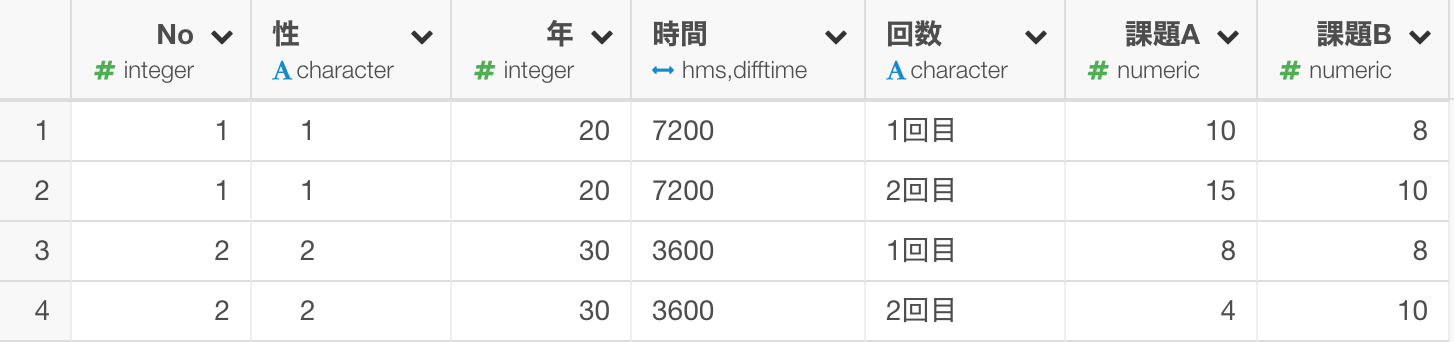
このような1行1ユーザーというデータがあったとしましょう。

課題A、課題Bという列がありますがそれぞれの課題を行った回数が1回、2回とあるのですが、この回数毎に行を作り、課題A、課題Bというものだけを列にしておきたいとします。
つまり、以下のようなデータの形にしたいとします。
