
“If you can’t measure it, you can’t improve it.”
“計測することができないなら、改善することはできない。”
by Peter Drucker
こんにちは、Exploratoryの西田です!
もうすでに9月になってしまいました。来月の頭に予定しているExploratoryの次期バージョンv5.0に向けての開発の最終コーナーを回り始めていますが、異様に忙しい毎日です。UIの方が大幅に変わるので、これまでのドキュメントやトレーニングなど、様々なコンテンツを大幅に変更しなくてはいけないのですが、プロダクトがさらに進化していく過程なので、これはしょうがないと思って猪突猛進しています。(笑)
ところで次回の10月のトレーニングの方は受付を終了しましたが、その次の1月のトレーニングの方の受付を開始しています。現在、早割の期間中ですので、データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にぜひご検討下さい!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
スタートアップをやっているとよく聞く言葉の一つに、ネットワーク効果(もしくは、日本語ではネットワーク外部性ともいうらしい。)というのがあります。Facebookのようなソーシャル・ネットワークを想像してもらえばわかりやすいのですが、より多くのユーザーが参加すると、その事自体がそのサービスの価値を上げるので、さらに多くのユーザーが参加してきます。そして、そのことがさらなる価値を生み出すという成長のサイクルが描かれます。こうしたネットワーク効果を持ったサービスは多くの場合、市場を独占することになります。Facebook、Airbnb、Uber、Pinterestなどがこの典型です。ただ、これはとくに新しいコンセプトではなく、そもそも電話のサービスというのはこの典型だったわけです。つまり、電話できる人が多くなればなるほど、電話サービスの質は上がるわけですから。
これと基本的には同じ仕組みなのですが、少し違うものとして、データ・ネットワーク効果というものがあります。これは、データによって価値のあるサービスを提供し、そのことがより多くのユーザーがそのサービスを使う、もしくは既存のユーザーがもっと頻繁にそのサービスを使うことを促し、そのことでさらに多くのデータが集まり、多く集まったデータがサービスの質をさらに向上させるという成長のサイクルが描かれます。
そして、ネットワーク効果と同じく、最終的にはこうしたデータ・ネットワーク効果をもったサービスが市場を独占することになるというものです。Netflix、Amazon、Youtubeといったレコメンデーションがユーザーがサービスを使う上での重要な位置を占めているようなサービスがいい例です。
他にも、Tesla、Uber、Wazeなど、走っている車からどんどんと集めてきたデータを使って、自動運転に必要な予測をしたり、最適なルートをレコメンドしたりといったサービスも、より多くのデータをもっていることが優位になるので、データ・ネットワーク効果のいい例です。
このデータを使ったネットワーク効果というのは比較的新しく、現在もある意味その効果を実験している最中という面があると思います。これは、データを持っていればよいというわけではなく、データを使ってサービスの価値が向上し、そのことによって、より多くのデータが集まることになる仕組みができているということがキーとなります。そして、この仕組みの作り方がうまく、早い段階からビジネスの成長戦略に組み込んでいるスタートアップが多いのがシリコンバレーです。この辺はちょっと前に「データサイエンスのすゝめ — シリコンバレーに全てを飲み込まれる前に」として書いたことがあるので、もしよかったら読んでみてください。
ところで、先週、このデータ・ネットワーク効果の対する考え方として参考になる面白い記事が先週2点ほど出ていたので、ここで紹介したいと思います。
テスラ、ソフトウェア、そして破壊的なイノベーション
このWeekly Updateでも度々紹介しているA16Zのベネディクト・エヴァンズによる、テスラは破壊的なイノベーションなのかどうかに関する考察です。いつものように、ただテスラの素晴らしい部分を書き並べるのではなく、批評的に2つの面からの考察をもとに、論点を挙げていく彼のスタイルは勉強になります。クリティカル・シンキングのいい例です。
本文は長いのでその中でも、特にソフトウェアとデータが破壊的なイノベーションに果たす役割に関する考察を一部抜粋して紹介します。
