複数の列をいっぺんに集計する方法
例えば以下のようなデータがあって、全てのQで始まる列の平均を出したいとします。
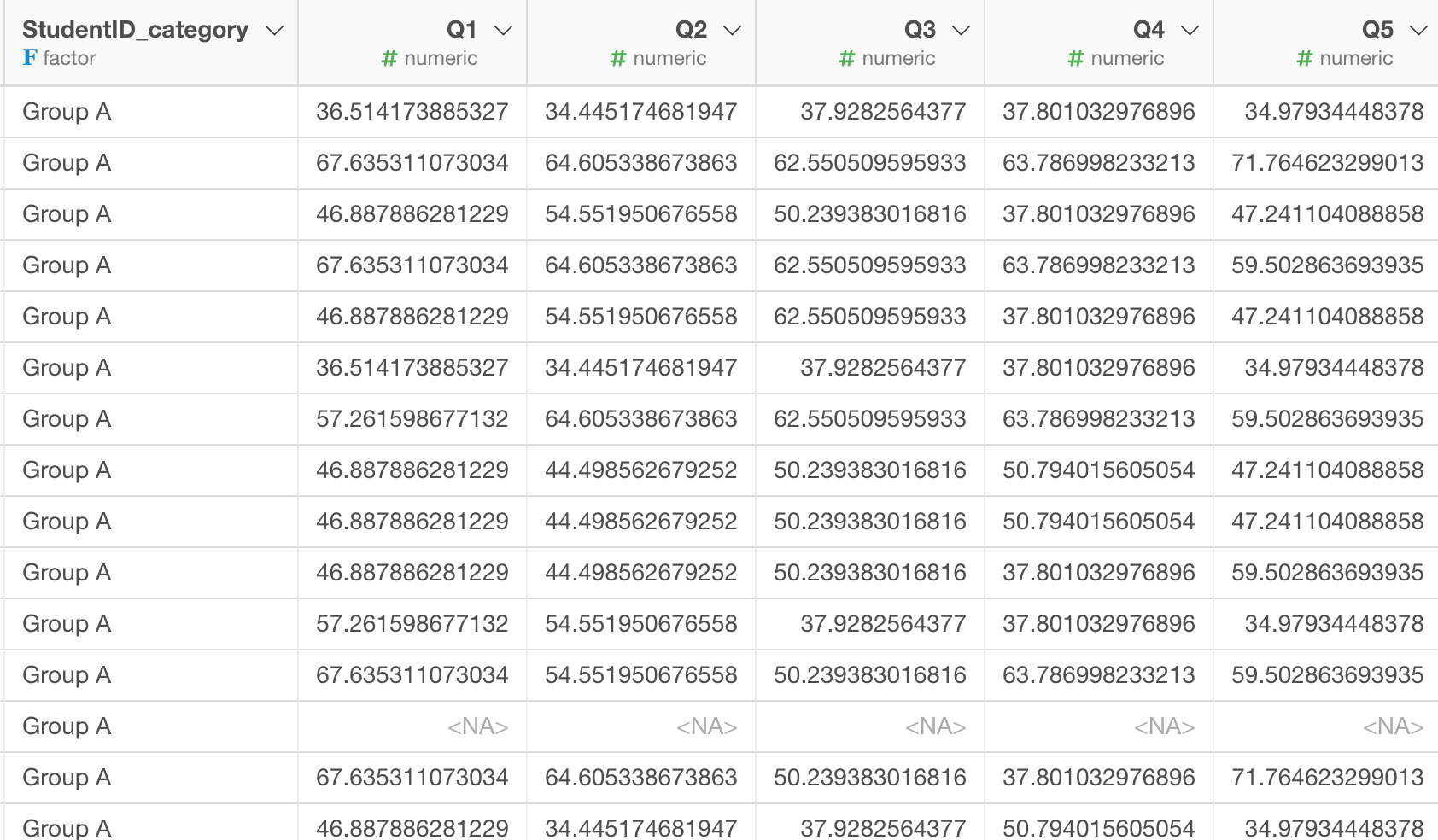
この場合、一列ずつやっていくのはめんどくさいですね。特に集計したい列が50個とかあった場合は大変です。
そんな時に便利なRのコマンドがあります。
Exploratoryの中で集計を行う時は、summarizeというコマンドを裏で使っているのですが、その家族のようなコマンドで以下のものがあります。
- summarize_all
- summarize_at
- summarize_if