このためには、よく使われるパターンなのですが、Gather-Separate-Spread という順番でデータを加工していくことで、上のようなデータの形にすることができます。
Gather
まずは、 課題A1回目, 課題A2回目, 課題B1回目, 課題B2回目の列を選んでから、列ヘッダーメニューからGather->選択された列を選びます。
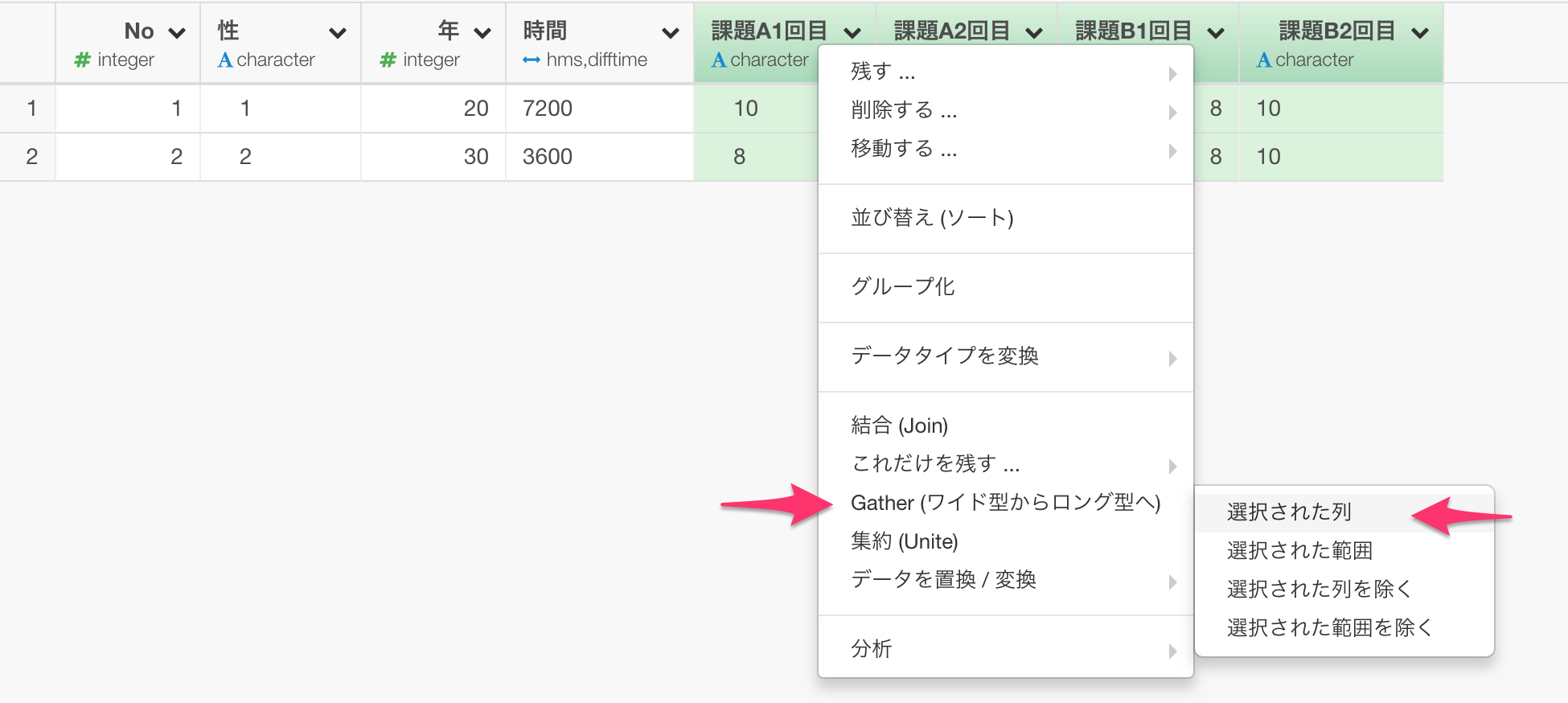
そのまま実行すると以下のようなデータの形になります。
