ワードクラウドを使ってテキストデータを可視化する

ワードクラウドは、テキストデータを視覚的に表現するのにとても効果的な方法です。Exploratoryでは、テキストデータを取得して、ワードクラウドを作ることが簡単にできます。ここでは、実際にTwitterから、安倍首相に関するツイートのデータを取得して、実際にワードクラウドを作る方法について説明します。
データの取得
まず、Twitterからツイートのデータを取得します。プロジェクトを開き、画面左側の「データフレーム」の右にあるプラスボタンをクリックして、「クラウドアプリケーションデータ」を選択します。
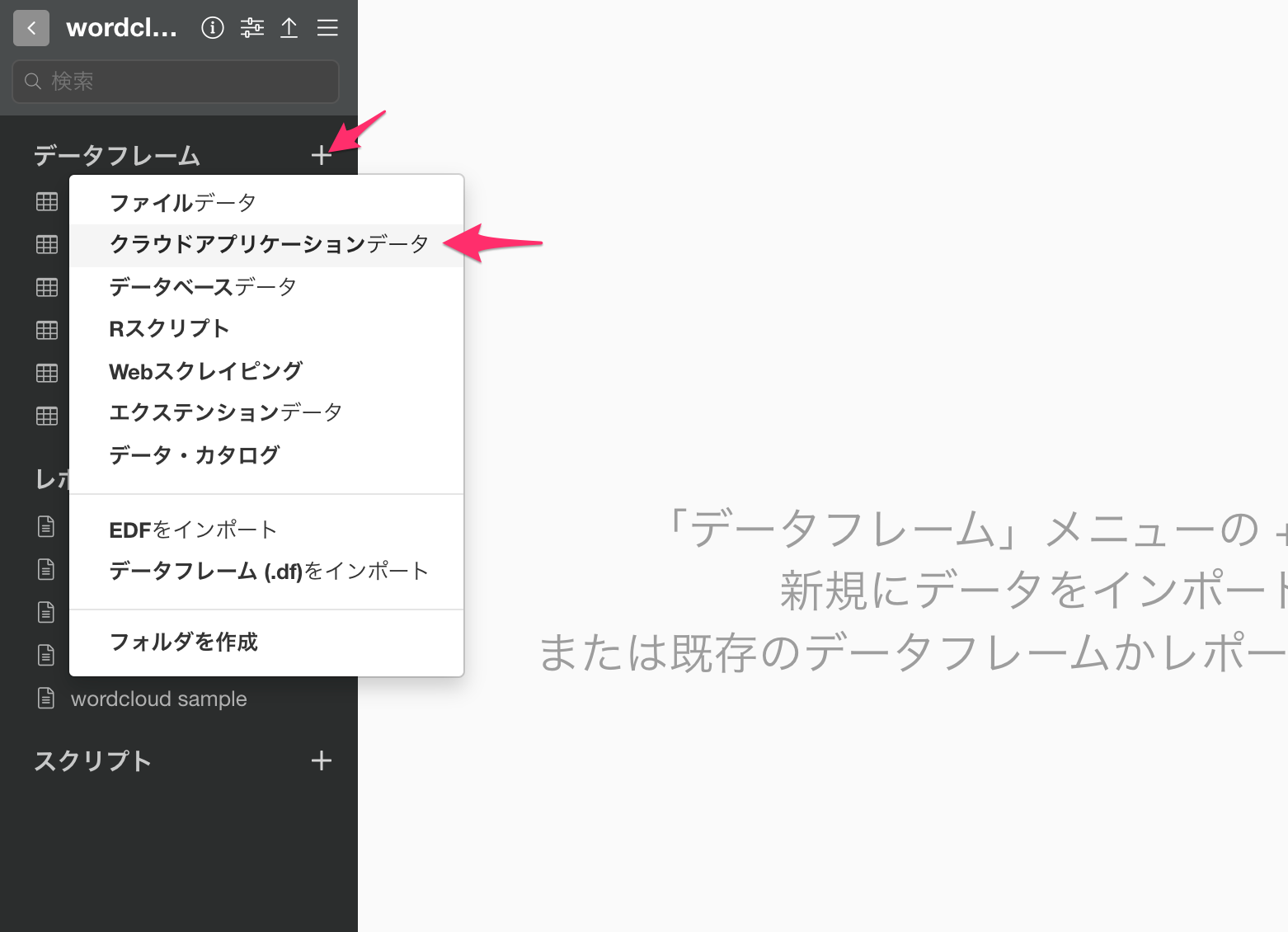
「Twitter Search」を選択します。
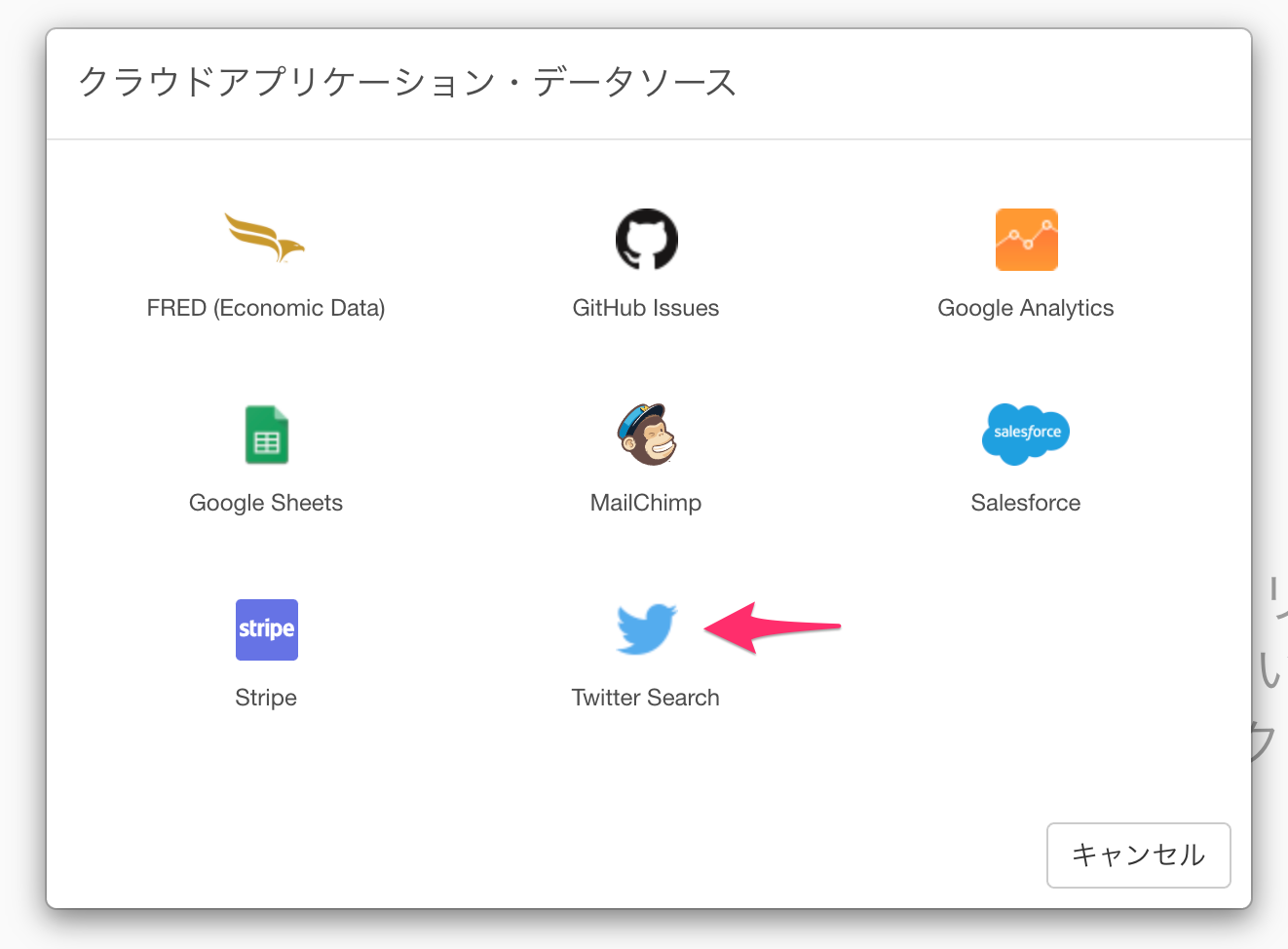
検索キーワードに「安倍首相」と入力し、言語に「日本語」を選択して、「実行」ボタンを押します。すると、「安倍首相」をキーワードに含むツイートの一覧が表示されます。「保存」ボタンを押して、データをデータフレームに保存します。
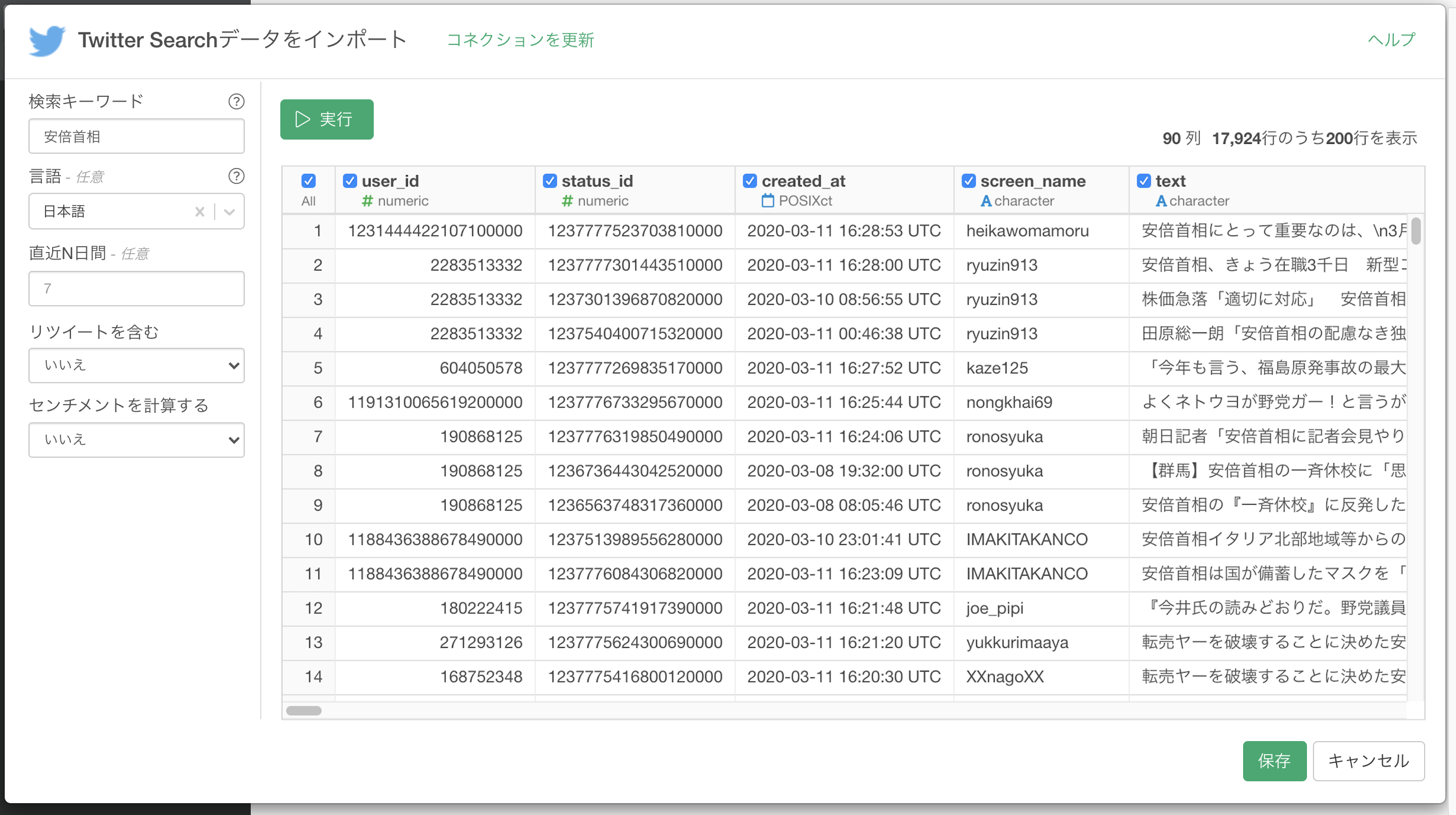
