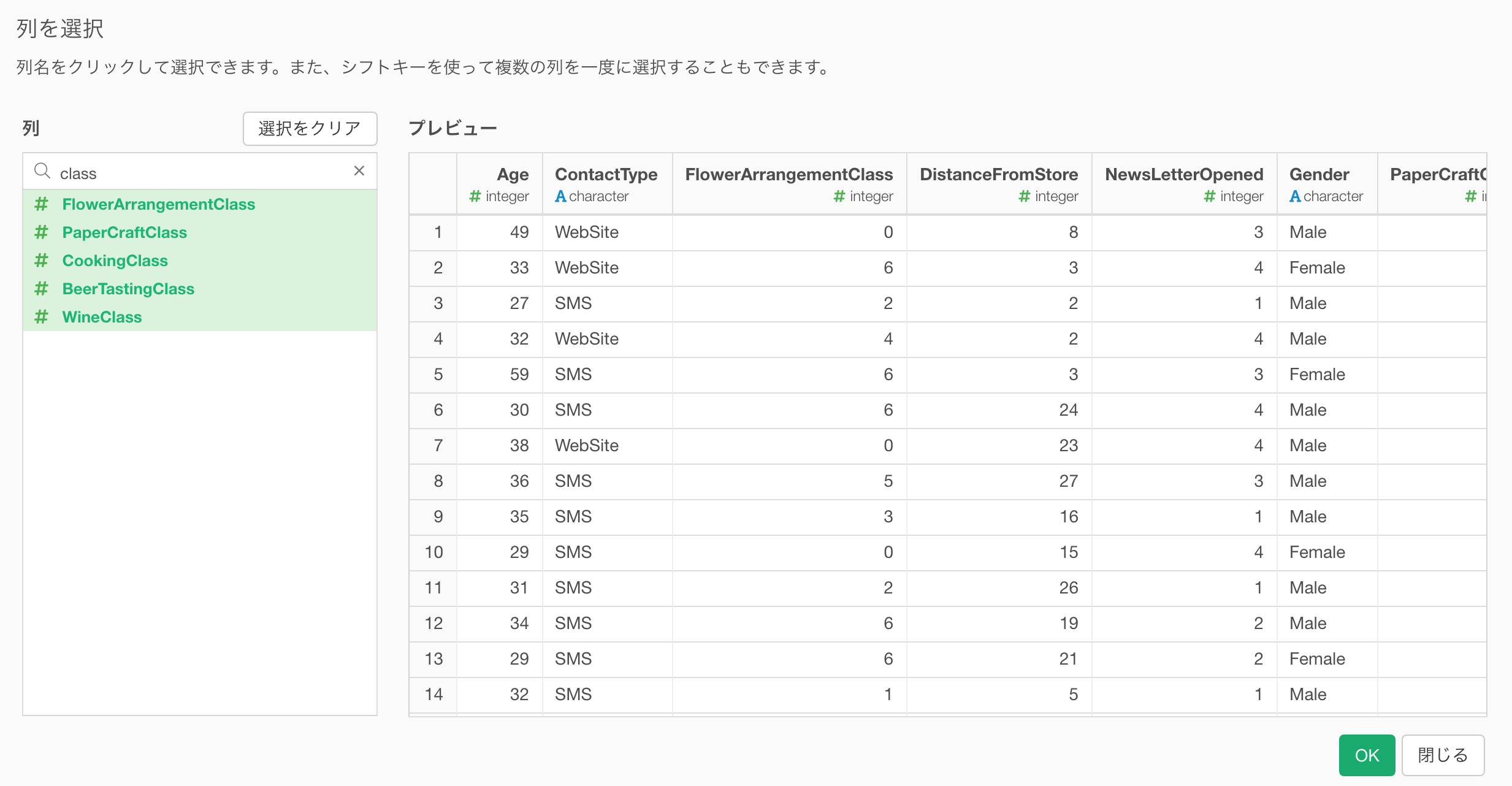
列の選択
新しくできた、列の選択のダイアログでは左側の列リストを使って列を選ぶのがより簡単になりました。
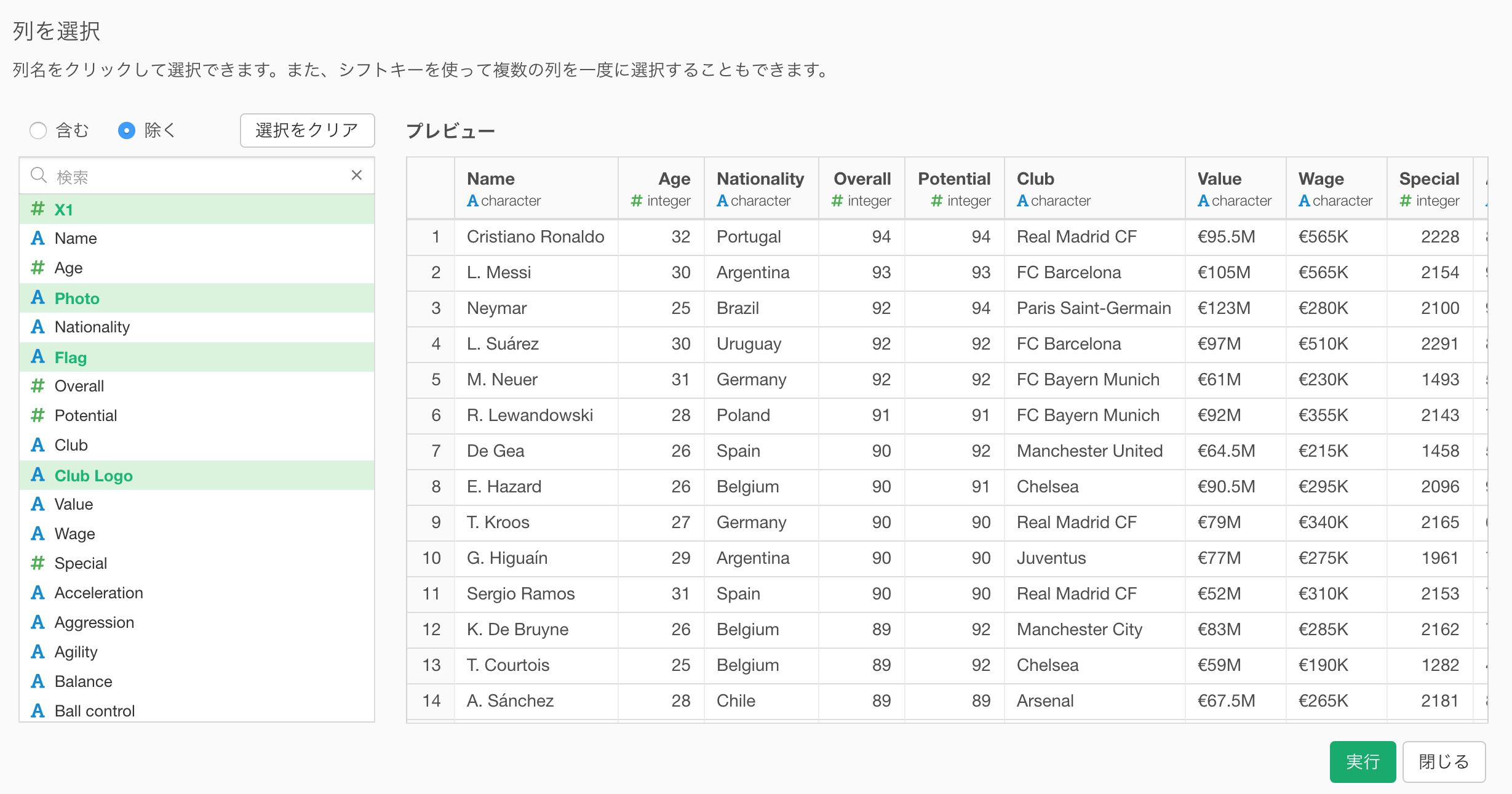
列がたくさんあるときなどは、ぜひ列の一部の名前を入れることで絞り込みができるようになりました。
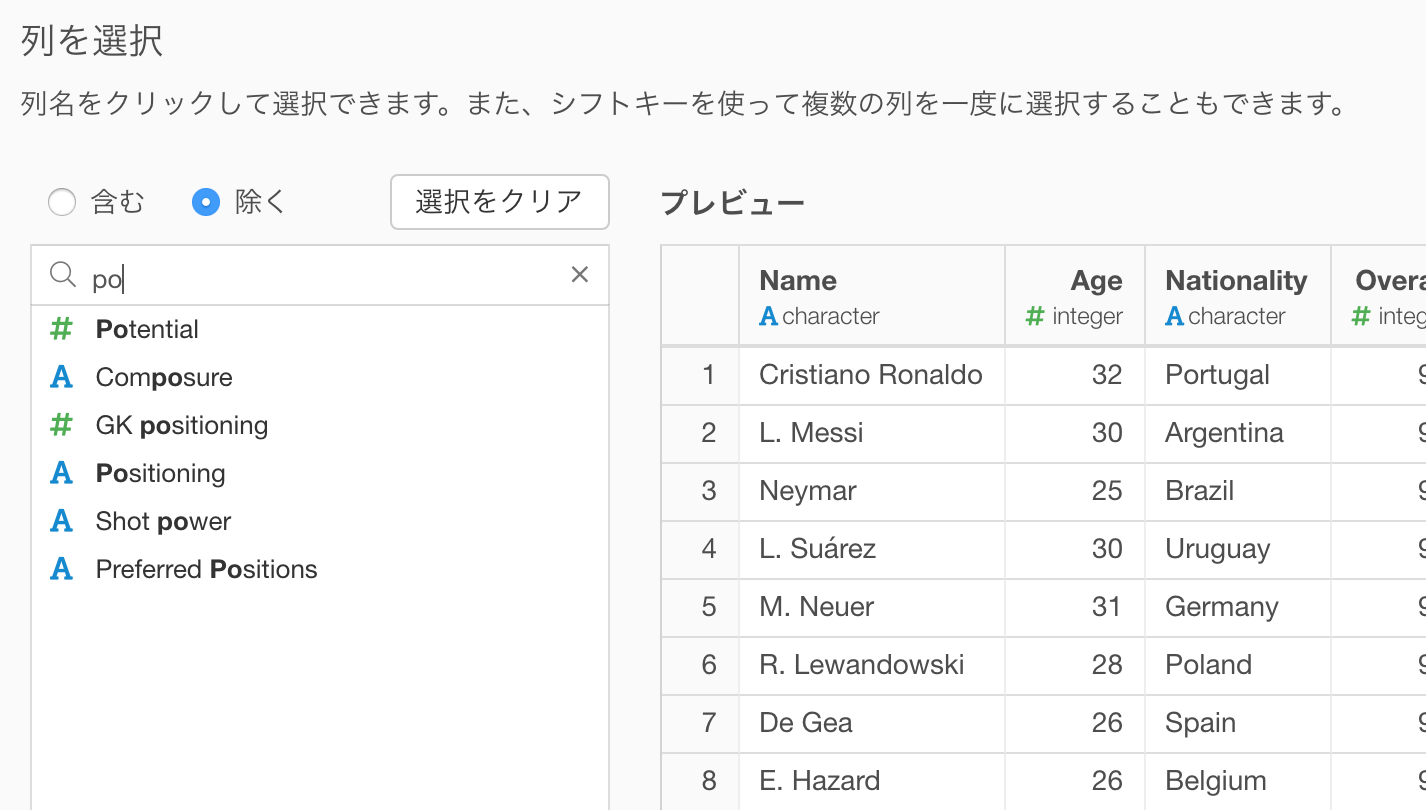
列を選択するには、「含む」と「除く」の2つのモードがあります。用途に応じて使い分けてみてください。
ちなみにこの「列の選択」のダイアログはチャートやアナリティクス・ビューで複数の列を選ぶようなときに出てくるダイアログとしても共有されています。
列の順番の並び替え
列の順番を変えたいということはよくあります。そこで、このリリースではこのタスクを簡単に行うための専用のUIを用意しました。
以前と同じで、列を一番左端に持っていきたい場合は、列を選んで、列ヘッダー・メニューから、
列の移動 -> 先頭
を選びます。
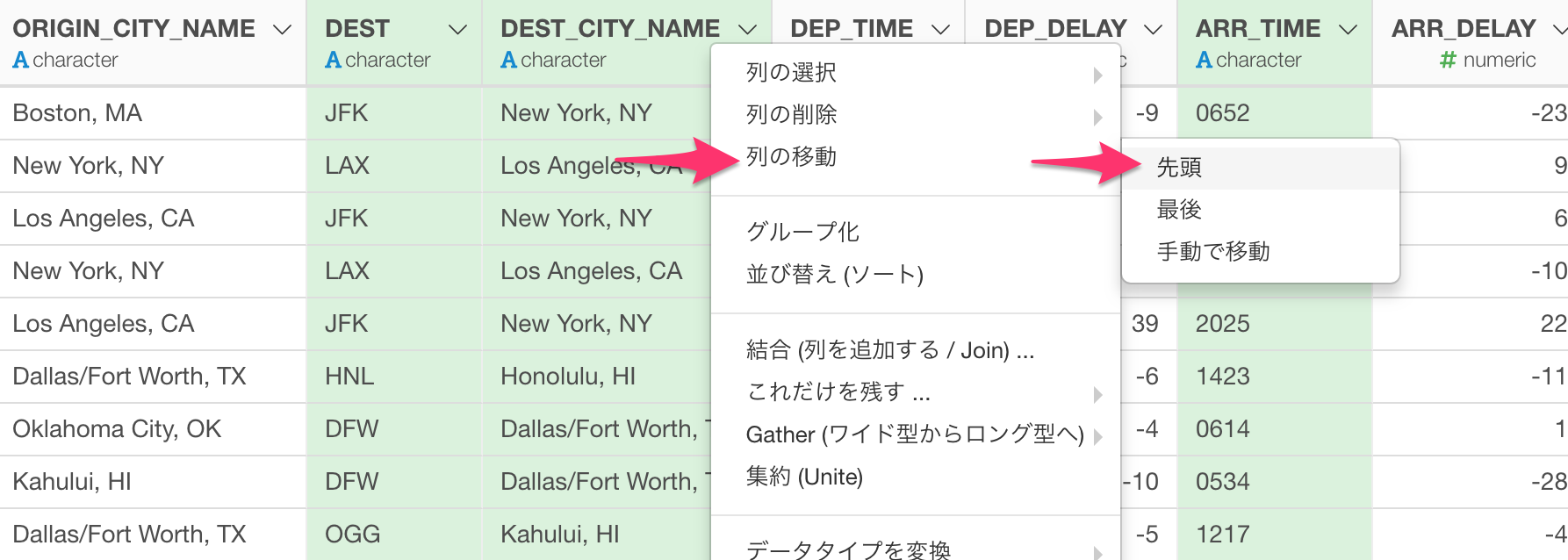
さらに、もっと柔軟に列の位置を変えたいときは、先ほどのオペレーションでできたステップのトークンをクリックするか、
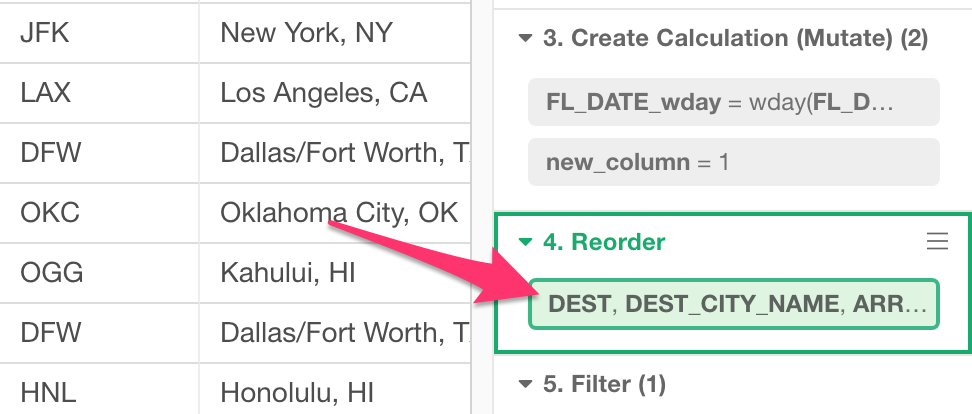
または、列ヘッダー・メニューから
「列の移動」-> 「手動で移動」
を選ぶことで、
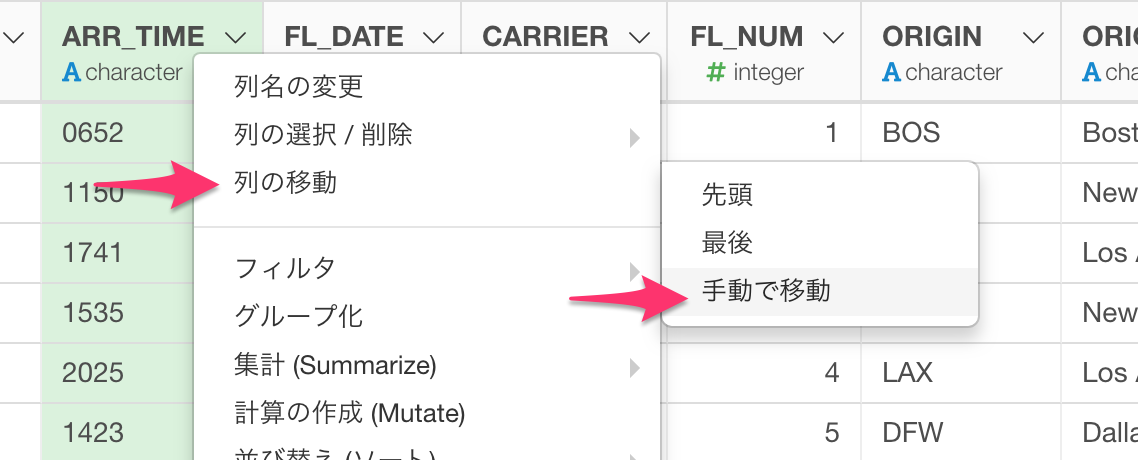
「列を並べ替える」ダイアログを開き、その中で列の順番をドラッグ・アンド・ドロップで変えることができます。
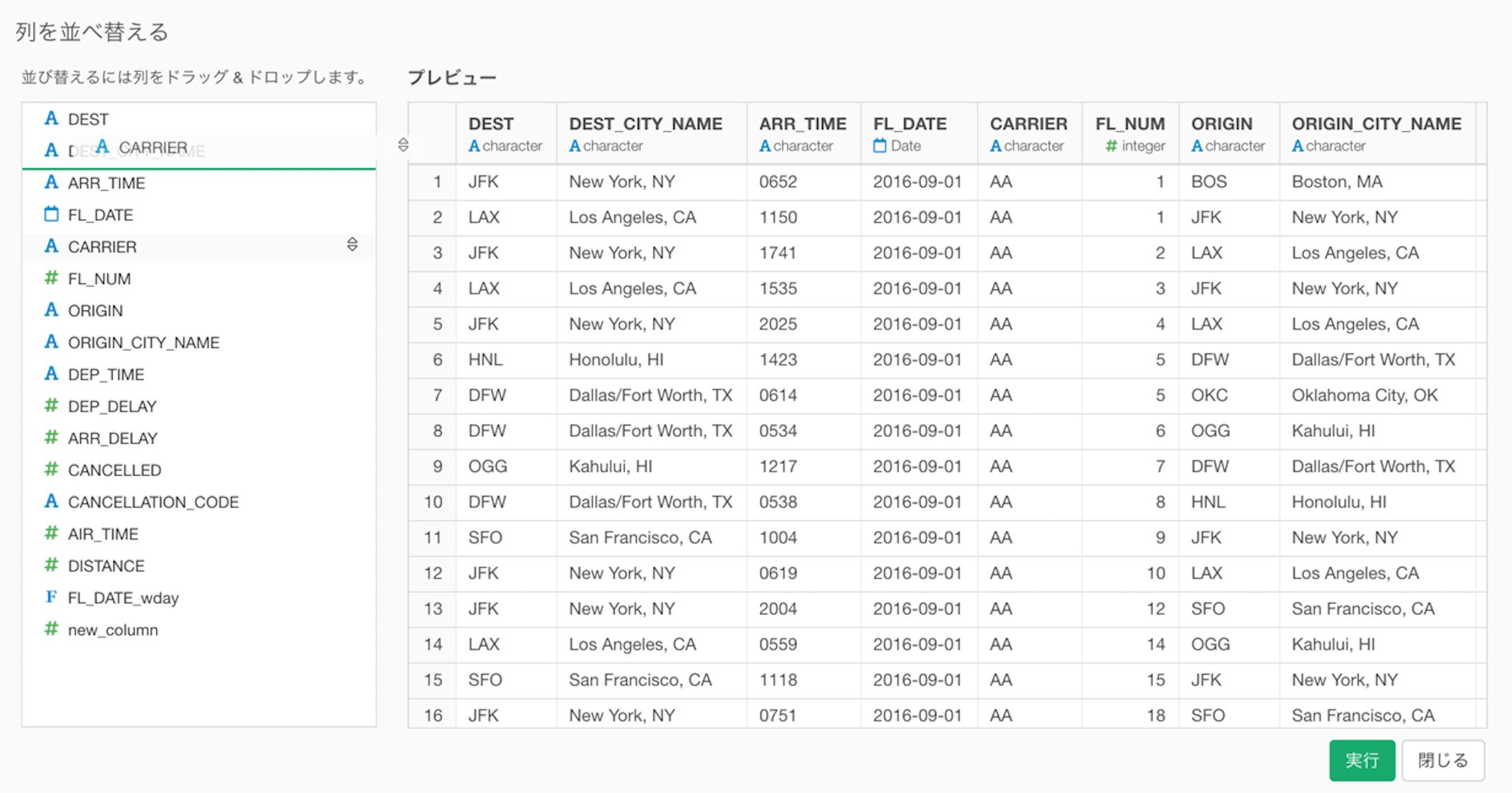
カスタム・コマンドの入力
Exploratoryの中で私が個人的に気に入っている機能の1つは拡張性です。そして、それが光るのはデータラングリングのエリアです。