基本的にはどれも複数の列の集計をまとめてやってしまうものなのですが、どのように複数の列を選びたいかによって使い分けすることができます。
これからそれぞれを紹介したいと思いますが、まずその前に2つほど。
データのグループ化
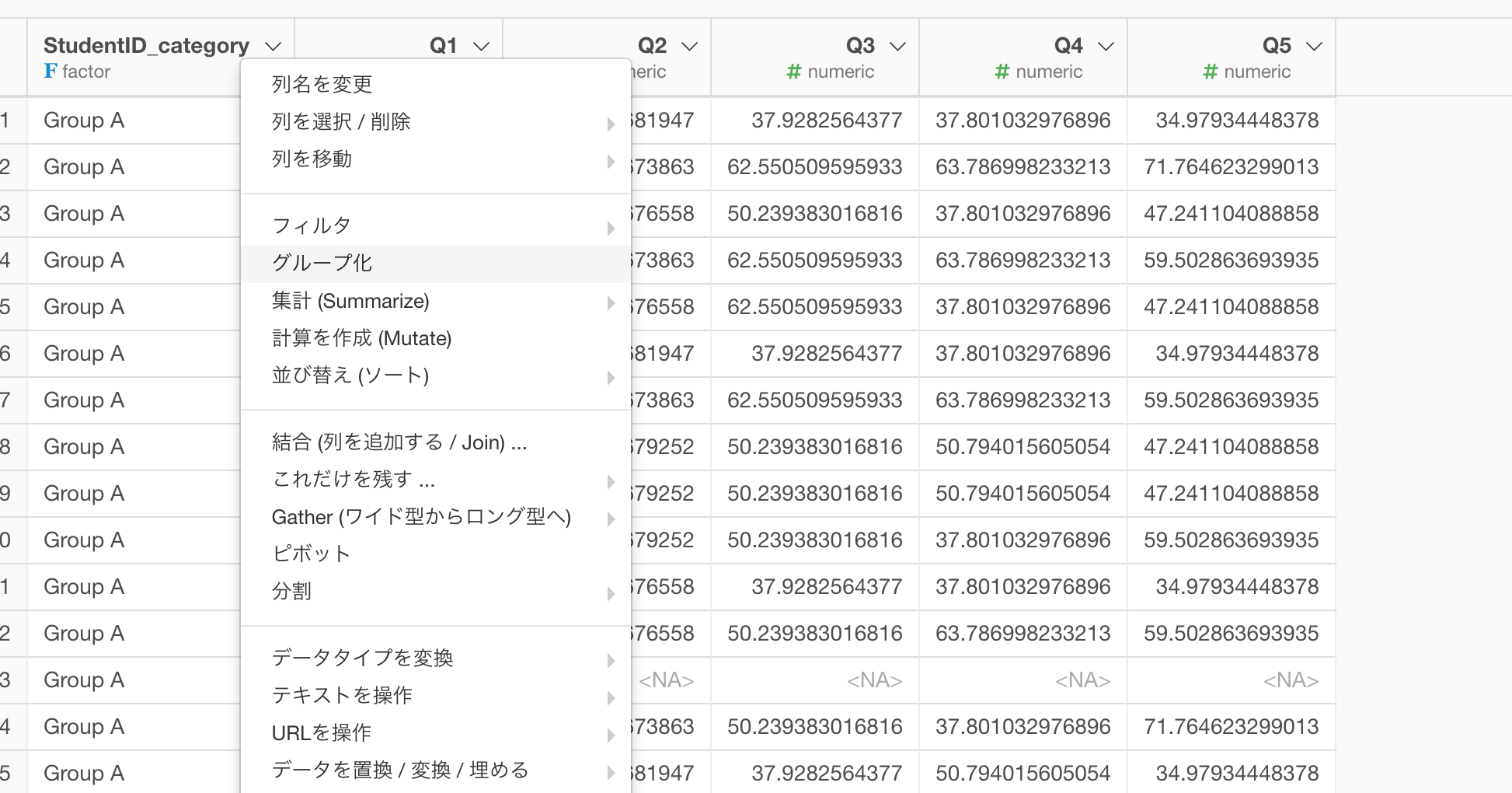
集計の処理を行うのでまず最初にデータをグループ化しておく必要があります。今回は「StudentID_category」という列の値ごとにそれぞれの列(Q1、Q2、など)の平均を求めたいので、StudentID_category列を使ってグループ化します。
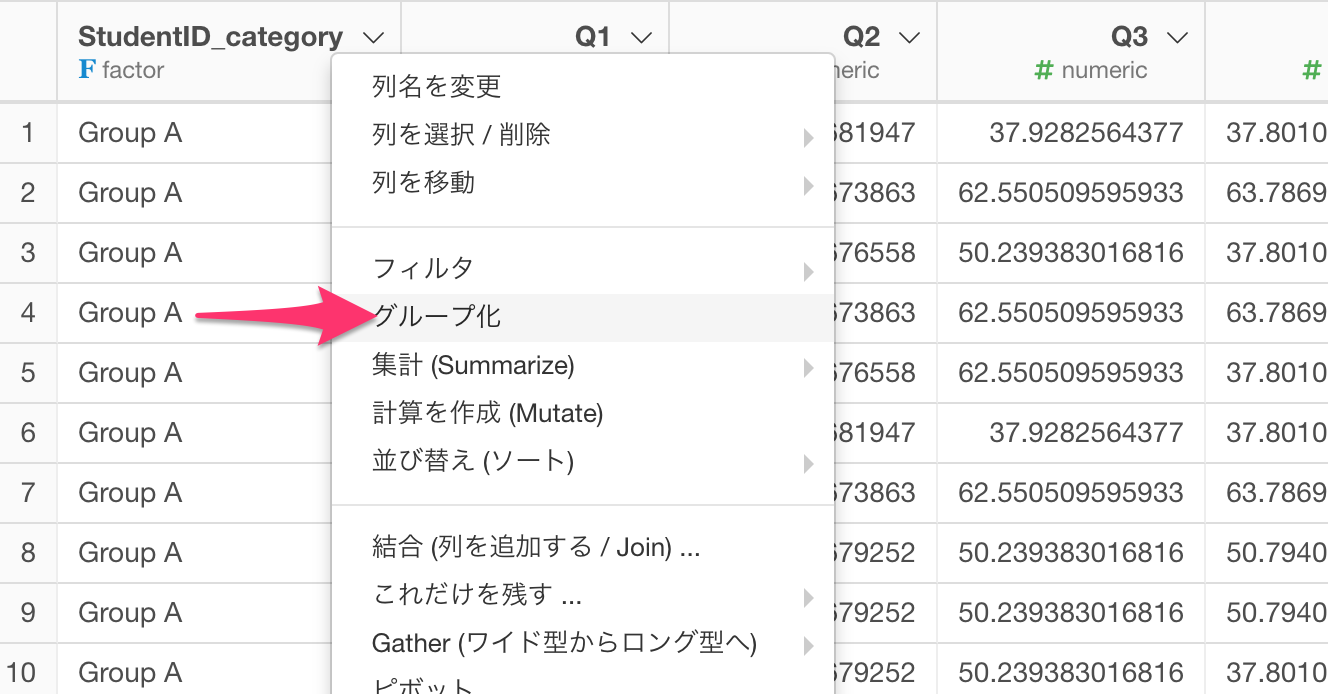
