Rename Multiple Columns at Once
Changing the column names is a common and an important task for any data wrangling works.
You want to make the column names easy to read and clean. You want to make sure the column names are clean without special characters (e.g. bracket, double quotes, etc.) and with consistent case rules (upper case, lower case, snake case, etc.) to improve the readability.
In Exploratory, you can use rename command to change the column names. That is easy and simple.
But when your data has dozens or hundreds of columns, changing the column names one by one is a bit of hustle.
The good news is there are a set of commands to make your life easier when it comes to renaming the column names.
In this post, I’m going to demonstrate the following topics in this area.
- Rename Basic
- Rename Multiple Columns Together
- Clean up Column Names
- Make the Case (UPPER / lower) Consistent Among All Columns
Rename Basic
Let’s take a look at the very basic. Renaming a column one by one.
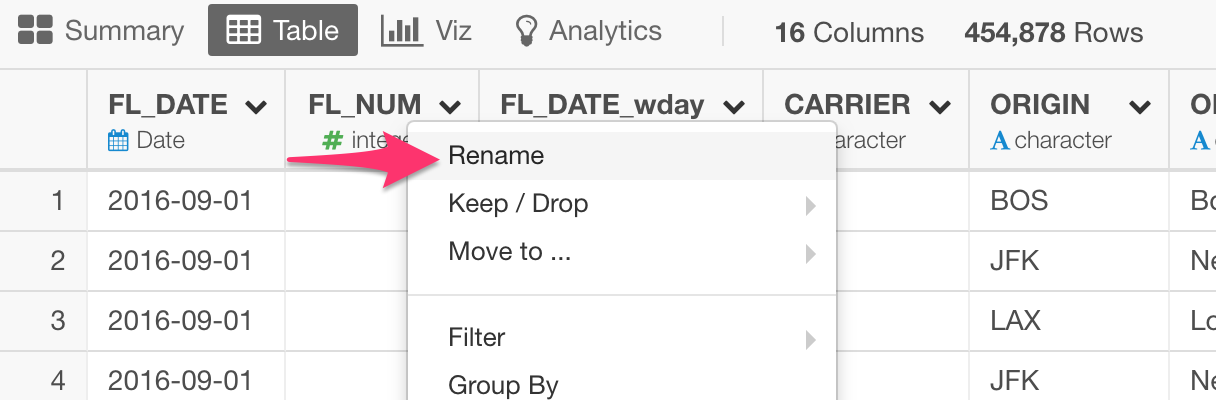
Select ‘Rename’ from the column header menu of the column you want to change the name.