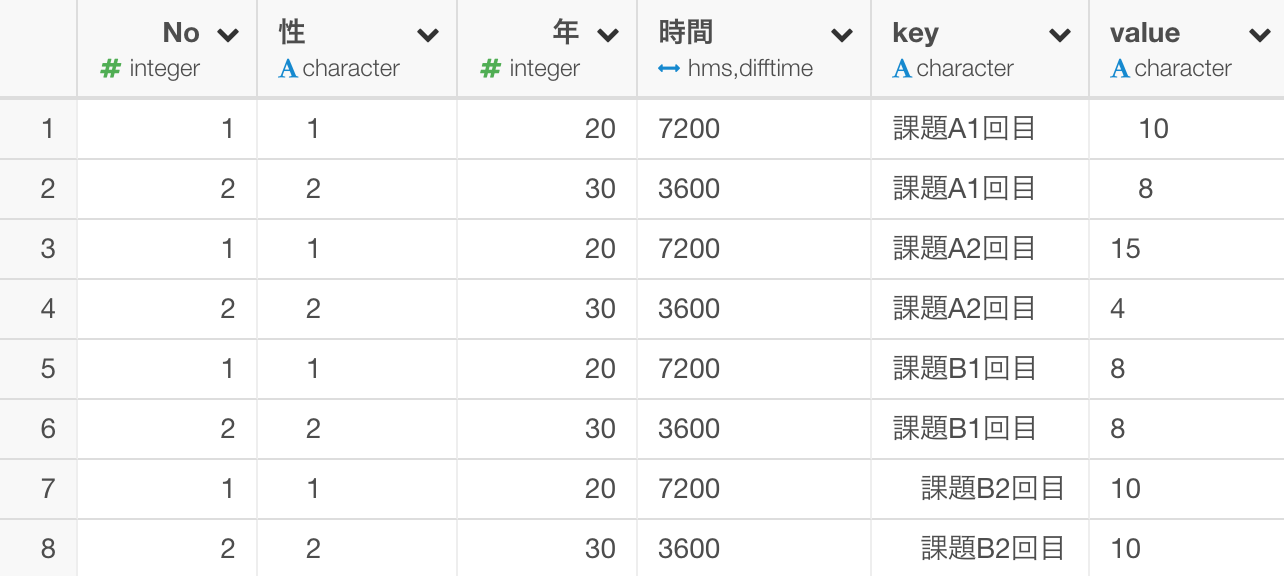
もともとの4つの列の名前が key という新しくできた列の値となり、もともとの値がvalueという列の値となりました。
テキストをクリーンアップ
ちょっとデータのほうが汚いので、きれいにします。
まずは、key列ですが、変なスペースが入っている行があります。これは、str_clean()という関数で除去できます。
