Introduction to Branch Data Frame
When you explore your data you will come up with a lot of different questions. And you want to build different data wrangling or data analysis steps against the same data set quickly and flexibly.
There is a feature called ‘Branch Data Frame’, which is designed to address this challenge in an elegant way.
To understand how this works and why you want to use this, let’s take a look at a few scenarios below.
Create Branch Data Frames to Run Multiple Experiments
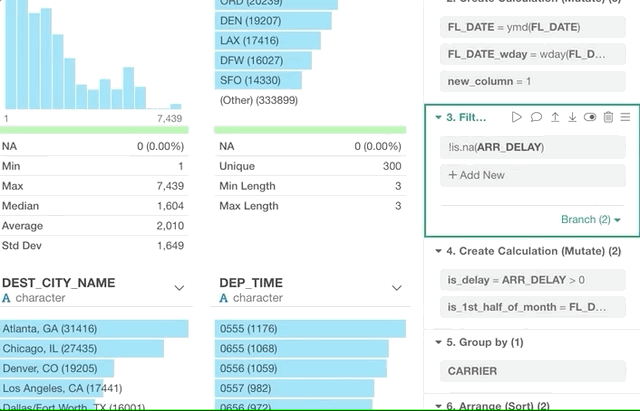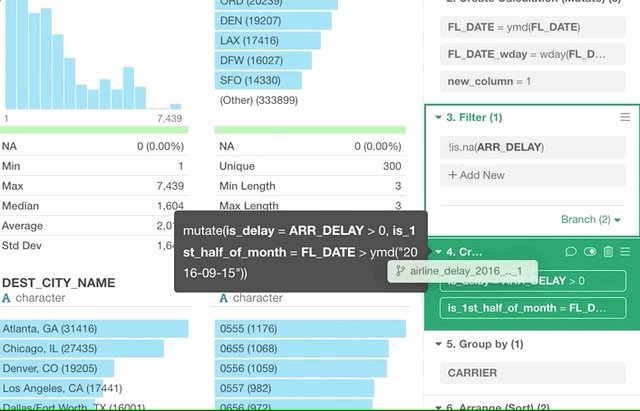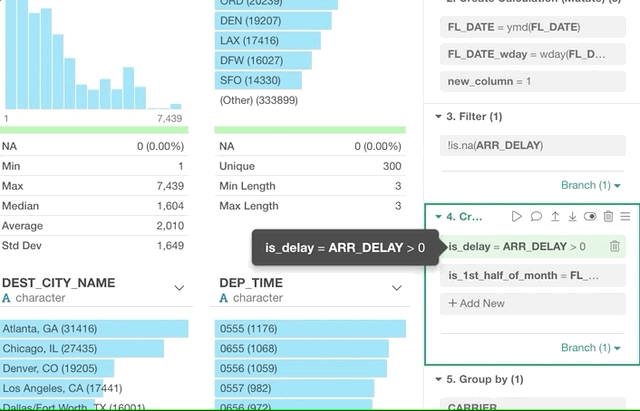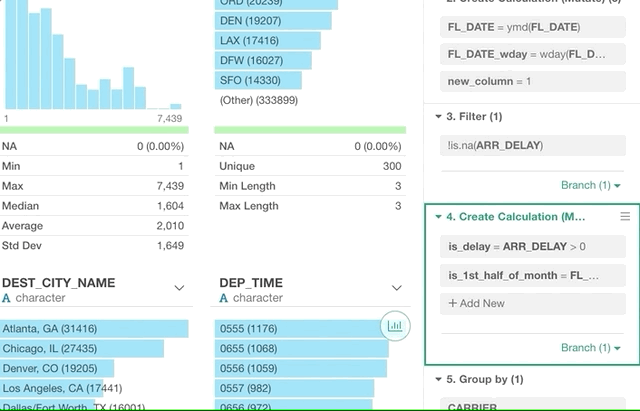
Let’s say we have done a quick data wrangling by cleaning up NA values, extracting week day information, and summarizing (or aggregating) the data. The steps would look like below.
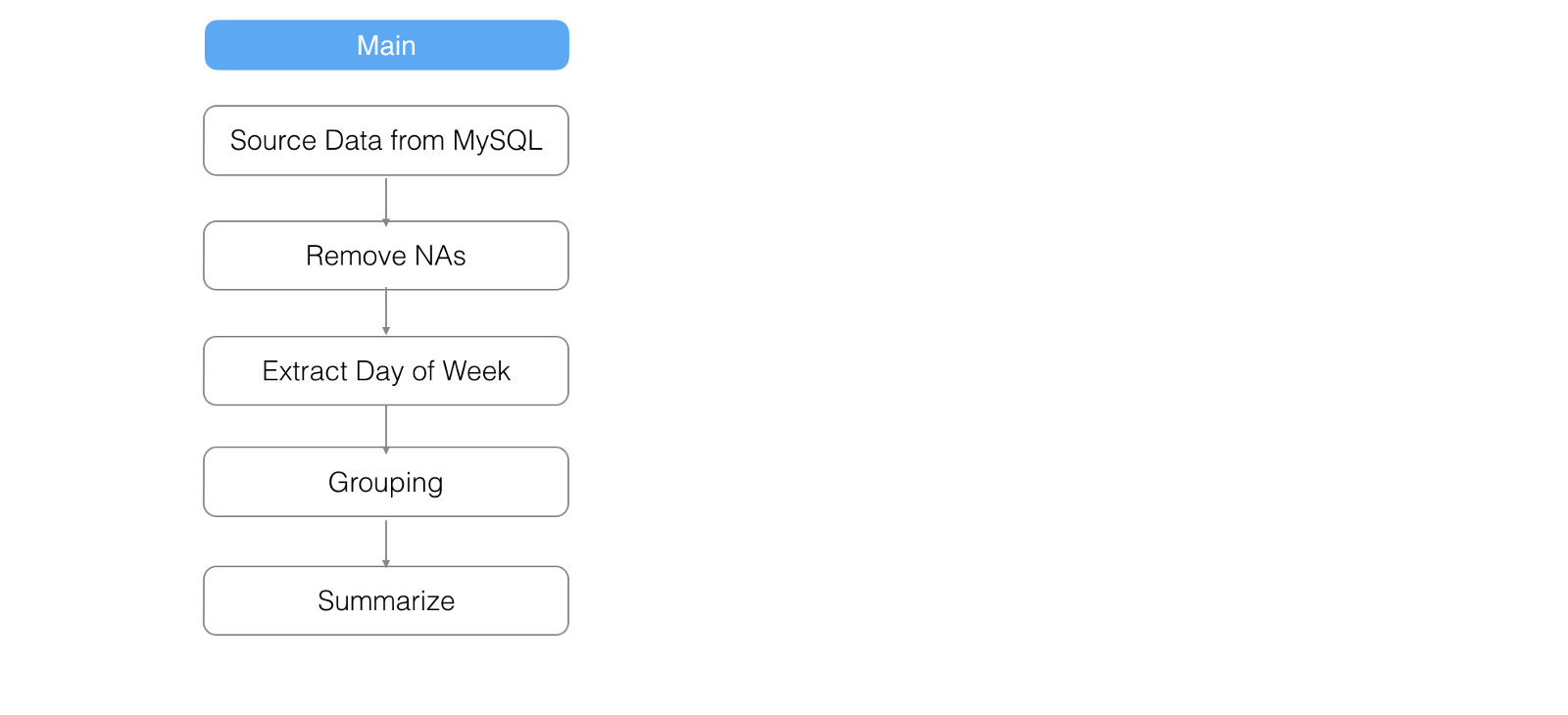
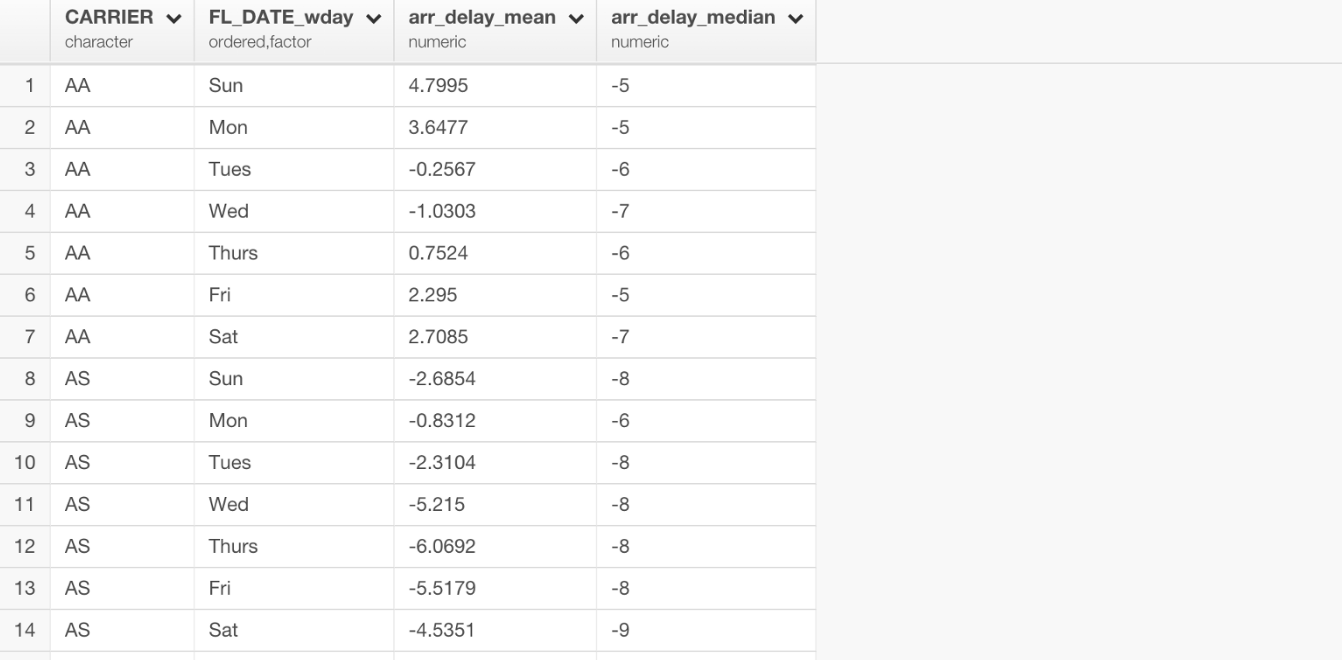
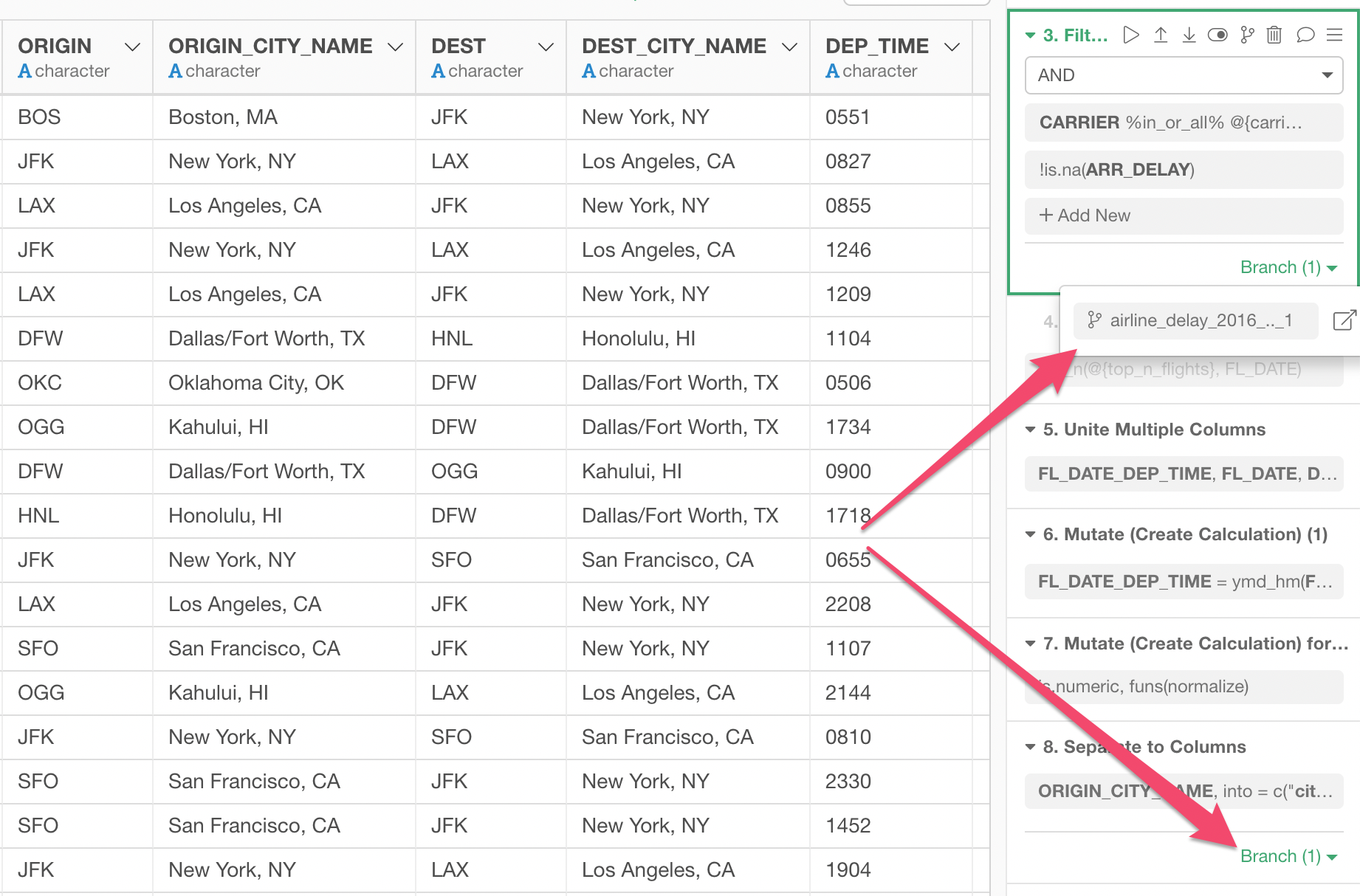