列ヘッダー・メニューから行いたいオペレーションを選び、UIをもとにデータラングリングを行うかわりに、カスタムのRのコマンドを直に書くことができます。そのRのコマンドはデータフレームをインプットとしてとり、データフレームをアウトプットとして返すという決まりがありますが、それ以外は自由です。
データラングリング・ステップの上部にあるプラスボタンから、「カスタム・コマンド」を選びます。
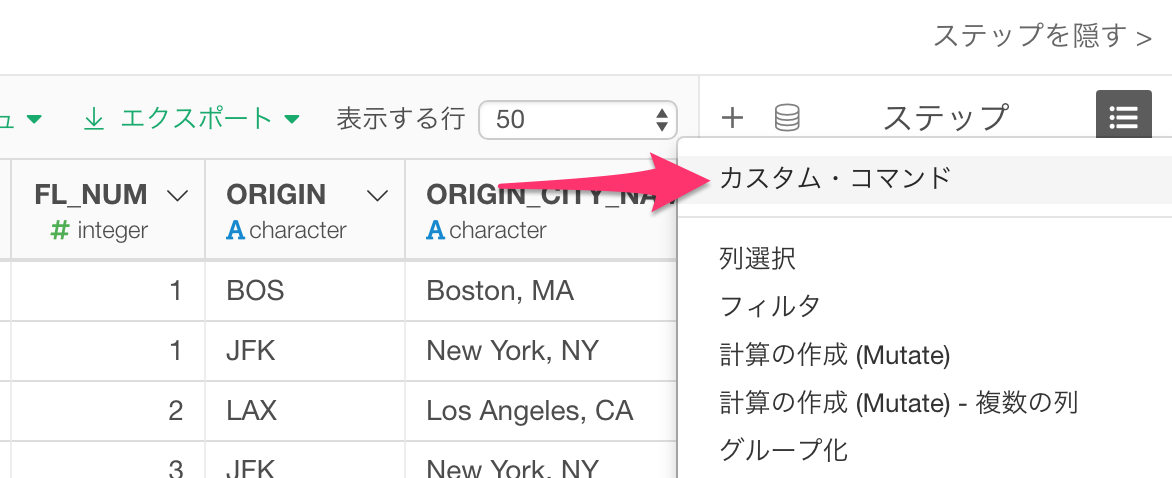
新しくなったカスタム・コマンドのUIからRのコマンドを入力します。複数の行に渡るコマンドもサポートされています!
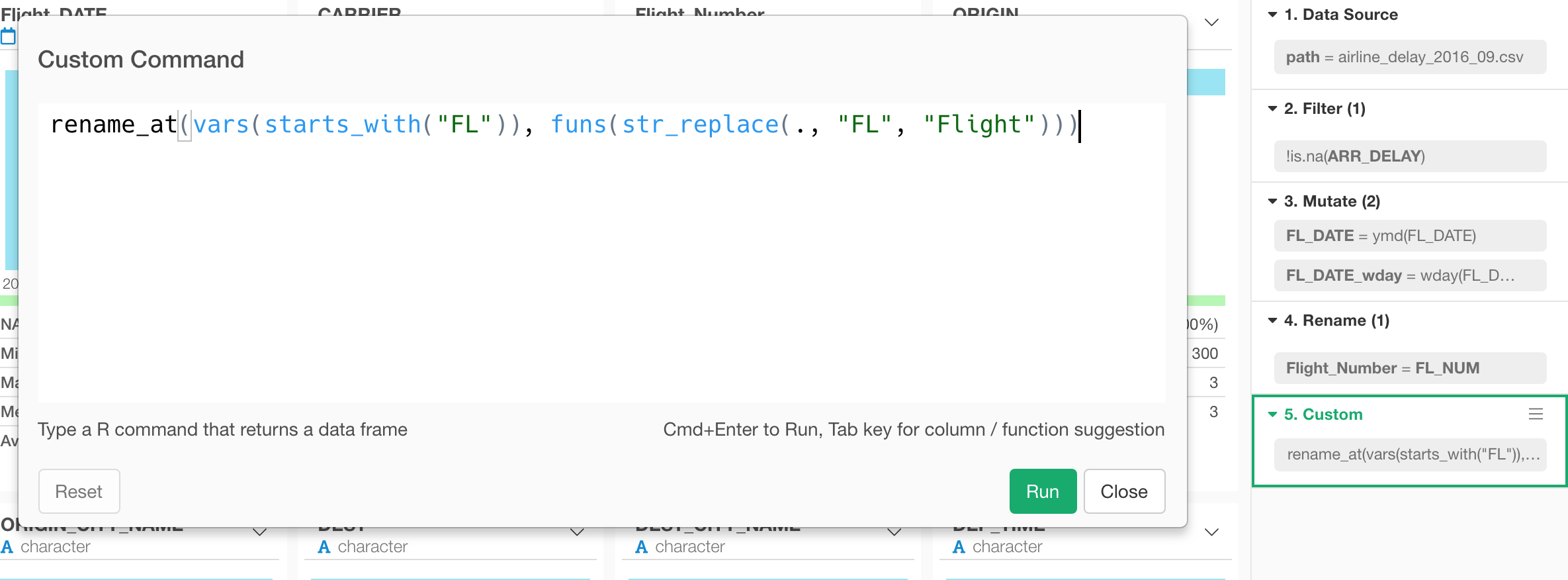
タイムゾーン・サポート
時間を扱うデータはタイムゾーンのせいで複雑になってしまうことがあります。というのも、タイムゾーンの情報が正しく入っていないデータをインポートすると、デフォルトではUTC(Coodinated Universal Time)つまり、イギリスと同じタイムゾーンだとして入ってしまいます。
もちろん、イギリスと同じタイムゾーンに住んでない限り、これは大きな問題です。
しかし、これがさらにやっかいなのは、UTCにしろ別のタイムゾーンにしろ、データがいったいどのタイムゾーンであるのかがわかりにくいことで、それがわからないと、直すにも直せません。
そこで、このリリースから日付と時間を含むデータのデータタイプであるPOSIXctの列に関してはテーブルビューではデータのタイムゾーンが表示されます。
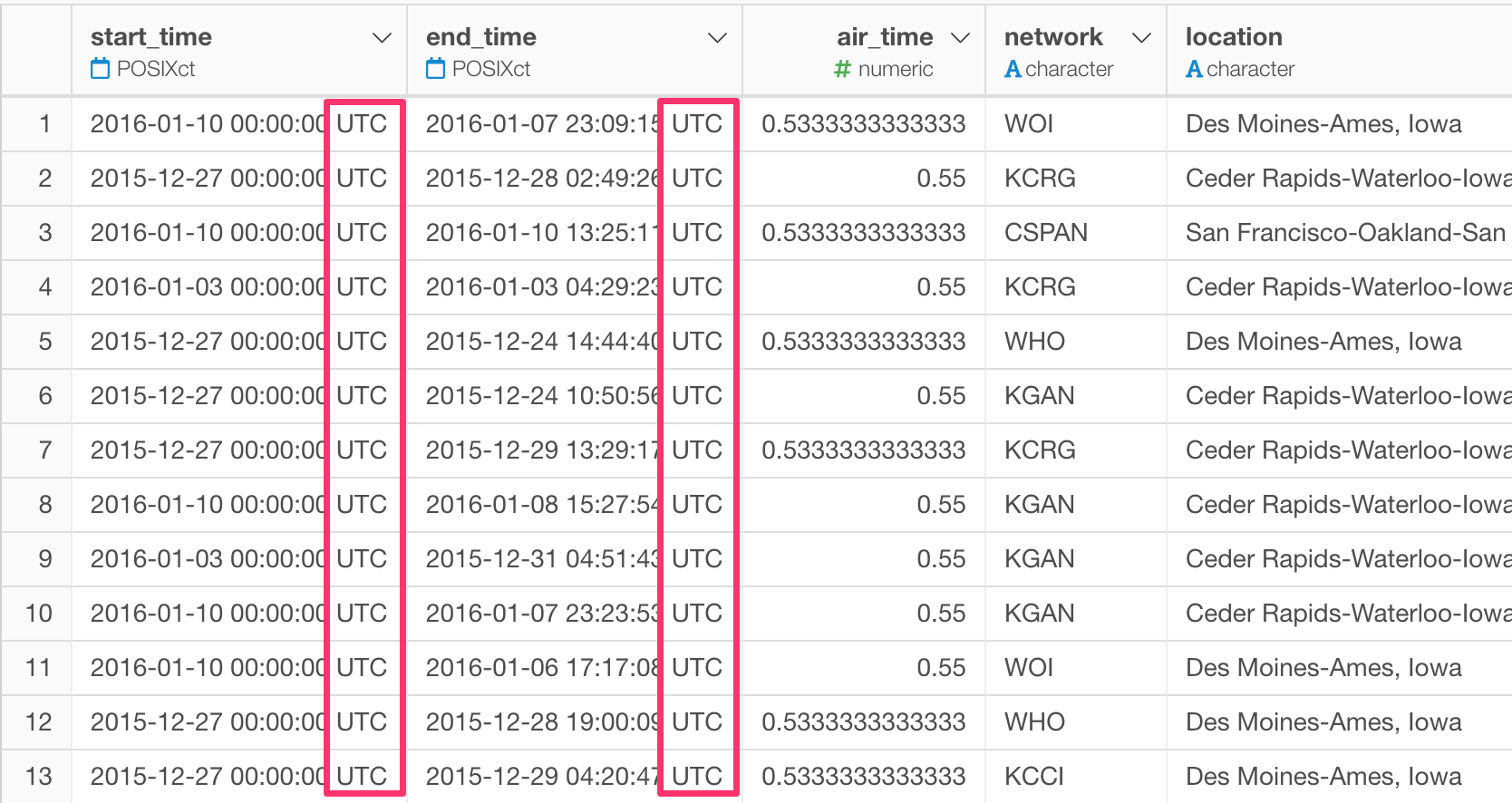
一度データの現在のタイムゾーンが何であるのかが分かれば、必要に応じて修正することもできます。以下のノートに、そのための方法に関する詳細をノートとしてまとめましたので、興味のある人は参照してみてください。
データフレーム・リストでのフォルダー・サポート
インポートしたデータが多くなってくると、だんだんとそれらを管理するのが大変になってくるものです。そこで、このリリースよりフォルダーをサポートすることになりました。
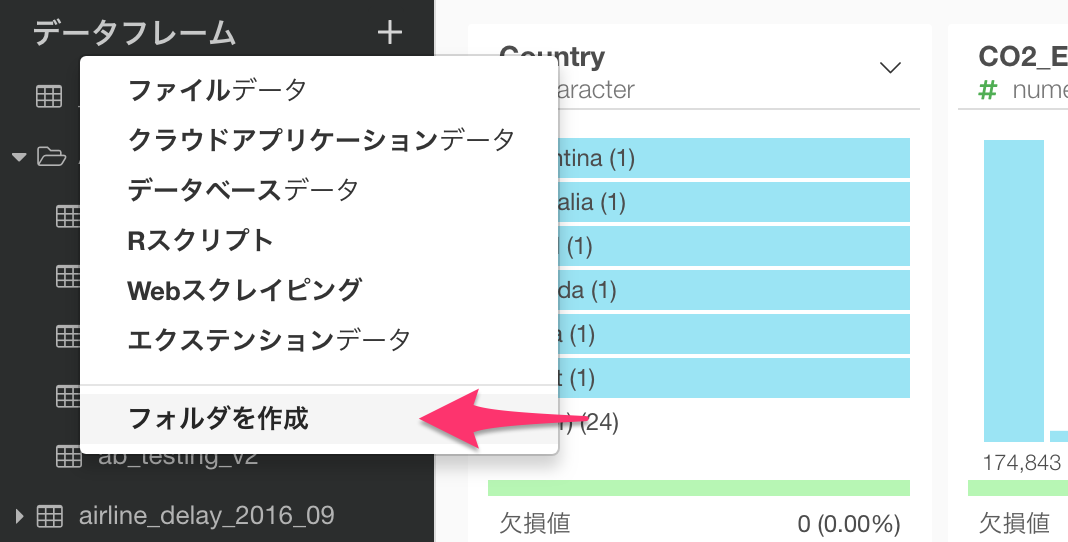
フォルダーを作ったら、そこにドラッグ・アンド・ドロップでデータフレームを動かすことができます。
