
こんにちは、Exploratoryの西田です。
今週は、明日Exploratoryの中でのダッシュボード、ノート、スライドの作り方に関してのセミナーをオンラインでやります。興味のある方はぜひ参加ください!
こちらのページに参加のためのURLがあります。
また、現在7月のデータサイエンス・ブートキャンプの参加者を受付中です。平日版は満席となってしまいましたが、週末版はまだ空きがあります。データサイエンスや統計の手法を1から体系的に習得したいという方はぜひこの機会にご参加を検討ください。
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
因果推論シリーズ Vol.2 - 予測は自動化できても因果推論は自動化できない
先週に引き続いて、今週も「A Second Chance to Get Causal Inference Right: A Classification of Data Science Tasks」という予測と因果推論の違いを説明し、今こそ「因果推論」というものをもっと多くの人に正しく広めようとするエッセイからの紹介です。
前回は、データサイエンスのタスクを、記述、予測、因果推論(反事実的予測)という3つのカテゴリーに分け、それぞれの定義的な違いの話をしました。
今回はより具体的に、予測と因果推論は何が違うのかというのを、機械と人間、もっと正確に言うと、自動化できるかどうか(機械)、人間によるドメイン知識を必要とする(人間)かどうか、といった点から解説している部分を紹介したいと思います。
大量のデータを持っていることが競争優位になるというのはただの勘違いだ
「データ・ネットワーク効果」という言葉を聞いたことありますか?
ネットワークに参加することによる価値が、参加者が増えれば増えるほど上がっていくというものです。
古い例としては電話があります。もしこの世に電話を持っている人が5人しかいなかったら大した価値はないでしょう。しかし電話を持つ人が増えれば増えるほど電話を使って話すことができる人の数が増えるので、この電話のネットワークの価値はそのことによってどんどんと上がっていくことになります。最近では、FacebookやInstagramなどのソーシャルネットワーク、UberやAirbnbなどがいい例だと思います。