Then type the name you want to change to.
Now, let’s imagine you have dozens or hundreds of columns. Changing the column name one by one is daunting.
This is where rename_at, rename_if, and rename_all commands come in handy.
rename_at: Renaming Multiple Columns with Column Selection Methods
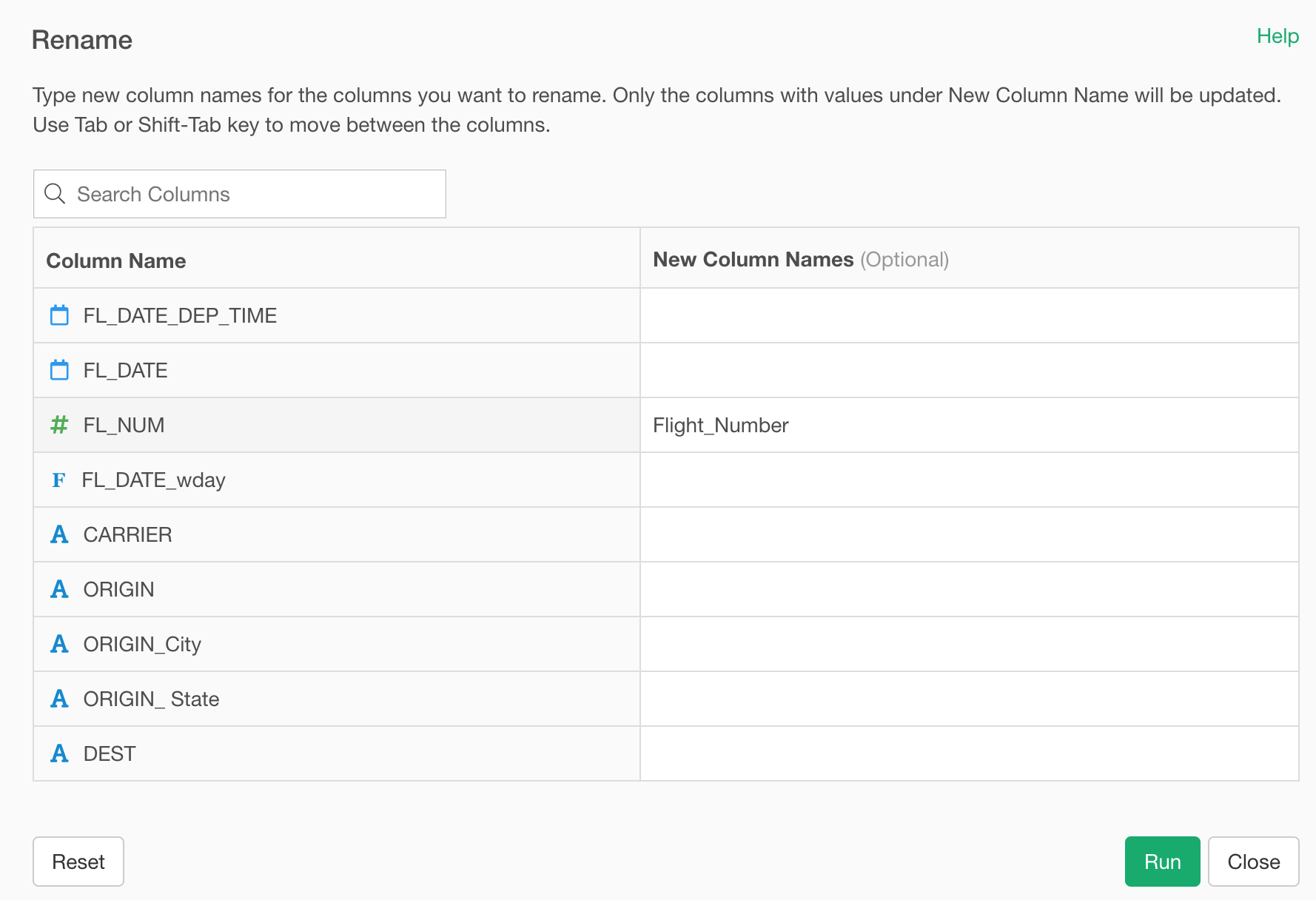
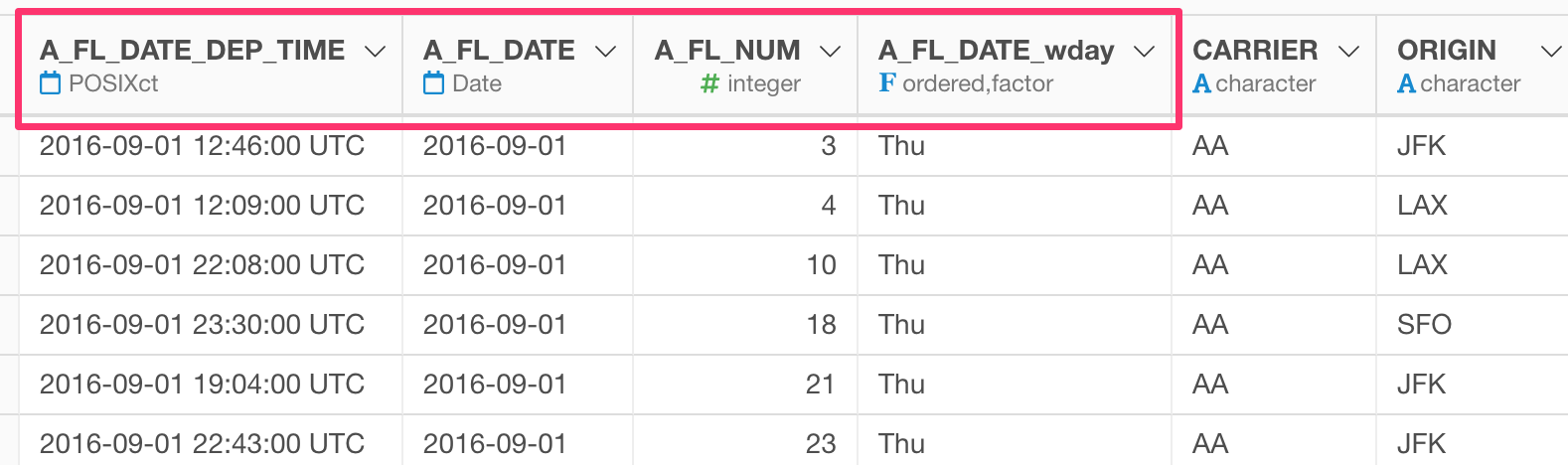
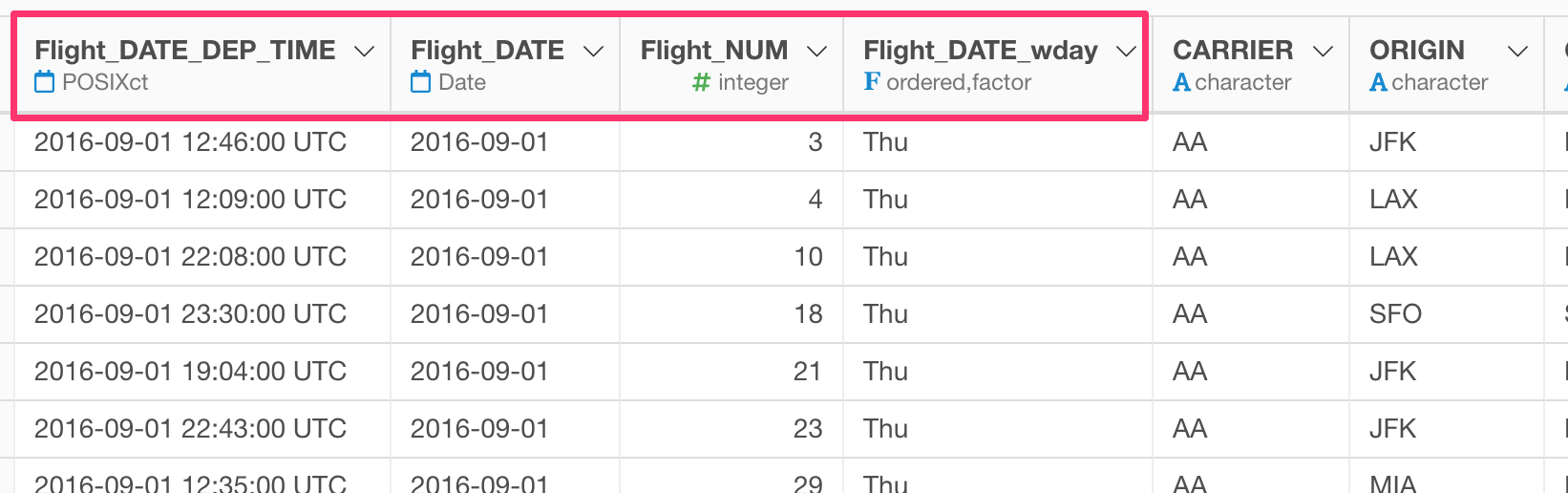
Here, we want to change the following 4 column names by replacing “FL” with “Flight”.
We can use the rename_at command from dplyr package, which allows you to select columns using the column selection methods and to use text wrangling functions.
Click the Plus button at the top of the data wrangling step pane and select ‘Custom Command’ menu.
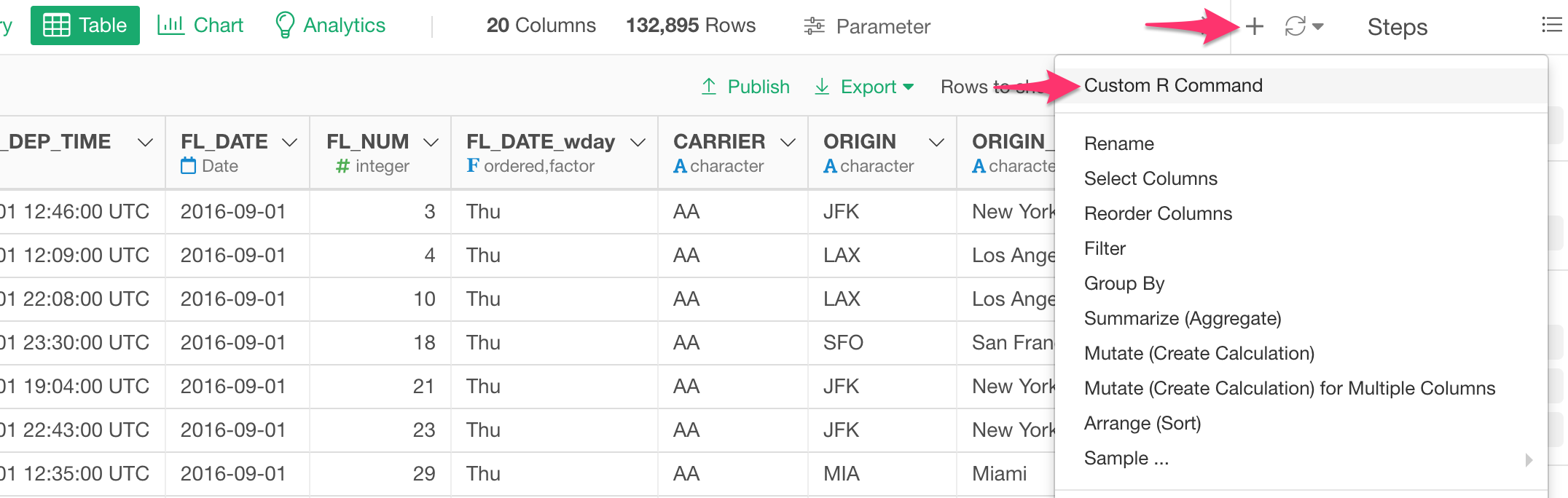
And you can type the rename_at command like the below.
rename_at(vars(starts_with("FL")), funs(str_replace(., "FL", "Flight")))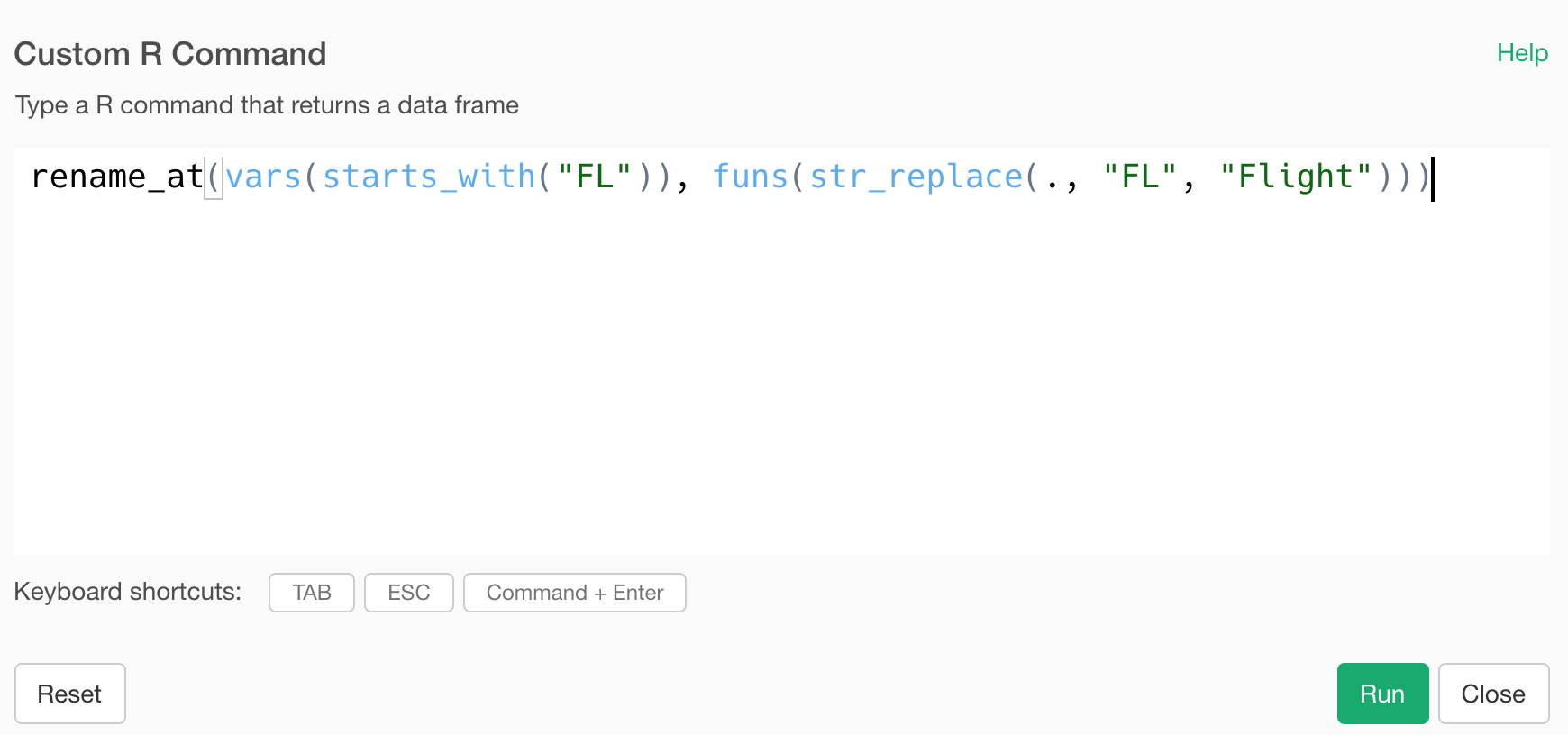
It is selecting the columns whose names starting with “FL” inside the vars function and using the str_replace function from stringr package to replace “FL” with “Flight” inside the funs function.