Tesla, software and disruption - Link
「普通に使える電話をどうやって作るかを理解するために数年ほど学び続け、そして苦しみました。PCのやつらに、これを理解することはとうてい無理でしょう。ただやればいいというわけではないのですから。」
とは、2006年当時、Appleが携帯電話を作っているという噂に対するPalmのCEOであったEd Colliganのコメントです。2006年といえば、iPhoneの発表がある前の年です。
Nokiaの人間が初代のiPhoneを見たとき、彼らは自分たちでも作れるいくつかのクールな機能がついているだけの、大したことのない電話だと決めつけました。当時の彼らが売っている量からすると取るに足りない数が売れるだけの電話だと考えていたのです。「3Gもなく、カメラもたいしたことない!」と片付けてしまったのです。
破壊的なイノベーションというのは、新しいコンセプトがある業界での競争のルールを変えるということを意味します。最初の段階では、その新しいものや、それを持ち込んでくる新しい企業は、既存のビジネスが大事だと思うことに関しては、たいしたことなかったりするので、笑いの種にされたりするものです。
ところが、そうした新しい参入者は既存のものをどんどんと学んでいくことができます。それとは逆に、既存のビジネスは、勘違いして、新しく出てきたものを価値がない、もしくは自分たちでも簡単にできると決めつけてしまうのです。
Appleはソフトウェアを電話に持ち込み、電話そのものを学びました。Nokiaは素晴らしい電話を持っていたのですが、ソフトウェアを学ぶことができなかったのです。
続きは、こちらよりどうぞ。
これからはデータドリブンではなくて、モデルドリブン・ビジネスの時代だ
先週、”Models Will Run the World(モデルがこれからの世界をまわしていく)”という、データドリブンではなくモデルドリブンなビジネスがこれからのビジネスだという記事がウォール・ストリート・ジャーナルにでていました。
モデルドリブン・ビジネスというのはたしかに言葉遊びとしては、おもしろいのですが、それ以上に、先ほども出てきたデータ・ネットワーク効果をうまく説明していると思ったのでその点から一部を抜粋して紹介します。
以下、抜粋の要訳
Models Will Run the World - Link
Marc Andreessenの“Why Software is Eating the World”という記事がこのウォール・ストリート・ジャーナルで発表されたのは、2011年の8月20日です。
ソフトウェアが世界を飲み込むのであれば、その仕組みを作るのはモデルです。
モデルとはアルゴリズムがデータからロジック(論理)を導き出す意思決定のフレームワークです。開発者がプログラムとして明示的に定義したり、人間の勘によって暗示的に導かれたりするのとは違います。アウトプットは予測で、それをもとに意思決定を行います。一度作られると、モデルはその成功や失敗から学ぶことができます。そのスピードと洗練度は人間がかなうものではありません。
モデルドリブン・ビジネスは収入やコストの最適化などビジネスのプロセスに関わる重要な決定のためにモデルを使います。このシステムを作るにはデータを収集し、データからモデルを構築するためのソフトウェアを使った仕組みが必要になります。
モデルドリブン・ビジネスはデータドリブン・ビジネス以上のものです。データドリブン・ビジネスはデータを収集し、分析することで人間がより良いビジネスの意思決定を行うというものです。モデルドリブン・ビジネスとはビジネスを絶えず継続的に改善するためのモデルのまわりにシステムを作っていきます。データドリブン・ビジネスではデータがビジネスをサポートしますが、モデルドリブン・ビジネスではモデルがビジネスなのです。
WeChatのメーカーでもある中国のメディアの巨人であるテンセントはこの新しいビジネスモデルのいい例です。
「私達は、ソーシャル・メディア、支払い、ゲーム、メッセージング、メディア、音楽などに渡る顧客に関するデータをもっていて、その規模は何億人分ものでーたになります。これほどのデータをもっているのは他にないでしょう。私達の連略はこのデータを何千人ものデータサイエンティストの手に渡して、広告の最適化をどんどんと行っていくことです。」
続きは、こちらよりどうぞ。
What Are We Writing?
先週は、以下の記事をTeam Exploratoryより出しました。
What Are We Working On?
