
こんにちは、Exploratoryの西田です。
さっそくですが、ついにExploratory v5.1がリリースされました!
いやー、今回はほんとうに長かった。。。思わずため息が出てしまいました。😁
しかし時間をかけただけあって、かなりおもしろいものが出来上がったという自信があります!
現在英語版しかないのですが、こちらにv5.1リリースのアナウンスメントの記事があるので、興味のある方はご覧ください。
最後に、この5月に行なう予定の「SaaS・サブスクリプションビジネスのためのアナリティクス」トレーニングと「探索的データ分析」トレーニングの開催日時が決まりました。
データを使ってビジネスを効率的に成長させていきたいという方は、ぜひ参加の方、ご検討ください!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
モデル思考できる人間がよりよい意思決定を行えるのはなぜか
データを使った意思決定という話をする前に、どうしても「モデル」というコンセプトを理解する必要があると思うのですが、この「モデル」という言葉やコンセプトはまだまだ世の中に受け入れられていないような気がします。
もちろん、ここで言っている「モデル」とは、ファッションのモデルでも車のモデルでもありません。データの文脈の中でのモデル、もしくは予測モデルのことです。😅
しかし、「モデル」とは現実の世界を私達人間が理解できるように、または行動を起こせるように抽象化したもので、私達の意思決定のもととなるものです。そして、ふだん統計や機械学習のアルゴリズムなどによるモデルを作っていない人でも、実は自分の頭の中で顧客、ビジネス、交際相手、友達などを理解するために無意識のうちに作っているものなのです。
例えばの話ですが、アメリカ人というのは「体が大きく」、「がさつ」、「声が大きい」などというのはアメリカ人を理解するために自分の頭の中に持っている「モデル」だと考えることができます。
そして、あるアメリカ人に出会った時にその人がたまたま「小さく」、「丁寧」な人だったりすると、驚くことになったりします。つまり「予測」が外れていたから驚くのです。
こうした私達が頭の中に持つモデルというのは、あまり当てになるものではありません。バイアスがあまりにも多いし、データ量もあまりにも限られているからです。
そこでデータを使って、統計や機械学習のアルゴリズムを使ってしっかりとモデルを作ろうということになるわけです。
つまり、世の中でおきていることをより正確に理解することで、よりよい意思決定を行っていくことができるという期待があるわけです。
こうした意味で、全ての意思決定に関わる人はこの「モデル」というコンセプトを理解することが重要になります。
最近、このことについて、もっと深く切り込んでうまくまとめている「The Model Thinker」という本がUSで出版されました。ミシガン大学の教授で複雑系システム、政治学、経済学を教えているScott Pageによるものです。
その彼が「ハーバード・ビジネス・レビュー」の方に、「なぜ複数のモデルを使って思考できる人はよりよい意思決定ができるのか」というタイトルのエッセイを出していたので、こちらで紹介したいと思います。
データサイエンスをいつ始めるべきなのか
ちょっと前のWeekly Updateで、シリコンバレーのInstacartで、データサイエンスのVP(バイス・プレジデント)をやっているJeremy Stanleyによる「あなたのビジネスのデータサイエンス本気度を試す4つの質問」という記事を紹介しました。
今回はその続きです。
上の記事の質問に答え、データサイエンスに対して本気であるということが確認できたとします。その場合、いつ始めればよいのかという質問が出てくるかと思います。
そこで、いくつものシリコンバレーのデータ先進企業でデータサイエンスのチームを作り、率いてきたJeremyとDanielによるアドバイスをここで、要訳という形で紹介します。
Quote of the Week
“A good model can be useful even when it fails.”
よいモデルというのは役に立つものだ、たとえ失敗したとしても。
by ネイト・シルバー
What Are We Writing?
以下の記事を最近Team Exploratoryから出しました!
What Are We Working On?
