
レコメンドシステムの落とし穴 Part 1 - ユーザーの「好み」と「選択」と「幸福」
AmazonやSpotifyなどが、自分が「好む」だろうコンテンツを優先的に表示する仕組みであるレコメンドエンジンは、今や当たり前となっています。しかし、こうしたシステムによって表示されるものは、必ずしも自分がほんとうに「好む」ものであるとは限らず、見当違いなものが多かったり、ある一定のもの(例えばたまたま最近クリックしたもの)にものすごく偏っていたりなど、イマイチであるという体験を持ってる人も多いのではないでしょうか。
これは、レコメンドエンジンだけに限らず、データ分析や予測モデルの構築の際も同じです。顧客が「好む」であろうものを知ろうとデータ分析し、そこから得られた知見を元に何らかの施策を打ったり、顧客に何かを提案したりするのですが、そう簡単に結果が出るものではない、というのはやったことがある人であれば経験があるのではないでしょうか。
これはユーザーの「好み」とユーザーがとる「選択」は必ずしも一致していない、ということからくる限界のようなものです。
データ分析をする私達、またはレコメンドシステム側からして、取れるデータというのは、例えばあるユーザーがあるビデオを見た、といった何らかの行動を記録したものです。しかし、このユーザーの「選択」という行動は必ずしもそのユーザーの「好み」を反映しているわけではありません。
ユーザーにとってはたまたまクリックしてしまっただけで、別に自分の「好み」でもなんでもない、ということはよくあります。
言われると、誰もがわかることでもあるのですが、難しいのは、選択に関するものはデータとして正確に取りやすいのですが、ユーザーの「好み」はデータとして正確には取りにくいため、選択から「好み」を推測せざるを得ないということです。
そこで、データ分析や予測モデルまたはレコメンドエンジンを作るときによくありがちな間違いを避けるために、「好み」と「選択」の違いをはっきりさせようと思っていたら、まさにこのユーザーの「好み」と「選択」の関係を整理し、さらに「好み」に影響を与えるユーザーの「幸福」や「価値観」との関係を整理し、さらにユーザーの「好み」をより正確につかむために何ができるのかをまとめた「What Does it Mean to Give Someone What They Want? The Nature of Preferences in Recommender Systems」という素晴らしい記事を見つけました。
これからその要約を3回に分けてみなさんと共有していきたいと思います。
このポストの中では「好み」という言葉を使いますが、もとの英語は「Preference」です。
以下、要約。
「好み」とは?
レコメンドのシステムの中心的なゴールはユーザーの「好み」をもとに商品やコンテンツを選ぶことです。「好み」とは様々な文脈で使われますが、簡単に言うと「ユーザーが何を欲しいか」ということです。
しかし、実際にはたいていのレコメンドエンジンはエンゲージメントの最適化をゴールとしています。というのも、人々はいつも自分の欲しい物を選ぶという「顕示選考(明らかにされた選択)」として知られた20世紀の経済学における考えが前提となっています。
しかし、こうした「好み」に対するアプローチは、クリックベイト、中毒、アルゴリズムを使った操作といった様々な望まない結果をもたらすことになります。