The dot as the first argument inside the str_replace function is the placeholder for all the columns that are returned by the vars function.
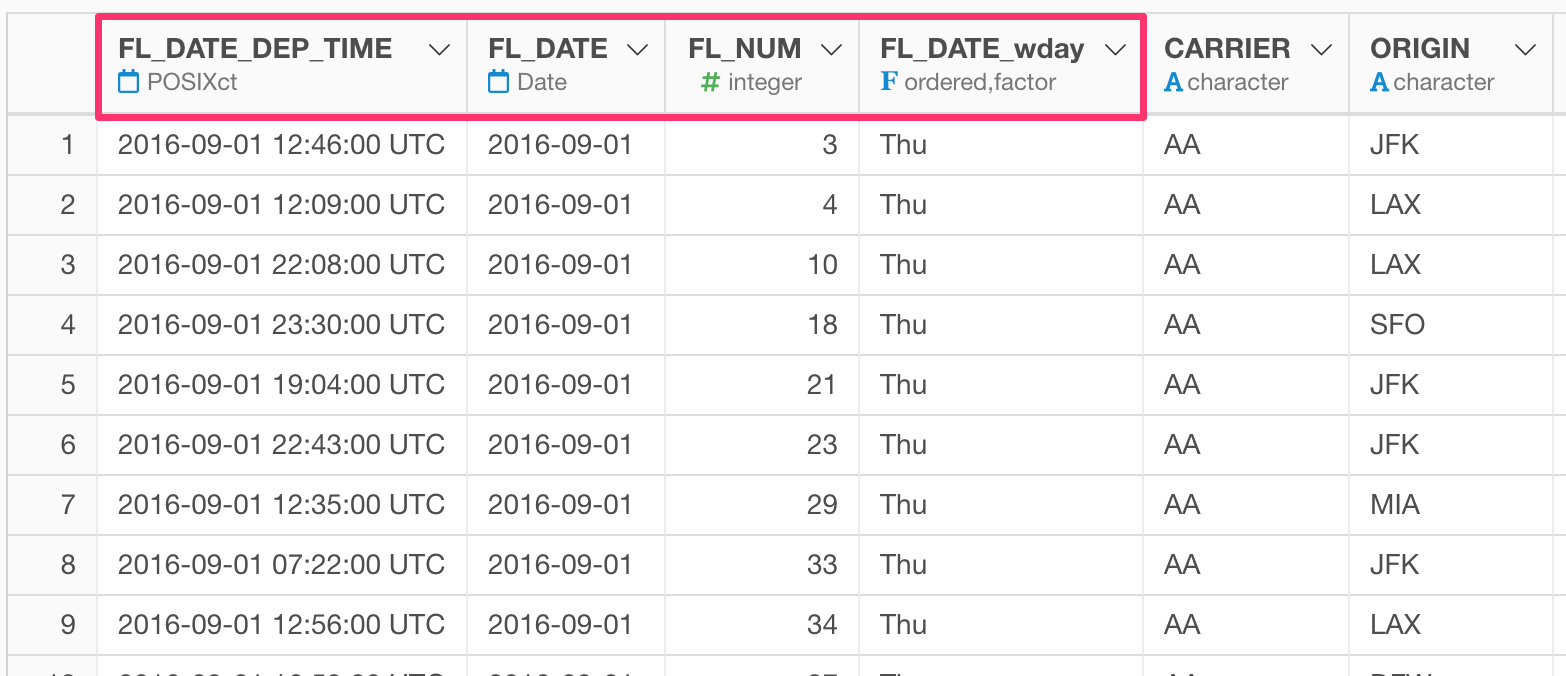
You will get the following result by running the command.
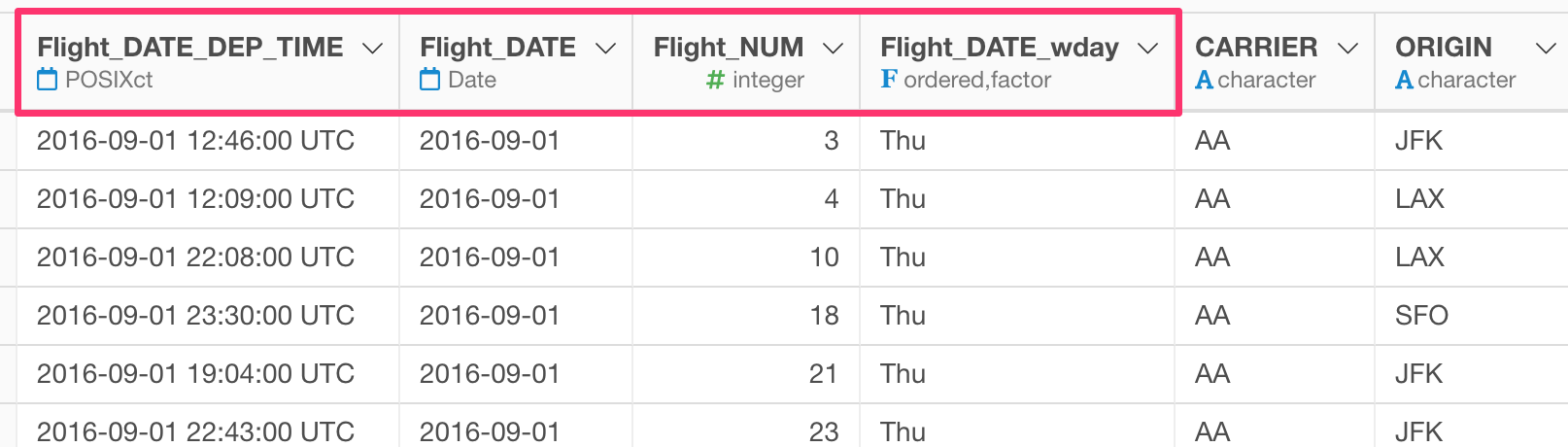
Here is an example of making the column selection rule a bit tighter. It’s restricting it to select columns whose names starting with “FL_DATE”.