データフレームだけでなく、ダッシュボード、ノート、スライドもフォルダーを使って整理することができます。ただ、あくまでもこれらは「レポート」の下でとなり、データフレームと混ぜることはできません。
データの可視化・チャート
チャートのピン
チャートをピンするという機能はすごく便利で、Exploratoryのユニークなエクスペリエンスでもあるのですが、けっこう知らない人が多かったりします。
そしてこれを知らないと、ステップを移動したときに、チャートが壊れてしまったりすることがあって、そのことが混乱のもとになってしまったりすることがあります。
そこでこのリリースではこのあたりにいくつかの変更を加えました。
まず最初に、すべての新しく作るチャートはその時に選択されているステップに「ピン」されている状態になります。
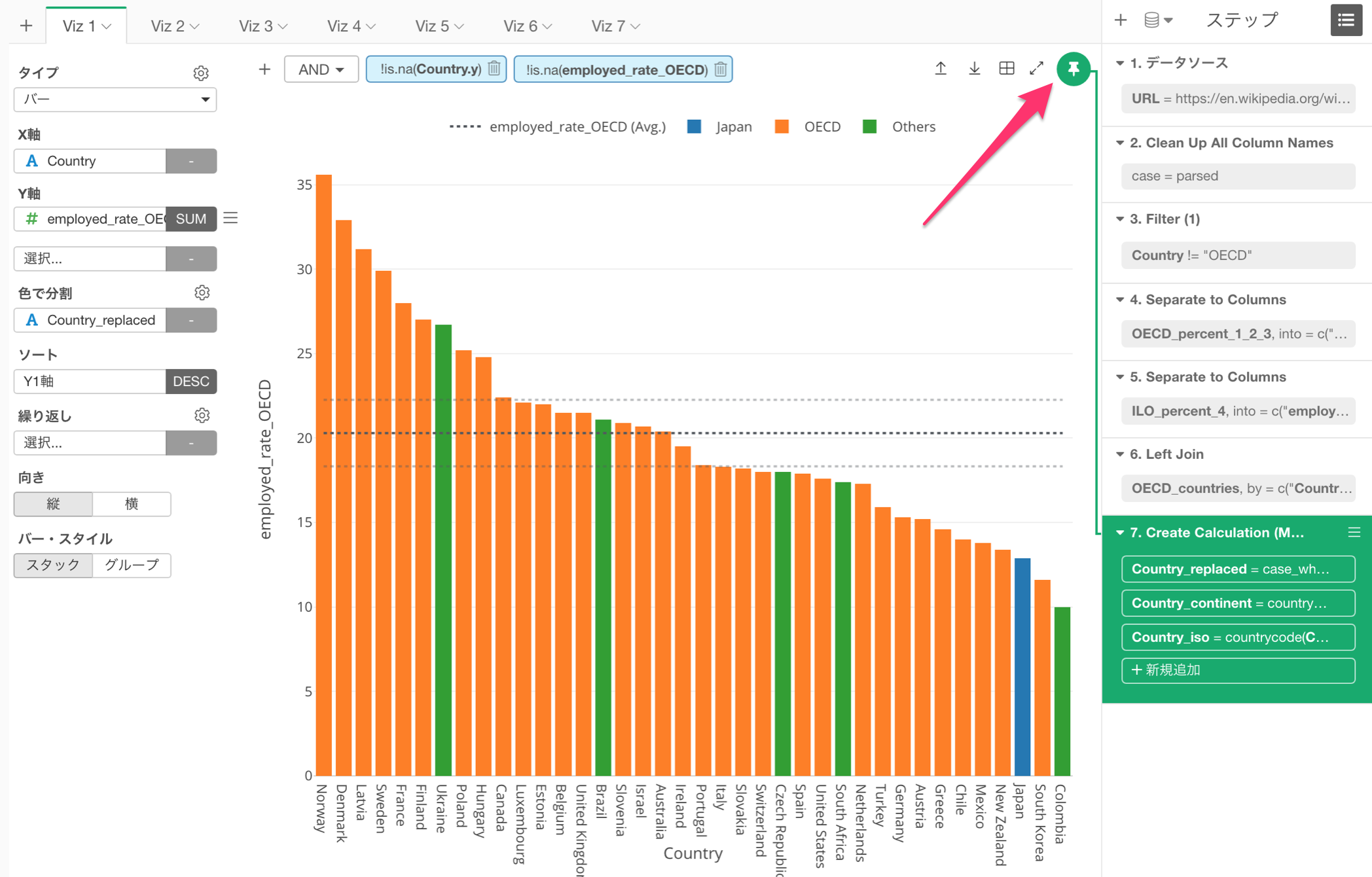
「ピン」されているステップは緑のバックグラウンドで表示されます。
ただこれにより、今まで以上に「ピン」されているステップを動かしたくなるときが多くなると思います。例えば、新しい列を「計算の作成」というデータラングリングのステップとして足したとき、チャートはその前のステップに「ピン」されたままなので、その新しい列をチャートで表示することができません。
そんなときは、もちろんこの「ピン」ボタンをクリックしてピンを外し、表示したいステップに移動した後で、もう一度「ピン」ボタンをクリックしてステップを固定することができるのですが、このリリースからはもっと単純に、「ピン」ボタンをドラッグ・アンド・ドロップで「ピン」したいステップに動かすことができます。
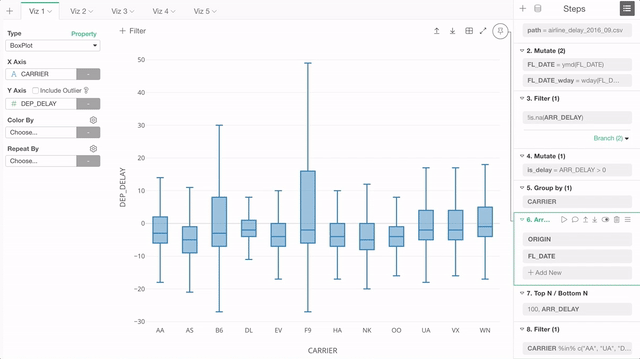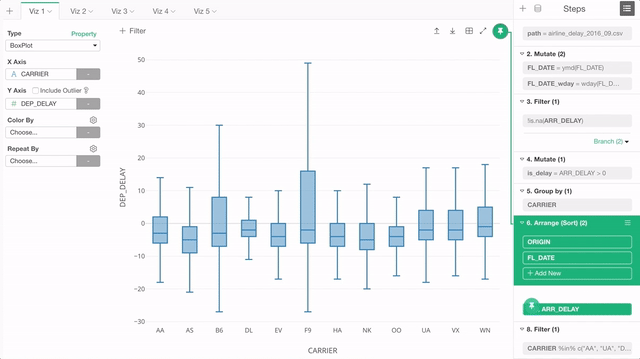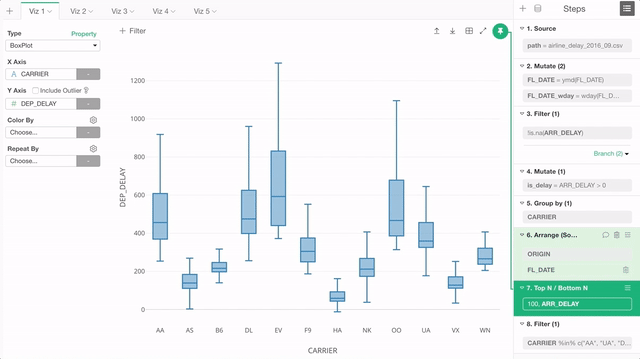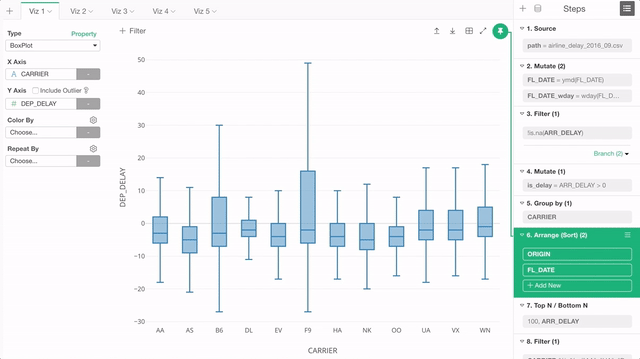
チャートのタブのスクロール・サポート