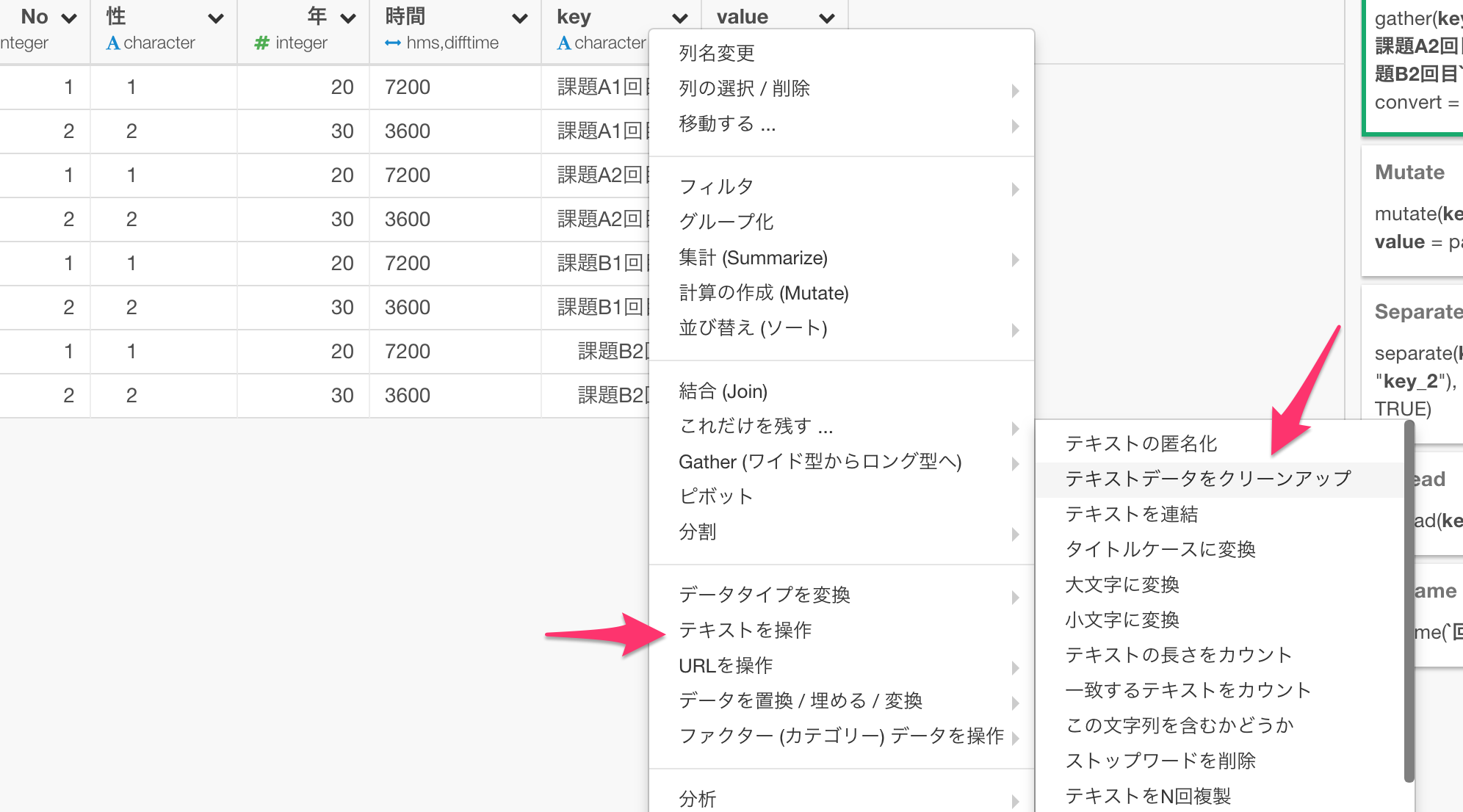
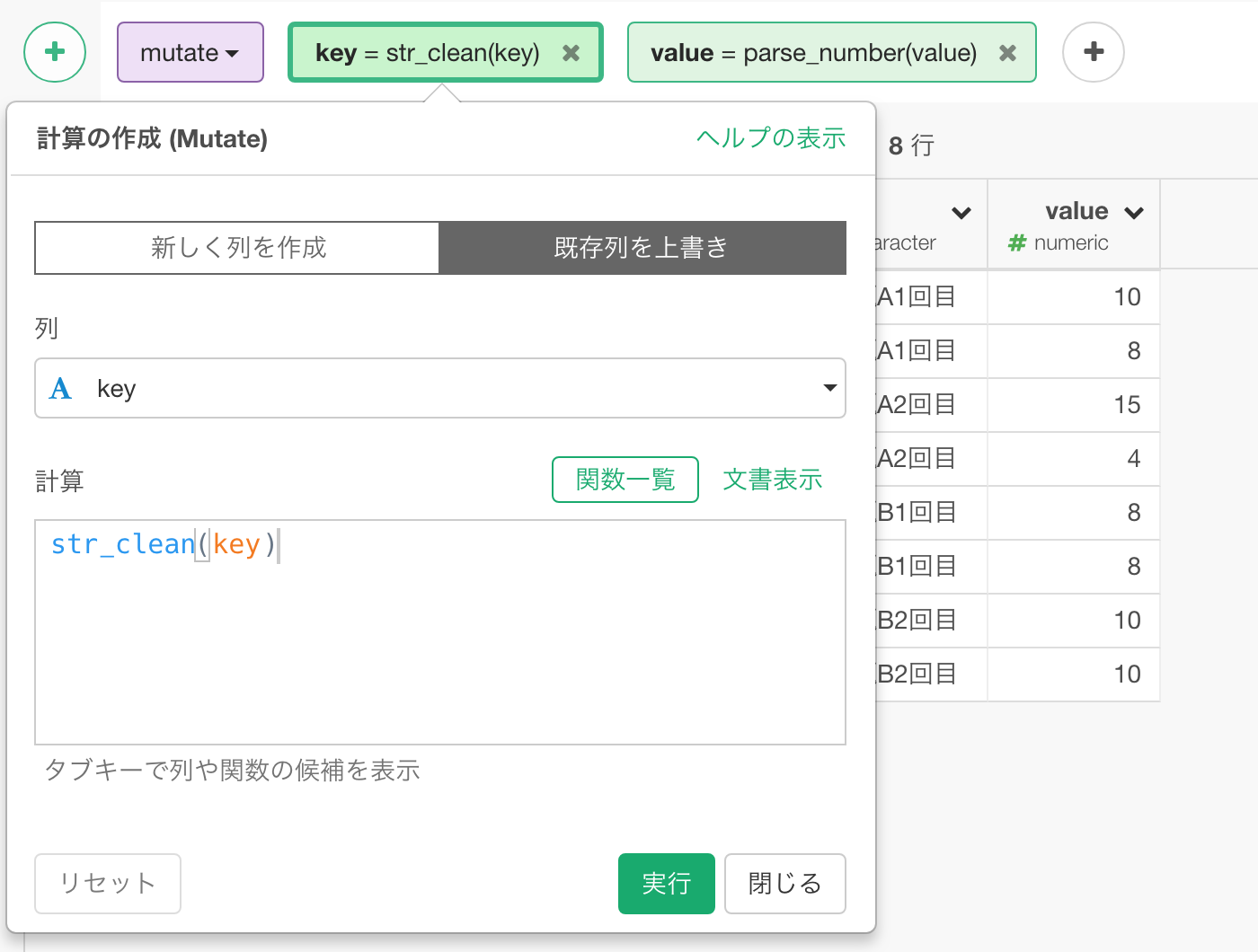
そのまま実行すると以下のようなデータの形になります。
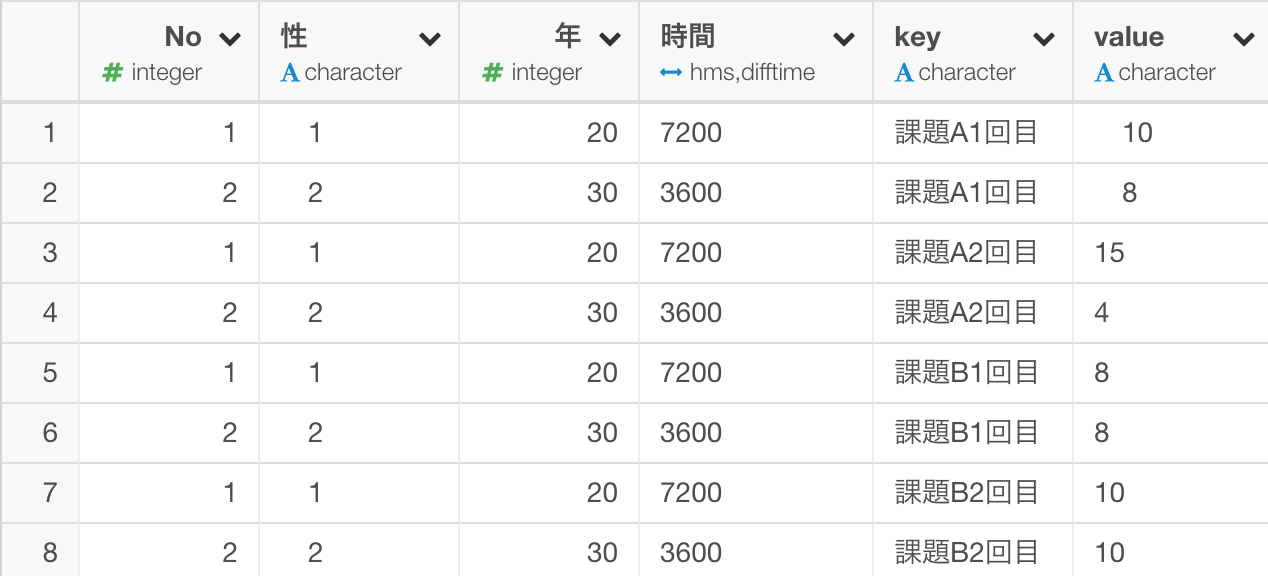
次にvalue列ですが、こちらは数値のはずが数値のデータタイプとなっていないので、数値に変換します。
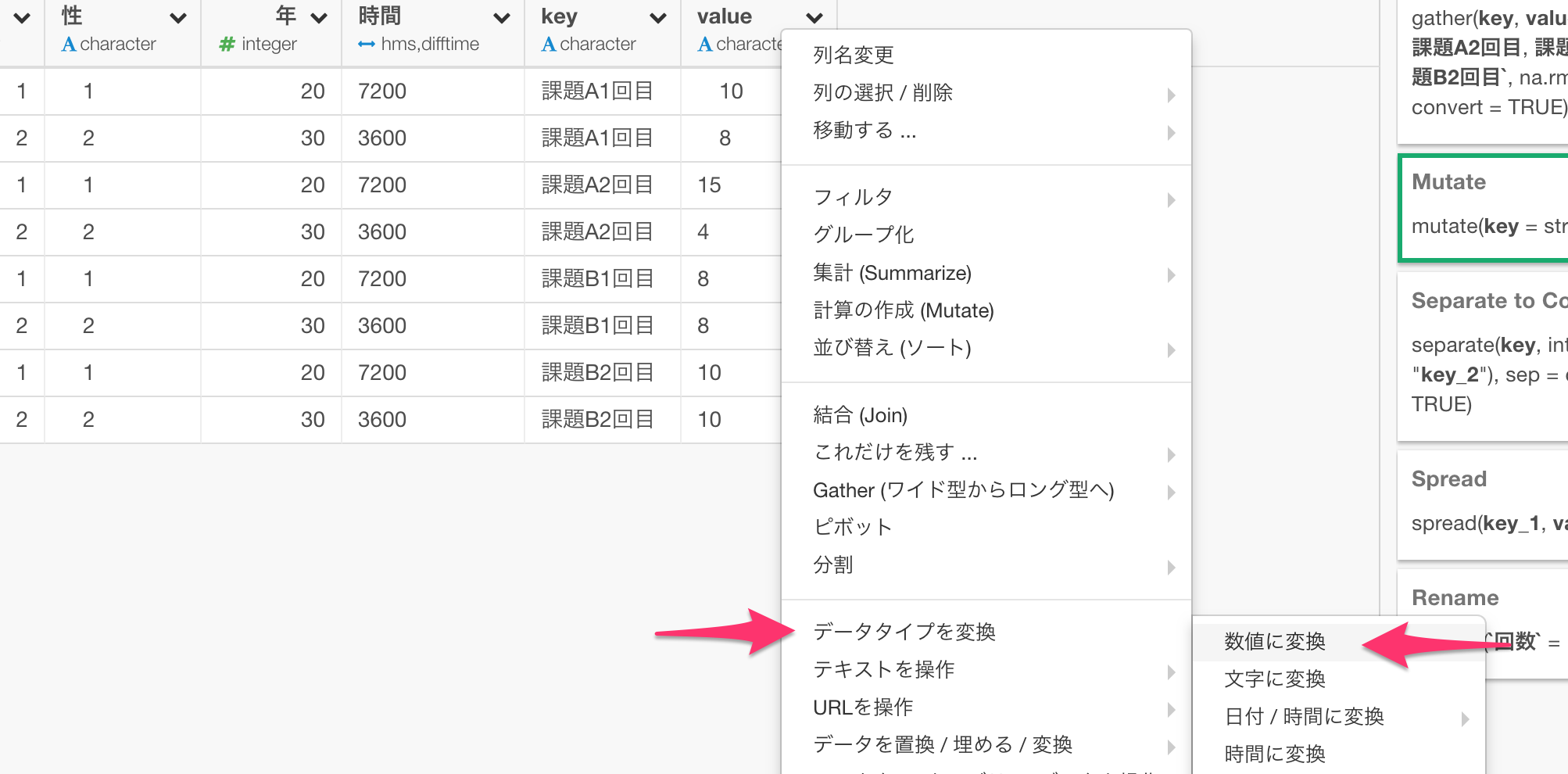