And the data would look something like below.
Now, we want to run a quick experiment by building a linear regression model to see any correlation between the two variables, Arrival Delay Time and Departure Delay Time in this ‘flight delay’ data example.
But, as you can see, we don’t have all the data we need for building the mode at this point of the step because we have just lost the detail level of the data and the columns that are not included in the summarized data at the end of this data wrangling path!
We can create a separate data frame but that means we will need to repeat the same data wrangling steps to clean up the data. This is when the branch feature comes in handy.
With this feature, we can simply create a branch called ‘Linear_Regression’ off from ‘Extract Day of Week’ step as you see below.
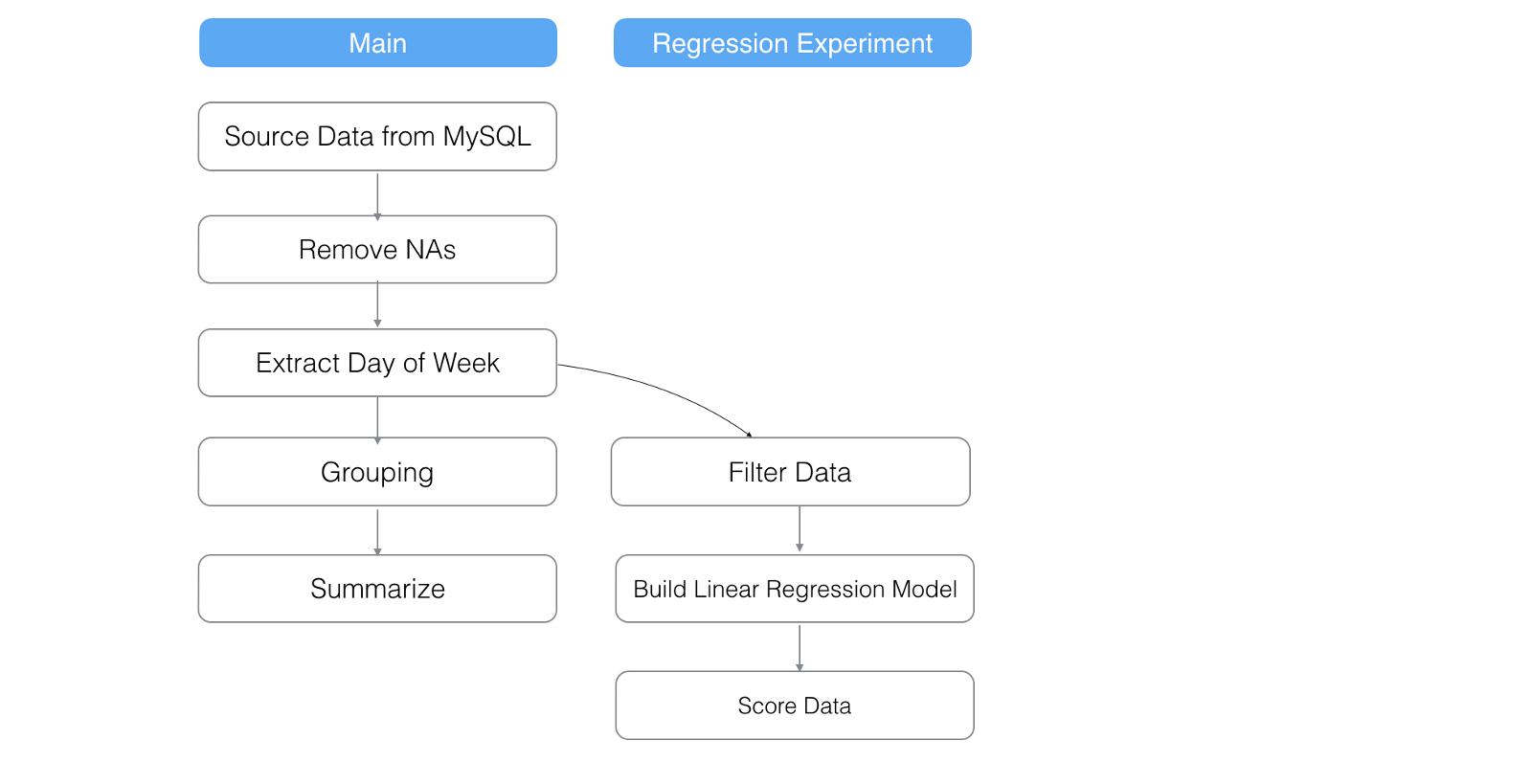
You can simply click ‘Branch’ icon in any step of the data wrangling like below.