チャートをたくさん作ると、以前は「More」メニューが出てきてそこにリストアップされたチャートを選ぶことになりましたが、このリリースから、チャートは右側にどんどんと足されていきます。そして画面から溢れ出してしまったチャートは、単純にスクロールしてアクセスすることができます。
これでどのチャートでもそのイメージを簡単に見ることができるので、どんなにチャートがたくさんあるときでも見たいチャートにアクセスするのが簡単になりました。
アナリティクス
決定木
Exploratoryではランダム・フォレストやXGBoostなどのアンサンブル機械学習のアルゴリズムがサポートされていますが、機械学習などに詳しくない意思決定者にデータの中にあるルールをわかりやすく伝えるためには、やはり決定木に勝るものはありません。
そこでこのリリースでは決定木のサポートををアナリティクス・ビューに加えました。
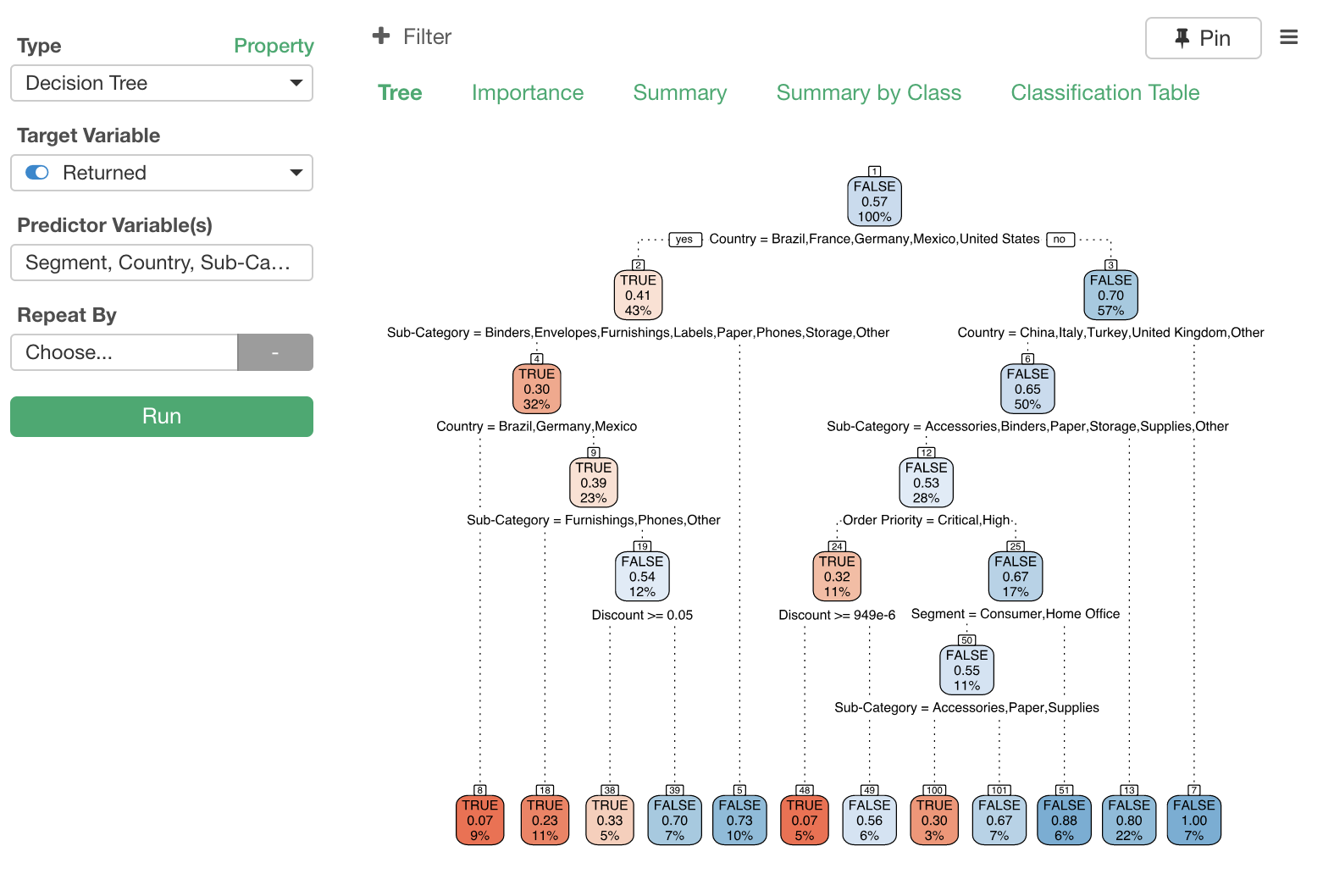
メインはやはり、決定木そのものの可視化のためのチャート・ビューですが、それ以外にも、ランダム・フォレストで見られるような以下のような情報を提供しています。
- Tree - 決定木そのものを可視化したものです。どのようなルールをたどると、どの結果になる確率が高くなるのかを理解することができます。
- Importance - どの変数がより結果に対して重要な役割を持っているのかがわかります。
- Summary - モデルの予測パフォーマンスの指標があります。
- Summary by Class - モデルの予測パフォーマンスの指標がクラス(例えば、目的変数のデータタイプがロジカルである場合は、TRUEかFALSE)ごとに出ています。
- Prediction Matrix - これは一般的には混同行列と呼ばれているものです。予測結果と実測値(実際の値)の対比を表したものですが、これよりどういったタイプの予測が得意で、どういったタイプの間違いがどれくらいあるのかということがわかります。
マーケット・バスケット分析 / アソシエーション・ルール
