
“To improve is to change, so to be perfect is to have changed often.”
改善するというのは変えること。完全を求めるのであれば変えることだ、それも頻繁に。
by ウィンストン・チャーチル(第2時世界大戦時のイギリスの首相)
こんにちは、Exploratoryの西田です!
先週はフィリピンや香港など中国南部を直撃の台風22号、またこちらアメリカでは本土直撃のハリケーン・フローレンスと、またもや台風・ハリケーンでたいへんな週となってしまいました。ここ最近はやってくるたびに化物のような感じになってきているような気がします。
先週、日本にやってきた今年の台風の経路を可視化したものをこちらのノートにまとめたのですが、今回の台風22号も加えました。
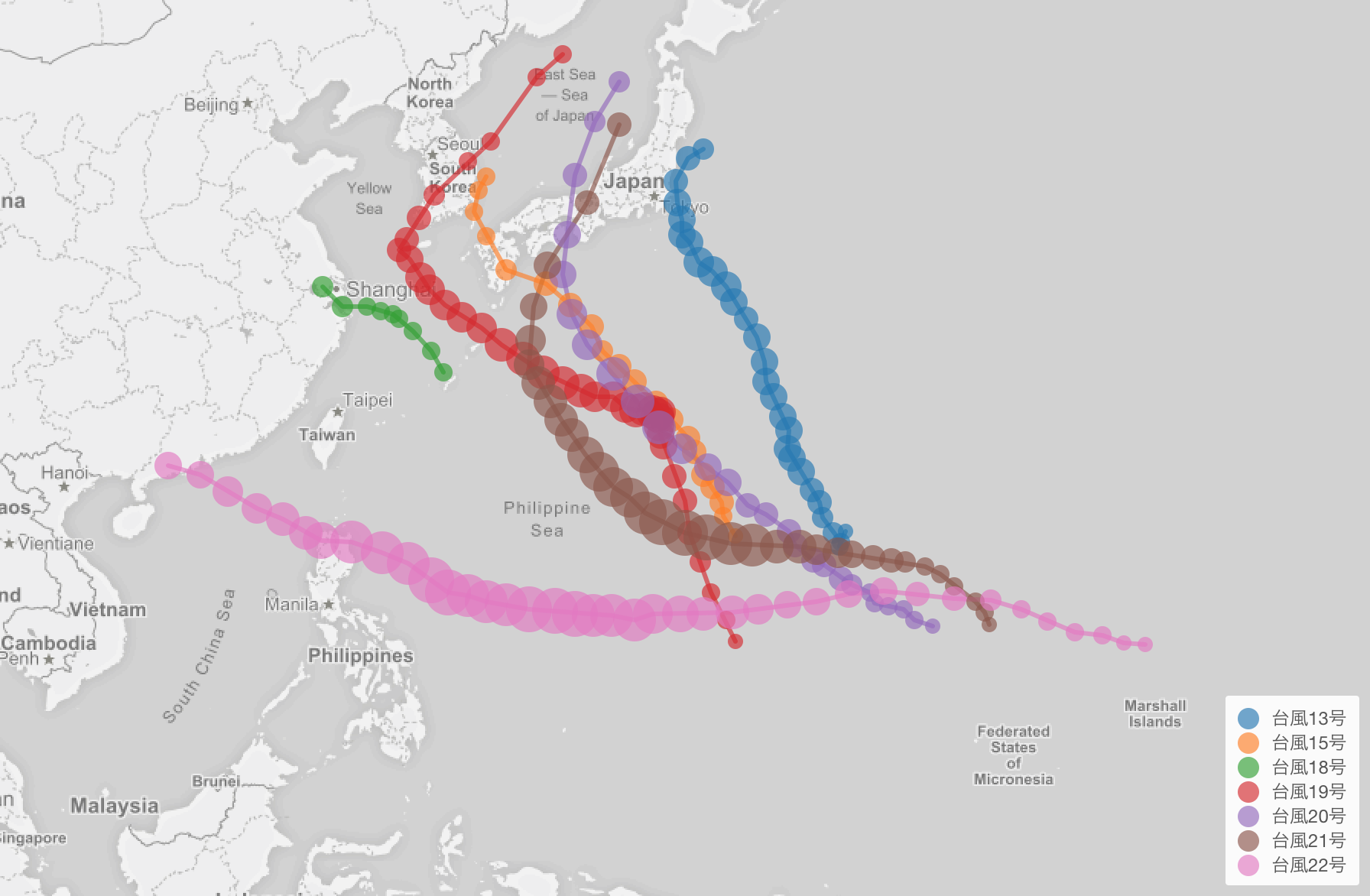
ピンクが今回の台風22号です。フィリピンに上陸したときは風力が時速265kmと、とんでもない規模です。
ちなみに、アメリカを直撃したハリケーンに関してまとめたノートはこちらにあります。
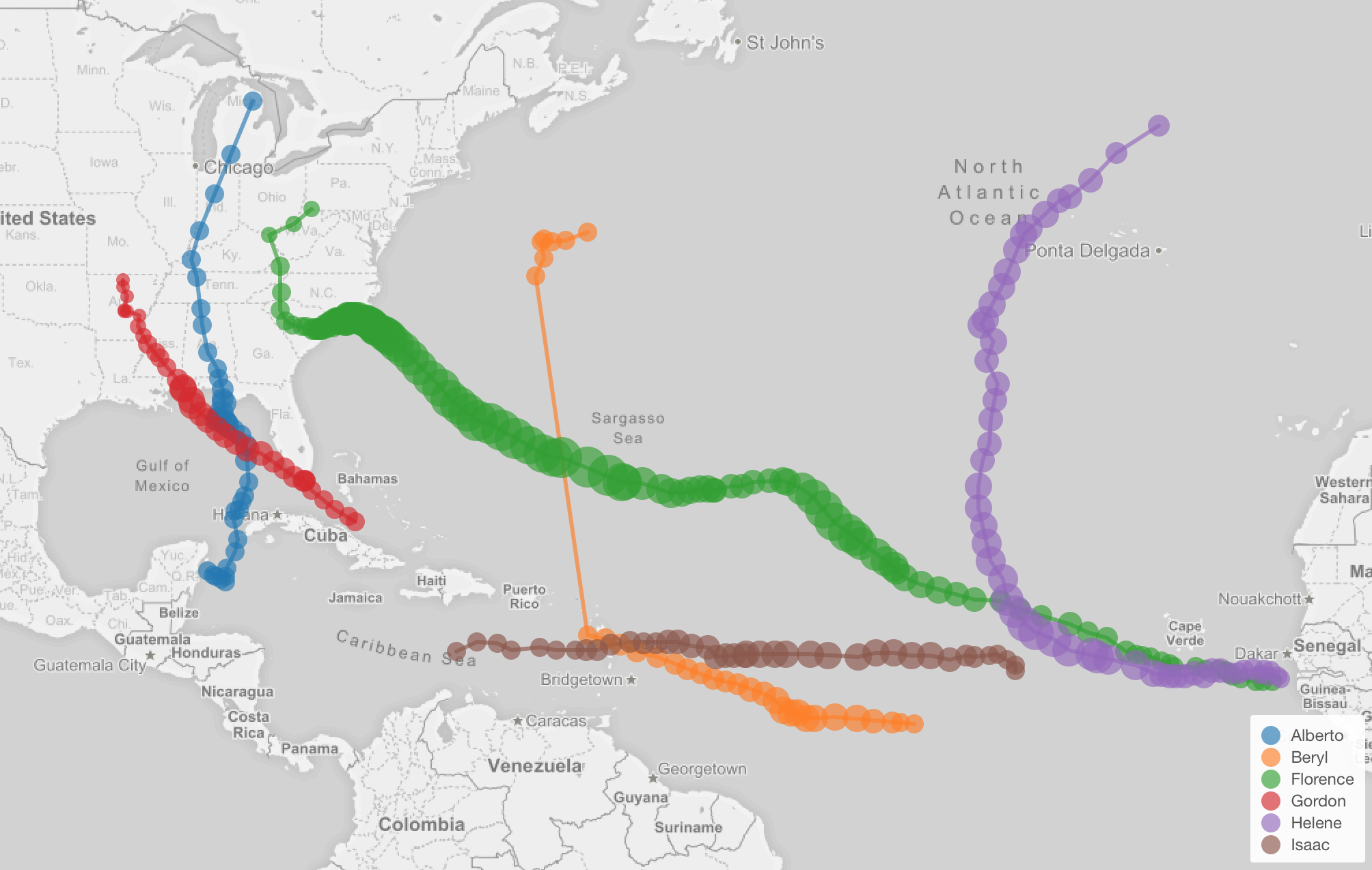
緑が今回のフローレンスです。
今年はもうこれで勘弁してくれと言った感じです。
ところで次回の10月のトレーニングの方は受付を終了しましたが、その次の1月のトレーニングの方の受付を開始しています。早割の方は今月いっぱいですので、データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、お早めにお申込み下さい!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
意思決定は全ての高校での必修科目であるべきだ
Decision-Making Should Be a Required Course in Every High School - リンク
データサイエンスの業界にいると意思決定についてよく話します。そもそもデータを分析するのはよりよい意思決定を行いたいからです。
実は、この意思決定というのは人間の生まれ持つ才能ではなく、学び、改善していくことのできるスキルだということは広く知られていることです。
しかし、それにもかかわらず、いまだにこの意思決定のスキルを学校で体系的に教えないというのは不思議です。この20年の間に、Googleなどのサービスを使ってどのような情報でも簡単に探してくることができるようになりました。そのような時代には物事を記憶することよりも、そうして集められた情報をもとにどう意思決定を行っていくのかこそが成功していくためには重要です。
現在のように、AIによって一部の意思決定が置き換わっていく時代には、私達が人間にしかできないと思い込んでいるこの意思決定のプロセスをもっと科学的にアプローチして解明し、そのスキルを習得していくことで、AIに置き換えられるのではなく、AIを使いこなすことができる人間になることをもっと真剣に考えるべきだと思います。