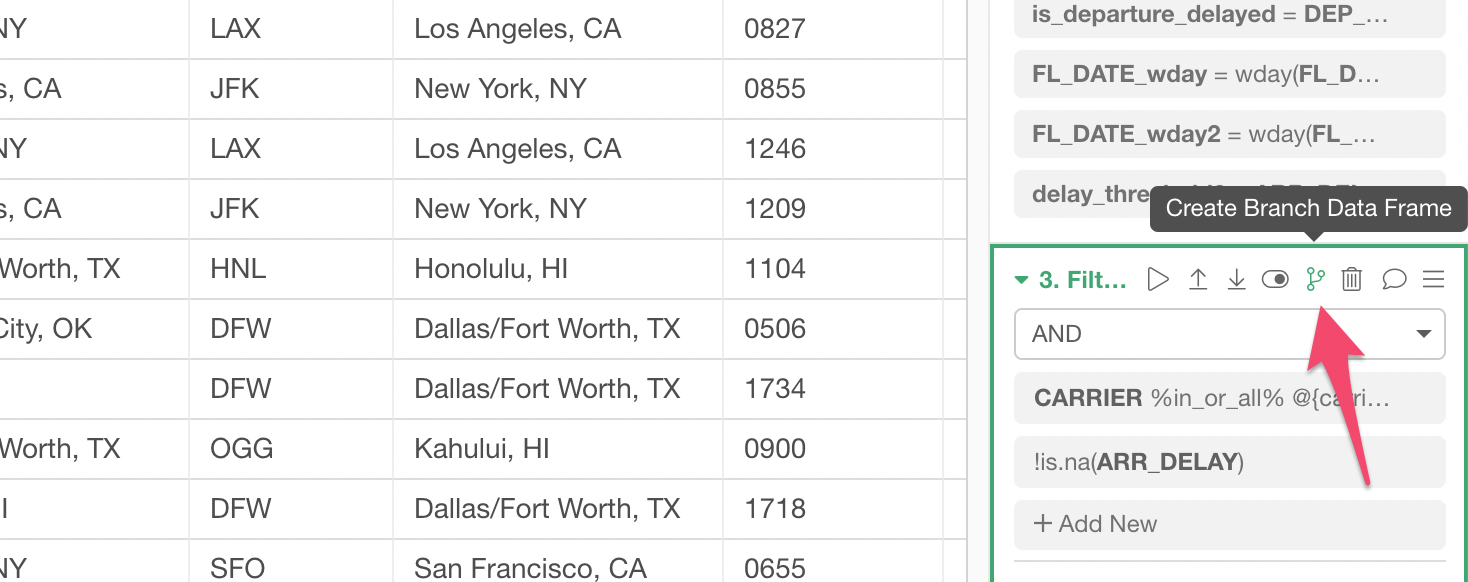
You will see the branch data frames listed underneath the main data frames.
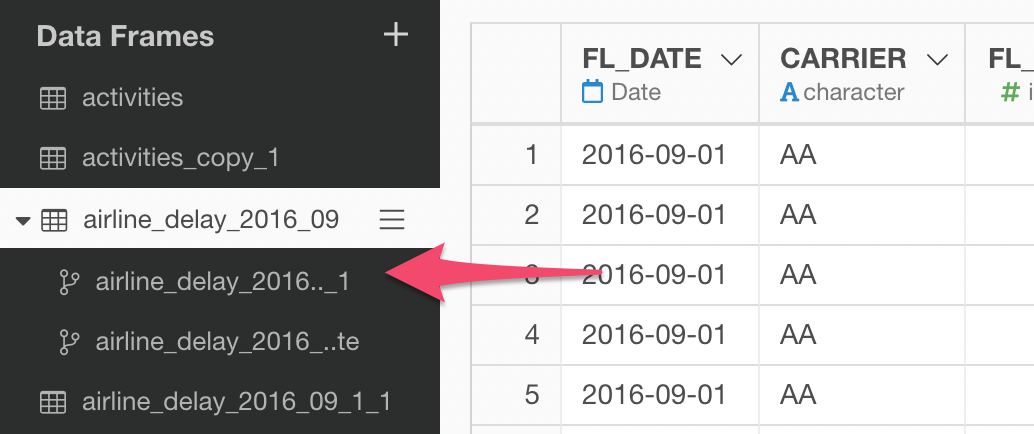
Ye can add any data wrangling steps that are specific to each branch data frame.
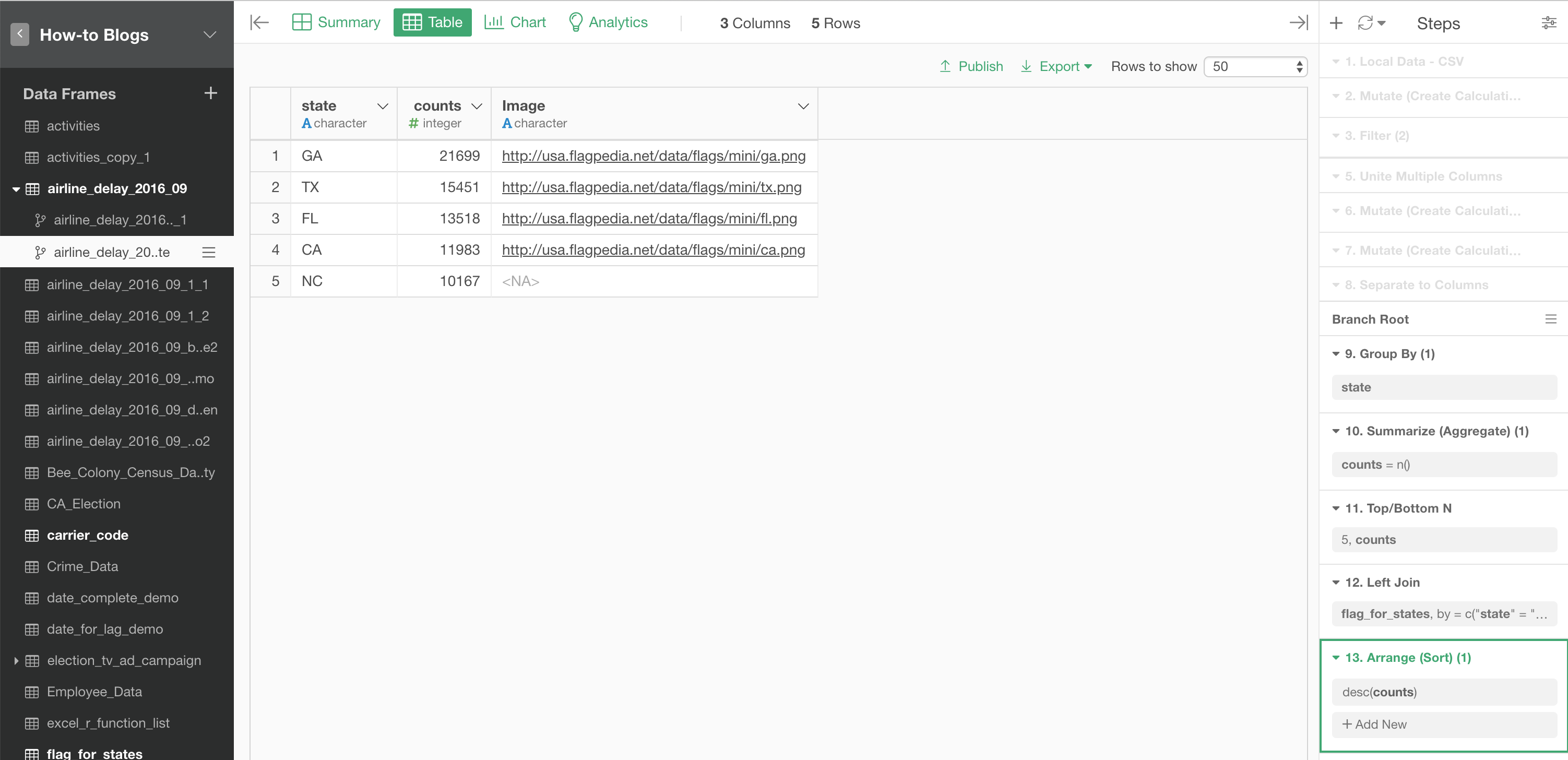
You will see the steps that are created in the main data frame with blurred background color at the top and you start adding the data wrangling steps after the Branch Root step.
