
こんにちは、Exploratoryの西田です。
突然ですが、毎週木曜日にやっているオンラインセミナーですが、今週だけ、金曜日の開催となります。内容は、ファクターという順序付きカテゴリーのためのデータタイプの紹介をします。
このデータタイプはチャート、統計、機械学習など、いろんな場面で出てくるので、ぜひ皆さんに知ってもらって使いこなせるようになってもらえればと思っています。
ところで、毎回好評いただいているデータサイエンス・ブートキャンプは次回11月に開催です。
早割のほうが今週いっぱいですので、興味のある方はこの機会にぜひご検討下さい!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
シリコンバレーの企業は、どうやってNorth Star指標を選んでいるのか?
Team Exploratoryの村里がやっているSaaSアナリティクスシリーズですが、今週はNetflix、LinkedIn、Instacart、Dropboxなどのシリコンバレーのテック企業がどのようにNorth Star指標を設定しているのかについて書かれている記事を紹介しています。
ファッション業界もデータを使ってトレンドを理解する時代
ファッション業界こそ、クリエイティブな世界なので、データとは相性がよくなさそうですが、それでも確実にその波は来ているようです。
ちょっと前になりますが、Vogueで「Analytics are reshaping fashion’s old-school instincts」という記事が出てて、その中でブランドやデパートがデータやアナリティクスを使ってファッションのトレンドを追っていると言う話がありました。
ただ、トレンドを作るといったクリエイティブな作業がデータやアナリティクスに置き換わるということではなくて、むしろファッション業界ではトレンドを追いかける、モニターするというのがビジネス上重要で、そこでは、トレンドを追うプロの人がデータやアナリティクスを使ってトレンドを客観的に理解し、そのタイミングをより正確に予測しようとしているという話です。
なぜUSは健康保険が異様に高いのか説明してくれる4つのチャート
USに住んでて病院に行ったりするたびにつくづく思うのは、ヘルスケアのコストの高さです。
特に、以前働いていたOracleのような大企業であれば会社を経由して加入する保険がすごくよいのでそこまで気にしてなかったのですが、2016年にExploratoryを起ち上げて最初に痛みを感じたのが、このヘルスケアに関するコストでした。(笑)
こういった保険には個人で加入することになるのですが、はっきり言ってボッタクリに近いくらい高く、さらに毎回病院に行く度に、請求書を巡って電話でやり合わなくてはいけなく、むちゃくちゃめんどくさいです。
なんでこんなにコストが高いのか、疑問に思っていたのですが、最近出版された、”Priced Out - The Economic and Ethical Costs of American Health Care”という本の中に答えがあると知り合いに教えてもらいました。
経済と公共政策の分野で有名なUwe E. Reinhardtというプリンストン大学の教授(すでに亡くなっている)が最後に書いた本のようです。
ヘルスケア関連のコストそのものがなぜUSは高いのかを理解する上で役に立つ4つのチャートをまとめている記事があったので紹介しています。
アメリカで急成長する「ウェルス・ワーク」と言う仕事
以下のチャートは、2017年の時点で、2010年に比べてどれだけ仕事の数の成長率を表していますが、左から、ネイル、マッサージ、スキンケア、ペットの面倒をみる、プライベートの料理人、フィットネスのトレーナーです。
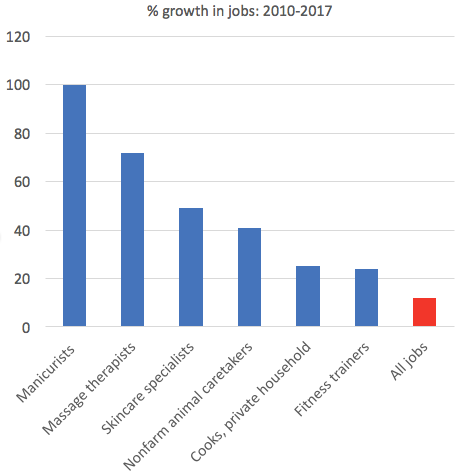
一番右にある「全ての職」の成長率に比べてどれもかなり成長しているのがわかります。
これは「The New Servant Class」という、「新しい使用人階級」というなんともいやらしいタイトルをつけた記事が最近出てましたが、その中にあったチャートです。