rename_at(vars(starts_with("FL_DATE")), funs(str_replace(., "FL", "Flight")))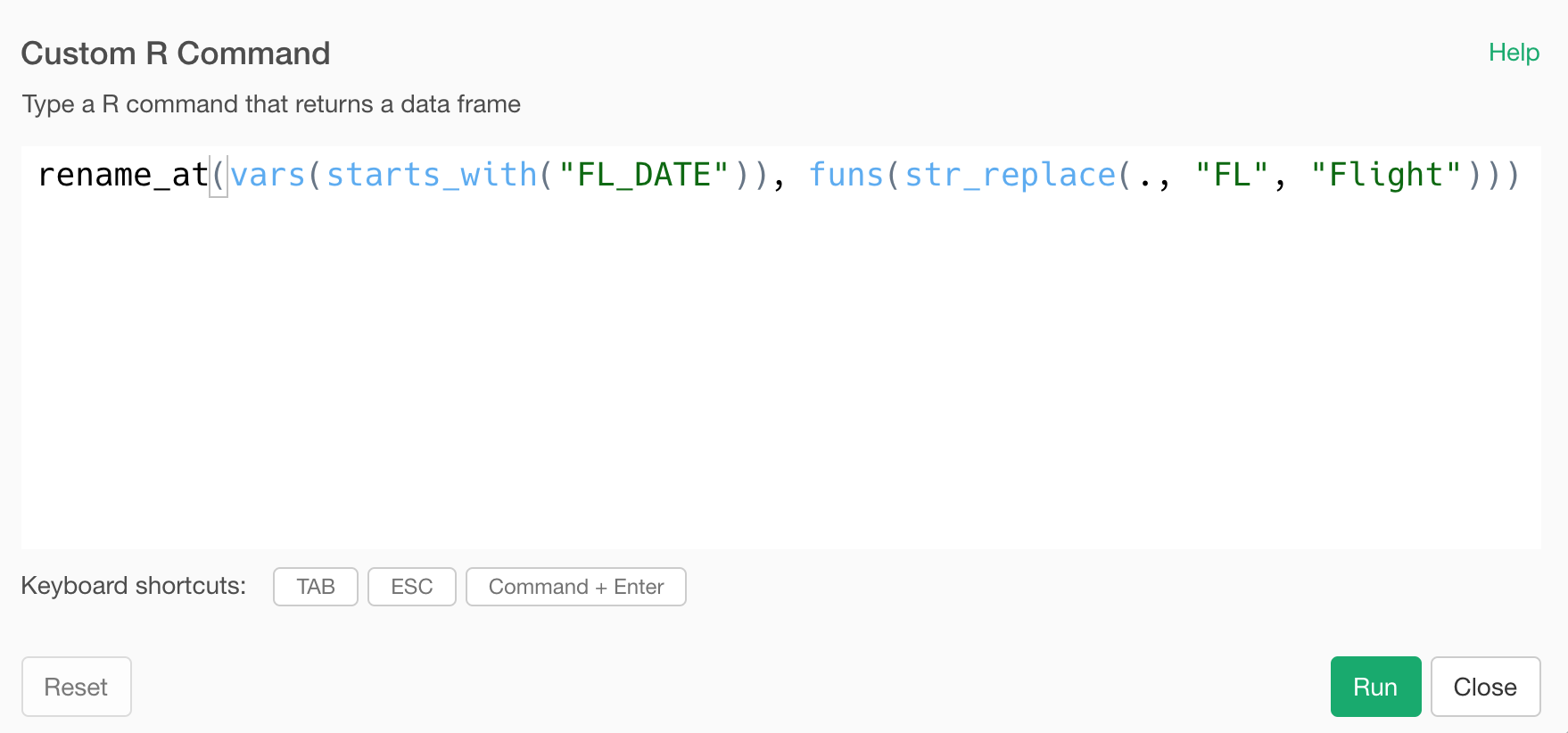
Remove a text from the column names
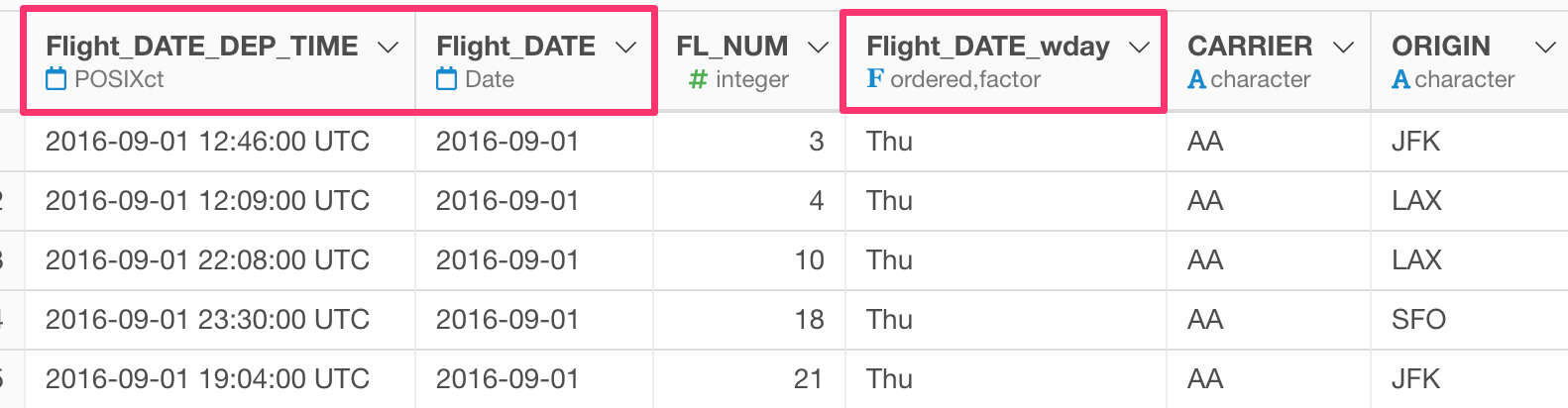
What if you just want to remove “FL_” from the column names?
You can use str_remove function inside the funs function like the below.
rename_at(vars(starts_with("FL")), funs(str_remove(., "FL_")))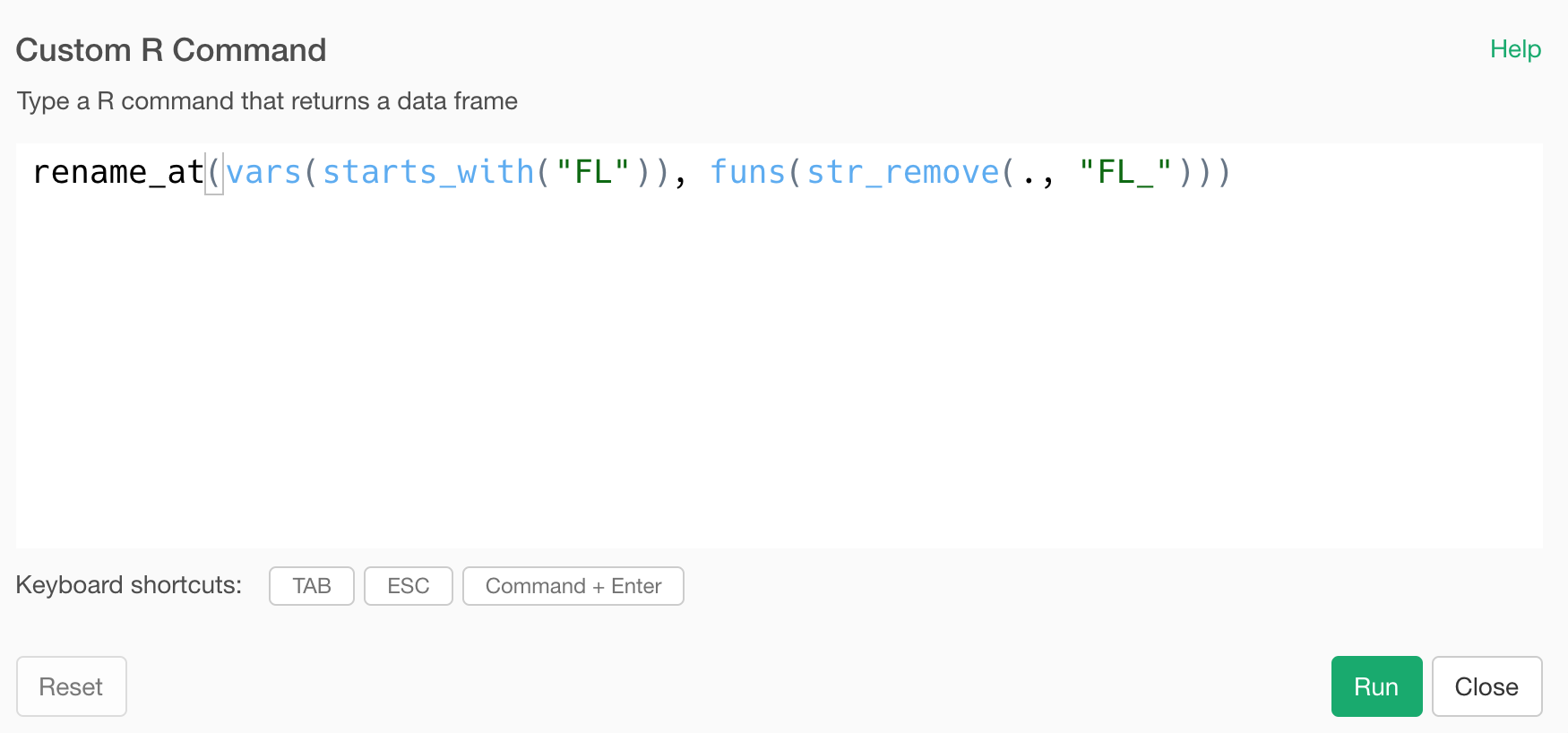
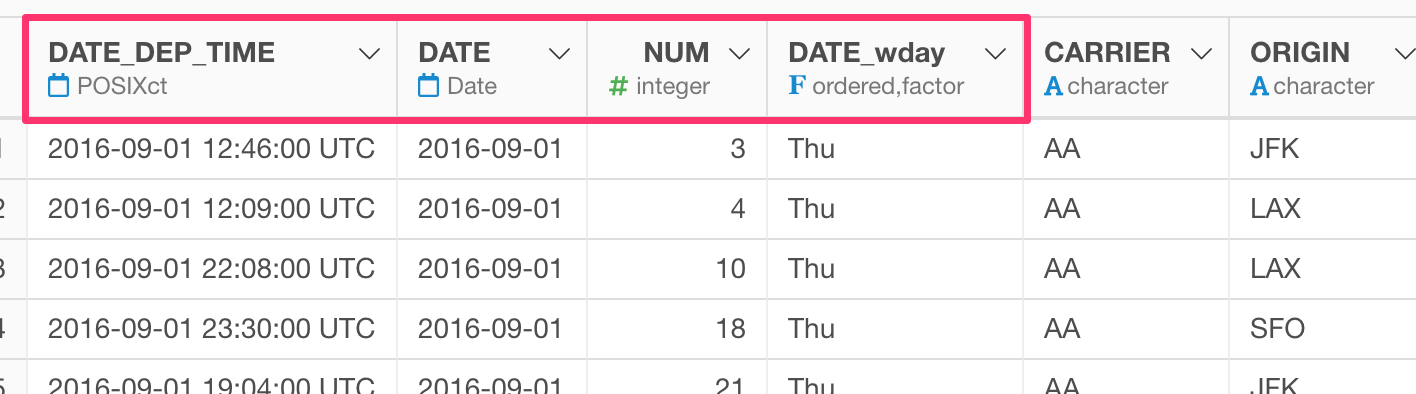
Add a text at the beginning of column names
If you want to add a text at the top of the column names, you will need to use a bit of the regular expression.