最近、こちらで、「Farsighted: How We Make the Decisions That Matter the Most」という意志決定に関する本が出版されましたが、その著者による本の紹介的なエッセイが先週出ていたので、その一部をこちらに紹介します。
以下、一部抜粋。
私達は子どもたちに、彼らが人生を通して役に立つスキルを教える代わりに、多くの事実を覚えさせることに時間をかけすぎています。
私が思い出す限り、全ての学校時代を含め、どうやって複雑な意思決定を行えばいいかを教えてくれるクラスは一つもありませんでした。必要な情報をもとにした、独創的な意思決定を行うことができるスキルというのは私達の生活のさまざまな場面で必要であるにもかかわらずです。
他に意思決定と同じくらい重要なものがあるとすると、それらはクリエイティビティ、エンパシー(共感する力)、レジリエンス(くじけない力)などでしょう。しかし、「複雑な意思決定」はそうしたリストのトップにあるべきものです。私達が”賢明”という言葉を使うときに意味するのは、「複雑な意思決定」を行うことができるということでもあります。それなのに、なぜ私達は学校で教えないのでしょうか。
あなたが自分の人生で何を行うにしろ、どんなキャリアを気付いていくにしろ、人生にとって重要な意思決定を行うスキルは、あなたが大人になってからの人生において、全ての場面で大きく貢献することになるのです。
意思決定には才能が必要なわけではありません。そのかわりに必要なのはテクニックです。それは、問題に立ち向かい、一つ一つのユニークな問題を探索し、さまざまなオプションを考慮していくためのいくつかの具体的なステップなのです。
私達は、判断をする前に、慎重に、さまざまなオプションを考慮し、異なる考え方にも耳を貸すためにもっと時間を費やすべきです。
抜粋、以上。
世界の経済にAIが与えるインパクトをモデリングする
Modeling the impact of AI on the world economy - リンク
最近マッキンゼーが、AIが国、企業、個人に与えるインパクトを測るためのシミュレーションモデルを作り、それをもとにした考察をまとめたレポートを出していたので、その一部をこちらで紹介したいと思います。
以下、一部抜粋。
AIの経済的インパクト
AIの経済的なインパクトは時間とともに少しづつ段階的に現れてくるでしょう。それはリニア(直線的)ではなく、時間とともに加速的になっていきます。それはS字カーブのようになります。つまり、AIの採用による成長は、初期にこうしたテクノロジーの学習と採用のためにかかる大きなコストと投資関連のコストのため、ゆっくりとスタートし、その後、市場での競争力と補足的な能力の改善によって得られる累積される効果によってどんどんと加速していくのです。