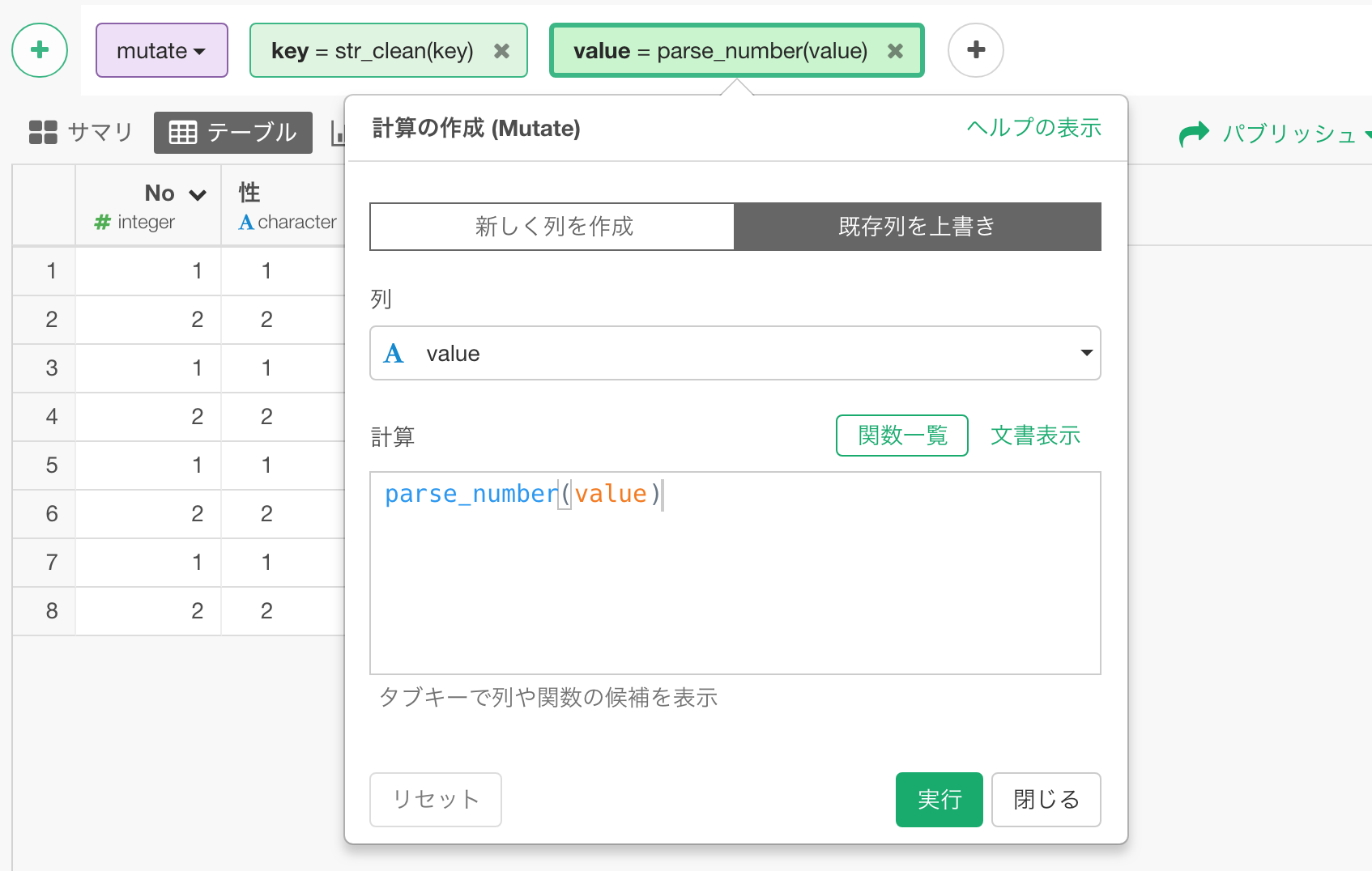
そのまま実行すると以下のようなデータの形になります。
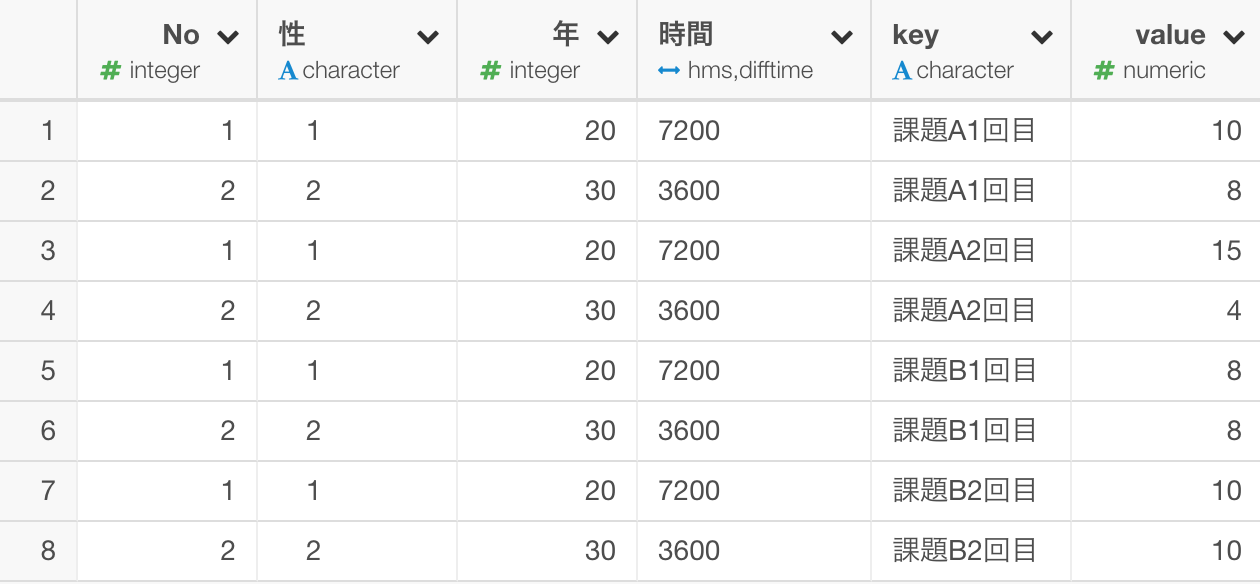
Separate
次は、課題A、課題Bというのと1回目、2回目というのを分けます。これは、単純に3文字目より前か後にくるかで分けれそうです。