アソシエーション・ルールのアルゴリズムはどういった商品がいっしょに買われるのかを理解するのに役立ちます。例えば、赤ちゃんのおしめを買う人はビールも買うことが多いと言った場合です。(これはアメリカの場合は特にオシメのようにかさばるものを買うのは父親の役割で、そうした父親はついでにビールも買っていくことが多いからです。)
Rには、arulesというアソシエーション・ルールのアルゴリズムを実装したパッケージがあり、これまでもExploratoryのユーザーはデータラングリングのステップとして使うことが出来たのですが、このリリースよりこの機能をもっと使いやすいように、アナリティクス・ビューより提供することになりました。
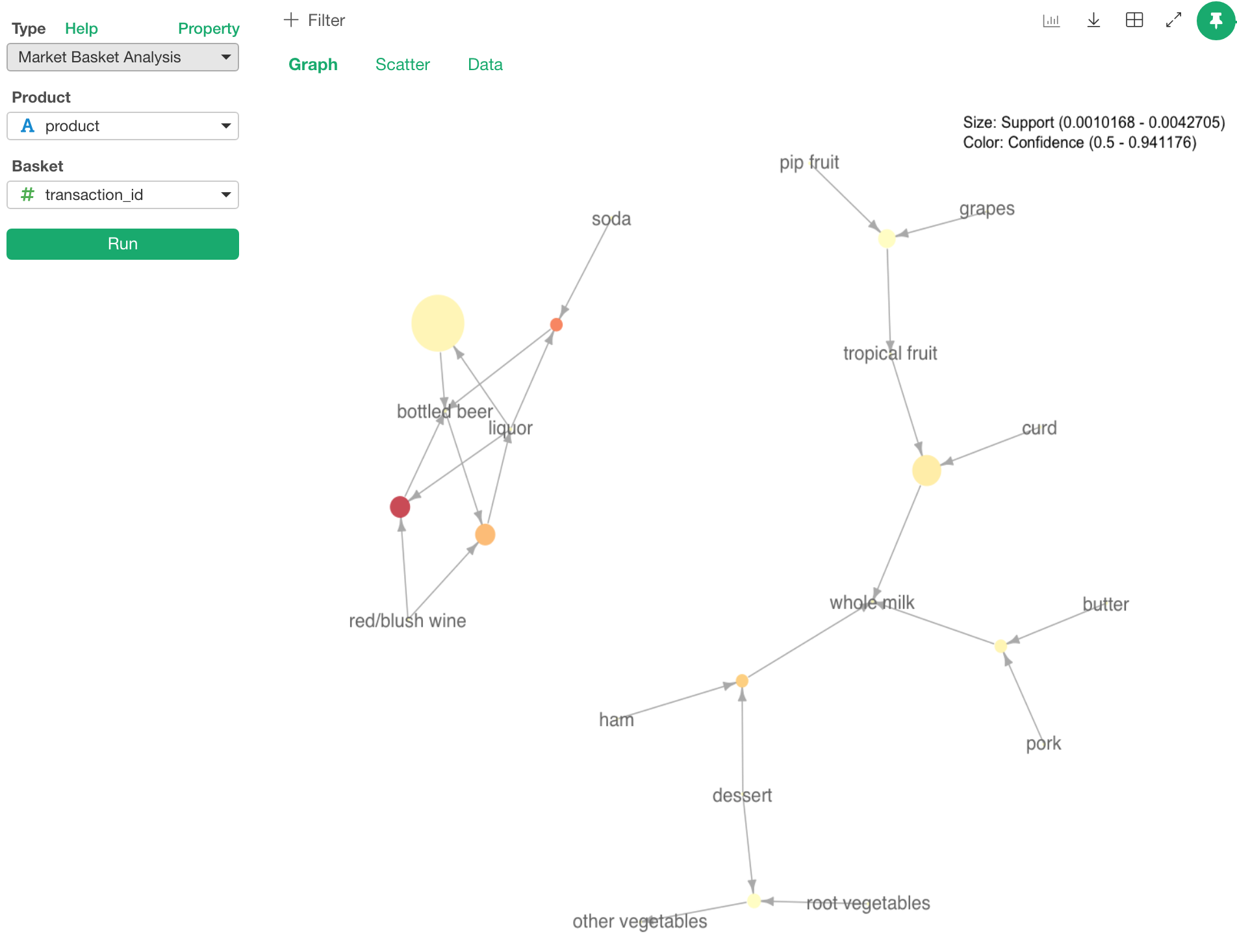
こちらに、ちょっと前になりますが、Exploratoryの中でデータラングリングのステップとしてアソシエーション・ルールをどう使うかというブログポストがありますので、興味のある人は参照してみてください。アソシエーション・ルールが何であるかという理解にも向いています。
アナリティクス・ビューでの使い方に関しては近日中にノートを公開する予定です。
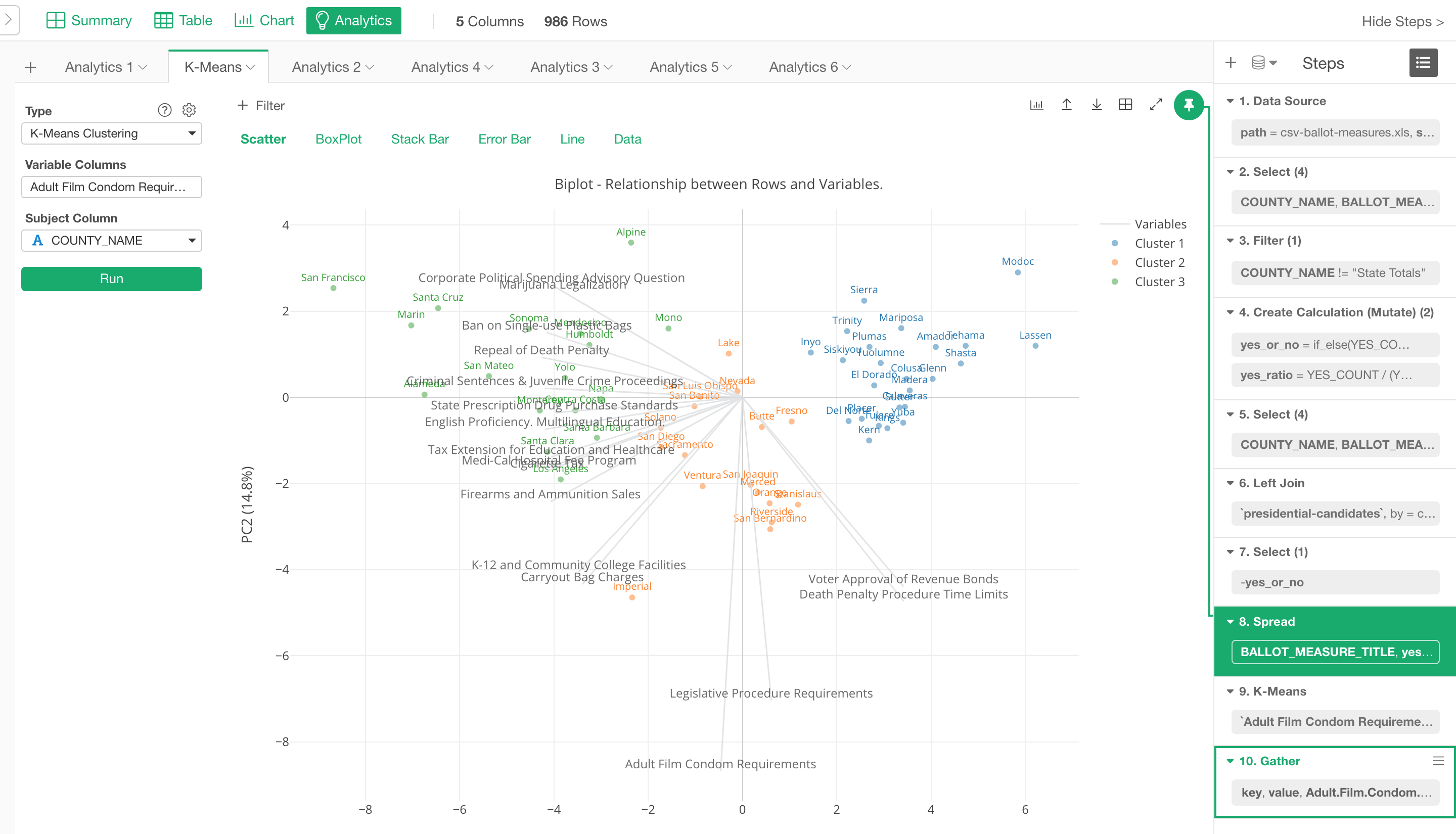
K-Means クラスタリング
このリリースからK-meansクラスタリングをアナリティクス・ビューに加えました。
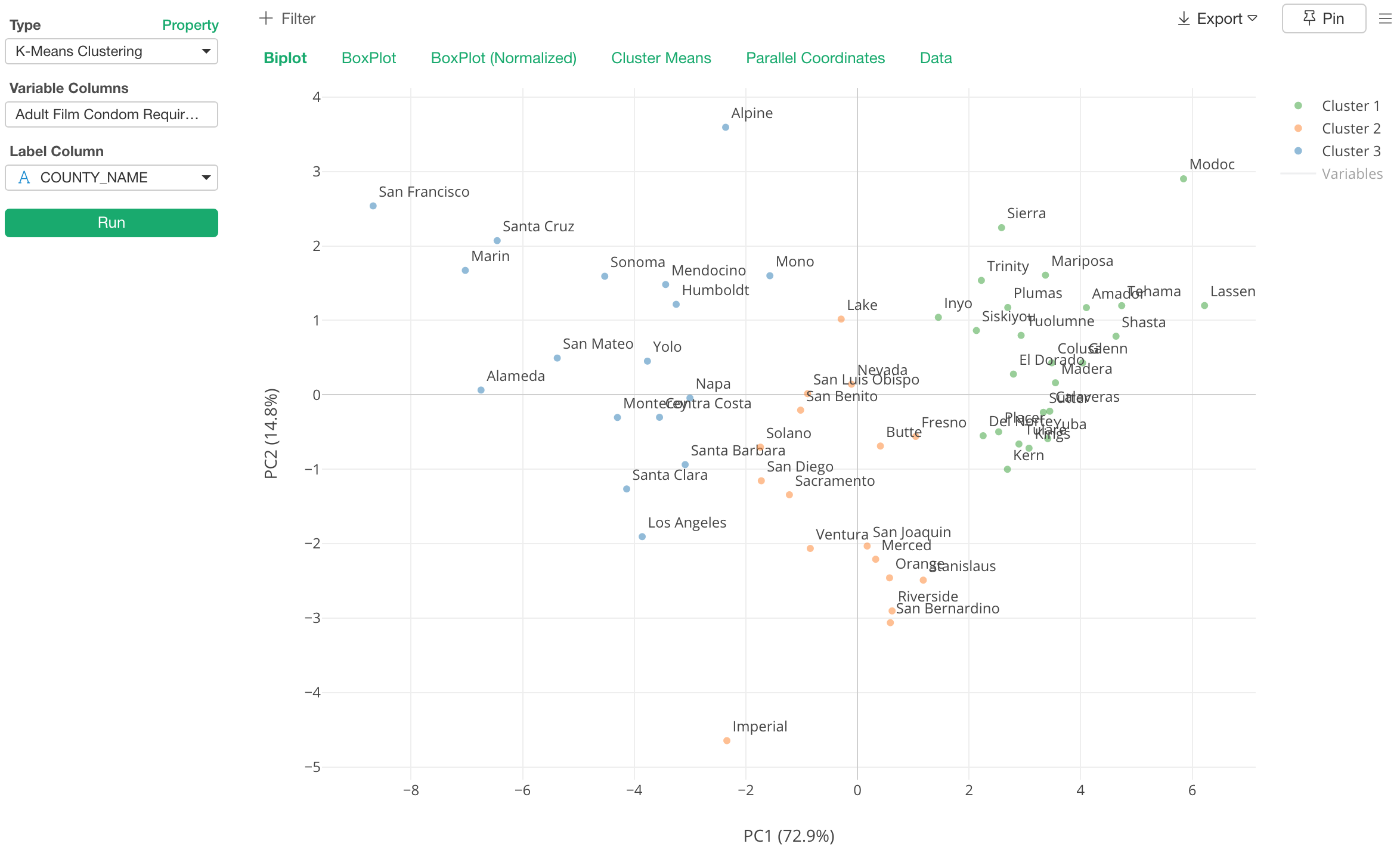
以前からデータラングリングのステップとしてK-meansのアルゴリズムを使ってデータをクラスタリングし、結果を柔軟にチャート・ビューから可視化することができました。
しかし、2つの大きな問題がありました。1つ目はどうやって、いわゆるKであるクラスタの数を決めるのかという問題。
2つ目はいくつかのクラスターに分けた後に、どうやってそれぞれのクラスターの特徴を理解すればいいのかという問題です。
これらの問題を解決するためにK-meansクラスタリングをアナリティクス・ビューに追加しました。
この機能に関しては詳細を別のノートに書いたので、興味のある方はぜひこちらより見てみてください。