rename_at(vars(starts_with("FL")), funs(str_replace(., "^", "A_")))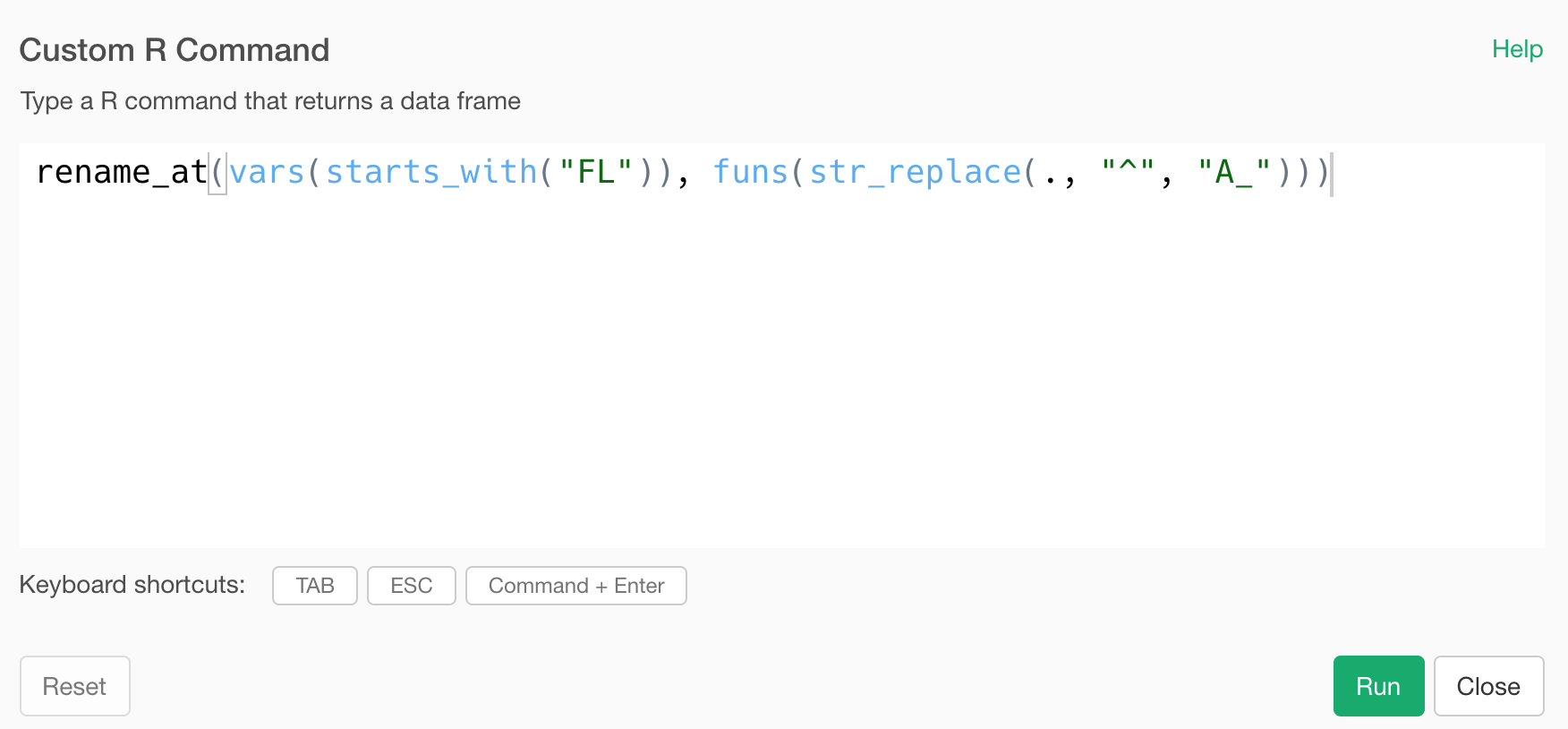
The ‘^’ symbol means the beginning of the text. So the ‘str_replace’ function is going to ‘replace’ the beginning of the text with “A_”, which is same thing as adding “A_” at the beginning of the text.
rename_if: Rename Multiple Columns based on Data Type
You can select the columns based on their data types and rename them with rename_if command from dplyr package.
Here is an example of selecting the columns whose data types are numeric including integer and double and applying str_replace function to change the name.