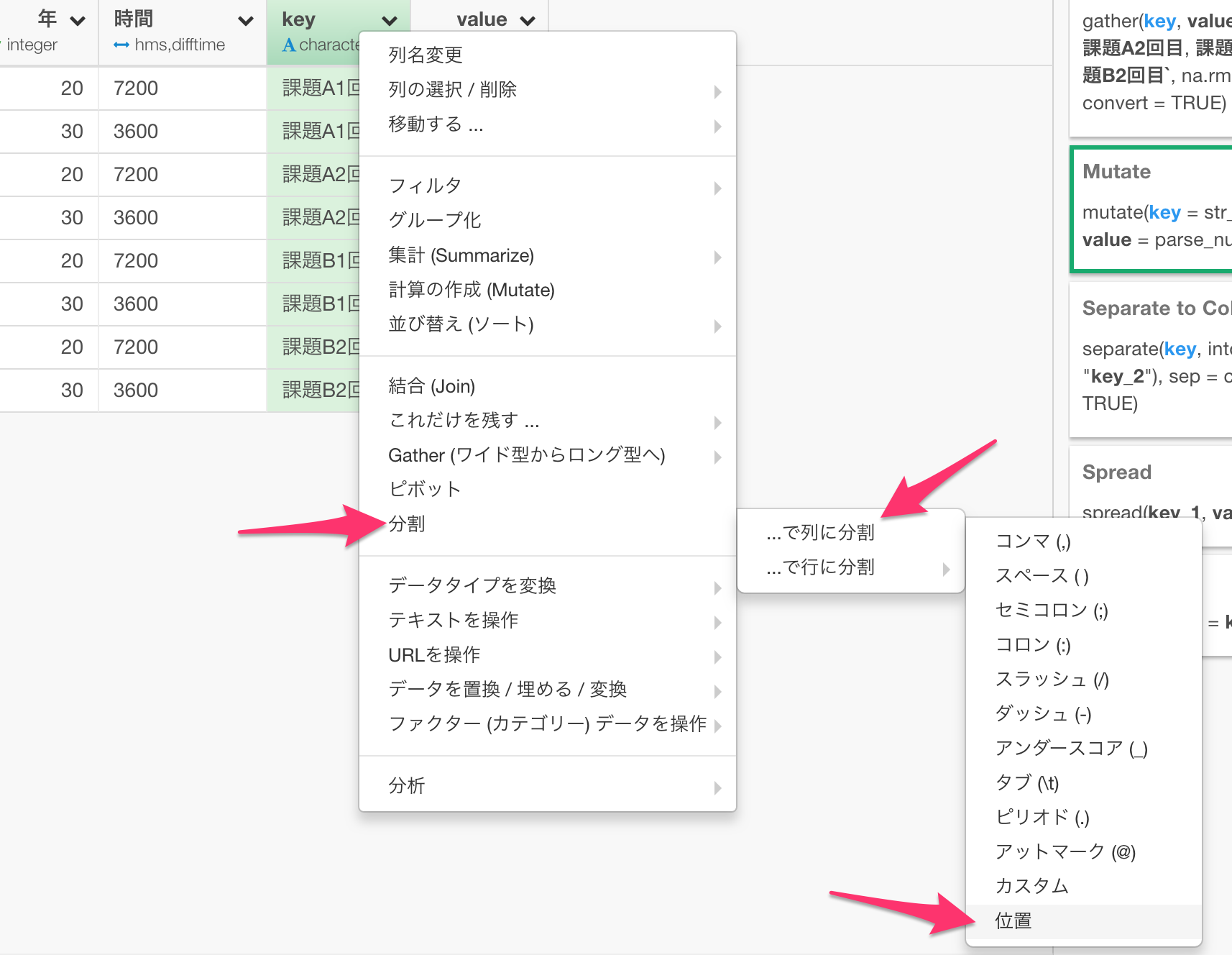
出てきたSeparateのダイアログの中で分割する場所を決めます。今回は、3番目の文字の前後で分割したいので、位置の方を3にします。
そのまま実行すると以下のようなデータの形になります。key_1とkey_2という2つの列に分かれました。
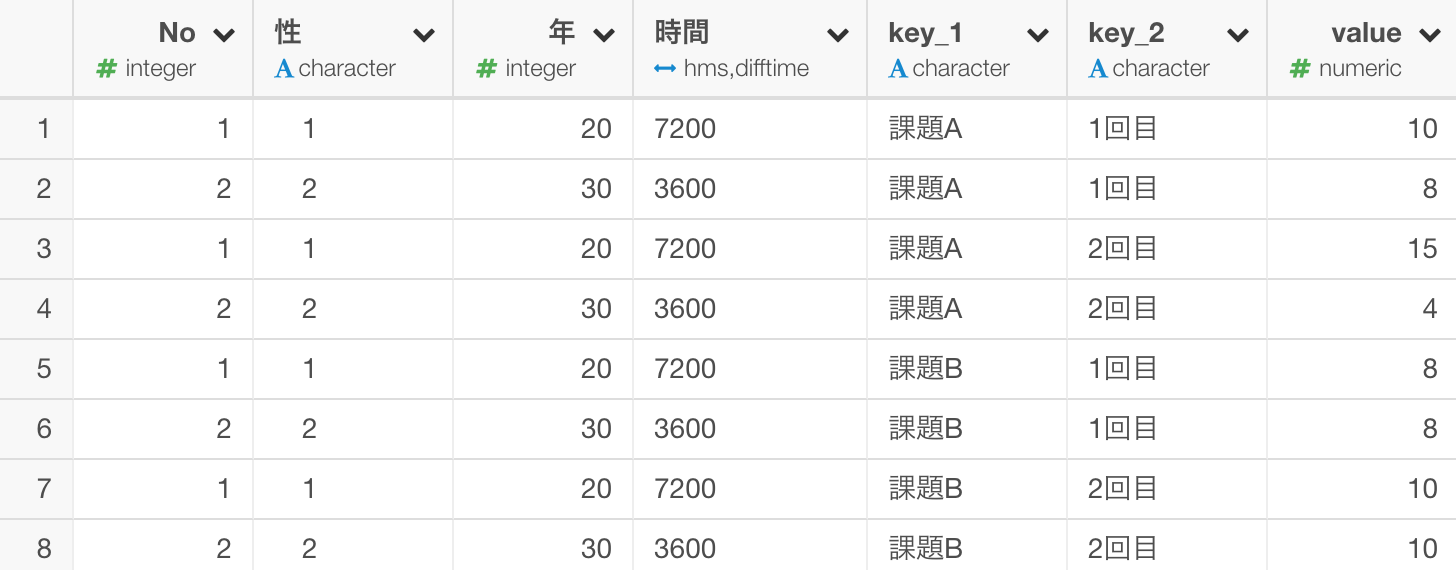
Spread
あとはそれぞれの課題(課題A、課題Bなど)を列とするだけです。