- Introduction to K-Means Clustering under Analytics View - Link
時系列予測 - Prophet
アナリティクス・ビューの下にある「時系列予測 - Prophet」に以下のプロパティが追加されました。
祝日データのサポート
祝日のような特別な日には特別なトレンドが見られたりしますが、Prophetのアルゴリズムはこうしたデータを考慮してより現実にあった予測モデルを作ることができます。このリリースでは、もしこうしたデータを別の列として持っていた場合に、祝日データとして指定できるようになりました。
トレンドの下限値
データによっては下限が決まっているものがあります。例えば、顧客の数であれば0より下がることはないはずですし、割合のようなデータであれば0%より低い数字になることはないはずです。このリリースから、上限値とともに下限値も指定できるようになりました。
Daily Seasonality・ビュー
データが時間レベルなどの場合は、Daily Seasonalityが出るようになりました。これで、一日の中のどのへんの時間が数字が大きくなる、または小さくなるというトレンドがあるのかがわかりやすくなります。
列の選択
データラングリングのところにも出てきた、列の選択のための新しいUIをアナリティクス・ビューにも持ち込みました。これで複数の列を選ぶのがだいぶ簡単になります。
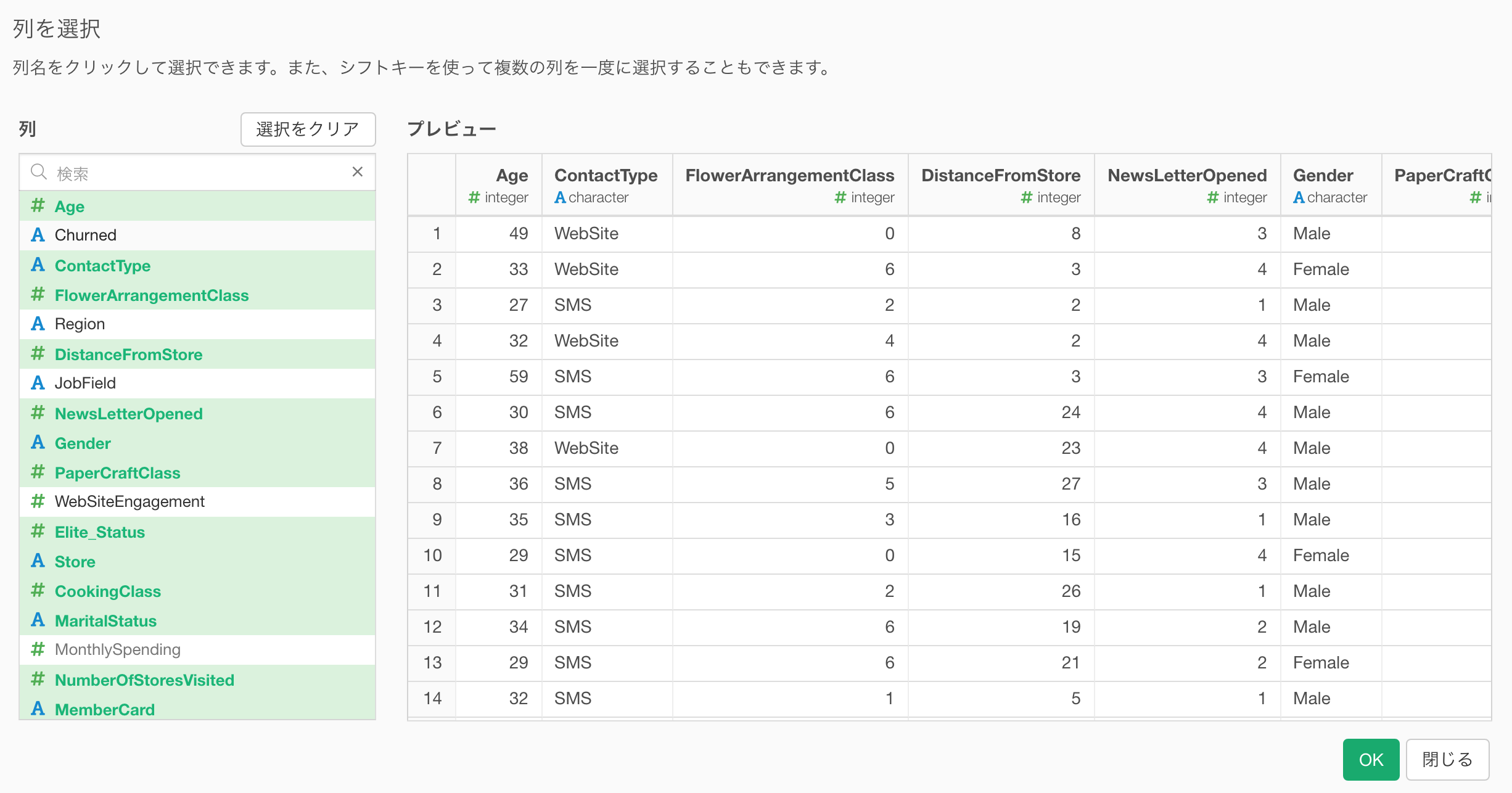
Shiftキーを使って、複数の列をすばやく選んでいくことができます。
また、列がたくさんあるときなどは、列名の一部を入力して検索することもできます。
チャートをイメージとして保存
アナリティクスのチャートもイメージとしてエクスポートすることができるようになりました。
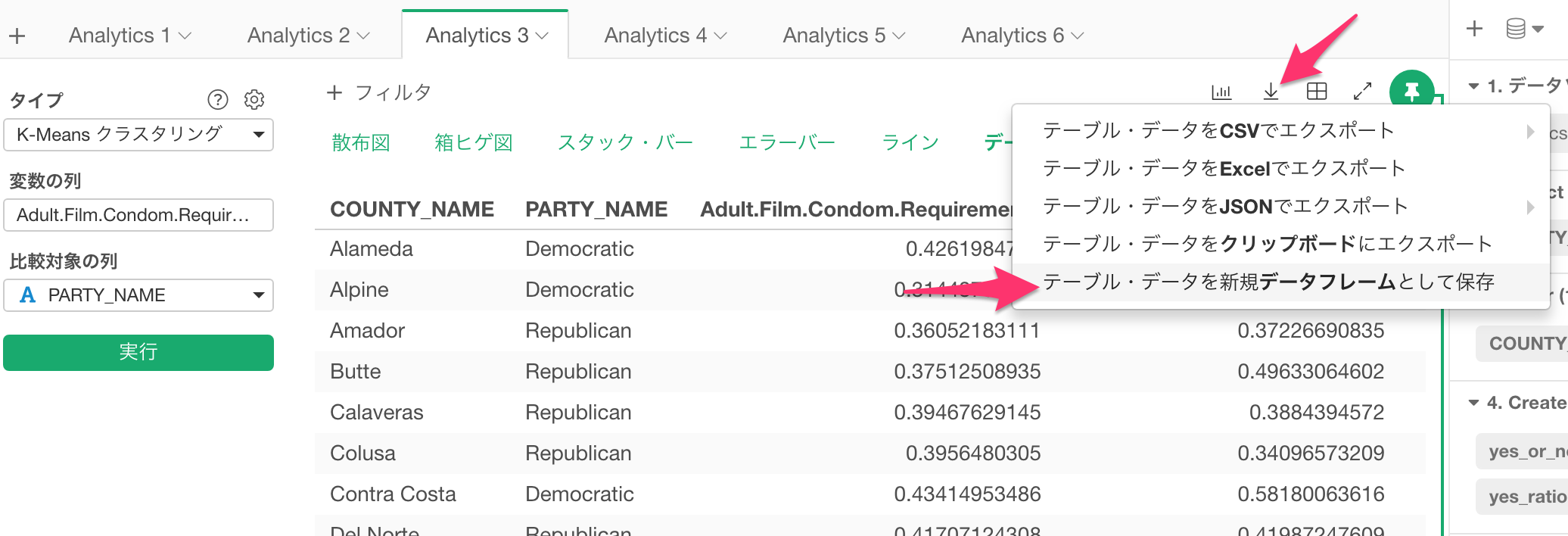
データをデータフレームとして保存
アナリティクスを実行して表示されているデータはその後さらにデータラングリングや可視化などしたいこともあると思います。
そんなときは、エクスポートボタンをクリックして「チャート(またはテーブル)・データを新規データフレームとして保存」を選んで、新たなデータフレームとして作ることができます。
