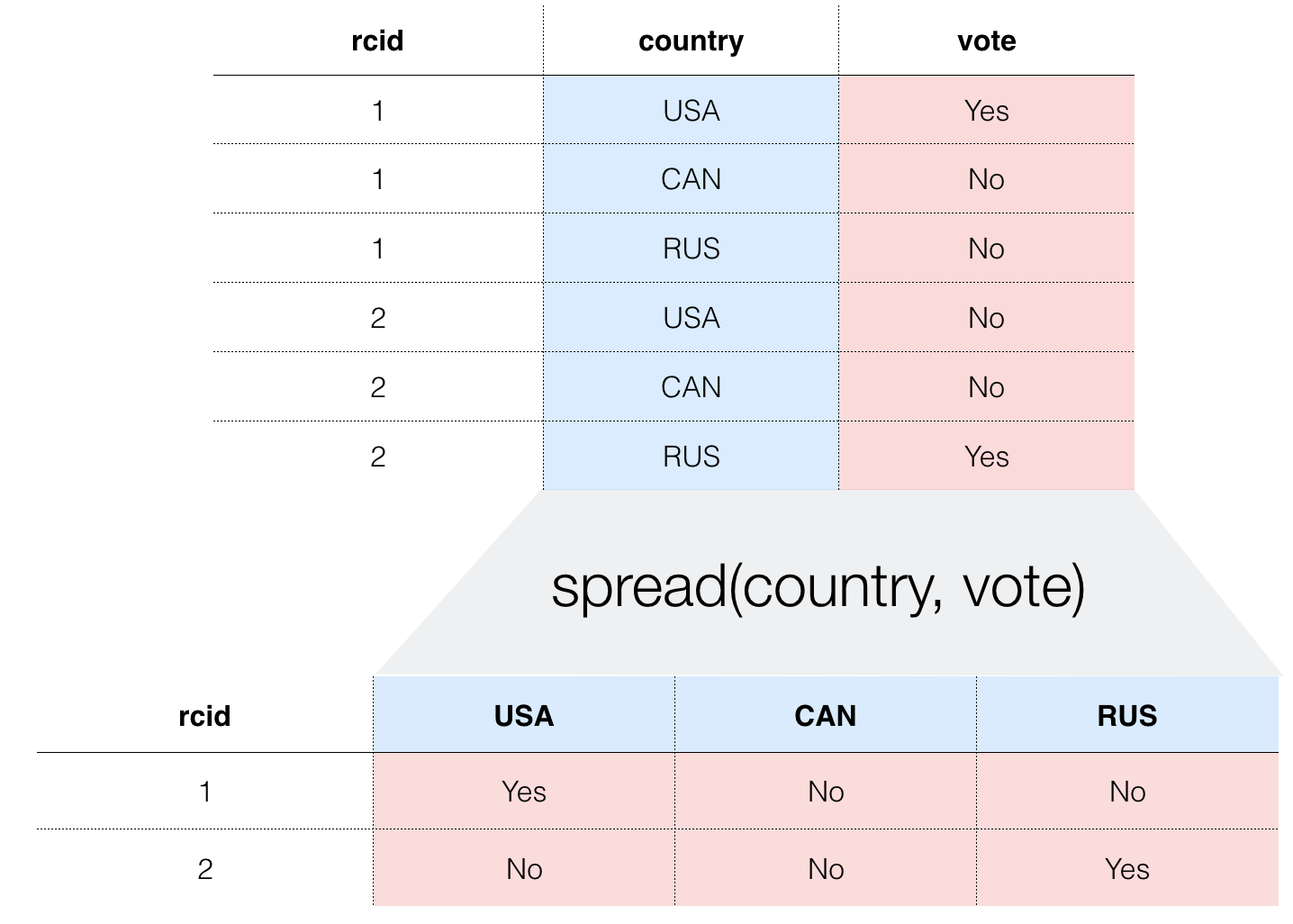
あるカテゴリー列にあるデータを、カテゴリーごとに独立した複数の列にデータの形を変換するSpreadという操作についてご紹介します。なお、この操作は、横に広がったデータ(ワイド型)を縦に広がるデータ(ロング型)に変換するで紹介しているGatherという操作の反対の操作になります。
どんなときに使うのか
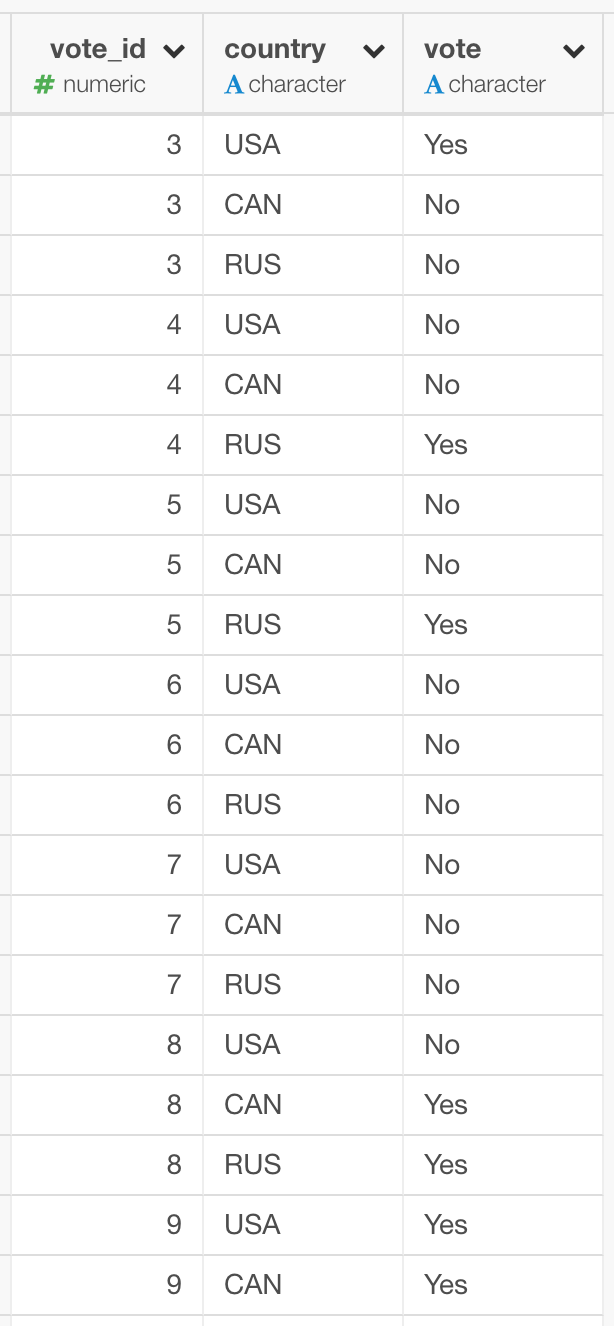
Dataverseの国連総会投票データページにある、国連決議への投票データを例に説明したいと思います。このデータの各行は、それぞれの決議ごとへのそれぞれの国の投票内容が入っています。