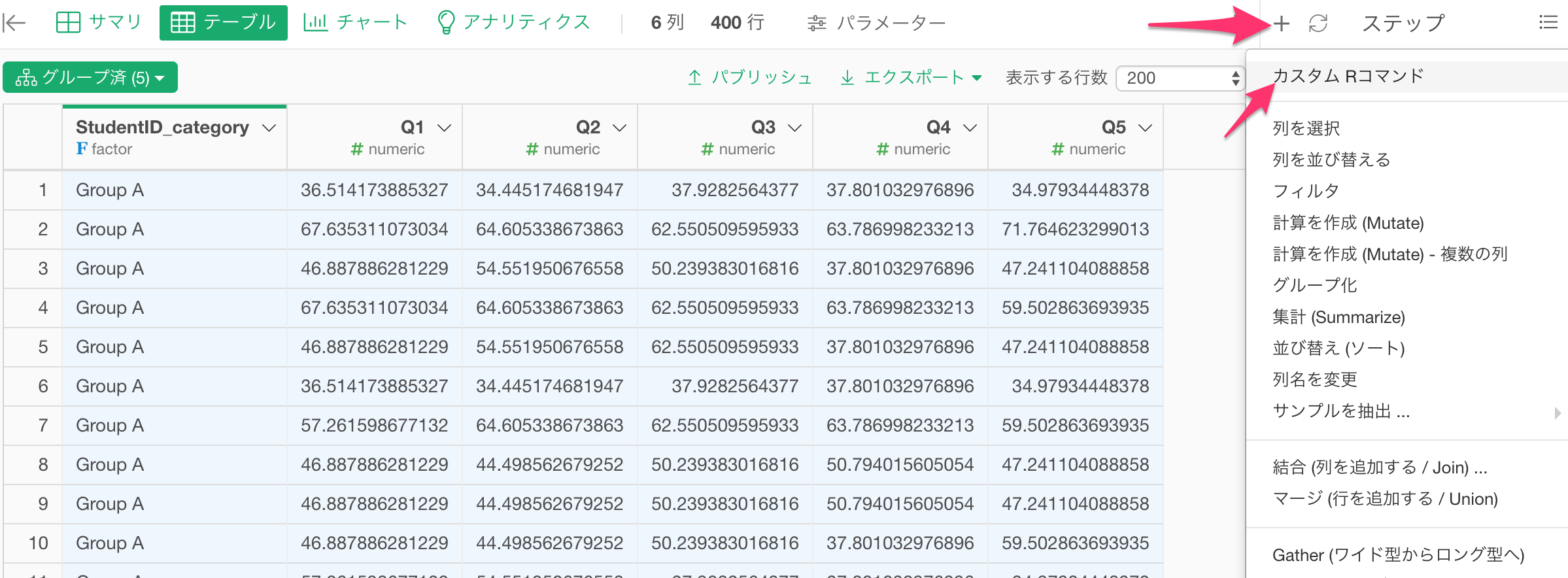
カスタムRコマンド
今回使うコマンドはUIでサポートされていない、Rのコマンドなので、カスタムRコマンドのステップを使うことになります。
それでは、1つずつ見ていってみましょう。
Summarize All
これは、問答無用に全ての列に対して集計処理を行います。(笑)
今回の場合はこれでもいいです。
以下のコマンドをカスタムRコマンドとして入力します。
summarize_all(funs(mean(., na.rm=TRUE)))
summarize_allの中身ですが、funsという関数の中にどのような集計処理をしたいかを記述します。今回は平均を出したいので、meanという関数を呼んでいます。