ダッシュボード、ノート、スライド
ノートとスライドでの「横並び」と「シングル・ビュー」モードの切り替え
ノートやスライドを編集する時にサイド・バイ・サイド・ビューというのがありますが、左側に編集画面、右側にランタイムのアウトプットが表示されるビューです。このサイド・バイ・サイド・ビューがこのリリースからのデフォルト・ビューとなります。
しかし、もっと広いスペースで編集したい、またはアウトプットを確認したいということがあるかもしれません。そんなときは、「シングル・ビューに切り替える」というボタンを押して、モードを切り替えることができます。
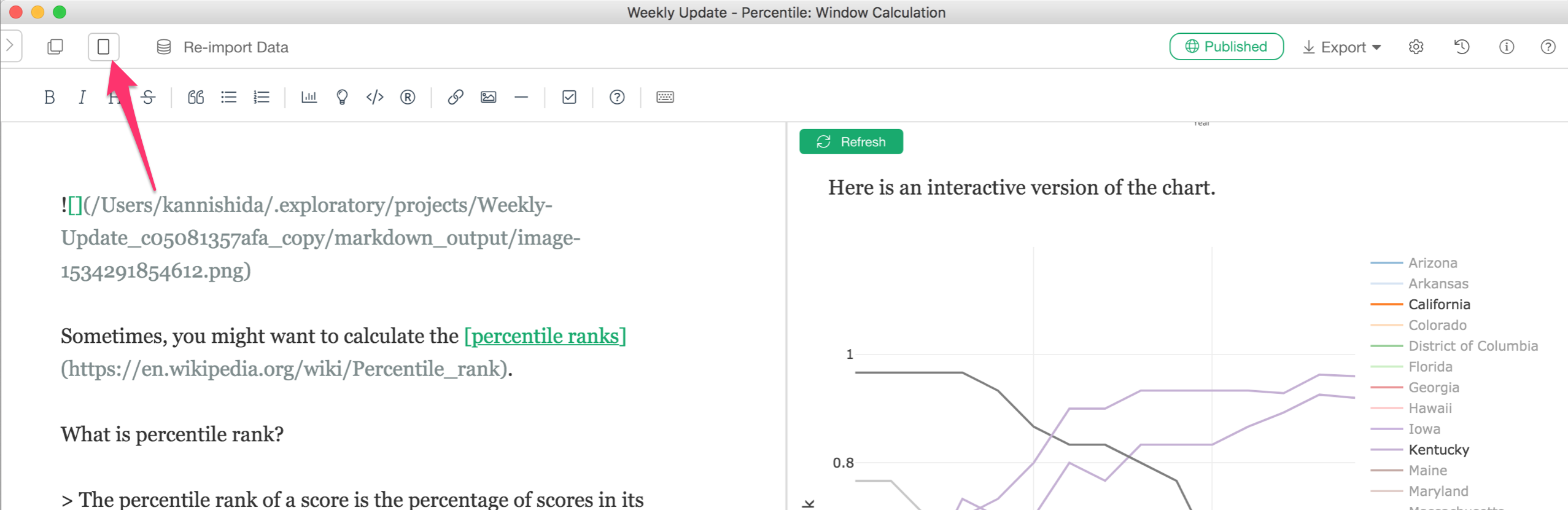
別ウィンドウでダッシュボード、ノート、スライドを開く
ダッシュボード、ノート、スライドを編集しながらデータフレームのデータラングリングやチャートの設定を変えたいということはよくあります。そんなときは、ノートを別画面として開くのが使いやすいです。
そこで、このリリースから、ダッシュボード、ノート、スライドに関しては別画面で開くというのがデフォルトの動きとなります。
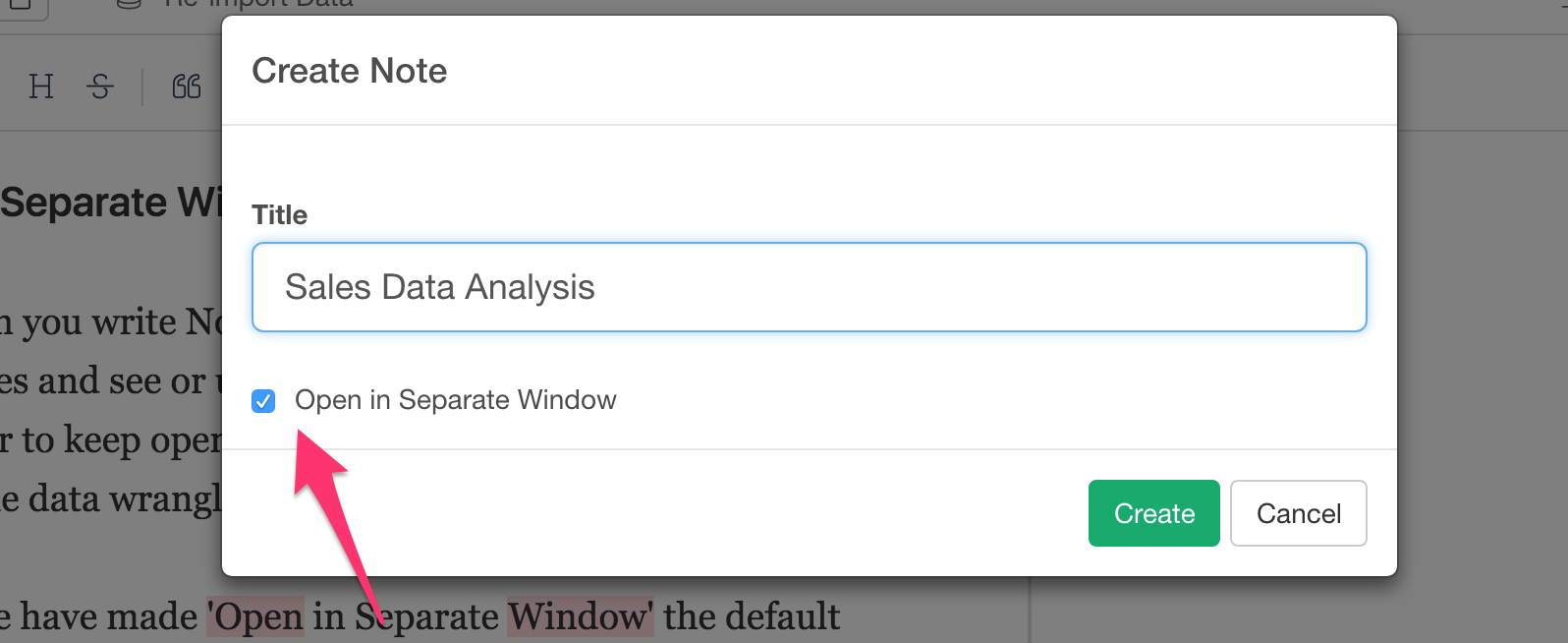
また、現在データフレームで作業している場合は、そのデータフレームを閉じることなしに、直接ダッシュボード、ノート、スライドを開くことができます。
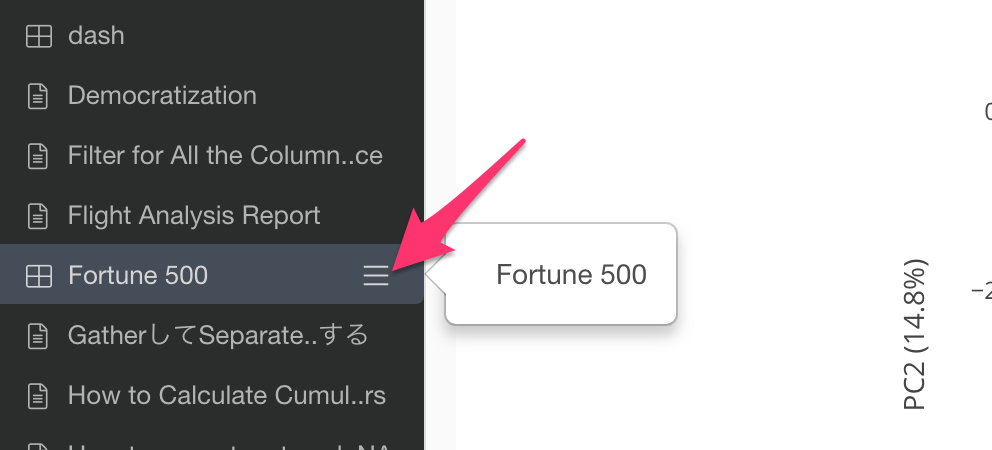
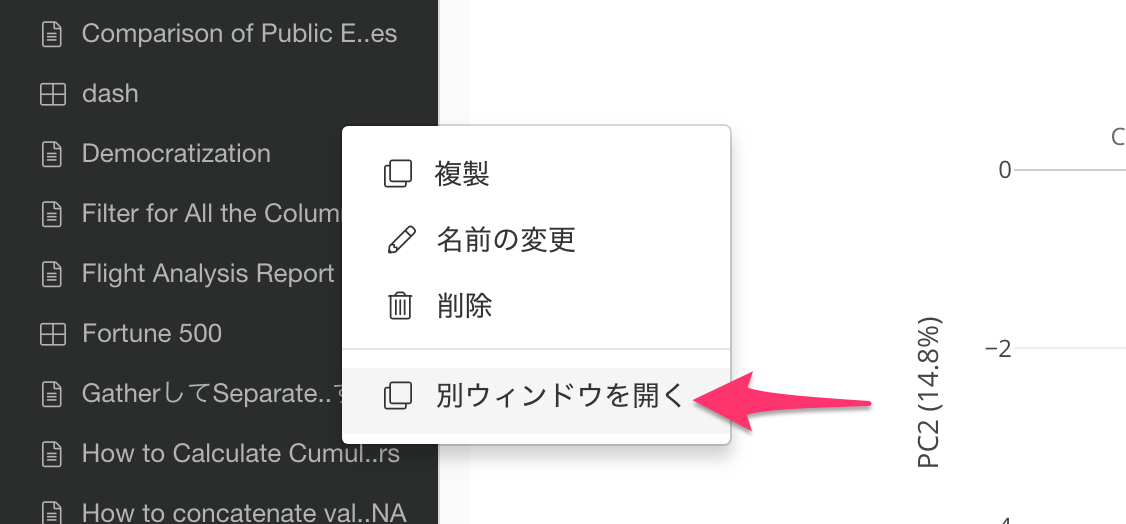
ダッシュボード、ノート、スライドをメイン画面で開いている場合でも、「別ウインドウで開く」ボタンをクリックすることで別ウインドウで開くことができます。
エクスポート・メニュー
ダッシュボード、ノート、スライドのエクスポートに関してのアップデートがあります。
まずは、自分のPCのウェブ・ブラウザで見たい時のメニュー「ブラウザで開く」がこのエクスポートのメニューに統合されました。