ですので、AIを採用して間もない頃に見られるゆったりとしたAIのインパクトをみて、AIの効用は限られていると解釈してしまうのは間違いです。
AIのイノベーションの恩恵を最大化するにはマネージメントのサポートとプロセス・イノベーションが必要となるでしょう。
AI投資
AIの経済的なインパクトは新しいAI関連のスタートアップや研究に対する投資と、既存企業のAIへの投資が十分かどうかで決まります。AI関連の投資はすごい勢いで伸びていますが、そのほとんどはアメリカと中国です。テックのジャイアント企業であるGoogleやBaiduは20ビリオンドルから30ビリオンドル(およそ2.2兆円から3.3兆円)を2016年だけで費やしています。CBInsightsによると2017年には15.2ビリオンドル(およそ1.7兆円)が世界中のAIスタートアップに投資され、そのほぼ半分が(48%)中国、38%がアメリカに投資されました。アメリカは中国よりもまだ多くのAIスタートアップがありますが、中国がAI分野ではこうした投資案件に関して果敢に攻め込んでいます。
AIによる格差は、国、企業、そして個人の間でどんどんと開いていきます。
国
AIテクノロジーの採用においてフロントランナーに属する国は次の5年から7年の間に不釣合いなほど多くの利益を得ることになるでしょう。2030年までには彼らのキャッシュフローは2倍になり(経済的な利益からそれに関連する投資と移行費用を差し引いたもの)、それは一年あたりのキャッシュフローの成長が6%の割合でその後10年に渡って伸びていくことになります。
現在入手可能なデータをもとにどれだけAIの採用の準備ができているかのスコアをもとに似通っているグループ分けを行った結果、以下の4つのグループに分けられる事がわかりました。
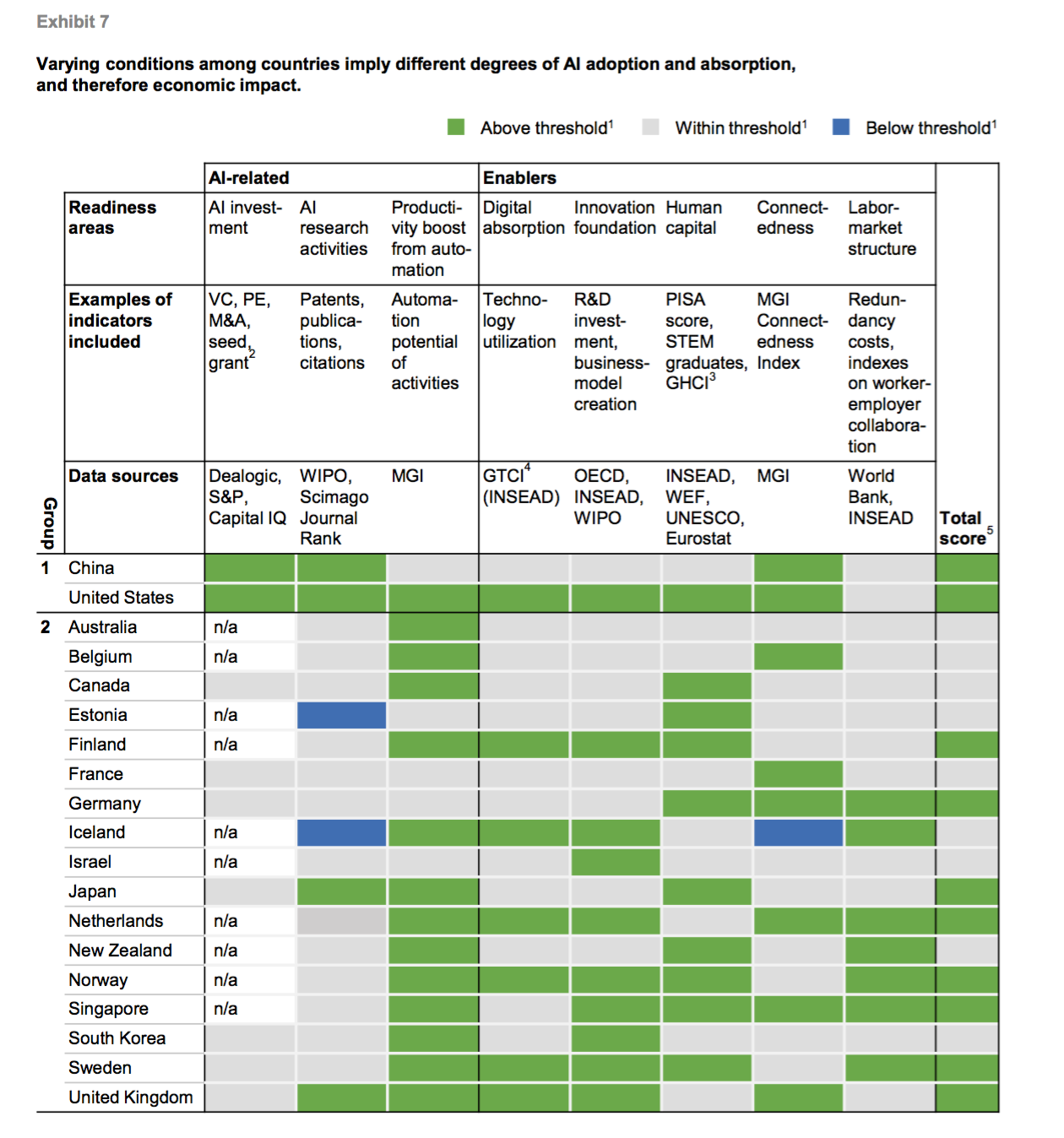
1. 活発なグローバルリーダー
このトップのグループはUSと中国です。
AI関連の特許、論文、文献などにおいて他の国々をダントツに引き離しています。
外部からの投資(ベンチャーキャピタル、プライベート・エクイティ、買収などを含む)という点では、2016年にはアメリカは全体の66%を占め、その次に遠く離れた2位の位置にあるのが中国で、17%を占めています。この2つの国は2016年にはGDPの2から3%ほどをAIの研究開発に投資しています。
2. Economies with strong comparative strengths.
このグループはAIを採用したいという高い動機を持っています。どの国も生産性の伸びのペースが落ちてきているからです。こうした国では労働コストが高いので、それがAIを採用したいという動機でもあります。ドイツ、日本、イギリスの様な大きな経済圏の国は大きな規模でのイノベーションの原動力となりAIソリューションの商業化を活発化させる力を持っています。
Economies with moderate foundations.