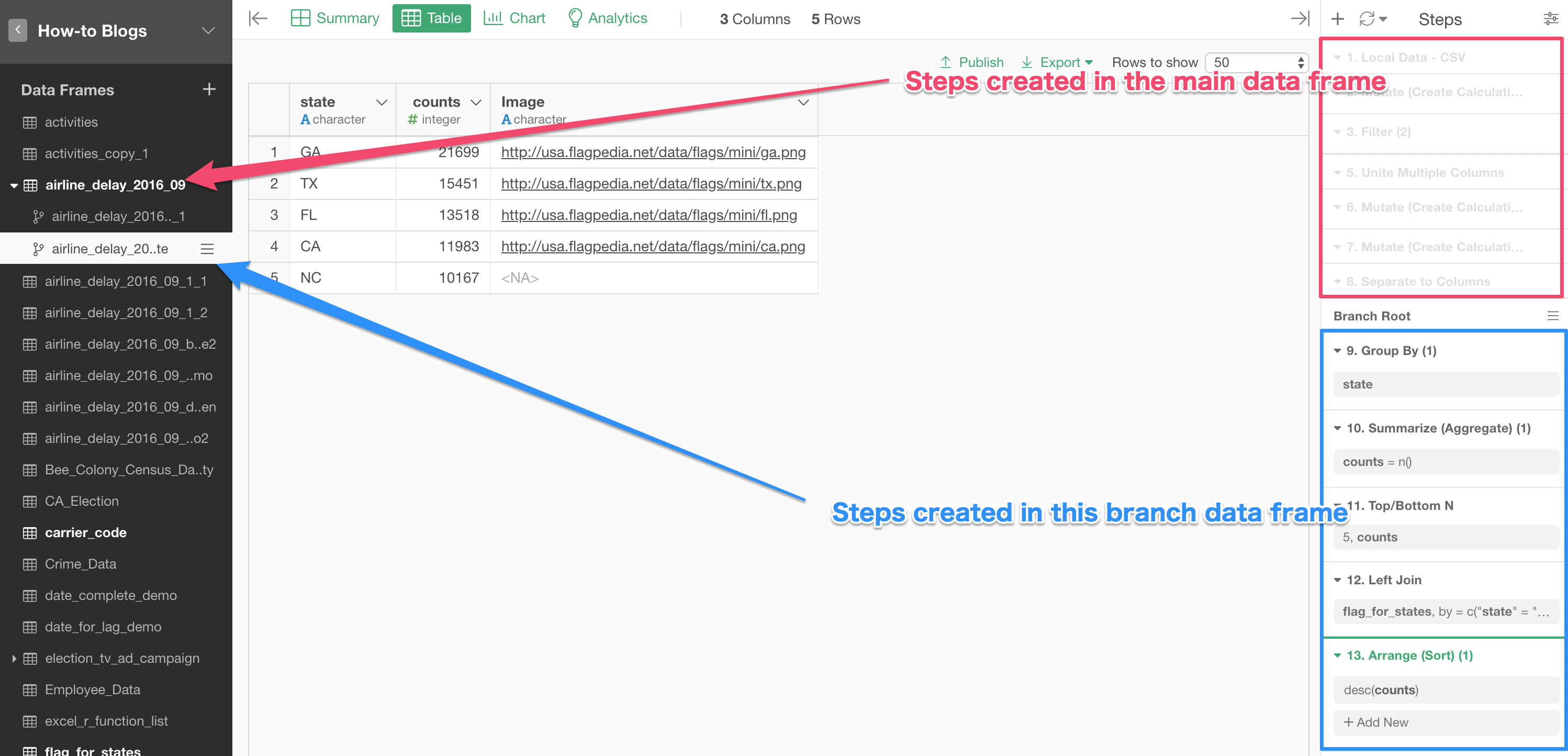
You can create the Branch data frames off of any step of the main data frame.
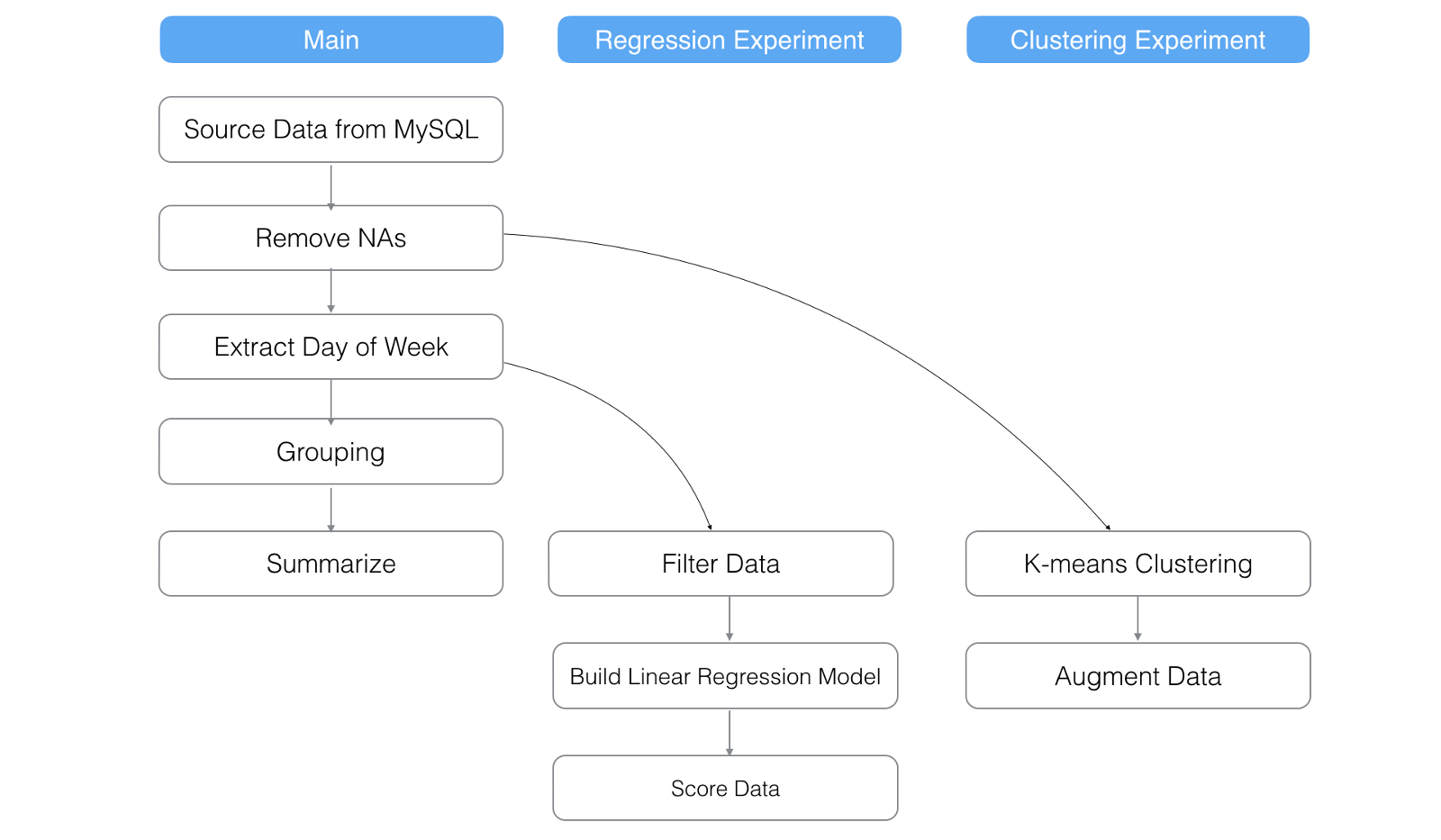
And in the main data frame, you can see which branch data frames are branched off from which steps.
