複数の列の値を調べる
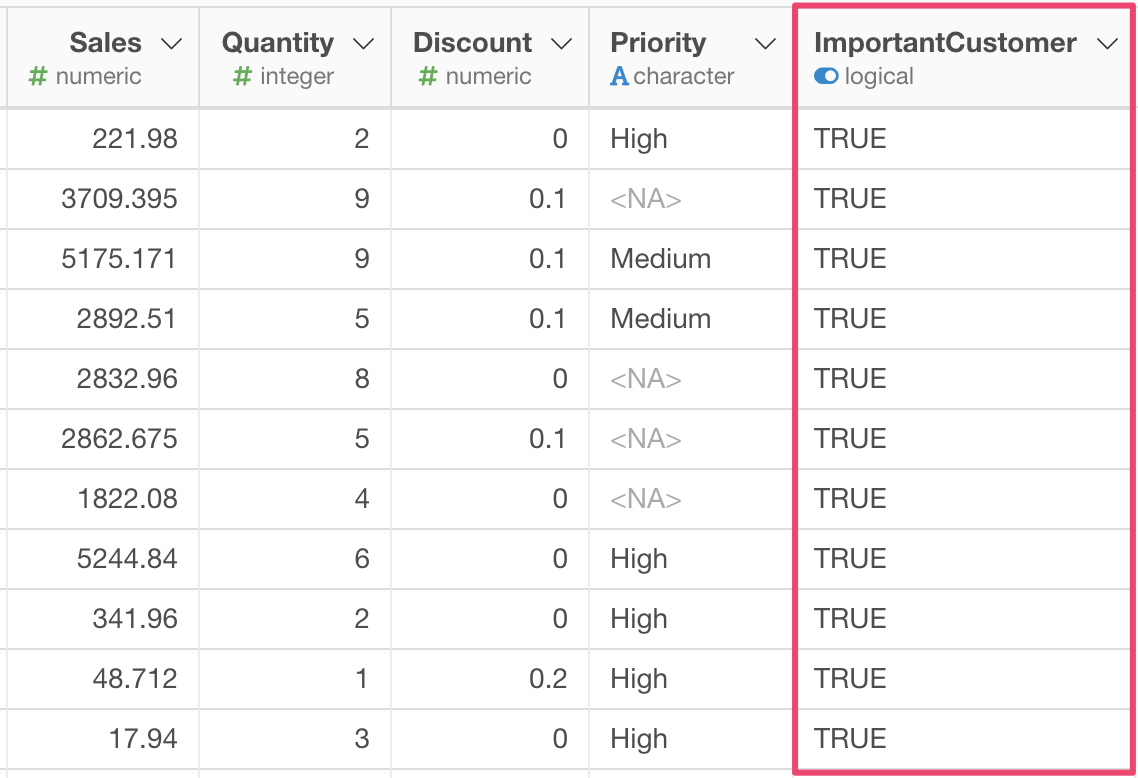
たとえば、以下のような売上データがあるとします。この中に、売上をあらわすSalesという列と、優先度をあらわすPriorityという列があります。
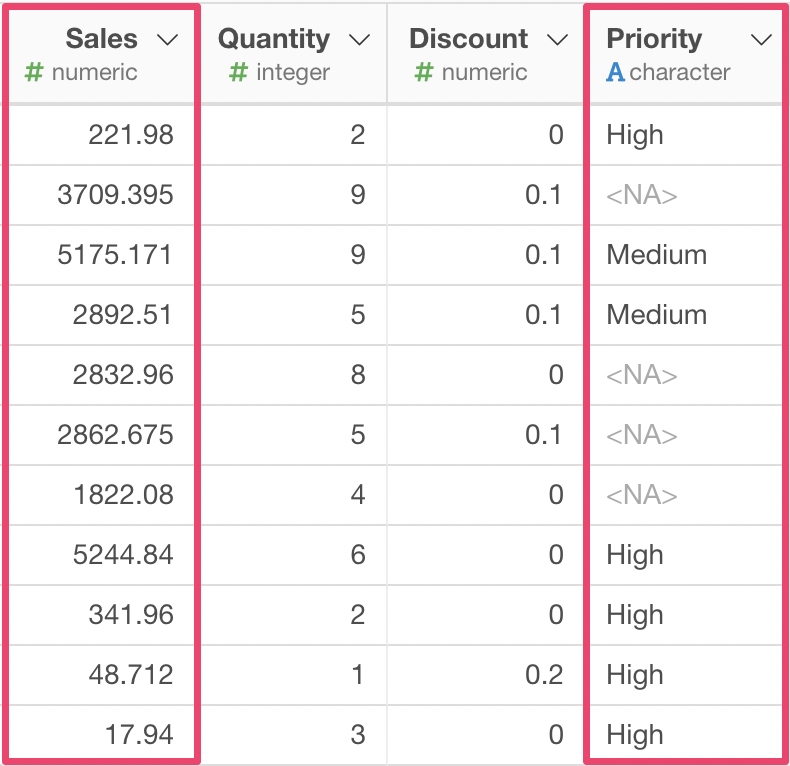
ここで、Sales (売上)の数字が大きく、なおかつPriority (優先度)がNAでないデータは重要な顧客による売上ということで区別をしたいとします。
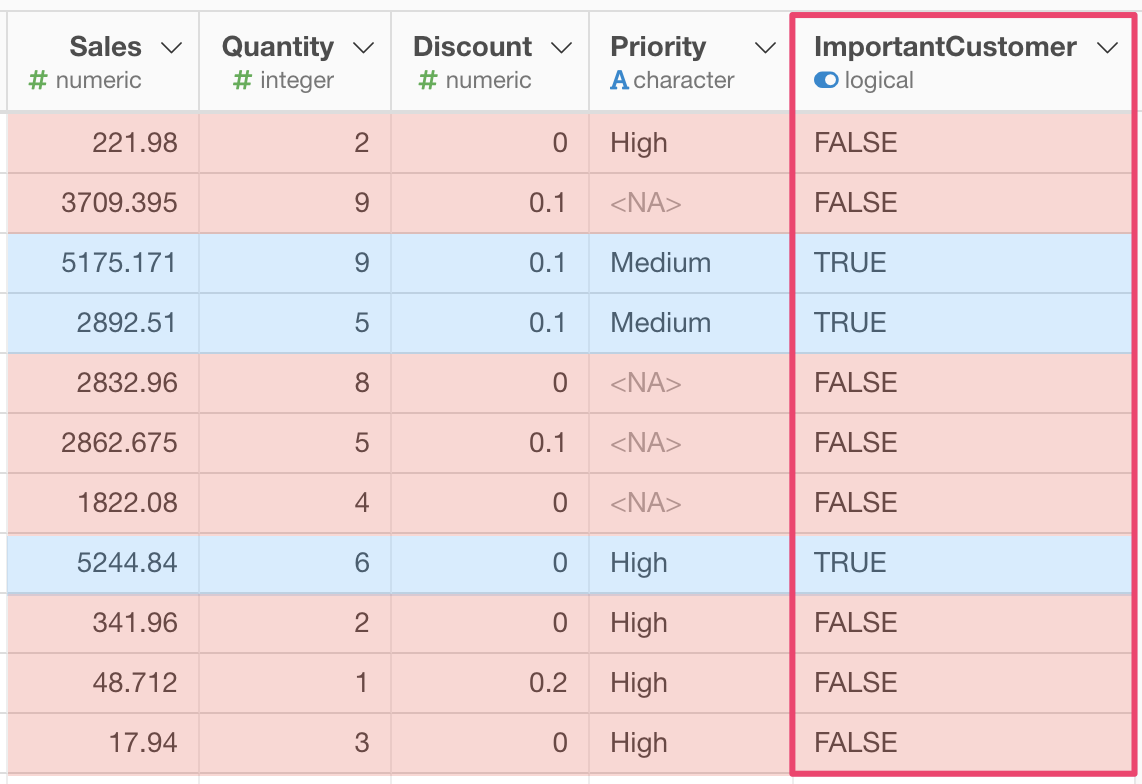
そこで、Sales が1000より大きく、なおかつPriorityがNAでないときにはTRUE、それ以外のときはFALSEの値が入るようなImportantCustomerという新しい列を作りたいとします。