インド、イタリア、マレーシアを含むこのグループはAIから利益を受けるためのそれなりの能力を持っていますが、高くはありません。。例えば、インドはデジタル基盤があまり開発されておらず、自動化の可能性のある分野も比較的低いのが現状です。しかしSTEM(Science, Technology, Engineering and Math)の学位をもった人材学生が毎年170万人卒業していきます。これはG7の国々全てをまとめたよりも多い数です。さらにインドの輸出の主なものはICT(Information and Communication Technology)関連です。
Economies that need to strengthen foundations
このグループに属する国々はAIから大きな恩恵を受けるのが比較的難しいでしょう。こうした国では、給料がそもそもすでに低いので自動化の可能性が限られています。労働者を置き換えて生産性を上げるという動機があまりないのです。こうした国ではデジタル基盤と、イノベーションと投資の能力と、さらにデジタルのスキルが比較的あまり開発されていません。そしてグローバルな商取引とデータの流れから切り離されています。
企業
フロントランナー企業は経済的な価値(経済的なアウトプットからAI関連の投資と移行コストを差し引いたもの)を2030年までに122%増加し、次の12年の間に年6%の率でキャッシュを生成し続けます。
逆方向にいるのがロングテールの「ラガード」に属する企業群です。このグループは2030年までにAIテクノロジーを全く採用しないか、採用しきれていない企業群で、世界中で60%から70%を占めることになります。このグループは現在に比べてキャッシュフローが20%ほど減少します。コストと収益モデルが今日と同じであるという前提でですが。
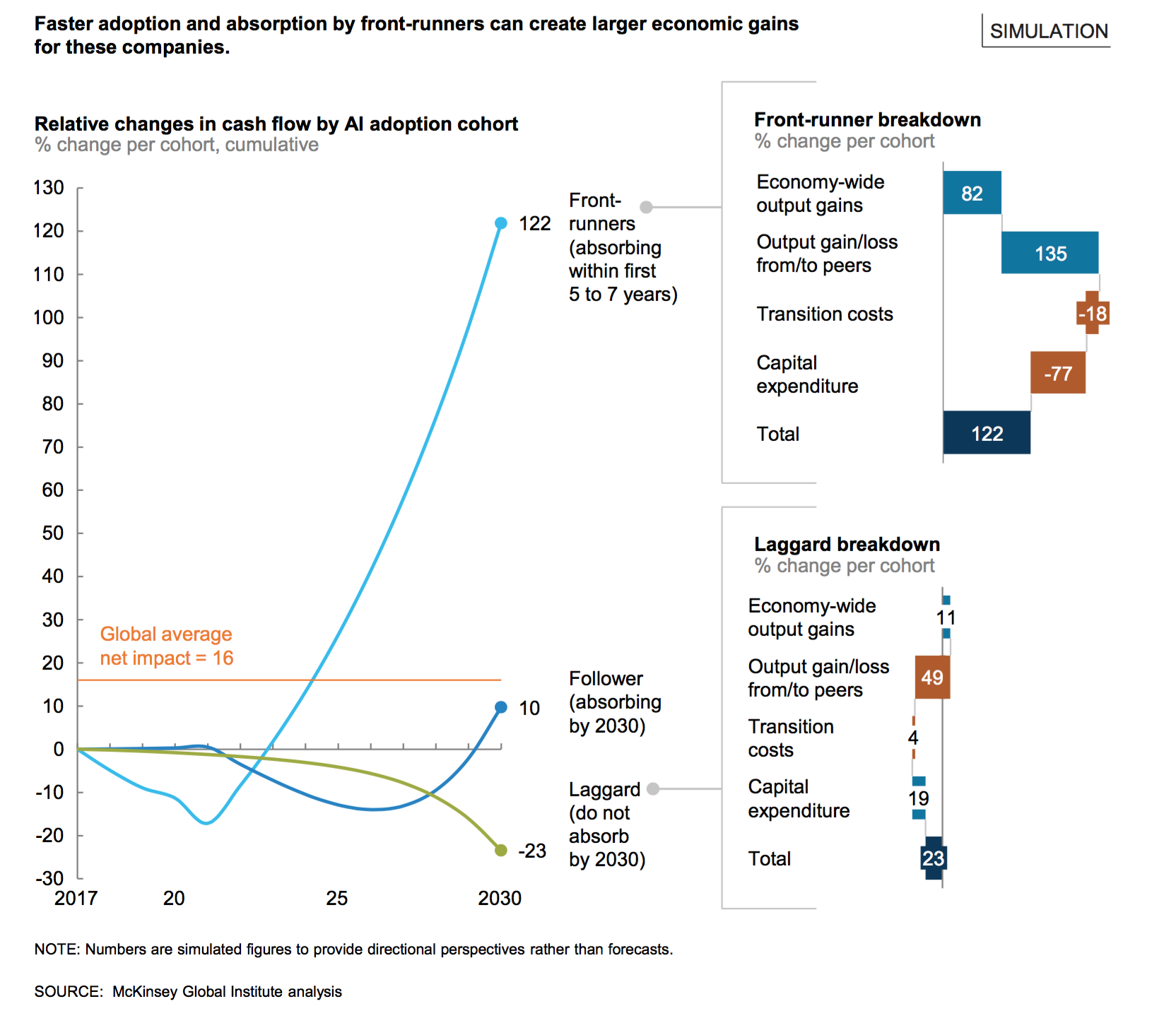
個人
繰り返しがなく、高いデジタルスキルを求められる仕事に関わる労働者の給料は上昇していきます。それは彼らのスキルが供給不足であり、彼らは企業の生産性を上昇するのに貢献できるからです。このタイプの仕事は現在の42%から53%まで上昇します。
逆に繰り返しが多く、デジタルスキルが要求されない仕事のタイプは給料が上がらない、もしくは給料カットが見込まれるでしょう。このタイプの仕事は今日、全体の43%を占めますが、2030年までには32%まで落ちます。