簡単にするために、列を決議ID(vote_id)、国名(country)、投票内容(vote)の3つに絞り、アメリカ、カナダ、ロシアの3カ国にフィルターしたデータの例が下の図になります。データは、1行目は決議3に対するアメリカ(USA)の投票、2行目はカナダ(CAN)の投票、3行目はロシア(RUS)の投票、というような構造になっています。
データの加工をしていると、しばしば、こういったデータを以下の図のように、このアメリカ、カナダ、ロシア、といった国々を、それぞれの列に割り当てるような形にデータを変換したい、というケースにぶつかります。
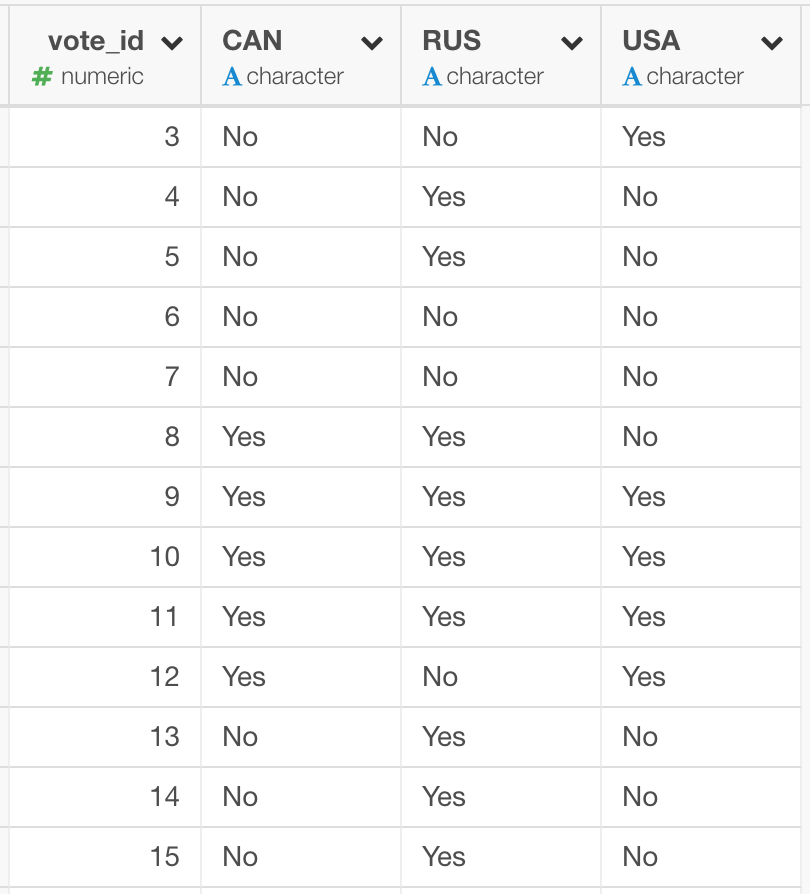