Branch (Data Frame) Root Switch
Sometimes you might want to change the branch root step after creating one.
You can do it simply by drag and drop!
Click the Branch button and drag the branch data frame token to the step you want to move the branch root to.
Exploratory DAG Engine Manages Data Dependency and Reproducibility
Branch feature is built on top of our Exploratory DAG (Directed Acyclic Graph) engine we built from the ground up. This means, not only you can create a branch off of any step of the data wrangling step but also the dependency between the data frames and data wrangling steps are all managed automatically. It just works.
What will happen when the data wrangling steps in Main changed? Creating a new branch off from one of the steps in the main is actually the easiest part.
As you might have known, each step of the data wrangling has corresponding data cache internally to make the performance better.
Now, when you update one of the data wrangling steps in the main data frame, what will happen to the related branch data frames?
Any changes in the main data frame including the source step for querying against data sources will be reflected automatically in the associated branch data frames when expected.
A Few Example Scenarios
Let’s take a look a few scenarios to see how this really works.
1. Reload the data from the data source
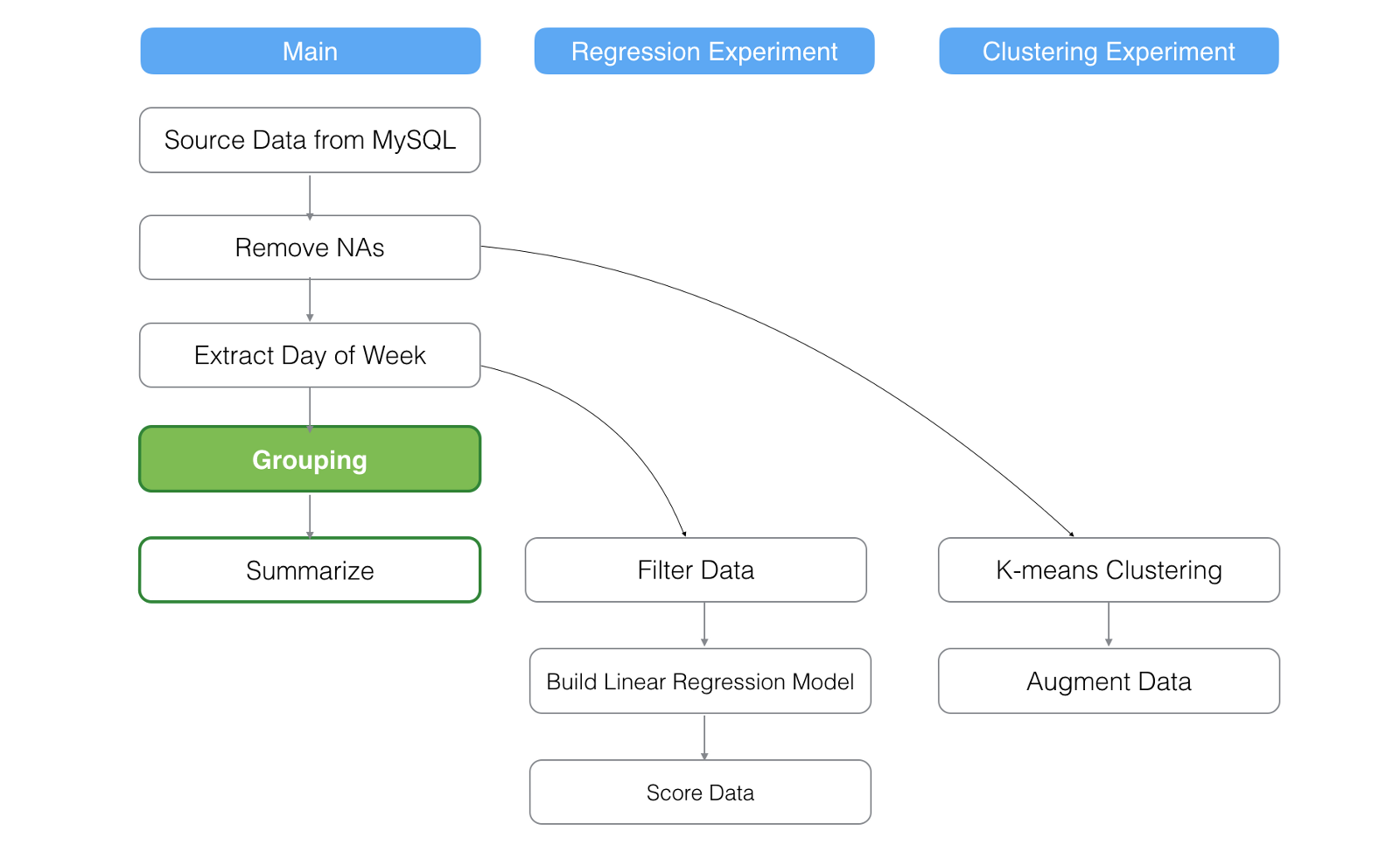
Let’s say we have re-loaded the data from a remote database by clicking on ‘Refresh’ button at the top of the data wrangling step.
This will refresh all the steps in the main data frame as well as the branch data frames.
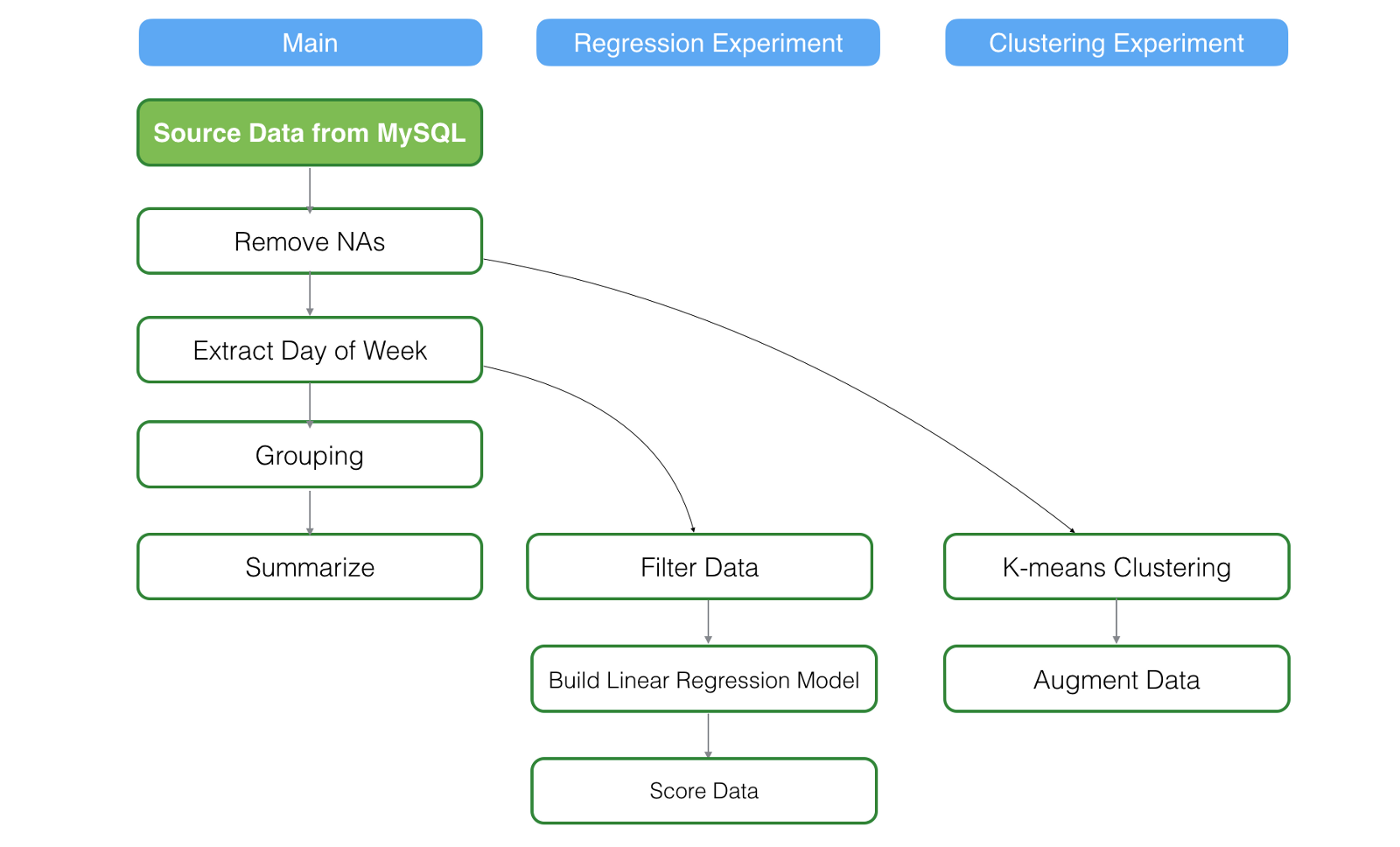
The green background box indicates the step that a user updates. The white background with green border boxes indicate that they will be refreshed automatically.