Exploratory v5.1
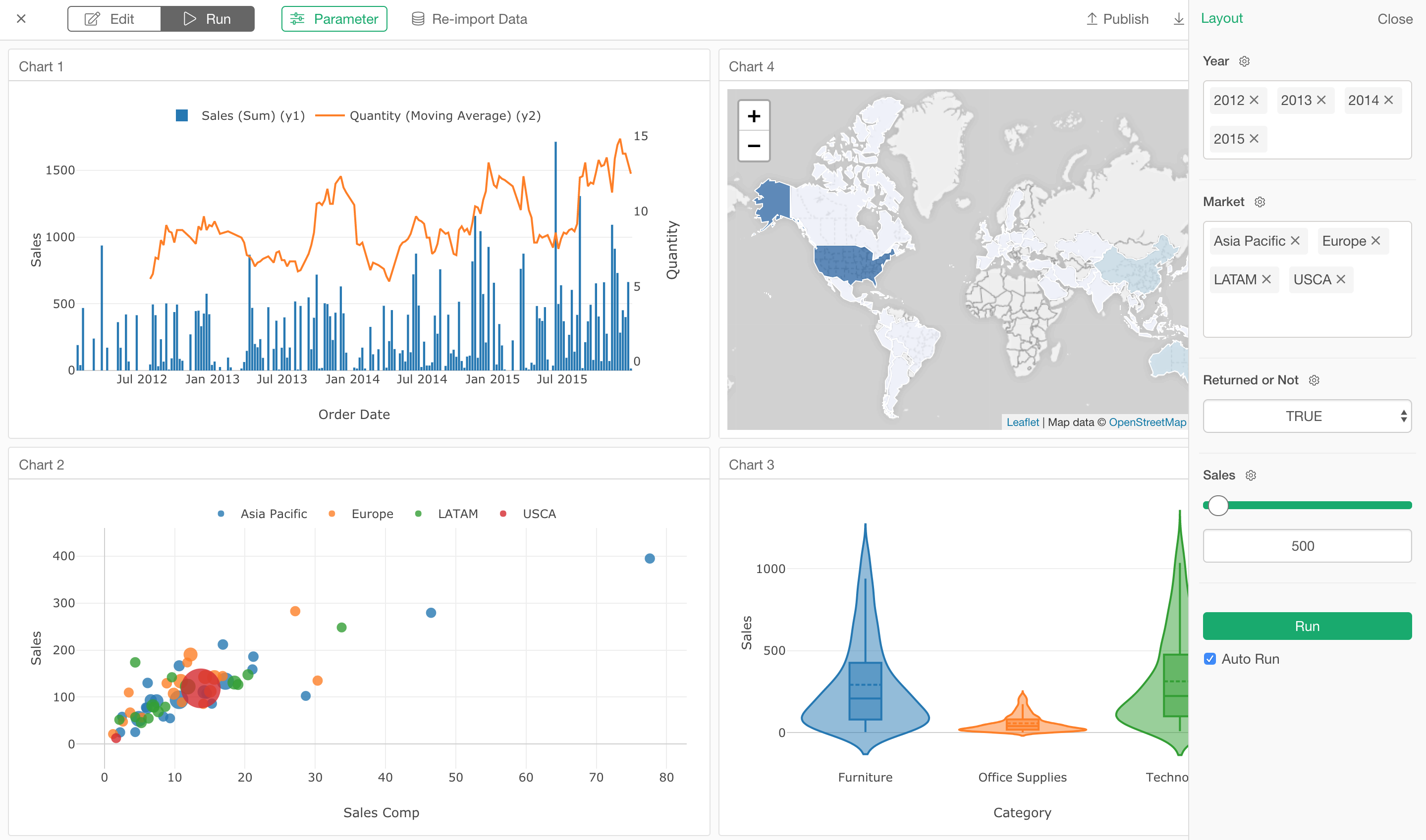
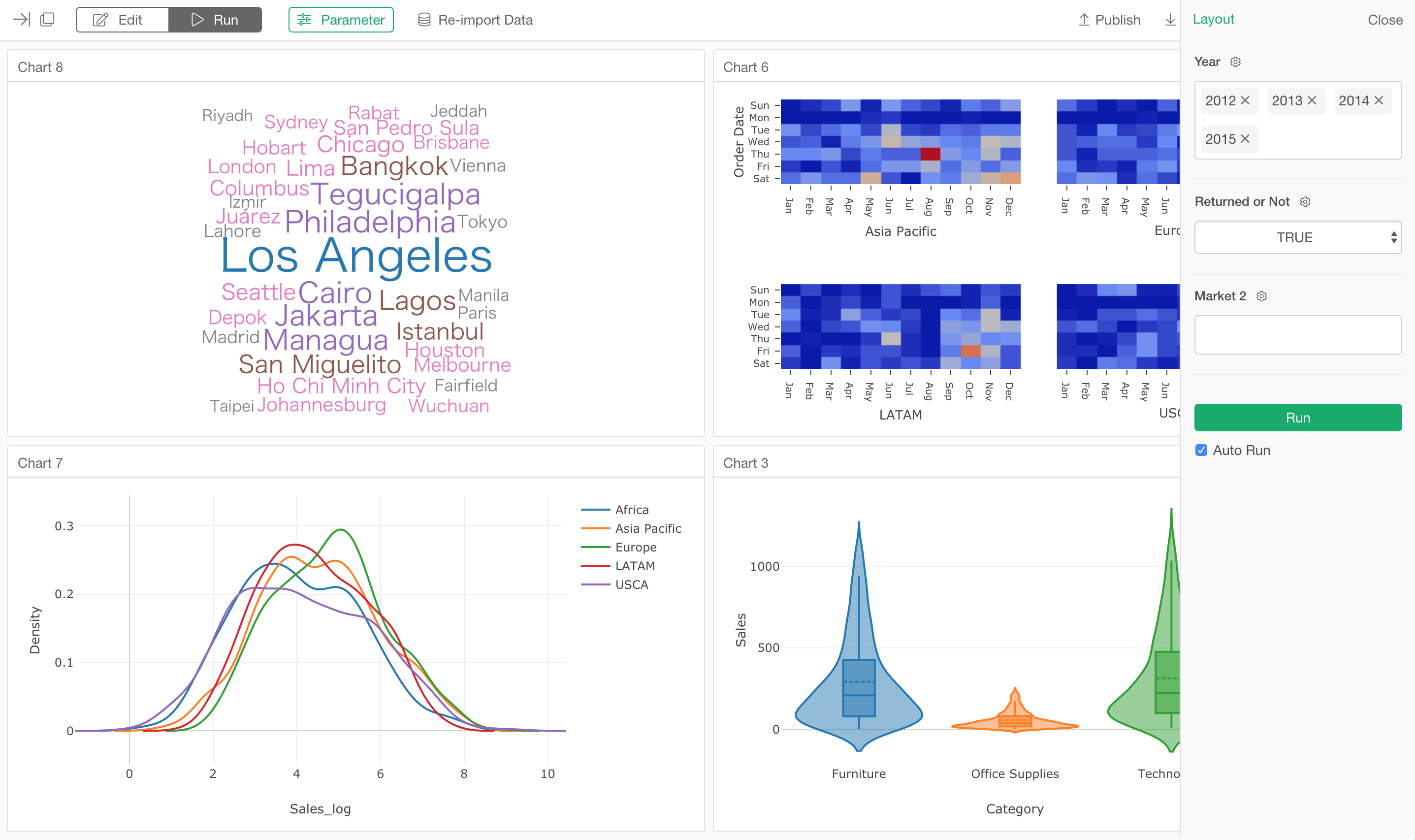
冒頭でも書いたように、ようやくv5.1出すことができました!
時間が少しかかってしまいましたが、今回も力作です。
まずは、パラメータのサポートで、これを使うと、SQLのクエリやデータラングリングのステップをパラメーター化することができます。そして、さらにダッシュボードなどをインタラクティブにすることができます。
チャートに関しては、バイオリン、密度プロット、スカッター(散布図)・マトリックス、ワード・クラウドといった新しいチャートタイプが追加されました。
アナリティクス・ビューでは、GLMファミリーが新しく加わり、ランダム・フォレストにはBoruta、ロジスティック回帰には限界効果、線形回帰には変数重要度が新しく加わっています。
新しいデータソースとしては、今回はAWSのS3のAthena、Teradataが加わっています。
また、インストールまわりもだいぶ改善されました。そして、Windows版はインストーラーをつけました!
詳しくは、こちらのアナウンスメントの記事(英語です)をご覧ください。
他にもたくさんの新機能や機能強化、さらにバグの修正が入っているので、ぜひ試してみてください!
もう一度トライしてみたい方へ
もし、過去に試して、トライアル期間が切れてしまった人でも、このバージョンをダウンロードして起動すると、Exploratoryの中から期間の延長ができるようになっているので、ぜひ試してみてください!
5月のトレーニング開催決定
以下の2つの新しいトレーニングの開催日時が決まりました!
SaaS アナリティクス・トレーニング
SaaSを始めとするサブスクリプション型のビジネスに携わる方を対象に、データサイエンスの手法を使った、ビジネス改善のためのKPIの構築から、データ分析、施策立案までのスキルを身につけていただくことを目的としたトレーニングです。
5月20日 (月)です!
探索的データ分析・トレーニング
データを様々な角度から可視化することで、ビジネスを予測または因果関係を理解するための仮説を構築していく「探索的データ分析」という手法を使いこなせるようになっていただくためのトレーニングです。
5月27日 (月) です!
4月のセミナー
上記の2つのトレーニングの一部の紹介を兼ねたセミナーをこの4月18日(木)に開催します!
ぜひ、遊びに来て下さい!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。