ただ、このデータの中にはNAの行があります。その場合mean関数をそのまま使うとNAという計算結果が帰ってきてしまいます。
そこで、mean関数の中でna.rm=TRUEという引数を設定しておく必要があります。na.rm はNAをRemove(取り除く)という意味です。
また、最初のドット (.)ですが、これは複数の列に対して行う処理なのでどれか一つの列の名前を指定する代わりに、このドットで「それぞれの列」ということを表しています。
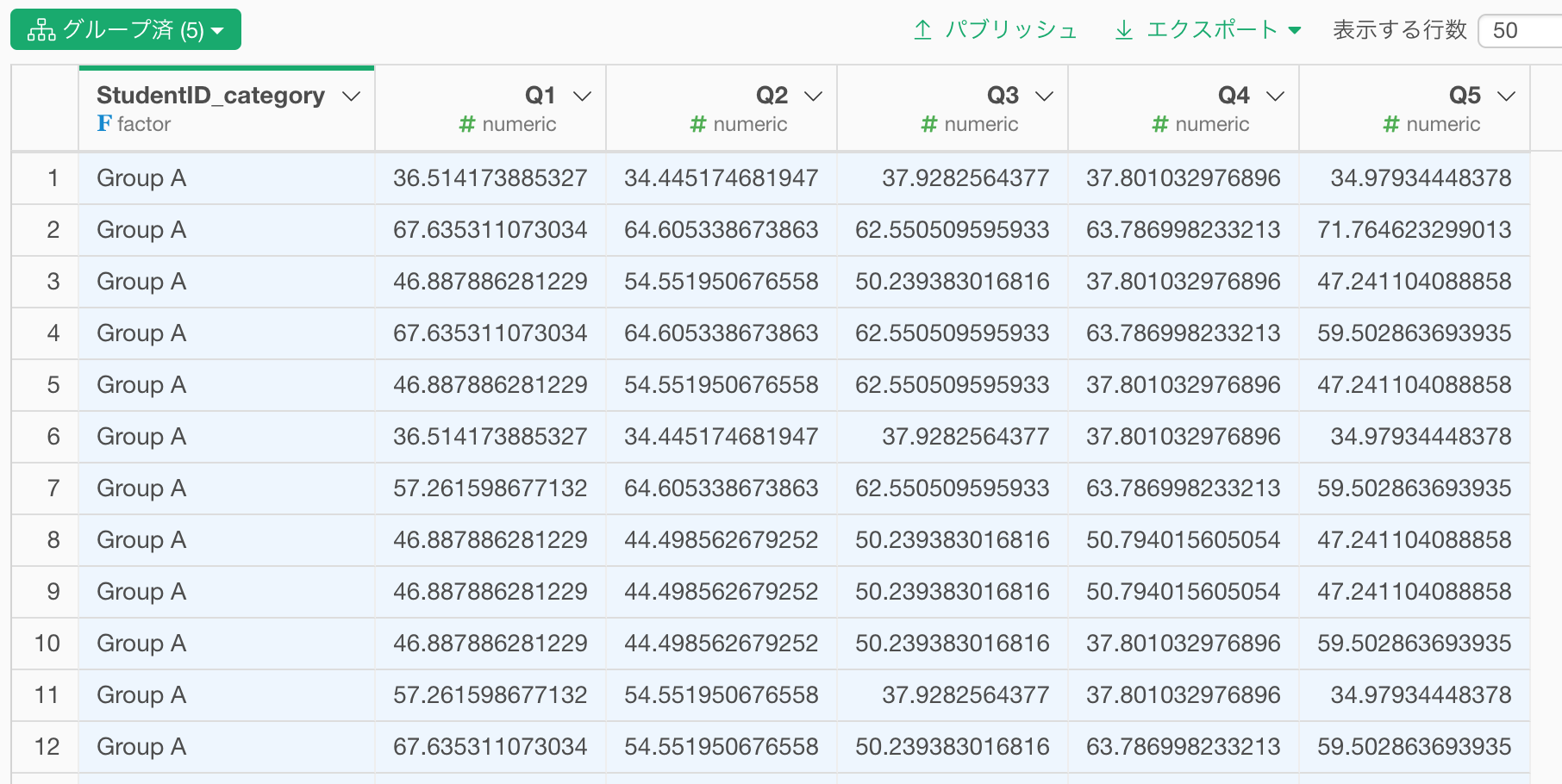