この操作を実現するのが、Spreadコマンドです。
ちなみに、この変換後の、国が増えてごとにデータが横方向に伸びていく(列が増えていく)ようなデータ構造をワイド型のデータ、それの対して、変換前の、データが増えると行が増えていくようなデータ構造をロング型のデータと呼びます。Spreadコマンドは、ロング型のデータをワイド型に変換する操作です。
使い方
上記の例のロング型のデータをワイド型に変換するの場合、以下のように行います。
テーブルビューを表示し、コマンドキー(Windowsの場合はコントロールキー)を押しながらcountry列、voteの列をクリックし両方のカラムを選択します。その後、列ヘッダメニューからSpread(ワイド型からロング型へ)を選択します。
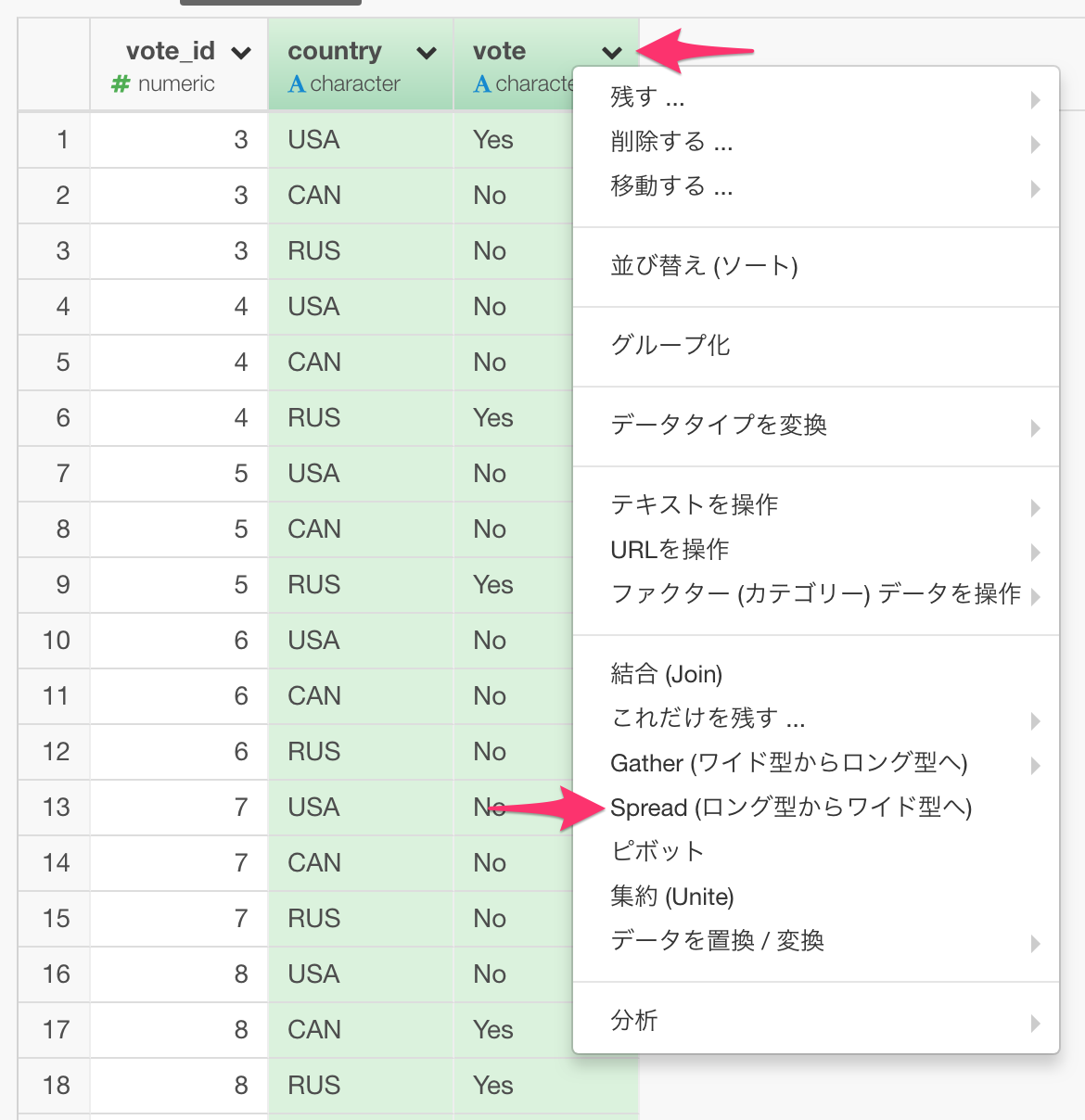
ダイアログが現れるので、キー列に“country”、値の列に“vote”が選択されているのを確認して実行します。
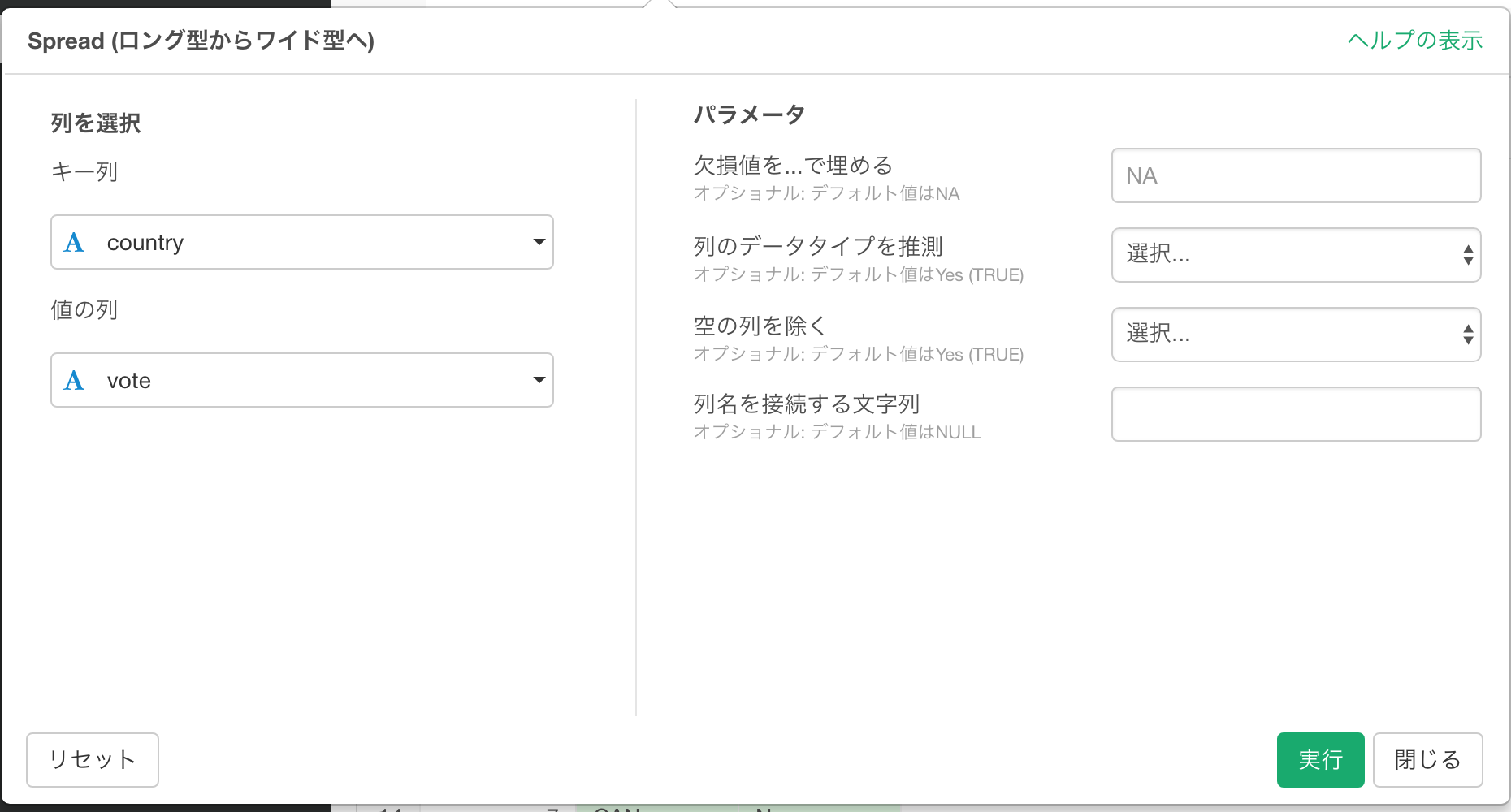
Spreadの操作が完了し、データ構造が変換されました。
まとめ
今回は、ロング型のデータをワイド型に変換するSpreadコマンドを紹介しました。Spreadコマンドの動きを図にまとめてみましたので、復習もかねて参考にしていただければと思います。
ちなみにこちらのSpreadによるデータの加工は、ベン図による分析を行うための前処理で行いました。興味がある方はこちらもぜひご覧ください。また、こちらに今回使用したデータをまとめておきました。EDFファイルをダウンロードしてExploratoryにインポートすることで、実際にどのようにステップが作られているかがわかります。
データ分析をさらに学んでみたいという方へ
Exploratory社がシリコンバレーで行っている研修プログラムを日本向けにした、データサイエンス・ブートキャンプが東京で行われます。上記のようなデータサイエンスの手法を、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。