rename_if(is.numeric, funs(str_replace(., "FL", "Flight")))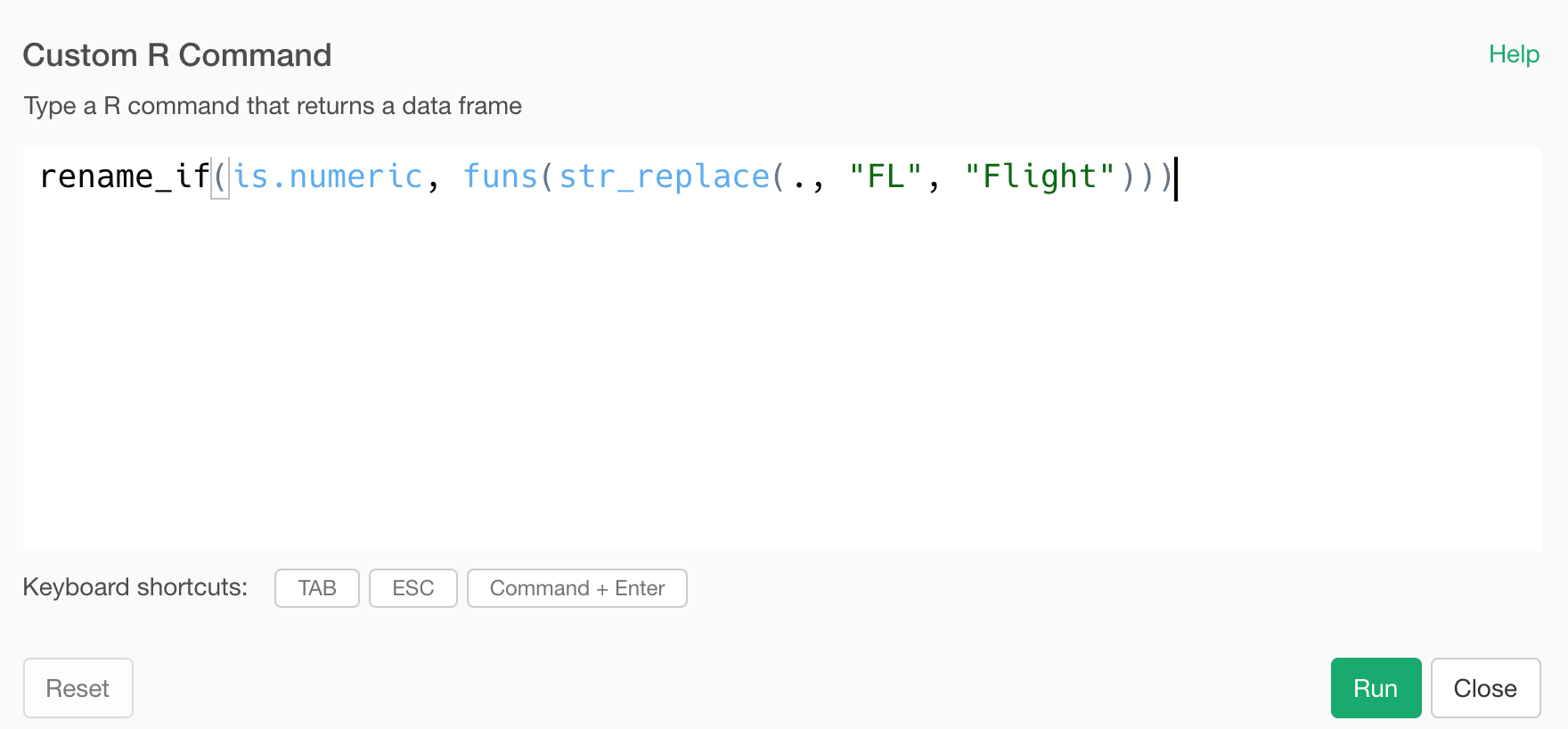
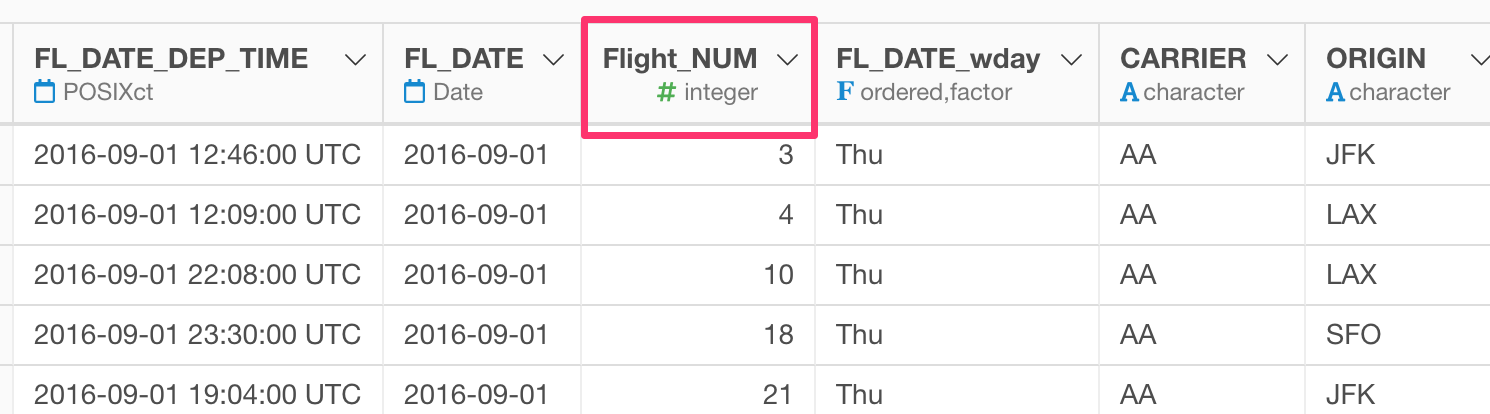
In this data, there are several columns whose data types are numeric, so they are the candidates for applying the str_replace function. But only the ‘FL_NUM’ column has the matching text of “FL” as part of the column name so we end up seeing only this column name being changed here.
rename_all
If you would rather just change all the column names as long as they include “FL” as part of the column names, then you can simply use rename_all function from dplyr package.
rename_all(funs(str_replace(., "FL", "Flight")))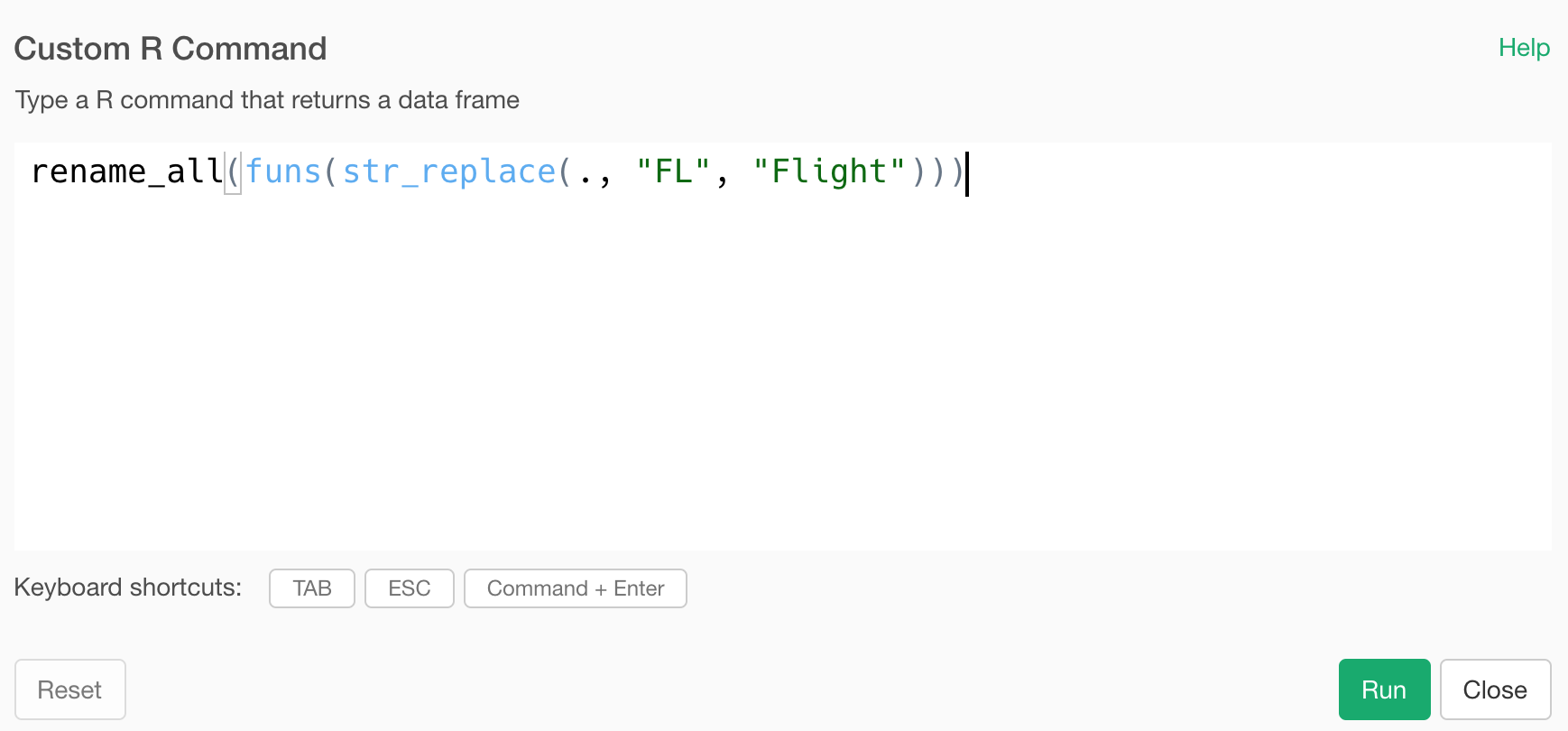
Clean Up All Column Names
Most often than not, the column names of the data are not clean. This happens especially when you import Excel data or scrape the data from websites.