Exploratory v5.0
これまでもすでにK-meansクラスタリングはコマンドとしてサポートされていたのですが、今回アナリティクス・ビューの方で簡単にできるようになりました。
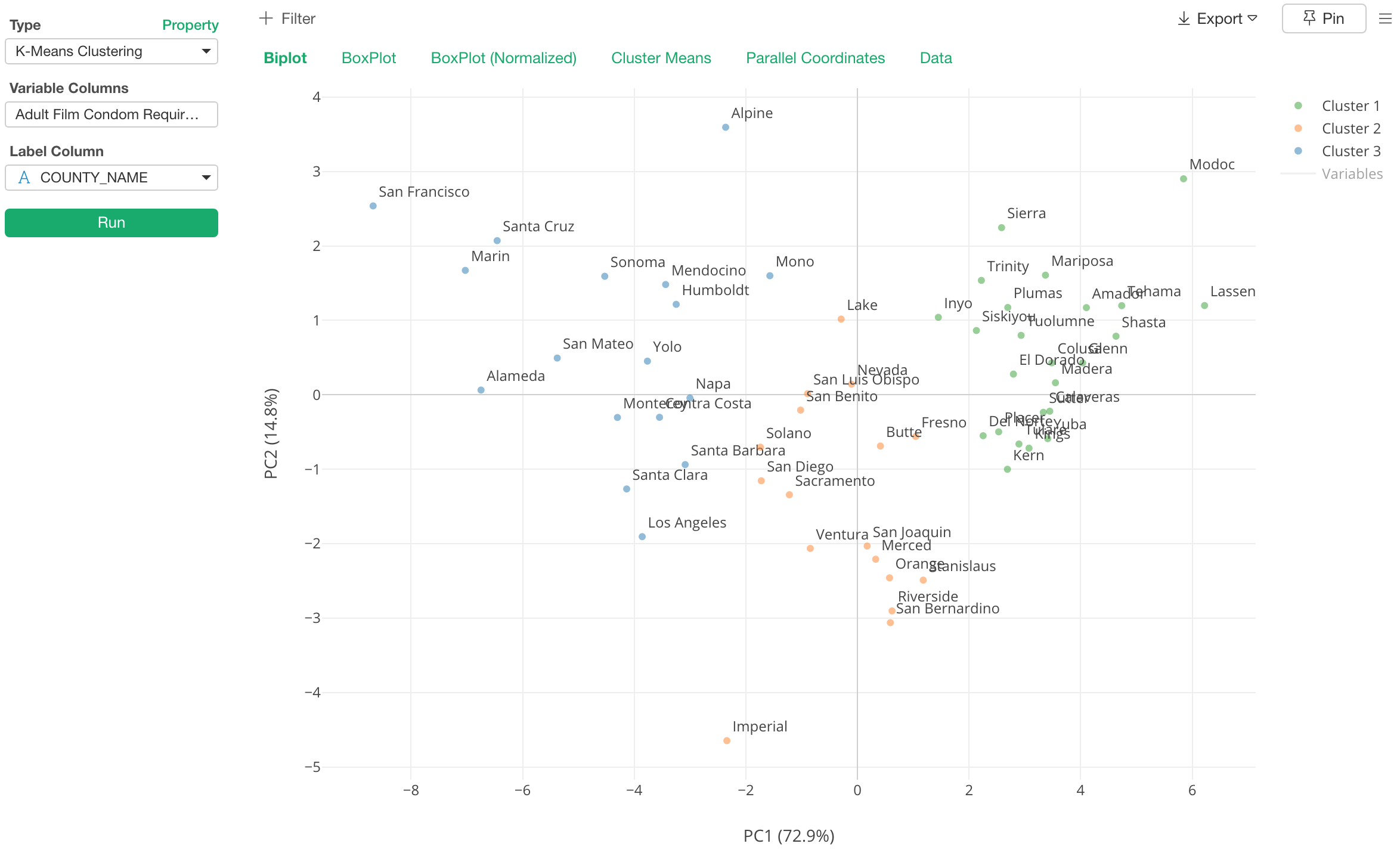
それぞれのクラスターの特徴を見つけやすくするためのチャートをいくつか用意しています。
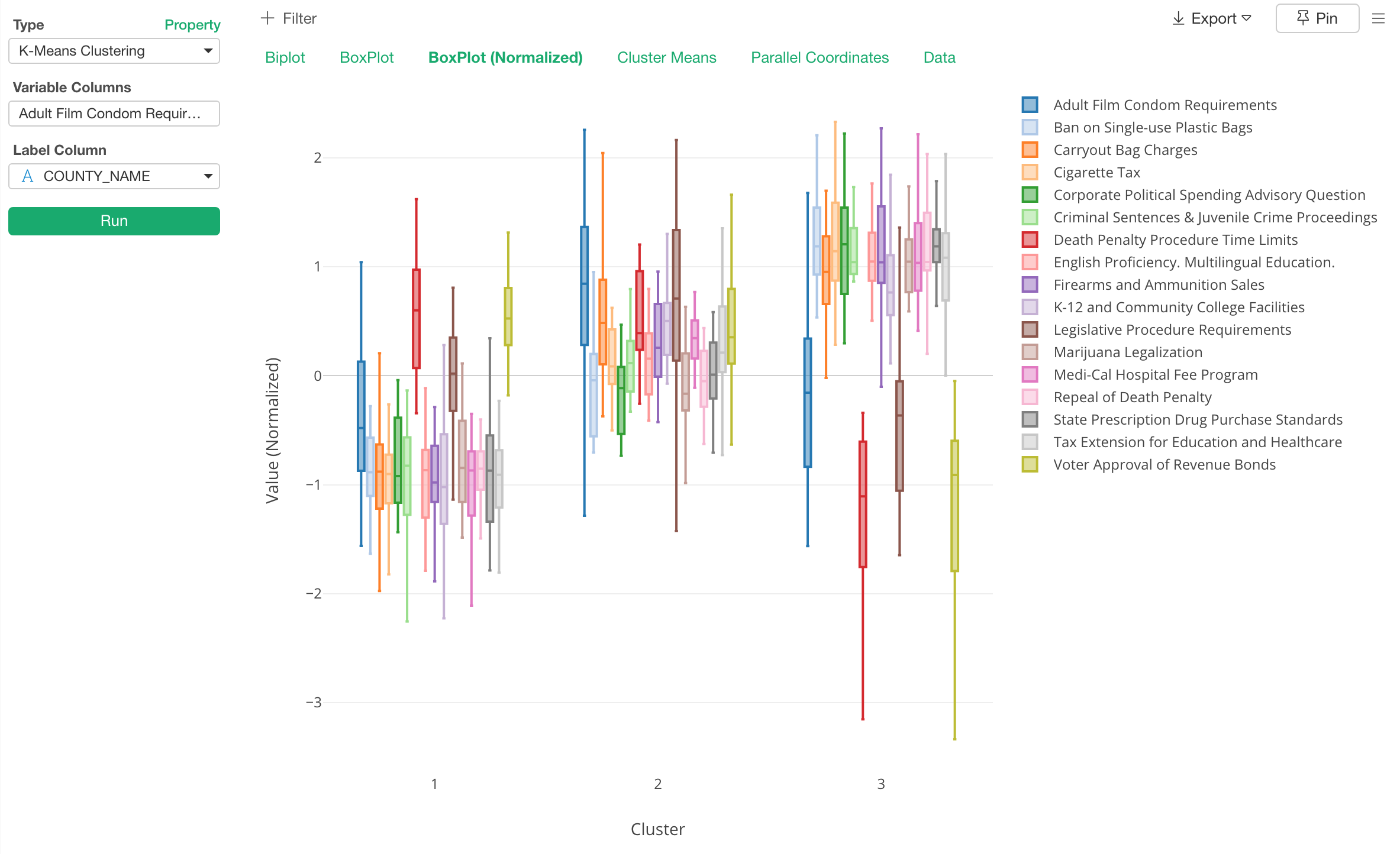