以下のようなデータフレームが作成されました。
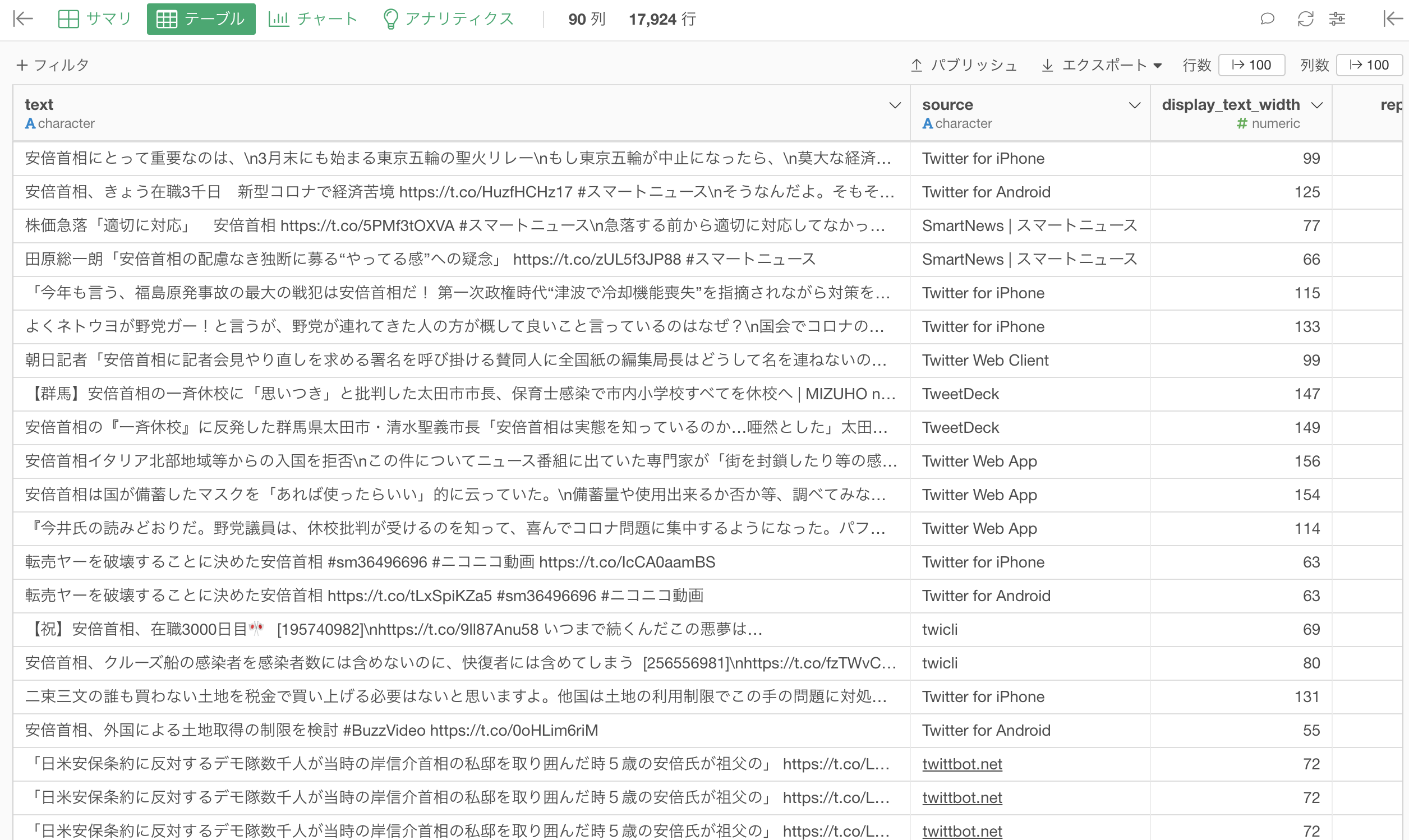
ワードクラウドを作成する
データの準備ができたので、次に、ワードクラウドを作成してみましょう。「単語のカウント」のアナリティクスを使うと、簡単に作成することができます。
アナリティクスのタブをクリックし、新規にアナリティクスを作成します。タイプには「テキスト分析」の下にある「単語のカウント」を選択します。
「テキストの列」にtext列を選択して、「実行」ボタンを押します。すると、ワードクラウドが表示されます。