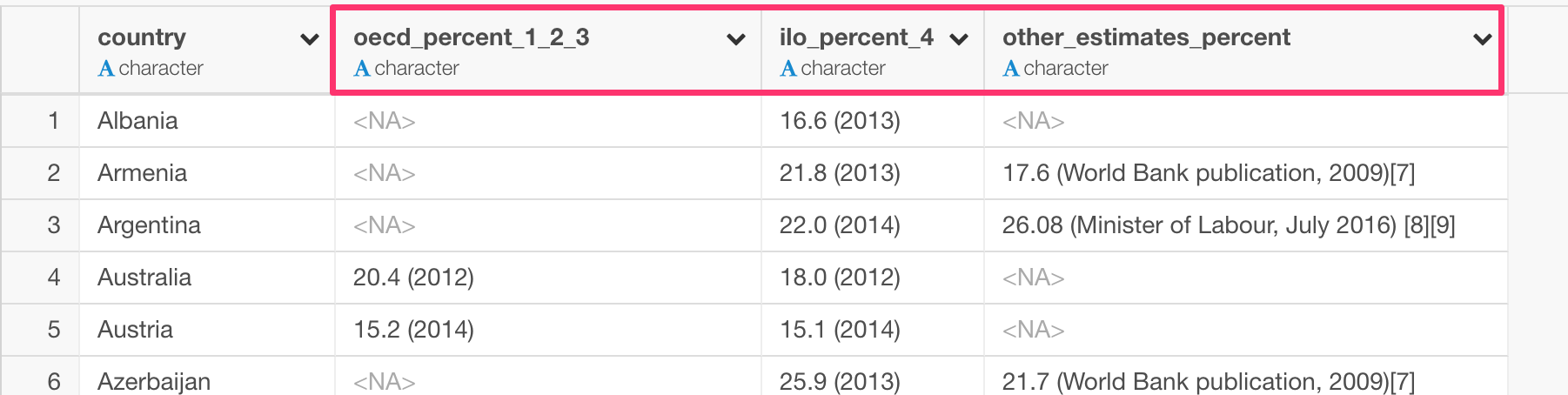
Here is a wiki page that contains a table data about the public sector employment for the countries who are the members of either OECD (Organization for Economic Co-operation and Development) or ILO (International Labour Organization).
You can import it by copy and paste the URL in Exploratory.
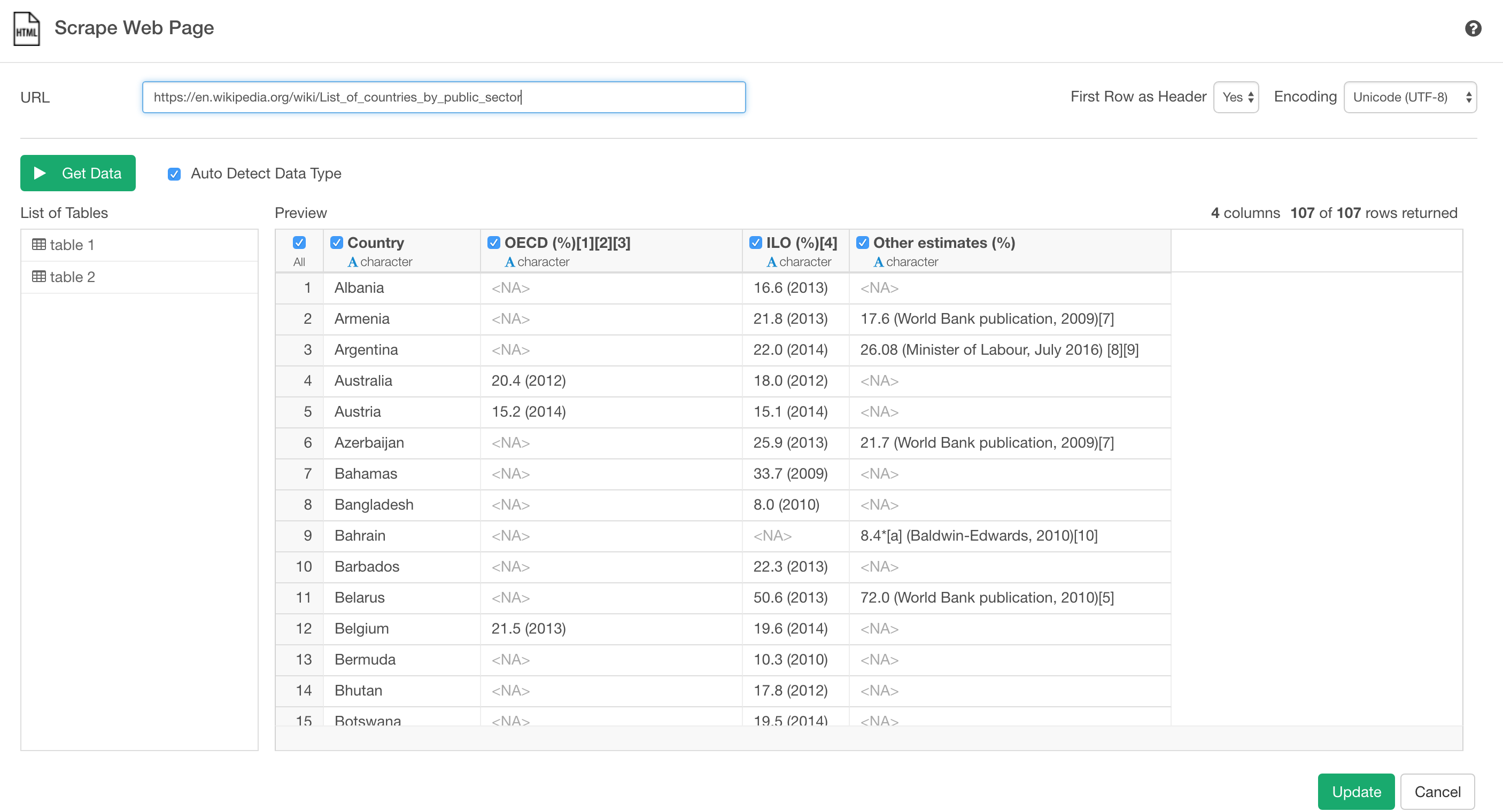
Now, here is the problem.
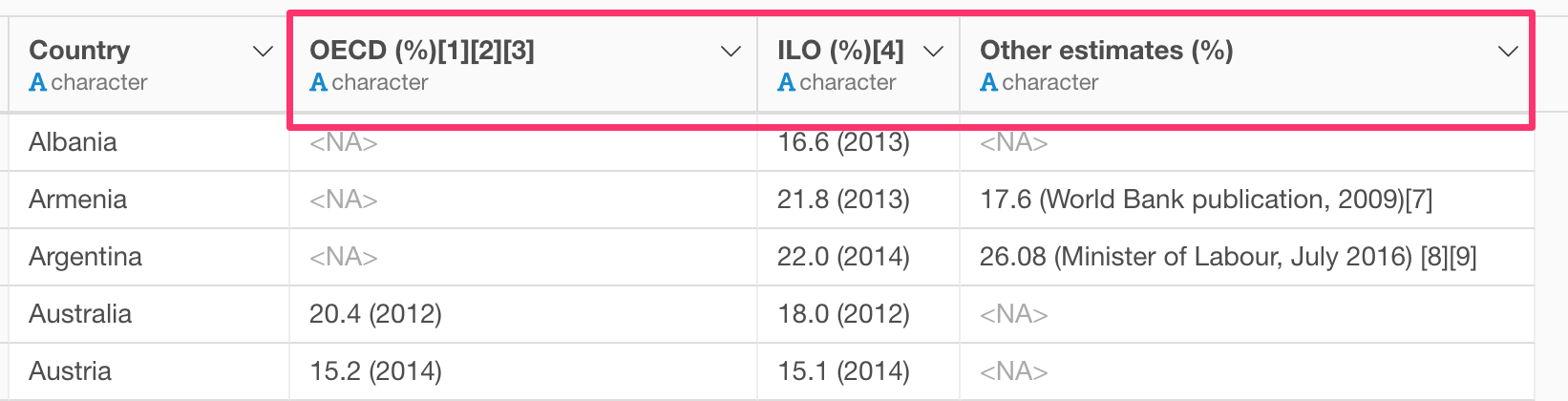
Some of the column names contain the annotation numbers and the unit information (%). This informations of course is useful for interpreting the data at the beginning, but not so much once you start working with data.