スタートアップがユニコーンになるかどうかの一つの指標が「ネットワーク効果」を持っているかどうかですが、それはこの「ネットワーク効果」を持っている企業がその市場を独占することになるのが分かっているからで、そのことによって大きな成長を期待することができるからです。
それとは別に、特に昨今のスタートアップのビジネスの成長にとって重要なのは、「データ」です。プロダクトがデータと機械学習のアルゴリズムを使ったものであるのか、ビジネスがデータから得られるインサイトを使って成長させていけているのかということが重要なポイントとなります。
そこで、この2つの「ネットワーク効果」と「データ」を組み合わせ、「データネットワーク効果」という言葉を使っている人たちがけっこういたりします。こうした人達にとってはデータを集めれば集めるほど、そのことによって価値が上がっていくので、そのことが競争相手に対するモート(防御壁)になるということになります。
ところが、そんなものはただの勘違いだ、というエッセイがA16Zというシリコンバレーでは有名なベンチャーキャピタルから数週間前に出ていて、スタートアップシーンではけっこう話題になっていたのでみなさんに紹介したいと思います。
Quote of the Week
Some decisions are best made after acquiring more information; some are best immediately.
意思決定には、もっと多くの情報を得てから行った方がいいものもあれば、すぐに行ったほうがいいものもある。
レイ・ダリオ
What Are We Writing?
データの可視化シリーズ
好評のTakatoによる「Exploratoryを使ったデータの可視化シリーズ」です。
What Are We Working On?
Exploratory v5.3
引き続き、来月に予定しているExploratory v5.3の開発をしている最中です。