もとの記事に中では、こうした仕事はお金に余裕のある人達に雇われるような仕事だということで、ウェルス・ワークと呼んでいましたが、逆に、昔であればお金持ちの人たちにしかアクセスすることができなかったようなサービスが、今ではより多くの人達がスマホのアプリなどを通して気軽に使えるようになったということではないでしょうか。
「ギグ・エコノミー」とかいわれているやつですね。
ただこうした仕事は、都市部に多く、給料が安く、多くは女性によって行われています。そして、そのうちの20%ほどがアメリカ人ではない移民の人たちによって行われているというのも事実です。
こうした仕事はAIの自動化の波で失くなっていくのではなく、逆にもっと多くの人を必要としているというのは、ついつい見落としがちです。
特にシリコンバレーでは、あいかわらずの好景気で、スタートアップは増え続け、IPO(株式公開)や買収を通してお金持ちの人たちもどんどん大量生産されているので、そういった人たちの需要を満たす「ウェルス・ワーク」というのは今後もさらに成長していくようです。
Quote of the Week
“Learning is the only thing the mind never exhausts, never fears, and never regrets.”
「学ぶ」というのは、心が疲れ切ってしまうことがなく、恐れることがなく、後悔することがない唯一のものだ。
レオナルド・ダ・ビンチ
What Are We Working On?
Exploratory v5.3.2
まだ、Exploratory v5.3.2パッチ、出せていません!
Oh Noooooo!!!!!
しかし、Good Newsは、遅れたせいでピボット・テーブルでカスタムの計算ができるようになりました!
さらに、ノートやダッシュボードを開くのがデフォルトで別ウィンドウで開くようになるのですが、その開くときのパフォーマンスかなり改善されました。
数日中に出ると思いますので、ユーザーの方はしばしお待ち下さい!
Exploratory データ・アカデミー
EDAサロン
探索的データ分析を実際にやりながらオンラインで学ぶ場として「EDAサロン」をやっています。
今月8月は世界の家畜生産量データです。
詳細はこちらのページにあります。誰でも参加できるので、ぜひカジュアルに参加してみてください!
先日、Team Exploratoryの林が一人あたりの羊の数をチャートにして出しています。
- 人口一人当たりの家畜の頭数の推移(大陸別) - リンク
Exploratoryアワー
毎週火曜日のお昼12時はExploratoryアワーです。
Exploratoryのユーザーの方からいただいた、データに関する質問にライブデモを通して答えています。
先週は、以下の2つの質問に答えました。
- データをExcelやCSVのフォーマットで共有できますか?
- データを再現可能な形で共有できますか?
詳細や過去の録画はこちらのページにあります。
Exploratory オンラインセミナー
冒頭にもお伝えしたように、今週のオンラインセミナーは金曜日30日の午後12時(日本時間)です!
今週は、「ファクター」という順序付きカテゴリーのためのデータタイプの紹介をします。
このデータタイプはチャート、統計、機械学習など、いろんな場面で出てくるので、ぜひ皆さんに知ってもらって使いこなせるようになってもらえればと思っています。
ちなみに先週の「線形回帰 Part 2 - 重回帰、係数の解釈、変数重要度」のセッションの録画とスライドはオンライン・セミナーのページにアップしてあります。
データサイエンス・ブートキャンプ、11月開催!
毎回好評をいただいているデータサイエンス・ブートキャンプですが、次回は11月です!
データサイエンス、統計の手法、データ分析を1から体系的に学び、ビジネスの現場で使えるようになりたいという方は、ぜひこの機会に参加をご検討ください!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。