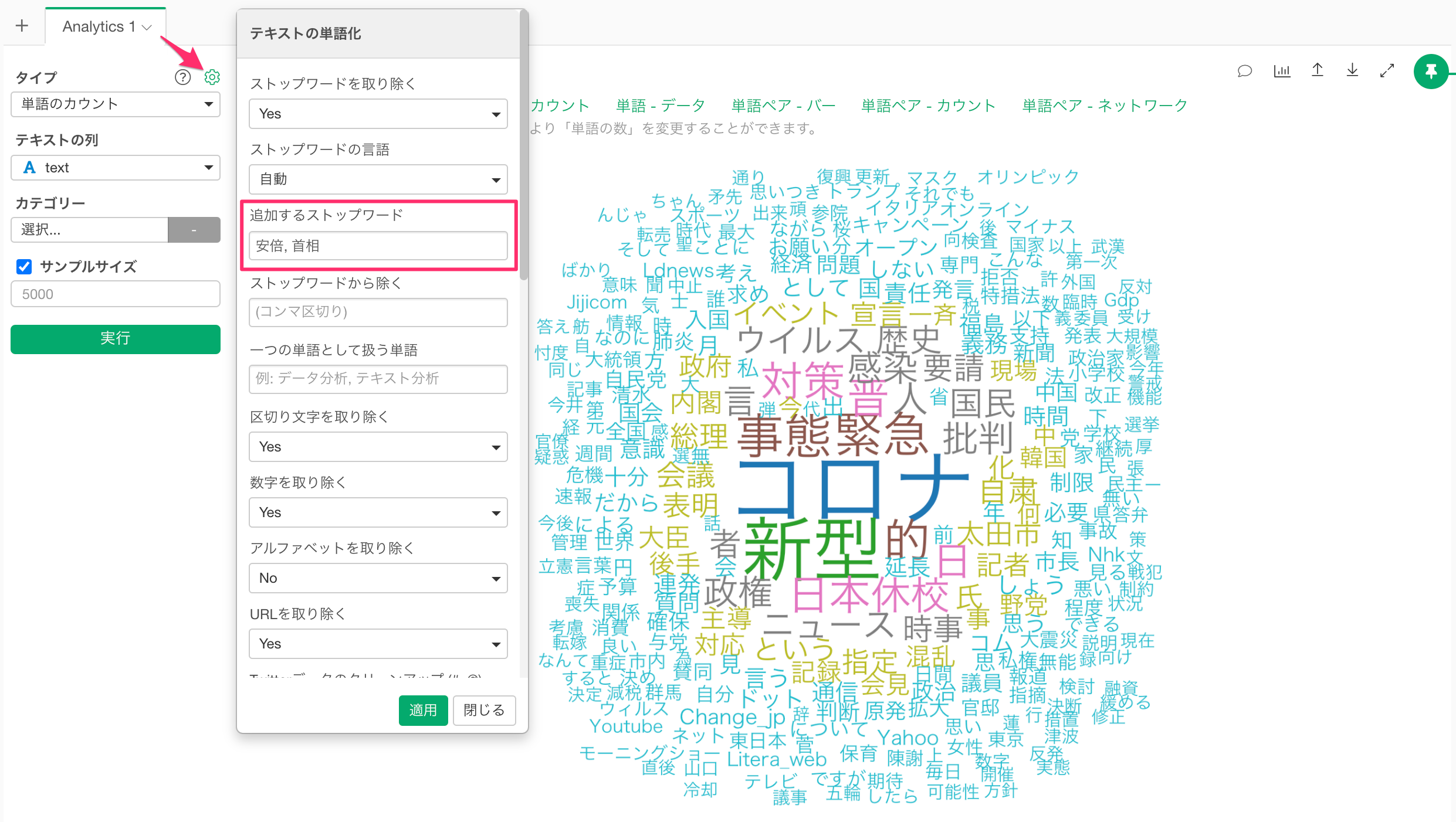
「安倍」「首相」をワードクラウドから取り除く。
作成されたワードクラウドの中央には、大きく「安倍」「首相」という二つの単語が表示されています。これは、データが「安倍首相」について検索した結果なわけですので、ある意味当たり前です。ワードクラウドから、これらの単語を取り除くには、歯車のアイコンをクリックし、「追加するストップワード」に「安倍,首相」とカンマ(,)で区切って入力します。入力が終わったら「適用」ボタンをクリックしてください。
自分で試してみる
まだExploratoryをお持ちでない方は、この機会にぜひ試してみて下さい!
こちらのページよりサインアップ(無料)した後、Exploratoryをダウンロードし始めることができます!
データサイエンスを学ぶ
データサイエンスやデータ分析の手法を1から体系的に学び、現場で使えるレベルのスキルを身につけていただくためのトレーニングを定期的に開催しています。
データを使ってビジネスの問題を解決していくための、質問や仮説の構築の仕方などを含めたデータリテラシーも基礎から身につけていただくものとなっております。
ぜひこの機会に参加をご検討ください!