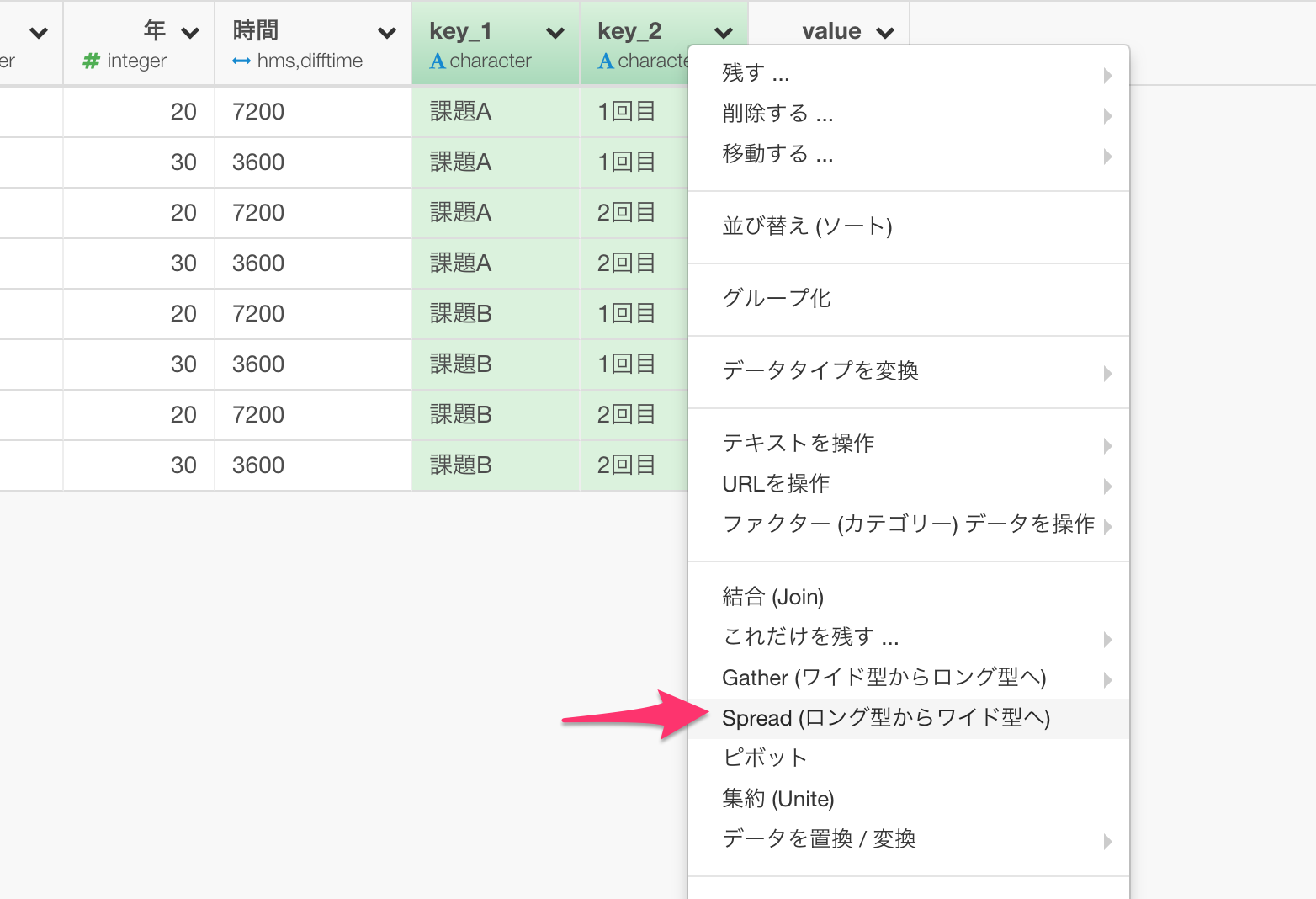
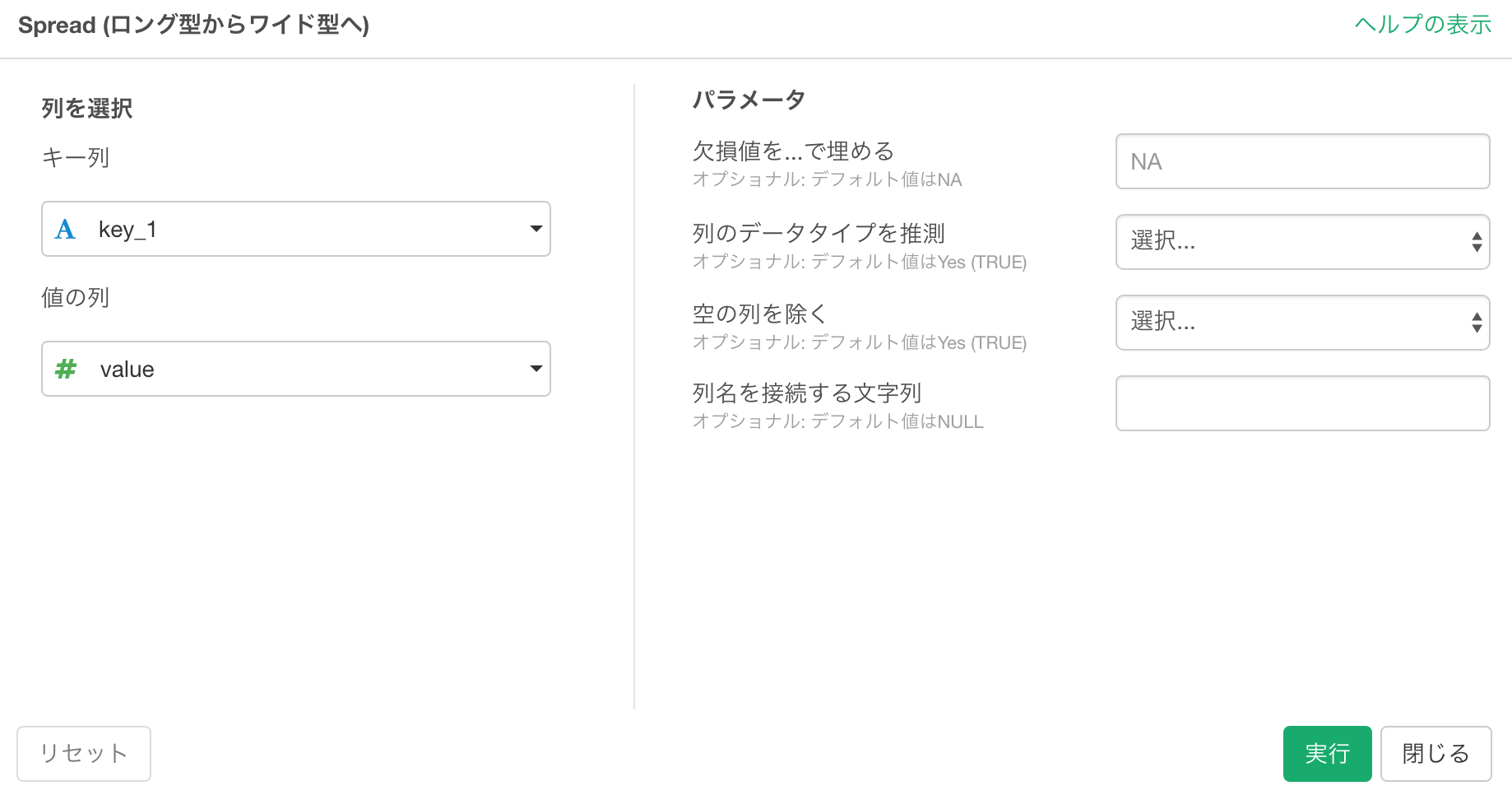
そのまま実行すると以下のようなデータの形になります。
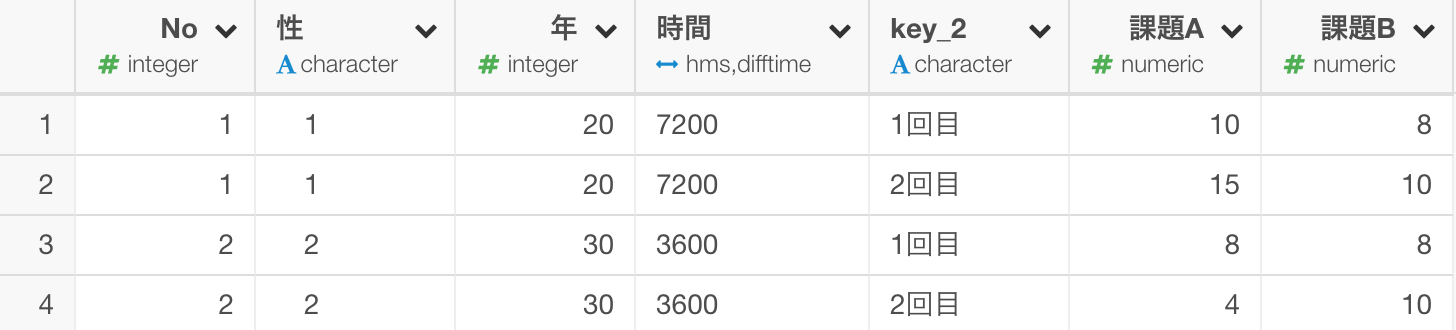
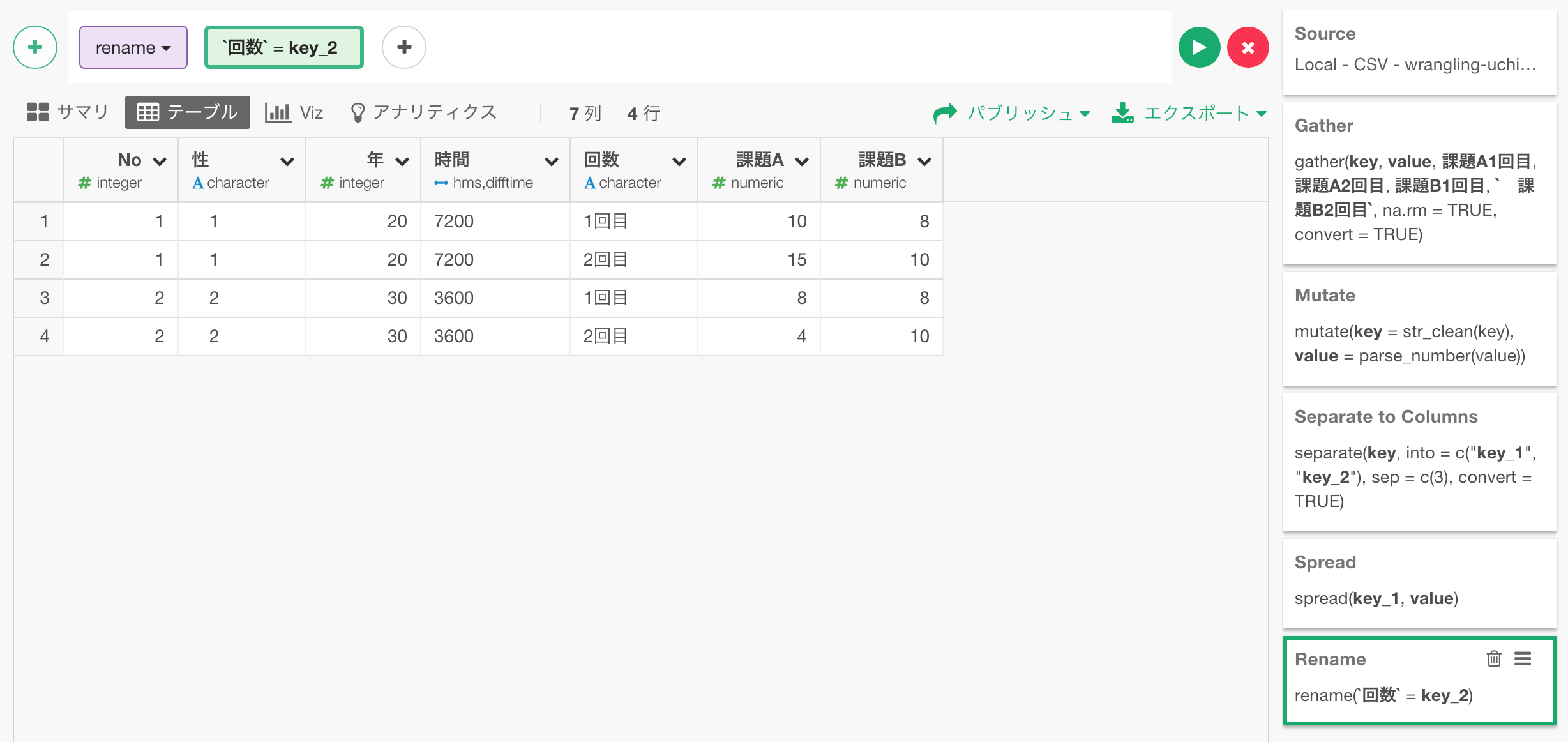