2. Update a Step in the Main Data Frame
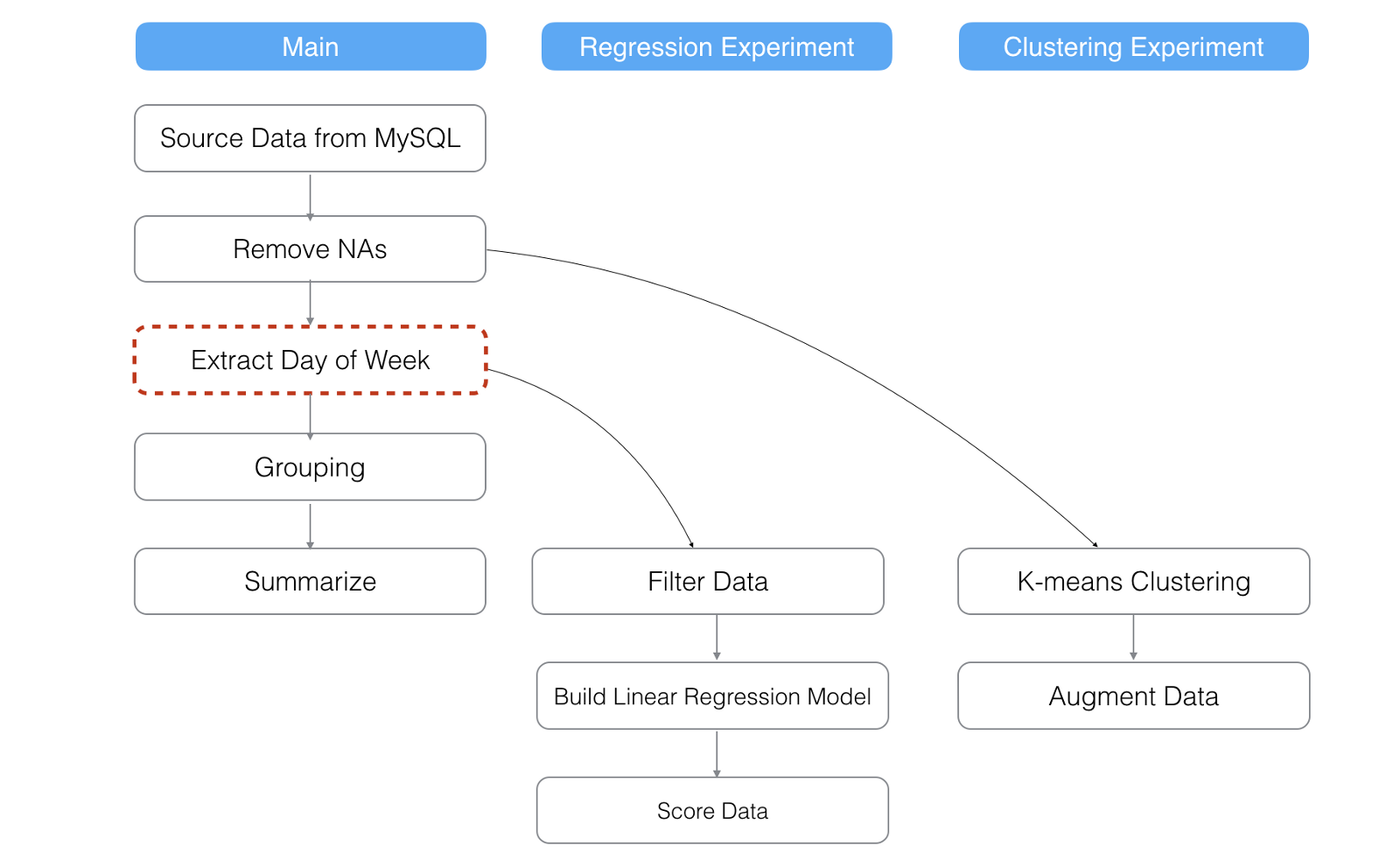
Let’s say you have updated one of the steps called ‘Extract Day of Month’ in the main data frame.
This will refresh all the steps after the ‘Extract Day of Month’ step in the main data frame as well as any steps in the branch data frames that have the data dependency to the ‘Extract Day of Month’ step.
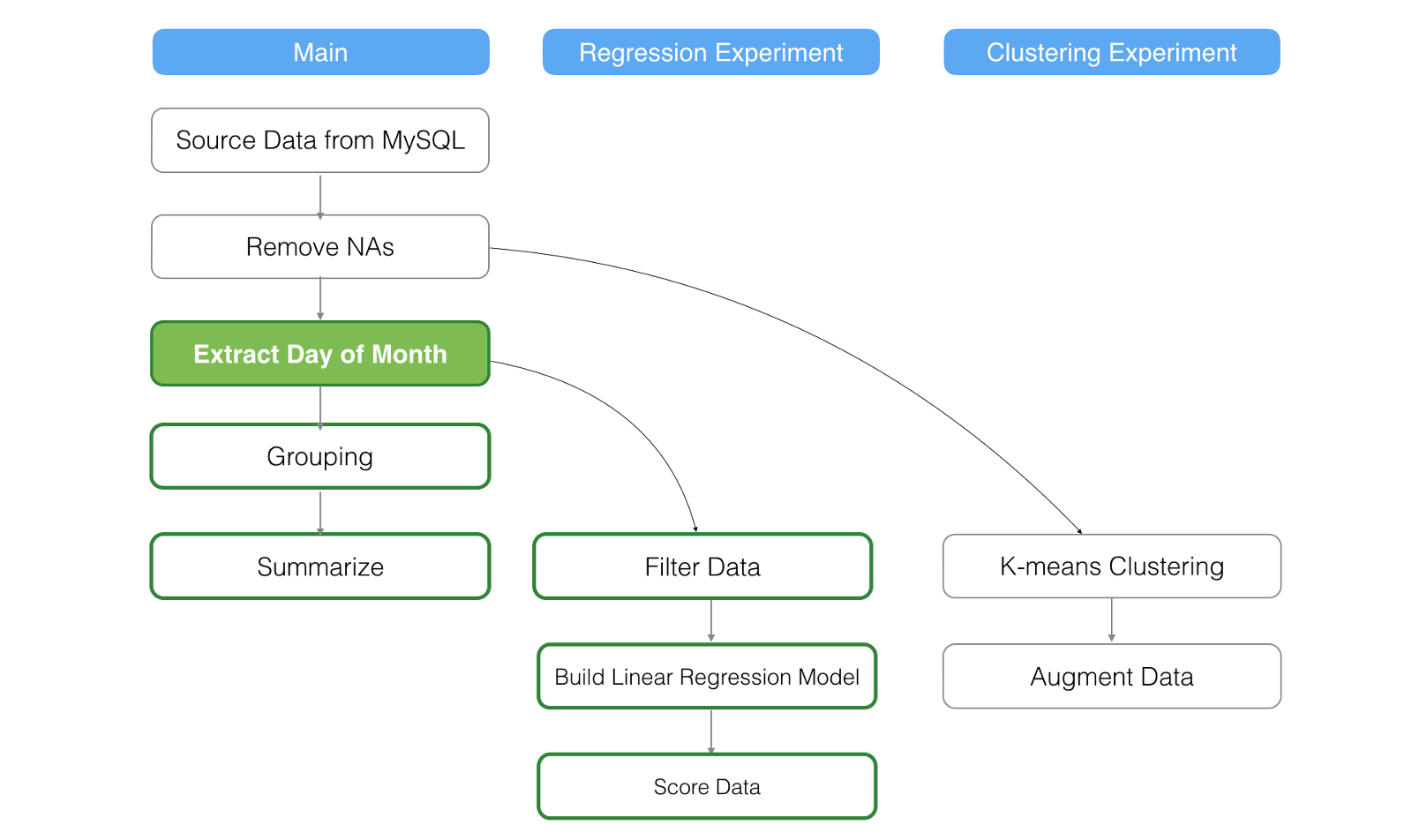
In the above scenario, ‘Clustering Experiment’ branch data frame will not get updated at all because it doesn’t depend on the ‘Extract Day of Month’ step.