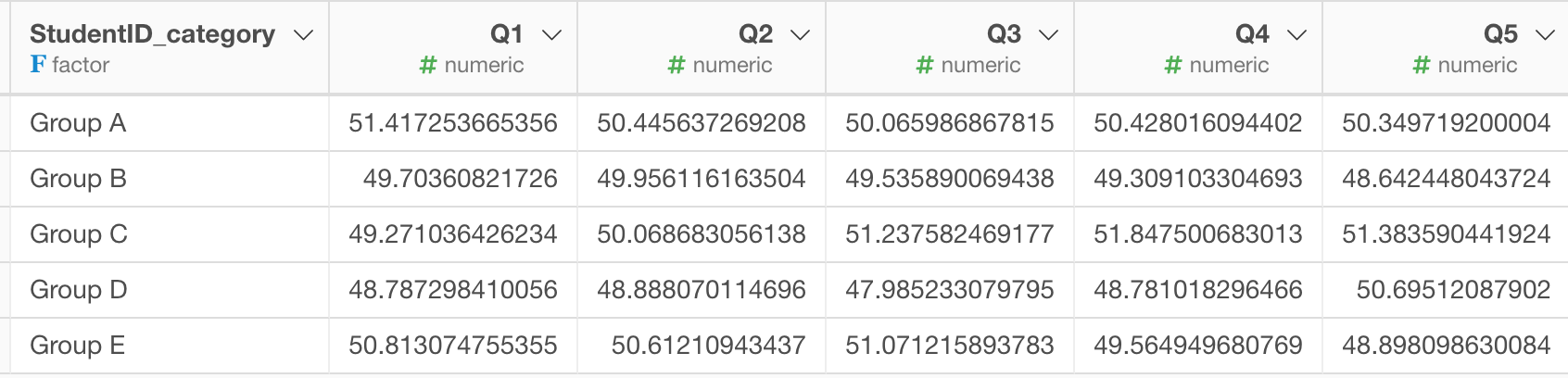
上のコマンドを実行すると以下のようにそれぞれの列に対する集計処理が一気にできます。
Summarize At - summarize_at
このコマンドは列を丁寧にしていくことができます。
varsという関数の中で列を選んでいくことになります。
例えば、今回はQ1という列から始まって、Q5 という列までの全ての列に対しての集計を行いたいので、
vars(Q1:Q5)と指定することができます。
今回の場合は、summarize_atコマンドは以下のようになります。
summarize_at(vars(Q1:Q5), funs(mean(., na.rm=TRUE)))