社会的、感情的なスキルはAIアプリケーションによって簡単には置き換えることができないので、高いデジタルスキルが要求されなくとも、繰り返しの少ないタスクを含むヘルスケアなどの仕事は、今後緩やかに増加していくことでしょう。
この職と給料において拡大する格差は、企業を人材獲得のための熾烈な戦いへと導くでしょう。特にAIツールを使いこなすことができるスキルを持った人材は貴重です。
政治家・官僚、企業、教育機関、そして個人にはこうした大きな変化に対応するために大変な努力が要求されます。再トレーニング、仕事探し、mobility(職業の流動性)プログラムが必要になります。
以上、抜粋終わり。
因果関係と機械学習
The Seven Tools of Causal Inference with Reflections on Machine Learning - リンク
以前、こちらのWeekly Updateでも紹介しましたが、因果関係、ベイジアンネットワークの第一人者であるJudea Pearlによる現在の機械学習の限界を因果関係という面から議論する論文が最近(7月)出ていたので、こちらでそのさわりの部分のみを簡単に紹介します。特に、彼の提唱するインテリジェンスの3つのレーヤー(階層)を認識しておくことは、現在のAIに何ができて何ができないのかを理解する上で役に立つと思います。
以下、一部抜粋。
機械学習の限界
機械学習には3つの限界があります。
まず最初に適用力(adaptability)と強靭さ(robustness)です。現在の機械学習は学習していない新しい状況に対応できないというのはよく言われていることです。もちろん、転移学習(トランスファー・ラーニング)、ドメイン・アダプテーション、ライフロング・ラーニングといったものでそうした問題を解決するためのセオリーの構築や実験が行われています。
2つ目の限界は、説明能力(explainability)です。機械学習のモデルはいまだに、たいていがブラックボックスです。予測やレコメンデーションの背後にある原因を説明できないのです。これがユーザーの信用を傷つけ、また何かがおかしいときの解明や修復を難しくします。
3つ目の限界が、原因と結果の結びつけに関するものです。この人間のもつ優れた認識能力は、コンピューターがインテリジェンス(知能)を獲得するために必要な要素です。(十分ではないが。)これはコンピューターのシステムがまわりの環境をモデル化し、このモデルをいろいろな角度から調べあげ、さらに想像力を駆使していろいろな形にし、最終的には、「これをやったらどうなる(What if)」といった質問に答えることを言います。
例えば、「もし私がこれをやったらどうなる?」といったものが介入(intervention)の質問で、「もし私が違うことを行ったらどうなっていただろう」、「もし私の飛行機が遅れていなかったらどうなっていただろう」というのが、過去を振り返る(retrospective)、もしくは説明するための(explanatory)質問です。
3つの因果の階層
因果には3つの階層があり、それぞれの階層には答えることができる因果情報というものがあります。それは以下の図にまとめられています。
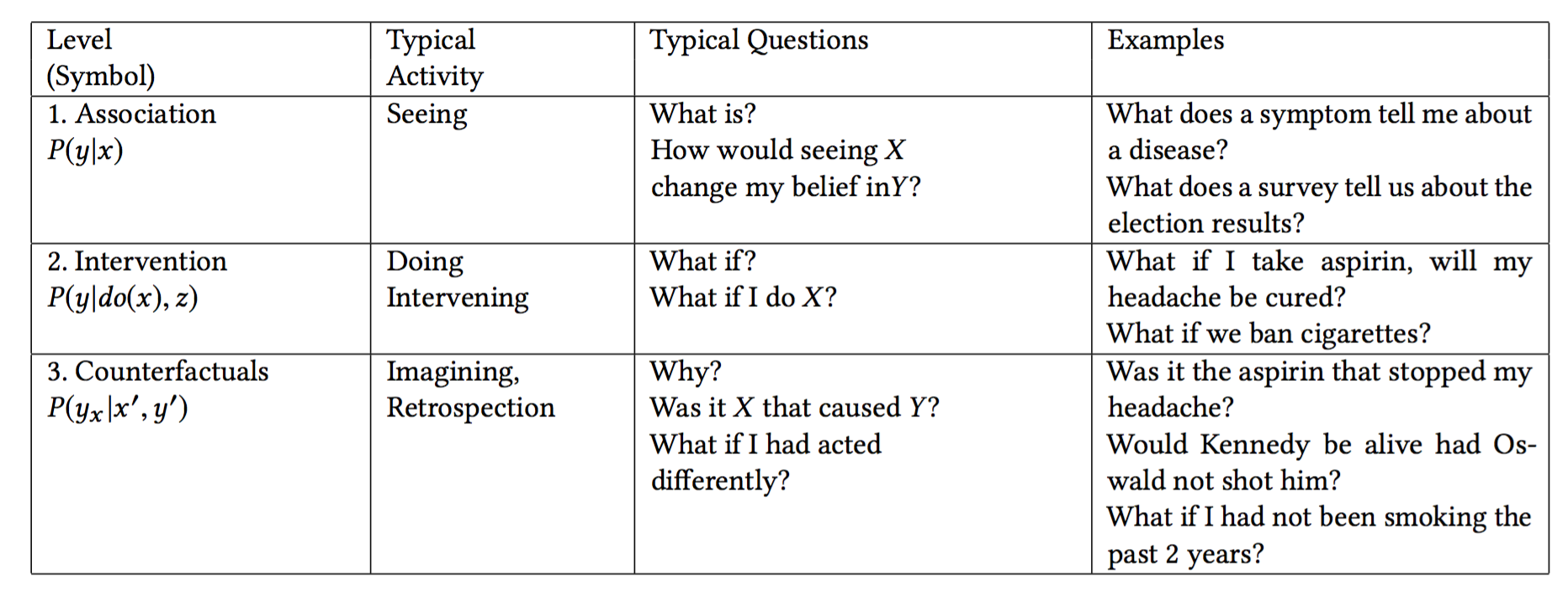
それぞれのレベルは相関(Association)、介入(Intervention)、反事実(Counterfactuals)です。
この中で一番下のレベルにあるのが相関です。なぜならそれは、もとのデータから得られた統計的な関係性のみを問題とするからです。例えば、歯磨き粉を買う顧客は多くの場合デンタルフロスも買っているというものです。そうした相関は、前提となる条件を用いることで、観察されたデータから推測することができます。
2番めのレベルは、介入です。これは相関よりも高いレベルにランク付けされます。なぜなら、単に何であるのかを見るだけではなく、何を見るかを変えることになるからです。 このレベルにおける典型的な質問は、「もし値段を2倍にしたらどうなるのか。」というものです。こうした質問は、売上データからだけでは答えることができません。なぜなら、顧客の行動の変化、つまり新しい値段に対する反応を巻き込むことになるからです。
最後が、トップレベルである、Counterfactuals (反事実)です。この言葉の出現は、もともと哲学者であるデービッド・ヒュームやジョン・スチュワート・ミルの時代までさかのぼることができるのですが、過去20年にわたってコンピューターにとって扱いやすい意味(semantics)を与えてくれました。このカテゴリーの典型的な質問は、「もし実際にやったこととは別のことを行っていたらどうなっていただろう」という、過去を振り返った理由付けです。