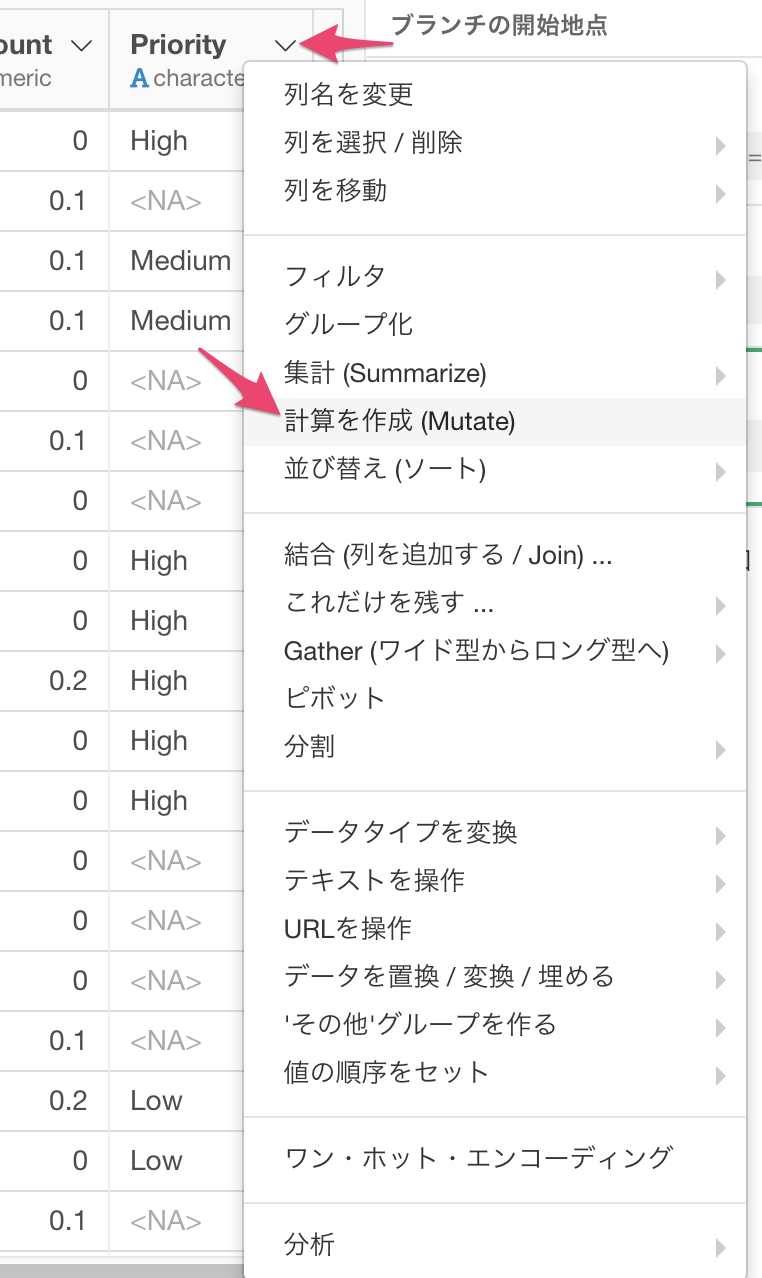
さっそく、作り方を見ていきましょう。まず、Priority列のカラムヘッダメニューから、計算を作成(Mutate)を選びます。
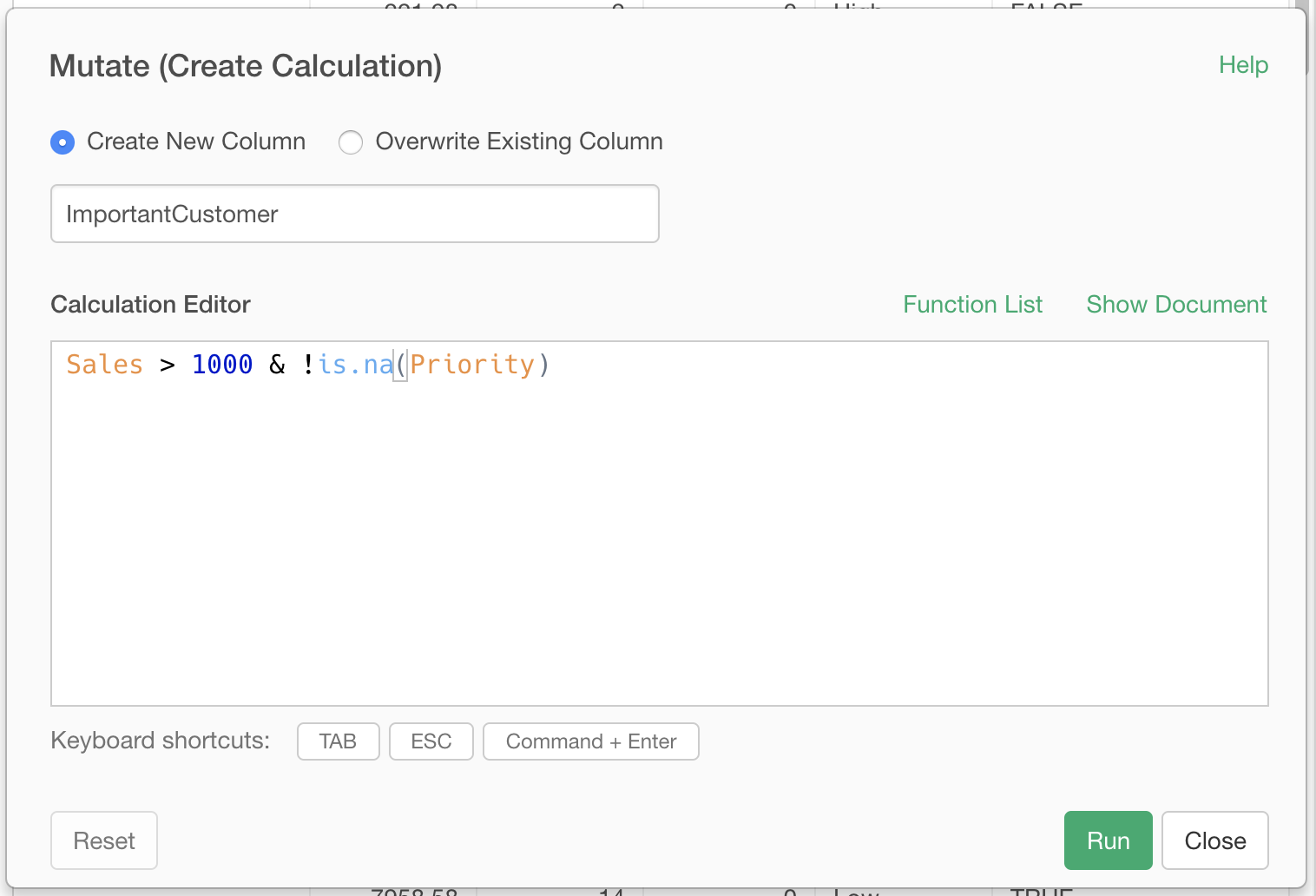
列名にImportantCustomerと入力し、計算エディタの中に