しかし、一番の目玉は、ダッシュボード、ノート、スライドをEDF(Exploratory Data Format)としてエクスポートできるということです。これはどういうことかというと、例えばダッシュボードをエクスポートしたとします。するとエクスポートされたEDFというファイルの中には、ダッシュボード自体の情報だけでなく、そこで使われているチャートを再現するために必要なデータ・フレームとそれに付随するデータラングリングのステップ、また、もし他のデータ・フレームを結合などのかたちで参照している場合はそうした関連のあるすべてのデータフレームを再現するために必要な情報がつまっています。
つまり、このEDFを他のExploratoryユーザーにわたしてあげると、その人はまったく同じダッシュボードをデータのレベルから再現することができます。
そして、これはもちろん、ノートもスライドもいっしょです。
最終的に、データ分析はサイエンスなわけですから、やはり再現性なくしては成り立たないわけですが、こうして最終的な成果物であるダッシュボード、ノート、スライドのレベルでも安心して再現性が保てるというのは強力だと思います。
これは、もちろんExploratory CloudもしくはExploratory Collaboration Serverにパブリッシュした場合も同じです。
以上です!
他にも多くのエンハンスメント(機能強化)とバグの修正がありますが、詳細はこちらのリリースノートをご参照下さい。
ぜひ、Exploratory v5.0をこちらよりダウンロードして使ってみてください。フィードバックの方もお待ちしております!
Exploratoryのアカウントをまだお持ちでない方は、ぜひこちらよりサインアップしてみて下さい。最初の30日は無料トライアル(お試し)期間となっています!すでにトライアル期間が過ぎてしまったが、この新しいバージョンを試してみたいという人は、ぜひこちら(support@exploratory.io)までご連絡ください。
現在、学校で先生や生徒である方は、コミュニティ版を無料で使うことができます!
Happy Exploratory v5.0! 🍾
引き続きよろしくお願いいたします!
西田