Counterfactuals (反事実)はこの階層のトップに位置づけられています。なぜなら、介入と相関の質問を包含するからです。もしCounterfactuals (反事実)の質問に答えることのできるモデルがあれば、私達は介入と相関の質問に答えることができます。例えば、介入の質問である「もし値段を倍にしたらどうなる」という質問は、Counterfactuals (反事実)の質問をすることで答えることができます。「もし値段を2倍にしていたらどうなっていただろうか」というふうにです。
同じように相関の質問は、介入の質問に答えることによって答えることができます。介入の質問のアクションの部分を無視して観察の部分に注目すればいいだけだからです。
しかしこうした翻訳は逆方向には働きません。介入の質問は、純粋な観察情報(例えば、統計的なデータだけといったような)だけでは答えられません。過去を振る返るようなCounterfactuals (反事実)の質問は、コントロールされた実験といった純粋な介入による情報だけでは答えることができません。ある薬を与えられた患者のグループが、もし薬を与えられていなかったとしたらどうなっていただろうと観察するために、もう一度実験をおこなうことはできないからです。ですので、この階層は一方通行で、トップレベルがもっとも強力なものです。
以上、抜粋終わり。
GoogleとMastercardがリテールでの売上情報とGoogleの広告情報をつなぐための契約を結ぶ
Google and Mastercard Cut a Secret Ad Deal to Track Retail Sales - Link
実はGoogleはすでにクレジットカード会社とパートナーシップを結んで、オンラインの広告とオフラインでの購買などのトランザクションを結びつけているんですね。Googleによると、GoogleのStore Sales Measurementのユーザーはすでに全米の70パーセントのクレジットカードのデータにアクセスして、広告の効果をモニターすることができるらしいです。
Amazonも最近は広告に力を入れていて、さらに最近買収したWhole Foodsをふくめたオフラインの購買データの取得と連携で、果敢に攻めています。Google HomeとAmazon Alexaをふくめ、このGoogleとAmazonのビッグデータ、AIを使った戦いはいよいよ激しさを増しているようです。
What Are We Writing?
先週は、以下の記事をTeam Exploratoryより出しました。
What Are We Working On?