例えば、以下の箱ひげ図ではそれぞれの変数(列、属性)の値の分布を可視化することで、それぞれのクラスターに対する重みがわかります。
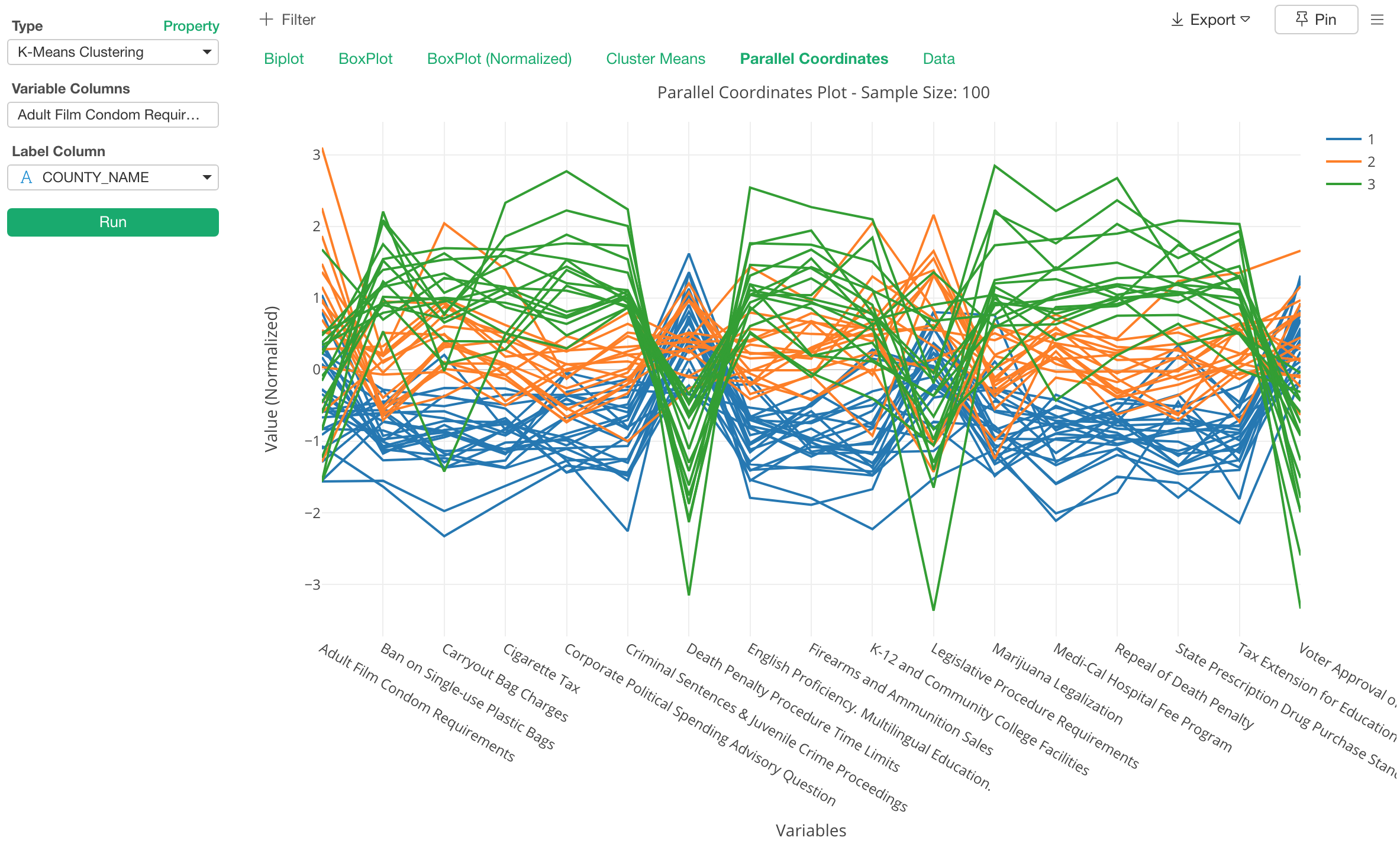
また、以下のチャートでは、それぞれの観察対象(行)がそれぞれの変数に対してどのような値を取るかを可視化することで、それぞれのクラスターの特徴がつかみやすくなります。いわゆる、パラレル・コーディネートというチャートですね。