せっかくですので、key_2という列の名前を「回数」とわかりやすくしておきましょう。
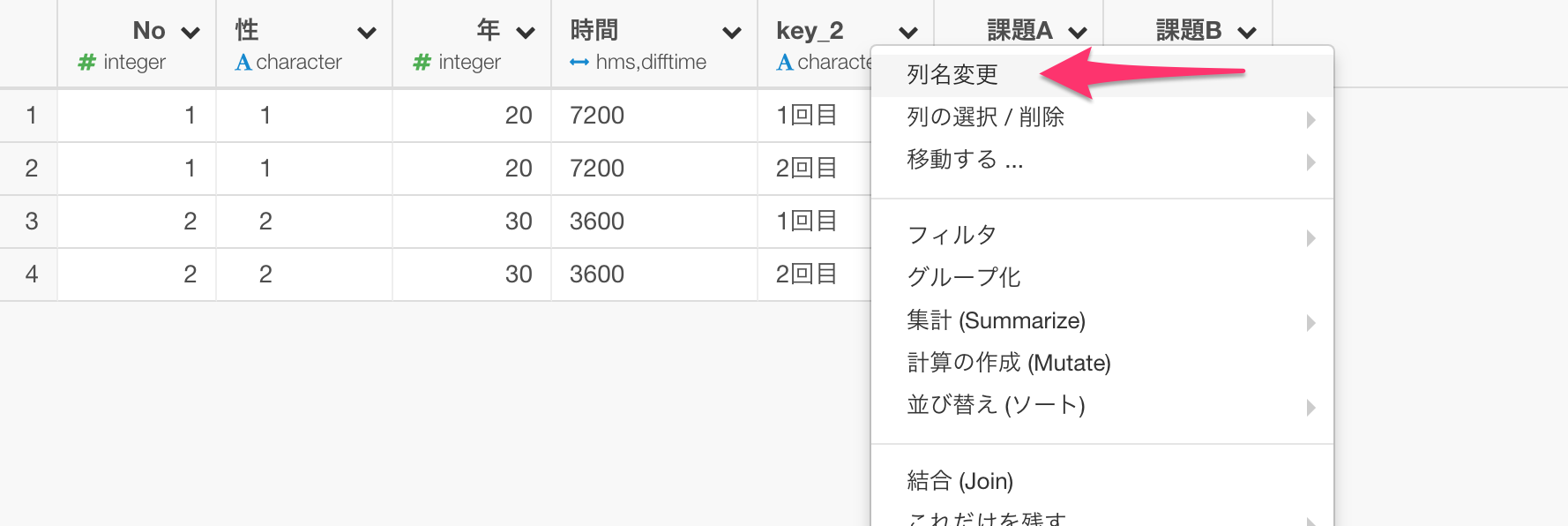
これでデータの準備が終わりました。
こちらにサンプルのデータをEDF(Exploratory Data Format)の形で置いておきました。こちらはExploratoryの方にインポートすると再現ステップもついてくるのでどのようにデータが加工されたのかが分かって便利です。