初めてExploratoryをインストールしました。 「習うより慣れろ」ということで、EDASalon 第6回 - 日本の統計データ(e-Stat)のデータラングリング大会の趣味・娯楽の種類別行動者率データのラングリングに挑戦してみました。
データの概要
まずデータを確認します。 
まず以下の点に注目しました
4行目を列名にしたい
4行目に列名にあたるものがありそうです。1〜3列目をみると特に必要なさそうなので、csvの取り込みの際にskip = 4 を使えばできそうです。
総数はいらない
総数の列が複数あります。ラングリングする時は総数の行は無いほうがいいことがあります。 よくよく見るとX__11の列がNAの行は総数、またはデータに関係ない行のようなので、X__11の列でfilterすればよさそうです。ただ列名にする4行目がNAなので注意が必要そうです。
いらない列を減らす
集計に必要ない列がいくつかあります。 必要な列はX__11と列名(4行目)に名前がついている列になります。 そのためX__11をrenameで変更し、select関数でXで始まる列を省けばよさそうです。
計算できるように型を変更
全ての列がcharacterなので型を変更します。
性別の列を作る
ここまで進むと39行になります。X__30をみると男女合計13行、男性13行、女性13行と集計されていることがわかります。 そのためmutate関数とc関数、rep関数を使って性別の列を作りました。
mutate(性別 = c(rep("全体", 13), rep("男性", 13), rep("女性", 13)))longデータに変換
このままnestしてpurrrのmapで分析と思ったのですがExploratoryでのやり方が分からなかったのでlongデータに変換することにしました。
割合から人数を計算
割合が出ているのですが、直接的な人数を出して比較するのも面白そうかな、人数がわかれば金額的な比較にもつながるかもと思い人数を計算しました。人数はサンプルサイズでなく推定人口から計算しました。
mutate(推定人数 = `推定人口(15歳以上)` * 10^3 * 割合)ここまでのコード
exploratory::read_delim_file("../committed_data/dataframe.csv" , ",", quote = "\"", skip = 4 , col_names = TRUE , na = c('','NA') , locale=readr::locale(encoding = "UTF-8", decimal_mark = ".", grouping_mark = "," ), trim_ws = TRUE , progress = FALSE) %>%
readr::type_convert() %>%
exploratory::clean_data_frame() %>%
rename(`年齢` = X3, `サンプルサイズ` = X4, `推定人口(15歳以上)` = X5, `全体` = `総 数`) %>%
filter(!is_empty(年齢)) %>%