そこで、もっと現実的でより良いレコメンドシステムを作るためには、ユーザーが何をするかを見るだけではなく、彼らに何が欲しいのかを聞くこと。そして動機、行動、そして結果を分けたモデルを使うことです。
「好み」とは、ある人が何かを選択するときに判断基準として思い出す、または構築するものです。
これは、人々が何を欲しいのかを説明するには普通でないように聞こえるかもしれません。しかし、これには2つの重要なアイデアを強調する意図があるのです。
まず最初の点は、「好み」は心理的なものであり、行動的なものではないということです。
「選択」は「好み」と相関することが多いのですが、それらは同じものではありません。さらに「好み」も「選択」もユーザーにとっての「幸福」と完全にマッチするとは限りません。
2番目の点は、多くの場合人々は「好み」をその場で作り出すということです。望むものが安定しいつも同じだという人も中にはいるでしょう。しかし、多くの質問に関して、私達はそのことについて考えるまで自分が何が欲しいのか知らないものなのです。そして多くの場合、実は私達のそうした質問に対する答えはその場次第だったりするのです。
この点は「好み」に関してよく使われる標準的な数式モデルとは矛盾するものです。
このような点は「好み」を理解するにあたってとても重要なことです。というのも、現在多くのレコメンド・システム(一般的にAIと言われるものの多く)は「好み」に関して便宜的だが現実的ではない考え方に頼っているからです。
経済学者は長い間、「好み」に関する理論を消費者の行動様式モデルを元に構築してきました。つまり、人々がどの値段で何を買うかということです。
ポール・サムエルソンは、個人の選択はいつも首尾一貫しているという1つの前提の上に消費者の行動理論を構築し、1938年に論文として発表しました。それは、もし私達がYの代わりにXを選択するのであれば、他のどんな同じような状況でも私達はYの代わりにXを選択するだろうというものです。
この前提に立つと、経済学者は選択という情報(私達に直接観察できるもの)を使って「好み」(私達には直接観察できない)を再構築できるということになります。このパラダイムは「明らかにされた好み(revealed preference)」として知られています。
「好み」と「選択」と「幸福」
しかし、20世紀後半になるとノーベル経済学賞の受賞歴のあるアマルティア・センのような経済学者や哲学者によって、この「明らかにされた好み」のパラダイムは批判されるようになりました。というのも、「明らかにされた好み」のパラダイムは以下の3つのコンセプトを区別してないと言うのです。
- 好み - 人々は何が欲しいのか(Want) - 欲求、動機
- 選択 - 人々は何をするのか(Do) - 行動、エンゲージメント
- 幸福 - 行動の結果、何が起きるのか(Result)- 充実、価値観
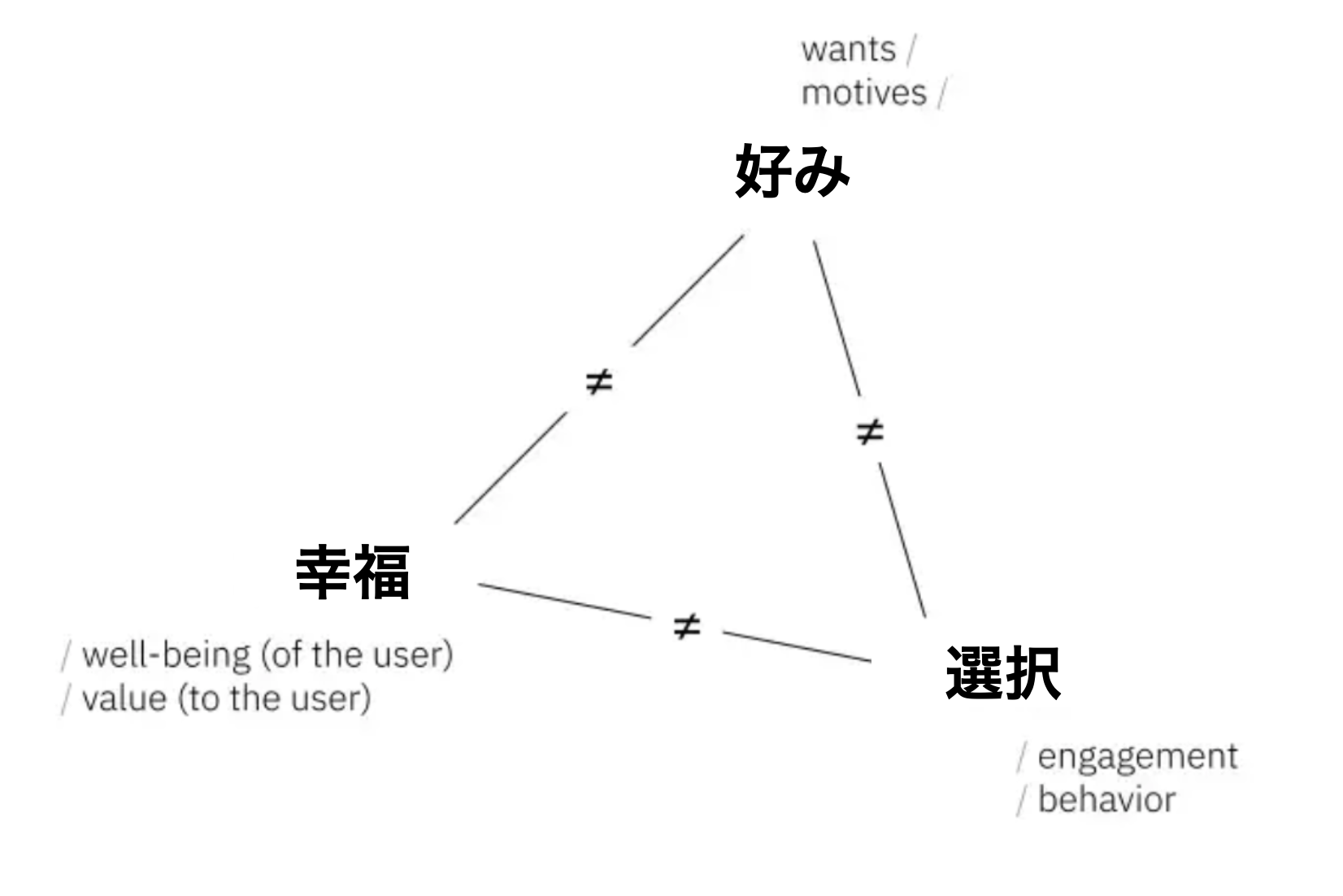
これらのコンセプトを区別することは経済学者にとって重要なことでした。というのも、もし人々はいつも自分たちの幸福や価値観に見合った選択をするわけではないのであれば、市場の機能は個人や社会の幸福を最大化するものであるとは言えなくなってしまうからです。