Now, if we updated ‘Grouping’ step in the main data frame, none of the branch data frames will be updated.
3. Remove a Step that a Branch Data Frame was Branched Off
Once the step is deleted in the main then any branch data frames that were depending on the step will be adjusted to branch off from the previous step of the deleted step.
Consider the following case.
We removed ‘Extract Day of Week’ step which ‘Regression Experiment’ branch was branched off from. This would make ‘Regression Experiment’ branch an ‘orphan’ branch, but Exploratory DAG engine will automatically re-connect it to the step before the deleted step.
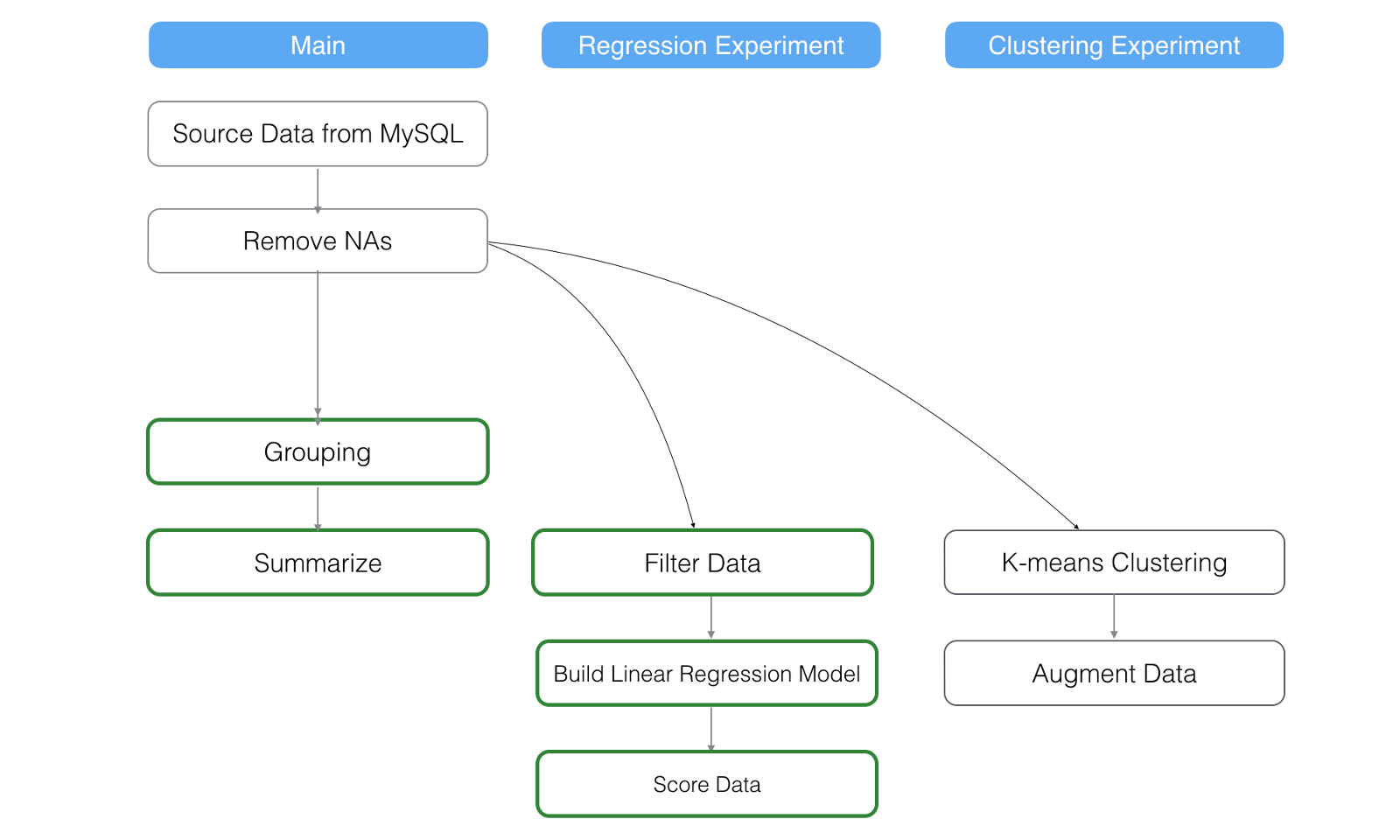
And, it will refresh the data cache for all the steps in the main data frame and all the steps in the branch data frame.
4. What If the Updates Are Coming from Other Data Frames?
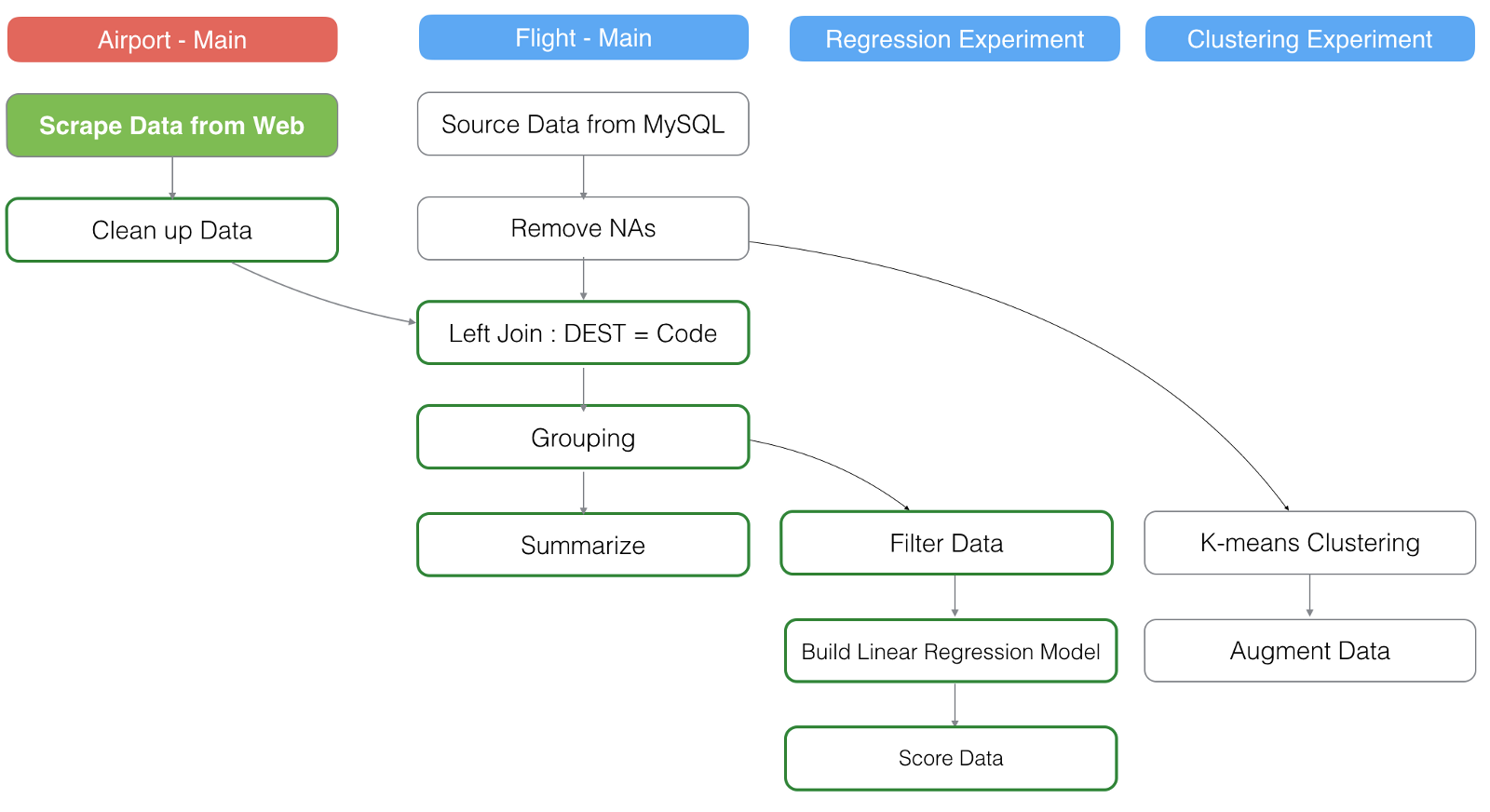
You might be joining or merging with other data frames.