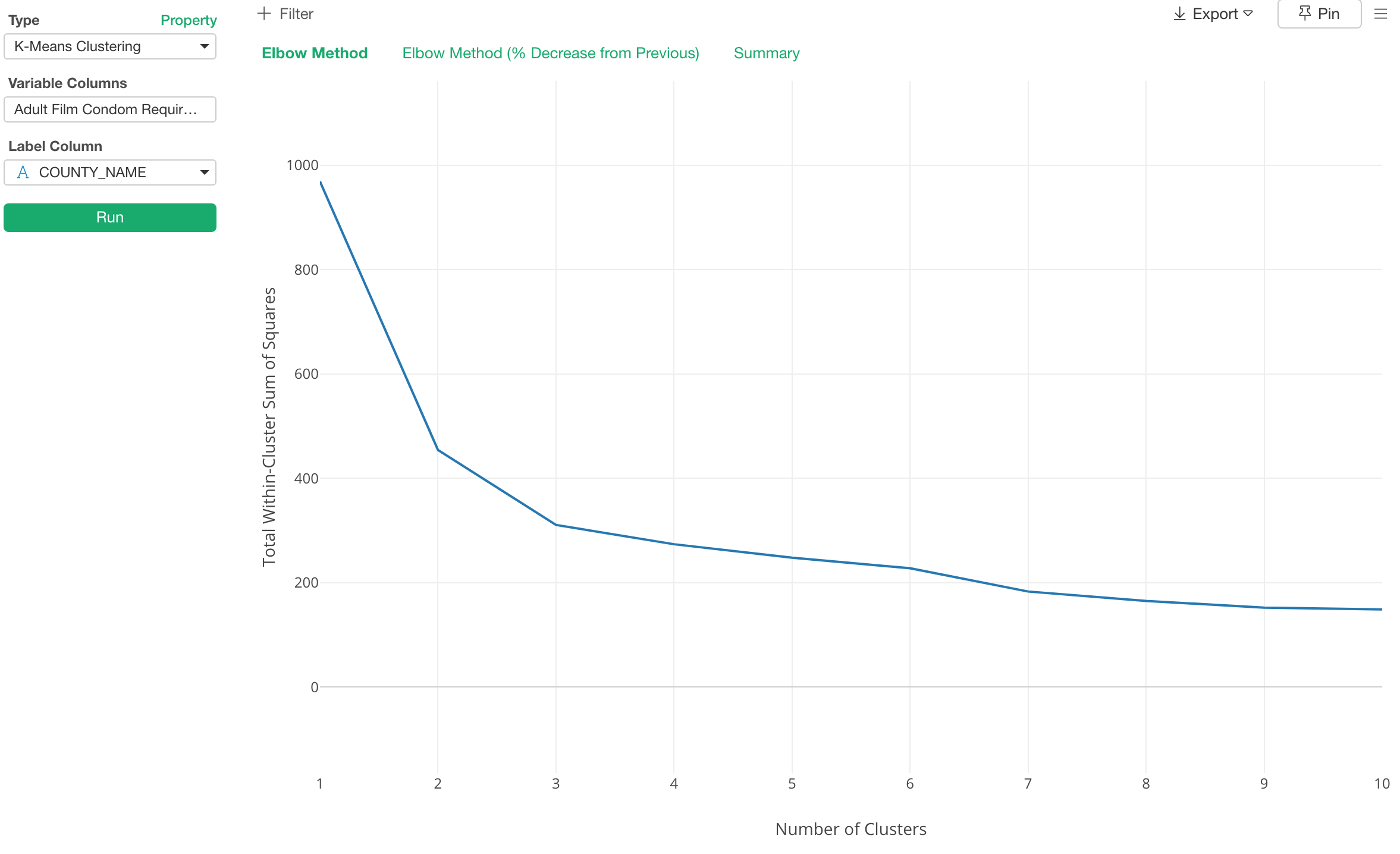
また、K-meansのアルゴリズムを流すときには、いくつのクラスターを作るのかを指定しなくてはいけないのですが、いったいいくつのクラスターがよいのかというのは誰もが悩むところです。
この答えを導き出すために使われる一つの方法として、エルボー(ひじ)カーブというのがありますが、こちらも、UIから簡単に描けるようになっています。
次回データサイエンス・ブートキャンプ10月開催!
冒頭にも触れましたが、おかげさまで10月のデータサイエンス・ブートキャンプはすでに満席となってしまいましたので、その次の開催の募集を始めています。次は1月です!
データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にぜひご検討下さい!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。