上記3つのコンセプトは大きな抽象的概念であり、それらを説明するものとして様々な言葉が異なる文脈で使われてきました。レコメンド・システムの場合、エンゲージメントとはある行動の1つのタイプであり、それはユーザーの選択でもあります。幸福はユーザーの満足感、ユーザーの価値観でもあります。「好み」は基本的には心理的なものであり、それは動機、判断、興味、必要性、そして欲求を含むものです。
「好み」と「幸福」の違い
なぜ「好み」と「幸福」は同じものでないのか、その理由はいくつかあります。私達が何かを選択するにあたってそのための判断基準を構築するとき、それはいつも自分にとっての利益を優先させたものであるとは限りません。レコメンド・システムという文脈でいくつかの例を見てみましょう。
影響
「好み」は、その人にとってほんとうにいいものであるとは言えないものでも、「説得する努力」によって影響されてしまいます。例えばNetflixの場合、あるユーザーはたまたま広告として流れた映画を目にした後、その映画を「選択」して見ることになるかもしれません。
文脈、コンテクスト - 「好み」はその場の環境によって影響され、このことはある人の判断基準をある特定な方法で構築するよう導くことさえあります。例えば、ユーザーは通知機能を頻繁にチェックしなければと思うかもしれませんが、それはユーザー・インターフェースがそうした中毒性を誘うようにデザインされているだけだからなのかもしれません。
信仰
人々は多くの場合、いくつかあるはずの別の選択をした場合どうなるか、その結果を評価するための時間や情報を持っていません。このことによって、もう少し良く考えたり、もっと多くの情報を得ていたら欲しいとは思わなかったものを欲しいと思ってしまったりします。
例えばあるユーザーはYoutubeで流れてくるクリックベイト(クリックされることを誘導するための見出し)を使ったサムネイル・イメージをクリックしてしまうかもしれません。しかしそれは、その表紙やタイトルがそのビデオの中身についてユーザーを誤って誘導したからに過ぎません。
期待
何らかのトピックに関して能力に自信のない人は、自分の「好み」を限定されたレベルに合わせてしまうかもしれません。やってみて後でだめだったとがっくりすることを避けるために、自分の望みを低く設定してしまうのです。
例えば、あるユーザーはある有名な学校で勉強する機会やある仕事の機会に関しての記事をクリックしないかもしれません。というのも、自分みたいな人間が応募してもどうせ受からないだろうと、すでに決めつけてしまっているからです。
利他
人は自分のことだけでなく、他の人が幸せになるようなことを好むものです。例えば、あるユーザーは自分の友達をサポートするためにその友達が作ったものを共有したり、「ライク」ボタンを押したりするかもしれません、例えそれは自分にとっては価値のないものだったとしても。
「好み」と「選択」の違い
「好み」は「選択」と違う、より正確に言うと、ある選択がされたという観察からはその選択が「なぜ」されたのかが分からない、その理由もいくつかあります。
無関心
何を選択していいのか分からないが、何かを選択しなくてはいけない、そうしたときに人々はしょうがなく選択することがあります。
(Youtubeなどの)推奨リストに出てきたもののうち、ユーザーはどれにも特に興味なかったとしても、時間つぶしのためにそのうちのどれかをなんとなく選んだりすることがあります。
好みの偽造