Summarize IF - summarize_if
このコマンドは、列を「条件」を使って選ぶことができます。たいていの場合は、列のデータタイプを条件として使うことになります。
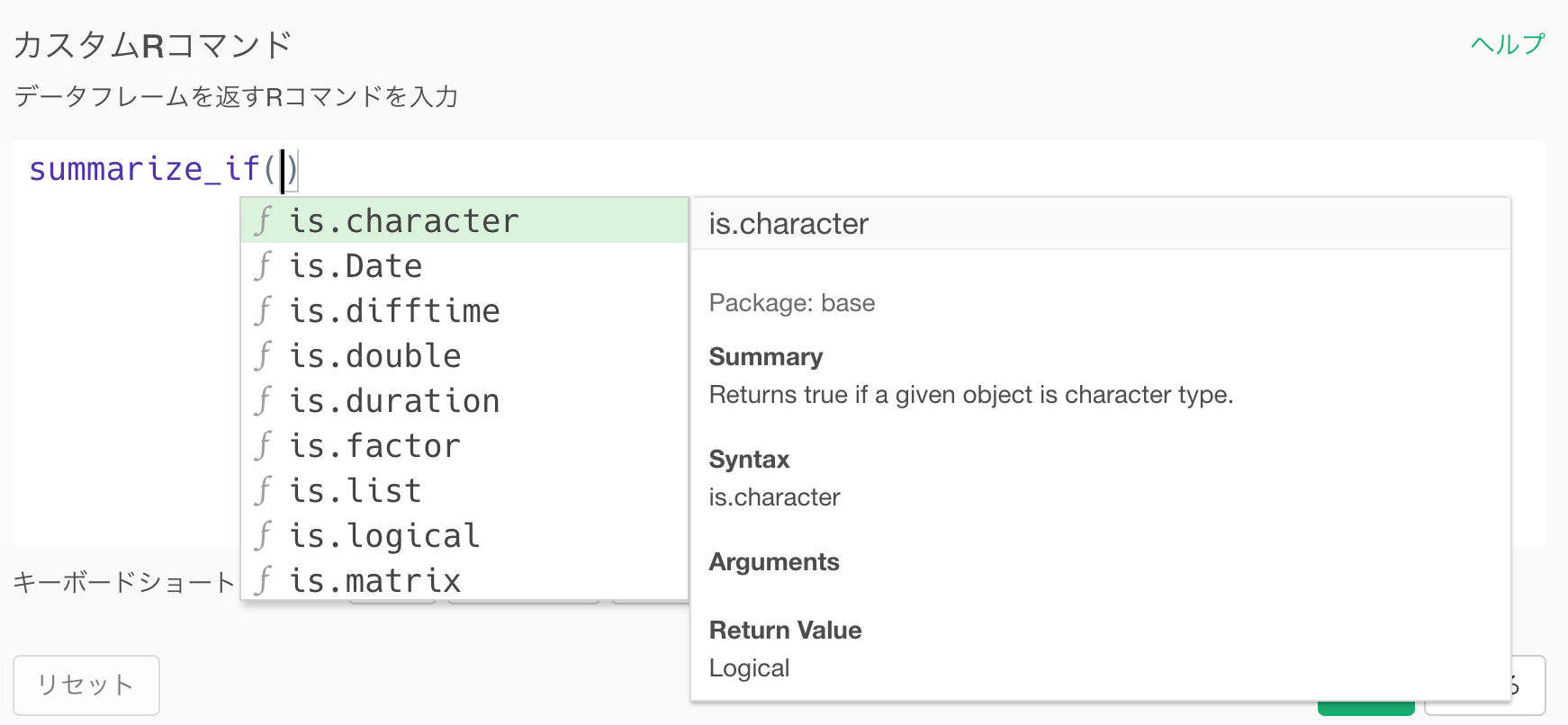
例えば、今回の場合は全ての数値型(numeric)の列に対して集計作業を行いたいので、is.numericという関数をかっこ無しで最初に指定します。
summarize_if(is.numeric, funs(mean(., na.rm=TRUE)))これで、例え他に数値型以外の列があったとしても、数値型の列だけに対して集計処理をし、後は無視します。