Exploratory v5.0
v5.0の開発を引き続き行っておりますが、来月頭のリリースに向けて、最終コーナに全速力で向かっていっているところです。
次期バージョンのv5.0では、UIが全面的にリフレッシュされるのですが、今日はその一部の紹介をしたいと思います。
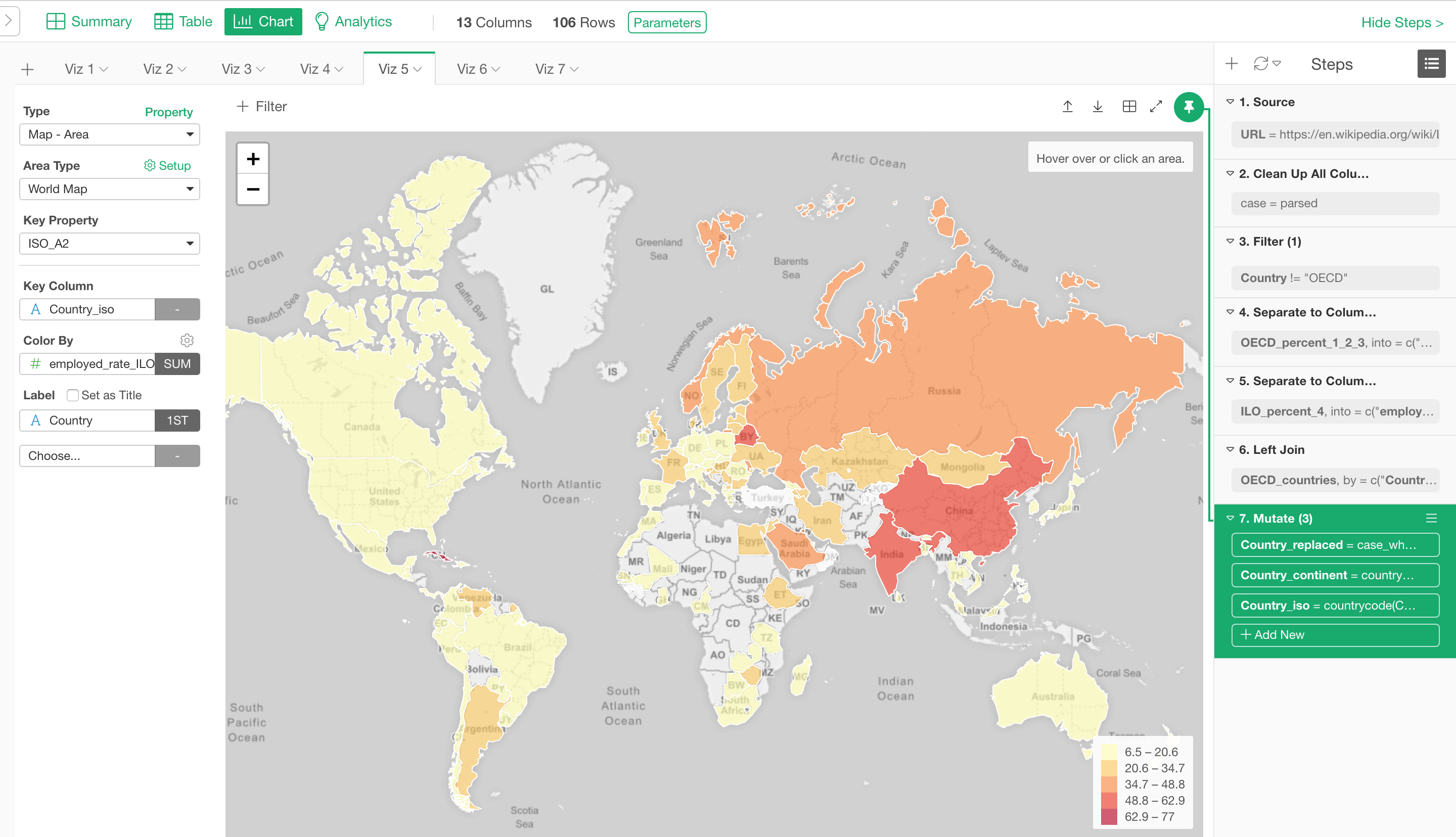
大きな違いはデータラングリングのステップがある右側です。データを分析しているとステップがどんどんと増えていくものだと思います。そうしたときでもより使いやすいようにと、デザインの変更を行っています。
まずは、右上のボタンを押すことでステップをコンパクトにできます。たくさんステップがある時に、見やすくなります。
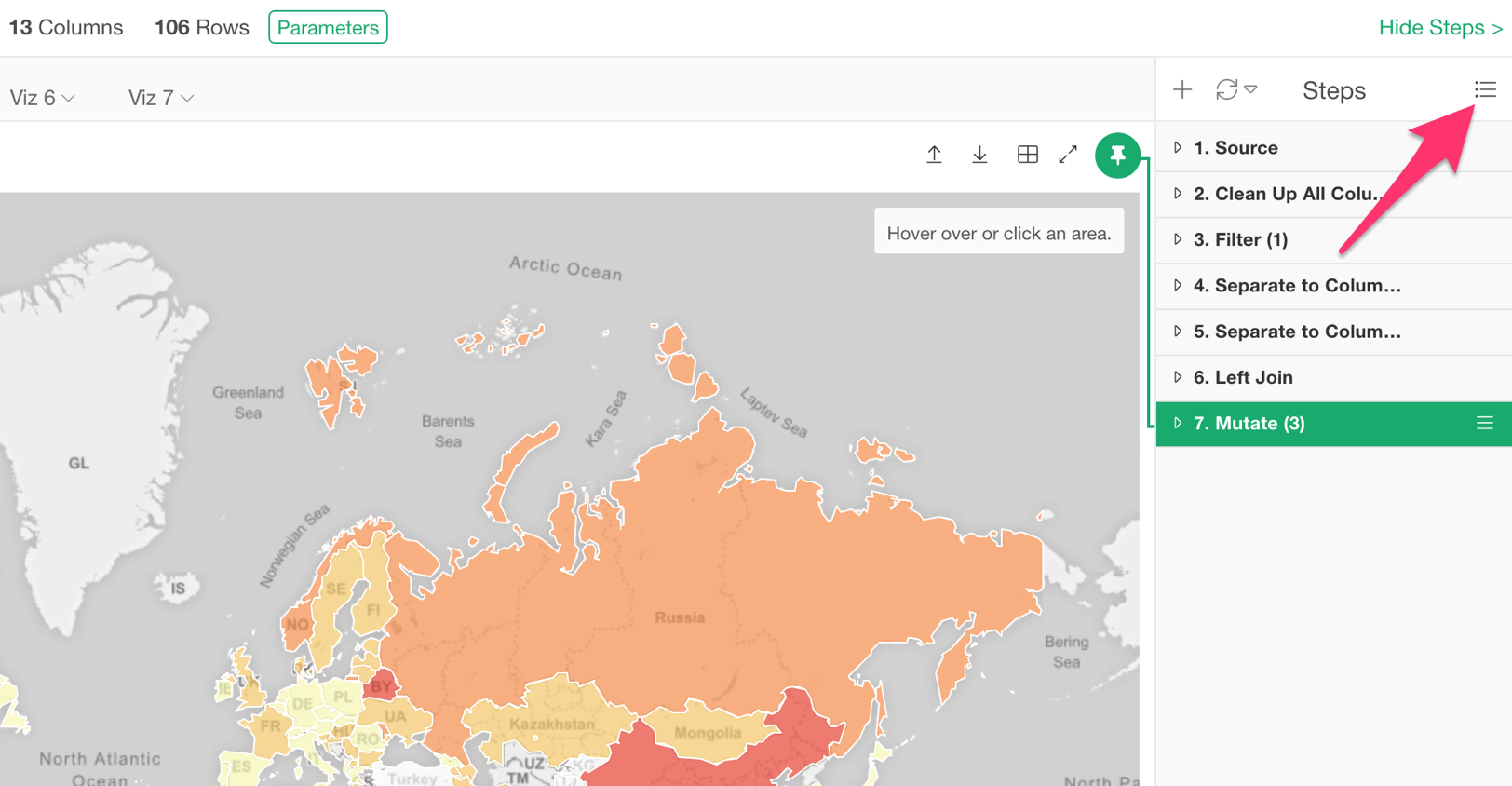
ステップがじゃまなときは、隠すこともできます。チャートがごちゃごちゃしてきて、大きく表示したいなというときなどに便利です。
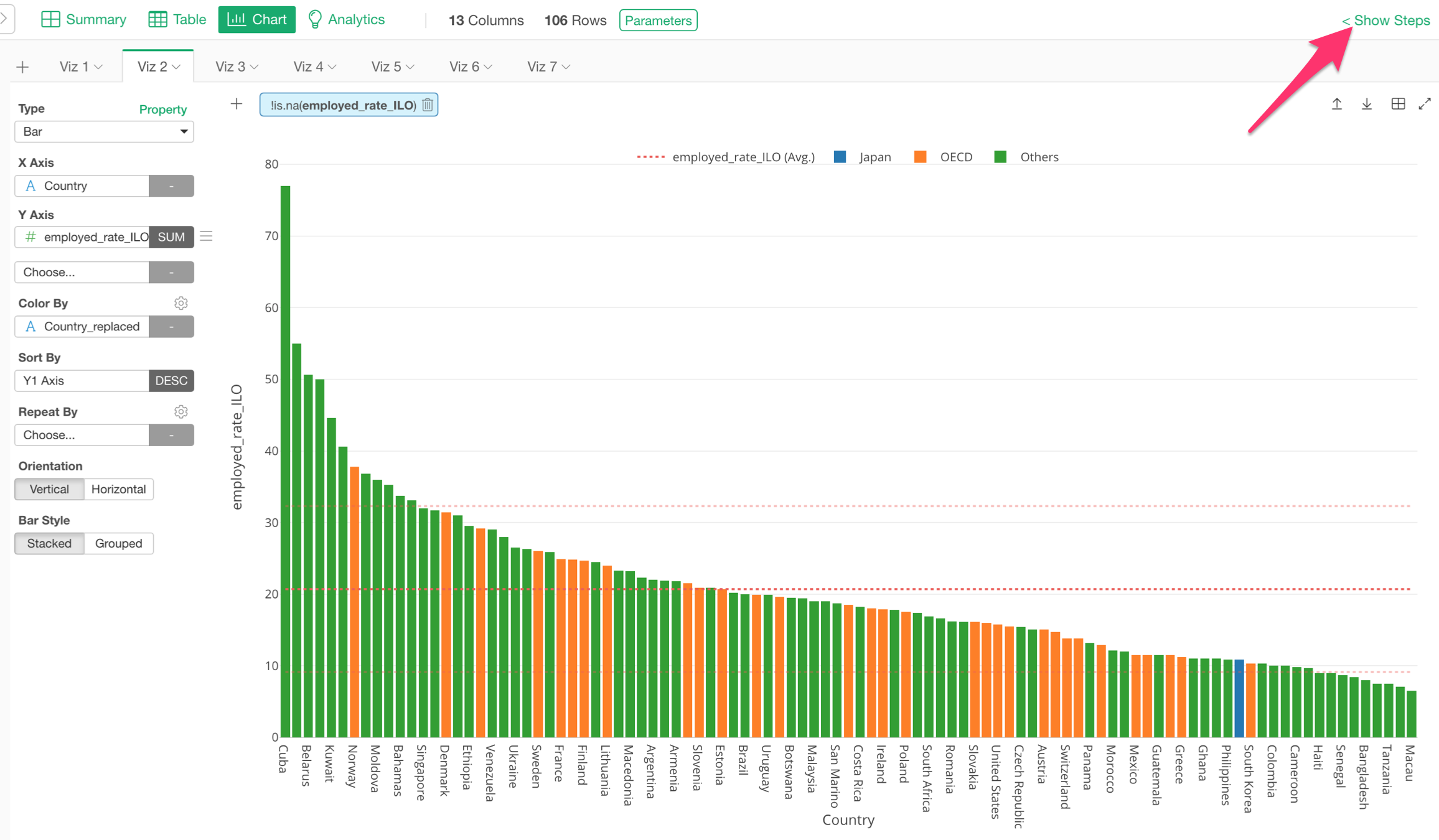
また、それぞれのトークンをクリックして編集のためのダイアログを直接開けるようになります。これで視線をあっちへ、こっちへと動かす必要がなくなりますね。
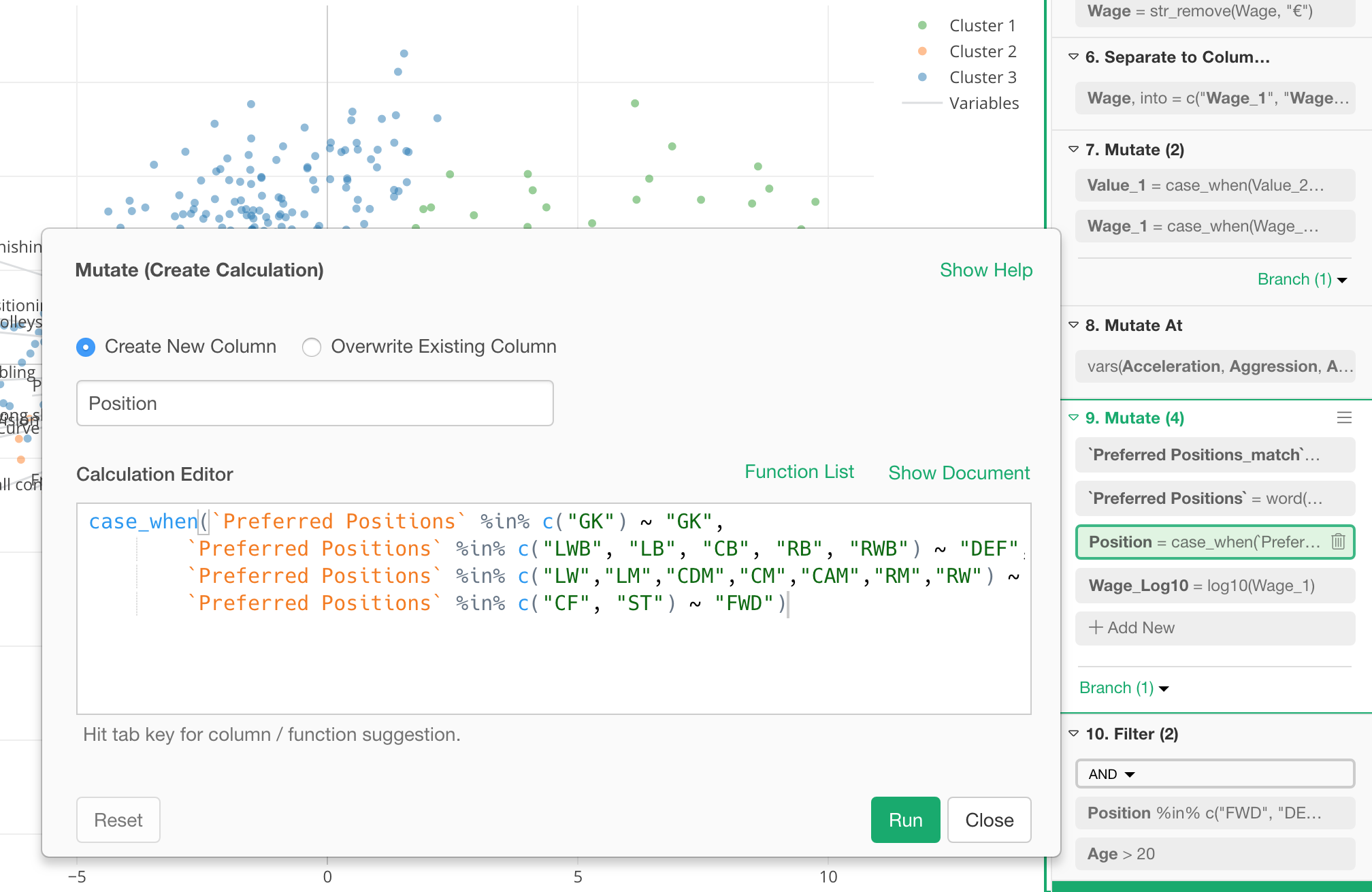
他にもさまざまな便利な機能を付け加えていますが、来週以降追って紹介していきます!
Exploratory社主催セミナー in 10月
10月のデータサイエンス・ブートキャンプで来日の際にセミナーを行います。データ分析を使ってビジネスを改善するために多くのシリコンバレーの企業で使われているフレームワークであるアナリティカル・シンキングの紹介をします。これからデータ分析を行っていきたいがどう始めていいか、ビジネスの成果にどう結びつけていけばいいかなど、疑問をお持ちの方はぜひこの機会にご参加ください。
データサイエンス・ブートキャンプ、1月開催!
おかげさまで来月10月のデータサイエンス・ブートキャンプはすでに満席となってしまいましたので、その次の開催の募集を始めています。次は1月です!
データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にぜひご検討下さい!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。