
Photo by Alexander Hafemann on Unsplash
P値の問題は氷山の一角だ
統計を勉強するときに避けて通れないものの一つに、P値というものがあります。(正確には頻度派ですが。。。)仮説検定のときに出てくるやつです。
しかし、最近は統計の世界にはびこっているこのP値に対する盲目的な信仰がいろいろと批判の対象になっていたりもします。
そんなおり、Jonhs Hopikins大学でデータサイエンスを教えるRoger D. PengとJeffrey T. Leekがネイチャー誌に興味深いエッセイを出していました。
P値に対する批判ばかりに目を取られるのではなく、データ分析にとってもっと重要な別のタスクやツールに関しての議論をもっとするべきだというものです。
ちなみにこの2人は、Rやデータサイエンスの世界では有名で、彼らがCourseraで教えるオンラインのデータサイエンスのクラスも人気があります。
学問的な話というよりも、実際に現場でデータ分析をする人が注意すべきことが書かれてあって、おもしろいなと思ったので、こちらに紹介します。
P values are just the tip of the iceberg - Link
NHST(Null Hypothesis Significance Test / 帰無仮説有意差検定)が“Basic and Applied Social Psychology”といった機関紙で禁止されたことを勝利のように騒ぐ人たちがいるのは驚くべきことではありません。
しかし、そうした決定は発表されているサイエンスの研究結果のクオリティにたいして、大きな影響を与えることにはならないでしょう。
そもそも研究を成功に導くためのデザインと分析にはたくさんのステップがあり、P値のような推計統計をどう計算するのか、また、例えば5%以下なら有意にするかどうかといった決断は、こうしたステップの最後にあるものの一つに過ぎないのです。
データ・パイプラインのイメージ
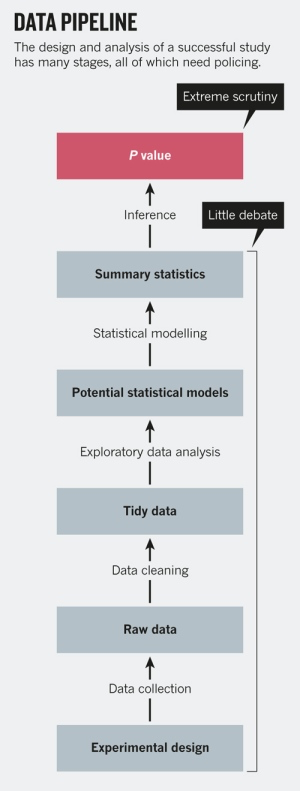
データ分析の初期段階で下された意思決定は研究の結果により大きな影響を及ぼします。仮説を検証するための実験のデザインや効果量をどうするか、調整がしっかりできていない交絡要素、単純な計測のさいのエラーなどと様々です。
恣意的な統計的有意のレベルは、データがどう整理され、集計され、さらにモデル化される過程での設定によって決まってくるものです。
P値は批判のターゲットになりやすいです。それは多くの人に使われ、多くの場面で正しくない使われ方をされているからです。
しかし、統計的な有意に関してそれまで使われていたルールを緩めるという決定は、実際には自分たちがほしい結果を得るために統計をごまかす道にドアを開くことになります。
P値の代わりにベイズ・ファクターや別の統計値を使うというのは、結局は真陽性と偽陽性に関する別のトレードオフの方法を選択するということに過ぎません。
結局、P値に関してああでもないこうでもないと議論するのは、文章の中の間違っている論点に目を向ける代わりに、一つの単語のつづりの間違いに注目しているようなものです。
こうした問題を解決するのに必要なのは、よりよい教育です。DNAシークエンシングやリモート・センシングを行う人はだれでもそのための機械を使いこなすためのトレーニングをする必要があるのと一緒で、データを分析する人間はだれでもそれを行うためのソフトウェアと基本となるコンセプトに関するトレーニングを受けるべきです。
もちろん、教育だけで解決できると言っているのではありません。実際データ分析は徒弟制度のようなモデルを通して、現場で時間をかけて先輩から教えられるものです。
また分野が違うと、それぞれ独自の分析の文化が出来上がっているものです。意思決定というのは、実証的なエビデンスというよりはそれぞれのコミュニティの中での文化的なしきたりにのっとって行われるものです。
例えば、時間の推移とともに計測されたデータのことを経済学者は「パネル・データ」と呼び、よく混合効果モデル(mixed-effects models)を使います。しかしバイオ・メディカルのサイエンティストたちはそういったタイプのデータを時系列データ(longitudinal data)と呼び、一般化推定方程式を使います。
最終的なゴールはエビデンスに基づいたデータ分析です。
これはエビデンスに基づいた薬に似ています。そこでは、医者はコントロール・テストで効果が証明されている処方のみを使うことが求められています。
統計学者や彼らの教え子やコラボレーションを行う人たちはいつまでもP値に関して議論するのではなく、もっと大きな視点からデータ分析が失敗しない方法を考えることにもっと多くの時間を費やすべきです。
要訳、以上。
あとがき
P値に関しては、仮説検定を行ったり統計学習モデルを作ったりするさいに必要なコンセプトなので、私達のデータサイエンス・ブートキャンプ・トレーニングでも、もちろんカバーしているのですが、鬼門です。
多くの人がここで首を傾げます。(笑)
慣れてない人にとっては、その裏にある考え方とその使い方がややこしく、一度聞いただけでは正体が掴みにくいコンセプトであることは間違いありません。
ただ、一度分かってしまうと、データ分析のさいにはかなり便利なツールなので、私達のトレーニングでもじっくりと時間をかけて、様々な例を使って手を動かしながら慣れていってもらうように努めています。
そんなP値ですが、ここ最近では、特に学問や研究の世界で、これまで見られたようなまるで神にたいする信仰のような態度を抑制するような流れが見られます。比較的新しい話では、心理学の分野の機関紙である、”Basic and Applied Social Psychology”によるP値だけを使って効果をレポートすることを禁止するものです。
しかし、こうした話に注目し、それではP値は知っておく必要がないかと言うとそんなことはないと思います。
これは今でも多くのシリコンバレーのデータ先進企業で、特にA/Bテストなどではその有意性を調べるために広く使われ、また探索的データ分析で仮説を構築していく段階でもよく使われています。逆にこれを使わない方法で、使う方法よりも明らかにいいやり方があるわけではありません。(ここでは頻度派対ベイズ派の話はやめましょう。)
重要なのは、このP値とはどういうものなのか、意思決定にどう役立つものなのか、さらにその前提、背景、限界といったものをしっかりと理解した上で使っていけば、ふだんのデータ分析にはたいへん役立つツールだということです。
逆に本当の問題は、現在そういった事を気にすることなしに、バー・チャートやパイ・チャートで目で見ることのできる違いを意味のある違いだと思い込んだり、目では気づきにくい違いを見逃してしまったまま、「データ・ドリブン」な意思決定を行っている多くの人たちがいるという現実だと思います。
現在のように分析することのできるデータがどんどん増えていきている今こそ、本文の中でも言われていたように、より多くの人がP値だけでなく統計全般に関しての正しい知識と使い方を学んでいくべきだと思います。
データサイエンス・ブートキャンプ、3月開催!
今年の3月の中旬に、Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプを東京で開催します。
データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に参加を検討してみてください。詳しい情報はこちらのホームページにあります!