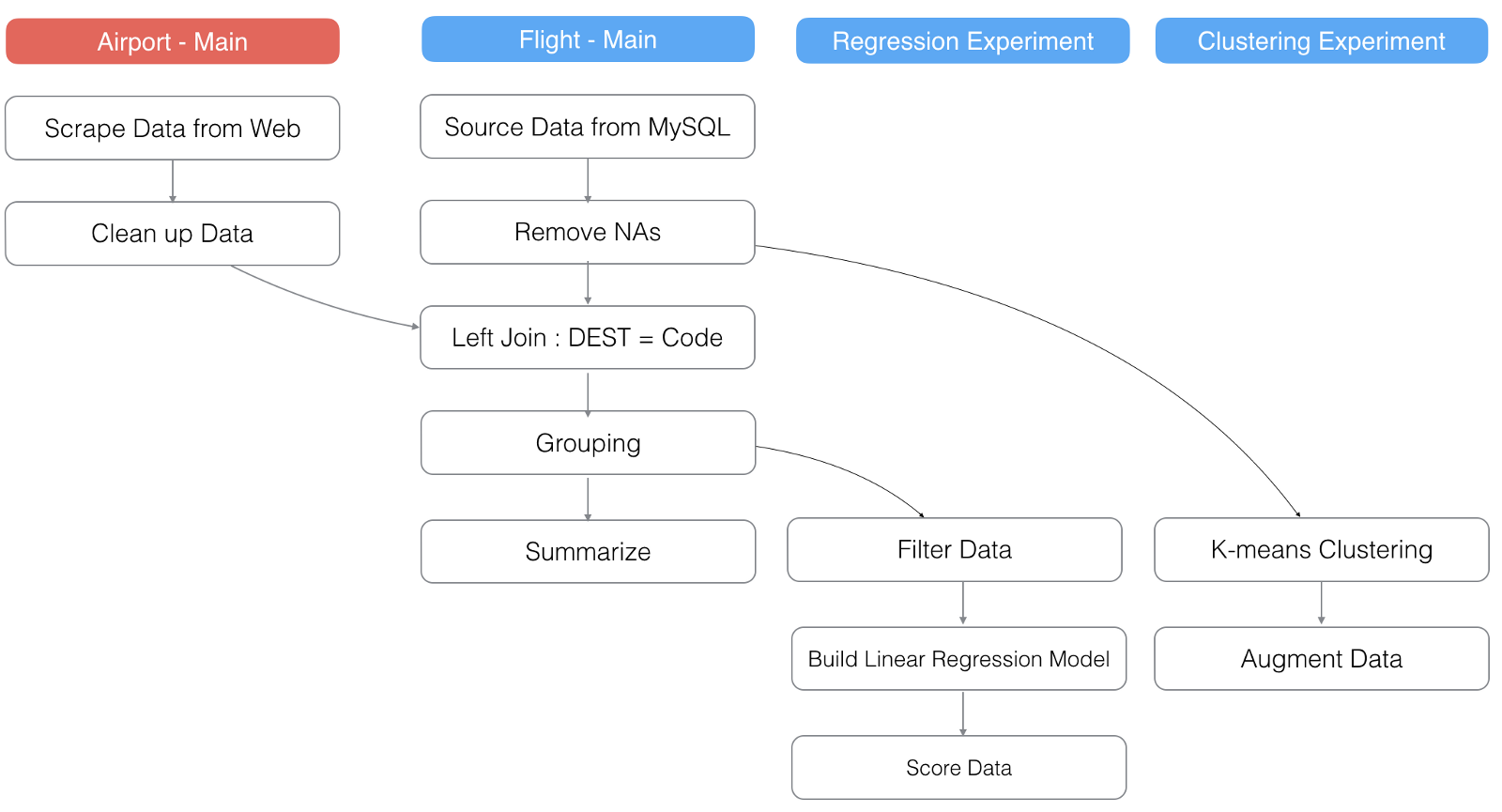
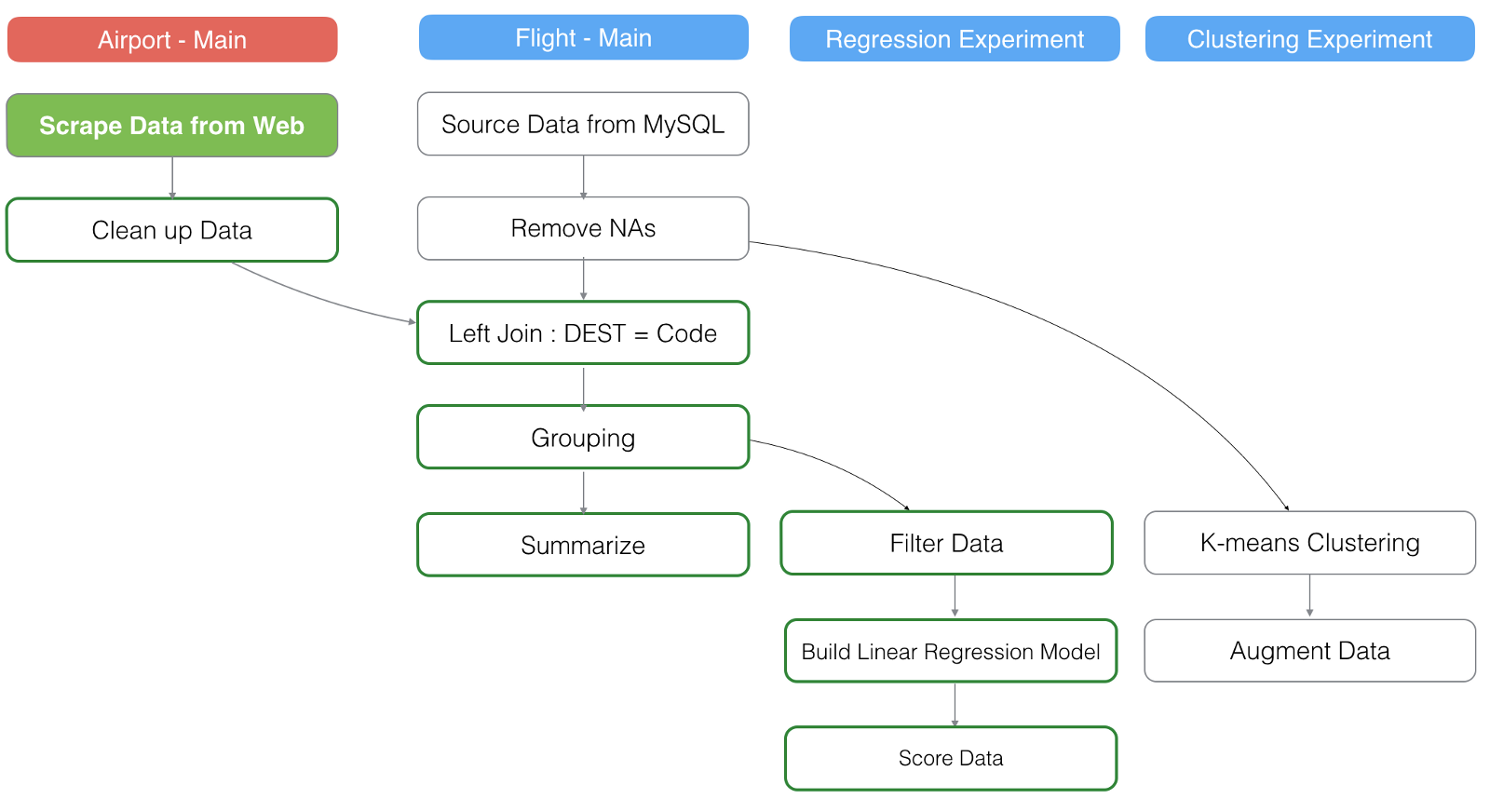
In the above picture, the red background box ‘Aiport — Main’ is a different data frame and it is joined to the ‘Flight Main’ data frame at the third step.
Let’s say we have re-loaded the ‘Airport’ data from the original website.
This will refresh ‘Clean up Data’ step in the main of ‘Airport’ data frame, which will make the ‘Left Join’ step to be refreshed, which will make all the steps after it to be refreshed.
And since one of the steps just being updated in the main data frame, this will make all the steps in the branch data frame ‘Regression Experiment’ to be refreshed.
However, the other branch data frame ‘Clustering Experiment’ will not be refreshed because it doesn’t have any dependency on the steps that have been refreshed this time.
Lazy Data Caching
By the way, the refreshing of the data cache for each data wrangling step happens only when it is needed.
This means that nothing happens in the branch data frames when the related steps in the main data frame are updated until you open the branch data frame.
Closing
We are a creative human being. We are always curious and have a lot of questions about the world.
Our goal is to provide a fast, interactive, and iterative data exploration experience.
With this Branch data frame feature, which takes care of the data dependency and reproducibility behind the scene, you will have more time for forming your questions and exploring data to find answers.
Happy Branching!