select(-X1, -X2, -X22, -X23, -X24, -X25, -X26, -X46, -X47) %>%
mutate_at(vars(サンプルサイズ, `推定人口(15歳以上)`, 全体, `スポーツ観覧(テレビ・スマートフォン・パソコンなどは除く)`, `美術鑑賞(テレビ・スマートフォン・パソコンなどは除く)`, `演芸・演劇・舞踊鑑賞(テレビ・スマートフォン・パソコンなどは除く)`, 映画館での映画鑑賞, `映画館以外での映画鑑賞(テレビ・DVD・パソコンなど)`, `音 楽 会などによるクラシック音楽鑑賞`, `音 楽 会などによるポピュラー音 楽・歌謡曲鑑賞`, `CD・スマートフォンなどによる音楽鑑賞`, 楽器の演奏, `邦 楽(民 謡,日本古来の音楽を含む)`, `コーラス・声 楽`, カラオケ, `邦 舞・お ど り`, `洋 舞・社交ダンス`, `書 道`, `華 道`, `茶 道`, `和裁・洋裁`, `編み物・手 芸`, `趣 味としての料 理・菓子作り`, `園 芸・庭いじり・ガーデニング`, 日曜大工, `絵画・彫刻の 制 作`, `陶芸・工芸`, `写 真 の撮 影・プリント`, `詩・和歌・俳句・小説などの創作`, `趣 味としての読 書`, `囲 碁`, `将 棋`, パチンコ, `テレビゲーム・パソコンゲーム(家庭で行うもの,携帯用を含む)`, `遊 園 地,動植物園,水 族 館などの見物`, キャンプ, その他), funs(parse_number)) %>%
mutate(性別 = c(rep("全体", 13), rep("男性", 13), rep("女性", 13))) %>%
mutate(性別 = factor(性別)) %>%
gather(`項目`, `割合`, -年齢, -性別, -`推定人口(15歳以上)`, -サンプルサイズ, na.rm = TRUE, convert = TRUE) %>%
mutate(推定人数 = `推定人口(15歳以上)` * 10^3 * 割合)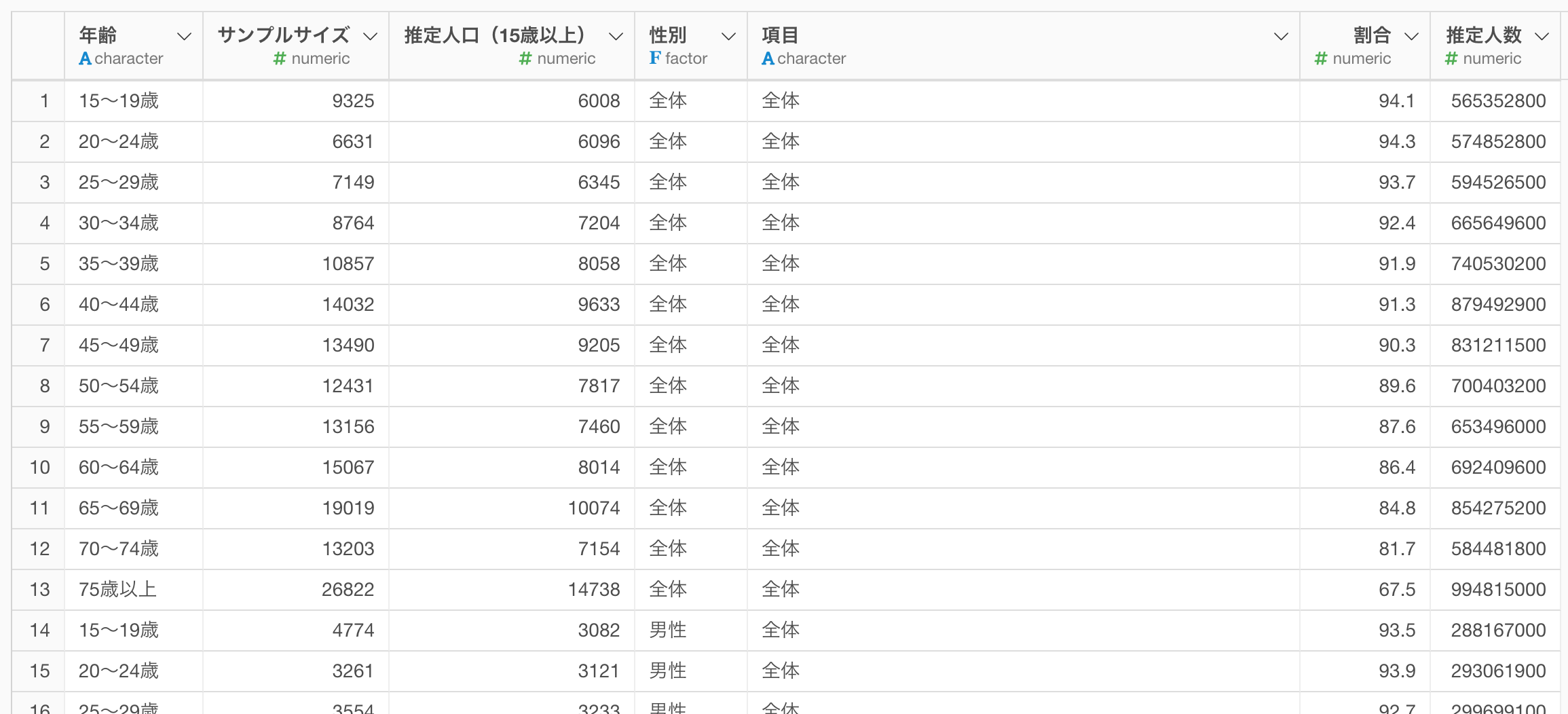
ブランチで性別ごとにデータを分ける
nestからのmapの使い方、もしくはfacet_wrapの使い方がわからなかったので、とりあえずブランチを使い3つ複製した後filterを使って性別の全体、男性、女性のデータに分けました。 
とりあえず可視化
今回はヒートマップで可視化してみました。 全てのブランチで項目の「全体」は省いています。
全体
割合
世代別にみると多くは世代が上がることに割合は下がり、ガーデニングが60台以上で増える傾向です。遊園地は子供がいる世代で上がっており、数は少ないですがキャンプも似たような傾向に感じます。ここは相関係数やkmeanなど使って分析を進めていっても良さそうです。
人数
男性
割合
女性
割合
人数
まとめ
今回はラングリングということでヒートマップにしたところで終えます。Exploratoryを初めて使いましたが、データ分析の流れが可視化でき再現性があるところがとてもいいなと感じました。
クラスタリングとかまで進めてみたかったですが、また機会があった時に挑戦してみたいと思います。