Sales > 1000 & !is.na(Priority)と入力します。この式は、2つの式と&演算子で成り立っています。詳細を見ていきましょう。
Sales > 1000この式は、Salesが1000より大きいときにTRUE、そうでないときはFALSEを返します。
!is.na(Priority)この式は、PriorityがNAじゃないときにTRUEを、そうでないときはFALSEを返します。詳しくはこちらの記事をご覧ください。
&“&” 演算子は、「なおかつ」を意味します。これは、比較する2つがともにTRUEのときにだけTRUEを、それ以外のときにはFALSEを返します。
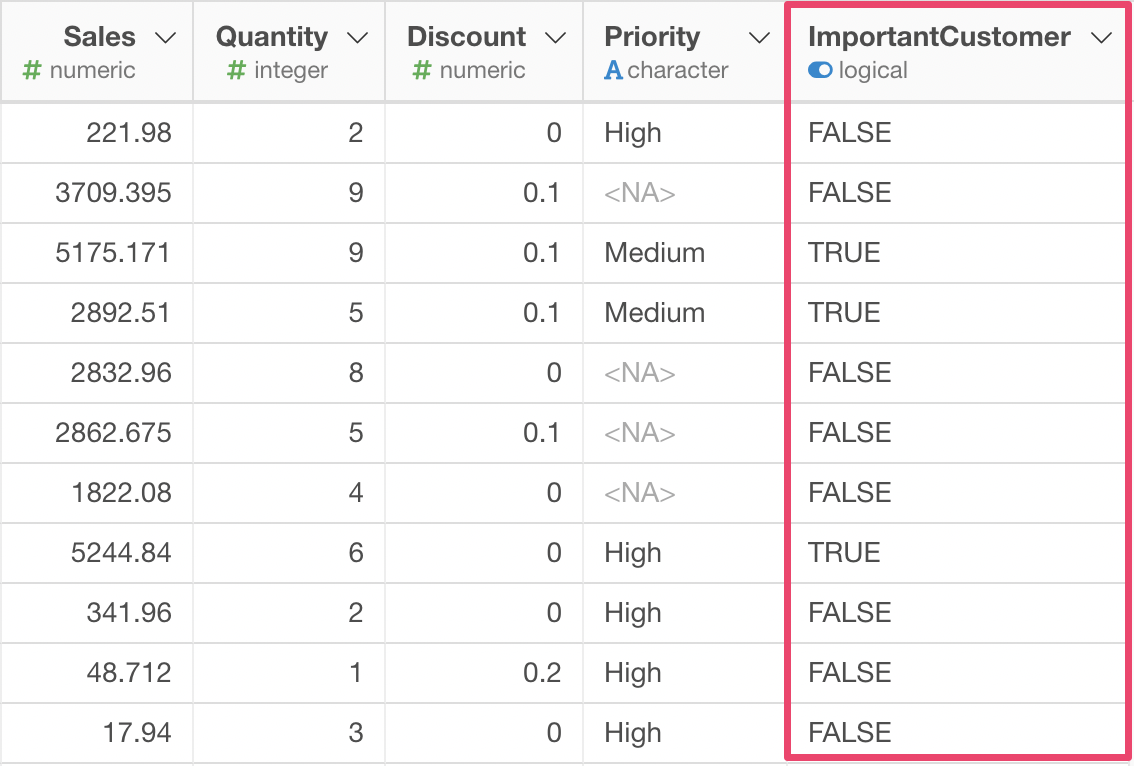
新しい列が作成されました。
「なおかつ」ではなく「もしくは」で計算したいとき。
もし、計算方法を、Sales が1000より大きい、もしくは、PriorityがNAでないときにはTRUE、それ以外のときはFALSEの値が入るようにしたい場合は、“&” 演算子のかわりに “|” 演算子 を使うことができます。
Sales > 1000 | !is.na(Priority)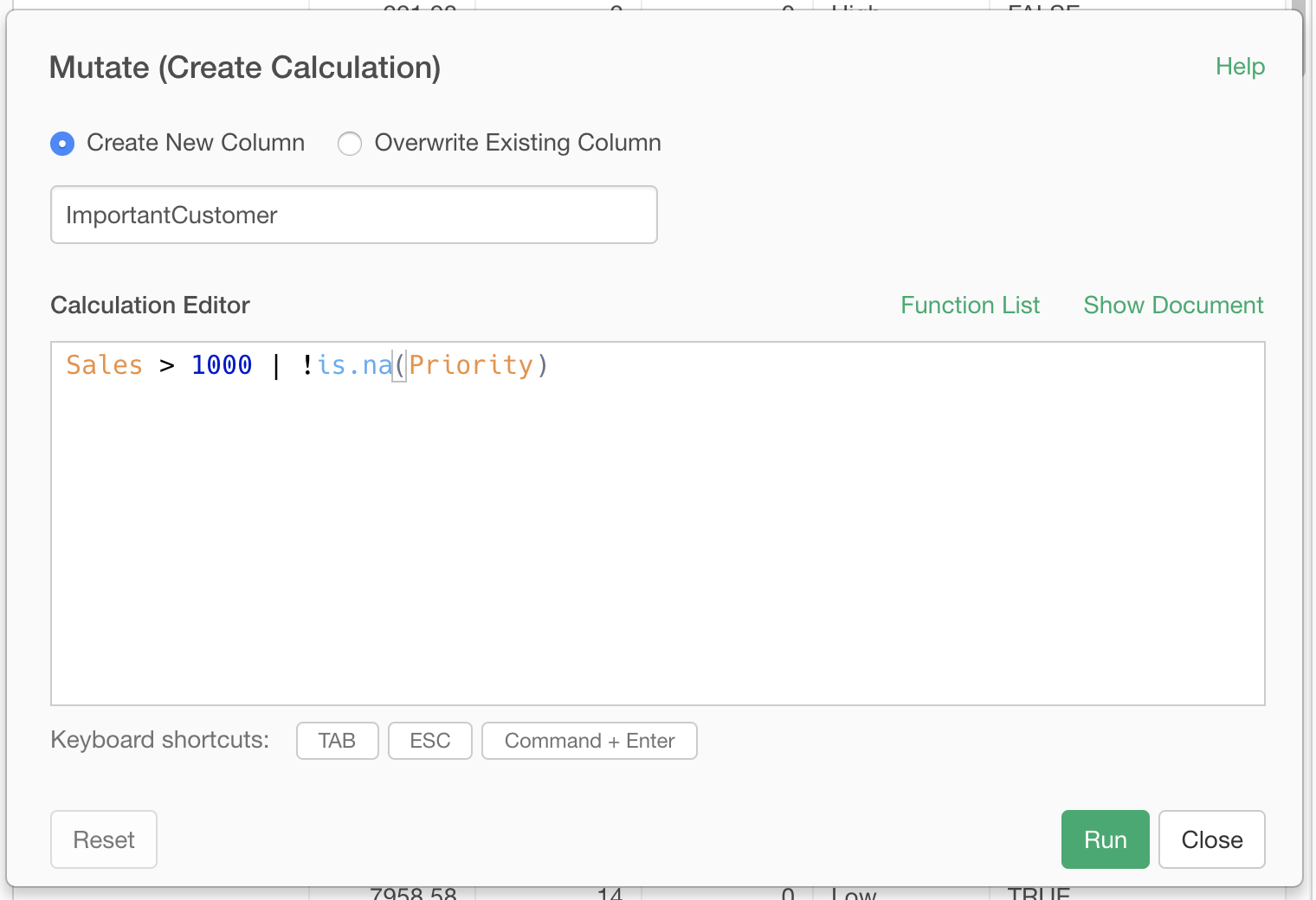
新しく作成される列はこのようになります。この場合はここに見えているデータに関してはすべてが条件を満たすようです。