Luckily, there is a command called Clean Up All Column Names, which you can find under the Plus button -> “Others…”
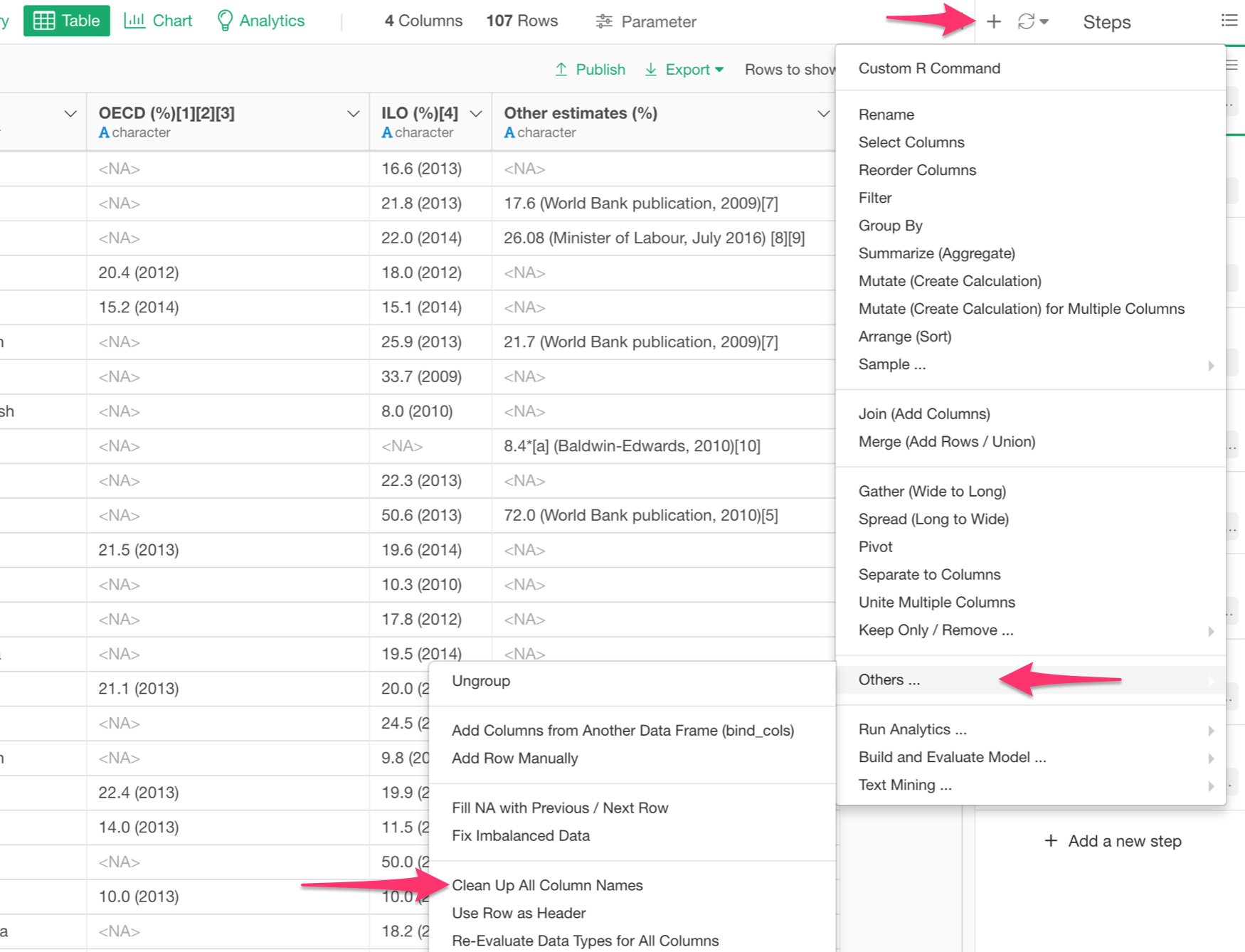
There are a couple variations to clean up the column names.
Convert Special Characters to Standard Characters
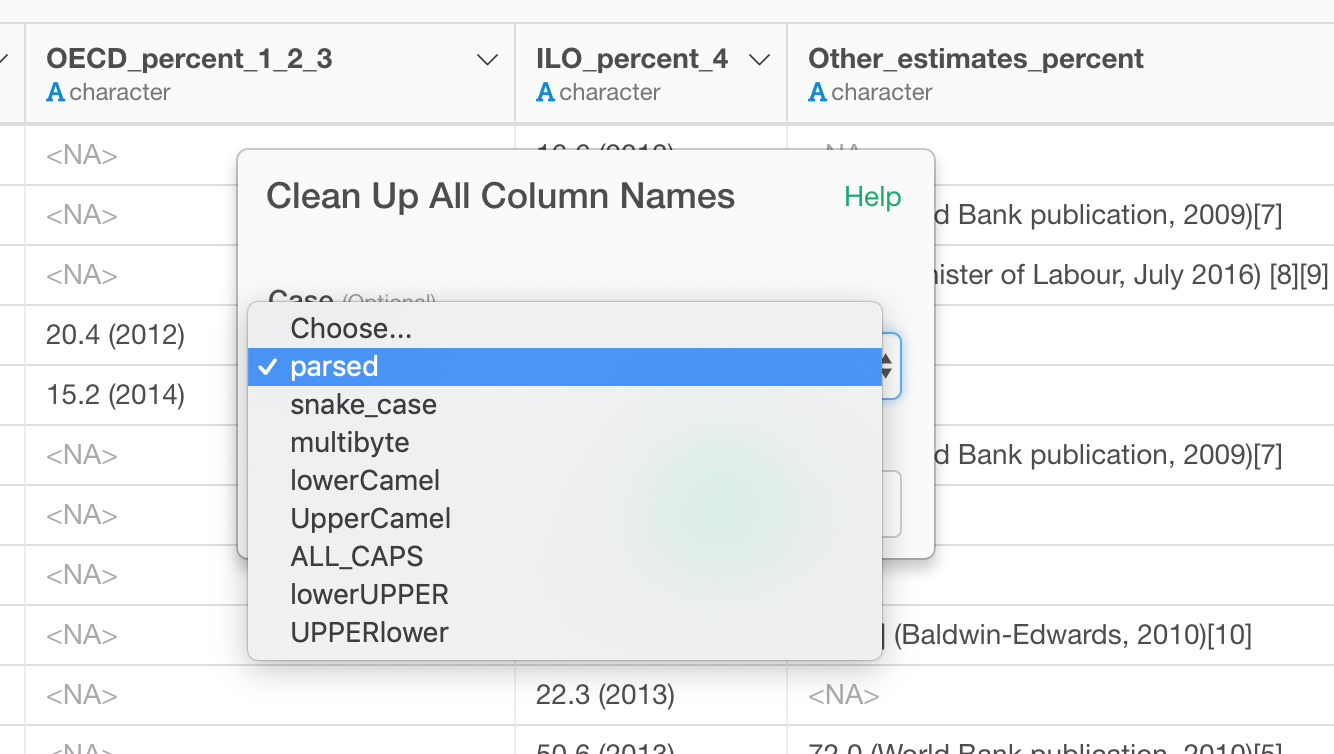
I personally like ‘parsed’ option. This simply gets rid of the special characters like square brackets, spaces, etc. and converts symbols like ‘%’ to a spell out letters as ‘percent’ while it respects the original case rule.

Make Cases Consistent Among All Columns
But sometimes, you might want to make the cases consistent among all the columns. Then, you can try one of the case fixing methods.
Here, I’m selecting ‘all_lower’ to make all the letters to be in lower cases.