いろいろと新しい機能や機能強化があるですが、今回紹介したいのはチャートの「数値のカテゴリー分け」というものです。これを使うと、例えば、「色」に数値型の列を割り当てた時に、数値をカテゴリー化することができるようになります。
例えば、年齢という数値型のデータを頻度で分けて5等分にし、それをヒストグラムに「色」として割り当てることができます。
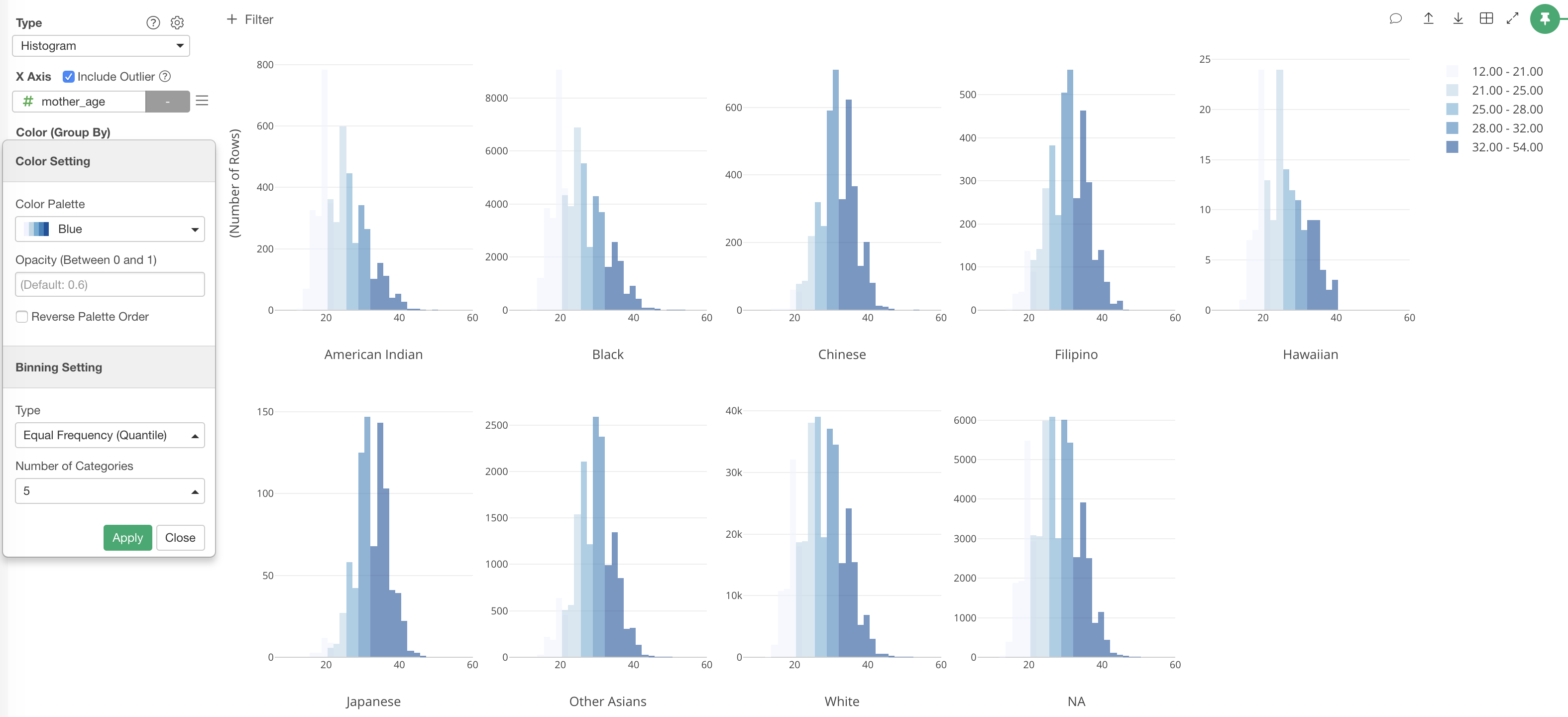
この数値型データをカテゴリー分けする方法は他にもいくつかあります。私の個人的なお気に入りは、アウトライアー(異常値)というやつです。例えば、赤ちゃんを産んだ時のお母さんの年齢が低すぎるまたは高すぎる人たち(アウトライアー)を人種ごとに先ほどのヒストグラムを使って可視化すると以下のようになります。
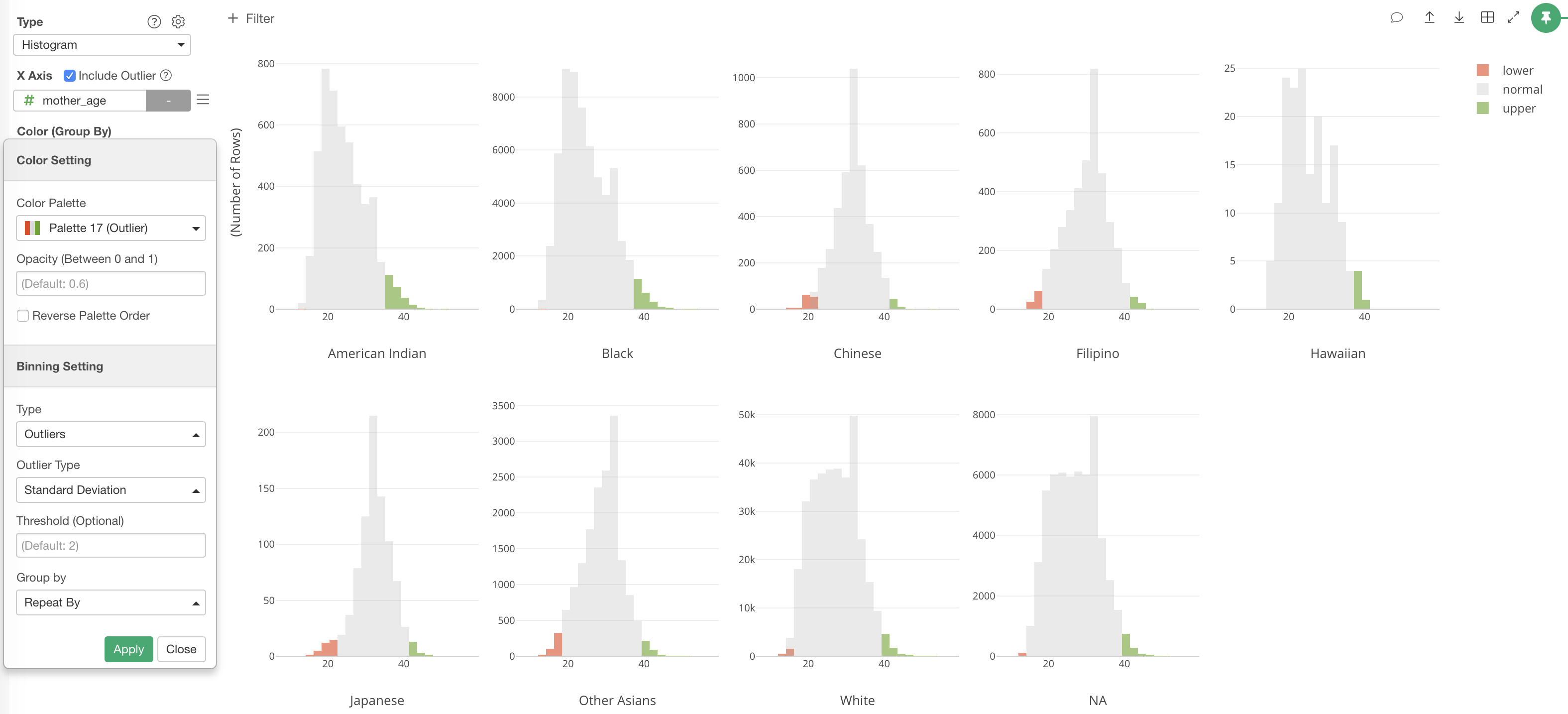
例えば、20歳で赤ちゃんを産むということがアウトライアー(赤色)なのかどうか、それぞれの人種ごとで違うということがわかります。
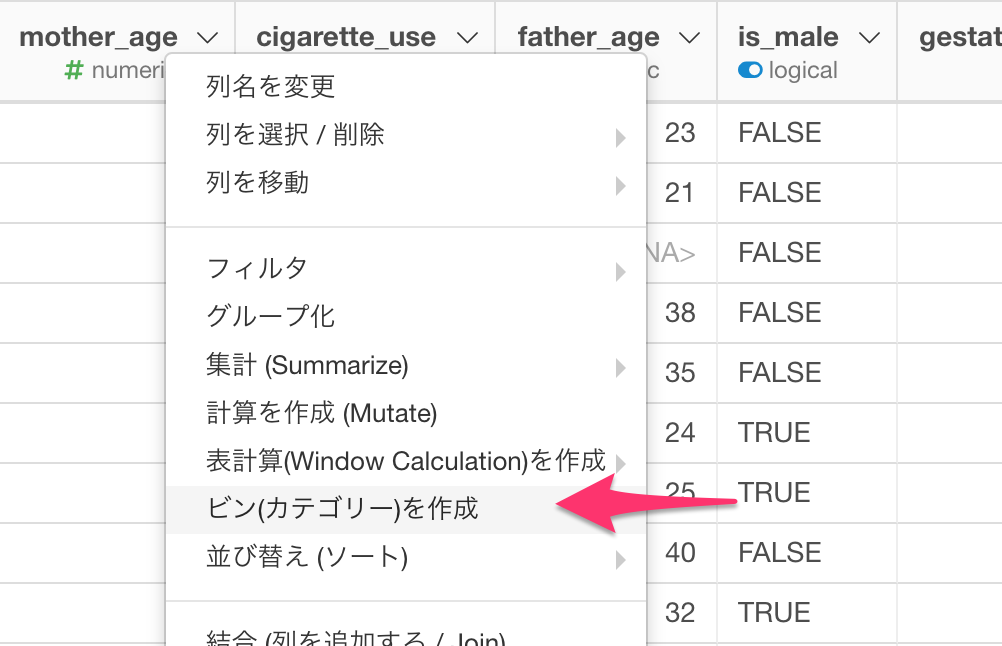
この「数値のカテゴリー分け」というのは、現在のバージョンでは、列ヘッダーメニューから「ビン(カテゴリー)」を選んで、データラングリングのステップとしてできるのですが、次のバージョンv5.3では、チャートの中でいきなりできるようになります!💪
Exploratory オンラインセミナー
今週の木曜日、20日の午後12時(日本時間)にオンラインセミナー(無料)をやります。
今回はExploratoryの中での以下のレポーティング機能の紹介です!
- ダッシュボード
- ノート
- スライド
- パラメーター
興味のある方はぜひご参加ください!
データサイエンス・ブートキャンプ、7月開催!
毎回好評をいただいているデータサイエンス・ブートキャンプですが、次の開催は7月です!
データサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使えるようになりたいという方は、ぜひこの機会に参加をご検討ください!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。