あるゴールを達成するために自分の好みとは異なるような選択をユーザーが戦略的に行うことがあります。例えば、あるユーザーが自分の政治的な信条とマッチするコンテンツが出てきたとしても、それが議論を呼ぶものであれば、そうしたものを支持するグループと関係があると思われるのを避けるために、見ることも、共有することもないかもしれません。
手段としての選択
単にある特定のゴールを達成するための手段として、「選択」がされることがあります。結果に対する「好み」はあるが、その結果を得るための手段に対しては自分の「好み」はどうでもいいと割り切れる場合です。
例えば、家の修理プロジェクトを行っている人は、そのために必要な道具をAmazonのようなオンラインサイトで買うかもしれませんが、そうしたプロジェクトが終わればその道具に対しての「好み」をその後も持ち続けることはないかもしれません。
あとがき
データを分析するときユーザーや顧客の「好み」を理解することは重要です。というのも「好み」によってユーザーや顧客は「動機」づけされ、ある特定の製品やサービス、またはコンテンツを選択することになるからです。
しかし、実際にデータとして取れるのは「観察」された「選択」に関するもののみです。そのため、この「選択」という観察データからユーザーや顧客の「好み」を解き明かしていくことになるわけです。
ところが、今回見てきたように、「好み」と「選択」はいつも合っている、データ分析の言葉で言うなら「相関」する、とは言い切れません。
さらに、ユーザーや顧客の行動を理解する際に、ユーザーや顧客にとっての「幸福」や「価値観」というものも重要です。これはユーザーの行動に大きな影響を与えそうなものですが、ただいつもそうであるとは限りません。健康的な生活を送ることがあるユーザーにとっては「幸福」であり本来望むものであったとしても、健康的でない飲食を続けてしまうということはよくあります。
そのため、「観察された選択」というデータやアンケートデータなどを元に、ユーザーや顧客が何を「好み」とし、どういった「価値観」や「幸福観」を持っているのかを知るのは難しく、そのためユーザーや顧客が何を選択するのかを予測するのも思った以上に難しいわけです。
多くの人がAIとビッグデータを使って予測モデルやレコメンドエンジンを作れば業績が改善できる!と思ってしまいがちですが、実はそんなに単純ではないということですね。そうしたモデルやエンジンは過去のユーザーの「選択」データを元にユーザーの「選択」をモデル化しているのですが、ユーザーは「好み」をもとに選択をすることが多く、しかしその「好み」は必ずしも「選択」として表現されているわけではない、という点に罠が隠されています。
これはデータ分析においても重要な点で、私達の誰もが謙虚に注意しておくべき点ですね。
今回は以上となります。
次回のPart 2では、このユーザーの「好み」そのものも必ずしもいつも同じであるとは限らず、実は「好み」がその場の状況によって動的に作られることがあり、それは簡単に外部によって操作されることもあるという話を紹介します。
データサイエンス・ブートキャンプ・トレーニング

データサイエンス、統計の手法、データ分析を1から体系的に学ぶことで、ビジネスの現場で使える実践的なスキルを身につけたいという方は、ぜひこの機会に参加をご検討ください!
ビジネスのデータ分析だけでなく、日常生活やキャリア構築にも役立つデータリテラシー、そして「よりよい意思決定」をしていくために必要になるデータをもとにした科学的思考もいっしょに身につけていただけるトレーニングとなっています。